ダイアログブースト:AmazonがAIでテレビ番組や映画の会話を強化する方法
Amazon は深層学習の圧縮技術を活用し、音声分離機能をオンデバイスで実行する「Dialogue Boost」をリリースし、聴覚障害者を含む全てのユーザーが背景音を抑えて明確な対話を視聴できる環境を提供した。
キーポイント
オンデバイスでの実装とアクセシビリティ向上
深層ニューラルネットワークの圧縮技術により、クラウド依存なしで端末上で動作するようになり、Prime Video 以外の Netflix や YouTube など全てのメディアコンテンツに対応可能となった。
音声分離による明確な対話強調
機械学習と高度な音声分離技術を用いて、音楽や効果音を抑圧しつつ対話を増幅する仕組みにより、音量を上げなくても会話が聞き取りやすくなる。
現代のサウンドミキシング課題への対応
映画館向けと家庭用テレビ向けのサウンドミックスの違いによる聴き取り難さという長年の課題に対し、AI 技術で個別に処理する解決策を提示している。
聴覚障害者支援への貢献
世界人口の約 20% が抱える聴覚障害の問題に対し、字幕以外の選択肢として機能し、視聴体験の質を向上させる社会的意義が強調されている。
周波数サブバンドによる計算効率の向上
音声スペクトルを周波数サブバンドに分割し並列処理を行うことで、計算コストを大幅に削減し、1%未満の演算量で最先端性能を実現しました。
疑似ラベル付けによる実世界データへの対応
合成データだけではカバーしきれない生放送や音楽イベントなどの稀なシナリオに対応するため、大規模モデルで生成した疑似ラベル付きの実データを学習に活用しています。
リアルタイム処理への移行と技術的進歩
クラウドベースからデバイス内でのリアルタイム処理へ移行し、知識蒸留(knowledge distillation)によりAIモデルのサイズを元の1%未満に圧縮しながら性能を維持しています。
影響分析・編集コメントを表示
影響分析
この技術は、AI を用いた音声分離がクラウド依存からエッジデバイスへ移行し、低遅延かつプライバシーに配慮した形で実社会のアクセシビリティ課題を解決できることを示す重要な転換点です。特に、映画やテレビ制作におけるサウンドミキシングの多様化による視聴難易度の増加という構造的な問題を、ソフトウェア的なアプローチで補完するモデルとして、業界全体での音声処理技術の標準化に寄与する可能性があります。
編集コメント
音声処理技術がクラウドからエッジへ移行し、リアルタイム性とプライバシーを両立させた事例として注目すべきニュースです。アクセシビリティという社会的課題に対して、AI が直接的かつ効果的に介入できる可能性を示しており、今後のスマートデバイスにおける標準機能化への期待が高まります。
Dialogue Boost:Amazon が AI を活用してテレビや映画のセリフを強化する方法
新しいオーディオ処理技術により、数百万人の視聴者にとってエンターテインメントがよりアクセスしやすくなっています。
会話型 AI
Yuzhou Liu, Trausti Kristjansson
12 月 10 日 午前 10:22
Amazon では、選択された Echo スマートスピーカーおよび Fire TV デバイスで利用可能な、新しい AI 搭載の Dialogue Boost(ダイアログブースト)技術をご紹介できることを嬉しく思います。Dialogue Boost は、映画やテレビ番組のセリフの明瞭さを向上させると同時に、背景音楽や効果音を適応的に抑制します。機械学習と高度なオーディオ分離技術のおかげで、Dialogue Boost を利用すれば、視聴者は音量を最大限に上げることなく、お気に入りのテレビ番組、映画、ポッドキャストの会話を聞き取ることができます。Dialogue Boost はすべての顧客の視聴体験を向上させるものですが、特に世界的に聴覚障害を抱える約 20% の人々にとって有用です。
