ジェミニが主導権を握り、投資家が自律型 AI に不安、グローバル AI サミットで楽観論、ローカルとクラウドの対立
Andrew Ng が、AI スキルの可視化と学習経路の提案を行う新しいツール「Skill Builder」を発表し、AI 業界の急速な変化の中で個人がキャリアを構築する際の指針を提供した。
キーポイント
新ツールの発表: Skill Builder
DeepLearning.AI が、ユーザーの現在の AI スキルレベルを評価し、学習すべき分野や次のステップを提案する対話型ツール「Skill Builder」をリリースした。
メンター機能としての役割
急速に変化する技術環境において、知識のギャップ(自分が何を知らないか)を埋めるため、信頼できるメンターの代わりとして機能することを目的としている。
多様なユーザー層への対応
ChatGPT によるプロンプト利用から複雑なアジェンティックワークフローの構築まで、初心者から上級者までの幅広い層を対象に設計されている。
学習成果の可視化と推奨
対話終了後には要約レポートが表示され、DeepLearning.AI Pro 会員はより詳細なフィードバックを受けられる仕組みとなっている。
Gemini 3.1 Pro の登場と性能向上
Google が新モデル「Gemini 3.1 Pro Preview」を発表し、推論コストを抑えつつ複数のベンチマークで最高性能を達成しました。特にARC-AGI-2などの視覚的論理タスクで前世代や競合他社を大きく上回る結果となりました。
AI による SaaS ビジネスへの脅威と市場の混乱
Anthropic のエージェント機能強化により、従来のソフトウェアサービス(SaaS)が不要になる懸念から「SaaSpocalypse」と呼ばれる株価暴落が発生しました。しかし、 proprietary データや規制対応など独自の強みを持つ企業は生き残ると分析されています。
ローカル AI のエネルギー効率の劇的向上
スタンフォード大学などの研究により、2023 年から 2025 年にかけてローカル端末での「ワットあたりの知能」が 5.3 倍に向上しました。クラウドと同等の精度を維持しつつ電力消費を大幅に減らせるようになり、分散型 AI の経済的合理性が高まっています。
影響分析・編集コメントを表示
影響分析
本記事は、AI 業界の急激な成長と変化の中で、個人開発者やエンジニアが自身のスキルギャップを把握し、効果的に学習するための実用的なソリューションを提供するものです。特に「自分が何を知らないか」を可視化する機能は、キャリアパスの迷いやすい初学者にとって大きな価値があり、教育プラットフォームとしての DeepLearning.AI の役割強化を示唆しています。ただし、これは特定の技術的ブレイクスルーや市場構造の変化を直接示すものではないため、業界全体への即時的なインパクトは限定的です。
編集コメント
本ニュースは、AI ツールの開発競争というよりは、急速に進化する業界において個人の学習効率を高めるためのインフラ整備として捉えるべき内容です。技術的な革新性よりも、教育ツールの実用性とアクセシビリティの向上に焦点が当てられています。
親愛なる皆様、
私たちは、AI におけるご自身の強み、さらに学習すべき領域、そしてスキルを継続して高めるための次のステップを理解するための Skill Builder ツールをリリースしました。ぜひ、このツールと対話してみてください。
AI 分野には多くの雇用機会があります!企業は AI スキルを持つ人材を積極的に採用しようとしています。しかし、AI テクノロジーの状況は広大で、成長しており、急速に変化しています。この状況をナビゲートするために、多くの人々は、知識豊富で信頼できるメンターとの偶発的な対話が、次のステップを決める上で役立つと感じています。
私たちの Skill Builder はその役割を果たします。AI プロジェクトについて教えていただければ、現在の状況に関するパーソナライズされたフィードバックを提供し、AI スキルを次のレベルへと引き上げるための方法を提案します。これは、ChatGPT へのプロンプトのみを使用して AI を利用する初心者から、複数の AI ビルドブロックと洗練された開発プロセスを用いて複雑なアジェンシーワークフロー(agentic workflows)を構築する上級者まで、すべての人を対象に設計されています。
新しいスキルを学ぶ際、自分がその分野でどこに位置しているのかを理解するのは難しく、まだ自分が何を知らないのかもわからないからです。Skill Builder は AI スキルに関するこの課題に対応しています。誰でも無料で利用でき、多くの人が会話を通じて有益な情報を得たと報告しています。会話を終えると、全員にサマリーレポートが表示され、次に学ぶべき内容が推奨されます。DeepLearning.AI Pro のメンバーはさらに詳細な個別フィードバックも受けられます。
スキルを確認したり、次のプロジェクトを決めたり、どのコースを受講するか選択したり、就職面接の準備をしたりする際、Skill Builder が明確さを持って前進するための助けとなることを願っています。
スキルを磨き続けてください!
Andrew
DEEPLEARNING.AI からのメッセージ
 imageアプリを構築するためにプログラミングの学習が必要ではありません。*Build with Andrew*(アンドリュー・ン氏と作る)では、シンプルな指示を用いてアイデアを実働する Web アプリに変換する方法を、アンドリュー・ン氏が解説しています。初心者にも最適で、始めるのを待っていた人に簡単に共有できます。今日コースをご覧ください!
imageアプリを構築するためにプログラミングの学習が必要ではありません。*Build with Andrew*(アンドリュー・ン氏と作る)では、シンプルな指示を用いてアイデアを実働する Web アプリに変換する方法を、アンドリュー・ン氏が解説しています。初心者にも最適で、始めるのを待っていた人に簡単に共有できます。今日コースをご覧ください!
