スクラッチから理解するLLMのKVキャッシュの仕組みと実装
Sebastian Raschka氏は、大規模言語モデル(LLM)の推論効率化に不可欠なKVキャッシュの概念とゼロからの実装方法を、コード例と図解を用いて詳細に解説している。
キーポイント
KVキャッシュの目的と利点
KVキャッシュはLLMの推論時に中間的なキー(K)と値(V)の計算結果を保存・再利用することで、テキスト生成速度を大幅に向上させる技術である。
動作原理と冗長性の解消
LLMがトークンを逐次生成する際、過去のコンテキスト(例:「Time flies」)を毎回再エンコードする冗長性を、KVキャッシュが解消する仕組みを図解で説明している。
実装上のトレードオフ
KVキャッシュは推論速度を向上させる一方で、コードの複雑化とメモリ要件の増加を招き、学習時には使用できないという制約がある。
実践的なチュートリアルとしての価値
著者は自身の書籍では扱わなかったこのトピックについて、スクラッチからの人間が読める実装コードを提供し、実務家向けの教育的価値を高めている。
KVキャッシュの必要性
LLMの自己回帰的なテキスト生成では、各ステップで過去のトークンのキー・バリューベクトルを再計算する非効率性があり、KVキャッシュはこれを解消するために導入される。
注意機構の計算の非効率性
「Time flies fast」の生成例で示されるように、3番目のトークン「fast」を生成する際に、既に計算済みの最初の2トークンのキー・バリューベクトルを再計算する無駄が生じる。
KVキャッシュの動作原理
KVキャッシュは、以前に計算されたキーと値のベクトルを保存し、新しいトークン生成時に再利用することで、冗長な計算を回避する。
影響分析・編集コメントを表示
影響分析
この記事は、LLMを実運用するエンジニアや研究者にとって必須の最適化技術であるKVキャッシュを、理論と実装の両面から包括的に解説しており、実務知識の普及と実装スキルの向上に直接寄与する。特に、著者が書籍で割愛した内容を補完する形で公開された点で、コミュニティへの貢献度が高い。
編集コメント
LLMの実運用において不可欠なKVキャッシュを、コード付きでゼロから解説する貴重な実践的ガイド。著者の書籍未収録トピックという背景も興味深い。
LLM の本番環境における効率的な推論において、KV キャッシュは最も重要な技術の一つです。KV キャッシュは、本番環境での計算効率の高い LLM 推論を実現するための重要なコンポーネントです。この記事では、概念とコードの両面から KV キャッシュがどのように動作するかを、人間が読みやすい形式でゼロから実装した例を用いて解説します。
LLM の基本概念を説明する技術チュートリアルを提供してから随分経ちました。現在、怪我からの回復中であり、より大規模な LLM 研究に焦点を当てた記事に取り組んでいるため、読者の方々からいくつかご要望いただいたトピック(私の『ゼロから作る Large Language Model』の書籍には含まれていなかったため)についてチュートリアル記事を共有しようと思いました。
お楽しみください!
概要
簡単に言えば、KV キャッシュは推論時(トレーニング後)に再利用するために、中間的なキー (K) とバリュー (V) の計算結果を保存するものであり、これによりテキスト生成時の速度が大幅に向上します。KV キャッシュの欠点は、コードの複雑さが増し、メモリ要件が高まること(これが当初書籍に含めなかった主な理由です)、そしてトレーニング時には使用できないことです。しかし、本番環境で LLM を使用する際、コードの複雑さとメモリのトレードオフに対して、推論速度の向上は十分に価値があると言えます。
KV キャッシュとは何か?
