エージェント対応スコアの導入:あなたのサイトはエージェント対応していますか?
Cloudflareは、ウェブサイトがAIエージェントとの連携に最適化されているかを評価する「Agent Readiness score」と専用ツール、および関連データセットを公開し、エージェント対応標準の普及状況を可視化した。
キーポイント
Agent Readiness Scoreツールの公開
isitagentready.comにてURLを入力するだけで、認証・コンテンツ制御・フォーマット・決済対応などのエージェント最適化度をスコアリングし、サイト運営者に具体的な改善指針を提供する。
エージェント標準の普及状況と課題
上位20万ドメインをスキャンした結果、robots.txtは普及しているもののAI向け設定は4%に留まり、Markdown交渉やMCP/APIカタログなどの新標準は未普及であり、早期対応が競争優位につながると指摘。
Cloudflare自身の実践例とデータ公開
同社の開発者ドキュメントをエージェント対応に最適化した事例を開示するとともに、Cloudflare RadarのAI Insightsページで週間更新されるデータとAPIアクセスを提供し、業界標準化を促進する。
4次元に基づくエージェント対応スコア
Discoverability、Content、Bot Access Control、Capabilitiesの4つの基準でサイトを評価し、エージェント利用者のベストプラクティス採用を促進する。
自動化対応と実証的なサイト設計
未対応項目にはコード生成エージェント向けの修正プロンプトを提供し、サイト自体もMCPサーバーとAgent Skillsインデックスを公開して実装例を示している。
エージェント向けコンテンツ発見の標準
クロールルールとサイトマップを定義するrobots.txt、およびHTML解析不要で直接リソースリンクを取得できるHTTP Linkヘッダー(RFC 8288)が重要である。
API Catalogによる公開APIの一元管理
RFC 9727準拠の/.well-known/api-catalogエンドポイントにより、エージェントがスクレイピングやドキュメント読解なしでAPI一覧と仕様を自動発見できる。
影響分析・編集コメントを表示
影響分析
本記事は、AIエージェントが情報取得の主要なインターフェースとなる中で、Webサイト側が対応するインフラ整備の必要性を明確に示している。Cloudflareが提供したスコアリングツールと公開データは、開発者やサイト運営者に具体的な最適化の指針を与え、エージェント対応Web標準の普及を加速させる契機となるだろう。
編集コメント
エージェント時代のWebインフラ整備において、Cloudflareが提供した可視化ツールは標準化のボトルネックを解消する重要な一歩である。開発者は「Content Signals」やMCP対応を優先的に実装し、エージェントからのアクセス最適化を図るべきだ。
ウェブは常に新しい標準への適応を余儀なくされてきました。ウェブブラウザと通信する方法を学び、次に検索エンジンと通信する方法を習得しました。今や、AIエージェント(AI agents)と通信する必要があります。
本日、私たちはisitagentready.comのご紹介を発表できることを嬉しく思います。これはサイト所有者が、エージェントへの認証方法の案内から、エージェントが閲覧できるコンテンツの制御、提供形式、課金方法に至るまで、サイトをエージェント向けに最適化する方法を理解するのを支援する新しいツールです。また、インターネット全体で各エージェント標準の採用状況を追跡する新しいデータセットをCloudflare Radarに追加することもご紹介します。

私たちは手本を示すことで先導したいと考えています。そのため、最近CloudflareのDeveloper Documentationを大幅に改訂し、エージェントに最も優しいドキュメントサイトにした方法についても共有いたします。これにより、AIツールがより高速かつ大幅に低コストで質問に回答できるようになります。
How agent-ready is the web today?
簡潔な答えは、「それほどではない」です。これは予想される結果ですが、標準が採用されれば、今日のエージェントよりもはるかに効果的になる可能性があることを示しています。
この分析のため、Cloudflare Radarはインターネット上で最も訪問数の多い20万のドメインを取得し、エージェント対応が重要ではないカテゴリ(リダイレクト、広告サーバー、トンネリングサービスなど)を除外して、AIエージェントが実際にやり取りする必要がある可能性が高い企業、パブリッシャー、プラットフォームに焦点を当てました。その後、新しいツールを使用してこれらをスキャンしました。
その結果、複数のドメインカテゴリにわたる各標準の採用状況を測定できる新しい「Adoption of AI agent standards」チャートが、Cloudflare RadarのAI Insightsページで確認できるようになりました。

個別のチェック項目を見てみると、いくつかの点が際立っています:
robots.txtはほぼ標準化されています(サイトの78%が導入)—ただし、その大半は従来の検索エンジンクローラー向けに記述されており、AIエージェント(AI agents)向けではありません。
Content Signals:4%のサイトが、robots.txt内でAI利用に関する設定を宣言しています。これは勢いを増しつつある新しい標準です。
Markdownコンテンツネゴシエーション(Markdown content negotiation:Accept: text/markdownリクエストに対してtext/markdownを返す処理)は、3.9%のサイトで成功しています。
MCP Server CardsやAPIカタログ(RFC 9727)といった新たな浮上標準の組み合わせは、データセット全体で15サイト未満にしか見当たりません。まだ初期段階であり、新しい標準をいち早く採用しエージェントとの連携を最適化することで、目立つ大きな機会があります。
このチャートは毎週更新され、Data ExplorerまたはRadar APIを通じてデータにアクセスすることも可能です。
Get an agent readiness score for your site
自身のウェブサイト向けにエージェント対応スコアを取得するには、isitagentready.comにアクセスし、サイトのURLを入力してください。
