LangGraph と LangSmith を活用した Lyft のセルフサービス AI エージェントプラットフォーム構築事例
Lyft は LangGraph と LangSmith を活用したセルフサービス AI エージェントプラットフォームを構築し、非技術系のドメインエキスパートが直接エージェントを開発・運用できる体制を整え、開発期間を約 6 ヶ月から数週間に短縮しました。
キーポイント
セルフサービスの開発モデルへの転換
機械学習エンジニア(MLE)に依存する従来の開発フローから脱却し、オペレーションチームや製品マネージャーがプロンプトと設定を通じて直接エージェントを定義できる仕組みを導入しました。
LangGraph による複雑なワークフローの管理
ライダーとドライバーの多様な問い合わせに対応するため、Router ベースのマルチエージェントアーキテクチャを採用し、安全チェックや状態管理を組み込んだ高度なルーティングを実現しています。
品質保証のための評価・監視体制
LangSmith を活用したトレーシングとダッシュボードに加え、「LLM-as-a-judge」による自動評価システムを導入し、構造化されたプロンプト記述の重要性を強調しています。
影響分析・編集コメントを表示
影響分析
この事例は、大規模 AI エージェントの開発を専門エンジニアに限定する従来のパラダイムから、ドメイン知識を持つ現場の担当者が直接関与できる民主化された開発モデルへの転換を示す重要なマイルストーンです。特に LangGraph を用いた複雑な状態管理とルーティングの実装例は、実社会での大規模 AI 導入における信頼性と拡張性を担保する具体的な指針となり、業界全体の開発スピードと品質向上に寄与すると考えられます。
編集コメント
専門エンジニアの負担を減らしつつ、ドメイン知識を活かして AI エージェントの開発スピードを劇的に向上させた実証事例として非常に参考になります。特に「LLM-as-a-judge」による評価プロセスと、非技術者への権限委譲のバランス感覚は、今後の企業内 AI 導入の標準モデルとなり得る内容です。

