ローカルコーディングエージェントの構築方法
Sebastian Raschka は、オープンソースツールとローカル LLM を活用したプロダクション対応のコーディングエージェント構築チュートリアルを提供し、プライバシーとコスト効率を重視する開発者への代替案を示している。
キーポイント
完全ローカル環境の構築方法
推論エンジンやランタイムサーバーを介してホストされたローカル LLM と、ファイル編集・コマンド実行・変更検証が可能なローカルコーディングハッチを組み合わせた、完全にオフラインで動作するエージェント構成を解説している。
プロプライエタリサービスとの比較
GitHub Copilot (Codex) や Claude Code などのクローズドなサービスに対し、ローカル設定は透明性が高く、コストがほぼゼロ(電気代とハードウェアのみ)であり、データプライバシーが保証される利点を強調している。
制御可能性とカスタマイズ
ローカル環境ではエージェントの動作を完全にユーザーが支配でき、コーディングハッチを自由に修正・拡張できるため、特定のワークフローや研究目的に最適化しやすい点を指摘している。
今後の業界動向への備え
プロプライエタリサービスがパフォーマンス制限やプラン制限を強化する可能性を踏まえ、オープンウェイトモデルを活用したローカル環境を堅牢なバックアップ戦略として位置づけている。
ローカル LLM とコーディングハーンチの主な動機
コストの予測可能性、API 価格変動からの免疫、モデルアップグレードによる再現性の向上、そしてオフライン環境での利用が可能になる。
モデル固有のハーンチが最適化される傾向
LLM 開発者が独自のコーディングハーンチを開発した場合、そのモデルはまず自社のハーンチ向けに最適化されており、他のハーンチでも動作するが性能は異なる可能性がある。
Qwen-Code の採用理由とベンチマーク結果
オープンソースであること、Qwen モデルへの最適化、および Codex との並列実行が可能であるため Qwen-Code を使用し、Nvidia の論文では Qwen3.5-4B が同ハーンチで最高性能を示すと報告されている。
影響分析・編集コメントを表示
影響分析
この記事は、大規模言語モデルの利用における「クラウド依存」から「ローカル自律型」への転換を促す重要な指針を示しています。特にプライバシー意識の高い開発者や企業にとって、オープンソースの LLM とローカル実行環境を組み合わせたアーキテクチャが、次世代の開発ワークフローとして確立される可能性を高めています。
編集コメント
クラウド依存からの脱却とデータ主権の確保を願う開発者にとって、非常にタイムリーで実践的なガイダンスです。プロプライエタリサービスの制限が深まる中で、ローカル環境の構築スキルは重要な競争優位性となるでしょう。
過去に、多くの人から私のローカルエージェントスタックやその設定方法について問い合わせがありました。
そこで、オープンソースツールとオープンウェイトのLLMを使用して、ローカル(コーディング)エージェントを設定する方法についての簡単なチュートリアルを作成してみようと思いました。
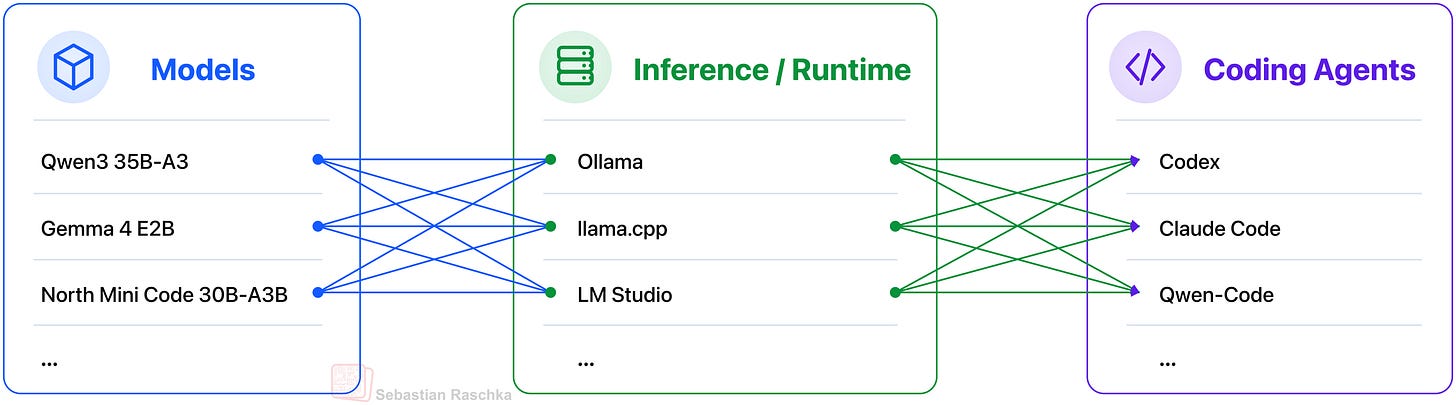
図 1: ローカルスタックの概要。つまり、推論エンジン/ランタイムサーバーを介してホストされるローカルモデルを利用するコーディングエージェントハネスです。
この記事は、完全にローカルのスタックを用いて本番環境対応型のコーディングエージェントを設定するためのチュートリアルです。上記の図に示すように、ファイルを閲覧し、編集を行い、コマンドを実行し、変更を検証できるローカルで提供されるLLMと、ローカルのコーディングハネスを使用します。
ここでは、LLM を推論とコード生成を提供するエンジンと捉え、周囲のハネスが、LLM が私たちのローカルプロジェクトで意味のあるコーディング作業を行えるような運用環境を提供すると考えられます。
なぜローカルなのか?多くのコーディングワークフローにおいて、ローカル環境は GPT in Codex や Claude Code の Opus といった専用サービスに対する興味深い代替手段となります。ローカル環境は透明性があり、検証可能で、ハードウェアと電気代以外のランニングコストは無料です。また、完全にユーザーの制御下にあり、コーディングハッチを好きなように変更できます。さらに、非常に楽しいのです!
ちなみに、コーディングエージェントハッチに関するもう少し詳しい背景情報が必要な場合は、コーディングエージェントのコアコンポーネント(学習目的でゼロからコーディングエージェントを構築する方法)についてこちらで解説しています:
