Amazon SageMaker AIが最適化された生成AI推論の推奨機能を提供開始
AWSはAmazon SageMaker AIに最適化された生成AI推論推奨機能を追加し、GPU構成や手動ベンチマークに要する数週間のデプロイ作業を自動化・最適化する。
キーポイント
デプロイのボトルネック
生成AIモデルを実環境に展開するには、GPUインスタンスの選定、並列化戦略、最適化技術の組み合わせ検証に数週間を要し、レイテンシやコスト目標の達成が困難だった。
自動推奨機能の提供
SageMaker AIが検証済みかつ最適なデプロイ構成とパフォーマンス指標を自動的に提供し、開発者がインフラ管理からモデル精度の向上へ集中できる環境を整えた。
NVIDIA AIPerfの統合
ベンチマーク基盤としてNVIDIA DynamoのAIPerfを採用し、CLIと並列制御機能により多様なワークロードを迅速にテスト可能な基盤を提供している。
運用目標の標準化
レイテンシSLA、スループット上限、コスト制約を満たすためのインフラ設定を標準化し、再現性の高いデプロイフローを確立した。
SageMaker AI最適化推薦のプログラム抽出
提供コードは、SDKレスポンスからモデルパッケージARN、推論仕様名、推奨インスタンスタイプを抽出する実装例を示している。
推論環境構築に必要なリソース情報の取得
ModelPackageArnとInstanceTypeを取得することで、コスト最適化されたGenerative AIの推論エンドポイントを自動的に構築・デプロイできる。
影響分析・編集コメントを表示
影響分析
本機能は、生成AIのビジネス展開における最大のボトルネックである「インフラ最適化とベンチマーク」をクラウド上で自動化する画期的な取り組みである。これにより、スタートアップから大企業まで、モデル開発に集中できる環境が整い、GenAIの普及スピードとROIが加速すると期待される。ただし、推奨結果の解釈や特定ユースケースでの微調整には依然として専門知識が求められる点には留意が必要だ。
編集コメント
AWSとNVIDIAの連携は、生成AIの実装コストを下げ、企業内のAI採用障壁を下げる重要な一歩です。ただし、推奨設定が万能ではないため、ワークロード特性に応じた検証は引き続き開発者の責任となります。
組織は、インテリジェントアシスタント、コード生成ツール、コンテンツエンジン、顧客向けアプリケーションを駆動するために、生成 AI(generative AI)モデルを実環境(production)へのデプロイ競争を繰り広げています。しかし、これらのモデルを実環境にデプロイするのは、GPU 構成(GPU configurations)の選定、最適化手法(optimization techniques)の適用、手動ベンチマーク(manual benchmarking)の実行を巡る数週間かかるプロセスであり、これらのモデルが本来持つ価値の提供が遅れる原因となっています。
本日、Amazon SageMaker AI は 最適化された生成 AI 推論推奨設定(optimized generative AI inference recommendations) をサポートするようになりました。検証済みで最適なデプロイ構成とパフォーマンス指標(performance metrics)を提供することで、Amazon SageMaker AI はモデル開発者がインフラの管理ではなく、正確なモデルの構築に集中し続けることを可能にします。
当社は複数のベンチマークツール(benchmarking tools)を評価し、NVIDIA Dynamo のモジュールコンポーネント(modular component)である NVIDIA AIPerf を採用しました。これは、詳細で一貫性のあるメトリクスを公開し、多様なワークロード(workloads)を初期設定なしでサポートするためです。CLI(コマンドラインインターフェース)、並行性制御(concurrency controls)、データセットオプションにより、最小限の設定で迅速に反復処理を行い、多様なシナリオをテストする柔軟性が得られます。
「オープンソースの NVIDIA Dynamo 分散推論フレームワーク(distributed inference framework)のモジュールコンポーネントを Amazon SageMaker AI に直接統合することで、AWS は企業が生成 AI モデルを確信を持ってデプロイしやすくしています。AWS は深い協力と技術的貢献を通じて、AIPerf の発展に重要な役割を果たしてきました。NVIDIA AIPerf の統合は、標準化されたベンチマークが数週間にわたる手動テストを排除し、検証済みでデプロイ準備が整った構成を終端ユーザーに提供する方法を示しています。」
- Eliuth Triana、NVIDIA デベロッパーリレーションズマネージャー
課題:モデルから実環境(production)へのデプロイに数週間を要する
大規模なモデルのデプロイには、明確なパフォーマンス目標(レイテンシサービスレベル契約(SLA)、スループット目標、またはコスト上限のいずれか)を満たす本番環境用推論エンドポイント(production inference endpoints)が必要です。それを実現するには、特定のモデルとトラフィックパターンに最適化された、GPU インスタンスタイプ、サービングコンテナ(serving container)、並列化戦略(parallelism strategy)、最適化手法の適切な組み合わせを見つける必要があります。
 image
image
Figure 1: チームが生成 AI モデルを実環境にデプロイする際に対峙する 3 つの中核課題
決定空間は途方もなく広大です。単一のデプロイメントでは、12種類以上のGPUインスタンスタイプ、複数のサービングコンテナ(serving containers)、さまざまな並列度(parallelism degrees)、そしてスペキュラティブ・ディコーディング(speculative decoding)などの最適化技術の選択肢から選ぶ必要があります。これらはすべて互いに複雑に絡み合い、検索を絞り込むための検証済みのガイドラインはありません。正しい構成を見つける唯一の方法は実際にテストすることであり、そこで本当のコストが発生します。チームはインスタンスをプロビジョニングし、モデルをデプロイし、負荷テストを実行して結果を分析し、これを繰り返します。このサイクルにはモデルごとに2〜3週間がかかり、GPUインフラストラクチャ、サービングフレームワーク(serving frameworks)、パフォーマンス最適化に関する専門知識が必要となりますが、そのようなスキルを社内にて保有しているチームはほとんどありません。
