Databricks Unity Catalog と Amazon SageMaker AI を用いた大規模言語モデルのファインチューニング
AWS と Databricks は、LLM のファインチューニングにおいてデータガバナンスと監査証跡を維持するための統合アーキテクチャを提示し、規制業界での実用性を高めた。
キーポイント
ガバナンスとセキュリティの統合課題
SageMaker AI で Databricks Unity Catalog のデータを直接アクセスする際、権限モデルを迂回すると監査証跡が失われ、コンプライアンスリスクが生じる問題点を明確化している。
EMR Serverless を活用した安全なワークフロー
Amazon EMR Serverless と Apache Spark を前処理工程に組み込むことで、Unity Catalog の厳格な権限管理を維持しつつデータを安全に取得・加工する手法を示している。
エンドツーエンドのデータラインージ追跡
ソースデータからファインチューニングされたモデル(Ministral-3-3B-Instruct)までの完全なデータ系譜を Unity Catalog に登録し、トレーサビリティとコンプライアンスを確保する。
規制業界向けの実装パターン
金融や医療など厳格な規制が適用される業界において、既存の ML サービスを活用しながら中央集権的なガバナンスを損なわないための具体的な実装例を提供している。
影響分析・編集コメントを表示
影響分析
この記事は、大規模言語モデルの実運用において最も課題となる「データガバナンス」と「AI の柔軟性」の両立を解決する具体的な技術的アプローチを示しています。特に規制の厳しい業界における AI 導入の障壁を下げる実証例として、企業アーキテクトや ML エンジニアにとって即座に参照すべき重要なガイドラインとなります。
編集コメント
LLM の実装において技術的な機能だけでなく、ガバナンスとコンプライアンスをどう担保するかが決定的な課題となっている中、両社の連携による具体的な解決策は非常に価値が高いです。
Amazon SageMaker AI を使用して大規模言語モデル(LLM)をファインチューニングする際、Databricks Unity Catalog も併用すると、ベスト・イン・クラスのマシンラーニング(ML)サービスを利用しながら厳格なデータガバナンスを維持する方法など、独自の課題に直面することがあります。
Unity Catalog はメタデータと権限を管理しますが、Databricks Workspace のクラウド環境として AWS を選択した場合、基盤となるデータは [Amazon Simple Storage Service (Amazon S3)] に存在します。[SageMaker AI Training job] がそのデータにアクセスする際、Unity Catalog のきめ細かい認可モデルを維持し、迂回してはなりません。構造化された統合パターンがない場合、ポリシーの適用が不整合になったり、監査上の隙が生じたり、コンプライアンスリスクが高まったりする恐れがあります。例えば、SageMaker AI Training job が S3 オブジェクトを読み取る際に Unity Catalog の認可モデルを迂回すると、どのデータがどのモデルのトレーニングに使用されたかの可視性が失われます。これは、規制産業や本番ワークロードにおいて特に重大なコンプライアンスリスクを生み出します。
本稿では、Amazon EMR Serverless を用いた前処理を通じて、Unity Catalog と Amazon SageMaker AI を統合した、安全で完全な LLM(大規模言語モデル)のファインチューニングワークフローを構築する方法を実演します。このソリューションでは、ガバナンスされたデータへの安全なアクセス方法、サービス間での行方追跡(ラインージ)の維持、Ministral-3-3B-Instruct モデルのファインチューニング、およびトレーニング済みアーティファクトを Unity Catalog へ登録する方法を示しています。このアプローチにより、既存のサービスを継続して使用しつつ、中央集権的なガバナンスを維持し、セキュリティやコンプライアンス要件を損なうことなくデータの行方を追跡することが可能になります。
ソリューション概要
本稿で説明するワークフローは、以下のことを実現します:
- 適切なガバナンス制御を持つ Unity Catalog 管理テーブルからトレーニングデータを読み取る
- Apache Spark を使用した EMR Serverless でデータを前処理する
- SageMaker AI のトレーニングジョブを使用して Ministral-3-3B-Instruct モデルをファインチューニングする
- ソースデータからトレーニング済みモデルに至るまでのデータの行方を Unity Catalog で追跡する
以下の図はアーキテクチャを示しています:
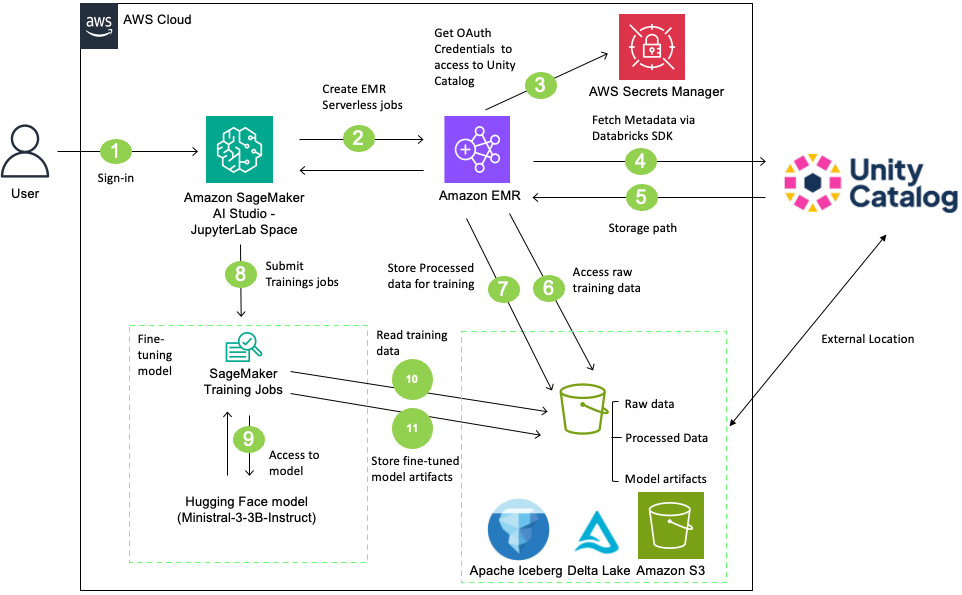 image
image
図 1: SageMaker AI Studio、EMR Serverless、Databricks Unity Catalog の間のデータフローを示すソリューションアーキテクチャ
コンポーネント
目的
Amazon SageMaker AI Studio – JupyterLab Space
