標準的な大規模言語モデルを超えて
Sebastian Raschka は、標準的な自己回帰型トランスフォーマーに代わるリニアアテンションハイブリッドやテキスト拡散モデルなどの代替アーキテクチャを体系的に解説し、今後の LLM 発展の多様性を示唆している。
キーポイント
標準 LLM の現状と限界
DeepSeek R1 や MiniMax-M2 など、現在の最先端オープンウェイトモデルは依然としてマルチヘッドアテンションに基づく自己回帰型デコーダトランスフォーマーが主流だが、効率性や性能向上のための代替案への関心が高まっている。
主要な代替アーキテクチャの紹介
本記事では、計算コスト削減を目指すリニアアテンションハイブリッド、生成プロセスの多様性を提供するテキスト拡散モデル、およびコード推論に特化したコードワールドモデルなど、非標準的な LLM 構造を重点的に取り上げている。
PyTorch Conference 2025 の補足
著者は PyTorch Conference 2025 で発表した内容を基に、従来のトランスフォーマー比較記事への質問回答として、これらの代替アプローチの詳細な解説をこの記事で提供している。
今後の研究動向の展望
各アーキテクチャは単独で深い議論が必要となるほど重要であり、本稿はそれらへの入門として位置づけられ、将来的には個別のトピックも詳細に扱う予定である。
Transformer-SSM ハイブリッドの分類における著者の見解
著者は、Qwen3-Next や Kimi Linear を「SSM に Transformer コンポーネントを組み込んだもの」とは捉えず、「Transformer に SSM コンポーネントを組み込んだもの」として区別しています。
効率的なアテンション機構の活用
grouped-query attention、sliding-window attention、multi-head latent attention などの効率化技術が実装され、入力トークン数に対して線形にスケールするアプローチへの回帰が進んでいます。
標準的な Transformer の限界と代替案の必要性
従来の scaled-dot-product attention は計算コストが二次関数的に増加するため、研究者やエンジニアはより効率的な代替案の開発を続けており、それが現在のトレンドとなっています。
影響分析・編集コメントを表示
影響分析
この記事は、業界が「より大きな自己回帰モデル」への一極集中から脱却し、計算効率や特定タスク(コード生成など)に特化した多様なアーキテクチャへ注目を移す転換点を示しています。技術者や研究者にとって、次世代 LLM の設計指針を探る上で不可欠なロードマップとなり、実装の選択肢を広げるきっかけとなるでしょう。
編集コメント
標準的なトランスフォーマーの限界を打破する次世代アーキテクチャへの包括的な解説であり、技術選定の視座を広げる重要な記事です。特にコード生成や推論効率に特化した新しいアプローチについて、初学者から上級者まで幅広く参考になる内容となっています。
標準LLMを超えて
線形アテンション・ハイブリッド、テキスト拡散、コード世界モデル、小型再帰トランスフォーマー
 Sebastian Raschka, PhDNov 04, 20253612836ShareDeepSeek R1からMiniMax-M2まで、今日の最大かつ最も能力の高いオープンウェイトLLMは、依然としてオートリグレッシブ(自己回帰)デコーダー式トランスフォーマーであり、それは元のマルチヘッド・アテンション機構の派生形に基づいて構築されています。
Sebastian Raschka, PhDNov 04, 20253612836ShareDeepSeek R1からMiniMax-M2まで、今日の最大かつ最も能力の高いオープンウェイトLLMは、依然としてオートリグレッシブ(自己回帰)デコーダー式トランスフォーマーであり、それは元のマルチヘッド・アテンション機構の派生形に基づいて構築されています。
しかし、近年では標準的なLLMに代わるアプローチも出現しており、テキスト拡散モデルから最近の線形アテンション・ハイブリッドアーキテクチャまで様々です。それらの一部はより高い効率性を目指しており、コード世界モデルのようにモデリング性能の向上を目指すものもあります。
数ヶ月前に、主要なトランスフォーマーベースのLLMに焦点を当てた「ビッグLLMアーキテクチャ比較」を共有した後、これらの代替アプローチについて私がどう考えているか、多くの質問を受けました。(また、私は最近2025年PyTorchカンファレンスでこれについて短い講演を行い、参加者に対してこれらの代替アプローチについての記事をフォローアップすると約束しました)。さて、ここにそれがあります!
