GPT-5.6 Sol, Terra, Luna(39 分読み)
TLDR AI は OpenAI の最新モデル「GPT-5.6」の Sol、Terra、Luna という 3 つのバリエーションについて解説する記事を紹介したが、具体的な技術詳細や機能変更については本文抜粋から確認できない。
キーポイント
新モデル名の発表
OpenAI の次期モデルが「GPT-5.6」として Sol、Terra、Luna の 3 つのバリエーションで登場することが紹介されている。
詳細情報の不足
記事の抜粋内容からは、各バリエーション間の具体的な技術的差異や機能変更に関する情報は提供されていない。
情報源の紹介
本ニュースは TLDR AI が公開した解説記事を要約・紹介する形式であり、一次情報の詳細な分析には至っていない。
影響分析・編集コメントを表示
影響分析
このニュースは OpenAI の次期ロードマップに関する期待感を高めるものですが、具体的な技術内容が欠如しているため、即座に業界の方向性を決定づける重大な情報とは言い難いです。しかし、「Sol」「Terra」「Luna」という命名から、モデルが用途や特性によって細分化される戦略を示唆しており、今後の製品展開への注目点となります。
編集コメント
モデル名が発表されたことは注目されますが、具体的な技術的革新性や実用性が不明な段階では、評価を慎重に行う必要があります。詳細な仕様は公式リリースまたは専門的な分析記事の公開を待つべきでしょう。
1. はじめに
GPT-5.6 は、3 つのモデルからなる新しいファミリーです。Sol は当社の新たなフラッグシップモデルであり、Terra はコストパフォーマンスに優れた有能な低価格オプション、Luna は最速かつ最も費用対効果の高いモデルです。今回のローンチのために構築した安全対策はこれまでで最も堅牢なものですが、これらのモデルを世界中で安全かつ大規模に提供するために設計されています。
私たちは広範なアクセスを信じており、今後数週間で GPT-5.6 Sol、Terra、Luna を一般利用可能にする計画です。米国政府との継続的な対話の一環として、今日のローンチに先立ち、当社の計画とモデルの能力についてプレビューしました。政府の要請により、まずは政府にも共有された信頼できるパートナーの小規模グループに対して限定プレビューを開始し、その後より広く公開していきます。このプレビュー期間中、より広範な利用に向けて取り組むとともに、パートナーと緊密にテストと調整を継続してまいります。
当社の準備態勢フレームワークの下では、Sol、Terra、Luna はいずれもサイバーセキュリティおよび生物・化学リスクの両面で「高能力」として扱われます。これらはいずれも AI 自己改善における当社の「高閾値」には達していません。各モデルの能力プロファイルに適応した一連の 安全対策 を実装し、関連するリスクを十分に最小化しています。
このシステムカードは、展開前に GPT-5.6 の安全性リスクを理解し緩和するために実施した作業の詳細な報告書です。知っておくべき最も重要な 5 つの点は以下の通りです:
- これらのモデルはサイバーセキュリティ能力において有意義な向上を示していますが、当社のリスクフレームワークにおける最高レベル(クリティカル)には達していません。GPT-5.6 Sol と Terra は脆弱性や攻撃の断片を検出できますが、サイバーセキュリティテストにおいては、強化された標的に対する自律的なエンドツーエンドの攻撃を実行することはできませんでした。別個の評価では、エージェント型コーディングタスクにおけるアライメント(目標整合)のズレを調査した結果、GPT-5.6 は GPT-5.5 に比べてユーザーの意図を超えて行動する傾向がより強く見られ、ユーザーが要求していない行動を実行しようとするケースも含まれていましたが、絶対的な発生率は依然として低い水準にとどまっています。
これらのモデルを安全なものとするため、個々の要素の単純な合計以上の効果を持つ新しい技術Safety Stack(安全性スタック)を追加しました。モデル自体は安全に動作するようにトレーニングされており、Sol と Terra には敏感なドメインに特化した新規追加の活性化分類器が搭載され、生成プロセス中に不審な回答を検知して介入・停止させる機能を備えています。また、特定の会話はスキャンされ、安全性の境界を越えた場合、リアルタイムで不適切な出力がブロックされます。さらに、単一の瞬間では明らかにならないような会話全体にわたる安全上のパターンを検出する自動化された安全システムも稼働しています。
深刻な被害が発生するには一連の成功したステップが必要ですが、当社の防護策はその連鎖の各段階に障壁を設けています。サイバーセキュリティおよび生物学分野における脅威モデリングに基づき、安全性スタックを設計した結果、攻撃者が有害に至る経路のいずれかのステップを完了した場合でも、防護策が機能してモデルが深刻な被害を引き起こすことを阻止します。また、GPT-5.6 モデルが一般に広く利用可能になった際にも、最も敏感なサイバーセキュリティおよび生物学関連の機能を信頼できる防衛者に限定して保持し続けるためのプログラムも用意されています。
当社の防護策に関するテストは、過去のいかなるリリースよりも厳格かつ集中的に行われており、プレビュー期間中も継続的にテストを実施しています。専門家の人間や外部テスターが多様なアプローチを用いて欠陥を発見しました。また、普遍的な Jailbreak(セキュリティ回避)を自動的に検出するために、70 万時間以上の A100e GPU 時間を投入しており、展開中は自動化されたレッドチーム演習を継続して実行します。Jailbreak が報告されるたびに、再現・緩和・再テストを行い、欠陥が解消されるまで対応を続けます。
