抽出機能のベンチマーク評価
LangChain がデータ抽出機能の精度を比較・評価するベンチマークを発表し、業界標準の確立と技術選定の指針を提供した。
キーポイント
抽出機能の定量化
LangChain が提供するデータ抽出機能の精度を数値化し、異なるモデルや設定間での比較を可能にするベンチマークを発表しました。
実用性の向上
開発者が特定のユースケースに最適な抽出手法を選定できるようになり、プロダクション環境での信頼性向上が期待されます。
業界標準の確立
LLM 応用におけるデータ抽出の品質評価において、客観的な指標を持つことで開発コミュニティ全体の成熟を促します。
影響分析・編集コメントを表示
影響分析
このベンチマークの発表は、LLM を活用したデータ処理において、主観的な判断に頼らず定量的な評価を行う基盤を提供します。開発現場では、抽出精度の向上やコスト対効果の最適化が容易になり、実装の信頼性が飛躍的に高まると予想されます。
編集コメント
データ抽出は RAG や自動化プロセスの根幹となる重要な要素であり、その評価基準が明確化されたことは開発者にとって大きな追い風となります。
2 週間前、私たちは langchain-benchmarks パッケージをリリースし、LangChain ドキュメントを対象とした Q&A データセットも公開しました。本日、チャットログから正しい構造化情報を推論する LLM の能力を測定する新しい extraction dataset を公開します。
この新しいデータセットは、構造化されていないテキストの分類や、機械可読な情報の生成、また混乱を招く情報の中で複数のタスクに推論を行うなど、LLM アプリケーション開発における一般的な課題を実践的な環境でテストできる場を提供します。
本稿の後半では、このデータセットの作成プロセスと初期ベンチマーク結果について解説します。会話型アプリケーションの開発においてお役に立てれば幸いです。また、皆様からのフィードバックを心よりお待ちしています!
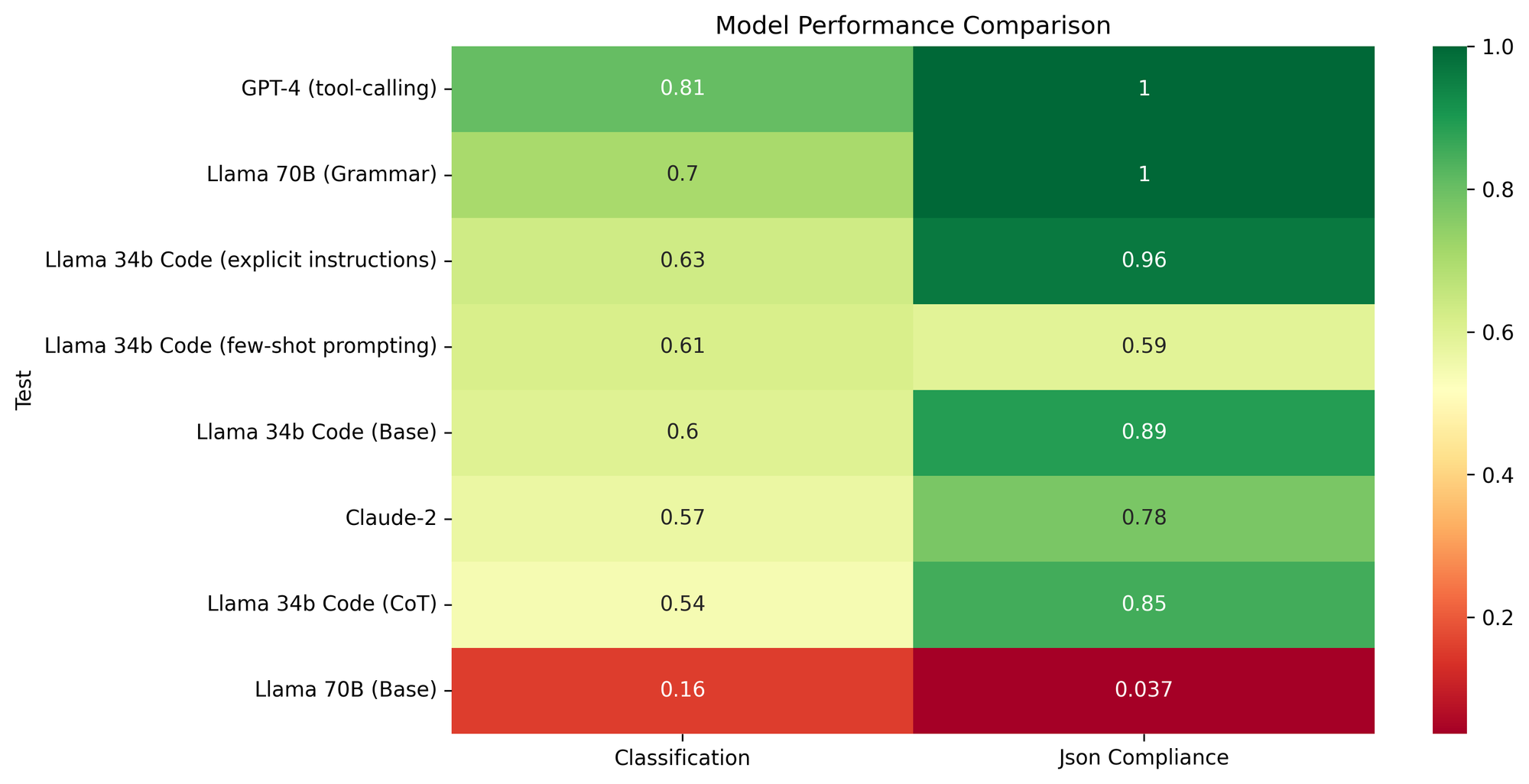
主要指標の比較
データセット作成の動機
私たちは、チャットボットのやり取りから構造化された洞察を引き出すという実世界の課題を軸に、データセットのスキーマを設計しました。
夏の間、優秀なインターンの Molly が、LangChain の Python ドキュメントを対象とした検索拡張生成(RAG: retrieval-augmented generation)アプリケーションである Chat LangChain (リポジトリ) の刷新を手伝ってくれました。これは「検索エンジン付きの LLM」のようなもので、「エージェントにメモリを追加するにはどうすればよいですか?」といった質問をすると、ドキュメント内で見つかった情報に基づいて回答を返してくれます。
このような プロジェクト の真の試練は、デプロイ後に始まります。そこで実際にどのように利用されているかを観察し、さらに改善を繰り返すことになります。通常、ユーザーが明示的なフィードバックを提供することは稀ですが、その会話内容からは多くのことが読み取れます。単に「ログを LLM に放り込んで 要約する」ことを試すこともできますが、構造化されたコンテンツを抽出して監視・分析を行うことでも大きなメリットを得られるケースが多々あります。これにより、従来のソフトウェアで容易に利用可能な構造化値を活用した分析ダッシュボードの構築や、ファインチューニング用のデータ収集パイプラインの強化につなげることができます。
「Chat Extraction」データセットは、現在の LLM(大規模言語モデル)群が、この種のデータから関連情報を抽出し分類する能力をいかによくテストできるかを設計したものです。次のセクションでは、どのようにしてこのデータセットを作成したかを紹介していきます。結果だけを見たい場合は、以下の要約グラフをご覧ください。結果の分析については、実験セクションへ直接お進みください。
ベンチマーク結果のスクリーンショット
データセットの作成
データセットを作成する主な手順は以下の通りです:
- 構造化された出力を表現するためのデータモデルを決定する。
- Q&A ペアでシードする。
- LLM を使用して候補回答を生成する。