LLM がテキストを生成している様子を想像してみてください。具体的には、LLM に以下のプロンプトが与えられていると仮定します:"Time"。ご存知の通り、LLM は一度に一つの単語(またはトークン)を生成するため、続く二つのテキスト生成ステップは、下の図に示すようなものになります:
この図は、LLM が1トークンずつテキストを生成する様子を示しています。プロンプト「Time」から始めると、モデルは次のトークン「flies」を生成します。次のステップでは、「Time flies」という完全なシーケンスが再処理され、トークン「fast」が生成されます。
生成された LLM のテキスト出力には冗長性があることに注意してください。これは次の図で強調されています:
この図は、各生成ステップで LLM が再処理しなければならない繰り返しコンテキスト(「Time flies」)を強調しています。LLM は中間のキー/バリュー状態をキャッシュしないため、新しいトークン(例えば「fast」)が生成されるたびに完全なシーケンスを再エンコードします。
LLM テキスト生成関数を実装する際、通常は各ステップから最後に生成されたトークンのみを使用します。しかし、上記の可視化は概念的なレベルでの主要な非効率性の一つを浮き彫りにしています。この非効率性(または冗長性)は、アテンションメカニズムそのものに焦点を当てて拡大して見ると、より明確になります(アテンションメカニズムについて詳しく知りたい場合は、私の著書『Build a Large Language Model (From Scratch)』の第 3 章、あるいは「LLM における自己アテンション、マルチヘッドアテンション、因果的アテンション、クロスアテンションの理解と実装」の記事をお読みください)。
以下の図は、LLM の中核をなすアテンションメカニズム計算の一部を示しています。ここでは、入力トークン("Time" と "flies")が 3 次元ベクトルとして符号化されています(実際にはこれらのベクトルははるかに大きくなりますが、そうすると小さな図に収めるのが難しくなるためです)。行列 W は、アテンションメカニズムの重み行列であり、これら入力を変換してキー、バリュー、クエリベクトルを生成します。
以下の図は、キーおよびバリューベクトルが強調表示された、基礎となるアテンションスコア計算の一部を示しています:
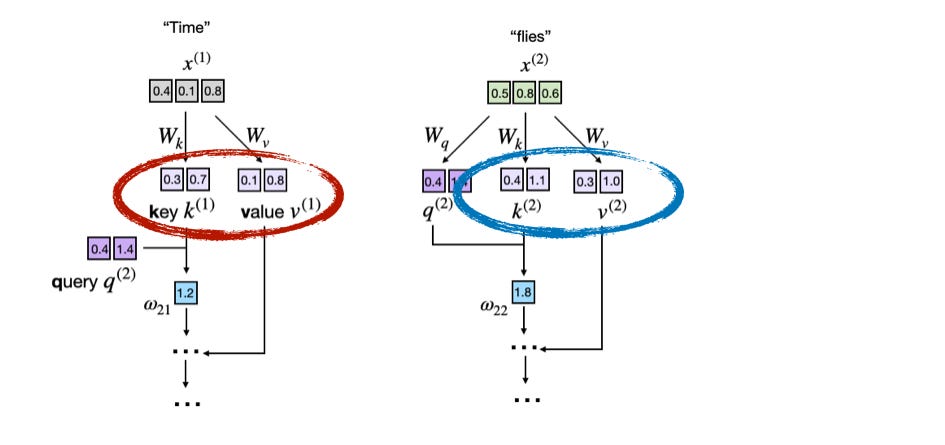
この図は、LLM がアテンション計算中にトークン埋め込みからキー (k) ベクトルとバリュー (v) ベクトルをどのように導出するかを示しています。各入力トークン(例:"Time" と "flies")は、学習された行列 W_k および W_v を用いて投影され、それぞれに対応するキーおよびバリューベクトルを取得します。
前述の通り、LLM は一度に 1 つの単語(またはトークン)を生成します。LLM が単語 "fast" を生成し、次のラウンドのプロンプトが "Time flies fast" になったと仮定しましょう。これは以下の図で示されています:

この図は、各生成ステップにおいて LLM が既知のトークン("Time" と "flies")に対するキーおよびバリューベクトルを再計算する様子を示しています。3 番目のトークン("fast")を生成する際、モデルは k(1)/v(1) および k(2)/v(2) ベクトルを再利用するのではなく、再度同じものを再計算します。この繰り返される計算は、自己回帰的デコーディング中に KV キャッシュを使用しないことの非効率性を浮き彫りにしています。
前述の 2 つの図を比較すると分かる通り、最初の 2 つのトークンに対するキーおよびバリューベクトルは完全に同一であり、次のトークンのテキスト生成ラウンドごとにそれらを再計算するのは無駄です。
さて、KV キャッシュの考え方は、以前に生成されたキーベクトルとバリューベクトルを保存して再利用するキャッシュ機構を実装し、これにより不要な再計算を防ぐことです。
LLM によるテキスト生成(KV キャッシュなしおよびあり)
前節で基本概念を確認した後、具体的なコード実装を見る前に、もう少し詳細を見ていきましょう。"Time flies fast"というテキストを KV キャッシュなしで生成する場合、以下のように考えることができます:

冗長性に注目してください:トークン"Time"と"flies"は、新しい生成ステップごとに再計算されています。KV キャッシュは、以前に計算されたキーベクトルとバリューベクトルを保存して再利用することで、この非効率性を解消します。
まず、モデルが入力トークンのキーベクトルとバリューベクトルを計算し、キャッシュに格納します。
次に、生成される各新しいトークンに対して、モデルはその特定のトークンに対するキーベクトルとバリューベクトルのみを計算します。
以前に計算されたベクトルはキャッシュから取得され、冗長な計算が回避されます。
以下の表は、計算およびキャッシュのステップと状態を要約しています:
ここでの利点は、「Time」は一度計算されて二度再利用され、「flies」は一度計算されて一度再利用されることです。(これは単純化のための短いテキスト例ですが、テキストが長くなるほど、すでに計算済みのキーと値をより多く再利用できることが直感的に理解でき、それによって生成速度が向上します。)
以下の図は、KV キャッシュありなしの両方を並べて比較した生成ステップ 3 を示しています。

KV キャッシュありなしのテキスト生成を比較。上部のパネル(キャッシュなし)では、各トークンステップごとにキーと値ベクトルが再計算され、冗長な演算が生じます。下部のパネル(キャッシュあり)では、高速化のために以前に計算されたキーと値を KV キャッシュから取得し、再計算を回避します。
したがって、コードで KV キャッシュを実装したい場合は、通常通りキーと値を計算した上で、次回ラウンドでそれらを取得できるように保存するだけです。次のセクションでは、具体的なコード例を用いてこれを説明します。
スクラッチから実装する KV キャッシュ
KV キャッシュを実装する方法は多数あり、その主な考え方は、各生成ステップにおいて新たに生成されたトークンのキーおよびバリューテンソルのみを計算することです。
私はコードの可読性を重視したシンプルな実装を選びました。実装方法を理解するには、コードの変更点をスクロールして確認するのが最も簡単だと考えています。
GitHub で公開している 2 つのファイルは、KV キャッシュあり・なしの両方でゼロから LLM を実装する自己完結型の Python スクリプトです:
gpt_ch04.py: 私の『Build a Large Language Model (From Scratch)』書籍の第 3 章および第 4 章から抜粋した自己完結型コードで、LLM の実装と単純なテキスト生成関数の実行を行います。
gpt_with_kv_cache.py: 上記と同じ内容ですが、KV キャッシュを実装するための必要な変更が加えられています。
KV キャッシュ関連のコード変更を確認するには、以下のいずれかの方法をとることができます:
a. gpt_with_kv_cache.py ファイルを開き、# NEW セクションとしてマークされた新しい変更箇所を探します:
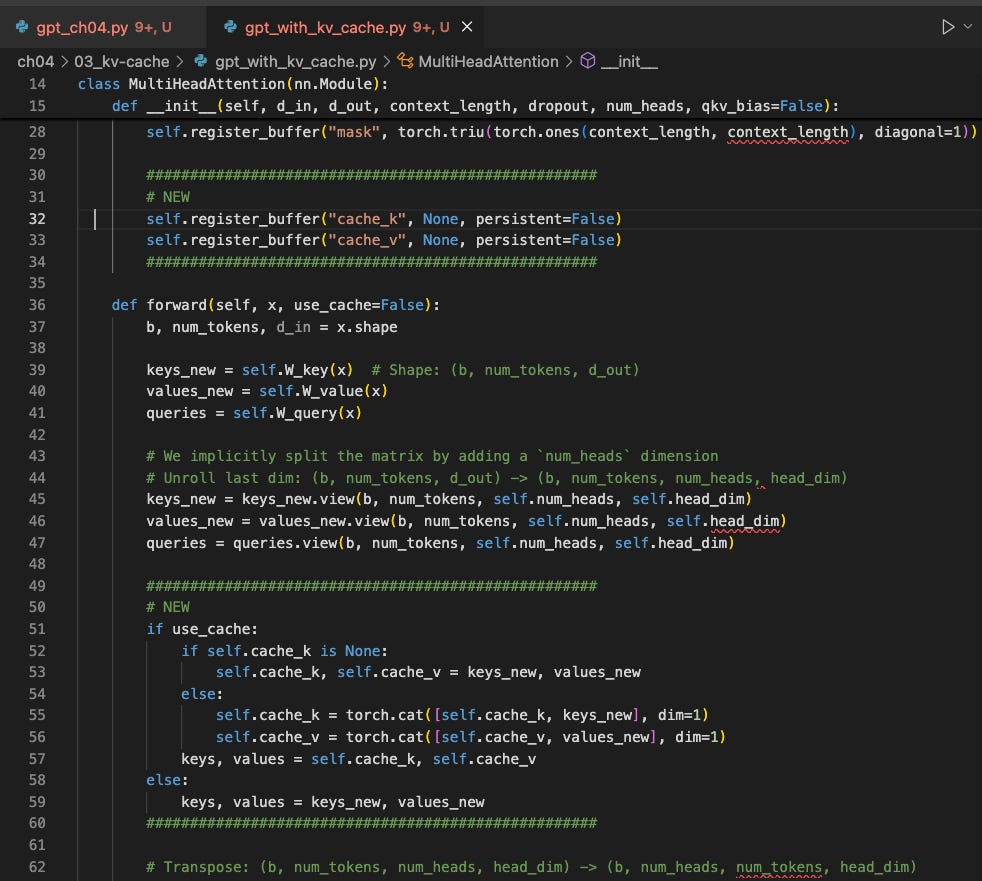
b. 任意のファイル差分ツールを使用して、2 つのコードファイルを比較し変更点を確認します:

さらに、実装の詳細を要約するために、以下の小節で簡単なウォークスルーを行います。
- キャッシュバッファの登録
MultiHeadAttention のコンストラクタ内では、ステップを超えて結合されたキーと値を保持する 2 つのバッファ、cache_k と cache_v を追加します:
self.register_buffer("cache_k", None)
self.register_buffer("cache_v", None) (バッファについてさらに学びたい場合は、YouTube で「Understanding PyTorch Buffers」という動画を公開しています。)
- use_cache フラグを使用したフォワードパス
次に、MultiHeadAttention クラスの forward メソッドを拡張し、use_cache 引数を受け付けるようにします:
def forward(self, x, use_cache=False):
b, num_tokens, d_in = x.shape
keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)
values_new = self.W_value(x)
queries = self.W_query(x)
#...