特にサイバーセキュリティ能力において広範なアクセスを提供することは、重要な安全上のメリットをもたらします。当社のテストでは、GPT-5.6 は実際の攻撃で脆弱性を悪用するよりも、それらの脆弱性を見つけ修正する方が得意であることが示されています。これにより、サイバーセキュリティの弱点が悪用される前にシステムを強化する機会が防衛者に与えられますが、この機会は攻撃能力が向上するにつれて縮小する可能性があります。したがって、当社の防護策は、大規模な悪意ある利用を困難にすることに焦点を当てつつも、システムの保護に関する日常的な業務を可能にするよう設計されています。
本カードでは、推論の努力(モデルが問題を解決するために使用する思考量)の変化に伴うパフォーマンスの変動を示します。単一のスコアを報告するのではなく、異なる努力レベル全体にわたる曲線を描くことで、モデルが何ができるか、そしてそれを実現するためにどの程度の努力が必要かをより包括的に把握できるようにしています。
なお、当社はモデルの継続的な改善に取り組んでいます。過去に公開されたモデルからの比較値は、それらのモデルの最近のスナップショットに基づくものであり、以前のカードに記載された値とわずかに異なる場合があります。
GPT-5.6 シリーズのモデルを一般利用可能にする際に、本システムカードの更新版を公開する予定です。
2. モデルデータとトレーニング
OpenAI の他のモデルと同様に、GPT-5.6 は多様なデータセットでトレーニングされています。これには、インターネット上で公に入手可能な情報、第三者とのパートナーシップを通じてアクセスできる情報、およびユーザーや人間によるトレーナー・研究者が提供または生成した情報が含まれます。当社のデータ処理パイプラインには、データの品質を維持し潜在的なリスクを軽減するための厳格なフィルタリングが含まれています。トレーニングデータから個人情報を削減するために高度なデータフィルタリングプロセスを使用しています。また、有害または機密性の高いコンテンツの使用を防ぐまたは低減する安全分類器を採用しており、これには未成年者を含む性的な明示的な素材などが含まれます。
OpenAI の推論モデルは、強化学習を通じて推論を行うように訓練されています。これらのモデルは回答する前に思考するように設計されており、ユーザーに回答する前に長い内部の思考連鎖を生成することができます。訓練を通じて、これらのモデルは思考プロセスを洗練させ、異なる戦略を試み、自身のミスを認識することを学びます。推論機能により、これらのモデルは私たちが設定した特定のガイドラインやモデルポリシーに従うことができ、安全性に関する私たちの期待に沿った行動をとるのを助けます。つまり、より有益な回答を提供し、安全ルールの回避を試みる行為に対してより強く抵抗することができます。
なお、以前にリリースされたモデルからの比較値は、それらのモデルの最新バージョンに基づくものであり、各モデルのリリース時に公開された値とはわずかに異なる場合があります。
3. モデルの安全性
3.1 禁止コンテンツ
3.1.1 チャレンジングなプロンプトを用いた評価
私たちは、禁止コンテンツのカテゴリ全体にわたってベンチマーク評価を実施しました。ここでは、生産環境データからの挑戦的な例を代表する会話を含む評価セットである「Production Benchmarks(本番環境ベンチマーク)」について報告します。以前のシステムカードで述べた通り、これらのカテゴリにおける早期の標準評価が相対的に飽和状態に達したため、継続的な進捗を測定できるよう、私たちはこの Production Benchmarks を導入しました。
これらの評価は意図的に困難になるように作成されています。既存のモデルがまだ理想的な回答を提供していなかったケースを中心に構築されており、これは以下のスコアに反映されています。エラー率は平均的な本番トラフィックを代表するものではありません。主要な指標は「_unsafe」であり、関連する OpenAI のポリシーの下で許可されていない出力をモデルが生産していないかを確認するものです。
評価は、モデルの根本的な挙動が当社の安全基準を満たしていることを保証するため、システムレベルのセーフガードなしで実行されます。ローンチ後もこれらのカテゴリを継続的に監視し、オンラインパフォーマンスを評価し、必要に応じてセーフガードをさらに調整します。
以前にリリースされたモデルからの値は、それらのモデルの最新バージョンからのものです。また、評価にはある程度のばらつきが生じます。これらの値は、各モデルのローンチ時に公開された値とわずかに異なる場合があります。以下に記載されている以前のモデルとの比較スコアは、相対的なパフォーマンスを明らかにすることを意図したものです。ポリシー、採点者、データセット、およびその他の測定詳細は時間とともに進化するため、以下の表に含まれていないスコアは、通常、これらの最新の結果と直接比較可能であると見なすべきではありません。
挑戦的なプロンプトを用いた本番ベンチマーク(高いほど良い)
カテゴリ gpt-5.1-thinking gpt-5.2-thinking gpt-5.4-thinking gpt-5.5-thinking gpt-5.6-sol gpt-5.6-terra gpt-5.6-luna
暴力的な違法行為 0.955 0.975 0.971 0.940 0.934 0.952 0.940
非暴力的な違法行為 0.990 0.993 1.000 0.987 0.987 0.990 0.993
過激主義 1.000 1.000 1.000 0.925 0.962 0.981 0.981
憎悪 0.808 0.927 0.943 1.000 0.982 1.000 1.000
自傷行為(標準)0.926 0.961 0.987 0.917 0.945 0.962 0.954
