「正解」が非確定的な場合の自律型エージェント行動の検証
GitHub は、自律型エージェントの非決定的な動作に対応するため、厳密な手順検証から「結果の信頼性」を重視する新しい検証層(Trust Layer)の必要性と実装アプローチを提唱している。
キーポイント
非決定的環境におけるテストの脆さ
エージェントが UI やブラウザを操作する際、ロード時間やタイミングの違いにより「正しく動作してもテストが失敗する」偽陽性(False Negative)が発生しやすく、従来のステップバイステップ検証は機能不全に陥る。
信頼ギャップの3つの要因
環境ノイズによるテスト失敗、実行パスの不一致による回帰フラグ、そして正しい結果が出ても手順が異なることへのコンプライアンス違反という3点が、エージェント検証における信頼を損なう主要因である。
Trust Layer の提案
厳密な実行経路の追跡ではなく、本質的な成果(Essential Outcomes)に焦点を当てた説明可能で軽量な検証モデルを導入し、CI パイプラインへの統合を可能にするアプローチが示されている。
生産環境での実装課題
GitHub Copilot Coding Agent のような自律システムを本番環境に展開する際、再現性よりも「結果の信頼性」を定義し直すことが、スケーラブルな開発プロセスには不可欠である。
従来のテスト手法の限界
既存のアプローチ(アサーションベース、記録再生など)は実行パスが固定されていることを前提としており、自律型エージェントの分岐する振る舞いや環境ノイズに対して脆弱である。
正しさの再定義:構造的整合性の重視
自律型システムでは「同じ見た目」ではなく「共通の論理構造」を持つことが重要であり、成功には必須の状態(Essential states)と環境に依存する任意の変動(Optional variations)を区別する必要がある。
信頼構築のための構造化された検証
真の開発者信頼を得るためには、線形スクリプトのチェックを超えて、異なる実行経路が最終的に同じ結果に収束するかを検証する「構造化された振る舞い」の検証へ移行しなければならない。
影響分析・編集コメントを表示
影響分析
この記事は、AI エージェントがソフトウェア開発プロセスに深く組み込まれる中で直面する根本的な課題——「非決定的な動作をどう検証するか」という命題に対して、具体的な解決策の方向性を示した点で極めて重要です。従来の自動化テストの限界を打破し、実運用レベルでの信頼性を確保するための新しい基準(Trust Layer)を提示することで、業界全体の QA プロセスと CI/CD 戦略に影響を与える可能性があります。
編集コメント
自律型 AI の実用化において、最も障壁となる「テストの信頼性」問題に対し、GitHub が自社の製品文脈で具体的な解決策を提示した重要な知見です。従来の自動化テストの限界を超え、AI の非決定的性質を許容する新しい検証基準の確立に向けた第一歩と言えます。
現代のソフトウェアテストは、正しい動作が反復可能であるという脆い前提の上に成り立っています。決定論的なコードにおいては、この前提は概ね成立します。しかし、GitHub Copilot Coding Agent(別名:Agent Mode)のような自律型エージェント、特に統合された「Computer Use」の最前線を探求する際には、その前提はほぼ即座に崩壊します。
エージェントが単純なコード提案を超えて、UI、ブラウザ、IDE といった実際の環境と対話するようになると、正しさは複数の経路を持つようになります。読み込み画面が表示されたり消えたりし、タイミングのズレが生じ、同じ結果に至る複数の有効なアクションシーケンスが存在します。GitHub Actions ワークフローがこの変動性を十分に考慮できるほど堅牢でない限り、エージェントがタスクを成功させたにもかかわらずテストが失敗するという「偽陰性」が発生し、生産環境の停止を引き起こすことが一般的です。
本ブログ記事では、もろく細いステップバイステップのスクリプトを超え、自律型検証のための独立した「信頼レイヤー」へと移行する方法を探ります。ここでは、堅苦しい経路ではなく本質的な成果に焦点を当てたモデルを実証し、説明可能で軽量であり、実世界の CI パイプラインですぐに活用できる振る舞いの検証手法を提供します。
エージェント駆動型検証の課題
GitHub Actions パイプラインを担当しており、Copilot Agent Mode を用いて実際のワークフローを検証している状況を想像してください。そのエージェントは、ワークフロー検証のために Computer Use を活用し、コンテナ化されたクラウド環境内をナビゲートしている可能性があります。
火曜日はビルドが成功しています。水曜日になると、コードに変更がないにもかかわらずテストが失敗します。
