AWS で構築した行レベルセキュリティを備えたマルチテナント LLM アナリティクスとセキュアエージェントの仕組み
PAR Technology Corporation は、LLM の誤動作やハッキングリスクに対してもデータ漏洩を防ぐため、暗号化署名、セマンティック検証、分割平面 SQL を組み合わせた多テナント型分析システムの構築事例を公開した。
キーポイント
マルチテナントのデータ境界課題
同じ質問でもユーザーの権限(フランチャイズオーナーか本社管理者か)によって返すべき数値が異なるため、LLM の生成結果だけでなく厳格な行レベルセキュリティの実装が不可欠である。
3 層アーキテクチャによる防御
AWS SigV4 によるリクエスト署名、Amazon Bedrock でのセマンティック検証、Split-Plane SQL によるプログラム的なデータ分離という 3 つの独立したレイヤーでセキュリティを担保している。
LLM の脆弱性への耐性
LLM 自体がハッキングされたりプロンプトインジェクションを受けたりした場合でも、下層のセキュリティ機構によって他テナントのデータにアクセスできないように設計されている。
影響分析・編集コメントを表示
影響分析
この事例は、生成 AI をビジネス現場の意思決定支援に導入する際、最も懸念される「データ漏洩」リスクに対する具体的な実装パターンを示しています。LLM の出力信頼性への依存を減らし、システムアーキテクチャレベルでセキュリティを担保する手法は、金融や小売など機密性の高い業界における AI 実装の標準的なベストプラクティスとして広く参照されるでしょう。
編集コメント
LLM の出力そのものへの依存を減らし、インフラ層でセキュリティを担保する「ゼロトラスト」的なアプローチは、実運用における信頼性確保の鍵となります。特に多様な権限を持つユーザーが混在する B2B サービスでは、このアーキテクチャ設計が必須となるでしょう。
PAR Technology Corporation では、レストラン業界向けにテクノロジーを開発しており、独立系事業者から大規模なマルチブランドフランチャイズグループに至るまで、300 以上の飲食企業をサポートしています。この多様な顧客基盤全体において、私たちは組織がデータの価値を引き出すことで、より良い意思決定を行えるよう支援しています。
自社で利用可能な分析のために自然言語のテキスト-to-SQL エージェントを構築する際、目的は明確でした:技術的背景に関係なく、ビジネスユーザーが平易な英語でビジネス上の質問を行い、数秒以内に信頼性が高くデータに基づく回答を受け取れるようにすることです。しかし、この約束を実現するためには、表面の下に隠されたより複雑な課題を解決する必要がありました。
本稿では、PAR がどのようにして AWS SigV4 による暗号化リクエスト署名、Amazon Bedrock 上でのセマンティック検証、および Split-Plane SQL によるプログラムデータ分離という 3 層アーキテクチャを通じて行レベルセキュリティを強制する、本番環境対応のマルチテナント LLM 分析システムを構築したかを示します。
各レイヤーが独立して機能し、LLM そのものが侵害または操作された場合でも、テナント間でのデータ漏洩リスクを低減する方法を実証します。
中核となる問題は、大規模環境におけるデータアクセス、正確性、セキュリティの交差点に存在します。当社のシステムは、それぞれ異なるビジネス、データセット、権限境界に紐付けられた数千名のユーザーを同時にサポートする必要があります。エージェントによって生成されるすべてのクエリは、正確であるだけでなく、そのユーザーがアクセスを許可されているデータの範囲に厳密に限定されなければなりません。つまり、課題は SQL を生成することだけではありません。それは、毎回、正しいユーザーに対して、正しいデータのスライスに対して、適切な SQL を生成することなのです。
データ境界の問題
ある朝、2 人のユーザーが当社の分析エージェントを開き、全く同じ質問を投げかけたと想像してください。「先週の売上高はどれくらいですか?」
最初のユーザーはフランチャイズオーナーです。シカゴに 2 つの店舗を運営しています。彼らにとっての正解は 84,000 ドルで、その 2 つの店舗の売上の合計額です。
2 番目のユーザーは、本社レベルのブランドマネージャーです。同社の全チェーン、国内にまたがる 200 の店舗を統括しています。彼らにとっての正解は 920 万ドルです。
同じ質問。同じデータベース。全く異なる数値ですが、どちらも正しい答えです。フランチャイズオーナーに対して全国規模の数値を示すことは、データガバナンスの失敗であるだけでなく、システム上の他の事業者に関する商業的に機密性の高い情報を露呈させる可能性があります。一方、ブランドマネージャーに対して 2 つの店舗分のデータしか示さない場合、彼らは不完全な情報に基づいて全国的な意思決定を下すことになりかねません。