ニュース
 imageGoogle は主力の Gemini モデルを更新し、複数のベンチマークで首位に立ちながら、ドルあたりのパフォーマンスにおいて競合他社を下回りました。
imageGoogle は主力の Gemini モデルを更新し、複数のベンチマークで首位に立ちながら、ドルあたりのパフォーマンスにおいて競合他社を下回りました。
何が変わったか: Google は、Gemini 3.1 Pro Preview を、その前身である Gemini 3 Pro Preview と同じ価格でリリースしました。Gemini 3.1 Pro Preview は、API を介して利用可能な 3 つの推論レベルとは別に存在する、専門的な推論モードである Gemini 3 Deep Think の最近のパフォーマンス向上の基盤となっています。
- 入力/出力:テキスト、画像、PDF、オーディオ、ビデオ(最大 100 万トークン)、テキスト出力(最大 64,000 トークン、秒間 108.6 トークン)
- アーキテクチャ:Mixture-of-experts (専門家混合) Transformer
- 機能:ツール使用(Google 検索、Python コード実行、ファイル検索、関数呼び出し)、構造化出力、調整可能な推論(低・中・高)
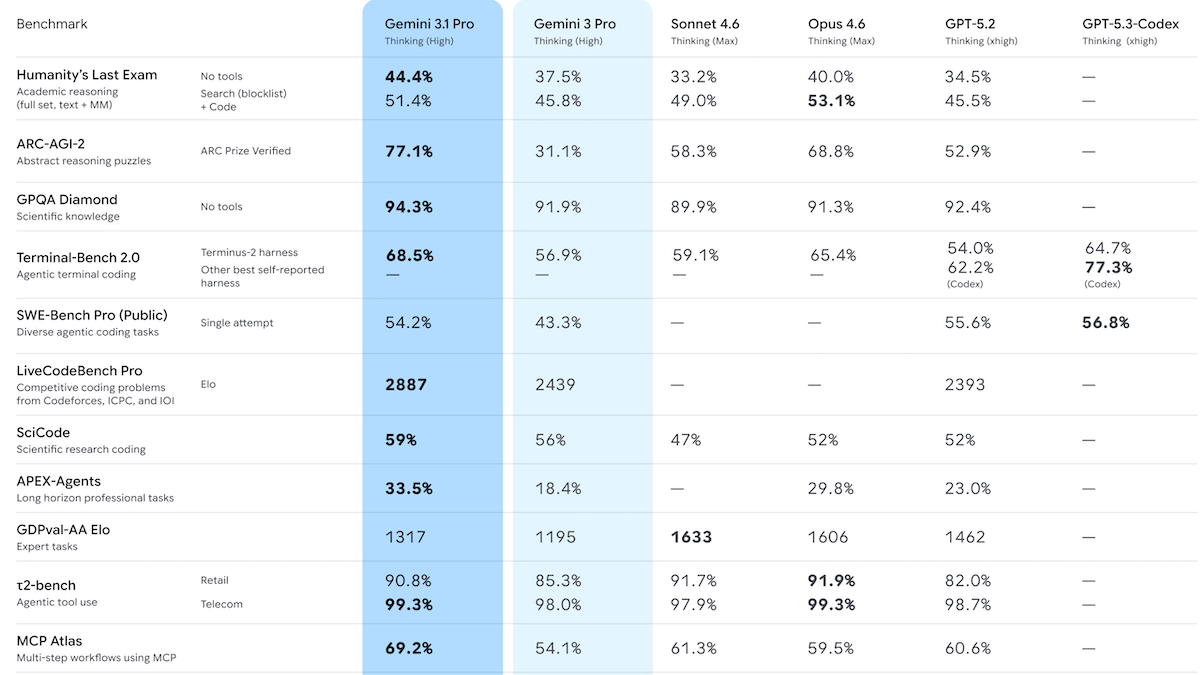
- パフォーマンス:推論機能付きの Gemini 3.1 Pro Preview(レベル未指定)が Artificial Analysis Intelligence Index で首位を獲得;ARC-AGI-2、GPQA Diamond、Humanity's Last Exam、MCP Atlas、BrowseComp、Terminal-Bench 2.0、MathArena Apex、MMLU-Pro において最先端の性能を達成
- 利用可能状況/価格:Gemini アプリ経由で Google AI Pro および Ultra のサブスクライバーに提供;有料サービスである Google AI Studio、Vertex AI、Gemini CLI、および Microsoft Visual Studio や GitHub CoPilot を含むサードパーティ製ツールと統合。API 料金は、入力コンテキストが 200,000 トークン未満の場合、入力/キャッシュ済み/出力トークンあたり 100 万単位でそれぞれ$2/$0.20/$12、200,000 トークンを超える場合、それぞれ$4/$0.40/$18(キャッシュ済みトークンあたり時間 100 万単位で追加$4.50)
- 知識の更新截止日:2025 年 1 月
- 非公開:パラメータ数、アーキテクチャの詳細、トレーニング手法
仕組みについて: Google は Gemini 3.1 Pro Preview に関する詳細をほとんど開示していません。このモデルは、ウェブから収集したテキスト、コード、画像、オーディオ、ビデオと、ライセンスされた資料、Google ユーザーデータ、合成データを組み合わせて事前学習されたスパースな Mixture-of-experts (専門家混合) Transformer です。多段階推論、問題解決、定理証明をカバーするデータセットを用いた強化学習(Reinforcement Learning)により微調整されています。その モデルカード は、読者を Gemini 3 Pro モデルカード へと案内しています。
パフォーマンス: Gemini 3.1 Pro Preview は、Artificial Analysis が実施したテストにおいてさまざまな最先端指標を達成しました。しかし、エージェント行動やユーザー選好ランキングに関する一部の測定項目では劣勢となりました。一部のテスト結果ソースでは推論設定が明記されておらず、Gemini 3.1 Pro Preview への API コールはデフォルトで高レベルの推論(high reasoning)に設定されています。
- Artificial Analysis Intelligence Index は、経済的に有用な作業に焦点を当てた 10 のベンチマークの加重平均であり、推論機能付きの Gemini 3.1 Pro Preview(コスト 892 ドルで 57 ポイント)は、最大推論設定の Claude Opus 4.6(53 ポイント、2,486 ドル)、xhigh 推論設定の GPT-5.2(51 ポイント、2,304 ドル)、オープンウェイト版 GLM-5(50 ポイント、547 ドル)を上回りました。同モデルは、このインデックスを構成する 10 のコンポーネントベンチマークのうち 6 つで首位に立ちました。
- ただし、Arena におけるコーディング能力では、推論機能の詳細が不明な Gemini 3.1 Pro Preview は 7 位でした。Arena は、盲検の直接比較においてユーザーの好意に基づいてモデルをランク付けするプラットフォームです。
- また、Artificial Analysis の GDPval-AA エージェントベンチマークでも後れを取り、Gemini 3.1 Pro Preview は 40 パーセントのスコアに留まりました。これに対し、最大推論設定の Claude Sonnet 4.6 は 57 パーセント、GLM-5 は 45 パーセントを記録しています。
- ARC-AGI-2 の視覚的ロジックパズルでは、Gemini 3.1 Pro Preview がタスクあたり 0.96 ドルのコストで 77.1 パーセントの達成率を記録しました。これは前世代の 31.1 パーセントの倍以上であり、高推論設定の Claude Opus 4.6(タスクあたり 3.47 ドルで 69.2 パーセント)を大きく上回っています。