- イントロダクション
正直に認めましょう。現時点では、まだ主に Codex と Claude Code を使い分けています。これは常に追加される新しいツールや機能に対応するためです。また、プラン制限(特に Codex の場合)は依然として非常に寛容で、これまでにコストを心配する必要はありませんでした。
しかし、私はローカルソリューションも長期間使用しており、何かと検証を行うためや、専用サービスと比較して完全にローカル環境を保有し利用すること自体に喜びを感じるからです。
いずれにせよ、ローカルソリューションは日々ますます魅力的になっています。その一側面がコストです。ハードウェアがあれば、実質的に無料で実行できます。もちろん、プライバシーの観点も重要です。例えば、領収書の整理や処理を行う際にも、データを OpenAI や Anthropic に送信するよりも、ローカルモデルで取り込む方が安心できるでしょう。
(その後、Anthropic が最近、LLM 研究のために自社のフラッグシップモデルのパフォーマンスを制限していることを念頭に置けば、 proprietary サービスは時間とともにより厳しくなる可能性があり、バックアップとしてオープンウェイトの代替案に慣れておくのが良い考えかもしれません。)
そして、そのような理由やユースケースは他にも数多く存在します。
ローカル LLM とコーディングハーンチスを使用する動機には以下が含まれる可能性があります:
サブスクリプションプランの制限に達した場合の予測可能で固定されたコスト、および API 価格変動に対する免疫性。
再現性; モデルがアップグレードされる場合(例:GPT 5.4 -> GPT 5.5 -> GPT 5.6)、すべてのクエリをより確実に解決してくれるのは良いことですが、これは既存のワークフローを破綻させる可能性もあります。
飛行機内での典型的なシナリオにおけるオフライン利用(インターネットが遅い場合やない場合)、または Starlink のサブスクリプションを持たずに森の中の小屋でコーディング/ライティングのリトリートに行く場合など。
そして、おそらく他にもいくつかあるでしょう。
したがって、この記事では、Codex や Claude Code などの人気のあるハーンチスをオープンウェイトモデルと共にセットアップして使用し、Qwen-Code for Qwen3.6 のようにモデル固有のハーンチスを使用することが追加の利点をもたらすかどうかを検証します。(もちろん、OpenCode、Cline、Pi、Noumena Code などの他のハーンチスも多数存在しますが、ほとんどの人が Codex または Claude Code のいずれかに筋肉記憶を持っているため、オープンウェイトモデルへの移行が少しスムーズになると考えました。)
- コーディングエージェントハーンチス概要
ほとんどのコーディングエージェント・ハネスは類似した原則に従っており、機能や特徴はおおむね同じです。しかし、実装の詳細は異なり、特定の LLM は通常、特定のハネス向けに主に最適化されています。もちろん、GLM 5.2 などの多くのオープンウェイト LLM(大規模言語モデル)であれば、Claude Code などを実行することも可能です。
ただし、LLM の開発者がコーディング・ハネスも同時に開発している場合、そのモデルはまず自社のハネス向けに最適化されていると仮定するのが比較的安全です(他社製にも対応しつつ)。
ここでは主に Qwen3.6 を Qwen-Coder コーディングクライアントと共に使用します。ただし、ローカル LLM を他のエージェント・ハネス(例えば Claude Code、Codex、そしてますます人気を博している Cline など)で利用する際の他の選択肢についても後ほど詳しく解説します。
Qwen モデルを使用する際に主に Qwen-Code を選ぶ理由は以下の通りです:
- Codex(https://github.com/openai/codex)と同様にオープンソースであり、Claude Code とは異なります;
- Qwen モデルは Qwen-Code ハネス向けに特に最適化されています(詳細は後述);
- 同一のマシン上で、最新 GPT モデルを搭載した Codex と Qwen-Code をローカル Qwen モデルと共に並列で実行でき、モデル間で手動で切り替える必要がありません。
