GitHubのステータスページにより透明性をもたらす
GitHubは、ステータスページの透明性向上のため、より正確なインシデント分類のための「性能低下」状態の追加、サービスごとの稼働率指標の公開、Copilot AIモデルプロバイダー向けの詳細なサービス中断情報提供など、3つの改善を実施した。
キーポイント
新たな「性能低下」状態の導入
GitHubは、サービスが動作しているが性能が低下している状態をより正確に分類するため、「性能低下」という新たなインシデント重大度レベルを導入し、部分的な障害や大規模な障害と合わせた3段階のシステムを構築した。
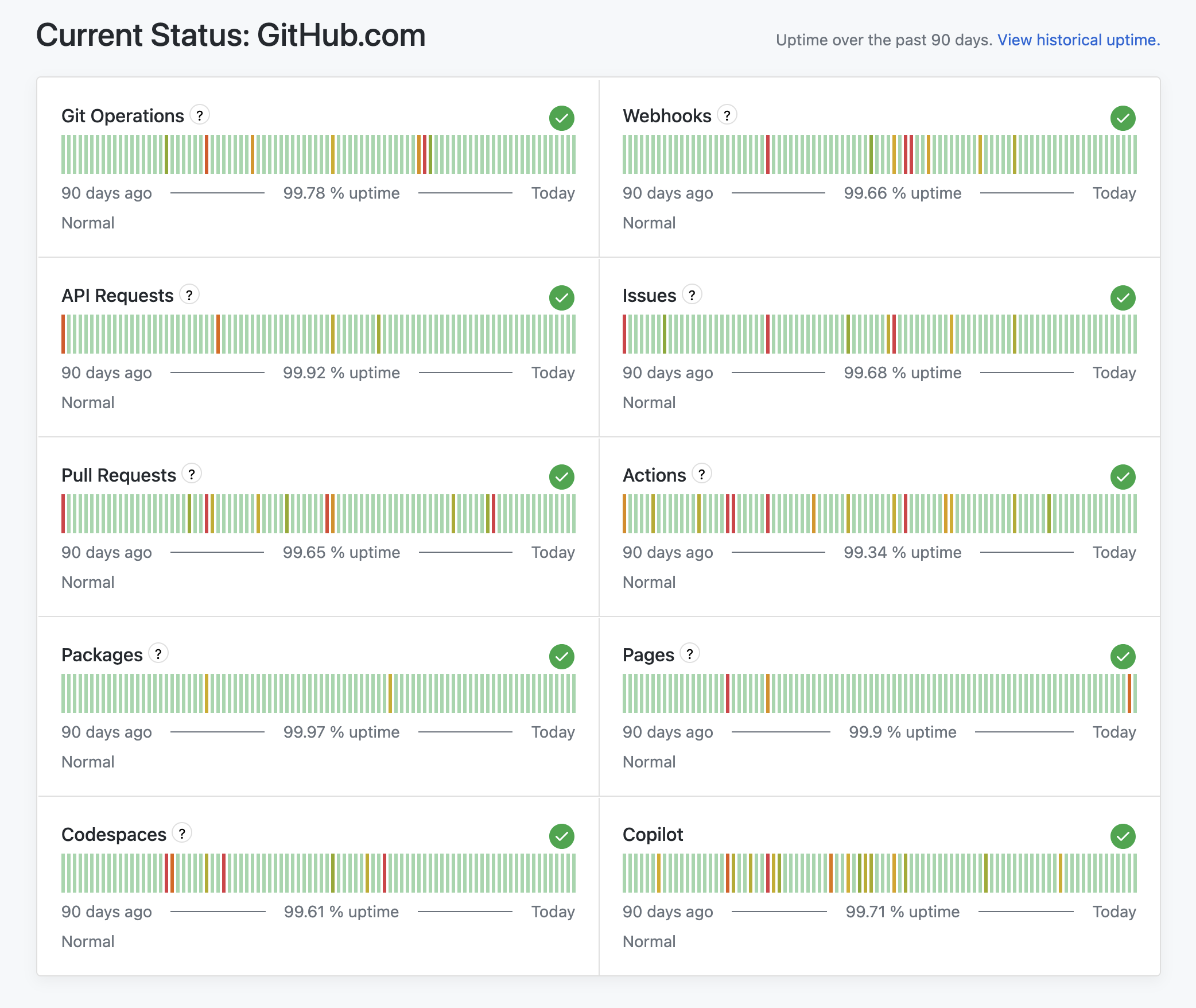
サービスごとの稼働率指標の公開
GitHubは、各サービスごとに過去90日間の稼働率パーセンテージをステータスページ上で公開し、ユーザーが各サービスの信頼性を迅速に把握できるようにした。
サービス中断に関する詳細な洞察の提供
GitHubは、サービス中断に関するより詳細な洞察を提供し始め、特にCopilot AIモデルプロバイダー向けに専用のコンポーネントを設けて、モデルプロバイダーの可用性に関する明確なコミュニケーションを実現した。
透明性、正確性、適時性を原則とした改善
GitHubは、透明性、正確性、適時性を指針として、サービス健全性の伝達方法に関する3つの変更を実施し、プラットフォーム全体の健全性に関するより良い洞察を提供している。
影響分析・編集コメントを表示
影響分析
この改善は、GitHubが大規模開発者コミュニティに対する責任を果たすための重要な一歩であり、特にAI駆動ツール(Copilot)の信頼性向上に直接寄与する。サービス健全性の透明性向上は、開発者の生産性維持と信頼構築に不可欠な要素である。
編集コメント
大規模開発者プラットフォームにおけるサービス健全性の透明性向上は、AIツールの信頼性確保においてますます重要になっている。特にCopilotのようなAI駆動機能の普及が進む中、このような取り組みは業界標準となる可能性がある。
タイトル: GitHubのステータスページにより高い透明性をもたらす
GitHubは、何百万人もの開発者が最も重要な作業を行う場所であり、私たちはその責任を真剣に受け止めています。今年初め、GitHubで最近発生した可用性の問題と、それらに対処するための取り組みについて最新情報を共有しました。これらの信頼性向上への投資に加え、私たちはインシデント発生中および発生後のコミュニケーション方法の改善、提供するデータの具体性向上、プラットフォーム全体の健全性に関するより良い洞察の提供を優先してきました。
透明性、正確性、迅速性を指針として、サービスの健全性に関するコミュニケーション方法に3つの変更を導入します。以下に概要を示します。
- より正確なインシデント分類のための新たな「性能低下」状態
- 各サービスごとに公開されるサービス別稼働率メトリクス
- サービス障害に関するより詳細な洞察(モデルプロバイダーの可用性を明確に伝えるための専用「Copilot AIモデルプロバイダー」コンポーネントから開始)
正確性の向上
新たなインシデント重大度レベルとして「性能低下」を追加します。これは既存の「部分障害」と「大規模障害」状態と並び、GitHubサービスに影響を与える可能性のある問題の幅をより正確に反映する3段階システムを構成します。
| 状態 | 意味 |
|---|---|
| 性能低下 | サービスは稼働しているが、性能が低下している。レイテンシの上昇、機能の縮小、または一部のリクエストに影響する断続的なエラーが発生する可能性があります。 |
| 部分障害 | サービスの大部分が利用できない、または相当数のユーザーに深刻な影響が生じています。 |
| 大規模障害 | サービスが広範囲で利用できず、大多数または全てのユーザーに影響を与えています。 |
以前は、サービスへの影響が最小限の場合でも、すべてのインシデントは少なくとも「部分障害」として分類されていました。これは顧客への実際の影響を正確に反映せず、サービスが機能している場合でも、ユーザーにサービスが利用できないと誤解させてしまう結果となっていました。