主なポイント
- Lyft は、顧客の問題を最もよく理解している人々の近くでエージェント開発を行いました。オペレーションチーム、VoC(Voice of Customer)責任者、プロダクトマネージャーがプロンプトと設定を通じてエージェントを定義できるようにしたことで、MLE(機械学習エンジニア)がすべての反復処理を管理する必要を減らすことができました。
- ルーター型マルチエージェントアーキテクチャは、複雑な顧客ワークフローのサポートに役立ちました。Lyft は LangGraph を使用して、ライダーとドライバーのリクエストを専門的なサブエージェント間でルーティングし、安全性チェック、状態管理、ハンドオフをフロー内に組み込んでいます。
- 本番環境での品質は、評価、モニタリング、プロンプトの規律に依存します。Lyft は LangSmith をトレーシング、ダッシュボード、LLM-as-a-judge(LLM を裁判官として用いた評価)に使用していますが、チームが发现したのは、構造化されたプロンプト記述がエージェントの信頼性における最大の要因の一つになったことです。
*これは、SCX データサイエンスおよび MLE チームが非技術的なドメインエキスパートでも AI エージェントをリリースできるマルチエージェント顧客サポートシステムを構築した Lyft の友人たちからのゲスト投稿です。機械学習エンジニアの Akshay Sharma がリーダーを務めました。ご協力ありがとうございます。*
TL;DR
LangGraph を活用して洗練されたマルチエージェントシステムをオーケストレーションすることで、Lyft は顧客サポート業務を変革し、ライダーとドライバー向けの数百万回のインタラクションを管理しています。私たちの「セルフサービス」プラットフォームは、LangGraph のサブグラフアーキテクチャと LangSmith の堅牢なトレーシングおよびモニタリングツールを統合しており、非技術的なドメインエキスパートが AI エージェントを独自に開発・改善できる環境を提供します。この転換により、LLM-as-a-judge(LLM を判事として用いた)評価システムによる自動化された高基準の維持を保ちながら、*エージェントの開発期間を約 6 ヶ月から数週間へと劇的に短縮*しました。
Lyft の目標:エージェントの反復を迅速に、かつ安全に
アカウントアクセス、損害請求、課金レビュー、収益に関する紛争など、多数のカテゴリーにおいて、Lyft の AI Assist はライダーとドライバー向けの顧客サポートを管理しています。私たちの取り組みは 2023 年に始まりましたが、当初のプロセスは労働集約的でした。各 AI エージェントの開発には、機械学習エンジニア(MLE)およびエンジニアリングチームから数ヶ月にわたる専念した作業が必要でした。私たちはライダーとドライバー向けのエージェントを順次リリースし効率化に成功しましたが、全体としてのペースは依然として大きなボトルネックとなっていました。
2026 年までに、既存の運用モデルは、新たなユーザーセグメント、追加の問題タイプ、自律型車両への対応などによって引き起こされた持続不可能な需要増に直面していました。開発サイクルは、ドメインエキスパートがワークフローの動作を定義し、それを MLE(機械学習エンジニア)がツール設定とプロンプトに変換するという、遅く反復的なループに依存していました。この往復のレビュープロセスでは、トレースを確認し、問題を指摘し、コードを調整するために、エージェントごとに数週間の協働が必要でした。その結果、顧客の問題について最も深い理解を持つ人々が、技術的な仲介者なしで解決策を実装することができませんでした。
