Anthropic、SpaceXと300MW・年間50億ドルのAIインフラ契約を締結しClaudeの管理エージェント機能を強化
Anthropic は SpaceX との提携により xAI の Colossus I インフラを独占利用し、年間 50 億ドル規模の契約で新クラウド事業へ参入すると発表し、同時に「1 人企業」や「データセンター内の天才集団」といった未来の AI エコシステムビジョンを示した。
キーポイント
xAI との超大規模インフラ提携
Anthropic は SpaceX の Colossus I データセンターを xAI が独占利用する契約に合意し、年間約 50 億ドル(300MW)規模で「ネオクラウド」事業を開始すると発表した。
8000% の ARR 成長と企業ビジョン
CEO Dario Amodei は過去 6 ヶ月間の年間契約収益(ARR)が 8000% 成長したことを発表し、2026 年には「1 人企業」や「チーム型 AI エージェント」が主流になると予測。
Claude Managed Agents の新機能
開発者向けイベントで Claude Code の更新に加え、組織全体の生産性を高めるための新しいマネージドエージェント機能が 3 つ発表された。
SpaceXとの大規模コンピュート提携とClaudeの制限緩和
AnthropicはSpaceXとの300MW/$5B/yrの契約によりColossus Iへのアクセスを得て、Claude Codeの5時間レート制限がPro以上で2倍に引き上げられ、ピーク時の制限も解除された。
Claudeの推論能力拡大と新機能への議論
Claudeの推論は数日以内にColossus上でスケールアップされる予定だが、開発者らは「Managed Agents」や「Outcomes」といった新機能が真の差別化要因か単なる標準機能かの議論を交わしている。
予想以上の需要増によるコンピュートボトルネック
今回の制限緩和の背景には、想定を上回る急激な利用増加により深刻なコンピュート不足が生じていたことがあり、ユーザーからは週次制限が変更されていない点への疑問も出ている。
Claude Code の利用制限緩和と Colossus I への移行
Anthropic は SpaceX との提携により、Pro/Max/Team エディションの Claude Code 利用制限を大幅に引き上げ、Opus モデルの API レートリミットも増強した。
影響分析・編集コメントを表示
影響分析
この提携は、AI モデル開発企業同士がインフラ面で競合からパートナーへ転じる稀有な事例であり、大規模計算リソースを巡る業界再編の兆候を示しています。また、単なるモデル性能向上だけでなく、「1 人企業」や「組織全体での AI 活用」というビジネスモデルの変革を加速させる重要な転換点となります。
編集コメント
競合である OpenAI との訴訟中にも関わらず、インフラ面で xAI と組むという戦略的な判断は業界に大きな衝撃を与えています。計算リソースを巡る「協力と競争」の境界線がさらに曖昧になりつつある現状を如実に示すニュースです。
今日は Anthropic の 2 回目の年次開発者イベントが開催され、その雰囲気は完璧でした。大きなモデルの発表はありませんでしたが、これは一部の人(過大評価された人々)が期待していたことではありませんでした。しかし、SpaceX とのパートナーシップ発表(Claude の過去最大のリリースに挑戦する軌道に乗っている)、Claude Managed Agents 向けの 3 つの新機能、そして過去 6 ヶ月間にリリースされたすべての内容のリキャップ/再紹介/祝賀会が行われました。
オープニング基調講演
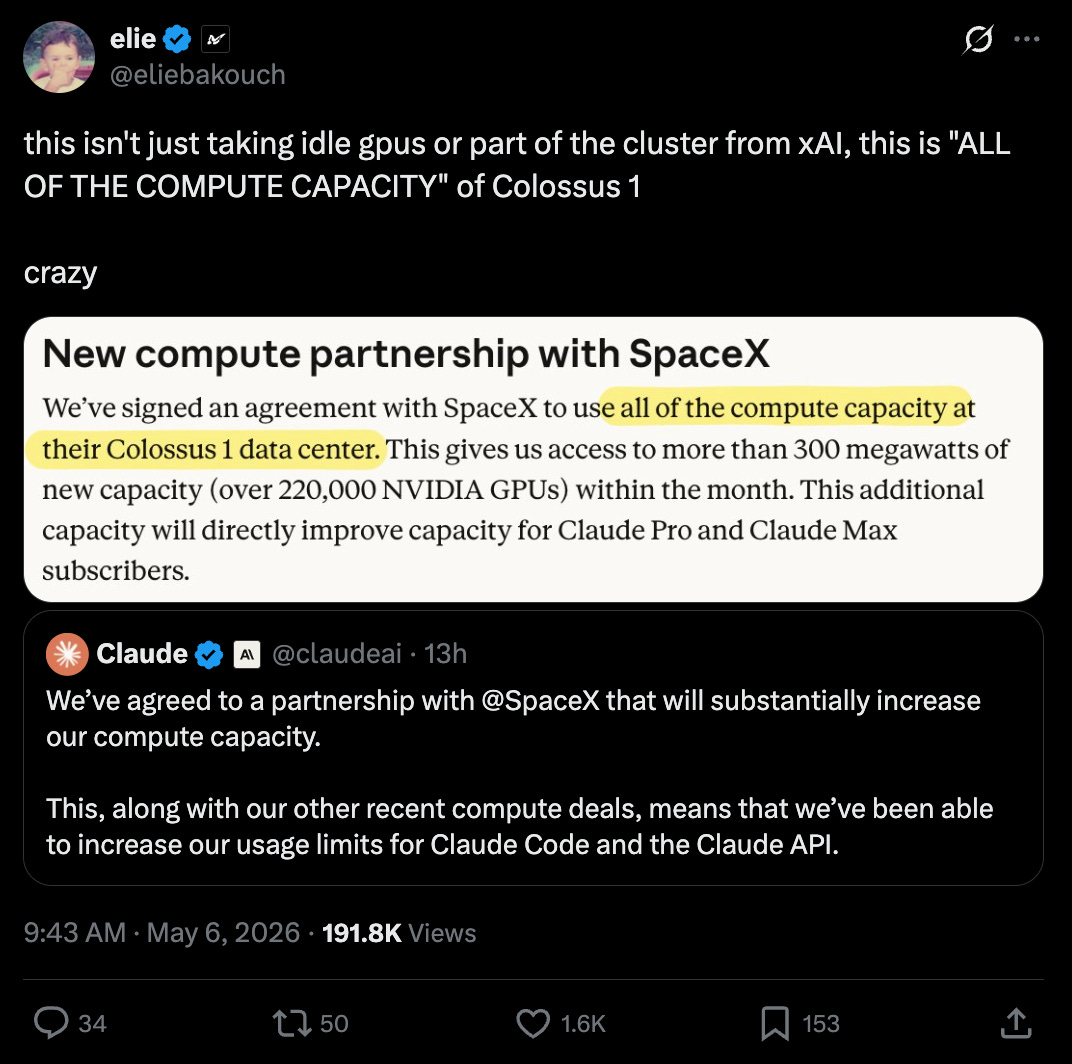
Elon がこれを承認した後、おそらく OpenAI に対する訴訟が裁判中であるという戦略的なタイミングで、Anthropic は Colossus 1 のすべてを驚くべき速度(「今後数日以内に」)で引き継いでいます。これは約 50 億ドル/年の契約と推定されており、xAI をネオクラウド(新クラウド)へと変貌させています。
もう一つの大きな見どころは、Amodei 兄弟とのモデレーション付きセッションで、80 倍の成長を発表し、米国および中国の競合他社に関するコメントを行いました。
ダリオが注目しているトレンド:
超小規模チーム: 彼は依然として、2026 年に「一人の億万長者企業」が登場する年になると考えています。「一人、あるいはごく少数の人々が、驚くべき成果を成し遂げる能力は極めて巨大です。以前は、アイデアやビジョンを実現するには、数年かけて多くのリソースを蓄積する必要がありましたが、今では個人や非常に小さなチームが驚くべきことを実現できるという独自の機会があります。モデルがコードを書く段階から、ソフトウェアエンジニアリング自体をタスクとして捉えるよう支援する段階へ、そしてビジネスや経済単位をどのように構築するかという課題に対する思考プロセスを支援する段階へと移行しています」。
マルチエージェント: 「部屋に集まった賢明な人々のチームから始め、最終的には『データセンター内の天才たちの国』へと発展させる」
エンタープライズサービス: 「Claude Code は個人の生産性を高めますが、私たちはますます、チーム全体や組織全体の生産性を高め、単なる部分の合計以上の成果を生み出すことを支援していくでしょう」。
ボトルネック: Claude はもちろん Claude の処理速度を向上させていますが、彼はアンダールの法則(Amdahl's Law)を念頭に置き、セキュリティや検証可能性といったソフトウェアエンジニアリングにおけるボトルネックを見つけ出し、それらを除去または加速させることで全体のプロセスを高速化することを目指しています。
残りのメインステージセッションには以下が含まれていました:
Claude Code のアップデートで必ず知っておくべき点:

内側ループと外側ループに関する Outcomes コンテンツの追加情報…

… エージェントの自動改善のためのものです:
2026 年 5 月 5 日〜6 日の AI ニュース。12 のサブレッド、544 件の Twitter(X)投稿を確認し、Discord は追加で確認していません。AINews のウェブサイトでは過去のすべての号を検索できます。念のためにお知らせしますが、AINews は現在 Latent Space のセクションの一部となっています。メールの配信頻度を選択的にオン/オフに設定可能です!
AI Twitter リキャップ
トップストーリー:Anthropic と Claude の発表・解説
Anthropic は、計算資源(compute)、Claude Code の制限、およびエージェントプラットフォームの方向性を中心とした、非常に多忙なニュースサイクルを迎えました。