上記リストの2点目について、QwenモデルはQwen-Codeにおいてより良く機能しますが、Nvidiaの「Polar: Agentic RL on Any Harness at Scale」論文(2026年5月)には、Qwen3.5-4Bベースモデルが同Qwen-Codeハッチス(トレーニング前およびPolar-RLトレーニング後の両方)で最良のコーディングパフォーマンスを示すベンチマークが含まれており、それを以下に示します。
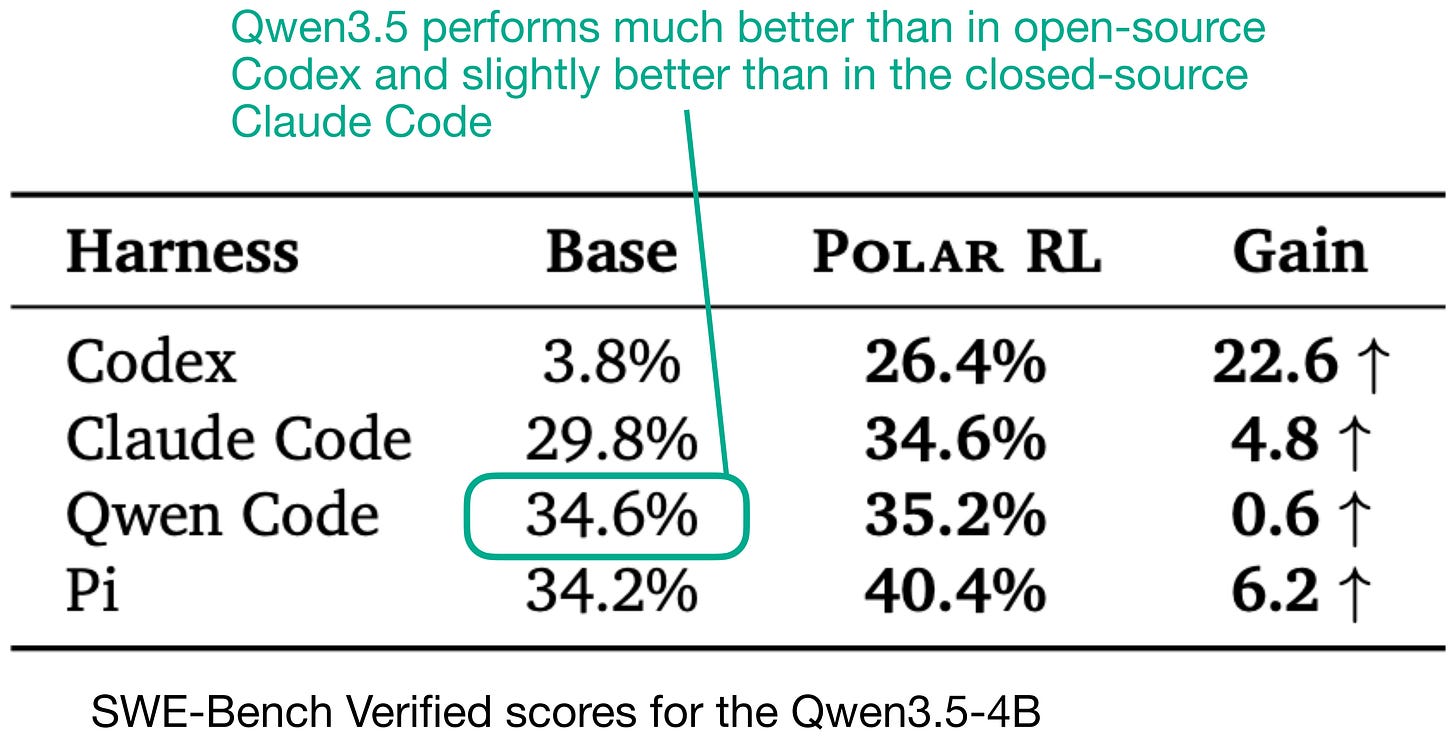
図2: Polar: Agentic RL on Any Harness at Scale(https://arxiv.org/abs/2605.24220)による、異なるコーディングハッチスにおけるQwenモデルのパフォーマンス
上記表のベンチマークは、より古いQwen3.5モデルを対象としたものですが、最新のQwen3.6モデルは特にQwen-Codeでのパフォーマンス向上のためにさらに最適化されていると推測しています。
なお、Pi(https://github.com/earendil-works/pi)も非常に興味深い候補であり、今後実際に試してみたいと考えています。
ちなみに、Qwen3.6 35B-A3Bのダウンロードサイズは約22GBで、RAMは概ね30〜40GBを必要としますが、M4搭載のMac MiniおよびDGX Sparkの両方で非常に高速に動作します。
Cohereが今年6月初めに共有した最新のベンチマークに基づくと、同サイズのクラスでは現在、最も優れたローカルモデルとなっています。
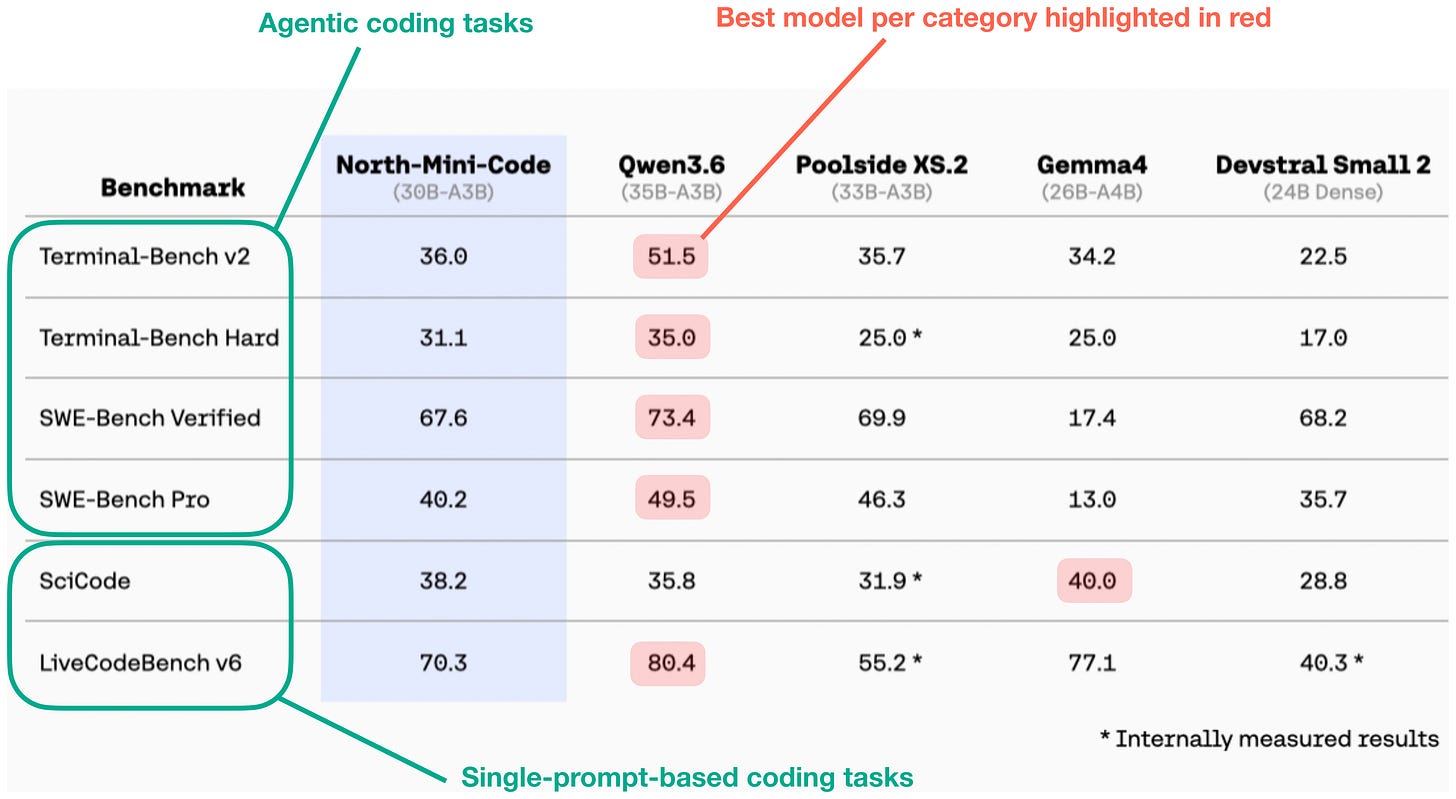
図 3: 6 月に公開された North Mini Code のレポート(https://huggingface.co/blog/CohereLabs/introducing-north-mini-code)に基づく Cohere ベンチマーク結果
上記の通り、Qwen3.6 35B-A3B はこのサイズクラスにおけるベンチマークのほぼすべてで他を圧倒しています。ただし、Qwen Code は汎用的なフレームワークであり、他の種類のモデルもサポートしています。例えば、Qwen Code にて North Mini Code や Gemma 4 を接続することも可能です。
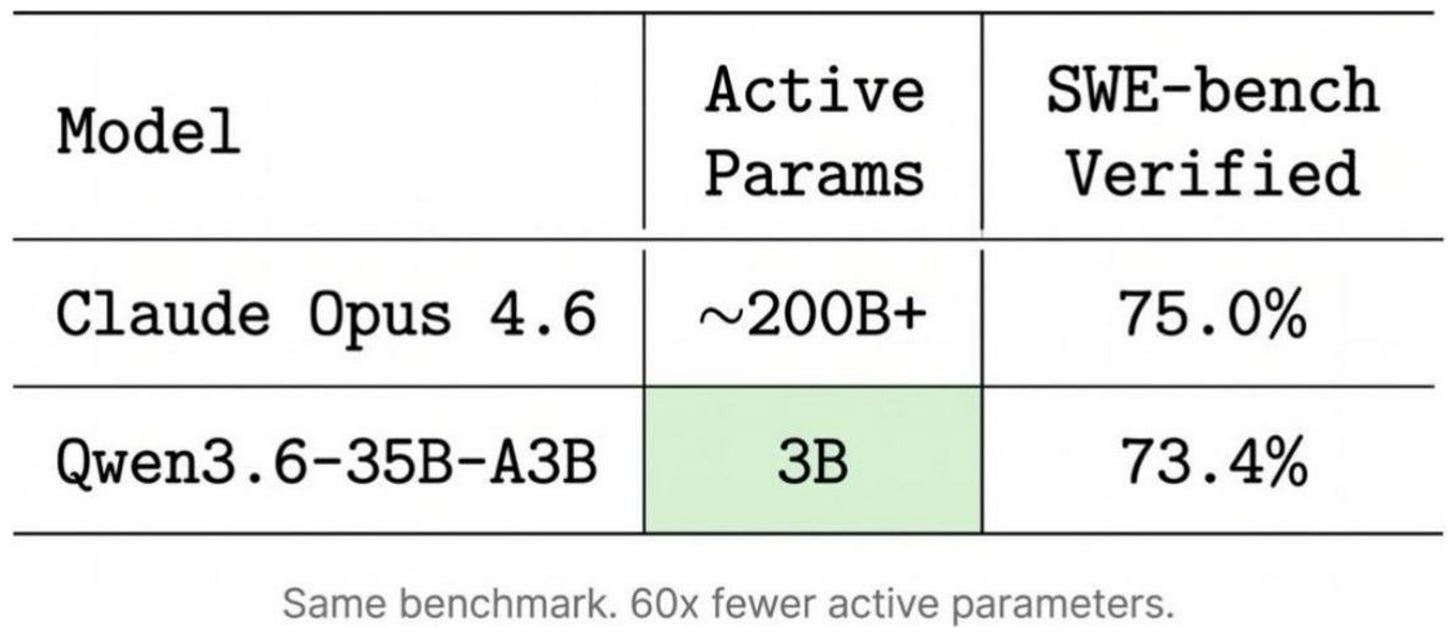
図 4: はい、Qwen3.6 35B-A3B は非常に優れたモデルです!(Via x.com/pupposandro/status/2064707907489272147/)
アーキテクチャの観点から、Qwen3.6 35B-A3B モデルは Qwen3-Coder や Qwen3.5 と同様にハイブリッドアテンション(hybrid attention)を採用しています。これについては「標準的な大規模言語モデルを超えて」で詳しく解説しました。
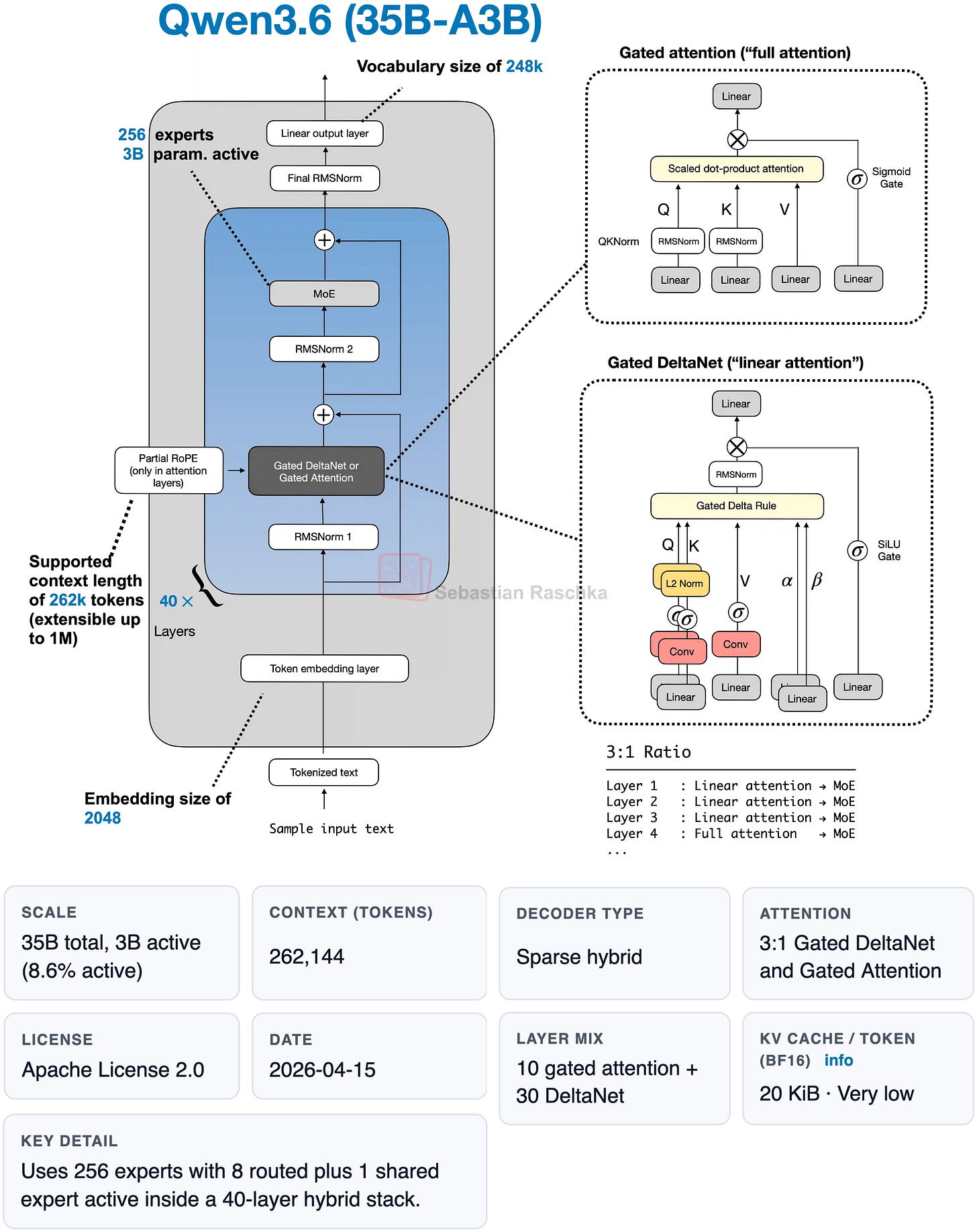
図 5: 私の LLM ギャラリーから抜粋した Qwen3.6 のアーキテクチャとファクトシート。
あるいは、Qwen3.6 を使用したくない場合は、Cohere の North Mini Code が現在のところこのサイズクラスにおいて最も興味深く、能力の高い代替案である可能性があります。このモデルについては、次のローカル LLM セットアップセクションでも取り上げます。
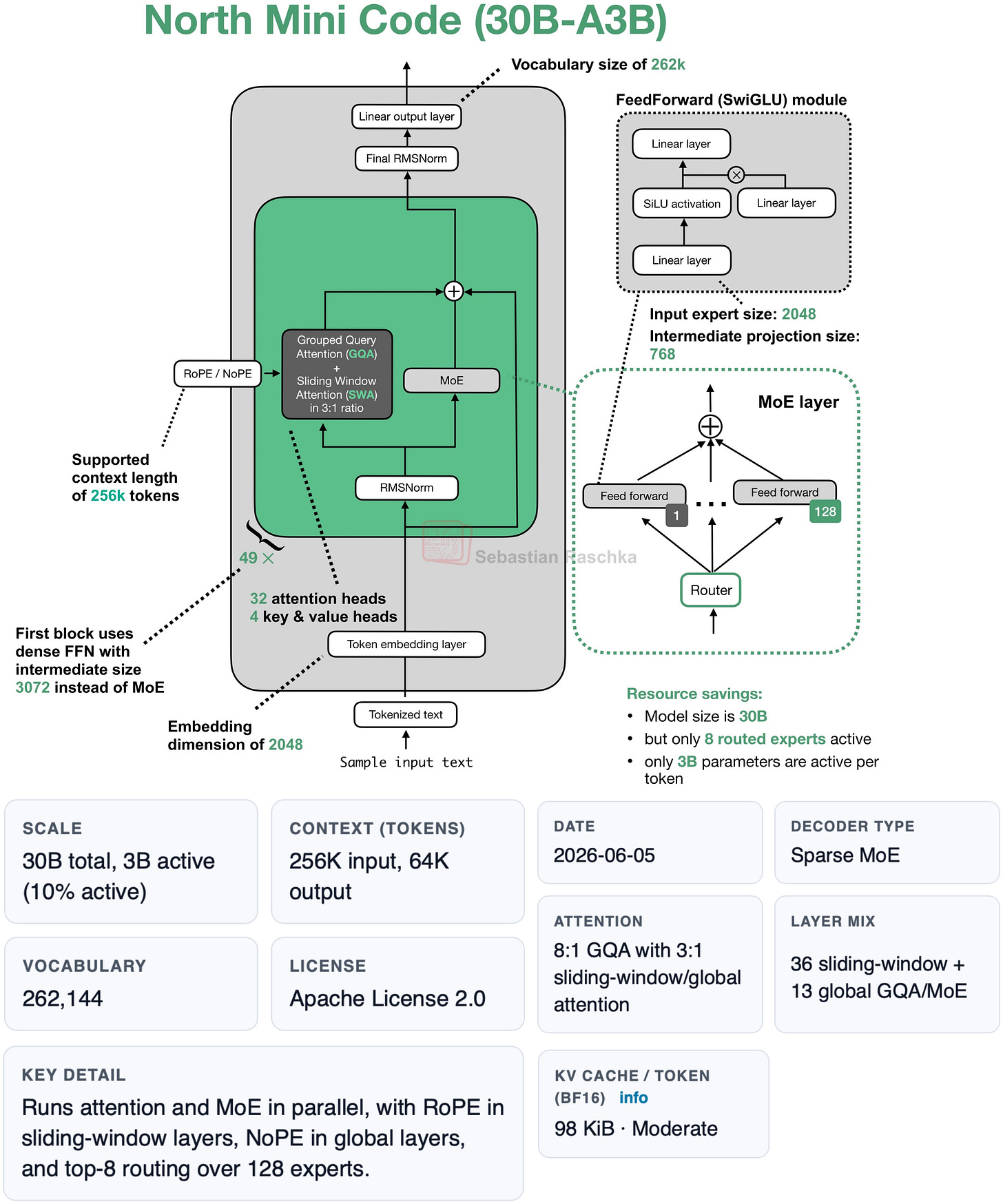
図 6: 私の LLM ギャラリーから見た North Mini Code のアーキテクチャとファクトシート。
- ローカル LLM セットアップ
Qwen-Code、Codex、Claude Code のいずれのエージェントハネスを使用する場合でも、まず Qwen3.6 35B-A3B などのローカル LLM をセットアップする必要があります。
モデルをローカルで提供するための選択肢としては、Ollama、LM Studio、vLLM、SGLang、MLX などがあります。私の「ゼロから大規模言語モデルを構築する」および「ゼロから推論モデルを構築する」というプロジェクトでご存知の通り、私はこれらの実装を自分でコード化することを好みます。ゼロからモデルを実装することには、スタック全体を理解できるという利点に加え、修正や追加トレーニング、ファインチューニングを自在に行えるというメリットがあります。
