Gemma 4:バイト単位で最も能力の高いオープンモデル
Google DeepMindがApache 2.0ライセンスの視覚対応推論LLM「Gemma 4」シリーズを発表し、パラメータ効率を最大化した小型モデル開発の新たな進展を示した。
キーポイント
Gemma 4モデルシリーズの発表
Google DeepMindが2B、4B、31B、26B-A4B Mixture-of-Expertsの4つの視覚対応推論LLMをApache 2.0ライセンスで公開した。
パラメータ効率の革新
小型モデル(E2B/E4B)にPer-Layer Embeddings(PLE)技術を採用し、パラメータ数を抑えつつ性能を最大化する「パラメータあたりの知性」を強調している。
実用性能の実証
著者がLM Studioでテストした結果、2Bから26B-A4Bモデルまで動作し、特に26B-A4Bモデルはラップトップ上で優れた画像生成品質(ペリカン描画)を示した。
アクセス手段の提供
GoogleはAI Studioを通じて大規模モデルへのAPIアクセスを提供し、コミュニティツール(llm-gemini)への統合も進められている。
影響分析・編集コメントを表示
影響分析
この発表は、オープンソースLLMの性能競争が小型化・効率化の方向にシフトしていることを示す重要なマイルストーンである。特にApache 2.0ライセンスでの提供は、企業や研究者による自由な利用・改良を促進し、エッジデバイス向けAI応用の加速につながる可能性が高い。
編集コメント
小型モデルの性能向上が実証されたことで、ローカル環境での高品質なマルチモーダルAI応用が現実味を帯びてきた。技術詳細(PLE)の説明がやや専門的だが、実用テスト結果が分かりやすく補完している。
Gemma 4: バイト単位で見れば、最も能力の高いオープンモデル
Google DeepMind から、2B、4B、31B のサイズに加え、26B-A4B の Mixture-of-Experts(専門家の混合)アーキテクチャを採用した、新しいビジョン対応の Apache 2.0 ライセンス付き推論型大規模言語モデル(LLM)が 4 つ登場しました。
Google は「パラメータあたりの知能レベルにおいて前例のないもの」と強調しており、有用な小型モデルを作成することが現在の研究で最もホットな分野の一つであるというさらなる証拠を提供しています。
実際には、2 つの smaller モデルは「Effective(有効)」パラメータサイズを表すため、E2B および E4B とラベル付けされています。システムカードによると以下の通りです。
小型モデルは、オンデバイス展開におけるパラメータ効率を最大化するために、Per-Layer Embeddings(層別埋め込み)を採用しています。モデルに層やパラメータを追加するのではなく、PLE は各デコーダー層に対してトークンごとに独自の小さな埋め込みを提供します。これらの埋め込みテーブルは大きくなりますが、クイックルックアップのためにのみ使用されるため、有効なパラメータ数は総数よりもはるかに小さくなります。
私はその仕組みを完全に理解しているわけではありませんが、どうやら E2B における「E」の意味はそれのようです!
LM Studio の GGUF ファイルを使用して試してみましたが、2B(4.41GB)、4B(6.33GB)、および 26B-A4B(17.99GB)のモデルはすべて完璧に動作しました。一方、31B(19.89GB)のモデルは破損しており、試したすべてのプロンプトに対して「---\n」をループして出力し続けていました。
2B から 4B、そして 26B-A4B へと続く pelican quality の継承は注目すべき点です:
E2B:
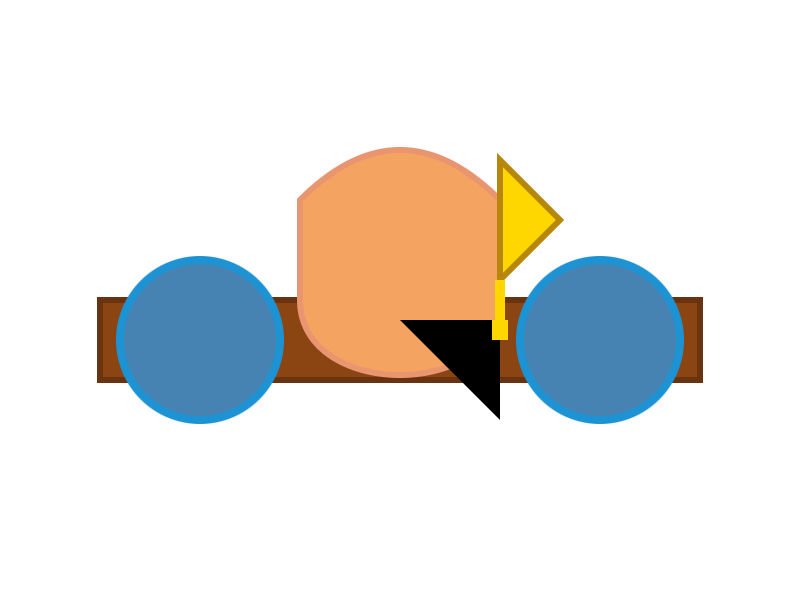
E4B:
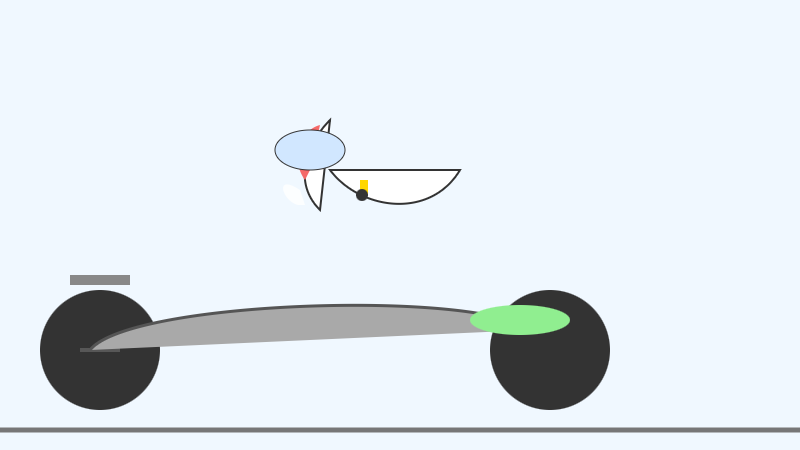
26B-A4B:

(この画像は実際には SVG エラー「18 行目の 88 カラム目:属性 x1 の再定義」が発生していましたが、それを修正した後、私のノートパソコンで動作するモデルからはおそらくこれまで見た中で最高のペリカンの SVG が生成されました。)
Google は、AI Studio を通じて、2 つのより大きな Gemma モデルへの API アクセスを提供しています。私は llm-gemini にサポートを追加し、その後、その 31B モデルを使用してペリカンの SVG を生成するスクリプトを実行しました:
llm -m gemini/gemma-4-31b-it 'Generate an SVG of a pelican riding a bicycle'
非常に良い出来ですが、自転車のフレームの前部が欠けています。

Tags: google, ai, generative-ai, local-llms, llms, llm, vision-llms, pelican-riding-a-bicycle, llm-reasoning, gemma, llm-release, lm-studio
Gemma 4 は、バイト単位で見れば最も能力の高いオープンモデルです。これは、Google が公開した最新の言語モデルで、従来のオープンソースモデルと比較して、より高い精度と効率性を誇ります。