なぜ重要なのか: Gemini 3.1 Pro の性能向上は、推論時の追加計算資源よりもモデル品質の改善に起因しているようです。Artificial Analysis Intelligence Index の完了において、同モデルが消費したトークン数は前世代とほぼ同じでしたが、スコアは大幅に向上しました。これは、モデルを洗練させることで、推論コストを増大させることなく、依然として顕著な性能向上をもたらすことができる可能性を示唆しています。
私たちが考えていること: ARC-AGI-2 において、推論能力を最高レベルに設定したと見られる Gemini-3.1 Pro Preview のパフォーマンスは、Gemini 3.1 Deep Think(77% 対 85%)にはわずかに劣るものの、そのコストは 13 分の 1 です(タスクあたり 0.96 ドル対 13.62 ドル)。これは、Deep Think を極めて困難な問題に限定して使用するよう促すインセンティブとなります。

グローバル AI サミットで楽観視が広がる
第 4 回グローバル AI サミットは、理論的な危険性への焦点から、世界中に AI の恩恵を広げる方針へと決定的な転換を示しました。
最新情報: AI インパクト・サミットは、米国および中国に対する対抗軸としてのインドの野望を披露しました。今年度の政府関係者、ビジネスリーダー、研究者による集まりは、2 月 16 日から 20 日までニューデリーで開催されました。
仕組み: グローバル・サウスで開催される初のグローバル AI サミットと称して、この会議には数十万人の参加者と 100 カ国以上の代表者が集まりました。インド、ブラジル、フランス、スペイン、ボリビア、モーリシャス、スリランカの各国首脳が出席し、国連事務総長のアントニオ・グテーレス氏、ホワイトハウス科学技術政策室所長マイケル・クラティオス氏に加え、アルファベットのサンダル・ピチャイ氏、OpenAI のサム・アルトマン氏、Anthropic のダリオ・アモダイ氏といったスター CEO も参加しました。しかし、ある参加者 報告 によると、「中国の参加はほとんど見られなかった」とのことです。これは、会議日程が中国の旧正月行事と重なったためです。
- アメリカや中国を含む85カ国以上が、AI の経済成長、社会への貢献、そして共有された世界的利益のために活用し、狭い国家的または企業の利益のためではないことを目指す非拘束力のある合意である「ニューデリー AI 影響に関する宣言」を支持しました。この宣言は、7 つの原則を強調しています:AI リソースの民主化、社会へのエンパワーメント、経済成長と社会貢献、安全で信頼できる AI、科学のための AI、スキルと教育の育成、そして持続可能な AI システムです。
- 首脳会議での登壇において、ナレンドラ・モディ首相は、多様な対象者を想定した手頃な価格の技術を提供する力としてインドを推進しました。モディ氏は、インドが持つ技術人材の供給、公共技術インフラ、そして世界で3番目に大きいスタートアップエコシステムを称賛しました。
- 主要な AI 企業がインドでの存在感を拡大しています。Anthropic と OpenAI はそれぞれベンガルールとムンバイにオフィスを開設しました。OpenAI はタタ・コンサルティング・サービスのデータセンターを利用し、ChatGPT Enterprise サービスを提供する合意を発表しました。Google は南東部の港湾都市ビサカパトナムに AI ハブを建設することにコミットし、インド、米国、および他の国々の間に追加の海底ケーブルを敷設することを約束しました。
- 人権団体は、AI ガバナンスにおける格差への対応が不十分だったとして首脳会議を批判しました。例えば、アムネスティ・インターナショナルは、インドにおける AI が「すでに市民権侵害が行われている有害な文脈において、『大規模監視システム』に寄与している」と指摘し、この首脳会議を「拘束力のある権利保護の推進においてほとんど無関係で非効果的である」と呼び、デジタルに安全な未来のための規制を求めました。
ニュースの背景: 主要な AI 企業がインドへの投資を約束し、中央政府が自らの AI 支出を増強しているため、インドは注目の的となっています。
- Google は、人工知能ハブを設立するために5年間で150億ドルを拠出することを約束しました。Microsoft は、インドのクラウドおよびAIインフラストラクチャに4年間で175億ドルを投資します。Amazon は2030年までにインドでの事業構築のために350億ドルを支出する計画です。
- 会議が開会されると同時に、インドはAIおよびその他のハイテク分野のスタートアップ資金として11億ドルを割り当てました。
- 政府は、比較的小さな処理予算で動作しながら、22の公式に認められた言語を処理できるモデルを構築するために国内スタートアップへの資金提供を行っています。
なぜ重要なのか: AI の進展は世界的な取り組みであり、各国政府間のコミュニケーションはその重要な一部です。今年のサミットでは、処理と接続性の確保や市場における競争の促進といった現実的な課題に焦点が当てられました。これは、最初のイベントで支配的だった非現実的なSF 的な懸念からの歓迎すべき変化です。2023 年。今年の楽観的な雰囲気は、2024 年および2025 年のサミットが、参加者にAI の価値を認識させるのに役立ったことを示しています。同時に、批判者は、AI の急速な構築と民主的価値観の整合性を保つという継続的な課題に言及しました。
私たちが考えていること: グローバルな指導者たちが集まり、対話を続けることが重要です。AI サミットが継続しており、政府がすべての人の利益のために AI を活用しようとしていることを嬉しく思います。
エージェント型 AI に対する投資家のパニック
大企業で稼働するソフトウェアのメーカーは、AI システムが自社の事業を脅かす可能性があると懸念した結果、株価が急落しました。今週、Anthropic が同様の企業と提携したことで、これらの企業の株価は多少回復しました。
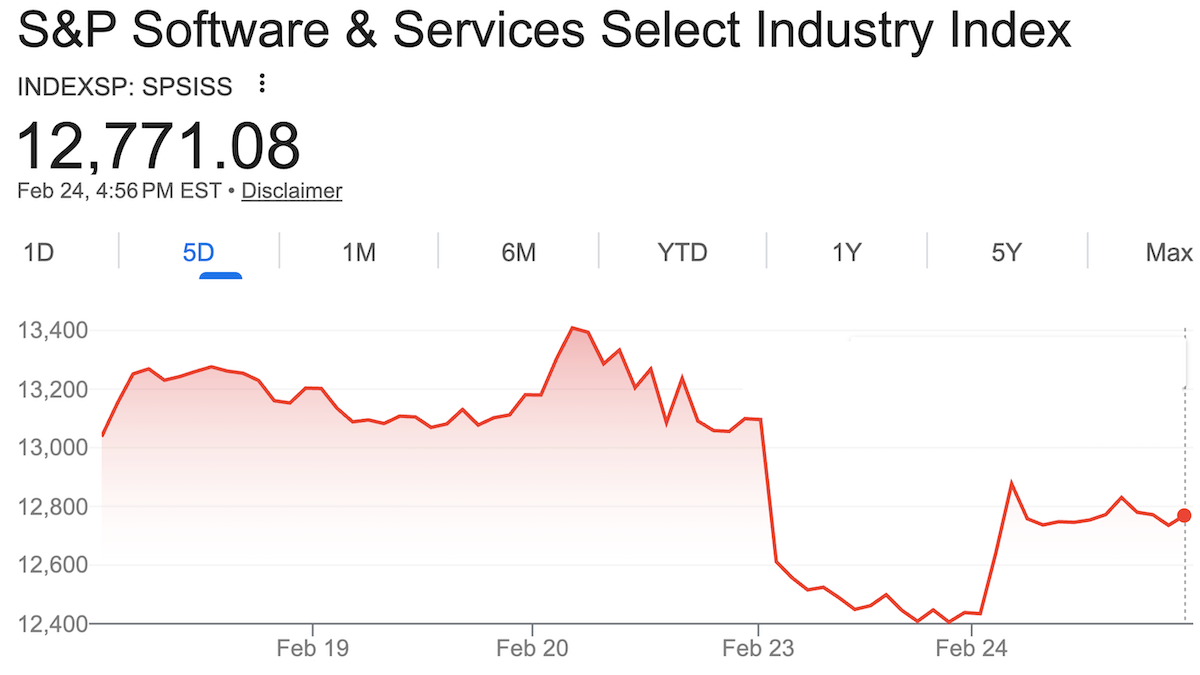