何が起きたかといえば、ホストされたランナーでわずかなネットワークの遅延が発生し、読み込み画面が数秒間続いたためです。エージェントは待機し、適応してタスクを正しく完了しました。しかし、CI パイプラインは実行パスが記録されたスクリプトやアサーションのタイミングと一致しなくなったという理由だけで、その実行を失敗としてフラグ付けました。
エージェントが失敗したわけではありません。検証側が失敗したのです。
これにより、エージェント駆動型テストにおける「信頼のギャップ」を生み出す3 つの recurring な課題が浮き彫りになります:
偽陽性(False negatives):タスクは成功したが、テストランナーが変動を許容できなかった。
脆弱なインフラストラクチャ:タイミング、レンダリング、または正しさとは無関係な環境ノイズによってテストが失敗する。
コンプライアンスの罠:結果は正しいにもかかわらず、エージェントの振る舞いが自動化されたテストが想定したものと逸脱しているため回帰としてフラグ付けされる。
GitHub Copilot Coding Agent などのエージェントシステムが開発を加速させる一方で、従来の検証アプローチは依然として硬直化しています。決定論的ソフトウェアでは、正しさとは特定の入力と既知の出力を一致させるという単純な問題です。しかし、エージェントにおいては、その間のプロセスは意図的に非決定論的です。エージェントが本番環境でますます広く導入されるにつれ、正しさとは「規定された手順に従うこと」ではなく、「本質的な成果を確実に達成すること」を意味するようになります。
これらのシステムを拡張するには、「偶発的なノイズ」(例:読み込み画面)と「致命的な失敗」(例:データの保存に失敗する)を区別できる検証フレームワークが必要です。正しさの基準は「これが起きたか?」から「成功が真のものとなるために何が必要だったか?」へとシフトします。
既存のテスト手法が自律型エージェントで機能しなくなる理由
実行パスが固定されている場合、従来のテストツールはよく機能します。しかし、振る舞いが分岐する状況ではこれらのツールは機能不全に陥ります。これはツールが不十分に設計されているからではなく、安定したシーケンスを前提としているからです。
これらを Copilot Coding Agent に適用し、コンテナ化された環境内でのナビゲーションを含む場合、4 つの一般的なパラダイムにおいて限界が明確になります:
アサーションベースのテスト:各チェックに対して手作業で労働集約的な仕様が必要であり、有効な代替実行パスを考慮していません。
記録・再生ツール:環境ノイズに極めて敏感です。わずかなレンダリングの違いやタイミングの変動が誤った失敗を引き起こすことがよくあります。
ビジュアル回帰テスト:スクリーンショットを孤立して比較するだけで、より広範な実行フローや意味内容を理解していません。
ML オラクル(機械学習オラクル):これらの「ブラックボックス」は数千のトレーニング例を必要とし、振る舞いを誤りと判定した際に説明可能性を提供しません。
これらアプローチの実装方法は異なりますが、「正しさは特定の観測可能な状態シーケンスへの準拠によって定義される」という共通の構造的仮定を共有しています。
エージェントシステムにおいて、その前提は崩壊します。GitHub Copilotを含むこれらのシステムに対する真の開発者信頼を構築するには、線形スクリプトのチェックを超えて、構造化された行動を検証し始めなければなりません。
正しさの再定義:必須と任意の行動
脆いテストを乗り越え、Trust Layer(信頼層)を構築するためには、「正しさ」を定義する方法を根本的に変える必要があります。エージェントシステムでは、正しい実行が外見上完全に同一である必要はありません。しかし、共通する論理的構造を共有していることは必須です。
概念的な転換
コンテナ化されたクラウド環境でVS Code内を検索する、コンピューター使用機能を備えたGitHub Copilot Coding Agent(コーディングエージェント)を想像してください。ある実行では数秒間読み込み画面が表示されますが、別の実行ではUIが即座にロードされます(以下参照)。
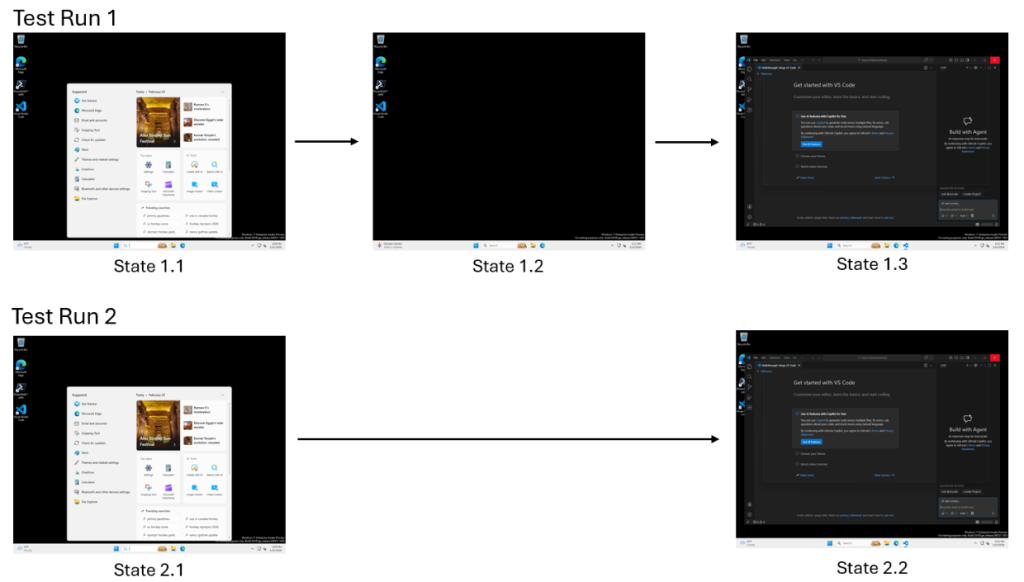 imageシナリオ:VS Codeの起動
imageシナリオ:VS Codeの起動
従来のテストではこれらを異なる結果として捉えます。しかし、開発者にとって読み込み画面は付随的なものであり、タスクが成功したかどうかには影響しません。
エージェントの行動を3つのカテゴリに分類できます。
必須状態(Essential states):成功が真のものとなるために必ず発生しなければならないマイルストーン(例:「検索結果」画面への到達)。
任意の変動(Optional variations):環境に応じて変動する、ローディングスピナーや装飾的なUI変更などの付随的な状態。
収束パス(Convergent paths):ホットキーの使用とメニューの使用など、異なる手順のシーケンスが最終的に同じ結果で合流する経路。