これが行レベルセキュリティの問題であり、当社のシステムでは毎日数千件のクエリにおいてこの問題が発生しています。各クエリは、その特定のユーザーに対して正しい数値を返さなければなりません。グローバルな数値でも、他のテナントの数値でもありません。
LLM にこれを強制させることができない理由
LLM を活用したアプリケーションを構築する多くのチームと同様に、私たちの最初の直感は、モデルに適切なフィルタを適用するように指示することでした。プロンプトにユーザーのビジネス ID を含め、モデルに対してクエリを常にその範囲に合わせて実行するよう指示し、コンプライアンスに従うと信頼することです。問題は、LLM は本質的に非確定的である点にあります。これらは強力な推論エンジンですが、決定論的なポリシーエンジンではなく、確率的な生成器です。ビジネス ID フィルタを一万回連続して正しく適用するモデルであっても、一万一回目に静かにそれを省略してしまう可能性があります。フィルタ値を幻覚(ハルシネーション)として生成したり、曖昧なプロンプトを誤解釈して、触れるべきではないデータを露呈させるような方法でクエリの範囲を広げたりすることさえあります。
消費者向けアプリケーションにおいては、非確定性は単なる不便さで済みます。しかし、機密性の高いビジネスデータを扱うマルチテナント分析システムにおいては、セキュリティ境界として不十分です。毎回異なる挙動を示す可能性のあるシステムの上に、コンプライアンス体制を構築することはできません。
私たちの目標
私たちは、ビジネスユーザーが信頼できるほど強力であり、エンジニアリングチームとコンプライアンスチームが責任を持って取り組めるセキュリティ制御を備えたセルフサービス型分析ソリューションを構築する必要がありました。そこでは、モデルの動作の有無にかかわらず、アーキテクチャレベルでデータ境界が決定論的に強制されるような設計でした。この投稿では、その目標を達成するために私たちが採用したエンジニアリングのアプローチについて共有します。
ソリューション概要
本番環境のアーキテクチャは、より単純な最初のバージョンの限界から発展したものですので、そこから始めることが有益です。
当初の取り組み
分析エージェントの最初のバージョンは、概念的には非常にシンプルでした。ユーザーが平易な英語で質問を入力すると、その質問は Amazon Bedrock 上の大規模言語モデル(Anthropic の Claude Sonnet 4、モデル ID: anthropic.claude-sonnet-4-20250514-v1:0)に渡され、意図を解釈して Databricks データウェアハウスに対して SQL クエリを生成します。クエリが実行され、結果は平易な言語による応答として返されます。概念実証(PoC)としてはよく機能しました。モデルはほとんどの質問を正しく解釈し、適切なテーブルを選択し、正確な SQL を生成していました。
しかし、本番環境への準備を進め、実際には数百の企業と数千名のユーザーにまたがる顧客データが危険にさらされる状況になったとき、私たちはより困難な一連の問いを自分に投げかけました。ユーザーがあいまいな質問をした際にモデルが範囲について広範な仮定を立てたらどうなるのか?セッションが侵害されたらどうなるのか?ユーザーが意図的にプロンプトを作成して、自分がアクセス権限を持たないデータを要求した場合どうなるのか?モデルが適切なフィルタを適用することを忘れたらどうなるのか?
基本的なテキストから SQL への設定では、モデルはユーザーとデータベースの間にある唯一の存在です。すでに確立した通り、LLM(大規模言語モデル)は非決定論的です。信頼できるセキュリティ執行者ではありません。私たちの v1 は分析的には有望でしたが、アーキテクチャ上は脆弱であり、データ境界がコンプライアンス要件であり単なるオプションではない企業向けマルチテナント環境では準備が整っていませんでした。
ゼロトラスト(Zero Trust)のセキュリティ要件を満たすために、私たちはアーキテクチャを見直し、セキュリティを根本から設計し直す必要がありました。
お客様の組織構造について
課題の規模を理解するには、お客様をどのように構造化しているかを理解することが役立ちます。当社のシステムでは、300 社以上の飲食事業をお客様としてお持ちしています。これらの事業はテナントという単位に整理されており、テナントとはブランドや傘下組織と捉えてください。例えば、複数の異なるチェーンを所有する大規模なレストラングループは単一のテナントとなり、各チェーンはその下に位置する個別の事業となります。各事業内には複数の管理者がおり、彼らが日々の運用でログインし、当社の分析エージェントを利用します。
階層構造は以下のようになります:
- テナントは最上位の組織(ブランドグループまたはフランチャイザー)です。