公式発表において、Anthropic は SpaceX と新たな計算リソースパートナーシップを締結したと発表し、これにより「大幅に」容量が増強され、Claude プロダクトの利用制限が直ちに引き上げられる見込みです。@claudeai によると、この契約は Claude Code の利用制限を引き上げるのに十分な計算リソースを提供するものであり、具体的な内容は以下の通りです:Pro、Max、Team、および seat ベースの Enterprise 向けに、Claude Code の 5 時間ごとのレート制限が倍増されます。また、Pro と Max ではピーク時の制限引き下げ措置が撤廃され、Opus API のレート制限も大幅に引き上げられます。
xAI はこの契約を、SpaceXAI を通じて Anthropic が Claude 用の「追加容量」へのアクセスを得るものとして位置づけました @xai。一方、Anthropic の CTO トム・ブラウン氏は、Claude の推論処理が Colossus 上で「今後数日中に」本格稼働すると付け加えました @nottombrown。
同社はまた、「Code with Claude」というイベントを開催し、ライブ配信された基調講演や、Claude Code、GitHub スケールでの利用、マネージドエージェントに関するセッションを行いました @ClaudeDevs。これにより、開発者や観察者たちから @simonw や @latentspacepod といった方々による活発なリアルタイムのコメントが寄せられました。
この出来事に関連して、議論は以下の 4 つのテーマに枝分かれしました:
(1) 計算リソースのボトルネックは多くの人が想定していたよりも深刻であり、その原因は予期せぬ利用量の急増によるものだと報じられています;
(2) ユーザーたちは 5 時間ごとの制限引き上げを歓迎しましたが、変更されていない週次制限については疑問を呈しました;
(3) 人々は、Anthropic の新しいマネージドエージェント機能であるメモリや「Dreaming」、およびルブリックや「Outcomes」が、真の製品差別化要因なのか、それとも汎用化可能なハーン(基盤)機能なのかについて議論を行いました;
(4) アンソロピックの安全性・ガバナンスに関する立場は、賞賛と批判の両方を引きつけ続けています。批判派からは「AGI を信頼できるのは私たちだけだ」という姿勢を一部の従業員が示しているとの主張があり、アンソロピックに隣接する声からは、より一般的な内部の見解は「私たちだけ」ではなく「誰も AGI を信頼できない」という考えに近いという反論があります @aidan_clark, @kipperrii。
公式な事実と確認された詳細
アンソロピックは、計算能力の増強を目的としたスペースXとの計算パートナーシップを発表しました @claudeai。
即時発効として、アンソロピックは以下を実施します:
- Pro、Max、Team、および座席ベースのEnterprise向けに、Claude Code の5時間利用制限を倍増させる
- Pro および Max 向けの Claude Code におけるピーク時間帯の利用制限削減を撤廃する
- Opus モデルの API 利用制限を大幅に引き上げる
出典:@claudeai
アンソロピックは、より高い利用制限とスペースXとの計算契約に関する公式解説ページをリンクしました @claudeai。
xAI の発表では、この取り決めについて、スペースXAI がアンソロピックに対して追加の Claude 容量のために Colossus 1 にアクセス権を提供するものとして説明されています @xai。
アンソロピックの CTO(最高技術責任者:Chief Technology Officer)トム・ブラウンは、Claude の推論処理が数日以内に Colossus で段階的に開始されると述べています @nottombrown。
アンソロピックのプロダクト/エンジニアリング担当であるアモル・アバサレは、週次利用制限はまだ引き上げられていないと明確にしました。その理由は、週次制限に達するユーザーがごく一部であるのに対し、5時間制限に達するユーザーがはるかに多いからです。計算リソースの導入が進むにつれて、さらなる変更が行われる可能性があります @TheAmolAvasare, @TheAmolAvasare。
Anthropic/Claude は、基調講演、Claude Code の更新、GitHub スケールでの利用、管理されたエージェントなどを含むセッションを備えた「Code with Claude」イベントを開催しました。
Anthropic の Alex Albert がこのイベントを宣伝し、後に発表内容を「より多くのチップ、より多くの Claude」と要約しました @alexalbert__, @alexalbert__。
専用アカウントである Claude Code アカウントは、Pro/Max/Team に対する制限の引き上げを再確認しました @claude_code。
計算リソースの詳細と規模に関する主張
SpaceX/xAI の提携に関する規模の数値的主張を示すツイートが複数投稿されました。これらは Anthropic の主要な発表ツイートのものではありませんが、広く流通しました:
@arohan は「300 メガワット以上の新規容量」と「1 ヶ月以内に 220,000 個を超える NVIDIA GPU(グラフィックプロセッシングユニット)」を引用しました。
@scaling01 は、Colossus 1 には約 150,000 個の H100、50,000 個の H200、30,000 個の GB200 が含まれると主張しました。
@Yuchenj_UW は 220,000 個という GPU の数値を繰り返すと同時に、Anthropic が Google TPU(テンソルプロセッシングユニット)に 2,000 億ドルをコミットしたという未検証の主張を追加しました。
@eliebakouch は、この契約は Anthropic が単なるアイドル状態の GPU を得るのではなく、Colossus 1 の容量を実質的にすべて獲得するものだと解釈しました。
その後、Elon Musk は、xAI がすでにトレーニングを Colossus 2 に移行しているため、SpaceXAI は Colossus 1 のリースに問題ないと述べました @elonmusk。また、@eliebakouch は、Colossus 2 はすでに約 500,000 個の Blackwell(ブラックウェル)に達していると主張しました。
これらの数値は、Anthropic の公式発表スレッドにおいて完全に正統化されたものではなく、一部公式に近い扱いとすべきです。重要な事実は、正確な在庫内訳よりも、Anthropic が非常に大規模で近未来の外部推論能力拡張を確保したという点にあります。
ボトルネックの実在を示す証拠
繰り返される解釈として、Anthropic の制約は価格や製品設計ではなく、実際に計算資源(compute)であったとする見方がありました。
@kimmonismus はライブストリーミング中または直後に、Anthropic が追加料金なしで Claude Code のレートリミットを倍増させたかどうかを尋ねました。
@kimmonismus は後日、Dario と Daniela のインタビューからの発言を要約し、利用量が予期せぬ約 80 倍に増加したことが計算資源の不足を引き起こし、SpaceX との契約がその課題に対処する最初の主要な試みであると述べたとまとめました。