読み込み画面が表示される場合もあれば、表示されない場合もあります。ただし、検索結果は必ず表示されなければなりません。正しさを決定するのはこのうちどちらか一方だけです。
直感から理論へ:ドミネーター分析
「必須」動作と「付随的」動作の区別という概念は、コンパイラ理論におけるドミネーター関係(dominator relationships)に根ざしたものです。
制御フローグラフにおいて、始点からノード B へのすべての経路が必ずノード A を通る場合、ノード A はノード B を「支配する」(dominates)と言います。
ドミネーター分析をエージェントの実行トレースに適用することで、自動的に以下を特定できます:
- 必須のステート(状態)
- オプションのステート(状態)
- 異なる経路が収束する場所
これにより、最小限で説明可能な正しさの定義を抽出することが可能になります。
スクリプトではなくグラフとして実行をモデル化する
エージェントの行動の複雑さを捉えるためには、実行を線形で一次元的なスクリプトとして扱うことから離れなければなりません。代わりに、私たちのフレームワークはプレフィックスツリーアクセプター(Prefix Tree Acceptor: PTA)と呼ばれるグラフベースの構造を用いて行動をモデル化します。
線形トレースから構造化されたグラフへ
このモデルにおいて、実行は一連のコマンドではなく、以下の特徴を持つ有向グラフとして表現されます:
- ノードは、UI エージェントの場合はスクリーンショット、開発エージェントの場合はコードスナップショットなど、観測可能なステート(状態)を表します。
- エッジは遷移を表し、ステート間を移動するために実行されたアクション(クリック、キー入力、または API 呼び出し)を捉えます。
なぜグラフが重要なのか
実行をグラフとして扱うことで、分岐と収束という概念を表現することが可能になります。これらは線形スクリプトでは決して捉えることができないものです。
分岐は、読み込み画面の有無など、非決定的な環境の変化に対応するために用いられます。
収束は、これらの異なる経路が再び合流する地点を特定し、エージェントが多様な変遷を無事にナビゲートして主要なタスクフローに戻ったことを示すシグナルとなります。
ステップの列から構造化された行動モデルへと表現を転換することで、エージェントが異なる経路を選んだことに対してペナルティを与えるのをやめ、その経路が論理的に妥当であったかどうかを検証するようになります。
解決策:正しさに対する構造的アプローチ
実験的なデモから本番環境向けのインフラへエージェントを進化させるため、当チームは堅苦しいスクリプトに頼らず、例から学習する革新的な検証アルゴリズムを開発しました。これをテストするため、私たちは複雑な非決定的な環境に焦点を当てました。それは「Computer Use」を通じて Visual Studio Code をナビゲートする AI エージェントです。成功したセッションをわずか 2〜10 回観察するだけで、当アルゴリズムは自動的にエージェントの正当な変異と実際の失敗を区別する「グランドトゥルース(正解)」モデルを構築します。
ワークフロー:トレースから「マスター」グラフへ
キャプチャ (PTA 構築): 2〜10 の成功した実行トレースを収集し、それらを接頭辞木受容機 (Prefix Tree Acceptors: PTA) に変換しました。これは、ノードが観測可能な UI 状態を表し、エッジが行動を表す有向グラフです。
一般化(セマンティックマージング):当社のアルゴリズムはこれらのトレースを統合グラフに結合しました。これは、高速な視覚指標と大規模言語モデル(LLM)による意味分析を組み合わせた 3 段階の等価性検出フレームワークを採用しており、タイムスタンプの変更は無視しつつ欠落した UI コントロールを検知するなど、2 つの状態が論理的に等しいかどうかを判断します。
骨格の抽出(支配者解析):統合グラフに対して支配者解析を適用し、すべての成功した実行で必ず通過する「必須状態」すなわちマイルストーンを特定すると同時に、読み込みスピナーのような「任意の状態」を自動的にフィルタリングしました。
このアプローチは、手動での仕様記述や大規模モデルのトレーニングを一切必要としない点で開発者にとって独自に強力です。結果として得られるモデルが実際の実行状態からなるグラフであるため、その判断プロセスは完全に説明可能です。検証が失敗した場合でも、当社のアルゴリズムはどの必須状態が欠落したかを特定することで、明確な失敗理由を提供します。
2 つの状態を「同じ」とみなすタイミングの決定
状態の等価性は、エージェント検証における最も困難な問題です。例えば、異なる 2 つのスクリーンショットが論理的に同一の UI 状態を表しているかどうかを、どのようにして判断すればよいのでしょうか?
