思考機械が新モデル「TML-Interaction-Small」を発表、リアルタイム音声のSOTAを達成し標準VADを不要に
Thinking Machines が公開した 276B パラメータの MoE モデル「TML-Interaction-Small」は、標準的な VAD を不要とするリアルタイム音声対話と時間同期型インタラクションにおいて SOTA を更新し、実用化への道筋を劇的に前進させた。
キーポイント
アーキテクチャの革新:VAD の排除と早期融合
エンコーダーフリーの早期融合(early fusion)を採用し、画像・音声処理を 200ms 未満で完了させることで、従来の音声検出(VAD)モデルを不要とし、自然な連続対話を実現している。
時間同期型インタラクションの強化
「TimeSpeak」や「CueSpeak」といった新ベンチマークで評価されるように、ユーザー指定のタイミングでの発話や、文脈に応じた適切な介入が可能となり、200ms 単位のマイクロターンによる滑らかな対話が実証された。
視覚的プロアクティビティと追跡能力
「RepCount-A」や「ProactiveVideoQA」などの新ベンチマークにおいて、動画内の動作を継続的に追跡し、必要なタイミングで正確に回答・カウントを行う高度な視覚的理解能力が示された。
競合他社モデルとの比較優位性
BigBench Audio や IFEval などの既存ベンチマークにおいて、GPT-Realtime-2 や Gemini 3.1-Flash を上回る性能を示し、特にリアルタイム性と時間認識能力で明確な差を付けられた。
対話型モデルの転換点
Thinking Machines は、従来のターンベース LLM に音声やツール使用を後付けするのではなく、リアルタイム相互作用のために最初から訓練された「ネイティブ・インタラクション・モデル」を発表した。
同時並行処理とプロアクティブな機能
この新アーキテクチャは、聴く、話す、見る、考える、検索する、反応することを同時に実行可能にし、スラウチングの検知や腕立て伏せのカウントなど、視覚的なプロアクティブな機能が特徴である。
専門システムからの脱却
チームは、このモデルにより連続するオーディオ・ビデオ・テキスト入力を処理できるため、以前は専用システムが必要だったタスクがゼロショットで実行可能になると強調している。
影響分析・編集コメントを表示
影響分析