これにより、私たちは決定的な問いに直面しました:運用チーム、VoC(Voice of Customer)責任者、プロダクトマネージャーが、自然言語を用いてエージェントを直接構築・改善できるでしょうか?私たちの目標は、学習とデプロイメントの加速のために、日常の反復プロセスから技術的な仲介者を排除することでした。重要なのは、このセルフサービスへの移行が、経験、精度、安全性に関する厳格な基準を損なってはならないということです。すべてのエージェントは、手動で設計されたシステムと同様の品質を満たす必要がありました。
アーキテクチャ:LangGraph に基づくマルチエージェントシステム
The Router Multi-Agent Pattern
Our system follows LangGraph'srouter multi-agent architecture. A meta agent acts as a stateful router: it classifies the incoming request and uses Command(goto=...) to dispatch to the appropriate specialized subagent. Each subagent is a full LangGraph StateGraph, registered as a subgraph node in the meta agent.
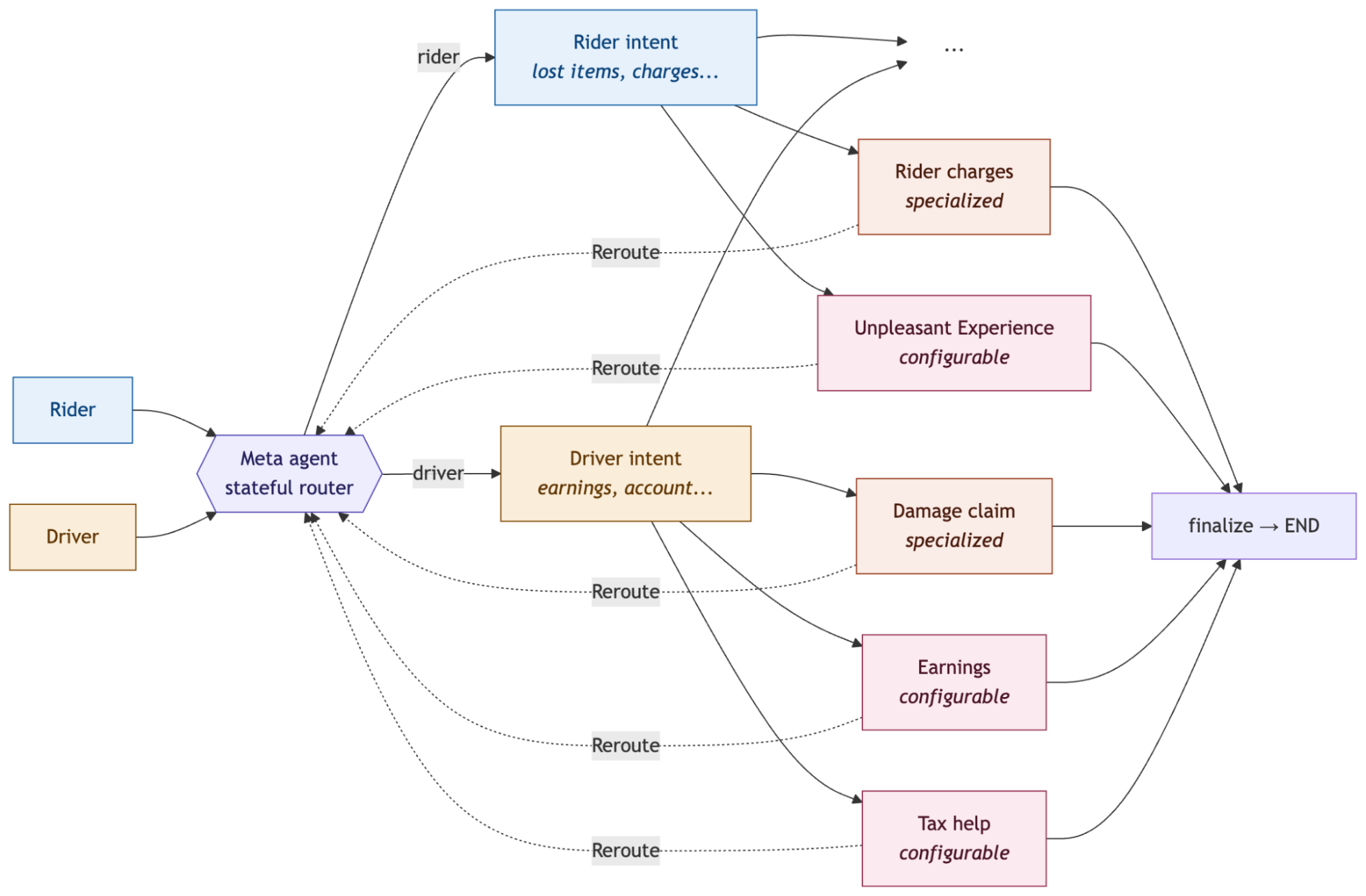
We run separate router instances for riders and drivers. When a rider contacts support, the meta agent routes to the rider_intent subagent, which classifies across rider-specific intents (e.g. lost items, charge disputes, trip issues). For drivers, it routes to the driver_intent subagent, which handles driver-specific intents (e.g. earnings, account access, damage claims). If the intent agent determines during a conversation that the user needs a more specialized agent, it uses Command(goto=..., graph=Command.PARENT) to hand control back to the meta agent, which re-routes to the appropriate specialist, for example, jumping from the driver intent agent to the damage claim agent mid-conversation.
Each subagent, regardless of specialization, follows a consistent node pattern:

これにより、2 つの重要な特性が得られます。第一に、安全性はあらゆる局面で並列的に実行されます。悪意ある意図の検出と安全性の問題検出は、LLM の推論が行われる前に、LangGraph の Command(goto=[...]) ファンアウト機能を通じて同時に実行されます。第二に、サブエージェントはモジュール化されており、個別にデプロイ可能です。新しいエージェントを追加する場合は、新しいサブグラフを定義し、メタエージェントに登録するだけです。
専門型エージェントと設定可能型エージェント
私たちはエージェントを2 つのカテゴリに分類しています:
専門型エージェント (Specialized agents) は、複雑でリスクの高いワークフローのために MLE によって手動で構築されます。例えば、当社の損害請求処理エージェントは、画像処理、不正検出、多段階分類、および低コードアプローチでは対応が難しい自動化呼び出しの支援を行います。
設定可能型エージェント (Configurable agents) はセルフサービス層です。これらは、内部構成サービスに保存された JSON 構成ファイルからランタイム時に初期化され、プロンプトは LangSmith の Prompt Hub から取得されます。ドメインエキスパートが構造化テンプレート(役割、範囲、ワークフローフェーズ、コンテンツガイドライン)に従ってプロンプトを作成し、ConfigurableAgent クラスが残りの処理を担当します:グラフの構築、ツールのバインディング、安全性ゲート、および状態管理です。