しかしここでは、現時点でトレーニングやファインチューニングを行う予定がないため、推論速度とリソース要件に対して超最適化されたモデル提供フレームワークを探しています。(追加ステップとして、独自にゼロから作成したファインチューンドモデルを変換・インポートしてこれらの効率的な提供スタックに取り込むことは可能ですが、これは本記事の範囲外です。)
このチュートリアルでは、Ollama を効率的なモデルサービングエンジンとして使用します。これは、異なるオペレーティングシステム間でコマンドラインから比較的簡単にインストールして使用できるためです(LM Studio も非 GUI の llmster クライアントを追加しましたが、私はそれについてはあまり詳しくありません)。
ちなみに、私はこの記事で言及されているツールのいずれにも所属していませんが、Ollama の良い点の一つは、クラウド上でホストされたオープンウェイトモデルをオプションでサポートしていることです。これには現在最も強力なオープンウェイトモデルである GLM 5.2 も含まれており、これはコンシューマー向けハードウェアではローカルで実行するには大きすぎます。(もちろんクラウドモデルは無料ではありませんが、ChatGPT や Claude と同様のサブスクリプションプランを持っています。しかし、最新の最先端オープンウェイトモデルを「ローカル」で便利にテストできるという選択肢が存在することは素晴らしいことです。)
ともあれ、Ollama のセットアップは非常に簡単です。公式の macOS/Linux/Windows 用ダウンロード手順は、ダウンロードページで見つけることができます。
インストール後、クイックテスト実行のためにモデルをダウンロードすることをお勧めします。例えば、macOS では ollama アプリを使用して、GUI を介して直接モデルをダウンロードできます:
図 7:Ollama アプリを使用してモデルを検索およびダウンロードする
あるいは、これはコマンドラインでも以下のように実行できます:
ollama pull qwen3.6:35b-mlx
なお、上記のqwen3.6:35b-mlxは、AppleのMetal Performance Shaders(MPS)を利用したモデルであり、Appleシリコンチップを搭載したMac向けに最適化されています。Macで動作するモデルについては、可能であれば*-mlxバージョンの使用を強く推奨します。
図 8: Appleシリコンチップを搭載したMacを使用する場合は、MLXバージョンを優先してください。
Linuxマシンでは、非MLXバージョンを使用します:
ollama pull qwen3.6:35b
その後、動作確認のために、再度GUIを利用するか、コマンドラインからOllamaを起動します。
図 9: ターミナルでOllamaを実行中。
このセッションは、/byeコマンドで終了できます。
前述の通り、現在Qwen3.6 35B-A3Bモデルに対する最良の代替案は、同サイズのNorth Mini Code 1.0です。
図 10:Qwen3.6 35B A3B の代替案としての North Mini Code 1.0
- シンプルな速度パフォーマンス評価
LLM をローカルコーディングエージェントとして使用するかどうかを決定する前に、素早い速度と品質の評価を実行するのは通常悪い考えではありません。ここでは速度評価のために、秒間あたりのトークン数(tokens/sec)のパフォーマンスを確認します。さらに、アジェンティックなコーディングワークフローで通常扱うような(非常に)長いコンテキストにおいても、このパフォーマンスが安定していることを確認する必要があります(これはより単純なチャットボットとは対照的です)。
もちろん、メモリコストが爆発することも避けたいものです。
簡単なチェックを行うには、私の ollama_speed_memory_bench.py スクリプトを実行できます。要約すると、このスクリプトは Ollama モデルに対して 1,000 語から 50,000 語までの異なるプロンプトを送信し、デフォルトでは最大 8,000 トークンの生成を要求します。Ollama のプロンプト評価メトリクスからのプリフィル速度(prefill speed)、出力トークンタイミングからの生成速度(generation speed)、そして利用可能な場合は Ollama プロセスおよび NVIDIA GPU メモリからのメモリ使用量といった、単純な統計情報を報告します。
例えば、macOS 上で qwen3.6:35b-mlx を評価する場合、https://github.com/rasbt/local-coding-agent-evals からスクリプトをダウンロードまたはクローンしていれば、以下を実行できます(約 5 分かかります):
