大規模言語モデルの拡張方法(14 分読了)
この書籍は、大規模言語モデルのトレーニングと推論を効率的に実行するためのハードウェア(TPU/GPU)の仕組みや並列化戦略、コスト管理に関する包括的な技術的ガイドを提供する。
キーポイント
ハードウェアアーキテクチャの理解
TPU と GPU の動作原理、および大規模モデルを動かす際の相互通信メカニズムについての科学的解説が含まれている。
大規模並列化戦略
トレーニングと推論の両フェーズにおいて、モデルを効率的に分散・並列化し、巨大スケールで動作させるための具体的な手法が示されている。
コストとリソース管理
モデル学習にかかる費用感や、サービス提供に必要なメモリ容量の算出方法など、実務におけるリソース計画に関する重要な知見が含まれる。
影響分析・編集コメントを表示
影響分析
この書籍は、AI エンジニアやアーキテクトが直面する「大規模化の壁」を突破するための実用的な指針となり、単なる理論ではなく現場での適用可能性に焦点を当てています。特にコストとリソース管理に関する洞察は、予算制約下でモデルを運用する組織にとって即座に価値のある知見となります。
編集コメント
実務レベルの AI スケーリング課題に対する、非常に実践的な技術書と言えます。理論と現場のギャップを埋める内容が豊富です。
コンテンツ
 image ディープラーニングの多くはまだ一種のブラックボックス的な魔法に頼っていますが、モデルのパフォーマンスを最適化することは必ずしもそうである必要はありません。巨大なスケールにおいても同様です。比較的シンプルな原則は、単一のアクセラレータから数万台規模に至るまでどこでも適用可能です。これらの原則を理解することで、多くの有用なことが可能になります:
image ディープラーニングの多くはまだ一種のブラックボックス的な魔法に頼っていますが、モデルのパフォーマンスを最適化することは必ずしもそうである必要はありません。巨大なスケールにおいても同様です。比較的シンプルな原則は、単一のアクセラレータから数万台規模に至るまでどこでも適用可能です。これらの原則を理解することで、多くの有用なことが可能になります:
- モデルの各部分が理論的な最適値にどれだけ近づいているかを概算する。
- 異なるスケールにおいて、さまざまな並列化スキーム(計算を複数のデバイス間でどのように分割するか)について情報に基づいた選択を行う。
- 大規模な Transformer モデルのトレーニングと実行に必要なコストと時間を推定する。
- 特定のハードウェアの特性を活かすアルゴリズムを設計する。
- 現在のアルゴリズムのパフォーマンスを制限する要因を明示的に理解し、それに基づいてハードウェアを設計する。
想定される前提知識: LLM(大規模言語モデル)と Transformer アーキテクチャに関する基本的な理解はあるが、スケールした運用における詳細については必ずしも知らないという前提で進めます。LLM のトレーニングの基礎は知っており、できれば JAX についても基本的な親和性を持っていることを期待します。有用な背景知識として、Transformer アーキテクチャについての このブログ記事 や、オリジナルの Transformer 論文 を参照してください。また、さらに有用な同時進行および将来の読書リストについては、こちら もチェックしてみてください。
目標とフィードバック: この章を終える頃には、特定のハードウェアプラットフォーム上で Transformer モデルに最適な並列化スキームを見積もることや、トレーニングおよび推論にかかるおおよその時間を概算することに自信が持てるようになっているはずです。もしそう感じられない場合は、メールをお送りいただくかコメントを残してください。どのようにすればより明確にできるか、ぜひ知りたいです。
また、NVIDIA GPU に関する新しい 第 12 章 もお楽しみいただけるかもしれません!