多くのチームは手動で作業を開始します。数種類のインスタンスタイプを選択し、モデルをデプロイして負荷テストを実行後、レイテンシ(latency)、スループット(throughput)、コストを比較し、これを繰り返します。より成熟したチームは、ベンチマークツール(benchmarking tools)、デプロイメントテンプレート(deployment templates)、または継続的インテグレーションおよび継続的デリバリー(CI/CD)パイプラインを用いて、プロセスの一部をスクリプト化することが一般的です。ワークロードがスクリプト化されていても、チームは依然として大きな作業負担に直面します。スクリプトのテストと検証を行い、ベンチマーク対象の構成を選択し、環境を整備し、結果を解釈し、レイテンシ、スループット、コストの間のトレードオフ(trade-offs)を調整する必要があります。
チームは、より優れたコスト効率の高いオプションが存在するかどうかを確認できぬまま、重大なインフラストラクチャの決定を迫られることがよくあります。彼らはオーバープロビジョニング(over-provisioning)に頼り、必要なものよりも高価なGPUインフラストラクチャを選択し、支払っているコンピューティングリソース(compute resources)を完全に活用しない構成で運用します。本番環境でのパフォーマンス不足のリスクは、コンピューティングコストの過剰支出よりもはるかに深刻です。その結果、デプロイされるモデルの数やエンドポイント(endpoint)の稼働月数が増えるたびに、無駄なGPU支出が複合的に積み重なっていきます。
最適化された生成AI推論推奨機能の仕組み
独自の生成AIモデル(generative AI model)を持ち込み、期待されるトラフィックパターン(traffic patterns)を定義し、単一のパフォーマンス目標を指定します:コスト最適化、レイテンシ最小化、またはスループット最大化。その後、SageMaker AIが3つのステージで処理を引き継ぎます。
ステージ1:構成空間の絞り込み
SageMaker AIはモデルのアーキテクチャ、サイズ、メモリ要件を分析し、目標を現実的に満たすことができるインスタンスタイプと並列化戦略(parallelism strategies)を特定します。考えられるすべての組み合わせをテストするのではなく、選択したインスタンスタイプ(最大3種類)にわたって評価価値のある構成に検索を絞り込みます。
ステージ2:目標に合わせた最適化の適用
選択したパフォーマンス目標に基づき、SageMaker AIは各候補構成に対して以下の最適化技術を適用します。
- スループットを重視する場合は、フォワードパスごとに複数のトークンを生成できるスペキュラティブ・デコーディング(speculative decoding)モデル(EAGLE 3.0など)を学習させ、トークン生成速度(tokens per second)を大幅に向上させます。
- レイテンシを重視する場合は、トークンあたりの処理時間を削減するために計算カーネル(compute kernels)を最適化し、ファーストトークン生成時間(time to first token)を短縮します。
- モデルのサイズとインスタンスタイプの能力に応じてテンソル並列処理(Tensor parallelism)を適用し、単一GPUのメモリ容量を超えるモデルでも利用可能な複数のGPUに分散して処理できるようにします。
ご自身の目標にどの技術が適しているかを知る必要はありません。SageMaker AI が最適化を自動的に選択し、適用します。
Stage 3: Benchmark and return ranked recommendations
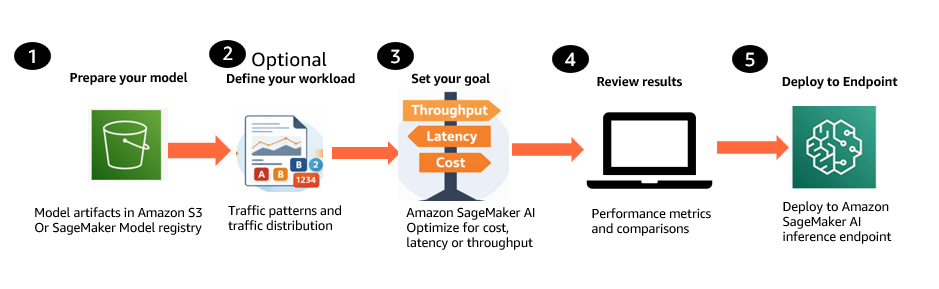
SageMaker AI は、NVIDIA AIPerf を使用して実際のGPUインフラ上で各最適化済み構成をベンチマークし、ファーストトークン生成時間(time to first token)、インタートークンレイテンシ(inter-token latency)、P50/P90/P99 リクエストレイテンシ(P50/P90/P99 request latency)、スループット、コストを計測します。その結果、各構成とインスタンスタイプに対して検証済みのメトリクスを備えた、ランク付けされたデプロイ準備完了の推奨構成が返されます。SageMaker AI API を使用した場合、ワークフローは以下のようになります。
 image
image
Figure 2: Generative AI inference recommendations workflow
- モデルの準備を行います。Amazon Simple Storage Service(Amazon S3)または SageMaker Model Registry から生成AIモデルを取得します。これには、SafeTensor ウェイトを備えた Hugging Face チェックポイント形式、ベースモデル、および独自データで学習したカスタムまたはファインチューニング済みモデルが含まれます。
- ワークロードを定義します(オプション)。入力および出力トークンの分布と同時実行数レベルを含む、予想されるトラフィックパターンを記述します。これらはインラインで指定するか、Amazon S3 からの代表データセットを使用できます。
- 最適化の目標を設定します。単一の目的を選択してください:コストの最適化、レイテンシの最小化、またはスループットの最大化です。比較対象として最大3つのインスタンスタイプを選択します。
- ランク付けされた推奨レビューを行います。SageMaker AI は、ファーストトークン生成時間(Time to First Token)、インタートークンレイテンシ(inter-token latency)、P50/P90/P99 リクエストレイテンシ、スループット、コスト見込み値などの検証済みメトリクスを備えたデプロイ準備完了の構成を返します。推奨事項を比較し、最適な選択を行います。