uv run speed-memory-benchmark/ollama_speed_memory_bench.py --model qwen3.6:35b-mlx
Linux では、以下を実行できます:
uv run speed-memory-benchmark/ollama_speed_memory_bench.py --model qwen3.6:35b
なお、これは前節で説明した通り、それぞれのモデルをすでにダウンロード済みであることを前提としています。また、システムによっては 30 GB 未満の RAM をお持ちの場合、gemma4:e2b のように長いコンテキストでも約 8 GB の RAM を使用するようなより小さなモデルを使用する必要があるかもしれません。もちろん、より小さなモデルも多数存在しますが、私の経験では、それらは非常に質の低いローカルコーディングエージェントとなってしまいます。
なお、モデルにおける RSS メモリレポートは macOS(特に Metal バックエンドを利用する mlx モデルバリアントの場合)では必ずしも正確ではなく、実行中は Ollama の Activity Monitor での RAM 使用量にも注意を払うことをお勧めします。この場合、RAM 使用量は 20〜29 GB の間で変動しました。
いずれにせよ、結論として、50k コンテキストの場合、Qwen3.6 および North Mini Code モデルは、最新の Mac Mini では約 40 トークン/秒、DGX では 30 トークン/秒で出力を生成し、それぞれ最大 30 GB の RAM を使用します。
以下に、異なる実行結果の視覚的な要約を示します。
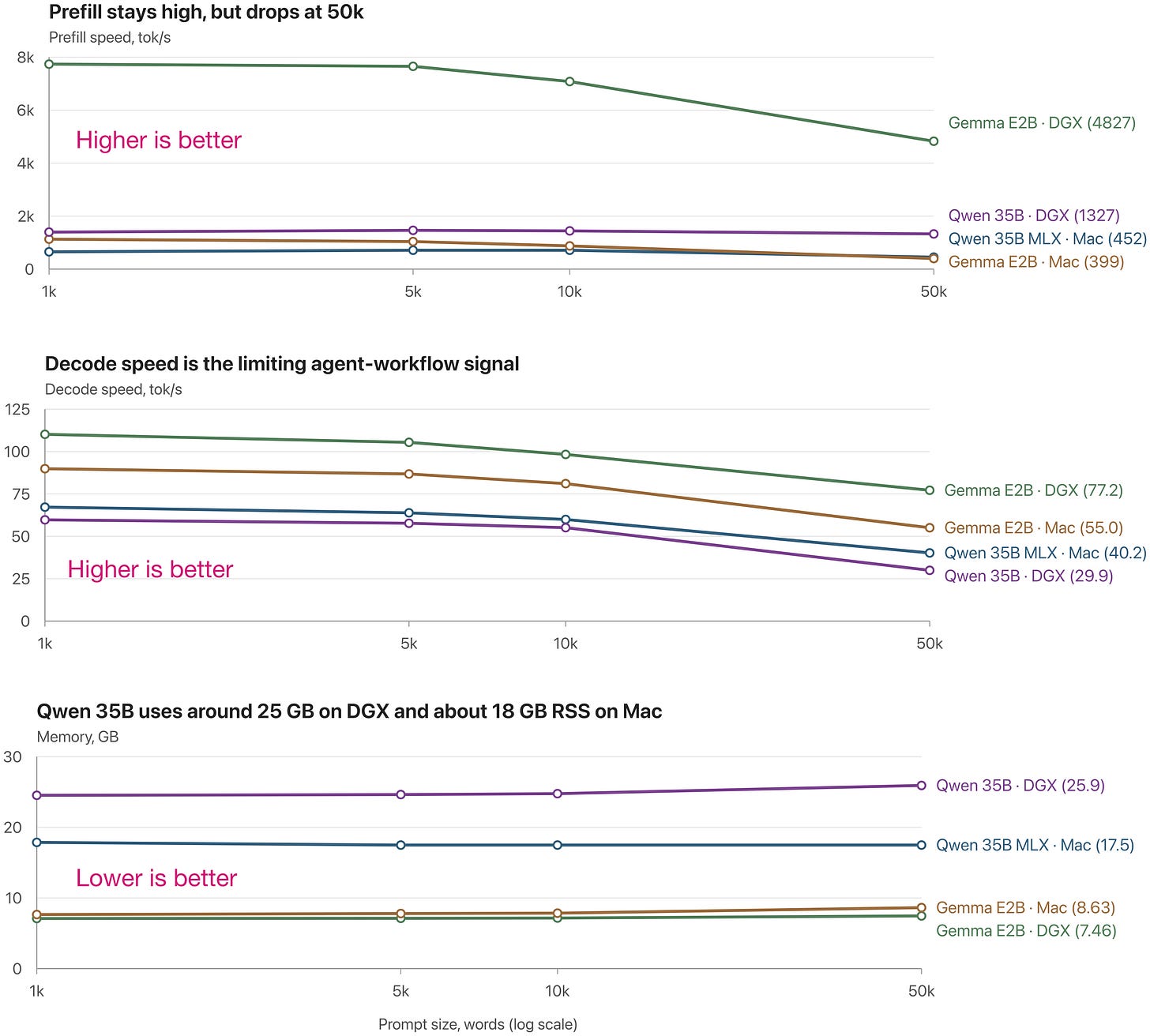
図 11:異なるシステム上での各モデルのクイック速度比較。なお、macOS の RAM 消費量はそこそこの精度しかありません。また、MLX バージョンの最適化により、Qwen 35B-A3B モデルは Mac 上で DGX Spark よりも高速に動作します(これは Gemma 4 E2B モデルでは逆の結果です)。再現用のコード:https://github.com/rasbt/local-coding-agent-evals
もう一つの興味深い質問として、Qwen 35B-A3B は同サイズの Cohere North Mini モデルと比較してどうでしょうか?同様に量子化されたモデルを考慮すると(上記では Qwen3.6 のデフォルトを使用しましたが)、両者は非常に似ており、North Mini の方が全体としてわずかに上回っている可能性があります。以下にその結果を示します。
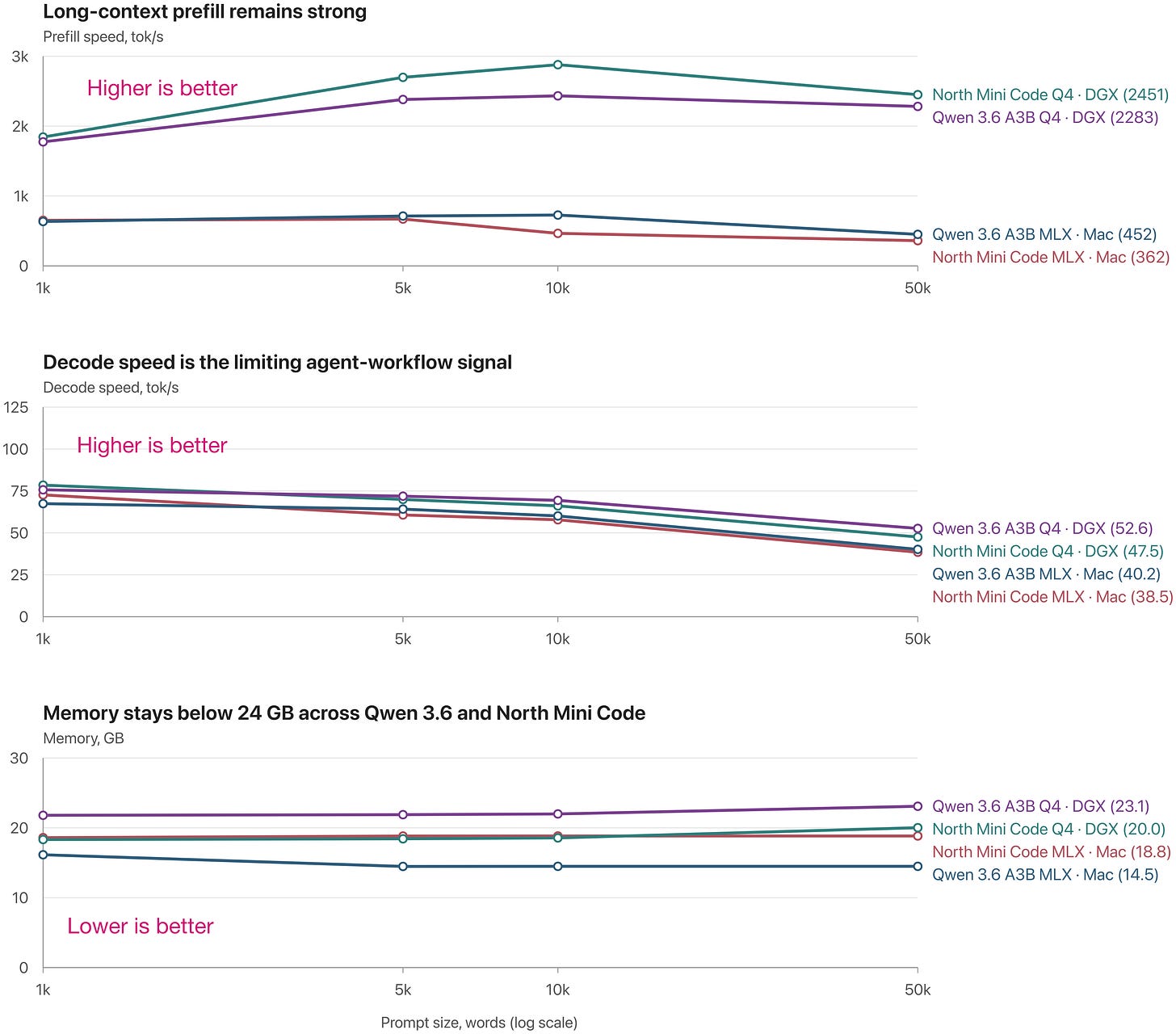
図 12:Q4 量子化された Qwen3.6 35B と North Mini Code の比較。再現用のコード:https://github.com/rasbt/local-coding-agent-evals
いずれにせよ、結論として私の意見では、ローカルエージェントの作業において 20〜30 トークン/秒よりも速い速度であれば十分実用的です。これは「高」推論モードでの GPT 5.5 とほぼ同等の速度です。この場合、両モデルとも基準を容易にクリアしています。
ちなみに、個人的にはエージェントをほとんど DGX Spark で実行しています。Mac Mini が過熱するのを避けたいのと、他のタスクのために RAM を確保しておきたいからです。
もちろん、Ollama 以外の異なるフレームワークや量子化(quantization)、MTP などを用いてさらに最適化する道は常に存在します。しかし、Ollama は最小限の設定時間で簡単に動作する優れたプラグ&プレイのオールラウンダーであり、さまざまなコーディングエージェント・フレームワークに容易に接続でき、異なるモデルへの切り替えや試行が非常に簡単です。
- シンプルなベンチマーク性能評価
モデルがローカル作業に適した十分な速度を持っていることを確認した後、簡単なモデル性能の評価を行うことをお勧めします。もちろん、参照できる標準化されたベンチマークは多数存在し、自ら実行することも可能です。
通常、関連するベンチマークの数値は、モデルの技術レポートやモデルハブページで見つけることができます。また、https://artificialanalysis.ai/models/ において他のモデルとの相対比較を確認するのも有用だと感じています。