私たちは、高速な視覚指標から深い意味理解へと移行する 3 段階の等価性検出フレームワークを用いてこの課題を解決します。
視覚指標:ほぼ同一の状態を即座に捉えるため、高速な知覚ハッシュと構造的類似度(SSIM)を使用します。
LLM を用いた意味解析:視覚的指標が曖昧な場合、マルチモーダル LLM を使用して、差異が意味上有効かどうかを判断します。例えば、LLM はタイムスタンプの変更やウィンドウ装飾の違いは無視すべきことを知っていますが、異なるエラーメッセージや欠落した UI コントロールについては警告を発します。
保守的なマージ:モデルが状態が等価であると確信している場合のみマージを行い、実行パスが実際に分岐する箇所ではグラフが自然に分岐するようにしています。
これは単純なピクセル単位の比較でもなく、「LLM による手抜き」つまりモデルにタスク全体を判断させるようなものでもありません。LLM を防御的に、かつ限定的に用いて特定の曖昧さを解決することで、当社のフレームワークは UI のノイズに対処する十分な堅牢性を保ちつつ、実際の回帰を検出するための精度も維持されます。
ドミネーター分析により実際に重要な要素を抽出
さまざまな実行トレースが統合グラフにマージされた後、当社のアルゴリズムはドミネーター分析(dominator analysis)を適用して、タスクの中核となる骨格を特定します。
ドミネーションを通じた「本質」の定義:グラフ理論において、状態 A が状態 B を支配するとは、開始点から B へのあらゆる可能なパスが必ず A を経由することを意味します。当社のモデルでは、タスクの成功した完了にとって支配的な状態を「本質的」と定義します。
フィルタリングプロセス:これらの数学的関係を計算することで、アルゴリズムは自動的に「必須」のマイルストーンと「付随的な」ノイズを区別します。
VS Code の実験において、「検索ダイアログ」の状態は、数学的な支配点(ドミネーター)であるため不可欠なマイルストーンとして特定されます。なぜなら、検索を最初にトリガーしなければ結果に到達することは論理的に不可能だからです。一方、「読み込み中」画面は何も支配していません。より高速な実行ではこれをバイパスするため、アルゴリズムはそれを成功のための要件ではなく、オプションのバリエーションとしてフラグ付けします。これにより、「Trust Layer」フレームワークは、環境が変動する時ではなく、重要なステップが見落とされた時にのみアラートを発します。
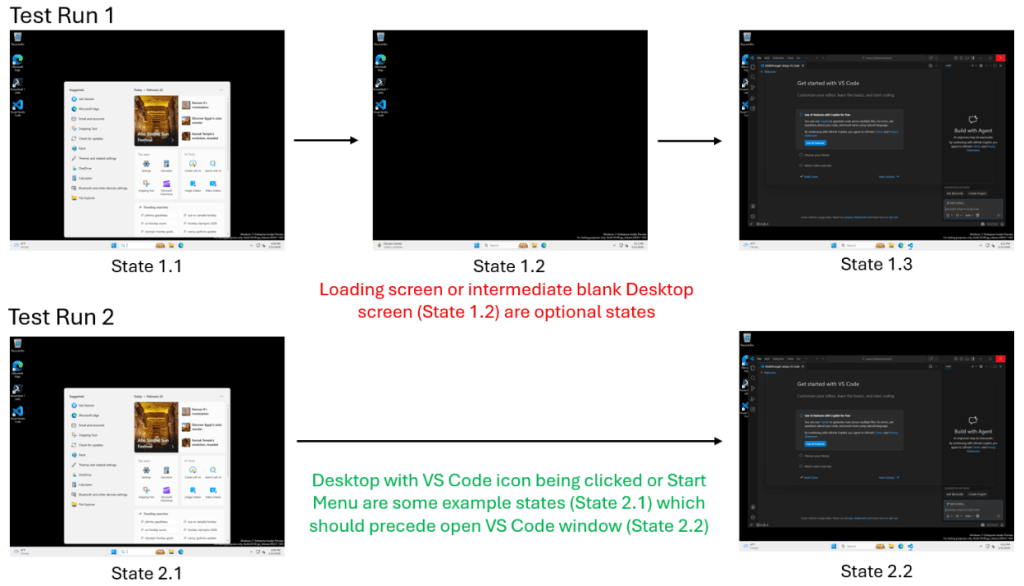 imageシナリオ:VS Code の起動
imageシナリオ:VS Code の起動
これらの不可欠なノードを支配点のサブツリーに抽出することで、最小限で説明可能な正しさの定義を表す「グランドトゥルース(事実基準)」モデルが作成されます。これにより、検証の焦点はエージェントが実行した具体的な手順から、達成する必要があった重要なチェックポイントへとシフトします。
実践における新規実行の検証
支配点ツリーをグランドトゥルースとして確立することで、新しい未見の実行を検証するプロセスは、完全な一致を探すことではなく、構造的比較のプロセスとなります。これにより、エージェントモードが「必須」のマイルストーンに到達していれば、環境を自由にナビゲートしたり、統合されたコンピュータ使用パスを必要に応じて適応させたりすることが可能になります。
新しい実行トレースが到着すると、検証アルゴリズムはその状態シーケンスを抽出し、トポロジカル部分列マッチング(topological subsequence matching)を用いて支配木(dominator tree)に対して照合を行います。
論理:新しいトレースが参照と完全に同一である必要はありません。重要なのは、本質的な状態が正しい相対順序で現れることです。
余分な状態の処理:参照シーケンスが A → B → C であり、エージェントが A → X → B → Y → C を生成した場合でも、テストは合格します。これは、追加された状態(X, Y)が付随的なノイズとして扱われるためです。
失敗の検出:本質的な状態がスキップされるか、または必要な論理的順序から外れて出現した場合にのみ、失敗トリガーが発動します。
スコアリングと説明可能性
当フレームワークは単なる合格/不合格の二値結果だけでなく、カバレッジ指標(coverage metric)と明確な説明を提供します:
カバレッジ:参照モデル内の状態総数に対する一致した本質的状态の割合として計算されます。
失敗理由の説明:トレースが失敗した場合、アルゴリズムは具体的にどの状態が欠落しているかを特定します(例:「失敗:『検索ダイアログ』後に『検索結果』の状態に到達しませんでした」)。
このレベルの詳細さは、検証を単なる"ブラックボックス"から、開発者がエージェントやその環境のデバッグに実際に活用できる診断ツールへと変換します。
評価から得た教訓
Trust Layer のこの構造的アプローチの有効性を証明するため、実世界のシナリオである Copilot Agent 用カスタム VS Code 拡張機能のテストスイートにおいて、Dominator Tree(支配木)メソッドとエージェントの自己評価(Computer-Use Agent、または CUA が自身の成功を報告するもの)を比較した制御実験を実施しました。
精度のギャップ
製品バグやエージェントのエラーによって失敗した実行と、成功した実行を区別するように設計されたテストにおいて、結果は決定的でした:
指標 CUA 自己評価 PTA(Dominator Tree)
精度 82.2% 100% (+17.8)
適合率 83.3% 100% (+16.7)
再現率 60.0% 100% (+40.0)
F1 スコア 69.8% 100% (+30.2)
エージェント(CUA)は、タイムアウトや自身の状態の誤解釈などにより失敗を成功として頻繁に報告していましたが、Dominator Tree は本質的なマイルストーンが実際に達成されたかどうかに着目することで、完璧な区別を実現しました。
「バグではない」シナリオの特定