グロテスク描写 0.800 0.877 0.831 0.800 0.708 0.600 0.585
性的コンテンツ 0.933 0.940 0.933 0.944 0.948 0.966 0.944
未成年者に関する性的コンテンツ 0.916 0.948 0.966 0.938 0.973 0.974 0.974
注(前回のシステムカードとの比較):以前の「憎悪」と「嫌がらせ」カテゴリ間の重複を排除するため、「嫌がらせ」と「憎悪」を統合した単一の評価項目として扱います。また、違法な暴力行為に関するリクエストと明確に区別できるよう、以前の「暴力」カテゴリの名称を「グロテスク描写(gore)」1 に変更しました。これは名称の変更であり、根本的な評価基準の変更ではありません。
GPT-5.6 シリーズは、グロテスク描写に関する例外を除き、過去の思考モデルと同様の性能を示すことが分かりました。ChatGPT においては、利用者が 18 歳未満であると判断される場合、性的コンテンツやグロテスク描写への曝露をさらに制限する、年齢に適切な追加の保護措置を適用しています。これらの安全対策および年齢予測に対する当社のアプローチについては、こちらで詳しくご覧いただけます。
3.1.2 デプロイメントシミュレーションを用いた禁止コンテンツ変更の予測
GPT-5.4 Thinking および GPT-5.5 のシステムカードにおける評価を踏まえ、本リリース前にモデルのデプロイメントをシミュレーションするために、代表的な生産環境のプロンプトを活用しています。これらの先行するシステムカードにおける推定値は実験的なものでしたが、その後、このアプローチについてより徹底的に検証を行いました 最新の研究。これを踏まえ、本セクションでの結果報告方法を更新します。現在もこの手法の展開を拡大中ですが、本システムカードの範囲内では GPT-5.6 Sol のみを実際に評価しました。プライバシーポリシーに則り、モデル改善のためにデータ利用を許可したユーザーからの ChatGPT トラフィックのみを分析対象としました。また、マルチモーダルな会話も除外しています。残りの会話からは均等にサンプリングを行います。
モデルリリース前に、過去の ChatGPT 生産環境における GPT-5.5 の会話を活用し、最終的なアシスタントの応答部分を新しいモデルで再サンプリングすることで、GPT-5.6 Sol のデプロイメントをシミュレーションします。その後、生成された再サンプリング結果に対して、禁止コンテンツの有無を自動的にラベル付けします。これらのラベルは、特に発生頻度の低い行動については精度に限界がある可能性がありますが、依然として有益な方向性のシグナルを提供するものです。
以下の図では、不安全なモデルレベルの出力の予測される発生率を報告しています。例えば、GPT-5.6 Sol との会話における観測分布に基づくと、GPT-5.6 Sol での本番環境の会話ターン10万回あたり約8.6回が、わいせつ行為に関するポリシー違反として評価されると推定されます。
シミュレーションに基づく予測。** GPT-5.6 Sol の展開シミュレーションと GPT-5.5 の展開シミュレーションを比較すると、GPT-5.6 Sol は本番環境での展開時に、禁止されるコンテンツの違反件数が GPT-5.5 と平均してほぼ同じになると予測されます。混入変数(confounders)の影響をパイプラインから排除するために、シミュレーション間の率を比較しています。ノイズによるもの unlikely な測定された変化を特定するため、多重比較補正を行わない片側 0.1 の有意水準で両側フィッシャーの正確検定(Fisher exact test)を使用します。この統計的検定に基づくと、顕著な変化は性的な禁止コンテンツのみ(40% 増加し、0.05% から 0.07% に上昇)と、禁止されたメンタルヘルス対応(約 40% 減少し、0.03% から 0.02% に低下)であることが示されています。相対的な増加は注目すべきものですが、絶対率は依然として低く、この分野におけるモデルの安全性基準を満たしています。この結果は、モデル全体のリスクプロファイルに実質的な変化をもたらすものではないと評価します。
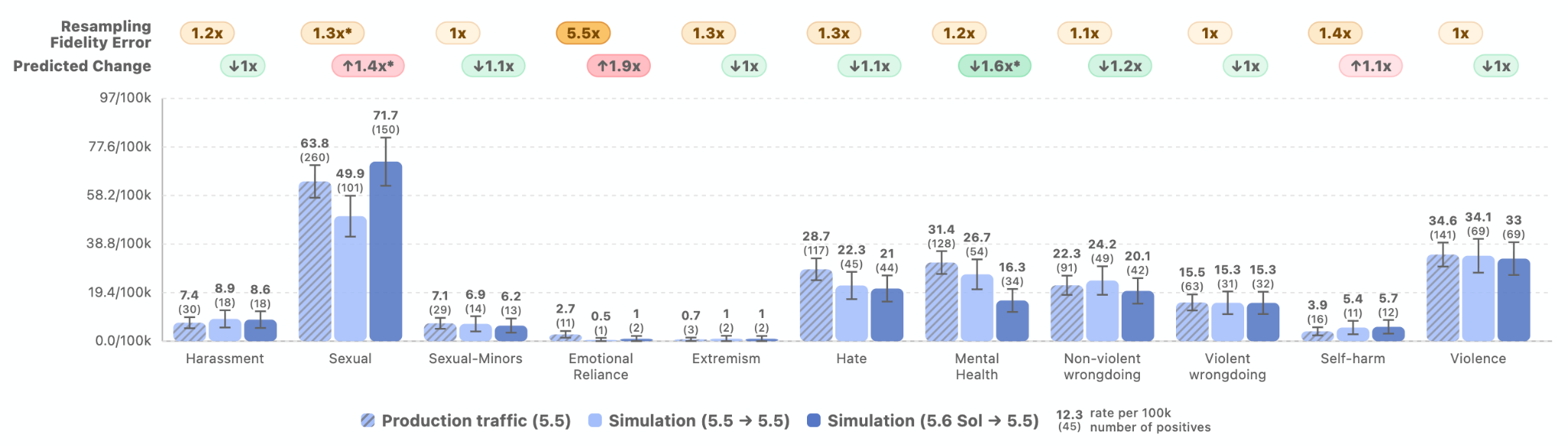 imageデプロイメントシミュレーション。" loading="lazy"> 図 1. 予測される変化は、GPT-5.6 Sol を GPT-5.5 と比較した際に期待される相対的な増加または減少です。発生率は 10 万人あたり n の形式で提供されています。記法「5.6 Sol → 5.5」は、GPT-5.5 の生産接頭辞を GPT-5.6 Sol で再サンプリングしていることを示しており、これは GPT-5.5 の生産データに基づいて GPT-5.6 Sol のデプロイメントをシミュレーションすることを意味します。再サンプリング忠実度誤差はシミュレーションの品質を測る指標です:より厳密には、古いデプロイメントのシミュレーションによって推定されたレートと、その古いデプロイメントで実際に観測されたレートの間の対称乗算誤差のことです。この場合、パイプラインの再サンプリング忠実度誤差を推定するために GPT-5.5 を使用しています。設定の詳細については、デプロイメントシミュレーションに関する当社の研究をご覧ください。