なぜ気にする必要があるのか
3〜4年前であれば、この本の内容のほとんどを理解する必要はないと考えていた ML 研究者は多かったでしょう。しかし今日では、「小規模」なモデルでさえハードウェアの限界に極めて近い状態で動作しており、画期的な研究を行うためにはスケーリングにおける効率性を考慮する必要があります。歴史的に見れば、ML 研究はシステム革新とソフトウェア改善の間を「チクタク」と繰り返すサイクルに従ってきました。Alex Krizhevsky は CNN を高速化するために不浄な CUDA コードを書く必要がありましたが、数年後には Theano や TensorFlow といったライブラリが登場し、そのような手間が不要になりました。もしかするとここでも同様のことが起こり、本書の内容も数年のうちにすべて抽象化されてしまうかもしれません。しかし、スケーリング法則はモデルを常にハードウェアの最前線へと押し上げており、今後見通せる範囲では、最先端の研究を行うことは、大規模なハードウェアトポロジーに対してモデルを効率的にスケールさせる方法を理解することと不可避的に結びついていると考えられます。ベンチマークで 20% の勝利を得ても、ルーフライン効率(roofline efficiency)が 20% 低下するならば、それは無意味です。 有望なモデルアーキテクチャは、スケーリング時に効率的に実行できないか、あるいはそれを実現するために誰も努力を払わないために、ことごとく失敗しています。
「モデルのスケーリング」の目標は、トレーニングまたは推論に使用するチップ数を増やしながらも、スループットが比例的かつ線形に増加することを実現できることです。これを「*ストロングスケーリング*」と呼びます。追加のチップ(「並列化」)を追加すると通常は計算時間が短縮されますが、その一方でチップ間の通信コストが増加するという代償を伴います。通信にかかる時間が計算時間を上回ると、「通信バウンド」となり、ストロングスケーリングができなくなります。計算時間が短くなるにつれて、単一のチップレベルでもボトルネックに直面することが一般的です。最新のTPUやGPUは1秒間に500兆回の演算が可能と評価されていても、メモリ内のパラメータを移動させる処理で足踏みさせられれば、その性能の1割しか発揮できないことも十分にあり得ます。チップごとの計算能力、メモリー帯域幅、そして総メモリの相互関係が、スケーリングの物語において極めて重要です。これらのボトルネックがどこに発生するかを予測できるほどハードウェアをよく理解していれば、モデルを設計し直すか再構成することで、それらを回避することが可能になります。
ハードウェア設計者は逆の問題に直面しています:アルゴリズムに必要な計算能力、帯域幅、メモリをちょうど十分に提供しつつ、コストを最小化するハードウェアを構築することです。最初のチップが実際に利用可能になるまで通常2〜3年後となる中で、どのようなアルゴリズムが主流になるかを賭けなければならないこの「共同設計」の問題がいかにストレスフルか想像に難くありません。TPUの物語は、このゲームにおける明確な成功例です。行列乗算は、メモリ1バイトあたりのFLOPs(浮動小数点演算回数)が他のほぼあらゆるアルゴリズムよりもはるかに多いという点で(N FLOPs/byte)、ユニークなアルゴリズムです。初期のTPUとそのソリステックアレイアーキテクチャは、当時構築されたGPUと比較して、はるかに優れたパフォーマンス対コスト比を達成しました。TPUは機械学習ワークロードのために設計されており、Tensor Cores(テンソルコア)を搭載したGPUも急速にこのニッチを埋める方向へ変化しています。しかし、ニューラルネットワークが勃興しなかった場合や、TPU(これは本質的にGPUよりも柔軟性に欠けます)が処理できない根本的な何らかの変化があった場合に、どれほどコストがかかるか想像してみてください。
*本書の目的は、TPU(および GPU)ハードウェアがどのように動作し、Transformer アーキテクチャが現在のハードウェア上で高いパフォーマンスを発揮するためにどのように進化してきたかを解説することです。これが、新しいアーキテクチャを設計する研究者や、現在の世代の LLM を高速化するために取り組むエンジニアの両方にとって有益となることを願っています。
高レベルな構成概要
本書全体の構造は以下の通りです:
セクション 1 では、ルーフライン分析と、スケーリング能力を制限する要因(通信、計算、メモリ)について解説します。セクション 2 と セクション 3 では、TPU が個々のチップとして、そしてより重要なのは帯域幅とレイテンシが限られた相互接続リンクを備えた相互接続システムとしてどのように動作するかについて詳細に論じます。以下のような質問に答えます:
- 特定のサイズの行列乗算にはどれくらいの時間がかかるべきでしょうか?計算量、メモリ帯域幅、通信帯域幅のいずれに制約されるのか、その境界点はどこでしょうか?
- TPUs はどのように配線されてトレーニングクラスターを形成しているのでしょうか?システムの各部分はどの程度の帯域幅を持っていますか?
- 複数の TPU にわたって配列を集約(gather)、散乱(scatter)、または再配布するのにはどれくらいの時間がかかりますか?