ワークフローのオーケストレーションとモデルトレーニング
Amazon EMR Serverless
クラスター管理なしの Spark ベースデータ前処理
Databricks Unity Catalog
メタデータカタログ、ガバナンス、および行方追跡
Hugging Face
事前学習済みモデルへのアクセス
Amazon S3
データとモデルアーティファクトのストレージ
認証情報の管理
このソリューションでは、ユーザーは SageMaker AI Studio にサインインし、EMR Serverless ジョブを使用してデータ前処理を開始します。EMR Serverless ジョブは、AWS Secrets Manager に保存された OAuth 認証情報を用いて Unity Catalog の Open REST APIs を経由し、Unity Catalog で管理される S3 バケットからデータをアクセスして処理します。データの処理後、処理済みのデータを含むテーブルを Unity Catalog に作成します。その後、SageMaker AI 学習ジョブは Hugging Face から Ministral-3-3B-Instruct モデルを取得し、処理済みテーブル上でファインチューニングを行い、生成されたモデルアーティファクトを再度 Unity Catalog で管理される S3 バケットに保存します。最後に、Unity Catalog にモデルを登録し、外部データ行方を作成します。この完全なワークフローは、ガバナンス付きでスケーラブルな LLM のファインチューニングのために SageMaker AI、EMR Serverless、および Databricks Unity Catalog を統合しています。
前提条件
開始前に、以下の項目が揃っていることを確認してください:
サービス
要件
詳細
AWS
AWS アカウント
以下の AWS サービスに対する権限
- Amazon SageMaker AI
- Amazon EMR Serverless
- Amazon S3
- AWS Secrets Manager
- AWS Identity and Access Management (IAM)
- Amazon Virtual Private Cloud (Amazon VPC)
- Amazon CloudWatch Logs
- Amazon Elastic Container Registry (Amazon ECR)
Amazon VPC
インターネットアクセスを許可した VPC およびセキュリティグループを設定する
Databricks
ワークスペースで Unity Catalog を設定する
ワークスペース用の Unity Catalog のセットアップ。
外部アクセスの設定
メタストア上で外部データアクセスを設定する。このオプションはデフォルトでオフになっています。
OAuth 認証情報の生成
Databricks へのプログラムアクセス用の OAuth 認証情報(クライアント ID およびシークレット)を作成する。
ウォークスルー
このセクションでは、Unity Catalog が管理するデータを使用して大規模言語モデル(LLM)をファインチューニングする完全なプロセスを追跡します。完全なノートブック LLM_Finetunig_SageMaker_AI_Unity_Catalog.ipynb をダウンロードし、以下の手順に従って SageMaker AI Studio で実行してください:
- Amazon SageMaker AI コンソールに移動します。
- 既存のドメインがない場合は、クイックセットアップを使用して SageMaker Studio ドメインを作成します。
- SageMaker AI Studio にログインします。
- 以下の構成で JupyterLab スペースを作成します
インスタンスタイプ:ml.m5.2xlarge
- イメージ:Sagemaker Distribution 3.8.0
- ストレージ:5 GB
- ダウンロードした Jupyter ノートブックをアップロードします。
- ノートブックを開きます(カーネルとして Python3 (ipykernel) を選択)。
以下のセクションでは、主要なステップを高レベルで概説します。完全なコード実装についてはノートブックを参照してください。
ステップ 1: AWS セットアップ
このステップの完了までに、以下のセットアップが完了します。
要件
詳細
Amazon S3 バケット
Unity Catalog で管理される S3 バケットを作成し、データをアップロードする
AWS Secrets Manager
Databricks OAuth 認証情報を保存するためのシークレットを作成する
SageMaker AI 実行ロールと EMR Serverless ジョブランタイムロールを作成する
S3 バケット設定 / データセットのアップロード