if use_cache:
if self.cache_k is None:
self.cache_k, self.cache_v = keys_new, values_new
else:
self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)
self.cache_v = torch.cat([self.cache_v, values_new], dim=1)
keys, values = self.cache_k, self.cache_v
else:
keys, values = keys_new, values_new ここでキーと値の保存および取得は、KV キャッシュ (Key-Value Cache) の核心的なアイデアを実装しています。
保存
具体的には、if self.cache_k is None: を通じてキャッシュを初期化した後、self.cache_k = torch.cat(...) および self.cache_v = torch.cat(...) を用いて、新たに生成されたキー(keys)と値(values)をそれぞれキャッシュに追加します。
取得
次に、keys, values = self.cache_k, self.cache_v によって、キャッシュから保存されていた値とキーを取得します。
これが KV キャッシュの核心的な格納・取得メカニズムです。続くセクション 3 と 4 では、実装における細部の処理を担当します。
- キャッシュのクリア
テキスト生成を行う際、2 つの別々のテキスト生成呼び出しの間には、必ずキーと値のバッファをリセットする必要があります。これを怠ると、新しいプロンプトのクエリ(queries)が前のシーケンスから残された古くなったキーに注意を向けてしまい、モデルが無関係な文脈に依存して一貫性のない出力を生み出す原因となります。これを防ぐため、後でテキスト生成呼び出しの間で使用できるように、MultiHeadAttention クラスに reset_kv_cache メソッドを追加します:
def reset_cache(self):
self.cache_k, self.cache_v = None, None- 全体モデル内での use_cache の伝播
MultiHeadAttention クラスへの変更を適用した上で、今度は GPTModel クラスを変更します。まず、トークンインデックスの位置追跡をインストラクターに追加します:
self.current_pos = 0これは、増分的な生成セッション中にモデルがすでにキャッシュしているトークンの数を記憶する単純なカウンターです。
次に、1 ラインのブロック呼び出しを明示的なループに置き換え、各トランスフォーマーブロックに use_cache を渡します:
def forward(self, in_idx, use_cache=False):
# ...
if use_cache:
pos_ids = torch.arange(
self.current_pos, self.current_pos + seq_len,
device=in_idx.device, dtype=torch.long
)
self.current_pos += seq_len
else:
pos_ids = torch.arange(
0, seq_len, device=in_idx.device, dtype=torch.long
)
pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)
x = tok_embeds + pos_embeds
# ...
for blk in self.trf_blocks:
x = blk(x, use_cache=use_cache)use_cache=True を設定した場合、上記の動作は、self.current_pos から開始して seq_len 分だけステップを進めることを意味します。その後、カウンターをインクリメントして、次のデコーディング呼び出しが中断した場所から継続できるようにします。
self.current_pos の追跡が必要な理由は、新しいクエリがすでに保存されているキーと値の直後に正しく配置される必要があるからです。カウンターを使用しない場合、各新しいステップは位置 0 から再び開始することになり、モデルは新しいトークンを以前のトークンと重複しているとみなしてしまいます。(あるいは、offset = block.att.cache_k.shape[1] を通じて追跡することも可能です。)
上記の変更により、TransformerBlock クラスにも use_cache 引数を受け取るための小さな修正が必要になります:
def forward(self, x, use_cache=False):