- アノテーションキュー内で結果を手動レビューし、必要に応じてタクソノミーを更新する。
LangChain は長年、初期データのブートストラップに役立つ 合成 データセット 生成 ユーティリティを提供してきましたが、最終版では常に適切な品質を確保するために何らかの人間によるレビューを含める必要があります。そのため、LangSmith に データアノテーションキュー を追加し、データのフライホイール構築を支援するためのツールリングの改善を続けていきます。
初期データセットが整ったら、ラベル付きデータをシード生成モデル内のフューショット例として使用して、人間によるレビューのために提供されるデータの品質を向上させることができます。これにより、グラウンドトゥルースを更新する際に必要な作業量や変更量を削減できます。
評価
このベンチマークは構造と分類に焦点を当てているため、LLM-as-a-judge の指標を使用する必要はありません。代わりに、カスタムの LangSmith 評価器を作成しました(詳細は こちら のコード定義を参照)。以下に測定項目を示します:
- Structure verificationjson_schema : 正しい場合は1、そうでない場合は0。タスクのスキーマを用いて、各モデルから解析された出力を検証します。
- Classification tasksquestion_category: 25 の有効な列挙値全体における分類精度。
- off_topic_similarity: LLM がその質問をトピック外とみなしたかどうかの二値分類精度。
- toxicity_similarity: ユーザー質問の「毒性」レベル予測値の正規化された差分。
- programming_language_similarity - ユーザーの質問が参照するプログラミング言語の予測値の分類精度。多くの場合、これは「不明」となります。
- confidence_level_similarity - 応答の予測される「自信度」とラベル付けされた自信度の間の正規化された類似度。
- sentiment_similarity - 予測値とラベル値の正規化された差分。感情は負/中立/正に対してそれぞれ0/1/2 でスコアリングされます。
- Overall differencejson_edit_distance: これは実質的に包括的な指標であり、まず予測された JSON とラベル付けされた JSON を標準化した上で、両者のシリアライズ形式間の Damerau-Levenshtein 文字列距離を計算します。
Experiments
このデータセットを作成するにあたり、私たちはいくつかの問いに答えようと考えました:
- 最も人気のあるクローズドソースのLLM(大規模言語モデル)はどのように比較されるのか?
- オフザ shelf のオープンソース LLM は、クローズドソースモデルと比較してどの程度パフォーマンスを発揮するのか?
- シンプルなプロンプト戦略は、抽出性能を向上させるのにどれほど効果的なのか?
- 有効なレコードを出力するようにLLMの文法を制御した場合、個々の分類指標に対してこれはどの程度の重要性を持つのか?
以下のLLMを評価しました:
- gpt-4-1106-preview: GPT-4 の最近の長文脈対応・圧縮版。
- claude-2: Anthropic 製のLLM。
- llama-v2-34b-code-instruct: 命令データセットでファインチューニングされた、Code Llama 2 のパラメータ数 340 億(34b)のバリアント。
- llama-v2-chat-70b: チャット用にファインチューニングされた、Llama 2 のパラメータ数 700 億(70b)のバリアント。
- yi-34b-200k-capybara: Nous Research 製の、パラメータ数 340 億(34b)のモデル。
実験 1:GPT vs. Claude
まず、クローズドソースのLLMであるClaude-2とGPT-4を比較しました。GPT-4については、JSONスキーマを提供してそれを埋め込ませるツール呼び出しAPI(tool-calling API)を使用しました。Anthropic はまだ同様のツール呼び出しAPI をリリースしていないため、スキーマを指定する 2 つの異なる方法をテストしました:
- JSON スキーマとして直接指定。
- XSD(XML スキーマ定義)として指定。
個々の予測結果は リンクされたテスト で並べて確認できます。また、以下の要約グラフと表もご覧ください:
GPT-4 と Claude の比較
テスト
信頼度レベルの類似性
JSON 編集距離
JSON スキーマ
トピック外類似性
プログラミング言語の類似性
質問カテゴリ
感情の類似性
毒性の類似性
0.97
0.39
0.52
0.00
0.52
0.37
0.91
1.0
claude-2-json-schema-to-xml-5689
0.97
0.37
0.78
0.00
0.44
0.48
0.93
1.0
0.94
0.28
1.00
0.89
0.59
0.56
1.00
0.0
予想通り、GPT-4 はほぼすべての指標でより良いパフォーマンスを示しました。一方、Claude に対しては、一度の試行で望ましいスキーマを完全に出力させることはできませんでした。興味深いことに、JSON スキーマ(JSON schema)を使用してプロンプトされた Claude モデルの方が、同じ情報を XSD(XML スキーマ)形式で提供した場合よりもわずかに良い結果を示しました。これは少なくともこのケースにおいては、スキーマの一貫したフォーマットがそれほど重要ではないことを示唆しています。
いくつかの共通するスキーマの問題が見て取れます。例えば、このラン と このラン では、モデルがフォローアップアクションに対して適切にタグ付けされた要素ではなく、箇条書きリストを出力してしまい、それが文字列としてパースされてリストとして認識されませんでした。以下にその例を示します。

スキーマエラーこれらのパースエラーはケースバイケースで修正可能ですが、予測不可能性が全体的な開発体験を阻害しています。ある抽出チェーンから別のタスクへ適応する際にもオーバーヘッドが増大し、パーサーやその他の挙動がより一貫性を欠くようになります。また、XML 構文は GPT と比較して Claude の全体的なトークン使用量を増加させます。「トークン」自体を直接比較することはできませんが、冗長な構文は応答時間の遅延とコストの上昇をもたらす可能性が高いです。
実験 2: オープンソースモデル
次に、市販の一般的なオープンソースモデルをベンチマークしたく、同じ基本プロンプトを 3 つのモデルで比較することから始めました。
- llama-v2-34b-code-instruct - 指示データセット上で微調整された、Code Llama 2 の 340 億パラメータ版バリアント。
- llama-v2-chat-70b - チャット用に微調整された、Llama 2 の 700 億パラメータ版バリアント。
- yi-34b-200k-capybara - Nous Research 製の 340 億パラメータモデル。
LangSmith で出力を確認するにはリンクされた比較をご覧ください。または、以下の集計メトリクスを参照してください:
比較対象: ベースラインオープンソースモデル
テスト項目
信頼性レベル類似度 (confidence_level_similarity)
JSON 編集距離 (json_edit_distance)
JSON スキーマ適合度 (json_schema)
トピック外類似度 (off_topic_similarity)
プログラミング言語類似度 (programming_language_similarity)
質問カテゴリ分類 (question_category)
感情類似度 (sentiment_similarity)
毒性類似度 (toxicity_similarity)
-0.30
0.16
0.37
0.41
0.15
0.15
0.28
0.41
0.30
0.43
0.04
0.30
0.15
0.04
0.30
0.00
llama-v2-34b-code-instruct-bcce-v1
0.93
0.41
0.89
0.89
0.44
0.07
0.59
1.00