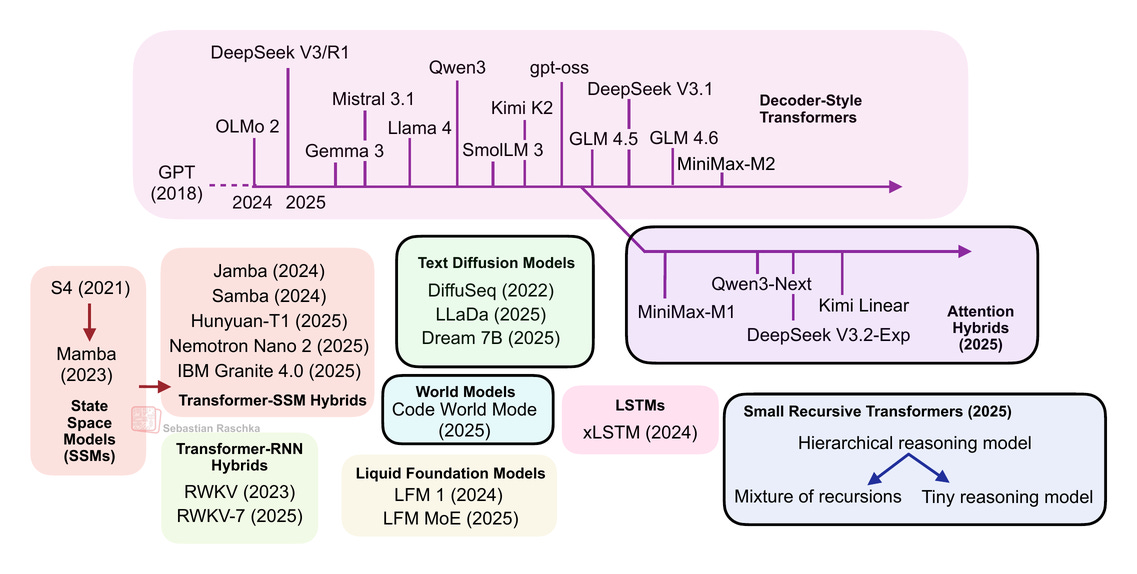 図1: LLMの状況の概要。この記事では、黒い枠で囲まれたアーキテクチャをカバーします。デコーダー式トランスフォーマーは私の「The Big Architecture Comparison」記事でカバーしています。枠で囲まれていない他のアーキテクチャは、将来の記事でカバーされるかもしれません。
図1: LLMの状況の概要。この記事では、黒い枠で囲まれたアーキテクチャをカバーします。デコーダー式トランスフォーマーは私の「The Big Architecture Comparison」記事でカバーしています。枠で囲まれていない他のアーキテクチャは、将来の記事でカバーされるかもしれません。
なお、上図に示されている各トピックは、理想的にはそれぞれが少なくとも記事1本分に値する内容です(そして将来的にはそうなることを願っています)。ですから、この記事を適切な長さに保つために、多くのセクションはかなり短くなっています。しかし、近年出現したすべての興味深いLLMの代替案への入門として、この記事が依然として有用であることを願っています。
追記:前述のPyTorchカンファレンス講演は、公式PyTorch YouTubeチャンネルにアップロードされる予定です。それまでの間、興味があれば、下記に練習用の録画バージョンを見つけることができます。
(YouTube版もこちらにあります。)
- トランスフォーマーベースのLLM
古典的な「Attention Is All You Need」アーキテクチャに基づくトランスフォーマーベースのLLMは、テキストとコードの両方において依然として最先端です。2024年後半から今日までのハイライトだけを考慮すると、注目すべきモデルには以下が含まれます:
Mistral Small 3.1
(上記のリストはオープンウェイトモデルに焦点を当てています;GPT-5、Grok 4、Gemini 2.5などのプロプライエタリモデルもこのカテゴリーに該当します。)
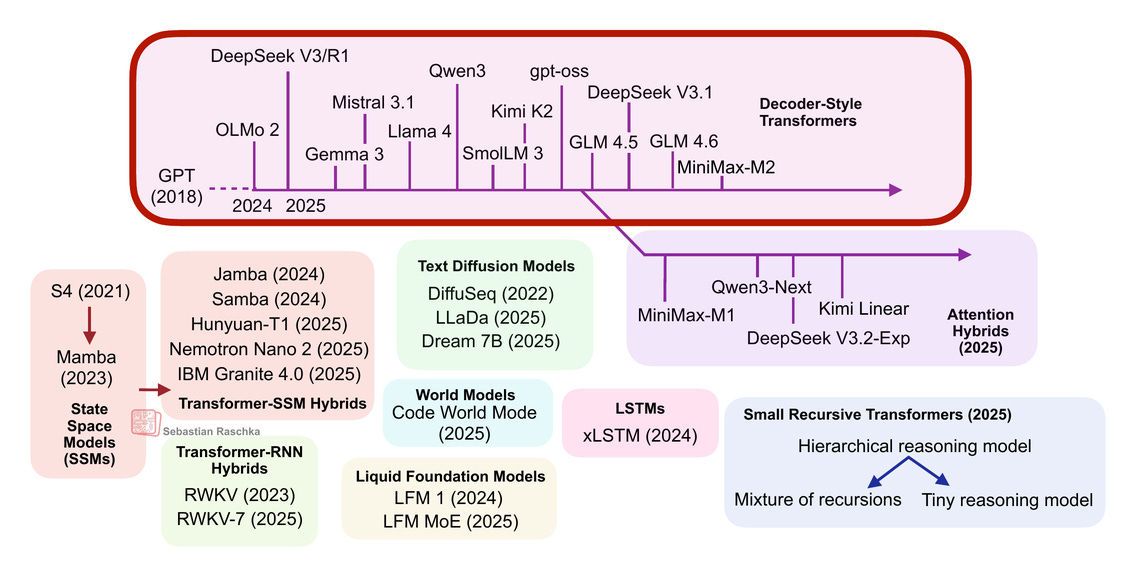 図2: 過去1年間にリリースされた最も注目すべきデコーダー式トランスフォーマーの概要。
図2: 過去1年間にリリースされた最も注目すべきデコーダー式トランスフォーマーの概要。
トランスフォーマーベースのLLMについては何度も話し、書いてきたので、大まかな考え方とアーキテクチャには親しんでいるものと想定します。より深いカバレッジをご希望の場合は、上記リスト(および下図に示す)のアーキテクチャを私の「The Big LLM Architecture Comparison」記事で比較しています。