開発者にとって最も大きな影響は、「偽陽性(false alarms)」の削減にあります。テストが失敗した場合、製品コードが破損しているのか、それともエージェントが環境ノイズによって単につまずいたのかを知るために、高信号フィードバックが必要です。
「自己検証」ギャップ:評価において、エージェントの内部自己評価(CUA)は「バグではない」シナリオを特定する能力が全くなく(F1 スコア 0%)、これは非決定論的環境においてエージェントがまだ自身の課題を信頼性を持って採点できないことを示しています。
構造的優位性:ドミネーターモデル内で状態と動作の同等性を活用することで、当社の独立した信頼レイヤーは、失敗がエージェントの実行エラーであるのか製品回帰であるのかを正しく識別する際に 52.2% の F1 スコアを達成しました。
教訓
構造的検証は自己報告された成功よりも大幅に優れています。真の基準となる「ソース・オブ・トゥルース」をエージェントの内部ロジックから学習された外部構造へ移行することで、CI パイプラインにおける不安定なテスト結果や偽陽性のために浪費される手動レビュー時間を大幅に削減できます。
現在の開発ワークフローにおける位置づけ
この信頼レイヤー・フレームワークが効果を発揮するためには、研究用プロトタイプを超えて、開発者が毎日使用するシステムに直接統合されなければなりません。正しさを厳格なスクリプトではなく学習された構造として扱うことで、GitHub エコシステム内での本番グレードの自動化の信頼性を大幅に向上させることができます。
統合ポイント
このアプローチは、ソフトウェア開発ライフサイクルのいくつかの重要な領域を強化するように設計されています:
GitHub Actions パイプライン:環境ノイズ(一時的な読み込み画面など)によって引き起こされる偽陰性を削減することで、自動化されたビルドに対して「より高いシグナル」を提供し、不要なパイプラインのブロックを防ぎます。
回帰テスト:開発者は、安定版からの数個の検証済みトレースを使用して、将来の更新を自動的に検証する「グラウンド・トゥルース(正解)」モデルを作成できます。
エージェント評価:エージェント自身に成功を報告させるのではなく、チームは構造化検証を用いて、エージェントが実際に重要なマイルストーンに到達する頻度を測定できます。
UI 自動化:このフレームワークにより、バージョン間で UI 要素やパスがわずかに変化する可能性のある複雑なデスクトップおよび Web アプリケーションの、より堅牢な自動化が可能になります。
このフレームワークの究極的な目標は、エージェントを「実験的なデモ」から「本番環境インフラ」へと移行させることです。失敗が明確に欠落した必須状態を指し示すような推論を提供することで、開発者はワークフロー内で自律システムを信頼するために必要な透明性を得られます。
今後の展望
構造化検証は大きな飛躍を表していますが、完全な成熟に向けて進むにつれて、現在のフレームワークにはいくつかの限界があります。
現在の制限事項には以下が含まれます:
成功トレーサビリティの要件:アルゴリズムは「例によって学習」するため、正解モデルを構築するには 2〜10 の成功実行トレーサが必要となります。失敗ログのみから正しさを学習または定義することはまだできません。
LLM への依存:現在の意味的等価性チェックにはマルチモーダル LLM(大規模言語モデル)へのアクセスに依存しています。これによりタイムスタンプやウィンドウ装飾を無視する「知能」が可能になりますが、検証層に外部 API の依存性とそれに伴う遅延をもたらします。
時間的な盲点:現在の実装はイベントの順序を検証しますが、特定の状態(例えば読み込みスピナーなど)が長期間持続しているかどうかを警告することはまだできません。
今後の研究課題には以下が含まれます:
時間的制約とネガティブ制約:今後の研究では、タイミング要件(例:"読み込みは 5 秒以内に完了しなければならない")の捕捉と、既知の失敗経路を明示的にブロックするためにネガティブ事例からの学習に焦点を当てます。
階層的・多モーダル抽象化:本フレームワークは、低レベルのスクリーンショットを高レベルの概念(例:"起動シーケンス")へとクラスタリングし、DOM 構造、アクセシビリティツリー、ネットワークトラフィックなどの非視覚的信号を統合するよう進化します。
オンライン学習:リアルタイムでのモデル改良の実装を目指します。アルゴリズムが新しい成功した実行を検証するにつれ、ドミネーター(支配者)を再計算し、何が真に"本質的"であるかという理解を継続的に高めていきます。
なぜ今これが重要なのか
AI エージェントが実験的なデモから中核インフラへと移行する中で、検証もそれらと共に進化し、脆いスクリプトから回復力のあるシステムへと移行する必要があります。
ブラックボックスモデル同士を判断させる必要はありません。開発者が検査・推論・信頼できる構造的保証が必要です。
古典的なコンパイラ理論(すなわちドミネーター解析)と多モーダル AI を組み合わせることで、ほんの数例の事例から説明可能で堅牢な成功の定義を学習することが可能であることを示しました。この Trust Layer 用のフレームワークは以下の点を提供します:
効率的な学習:合格した事例からの真偽値の自動導出。
運用上の堅牢性:非決定論的動作や環境ノイズに対する安全な処理。
完全な透明性:開発者が理解できる明確な推論を伴う説明可能な結果
(注:入力テキストは断片的であり、文脈が不足しているため、提供された部分のみを自然な日本語に翻訳します。原文の段落構造(空行区切り)に従い、1 段落として出力します。)
原文を表示
Modern software testing is built on a fragile assumption: correct behavior is repeatable. For deterministic code, that assumption mostly holds. But for autonomous agents like Github Copilot Coding Agent (aka Agent Mode), especially as we explore the frontiers of integrated “Computer Use,” that assumption breaks down almost immediately.