実行可能なフィードバック(actionable feedback)を提供するスコアリングと監査は、これまで新標準の普及を促進してきました。例えば、Google Lighthouse はウェブサイトのパフォーマンスとセキュリティのベストプラクティスに基づいてスコアを付け、サイト所有者が最新の Web プラットフォーム標準(web platform standards)を採用するよう導きます。エージェント向けのベストプラクティス採用を支援するために、同様のものが存在すべきだと私たちは考えています。
あなたのサイトを入力すると、Cloudflare はそのサイトに対してリクエストを送信し、どの標準をサポートしているかを確認します。そして、4 つの次元に基づいてスコアを提供します:
検索性(Discoverability): robots.txt、sitemap.xml、Link Headers (RFC 8288)
コンテンツ(Content): エージェント向け Markdown(Markdown for Agents)
ボットアクセス制御(Bot Access Control): コンテンツシグナル(Content Signals)、robots.txt 内の AI bot ルール(AI bot rules in robots.txt)、ウェブボット認証(Web Bot Auth)
機能(Capabilities): エージェントスキル(Agent Skills)、API カタログ(API Catalog)(RFC 9727)、RFC 8414 および RFC 9728 を介した OAuth サーバー検出(OAuth server discovery)、MCP サーバーカード(MCP Server Card)、WebMCP
 image
image
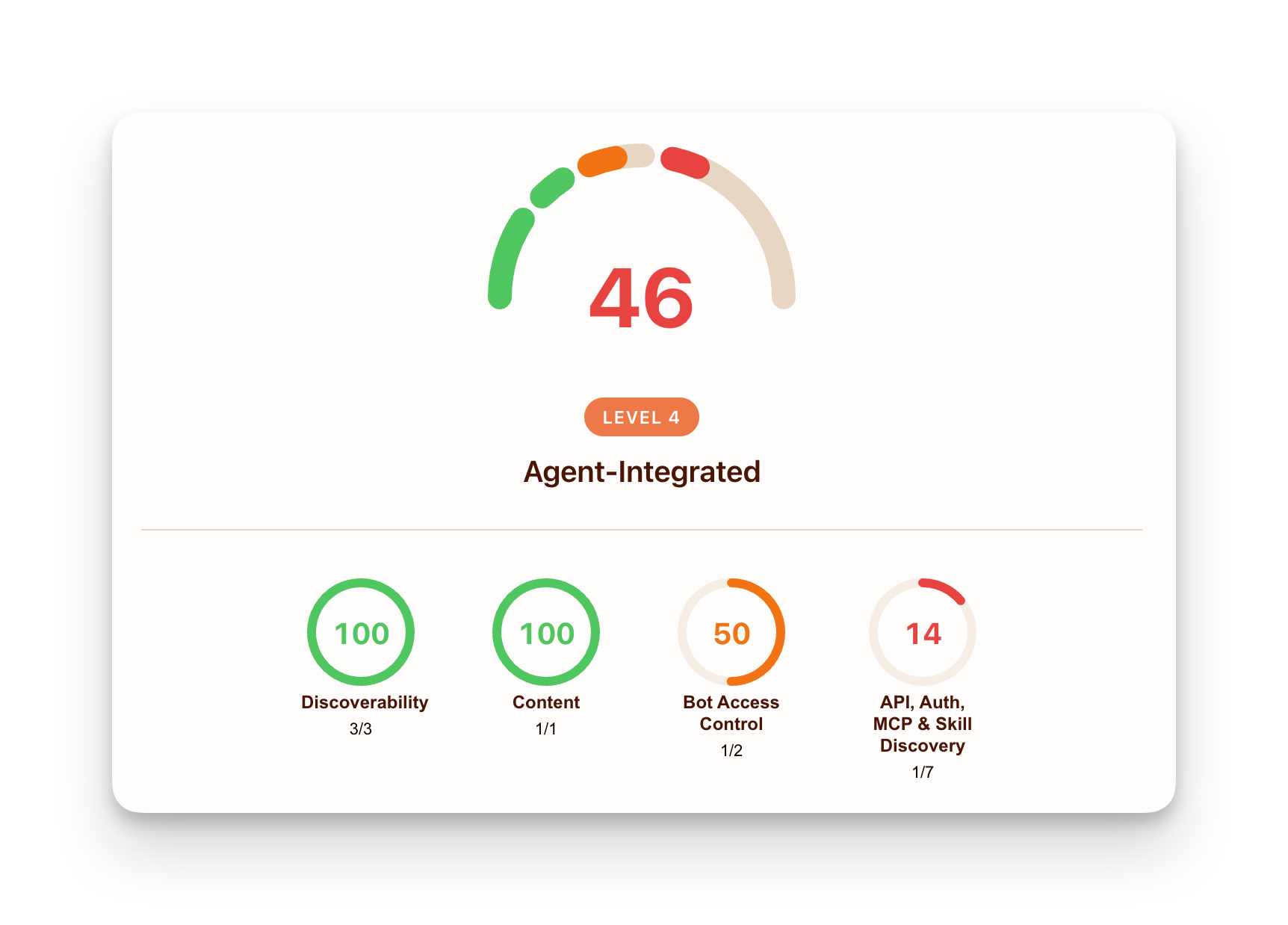
エージェント対応度チェック(agent-readiness check)の結果スクリーンショット。例のウェブサイトに対するもの。
さらに、当サイトが x402、Universal Commerce Protocol、Agentic Commerce Protocol を含むエージェント型商業標準(agentic commerce standards)をサポートしているかどうかを確認しますが、これらは現時点でスコアには反映されません。
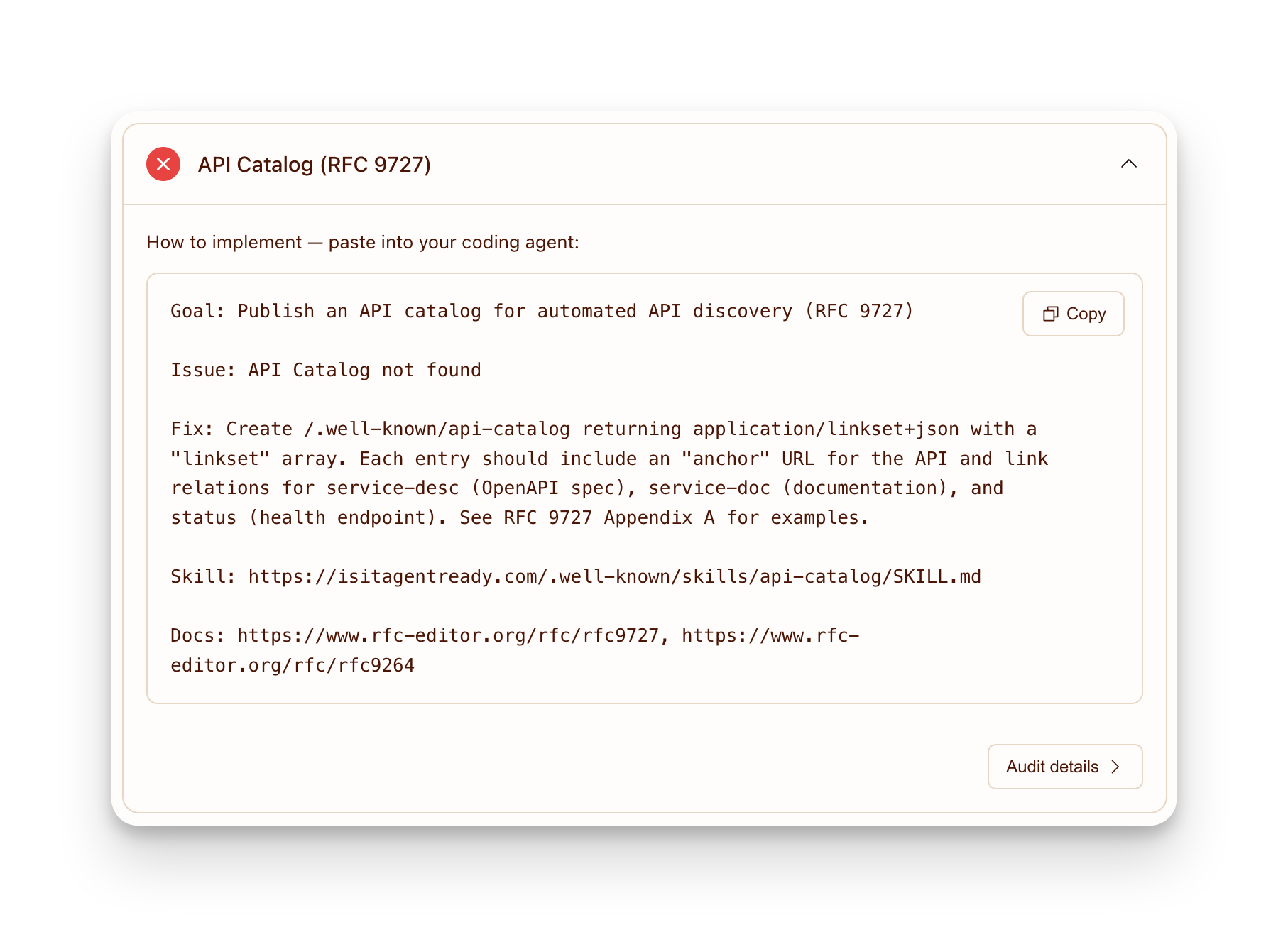
各チェックで失敗した場合、コード実行エージェント(coding agent)に渡して代わりにサポートを実装させるためのプロンプトを提供します。
 image
image
このサイト自体もまた agent-ready であり、説くことを実践しています。ストリーマブル HTTP(Streamable HTTP)を介して scan_site ツール付きのステートレス MCP サーバー(stateless MCP server)(https://isitagentready.com/.well-known/mcp.json)を公開しており、MCP 互換エージェント(MCP-compatible agent)であれば Web インターフェースを使用せずにプログラムでウェブサイトをスキャンできます。また、チェックするすべての標準に対するスキルドキュメントを備えたエージェントスキルインデックス(Agent Skills index)(https://isitagentready.com/.well-known/agent-skills/index.json)も公開しており、エージェントは修正すべき内容だけでなく、その方法も把握できます。
それぞれのカテゴリにおけるチェック内容と、エージェントにとってなぜ重要なのかを詳しく見ていきましょう。
Discoverability
robots.txt は 1994 年から存在しており、ほとんどのサイトに設置されています。エージェントにとっての役割は 2 つあります:アクセスルール(crawl rules)を定義すること、およびサイトマップ(sitemaps)への参照を示すことです。サイトマップはウェブサイト上のすべてのパスをリストアップした XML ファイルであり、エージェントがすべてのリンクをクロールすることなくコンテンツをすべて発見できるよう導く地図のようなものです。エージェントはまず robots.txt を確認します。
サイトマップに加え、エージェントは HTTP レスポンスヘッダー(HTTP response headers)から直接重要なリソースを発見することもできます。具体的には、Link レスポンスヘッダー(Link response header)(RFC 8288) を使用します。HTML の内部に埋め込まれたリンクとは異なり、Link ヘッダーは HTTP レスポンス自体の一部であるため、エージェントはマークアップ(markup)を解析することなくリソースへのリンクを見つけることができます:
HTTP/1.1 200 OK
Link: </.well-known/api-catalog>; rel="api-catalog"
コンテンツアクセシビリティ (Content accessibility)
エージェントをサイトに導入することは一つのこと。実際にそのコンテンツを読み取れるようにするのはまた別の話だ。
2024年9月という時期は、AIの進化速度を考慮すれば永遠に感じられるほど遠い過去のことだが、llms.txtはウェブサイトの大規模言語モデル(LLM)向け表現を提供し、モデルのコンテキストウィンドウ(context window)に収まるようにする手段として提案された。llms.txtはサイトのルートにあるプレーンテキストファイルで、エージェントに構造化された読書リストを提供する:サイトが何であるか、そこに何が掲載されているか、そして重要なコンテンツはどこにあるか。クローラーがインデックスを作成するためではなく、LLMが読み取るために書かれたサイトマップだと考えてもらえればよい。
# My Site
A developer platform for building on the edge.
Documentation
Changelog
マークダウンコンテンツネゴシエーション(Markdown content negotiation)はさらに一歩踏み込んだ機能だ。エージェントが任意のページを取得し、Accept: text/markdownヘッダーを送信すると、サーバーはHTMLの代わりにクリーンなマークダウン形式で応答する。このマークダウン版は必要なトークン(tokens)が大幅に少なく、場合によっては最大80%の削減を確認している。これにより応答は高速化・低コスト化し、さらに大半のエージェントツールがデフォルトで持つコンテキストウィンドウ(context window)の制限を考慮しても、コンテンツ全体が消費される可能性が高まる。