(補足:概要図ではQwen3-NextとKimi Linearを他のトランスフォーマー状態空間モデル(SSM)ハイブリッドと一緒にグループ化することもできたでしょう。個人的には、これらの他のトランスフォーマー-SSMハイブリッドを、トランスフォーマーコンポーネントを持つSSMと見なし、ここで議論するモデル(Qwen3-NextとKimi Linear)をSSMコンポーネントを持つトランスフォーマーと見なしています。しかし、IBM Granite 4.0とNVIDIA Nemotron Nano 2をトランスフォーマー-SSMボックスにリストしているので、それらを単一カテゴリーにまとめる議論も可能かもしれません。)
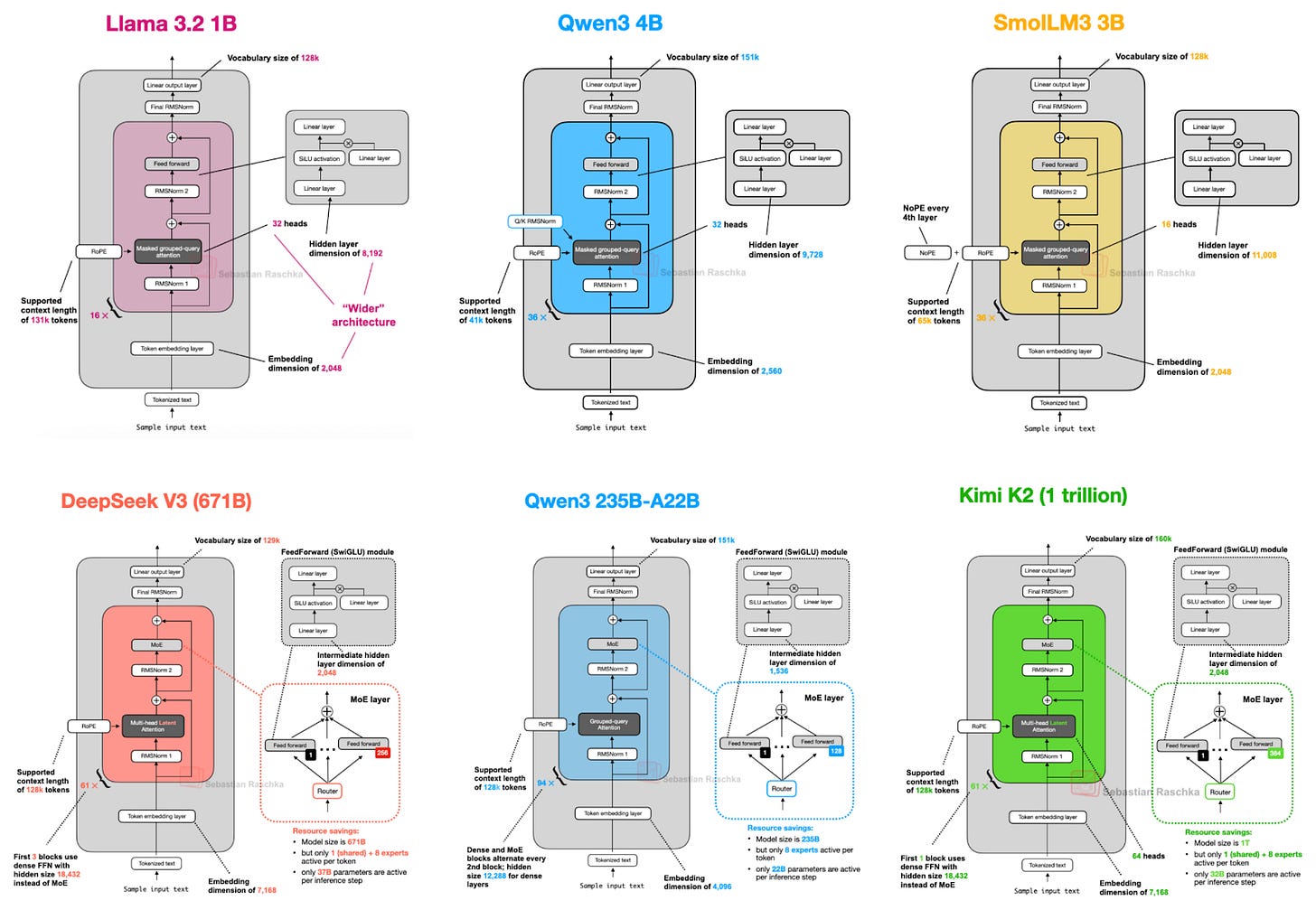 図3. 私の「The Big Architecture Comparison」(https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison)記事で議論されたアーキテクチャの一部。
図3. 私の「The Big Architecture Comparison」(https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison)記事で議論されたアーキテクチャの一部。
もしあなたがLLMを扱っている、あるいはLLMについて作業しているのであれば、例えばアプリケーションの構築、モデルのファインチューニング、新しいアルゴリズムの試行などにおいて、私はこれらのモデルを第一選択にするでしょう。それらはテスト済みで実証されており、よく機能します。
さらに、「The Big Architecture Comparison」記事で議論したように、グループ化クエリアテンション、スライディングウィンドウアテンション、マルチヘッド潜在アテンションなど、多くの効率化の改善があります。
しかし、研究者やエンジニアが代替案を試みる努力をしなかったら、それは退屈です(そして近視眼的です)。ですから、残りのセクションでは、近年出現したいくつかの興味深い代替案をカバーします。
- (線形)アテンション・ハイブリッド
より「異なる」アプローチを議論する前に、まず、より効率的なアテンション機構を採用したトランスフォーマーベースのLLMを見てみましょう。特に、入力トークン数に対して二次関数的ではなく線形的にスケールするものに焦点を当てます。
最近、LLMの効率を改善するための線形アテンション機構の復活がありました。
「Attention Is All You Need」論文(2017年)で導入されたアテンション機構、別名スケールドドットプロダクトアテンションは、今日のLLMにおいて依然として最も人気のあるアテンションの変種です。従来のマルチヘッドアテンションに加えて、私の講演で議論したグループ化クエリアテンション、スライディングウィンドウアテンション、マルチヘッド潜在アテンションなどのより効率的な派生形でも使用されています。