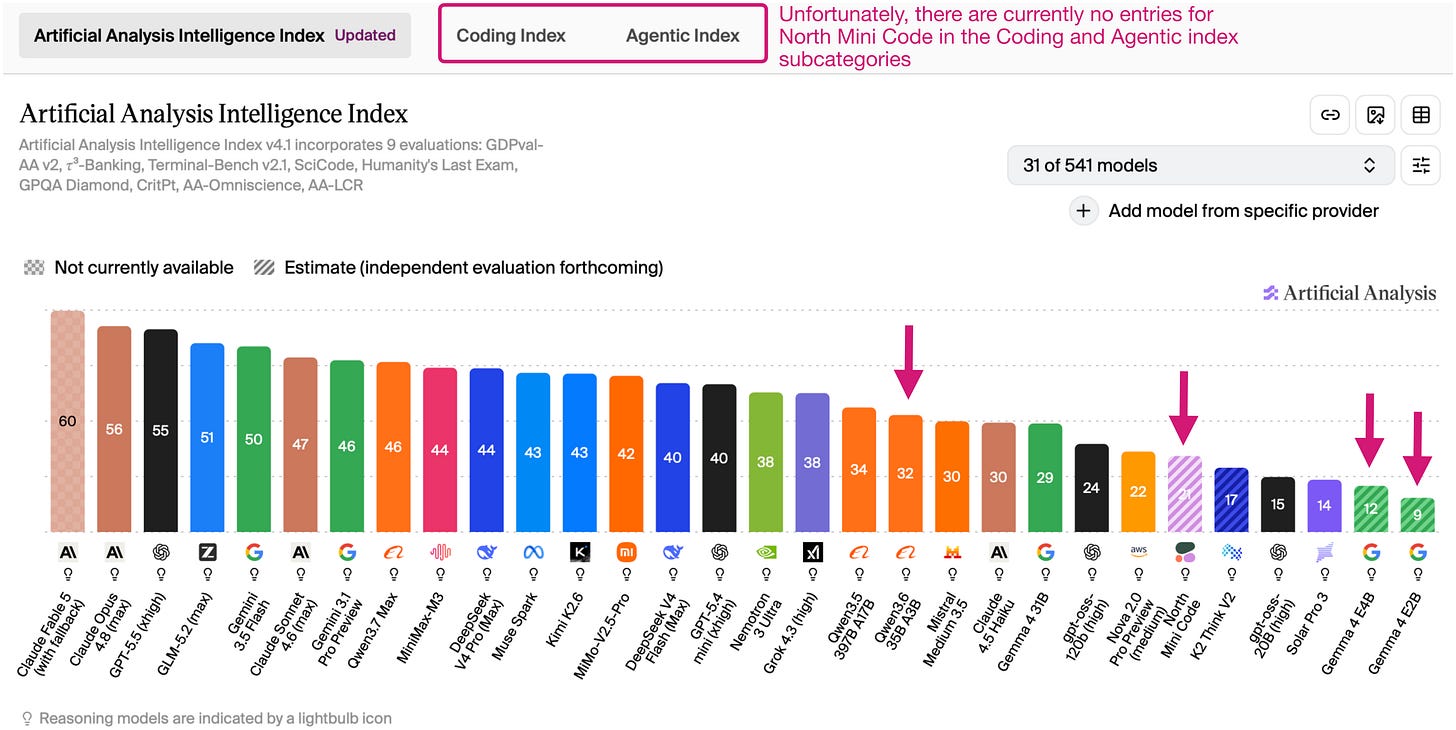
図 13: https://artificialanalysis.ai/models/ のベンチマーク。平均性能(上部)、コーディング性能(中央)、エージェント性能(下部)。
上記の図から、Qwen3 35B-A3B は、例えば Gemma 4 E4B や E2B モデルよりもはるかに能力が高いことがわかります。
人工知能指数の数は、ベンチマークの切り替えや重み付けの更新に伴い時間とともに変化するため、「どのモデルが十分か」を判断するための絶対的な基準となる数値は存在しません。むしろ、新しい興味深いモデルを、以前使用したモデルをアンカーまたは参照点として比較することをお勧めします。
標準ベンチマークに加えて、ご自身に関連するタスクの個人的なセットを策定し、そのモデルがあなたが望むあらゆる種類の作業に適合しているかどうかを迅速に確認することも重要です。
以下は、推論およびコード関連の質問セットに対する出力であり、これらはモデルのツール呼び出し機能もテストするものです。ここでは、モデルはツール呼び出しを返しますが、コード自体を実行することはありません。
➜ uv run ollama_hard_reasoning_bench.py --model qwen3.6:35b
PASS debug_empty_tokenizer_regression: ok
PASS review_shell_command_injection: ok
FAIL choose_minimal_edit_for_cross_platform_path: argument instructions missing required content
FAIL triage_import_error_after_refactor: wrong tool: expected read_file, got ask_clarification
PASS debug_mutable_default_cache_leak: ok
スコア:3/5 合格(60.0%)➜ uv run ollama_hard_reasoning_bench.py --model north-mini-code-1.0
FAIL debug_empty_tokenizer_regression: 誤ったツール:最終回答を期待したが、edit_file を取得
PASS review_shell_command_injection: 成功
FAIL choose_minimal_edit_for_cross_platform_path: 不正な JSON: 余分なデータ:2 行目 1 カラム(文字番号 235)
FAIL triage_import_error_after_refactor: 誤ったツール:ファイル読み取りを期待したが、ask_clarification を取得
FAIL debug_mutable_default_cache_leak: 誤ったツール:最終回答を期待したが、edit_file を取得
スコア:1/5 合格(20.0%)uv run ollama_hard_reasoning_bench.py --model gemma4:e2b
FAIL debug_empty_tokenizer_regression: 誤ったツール:最終回答を期待したが、edit_file を取得
FAIL review_shell_command_injection: 誤ったツール:最終回答を期待したが、ask_clarification を取得
FAIL choose_minimal_edit_for_cross_platform_path: 誤った引数 path: 'code/tool-reasoning-benchmark/ollama_tool_reasoning_bench.py' を期待したが、'code/tool-reasoning-benchmark/personal_tool_reasoning_tasks.jsonl' を取得
FAIL triage_import_error_after_refactor: 誤ったツール:期待
原文を表示
Many people reached out to me in the past asking about my local agent stack as well as how I set up my local agent stack.