デフォルトでは、サイトがマークダウンコンテンツネゴシエーション(Markdown content negotiation)を正しく処理しているかどうかのみをチェックし、llms.txtの有無は確認しない。必要に応じてスキャンをカスタマイズし、llms.txtのチェックを含めることも可能だ。
ボットアクセス制御 (Bot Access Control)
エージェントがサイトを巡回し、コンテンツを消費できるようになった今、次の問いはこうだ:本当にすべてのボットにそれを許可したいか?
robots.txtはサイトマップへの参照以上の役割を果たす。それはアクセスルールを定義する場所でもある。どのクローラー(crawlers)を許可し、特定のパスに至るまで何にアクセスできるかを明示的に宣言できる。この規約は確立されており、健全な動作をするボットが巡回を開始する前に最初に確認する場所であり続けている。
コンテンツシグナル(Content Signals)を使えば、より詳細な指定が可能だ。単に許可またはブロックするだけでなく、AIがコンテンツに対して具体的に何を行えるかを宣言できる。robots.txt内でContent-Signalディレクティブ(Content-Signal directive)を使用することで、以下の3つの項目を独立して制御できる:コンテンツがAIのトレーニング(ai-train)に使用されるかどうか、推論やグラウンディング(grounding)のためのAI入力として利用されるかどうか、そして検索結果に表示されるべきかどうかである。
User-agent: *
Content-Signal: ai-train=no, search=yes, ai-input=yes
一方、Web Bot Auth IETFドラフト標準(Web Bot Auth IETF draft standard)は、信頼できるボットが自身を認証することを可能にし、ボットからのリクエストを受信するウェブサイトがそれらを識別できるようにする。ボットはHTTPリクエスト(HTTP requests)に署名し、受信サイトはその署名をボットの公開鍵を用いて検証する。
公開鍵は、スキャンの一部として確認するよく知られたエンドポイント(well-known endpoint)/.well-known/http-message-signatures-directory に配置されています。
全てのサイトがこれを実装する必要はありません。コンテンツを配信するだけで、他のサイトに対してリクエストを送信しないサイトであれば、必要ありません。しかし、インターネット上のより多くのサイトが他のサイトに対してリクエストを送信する独自のエージェントを運用するようになるにつれて、これは時間とともにますます重要になると予想しています。
Protocol Discovery
受動的なコンテンツの消費を超えて、エージェントはAPI(Application Programming Interface)を呼び出し、ツールを起動し、自律的にタスクを完了することで、あなたのサイトと直接やり取りすることもできます。
サービスに1つ以上の公開APIがある場合、APIカタログ(RFC 9727)(API Catalog / RFC 9727)はエージェントに対して、それらすべてを発見するための単一のよく知られた場所を提供します。/.well-known/api-catalog にホストされており、エージェントが開発者ポータルをスクレイピングしたりドキュメントを読んだりする必要なく、APIの一覧とその仕様、ドキュメント、ステータスエンドポイントへのリンクを記載します。
エージェントについて語る際にMCP(Model Context Protocol)に言及しないことはできません。モデルコンテキストプロトコル(Model Context Protocol)は、AIモデルが外部データソースやツールに接続できるようにするオープンスタンダードです。すべてのAIツールに対してカスタム統合を構築するのではなく、1つのMCPサーバーを構築すれば、互換性のある任意のエージェントがそれを利用できます。
エージェントがMCPサーバーを見つけられるようにするため、MCPサーバーカード(MCP Server Card)を公開できます。これはエージェントが接続する前にサーバーの説明を記載した /.well-known/mcp/server-card.json 内のJSONファイルです:公開されているツール、到達方法、認証方法を記します。エージェントはこのファイルを読み取り、サーバーの使用を開始するために必要な情報をすべて把握します:
{
"$schema": "https://static.modelcontextprotocol.io/schemas/mcp-server-card/v1.json",
"version": "1.0",
"protocolVersion": "2025-06-18",
"serverInfo": {
"name": "search-mcp-server",
"title": "Search MCP Server",
"version": "1.0.0"
},
"description": "Search across all documentation and knowledge base articles",
"transport": {
"type": "streamable-http",
"endpoint": "/mcp"
},
"authentication": {
"required": false
},
"tools": [
{
"name": "search",
"title": "Search",
"description": "Search documentation by keyword or question",
"inputSchema": {
"type": "object",
"properties": {
"query": { "type": "string" }
},
"required": ["query"]
}
}
]
}
エージェントは、特定のタスクの遂行を支援するエージェントスキル(Agent Skills)を持っている場合に最も効果的に動作しますが、エージェントはサイトが提供するスキルをどのように発見できるのでしょうか?私たちは、サイトがこの情報を .well-known/agent-skills/index.json で利用可能にすることを提案しています。これは、利用可能なスキルとその場所をエージェントに伝えるエンドポイントです。.well-known 標準(.well-known standard / RFC 8615)が多くの他のエージェントおよび認可のスタンダードで使われていることに気づくかもしれません。この標準を策定したCloudflare所属のMark Nottingham氏、およびその他のIETF貢献者に感謝します!