 image Dialogue Boost のメニュー。もともと 2022 年に Prime Video で発売されたこの新機能は、ディープニューラルネットワークの圧縮に関する画期的な進歩を活用してデバイス上で直接動作するため、Netflix、YouTube、Disney+ を含むすべてのメディアで利用可能になりました。
image Dialogue Boost のメニュー。もともと 2022 年に Prime Video で発売されたこの新機能は、ディープニューラルネットワークの圧縮に関する画期的な進歩を活用してデバイス上で直接動作するため、Netflix、YouTube、Disney+ を含むすべてのメディアで利用可能になりました。
映画鑑賞のための明瞭なセリフ
聴覚に障害がある人にとって、映画やテレビ番組全体の音量を上げてもセリフが明確になるわけではありません。音楽やその他の背景音も同時に増幅されてしまうためです。この問題の解決策として、多くの人がクローズドキャプション(字幕)を使用していますが、すべての顧客にとってこれが最適な視聴スタイルとは限りません。
映画における聞き取りにくいセリフの問題は、過去 10 年間で悪化しています。その一因として、現代の劇場や家庭用サウンドシステムの複雑さと多様性が増していることが挙げられます。つまり、すべての再生設定でうまく機能する単一のミックスが存在しないのです。
例えば、ハリウッドのサウンドエディターは、前方からセリフチャンネルが、側方から効果音が鳴るなど、数十チャンネルを備えた劇場システムを対象にミックスを行うことがあります。しかし、テレビ版では、効果音、音楽、セリフがすべて同じチャンネルにダウンミックスされるため、何を言っているのかを理解することがさらに困難になります。
音声ソース分離
顧客体験を向上させるためには、音楽や効果音を抑制しつつ会話を強化する方法が必要だと私たちは気づきました。これを実現するために、複数の段階でオーディオを処理するサウンドソース分離システムを使用しています。
第一段階は分析であり、入力されるオーディオストリームが時間周波数表現に変換されます。これは、異なる周波数帯域におけるエネルギーを時間に対してマッピングするものです。
次の段階では、さまざまな言語、アクセント、録音状況、効果音の組み合わせ、背景ノイズなどを含む数千時間の発話条件でトレーニングされたニューラルネットワークが使用されます。このモデルは、時間周波数表現をリアルタイムで分析し、音声と他の音を区別します。
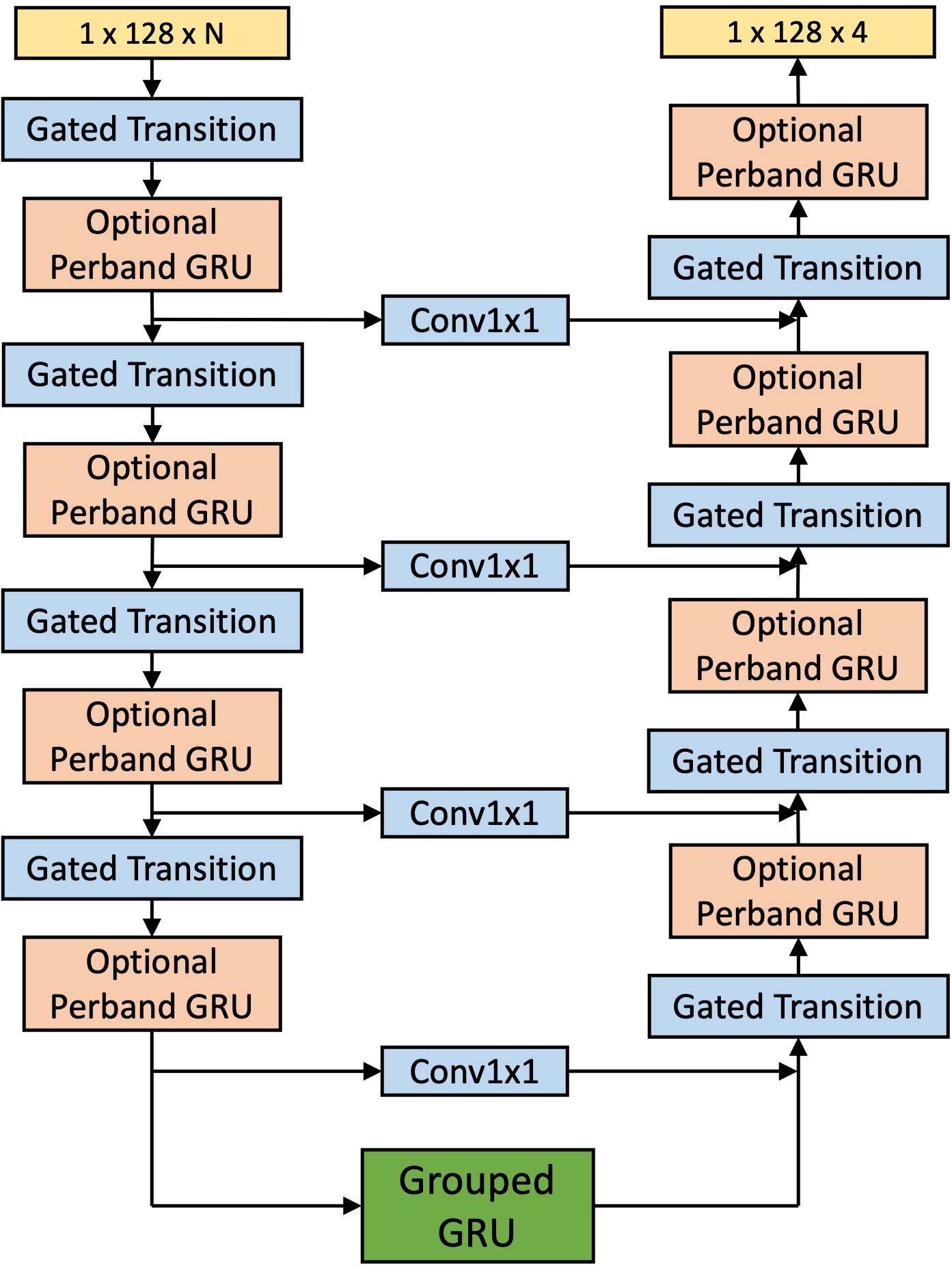 image Dialogue Boost 深層ニューラルネットワーク分離モデル。Dialogue Boost を Fire TV Stick や Echo スマートスピーカーに搭載するために、チームが実現した2つの重要な革新があります。それは、オーディオを周波数サブバンドで処理するより効率的な分離アーキテクチャと、モデル自身がラベル付けしたデータに対してファインチューニングを行う擬似ラベリング(pseudo-labeling)に依存するトレーニング手法です。
image Dialogue Boost 深層ニューラルネットワーク分離モデル。Dialogue Boost を Fire TV Stick や Echo スマートスピーカーに搭載するために、チームが実現した2つの重要な革新があります。それは、オーディオを周波数サブバンドで処理するより効率的な分離アーキテクチャと、モデル自身がラベル付けしたデータに対してファインチューニングを行う擬似ラベリング(pseudo-labeling)に依存するトレーニング手法です。
多くの既存のネットワークは、LLM のトークンシーケンスモデリングと同様の時間的シーケンスモデリングを通じてすべての周波数コンテンツを一度に処理しており、これは計算集約的なアプローチです。
オーディオスペクトラムを周波数サブバンドに分割することで推論を並列化でき、各サブバンドは時間軸方向のみを処理すればよいため、計算タスクが大幅に簡素化されます。また、サブバンドを統合する軽量なブリッジングモジュールを実装し、帯域間の一貫性を向上させました。