imageデプロイメントシミュレーション。" loading="lazy"> 図 1. 予測される変化は、GPT-5.6 Sol を GPT-5.5 と比較した際に期待される相対的な増加または減少です。発生率は 10 万人あたり n の形式で提供されています。記法「5.6 Sol → 5.5」は、GPT-5.5 の生産接頭辞を GPT-5.6 Sol で再サンプリングしていることを示しており、これは GPT-5.5 の生産データに基づいて GPT-5.6 Sol のデプロイメントをシミュレーションすることを意味します。再サンプリング忠実度誤差はシミュレーションの品質を測る指標です:より厳密には、古いデプロイメントのシミュレーションによって推定されたレートと、その古いデプロイメントで実際に観測されたレートの間の対称乗算誤差のことです。この場合、パイプラインの再サンプリング忠実度誤差を推定するために GPT-5.5 を使用しています。設定の詳細については、デプロイメントシミュレーションに関する当社の研究をご覧ください。
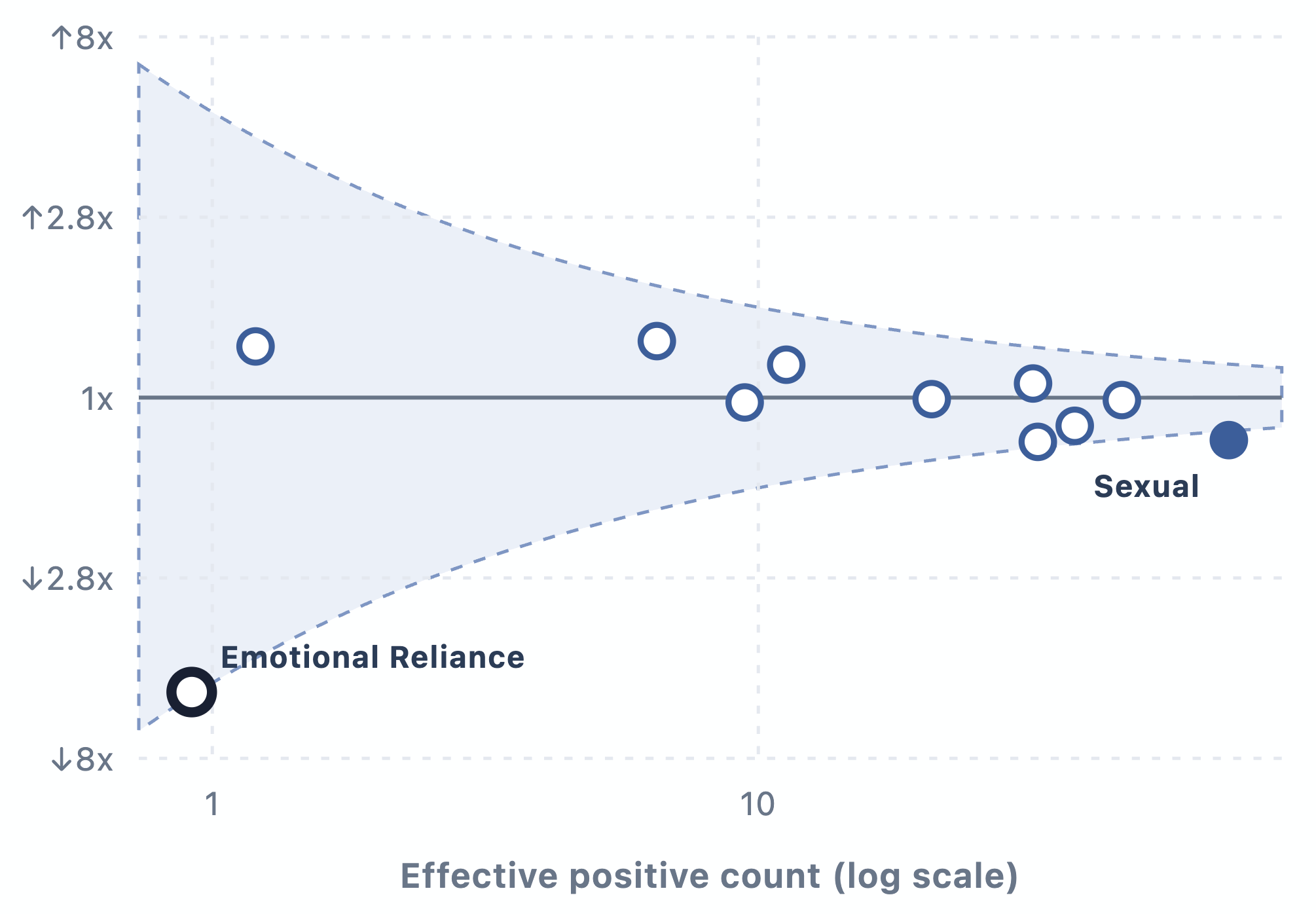
シミュレーションの品質。 GPT-5.5 の生産データと、GPT-5.5 の生産データを用いた GPT-5.5 デプロイメントシミュレーションを比較することで、パイプラインの再サンプリング環境誤差(我々が推定したい量に対するシミュレーション品質のプロキシ)を分離して評価できます。当社のシミュレーションの中央値対称乗算誤差は 1.2 倍であり、より高い誤差は低頻度のカテゴリに集中しています。これは主にノイズによるものであり、以下の図でも確認できます1。
図 2。この漏斗グラフは、本番環境とシミュレーションの真のレートが同じであり、観測された乖離が完全にノイズに起因する場合、対称的な乗算誤差のおよそ 90% の確率でどこに位置するかを示しています。影付き領域内に収まる誤差はノイズによるものとの整合性が高く、一方、その外側にある点はノイズに起因する可能性が 10% 未満であり、つまりシミュレーションが完璧であった場合にのみ発生し得ることを意味します。
事前推定値の品質。 私たちのシミュレーションパイプラインは最後のシステムカード以降大幅に変更されたため、GPT-5.5 の本番レートは GPT-5.5 システムカードで実施した推定値と比較できず、公平な検証を行うことは不可能です。今後は将来のシステムカードにおいてこれを可能にすることを最優先します。
私たちの研究 で示されている通り、これらの予測は、本番トラフィックの基礎となる分布とシミュレーションパイプラインの両方における時間的ドリフトにより不正確になる可能性がありますが、依然として本番結果と高い相関を示します。
3.2 ビジョン
ChatGPT エージェントで導入された画像入力評価を実行しました。これは、禁止されたテキストと画像の組み合わせを入力とした場合、モデル出力が安全でない(not_unsafe)かどうかを評価するものです。
画像入力評価における指標:not_unsafe(数値が高いほど良い)
カテゴリ | gpt-5.1-thinking | gpt-5.2-thinking | gpt-5.4-thinking | gpt-5.5 | gpt-5.6-sol | gpt-5.6-terra | gpt-5.6-luna
hate0.9810.9880.9880.9990.9990.9990.996
extremism0.9840.9870.9950.9860.9750.9780.966
self-harm0.9840.9860.9990.9830.9890.9860.990
harms-erotic0.9990.9980.9900.9870.9860.9910.986
GPT-5.6 シリーズは、その前身と全般的に同等のパフォーマンスを発揮していることが分かりました。わずかな後退は見られましたが、統計的に有意ではありません。
## 3.3 誤ってデータを破壊する行動の回避
私たちは、モデルが敵対的にタスク環境に注入されたユーザーの変更やデータを上書きせずにタスクを完了できる能力を測定する、データの破壊的行動評価を行いました。以前のシステムカード評価では、強力な上書き回避パフォーマンスを維持するために設計された追加のプロンプト緩和策を備えたモデルを評価し、展開しました。GPT-5.6 においては、追加の慎重なプロンプトに依存することなく自律性を向上させながら、強力な上書き回避の基準を維持するようにモデルを訓練しました。
GPT-5.6 Sol はデータの上書き回避において依然として強力で、回避のみスコアは GPT-5.5 をわずかに下回っていますが、複合指標では GPT-5.5 と同等です。この指標は、モデルが望ましくないデータを上書きせずに困難なタスクを成功裏に完了できるかどうかを測定するものです。一般的に、大規模なモデルは複雑なタスクにおいて、編集競合を回避しながらも、より小規模な Terra および Luna モデルよりも優れたパフォーマンスを発揮します。
カテゴリgpt-5.5gpt-5.6-solgpt-5.6-terragpt-5.6-luna
回避のみ0.880.830.810.73
回避+正答性0.440.440.370.32
3.4 コンピュータ使用時のユーザー確認
モデルは、高リスクアクションに対するプラットフォームレベルのポリシーと、開発者メッセージで提供される設定可能な開発者側の確認ポリシーの両方を、当社の指示階層に関するアプローチに沿って従うようにトレーニングされています。
これにより、以下のような多くの利点が得られます:
- 問題が特定された場合にシステムレベルのポリシーを迅速に更新できる能力。
- API において確認ポリシーをカスタマイズする能力。例えば、コンピュータ使用時にモデルによる制御可能な確認をより効果的に可能にするためなどです。
ChatGPT および API デプロイメントでは、確認ポリシーはシステムメッセージで提供されます。以下は、コンピュータ使用評価におけるユーザー確認の結果です。