最新動向: AI によるコーディングシステムが人気のあるソフトウェアツールを複製する可能性があるという見通しに驚いた投資家たちが、Microsoft、Oracle、Salesforce、Workday などのソフトウェア大手を含む S&P ソフトウェア・サービス指数(S&P Software & Services Index)の下落を招きました。この指数は、Anthropic が専門業務用のエージェント「Claude Cowork」を発表した1月12日から、回復の兆しが見られた2月23日までの間に価値の25%を失いました。
SaaSpocalypse now: 株式の売りが主にウェブ経由でのソフトウェアサブスクリプション、すなわちソフトウェア・アズ・ア・サービス(Software as a Service, SaaS)と呼ばれるビジネスモデルを扱うベンダーに影響を与えました。投資会社ジェフリー・ファイナンスグループ(Jefferies Financial Group)のストラテジストであるジェフリー・ファブッツァ氏は、この出来事を「SaaSpocalypse」と名付けました。
- アンソロピックは、SaaS オファリングによって通常行われるタスクに対処するよう設計されたさらなるリリースで火に油を注ぎました。1 月 30 日、アンソロピックはホワイトカラーの職務機能それぞれを対象とした 11 のオープンソースプラグインをリリースしました。対象となる機能には、カレンダー管理、ドキュメント検索および取得、営業、財務分析、データ照会および可視化、法的レビューとコンプライアンス、マーケティング、カスタマーサポート、製品管理、生物学研究に加え、新しいプラグインを作成・カスタマイズするプラグインが含まれます。独立した開発者たちはすぐに貢献し、他のビジネスソフトウェアと同様の機能を提供する一連のプラグインを次々と生み出しました。
4 日後、S&P ソフトウェア&サービス指数は 4%下落し、時価総額から 2,850 億ドル以上を消し飛ばしました。JP モルガンのソフトウェア指数も 7%下落しました。LegalZoom.com の株価はほぼ 20%急落し、トムソン・ロイターは 16%下落しました。
2 月 20 日、アンソロピックは、人間のレビュー後にソフトウェアの脆弱性を検出および修正するためのサイバーセキュリティアプリケーションである Claude Code Security を発表しました。これに続き、セキュリティソフトウェア企業の株価が売られました。(Google の CodeMender と OpenAI の Aardvark も同様に AI 駆動型のセキュリティ機能を実行しています。)
2 月 24 日、アンソロピックは、Cowork が脅威となっている一部の企業との統合を発表し、ソフトウェア企業に対してオリーブの枝を差し出しました。対象企業には Docusign、FactSet、Google の Gmail、Intuit、Salesforce が含まれます。これらのアプリケーションを迂回するのではなく、新しい波の Cowork プラグインはこれらに直接接続します。この新たなアプローチにより、企業はプラグインの使用と監視方法についてより多くのコントロールを得ることができます。SaaS 関連株は上昇しましたが、以前の損失を完全に回復したわけではありません。
ニュースの背景: AI を活用したコーディングの台頭に伴い、観測者たちは、AI がその機能を複製するか、エージェントが人間ユーザーを代替することで、従来のソフトウェアに打撃を与える可能性があると指摘しています。後者のシナリオでは、顧客が特定のベンダーのユーザーインターフェースやワークフローに適応したくないという理由で特定のサービスに忠誠を誓う「ロックイン」効果が AI によって解消されることになります。12 月、AI を活用したコーディングツールを開発する Cursor の開発者教育担当副社長であるリー・ロビンソンは、記事 で、同社が以前有料で利用していたコンテンツ管理システム(CMS)である Sanity を、ゼロから構築したカスタムセットアップに完全に置き換えたことを明かしました。同社は現在、git を用いてウェブページを管理しており、 recurring fees(継続的な手数料)として年間数万ドルを節約しています。Sanity の広報担当者である Knut Melvær は、公開された返信 で、Sanity の製品は Cursor のセットアップでは容易に複製できない、コラボレーションの促進など特定の目的を果たしていることを指摘しました。
なぜ重要なのか: 投資家がパニックに陥ったとしても、その関心が誤っているわけではありません。AI はソフトウェア市場を変革しています。それでもなお、多くの SaaS 企業は繁栄を続け、新たな機会も生まれ続けます。大規模言語モデル(LLM)はいくつかの競争障壁を溶解させることができますが、他の障壁は依然として堅固です。Fintool の CEO ニコラス・ブスタマンテ氏は、洞察に満ちたソーシャルメディアの 投稿 でその理由を説明しています。エージェントは、見慣れないユーザーインターフェースを操作し、複雑なビジネスプロセスをナビゲートし、公開データセットにアクセスし、複数の分野の専門知識を一つのアプリケーションに集約することができます。一方、LLM に基づくシステムは、独自データや規制コンプライアンス、ネットワーク効果、埋め込み取引に依存する SaaS 製品を必ずしも代替できるわけではありません。「SaaSpocalypse(SaaS の終焉)」のメッセージは、ソフトウェアが死んだということではありません。それは、小規模チームでも競争力のある製品を迅速に構築できるようになった一方で、生き残る力を備えた製品は LLM の手が届かないリソースの上に築かれるべきだということです。
私たちが考えていること: SaaS は死滅するのではなく、AI ネイティブへと進化しているのです。
ローカル AI はクラウドの代わりになれるか?