2.1 従来のアテンションと二次コスト
元のアテンション機構は、シーケンス長に対して二次関数的にスケールします:
これは、クエリ(Q)、キー(K)、値(V)がn×d行列であるためです。ここで、dは埋め込み次元(ハイパーパラメータ)、nはシーケンス長(つまりトークン数)です。
(詳細は私の「Understanding and Coding Self-Attention, Multi-Head Attention, Causal-Attention, and Cross-Attention in LLMs」記事で見つけることができます)
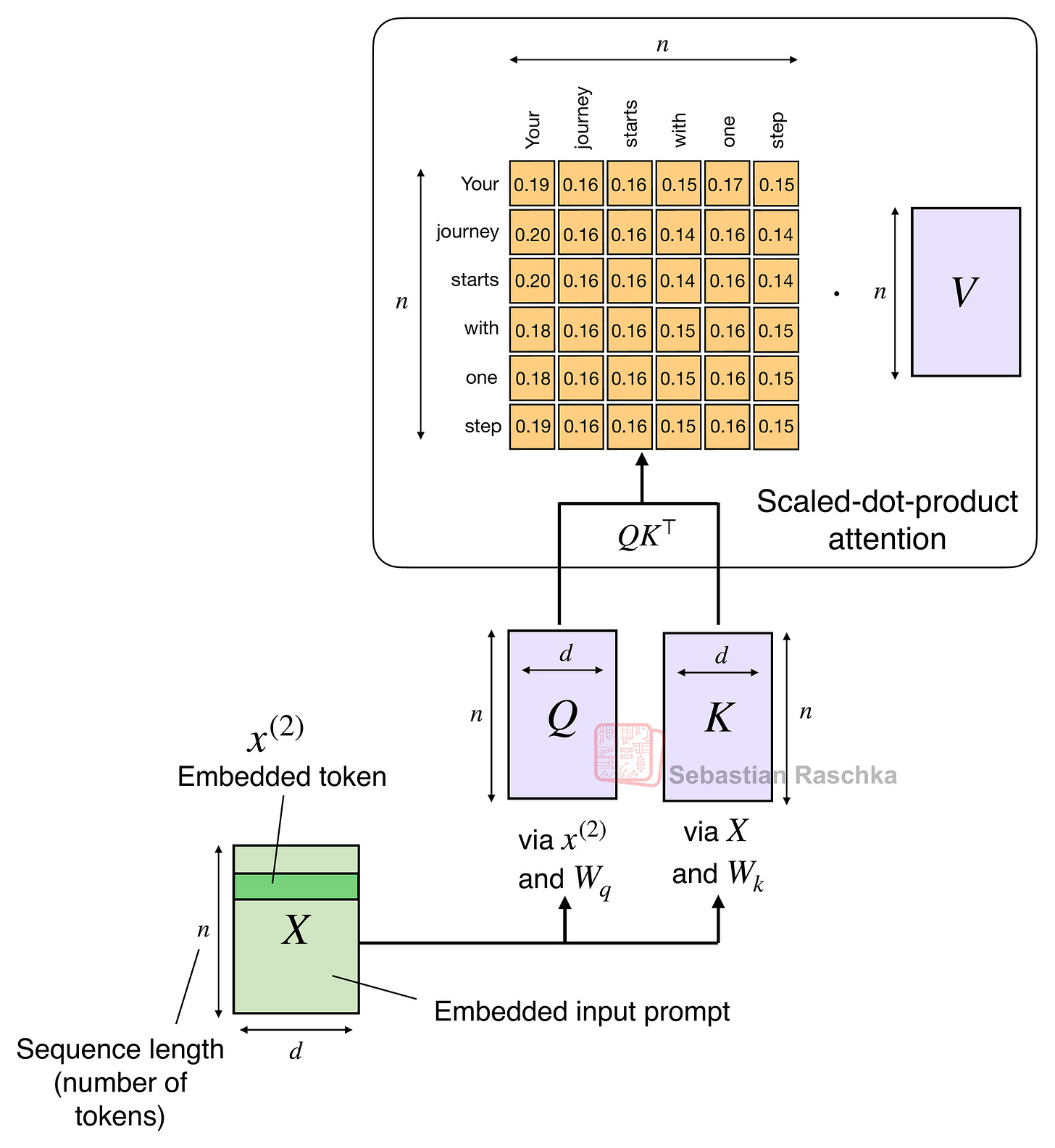 図4: マルチヘッドアテンションにおける従来のスケールドドットプロダクトアテンション機構の図解;シーケンス長nによるアテンションの二次コスト。
図4: マルチヘッドアテンションにおける従来のスケールドドットプロダクトアテンション機構の図解;シーケンス長nによるアテンションの二次コスト。
2.2 線形アテンション
線形アテンションの変種は長い間存在しており、2020年代に大量の論文を見たのを覚えています。例えば、私が思い出す最も初期のものの一つは、2020年の「Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention」論文で、研究者たちはアテンション機構を近似しました:
ここで、ϕ(⋅)はカーネル特徴関数で、ϕ(x) = elu(x)+1に設定されます。
この近似は、n×nアテンション行列QKTを明示的に計算することを避けるため効率的です。
これらの古い試みについてあまり長く立ち入りたくはありません。しかし要点は、それらが時間とメモリの複雑さをO(n2)からO(n)に減らし、長いシーケンスに対してアテンションをはるかに効率的にしたことです。
しかし、それらはモデルの精度を低下させたため、本当に広く受け入れられることはなく、これらの変種のいずれかがオープンウェイトの最先端LLMに適用されているのを実際に見たことはありません。
2.3 線形アテンションの復活
今年の後半には、線形アテンション変種の復活があり、また下図に示すように、一部のモデル開発者間で行き来も少しありました。
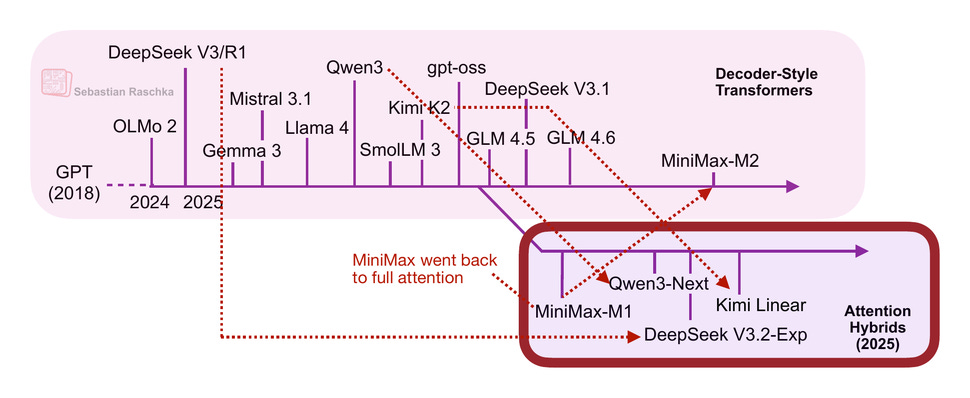 図5: の概要
図5: の概要
原文を表示
Beyond Standard LLMs
Linear Attention Hybrids, Text Diffusion, Code World Models, and Small Recursive Transformers
Sebastian Raschka, PhDNov 04, 20253612836ShareFrom DeepSeek R1 to MiniMax-M2, the largest and most capable open-weight LLMs today remain autoregressive decoder-style transformers, which are built on flavors of the original multi-head attention mechanism.
However, we have also seen alternatives to standard LLMs popping up in recent years, from text diffusion models to the most recent linear attention hybrid architectures. Some of them are geared towards better efficiency, and others, like code world models, aim to improve modeling performance.
After I shared my Big LLM Architecture Comparison a few months ago, which focused on the main transformer-based LLMs, I received a lot of questions with respect to what I think about alternative approaches. (I also recently gave a short talk about that at the PyTorch Conference 2025, where I also promised attendees to follow up with a write-up of these alternative approaches). So here it is!
Figure 1: Overview of the LLM landscape. This article covers those architectures surrounded by the black frames. The decoder-style transformers are covered in my “The Big Architecture Comparison” article. Other non-framed architectures may be covered in future articles.