多くのサイトでは、アクセスするためにまずサインインする必要があります。これにより、人間がエージェントにこれらのサイトに代わってアクセスする権限を付与することが困難になり、その結果、一部のサイトでは、ログイン済みセッションを含むユーザーのウェブブラウザにエージェントがアクセスできるという、安全面から疑問が残る回避策を採用しています。
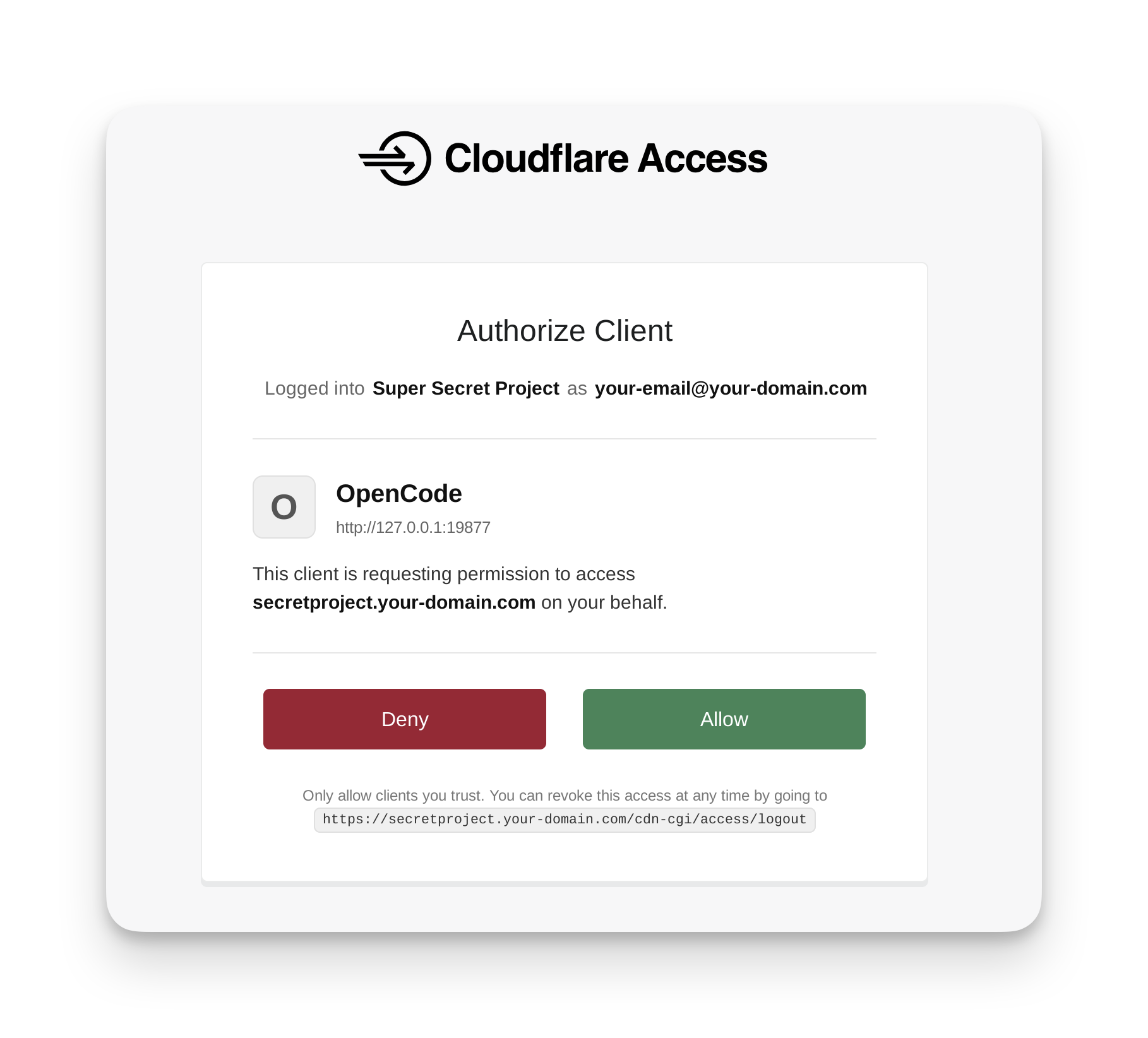
より良い方法として、人間が明示的にアクセスを付与できる仕組みがあります。OAuthをサポートするサイトは、認証サーバー(authorization server)(RFC 9728)の場所をエージェントに通知できます。これにより、エージェントは人間をOAuthフロー(OAuth flow)に誘導し、人間がエージェントへの適切なアクセス権限を付与するかどうかを選択できるようになります。Agents Week 2026で発表されたCloudflare Accessは、このOAuthフローを完全にサポートしており、ユーザーが保護されたURL(protected URLs)をエージェントに提供した際にOpenCodeのようなエージェントがこの標準を活用してスムーズに動作する様子も示しました:
 image
image
Commerce
エージェントはあなたの代わりに商品を購入することもできますが、ウェブ上の決済(payments)は人間向けに設計されています。カートに追加し、クレジットカード情報を入力して「購入」をクリックするだけです。しかし、購入者がAIエージェントの場合、このフロー(flow)は完全に機能しなくなります。
x402は、1997年から仕様(spec)に存在しながら広く使われることのなかったステータスコード「HTTP 402 Payment Required(支払い必要)」を復活させることで、プロトコルレベルでこの問題を解決します。フローはシンプルです。エージェントがリソースを要求すると、サーバーは402ステータスコードと支払い条件(payment terms)を記述した機械可読のペイロード(machine-readable payload)で応答し、エージェントが決済して再試行します。CloudflareはCoinbaseと提携してx402 Foundationを設立し、そのミッションはインターネット決済のオープンスタンダードとしてx402の普及を推進することです。
また、Universal Commerce Protocol(ユニバーサルコマースプロトコル)とAgentic Commerce Protocol(エージェント型コマースプロトコル)のサポートも確認しています。これらは、人間が通常eコマースストアフロント(ecommerce storefronts)やチェックアウトフロー(checkout flows)で購入する製品をエージェントが発見・購入できるように設計された、新興のエージェント型コマース標準規格(agentic commerce standards)です。
Integrating agent readiness into Cloudflare URL Scanner
CloudflareのURL Scanner(URLスキャナー)を使用すると、任意のURLを提出して詳細なレポートを取得できます。これにはHTTPヘッダー(HTTP headers)、TLS証明書(TLS certificates)、DNSレコード(DNS records)、使用されているテクノロジー、パフォーマンスデータ、セキュリティシグナル(security signals)が含まれます。これは、URLが実際にどのような処理を行っているかを理解したいセキュリティ研究者や開発者にとって不可欠なツールです。
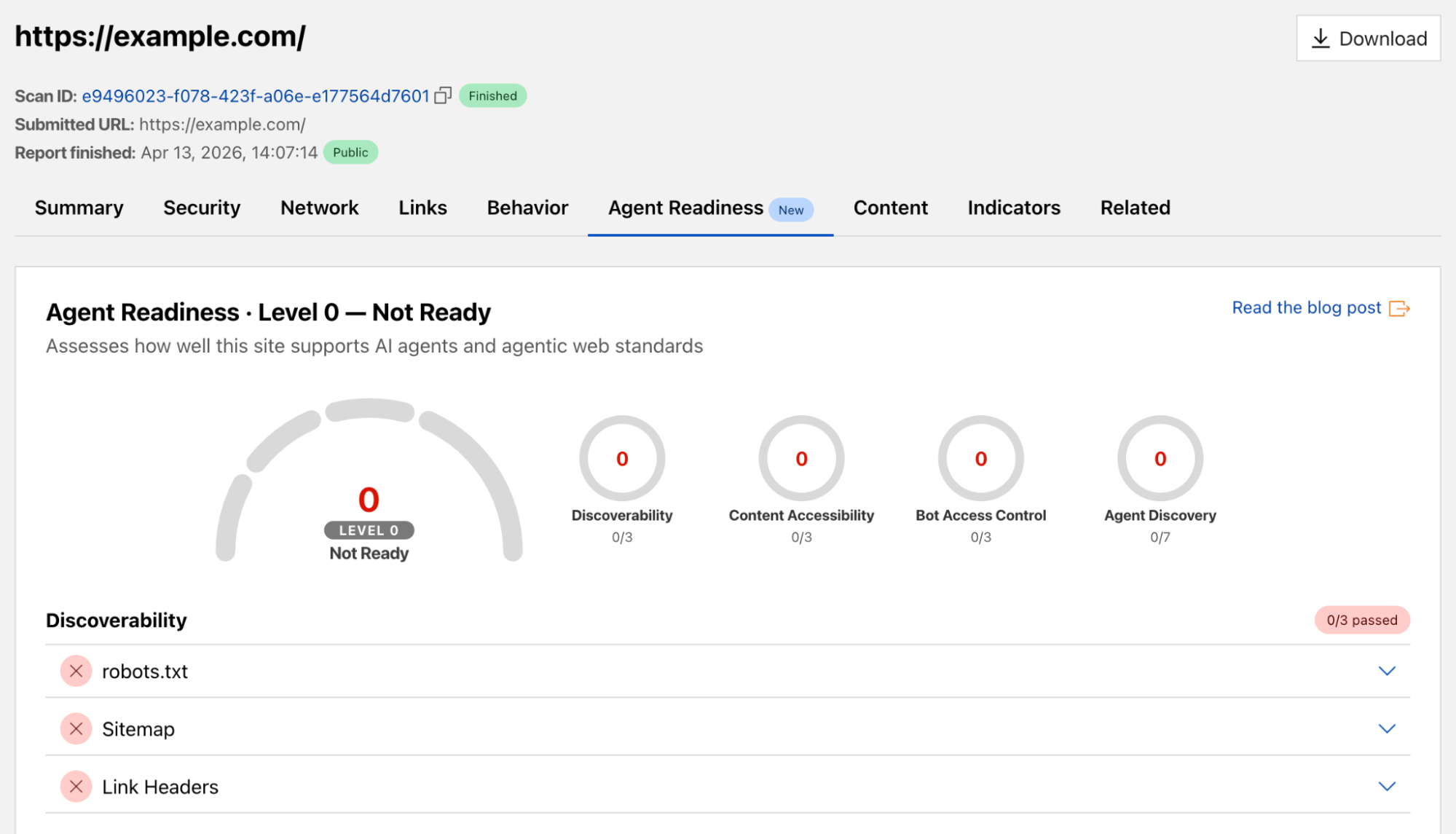