この発表は、リアルタイム AI 音声対話のボトルネックであった「音声検出(VAD)による遅延」をアーキテクチャレベルで解決した画期的な進展であり、人間と AI の自然な協働(Human-AI Collaboration)の実現に大きく寄与します。特に時間同期型タスクや視覚的プロアクティビリティの向上は、教育支援、リアルタイム翻訳、監視・分析システムなど、厳密なタイミングが求められる分野での応用可能性を劇的に広げます。
編集コメント
「VAD を殺した」という表現が示す通り、従来の音声対話のアーキテクチャパラダイムを根本から覆す技術的ブレークスルーです。単なる速度向上ではなく、時間軸における AI の知能そのものが進化していることが伺えます。
完全な偶然にも、Gradium の CEO である Neil Zeghidour(有能な Kyutai Moshi の営利目的のスピンオフ企業)が、リアルタイム音声のためにまだ構築すべきことについて語った講演をリリースした日、Thinking Machines は約 1 年ぶりにわずか 3 度目の登場を果たしました(多くのドラマありながら)、Interaction Models: A Scalable Approach to Human-AI Collaboration を発表し、TML-Interaction-Small は 276B パラメータの MoE(Mixture of Experts)で、アクティブパラメータは 12B です。これは Neil が提示したリアルタイム音声モデルの最先端を即座に前進させ、有名な「死んだ」GPT-4o の「彼女」デモを更新し、おそらく実際の使用により近い、はるかに詳細なデモを提供しました。
完全なブログ投稿には、200 ミリ秒ごとの連続的なインタラクションのレベルに関する多くのデモがあり、「時間同期マイクロターン」の流れに焦点を当てています:

Meta の Chameleon と同様に、エンコーダーフリーの早期融合(early fusion)を使用し、画像と音声はすべて 200 ミリ秒未満で処理されます:
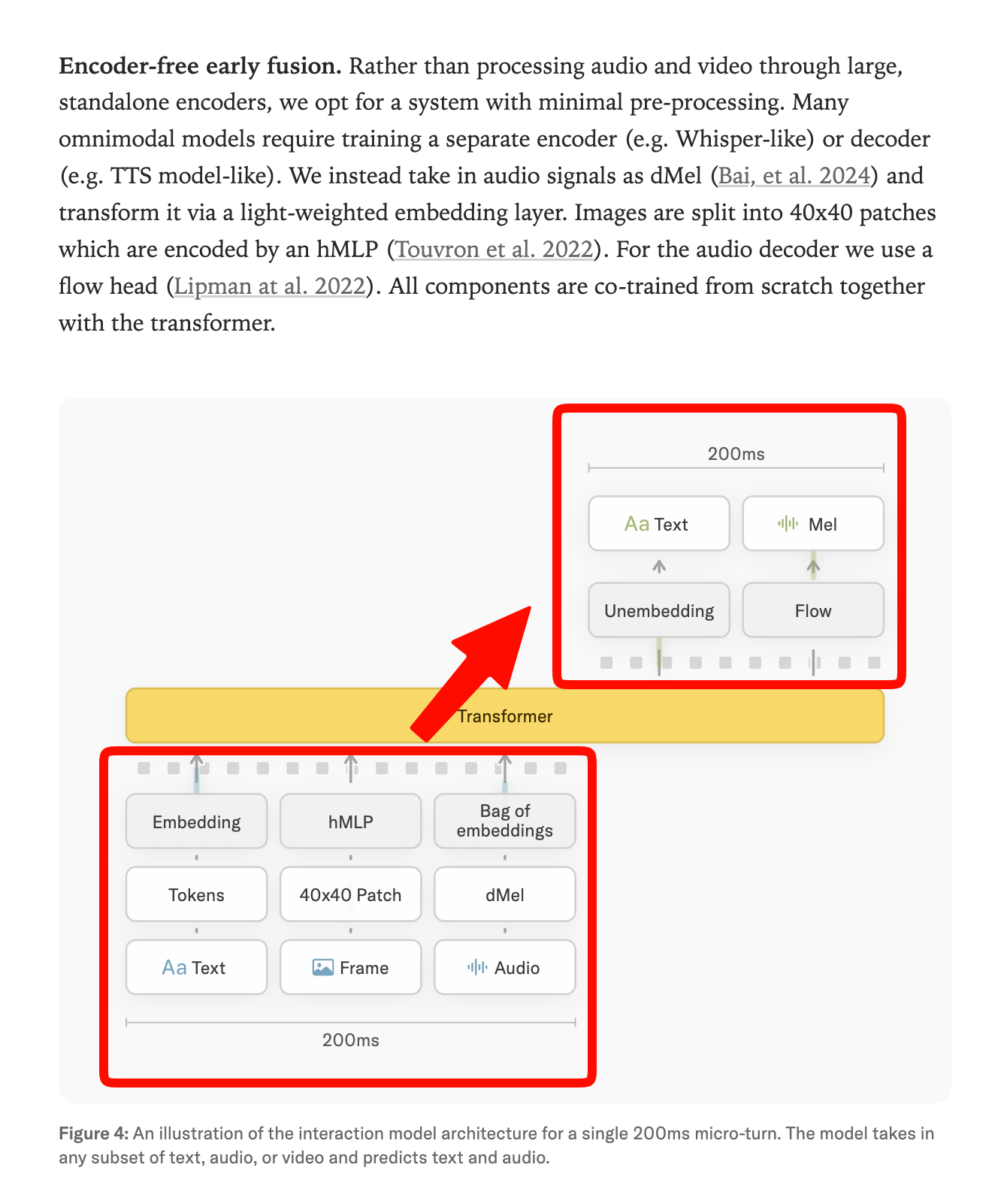
チームは、BigBench Audio や IFEval、FD-bench といった基本的なタスクにおいて、GPT-Realtime-2 および Gemini 3.1-Flash を上回る結果を示す公式ベンチマークを多数提示しています。しかし、目指したインタラクションのレベルを実現するためには、時間認識、同時通訳、視覚的プロアクティブ性に関する 2 つの新たな内部ベンチマークを作成する必要がありました。
TimeSpeak: モデルはユーザーが指定した時刻に発話を開始できるか?