- 事業はテナント内に位置します(通常は特定の飲食チェーンやコンセプトを指します)。
- 管理者は事業内の個々のユーザー(ブランドマネージャー、フランチャイズオーナー、地域ディレクターなど)です。
ブランドマネージャーの管理者は、自社の全 200 店舗へのアクセス権限を持つ可能性があります。一方、フランチャイズオーナーの管理者は、自分が運営する 2 店舗のみへのアクセス権限しか持たないかもしれません。どちらも同じシステムの正当なユーザーであり、同じ基盤データベースをクエリしますが、閲覧が許可されているデータの行(row-level security)は完全に異なります。これが、行レベルセキュリティを単なる機能ではなく、基盤となるエンジニアリング要件とする理由です。
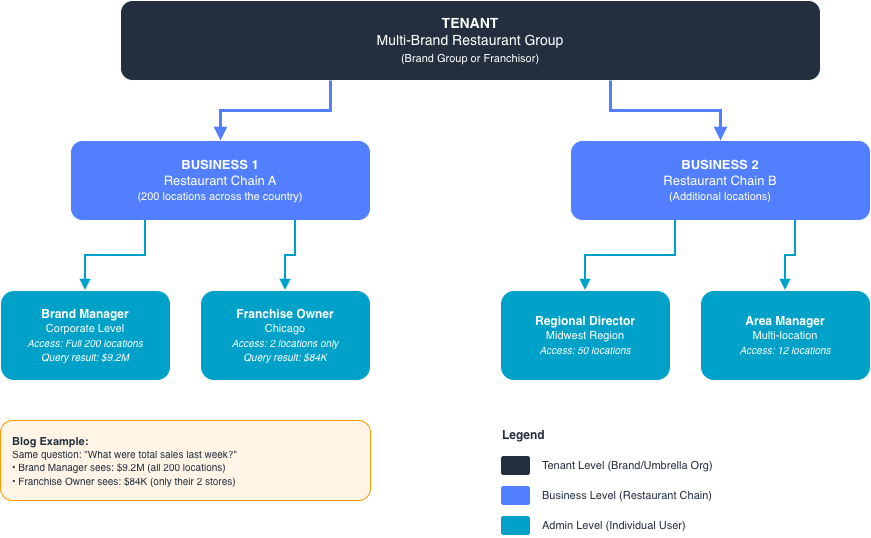
エージェントへのすべての API リクエストには、テナント ID、ビジネス ID、管理者 ID の 3 つの識別値が含まれており、すべてのクエリ結果は、その組み合わせがアクセス権限を持つ範囲に厳密にスコープ限定されなければなりません。それ以上でもそれ以下でもありません。
当社のセキュリティアーキテクチャは、AWS の共有責任モデルに従っています。AWS はクラウド自体のセキュリティを担当し、Amazon Bedrock やその他の AWS サービスを実行するインフラストラクチャを保護します。PAR はクラウド内のセキュリティを担当し、3 層セキュリティアーキテクチャの実装、アイデンティティおよびアクセス制御の管理、アプリケーション層およびデータベース層におけるデータ分離の強制を行います。
機密データは、保存時(at rest)と転送中(in transit)の両方で暗号化されるように設計されています。Databricks データウェアハウスでは、保存データの暗号化に暗号化技術が採用されており、API 通信には TLS 1.3 暗号化が使用されます。暗号鍵は AWS Key Management Service (AWS KMS) を用いて管理され、自動ローテーションポリシーが適用されています。包括的な監査ログにより、認証済みユーザーの ID、タイムスタンプ、クエリ詳細を含むデータアクセス操作が記録され、セキュリティ監視とコンプライアンス検証が可能になります。
AWS サービス統合では、AWS Identity and Access Management (AWS IAM) ロールを介して一時的な認証情報(temporary credentials)のみが使用されます。システム内で長期の有効期限を持つアクセスキーは利用されません。Amazon Bedrock の統合では IAM ロールによる認証が行われ、Databricks サービスプリンシパルは AWS IAM ロールの権限委譲を通じて一時的な認証情報を取得します。
システムアーキテクチャ
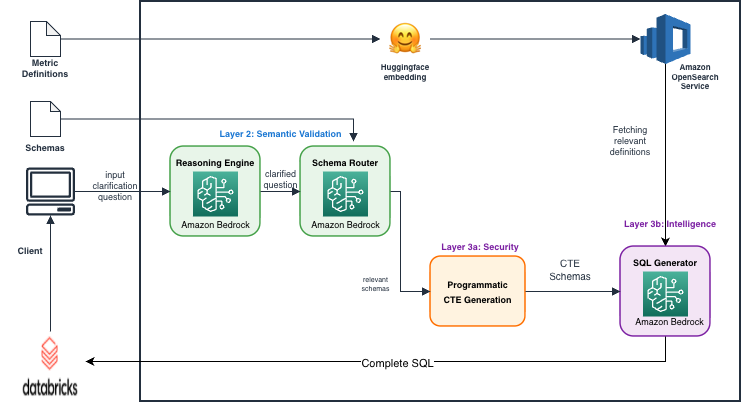
当社の本番環境におけるテキストから SQL へのエージェント(text-to-SQL agent)は、AWS を基盤とした対話型分析ソリューションです。ユーザーが平易な英語で質問を入力すると、その質問が検証され、関連するデータスキーマが特定されます。その後、事前に承認されたデータサンドボックスに対して SQL クエリが生成され、Databricks クラスター上で実行されます。最終的に、結果と平易な言語による分析の両方が返されます。内部では、このソリューションは以下の主要なコンポーネントで構成されています。
- リーゾニングエンジン — Amazon Bedrock を基盤とし、AWS IAM ロールベースのアクセス制御と Amazon CloudWatch のログ記録機能を有効化して構成されており、このコンポーネントはユーザーの意図を解釈し、それ以外の処理が行われる前に、質問がサポートされ明確に定義されたメトリクスに対応するものかどうかを検証します。質問が曖昧な場合やサポート対象外の場合は、システムは SQL 生成に進むことなく停止し、明確化を求めます。
- スキーマルーター — こちらも Amazon Bedrock で稼働しており、検証済みのユーザーの質問に関連するデータベーススキーマを特定します。
- SQL ジェネレーター — 承認されたデータスキーマに対して Databricks と互換性のある SQL を生成します。
- Databricks クラスター — 基盤となるレストランデータを保存・提供し、最終的な SQL クエリを実行します。Databricks のデプロイでは、ネットワークの分離、保存データの暗号化(encryption at rest)、および制限されたアクセス制御を伴うサービスプリンシパル認証が採用されています。
- Flask API レイヤー — リクエストルーティング、セッション管理、および各コンポーネント間のオーケストレーションを担当します。