- 異なるデバイス上で異なる方法で分散された行列を効率的に乗算するにはどうすればよいでしょうか?
 image 図: セクション 2 から引用した図で、TPU が要素ごとの積(elementwise product)を実行する方法を示しています。配列のサイズや各種リンクの帯域幅に応じて、計算量に制約される状態(ハードウェアの計算能力を最大限に活用している状態)か、メモリ負荷がボトルネックとなるメモリ制約の状態になる可能性があります。
image 図: セクション 2 から引用した図で、TPU が要素ごとの積(elementwise product)を実行する方法を示しています。配列のサイズや各種リンクの帯域幅に応じて、計算量に制約される状態(ハードウェアの計算能力を最大限に活用している状態)か、メモリ負荷がボトルネックとなるメモリ制約の状態になる可能性があります。
5 年前の機械学習には、ConvNets、LSTMs、MLPs、Transformers など多彩なアーキテクチャが存在しましたが、現在では主に Transformer のみが主流となっています。Transformer アーキテクチャのすべての構成要素を理解する価値が十分にあると私たちは強く信じています:各行列の正確なサイズ、正規化(normalization)が行われる場所、各部分に含まれるパラメータ数と FLOPs(Floating Point Operations、つまり必要な加算および乗算の総数)。多くの資料では FLOPs を「1 秒あたりの演算数」として扱っていますが、ここでは明示的に「FLOPs/s」を用いてその意味を区別します。セクション 4 ではこの「Transformer の数学」を慎重に解説し、トレーニングと推論の両方におけるパラメータ数と FLOPs のカウント方法を詳述しています。これにより、モデルが使用するメモリ量、計算や通信に費やす時間、そしてフィードフォワードブロックに対してアテンション(attention)が重要となるタイミングがわかります。
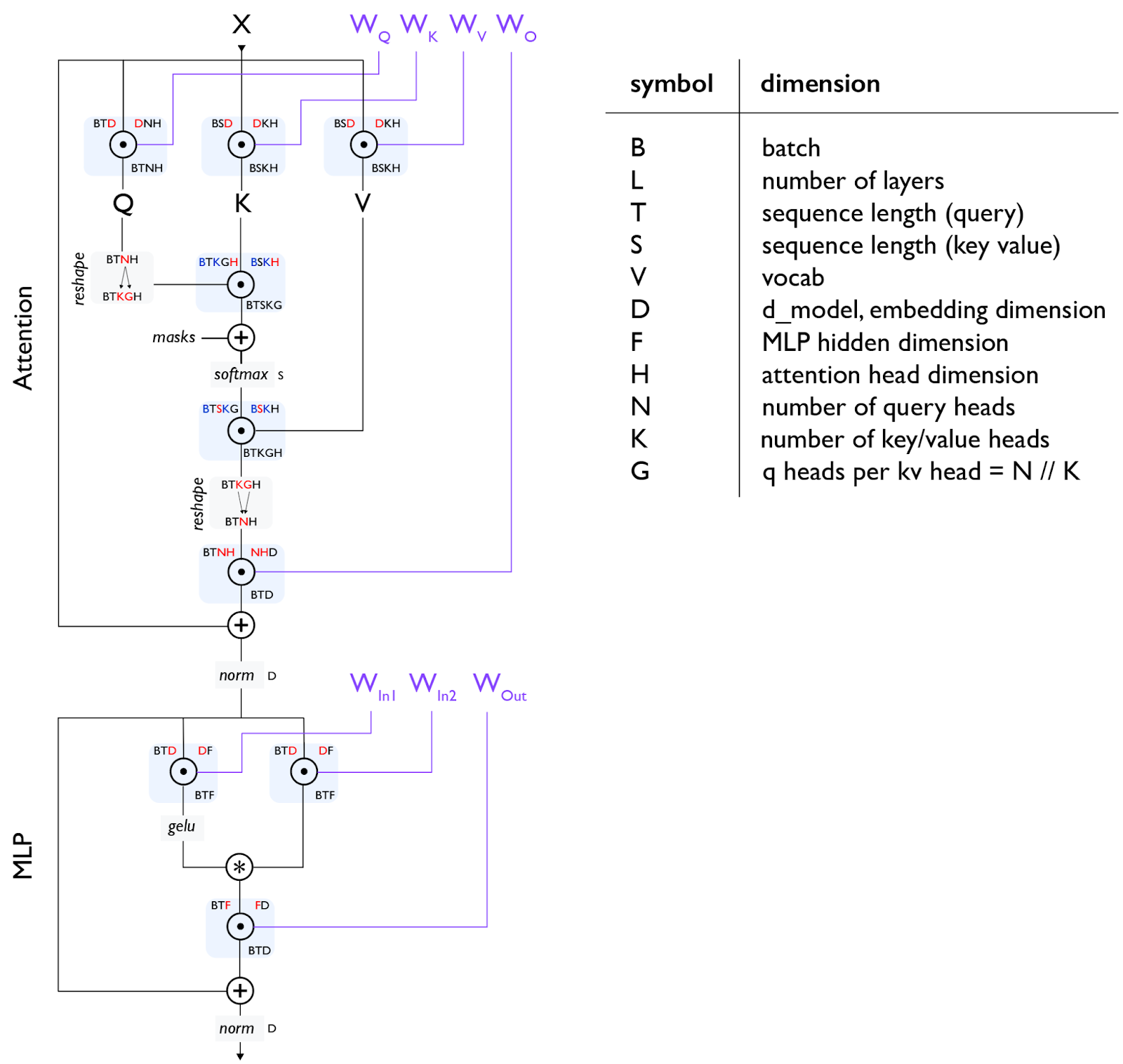 image 図: 各行列乗算 (matmul) が円内の点として示された標準的な Transformer レイヤー。すべてのパラメータ(正規化層を除く)は紫色で表示されています。セクション 4 では、この図をより詳細に解説しています。 セクション 5: トレーニング と セクション 7: 推論 は本書の核心部分であり、ここでは根本的な問いについて議論します:ある規模のモデルと特定の数のチップが与えられた場合、どのようにモデルを並列化して「ストロングスケーリング」のレジーム内に留めるか?