isitagentready.comから同じチェック項目を抽出し、新しいAgent Readinessタブ(Agent Readiness tab)としてURL Scannerに追加しました。任意のURLをスキャンすると、既存の分析結果 alongside に、完全なエージェント準備度レポート(agent readiness report)が表示されます。これには、どのチェックに合格したか、サイトのレベルはどの程度か、スコアを向上させるための具体的なガイダンス(actionable guidance)が含まれます。
本機能はURL Scanner API(URLスキャンAPI)を通じてプログラム的に利用することも可能です。スキャン結果にエージェント準備度スコアを含める場合、リクエストに agentReadiness オプションを渡してください:
curl -X POST https://api.cloudflare.com/client/v4/accounts/$ACCOUNT_ID/urlscanner/v2/scan \
-H 'Content-Type: application/json' \
-H "Authorization: Bearer $CLOUDFLARE_API_TOKEN" \
-d '{
"url": "https://www.example.com",
"options": {"agentReadiness": true}
}'
手本を示す:Cloudflare Docsのアップグレード
Webの準備度を測定するツールを開発するにあたり、私たちは自社のドキュメントを整備しなければならないと理解していました。お客様の使用するエージェントが容易にコンテンツを解析できる状態である必要があります。
上記のコンテンツサイト向け標準を自然と採用し、スコアはここで確認できます。しかし、私たちはそこで終わりませんでした。以下は、CloudflareのDeveloper Docs(開発者向けドキュメント)をWeb上で最もエージェントフレンドリーなリソースに仕上げるまでの取り組みです。
/index.mdファイルを用いたURLフォールバック
残念ながら、2026年2月現在、テストした7つのエージェントのうち、Claude Code、OpenCode、Cursorのみがデフォルトで Accept: text/markdown ヘッダーを付けてコンテンツをリクエストします。残りのエージェントについては、シームレスなURLベースのフォールバックが必要でした。
これを実現するため、各ページのURL相対パスとして /index.md にMarkdown形式でページを個別に公開しています。静的ファイルの複製を行わず動的にこれを行うため、以下の2つのCloudflare Rules(Cloudflareルール)を組み合わせています:
/index.md で終わるリクエストにマッチするURL Rewrite Rule(URL書き換えルール)が、regex_replace を使用して /index.md を除去し、ベースパスに動的に書き換えます。
書き換え前の元のリクエストパス(raw.http.request.uri.path)にマッチするRequest Header Transform Rule(リクエストヘッダー変換ルール)が、自動的に Accept: text/markdown ヘッダーを設定します。
この2つのルールにより、URLの末尾に /index.md パスを追加するだけで、任意のページをMarkdown形式で取得できます:
https://developers.cloudflare.com/r2/get-started/index.md
これらの /index.md URLは、当社の llms.txt ファイルで参照されています。実質的に、これらの /index.md パスに対しては、クライアントが設定するヘッダーに関係なく常にMarkdownを返します。これらは追加のビルドステップやコンテンツの複製なしで実現しています。