- 選択した構成を展開します。API を介してプログラムで、選択した構成を SageMaker inference endpoint にデプロイします。
Additional options: 既存の運用エンドポイントをベンチマークして現在の性能を検証したり、新しい構成と比較することもできます。SageMaker AI は、追加の計算コストなしで既存のマシンラーニング(ML)Reservations(Flexible Training Plans)を使用するか、オンデマンドで自動的にプロビジョニングされた計算リソースを使用できます。
価格設定
最適化された生成AI推論(generative AI inference)の推奨を生成することに対して、追加コストはありません。顧客は、最適化された構成を生成する最適化ジョブ(optimization jobs)と、ベンチマーク中にプロビジョニングされるエンドポイント(endpoints)に対して、標準的なコンピューティングコストを負担します。既存のML予約(Flexible Training Plans)を保有する顧客は、追加コストなしで予約済みの容量上でベンチマークを実行できるため、発生するコストは最適化ジョブ自体のみとなります。
最適化された生成AI推論の推奨機能の使用開始には、SageMaker AIでの数回のAPI呼び出し(API calls)のみが必要です。
詳細なAPIの手順解説、コード例、サンプルノートブックについては、SageMaker AI documentationおよびGitHub上のサンプルノートブックをご覧ください。
ベンチマークの厳密性の組み込み
SageMaker AIからのすべての推奨は、見積もりやシミュレーションではなく、実際の測定値に基づいています。内部では、SageMaker AIはオープンソースのベンチマークツールであるNVIDIA AIPerfを使用して、実際のGPUインフラストラクチャ(GPU infrastructure)上ですべての構成をベンチマークします。このツールは、最初のトークンまでの時間(time to first token)、トークン間レイテンシ(inter-token latency)、スループット(throughput)、1秒あたりのリクエスト数(requests per second)といった主要な推論指標を測定します。
AWSはAIPerfへの貢献を通じて、ベンチマーク結果の統計的基盤を強化しました。これらの貢献にはマルチランの信頼度レポート(multi-run confidence reporting)が含まれており、これにより反復されたベンチマーク試行全体での分散を測定し、統計的に根拠のある信頼区間(confidence intervals)を用いて結果の品質を定量化できます。これにより、モデル選択(model selection)、インフラストラクチャのサイズ調整(infrastructure sizing)、パフォーマンスの劣化(performance regressions)に関する判断を下す際に信頼できるベンチマーク結果へと、脆い単一試行の数値から踏み出すことができます。AWSはまた、適応型収束と早期停止(adaptive convergence and early stopping)も貢献しており、これにより指標が安定した時点でベンチマークを停止でき、固定数の試行を常に実行する必要がなくなります。これにより、厳密性を犠牲にすることなく、ベンチマークコストの削減と結果までの時間短縮が実現します。より広い推論コミュニティにとって、これは単一の試行の見出し数字ではなく、反復可能性、統計的信頼度、分布を考慮した分析に焦点を当てることで、ベンチマーク手法の品質を向上させます。
最適化の実際の適用
これらの目標に合わせた最適化が実際にどのように見えるかを確認するため、実際の例を考えてみましょう。GPT-OSS-20Bを単一のml.p5en.48xlarge(H100)インスタンスにデプロイする顧客が、パフォーマンス目標としてスループットの最大化(maximize throughput)を選択した場合を想定します。SageMaker AIは、この目標に対してスペキュラティブデコーディング(speculative decoding)が適切な最適化であることを特定し、EAGLE 3.0のドラフトモデル(draft model)をトレーニングし、サービング構成(serving configuration)に適用します。その後、実際のGPUインフラストラクチャ上でベースラインと最適化された構成の両方をベンチマークします。
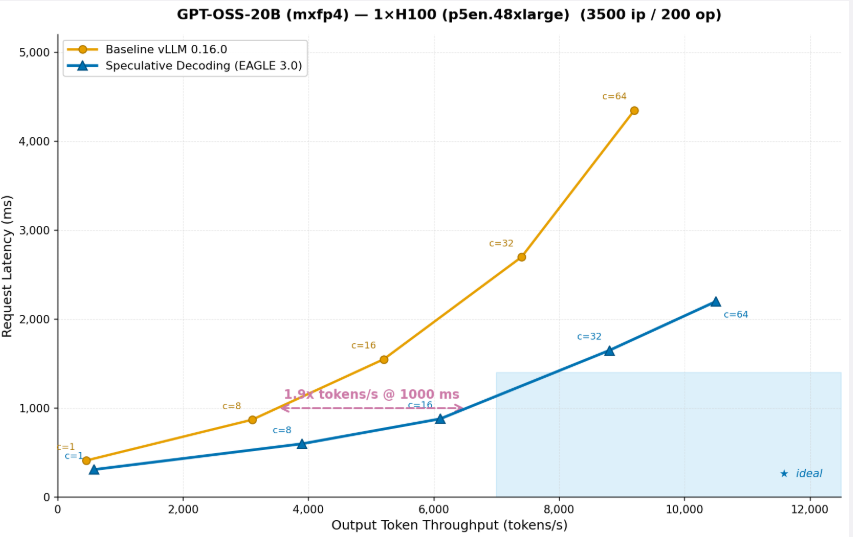
Figure 3: GPT-OSS-20B (mxfp4) on 1x H100 (p5en.48xlarge) (3500 ip / 200 op)
同グラフは、OSS-20Bモデルでスループット最適化(throughput optimization)を実行した後、同じインスタンスタイプでリクエストレイテンシ(request latency)を維持しつつ2倍のトークンを処理できることを示しています。スループット最適化後、同じインスタンスは1,000msのレイテンシで2倍のトークン/秒(tokens/s)を処理できるため、同じハードウェア上で2倍のユーザーに対応可能となり、結果としてトークンあたりの推論コスト(inference cost)を半分に抑えることができます。これは、スループット目標を選択した際にSageMaker AIが自動的に適用する最適化の典型です。スペキュラティブディコーディング(speculative decoding)が適切な手法であることや、ドラフトモデルの訓練方法、特定のモデルとハードウェアへの設定方法をユーザーが知る必要はありません。SageMaker AIがエンドツーエンドで処理し、ランク付けされた推奨事項の一部として検証済みの結果を返します。
Customer value
Cost efficiency and transparency: 選択したインスタンスタイプ間での明確な価格対パフォーマンス比較により、最も高価なオプションにデフォルトで依存するのではなく、適切なサイズ設定(right-sizing)が可能になります。パフォーマンス不足のリスクを避けるために過剰なプロビジョニング(over-provisioning)を行う必要はなく、必要なパフォーマンスを適切なコストで提供できる構成を選択できます。デプロイされるモデルごとに、エンドポイントが稼働する月数ごとに、節約効果は複合的に蓄積していきます。
