Claude Code とローカルモデルの組み合わせ
本記事は、高コストなクラウド API に依存する Claude Code の運用を、Ollama や LM Studio を用いたローカル推論モデルへ接続することでコスト削減と安定性を向上させる具体的な実装ガイドを提供している。
キーポイント
ローカル推論への移行の必要性
Agentic coding セッションはトークン消費量が膨大で、API 依存によるレート制限や価格変動リスクがあるため、コストゼロかつ制限のないローカルモデルの実用性が示唆されている。
Anthropic API フォーマットへの互換性
Claude Code は Anthropic Messages API 形式でリクエストを送信するため、ANTHROPIC_BASE_URL を設定するだけで Ollama や llama.cpp などのローカルサーバーに通信を転送可能である。
環境変数による簡易設定
ANTHROPIC_API_KEY に「local」や「ollama」といったプレースホルダーを設定し、ANTHROPIC_BASE_URL にローカルサーバーのアドレスを指定するだけで接続が完了する。
推奨される推論バックエンド
Ollama, LM Studio, llama.cpp の 3 つの主要なローカル推論エンジンが紹介され、それぞれの特徴と設定方法が解説されている。
環境変数によるローカルモデル接続
ANTHROPIC_BASE_URL を設定して API エンドポイントをローカルサーバーにリダイレクトし、ANTHROPIC_DEFAULT_*_MODEL で使用するローカルモデル名をマッピングすることで、Claude Code が Ollama などのローカル推論サーバーと直接通信可能になります。
Ollama のネイティブ API サポート
2026年1月に Ollama が Anthropic Messages API をネイティブサポートしたことで、翻訳プロキシなしで Claude Code との連携が実現し、モデル管理や推論負荷分散を CLI で簡易に扱えるようになりました。
LM Studio と llama.cpp の対応状況
LM Studio はバージョン 0.4.1 から、llama.cpp は以前からそれぞれ Anthropic API にネイティブ対応しており、これらも Claude Code との連携が可能です。
影響分析・編集コメントを表示
影響分析
この記事は、大規模言語モデルの実装コストと依存リスクに対する現実的な解決策を示しており、開発者がクラウド API に過度に依存しない自律的な開発環境を構築するための重要な指針となる。特に Agentic AI の運用が拡大する中で、ローカル推論の品質向上と互換性確保が実用化への大きな転換点であることを示唆している。
編集コメント
クラウド API のコストと安定性課題に対し、技術的な互換性を活用したローカル環境への移行を提案する極めて実践的な記事です。開発者のインフラ選定において重要な判断材料となるでしょう。
 image**
image**
# イントロダクション
エージェント型コーディングセッションは高価です。単一の Claude Code セッション(ファイルの読み込み、コードの記述、テストの実行、反復処理など)では、通常のチャット会話と比較して 10〜50 倍ものトークンを消費する可能性があります。スケールを考えると、これはすぐに大きなコストになります。さらに、セッション中に長期実行中のワークフローを中断させる可能性のあるレート制限や、価格変更の適用、より厳格なポリシーの強制、あるいは突然の利用不可といったリスクを伴うサードパーティ製 API への依存を考慮すると、ローカル推論(local inference)を採用する理由は明白になります。
2026 年におけるローカルモデルは、実用的なレベルに達しています。Claude Code が日常的に扱うタスク——コード補完、リファクタリング、デバッグ、コードベースの解説など——については、適切に選択された量子化(quantization)済みモデルをローカルで実行すれば、トークンあたりのコストゼロかつレート制限なしで、実際のユースケースの绝大多数をカバーできます。本記事では、3 つの推論バックエンド(Ollama、LM Studio、および llama.cpp)について解説し、それぞれを Claude Code に接続するための正確な環境変数と設定ファイル、実行する価値のあるモデルを厳選した一覧表、そして実際に遭遇する可能性のある問題に対するトラブルシューティングの解決策を取り上げます。
**
仕組みは、多くのガイドが示すほど複雑ではありません。Claude Code は Anthropic Messages API の形式でリクエストを送信します。デフォルトではこれらのリクエストは Anthropic のサーバー宛てに送信されますが、ANTHROPIC_BASE_URL を設定することで、同じ形式に対応する任意のサーバー(現在は Ollama、LM Studio、llama.cpp がネイティブ対応しています)へリダイレクトできます。
公式の Claude Code 環境変数ドキュメントによると、このセットアップに関係する重要変数は以下の通りです:
- ANTHROPIC_BASE_URL: Anthropic のサーバーからのすべての API 呼び出しを、設定した URL へリダイレクトします。ローカル推論サーバーのアドレスを設定してください。
- ANTHROPIC_API_KEY: リクエストヘッダーに送信される API キーです。ローカルサーバーは通常認証を無視するため、これは「local」や「ollama」といったプレースホルダ文字列として設定されることがほとんどです。
- ANTHROPIC_AUTH_TOKEN: 代替の認証ヘッダーです。一部のローカルサーバーでは API キーではなくこちらをチェックします。同じプレースホルダを設定してください。
ANTHROPIC_DEFAULT_SONNET_MODEL、ANTHROPIC_DEFAULT_HAIKU_MODEL、および ANTHROPIC_DEFAULT_OPUS_MODEL: Claude Code はタスクに応じて内部で異なるモデルティアを要求します。これら 3 つの変数は、各ティアをローカルモデルの名前にマッピングします。これらが設定されていない場合、Claude Code は「claude-sonnet-4-20250514」というリクエストをローカルサーバーへ送信しますが、ローカルにそのようなモデルが存在しないため、リクエストは拒否されます。
**
2026 年 1 月、Ollama は Anthropic Messages API のネイティブサポートを追加しました。これは、翻訳プロキシなしでこのワークフローを実用的にする技術的変更でした。LM Studio はバージョン 0.4.1 でネイティブの /v1/messages エンドポイントを追加しました。llama.cpp はより長い間、直接の Anthropic API サポートを提供しています。これら 3 つは現在、Claude Code のネイティブプロトコルに対応しています。