本ノートブックは、LLM のファインチューニングに SEC EDGAR(米国証券取引委員会電子データ収集・分析・検索システム)の提出書類データ を使用します。SEC EDGAR は、企業の提出書類を公開している SEC のデータベースです。本ソリューションでは、2023 年から 2024 年にかけての S&P 500 企業に対する 10-K および 10-Q 様式を SEC のパブリック API を通じて取得し、提出書類をダウンロードしてリスク要因(Risk Factors)セクションを抽出した後、データを Amazon S3 バケットにアップロードします。ファイルは JSON 形式で保存され、各レコードには企業識別子(CIK)、ティッカーシンボル、エンティティ名、提出書類の種類、会計期間が含まれており、さらに企業が潜在的な事業・財務・規制・運用上のリスクについて記述しているリスク要因開示の全文も含まれています。データをアップロードした後、S3 バケット内には以下の構造が表示されます:
s3://aws-blog-smai-uc-bucket-ACCOUNTID/
├── raw/
│ └── risk_factors/
│ ├── form_type=10-K/
│ │ └── fiscal_year=2024/
│ │ └── cik=0000320193/
│ │ └── risk_factors.json
│ └── form_type=10-Q/
│ └── fiscal_year=2024/
│ └── quarter=1/
│ └── cik=0000320193/
│ └── risk_factors.json
├── curated/
│
└── ml/
Databricks の認証情報を保存する
Databricks は、リソースへのアクセスを制御するために複数の認証および認可メソッドをサポートしています。本ソリューションでは、サービスプリンシパル向けの OAuth (OAuth M2M) を使用しており、これによりサービスプリンシパルに対して短期有効な OAuth トークンを発行します。コンソール外から Databricks にアクセスする際の推奨認証プロトコルは OAuth 2.0 です。OAuth による認可には、クライアント ID とクライアントシークレットが必要です。サービスプリンシパルが認証され同意が与えられると、OAuth は SDK やその他のツールで使用するためのアクセストークンを発行します。まず、Databricks の ドキュメント に従ってサービスプリンシパルを作成し、OAuth シークレットを生成してください。その後、クライアント ID とシークレットを AWS Secrets Manager に保存して、認証情報の安全な管理と取得を実現します。
IAM ロールの作成
後続の手順では、EMR Serverless ジョブと SageMaker AI 学習ジョブを使用します。これらはいずれも他の AWS サービスへのアクセスおよびジョブの実行に IAM ロールを必要とします。EMR Serverless ジョブや SageMaker AI が IAM とどのように連携するかについては、Amazon EMR Serverless のジョブ実行用ロール および SageMaker AI 実行ロールの使用方法 を参照して詳しく学習してください。以下に、各 IAM ロール用のサンプル IAM ポリシーを示します。完全な実装ガイドについては、ノートブックのセクション「1-4 IAM ロールの作成」を参照してください。
EMR Serverless Runtime Role
emr_policy = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket"
],
"Resource": [
f"arn:aws:s3:::{UC_MANAGED_BUCKET}/*",
f"arn:aws:s3:::{UC_MANAGED_BUCKET}"
]
},
{
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue"
],
"Resource": [
f"arn:aws:secretsmanager:{AWS_REGION}:{AWS_ACCOUNT_ID}:secret:databricks/*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": f"arn:aws:logs:{AWS_REGION}:{AWS_ACCOUNT_ID}:*"
}
]
}
SageMaker AI 実行ロールポリシー
sagemaker_policy = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket"
],
"Resource": [
f"arn:aws:s3:::{UC_MANAGED_BUCKET}/*",
f"arn:aws:s3:::{UC_MANAGED_BUCKET}"
]
},
{
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue"
],
"Resource": [
f"arn:aws:secretsmanager:{AWS_REGION}:{AWS_ACCOUNT_ID}:secret:databricks/*" # All Databricks secrets
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:DescribeLogStreams"
],
"Resource": f"arn:aws:logs:{AWS_REGION}:{AWS_ACCOUNT_ID}:*"
},
{
"Effect": "Allow",