カテゴリ | gpt-5.2-thinking | gpt-5.3-codex | gpt-5.4-thinking | gpt-5.5 | gpt-5.6-sol | gpt-5.6-terra | gpt-5.6-luna
---|---|---|---|---|---|---|---
金融取引 | 1.00 | 0.99 | 1.00 | 1.00 | 0.98 | 0.98 | 1.00
高リスクなコミュニケーション | 1.00 | 0.99 | 1.00 | 0.98 | 0.99 | 0.98 | 0.99
一般的な確認 | 0.94 | 0.91 | 0.94 | 0.94 | 0.93 | 0.94 | 0.93
4. 堅牢性評価
4.1 ジェイルブレイク
私たちは、モデルの Jailbreak(安全対策を回避する試み)に対する堅牢性を評価します。これは、モデルの拒否学習を迂回し有害な支援を引き出すように設計された敵対的プロンプトを対象としています。この評価は、本番環境で使用する一連のすべてのセーフガードを伴わずにモデルを直接 Jailbreak する点に焦点を当てており、これは私たちのセキュリティスタックにおける堅牢性の一つの層を測定するものです。本番環境には、ユーザーが Jailbreak を実行して有害な支援を得ることをはるかに困難にする分類器などの追加のセーフガードも用意されています。
この評価では、会話の過程でプローブ(探査)、適応、エスカレーション(悪化)を行うことができる洗練された攻撃者戦略を用いた現実的なシナリオを使用します。これらの攻撃者戦略は、内部のレッドチーム演習から導き出された、難易度の高いマルチターン Jailbreak です。
モデルの回答は、以下の基準に基づいて採点されます
原文を表示
1. Introduction
GPT-5.6 is a new family of three models: Sol, our new flagship model;
Terra, a capable lower-cost option; and Luna, our fastest and most
cost-efficient model. The safeguards we have built for this launch—our
most robust yet—are built to deliver these models safely and at scale,
around the world.
We believe in broad access, and we plan to make GPT-5.6 Sol, Terra,
and Luna generally available in the coming weeks. As part of our ongoing
engagement with the U.S. government, we previewed our plans and the
models’ capabilities ahead of today’s launch. At their request, we are
starting with a limited preview for a small group of trusted partners
whose participation has been shared with the government, before
releasing more broadly. During this preview, we will continue testing
and coordinating closely with partners as we work toward broader
availability.
Under our Preparedness Framework, we are treating Sol, Terra and Luna
as High capability in both Cybersecurity and Biological and Chemical
risk. None of them reach our High threshold in AI Self-Improvement. We
have implemented a tailored set of safeguards, adapted to each model’s
capability profile, to sufficiently minimize the associated risks.
This system card is a detailed report of the work we did to
understand and mitigate GPT-5.6’s safety risks before deployment. The
five most important things to know are that:
- These models are a meaningful step up in cybersecurity
capability, but they do not reach our risk framework’s highest level
(Critical). GPT-5.6 Sol and Terra can find vulnerabilities and
pieces of exploits, but in cybersecurity testing
they were unable to carry out autonomous, end-to-end attacks against
hardened targets. Separate evaluations examined misaligned