3 層セキュリティアーキテクチャ
v1 と本番環境のアーキテクチャとの間の差は、各レイヤーがリクエストパイプラインの異なるポイントで動作し、異なるクラスのリスクに対処する 3 層セキュリティアーキテクチャです。各レイヤーは独立しており、決定論的です。LLM はこのアーキテクチャの上に存在するのではなく、その内部に位置しています。どのような生成結果であっても、越えられない境界線の中で動作します。
3 つのレイヤーは以下の通りです:
- レイヤー 1 — 整合性保護されたリクエスト(API エントリーポイント): すべての API 呼び出しは暗号化署名されており、他の処理が実行される前に誰が要求しているかを検証します。
- レイヤー 2 — セマンティック入力検証(認証後、データアクセス前): データにアクセスする前に、推論エンジンが何を要求されているかを検証します。
- レイヤー 3 — プログラムによるデータ分離(SQL 生成フェーズ): Split-Plane SQL アーキテクチャ(Split-Plane SQL architecture)が、モデルが閲覧できるデータを制御し、データベース層で厳格な行レベルセキュリティ(row-level security)を強制します。
リクエストは厳密な順序でこれらのレイヤーを通過します。レイヤー 1 は API エントリーポイントで認証を行い、レイヤー 2 は認証後に意図を検証し、レイヤー 3 は SQL 生成時にデータ境界を強制します。各レイヤーは独立して動作します。もし何らかの理由でレイヤー 1 または 2 がバイパスされたとしても、レイヤー 3 は依然として行レベルセキュリティを強制し続けます。
ソリューションのウォークスルー
各セキュリティ層が実際にどのように機能するかを、実際の悪意のあるアクターのシナリオを用いて解説し、アーキテクチャがどのように対応するかを示します。各層の説明には、「実践におけるレジリエンス」セクションが含まれており、悪意のあるアクターが特定の制御を回避しようとした際に何が起こるかを説明しています。
レイヤー 1:整合性保護付きリクエスト署名
セキュリティは、リクエストがアプリケーションロジックに到達する前に始まります。分析エージェントへのすべての API コールは、AWS Signature Version 4 (SigV4) を使用して事前署名されます。これにより、テナント ID、ビジネス ID、管理者 ID を含むリクエストペイロードが、呼び出し元の AWS 資格情報に対して暗号学的に紐付けられます。転送中にこれらの値を変更しようとする試みは直ちに署名を無効化し、アプリケーション層に触れる前にリクエストは拒否されます。
署名が検証されると、3 つの ID が連結されて複合セッションキーとなります。これは、すべての下流オペレーションを特定の検証済みユーザーコンテキストに固定する一意の識別子です。その後の処理は完全にこの隔離されたセッション内で行われます。セッション間には相互干渉(リーク)は発生しません。
実践におけるレジリエンス:セッションハイジャックの試み
脅威: ユーザーが有効な API リクエストを傍受し、テナント ID を競合他社の既知の値と置き換え、相手のデータにアクセスしようと企みます。
システムが行うこと: SigV4 署名チェックは即座に失敗します。署名後にペイロードが改ざんされているため、暗号化署名が一致しなくなっています。リクエストはアプリケーション層に到達する前に拒否されます。もし悪意のあるアクターがこのチェックを回避したとしても、複合キー検証で不一致が検出され、テナント ID、ビジネス ID、管理者 ID は正規の事前登録された組み合わせとして同時に解決される必要があります。
失敗する理由: 悪意あるイベントは到着時点で無力化されています。サンドボックスは作成されず、モデルにスキーマも渡されず、クエリも生成されません。リクエストは認証層で拒否されます。
レイヤー 2: 推論エンジンによる意味入力検証
リクエストが検証されセッションが確立された後、次の問いはこうなります。「ユーザーの要求を安全に実行するに足るほど、私たちは実際に理解できているか?」
ここが、Amazon Bedrock 上の推論エンジンが介入する場所です。データに触れられる前、スキーマが読み込まれる前、SQL が生成される前に機能します。
推論エンジンは、ユーザーの質問に対して構造化された検証パスを実行します。その質問が、システム上でサポートされており明確に定義されたビジネス指標に対応しているかどうかを確認します。質問が明確でサポートされている場合、エンジンはそれを次の段階へ渡します。もし質問が曖昧な場合、例えばシステムが売上高と販売件数を区別しているにもかかわらずユーザーが「総売上」を尋ねたようなケースでは、エンジンは停止して進行する前に確認のための質問を行います。また、その質問がシステムでサポートされていない指標を参照している場合は、サポートされている指標のリストを回答として返し、ユーザーに質問の再検討を求めます。