"Action": [
"ecr:GetAuthorizationToken",
"ecr:BatchCheckLayerAvailability",
"ecr:GetDownloadUrlForLayer",
"ecr:BatchGetImage"
],
"Resource": "*"
}
]
}
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
ステップ 2: Databricks Unity Catalog のセットアップ
次に、Databricks Unity Catalog 側で以下のセットアップ手順を完了し、Databricks SDK を通じて Unity Catalog テーブルへのアクセスを確認してください。
要件
詳細
外部ロケーションの設定
S3 のデータへのアクセスを設定するために、S3 バケットを Unity Catalog で外部ロケーションとして登録してください。
Unity Catalog データベースオブジェクトの作成
Unity Catalog 環境内で以下のデータベースオブジェクトを設定します:
- カタログ: カタログを作成する
- スキーマ: スキーマを作成する
- 外部テーブル: 外部テーブルを作成する
権限の付与
サービスプリンシパルに必要な特権を付与してください。
必要な権限:
- カタログに対する USE CATALOG
- スキーマに対する USE SCHEMA
- 生データテーブルに対する SELECT
- 加工済みおよび ML スキーマに対する CREATE TABLE
完了すると、サービスプリンシパルに対して適切な権限が設定された以下の Unity Catalog 構造になります:
<td style="padding: 10px;border: 1px solid #ddd
原文を表示
When you fine-tune large language models (LLMs) with Amazon SageMaker AI while using Databricks Unity Catalog, you might face unique challenges like how to maintain strict data governance while using best-in-class machine learning (ML) services.
Unity Catalog governs metadata and permissions, while the underlying data resides in Amazon Simple Storage Service (Amazon S3) when you choose AWS as the cloud environment for their Databricks Workspace. When SageMaker AI Training job accesses that data, you must preserve and not bypass the Unity Catalog’s fine-grained authorization model. Without a structured integration pattern, you risk inconsistent policy enforcement, audit gaps, and compliance exposure. For example, if SageMaker AI Training jobs bypass Unity Catalog’s authorization model when reading S3 objects, you lose visibility into which data trained which models. This creates critical compliance risks particularly in regulated industries and production workloads.
In this post, we demonstrate how to build a secure, complete LLM fine-tuning workflow that integrates Unity Catalog with Amazon SageMaker AI using Amazon EMR Serverless for preprocessing. The solution shows how to securely access governed data, maintain lineage across services, fine-tune the Ministral-3-3B-Instruct model, and register trained artifacts back into Unity Catalog. With this approach, you can continue using your existing services while preserving central governance, tracking data lineage without compromising security or compliance requirements.