@czajkadev はこの更新を明確に、計算資源(compute)がボトルネックであったことの証拠として解釈しました。
@theo は別個に、業界の問題は「単にお金ではなく、計算資源(compute)の問題である」と主張し、これはより広範な指摘ではあるものの Anthropic の物語にも合致すると論じました。
@scaling01 はこの契約からマクロ的な仮説を一般化し、最先端研究所は競合他社からデータセンターを借りるほど計算資源(compute)に制約されているとしました。
これはデータセットにおける最も強力な事実・市場シグナルの一つです:Anthropic のユーザー向けレートリミットは、主要な計算資源契約の後に初めて実質的に変更されました。
製品への影響:Claude Code、API、および管理エージェント
Anthropic の実際のユーザーへの影響は明確です:
Claude Code のパワーユーザーは、5 時間のウィンドウ内でより利用可能なバースト容量を得られます。
ピーク時のスロットリング制限が緩和され、Pro/Maxプランでも利用しやすくなりました。
Opus API ユーザーにはより高いレート制限が適用され、エージェントワークロードや本番環境での統合において重要な意味を持ちます。
今回のイベントでは、エージェントに関するアンソロピックの広範なプラットフォームへの野心も浮き彫りになりました。公式のツイートは主にイベント自体についてのものでしたが、解説からは以下のような機能に言及する声が見られます:
Dreaming = メモリ / 跨セッションコンテキスト(文脈)
Outcomes = ルーブリック / 採点 / 客観的追跡
エージェントオーケストレーション / マネージドエージェントへの方向性
解説コメント:
@RichNwan は、アンソロピックが Dreaming と Outcomes を通じて「マネージドエージェントプラットフォームを構築中」だと指摘しましたが、これらがオープンなハーン(枠組み)と比べて意味ある差別化となっているかどうかについては疑問を呈しました。
@eliebakouch は、これらはパワーユーザーにとって重要であり、特にメインのエージェントのコンテキストウィンドウを維持し、別の採点者を使用して品質・安全性・報酬ハッキングを管理するために有用だと見ました。
@latentspacepod は、アンソロピックのスピーカーが検証(verification)を強調し、「ルーティンは高次プロンプトである」と述べたこと、また残されたギャップは多くの場合、生来の能力ではなくデプロイメントや運用化にあるという考え方を引用しました。
この最後の点は、アンソロピックが「ワンショットチャットボット」から、メモリ、分解、採点、検証を備えた構造化されたエージェントシステムへと移行する広範な潮流と一致していることを示しています。
議論における異なる意見
1) 肯定的・支持派
多くの返信はこれをユーザーにとっての勝利であり、アンソロピックが積極的に対応している証拠として捉えました。
@alexalbert__:「より多くのチップ、より多くの Claude」
@_sholtodouglas:「より多くの計算リソース → 直接あなたへ」
@kimmonismus は制限の倍増と Opus API のキャップ引き上げを強調しました。
@TheRundownAI はこれを明確なユーザー利益として要約しました。
@DannyLimanseta は企業間の協力に好感を持ち、Anthropic の慎重さが SpaceXAI の楽観性によってバランスが取られることを願いました。
@AmandaAskell は発表の象徴的な意味に対して肯定的に反応しました。
2) 混合的・実用的な見解
これらの意見は変更を歓迎しつつも、運用上の詳細や残された制限点に焦点を当てました。
@btibor91 と @kimmonismus は直ちに、おそらくの条件付きとして「週ごとのキャップは変更されていない」点を指摘しました。
@TheAmolAvasare はこれに対して直接回答しました。
@sbmaruf は変更後もレート制限(rate limits)を確認しており、ロールアウトと信頼性の調整が進行中であることを示唆しています。
@zachtratar は段階的な展開期間中は忍耐を求めました。
3) 競争的・戦略的批判
別のグループは、この発表を OpenAI と Anthropic の製品戦争の文脈で捉えました。
@scaling01 は、Anthropic が成長の優位性を失ったのは待ちすぎたためであり、おそらく年間経常収益(ARR)において数十億ドルを OpenAI に譲渡したと主張しました。
@Yuchenj_UW は、この動きは Dario が OpenAI Codex の成長に反応して攻撃的になっていると読み解きました。
@arohan は「ビッグテックは Claude のラッパーになった」と冗談めかして述べ、Claude の開発者層におけるシェアの高さを指摘しました。
@dejavucoder による「claude がダウンしている、聖ティボよ、codex の制限をリセットしてくれ」という発言は、一つのサービスが容量制約に直面した際にコードツール間でマルチホミング(複数利用)を行う際の現実的な状況を捉えています。
4) ガバナンス・安全性・文化への批判
これが最も深い哲学的な対立点です。
@aidan_clark は、Anthropic の同僚から繰り返し聞かされているという主張を批判した。それは「AI を構築するのは私たち alone が信頼されるべきだ」という信念である。
@kipperrii は、「私たちだけが信頼できる」という枠組みは悪だと部分的に同意しつつも、真の多数派の見方は「AGI については誰も信頼できない」に近いが、それでも個人的には Anthropic を他社よりもより信頼しているという立場を主張した。
@elonmusk は Anthropic のリーダーたちとの会合後に、驚くべき支持表明を行った。
@Yuchenj_UW は、これは以前の Anthropic への批判を考えると皮肉だと指摘した。
@teortaxesTex は、Musk/xAI と Anthropic の間の急速な和解を皮肉った。
@teortaxesTex はまた、AI リスクを他者に警告しながら、「Mythos」のような強力なクローズドシステムを構築することは矛盾していると論じた。
@goodside は Anthropic のガバナンスに直接言及していないが、Anthropic を巡って頻繁に議論される広範な道徳的・AI 規範の議論に寄与した。
Claude モデルのパフォーマンスと比較に関する解説
これらのツイートに Claude の主要な新モデルは登場しないものの、Claude は製品および評価の議論において参照点として残っていた。
@giffmana は、「Opus 4.6」、ChatGPT Pro、Muse Spark を数学的な不一致について比較した。彼の見解は以下の通りである。
Opus 4.6 は誤った証明を自信を持って擁護し(「ガスライティング」された)、
ChatGPT Pro は数式を正しく統合したが解釈を加えなかった、