Note that ideally each of these topics shown in the figure above would deserve at least a whole article itself (and hopefully get it in the future). So, to keep this article at a reasonable length, many sections are reasonably short. However, I hope this article is still useful as an introduction to all the interesting LLM alternatives that emerged in recent years.
PS: The aforementioned PyTorch conference talk will be uploaded to the official PyTorch YouTube channel. In the meantime, if you are curious, you can find a practice recording version below.
(There is also a YouTube version here.)
- Transformer-Based LLMs
Transformer-based LLMs based on the classic Attention Is All You Need architecture are still state-of-the-art across text and code. If we just consider some of the highlights from late 2024 to today, notable models include
Mistral Small 3.1
(The list above focuses on the open-weight models; there are proprietary models like GPT-5, Grok 4, Gemini 2.5, etc. that also fall into this category.)
Figure 2: An overview of the most notable decoder-style transformers released in the past year.
Since I talked and wrote about transformer-based LLMs so many times, I assume you are familiar with the broad idea and architecture. If you’d like a deeper coverage, I compared the architectures listed above (and shown in the figure below) in my The Big LLM Architecture Comparison article.
(Side note: I could have grouped Qwen3-Next and Kimi Linear with the other transformer-state space model (SSM) hybrids in the overview figure. Personally, I see these other transformer-SSM hybrids as SSMs with transformer components, whereas I see the models discussed here (Qwen3-Next and Kimi Linear) as transformers with SSM components. However, since I have listed IBM Granite 4.0 and NVIDIA Nemotron Nano 2 in the transformer-SSM box, an argument could be made for putting them into a single category.)
Figure 3. A subset of the architectures discussed in my The Big Architecture Comparison (https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison) article.
If you are working with or on LLMs, for example, building applications, fine-tuning models, or trying new algorithms, I would make these models my go-to. They are tested, proven, and perform well.
Moreover, as discussed in the The Big Architecture Comparison article, there are many efficiency improvements, including grouped-query attention, sliding-window attention, multi-head latent attention, and others.
However, it would be boring (and shortsighted) if researchers and engineers didn’t work on trying alternatives. So, the remaining sections will cover some of the interesting alternatives that emerged in recent years.
- (Linear) Attention Hybrids
Before we discuss the “more different” approaches, let’s first look at transformer-based LLMs that have adopted more efficient attention mechanisms. In particular, the focus is on those that scale linearly rather than quadratically with the number of input tokens.
There’s recently been a revival in linear attention mechanisms to improve the efficiency of LLMs.
The attention mechanism introduced in the Attention Is All You Need paper (2017), aka scaled-dot-product attention, remains the most popular attention variant in today’s LLMs. Besides traditional multi-head attention, it’s also used in the more efficient flavors like grouped-query attention, sliding window attention, and multi-head latent attention as discussed in my talk.
2.1 Traditional Attention and Quadratic Costs
The original attention mechanism scales quadratically with the sequence length:
This is because the query (Q), key (K), and value (V) are n-by-d matrices, where d is the embedding dimension (a hyperparameter) and n is the sequence length (i.e., the number of tokens).
(You can find more details in my Understanding and Coding Self-Attention, Multi-Head Attention, Causal-Attention, and Cross-Attention in LLMs article)
Figure 4: Illustration of the traditional scaled-dot-product attention mechanism in multi-head attention; the quadratic cost in attention due to sequence length n.
2.2 Linear attention
Linear attention variants have been around for a long time, and I remember seeing tons of papers in the 2020s. For example, one of the earliest I recall is the 2020 Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention paper, where the researchers approximated the attention mechanism:
Here, ϕ(⋅) is a kernel feature function, set to ϕ(x) = elu(x)+1.
This approximation is efficient because it avoids explicitly computing the n×n attention matrix QKT.
I don’t want to dwell too long on these older attempts. But the bottom line was that they reduced both time and memory complexity from O(n2) to O(n) to make attention much more efficient for long sequences.
However, they never really gained traction as they degraded the model accuracy, and I have never really seen one of these variants applied in an open-weight state-of-the-art LLM.
2.3 Linear Attention Revival
In the second half of this year, there has been revival of linear attention variants, as well as a bit of a back-and-forth from some model developers as illustrated in the figure below.
Figure 5: An overview of the linear attention hybrid architectures.
The first notable model was MiniMax-M1 with lightning attention.
MiniMax-M1 is a 456B parameter mixture-of-experts (MoE) model with 46B active parameters, which came out back in June.
Then, in August, the Qwen3 team followed up with Qwen3-Next, which I discussed in more detail above. Then, in September, the DeepSeek Team announced DeepSeek V3.2. (DeepSeek V3.2 sparse attention mechanism is not strictly linear but at least subquadratic in terms of computational costs, so I think it’s fair to put it into the same category as MiniMax-M1, Qwen3-Next, and Kimi Linear.)
All three models (MiniMax-M1, Qwen3-Next, DeepSeek V3.2) replace the traditional quadratic attention variants in most or all of their layers with efficient linear variants.