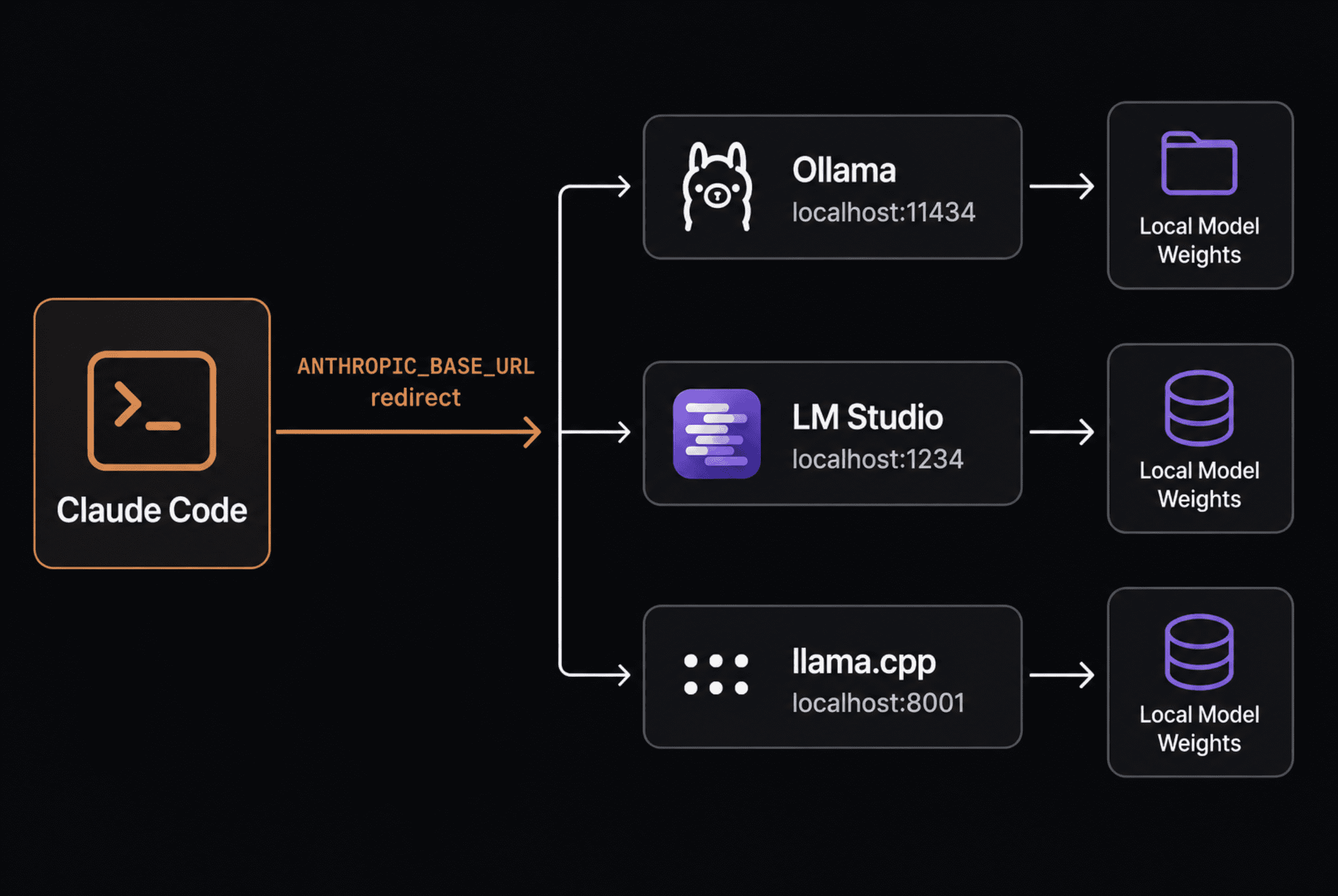
Claude Code、Ollama、LM Studio、および llama.cpp を示すクリーンなアーキテクチャ図 | 画像提供:著者
# バックエンド 1: Ollama
Ollama は適切な出発点です。モデル管理の複雑さ — ウェイトのダウンロード、量子化(quantization)、GPU と CPU の割り当て、そしてサービング — をすべて、シンプルなコマンドラインインターフェース(CLI)の背後で処理します。インストールには 1 つのコマンド、モデルの取得には 1 つのコマンド、設定には数個の環境変数です。インストール後はバックグラウンドサービスとして動作するため、手動でのサーバー起動は不要です。
前提条件**
- macOS、Linux、または Windows(Windows では WSL2 を推奨)
- 実用的な使用には少なくとも 16 GB の RAM(32 GB を推奨)
- GPU 推論には VRAM 8GB 以上の GPU、または十分な RAM を備えた CPU のみ
- Anthropic Messages API サポートには Ollama v0.14.0 以降が必要
Ollama のインストール:
macOS および Linux -- コマンド 1 つでインストール
curl -fsSL https://ollama.com/install.sh | sh
バージョンを確認する -- Claude Code との互換性のためには 0.14.0 以上が必要
ollama version
期待される結果:ollama のバージョンは 0.14.x 以上であること
Windows: インストーラーを https://ollama.com からダウンロード
最近のリリースでネイティブ Windows サポートが大幅に改善されました
インストール後、Ollama はポート 11434 でバックグラウンドサービスとして自動的に起動します。実行中であることを確認できます:
Ollama サーバーが稼働しているか確認する
curl http://localhost:11434
期待される応答:
Ollama is running
コーディング用モデルをダウンロード(pull)します:
GLM-4.7-Flash -- おすすめのスタートポイント
強力なツール呼び出し機能、128K コンテキスト、8 GB VRAM で動作可能
Apache 2.0 ライセンス
ollama pull glm-4.7-flash:latest
Qwen3-Coder -- 強力なコード生成と指示従順性
フルモデルには 20 GB 以上の VRAM が必要
ollama pull qwen3-coder
Devstral-Small -- エージェント型コーディングワークフロー用に特別に設計
Claude Code との互換性がコミュニティでテスト済み
24B パラメータ、16 GB 以上の VRAM が必要
ollama pull devstral-small-2:24b
モデルがダウンロードされ準備完了したことを確認する
ollama list
ダウンロードされたすべてのモデルとそのサイズ、更新日を表示
// Claude Code の設定で Ollama を使用
オプション 1:シェル環境変数のエクスポート(現在のターミナルセッションのみ)
Claude Code をローカルの Ollama サーバーにリダイレクトする
export ANTHROPIC_BASE_URL="http://localhost:11434"
ローカルサーバーには実際の認証は不要
これらは空でない文字列のいずれかに設定 -- Ollama は値を無視します
export ANTHROPIC_API_KEY="ollama"
export ANTHROPIC_AUTH_TOKEN="ollama"
Claude Code のモデルティアリクエストをローカルモデル名にマッピングする
Claude Code は内部的に sonnet/haiku/opus を要求しますが、これらの変数は
それらのティア名をローカルでプルした任意のモデル名に変換します
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash:latest"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash:latest"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash:latest"
Claude Code を起動 -- これで Anthropic API ではなく Ollama が使用されます
claude
オプション 2: ~/.claude/settings.json(永続的、全セッションに適用)
このアプローチはターミナルの再起動後も維持され、Claude Code を起動するたびに適用されます。Claude Code は起動時に settings.json から環境変数を読み込むため、claude がどのように起動されたかに関わらず即座に有効になります。
~/.claude/settings.json の作成または編集:
{
"env": {
"ANTHROPIC_BASE_URL": "http://localhost:11434",
"ANTHROPIC_API_KEY": "ollama",
"ANTHROPIC_AUTH_TOKEN": "ollama",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7-flash:latest",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.7-flash:latest",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.7-flash:latest"
}
}
オプション 3: プロジェクトディレクトリ内の .env ファイル(プロジェクトごとの上書き)
グローバル設定を Anthropic API に維持したまま、特定のプロジェクトで異なるモデルを使用したい場合:
プロジェクトのルートにある .env ファイル -- Claude Code によって自動的に読み込まれます
ANTHROPIC_BASE_URL=http://localhost:11434
ANTHROPIC_API_KEY=ollama
ANTHROPIC_AUTH_TOKEN=ollama
ANTHROPIC_DEFAULT_SONNET_MODEL=qwen3-coder
ANTHROPIC_DEFAULT_HAIKU_MODEL=qwen3-coder
ANTHROPIC_DEFAULT_OPUS_MODEL=qwen3-coder
接続を確認します:
簡単なテストで Claude Code を起動
claude
Claude Code 内で基本的なプロンプトを実行:
> What model are you running?