# ...
self.att(x, use_cache=use_cache)最後に、利便性のために GPTModel にモデルレベルのリセットを追加し、すべてのブロックキャッシュを一度にクリアします:
def reset_kv_cache(self):
for blk in self.trf_blocks:
blk.att.reset_cache()
self.current_pos = 05. 生成におけるキャッシュの使用
GPTModel、TransformerBlock、および MultiHeadAttention への変更により、ついに KV キャッシュを単純なテキスト生成関数でどのように使用するかを示します:
def generate_text_simple_cached(
model, idx, max_new_tokens, use_cache=True
):
model.eval()
ctx_len = model.pos_emb.num_embeddings # max sup. len., e.g. 1024
if use_cache:
# Init cache with full prompt
model.reset_kv_cache()
with torch.no_grad():
logits = model(idx[:, -ctx_len:], use_cache=True)
for _ in range(max_new_tokens):
# a) pick the token with the highest log-probability
next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)
# b) append it to the running sequence
idx = torch.cat([idx, next_idx], dim=1)
# c) feed model only the new token
with torch.no_grad():
logits = model(next_idx, use_cache=True)
else:
for _ in range(max_new_tokens):
with torch.no_grad():
logits = model(idx[:, -ctx_len:], use_cache=False)
next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)
idx = torch.cat([idx, next_idx], dim=1)
return idx
このコードでは、c) のステップで logits = model(next_idx, use_cache=True) として新しいトークンだけをモデルに渡しています。キャッシュを使用しない場合、保存されたキー(keys)や値(values)を再利用できないため、logits = model(idx[:, -ctx_len:], use_cache=False) として入力全体をモデルに渡すことになります。
簡単なパフォーマンス比較
KV キャッシュについて概念的に解説した後、大きな疑問は、この仕組みが実際には小規模な例においてどれほど効果的に機能するかという点です。実装を試すために、前述の 2 つのコードファイルを Python スクリプトとして実行できます。これにより、4 トークンのプロンプト「Hello, I am」から開始して、1.24 億パラメータの小規模な大規模言語モデル(LLM)が 200 個の新しいトークンを生成します:
pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/requirements.txt
python gpt_ch04.py
python gpt_with_kv_cache.py
M4 チップ(CPU)を搭載した Mac Mini での結果は以下の通りです:

ご覧の通り、わずか 1.24 億パラメータの小規模モデルと短い 200 トークンのシーケンス長であっても、すでに約 5 倍の高速化が実現されています。(なお、この実装はコードの可読性を最適化したものであり、CUDA や MPS ランタイムでの速度を最適化したものではありません。後者の場合、テンソルを再構築して結合するのではなく、事前にテンソルを確保する必要があります。)
注記:どちらの場合もモデルは「意味不明なテキスト」を生成します。具体的には以下のようなテキストです:
出力テキスト: Hello, I am Featureiman Byeswickattribute argue logger Normandy Compton analogous bore ITVEGIN ministriesysics Kle functional recountrictionchangingVirgin embarrassedgl ...
これは、まだモデルを訓練していないからです。次の章ではモデルの訓練を行い、訓練済みモデルで KV キャッシュを使用して一貫性のあるテキストを生成できます(ただし、KV キャッシュは推論時のみ使用することを意図しています)。ここではコードを単純に保つために、未訓練のモデルを使用しています。
さらに重要なのは、gpt_ch04.py と gpt_with_kv_cache.py の両方の実装が全く同じテキストを生成することです。これは、KV キャッシュが正しく実装されていることを示しています——インデックス付けのミスは結果の乖離につながる可能性があり、非常に簡単に起こり得ます。
Ahead of AI をお読みいただきありがとうございます!新しい投稿を受け取り、私の活動を支援するために無料で購読してください。
KV キャッシュの利点と欠点
シーケンス長が増加するにつれて、KV キャッシュのメリットとデメリットは以下の通りより顕著になります:
[良い] 計算効率の向上:キャッシュを使用しない場合、t ステップでのアテンションは新しいクエリを t 個の以前のキーと比較する必要があり、累積的な作業量は二次関数的に O(n²) でスケーリングします。キャッシュを使用すると、各キーと値は一度計算されその後再利用されるため、ステップごとの総複雑度が線形 O(n) に削減されます。
[悪い] メモリ使用量の線形的増加:新しいトークンごとに KV キャッシュに追加されます。長いシーケンスや大規模な LLM の場合、累積的な KV キャッシュは大きくなり、(GPU) メモリの大幅な、あるいは実質的に許容できない量を消費する可能性があります。回避策として KV キャッシュを切り捨てることもできますが、これによりさらに複雑さが増します(ただし、LLM をデプロイする際には、その価値がある場合も十分にあります)。
KV キャッシュの実装の最適化
上記の概念実装は明確さを保つために役立ち、主にコードの可読性と教育目的に焦点を当てていますが、実際の運用環境(特に大規模モデルや長いシーケンス長の場合)でデプロイする場合は、より慎重な最適化が必要です。
キャッシュのスケーリング時の一般的な落とし穴
メモリの断片化と繰り返しの割り当て:前述のように torch.cat を使用してテンソルを連続的に結合すると、頻繁なメモリ割り当てと再割り当てによりパフォーマンスのボトルネックが生じます。
メモリ使用量の線形的増加:適切に処理されない場合、KV キャッシュのサイズは非常に長いシーケンスに対して実用的ではなくなります。
ヒント 1: メモリの事前割り当て
テンソルを繰り返し結合するのではなく、予想される最大シーケンス長に基づいて十分に大きなテンソルを事前に割り当てることもできます。これによりメモリ使用量が一定に保たれ、オーバーヘッドが削減されます。擬似コードでは以下のように記述できます。
キーと値の事前割り当て例
max_seq_len = 1024 # 予想される最大シーケンス長
cache_k = torch.zeros(
(batch_size, num_heads, max_seq_len, head_dim), device=device
)
cache_v = torch.zeros(
(batch_size, num_heads, max_seq_len, head_dim), device=device
)推論時には、これらの事前に割り当てられたテンソルのスライスに単に書き込むだけで済みます。
ヒント 2: スライディングウィンドウによるキャッシュの切り捨て
GPU メモリを爆発させないために、動的な切り捨てを伴うスライディングウィンドウアプローチを実装できます。スライディングウィンドウを通じて、キャッシュには最後の window_size トークンだけを保持します:
スライディングウィンドウキャッシュの実装
window_size = 512
cache_k = cache_k[:, :, -window_size:, :]
cache_v = cache_v[:, :, -window_size:, :]
Optimiz
原文を表示
KV caches are one of the most critical techniques for efficient inference in LLMs in production. KV caches are an important component for compute-efficient LLM inference in production. This article explains how they work conceptually and in code with a from-scratch, human-readable implementation.