これは一見単純な質問ですが、驚くほど複雑な答えを伴います。高レベルでは、モデルを複数のチップに分割するために使用される 4 つの主要な並列化手法(データ並列, テンソル並列, パイプライン並列, および エキスパート並列)と、メモリ要件を削減するための多数の他の技術(リマテリアライゼーション, オプティマイザー/モデルシャードリング (別名 ZeRO), ホストオフロード, 勾配累積)があります。これらについてここでは多くを議論します。
image 図: 各行列乗算 (matmul) が円内の点として示された標準的な Transformer レイヤー。すべてのパラメータ(正規化層を除く)は紫色で表示されています。セクション 4 では、この図をより詳細に解説しています。 セクション 5: トレーニング と セクション 7: 推論 は本書の核心部分であり、ここでは根本的な問いについて議論します:ある規模のモデルと特定の数のチップが与えられた場合、どのようにモデルを並列化して「ストロングスケーリング」のレジーム内に留めるか?これは一見単純な質問ですが、驚くほど複雑な答えを伴います。高レベルでは、モデルを複数のチップに分割するために使用される 4 つの主要な並列化手法(データ並列, テンソル並列, パイプライン並列, および エキスパート並列)と、メモリ要件を削減するための多数の他の技術(リマテリアライゼーション, オプティマイザー/モデルシャードリング (別名 ZeRO), ホストオフロード, 勾配累積)があります。これらについてここでは多くを議論します。
これらのセクションを終える頃には、読者自身が新しいアーキテクチャや設定に対してこれらの中から選択できるようになることを願っています。セクション 6 と セクション 8 は、人気のあるオープンソースモデルである LLaMA 3 にこれらの概念を適用する実践的なチュートリアルです。
最後に、セクション 9 と セクション 10 では、これらのアイデアを JAX でどのように実装するか、また問題が発生した際にコードのプロファイリングやデバッグを行う方法について取り上げます。セクション 12 は GPU に深く掘り下げる新しいセクションです。
全体を通じて、読者自身で取り組むべき課題を提供するように努めています。すべてのセクションを読む必要や、順序通りに読む必要があるというプレッシャーは全くありません。また、フィードバックをぜひお寄せください。現時点ではこれはドラフト版であり、今後も改訂が続けられていきます。ありがとうございます!