Muse Spark は両方をよく行った。
これは anecdotal(個人的な事例)であるが、このセットの中で最も具体的な比較的定性的モデル報告の一つである。
@kimmonismus は、Substack の分析を要約し、サイバーセキュリティ分野では GPT-5.5 が Claude Mythos Preview とほぼ同等か、むしろコスト効率に優れていると主張している一方、Mythos は一部の一般ベンチマークや SWE-bench Pro においてわずかに先行していると指摘しました。また、なぜ Mythos が依然として秘密主義を続けているのか疑問を呈しています。
@AssemblyAI は、ゲートウェイにおける Claude 4.5 以降のモデルが構造化 JSON をサポートしていることを示唆しました。
@OpenRouter/TencentHunyuan は、Claude Code を Hy3 の利用を牽引する主要なアプリケーションの一つとしてリストアップし、裏側でサードパーティ製モデルが使用されている場合でも、コーディングツールエコシステムにおける Claude の重要性を示しています。
これらのコメントは厳密なモデルランキングを確立するものではありませんが、Claude が依然としてコーディングエージェントワークフローの主要なベンチマークであり、先進的なユーザーが単なる基礎的な知能だけでなく、モデル+ハネス(harness)+制限+信頼性を組み合わせて比較するようになっていることを示しています。
Claude Code とハネスエンジニアリングの文脈
データセット全体にわたる注目すべき背景として、多くのエンジニアがエージェントのパフォーマンスはハネス(システムプロンプト、ツール、ミドルウェア、分解戦略、モデル固有のチューニング)に大きく依存していると考えているという点があります。
関連する Anthropic 以外のコメント:
@masondrxy: 同じモデル、同じタスクでも、プロンプトやツール、ミドルウェアの違いによりスコアが大幅に異なり、tau2-bench では 10〜20 ポイントの差が生じると指摘。
@LangChain: OpenAI、Anthropic、Google の各モデル向けのハネスプロファイルを提供。
@jakebroekhuizen: モデルの進化に伴う時間的なハネスの変化と、異なるモデルファミリー間での横断的なチューニングを区別。
@Vtrivedy10:独自に設計されたハレス(harness)は、デフォルトの Codex や Claude Code に比べて多くのタスクで優れたパフォーマンスを発揮できると主張しています。しかし、多くのエージェント設計において、実際に使用可能なコンテキストウィンドウは依然として効果的に 50,000〜100,000 トークン程度に制限されています。
@kieranklaassen:「Claude CLI で作業を完了できない場合、Claude はあなたのために働くことはできません」と述べています。
これは重要なのです。なぜなら、Anthropic のプラットフォームにおけるいくつかの動き——メモリ機能、評価(grading)、管理型エージェントなど——は、ハレスの一部を製品化しようとする試みとして解釈できるからです。これが中心的な議論を説明する助けとなります:これらは防衛可能なプラットフォームの基盤(primitives)なのか、それともオープンなフレームワークが模倣できるパターンを自社でパッケージ化したものに過ぎないのか。
より広い文脈:なぜこれが重要なのか
推論(inference)は、トレーニングだけでなく、現在におけるフロンティアのボトルネックとなっています。
今回のニュースは新しいモデルの発表ではなく、容量(キャパシティ)の拡大に関するものでした。これはフロンティア領域においてますます一般的な傾向です。
計算資源市場は流動的かつ戦略的なものへと変化しています。
Anthropic が SpaceX や xAI のインフラストラクチャと提携することは、「各フロンティア研究所が自社の垂直統合型スタックの上にのみ存在する」といった単純化された物語を崩すものです。
開発者向け製品のシェアは、信頼性と制限条件に敏感です。
Claude は開発者に強い愛着を持たれているようですが、レートリミットやサービス停止により、ユーザーはすぐに Codex、Cursor、その他のツールへと流れてしまいます。
戦場は基本モデルからエージェントシステムへとシフトしています。
「Code with Claude」、管理型エージェント、Dreaming、Outcomes、そしてそれを取り巻く議論はすべて、次の競争の層がメモリ機能、オーケストレーション(調整)、評価(evals)、ワークフロー統合にあることを示唆しています。
Anthropic のブランドは依然として二極化しています。
同時に、
製品品質と安全性への真剣さにおいて称賛され、
父権主義や排他的であるという見方から批判され、
今では以前よりも計算資源に対してより商業的に積極的であると見なされています。
結論
Anthropic のニュースは派手な新モデルについてというよりは、構造的な現実に関するものでした:Claude への需要が利用可能な計算リソースを凌駕しており、Anthropic は主要な外部インフラ契約を締結してすぐに @claudeai, @claudeai の重要なユーザー制限を緩和しました。最も重要な技術的・経済的なシグナルは、容量、レート制限、エージェント製品の使いやすさが、リーダーボードの差分と同様に戦略的に重要になったということです。主な未解決の疑問は、Anthropic がこの容量を持続的な製品モメンタムに変換できるか、そのマネージドエージェント機能が本当に差別化されているか、そして OpenAI、Google、xAI、オープンモデルエコシステムとの競争が激化する中で、その安全性・ガバナンス姿勢が地位を助けるのか阻害するのかという点です。
インフラ、推論、およびシステム
OpenAI とパートナーは、OpenAI の最大のスーパーコンピューターにすでに展開されている大規模 AI 学習クラスター向けのオープンなネットワークプロトコルである MRC(Multipath Reliable Connection)を発表しました @OpenAI, @OpenAI。解説では、マルチパスルーティング、マイクロ秒単位のフェイルオーバー、そしてネットワークが主要なフロンティアのボトルネックへと移行したことが強調されました @kimmonismus, @gdb。
Perplexity は、埋め込みからトリリオンパラメータの LLM までをカバーする独自推論エンジン「ROSE」を開発し、Hopper および Blackwell 上で特殊なカーネル開発を加速するために CuTeDSL を活用していると述べています @perplexity_ai。
vLLM と Mooncake は、再利用可能なプレフィックスを持つエージェントワークロードに対して強力なシステム結果を示しました:スループットが 3.8 倍、P50 TTFT(Time To First Token)が 46 分の 1 に低下し、エンドツーエンドのレイテンシが 8.6 分の 1 に短縮され、キャッシュヒット率が 1.7% から 92.2% に改善されました。これは 60 台の GB200 GPU までスケーリング可能です @vllm_project。