Interestingly, there was a recent plot twist, where the MiniMax team released their new 230B parameter M2 model without linear attention, going back to regular attention. The team stated that linear attention is tricky in production LLMs. It seemed to work fine with regular prompts, but it had poor accuracy in reasoning and multi-turn tasks, which are not only important for regular chat sessions but also agentic applications.
This could have been a turning point where linear attention may not be worth pursuing after all. However, it gets more interesting. In October, the Kimi team released their new Kimi Linear model with linear attention.
For this linear attention aspect, both Qwen3-Next and Kimi Linear adopt a Gated DeltaNet, which I wanted to discuss in the next few sections as one example of a hybrid attention architecture.
Let’s start with Qwen3-Next, which replaced the regular attention mechanism by a Gated DeltaNet + Gated Attention hybrid, which helps enable the native 262k token context length in terms of memory usage (the previous 235B-A22B model model supported 32k natively, and 131k with YaRN scaling.)
Their hybrid mechanism mixes Gated DeltaNet blocks with Gated Attention blocks within a 3:1 ratio as shown in the figure below.
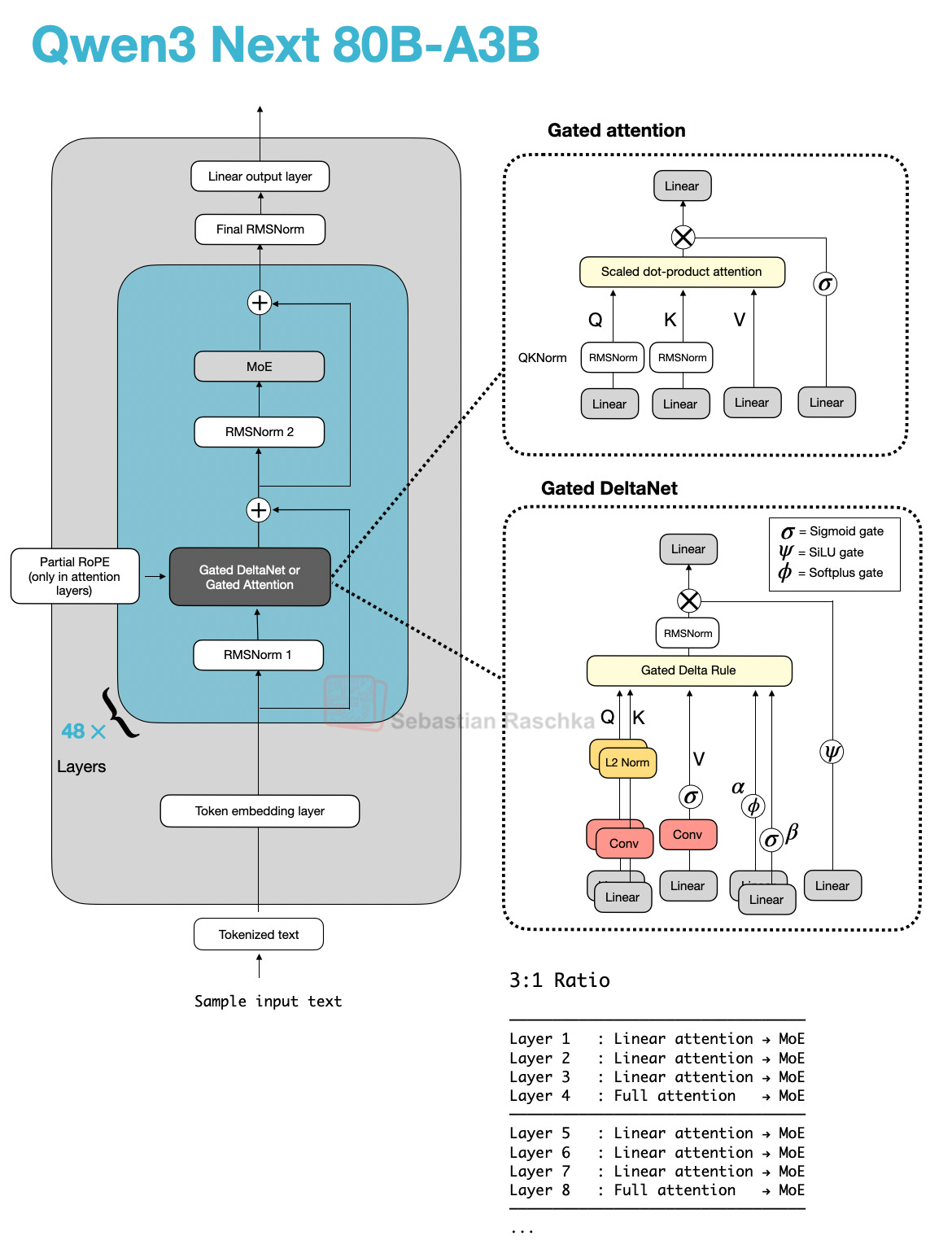 Figure 6: Qwen3-Next with gated attention and Gated DeltaNet.
Figure 6: Qwen3-Next with gated attention and Gated DeltaNet.