*本書の多くのアイデアを導き出したジェームズ・ブラッドベリーとブレイク・ヘックトマンに感謝いたします。
余計な前置きはなしで、TPU のルーフラインに関するセクション 1 をご紹介します。
セクションへのリンク
*このシリーズは必要以上に長いかもしれませんが、それがあなたを遠ざけることはないでしょう。最初の 3 つの章は予備知識であり、すでに内容に精通している場合はスキップできますが、後で使われる記法を紹介しています。最後の 3 つの部分は、実際のモデルとどのように向き合うかを説明しているため、最も実用的な価値があるかもしれません。
パート 1: 予備知識
- 第1章:Roofline分析の簡単な紹介。アルゴリズムは、計算能力(compute)、通信(communication)、メモリという3つの要因によって制約されます。これらを用いて、アルゴリズムがどの程度の速度で実行されるかを近似することができます。
- 第2章:TPUについての考え方。TPUはどのように動作するのか?それが、訓練および推論可能なモデルにどのような影響を与えるのか?
- 第3章:シャード化された行列とその乗算方法。ここでは、お気に入りの演算である(シャード化された)行列乗算を通じて、モデルのシャード化とマルチTPU並列処理について解説します。
パート2:Transformer
- 第4章:トランスフォーマーに必要なすべての数学。フォワードパスとバックワードパスでトランスフォーマーはどれだけのFLOPs(浮動小数点演算数)を使用するのか?パラメータ数は計算できるか?KVキャッシュのサイズはどうなるのか?ここではその数学を詳しく解説します。
- 第5章:トレーニングのためのトランスフォーマー並列化手法。FSDP、Megatronシャードリング、パイプライン並列化。与えられたチップ数で、特定のバッチサイズを用いて特定のサイズのモデルをいかに効率的にトレーニングするか?
- 第6章:TPU上でのLLaMA 3のトレーニング。LLaMA 3をTPU上でどのようにトレーニングするのか?どれくらいの時間がかかるのか?コストはいくらかかるのか?
- 第7章:トランスフォーマー推論に関するすべて。モデルをトレーニングしたら、次はそれをサービス提供する必要があります。推論では新たな考慮事項であるレイテンシ(遅延)が加わり、メモリ環境も変化します。非集約型サービス提供の仕組みや、KVキャッシュについてどう考えるべきかについて議論します。
- 第8章:TPU上でのLLaMA 3のサービス提供。TPU v5e上でLLaMA 3をサービス提供する場合のコストはいくらか?レイテンシとスループットのトレードオフはどうなるのか?
パート3:実践的チュートリアル
- 第9章:TPUコードのプロファイリング方法。実際の大規模言語モデル(LLM)は、上記の理論ほど単純ではありません。ここではJAX + XLAスタックの説明と、JAX/TensorBoardプロファイラを使用して実際の課題をデバッグし修正する方法について解説します。
- 第10章:JAXによるTPUプログラミング。JAXには並列計算のための魔法のようなAPIが多数用意されていますが、その使い方を知らなければなりません。楽しい例題と解き方の問題集です。
パート4:結論と追加コンテンツ
- 第11章:結論とさらに読むべき資料。TPU と大規模言語モデル(LLM)に関する結びの言葉と、さらに深く学ぶための読書リスト。
- 第12章:GPU をどう考えるか。GPU の動作原理、ネットワーク構成、そして TPU との屋根線(roofline)の違いについて解説するボーナスセクション。
原文を表示
Contents
Much of deep learning still boils down to a kind of black magic, but optimizing the performance of your models doesn’t have to — even at huge scale! Relatively simple principles apply everywhere — from dealing with a single accelerator to tens of thousands — and understanding them lets you do many useful things:
- Ballpark how close parts of your model are to their theoretical optimum.
- Make informed choices about different parallelism schemes at different scales (how you split the computation across multiple devices).
- Estimate the cost and time required to train and run large Transformer models.
- Design algorithms that take advantage of specific hardware affordances.
- Design hardware driven by an explicit understanding of what limits current algorithm performance.
Expected background: We’re going to assume you have a basic understanding of LLMs and the Transformer architecture but not necessarily how they operate at scale. You should know the basics of LLM training and ideally have some basic familiarity with JAX. Some useful background reading might include this blog post on the Transformer architecture and the original Transformer paper. Also check out this list for more useful concurrent and future reading.