As agents move beyond simple code suggestions to interacting with real environments like UIs, browsers, and IDEs, correctness becomes multi-path. Loading screens can appear or disappear, timing shifts, and multiple valid action sequences can lead to the same result. Unless our GitHub Actions workflows are robust enough to account for this variability, it’s common for an agent to succeed at a task while the test still fails—a “false negative” that halts production.
This blog post explores how to move past brittle, step-by-step scripts and toward an independent “Trust Layer” for agentic validation. We will demonstrate a model that focuses on essential outcomes rather than rigid paths, providing a way to validate behavior that is explainable, lightweight, and ready for real-world CI pipelines.
The challenges of agent-driven validation
Imagine you’re responsible for a GitHub Actions pipeline that relies on Copilot Agent Mode to validate real-world workflows. The agent could be leveraging Computer Use, navigating within a containerized cloud environment, for the workflow validation.
On Tuesday, the build is green. On Wednesday, the test fails—even though no code has changed.
Here’s what happened: A minor network lag on the hosted runner caused a loading screen to persist for a few extra seconds. The agent waited, adapted, and successfully completed the tasks correctly. But your CI pipeline still flagged the run as a failure—not because the task failed, but because the execution path no longer matched the recorded script or assertion timing.
The agent didn’t fail. The validation did.
This surfaces three recurring pain points that create a “trust gap” in agent-driven testing:
False negatives: The task succeeded, but the test runner could not tolerate variation.
Fragile infrastructure: Tests fail due to timing, rendering, or environmental noise unrelated to correctness.
The compliance trap: The outcome may be correct, but a regression is flagged because the agent’s behavior diverges from what the automated test expected.
We’re in a transition period where agentic systems like Github Copilot Coding Agent are enabling faster development, but our traditional validation approaches remain rigid. In deterministic software, correctness is as simple as matching a specific input to a known output. But with agents, the process in between is intentionally non-deterministic. As agents are increasingly deployed in production, correctness isn’t about following a prescribed set of steps—it’s about “reliably achieving the essential outcomes.”
To scale these systems, we need a validation framework that can distinguish between “incidental noise” (e.g., a loading screen) and “critical failures” (e.g., failing to save data). Correctness shifts from “did this happen?” to “what had to happen for success to be real?”
Why existing testing approaches break down for autonomous agents
Traditional testing tools work well when execution paths are fixed. They struggle when behavior branches—the tools begin to fracture, not because they’re poorly engineered, but because they assume a stable sequence.
When we apply these to a Copilot Coding Agent, including when navigating a containerized environment, the limitations become clear across four common paradigms:
Assertion-based testing: Requires manual, labor-intensive specifications for every check and fails to account for valid alternative execution paths.
Record-and-replay tools: Highly sensitive to environmental noise; minor rendering differences or timing variations often trigger false failures.
Visual regression testing: Compares screenshots in isolation without understanding the broader execution flow or semantic meaning.
ML oracles: These “black boxes” require thousands of training examples and offer no explainability when they flag a behavior as incorrect.
While these approaches differ in implementation, they share a common structural assumption: Correctness is defined by adherence to a particular sequence of observable states.
For agentic systems, that assumption breaks down. To build true developer trust in these systems, including Github Copilot, we must move beyond checking linear scripts and start validating structured behaviors.
Reframing correctness: Essential vs. optional behavior
To move past brittle tests and build the Trust Layer, we have to fundamentally change how we define “correct.” In agentic systems, correct executions don’t have to look identical. They do need to share a common logical structure.
The conceptual shift
Think of a computer use-enabled Github Copilot Coding Agent performing a search in VS Code in a containerized cloud environment. In one run, a loading screen appears for several seconds; in another, the UI loads instantly (shown below).
imageScenario: Opening VS Code
A traditional test sees these as two different results. But to a developer, the loading screen is incidental; it doesn’t change whether the task was successful.
We can classify agent behavior into three categories:
Essential states: Milestones that must occur for success to be real, such as reaching the “Search Results” screen.
Optional variations: Incidental states such as loading spinners or decorative UI changes that vary based on environment.