大規模言語モデルからの出力に対する需要予測が、データセンターの大規模な建設を促しています。研究者たちは、ローカルデバイスで動作する小規模モデルがこの負荷を実質的に軽減できるかどうかについて問いかけています。
最新動向: Stanford University(スタンフォード大学)および Together AI(ソフトウェア開発とトレーニングを提供する企業)の Jon Saad-Falcon 氏、Avanika Narayan 氏らによる研究では、彼らが「ワットあたりの知能」と呼ぶ指標に基づき、ラップトップがクラウドコンピューティングに代わる能力をますます備えつつあることが示されました。この指標の詳細は こちら です。
重要な洞察: クラウドシステムは通常、ユーザーあたりのエネルギー効率がローカルシステムよりも優れていますが、小規模かつ高性能なモデルの登場により、ローカルシステムの効率運用がますます可能になっています。過去の時代には、パーソナルコンピュータが十分な性能を発揮しつつ、同じかそれ以下のエネルギー消費で動作できるようになったことで、処理の主役はメインフレームからパーソナルコンピュータへと移行しました。同様に、ラップトップ上で動作する小規模モデルが十分な精度を維持しながら、クエリあたりの電力消費を削減できるのであれば、AI ワークロードもデータセンターから個人デバイスへシフトさせることが可能です。ローカルコンピューティングとクラウドコンピューティングのどちらが実現可能かを測る指標として、「ワットあたりの知能」を計算できます。これは、特定のタスクにおける精度を、その達成に要した消費電力で割った値です。仮にローカルシステムとクラウドシステムが同程度の精度を達成できるとすれば、ワットあたりの知能が高い方がより効率的な選択肢となります。
仕組み: 著者らは、ラップトップやデータセンターサーバー向けに設計されたハードウェア上で、さまざまなオープンウェイト大規模言語モデルを実行しました。時間経過に伴うワットあたりの知能の傾向を測定するため、最新のモデル(Qwen3、GPT-OSS、Gemma3、IBM Granite 4.0 ファミリーからのもの、2025 年後半製)と旧式のモデル(Mixtral-8x7B および Llama -3.1-8B、2023〜2024 年頃)、最新のプロセッサ(Apple M4 Max ラップトップチップや Nvidia H100 データセンターチップを含む)と旧式のプロセッサ(2018 年製の Nvidia Quadro RTX 6000 など)の両方を含めました。彼らは、モデルに対して 実世界の会話、科学、学問 の分野からの 100 万クエリを入力しました。
- 精度を測定するため、著者らは固定された出力を正解データと比較し、自由記述形式の回答については GPT-4o を用いて評価を行いました。
- 同時に、消費電力も記録されました。
- 著者らはこのデータを用いて、クエリをモデルへルーティングする理想的なシステムをシミュレーションしました。各クエリについて、ローカルまたはクラウド上でホストされているいずれのモデルが、最小限の電力消費で正しく応答したかを追跡し、そのモデルがクエリを処理したと仮定しました。
結果: 現時点では、ワットあたりの知能性能においてローカルシステムはクラウドシステムにまだ及びませんが、より高性能を発揮する小型モデルの開発が進むにつれて改善されています。もしローカルシステムの精度がクラウドシステムと同等であれば、クエリをローカルシステムへルーティングすることで、大幅なエネルギー節約が可能となります。
- クラウドコンピューティングシステムはワットあたりの知能効率がより高くなっています。Nvidia B200 チップ上で動作する小規模モデルは、ローカルチップ上で同じモデルが動作する場合と比較して、ワットあたりで少なくとも 1.4 倍高い知能効率を達成しました。
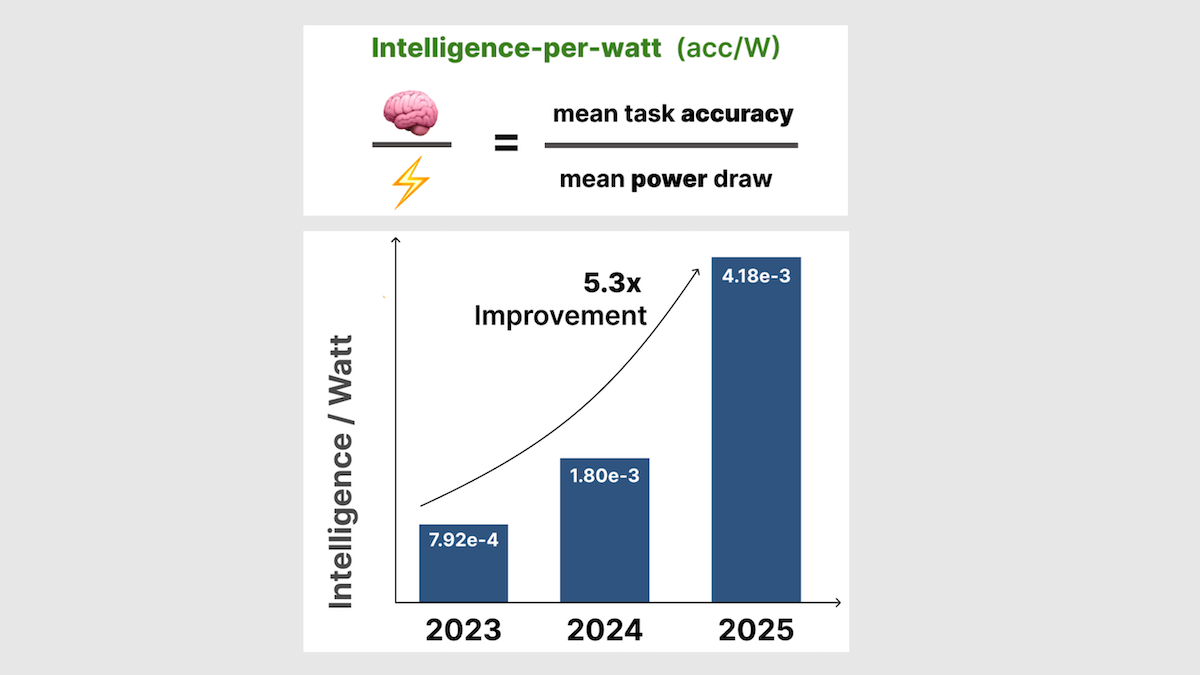
- ただし、ローカルシステムにおいてもワットあたりの知能効率は劇的に向上しています。2023 年から 2025 年の間に、アルゴリズムの進歩とハードウェアの改善により、ワットあたりの知能効率は 5.3 倍に上昇しました。
- 著者による単一ターンチャットおよび推論クエリに関する分析では、小規模モデルを動作させたローカルシステムは、クラウドシステムと比較して約 88.7% のクエリを正しく回答しながら、大幅に少ない電力で動作できました。シミュレーションされたハイブリッドシナリオでは、電力節約率は 80% を超えました。
ただし: 著者は OpenAI GPT-5 などの独自モデルのワットあたりの知能効率については評価していません。おそらく、これらのモデルがどの程度の電力を消費するか不明確であるためです。しかし、独自モデルの精度については比較を行いました。最も精度の高いローカルモデル(Qwen3-14B)は、GPT-5、Gemini-2.5-Pro、Claude Sonnet 4.5 に比べて、精度で 11% から 13% ほど劣りました。
なぜ重要なのか: 研究者たちは大規模言語モデルを急速に改善しており、同じ電力消費量でより高性能なモデルを実現しています。この性能向上を追跡することで、時間経過に伴う電力とパフォーマンスの間の相対的なトレードオフが明らかになります。そのトレードオフが低電力デバイスへと傾いていくにつれ、人々はより多くの選択肢を得ます。これらの選択肢は、計算負荷を分散させ、機械知能をより広く分布させる可能性を提供します。
私たちが考えていること: プライバシーは往々にしてローカル AI に関する議論を主導します。ワットあたりの知能が向上する見通しは、魅力的な経済的根拠を生み出します。
原文を表示
Dear friends,
We just released a Skill Builder tool to help you understand in which areas of AI you’re strong, where you can learn more, and what to do next to keep building your skills. I invite you to have a conversation with it.
There are many job opportunities in AI! Employers are eager to hire people with AI skills. But the landscape of AI technology is large, growing, and rapidly changing. To navigate this landscape, many people find that occasional conversations with a knowledgeable, trusted mentor are helpful for deciding where to go next.
Our Skill Builder serves this role. Tell it about your AI projects, and it will provide personalized feedback on where you are and suggest ways to take your AI skills to the next level. This is designed for everyone, from beginners who use AI only by prompting ChatGPT to advanced users who are building complex agentic workflows with multiple AI building blocks and a sophisticated development process.