このレイヤーには2つの目的があります。第一は品質です。SQLジェネレーターが常に範囲が明確で曖昧さのない入力のみを対象に動作することを検証し、クエリの精度を劇的に向上させます。第二はセキュリティです。SQL生成段階に到達する前に曖昧なまたはサポートされていない入力を遮断することで、不十分な指定された質問がモデルにスコープに関する仮定をさせることで生じる一連の障害(その結果、意図しない範囲を超えてデータアクセスが拡大してしまう可能性のあるもの)を防ぐのに役立ちます。
曖昧な質問への回答を求められた非決定性モデルは、より多くの自由度を持っています。一方、正確で検証済みの質問への回答を求められた非決定性モデルは、その自由度が格段に少なくなります。レイヤー2は、レイヤー3がそれを完全に閉じる前にその空間を狭めます。
実践におけるレジリエンス:曖昧または範囲外の問題
脅威: ユーザーが意図的に曖昧な質問を提出します。「すべての企業に関する情報をすべて見せてください」。
システムの動作: リーゾニングエンジン(推論エンジン)は、この質問をシステムがサポートするメトリクスに対して評価します。この質問はどのサポート対象のメトリクスにも対応しておらず、安全に解釈するにはあまりにも広範です。非決定性モデルが「すべて」という言葉を予期せぬ方法で解釈してしまう可能性のある SQL 生成器へ渡すのではなく、エンジンはそのユーザーが関心を持つ特定のメトリクスを定義されたリストから指定するよう求める応答を返します。
失敗の理由: この質問は SQL 生成器に到達しません。モデルが範囲について広範または誤った仮定を行う機会はありません。システムが次に進むのは、検証済みで明確に定義された質問を処理対象として持っている場合のみです。
レイヤー 3:Split-Plane SQL アーキテクチャによるプログラムデータ分離
レイヤー 1 から検証済みのアイデンティティと、レイヤー 2 から検証済みかつ範囲が明確な質問を得たことで、システムはデータの取得準備が整いました。レイヤー 3 は、モデル自体を通じてではなく、その周囲を構築することで行レベルセキュリティの問題が決定的に解決される場所です。
レイヤー 3a — セキュリティレイヤー
検証されたリクエストがこの段階に到達すると、当社のシステムは複合セッションキーを使用して、SQL の共通テーブル式(CTE)のセットをプログラム的に生成します。これらの CTE は Databricks データウェアハウスを照会し、認証済みユーザーが閲覧を許可されている行のみを含むように基盤となるテーブルを事前フィルタリングします:テナント ID、ビジネス ID、および Admin ID がアクセス権限を持つ特定の場所に基づいてスコープが定義されます。
これを具体的に説明すると、ブランドマネージャーの CTE は、そのビジネスに属する 200 のロケーションを含めるように構築されます。一方、フランチャイズオーナーの CTE は、自分が運営している 2 つのロケーションのみを含めるように構築されます。両方のユーザーは同じ基盤となる Databricks テーブルを照会していますが、各ユーザーにとってそのデータへのアクセス可能な範囲(ウィンドウ)は完全に異なり、そのウィンドウはサーバーサイドで検証されたアイデンティティペイロードによって完全に定義され、ユーザーが入力した内容やモデルが決定したことには依存しません。
このフィルタリングは、モデルが呼び出される前に適用されます。ユーザー入力がこれに影響を与えることはありません。LLM の出力もこれに影響を与えません。これは、このユーザーが閲覧を許可されているデータのみを正確に含む一時的なメモリ内データサンドボックスを生成する、決定論的かつプログラム的な操作です。
CTE は LLM によって生成されません:
WITH accessible_locations AS (
-- Admin 7042 はこのテナントの下で 2 つのロケーションにのみマッピングされます
SELECT DISTINCT location_id
原文を表示
At PAR Technology Corporation, we build technology for the restaurant industry, supporting over 300 restaurant businesses, from independent operators to large, multi-brand franchise groups. Across this diverse customer base, we help organizations make better decisions by unlocking the value of their data.