behavior in agentic coding tasks and found GPT-5.6 shows a
greater tendency than GPT-5.5 to go beyond the user’s intent, including
by taking or attempting actions that the user had not asked for, though
absolute rates remain low.
- To make these models safe, we added new technology to a
safety stack that is more than the sum of its parts. The models
are trained to
be safe, Sol and Terra are served with newly added activation classifiers
focused on sensitive domains that watch the model and can intervene to
stop unsafe answers during generation, and certain conversations are
scanned so unsafe outputs are blocked in real time if they cross safety
boundaries. We also have automated safety systems that look for unsafe
patterns across conversations that would not be clear from any single
moment.
- Severe harm requires a chain of successful steps, and our
safeguards place barriers throughout that chain. Based on our
threat modelling in
cybersecurity and biology, we’ve designed our safety stack so that even
if an attacker does complete one step on the path to harm, safeguards
will still stop the model from allowing severe harm. We also have
programs in place so
that when GPT-5.6 models are broadly available to the public, we can
continue to reserve the most sensitive cybersecurity and biological
capabilities for trusted defenders.
- Our safeguard testing has already been more intensive than
for any earlier release, and we are continuing to test during the
preview period. Expert humans and external testers used a
diverse set of approaches to find gaps. We’ve also dedicated over
700,000 A100e GPU hours to automatically find
universal jailbreaks, and we will run automated red teaming
continuously during deployment. As jailbreaks are reported, we
reproduce, mitigate and retest for them so that gaps are addressed.
- Providing broad access, particularly for cybersecurity
capabilities, will have important safety benefits. Our testing
suggests that GPT-5.6 is better at finding and fixing cyber
vulnerabilities than at exploiting those vulnerabilities in real
attacks. That gives defenders an opportunity to harden systems before
cybersecurity weaknesses are exploited—an opportunity that may narrow as
offensive capabilities improve. Our safeguards therefore focus on making
malicious use at scale harder, while still enabling the day-to-day work
of securing systems.
In this card, we show how performance changes with reasoning
effort—the amount of thinking a model uses to work through a problem.