このモデルは、多様なタスクに対応できるよう設計されており、自然言語処理や画像認識など、幅広い分野で優れたパフォーマンスを発揮します。特に、複雑な推論タスクにおいてその真価を発揮し、ユーザーに高度なサポートを提供します。
Gemma 4 の開発には、Google の最先端技術が結集しており、その結果として生まれたモデルは、オープンソースコミュニティ全体にとって大きな前進となっています。今後も、このモデルの活用を通じて、AI の可能性をさらに広げていくことが期待されます。
原文を表示
Gemma 4: Byte for byte, the most capable open models
Four new vision-capable Apache 2.0 licensed reasoning LLMs from Google DeepMind, sized at 2B, 4B, 31B, plus a 26B-A4B Mixture-of-Experts.
Google emphasize "unprecedented level of intelligence-per-parameter", providing yet more evidence that creating small useful models is one of the hottest areas of research right now.
They actually label the two smaller models as E2B and E4B for "Effective" parameter size. The system card explains:
The smaller models incorporate Per-Layer Embeddings (PLE) to maximize parameter efficiency in on-device deployments. Rather than adding more layers or parameters to the model, PLE gives each decoder layer its own small embedding for every token. These embedding tables are large but are only used for quick lookups, which is why the effective parameter count is much smaller than the total.
I don't entirely understand that, but apparently that's what the "E" in E2B means!
I tried them out using the GGUFs for LM Studio. The 2B (4.41GB), 4B (6.33GB) and 26B-A4B (17.99GB) models all worked perfectly, but the 31B (19.89GB) model was broken and spat out "---\n" in a loop for every prompt I tried.
The succession of pelican quality from 2B to 4B to 26B-A4B is notable:
E2B:
E4B:
26B-A4B:
(This one actually had an SVG error - "error on line 18 at column 88: Attribute x1 redefined" - but after fixing that I got probably the best pelican I've seen yet from a model that runs on my laptop.)
Google are providing API access to the two larger Gemma models via their AI Studio. I added support to llm-gemini and then ran a pelican through the 31B model using that:
llm -m gemini/gemma-4-31b-it 'Generate an SVG of a pelican riding a bicycle'
Pretty good, though it is missing the front part of the bicycle frame:
Tags: google, ai, generative-ai, local-llms, llms, llm, vision-llms, pelican-riding-a-bicycle, llm-reasoning, gemma, llm-release, lm-studio
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み