Solution overview
The workflow described in this post accomplishes the following:
- Reads training data from a Unity Catalog managed table with proper governance controls
- Preprocesses the data using EMR Serverless with Apache Spark
- Fine-tunes a Ministral-3-3B-Instruct model using SageMaker AI Training jobs
- Tracks data lineage in Unity Catalog from source data through to the trained model
The following diagram illustrates the architecture:
Figure 1: Solution architecture showing data flow between SageMaker AI Studio, EMR Serverless, and Databricks Unity Catalog
Component
Purpose
Amazon SageMaker AI Studio – JupyterLab Space
Workflow orchestration and model training
Amazon EMR Serverless
Spark-based data preprocessing without cluster management
Databricks Unity Catalog
Metadata catalog, governance, and lineage tracking
Hugging Face
Access to pre-trained models
Amazon S3
Storage for data and model artifacts
Credential management
In this solution, users sign in to SageMaker AI Studio and initiate data preprocessing using an EMR Serverless job. The EMR Serverless job accesses and processes data from a Unity Catalog-managed S3 bucket using Unity Catalog’s Open REST APIs with OAuth credentials stored in AWS Secrets Manager. After processing the data, create a table in the Unity Catalog with the processed data. Then, SageMaker AI training job retrieves the Ministral-3-3B-Instruct model from Hugging Face, fine-tunes it on the processed table, and stores the resulting model artifacts back to the Unity Catalog-managed S3 bucket. Finally, register the model in Unity Catalog and create external data lineage. This complete workflow integrates SageMaker AI, EMR Serverless, and Databricks Unity Catalog for governed, scalable LLM fine-tuning.
Prerequisites
Before you begin, verify that you have the following:
Service
Requirement
Details
AWS
AWS Account
Permissions for following AWS Services
- Amazon SageMaker AI
- Amazon EMR Serverless
- Amazon S3
- AWS Secrets Manager
- AWS Identity and Access Management (IAM)
- Amazon Virtual Private Cloud (Amazon VPC)
- Amazon CloudWatch Logs
- Amazon Elastic Container Registry (Amazon ECR)
Amazon VPC
VPC and security groups configured with internet access
Databricks
Set up Unity Catalog for Workspace
Set up Unity Catalog for your Workspace.
Set up External Access
Set up external data access on your Metastore. This option is turned off by default.
Generate OAuth Credentials
Create OAuth credentials (Client ID and secret) for programmatic access to Databricks.
Walkthrough
This section walks through the complete process for fine-tuning LLM using data that Unity Catalog governs. Download the complete notebook LLM_Finetunig_SageMaker_AI_Unity_Catalog.ipynb and run it in SageMaker AI Studio using the following steps:
- Navigate to the Amazon SageMaker AI Console.
- Create a SageMaker Studio Domain using Quick Setup (if you don’t have existing domain).
- Log in to SageMaker AI Studio.
- Create a JupyterLab Space with the following configuration
Instance Type: ml.m5.2xlarge
- Image: Sagemaker Distribution 3.8.0
- Storage: 5 GB
- Upload the downloaded Jupyter notebook.
- Open the notebook (select Python3 (ipykernel) as the kernel).
The following sections outline the key steps at a high level. Refer to the notebook for the full code implementation.
Step 1: AWS setup
By the end of this step, you complete following setups.