このアーキテクチャにより、当社のモデルは以前の最先端性能を達成または上回り、はるかに大規模なモデルと競合しながらも、必要な演算量は 1% 未満、モデルパラメータ数は約 2% で済みます。
これまでの多くの先行研究では、トレーニングが音声、背景音、効果音の合成ミックスに大きく依存していました。しかし、この合成データはライブ放送や音楽イベントなど、すべての実世界条件を網羅していませんでした。
最近のマルチモーダル大規模言語モデル(LLM)のトレーニングに関する研究に触発され、最先端モデルが疑似ラベリングパイプラインから恩恵を受けることを踏まえ、実メディアコンテンツに対してトレーニングターゲットを生成するシステムを作成しました。これにより、これらの稀なシナリオをより適切に処理できます。まず、大規模で強力なモデルを合成データでトレーニングし、それを用いて実データから音声信号を抽出します。次に、疑似ラベル付けされた実データを合成データと組み合わせ、モデルを再トレーニングします。
このプロセスは、さらに多くのトレーニングエポックを行ってもモデルの精度が向上しなくなるまで続きます。この時点で、知識蒸留(knowledge distillation)と呼ばれるプロセスにおいて、完全にトレーニングされた大規模モデルを用いて、オーディオ信号をリアルタイムで処理できるほど小型かつ効率的なモデルのためのトレーニングターゲットを生成します。
最終段階はインテリジェントミキシングであり、単なる音量調整を超えたものです。このシステムは複数の技術を組み合わせ、元のミキシングの芸術的意図を維持しながら対話を強化します。具体的には、音声優位のオーディオチャネルを特定し、ソース分離を適用して対話部分を分離し、発音の明瞭さに重要な周波数帯域を強調し、これらの要素を元のオーディオと再ミックスします。視聴者は対話の目立たせさを調整できますが、システムは全体的なサウンドクオリティと芸術的バランスを維持します。
Amazon Prime Video が当初 Dialogue Boost を導入した際、クラウドベースのプロセッシングを用いてオーディオトラックを事前強化していました。知識蒸留(knowledge distillation)により、元の AI モデルのサイズを 1% 未満に圧縮できました。現在、私たちのモデルはデバイス上の制約内でリアルタイムで動作可能でありながら、クラウドベースの手法とほぼ同等のパフォーマンスを維持しています。
リスニング体験
私たちの研究によると、弁別的なリスニングテストでは、参加者の 86% 以上が、複雑なサウンドスケープを含むシーン(アクションシーケンスなど)において、Dialogue Boost で強化されたオーディオの明瞭さを未処理オーディオよりも好むと回答しました。
難聴を持つユーザー向けには、私たちの研究で機能への承認率が 100% と示され、映画鑑賞中のリスニング負荷が大幅に軽減されたという報告がありました。
ユーザーからは、Dialogue Boost がささやき声の会話や、多様なアクセントや方言を含むコンテンツ、アクション満載のシーンでのセリフを理解する助けになると報告されています。また、字幕による気散じを避けながら映画を楽しめる点も評価されています。さらに、深夜視聴者や、他の人が寝ている間にテレビを見る人々にとって、この技術は特に価値があることが実証されています。音量を頻繁に調整したり、字幕に頼ったりする代わりに、視聴者は快適な聴取レベルを維持しつつ、セリフが明確で理解しやすい状態を保つことができます。
Dialogue Boost は、Amazon Lab126 と Prime Video チーム間の協力によって実現されたものです。ゴードン・ハン、ベルカンタ・タセル、フィル・ヒルメス、ピーター・コーン、ルイ・ワン、アリ・ミラニ、スコット・イザベール、ヴィマル・バト、リンダ・リュー、モハメド・オマル、ラクシュミー・ジスキン、ロヒト・マイソール、ビジャヤ・クマールに感謝いたします。
サブバンド処理
疑似ラベル付け
謝辞
研究分野:会話型 AI
タグ: 信号処理