モデルサイズが大きいにもかかわらず、Llama 2 の 70B バリアントは JSON を確実に出力しませんでした。これは、事前トレーニングおよび SFT コーパスに含まれるコードの量が少なかったためです。Yi-34b はこの点でより信頼性がありましたが、それでも必要なスキーマに一致するのは 37% の場合に限られました。また、分類タスクの中でも最も困難な質問カテゴリ分類(question_category classification)においては、より良いパフォーマンスを示しました。
34B Code Llama 2 は有効な JSON を出力でき、他の指標においても decent な結果を残したため、以下のプロンプト実験のベースラインとして使用します。
Experiment 3: スキーマ準拠のためのプロンプティング
3 つのオープンモデルベースラインの中で、34B Code Llama 2 バリアントが最も優れたパフォーマンスを示しました。このため、このモデルを選択し、「単純なプロンプト手法は、モデルに信頼性の高い構造化された JSON を出力させるためにどの程度機能するのか」という問いに対する回答としました(ヒント:あまりうまくいきません)。こちらの手順書を使用して、実験を再実行することができます。
ベースライン実験において、最も一般的な失敗モードは、無効な Enum 値のハルシネーション(例:こちらの実行結果を参照)や、質問の感情分析(question sentiment)のような単純なタスクにおける分類性能の低さでした。
これらが集計パフォーマンスにどのような影響を与えるかを確認するため、3 つのプロンプト戦略をテストしました。
- タスク固有の指示を追加する:スキーマには各値の説明が含まれているが、例えばリストから有効な列挙型値を慎重に選択するという追加の指示が役立つかどうかを確認したかった。このアプローチは数々のプレイグラウンド例でテストしたが、場合によっては効果があることがわかった。
- 思考連鎖(Chain-of-thought):最終出力を生成する前に、スキーマ構造について段階的に考えるようモデルに求める手法。
- フューショット例(Few-shot examples):明示的な指示とスキーマに加えて、モデルが従うべき期待される入力 - 出力ペアを手作業で作成した。LLM は(人間と同様に)、指示から学ぶよりも数例を見ることでよりよく学習することがある。
以下に結果を示す:
OSS モデルにおけるプロンプト戦略の比較
テスト
プロンプト
confidence_level_similarity
json_edit_distance
json_schema
off_topic_similarity
programming_language_similarity
question_category
sentiment_similarity
toxicity_similarity
llama-v2-34b-code-instruct-bcce-v1
ベースライン
0.93
0.41
0.89
0.89
0.44
0.07
0.59
1.00
llama-v2-34b-code-instruct-e20e-v1
指示
0.95
0.38
0.96
0.89
0.63
0.11
0.54
1.00
llama-v2-34b-code-instruct-34b8-v2
few-shot(少例学習)
0.89
0.38
0.59
0.85
0.33
0.07
0.85
0.96
llama-v2-34b-code-instruct-d3a3-v2
CoT(Chain of Thought:思考の連鎖)
0.97
0.42
0.85
0.85
0.44
0.04
0.57
0.81
提示されたプロンプト戦略のいずれも、対象となる指標において意味のある改善を示していません。few-shot 学習(少例学習)の手法は、むしろ JSON スキーマテストにおけるモデルのパフォーマンスを低下させています(参照:example)。これは、プロンプト内のコンテンツ量が増加し、生きたスキーマから注意が逸れてしまったためかもしれません。指示を明示化することは、モデルに質問に集中するよう指示しているため、プログラミング言語分類のパフォーマンス向上につながっているように見えます。しかし、その寄与はわずかであり、感情分析の指標においては、モデルは依然として*レスポンス*の感情に気を取られ続けています。
Experiment 4: Structured Decoding