大規模サイト向けの効果的なllms.txtファイルの作成
llms.txt はエージェントにとっての「ホームベース」として機能し、LLM(大規模言語モデル)がコンテンツを検出できるようページディレクトリを提供します。しかし、単一ファイルに5,000ページ以上のドキュメントを格納すると、モデルのコンテキストウィンドウ(context window)の上限を超えてしまいます。
巨大な単一ファイルにするのではなく、ドキュメント内の各トップレベルディレクトリごとに個別の llms.txt ファイルを生成し、ルート llms.txt はこれらのサブディレクトリを単に参照しています。
https://developers.cloudflare.com/llms.txt
https://developers.cloudflare.com/r2/llms.txt
当社はまた、大语言模型(LLM)にとってセマンティック(意味的)価値が低い数百のディレクトリリストページを削除し、各ページに豊富な記述コンテキスト(タイトル、セマンティック名、説明)が含まれるようにしています。
例えば、https://developers.cloudflare.com/workers/databases/ のように、ローカルディレクトリリストとしてのみ機能する約450ページは省略しています。
 image
image
これらのページはサイトマップに含まれていますが、大语言模型(LLM)にとって有用な情報はほとんど含まれていません。llms.txt には子ページがすべて個別にリンクされているため、ディレクトリページを取得してもリンクの冗長なリストしか得られず、エージェントは実際のコンテンツを見つけるために別のリクエストを送信せざるを得ません。
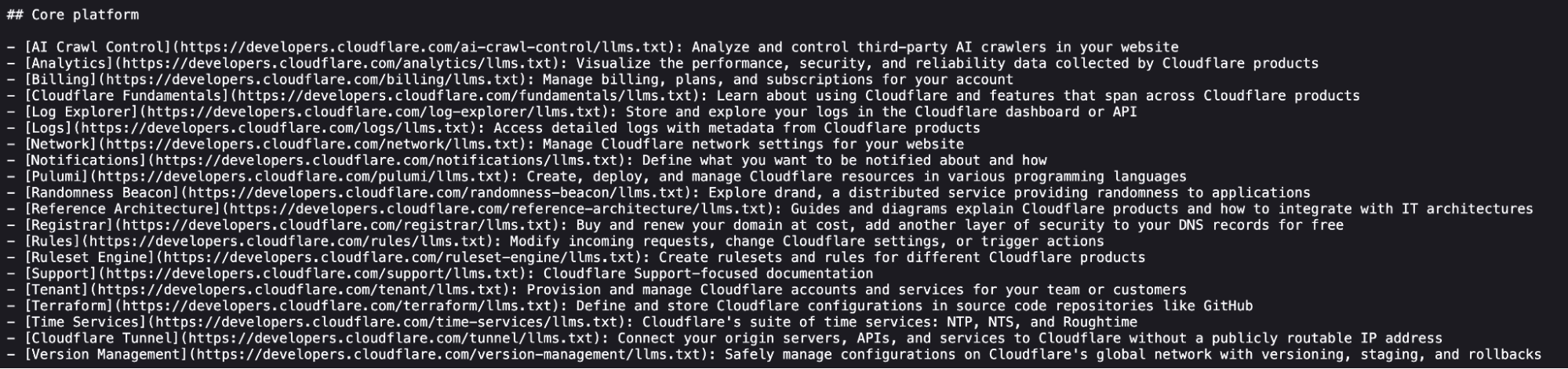
エージェントが効率的にナビゲートできるよう、各 llms.txt のエントリはコンテキストは豊富だがトークン数は軽量である必要があります。人間が前書き情報(frontmatter)やフィルタリングラベルを無視することがあっても、AIエージェントにとってこのメタデータは操縦桿(ステアリングホイール)のようなものです。そのため、Product Content Experience (PCX) チームはページタイトル、説明、URL構造を最適化し、エージェントが常に取得すべきページを正確に把握できるようにしています。
ルート llms.txt の一部を以下にご覧ください。
 image
image
各リンクには、セマンティック名、対応するURL、そして高価値な説明が含まれています。llms.txt 生成のために追加の作業は必要ありませんでした。これらはすべてドキュメントの前書き情報(frontmatter)ですでに利用可能でした。トップレベルディレクトリの llms.txt ファイル内のページも同様です。これらのコンテキストすべてが、エージェントが関連情報をより効率的に見つけることを可能にします。
カスタムエージェントフレンドリードキュメンテーション(afdocs)ツール
さらに、コンテンツの発見やナビゲーションなどの観点からドキュメントサイトをテストできる、新興のエージェントフレンドリードキュメンテーション仕様でありオープンソースプロジェクトである afdocs に対して、当社のドキュメントをテストしています。この仕様により、独自の監査ツール(audit tooling)を構築することができました。ユースケースに特化したいくつかの意図的なパッチを追加することで、簡単な評価ができるダッシュボードを作成しました。
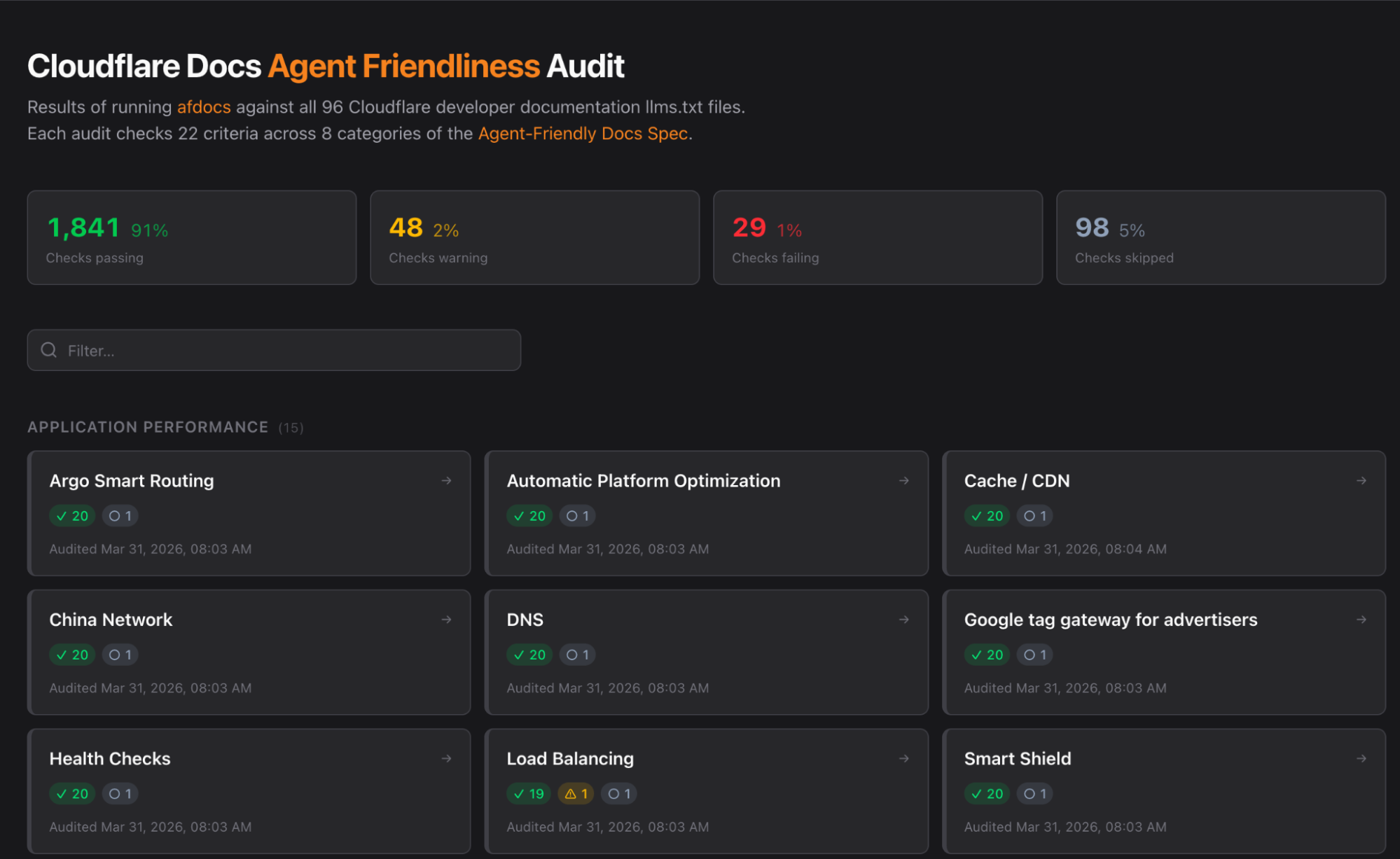 image
image
ベンチマーク結果:より高速で低コスト
当社はエージェント(OpenCode経由のKimi-k2.5)を他の大手テクノロジー企業の...