ローカルモデルであれば、Anthropic API への呼び出しを行わずに回答します。
外部への呼び出しが行われていないことを確認するには、詳細ログ付きで実行:
claude --verbose
localhost:11434 宛てのリクエストが表示される行を探す
api.anthropic.com 宛てのものではなく
ゼロから完全な動作手順:
curl -fsSL https://ollama.com/install.sh | sh # 1. Ollama のインストール
ollama pull glm-4.7-flash:latest # 2. モデルの取得(約 4 GB)
export ANTHROPIC_BASE_URL="http://localhost:11434" # 3. Claude Code のリダイレクト設定
export ANTHROPIC_API_KEY="ollama" # 4. プレースホルダー認証の設定
export ANTHROPIC_AUTH_TOKEN="ollama"
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash:latest"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash:latest"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash:latest"
claude # 5. 起動
# バックエンド 2: LM Studio
**LM Studio は、ターミナルだけで完結させるのではなく、モデルの閲覧や管理にグラフィカルインターフェースを求めたい場合に最適な選択肢です。バージョン 0.4.1 以降では、Claude Code が期待するパスであるネイティブな Anthropic 互換 /v1/messages エンドポイントが実装されており、変換層やプロキシは不要となっています。
前提条件:
- macOS、Windows、または Linux
- GPU の搭載を推奨(VRAM 6GB 以上)。CPU のみでの実行も可能ですが、速度は遅くなります
- lmstudio.ai からダウンロードするか、ヘッドレスサーバー向けに CLI インストーラーを使用してください
LM Studio のインストールと設定:
GUI が無いサーバーまたは VM 上 -- CLI インストーラー
curl -fsSL https://releases.lmstudio.ai/cli/install.sh | bash
または、GUI 利用のためにデスクトップアプリを https://lmstudio.ai からダウンロードしてください
GUI のセットアップ手順:
- LM Studio を開き、コーディング用モデルを検索します("qwen coder" または "devstral" と検索)。
- モデルをダウンロードします。LM Studio が量子化の選択を自動的に処理します。
- 「Local Server」タブ(左サイドバーの <> アイコン)に移動します。
- コンテキストサイズを設定します。LM Studio では、より良い結果を得るために少なくとも 25,000 トークンから開始し、必要に応じて増やすことを推奨しています。
- [Start Server] をクリックします。
- ポート番号(デフォルト: 1234)をメモし、モデル名を表示されている通りに正確にコピーしてください。
注意: モデル識別子を正確にコピーしてください。LM Studio は、ANTHROPIC_DEFAULT_SONNET_MODEL に渡す必要がある正確な文字列を表示します。ここでの不一致が最も一般的な失敗モードです。
Claude Code の設定:
LM Studio のローカルサーバーのベース URL を設定する
export ANTHROPIC_BASE_URL="http://localhost:1234"
export ANTHROPIC_API_KEY="lm-studio"
export ANTHROPIC_AUTH_TOKEN="lm-studio"
モデル名は、LM Studio で読み込まれたモデルとして表示されているものに置き換えてください
バージョンのサフィックスや量子化タグを含めて、正確にコピーしてください
export ANTHROPIC_DEFAULT_SONNET_MODEL="qwen2.5-coder-32b-instruct"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="qwen2.5-coder-32b-instruct"
export ANTHROPIC_DEFAULT_OPUS_MODEL="qwen2.5-coder-32b-instruct"
または、~/.claude/settings.json に恒久的に設定する:
{
"env": {
"ANTHROPIC_BASE_URL": "http://localhost:1234",
"ANTHROPIC_API_KEY": "lm-studio",
"ANTHROPIC_AUTH_TOKEN": "lm-studio",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "qwen2.5-coder-32b-instruct",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "qwen2.5-coder-32b-instruct",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "qwen2.5-coder-32b-instruct"
}
}
実行方法:
1. GUI から LM Studio サーバーを起動する (Local Server タブ > Start Server)
2. 環境変数を設定する
export ANTHROPIC_BASE_URL="http://localhost:1234"
export ANTHROPIC_API_KEY="lm-studio"
export ANTHROPIC_AUTH_TOKEN="lm-studio"
export ANTHROPIC_DEFAULT_SONNET_MODEL="your-model-name-here"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="your-model-name-here"
export ANTHROPIC_DEFAULT_OPUS_MODEL="your-model-name-here"
3. 起動
claude
# バックエンド 3: llama.cpp
推論パラメータ(量子化タイプ、KV キャッシュ設定、バッチサイズ、スレッド数など)を直接制御する必要がある場合や、サーバー上で実行してオーバーヘッドを最小限に抑えたい場合に、llama.cpp が最適な選択肢です。ネイティブの Anthropic Messages API サポートを提供するため、プロキシや変換レイヤーは不要です。
前提条件:
- GGUF 形式のモデルファイル(Hugging Face からダウンロード; 任意のモデルの「GGUF」バージョンを検索)
- GPU 推論には CUDA 対応 GPU を、または CPU のみの場合は低速な推論が可能
- ソースビルドには CMake と C++ コンパイラが必要(Linux/CUDA の場合、ソースからのビルドが推奨されます)
llama.cpp のインストール:
macOS -- Homebrew が最も簡単
brew install llama.cpp
CUDA 対応 Linux -- GPU パフォーマンスを最大化するにはソースからビルド
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
cmake -B build -DGGML_CUDA=ON # CUDA アクセラレーションを有効化
cmake --build build --config Release # ビルド実行
バイナリは ./build/bin/ に配置されます
CPU のみの Linux 向けビルド
cmake -B build
cmake --build build --config Release
Windows -- 事前ビルド済みバイナリは以下で利用可能:
https://github.com/ggml-org/llama.cpp/releases
ハードウェアに合わせた CUDA または CPU バリアントをダウンロード
GGUF モデルのダウンロード:
Hugging Face CLI をまだインストールしていない場合は以下を実行
pip install huggingface-hub
GLM-4.7-Flash を Q4_K_XL 量子化(約 4.5 GB)でダウンロード
この量子化は、コーディングにおけるサイズと品質のバランスに優れています
huggingface-cli download unsloth/GLM-4.7-Flash-GGUF \
GLM-4.7-Flash-UD-Q4_K_XL.gguf \
--local-dir ./models/
または、Qwen3-Coder を Q4 量子化(32B で約 15 GB)でダウンロードすることも可能です
huggingface-cli download Qwen/Qwen3-Coder-32B-Instruct-GGUF \