Speed to production: チームはより迅速に反復作業を繰り返し、より多くの構成をテストし、本番環境への展開(production)を早期に完了できます。デプロイで節約された1日とは、生成AIへの投資が顧客に価値を提供し始める1日です。
Confidence in production: すべての推奨事項は、見積もりやシミュレーションではなく、NVIDIA AIPerfを使用して実際のGPUインフラ上で取得した実測値に基づいています。特定のモデルとワークロードに対して、本番環境の条件に一致するパーセンタイルレベルの精度で検証された構成であることを確信してデプロイできます。
Use cases
- Pre-deployment validation: 本番環境への展開(production deployment)に着手する前に、新モデルの最適化とベンチマーク(benchmark)を実施します。スケーリングへの投資を行う前に、そのパフォーマンスを正確に把握できます。
- Regression testing after updates: コンテナの更新、フレームワークのアップグレード、またはサービングライブラリ(serving library)のリリース後にパフォーマンスを検証します。本番環境への展開(pushing to production)前に、構成が依然として最適であることを確認します。
- Right-sizing when conditions change: トラフィックパターンが変化したり、新しいインスタンスタイプが利用可能になったりした場合、数週間にわたる手動プロセスをやり直すのではなく、数時間で最適化された生成AI推論推奨事項(optimized generative AI inference recommendations)を再実行します。
- Model comparison: 本番環境への展開前に、異なるインスタンスタイプにわたる複数のモデルバリアントのパフォーマンスとコストを比較し、情報に基づいた選択を行います。
- Cost optimization: 既存の本番環境エンドポイント(production endpoints)をベンチマークし、過剰にプロビジョニングされたインフラを特定します。その結果を用いて適切なサイズ設定を行い、継続的な推論コストの削減を図ります。
ベンチマーク推論エンドポイント
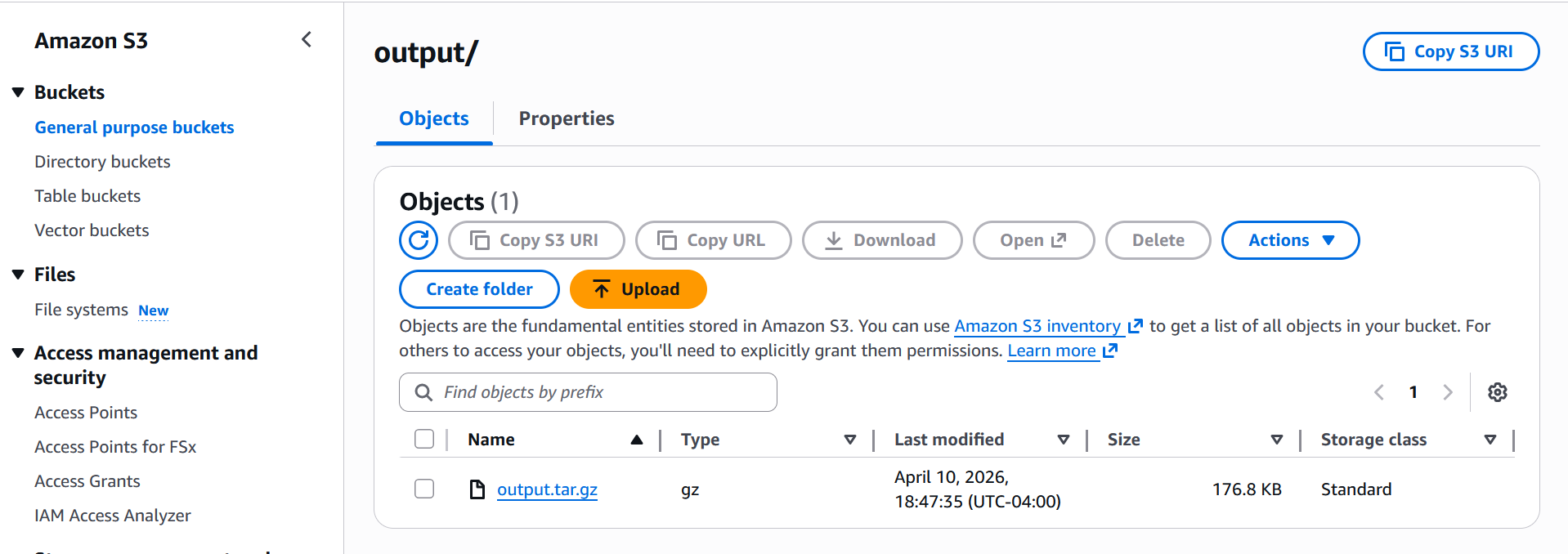
AIベンチマークジョブ(AI benchmark job)は、事前に定義されたワークロード構成(workload configuration)を使用して、SageMaker AI推論エンドポイント(SageMaker AI inference endpoints)に対してパフォーマンスベンチマークを実行します。最適化前後の生成AI推論インフラストラクチャ(generative AI inference infrastructure)のパフォーマンスを測定するためにベンチマークジョブを使用してください。ベンチマークジョブが完了すると、結果は指定したAmazon S3出力ロケーション(Amazon S3 output location)に保存されます。ジョブ完了後、すべての結果は以下スクリーンショットに示すように、S3出力パスのoutputフォルダに書き込まれます:
zip形式の出力ファイルをダウンロードして展開すると、以下のファイルが生成されます。
output/
├── profile_export_aiperf.json # aggregated metrics
├── profile_export_aiperf.csv # same metrics in CSV
├── profile_export.jsonl # raw per-request data
├── inputs.json # prompts sent during the run
├── benchmark_summary.txt # completion summary
├── MANIFEST.txt # index of all files with sizes
├── plot_generation.log # plot generation log
├── plots/
│ ├── ttft_timeline.png # TTFT per request over time
│ ├── ttft_over_time.png # TTFT aggregated over run duration
│ ├── summary.txt # list of generated plots
│ └── aiperf_plot.log # plot generation trace
└── logs/
└── aiperf.log # full AIPerf execution log
主要な出力はprofile_export_aiperf.jsonであり、CSV版のprofile_export_aiperf.csvも同じ集計メトリクス(aggregated metrics)を含みます。これには、レイテンシパーセンタイル(latency percentiles)、出力トークンスループット(output token throughput)、初回トークン生成時間(time-to-first-token, TTFT)、およびトークン間レイテンシ(inter-token latency, ITL)が含まれます。これらは、シミュレートされた負荷下でモデルがどのようにパフォーマンスを発揮したかを評価するために使用される数値です。
それに加えて、profile_export.jsonlはリクエストごとの生データ(raw per-request data)を提供します。各個別リクエストは、独自のレイテンシ、トークン数、タイムスタンプを記録してログに出力されます。集計統計では見逃されがちな外れ値(outliers)を特定したり、独自の分析を行ったりしたい場合に有用です。
私たちはGithubにサンプルノートブックを作成しました。このノートブックは、ml.g6.12xlargeインスタンス(4× NVIDIA L40S GPU)にデプロイされたopenai/gpt-oss-20bを、vLLMコンテナ経由でInference Componentとして提供し、ベンチマークを実行します。合成プロンプト(synthetic prompts)を使用して現実的なワークロードをシミュレートし、10人の同時ユーザーで300リクエスト、リクエストあたり約500入力トークンと約150出力トークンを処理する負荷下でのモデルパフォーマンスを測定します。