So, I thought it might be useful to put together a little tutorial on how to set up a local (coding) agent using open-source tools and open-weight LLMs.
Figure 1: Overview of the local stack, that is, a coding agent harness that uses a local model hosted through an inference engine / runtime server.
This article is a tutorial on setting up a production-ready coding agent with a fully local stack. We will use a locally served LLM together with a local coding harness that can read files, make edits, run commands, and verify changes as shown in the figure above.
Here, we can think of the LLM as the engine that provides the reasoning and code generation. And the surrounding harness provides the operating environment that allows the LLM to do meaningful coding work in our local projects.
Why local? For many coding workflows, a local setup is an interesting alternative to proprietary services such as GPT in Codex or Opus in Claude Code. The local setup is transparent, inspectable, and free to run apart from hardware and electricity costs. It also stays fully under your control, and you can modify the coding harness in any way you like. Plus, it’s a lot of fun!
By the way, in case you want a bit more background information on coding agent harnesses, I covered the core components of coding agents (and building a coding agent from scratch for learning purposes) here:
- Intro
I have to admit that I still primarily alternate between Codex and Claude Code as my daily drivers, for now (and just to keep up with the new tooling and functions that are constantly being added). Also, the plan limits (especially for Codex) are still so generous that I haven’t had to worry about costs so far.
However, I’ve been using local solutions for a while, too, to test things and because it somehow gives me joy to have and use a fully local setup (versus proprietary services).
Either way, local solutions become more and more attractive each day. One aspect is the costs. If you have the hardware, they are practically free to run. And then there’s, of course, the privacy angle. For example, for organizing and processing my receipts, I’d be more comfortable with a local model ingesting them rather than sending the data over to OpenAI or Anthropic.
(Then, if we keep in mind that Anthropic was recently throttling their flagship model’s performance for LLM research, proprietary services may become more restrictive over time, and it’s maybe a good idea to be comfortable with open-weight alternatives as a backup.)
And there are many, many additional reasons and use cases like that.
Your motivations for using local LLMs and coding harnesses may include:
Predictable, fixed costs if you reach your subscription plan limits, and immunity to API price changes.
Reproducibility; sometimes it’s nice if a model is upgraded (e.g., GPT 5.4 -> GPT 5.5 -> GPT 5.6) and it solves all your queries more reliably. However, this can also break existing workflows.
Offline use in the classic airplane flight scenario with slow or no internet, or when going on a coding/writing retreat in the cabin in the woods w/o a Starlink subscription.
And there are probably several others.
So, in this article, we will set up and use popular harnesses like Codex and Claude Code with open-weight models and investigate whether using a model-specific harness (like Qwen-Code for Qwen3.6) brings any additional benefits. (Of course, there are many more harnesses like OpenCode, Cline, Pi, and Noumena Code, but I thought that most people already have muscle memory with either Codex or Claude Code, which makes switching to open-weight models a bit smoother).
- Coding Agent Harness Overview
Most coding agent harnesses follow similar principles and have more or less the same features and functionality. However, the implementation details may differ, and certain LLMs have usually been primarily optimized for a specific harness. Of course, many open-weight LLMs like GLM 5.2, for example, would run Claude Code, etc.
However, if an LLM developer also develops a coding harness, it is somewhat safe to assume that their model is optimized for their own harness first (while also supporting others).
Here, I am primarily going to use Qwen3.6 with the Qwen-Coder coding client. However, I will also go over other options for using a local LLM with other agent harnesses, for example, Claude Code, Codex, and the increasingly popular Cline, but more on that later.
The reason why I am primarily using Qwen-Code when working with Qwen models is that:
it is open-source, like Codex (https://github.com/openai/codex) but unlike Claude Code;
Qwen models have been specifically optimized for the Qwen-Code harness (more information below);
I can run both Codex (with the latest GPT model) and Qwen-Code with a local Qwen model side by side on the same machine without having to switch manually back and forth between models.
Regarding the second point in the list above, that Qwen models work better in Qwen-Code, Nvidia’s Polar: Agentic RL on Any Harness at Scale paper (May 2026) has a benchmark showing that the Qwen3.5-4B base model has the best coding performance in said Qwen-Code harness (both before and after their Polar-RL training), which I included below.
Figure 2: Qwen model performance in different coding harnesses via Polar: Agentic RL on Any Harness at Scale (https://arxiv.org/abs/2605.24220)
The benchmark in the table above is for an older Qwen3.5 model, and I am assuming that the latest Qwen3.6 models are even further optimized to do well in Qwen-Code specifically.
However, Pi (https://github.com/earendil-works/pi) also seems to be a very interesting candidate that I need to play around with in the future.
By the way, Qwen3.6 35B-A3B is about 22 GB to download, requires roughly 30-40 GB of RAM, and runs pretty swiftly on both a Mac Mini with M4 and a DGX Spark.
Based on the recent benchmarks shared by Cohere earlier in June, it is currently the best local model in its size class.
Figure 3: Cohere benchmark from North Mini Code report published in June (https://huggingface.co/blog/CohereLabs/introducing-north-mini-code)
As seen above, Qwen3.6 35B-A3B dominates all but one benchmark in this size class. However, that being said, Qwen Code is a general harness and also supports other types of models. For instance, we could also connect North Mini Code or Gemma 4 in Qwen Code.
Figure 4: Yes, Qwen3.6 35B-A3B is a really good model! (Via x.com/pupposandro/status/2064707907489272147/)
Architecture-wise, the Qwen3.6 35B-A3B model has hybrid attention similar to Qwen3-Coder and Qwen3.5. I wrote more about it in Beyond Standard LLMs.
Figure 5: Qwen3.6 architecture and fact sheet from my LLM gallery.
Alternatively, if you don’t want to use Qwen3.6, Cohere’s North Mini Code is probably the most interesting, capable alternative at this size class right now. I will go over this model in the next local LLM setup section as well.
Figure 6: North Mini Code architecture and fact sheet from my LLM gallery.
- Local LLM Setup
No matter what agent harness we use (Qwen-Code, Codex, or Claude Code), we have to set up a local LLM, such as Qwen3.6 35B-A3B, first.