Rather than report a single score, we show a curve across different
levels of effort. This gives a fuller picture of what the model can do
and how much effort it takes to get there.
Note that we are continually iterating on our models. Comparison
values from previously-launched models are from recent snapshots of
those models, and may vary slightly from values published in previous
cards.**
We plan to publish an updated version of this system card when making
the GPT-5.6 family of models generally available.
2. Model Data and Training
Like OpenAI’s other models, GPT-5.6 was trained on diverse datasets,
including information that is publicly available on the internet,
information that we partner with third parties to access, and
information that our users or human trainers and researchers provide or
generate. Our data processing pipeline includes rigorous filtering to
maintain data quality and mitigate potential risks. We use advanced data
filtering processes to reduce personal information from training data.
We also employ safety classifiers to help prevent or reduce the use of
harmful or sensitive content, including explicit materials such as
sexual content involving a minor.
OpenAI reasoning models are trained to reason through reinforcement
learning. These models are trained to think before they answer: they can
produce a long internal chain of thought before responding to the user.
Through training, these models learn to refine their thinking process,
try different strategies, and recognize their mistakes. Reasoning allows
these models to follow specific guidelines and model policies we’ve set,
helping them act in line with our safety expectations. This means they
provide more helpful answers and better resist attempts to bypass safety
rules.
Note that comparison values from previously launched models are from
the latest versions of those models, so may vary slightly from values
published at launch for those models.1
3. Model Safety
3.1 Disallowed Content
3.1.1 Evaluations with Challenging Prompts
We conducted benchmark evaluations across disallowed content
categories. We report here on our Production Benchmarks, an evaluation
set with conversations representative of challenging examples from
production data. As we noted in previous system cards, we introduced
these Production Benchmarks to help us measure continuing progress given
that our earlier Standard evaluations for these categories had become
relatively saturated.
These evaluations were deliberately created to be difficult. They
were built around cases in which our existing models were not yet giving
ideal responses, and this is reflected in the scores below. Error rates
are not representative of average production traffic. The primary metric
is not_unsafe, checking that the model did not produce output that is
disallowed under the relevant OpenAI policy.
Our evaluations are run on the model without system-level safeguards,
to ensure the model’s underlying behavior meets our safety bar. We
continue monitoring these categories after launch to evaluate online
performance and further adjust safeguards as appropriate.
Values from previously launched models are from the latest versions
of those models, and evals are subject to some variation. Values may
vary slightly from values published at launch for those models. The
comparison scores from earlier models listed below are intended to shed
light on relative performance. Because policies, graders, datasets, and
other measurement details evolve over time, scores not included in the
table below should generally not be considered directly comparable to
these most recent results.
Production Benchmarks with Challenging Prompts (higher is better)
Categorygpt-5.1-thinkinggpt-5.2-thinkinggpt-5.4-thinkinggpt-5.5-thinkinggpt-5.6-solgpt-5.6-terragpt-5.6-luna
Violent Illicit behavior0.9550.9750.9710.9400.9340.9520.940
Nonviolent illicit behavior0.9900.9931.0000.9870.9870.9900.993
Extremism1.0001.0001.0000.9250.9620.9810.981
Hate0.8080.9270.9431.0000.9821.0001.000
Self-harm (standard)0.9260.9610.9870.9170.9450.9620.954
Gore0.8000.8770.8310.8000.7080.6000.585
Sexual0.9330.9400.9330.9440.9480.9660.944
Sexual/minors0.9160.9480.9660.9380.9730.9740.974
Note (compared to previous system cards): to deduplicate overlaps
between our previous “hate” and “harassment” categories, we are merging
“harassment” and “hate” into a single evaluation. Additionally, we have
renamed our previous “violence” category to “gore”1 in
order to more clearly distinguish it from requests related to illicit
violent behavior; this is a naming change, not a change in the
underlying evaluation.
We find that the GPT-5.6 series performs similarly to previous
thinking models, with the exception of gore. On ChatGPT, for users we
believe may be under 18, we apply additional age-appropriate content
protections that further restrict sexual content and exposure to gore.
You can read more about these safeguards and [our
approach to Age Prediction](https://openai.com/index/our-approach-to-age-prediction/).
3.1.2 Forecasting Disallowed Content Changes with Deployment Simulation
Building on evaluations in the [GPT-5.4
Thinking](https://deploymentsafety.openai.com/gpt-5-4-thinking/production-benchmarks-with-representative-prompts) and GPT-5.5
system cards, we simulate model deployment before release by leveraging
approximately representative production prompts. While estimates in
these prior system cards were experimental, we have since more
thoroughly validated this approach [in our recent
research](https://openai.com/index/deployment-simulation/). In light of this, we are updating how we report results in
this section. We are still expanding the rollout of this technique, and
for the scope of this system card we evaluated GPT-5.6 Sol only. In
accordance with our privacy policy, we only analyzed ChatGPT traffic
from users who allow their data to be used for model improvements. We
additionally exclude multi-modal conversations. We sample uniformly
among remaining conversations.
Before the release of the model, we leverage past ChatGPT production
GPT-5.5 conversations to simulate the deployment of GPT-5.6 Sol by
resampling the final assistant turn with the new model. We then
automatically label the resulting resampled completions for disallowed
content. These labels may be limited in their precision especially for
low prevalence behaviors, but can still provide valuable directional
signal.