Unsloth と NVIDIA は、家庭用 GPU での LLM 学習を約 25% 高速化すると主張する 3 つのトレーニング最適化手法を発表しました:パケットシーケンスメタデータのキャッシュ、ダブルバッファ化されたチェックポイント再読み込み、そして高速な MoE(Mixture of Experts)ルーティングです @UnslothAI。
NVIDIA は、RL(強化学習)内のロスレス推測デコーディングに関する取り組みを強調し、235B スケールでエンドツーエンドの RL が最大約 2.5 倍高速化され、8B スケールではポリシー分布を変更せずにロールアウトスループットが約 1.8 倍向上すると発表しました @TheTuringPost。
Baseten は、クローズドウェイト(非公開モデル)ラボ向けに管理インフラ、API、認証、レート制限、課金を提供する「Frontier Gateway」を立ち上げました。Poolside は、 kickoff から本番環境までの期間が 7 週間で完了したと報告し、Laguna XS.2 では P50 TTFT が 146ms、Laguna M.1 では 605ms でした @tuhinone, @poolsideai。
ベンチマーク、評価、およびエージェントハッチ
ProgramBench は、言語モデルが修理スタイルの SWE(Software Engineering)タスクを超えて、プログラムをゼロから再構築できるかを問うものであり、Ofir Press はベンチマークは「我々が望む未来を指定する宝の地図」であると論じています @ComputerPapers, @OfirPress。
Terminal-Bench 2.1 は TB2.0 の 89 タスクのうち 28 を修正し、ランキングは維持されたものの絶対スコアは最大で 12 ポイント変動しました。これはエージェントベンチマークの維持が実質的に重要であるという有用な教訓です @terminalbench, @ekellbuch。
OBLIQ-Bench は、困難な第一段階検索に焦点を当てた主要な IR ベンチマークリリースとして登場しました。
原文を表示
It was Anthropic’s second annual developer event today, and the vibes were immaculate. No big model release, which some (miscalibrated) people were hoping for, but it was mostly the SpaceX partnership announcement (on track to challenge Claude’s biggest launch of all time), 3 new features for Claude Managed Agents, and a recap/reintroduction/celebration of all that has been shipped in the past 6 months:
opening keynote
After Elon signed off on it, possibly strategically just as his lawsuit against OpenAI is in trial, Anthropic is taking over all of Colossus 1 with surprising speed (“in the next few days”) which some estimate to be a roughly $5B/year deal, making xAI a neocloud:
The other big draw was the moderated session with the Amodei siblings, announcing the 80x growth and some commentary on US and Chinese competitors:
The trends Dario is watching:
Tiny Teams: He still thinks 2026 is the year we see a one person billion dollar company. “There is an enormous ability for one person or a tiny set of people to do a set of things that are incredible… Before, if you had an idea or vision there are so many resources you’d have to accumulate for several years in order to make that vision happen, and I think there’s a unique opportunity for single individuals or very tiny teams to do things that are incredible, where we move from the models are writing code, to the models are helping us think of software engineering as a task, to the models are helping us think of how can I build a business or economic unit as a task”.
Multiagents: “starting with a team of smart people in a room and working our way up to a ‘country of geniuses in a datacenter’”
Enterprise Services: “Claude Code helps individuals to be more productive, but we’re increasingly going to help whole teams and organizations be more productive and more than the sum of its parts”.
Bottlenecks: Claude is of course speeding up Claude, but he thinks about Amdahl’s Law - Security, Verifiability - finding the bottlenecks in software engineering and removing them/speeding up the overall process.
The rest of the mainstage sessions included:
Must know Claude Code updates:
More Outcomes content on the Inner vs the Outer Loop…
… for automatic improvement of agents:
AI News for 5/5/2026-5/6/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Top Story: Anthropic and Claude announcements/commentary
Anthropic had a dense news cycle centered on compute, Claude Code limits, and agent platform direction.
Officially, Anthropic announced a new compute partnership with SpaceX that will “substantially increase” capacity and immediately translate into higher limits for Claude products: @claudeai said the deal boosts compute enough to raise usage limits, followed by specifics from @claudeai: Claude Code’s 5-hour rate limits are doubled for Pro, Max, Team, and seat-based Enterprise; peak-hours limit reductions are removed for Pro and Max; Opus API rate limits are substantially increased.
xAI framed the deal as Anthropic getting access to Colossus 1 via SpaceXAI for “additional capacity for Claude” @xai, while Anthropic CTO Tom Brown added that Claude inference would be ramped up on Colossus “in the next few days” @nottombrown.
The company also ran its “Code with Claude” event, with a livestreamed keynote and sessions on Claude Code, GitHub-scale usage, and managed agents @ClaudeDevs, prompting substantial real-time commentary from developers and observers @simonw, @latentspacepod.
Around this, discourse branched into four themes:
(1) compute bottlenecks were more severe than many assumed, reportedly due to unexpected usage growth;
(2) users welcomed the 5-hour limit increase but questioned unchanged weekly limits;
(3) people debated whether Anthropic’s new managed-agent features like memory/“Dreaming” and rubrics/“Outcomes” are real product differentiation or commoditizable harness features; and
(4) Anthropic’s safety/governance positioning continued to attract both praise and criticism, including claims from critics that some Anthropic employees project “only we can be trusted with AGI,” and counterclaims from Anthropic-adjacent voices that the more common internal view is closer to “no one can be trusted with AGI” than “only us” @aidan_clark, @kipperrii.
Official facts and confirmed details
Anthropic announced a SpaceX compute partnership to increase capacity @claudeai.
Effective immediately, Anthropic says it is:
Doubling Claude Code’s 5-hour rate limits for Pro, Max, Team, and seat-based Enterprise
Removing peak-hours limit reduction on Claude Code for Pro and Max
Substantially increasing API rate limits for Opus models
Source: @claudeai
Anthropic linked an official explainer on the higher usage limits and the SpaceX compute deal @claudeai.
xAI’s announcement described the arrangement as SpaceXAI providing Anthropic access to Colossus 1 for additional Claude capacity @xai.
Anthropic CTO Tom Brown said Claude inference would start ramping on Colossus within days @nottombrown.
Anthropic product/eng lead Amol Avasare clarified that weekly limits were not increased yet because only a small percentage of users hit weekly limits, while a much larger percentage hit 5-hour limits; more changes may come as compute lands @TheAmolAvasare, @TheAmolAvasare.