qwen3-coder-32b-instruct-q4_k_m.gguf \
--local-dir ./models/
llama.cpp サーバーを起動します:
Anthropic API サポートと 128K コンテキストウィンドウを備えた llama-server を起動
llama-server \
--model ./models/GLM-4.7-Flash-UD-Q4_K_XL.gguf \
--alias "glm-4.7-flash" \ # この名前は ANTHROPIC_DEFAULT_SONNET_MODEL に記載します
--port 8001 \
--ctx-size 131072 \ # 128K コンテキスト — 大規模なコードベースには重要です
--flash-attn \ # メモリ効率の高いアテンション、速度向上に寄与
--n-gpu-layers 99 # すべてのレイヤーを GPU にオフロード; CPU のみの場合は削除
CPU のみでの推論(GPU なし)の場合:
llama-server \
--model ./models/GLM-4.7-Flash-UD-Q4_K_XL.gguf \
--alias "glm-4.7-flash" \
--port 8001 \
--ctx-size 32768 \ # メモリを管理可能な範囲に保つため、CPU ではコンテキストサイズを削減
--threads 8 # CPU コア数に合わせて設定
主要なフラグの説明:
- --alias: クロードコードがリクエスト内で送信するモデル名文字列。これを正確に一致させるために、ANTHROPIC_DEFAULT_SONNET_MODEL を設定してください。
- --ctx-size: トークン単位でのコンテキストウィンドウサイズ。131072 = 128K。コードベースの分析には大きい方が望ましいですが、VRAM(ビデオメモリ)をより多く消費します。メモリエラーが発生する場合は値を減らしてください。
- --flash-attn: Flash Attention は、アテンション計算を小さなブロックで処理することでピーク時の VRAM 使用量を削減します。ビルドがこれをサポートしている場合は必ず有効にしてください。
- --n-gpu-layers 99: すべてのトランスフォーマー層を GPU にオフロードします。VRAM が不足している場合、サーバーは自動的に使用する層数を減らします。
Claude Code の設定:
export ANTHROPIC_BASE_URL="http://localhost:8001"
export ANTHROPIC_API_KEY="llama-cpp"
export ANTHROPIC_AUTH_TOKEN="llama-cpp"
llama-server に渡した --alias と正確に一致させる必要があります
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash"
実行方法:
ターミナル 1: llama.cpp サーバーを起動
llama-server \
--model ./models/GLM-4.7-Flash-UD-Q4_K_XL.gguf \
--alias "glm-4.7-flash" \
--port 8001 \
--ctx-size 131072 \
--flash-attn \
--n-gpu-layers 99
ターミナル 2: Claude Code を設定して起動
export ANTHROPIC_BASE_URL="http://localhost:8001"
export ANTHROPIC_API_KEY="llama-cpp"
export ANTHROPIC_AUTH_TOKEN="llama-cpp"
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash"
claude
# settings.json の完全設定
環境変数のエクスポートは、ターミナルセッションが終了するまでしか持続しません。永続的な構成には ~/.claude/settings.json を使用してください。Claude Code は起動時にこのファイルから変数を読み取るため、ターミナルから、VS Code タスクから、またはスクリプトから Claude が起動されたかに関わらず、設定が適用されます。
以下に、すべての変数が説明された本番環境対応の settings.json を示します:
{
"env": {
"ANTHROPIC_BASE_URL": "http://localhost:11434",
"ANTHROPIC_API_KEY": "ollama",
"ANTHROPIC_AUTH_TOKEN": "ollama",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7-flash:latest",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.7-flash:latest",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.7-flash:latest",
"CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1"
}
}
なぜ CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS: "1" が重要なのか:**
Claude Code を Anthropic 以外のバックエンド経由で使用する場合、Claude Code はリクエストヘッダーに Anthropic 固有の実験的ベータフラグを追加します。これらのフラグはサードパーティ製やローカルサーバーでは認識されません。その結果、ほとんどのローカル推論サーバーで「Error: Unexpected value(s) for the anthropic-beta header」というエラーが発生します。この変数を "1" に設定すると、リクエスト送出前にこれらのヘッダーが削除されるため、Claude Code のコア機能に影響を与えることなく、エラーを解消できます。
バックエンドの切り替え:
複数のバックエンド(日常利用には Ollama、複雑なタスクには Anthropic API)を扱う場合、settings.json を行き来して編集するよりも、別々のシェルスクリプトを維持しておくのが最もクリーンなアプローチです:
use-local.sh -- Ollama に切り替え
export ANTHROPIC_BASE_URL="http://localhost:11434"
export ANTHROPIC_API_KEY="ollama"
export ANTHROPIC_AUTH_TOKEN="ollama"
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash:latest"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash:latest"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash:latest"
echo "Claude Code → ローカル Ollama (glm-4.7-flash)"
use-anthropic.sh -- Anthropic API に切り戻す
unset ANTHROPIC_BASE_URL
unset ANTHROPIC_AUTH_TOKEN
unset ANTHROPIC_DEFAULT_SONNET_MODEL
unset ANTHROPIC_DEFAULT_HAIKU_MODEL
unset ANTHROPIC_DEFAULT_OPUS_MODEL
ANTHROPIC_API_KEY は、rc ファイルですでに実際のキーに設定されているはずです
echo "Claude Code → Anthropic API"
現在のセッションでこれらのスクリプトをソースしてください:
source ./use-local.sh
claude
複雑なタスクに本物の API が必要な場合:
source ./use-anthropic.sh
claude
2026 年の Claude Code 向けベストなローカルモデル
**
ハードウェアが主な制約となります。Claude Code をローカルモデルでコーディングタスクに実際に活用可能にするためには、32 GB の RAM(Apple Silicon の統一メモリまたは PC の RAM)を目標としてください。16 GB でも小規模な量子化モデルと CPU オフロードを使用すれば実用可能ですが、マルチステップのエージェントタスクでは生成速度が明らかに低下します。
モデル
必要 VRAM
コンテキスト長
強み
ライセンス
プルコマンド
8 GB
128K
ツール呼び出し、高速、低 VRAM 消費
Apache 2.0
ollama pull glm-4.7-flash
16 GB
32K
エージェント型コーディングワークフロー
Apache 2.0
ollama pull devstral-small-2:24b
20 GB
128K
コード生成、指示処理
Apache 2.0
ollama pull qwen3-coder
20 GB
256K
強力なオールラウンド性能、巨大コンテキスト
Apache 2.0