Convergent paths: Different sequences of steps (like using a hotkey vs. a menu) that ultimately rejoin at the same outcome.
A loading screen may appear or not. But search results must appear. Only one of these determines correctness.
From intuition to theory: Dominator analysis
The distinction between “must-have” and “incidental” behaviors is a concept rooted in compiler theory known as dominator relationships.
In a control-flow graph, a node A “dominates” node B if every path from the start to B must go through A.
By applying dominator analysis to agent execution traces, we can automatically identify:
Which states are mandatory
Which states are optional
Where different paths converge
This lets us extract a minimal, explainable definition of correctness.
Modeling executions as graphs, not scripts
To capture the complexity of agentic behavior, we must move away from treating executions as linear, one-dimensional scripts. Instead, our framework models behavior using a graph-based structure known as a Prefix Tree Acceptor (PTA).
From linear traces to structured graphs
In this model, an execution is not a series of commands but a directed graph where:
Nodes represent observable states, such as screenshots for UI agents or code snapshots for development agents.
Edges represent transitions, capturing the actions (clicks, keystrokes, or API calls) taken to move between states.
Why graphs matter
Treating executions as graphs allows us to represent branching and convergence—concepts that are impossible to capture in a linear script.
Branching accounts for non-deterministic environment changes, like the presence or absence of a loading screen.
Convergence identifies where these different paths rejoin, signaling that the agent has successfully navigated a variation and returned to the primary task flow.
By shifting the representation from a sequence of steps to a structured behavior model, we stop penalizing agents for taking a different path and start validating whether they followed a logically sound one.
How we solve it: A structural approach to correctness
To move agents from experimental demos to production-grade infrastructure, our team developed a novel validation algorithm that moves away from rigid scripts and instead learns by example. To test this, we focused on a complex non-deterministic environment: an AI agent navigating Visual Studio Code via “Computer Use.” By observing just 2–10 successful sessions, our algorithm automatically constructs a “ground truth” model that distinguishes between an agent’s valid variations and actual failures.
The workflow: From traces to a “master” graph
Capture (PTA Construction): We collected 2–10 successful execution traces and converted them into Prefix Tree Acceptors (PTAs), directed graphs where nodes represent observable UI states and edges represent actions.
Generalize (Semantic Merging): Our algorithm merged these traces into a unified graph. It employed a three-tiered equivalence detection framework—combining fast visual metrics with LLM semantic analysis—to decide if two states are logically equivalent, such as ignoring a timestamp change while flagging a missing UI control.
Extract the Skeleton (Dominator Analysis): We applied dominator analysis to the merged graph to identify “essential states,” milestones every successful run must pass through—while automatically filtering out “optional” states like loading spinners.
This approach is uniquely powerful for developers because it requires no manual specification and no large-scale model training. Because the resulting model is a graph of actual execution states, the decisions are entirely explainable. When validation fails, our algorithm provides clear failure reasoning by identifying exactly which essential state was missed.
Deciding when two states are “the same”
State equivalence is the hardest problem in agent validation. For example, how do we know if two different screenshots represent the same logical UI state?
We solve this using a three-tier equivalence detection framework that moves from fast visual metrics to deep semantic understanding:
Visual metrics: We use fast perceptual hashes and structural similarity (SSIM) to catch near-identical states immediately.
Semantic analysis via LLM: When visual metrics are ambiguous, we use a multimodal LLM to decide if differences are semantically meaningful. For example, the LLM knows to ignore a timestamp change or a different window decoration but will flag a different error message or missing UI control.
Conservative merging: We only merge states when the model is certain they are equivalent, allowing the graph to naturally branch where execution paths genuinely diverge.
This is not a naive pixel-by-pixel comparison, nor is it “LLM hand-waving” where the model is asked to judge the whole task. By using the LLM defensively and sparingly to resolve specific ambiguities, our framework remains robust enough to handle UI noise but precise enough to detect a real regression.
Extracting what actually matters with dominator analysis
Once the various execution traces are merged into a unified graph, our algorithm applies dominator analysis to isolate the core skeleton of the task.
Defining “essential” through dominance: In graph theory, State A dominates State B if every possible path from the start to B must pass through A. In our model, we define a state as essential if it is a dominator for the successful completion of the task.
The filtering process: By calculating these mathematical relationships, the algorithm automatically distinguishes between “must-have” milestones and “incidental” noise.
In our VS Code experiments, the “Search Dialog” state is identified as an essential milestone because it is a mathematical dominator—it is logically impossible to reach the results without first triggering the search. Conversely, a “Loading” screen dominates nothing; because it is bypassed in faster runs, the algorithm flags it as an optional variation rather than a requirement for success. This ensures the “Trust Layer” framework only alerts you when a critical step is missed—not when the environment fluctuates.
imageScenario: Opening VS Code
By extracting these essential nodes into a dominator subtree, we create a “ground truth” model that represents the minimal, explainable definition of correctness. This shifts the validation focus away from the specific steps the agent took and toward the critical checkpoints it was required to hit.
Validating new executions in practice
With the dominator tree established as our ground truth, validating a new, unseen execution becomes a process of structural comparison rather than a search for a perfect match. This ensures that as long as an Agent Mode hits the “must-have” milestones, it is free to navigate the environment, or adapt its integrated Computer Use path, as it sees fit.
When a new execution trace arrives, our validation algorithm extracts its sequence of states and checks it against the dominator tree using topological subsequence matching.