プロンプト手法のいずれもモデル出力の構造化に顕著な向上をもたらさないため、スキーマ準拠の JSON を確実に生成する他の方法をテストすることにした。具体的には、ロジットバイアスや制約ベースサンプリング [constraint-based sampling] などの構造化デコーディング手法を適用したいと考えている。ガイド付きテキスト生成に関する調査については、Lilian Weng の 優れた投稿 を参照されたい。
本実験では、Llama 70B を用い、Llama.cpp の文法ベースの デコーディング機構 を適用して有効な JSON スキーマを保証する。ベースラインとの比較はこちらおよび以下の表を参照されたい。
Compare Baseline vs. Grammar-based Decoding
Test
Decoding
confidence_level_similarity
json_edit_distance
json_schema
off_topic_similarity
programming_language_similarity
question_category
sentiment_similarity
toxicity_similarity
baseline
0.30
0.43
0.04
0.30
0.15
0.04
0.3
0.0
structured
0.93
0.44
1.00
0.89
0.37
0.26
1.0
1.0
最も目立っており、かつ予想された改善点は、json_schema(JSON スキーマ)の正しさがほぼ常に誤りだったものが 100% の妥当性へと向上したことです。これは、他の値も信頼して解析できるようになったことを意味し、これらのフィールドにおける 0 の数が減少しました。ベースとなる Llama 70B チャットモデルは、以前の 34B モデル実験よりも規模が大きく能力が高いため、感情類似度や質問カテゴリにおいても改善が見られます。ただし、これらの指標における絶対的なパフォーマンスはまだ低いです。文法に基づくデコーディング(decoding)により出力構造が保証されますが、それだけでは値自体の品質を保証するには不十分です。
Full Results
上記の実験の完全な結果については、LangSmith テストリンク をご確認ください。また、こちら のノートブックの手順に従うことで、これらのベンチマークを独自モデルに対して実行することも可能です。
Related content

Case Studies
LangGraph
LangSmith
Tutorials & How-Tos
How Lyft Built a Self-Serve AI Agent Platform for Customer Support with LangGraph and LangSmith

Akshay Sharma
May 27, 2026
10
min

LangSmith
Agent Architecture
Deep Agents
Tutorials & How-Tos
How We Built LangSmith Engine, Our Agent for Improving Agents

Palash Shah
May 19, 2026
17 分

チュートリアル & ハウツーガイド
LangChain の GTM エージェントの構築方法

LangChain チーム
2026 年 3 月 9 日
11 分

エージェントが実際に何をしているかを確認する
LangSmith は、エージェントエンジニアリングプラットフォームであり、開発者がすべてのエージェントの意思決定をデバッグし、変更の評価を行い、ワンクリックでデプロイできるように支援します。
原文を表示

Two weeks ago, we launched the langchain-benchmarkspackage, along with a Q&A dataset over the LangChain docs. Today we’re releasing a new extraction dataset that measures LLMs' ability to infer the correct structured information from chat logs.