レコメンデーションからのモデルデプロイ
AIレコメンデーションジョブ(AI Recommendation Job)が完了すると、出力はSageMaker Model Packageとなります。これはバージョン管理されたリソースであり、すべてのインスタンス固有のデプロイ構成を単一のアーティファクトにパッケージ化したものです。
デプロイするには、まず CreateModel を呼び出して ModelPackageName(モデルパッケージ名)とターゲットとするインスタンスの InferenceSpecificationName(推論仕様名)を指定し、Model Package を Deployable Model(デプロイ可能モデル)に変換します。その後、endpoint configuration(エンドポイント構成)を作成し、標準的な SageMaker real-time endpoint(リアルタイムエンドポイント)または Inference Component(推論コンポーネント)としてデプロイします。
デプロイしたい推奨設定を選択する
resp = client.describe_ai_recommendation_job(
AIRecommendationJobName="my-recommendation-job"
)rec = resp["Recommendations"][0]
model_package_arn = rec["ModelDetails"]["ModelPackageArn"]
inference_spec_name = rec["ModelDetails"]["InferenceSpecificationName"]
instance_type = rec["InstanceDetails"][0]["InstanceType"]print(f"Model Package : {model_package_arn}")
print(f"Infere原文を表示
Organizations are racing to deploy generative AI models into production to power intelligent assistants, code generation tools, content engines, and customer-facing applications. But deploying these models to production remains a weeks-long process of navigating GPU configurations, optimization techniques, and manual benchmarking, delaying the value these models are built to deliver.
Today, Amazon SageMaker AI supports optimized generative AI inference recommendations. By delivering validated, optimal deployment configurations with performance metrics, Amazon SageMaker AI keeps your model developers focused on building accurate models, not managing infrastructure.
We evaluated several benchmarking tools and chose NVIDIA AIPerf, a modular component of NVIDIA Dynamo, because it exposes detailed, consistent metrics and supports diverse workloads out of the box. Its CLI, concurrency controls, and dataset options give us the flexibility to iterate quickly and test across different scenarios with minimal setup.
“With the integration of modular components of the open source NVIDIA Dynamo distributed inference framework directly into Amazon SageMaker AI, AWS is making it easier for enterprises to deploy generative AI models with confidence. AWS has been instrumental in advancing AIPerf through deep collaboration and technical contributions. The integration of NVIDIA AIPerf demonstrates how standardized benchmarking can eliminate weeks of manual testing and deliver validated, deployment-ready configurations to end users.”
– Eliuth Triana, Developer Relations Manager of NVIDIA.
The challenge: From model to production takes weeks