原文を表示
Dialogue Boost: How Amazon is using AI to enhance TV and movie dialogue
New audio-processing technology is making entertainment more accessible for millions of viewers.
Conversational AI
Yuzhou Liu Trausti Kristjansson December 10, 10:22 AM December 10, 10:22 AM At Amazon, were excited to introduce the new AI-powered Dialogue Boost technology available on select Echo smart speakers and Fire TV devices. Dialogue Boost enhances the clarity of movie and TV dialogue while adaptively suppressing background music and sound effects. Thanks to machine learning and advanced audio separation techniques, Dialogue Boost helps people hear conversations in their favorite TV shows, movies, and podcasts without having to blast the volume. Dialogue Boost can improve the viewing experience for all our customers, but its especially useful for the nearly 20% of the global population with hearing loss.
image The Dialogue Boost menu. Originally launched on Prime Video in 2022, the new Dialogue Boost leverages breakthroughs in deep-neural-network compression to run directly on-device, making it available to all media, including Netflix, YouTube, and Disney+.
Clearer dialogue for movie nights
For people with hearing loss, increasing the overall volume of a movie or TV show doesnt make dialogue clearer, since music and other background sounds are also amplified. Most people solve this problem by using closed captions, but that isnt the preferred viewing style for every customer.
The problem of hard-to-hear dialogue in movies has been getting worse over the last decade. This is due in part to the increased complexity and variety of modern theater and home sound systems, which means there isnt a single mix that works well on all playback configurations.