The new dataset offers a practical environment to test common challenges in LLM application development like classifying unstructured text, generating machine-readable information, and reasoning over multiple tasks with distracting information.
In the rest of this post, I'll walk through how we created the dataset and share some initial benchmark results. We hope you find this useful for your own conversational app development and would love your feedback!
Motivation for the dataset
We wanted to design the dataset schema around a real-world problem: gleaning structured insights from chat bot interactions.
Over the summer, our excellent intern Molly helped us refresh Chat LangChain (repo), a retrieval-augmented generation (RAG) application over LangChain's python docs. It’s an “LLM with a search engine”, so you can ask it questions like "How do I add memory to an agent?”, and it will tell you an answer based on whatever it can find in the docs.
The real test of such a project begins post-deployment, when you begin to observe how it's used and refine it further. Typically, users won't provide explicit feedback, but their conversations reveal a lot, and while you can try just “putting the logs into an LLM” to summarize it, you can also often benefit from extracting structured content to monitor and analyze. This could help drive analytic dashboards or fine-tuning data collection pipelines, since the structured values can easily be used by traditional software.
The Chat Extraction dataset is designed around testing how well today's crop of LLMs are able to extract and categorize relevant information from this type of data. In the following section, I’ll walk through how we created the dataset. If you just want to see the results, check out the summary graph below. You can feel free to jump to the experiments section for an analysis of the results.
Creating the Dataset
The main steps for creating the dataset were:
- Settle on a data model to represent the structured output.
- Seed with Q&A pairs.
- Generate candidate answers using an LLM.
- Manually review the results in the annotation queue, updating the taxonomy where necessary.
LangChain has long had synthetic dataset generation utilities that help you bootstrap some initial data, but the final version should always involve some amount of human review to ensure proper quality. That’s why we’ve added data annotation queue’s to LangSmith and will continue to improve our tooling to help you build your data flywheel.
Once you have an initial dataset, you can use the labeled data as few-shot examples within the seed-generation model to improve the quality of data given to humans for review. This can help reduce the amount of work and changes needed when updating the ground truth.
Evaluation
This benchmark is focused on structure and classification, and as such, we don't need to use any LLM-as-a-judge metrics. Instead, we wrote custom LangSmith evaluators (see the code definition here). Below is what we measured:
- Structure verificationjson_schema : 1 if correct, 0 if not. We validate the parsed output for each model using the task schema.
- Classification tasksquestion_category: classification accuracy over the 25 valid enum values.
- off_topic_similarity: binary classification accuracy of whether the LLM considered the question off-topic
- toxicity_similarity: normalized difference in predicted level of "toxicity" of the user question.
- programming_language_similarity - classification accuracy of the predicted programming language the user's question references. In most cases, this is "unknown".
- confidence_level_similarity the normalized similarity between the predicted "confidence" of the response and the labeled confidence.
- sentiment_similarity - Normalized difference between the prediction and label. Sentiment is scored as 0/1/2 for negative/neutral/positive.
- Overall differencejson_edit_distance: this is a bit of a catch-all that first canonicalizes the predicted json and label json and then computes the Damerau-Levenshtein string distance between the two serialized forms.
Experiments
In making this dataset, we wanted to answer a few questions:
- How do the most popular closed-source LLMs compare?
- How well do off-the-shelf open source LLMs perform relative to the closed-source models?
- How effective are simple prompting strategies improving extraction performance?