There are several options like Ollama, LM Studio, vLLM, SGLang, MLX, etc to serve models locally. You know from my Build A Large Language Model (From Scratch) and Build A Reasoning Model (From Scratch) projects that I like to code these myself. Implementing a model from scratch has the benefits that we understand the whole stack, plus we can modify and further train and fine-tune it.
However, here, we just look for a model serving framework that has been super optimized for inference speed and resource needs since we don’t plan to do any training or fine-tuning at this point. (We could, as an extra step, convert and import our own from-scratch fine-tuned model into these efficient serving stacks, but this is out of the scope for this article.)
For this tutorial, we will use Ollama as our efficient model serving engine because it’s relatively easy to install and use from the command line across different operating systems (although LM Studio also added a non-GUI llmster client, but I am less familiar with it).
By the way, I am not affiliated with any of the tools mentioned in this article, but one nice thing about Ollama is that they also optionally support open-weight models hosted in the cloud, including the currently strongest open-weight model, GLM 5.2, which is too large to run locally on consumer hardware. (The cloud models are not free, of course, but have similar subscription plans as ChatGPT and Claude; it’s still nice though that this option exists to conveniently test the latest state-of-the-art open-weight models “locally.”)
Anyways, setting up Ollama is pretty straightforward, and you can find the official macOS/Linux/Windows download instructions on their download page.
After installing, I recommend downloading a model for a quick test run. For instance, on macOS, we can use the ollama app to download models directly via the GUI:
Figure 7: Using the Ollama app to find and download models
Otherwise, this can be done on the command line as well via
ollama pull qwen3.6:35b-mlx
By the way, the above-mentioned qwen3.6:35b-mlx is a model using Apple’s Metal performance shaders, i.e., optimized for Macs with Apple silicon chips. I highly recommend using *-mlx versions of models working on Macs (if available).
Figure 8: Prefer the MLX version when using a Mac (with an Apple Silicon chip).
On a Linux machine, use the non-MLX version:
ollama pull qwen3.6:35b
Then, to make sure that it works, you can either use the GUI again or launch Ollama from the command line.
Figure 9: Running Ollama in the terminal.
You can exit this session via the /bye command.
As mentioned before, the currently best alternative to this Qwen3.6 35B-A3B model is North Mini Code 1.0 of similar size.
Figure 10: North Mini Code 1.0 as an alternative to Qwen3.6 35B A3B.
- Simple Speed Performance Assessment
Before deciding on whether to use an LLM as a local coding agent, it’s usually not a bad idea to run a quick speed and quality assessment. Here, for the speed assessment, I would look for tokens/sec performance. Additionally, I’d also make sure this stays stable for (very) long contexts, which is what we are usually dealing with during agentic coding workflows (as opposed to simpler chatbots).
Of course, we also don’t want the memory cost to explode either.
You could run my ollama_speed_memory_bench.py script to do a quick check. In a nutshell, it sends different prompts (ranging from 1k to 50k words) to an Ollama model and asks it to generate up to 8k tokens by default. It reports simple statistics like prefill speed from Ollama’s prompt evaluation metrics, generation speed from output-token timing, and memory use from the Ollama process plus NVIDIA GPU memory when available.
For example, to evaluate the qwen3.6:35b-mlx on macOS, if you downloaded or cloned the scripts from https://github.com/rasbt/local-coding-agent-evals, we can run the following, which takes about 5 minutes:
uv run speed-memory-benchmark/ollama_speed_memory_bench.py --model qwen3.6:35b-mlx
On Linux, we can run:
uv run speed-memory-benchmark/ollama_speed_memory_bench.py --model qwen3.6:35b
Note that this assumes that you already downloaded the respective model as explained in the previous section. Also, depending on your system, if you have less than 30 GB RAM, you may have to use a smaller model like gemma4:e2b, which uses up to about 8 GB RAM on long contexts. Of course, there are also many smaller models, but in my experience, they make pretty bad local coding agents.)
Note that for models, the RSS RAM report is not super accurate on macOS (especially for mlx model variants that utilize the Metal backend), and I suggest keeping an eye on the activity monitor’s RAM usage for Ollama during the run as well. In this case, the RAM usage fluctuated between 20 - 29 GB.
Anyways, the bottom line is that for 50k contexts, the Qwen3.6 and North Mini Code models use up to 30 GB RAM and generate output with about 40 tok/sec on a recent Mac Mini and 30 tok/sec on a DGX.
Below is a visual summary of the different runs.
Figure 11: Quick speed comparison of the different models on different systems. Note that the macOS RAM consumption is not super accurate there. Also, note that the Qwen 35B-A3B model is faster on Mac than on the DGX Spark (which is the other way around for the Gemma 4 E2B model) thanks to the optimized MLX version. Code to reproduce: https://github.com/rasbt/local-coding-agent-evals
Another interesting question is how Qwen 35B-A3B compares to the similarly-sized Cohere North Mini model? If we take similarly quantized models into account (above, I was using the Qwen3.6 default), they are pretty similar, although North Mini is perhaps slightly ahead overall, as shown below.
Figure 12: Q4-quantized Qwen3.6 35B vs North Mini Code. Code to reproduce: https://github.com/rasbt/local-coding-agent-evals
Anyway, the bottom line is that, in my opinion, anything faster than 20-30 tok/sec is pretty reasonable for local agent work. This is about the same speed as GPT 5.5 with “high” reasoning. In this case, both models clear the bar easily.
By the way, personally, I run my agents almost exclusively on my DGX Spark because I don’t want my Mac Mini to get too hot and I want to have the RAM available for other tasks.
Of course, there are always ways to optimize this more with different frameworks (other than Ollama), quantizations, MTP, and so on. However, Ollama is a good plug & play allrounder with minimal setup time that connects easily to various coding agent frameworks and where it’s super simple to swap and try out different models.
- Simple Benchmark Performance Assessment
After checking that the model is fast enough for convenient local work, I recommend doing a quick modeling performance assessment. Sure, there are many standardized benchmarks out there we could take a look at and even run ourselves.
Usually, you can find the numbers for relevant benchmarks in the model’s technical report or model hub page. Usually, I also find it useful to look at a relative comparison with other models on https://artificialanalysis.ai/models/.
Figure 13: Benchmark from https://artificialanalysis.ai/models/. Average performance (top), coding performance (center), agentic performance (bottom).
Based on the figure above, we can see that Qwen3 35B-A3B is much more capable than the Gemma 4 E4B and E2B models, for example.
Note that the Artificial Intelligence Index numbers keep changing over time as they swap benchmarks and update the weighting, so there are no “absolute” numbers we could use as a reference point for deciding which model is “good enough”. Rather, I would compare a new, interesting model to a model you used before as an anchor or reference point.
Beyond standard benchmarks, I would also curate a personal set of tasks that are relevant to you to do a quick check whether this model is even suitable for any type of work that you might want it to perform.
Below are the outputs of a reasoning- and code-related set of questions that also test the tool calling capabilities of the models. Here, the model returns the tool call but doesn’t execute the code itself.
➜ uv run ollama_hard_reasoning_bench.py --model qwen3.6:35b
PASS debug_empty_tokenizer_regression: ok
PASS review_shell_command_injection: ok
FAIL choose_minimal_edit_for_cross_platform_path: argument instructions missing required content
FAIL triage_import_error_after_refactor: wrong tool: expected read_file, got ask_clarification
PASS debug_mutable_default_cache_leak: ok
Score: 3/5 passed (60.0%)➜ uv run ollama_hard_reasoning_bench.py --model north-mini-code-1.0
FAIL debug_empty_tokenizer_regression: wrong tool: expected final_answer, got edit_file
PASS review_shell_command_injection: ok
FAIL choose_minimal_edit_for_cross_platform_path: invalid JSON: Extra data: line 2 column 1 (char 235)
FAIL triage_import_error_after_refactor: wrong tool: expected read_file, got ask_clarification
FAIL debug_mutable_default_cache_leak: wrong tool: expected final_answer, got edit_file
Score: 1/5 passed (20.0%)uv run ollama_hard_reasoning_bench.py --model gemma4:e2b
FAIL debug_empty_tokenizer_regression: wrong tool: expected final_answer, got edit_file
FAIL review_shell_command_injection: wrong tool: expected final_answer, got ask_clarification
FAIL choose_minimal_edit_for_cross_platform_path: wrong argument path: expected 'code/tool-reasoning-benchmark/ollama_tool_reasoning_bench.py', got 'code/tool-reasoning-benchmark/personal_tool_reasoning_tasks.jsonl'
FAIL triage_import_error_after_refactor: wrong tool: expected
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み