It's been a while since I shared a technical tutorial explaining fundamental LLM concepts. As I am currently recovering from an injury and working on a bigger LLM research-focused article, I thought I'd share a tutorial article on a topic several readers asked me about (as it was not included in my Building a Large Language Model From Scratch book).
Happy reading!
Overview
In short, a KV cache stores intermediate key (K) and value (V) computations for reuse during inference (after training), which results in a substantial speed-up when generating text. The downside of a KV cache is that it adds more complexity to the code, increases memory requirements (the main reason I initially didn't include it in the book), and can't be used during training. However, the inference speed-ups are often well worth the trade-offs in code complexity and memory when using LLMs in production.
What Is a KV Cache?
Imagine the LLM is generating some text. Concretely, suppose the LLM is given the following prompt: "Time". As you may already know, LLMs generate one word (or token) at a time, and the two following text generation steps may look as illustrated in the figure below:

The diagram illustrates how an LLM generates text one token at a time. Starting with the prompt "Time", the model generates the next token "flies." In the next step, the full sequence "Time flies" is reprocessed to generate the token "fast".
Note that there is some redundancy in the generated LLM text outputs, as highlighted in the next figure:

This figure highlights the repeated context ("Time flies") that must be reprocessed by the LLM at each generation step. Since the LLM does not cache intermediate key/value states, it re-encodes the full sequence every time a new token (e.g., "fast") is generated.
When we implement an LLM text generation function, we typically only use the last generated token from each step. However, the visualization above highlights one of the main inefficiencies on a conceptual level. This inefficiency (or redundancy) becomes more clear if we zoom in on the attention mechanism itself. (If you are curious about attention mechanisms, you can read more in Chapter 3 of my Build a Large Language Model (From Scratch) book or my Understanding and Coding Self-Attention, Multi-Head Attention, Causal-Attention, and Cross-Attention in LLMs article).
The following figure shows an excerpt of an attention mechanism computation that is at the core of an LLM. Here, the input tokens ("Time" and "flies") are encoded as 3-dimensional vectors (in reality, these vectors are much larger, but this would make it challenging to fit them into a small figure). The matrices W are the weight matrices of the attention mechanism that transform these inputs into key, value, and query vectors.
The figure below shows an excerpt of the underlying attention score computation with the key and value vectors highlighted:
This figure illustrates how the LLM derives key (k) and value (v) vectors from token embeddings during attention computation. Each input token (e.g., "Time" and "flies") is projected using learned matrices W_k and W_v to obtain its corresponding key and value vectors.
As mentioned earlier, LLMs generate one word (or token) at a time. Suppose the LLM generated the word "fast" so that the prompt for the next round becomes "Time flies fast". This is illustrated in the next figure below:
This diagram shows how the LLM recomputes key and value vectors for previously seen tokens ("Time" and "flies") during each generation step. When generating the third token ("fast"), the model recomputes the same k(1)/v(1) and k(2)/v(2) vectors again, rather than reusing them. This repeated computation highlights the inefficiency of not using a KV cache during autoregressive decoding.
As we can see, based on comparing the previous 2 figures, the keys and value vectors for the first two tokens are exactly the same, and it would be wasteful to recompute them in each next-token text generation round.
Now, the idea of the KV cache is to implement a caching mechanism that stores the previously generated key and value vectors for reuse, which helps us to avoid these unnecessary recomputations.
How LLMs Generate Text (Without and With a KV Cache)
After we went over the basic concept in the previous section, let's go into a bit more detail before we look at a concrete code implementation. If we have a text generation process without KV cache for "Time flies fast", we can think of it as follows:
Notice the redundancy: tokens "Time" and "flies" are recomputed at every new generation step. The KV cache resolves this inefficiency by storing and reusing previously computed key and value vectors:
Initially, the model computes and caches key and value vectors for the input tokens.
For each new token generated, the model only computes key and value vectors for that specific token.
Previously computed vectors are retrieved from the cache to avoid redundant computations.
The table below summarizes the computation and caching steps and states:

The benefits here are that "Time" is computed once and reused twice, and "flies" is computed once and reused once. (It's a short text example for simplicity, but it should be intuitive to see that the longer the text, the more we get to reuse already computed keys and values, which increases the generation speed.)n speed.)
The following figure illustrates generation step 3 with and without a KV cache side by side.