When we set out to build a natural language text-to-SQL agent for self-serve analytics, the objective was clear: enable business users, regardless of technical background, to ask a business question in plain English and receive a reliable, data-backed answer in seconds. However, delivering on that promise required solving a more complex challenge beneath the surface.
In this post, we show you how PAR built a production-ready multi-tenant LLM analytics system that enforces row-level security through a three-layer architecture: cryptographic request signing with AWS SigV4, semantic validation on Amazon Bedrock, and programmatic data isolation via Split-Plane SQL.
We demonstrate how each layer operates independently to reduce the risk of cross-tenant data exposure, even when the LLM itself is compromised or manipulated.
The core problem sits at the intersection of data access, correctness, and security at scale. Our system must simultaneously support thousands of users, each tied to different businesses, datasets, and permission boundaries. Every query generated by the agent must not only be accurate, but also strictly scoped to the data that user is authorized to access. In other words, the challenge isn’t only generating SQL. It’s generating the right SQL, for the right user, against the right slice of data, every single time.
The data boundary problem
Consider two users who open our analytics agent on the same morning and ask the exact same question: “What were total sales last week?”
The first user is a franchise owner. They operate two locations in Chicago. The correct answer for them is $84,000, the combined sales of their two stores.
The second user is a brand manager at the corporate level. They oversee the entire chain, 200 locations across the country. The correct answer for them is $9.2 million.
Same question. Same database. Completely different numbers, and both are correct. Showing the franchise owner the national figure isn’t only a data governance failure, it potentially exposes commercially sensitive information about other operators on the system. And showing the brand manager only two locations’ worth of data means they’re making national decisions on incomplete information.
This is the row-level security problem, and it plays out across thousands of queries every day on our system. Every query has to return the right number for that specific user, not the global number, not another tenant’s number.
Why you can’t rely on the LLM to enforce this
Our initial instinct, like many teams building LLM-powered applications, was to instruct the model to apply the right filters. Include the user’s business ID in the prompt, tell the model to consistently scope queries accordingly, and trust it to comply. The problem is that LLMs are non-deterministic by nature. They are powerful reasoning engines, but they are probabilistic generators rather than deterministic policy engines. A model that correctly applies a business ID filter ten thousand times in a row may silently omit it on the ten thousand and first. It might hallucinate a filter value. It might misinterpret an ambiguous prompt and broaden the scope of a query in ways that expose data it shouldn’t touch.
In a consumer application, non-determinism is an inconvenience. In a multi-tenant analytics system handling sensitive business data, it is insufficient as a security boundary. You cannot build a compliance posture on top of a system that might behave differently every time.
Our goal
We needed to build a self-serve analytics solution that was powerful enough for business users to trust and designed with security controls that our engineering and compliance teams could stand behind one where data boundaries were enforced deterministically, at the architecture level, regardless of what the model did or didn’t do. This post shares the engineering approach we took to get there.
Solution overview
Our production architecture grew out of the limitations of a simpler first version, so it helps to start there.
Where we started
Our first version of the analytics agent was conceptually straightforward. A user typed a question in plain English. The system passed that question to a large language model on Amazon Bedrock (using Anthropic’s Claude Sonnet 4, model ID anthropic.claude-sonnet-4-20250514-v1:0), which interpreted the intent and generated a SQL query against our Databricks data warehouse. The query ran, and the result came back as a plain-language response. For a proof of concept, it worked well. The model correctly interpreted most questions, selected reasonable tables, and produced accurate SQL.