原文を表示
The web has always had to adapt to new standards. It learned to speak to web browsers, and then it learned to speak to search engines. Now, it needs to speak to AI agents.
Today, we are excited to introduce isitagentready.com — a new tool to help site owners understand how they can make their sites optimized for agents, from guiding agents on how to authenticate, to controlling what content agents can see, the format they receive it in, and how they pay for it. We are also introducing a new dataset to Cloudflare Radar that tracks the overall adoption of each agent standard across the Internet.
image
We want to lead by example. That is why we are also sharing how we recently overhauled Cloudflare's Developer Documentation to make it the most agent-friendly documentation site, allowing AI tools to answer questions faster and significantly cheaper.
How agent-ready is the web today?
The short answer: not very. This is expected, but also shows how much more effective agents can be than they are today, if standards are adopted.
To analyze this, Cloudflare Radar took the 200,000 most visited domains on the Internet; filtered out categories where agent readiness isn't important (like redirects, ad-servers, and tunneling services) to focus on businesses, publishers, and platforms that AI agents might realistically need to interact with; and scanned them using our new tool.
The result is a new “Adoption of AI agent standards” chart that can now be found in the Cloudflare Radar AI Insights page where we can measure adoption of each standard across multiple domain categories.
image
Looking at individual checks, a few things stood out:
robots.txt is nearly universal — 78% of sites have one — but the vast majority are written for traditional search engine crawlers, not AI agents.
Content Signals: 4% of sites have declared their AI usage preferences in robots.txt. This is a new standard that is gaining momentum.
Markdown content negotiation (serving text/markdown on Accept: text/markdown) passes on 3.9% of sites.
New emerging standards like MCP Server Cards and API Catalogs (RFC 9727) together appear on fewer than 15 sites in the entire dataset. It’s still early — there is lots of opportunity to stand out by being one of the first sites to adopt new standards and work well with agents.
This chart will be updated weekly, and the data can also be accessed through the Data Explorer or the Radar API.
Get an agent readiness score for your site
You can get an agent readiness score for your own website by going to isitagentready.com and entering the site’s URL.
Scores and audits that provide actionable feedback have helped to drive adoption of new standards before. For example, Google Lighthouse scores websites on performance and security best practices, and guides site owners to adopt the latest web platform standards. We think something similar should exist to help site owners adopt best practices for agents.
When you enter your site, Cloudflare makes requests to it to check which standards it supports, and provides a score based on four dimensions:
Discoverability: robots.txt, sitemap.xml, Link Headers (RFC 8288)
Content: Markdown for Agents
Bot Access Control: Content Signals, AI bot rules in robots.txt, Web Bot Auth
Capabilities: Agent Skills, API Catalog (RFC 9727), OAuth server discovery via RFC 8414 and RFC 9728, MCP Server Card, and WebMCP
image
Screenshot of results from an agent-readiness check for an example website.
Additionally, we check if the site supports agentic commerce standards including x402, Universal Commerce Protocol, and Agentic Commerce Protocol, but these do not currently count towards the score.
For each failing check, we provide a prompt that you can give to your coding agent and have it implement support on your behalf.
image
The site itself is also agent-ready, practicing what it preaches. It exposes a stateless MCP server (https://isitagentready.com/.well-known/mcp.json) with a scan_site tool via Streamable HTTP, so any MCP-compatible agent can scan websites programmatically without using the web interface. It also publishes an Agent Skills index (https://isitagentready.com/.well-known/agent-skills/index.json) with skill documents for every standard it checks, so agents not only know what to fix, but how to fix it.
Let’s dig into the checks in each category, and why they matter for agents.
Discoverability
robots.txt has been around since 1994, and most sites have one. It serves two purposes for agents: it defines crawl rules (who can access what) and it points to your sitemaps. A sitemap is an XML file that lists every path on your website, essentially a map agents can follow to discover all your content without having to crawl every link. The robots.txt is where agents look first.
Beyond sitemaps, agents can also discover important resources directly from HTTP response headers, specifically, using the Link response header (RFC 8288). Unlike links buried inside HTML, the Link header is part of the HTTP response itself, which means an agent can find links to resources without having to parse any markup:
HTTP/1.1 200 OK
Link: </.well-known/api-catalog>; rel="api-catalog"
Content accessibility
Getting an agent onto your site is one thing. Making sure it can actually read your content is another.
Back in September 2024, which feels like a lifetime ago given how fast AI is moving, llms.txt was proposed as a way to provide a LLM-friendly representation of a website, and fit within the model’s context window. llms.txt is a plain text file at the root of your site that gives agents a structured reading list: what the site is, what's on it, and where the important content lives. Think of it as a sitemap written for an LLM to read rather than a crawler to index:
# My Site
A developer platform for building on the edge.
Documentation
Changelog
Markdown content negotiation goes even further. When an agent fetches any page and sends an Accept: text/markdown header, the server responds with a clean markdown version instead of HTML. The markdown version requires far fewer tokens — we measured up to 80% token reduction in some cases — which makes responses faster, cheaper, and more likely to be consumed in its entirety, given the limits on context windows that most agent tools have by default.
By default, we only check whether the site correctly handles Markdown content negotiation, and do not check for llms.txt. You can customize the scan to include llms.txt if you choose to.
Bot Access Control
Now that agents can navigate your site and consume your content, the next question is: do you want to let any bot do it?
robots.txt does more than point to sitemaps. It is also where you define your access rules. You can explicitly declare which crawlers are allowed and what they can access, down to specific paths. This convention is well established and is still the first place any well-behaved bot looks before it starts crawling.
Content Signals let you be more specific. Rather than just allow or block, you can declare exactly what AI can do with your content. Using a Content-Signal directive in your robots.txt, you can independently control three things: whether your content can be used for AI training (ai-train), whether it can be used as AI input for inference and grounding (ai-input), and whether it should appear in search results (search):
User-agent: *
Content-Signal: ai-train=no, search=yes, ai-input=yes
Inversely, the Web Bot Auth IETF draft standard allows friendly bots to authenticate themselves, and allows websites receiving requests from bots to identify them. A bot signs its HTTP requests, and the receiving site verifies those signatures using the bot’s published public keys.
Those public keys live at a well-known endpoint, /.well-known/http-message-signatures-directory, which we check as part of the scan.
Not all sites need to implement this. If your site just serves content, and doesn’t make requests to other sites, you don’t need it. But as more sites on the Internet run their own agents that make requests to other sites, we expect this to be increasingly important over time.
Protocol Discovery
Beyond passive content consumption, agents can also interact with your site directly by calling APIs, invoking tools, and completing tasks autonomously.
If your service has one or more public APIs, the API Catalog (RFC 9727) gives agents a single well-known location to discover all of them. Hosted at /.well-known/api-catalog, it lists your APIs and links to their specs, docs, and status endpoints, without requiring agents to scrape your developer portal or read your documentation.
We can't talk about agents without mentioning MCP. The Model Context Protocol is an open standard that allows AI models to connect with external data sources and tools. Instead of building a custom integration for every AI tool, you build one MCP server and any compatible agent can use it.