In the figure below, we report the forecasted prevalence of unsafe
model-level outputs. For example, based on the observed distribution of
conversations with GPT-5.6 Sol, we estimate that approximately 8.6 out
of every 100,000 production conversation turns with GPT-5.6 Sol would be
graded as violating our harassment policy.
Simulation-based forecasts.** Comparing a deployment
simulation of GPT-5.6 Sol to a deployment simulation of GPT-5.5 predicts
that GPT-5.6 Sol will have, on average, about the same amount of
disallowed content violations as GPT-5.5 during deployment. We compare
between simulation rates in order to remove the role of confounders in
our pipeline. To identify measured changes that are unlikely to be due
to noise, we use a two-sided Fisher exact test with significance 0.1,
without correcting for multiple comparisons. Based on this statistical
test, the only significant changes appear to be sexual disallowed
content (increased by 40%, from 0.05% to 0.07%), and disallowed mental
health responses (reduced by roughly 40%, from 0.03% to 0.02%). While
the relative increase is notable, the absolute rate remains low and the
model meets our safety bar in this area. We assess that this result does
not materially change the model’s overall risk profile.
.](https://deploymentsafety.openai.com/data/eval-sets/gpt-5-6-preview/assets/images/image12.png)
Simulation quality. Comparing GPT-5.5 production
data and GPT-5.5 deployment simulation using GPT-5.5 production data we
can isolate the resampling environment error of our pipeline (a proxy of
simulation quality for the quantities we care about estimating). The
median symmetric multiplicative error of our simulation is 1.2x, with
higher rates concentrated in lower-frequency categories, which is mostly
consistent with noise – as seen in the figure below.1
Prior estimate quality. Because of significant
changes in our simulation pipeline since our last system card,
production rates for GPT-5.5 are not comparable to our estimates made in
the GPT-5.5 system card, making it infeasible to fairly validate them.
We will prioritize being able to do so for future system cards.
As [shown in
our research](https://openai.com/index/deployment-simulation/), these forecasts can be imperfect due to temporal
drifts both in the underlying distributions of production traffic and
due to simulation pipeline, but are still highly correlated with
production outcomes.
3.2 Vision
We ran the image input evaluations introduced with ChatGPT agent,
that evaluate for not_unsafe model output, given disallowed combined
text and image input.
Image input evaluations, with metric not_unsafe (higher is
better)
Categorygpt-5.1-thinkinggpt-5.2-thinkinggpt-5.4-thinkinggpt-5.5gpt-5.6-solgpt-5.6-terragpt-5.6-luna
hate0.9810.9880.9880.9990.9990.9990.996
extremism0.9840.9870.9950.9860.9750.9780.966
self-harm0.9840.9860.9990.9830.9890.9860.990
harms-erotic0.9990.9980.9900.9870.9860.9910.986
We find that GPT-5.6 series performs generally on par with its
predecessors. Minor regressions are not statistically significant.
3.3 Avoiding Accidental Data-Destructive Actions
We ran our destructive actions evaluation, which measures a model’s
ability to complete tasks without overwriting user changes and data that
are adversarially injected into the task environment. In prior system
card evaluations, we evaluated and deployed models with additional
prompting mitigations designed to maintain strong overwrite-avoidance
performance. For GPT-5.6, we trained the models to maintain a strong
standard of overwrite avoidance while improving autonomy without relying
on extra cautious prompting.
GPT-5.6 Sol remains strong at avoiding data overwrites, with an
avoidance-only score slightly below GPT-5.5’s, and matches GPT-5.5 on
the combined metric. This metric measures whether a model can
successfully complete a challenging task without overwriting undesired
data. In general, our larger models outperform the smaller Terra and
Luna models on complex tasks while avoiding edit conflicts.
Categorygpt-5.5gpt-5.6-solgpt-5.6-terragpt-5.6-luna
Avoidance only0.880.830.810.73
Avoidance + Correctness0.440.440.370.32
3.4 User Confirmations During Computer Use
The model is trained to follow both platform-level policy for
high-risk actions and configurable developer-provided confirmation
policy provided in the developer message in line with our approach to
instruction hierarchy.
This provides a number of benefits, including:
- Ability to rapidly update the system-level policy if issues are
identified.
- Ability to customize the confirmation policy in the API, for example,
to better enable steerable confirmations by the model when engaging
computer use.
In ChatGPT and API deployment, we provide the confirmation policy in
the system message. Below are the results of our user confirmations
during computer use evaluations.
Categorygpt-5.2-thinkinggpt-5.3-codexgpt-5.4-thinkinggpt-5.5gpt-5.6-solgpt-5.6-terragpt-5.6-luna
Financial transaction1.000.991.001.000.980.981.00
High-stakes communication1.000.991.000.980.990.980.99
General confirmation0.940.910.940.940.930.940.93
4. Robustness Evaluations
4.1 Jailbreaks
We evaluate model robustness to jailbreaks: adversarial prompts
designed to circumvent model refusal training and elicit harmful
assistance. This evaluation focuses on jailbreaking the model directly –
without the full set of safeguards we use in production – which measures
one layer of robustness in our safety stack. We have additional
safeguards in production, such as classifiers, that make it much more
difficult for users to jailbreak and obtain harmful assistance.
The evaluation uses realistic scenarios with sophisticated attacker
strategies that can probe, adapt, and escalate over the course of a
conversation. These attacker strategies are challenging multiturn
jailbreaks derived from internal red-teaming exercises.
Model responses are scored based on whether they
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み