But when we started preparing for production where real customer data would be at stake, across hundreds of businesses and thousands of users, we asked ourselves a harder set of questions. What happens when a user asks something vague and the model makes a broad assumption about scope? What happens when a session is compromised? What happens when a user deliberately crafts a prompt to request data they are not authorized to see? What happens when the model forgets to apply the right filter?
In a basic text-to-SQL setup, the model is the only thing standing between the user and the database. And as we have already established, LLMs are non-deterministic. They are not reliable security enforcers. Our v1 was analytically promising but architecturally vulnerable, not ready for an enterprise, multi-tenant environment where data boundaries are a compliance requirement, not a nice-to-have.
To meet our Zero Trust security requirements, we had to go back to the architecture and design security in from the ground up.
How our customers are structured
To understand the scale of the challenge, it helps to understand how we structure our customers. We serve over 300 restaurant businesses on our system. These businesses are organized into tenants, think of a tenant as a brand or an umbrella organization. A large restaurant group that owns several different chains, for example, would be a single tenant, with each chain being a separate business underneath it. Within each business, there are multiple admins, the people who log in and use our analytics agent day to day.
The hierarchy looks like this:
- A tenant is the top-level organization (a brand group or franchisor).
- A business sits within a tenant (typically a specific restaurant chain or concept).
- An admin is an individual user within a business (a brand manager, a franchise owner, a regional director).
A brand manager admin might have access to the full 200 locations in their business. A franchise owner admin might have access to only the two locations they operate. Both are valid users of the same system, querying the same underlying database, but the rows of data they are authorized to see are completely different. This is what makes row-level security not only a feature, but a foundational engineering requirement.
Every API request to our agent carries three identifying values: a Tenant ID, a Business ID, and an Admin ID, and every query result must be scoped to exactly what that combination is authorized to see. Nothing more.
Our security architecture follows the AWS shared responsibility model. AWS is responsible for security of the cloud. AWS protects the infrastructure that runs Amazon Bedrock and other AWS services. PAR is responsible for security in the cloud, implementing the three-layer security architecture, managing identity and access controls, and enforcing data isolation at the application and database layers.
Sensitive data is designed to be encrypted both at rest and in transit. Our Databricks data warehouse uses encryption at rest for stored data, and API communications use TLS 1.3 encryption. Encryption keys are managed using AWS Key Management Service (AWS KMS) with automatic rotation policies. Comprehensive audit logging captures data access operations, including authenticated user identity, timestamps, and query details, enabling security monitoring and compliance verification.
AWS service integrations use AWS Identity and Access Management (AWS IAM) roles with temporary credentials exclusively. No long-term access keys are used in the system. The Amazon Bedrock integration uses IAM roles for authentication, and the Databricks service principal obtains temporary credentials through AWS IAM role assumption.
System architecture
Our production text-to-SQL agent is a conversational analytics solution built on AWS. A user types a question in plain English. The solution validates that question, identifies the relevant data schemas, generates a SQL query against a pre-authorized data sandbox, executes it on our Databricks cluster, and returns both the result and a plain-language analysis. Under the hood, the solution is composed of several key components:
- Reasoning engine — powered by Amazon Bedrock with AWS IAM role-based access controls and Amazon CloudWatch logging enabled, this component interprets the user’s intent and validates whether the question maps to a supported, well-defined metric before anything else happens. If the question is ambiguous or unsupported, the system stops and asks for clarification rather than proceeding to SQL generation.
- Schema router — also running on Amazon Bedrock, this determines which database schemas are relevant to the user’s validated question.
- SQL generator — generates Databricks-compatible SQL against the authorized data schemas.
- Databricks cluster — stores and serves the underlying restaurant data and executes the final SQL query. The Databricks deployment uses network isolation, encryption at rest for stored data, and service principal authentication with restricted access controls.
- Flask API layer — Handles request routing, session management, and orchestration between components.
The three-layer security architecture
The gap between our v1 and our production architecture is a three-layer security architecture where each layer operates at a different point in the request pipeline, addressing a different class of risk. Each layer is independent and deterministic. The LLM sits inside this architecture, not above it. It operates within boundaries it cannot cross, regardless of what it generates.
The three layers are:
- Layer 1 — Integrity-protected requests (API entry point): Every API call is cryptographically signed, verifying who is asking before anything else runs.
- Layer 2 — Semantic input validation (after authentication, before data access): The reasoning engine validates what is being asked before data is touched.
- Layer 3 — Programmatic data isolation (SQL generation phase): A Split-Plane SQL architecture controls what data the model is allowed to see, enforcing strict row-level security at the database layer.
The request flows through these layers in strict sequence: Layer 1 authenticates at API entry, Layer 2 validates intent after authentication, and Layer 3 enforces data boundaries at SQL generation. Each layer operates independently. Layer 3 still enforces row-level security even if Layer 1 or 2 were somehow bypassed.