ollama pull qwen3.5:27b
20 GB
256K
推論能力、コーディングベンチで 77% のスコア
Gemma License
ollama pull gemma4:26b
# よくある問題のトラブルシューティング
- クロードコード起動時に接続拒否される場合:推論サーバーが実行されていません。これが最も一般的な問題であり、診断も最も簡単です。
Ollama が実行されているか確認する
curl http://localhost:11434
期待される結果:"Ollama is running"
LM Studio サーバーが実行されているか確認する
curl http://localhost:1234/v1/models
読み込まれたモデルの JSON リストを返すはずです
llama-server が実行されているか確認する
curl http://localhost:8001/health
{"status":"ok"} を返すはずです
-- サーバーを起動していない場合は、まずサーバーを開始してから Claude Code を起動してください
ollama serve # Ollama
LM Studio: GUI の「Local Server」タブを使用してください
llama.cpp: Backend 3 セクションから llama-server コマンドを実行してください
- モデルが見つからない、または不明なモデルのエラー:ANTHROPIC_DEFAULT_SONNET_MODEL に指定されたモデル名が、サーバー側で認識されている名前と一致していません。
Ollama が利用可能なすべてのモデルを一覧表示する
ollama list
ANTHROPIC_DEFAULT_SONNET_MODEL のモデル名は、タグを含めて完全に一致させる必要があります -- "glm-4.7-flash:latest" であり、"glm-4.7-flash" ではありません。
サーバー側で何が見えているかを確認するために、直接 API を呼び出して検証します
curl http://localhost:11434/v1/models
- ツール呼び出しが失敗する、またはエラーを返す:Claude Code は関数やスクリプトを実行する際にストリーミング形式のツール呼び出しを使用しますが、これには Ollama バージョン 0.14.3-rc1 以降が必要です。0.14.x シリーズのそれ以前のバージョンでは、ストリーミング形式のツール呼び出しのサポートが不完全でした。
お使いの Ollama のバージョンを確認する
ollama version
バージョンが 0.14.3 より低い場合は、Ollama を更新してください
curl -fsSL https://ollama.com/install.sh | sh
- anthropic-beta ヘッダーのエラー:
エラーメッセージとして「Error: Unexpected value(s) for the anthropic-beta header」が表示されます。これは、Claude Code が追加する Anthropic 固有の実験的ベータフラグを、ローカルサーバーが認識できないために発生します。これを修正するには、settings.json の env ブロックに以下の設定を追加してください。
"CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1"
- Anthropic API への切り戻し:
Shell セッション -- リダイレクト変数を解除
unset ANTHROPIC_BASE_URL
unset ANTHROPIC_AUTH_TOKEN
unset ANTHROPIC_DEFAULT_SONNET_MODEL
unset ANTHROPIC_DEFAULT_HAIKU_MODEL
unset ANTHROPIC_DEFAULT_OPUS_MODEL
次に、実際の API キーが設定されていることを確認する
echo $ANTHROPIC_API_KEY
sk-ant-... で始まるキーが表示されるはずで、プレースホルダーではない
settings.json を使用していた場合 -- 環境変数ブロックを削除またはコメントアウトし、Claude Code を再起動する
- 生成速度の遅さ: エージェント型 Claude Code タスクでは、各ツール呼び出しが往復通信となるため、生成速度が重要になります。速度が不十分な場合は:
より小型、あるいはより積極的に量子化されたモデル(Q8 の代わりに Q4_K_M)に切り替える。
- llama.cpp でまだ設定されていない場合、--flash-attn を有効にする。
- コンテキストサイズを縮小する (--ctx-size); より大きなコンテキストはプリフィルに時間がかかる。
- Ollama の場合、環境変数で OLLAMA_NUM_GPU_LAYERS=99 を設定して、最大限の GPU オフロードを強制する。
# 結論
**
以前は壊れやすいアダプターやハックが必要だったものが、今は 5 ステップのプロセスになりました。推論バックエンドをインストールし、モデルをプルし、3 つの環境変数を設定するだけで、Claude Code は Anthropic の API ではなくローカルマシンにルーティングされます。モデルをダウンロードした後なら、設定には 5 分もかかりません。
実用的な結果として、セットアップ後は実行コストがかからず、レート制限もなく、コードを完全にローカルマシン上に保持し、1 年前にはローカルモデルでは実現できなかった品質レベルで、実際のコーディングユースケースの绝大多数をカバーするコーディングアシスタントが得られます。まずは Ollama と glm-4.7-flash から始めてください。これはハードウェア要件が最も低く、ツール呼び出しサポートが最も一貫しており、動作するセットアップへの最短ルートです。これが稼働したら、ご自身のハードウェアと実際に必要な品質レベルに応じてモデルをスケールアップしてください。
Shittu Olumide はソフトウェアエンジニアであり技術ライターで、最先端の技術を駆使して説得力のある物語を構築することに情熱を注いでおり、細部への鋭い眼と複雑な概念を簡素化する才能を持っています。Shittu は Twitter でも活動しています。
原文を表示
**
# Introduction
Agentic coding sessions are expensive. A single Claude Code session — reading files, writing code, running tests, iterating — can burn 10–50x more tokens than a plain chat conversation. At scale, that adds up fast. Add rate limits that can interrupt a long-running workflow mid-session, and the dependency on a third-party API that can change pricing, enforce stricter policies, or go down at any point, and the case for local inference becomes straightforward.
Local models in 2026 are good enough. For the tasks Claude Code handles daily — code completion, refactoring, debugging, codebase explanation — a well-chosen quantized model running locally covers the vast majority of real use cases at zero per-token cost and with no rate limits. This article covers three inference backends (Ollama, LM Studio, and llama.cpp**), the exact environment variables and configuration files to wire each one to Claude Code, a curated table of models worth running, and the troubleshooting fixes for the issues you will actually hit.
# How Claude Code Connects to Any Local Model
**
The mechanism is simpler than most guides make it look. Claude Code sends requests in the Anthropic Messages API format. By default those requests go to Anthropic's servers. Setting ANTHROPIC_BASE_URL redirects them to any server that speaks the same format, which now includes Ollama, LM Studio, and llama.cpp natively.