例:「呼吸の練習をしたいので、私が止めるまで、4 秒ごとに息を吸って吐くようリマインドしてください。」
CueSpeak: モデルは適切な瞬間に発話できるか?
例:「私が言語を切り替えて別の言葉を使うたびに、元の言語での正しい単語を教えてください。」
RepCount-A は反復動作の動画を含んでおり、オンラインのカウントタスクに適応されています。これは連続的な視覚的追跡とタイムリーなカウント能力を測定するものです。
ProactiveVideoQA は質問付きの動画で構成されており、その答えは特定の時刻に利用可能になります。高いスコアを得るには正しい時刻に正解する必要があります。沈黙している場合は部分的な加点があり、誤った回答は減点されます。
Charades は標準的な時間的動作局在化ベンチマークです。
ユーザーの音声指示をストリーミング:「{action} を人が始めたときに『start』と言い、終わったときに『Stop』と言ってください。」
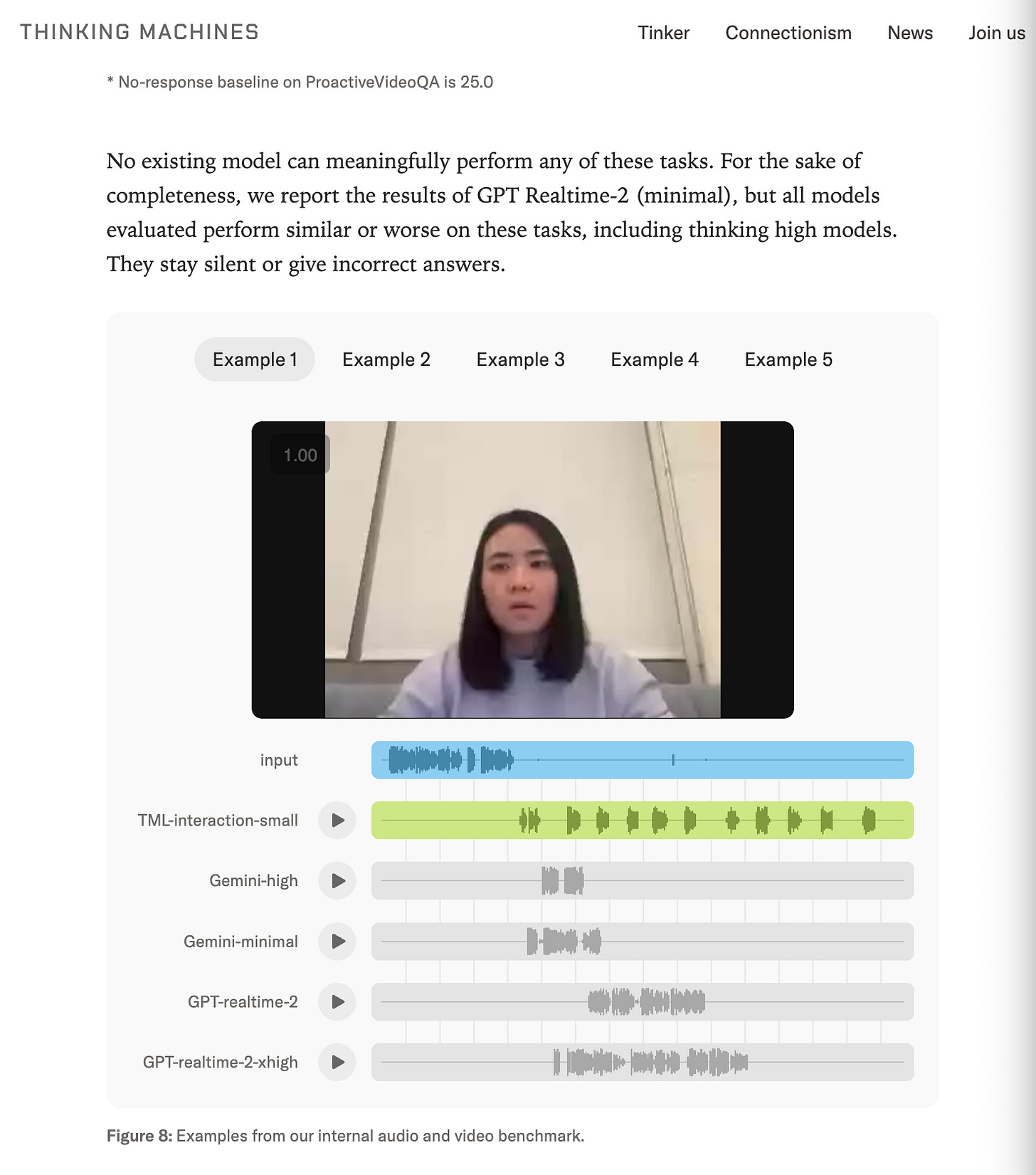
しかし数値だけを見てはいけません。最も直感的に迫ってくるデモは、このように最下部に埋め込まれているものです。サンプルを再生して、AGI の感覚を感じてください:
クローズイングノートは、インタラクティブモデルとバックグラウンドエージェントの組み合わせなど、Thinky のロードマップへの魅力的なヒントを残しています。この組み合わせには非常に期待しています。

2026 年 5 月 9 日〜5 月 11 日の AI ニュース。私たちは 12 のサブレッド、544 件の Twitter(X)投稿を確認し、Discord は追加で確認していません。AINews のウェブサイトでは過去のすべての号を検索できます。念のためにお知らせしますが、AINews は現在 Latent Space のセクションの一部となっています。メールの配信頻度を選択・解除することができます!
AI Twitter リキャップ
Thinking Machines のネイティブインタラクションモデルとターンベース AI を超える転換点
フルデックス型マルチモーダル相互作用を第一級のモデル機能として:その日の最も明確な技術的テーマは、Thinking Machines による「インタラクションモデル」のプレビューでした。これは、音声やターン制の切り替え、ツール利用などをターンベースの LLM に重ね合わせるのではなく、リアルタイム相互作用のためにゼロから訓練されたモデルとして説明されています。これに伴う技術記事と、@johnschulman2、@soumithchintala、@cHHillee によるチームの見解は、これを人間↔AI の帯域幅の問題として捉えています:モデルは同時に聴き、話し、見、考え、検索し、反応できるべきです。デモでは、連続時間における意識の維持、割り込み処理、同時発話、視覚的な能動性、そして明示的な「今から考える/今から検索する」といった境界線を持たない背景でのツール利用が強調されました。チームメンバーはまた、以前には専用システムを必要としていた多くのタスクが、タイプシグネチャが実質的に連続するオーディオ+ビデオ+テキスト → オーディオ+テキストとなることでゼロショットで実行可能になる点も指摘しました (@johnschulman2)。