- If we control the LLM grammar to output a valid record, how significant is this for the individual classification metrics?
We evaluated the following LLMs:
- gpt-4-1106-preview the recent long-context, distilled version of GPT-4.
- claude-2 - an LLM from Anthropic.
- llama-v2-34b-code-instruct - a 34b parameter variant of Code Llama 2 fine-tuned on an instruction dataset.
- llama-v2-chat-70b - a 70b parameter variant of Llama 2 fine-tuned for chat.
- yi-34b-200k-capybara - a 34b parameter model from Nous Research.
Experiment 1: GPT vs. Claude
We first compared Claude-2 and GPT-4, both closed-source LLMs. For GPT-4, we used its too-calling API, which lets you provide a JSON schema for it to populate. Since Anthropic has yet to release a similar tool-calling API, we tested two different ways of specifying the schema:
- Directly as a Json schema.
- As an XSD (XML schema)
You can review the individual predictions side-by-side at the linked tests. You can also check out the summary graph and table below:
Comparing GPT-4 and Claude
Test
confidence_level_similarity
json_edit_distance
json_schema
off_topic_similarity
programming_language_similarity
question_category
sentiment_similarity
toxicity_similarity
0.97
0.39
0.52
0.00
0.52
0.37
0.91
1.0
claude-2-json-schema-to-xml-5689
0.97
0.37
0.78
0.00
0.44
0.48
0.93
1.0
0.94
0.28
1.00
0.89
0.59
0.56
1.00
0.0
As expected, GPT-4 performs better across almost all metrics, and we were unable to get Claude to perfectly output the desired schema in a single shot. Interestingly enough, the Claude model prompted with a JSON schema does slightly better than the one prompted with the same information provided in an XSD (XML schema), indicating that at least in this case, consistent formatting of the schema isn't that important.
It's easy to see some common schema issues; for instance, in this run and this run, the model outputs a bullet-point list for the follow-up actions rather than properly tagged elements, which was parsed as a string rather than a list. Below is an example image of this:
While we can fix these parsing errors on a case-by-case basis, the unpredictability hinders the overall development experience. There's more overhead in adapting one extraction chain to another task since the parser and other behavior is less consistent. The XML syntax also increases the overall token usage of Claude relative to GPT. Though "tokens" aren't directly comparable, verbose syntaxes will likely lead to slower response times and higher costs.
Experiment 2: Open-Source Models
We next wanted to benchmark popular open-source models off-the shelf, and started out by comparing the same basic prompt across three models:
- llama-v2-34b-code-instruct - a 34b parameter variant of Code Llama 2 fine-tuned on an instruction dataset.
- llama-v2-chat-70b - a 70b parameter variant of Llama 2 fine-tuned for chat.
- yi-34b-200k-capybara - a 34b parameter model from Nous Research.
Check out the linked comparisons to see the outputs in LangSmith, or reference the aggregate metrics below:
Compare Baseline OSS Models
Test
confidence_level_similarity
json_edit_distance
json_schema
off_topic_similarity
programming_language_similarity
question_category
sentiment_similarity
toxicity_similarity
-0.30
0.16
0.37
0.41
0.15
0.15
0.28
0.41
0.30
0.43
0.04
0.30
0.15
0.04
0.30
0.00
llama-v2-34b-code-instruct-bcce-v1
0.93
0.41
0.89
0.89
0.44
0.07
0.59
1.00
Despite its larger model size, the 70B variant of Llama 2 did not reliably output JSON, since the amount of code included in its pretraining and SFT corpus was low. Yi-34b was more reliable in this regard, but it still only matched the required schema 37% of the time. It also performs better on the hardest of the classification tasks, the question_category classification.
The 34B Code Llama 2 was able to output valid JSON and did a decent job for the other metrics, so we will use it as the baseline for the following prompt experiments.
Experiment 3: Prompting for Schema Compliance
Of the three open model baselines, the 34B Code Llama 2 variant performed the best. Because of this, we selected it to answer the question "how well do simple prompting techniques work in getting the model to output reliably structured JSON" (hint: not very well). You can re-run the experiments using this notebook.