When I’m learning a new skill, I find it hard to understand where I stand in the field, since I don’t yet know what I don’t know. Skill Builder addresses this for AI skills. It’s free for everyone to use, and many have reported finding the conversations informative. Following the conversation, it will show everyone a summary report and recommend what to learn next. DeepLearning.AI Pro members additionally get more-detailed personalized feedback.
Whether you’re checking your skills, deciding what project to work on next, choosing which course to take, or preparing for job interviews, I hope Skill Builder will help you move forward with clarity.
Keep building your skills!
Andrew
A MESSAGE FROM DEEPLEARNING.AI
You don’t need to learn how to code to build an app. In *Build with Andrew*, Andrew Ng shows how to turn ideas into working web apps using simple instructions. Perfect for beginners and easy to share with someone who has been waiting to start. Explore the course today!
News
Google updated its flagship Gemini model, topping several benchmarks while undercutting competitors on performance per dollar.
What’s new: Google launched Gemini 3.1 Pro Preview at the same price as its predecessor Gemini 3 Pro Preview. Gemini 3.1 Pro Preview is the basis of recent performance gains by Gemini 3 Deep Think, a specialized reasoning mode separate from the three reasoning levels available via API.
- Input/output: Text, images, PDFs, audio, video in (up to 1 million tokens), text out (up to 64,000 tokens, 108.6 tokens per second)
- Architecture: Mixture-of-experts transformer
- Features: Tool use (Google search, Python code execution, file search, function calling), structured outputs, adjustable reasoning (low, medium, high)
- Performance: Gemini 3.1 Pro Preview with reasoning (level unspecified) topped Artificial Analysis Intelligence Index; achieved state of the art on ARC-AGI-2, GPQA Diamond, Humanity’s Last Exam, MCP Atlas, BrowseComp, Terminal-Bench 2.0, MathArena Apex, MMLU-Pro
- Availability/price: Available to Google AI Pro and Ultra subscribers via Gemini app; integrated with the paid services Google AI Studio, Vertex AI, Gemini CLI, and third-party tools including Microsoft Visual Studio and GitHub CoPilot; API $2/$0.20/$12 per million input/cached/output tokens for input contexts under 200,000 tokens, $4/$0.40/$18 per million input/cached/output tokens for input contexts greater than 200,000 tokens (plus $4.50 per million cached tokens per hour)
- Knowledge cutoff: January 2025
- Undisclosed: Parameter count, architecture details, training methods
How it works: Google disclosed few details about Gemini 3.1 Pro Preview. The model is a sparse mixture-of-experts transformer pretrained on text, code, images, audio, and video scraped from the web alongside licensed materials, Google user data, and synthetic data. It was fine-tuned via reinforcement learning on datasets that covered multi-step reasoning, solving problems, and proving theorems. Its model card points readers to the Gemini 3 Pro model card.