Deploying models at scale requires production inference endpoints that satisfy clear performance goals, whether that is a latency service level agreement (SLA), a throughput target, or a cost ceiling. Achieving that requires finding the right combination of GPU instance type, serving container, parallelism strategy, and optimization techniques, all tuned to the specific model and traffic patterns.
Figure 1: The three core challenges teams face when deploying generative AI models to production
The decision space is impossibly large. A single deployment involves choosing from over a dozen GPU instance types, multiple serving containers, various parallelism degrees, and a growing set of optimization techniques such as speculative decoding. These all interact with each other, and there is no validated guidance to narrow the search. The only way to find the right configuration is to test, and that is where the real cost begins. Teams provision instances, deploy the model, run load tests, analyze results, and repeat. This cycle takes two to three weeks per model and requires expertise in GPU infrastructure, serving frameworks, and performance optimization that most teams do not have in-house.
Many teams start manually: they pick a few instance types, deploy the model, run load tests, compare latency, throughput, and cost, then repeat. More mature teams often script parts of the process using benchmarking tools, deployment templates, or continuous integration and continuous delivery (CI/CD) pipelines. Even when workloads are scripted, teams still face significant work. They need to test and validate their scripts, choose which configurations to benchmark, set up the benchmarking environment, interpret the results, and balance trade-offs between latency, throughput, and cost.
Teams are often left making high-stakes infrastructure decisions without knowing whether a better, more cost-effective option exists. They default to over-provisioning, choosing more expensive GPU infrastructure than they need and running configurations that do not fully use the compute resources they are paying for. The risk of under-performing in production is far worse than overspending on compute. The result is wasted GPU spend that compounds with every model deployed and every month the endpoint runs.
How optimized generative AI inference recommendations work
You bring your own generative AI model, define your expected traffic patterns, and specify a single performance goal: optimize for cost, minimize latency, or maximize throughput. From there, SageMaker AI takes over in three stages.
Stage 1: Narrow the configuration space
SageMaker AI analyzes the model’s architecture, size, and memory requirements to identify the instance types and parallelism strategies that can realistically meet your goal. Instead of testing every possible combination, it narrows the search to the configurations worth evaluating, across the instance types you select (up to three).