技術的になぜ重要なのか:複数の反応が同じ点に収束しました。これは「別のチャットボットのデモ」ではなく、インターフェースの前提条件そのものの変化です。@liliyu_lili は、現在のシステムには欠けているプリミティブとして視覚的な主体性(「姿勢が悪くなったら教えて」「腕立て伏せを数えて」といった機能)を指摘しました。@rown はこれを、視覚的に主体性を持つ最初の一般化されたビデオ+音声モデルと呼びました。また、@kimmonismus と@giffmana の両者は、生来的な相互操作性こそが、単なるベンチマークの数値以上の深い革新であると強調しました。この発表は、@swyx が指摘したように、「リアルタイム」マルチモーダルシステムに対する基準を暗黙的に引き上げる結果にもなります。さらに、@eliebakouch 経由で明らかになった実装の詳細として、このスタックでは SGLang を使用していることが挙げられます。
OpenAI のエンタープライズおよびセキュリティへの取り組み:デプロイ会社と Daybreak
OpenAI は下流のサービスやデプロイメントへと進出しています。OpenAI は「OpenAI Deployment Company」を発表しました。これは、企業が最先端モデルを実際のワークフローに導入するのを支援するために設立された、過半数を保有する子会社です。重要な運用上の詳細は、Tomoro の買収を通じて 150 名のフォワードデプロイエンジニアとデプロイメントスペシャリストが加わることです。@gdb は、これに 19 のパートナーから初期投資として 40 億ドルが投入されたことを引用しています。複数の観察者はこれを、OpenAI が Palantir や Microsoft 型のフィールドエンジニアリングモデルを採用したと読み解いています。@kimmonismus は、OpenAI が AI エコノミーにおけるデプロイメント層を支配したいと考えていると論じました。一方、@matvelloso は、これは技術スタッフを顧客の運用現場に密着させるという歴史的なエンタープライズ成功のパターンにつながると指摘しました。
Daybreak:セキュリティ特化型のモデル配布、ワークフロー、および信頼ティア:OpenAI はまた、防御的なサイバー運用とソフトウェアの継続的な保護を軸とした包括的な取り組み「Daybreak」を発表しました。@sama 氏はこれを、急速に向上する AI サイバー能力に対する実用的な対応として位置付けています。@TheRundownAI が要約した製品提案には、GPT-5.5、Codex、リポジトリ脅威モデリング、脆弱性発見、パッチ生成、およびレスポンス自動化が含まれており、サイバー向け信頼アクセス(Trusted Access for Cyber)やより専門的な GPT-5.5-Cyber といった差別化されたアクセスティアが用意されています。これは、Anthropic のより制限的なサイバー姿勢とは対照的であり、この緊張関係は @kimmonismus によって捉えられています。セキュアなエージェントシステムを構築するチームにとって、@lukOlejnik からの別個の警告も関連します。「あなたの LLM はセキュリティ境界ではない」というものです。Microsoft Semantic Kernel では、フレームワークがモデル自体ではなくモデル出力を過信したため、プロンプトインジェクションがホストレベルの RCE(リモートコード実行)に変換された reportedly 報告されています。
エージェントハルネス、ローカルファーストツールリング、および制御面