Comparing text generation with and without a KV cache. In the top panel (without cache), key and value vectors are recomputed for each token step, which results in redundant operations. In the bottom panel (with cache), previously computed keys and values are retrieved from the KV cache to avoid recomputation for faster generation.
So, if we want to implement a KV cache in code, all we have to do is compute the keys and values as usual but then store them so that we can retrieve them in the next round. The next section illustrates this with a concrete code example.
Implementing a KV Cache from Scratch
There are many ways to implement a KV cache, with the main idea being that we only compute the key and value tensors for the newly generated tokens in each generation step.
I opted for a simple one that emphasizes code readability. I think it's easiest to just scroll through the code changes to see how it's implemented.
There are two files I shared on GitHub, which are self-contained Python scripts that implement an LLM with and without KV cache from scratch:
gpt_ch04.py: Self-contained code taken from Chapters 3 and 4 of my Build a Large Language Model (From Scratch) book to implement the LLM and run the simple text generation function
gpt_with_kv_cache.py: The same as above, but with the necessary changes made to implement the KV cache.
To read through the KV cache-relevant code modifications, you can either:
a. Open the gpt_with_kv_cache.py file and look out for the # NEW sections that mark the new changes:
b. Check out the two code files via a file diff tool of your choice to compare the changes:
In additoin, to summarize the implementation details, there's a short walkthrough in the following subsections.
- Registering the Cache Buffers
Inside the MultiHeadAttention constructor, we add two buffers, cache_k and cache_v, which will hold concatenated keys and values across steps:
self.register_buffer("cache_k", None)
self.register_buffer("cache_v", None)(I made a YouTube video if you want to learn more about buffers: Understanding PyTorch Buffers.)
- Forward pass with use_cache flag
Next, we extend the forward method of the MultiHeadAttention class to accept a use_cache argument:
def forward(self, x, use_cache=False):
b, num_tokens, d_in = x.shape
keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)
values_new = self.W_value(x)
queries = self.W_query(x)
#...
if use_cache:
if self.cache_k is None:
self.cache_k, self.cache_v = keys_new, values_new
else:
self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)
self.cache_v = torch.cat([self.cache_v, values_new], dim=1)
keys, values = self.cache_k, self.cache_v
else:
keys, values = keys_new, values_newThe storage and retrieval of keys and values here implements the core idea of the KV cache.
Storing
Concretely, after the cache is initialized via the if self.cache_k is None: ..., we add the newly generated keys and values via self.cache_k = torch.cat(...) and self.cache_v = torch.cat(...) to the cache, respectively.
Retrieving
Then, keys, values = self.cache_k, self.cache_v retrieves the stored values and keys from the cache.
And that's basically it: the core store & retrieve mechanism of a KV cache. The following sections, 3 and 4, just take care of minor implementation details.
- Clearing the Cache
When generating text, we have to remember to reset both the keys and value buffers between two separate text-generation calls. Otherwise, the queries of a new prompt will attend to stale keys left over from the previous sequence, which causes the model to rely on irrelevant context and produce incoherent output. To prevent this, we add a reset_kv_cache method to the MultiHeadAttention class that we can use between text-generation calls later:
def reset_cache(self):
self.cache_k, self.cache_v = None, None4. Propagating use_cache in the Full Model
With the changes to the MultiHeadAttention class in place, we now modify the GPTModel class. First, we add a position tracking for the token indices to the instructor:
self.current_pos = 0This is a simple counter that remembers how many tokens the model has already cached during an incremental generation session.
Then, we replace the one-liner block call with an explicit loop, passing use_cache through each transformer block:
def forward(self, in_idx, use_cache=False):
# ...
if use_cache:
pos_ids = torch.arange(
self.current_pos, self.current_pos + seq_len,
device=in_idx.device, dtype=torch.long
)
self.current_pos += seq_len
else:
pos_ids = torch.arange(
0, seq_len, device=in_idx.device, dtype=torch.long
)
pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)
x = tok_embeds + pos_embeds
# ...
for blk in self.trf_blocks:
x = blk(x, use_cache=use_cache)What happens above if we set use_cache=True is that we start at the self.current_pos and count seq_len steps. Then, bump the counter so the next decoding call continues where we left off.
The reason for the self.current_pos tracking is that new queries must line up directly after the keys and values that are already stored. Without using a counter, every new step would start at position 0 again, so the model would treat the new tokens as if they overlapped the earlier ones. (Alternatively, we could also keep track via an offset = block.att.cache_k.shape[1].)