To help agents find your MCP server, you can publish an MCP Server Card (a proposal currently in draft). This is a JSON file at /.well-known/mcp/server-card.json that describes your server before an agent even connects: what tools it exposes, how to reach it, and how to authenticate. An agent reads this file and knows everything it needs to start using your server:
{
"$schema": "https://static.modelcontextprotocol.io/schemas/mcp-server-card/v1.json",
"version": "1.0",
"protocolVersion": "2025-06-18",
"serverInfo": {
"name": "search-mcp-server",
"title": "Search MCP Server",
"version": "1.0.0"
},
"description": "Search across all documentation and knowledge base articles",
"transport": {
"type": "streamable-http",
"endpoint": "/mcp"
},
"authentication": {
"required": false
},
"tools": [
{
"name": "search",
"title": "Search",
"description": "Search documentation by keyword or question",
"inputSchema": {
"type": "object",
"properties": {
"query": { "type": "string" }
},
"required": ["query"]
}
}
]
}
Agents work best when they have Agent Skills that help them perform specific tasks — but how can agents discover what skills a site provides? We’ve proposed that sites can make this information available at .well-known/agent-skills/index.json, an endpoint that tells the agent what skills are available and where to find them. You might notice that the .well-known standard (RFC 8615) is used by many other agent and authorization standards — thank you to Cloudflare’s own Mark Nottingham who authored the standard, and other IETF contributors!
Many sites require you to sign in first in order to access them. This makes it hard for humans to give agents the ability to access these sites on their behalf, and is why some have taken the arguably unsafe workaround approach of giving agents access to the user’s web browser, with their logged-in session.
There’s a better way that allows humans to explicitly grant access: sites that support OAuth can tell agents where to find the authorization server (RFC 9728), allowing agents to send humans through an OAuth flow, where they can choose to properly grant access to the agent. Announced at Agents Week 2026, Cloudflare Access now fully supports this OAuth flow, and we showed how agents like OpenCode can make use of this standard to make things just work when users give agents protected URLs:
image
Commerce
Agents can also buy things on your behalf — but payments on the web were designed for humans. Add to cart, enter a credit card, click pay. That flow breaks down entirely when the buyer is an AI agent.
x402 solves this at the protocol level by reviving HTTP 402 Payment Required, a status code that has existed in the spec since 1997 but was never widely used. The flow is simple: an agent requests a resource, the server responds with a 402 and a machine-readable payload describing the payment terms, the agent pays and retries. Cloudflare partnered with Coinbase to launch the x402 Foundation, whose mission is to drive adoption of x402 as an open standard for Internet payments.
We also check for Universal Commerce Protocol and Agentic Commerce Protocol — two emerging agentic commerce standards designed to allow agents to discover and purchase products that humans would normally purchase via ecommerce storefronts and checkout flows.
Integrating agent readiness into Cloudflare URL Scanner
Cloudflare's URL Scanner lets you submit any URL and get a detailed report on it: HTTP headers, TLS certificates, DNS records, technologies used, performance data, and security signals. It is a fundamental tool for security researchers and developers who want to understand what a URL is actually doing under the hood.
We’ve taken the same checks from isitagentready.com and added them to URL Scanner with a new Agent Readiness tab. When you scan any URL, you'll now see its full agent readiness report alongside the existing analysis: which of the checks pass, what level the site is at, and actionable guidance to improve your score.
image
The integration is also available programmatically via the URL Scanner API. To include agent readiness results in a scan, pass the agentReadiness option in your scan request:
curl -X POST https://api.cloudflare.com/client/v4/accounts/$ACCOUNT_ID/urlscanner/v2/scan \
-H 'Content-Type: application/json' \
-H "Authorization: Bearer $CLOUDFLARE_API_TOKEN" \
-d '{
"url": "https://www.example.com",
"options": {"agentReadiness": true}
}'
Leading by example: upgrading Cloudflare Docs
As we built the tools to measure the Web’s readiness, we knew we had to ensure our own house was in order. Our docs must be easily digestible by the agents our customers use.
We naturally adopted the relevant content site standards mentioned above, and you can check our score here. However, we didn’t stop there. Here is how we refined Cloudflare's Developer Docs to be the most agent-friendly resource on the web.
URL fallbacks using index.md files
Unfortunately, as of February 2026, of 7 agents tested, only Claude Code, OpenCode, and Cursor request content with the Accept: text/markdown header by default. For the rest, we needed a seamless URL-based fallback.
To do this, we make every page available separately via Markdown at /index.md relative to the page’s URL. We do this dynamically, without duplicating static files, by combining two Cloudflare Rules:
A URL Rewrite Rule matches requests ending in /index.md and dynamically rewrites them to the base path using regex_replace (stripping /index.md).
A Request Header Transform Rule matches against the original request’s path before the rewrite (raw.http.request.uri.path) and automatically sets the Accept: text/markdown header.
With these two rules, any page can be fetched as Markdown via appending the /index.md path to the URL:
https://developers.cloudflare.com/r2/get-started/index.md
We point to these /index.md URLs in our llms.txt files. Effectively, for these /index.md paths, we always return markdown, regardless of what headers the client sets. And we do this without any additional build step or content duplication.
Creating effective llms.txt files for large sites
llms.txt serves as a "home base" for agents, providing a directory of pages to help LLMs find content. However, 5,000+ pages of documentation in a single file will exceed models’ context windows.
Instead of one massive file, we generate a separate llms.txt file for each top-level directory in our docs and the root llms.txt simply points to these subdirectories.
https://developers.cloudflare.com/llms.txt
https://developers.cloudflare.com/r2/llms.txt
https://developers.cloudflare.com/workers/llms.txt
We also remove hundreds of directory-listing pages that provide little semantic value to an LLM, and we ensure each page has rich descriptive context (titles, semantic names, and descriptions).
For example, we omit roughly 450 pages that only serve as localized directory listings, like https://developers.cloudflare.com/workers/databases/.
image
These pages appear in our sitemap, but they contain very little information for an LLM. Since all child pages are already linked individually in llms.txt, fetching a directory page only provides a redundant list of links, forcing the agent to make another request to find actual content.
To help agents navigate efficiently, each llms.txt entry must be rich in context but light on tokens. Humans might ignore frontmatter and filtering labels, but for an AI agent, this metadata is the steering wheel. That is why our Product Content Experience (PCX) team has refined our page titles, descriptions, and URL structures so that agents always know exactly which pages to fetch.
Take a look at a section from our root llms.txt.
image
Each link has a semantic name, a matching URL, and a high-value description. None of this required extra work for llms.txt generation. It was all already available in the docs frontmatter. The same goes for pages in top level directory llms.txt files. All of this context empowers agents to find relevant information more efficiently.
Custom agent-friendly documentation (afdocs) tooling
Additionally, we test our docs against afdocs, an emerging agent-friendly documentation spec and open-source project that allows teams to test docs sites for things like content discovery and navigation. This spec allowed us to build custom audit tooling of our own. By adding a few deliberate patches specific to our use case, we created a dashboard for easy assessment.
image
Benchmark results: faster and cheaper
We pointed an agent (Kimi-k2.5 via OpenCode) at other large tech
関連記事
Cloudflare Radar データが示すイランのインターネット一部復旧
Cloudflare は、米国とイスラエルの攻撃後に約 3 ヶ月続いた切断から、イラン政府による復旧宣言を受け、同国のインターネットアクセスが部分的に回復したことを Radar データで確認した。
AIの現実検証:3社がウォレット、住宅、ゲーム構築で学んだこと
シティ、ホームデポ、カプコンの経営陣は、AIエージェントが実験ツールから顧客対応業務へ移行する過程で得た知見を語った。次なる課題は、金銭や創造的出力に関わる際のガバナンスと信頼性の確保である。
アンストロピック「強力なAIモデルはより良い取引を実現し、劣るモデルを使う利用者は気づかない」
アンストロピックは社内市場で69のAIエージェントに取引をさせ、強力なモデルがより良い結果を出した。利用者は劣るモデルの差に気づかず、AIの実取引化は経済格差を拡大させる可能性がある。