ステータスページでのサービス別稼働率
過去90日間のサービス別稼働率のパーセンテージを、ステータスページに直接公開するようになりました。これにより、各サービスの最近の信頼性の実績を迅速に把握できます。
これらの稼働率パーセンテージは、個々のサービスごとのインシデントの数、重大度、継続時間に基づいて計算されます。この計算方法は、業界標準のステータスページの計算に準拠しています。
各重大度レベルには、特定のダウンタイム重みが設定されています:
| 重大度 | ダウンタイム重み |
|---|---|
| 大規模障害 | 100% — インシデントの全期間がダウンタイムとしてカウントされます |
| 部分障害 | 30% — 重大ではあるが完全ではないサービス損失を反映します |
| 性能低下 | 0% — ダウンタイムとしてカウントされません。サービスは機能を維持しています |
例えば、あるサービスが90日間のうちに1時間の部分障害を経験した場合、稼働率の計算では実効18分のダウンタイムとして扱われます(1時間全体ではありません)。一方、性能低下のインシデントは、稼働率パーセンテージに全く影響を与えません。
モデルプロバイダーのサービス障害に関する洞察
Copilot AIモデルプロバイダーを表す新しいコンポーネントを追加しました。
以前は、モデルプロバイダーで障害が発生した場合、影響が単一のモデルに限定されていても、Copilotサービスに対するインシデントとして宣言していました。これは必ずしもユーザーの体験を反映していませんでした。GitHub Copilot ChatやGitHub Copilotクラウドエージェント(旧コーディングエージェント)など、多くのCopilot機能は複数のモデルをサポートしているためです。これらの機能では、1つのモデルが利用できない場合、代替モデルを選択するか、自動モデル選択を利用してCopilotに利用可能な最適なオプションを選ばせることができます。
今後、モデルの可用性に関連するインシデントは、広範な「Copilot」コンポーネントではなく、新しい「Copilot AIモデルプロバイダー」コンポーネントの下で報告します。影響を受けるモデルなどの詳細については、公開されるインシデント更新を通じて共有し続けます。
透明性への継続的なコミットメント
私たちは、問題が発生した時にこそ、明確なコミュニケーションと透明性が最も重要であると認識しています。「性能低下」状態、サービス別稼働率パーセンテージ、専用の「Copilot AIモデルプロバイダー」コンポーネントは、ユーザーの運用について確信を持って判断するために必要な情報と詳細を提供するために設計されています。
GitHubが皆さんのチームにとって重要なインフラストラクチャであることを理解しており、必要な時に必要な場所でプラットフォームを利用可能にすること、そして利用できない場合には効果的かつ透明性を持ってコミュニケーションすることをお約束します。
この投稿「GitHubのステータスページにより高い透明性をもたらす」は、The GitHub Blogで最初に公開されました。
原文を表示
GitHub is where millions of developers do their most important work, and that comes with a responsibility we take seriously. Earlier this year, we shared an update on GitHub’s recent availability issues and the work we’re doing to address them. Alongside those reliability investments, we have prioritized improving how we communicate during and after incidents, increasing the specificity of the data we provide and giving better insight into the platform’s health overall.