設定可能なエージェントは起動時に動的に読み込まれます
for configurable_agent in load_configurable_agents():
self.configurable_subagents[configurable_agent.config.intent] = configurable_agent
それぞれがメタエージェントのサブグラフとして登録されます
for configurable_subagent in self.configurable_subagents.values():
graph_builder.add_node(
configurable_subagent.config.intent,
configurable_subagent.get_state_graph()
)
graph_builder.add_edge(configurable_subagent.config.intent, "finalize")
これは、プロダクトマネージャーがドライバーの税金に関する質問用などの新しいエージェントを定義する際、プロンプトと JSON 設定(config)を書くだけで済むことを意味します。機械学習エンジニア(MLE)によるコード変更は不要です。プラットフォーム側でグラフ構築、ツール実行、チェックポイント保存、トレーシング、および安全性の確保が自動的に処理されます。
DynamoDB を用いた状態永続化
多ターン会話には耐久性のある状態管理が必要です。私たちは LangGraph の BaseCheckpointSaver インターフェースを実装したカスタム DynamoDBSaver(DynamoDB セーバー)を構築し、メモリー内の仮定に依存することなく、ターンを超えた永続的な会話状態を実現しました。各チェックポイントには、グラフの状態全体、実行メタデータ、および親チェックポイントへの参照が保存されており、本番環境での会話の再生、デバッグ、および状態の検査が可能になります。
LangSmith: トレースから本番モニタリングへ
すべてのエージェントのターンを追跡する
すべての環境(開発、ステージング、本番)におけるすべてのエージェント呼び出しは、LANGSMITH_TRACING=true を設定することで LangSmith へ追跡されます。各トレースには、実行されたノード、LLM が目にした内容、呼び出されたツール、トークン使用量、および各ステップのレイテンシなど、グラフの実行全体が記録されます。
フィルタリング用のランタイムメタデータを作成するユーティリティを使用して、トレースにカスタムメタデータ(ユーザータイプ、エージェント名、意図、会話 ID)を追加します:
メタデータは LangSmith へ流れ込み、フィルタリングとデバッグに利用されます
tags = build_langsmith_metadata(
agent_name=self.name,
user_type=context.user_type,
interaction_id=context.interaction_id
)
これは非常に役立っています。ドライバーが混乱する応答を報告した場合、正確なトレースを引き出して各ノードの入力/出力を確認し、問題が意図分類、ツール実行、あるいは最終的な LLM 応答のいずれにあるかを特定し、数時間以内に修正できます。
LLM-as-a-Judge 評価パイプライン
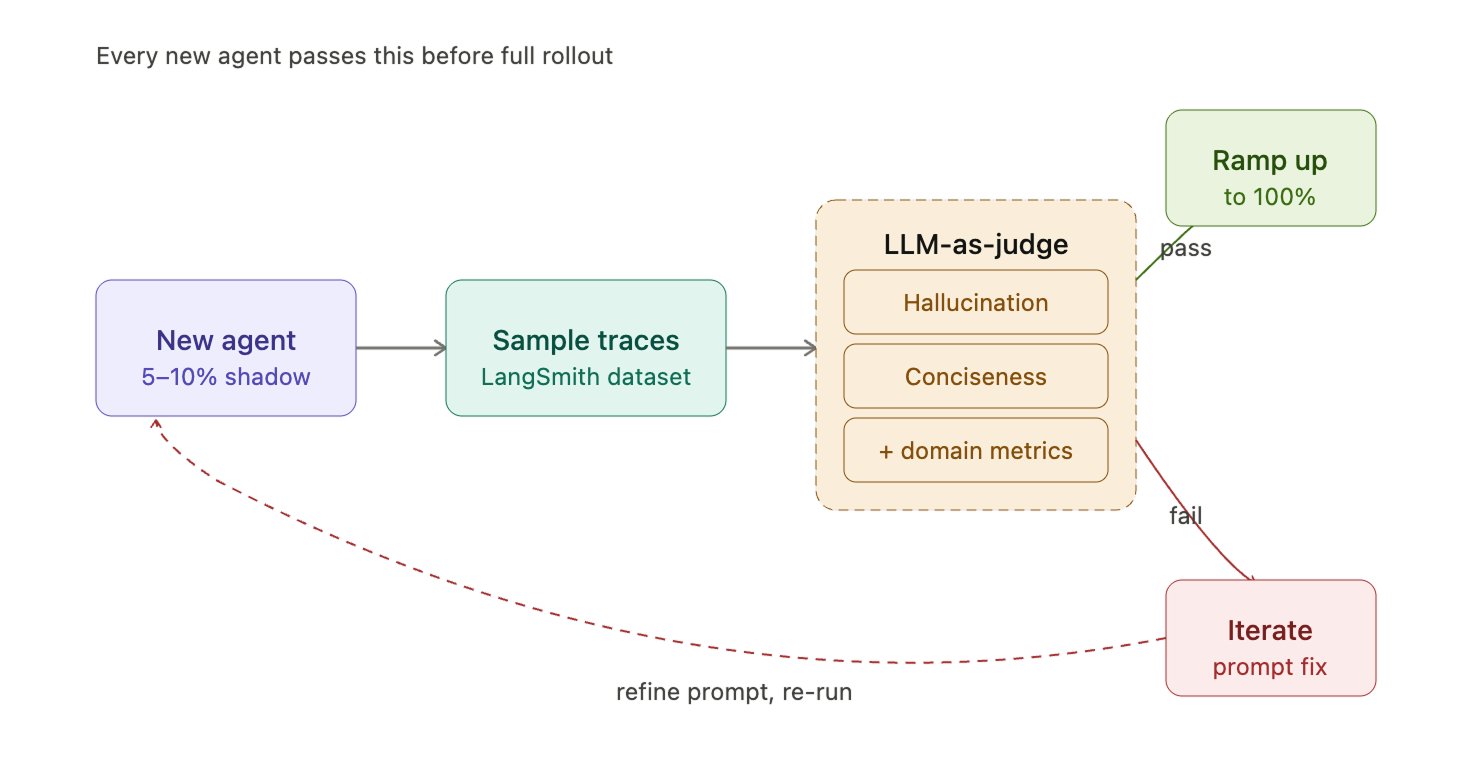
エージェントをトラフィックの 100% に展開する前に、必ず評価パイプラインを通過する必要があります。そのプロセスは以下の通りです:
- 小規模な本番展開(5–10%)— エージェントが低ボリュームで実際のトラフィックを担当します。
- 本番トレースのサンプリング — 実際の会話を評価データセットとしてキャプチャします。
- LLM-as-a-Judge 評価器の実行 — LangSmith の Prompt Hub から共有されるジャッジプロンプトテンプレートを使用し、エージェント固有のメトリクスを拡張して適用します。
私たちのベースライン評価指標(すべてのエージェントに適用):

その後、各専門エージェントに対してドメイン固有の指標を追加します。例えば、コア収益エージェントは、そのエージェントが関連するポリシーに従ったか逸脱したか、あるいは非論理的または一貫性のない推論を用いたかどうかを確認します。
評価者は、LangSmith のマルチターン評価器(multi-turn evaluator)を使用して本番環境のトレース上で自動的に実行されます。スレッドフィルター(例:ラン名が ride_earnings)とサンプリングレートで構成されており、初期展開時は高い値から始まり、信頼性が高まるにつれて徐々に低下します。
本番監視ダッシュボード
本番環境にあるすべてのエージェントには、以下の項目を追跡するクローンされた LangSmith の監視ダッシュボードが用意されています:
- ランボリュームとエラーレート — 予期しないスパイクや障害が発生していないか?
- p50/p95 レイテンシ — エージェントはリアルタイムサポートに必要な速度で応答しているか?
- トークン使用量 — コストは予算内に収まっているか?
- ツール呼び出し成功率 — 外部 API 統合は健全に動作しているか?
- LLM-as-a-Judge(LLM を裁判官として用いた評価)スコアの推移 — 品質は向上傾向にあるか、低下傾向にあるか?
また、LangSmith の指標に基づいて PagerDuty アラートを設定しています。エラーレートが 5% を超えるか、15 分ウィンドウ内で p95 レイテンシが 10 秒を超えた場合、オンコールのエンジニアに自動的にアラートが送信されます。