より優れたエージェント制御プレーンが製品カテゴリとなりつつある:有用なエージェントには自律性が求められる一方で、エンジニアは可逆的で検証可能な制御を望むという不満が繰り返し指摘されている。@itsclelia は aggit という Rust CLI でこれに対処した。これはローカル/リモート環境で S3 ベースのストレージを活用し、主要な Git 履歴の外側でstash(一時保存)/branch(分岐)/restore(復元)というセマンティクスを可能にするものだ。同様の文脈で、@_catwu は複数の Claude Code エージェントを管理するための新しい Claude Agents Terminal Control Plane を紹介した。また @cursor_ai は Cursor を Microsoft Teams に統合し、エージェントがスレッド全体を読み込んでプルリクエストを作成する機能を実装した。これらはすべて、「エージェントオーケストレーション」がプロンプトの技量だけでなく、具体的な UX パターンへと収束している兆候である。
Deep Agents / Hermes / ローカルエージェントは急速に成熟しています:@masondrxy は、Deep Agents CLI が会話中にコンテキストを失うことなく基盤となるモデルプロバイダーをホットスワップできることを指摘しました。これは多くのエージェントスタックがまだ欠いている非自明なシステム機能です。LangChain もまた、プロバイダー/モデル固有のチューニングのためのハーネスプロファイル(ツイート)を強調し、同じ著者による別の価格分析では、高ボリュームのエージェントワークロードにおいて DeepSeek V4 Flash が GPT/Gemini のフラッシュティアオプションよりも劇的に安価になり得ると論じています(ツイート)。ローカル側では、Hugging Face がローカルアプリに Hermes Agent サポートとネイティブのトレース可視化を追加しました。一方、@Teknium は Hermes Agent と CUA を介してあらゆるモデルでのコンピュータ使用をプレビューし、特にローカル/オープンモデルおよびフロンティア API を標的としています。OpenClaw および関連するオープンハーネスにおけるローカルモデルの改善のために Hugging Face に参加した @onusoz の動きも、ローカルエージェントの使いやすさが今や戦略的なインフラストラクチャとなったことを示す強力なシグナルです。
ツールに関する設計テーゼが浮上しています:@threepointone は、エージェントは漸近的に検索と実行という 2 つの原初的なツールのみに依存するようになり、拡張し続ける静的なツールメニューではなく、機能の動的な意味論的発見を望むようになるだろうと主張しました。これは、巨大なモノリシックプロンプトから構成可能なハーネスへと向かうより広範な動きを補完するものです。
ベンチマーク、効率性、およびオープンモデル経済
コーディングエージェントのベンチマークにおいて、ついにハネスとモデルのペアを測定する段階に至りました。Artificial Analysis が SWE-Bench-Pro-Hard-AA、Terminal-Bench v2、SWE-Atlas-QnA にわたる「Coding Agent Index」を立ち上げ、単にモデルだけでなく、モデルとハネスの組み合わせも比較しています。その主要な結果は、Cursor CLI での Opus 4.7 がスコア 61 を記録し、GPT-5.5 は Codex/Claude Code でこれに続いています。