Requirement
Details
Amazon S3 Buckets
Create an S3 Bucket that will be managed by Unity Catalog and Upload data
AWS Secrets Manager
Create a Secret to store Databricks OAuth credentials
Create a SageMaker AI Execution Role and EMR Serverless job runtime Role
S3 bucket setup / Upload dataset
The notebook uses SEC EDGAR (U.S. Securities and Exchange Commission Electronic Data Gathering, Analysis, and Retrieval) filings data for LLM fine-tuning. SEC EDGAR is the SEC’s public database of corporate filings. The solution fetches 10-K and 10-Q forms for S&P 500 companies from 2023–2024 through SEC’s public APIs, downloads filing documents, extracts the Risk Factors section, and uploads the data to an Amazon S3 bucket. Files are stored in JSON format, with each record containing the company identifier (CIK), ticker symbol, entity name, filing type, fiscal period, and the full text of risk factor disclosures where companies describe potential business, financial, regulatory, and operational risks. After uploading the data, you see the following structure within your S3 bucket:
s3://aws-blog-smai-uc-bucket-ACCOUNTID/
├── raw/
│ └── risk_factors/
│ ├── form_type=10-K/
│ │ └── fiscal_year=2024/
│ │ └── cik=0000320193/
│ │ └── risk_factors.json
│ └── form_type=10-Q/
│ └── fiscal_year=2024/
│ └── quarter=1/
│ └── cik=0000320193/
│ └── risk_factors.json
├── curated/
│
└── ml/
Store Databricks credentials
Databricks supports multiple authentication and authorization methods to control access to your resources. This solution uses OAuth for service principals (OAuth M2M), which provides short-lived OAuth tokens for service principals. Using OAuth 2.0 is the preferred auth protocol for accessing Databricks outside the console. The OAuth authorization requires client id and client secret. When a service principal authenticates and is granted consent, OAuth issues an access token for the SDK or other tool to use. First, create a Service Principal and generate a OAuth Secret by following the Databricks documentation. Then, store the client id and secret in AWS Secrets Manager to securely manage and retrieve the credentials.
Create IAM roles
In the later steps, you use EMR Serverless Job and SageMaker AI Training jobs. Both require IAM role to access other AWS services and execute the jobs. Review Job runtime roles for Amazon EMR Serverless and How to use SageMaker AI execution roles to learn more about how EMR Serverless jobs and SageMaker AI work with IAM. The following are sample IAM policies for each IAM role. Refer the the section *1-4 Create IAM Roles* of the notebook for the full implementation guidance.
EMR Serverless Runtime Role
emr_policy = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket"
],
"Resource": [
f"arn:aws:s3:::{UC_MANAGED_BUCKET}/*",
f"arn:aws:s3:::{UC_MANAGED_BUCKET}"
]
},
{
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue"
],
"Resource": [
f"arn:aws:secretsmanager:{AWS_REGION}:{AWS_ACCOUNT_ID}:secret:databricks/*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": f"arn:aws:logs:{AWS_REGION}:{AWS_ACCOUNT_ID}:*"
}
]
}
SageMaker AI Execution Role policy
sagemaker_policy = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket"
],
"Resource": [
f"arn:aws:s3:::{UC_MANAGED_BUCKET}/*",
f"arn:aws:s3:::{UC_MANAGED_BUCKET}"
]
},
{
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue"
],
"Resource": [
f"arn:aws:secretsmanager:{AWS_REGION}:{AWS_ACCOUNT_ID}:secret:databricks/*" # All Databricks secrets
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:DescribeLogStreams"
],
"Resource": f"arn:aws:logs:{AWS_REGION}:{AWS_ACCOUNT_ID}:*"
},
{
"Effect": "Allow",
"Action": [
"ecr:GetAuthorizationToken",
"ecr:BatchCheckLayerAvailability",
"ecr:GetDownloadUrlForLayer",
"ecr:BatchGetImage"
],
"Resource": "*"
}
]
}Step 2: Databricks Unity Catalog setup
Next, complete the following setup steps on the Databricks Unity Catalog side and confirm access to the Unity Catalog table through the Databricks SDK.
Requirement
Details
Configure External Location
Register your S3 bucket as an External Location in Unity Catalog to setup access to the data in S3.
Create Unity Catalog database objects
Set up the following database objects in your Unity Catalog environment:
- Catalog: Create catalog
- Schemas: Create schemas
- External Table: Create external table
Grant Permissions
Grant necessary privileges to your Service Principal.
Required Permissions:
- USE CATALOG on the catalog
- USE SCHEMA on the schemas
- SELECT on raw data table
- CREATE TABLE on curated and ml schemas
Upon completion, you have the following Unity Catalog structure with the appropriate permissions configured for your service principal:
<td style="padding: 10px;border: 1px solid #ddd
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み