The above change then also requires a small modification to the TransformerBlock class to accept the use_cache argument:
def forward(self, x, use_cache=False):
# ...
self.att(x, use_cache=use_cache)Lastly, we add a model-level reset to GPTModel to clear all block caches at once for our convenience:
def reset_kv_cache(self):
for blk in self.trf_blocks:
blk.att.reset_cache()
self.current_pos = 05. Using the Cache in Generation
With the changes to the GPTModel, TransformerBlock, and MultiHeadAttention, finally, here's how we use the KV cache in a simple text generation function:
def generate_text_simple_cached(
model, idx, max_new_tokens, use_cache=True
):
model.eval()
ctx_len = model.pos_emb.num_embeddings # max sup. len., e.g. 1024
if use_cache:
# Init cache with full prompt
model.reset_kv_cache()
with torch.no_grad():
logits = model(idx[:, -ctx_len:], use_cache=True)
for _ in range(max_new_tokens):
# a) pick the token with the highest log-probability
next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)
# b) append it to the running sequence
idx = torch.cat([idx, next_idx], dim=1)
# c) feed model only the new token
with torch.no_grad():
logits = model(next_idx, use_cache=True)
else:
for _ in range(max_new_tokens):
with torch.no_grad():
logits = model(idx[:, -ctx_len:], use_cache=False)
next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)
idx = torch.cat([idx, next_idx], dim=1)
return idxNote that we only feed the model the new token in c) via logits = model(next_idx, use_cache=True). Without caching, we feed the model the whole input logits = model(idx[:, -ctx_len:], use_cache=False) as it has no stored keys and values to reuse.
A Simple Performance Comparison
After covering the KV cache on a conceptual level, the big question is how well it actually performs in practice on a small example. To give the implementation a try, we can run the two aforementioned code files as Python scripts, which will run the small 124 M parameter LLM to generate 200 new tokens (given a 4-token prompt "Hello, I am" to start with):
pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/requirements.txt
python gpt_ch04.py
python gpt_with_kv_cache.pyOn a Mac Mini with M4 chip (CPU), the results are as follows:
So, as we can see, we already get a ~5x speed-up with a small 124 M parameter model and a short 200-token sequence length. (Note that this implementation is optimized for code readability and not optimized for CUDA or MPS runtime speed, which would require pre-allocating tensors instead of reinstating and concatenating them.)
Note: The model generates "gibberish" in both cases, i.e., text that looks like this:
Output text: Hello, I am Featureiman Byeswickattribute argue logger Normandy Compton analogous bore ITVEGIN ministriesysics Kle functional recountrictionchangingVirgin embarrassedgl ...
This is because we haven't trained the model yet. The next chapter trains the model, and you can use the KV cache on the trained model (however, the KV cache is only meant to be used during inference) to generate coherent text. Here, we are using the untrained model to keep the code simple(r).
What's more important, though, is that both the gpt_ch04.py and gpt_with_kv_cache.py implementations produce exactly the same text. This tells us that the KV cache is implemented correctly -- it is easy to make indexing mistakes that can lead to divergent results.
Thanks for reading Ahead of AI! Subscribe for free to receive new posts and support my work.
KV cache Advantages and Disadvantages
As sequence length increases, the benefits and downsides of a KV cache become more pronounced in the following ways:
[Good] Computational efficiency increases: Without caching, the attention at step t must compare the new query with t previous keys, so the cumulative work scales quadratically, O(n²). With a cache, each key and value is computed once and then reused, reducing the total per-step complexity to linear, O(n).
[Bad] Memory usage increases linearly: Each new token appends to the KV cache. For long sequences and larger LLMs, the cumulative KV cache grows larger, which can consume a significant or even prohibitive amount of (GPU) memory. As a workaround, we can truncate the KV cache, but this adds even more complexity (but again, it may well be worth it when deploying LLMs.)
Optimizing the KV Cache Implementation
While my conceptual implementation of a KV cache above helps with clarity and is mainly geared towards code readability and educational purposes, deploying it in real-world scenarios (especially with larger models and longer sequence lengths) requires more careful optimization.
Common Pitfalls When Scaling the Cache
Memory fragmentation and repeated allocations: Continuously concatenating tensors via torch.cat, as shown earlier, leads to performance bottlenecks due to frequent memory allocation and reallocation.
Linear growth in memory usage: Without proper handling, the KV cache size becomes impractical for very long sequences.
Tip 1: Pre-allocate Memory
Rather than concatenating tensors repeatedly, we could pre-allocate a sufficiently large tensor based on the expected maximum sequence length. This ensures consistent memory use and reduces overhead. In pseudo-code, this may look like as follows:
Example pre-allocation for keys and values
max_seq_len = 1024 # maximum expected sequence length
cache_k = torch.zeros(
(batch_size, num_heads, max_seq_len, head_dim), device=device
)
cache_v = torch.zeros(
(batch_size, num_heads, max_seq_len, head_dim), device=device
)During inference, we can then simply write into slices of these pre-allocated tensors.
Tip 2: Truncate Cache via Sliding Window
To avoid blowing up our GPU memory, we can implement a sliding window approach with dynamic truncation. Via the sliding window, we maintain only the last window_size tokens in the cache:
Sliding window cache implementation
window_size = 512
cache_k = cache_k[:, :, -window_size:, :]
cache_v = cache_v[:, :, -window_size:, :]Optimiz
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み