Stage 2: Apply goal-aligned optimizations
Based on your chosen performance goal, SageMaker AI applies the optimization techniques to each candidate configuration such as:
- For throughput goals, it trains speculative decoding models (such as EAGLE 3.0) that allow the model to generate multiple tokens per forward pass, significantly increasing tokens per second.
- For latency goals, it tunes compute kernels to reduce per-token processing time, lowering time to first token.
- Tensor parallelism is applied based on model size and instance capability, distributing the model across available GPUs to handle models that exceed single-GPU memory.
You do not need to know which technique is right for your goal. SageMaker AI selects and applies the optimizations automatically.
Stage 3: Benchmark and return ranked recommendations
SageMaker AI benchmarks each optimized configuration on real GPU infrastructure using NVIDIA AIPerf, measuring time to first token, inter-token latency, P50/P90/P99 request latency, throughput, and cost. The result is a set of ranked, deployment-ready recommendations with validated metrics for each configuration and instance type. Here is what the workflow looks like from your perspective using SageMaker AI APIs.
Figure 2: Generative AI inference recommendations workflow
- Prepare your model. Bring your generative AI model from Amazon Simple Storage Service (Amazon S3) or the SageMaker Model Registry, including Hugging Face checkpoint formats with SafeTensor weights, base models, and custom or fine-tuned models trained on your own data.
- Define your workload (optional). Describe expected traffic patterns, including input and output token distributions and concurrency levels. You can provide these inline or use a representative dataset from Amazon S3.
- Set your optimization goal. Choose a single objective: optimize for cost, minimize latency, or maximize throughput. Select up to three instance types to compare.
- Review ranked recommendations. SageMaker AI returns deployment-ready configurations with validated metrics such as Time to First Token, inter-token latency, P50/P90/P99 request latency, throughput, and cost projections. Compare the recommendations and select the best fit.
- Deploy the selected configuration. Deploy the chosen configuration to a SageMaker inference endpoint programmatically through the API.
Additional options: You can also benchmark existing production endpoints to validate current performance or compare them against new configurations. SageMaker AI can use existing machine learning (ML) Reservations (Flexible Training Plans) at no additional compute cost, or use on-demand compute provisioned automatically.
Pricing
There is no additional costs for generating optimized generative AI inference recommendations. Customers incur standard compute costs for the optimization jobs that generate optimized configurations and for the endpoints provisioned during benchmarking. Customers with existing ML Reservations (Flexible Training Plans) can run benchmarking on their reserved capacity at no additional cost, meaning the only cost is the optimization job itself.
Getting started with optimized generative AI inference recommendations requires only a few API calls with SageMaker AI.
For detailed API walkthroughs, code examples, and sample notebooks, see the SageMaker AI documentation and the sample notebooks on GitHub.
Benchmarking rigor built in
Every recommendation from SageMaker AI is grounded in real measurements, not estimates or simulations. Under the hood, SageMaker AI benchmarks every configuration on real GPU infrastructure using NVIDIA AIPerf, an open-source benchmarking tool that measures key inference metrics including time to first token, inter-token latency, throughput, and requests per second.
AWS has contributed to AIPerf to strengthen the statistical foundation of benchmarking results. These contributions include multi-run confidence reporting, enabling you to measure variance across repeated benchmark trials and quantify result quality with statistically grounded confidence intervals. This moves you beyond fragile single-run numbers toward benchmark results you can trust when making decisions about model selection, infrastructure sizing, and performance regressions. AWS also contributed adaptive convergence and early stopping, allowing benchmarks to stop once metrics have stabilized instead of always running a fixed number of trials. This means lower benchmarking cost and faster time to results without sacrificing rigor. For the broader inference community, it raises the quality of benchmarking methodology by focusing on repeatability, statistical confidence, and distribution-aware analysis rather than headline numbers from a single trial.
Optimizations in action
To see what these goal-aligned optimizations look like in practice, consider a real example. A customer deploying GPT-OSS-20B on a single ml.p5en.48xlarge (H100) instance selects maximize throughput as their performance goal. SageMaker AI identifies speculative decoding as the right optimization for this goal, trains an EAGLE 3.0 draft model, applies it to the serving configuration, and benchmarks both the baseline and the optimized configuration on real GPU infrastructure.
Figure 3: GPT-OSS-20B (mxfp4) on 1x H100 (p5en.48xlarge) (3500 ip / 200 op)
The graph shows that after running throughput optimization on the OSS-20B model, the same instance can serve 2x more tokens at the same request latency. After throughput optimization, the same instance delivers 2x more tokens/s at 1,000ms latency means you can serve twice as many users on the same hardware, effectively cutting inference cost per token in half. This is exactly the kind of optimization that SageMaker AI applies automatically when you select a throughput goal. You do not need to know that speculative decoding is the right technique, or how to train a draft model, or how to configure it for your specific model and hardware. SageMaker AI handles it end to end and returns the validated results as part of the ranked recommendations.