According to the official Claude Code environment variables documentation, the variables that matter for this setup are:
- ANTHROPIC_BASE_URL: redirects all API calls from Anthropic's servers to whatever URL you set. Set this to your local inference server address.
- ANTHROPIC_API_KEY: the API key sent in the request header. Local servers typically ignore authentication, so this is usually set to a placeholder string like "local" or "ollama."
- ANTHROPIC_AUTH_TOKEN: an alternative auth header. Some local servers check for this instead of the API key. Set it to the same placeholder.
ANTHROPIC_DEFAULT_SONNET_MODEL, ANTHROPIC_DEFAULT_HAIKU_MODEL, and ANTHROPIC_DEFAULT_OPUS_MODEL: Claude Code internally requests different model tiers depending on the task. These three variables map each tier to your local model's name. Without them, Claude Code sends requests for claude-sonnet-4-20250514 to your local server, which will reject the request because no such model exists locally.
In January 2026, Ollama added native support for the Anthropic Messages API, which was the technical change that made this workflow practical without translation proxies. LM Studio added a native /v1/messages endpoint in version 0.4.1. llama.cpp has had direct Anthropic API support for longer. All three now speak Claude Code's native protocol.
A clean architecture diagram showing Claude Code, Ollama, LM Studio, and llama.cpp | Image by Author
# Backend 1: Ollama
Ollama is the right starting point. It handles all the complexity of model management — downloading weights, quantization, GPU and CPU allocation, and serving — behind a simple command-line interface (CLI). One command to install, one command to pull a model, a few environment variables to configure. It runs as a background service after install, so there is no manual server start required.
Prerequisites**
- macOS, Linux, or Windows (WSL2 recommended on Windows)
- At least 16 GB RAM for practical use (32 GB recommended)
- GPU with 8+ GB VRAM for GPU inference, or CPU-only with enough RAM
- Ollama v0.14.0 or later required for Anthropic Messages API support
Install Ollama:
# macOS and Linux -- one command install
curl -fsSL https://ollama.com/install.sh | sh
# Verify the version -- must be 0.14.0+ for Claude Code compatibility
ollama version
# Expected: ollama version is 0.14.x or higher
# Windows: download the installer from https://ollama.com
# Native Windows support has improved significantly in recent releasesAfter installation, Ollama starts automatically as a background service on port 11434. You can verify it is running:
# Check the Ollama server is live
curl http://localhost:11434
# Expected response:
# Ollama is runningPull a coding model:
# GLM-4.7-Flash -- recommended starting point
# Strong tool calling, 128K context, fits on 8 GB VRAM
# Apache 2.0 license
ollama pull glm-4.7-flash:latest
# Qwen3-Coder -- strong code generation and instruction following
# Requires 20+ GB VRAM for the full model
ollama pull qwen3-coder
# Devstral-Small -- specifically designed for agentic coding workflows
# Community-tested for Claude Code compatibility
# 24B, requires 16+ GB VRAM
ollama pull devstral-small-2:24b
# Verify the model is downloaded and ready
ollama list
# Shows all pulled models with their sizes and modification dates// Configuring Claude Code to Use Ollama
Option 1: Shell export (current terminal session only)
# Redirect Claude Code to your local Ollama server
export ANTHROPIC_BASE_URL="http://localhost:11434"
# Local servers do not require real authentication
# Set these to any non-empty string -- Ollama ignores the value
export ANTHROPIC_API_KEY="ollama"
export ANTHROPIC_AUTH_TOKEN="ollama"
# Map Claude Code's model tier requests to your local model name
# Claude Code internally requests sonnet/haiku/opus -- these variables
# translate those tier names to whatever model you have pulled locally
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash:latest"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash:latest"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash:latest"
# Launch Claude Code -- it will now use Ollama instead of the Anthropic API
claudeOption 2: ~/.claude/settings.json (permanent, applies to all sessions)
This approach survives terminal restarts and applies every time you launch Claude Code. Claude Code reads environment variables from settings.json at startup so they take effect no matter how claude was launched.
Create or edit ~/.claude/settings.json:
{
"env": {
"ANTHROPIC_BASE_URL": "http://localhost:11434",
"ANTHROPIC_API_KEY": "ollama",
"ANTHROPIC_AUTH_TOKEN": "ollama",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7-flash:latest",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.7-flash:latest",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.7-flash:latest"
}
}Option 3: .env file in project directory (per-project override)
If you want a specific project to use a different model while keeping your global settings on the Anthropic API:
# .env in your project root -- loaded automatically by Claude Code
ANTHROPIC_BASE_URL=http://localhost:11434
ANTHROPIC_API_KEY=ollama
ANTHROPIC_AUTH_TOKEN=ollama
ANTHROPIC_DEFAULT_SONNET_MODEL=qwen3-coder
ANTHROPIC_DEFAULT_HAIKU_MODEL=qwen3-coder
ANTHROPIC_DEFAULT_OPUS_MODEL=qwen3-coderVerify the connection:
# Launch Claude Code with a simple test
claude
# Inside Claude Code, run a basic prompt:
# > What model are you running?
# A local model should respond without making any Anthropic API calls.
# To confirm no external calls are being made, run with verbose logging:
claude --verbose
# Look for lines showing requests going to localhost:11434
# rather than api.anthropic.comFull working sequence from scratch:
curl -fsSL https://ollama.com/install.sh | sh # 1. Install Ollama
ollama pull glm-4.7-flash:latest # 2. Pull model (~4 GB)
export ANTHROPIC_BASE_URL="http://localhost:11434" # 3. Redirect Claude Code
export ANTHROPIC_API_KEY="ollama" # 4. Set placeholder auth
export ANTHROPIC_AUTH_TOKEN="ollama"
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash:latest"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash:latest"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash:latest"
claude # 5. Launch# Backend 2: LM Studio
**
LM Studio is the right choice if you want a graphical interface for browsing and managing models rather than working entirely in the terminal. Since version 0.4.1, it includes a native Anthropic-compatible /v1/messages** endpoint — the same path Claude Code expects — so no translation layer or proxy is needed.
Prerequisites:
- macOS, Windows, or Linux
- GPU with 6+ GB VRAM recommended (CPU-only is possible but slow)
- Download from lmstudio.ai or use the CLI installer for headless servers
Install and configure LM Studio:
# On a server or VM without a GUI -- CLI installer
curl -fsSL https://releases.lmstudio.ai/cli/install.sh | bash
# Or download the desktop app from https://lmstudio.ai for GUI useGUI setup steps:
- Open LM Studio and search for a coding model (search "qwen coder" or "devstral").
- Download the model. LM Studio handles quantization selection automatically.