Guided by transparency, accuracy, and timeliness, we’re rolling out three changes to how we communicate service health—outlined below.
A new “Degraded Performance” state for more accurate incident classification
Per-service uptime metrics published for each service
More granular insights on service disruptions, starting with a dedicated “Copilot AI Model Providers” component for clearer communication around model provider availability
Improving accuracy
We’re adding a new incident severity level: Degraded Performance. This sits alongside our existing Partial Outage and Major Outage states, creating a three-tier system that more accurately reflects the spectrum of issues that can affect GitHub services.
State What It Means
Degraded Performance The service is operational but impaired. You may experience elevated latency, reduced functionality, or intermittent errors affecting a small percentage of requests.
Partial Outage A significant portion of the service is unavailable or severely impacted for a meaningful number of users.
Major Outage The service is broadly unavailable, affecting most or all users.
Previously, even with minimal service disruption, all incidents were classified at least as a partial outage. This did not accurately reflect customer impact and led users to believe a service was unavailable even if it was still functional.
Per-service uptime on the status page
We are now publishing per-service uptime percentages over the last 90 days directly on our status page, so you can quickly understand each service’s recent reliability track record.
These uptime percentages are calculated based on the number of incidents, their severity, and their duration for each individual service. These calculations are based on industry standard status page calculations.
Each severity level carries a specific downtime weight:
Severity Downtime weight
Major Outage 100% — the full duration counts as downtime
Partial Outage 30% — reflects significant but not total service loss
Degraded Performance 0% — does not count as downtime; the service remains functional
For example, if a service experienced a 1-hour Partial Outage over a 90-day period, that would count as 18 minutes of effective downtime in the uptime calculation—not the full hour. A Degraded Performance incident, by contrast, would not affect the uptime percentage at all.
Insights on model provider service disruptions
We’ve added a new component representing Copilot AI model providers.
Previously, when a model provider experienced an outage, we declared an incident against the Copilot service, even when the impact was limited to a single model. That didn’t always reflect your experience, because many Copilot features, such as GitHub Copilot Chat and GitHub Copilot cloud agent (formerly coding agent) support multiple models. On those features, if one model is unavailable, you can choose an alternative model or use auto model selection to have Copilot pick the best available option for you.
Going forward, incidents related to model availability will be reported under the new “Copilot AI Model Providers” component instead of the broader “Copilot” component. We’ll continue to share details, such as which models are affected, through public incident updates.
Our continued commitment to transparency
We recognize that clear communication and transparency matter most when things go wrong. The Degraded Performance state, per-service uptime percentages, and dedicated Copilot AI Model Providers component are designed to give you the context and details you need to make confident decisions about your operations.
We know GitHub is critical infrastructure for your teams, and we are committed to ensuring our platform is available when and where you need it; and communicating effectively and transparently when it is not.
The post Bringing more transparency to GitHub’s status page appeared first on The GitHub Blog.
関連記事
GitHub可用性レポート:2026年2月
GitHubは2026年2月に6件のインシデントが発生し、サービスパフォーマンスが低下したと報告した。同社は影響を認識し、根本原因と回復策をブログで公開し、システムの回復力向上に向けた投資を進めている。
NVIDIA Omniverseライブラリで既存アプリに物理AI機能を統合
NVIDIAは、物理的に接地されたシミュレーション環境で知覚・推論・行動する物理AIシステムを、既存アプリケーションに統合するOmniverseライブラリを提供している。これにより、ロボットや自動運転車の設計・検証プロセスが変革されている。
2026年2月20日のCloudflareサービス障害
2026年2月20日、Cloudflareがサービス障害を発生。BYOIP利用者の一部でBGP経由のインターネット接続が切断された。