Performance: Gemini 3.1 Pro Preview achieved a variety of state-of-the-art metrics in tests performed by Artificial Analysis. However, it trailed on some measures of agentic behavior and user-preference rankings. Some sources of test results don’t specify a reasoning setting; API calls to Gemini 3.1 Pro Preview default to high reasoning.
- On the Artificial Analysis Intelligence Index, a weighted average of 10 benchmarks that focus on economically useful work, Gemini 3.1 Pro Preview with reasoning (57 points at a cost of $892) outperformed Claude Opus 4.6 set to max reasoning (53 points, $2,486), GPT-5.2 set to xhigh reasoning (51 points, $2,304), and the open-weights GLM-5 (50 points, $547). It led six of the index’s 10 component benchmarks.
- However, Gemini 3.1 Pro Preview (reasoning unspecified) placed seventh in coding on Arena, which ranks models by user preference in blind head-to-head comparisons.
- It also trailed on Artificial Analysis’ GDPval-AA agentic benchmark, where it achieved 40 percent, behind Claude Sonnet 4.6 set to max reasoning (57 percent) and GLM-5 (45 percent).
- On ARC-AGI-2 visual logic puzzles, Gemini 3.1 Pro Preview achieved 77.1 percent at $0.96 per task — more than double its predecessor’s 31.1 percent — and well above Claude Opus 4.6 set to high reasoning (69.2 percent at $3.47 per task).
Why it matters: Gemini 3.1 Pro’s gains appear to stem more from improved model quality than additional computation during inference: In completing the Artificial Analysis Intelligence Index, it consumed roughly the same number of tokens as its predecessor, yet it scored significantly higher. This suggests that refining models can still yield significant performance gains without inflating inference costs.
We’re thinking: On ARC-AGI-2, the performance of Gemini-3.1 Pro Preview — presumably set to high reasoning — is less than 10 percent shy of Gemini 3.1 Deep Think’s (77 percent versus 85 percent) but 13 times less expensive ($0.96 per task versus $13.62 per task). That’s an incentive to reserve Deep Think for the very hardest problems.
Global AI Summit Shows Optimism
The fourth global AI summit marked a decisive shift from focusing on theoretical hazards to spreading AI’s benefits throughout the world.
What’s new: The AI Impact Summit showcased India’s ambition to serve as a counterweight to the United States and China. This year’s gathering of government officials, business leaders, and researchers took place in New Delhi from February 16 to February 20.
How it works: Billed as the first global AI summit to be hosted in the global south, the conference attracted hundreds of thousands of participants and representatives of more than 100 countries. The leaders of India, Brazil, France, Spain, Bolivia, Mauritius and Sri Lanka were in attendance, as well as UN Secretary-General António Guterres, Director of the White House Office of Science and Technology Policy Michael Kratsios, and star CEOs including Alphabet’s Sundar Pichai, OpenAI’s Sam Altman, and Anthropic’s Dario Amodei. But one participant reported that “Chinese participation was almost nonexistent,” as the schedule overlapped with Chinese New Year celebrations.
- More than 85 countries including the U.S. and China endorsed the New Delhi Declaration on AI Impact, a non-binding agreement to harness AI for economic growth, social good, and shared global benefit rather than narrow national or corporate advantage. The declaration emphasizes seven principles: democratization of AI resources, social empowerment, economic growth and social good, secure and trusted AI, AI for science, nurturing of skills and education, and sustainable AI systems.
- In his summit appearance, Prime Minister Nerendra Modi promoted India as a force for affordable technology designed for a diverse audience. Modi touted India’s supply of tech talent, public technology infrastructure, and startup ecosystem (third largest in the world).
- Top AI companies expanded their presences in India. Anthropic and OpenAI opened offices in Bengaluru and Mumbai, respectively. OpenAI announced an agreement to use Tata Consultancy Services’ data centers and provide its ChatGPT Enterprise service. Google committed to building an AI hub in the southeastern port city of Visakhapatnam and promised to route additional subsea cables between India, the U.S., and other countries.
- Human-rights organizations criticized the summit for failing to address gaps in AI governance. For instance, Amnesty International said that AI in India contributes to “systems of mass surveillance . . . in an already pernicious context of civil rights abuses.” The organization called the summit “largely irrelevant and ineffective at advancing binding rights protections” and called for “regulations for a digitally safe future.”
Behind the news: India is in the spotlight as major AI companies have pledged to invest there and the national government ramps up its own AI spending.
- Google has committed $15 billion over five years to establish an artificial intelligence hub. Microsoft will invest $17.5 billion over four years in India’s cloud and AI infrastructure. Amazon plans to spend $35 billion by 2030 to build its business in India.
- As the conference opened, India allocated $1.1 billion to fund startups in AI and other high-tech fields.
- The government is funding domestic startups to build models that can process its 22 officially recognized languages while running on relatively small processing budgets.
Why it matters: Advancing AI is a global effort, and communication among national governments is an important part. This year’s summit focused on realistic issues like ensuring access to processing and connectivity and encouraging competition in the market — a welcome change from the unrealistic science-fiction worries that dominated the initial event in 2023. This year’s optimistic atmosphere signals that the 2024 and 2025 summits helped attendees recognize AI’s value. At the same time, critics highlighted the ongoing challenge of aligning AI’s rapid build-out with democratic values.
We’re thinking: It’s important that global leaders get together and keep talking. We’re glad to see that the AI summit remains ongoing and governments are aiming to use AI for the benefit of all.
Investors Panic Over Agentic AI
Makers of software that runs large companies saw their share prices plunge as investors worried that AI systems could undermine their businesses. This week, their stocks rebounded somewhat as Anthropic partnered with some of the same companies.
What’s new: Investors, alarmed by the prospect that AI-enabled coding systems could reproduce popular software tools, drove down the S&P Software & Services Index, which includes software giants such as Microsoft, Oracle, Salesforce, and Workday. The index lost 25 percent of its value between January 12, when Anthropic introduced Claude Cowork, an agent designed for professional work, and February 23, when it showed signs of recovering.
SaaSpocalypse now: The stock selloff affected mostly vendors of software subscriptions via the web, a business known as software as a service (SaaS). Jeffrey Favuzza, a strategist at the investment firm Jefferies Financial Group, dubbed the event the “SaaSpocalypse.”