- Go to the Local Server tab (the <> icon in the left sidebar).
- Set the context size. LM Studio recommends starting with at least 25,000 tokens and increasing for better results.
- Click Start Server.
- Note the port (default: 1234) and copy the model name exactly as shown.
Note: Copy the model identifier exactly. LM Studio displays the exact string you need to pass to ANTHROPIC_DEFAULT_SONNET_MODEL. A mismatch here is the most common failure mode.
Configure Claude Code:
# Set the base URL to LM Studio's local server
export ANTHROPIC_BASE_URL="http://localhost:1234"
export ANTHROPIC_API_KEY="lm-studio"
export ANTHROPIC_AUTH_TOKEN="lm-studio"
# Replace the model name with what LM Studio shows for your loaded model
# Copy it exactly -- including any version suffix or quantization tag
export ANTHROPIC_DEFAULT_SONNET_MODEL="qwen2.5-coder-32b-instruct"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="qwen2.5-coder-32b-instruct"
export ANTHROPIC_DEFAULT_OPUS_MODEL="qwen2.5-coder-32b-instruct"Or persistently in ~/.claude/settings.json:
{
"env": {
"ANTHROPIC_BASE_URL": "http://localhost:1234",
"ANTHROPIC_API_KEY": "lm-studio",
"ANTHROPIC_AUTH_TOKEN": "lm-studio",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "qwen2.5-coder-32b-instruct",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "qwen2.5-coder-32b-instruct",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "qwen2.5-coder-32b-instruct"
}
}How to run:
# 1. Start the LM Studio server from the GUI (Local Server tab > Start Server)
# 2. Set environment variables
export ANTHROPIC_BASE_URL="http://localhost:1234"
export ANTHROPIC_API_KEY="lm-studio"
export ANTHROPIC_AUTH_TOKEN="lm-studio"
export ANTHROPIC_DEFAULT_SONNET_MODEL="your-model-name-here"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="your-model-name-here"
export ANTHROPIC_DEFAULT_OPUS_MODEL="your-model-name-here"
# 3. Launch
claude# Backend 3: llama.cpp
**
llama.cpp** is the right choice when you need direct control over inference parameters — quantization type, KV cache configuration, batch size, thread count — or when you are running on a server and want the lowest overhead. It has native Anthropic Messages API support, so no proxy or translation layer is needed.
Prerequisites:
- A GGUF-format model file (download from Hugging Face; search for "GGUF" versions of any model)
- CUDA-capable GPU for GPU inference, or CPU-only for slower inference
- CMake and a C++ compiler for source builds (on Linux/CUDA, source is recommended)
Install llama.cpp:
# macOS -- Homebrew is simplest
brew install llama.cpp
# Linux with CUDA -- build from source for best GPU performance
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
cmake -B build -DGGML_CUDA=ON # Enable CUDA acceleration
cmake --build build --config Release # Build
# Binaries in ./build/bin/
# Linux CPU-only build
cmake -B build
cmake --build build --config Release
# Windows -- pre-built binaries available at:
# https://github.com/ggml-org/llama.cpp/releases
# Download the CUDA or CPU variant matching your hardwareDownload a GGUF model:
# Install the Hugging Face CLI if you do not have it
pip install huggingface-hub
# Download GLM-4.7-Flash in Q4_K_XL quantization (~4.5 GB)
# This quantization offers a good size/quality balance for coding
huggingface-cli download unsloth/GLM-4.7-Flash-GGUF \
GLM-4.7-Flash-UD-Q4_K_XL.gguf \
--local-dir ./models/
# Or download Qwen3-Coder in Q4 quantization (~15 GB for 32B)
huggingface-cli download Qwen/Qwen3-Coder-32B-Instruct-GGUF \
qwen3-coder-32b-instruct-q4_k_m.gguf \
--local-dir ./models/Start the llama.cpp server:
# Start llama-server with Anthropic API support and a 128K context window
llama-server \
--model ./models/GLM-4.7-Flash-UD-Q4_K_XL.gguf \
--alias "glm-4.7-flash" \ # This name goes in ANTHROPIC_DEFAULT_SONNET_MODEL
--port 8001 \
--ctx-size 131072 \ # 128K context -- important for large codebases
--flash-attn \ # Memory-efficient attention, improves speed
--n-gpu-layers 99 # Offload all layers to GPU; remove for CPU-only
# For CPU-only inference (no GPU):
llama-server \
--model ./models/GLM-4.7-Flash-UD-Q4_K_XL.gguf \
--alias "glm-4.7-flash" \
--port 8001 \
--ctx-size 32768 \ # Reduce context size on CPU to keep memory manageable
--threads 8 # Match your CPU core countKey flags explained:
- --alias: the model name string Claude Code will send in requests. Set ANTHROPIC_DEFAULT_SONNET_MODEL to match this exactly.
- --ctx-size: context window in tokens. 131072 = 128K. Larger is better for codebase analysis but uses more VRAM. Reduce if you get out-of-memory errors.
- --flash-attn: Flash Attention reduces peak VRAM by processing attention in smaller blocks. Enable it whenever your build supports it.
- --n-gpu-layers 99: offloads all transformer layers to the GPU. The server automatically uses fewer layers if VRAM is tight.
Configure Claude Code:
export ANTHROPIC_BASE_URL="http://localhost:8001"
export ANTHROPIC_API_KEY="llama-cpp"
export ANTHROPIC_AUTH_TOKEN="llama-cpp"
# Must match the --alias you passed to llama-server exactly
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash"How to run:
# Terminal 1: start the llama.cpp server
llama-server \
--model ./models/GLM-4.7-Flash-UD-Q4_K_XL.gguf \
--alias "glm-4.7-flash" \
--port 8001 \
--ctx-size 131072 \
--flash-attn \
--n-gpu-layers 99
# Terminal 2: configure and launch Claude Code
export ANTHROPIC_BASE_URL="http://localhost:8001"
export ANTHROPIC_API_KEY="llama-cpp"
export ANTHROPIC_AUTH_TOKEN="llama-cpp"
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash"
claude# The Complete settings.json
**
Environment variable exports last only as long as the terminal session. For a durable configuration, use ~/.claude/settings.json. Claude Code reads variables from this file at startup so they apply no matter how Claude was launched — from the terminal, from a VS Code task, or from a script.
Here is a production-ready settings.json with all variables explained:
{
"env": {
"ANTHROPIC_BASE_URL": "http://localhost:11434",
"ANTHROPIC_API_KEY": "ollama",
"ANTHROPIC_AUTH_TOKEN": "ollama",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7-flash:latest",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.7-flash:latest",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.7-flash:latest",
"CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1"
}
}Why CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS: "1" matters:**
When using Claude Code through non-Anthropic backends, Claude Code adds Anthropic-specific experimental beta flags to request headers — flags that third-party and local servers do not recognize. This causes Error: Unexpected value(s) for the anthropic-beta header on most local inference servers. Setting this variable to "1" strips those headers before the request goes out, which eliminates the error without affecting any core Claude Code functionality.