ツール別のエラー率の例チャート(本番環境の監視ダッシュボードの一部)
本番環境で実行される、カスタム(エージェント固有)メトリクスを用いた LLM Judge 評価。ヒント:不正確でアクションに結びつきにくいスコアではなく、バイナリ出力(True/False または Pass/Fail)を使用してください。
厳しい教訓:ボトルネックはインフラストラクチャではなくプロンプトの質
非技術系のチームメンバーに対してエージェント構築を開放した当初、最も困難な部分はプラットフォーム自体がツールバインディングを正しく実装することや、グラフ内のエッジケースを処理し、状態管理を行うことだと考えていました。しかし、それは誤りでした。
最も困難だったのはプロンプトの質です。ドメインエキスパートは自らの扱う問題タイプについて深く理解していましたが、その知識を LLM が確実に従う指示へと翻訳する方法を常に知っているわけではありませんでした。私たちは、ハッピーパス(通常の成功ケース)では見事に機能する一方で、エッジケースでは崩壊してしまうエージェントを目撃しました。あるプロンプトでは、運転手が運賃に異議を唱えた場合にエージェントが取るべき行動は定義されていても、会話の途中で運転手が話題を変えた場合の対応については何も記述されていないことがありました。あるいは、トーンセクションで「共感的であれ」と指示していても、それが具体的に何を意味するのかを規定していないため、LLM が毎回異なる解釈をしてしまうこともありました。
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
失敗のモードは驚くほど一貫していました:スコープ外の定義の欠如(そのためエージェントはツールを持たない質問に答えようとし)、曖昧な分岐ロジック(明確なエントリまたは終了条件のないフェーズ)、そして紙面上では良く聞こえるが、大規模言語モデル(LLM)に過度な即興の余地を与えていた漠然としたコンテンツガイドラインです。
私たちはこの課題に二つの側面から取り組みました。
第一に、構造化されたプロンプト記述フレームワークです。 五つの必須コンポーネントを持つテンプレートを作成しました:アイデンティティ(このエージェントは誰か、どのようなユーザータイプか、どのトピック領域を扱うか)、主要な目的(曖昧な「支援」や「処理」ではなく具体的な動詞)、スコープ(対象範囲と非対象範囲の両方、および明確なルーティングアクション)、フェーズ別ワークフロー(エントリ条件付きの番号付きステップ、すべての if/else に対する分岐、各フェーズごとの終端アクション)、そしてコンテンツガイドライン(抽象的な原則ではなく、具体的な「行うべきこと」「行わないべきこと」ルールと例文)。これに、アクティベーション前に必ず通過させる必要があるレビューチェックリストを組み合わせました。例えば、「すべてのフェーズに終了条件はあるか?」「ツールが利用できない場合の指示はあるか?」といった項目です。

必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等)は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
第二に、プロンプトの自動検証です。 私たちは、Git を基盤としたプロンプトリンティングパイプラインを構築しており、これはあらゆるプロンプトが本番環境に到達する前に実行されます。ドメインエキスパートがビルダー UI でプロンプトの記述を終えると、設定リポジトリに対してプルリクエストが開かれます。その後、CI パイプラインが 2 つの層のチェックを実行します。まず、構文エラーのあるテンプレート変数、重複した意図スラッグ、スペルミスなどを検出する高速な静的ルールです。次に、プロンプトインジェクション脆弱性、矛盾する指示、会話フローに出口がない構造的な行き止まりを検出する LLM 駆動のルールが続きます。すべての違反はマージをブロックします。著者には UI 内でインラインフィードバックが表示され、機械学習エンジニア (MLE) を巻き込むことなく自身で問題を修正できます。

これらすべての背後にある重要な洞察は、プロンプトをコードのコメントではなく、製品仕様として扱うことです。プロンプトがより明示的であればあるほど、エージェントの一貫性は高まります。そして、品質上の問題を、実際の顧客が一度も出力を見る前に、できるだけ早く検出すればするほど、システム全体の改善スピードは速くなります。
結果
セルフサービス型エージェントプラットフォームの立ち上げ以降:
- エージェント開発期間:最初のドライバーエージェントでは約 6 か月かかっていましたが、新しい構成可能なエージェントでは約 2 週間に短縮されました。
- エージェントのカバレッジ:生産環境で複数の課題タイプをカバーする構成可能なエージェントが増加しており、いくつかの専門化されたエージェントも稼働しています。
- 評価カバレッジ:生産環境にあるすべてのエージェントに対して、ライブトレース上で実行される「LLM-as-a-Judge(LLM を裁判官として活用する)」パイプラインが自動化されています。
- 品質:LangSmith の評価指標に基づいて設定した幻覚防止ガードレールにより、幻覚や矛盾の発生率が 20% 減少しました。
- 運用効率:エンジニアリングチーム以外の多くのメンバーが、現在、エージェントを独自に構築・反復できるようになりました。
- AI 解決率:セルフサービスプラットフォームを使用していくつかのエージェントをリリースして以来、16% 向上しています。
次のステップ
このプラットフォームをさらに推進するために、私たちは以下の領域を検討しています:
- プロンプトリンティングパイプラインの完成 — 上記で説明した Git ベースの CI 検証は現在開発中です。完全に展開され次第、すべての設定可能なエージェントプロンプトは、本番環境に到達する前に自動的な静的解析と LLM(大規模言語モデル)によるチェックを通過し、一般的なエラーについては MLE(機械学習エンジニア)の手動レビューが不要になります。
- モックおよびシミュレーションインフラ — エージェントビルダーが本番トラフィックにデプロイする前に、合成された会話やモックされたツールレスポンスに対してテストできるシミュレーションレイヤーを構築し、新しいエージェントのフィードバックループを劇的に短縮します。
- ペアワイズ評価 — LangSmith のペアワイズ注釈キュー(Pairwise Annotation Queues)を活用して、リリース前に人間によるレビューとプロンプト改訂の A/B テストを実施します。
- 対象地域およびユーザータイプの拡大 — プラットフォームをヨーロッパの Freenow カスタマーや、自動運転車サポートシナリオにも展開していきます。
- より深い評価の自動化 — サンプリングベースの評価から、すべての本番トレースに対する継続的なスコアリングへ移行し、プロンプトの劣化に関する自動アラートを設定します。
関連コンテンツ