For example, Hollywood sound editors may target a theater system with dozens of channels, including separate dialogue channels coming from the front of the theater and sound effects emanating from the sides. In the TV version, however, sound effects, music, and dialogue are all down-mixed to the same channel, making it even harder to understand whats being said.
Sound source separation
We realized that, to improve our customers experience, we needed a way to suppress the music and sound effects while boosting the dialogue. We achieve this using a sound source separation system that processes audio in several stages.
The first stage is analysis, where the incoming audio stream is transformed into a time-frequency representation, which maps energy in different frequency bands against time.
The next stage involves a neural network trained on thousands of hours of speaking conditions including various languages, accents, recording circumstances, combinations of sound effects, and background noises. This model analyzes the time-frequency representation in real time to distinguish speech from other sounds.
image Dialogue Boost deep-neural-network separation model. Two key innovations allowed the team to bring Dialogue Boost to Fire TV Sticks and Echo smart speakers: a more efficient separation architecture that processes audio in frequency sub-bands and a training methodology that relies on pseudo-labeling, where a model is fine-tuned on data that it has labeled itself.
Many existing networks process all frequency content together through temporal sequence modeling, which is similar to token sequence modeling in LLMs a computationally intensive approach.
Dividing the audio spectrum into frequency sub-bands enables inference to be parallelized, and each sub-band needs to be processed only along the time axis, a much simpler computational task. We also implemented a lightweight bridging module to merge sub-bands, improving cross-band consistency.
This architecture enables our model to achieve or surpass the previous state-of-the-art performance, competing with much larger models while using less than 1% as many operations and requiring about 2% as many model parameters.
In most prior work, training relied heavily on synthetic mixtures of speech, background sound, and effects. But this synthetic data didn't cover all real-world conditions, such as live broadcasts and music events.
Inspired by recent work on training multimodal LLMs, where state-of-the-art models benefit from pseudo-labeling pipelines, we created a system that generates training targets for real media content, better handling these rare scenarios. First, we train a large, powerful model on synthetic data and use it to extract speech signals from real data. Then we combine the pseudo-labeled real data with synthetic data and retrain the model.
This process continues until further training epochs no longer improve the models accuracy. At this point, in a process known as knowledge distillation, we use the fully trained large model to generate training targets for a model thats small and efficient enough to process audio signals in real time.
The final stage is intelligent mixing, which goes beyond simple volume adjustment. The system combines multiple techniques to enhance dialogue while preserving the artistic intent of the original mix: it identifies speech-dominant audio channels, applies source separation to isolate dialogue, emphasizes frequency bands critical for speech intelligibility, and remixes these elements with the original audio. Viewers can adjust dialogue prominence while the system maintains overall sound quality and artistic balance.
When Amazon Prime Video first introduced Dialogue Boost, it relied on cloud-based processing to pre-enhance audio tracks. Knowledge distillation helped us compress the original AI models to less than 1% of their size. Our models are now able to run in real time, within device constraints, while maintaining nearly identical performance to cloud-based techniques.
The listening experience
Our research shows that in discriminative listening tests, over 86% of participants preferred the clarity of Dialogue-Boost-enhanced audio to that of unprocessed audio, particularly during scenes with complex soundscapes, such as action sequences.
For users with hearing loss, our research shows 100% feature approval, with users reporting significantly reduced listening effort during movie watching.
Customers have reported that Dialogue Boost also helps them understand whispered conversations, content with varied accents or dialects, and dialogue during action-heavy scenes, and it lets them enjoy movies without subtitle distraction. Additionally, for late-night viewers, or people who watch TV while others are sleeping, the technology has proven particularly valuable. Rather than constantly adjusting volume or relying on subtitles, viewers can maintain a comfortable listening level while ensuring that dialogue remains clear and understandable.
Dialogue Boost is the result of collaboration across Amazon Lab126 and Prime Video teams. We would like to thank Gordon Han, Berkant Tacer, Phil Hilmes, Peter Korn, Rui Wang, Ali Milani, Scott Isabelle, Vimal Bhat, Linda Liu, Mohamed Omar, Lakshmi Ziskin, Rohith Mysore, and Vijaya Kumar.
Sub-band processingPseudo-labelingAcknowledgements Research areas: Conversational AI
Tags: Signal processing
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み