Switching between backends:
If you work with multiple backends — Ollama for daily use, the Anthropic API for complex tasks — the cleanest approach is maintaining separate shell scripts rather than editing settings.json back and forth:
# use-local.sh -- switch to Ollama
export ANTHROPIC_BASE_URL="http://localhost:11434"
export ANTHROPIC_API_KEY="ollama"
export ANTHROPIC_AUTH_TOKEN="ollama"
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash:latest"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash:latest"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash:latest"
echo "Claude Code → local Ollama (glm-4.7-flash)"# use-anthropic.sh -- switch back to the Anthropic API
unset ANTHROPIC_BASE_URL
unset ANTHROPIC_AUTH_TOKEN
unset ANTHROPIC_DEFAULT_SONNET_MODEL
unset ANTHROPIC_DEFAULT_HAIKU_MODEL
unset ANTHROPIC_DEFAULT_OPUS_MODEL
# ANTHROPIC_API_KEY should already be set to your real key in your rc file
echo "Claude Code → Anthropic API"Source either script in your current session:
source ./use-local.sh
claude
# When you need the real API for a complex task:
source ./use-anthropic.sh
claude# Best Local Models for Claude Code in 2026
**
Hardware is the main constraint. For Claude Code with local models to be genuinely usable for coding tasks rather than just a demo, aim for 32 GB of RAM — Apple Silicon unified memory or PC RAM. 16 GB is viable with smaller quantized models and CPU offload, but generation speed will be noticeably slower on multi-step agentic tasks.
Model**
VRAM Needed
Context
Strengths
License
Pull Command
8 GB
128K
Tool calling, fast, low VRAM
Apache 2.0
ollama pull glm-4.7-flash
16 GB
32K
Agentic coding workflows
Apache 2.0
ollama pull devstral-small-2:24b
20 GB
128K
Code generation, instructions
Apache 2.0
ollama pull qwen3-coder
20 GB
256K
Strong all-round, huge context
Apache 2.0
ollama pull qwen3.5:27b
20 GB
256K
Reasoning, 77% coding bench
Gemma License
ollama pull gemma4:26b
# Troubleshooting Common Issues
- Connection refused when launching Claude Code: The inference server is not running. This is the most common issue and the easiest to diagnose.
# Check if Ollama is running
curl http://localhost:11434
# Expected: "Ollama is running"
# Check if LM Studio server is running
curl http://localhost:1234/v1/models
# Should return a JSON list of loaded models
# Check if llama-server is running
curl http://localhost:8001/health
# Should return {"status":"ok"}
# If not running -- start the server first, then launch Claude Code
ollama serve # Ollama
# LM Studio: use the GUI Local Server tab
# llama.cpp: run the llama-server command from the Backend 3 section- Model not found or unknown model error: The model name in your ANTHROPIC_DEFAULT_SONNET_MODEL does not match what the server knows.
# List all models Ollama has available
ollama list
# The model name in ANTHROPIC_DEFAULT_SONNET_MODEL must match EXACTLY
# including the tag -- "glm-4.7-flash:latest" not "glm-4.7-flash"
# Verify with a direct API call to confirm what the server sees
curl http://localhost:11434/v1/models- Tool calls failing or returning errors: For streaming tool calls, which Claude Code uses when executing functions or scripts, Ollama version 0.14.3-rc1 or later is required. Earlier versions in the 0.14.x series had incomplete streaming tool call support.
# Check your Ollama version
ollama version
# If below 0.14.3, update Ollama
curl -fsSL https://ollama.com/install.sh | sh- anthropic-beta header error:
You will see: Error: Unexpected value(s) for the anthropic-beta header. This happens because Claude Code adds Anthropic-specific experimental beta flags that local servers do not recognize. Fix it by adding this to your settings.json env block:
"CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1"- Reverting to the Anthropic API:
# Shell session -- unset the redirect variables
unset ANTHROPIC_BASE_URL
unset ANTHROPIC_AUTH_TOKEN
unset ANTHROPIC_DEFAULT_SONNET_MODEL
unset ANTHROPIC_DEFAULT_HAIKU_MODEL
unset ANTHROPIC_DEFAULT_OPUS_MODEL
# Then make sure your real API key is set
echo $ANTHROPIC_API_KEY
# Should show your sk-ant-... key, not a placeholder
# If you used settings.json -- remove or comment out the env block
# and restart Claude Code- Slow generation speed: For agentic Claude Code tasks, generation speed matters because each tool call is a round trip. If speed is inadequate:
Switch to a smaller or more aggressively quantized model (Q4_K_M instead of Q8).
- Enable --flash-attn in llama.cpp if not already set.
- Reduce context size (--ctx-size); larger contexts are slower to prefill.
- On Ollama, set OLLAMA_NUM_GPU_LAYERS=99 in your environment to force maximum GPU offload.
# Conclusion
**
What used to require fragile adapters and hacks is now a five-step process. Install the inference backend, pull a model, set three environment variables, and Claude Code routes to your local machine instead of Anthropic's API. The configuration takes under five minutes once you have the model downloaded.
The practical result is a coding assistant that costs nothing to run after setup, has no rate limits, keeps your code entirely on your machine, and covers the vast majority of real coding use cases at quality levels that were not available in local models a year ago. Start with Ollama and glm-4.7-flash — it has the lowest hardware requirement, the most consistent tool-calling support, and the fastest path to a working setup. Once that is running, scale up the model based on your hardware and the quality level you actually need.
Shittu Olumide** is a software engineer and technical writer passionate about leveraging cutting-edge technologies to craft compelling narratives, with a keen eye for detail and a knack for simplifying complex concepts. You can also find Shittu on Twitter.
関連記事
Claude Code がアーティファクト機能をサポート
Anthropic は Claude Code に「アーティファクト」機能を追加し、PR の解説やシステム説明などの作業セッションをライブで共有可能な視覚ページに変換しました。この機能は自動更新やバージョン履歴をサポートし、チームと企業向けベータ版として提供されています。
Claude Code がアーティファクト機能をサポート
Anthropic は開発者向けツール「Claude Code」に、コード生成結果を直接表示・編集できる「アーティファクト」機能を追加した。これにより、開発ワークフローの効率化が図られる。
Claude Code の操作:CLAUDE.md ファイル、スキル、フック、ルール、サブエージェントなど
Anthropic は Claude Code の制御機能を強化し、設定ファイルや自動化機能の拡張を発表した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み