LangChain
Open Source(オープンソース)
LangGraph
トークンストリームからエージェントストリームへ


C. Bromann,
N. Hollon
2026 年 5 月 21 日
9 分

LangSmith
LangSmith エージェントサンドボックスのネットワークアクセスを Auth Proxy がどのように保護するか

Mukil Loganathan
2026 年 5 月 21 日
9 分

企業アナウンスメント
LangSmith
Interrupt でリリースしたすべての新機能

Jacob Talbot
2026 年 5 月 14 日
11 分

エージェントが実際に何をしているかを確認する
LangSmith は、エージェントエンジニアリングプラットフォームとして、開発者がすべてのエージェントの意思決定をデバッグし、評価の変更を行い、ワンクリックでデプロイできるように支援します。
原文を表示
Key Takeaways
- Lyft moved agent development closer to the people who understand customer issues best. By letting ops teams, VoC leads, and product managers define agents through prompts and configuration, Lyft reduced the need for MLEs to manage every iteration.
- A router-based multi-agent architecture helped support complex customer workflows. Lyft uses LangGraph to route rider and driver requests across specialized subagents, with safety checks, state management, and handoffs built into the flow.
- Production quality depends on evaluation, monitoring, and prompt discipline. Lyft uses LangSmith for tracing, dashboards, and LLM-as-a-judge evaluation, but the team found that structured prompt writing became one of the biggest factors in agent reliability.
*This is a guest post from our friends at Lyft, where the SCX Data Science and MLE team built a multi-agent customer support system that enables non-technical domain experts to ship AI agents. Led by Akshay Sharma, Machine Learning Engineer. Thank you for your contribution.*
TL;DR
By leveraging LangGraph to orchestrate a sophisticated multi-agent system, Lyft has transformed its customer support operations, managing millions of interactions for riders and drivers. Our "self-serve" platform integrates LangGraph’s subgraph architecture with LangSmith’s robust tracing and monitoring tools, empowering non-technical domain experts to develop and refine AI agents independently. This shift has *accelerated agent development from roughly six months to just a few weeks*, all while upholding high standards through an automated LLM-as-a-judge evaluation system.
Lyft’s Goal: Speeding Up Agent Iteration, Safely
Across numerous categories including account access, damage claims, charge reviews, and earnings disputes, Lyft's AI Assist manages customer support for riders and drivers. Our journey began in 2023, but the process was labor-intensive; developing each AI agent demanded months of dedicated work from Machine Learning Engineers (MLEs) and engineering teams. Although we successfully launched agents for riders and drivers with increasing efficiency, the overall pace remained a significant bottleneck.
By 2026, our existing operating model faced an unsustainable surge in demand driven by new user segments, additional issue types, autonomous vehicle support, and more. The development cycle relied on a slow, iterative loop: domain experts would define workflow behaviors, which MLEs then translated into tool configurations and prompts. This back and forth reviewing traces, flagging problems, and adjusting code required weeks of collaboration for every single agent. Consequently, those with the deepest understanding of customer issues were unable to implement solutions without a technical middleman.
This led us to a pivotal question: Could we empower ops teams, VoC leads, and product managers to construct and refine agents directly using natural language? Our goal was to eliminate the technical intermediary from the daily iteration process to accelerate learning and deployment. Crucially, this shift toward self-service could not compromise our rigorous standards for experience, accuracy, and safety; every agent still had to match the quality of our manually engineered systems.
Architecture: A Multi-Agent System Built on LangGraph
The Router Multi-Agent Pattern
Our system follows LangGraph'srouter multi-agent architecture. A meta agent acts as a stateful router: it classifies the incoming request and uses Command(goto=...) to dispatch to the appropriate specialized subagent. Each subagent is a full LangGraph StateGraph, registered as a subgraph node in the meta agent.
We run separate router instances for riders and drivers. When a rider contacts support, the meta agent routes to the rider_intent subagent, which classifies across rider-specific intents (e.g. lost items, charge disputes, trip issues). For drivers, it routes to the driver_intent subagent, which handles driver-specific intents (e.g. earnings, account access, damage claims). If the intent agent determines during a conversation that the user needs a more specialized agent, it uses Command(goto=..., graph=Command.PARENT) to hand control back to the meta agent, which re-routes to the appropriate specialist, for example, jumping from the driver intent agent to the damage claim agent mid-conversation.
Each subagent, regardless of specialization, follows a consistent node pattern:
This gives us two important properties. First, safety runs in parallel at every turn, malicious intent detection and safety issue detection execute concurrently via LangGraph's Command(goto=[...]) fan-out before any LLM reasoning happens. Second, subagents are modular and independently deployable adding a new agent means defining a new subgraph and registering it with the meta agent.
Specialized vs. Configurable Agents
We have two categories of agents:
Specialized agents are hand-built by MLE for complex, high-stakes workflows. Our damage claim agent, for example, assists with image processing, fraud detection, multi-step classification, and automation calls too complex for a low-code approach.
Configurable agents are the self-serve layer. They're initialized at runtime from JSON configuration stored in our internal config service, with prompts pulled from LangSmith's Prompt Hub. A domain expert writes the prompt following our structured template (role, scope, workflow phases, content guidelines), and the ConfigurableAgent class handles the rest: graph construction, tool binding, safety gates, and state management.