Goals & Feedback: By the end, you should feel comfortable estimating the best parallelism scheme for a Transformer model on a given hardware platform, and roughly how long training and inference should take. If you don’t, email us or leave a comment! We’d love to know how we could make this clearer.
You might also enjoy reading the new Section 12 on NVIDIA GPUs!
Why should you care?
Three or four years ago, I don’t think most ML researchers would have needed to understand any of the content in this book. But today even “small” models run so close to hardware limits that doing novel research requires you to think about efficiency at scale.Historically, ML research has followed something of a tick-tock cycle between systems innovations and software improvements. Alex Krizhevsky had to write unholy CUDA code to make CNNs fast but within a couple of years, libraries like Theano and TensorFlow meant you didn't have to. Maybe that will happen here too and everything in this book will be abstracted away in a few years. But scaling laws have pushed our models perpetually to the very frontier of our hardware, and it seems likely that, for the foreseeable future, doing cutting-edge research will be inextricably tied to an understanding of how to efficiently scale models to large hardware topologies. A 20% win on benchmarks is irrelevant if it comes at a 20% cost to roofline efficiency. Promising model architectures routinely fail either because they *can’t* run efficiently at scale or because no one puts in the work to make them do so.
The goal of “model scaling” is to be able to increase the number of chips used for training or inference while achieving a proportional, linear increase in throughput. This is known as “*strong scaling*”. Although adding additional chips (“parallelism”) usually decreases the computation time, it also comes at the cost of added communication between chips. When communication takes longer than computation we become “communication bound” and cannot scale strongly.As your computation time decreases, you also typically face bottlenecks at the level of a single chip. Your shiny new TPU or GPU may be rated to perform 500 trillion operations-per-second, but if you aren't careful it can just as easily do a tenth of that if it's bogged down moving parameters around in memory. The interplay of per-chip computation, memory bandwidth, and total memory is critical to the scaling story. If we understand our hardware well enough to anticipate where these bottlenecks will arise, we can design or reconfigure our models to avoid them.Hardware designers face the inverse problem: building hardware that provides just enough compute, bandwidth, and memory for our algorithms while minimizing cost. You can imagine how stressful this "co-design" problem is: you have to bet on what algorithms will look like when the first chips actually become available, often 2 to 3 years down the road. The story of the TPU is a resounding success in this game. Matrix multiplication is a unique algorithm in the sense that it uses far more FLOPs per byte of memory than almost any other (N FLOPs per byte), and early TPUs and their systolic array architecture achieved far better perf / $ than GPUs did at the time they were built. TPUs were designed for ML workloads, and GPUs with their Tensor Cores are rapidly changing to fill this niche as well. But you can imagine how costly it would have been if neural networks had not taken off, or had changed in some fundamental way that TPUs (which are inherently less flexible than GPUs) could not handle.
*Our goal in this book is to explain how TPU (and GPU) hardware works and how the Transformer architecture has evolved to perform well on current hardware. We hope this will be useful both for researchers designing new architectures and for engineers working to make the current generation of LLMs run fast.*
High-Level Outline
The overall structure of this book is as follows:
Section 1 explains roofline analysis and what factors can limit our ability to scale (communication, computation, and memory). Section 2 and Section 3 talk in detail about how TPUs work, both as individual chips and — of critical importance — as an interconnected system with inter-chip links of limited bandwidth and latency. We’ll answer questions like:
- How long should a matrix multiply of a certain size take? At what point is it bound by compute or by memory or communication bandwidth?
- How are TPUs wired together to form training clusters? How much bandwidth does each part of the system have?
- How long does it take to gather, scatter, or re-distribute arrays across multiple TPUs?
- How do we efficiently multiply matrices that are distributed differently across devices?
Figure: a diagram from [Section 2 showing how a TPU performs an elementwise product. Depending on the size of our arrays and the bandwidth of various links, we can find ourselves compute-bound (using the full hardware compute capacity) or memory-bound (bottlenecked by memory loading).](https://jax-ml.github.io/scaling-book/assets/img/pointwise-product.gif)
Five years ago ML had a colorful landscape of architectures — ConvNets, LSTMs, MLPs, Transformers — but now we mostly just have the Transformer. We strongly believe it’s worth understanding every piece of the Transformer architecture: the exact sizes of every matrix, where normalization occurs, how many parameters and FLOPsFLoating point OPs, basically the total number of adds and multiplies required. While many sources take FLOPs to mean "operations per second", we use FLOPs/s to indicate that explicitly. are in each part. Section 4 goes through this “Transformer math” carefully, showing how to count the parameters and FLOPs for both training and inference. This tells us how much memory our model will use, how much time we’ll spend on compute or comms, and when attention will become important relative to the feed-forward blocks.