Anthropic/Claude held a Code with Claude event with sessions including keynote, Claude Code updates, GitHub-scale usage, and managed agents @ClaudeDevs.
Anthropic’s Alex Albert promoted the event and later summarized the announcement as “More chips, more Claude” @alexalbert__, @alexalbert__.
The dedicated Claude Code account reiterated the limit increase for Pro/Max/Team @claude_code.
Compute details and scale claims
Several tweets added quantitative claims about the scale of the SpaceX/xAI arrangement. These are not from Anthropic’s main announcement tweets, but they were widely circulated:
@arohan cited “more than 300 megawatts of new capacity” and “over 220,000 NVIDIA GPUs within the month.”
@scaling01 claimed Colossus 1 includes ~150,000 H100s, 50,000 H200s, and 30,000 GB200s.
@Yuchenj_UW repeated the 220,000 GPU figure and added an unverified claim that Anthropic had committed $200B on Google TPUs.
@eliebakouch interpreted the deal as Anthropic getting effectively all of Colossus 1 capacity, not just idle GPUs.
Elon Musk later said SpaceXAI was comfortable leasing Colossus 1 because xAI had already moved training to Colossus 2 @elonmusk, and @eliebakouch claimed Colossus 2 is already at ~500k Blackwells.
These numbers are best treated as partly official-adjacent but not fully canonized in Anthropic’s own announcement thread. The broad factual takeaway is stronger than the exact inventory breakdown: Anthropic secured a very large, near-term external inference capacity expansion.
Evidence the bottleneck was real
A recurring interpretation was that Anthropic’s constraint had genuinely been compute, not merely pricing or product design.
@kimmonismus asked during/after the livestream whether Anthropic was doubling Claude Code rate limits at no extra charge.
@kimmonismus later summarized remarks from a Dario/Daniela interview: usage grew ~80x unexpectedly, which purportedly caused the compute shortage, and the SpaceX deal is the first major attempt to address it.
@czajkadev explicitly interpreted the update as proof that compute was the bottleneck.
@theo separately argued the industry problems are “not just money, it’s about compute,” which fits the Anthropic story even though it’s a broader point.
@scaling01 generalized from this deal to a macro thesis: frontier labs are compute constrained enough to rent datacenters from competitors.
This is one of the strongest factual/market signals in the dataset: Anthropic’s user-facing rate limits moved materially only after a major compute deal.
Product implications: Claude Code, API, and managed agents
Anthropic’s practical user impact is clear:
Claude Code power users get more usable burst capacity over a 5-hour window.
Peak-time throttling is eased for Pro/Max.
Opus API users get higher rate limits, which matters for agent workloads and production integrations.
The event also highlighted Anthropic’s broader platform ambitions around agents. While the primary official tweets here are mostly about the event itself, commentary points to features such as:
Dreaming = memory / cross-session context
Outcomes = rubrics / grading / objective tracking
agent orchestration / managed agents direction
Commentary:
@RichNwan argued Anthropic is “building out their managed agents platform” with Dreaming and Outcomes, but questioned whether these are meaningfully differentiated versus open harnesses.
@eliebakouch saw these as important for power users, especially for preserving the main agent’s context window and using separate graders to manage quality/safety/reward hacking.
@latentspacepod quoted Anthropic speakers emphasizing verification, “routines are higher-order prompts,” and the idea that the remaining gap is often deployment/operationalization, not raw capability.
That last point aligns Anthropic with the broader shift from “one-shot chatbot” to structured agent systems with memory, decomposition, grading, and verification.
Different opinions in the discourse
1) Positive / supportive
A large set of replies treated this as a win for users and evidence Anthropic is responding aggressively.
@alexalbert__: “More chips, more Claude.”
@_sholtodouglas: “More compute -> straight to you.”
@kimmonismus highlighted doubled limits and raised Opus API caps.
@TheRundownAI summarized it as a straightforward user benefit.
@DannyLimanseta liked the cross-company cooperation and hoped Anthropic’s caution might be balanced by SpaceXAI’s optimism.
@AmandaAskell reacted positively to the announcement’s symbolism.
2) Mixed / pragmatic
These takes welcomed the change but focused on operational details and remaining limitations.
@btibor91 and @kimmonismus immediately noted the likely caveat: weekly caps unchanged.
@TheAmolAvasare answered this directly.
@sbmaruf reported still seeing rate limits after the change, implying rollout and reliability tuning were ongoing.
@zachtratar asked for patience during staged rollout.
3) Competitive / strategic critique
A different cluster viewed the announcement through the OpenAI-vs-Anthropic product war.
@scaling01 argued Anthropic blundered its growth advantage by waiting too long, possibly conceding billions in ARR to OpenAI.
@Yuchenj_UW read the move as Dario getting aggressive because of OpenAI Codex’s growth.
@arohan joked that “Big tech has become a claude wrapper,” pointing to Claude’s developer mindshare.
@dejavucoder saying “claude is down, saint tibo please reset codex limits” captured the practical reality of multi-homing among coding tools when one service is capacity constrained.
4) Governance / safety / culture critique
This is the deepest philosophical disagreement.
@aidan_clark criticized what he says he repeatedly hears from Anthropic colleagues: a belief they alone should be trusted to build AI.
@kipperrii partially agreed the “only we can be trusted” framing would be bad, but argued the real majority view is closer to “no one can be trusted with AGI” while still personally trusting Anthropic more than others.
@elonmusk offered a surprising endorsement after meeting Anthropic leaders.
@Yuchenj_UW called this reversal ironic given prior criticism of Anthropic.
@teortaxesTex mocked the rapid détente between Musk/xAI and Anthropic.
@teortaxesTex also argued it is inconsistent to warn others about AI risk while building powerful closed systems such as “Mythos.”
@goodside, while not directly about Anthropic governance, contributed to the broader moral/AI norms debate that often clusters around Anthropic.