- Anthropic poured fuel on the fire with further releases designed to take on tasks typically performed by SaaS offerings. On January 30, Anthropic released 11 open-source plugins, each targeting a white-collar job function. The functions include calendar management, document search and retrieval, sales, financial analysis, data queries and visualizations, legal review and compliance, marketing, customer support, product management, and biology research, plus a plugin that creates and customizes new plugins. Independent developers quickly contributed a wave of plugins that delivered functionality similar to other business software.
- Four days later, the S&P Software & Services Index dropped 4 percent to wipe out more than $285 billion in market capitalization. JPMorgan’s software index lost 7 percent. Shares of LegalZoom.com tumbled nearly 20 percent, Thompson Reuters 16 percent.
- On February 20, Anthropic unveiled Claude Code Security, a cybersecurity application designed to detect and patch software vulnerabilities after human review. A selloff of shares in security software companies followed. (Google’s CodeMender and OpenAI’s Aardvark similarly perform AI-powered security functions.)
- On February 24, Anthropic extended an olive branch to software companies when it announced integrations with some of the companies that Cowork threatens, including Docusign, FactSet, Google’s Gmail, Intuit, and Salesforce. Instead of bypassing their applications, a new wave of Cowork plugins connect to them directly. The new approach also gives companies more control over how the plugins are used and monitored. SaaS stocks jumped, although they did not recover their earlier losses.
Behind the news: With the rise of AI-assisted coding, observers have suggested that AI could disrupt traditional software either by replicating its capabilities or enabling agents to replace human users. In the latter scenario, AI would end the “lock-in” effect in which customers remain loyal to a particular service because they don’t want to adjust to a different vendor’s user interface or workflow. In December, Lee Robinson, vice president of developer education at Cursor, which makes AI-assisted coding tools, wrote that his company had completely replaced a content management system it previously paid for, Sanity, with a custom setup it built from scratch. The company now manages its web pages using git and saves tens of thousands of dollars in recurring fees. Sanity spokesman Knut Melvær wrote a public reply noting that Sanity’s product serves purposes, such as facilitating collaboration, that can’t easily be replicated using Cursor’s setup.
Why it matters: Investors may have panicked, but their attention isn’t misplaced: AI is changing the software market. Nonetheless, many SaaS companies will continue to thrive, and new opportunities will continue to emerge. Large language models can dissolve some competitive barriers, but others remain solid, as Fintool CEO Nicolas Bustamante explains in an insightful social media post. Agents can operate unfamiliar user interfaces, navigate complex business processes, access public datasets, and collapse expertise in multiple areas into one application. On the other hand, systems based on LLMs can’t necessarily replace SaaS offerings that rely on proprietary data, regulatory compliance, network effects, or embedded transactions. The message of the SaaSpocalypse is not that software is dead. It’s that small teams can build competitive products rapidly, and the products that have staying power will be built on resources that are beyond the reach of LLMs.
We’re thinking: SaaS isn’t dying, it’s becoming AI-native.
Can Local AI Stand In for the Cloud?
Projected demand for output from large language models is spurring a massive buildout of data centers. Researchers asked whether smaller models running on local devices could meaningfully lighten that load.
What’s new: Jon Saad-Falcon, Avanika Narayan, and colleagues at Stanford University and Together AI, a provider of software development and training, found that laptops are increasingly capable of substituting for cloud computing, based on a metric they call intelligence per watt.
Key insight: Cloud systems are typically more energy-efficient per user than local systems, but smaller, high-performance models increasingly enable local systems to run more efficiently. In a previous era, processing shifted from mainframes to personal computers when personal computers could perform well enough while using the same or less energy. Similarly, AI workloads can shift from data centers to personal devices if smaller models running on laptops can provide sufficient accuracy while using less energy per query. We can measure the viability of local versus cloud computing by computing intelligence per watt: the accuracy on a given task divided by the power consumed to achieve it. Assuming local and cloud systems achieve similar accuracy, the one with the higher intelligence per watt is a more efficient choice.
How it works: The authors ran various open-weights large language models on hardware designed for laptops and data-center servers. To measure the trend in intelligence per watt over time, they included both recent models (from the Qwen3, GPT-OSS, Gemma3, and IBM Granite 4.0 families, late-2025 vintage) and older models (Mixtral-8x7B and Llama -3.1-8B, circa 2023-2024), recent processors (including the Apple M4 Max laptop chip and Nvidia H100 data-center chip) and older processors (like the 2018-vintage Nvidia Quadro RTX 6000). They fed the models 1 million queries from real-world conversations, science, and academic disciplines.
- To measure accuracy, the authors compared fixed outputs to ground truth and used GPT-4o to evaluate open-ended responses.
- Simultaneously, they recorded power consumption.
- The authors used this data to simulate an ideal system for routing the queries to models: For each query, they tracked the model — whether hosted locally or in the cloud — that responded correctly while using the least power, and assumed that model processed the query.
Results: Local systems don’t yet match cloud systems for intelligence per watt, but they are improving as researchers develop smaller models that achieve higher performance. If local systems are as accurate as cloud systems, routing queries to them could save substantial amounts of energy.
- Cloud-computing systems are more intelligent per watt. Smaller models that ran on the Nvidia B200 chip achieved at least 1.4x higher intelligence per watt than the same models running on local chips.
- However, in local systems, intelligence per watt has risen dramatically. Intelligence per watt rose 5.3 times between 2023 and 2025, driven by algorithmic advances and hardware improvements.
- In the authors’ analysis of single-turn chat and reasoning queries, local systems that ran smaller models were able to answer approximately 88.7 percent of queries correctly relative to cloud systems while consuming substantially less power. In simulated hybrid scenarios, power savings exceeded 80 percent.
Yes, but: The authors did not assess the intelligence per watt of proprietary models like OpenAI GPT-5, likely because it’s unclear how much power they use. However, they did compare the accuracy of proprietary models. The most accurate local model (Qwen3-14B) trailed behind GPT-5, Gemini-2.5-Pro, and Claude Sonnet 4.5 by 11 percent accuracy to 13 percent accuracy.
Why it matters: Researchers are improving large language models rapidly, making higher performing models for the same amount of power usage. Tracking this performance increase reveals the relative trade-off between power and performance over time. As that tradeoff tilts more and more towards low-power devices, people have more options. These options offer the potential to spread the computational load and enable machine intelligence to be distributed more widely.
We’re thinking: Privacy often drives the conversation around local AI. The prospect of rising intelligence per watt creates an intriguing economic argument.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み