Figure: a standard Transformer layer with each matrix multiplication (matmul) shown as a dot inside a circle. All parameters (excluding norms) are shown in purple. [Section 4 walks through this diagram in more detail.](https://jax-ml.github.io/scaling-book/assets/img/transformer-diagram.png)
Section 5: Training and Section 7: Inference are the core of this book, where we discuss the fundamental question: given a model of some size and some number of chips, how do I parallelize my model to stay in the “strong scaling” regime? This is a simple question with a surprisingly complicated answer. At a high level, there are 4 primary parallelism techniques used to split models over multiple chips (data, tensor, pipeline, and expert), and a number of other techniques to reduce the memory requirements (rematerialisation, optimizer/model sharding (aka ZeRO), host offload, gradient accumulation). We discuss many of these here.
We hope by the end of these sections you should be able to choose among them yourself for new architectures or settings. Section 6 and Section 8 are practical tutorials that apply these concepts to LLaMA 3, a popular open-source model.
Finally, Section 9 and Section 10 look at how to implement some of these ideas in JAX and how to profile and debug your code when things go wrong. Section 12 is a new section that dives into GPUs as well.
Throughout we try to give you problems to work for yourself. Please feel no pressure to read all the sections or read them in order. And please leave feedback. For the time being, this is a draft and will continue to be revised. Thank you!
*We’d like to acknowledge James Bradbury and Blake Hechtman who derived many of the ideas in this book.*
Without further ado, here is Section 1 about TPU rooflines.
Links to Sections
*This series is probably longer than it needs to be, but we hope that won’t deter you. The first three chapters are preliminaries and can be skipped if you’re already familiar with the material, although they introduce notation used later. The final three parts might be the most practically useful, since they explain how to work with real models.*
Part 1: Preliminaries
- Chapter 1: A Brief Intro to Roofline Analysis. Algorithms are bounded by three things: compute, communication, and memory. We can use these to approximate how fast our algorithms will run.
- Chapter 2: How to Think About TPUs. How do TPUs work? How does that affect what models we can train and serve?
- Chapter 3: Sharded Matrices and How to Multiply Them. Here we explain model sharding and multi-TPU parallelism by way of our favorite operation: (sharded) matrix multiplications.
Part 2: Transformers
- Chapter 4: All the Transformer Math You Need to Know. How many FLOPs does a Transformer use in its forward and backward pass? Can you calculate the number of parameters? The size of its KV caches? We work through this math here.
- Chapter 5: How to Parallelize a Transformer for Training. FSDP. Megatron sharding. Pipeline parallelism. Given some number of chips, how do I train a model of a given size with a given batch size as efficiently as possible?
- Chapter 6: Training LLaMA 3 on TPUs. How would we train LLaMA 3 on TPUs? How long would it take? How much would it cost?
- Chapter 7: All About Transformer Inference. Once we’ve trained a model, we have to serve it. Inference adds a new consideration — latency — and changes up the memory landscape. We’ll talk about how disaggregated serving works and how to think about KV caches.
- Chapter 8: Serving LLaMA 3 on TPUs. How much would it cost to serve LLaMA 3 on TPU v5e? What are the latency/throughput tradeoffs?
Part 3: Practical Tutorials
- Chapter 9: How to Profile TPU Code. Real LLMs are never as simple as the theory above. Here we explain the JAX + XLA stack and how to use the JAX/TensorBoard profiler to debug and fix real issues.
- Chapter 10: Programming TPUs in JAX. JAX provides a bunch of magical APIs for parallelizing computation, but you need to know how to use them. Fun examples and worked problems.
Part 4: Conclusions and Bonus Content
- Chapter 11: Conclusions and Further Reading. Closing thoughts and further reading on TPUs and LLMs.
- Chapter 12: How to Think About GPUs. A bonus section about GPUs, how they work, how they’re networked, and how their rooflines differ from TPUs.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み