In the baseline experiments, the most common failure mode was hallucination of invalid Enum values (see for example, this run), as well as poor classification performance for simple things like question sentiment.
We tested three prompting strategies to see how they impact the aggregate performance:
- Adding additional task-specific instructions: the schema already has descriptions for each value, but we wanted to see if additional instructions to e.g., carefully select a valid Enum values from the list, would help. We had tested this approach on a couple of playground examples and saw that it could occasionally help.
- Chain-of-thought: Ask the model to think step by step about the schema structure before generating the final output.
- Few-shot examples: We hand-crafted expected input-output pairs for the model to follow, in addition to the explicit instructions and schema. Sometimes LLMs (like people) learn better by seeing a few examples rather than from instructions.
Below are the results:
Compare Prompt Strategies for OSS Models
Test
Prompt
confidence_level_similarity
json_edit_distance
json_schema
off_topic_similarity
programming_language_similarity
question_category
sentiment_similarity
toxicity_similarity
llama-v2-34b-code-instruct-bcce-v1
baseline
0.93
0.41
0.89
0.89
0.44
0.07
0.59
1.00
llama-v2-34b-code-instruct-e20e-v1
instructions
0.95
0.38
0.96
0.89
0.63
0.11
0.54
1.00
llama-v2-34b-code-instruct-34b8-v2
few-shot
0.89
0.38
0.59
0.85
0.33
0.07
0.85
0.96
llama-v2-34b-code-instruct-d3a3-v2
CoT
0.97
0.42
0.85
0.85
0.44
0.04
0.57
0.81
None of the prompting strategies demonstrate meaningful improvements on the metrics in question. The few-shot examples technique even decreases performance of the model on the JSON Schema test (see: example). This may be because we are increasing the amount of content in the prompt that distracts from the raw schema. Making the instructions explicit does seem to improve the performance of the programming language classification, since the model is instructed to focus on the question. The contribution is minor, however, and for the sentiment classification metric, the model continues to get distracted by the *response* sentiment.
Experiment 4: Structured Decoding
Since none of the prompting techniques offer a significant boost to the structure of the model output, we wanted to test other ways to reliably generate schema-compliant JSON. Specifically, we wanted to apply structured decoding techniques such as logit biasing / constraint-basedsampling. For a survey on guided text generation, check out Lilian Weng's excellent post.
In this experiment, we test Llama 70Busing Llama.cpp's grammar-based decoding mechanism to guarantee a valid JSON schema. See the comparison with the baseline here and in the table below.
Compare Baseline vs. Grammar-based Decoding
Test
Decoding
confidence_level_similarity
json_edit_distance
json_schema
off_topic_similarity
programming_language_similarity
question_category
sentiment_similarity
toxicity_similarity
baseline
0.30
0.43
0.04
0.30
0.15
0.04
0.3
0.0
structured
0.93
0.44
1.00
0.89
0.37
0.26
1.0
1.0
The most noticeable (and expected) improvement is that the json_schema correctness went from almost never correct to 100% validity. This means that the other values also could be reliably parsed, leading to fewer 0's in these fields. Since the base Llama 70B chat model is also larger and more capable than our previous 34B model experiments, we can see improvements in the sentiment similarity and question category as well. However, the absolute performance in these metrics is still low. Grammar-based decoding makes the output structure guaranteed, but it alone is insufficient to guarantee the quality of the values themselves.
Full Results
For the full results for the above experiments, check out the LangSmith test link. You can also run any of these benchmarks against your own model by following the notebook here.
Related content
Case Studies
LangGraph
LangSmith
Tutorials & How-Tos
How Lyft Built a Self-Serve AI Agent Platform for Customer Support with LangGraph and LangSmith
Akshay Sharma
May 27, 2026
10
min

LangSmith
Agent Architecture
Deep Agents
Tutorials & How-Tos
How We Built LangSmith Engine, Our Agent for Improving Agents
Palash Shah
May 19, 2026
17
min
Tutorials & How-Tos
How we built LangChain’s GTM Agent
The LangChain Team
March 9, 2026
11
min
See what your agent is really doing
LangSmith, our agent engineering platform, helps developers debug every agent decision, eval changes, and deploy in one click.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み