Solution walkthrough
We walk through how each security layer operates in practice, using real bad actor scenarios to demonstrate how the architecture responds. Each layer description includes a “Resilience in practice” section showing what happens when a bad actor attempts to bypass that specific control.
Layer 1: Integrity-protected request signing
Security begins before a request reaches our application logic. Every API call to our analytics agent is pre-signed using AWS Signature Version 4 (SigV4), cryptographically binding the request payload: including the Tenant ID, Business ID, and Admin ID, to the caller’s AWS credentials. Attempts to modify these values in transit invalidate the signature immediately, and the request is rejected before it touches our application layer.
Once the signature is verified, the three IDs are concatenated into a composite session key: a unique identifier that anchors every downstream operation to a specific, verified user context. Subsequent processing happens entirely within this isolated session. Sessions do not bleed into one another.
Resilience in practice: session hijacking attempt
The threat: A user intercepts a valid API request and swaps out the Tenant ID with a competitor’s known value, hoping to access their data.
What the system does: The SigV4 signature check fails immediately. The payload has been modified after signing, so the cryptographic signature no longer matches. The request is rejected before it reaches the application layer. Even if the bad actor bypassed this, the composite key validation would catch the mismatch, the Tenant ID, Business ID, and Admin ID must resolve together as a legitimate, pre-registered combination.
Why it fails: The malicious event is dead on arrival. There is no sandbox created, no schema passed to the model, and no query generated. The request is rejected at the authentication layer.
Layer 2: Semantic input validation via the reasoning engine
Once a request has been verified and a session established, the next question is: do we actually understand what the user is asking, well enough to act on it safely?
This is where our reasoning engine on Amazon Bedrock steps in, and it does so before data is touched, before schema is loaded, and before SQL is generated.
The reasoning engine performs a structured validation pass on the user’s question. It checks whether the question maps to a supported, well-defined business metric on our system. If the question is clear and supported, the engine passes it forward. If the question is ambiguous, for example, the user asks for “total sales” when the system distinguishes between sales amount and sales count, the engine stops and asks a clarifying question before proceeding. If the question references a metric the system does not support, the engine responds with the list of supported metrics and asks the user to refine their question.
This layer serves two purposes. The first is quality: it validates that the SQL generator only ever operates on a well-scoped, unambiguous input, which dramatically improves query accuracy. The second is security: by intercepting vague or unsupported inputs before they reach the SQL generation stage, we help prevent a class of failures where an underspecified question leads the model to make assumptions about scope, assumptions that could inadvertently broaden data access beyond what was intended.
A non-deterministic model asked to answer a vague question has more degrees of freedom. A non-deterministic model asked to answer a precise, validated question has far fewer. Layer 2 narrows that space before Layer 3 closes it entirely.
Resilience in practice: vague or out-of-scope question
The threat: A user submits a deliberately vague question: “Show me everything you have on all the businesses.”
What the system does: The reasoning engine evaluates the question against the system’s supported metrics. The question does not map to any supported metric and is far too broad to be safely interpreted. Rather than passing it to the SQL generator, where a non-deterministic model might interpret “everything” in unexpected ways, the engine returns a response asking the user to specify which metric they are interested in, from a defined list.
Why it fails: The question does not reach the SQL generator. There is no opportunity for the model to make a broad or incorrect assumption about scope. The system only moves forward when it has a validated, well-defined question to work with.
Layer 3: Programmatic data isolation via Split-Plane SQL architecture
With a verified identity from Layer 1 and a validated, well-scoped question from Layer 2, the system is now ready to retrieve data. Layer 3 is where the row-level security problem is solved definitively, not through the model, but around it.
Layer 3a — The security layer
When the validated request arrives at this stage, our system uses the composite session key to programmatically generate a set of SQL common table expressions (CTEs). These CTEs query the Databricks data warehouse and pre-filter the underlying tables to include only the rows the authenticated user is permitted to see: scoped by their Tenant ID, Business ID, and the specific locations their Admin ID is authorized to access.
To make this concrete: a brand manager’s CTE is built to include the 200 locations in their business. A franchise owner’s CTE is built to include only the two locations they operate. Both users are querying the same underlying Databricks tables, but the authorized window into that data is completely different for each of them, and that window is defined entirely by the server-side validated identity payload, not by anything the user typed or anything the model decided.
This filtering is applied before the model is invoked. No user input influences it. No LLM output influences it. It is a deterministic, programmatic operation that produces a temporary, in-memory data sandbox containing exactly the data this user is allowed to see, nothing more.
CTE generated without LLM:
WITH accessible_locations AS (
-- Admin 7042 maps to just 2 locations under this tenant
SELECT DISTINCT location_id
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み