Commentary on Claude model performance and comparisons
Though no major new Claude model appears in these tweets, Claude remained a reference point in product and eval discourse.
@giffmana compared “Opus 4.6,” ChatGPT Pro, and Muse Spark on a mathematical disagreement. His take:
Opus 4.6 confidently defended a wrong proof (“gaslit”)
ChatGPT Pro reconciled the formulas correctly but without interpretation
Muse Spark did both well
This is anecdotal, but it’s one of the more concrete comparative qualitative model reports in the set.
@kimmonismus summarized a Substack analysis claiming GPT-5.5 is basically tied with Claude Mythos Preview on cyber, perhaps more cost-efficient, while Mythos is only slightly ahead on some general benchmarks and SWE-bench Pro; he questioned why Mythos remains secretive.
@AssemblyAI noted support for structured JSON from Claude 4.5+ models in its gateway.
@OpenRouter/TencentHunyuan listed Claude Code among major apps driving Hy3 usage, showing Claude’s importance in the coding-tool ecosystem even when third-party models are used behind the scenes.
These comments don’t establish hard model ranking, but they do show Claude is still a primary benchmark in coding-agent workflows and that advanced users increasingly compare model + harness + limits + reliability, not just base intelligence.
Claude Code and harness engineering context
A notable background thread across the dataset is that many engineers now think agent performance is heavily dependent on the harness—system prompts, tools, middleware, decomposition strategies, and model-specific tuning.
Relevant non-Anthropic commentary:
@masondrxy: same model, same task, very different scores depending on prompts/tools/middleware; 10–20 point jumps on tau2-bench.
@LangChain: harness profiles for OpenAI, Anthropic, and Google models.
@jakebroekhuizen: distinguishes temporal harness evolution as models improve from lateral tuning across model families.
@Vtrivedy10: argues a tailored harness can outperform default Codex/Claude Code on many tasks; usable context windows are still effectively 50–100k for many agent designs.
@kieranklaassen: “If you cannot get your work done [in] the Claude CLI, Claude will not be able to work for you.”
This matters because some of Anthropic’s platform moves—memory, grading, managed agents—can be read as Anthropic productizing parts of the harness. That helps explain the central debate: are these defensible platform primitives, or just first-party packaging of patterns that open frameworks can clone?
Broader context: why this matters
Inference, not just training, is now a frontier bottleneck.
The news was not a new model launch; it was a capacity launch. That is increasingly common at the frontier.
Compute markets are becoming fluid and strategic.
Anthropic partnering with SpaceX/xAI infrastructure undercuts simplistic narratives that each frontier lab sits only atop its own vertically integrated stack.
Developer product share is sensitive to reliability and limits.
Claude appears to have strong developer affinity, but rate limits and outages push users toward Codex/Cursor/others quickly.
The battleground is shifting from base models to agent systems.
“Code with Claude,” managed agents, Dreaming, Outcomes, and the surrounding discourse all point toward the next layer of competition being memory, orchestration, evals, and workflow integration.
Anthropic’s brand remains bifurcated.
It is simultaneously:
admired for product quality and safety seriousness,
criticized for paternalism or perceived exclusivism,
and now seen as more commercially aggressive on compute than before.
Bottom line
Anthropic’s news was less about a flashy new model and more about a structural reality: Claude demand had outrun available compute, and Anthropic responded by striking a major external infrastructure deal and immediately easing key user limits @claudeai, @claudeai. The most important technical/economic signal is that capacity, rate limits, and agent-product ergonomics are now as strategically important as leaderboard deltas. The main open questions are whether Anthropic can convert this capacity into sustained product momentum, whether its managed-agent features are truly differentiated, and whether its safety/governance posture helps or hinders its standing as competition with OpenAI, Google, xAI, and open-model ecosystems intensifies.
Infrastructure, inference, and systems
OpenAI and partners released MRC (Multipath Reliable Connection), an open networking protocol for large AI training clusters, already deployed on OpenAI’s biggest supercomputers @OpenAI, @OpenAI. Commentary emphasized multipath routing, microsecond failover, and the shift of networking into a primary frontier bottleneck @kimmonismus, @gdb.
Perplexity said it built an in-house inference engine, ROSE, covering models from embeddings to trillion-parameter LLMs, and uses CuTeDSL to accelerate specialized kernel development on Hopper and Blackwell @perplexity_ai.
vLLM + Mooncake presented a strong systems result for agentic workloads with reusable prefixes: 3.8x throughput, 46x lower P50 TTFT, 8.6x lower end-to-end latency, and cache-hit improvement from 1.7% to 92.2%, scaling to 60 GB200 GPUs @vllm_project.
Unsloth + NVIDIA published three training optimizations claimed to make home-GPU LLM training ~25% faster: packed-sequence metadata caching, double-buffered checkpoint reloads, and faster MoE routing @UnslothAI.
NVIDIA work on lossless speculative decoding inside RL was highlighted as giving up to ~2.5x faster end-to-end RL at 235B scale and ~1.8x faster rollout throughput at 8B without changing policy distribution @TheTuringPost.
Baseten launched Frontier Gateway as managed infra/API/auth/rate-limit/billing for closed-weight labs; Poolside reported going from kickoff to production in 7 weeks, with P50 TTFT 146ms for Laguna XS.2 and 605ms for Laguna M.1 @tuhinone, @poolsideai.
Benchmarks, evals, and agent harnesses
ProgramBench asks whether language models can rebuild programs from scratch, extending beyond repair-style SWE tasks @ComputerPapers, with Ofir Press arguing benchmarks are “treasure maps” that specify the future we want @OfirPress.
Terminal-Bench 2.1 patched 28/89 tasks in TB2.0; rankings held but absolute scores moved by up to 12 points, a useful reminder that agent benchmark maintenance materially matters @terminalbench, @ekellbuch.
OBLIQ-Bench emerged as a major IR benchmark release focused on hard first-stage retrieval, whe
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み