Customer value
Cost efficiency and transparency: Clear price-performance comparisons across instance types of your choice enable right-sizing instead of defaulting to the most expensive option. Instead of over-provisioning because you cannot afford to risk under-performing, you can select the configuration that delivers the performance you need at the right cost. Savings compound with every model deployed and every month the endpoint runs.
Speed to production: Teams iterate faster, test more configurations, and get to production sooner. Every day saved in deployment is a day your generative AI investment is delivering value to customers.
Confidence in production: Every recommendation is backed by real measurements on real GPU infrastructure using NVIDIA AIPerf, not estimates or simulations. Deploy knowing your configuration has been validated against your specific model and workload, at percentile-level precision that matches production conditions.
Use cases
- Pre-deployment validation: Optimize and benchmark a new model before committing to a production deployment. Know exactly how it will perform before you invest in scaling it.
- Regression testing after updates: Validate performance after a container update, framework upgrade, or serving library release. Confirm that your configuration is still optimal before pushing to production.
- Right-sizing when conditions change: When traffic patterns shift or new instance types become available, re-run optimized generative AI inference recommendations in hours rather than restarting a weeks-long manual process.
- Model comparison: Compare the performance and cost of different model variants across instance types to make an informed selection before production deployment.
- Cost optimization: Benchmark existing production endpoints to identify over-provisioned infrastructure. Use the results to right-size and reduce recurring inference spend.
Benchmark inference endpoints
An AI benchmark job runs performance benchmarks against your SageMaker AI inference endpoints using a predefined workload configuration. Use benchmark jobs to measure the performance of your generative AI inference infrastructure before and after optimization. When the benchmark job is completed, the results are stored in the Amazon S3 output location that you specified. Once the benchmark job completes, all results are written to your S3 output path in output folder as shown below screenshot:
Once you download and extract the zip output file, you will get below files
output/
├── profile_export_aiperf.json # aggregated metrics
├── profile_export_aiperf.csv # same metrics in CSV
├── profile_export.jsonl # raw per-request data
├── inputs.json # prompts sent during the run
├── benchmark_summary.txt # completion summary
├── MANIFEST.txt # index of all files with sizes
├── plot_generation.log # plot generation log
├── plots/
│ ├── ttft_timeline.png # TTFT per request over time
│ ├── ttft_over_time.png # TTFT aggregated over run duration
│ ├── summary.txt # list of generated plots
│ └── aiperf_plot.log # plot generation trace
└── logs/
└── aiperf.log # full AIPerf execution logThe main output is profile_export_aiperf.json and its CSV counterpart profile_export_aiperf.csv both contain the same aggregated metrics: latency percentiles (p50, p90, p99), output token throughput, time-to-first-token (TTFT), and inter-token latency (ITL). These are the numbers you’d use to evaluate how the model performed under the simulated load.
Alongside that, profile_export.jsonl gives you the raw per-request data every individual request logged with its own latency, token counts, and timestamp. This is useful if you want to do your own analysis or spot outliers that the aggregated stats might hide.
We have created a sample notebook in Github which benchmarks openai/gpt-oss-20b deployed on a ml.g6.12xlarge instance (4× NVIDIA L40S GPUs), served via the vLLM container as an Inference Component. It simulates a realistic workload using synthetic prompts: 300 requests at 10 concurrent users, with ~500 input and ~150 output tokens per request, to measure how the model performs under that load.
Deploying model from recommendations
After the AI Recommendation Job completes, the output is a SageMaker Model Package which is a versioned resource that bundles all instance-specific deployment configurations into a single artifact.
To deploy, you first convert the Model Package into a Deployable Model by calling CreateModel with the ModelPackageName and the InferenceSpecificationName for the instance you want to target, then create an endpoint configuration and deploy as a standard SageMaker real-time endpoint or Inference Component.
Pick the recommendation you want to deploy
resp = client.describe_ai_recommendation_job(
AIRecommendationJobName="my-recommendation-job"
)
rec = resp["Recommendations"][0]
model_package_arn = rec["ModelDetails"]["ModelPackageArn"]
inference_spec_name = rec["ModelDetails"]["InferenceSpecificationName"]
instance_type = rec["InstanceDetails"][0]["InstanceType"]
print(f"Model Package : {model_package_arn}")
print(f"Infere
関連記事
NVIDIA Blackwellが金融分野におけるLLM推論でSTAC-AI記録を樹立
NVIDIAのBlackwellプラットフォームが、金融取引向け大規模言語モデルの推論性能でSTAC-AIベンチマーク記録を達成した。同技術は大量の非構造化データを分析し、金融取引の意思決定を支援する。
AI モデル推論パイプラインの摩擦を解消する方法
NVIDIA は、訓練済み AI モデルを実環境へ展開する際のボトルネック解消法を提示し、モデルのエクスポートや最適化プロセスにおける課題解決策を解説している。
Nvidia、AI投資家としての役割を強化し今年400億ドル超の株式投資へ
Nvidia は AI ブームの最大の受益者として、自社ハードウェアが基盤となるようサプライチェーン全体を資金支援している。同社は今年だけで 400 億ドル以上の株式投資を行い、チップ販売を超えた支配力を確保しようとしている。