Configurable agents are loaded dynamically at startup
for configurable_agent in load_configurable_agents():
self.configurable_subagents[configurable_agent.config.intent] = configurable_agent
Each one registers as a subgraph in the meta agent
for configurable_subagent in self.configurable_subagents.values():
graph_builder.add_node(
configurable_subagent.config.intent,
configurable_subagent.get_state_graph()
)
graph_builder.add_edge(configurable_subagent.config.intent, "finalize")
This means a product manager can define a new agent, such as for driver tax questions, by writing a prompt and a JSON config. No MLE code changes are required. The platform handles graph construction, tool execution, checkpointing, tracing, and safety.
State Persistence with DynamoDB
Multi-turn conversations require a durable state. We built a custom DynamoDBSaver that implements LangGraph's BaseCheckpointSaver interface, giving us persistent conversation state across turns without any in-memory assumptions. Each checkpoint stores the full graph state, execution metadata, and parent checkpoint references enabling conversation replay, debugging, and state inspection in production.
LangSmith: From Tracing to Production Monitoring
Tracing Every Agent Turn
Every agent invocation across all environments (development, staging, production) is traced to LangSmith with LANGSMITH_TRACING=true. Each trace captures the full graph execution: which nodes ran, what the LLM saw, which tools were called, token usage, and latency at every step.
We enrich traces with custom metadata (user type, agent name, intent, conversation ID) using a utility that builds runtime metadata for filtering:
Metadata flows through to LangSmith for filtering and debugging
tags = build_langsmith_metadata(
agent_name=self.name,
user_type=context.user_type,
interaction_id=context.interaction_id
)
This has been invaluable. When a driver reports a confusing response, we can pull the exact trace, see every node's input/output, identify whether the issue was in intent classification, tool execution, or the final LLM response, and fix it within hours.
LLM-as-a-Judge Evaluation Pipeline
Before any agent rolls out to 100% of traffic, it must pass our evaluation pipeline. The process:
- Small production rollout (5–10%) — the agent serves real traffic at low volume.
- Sample production traces — we capture real conversations as evaluation datasets.
- Run LLM-as-a-Judge evaluators — using a shared judge prompt template from LangSmith's Prompt Hub, extended with agent-specific metrics.
Our baseline evaluation metrics (applied to every agent):
We then add some domain specific metrics for each specialized agent. For example, the core earnings agent checks whether the agent followed or deviated from the relevant policies or used any illogical or inconsistent reasoning.
The evaluators run automatically on production traces using LangSmith's multi-turn evaluator, configured with thread filters (e.g., run name is ride_earnings) and sampling rates that start high during initial rollout and taper as confidence grows.
Production Monitoring Dashboards
Every agent in production has a cloned LangSmith monitoring dashboard tracking:
- Run volume and error rates — are we seeing unexpected spikes or failures?
- p50/p95 latency — is the agent responding fast enough for real-time support?
- Token usage — are costs within budget?
- Tool call success rates — are external API integrations healthy?
- LLM-as-a-Judge scores over time — is quality trending up or down?
We also set up PagerDuty alerts triggered by LangSmith metrics. If the error rate exceeds 5% or p95 latency crosses 10 seconds over a 15-minute window, the on-call engineer is paged automatically.
An example chart of error rate by tool (part of monitoring dashboard in production)
LLM Judge evaluation with custom (agent specific) metrics running in production. Tip: Use binary outputs (True/False or Pass/Fail) instead of scores which are inaccurate and non actionable.
The Hard Lesson: Prompt Quality Is the Bottleneck, Not Infrastructure
When we first opened agent building to non-technical teammates, we assumed the hardest part would be the platform itself getting tool bindings right, handling edge cases in the graph, and managing state. We were wrong.
The hardest part was prompt quality. Domain experts knew their issue types deeply but didn't always know how to translate that knowledge into instructions an LLM would follow reliably. We saw agents that handled the happy path beautifully but fell apart on edge cases. A prompt might define what the agent should do when a driver disputes a fare, but say nothing about what happens when the driver changes topic mid-conversation. Or the tone section would say "be empathetic" without specifying what that actually means so the LLM would interpret it differently every time.
The failure modes were surprisingly consistent: missing out-of-scope definitions (so the agent tried to answer questions it had no tools for), ambiguous branching logic (phases with no explicit entry or exit conditions), and vague content guidelines that sounded good on paper but gave the LLM too much room to improvise.
We attacked this on two fronts.
First, a structured prompt writing framework. We created a template with five required components: identity (who is this agent, what user type, what topic area), primary objective (concrete verbs, not vague "help" or "handle"), scope (both in-scope AND out-of-scope with explicit routing actions), phased workflow (numbered steps with entry conditions, branching for every if/else, and a terminal action for every phase), and content guidelines (concrete do/don't rules with example phrases, not abstract principles). We paired this with a review checklist that every prompt must pass before activation, things like "does every phase have an exit?" and "are there instructions for what to do when a tool is unavailable?"
Second, automated prompt validation. We're building a Git-backed prompt linting pipeline that runs before any prompt reaches production. When a domain expert finishes writing a prompt in our builder UI, it opens a pull request against our config repository. A CI pipeline then runs two layers of checks: fast static rules (catching malformed template variables, duplicate intent slugs, spelling errors) followed by LLM-powered rules that detect prompt injection vulnerabilities, contradictory instructions, and structural dead-ends where a conversation flow has no way out. All violations block the merge. The author gets inline feedback in the UI and can fix issues themselves without pulling in an MLE.
The key insight behind all of this: treat prompts like product specs, not code comments. The more explicit the prompt, the more consistent the agent. And the earlier you catch quality issues, ideally before a single real customer ever sees the output, the faster the whole system improves.
Results
Since launching the self-serve agent platform:
- Agent development time: Reduced from ~6 months (first driver agent) to ~2 weeks for new configurable agents.
- Agent coverage: A growing number of configurable agents in production covering multiple issue types, alongside several specialized agents.
- Evaluation coverage: 100% of production agents have automated LLM-as-a-Judge pipelines running on live traces.
- Quality: Hallucination and contradiction rates have decreased by 20% with hallucination guardrails we have set up based on Langsmith evaluation metrics.
- Operational efficiency: Many non-engineering team members are now building and iterating on agents independently.
- AI Resolution Rate: Up by 16% since we launched a few agents using our self-serve platform.
What's Next
We're looking at several areas to push this platform further:
- Completing the prompt linting pipeline — the Git-backed CI validation described above is actively in development. Once fully rolled out, every configurable agent prompt will pass through automated static and LLM-powered checks before it can reach production, with zero manual MLE review needed for common errors.
- Mocking and simulation infrastructure — building a simulation layer that lets agent builders test against synthetic conversations and mocked tool responses before deploying to real traffic, dramatically shortening the feedback loop for new agents.
- Pairwise evaluation — using LangSmith's Pairwise Annotation Queues to A/B test prompt revisions with human reviewers before shipping.
- Expanding to more geographies and user types — bringing the platform to Freenow customers in Europe and autonomous vehicle support scenarios.
- Deeper eval automation — moving from sampled evaluation to continuous scoring on all production traces, with automatic prompt degradation alerts.
Related content
LangChain
Open Source
LangGraph
From Token Streams to Agent Streams
C. Bromann,
N. Hollon
May 21, 2026
9
min
LangSmith
How Auth Proxy secures network access for LangSmith agent sandboxes
Mukil Loganathan
May 21, 2026
9
min
Company Announcements
LangSmith
Everything we shipped at Interrupt
Jacob Talbot
May 14, 2026
11
min
See what your agent is really doing
LangSmith, our agent engineering platform, helps developers debug every agent decision, eval changes, and deploy in one click.
関連記事
NVIDIA SkillSpector ガイド:静的解析と SARIF レポートによる AI スキルのセキュリティリスクスキャン
NVIDIA は、SkillSpector を用いて実運用前の AI スキルにおけるセキュリティリスクを評価する手法を解説した。同ツールは悪意のある脆弱性を含むサンプルを用いた制御されたコーパスを静的解析し、リスクスコアと発見事項を SARIF 形式で出力・可視化する。
エージェント間通信プロトコル「A2A」が構築する協調型エージェントの世界
Google Developers AI は、エージェント間通信(A2A)プロトコルの1周年を記念し、従来のAPIの硬直性を排除して自律型AIエージェントが安全に協力・タスク引継ぎを行う仕組みについて紹介した。
Factory が LangSmith を活用してフィードバックループを自動化し、反復速度を 2 倍に向上させた事例
LangChain のブログは、企業 Factory が LangSmith ツールを使用してフィードバックループの自動化を実現し、開発の反復速度を 2 倍に加速させた具体的な事例を紹介している。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み