As depicted in the figure above, the attention mechanism is either implemented as gated attention or Gated DeltaNet. This simply means the 48 transformer blocks (layers) in this architecture alternate between this. Specifically, as mentioned earlier, they alternate in a 3:1 ratio. For instance, the transformer blocks are as follows:
────────────────────────────────── Layer 1 : Linear attention → MoE Layer 2 : Linear attention → MoE Layer 3 : Linear attention → MoE Layer 4 : Full attention → MoE ────────────────────────────────── Layer 5 : Linear attention → MoE Layer 6 : Linear attention → MoE Layer 7 : Linear attention → MoE Layer 8 : Full attention → MoE ────────────────────────────────── ...
Otherwise, the architecture is pretty standard and similar to Qwen3:
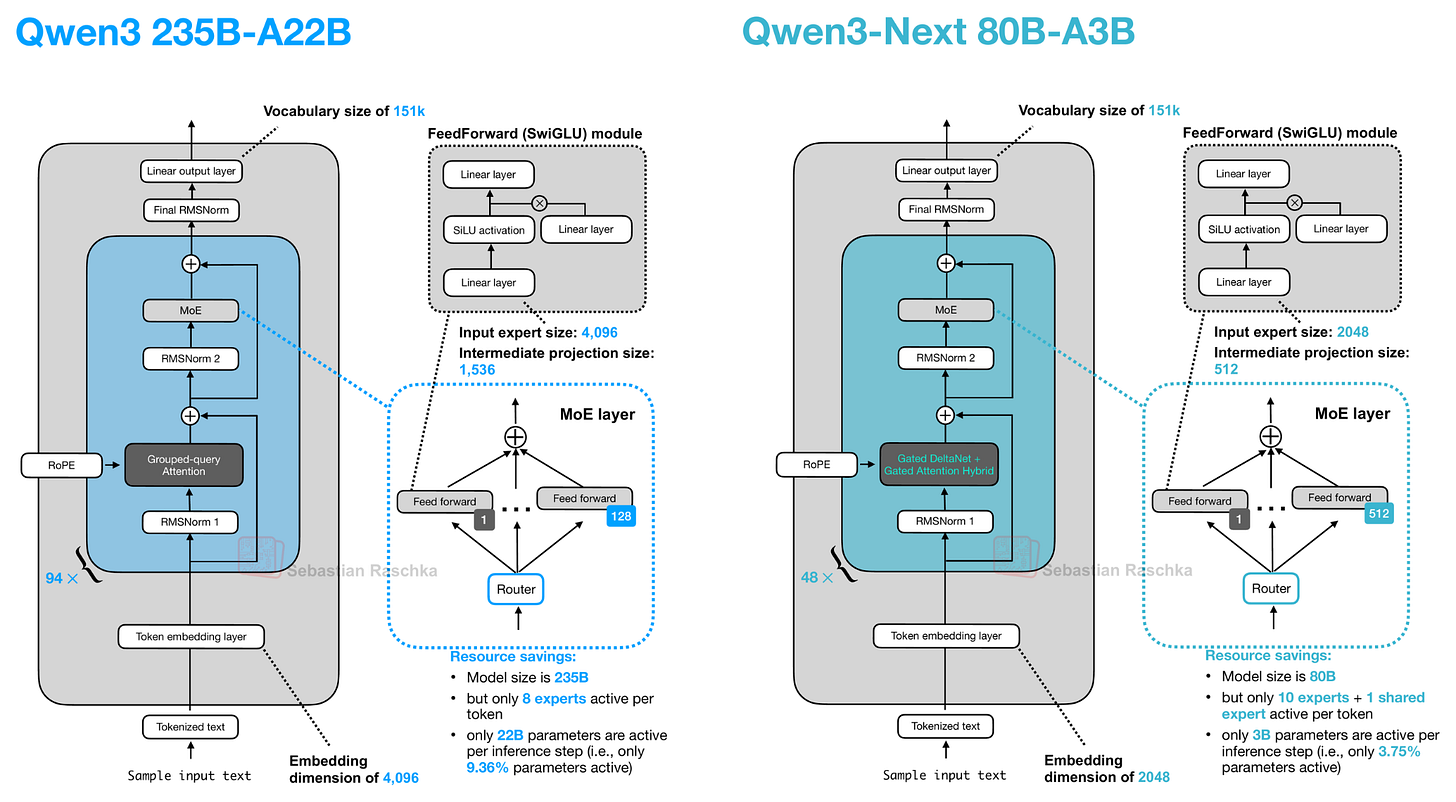 Figure 7: A previous “regular” Qwen3 model (left) next to Qwen3-Next (right).
Figure 7: A previous “regular” Qwen3 model (left) next to Qwen3-Next (right).
So, what are gated attention and Gated DeltaNet?
2.5 Gated Attention
Before we get to the Gated DeltaNet itself, let’s briefly talk about the gate. As you can see in the upper part of the Qwen3-Next architecture in the previous figure, Qwen3-Next uses “gated attention”. This is essentially regular full attention with an additional sigmoid gate.
This gating is a simple modification that I added to an MultiHeadAttention
![](https://substackcdn.com/image/fetch/$s_!INZl!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazo
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み