The logic: We don’t require the new trace to be identical to the reference; we only require that the essential states appear in the correct relative order.
Handling extras: If the reference sequence is A → B → C and the agent produces A → X → B → Y → C, the test still passes because the extra states (X, Y) are treated as incidental noise.
Detecting failure: A failure is triggered only if an essential state is skipped or if the states appear out of the required logical order.
Scoring and explainability
Our framework produces more than just a binary pass/fail; it provides a coverage metric and a clear explanation:
Coverage: Calculated as the percentage of matched essential states relative to the total number of states in the reference model.
Failure reasoning: If a trace fails, our algorithm identifies exactly which state was missing (e.g., “Failed: State ‘Search Results’ never reached after ‘Search Dialog’”).
This level of detail transforms the validation from a “black box” into a diagnostic tool that developers can actually use to debug their agents and their environments.
What we learned from evaluation
To prove the efficacy of this structural approach for Trust Layer, we conducted a controlled experiment comparing our Dominator Tree method against an agent’s self-assessment (where the Computer-Use Agent, or CUA, reports its own success) in a real-world scenario: a Copilot Agent custom VS Code extension test suite.
The accuracy gap
In tests designed to differentiate successful executions from those failing due to product bugs or agent errors, the results were definitive:
MetricCUA Self-AssessmentPTA (Dominator Tree)
Accuracy82.2% 100% (+17.8)
Precision83.3% 100% (+16.7)
Recall60.0% 100% (+40.0)
F1-Score69.8%100% (+30.2)
While the agent (CUA) frequently misreported failures as successes, often due to timing out or misinterpreting its own state, the Dominator Tree achieved perfect differentiation by focusing on whether essential milestones were actually reached.
Identifying “not a bug” scenarios
The most significant impact for developers is in the reduction of “false alarms.” When a test fails, you need high-signal feedback to know if the product code is broken or if the agent simply stumbled due to environmental noise.
The “Self-Verification” Gap: In our evaluation, the agent’s internal self-assessment (CUA) was completely unable to identify “Not a Bug” scenarios (0% F1-score). This shows that agents cannot yet reliably grade their own homework in non-deterministic environments.
The Structural Advantage: By using state and action equivalence within the dominator model, our independent Trust Layer achieved a 52.2% F1-score in correctly identifying when a failure was an agent execution error rather than a product regression.
The takeaway
Structural validation beats self-reported success by a wide margin. By moving the “source of truth” from the agent’s internal logic to a learned external structure, we can significantly reduce the manual review time wasted on flaky test results and false positives in CI pipelines.
Where this fits in developer workflows today
For this Trust Layer framework to be effective, it must move beyond a research prototype and integrate directly into the systems developers use every day. By treating correctness as a learned structure rather than a rigid script, we can significantly improve the reliability of production-grade automation within the GitHub ecosystem.
Integration points
This approach is designed to strengthen several critical areas of the software development lifecycle:
GitHub Actions Pipelines: By reducing false negatives caused by environmental noise (like transient loading screens), this method provides a “higher signal” for automated builds, preventing unnecessary pipeline blocks.
Regression testing: Developers can use a handful of verified traces from a stable version to create a “ground truth” model that automatically validates future updates.
Agent evaluation: Instead of relying on an agent to report its own success, teams can use structural validation to measure how often an agent actually hits essential milestones.
UI automation: The framework allows for more robust automation of complex desktop and web apps where UI elements or paths may shift slightly between versions.
The ultimate goal of this framework is to move agents from “experimental demos” to “production infrastructure.” By providing reasoning, where a failure clearly points to a missing essential state, we give developers the transparency they need to trust autonomous systems in their workflows.
What’s next
While structural validation represents a significant leap forward, our current framework has a few boundaries as it moves toward full maturity.
Current limitations include:
Requirement for success traces: The algorithm “learns by example,” meaning it requires 2–10 successful execution traces to build its ground truth model. It cannot yet learn or define correctness exclusively from failure logs.
LLM dependency: Our semantic equivalence checking currently relies on multimodal LLM access. While this enables the “intelligence” to ignore timestamps or window decorations, it introduces an external API dependency and associated latency into the validation layer.
Temporal blind spots: The current implementation validates the order of events, but cannot yet flag if a specific state (like a loading spinner) persists for too long.
Future work includes:
Temporal and negative constraints: Future work focuses on capturing timing requirements (e.g., “loading must resolve within five seconds”) and learning from negative examples to explicitly block known failure paths.
Hierarchical and multimodal abstraction: The framework will evolve to cluster low-level screenshots into high-level concepts (e.g., a “Launch Sequence”) while integrating non-visual signals like DOM structures, accessibility trees, and network traffic.
Online learning: We aim to implement real-time model refinement. As our algorithm validates new successful runs, it will recompute dominators to continuously improve its understanding of what is truly “essential.”
Why this matters now
As AI agents move from experimental demos to core infrastructure, validation has to evolve with them and move past brittle scripts to resilient systems.
We don’t need black-box models to judge other black-box models. We need structural guarantees developers can inspect, reason about, and trust.
By combining classic compiler theory (i.e., dominator analysis) with multimodal AI, we’ve demonstrated that it’s possible to learn an explainable, robust definition of success from just a handful of examples. This framework for the Trust Layer provides:
Efficient learning: Automatic derivation of ground truth from passing examples.
Operational robustness: Secure handling of non-deterministic behavior and environmental noise.
Total transparency: Explainable results with clear reasoning that developers can
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み