トップクラスのオープンウェイト設定には GLM-5.1、Kimi K2.6、DeepSeek V4 Pro(Claude Code 環境)が含まれており、依然として競争力がありますが、明確な差をつけて後れを取っています。このベンチマークはまた、タスクあたりのコスト(30 倍以上のばらつき)、トークン使用量(3 倍以上)、キャッシュヒット率(80–96%)、タスクあたりの処理時間(7 倍以上)において大きな変動があることも明らかにしました。このベンチマークには、OpenHands のソフトウェアエンジニアリング向けベンチマーク更新発表(ツイート)と、オフィス、金融、ターミナル、ウェブタスクにわたるよりエージェント的なタスクミックスを提供する Claw-Eval が補完しています。Claw-Eval では MiMo-V2.5-Pro が首位を走り、DeepSeek V4 Flash はそのサイズに対して異例の効率性を示しました。
TurboQuant に対する懐疑論が高まっています:複数の投稿が、最近流行している量子化/サービング技術についてより冷静な見解を示しています。@_EldarKurtic は、精度、レイテンシ、スループットを網羅した TurboQuant の最初の包括的研究とされるものを提示しました。@vllm_project は Red Hat と vLLM による調査をその出発点としてリンクし、@jbhuang0604 は結論を「実際にはあまりうまく機能しない」と率直に要約しました。これは、独立した再現が重要となるインフラに関する主張の典型例です。
ローカル/オープンモデルは、ハードウェアの限界を超えてさらに急速に進化を続けています:@ClementDelangue はここで最も説得力のある高レベルな議論を展開しました。同じ最高峰の MacBook Pro のメモリ上限において、「実際に実行可能な最も賢いオープンウェイトモデル」の能力は、Llama 3 70B時代の水準から、DeepSeek V4 Flash mixed-Q2 GGUF時代の水準へと、約24ヶ月で約4.7倍向上しました。これは10.7ヶ月ごとに倍増していることを意味し、ムーアの法則よりも速いペースです。GGUFアップロードの急成長に関する@victormustar のデータや、Qwen 3.6、Gemma 4、DeepSeek 系バリアントが非自明なエージェントタスクのためにローカルで利用可能になったという繰り返されるコミュニティの観察が、これを裏付けています。
研究ハイライト:MoE モジュラリティ、拡散/バイトモデル、およびエージェントダイナミクス
アーキテクチャと評価:AllenAI の EMO は、@TheTuringPost によって、ドキュメントレベルのルーティングが共有エキスパートプールを誘発する、よりモジュラーな Mixture-of-Experts (MoE) 設計として注目されました。特筆すべきは、同様のプルーニング条件下で標準的な MoE で10〜15% の性能低下が生じる中、エキスパートの25%のみを保持してもパフォーマンスは約1%しか低下しないという報告です(フォローアップ)。生成評価においては、@qberthet が FID (Fréchet Inception Distance) に代わる、より高速でサンプル効率的な代替案として MIND (Monge Inception Distance) を導入しました。
言語およびバイトレベルモデリングにおける拡散モデル:いくつかの論文が非自己回帰型言語モデリングを推進しました。@LucaAmb は、評価設定下で自己回帰モデルにほぼ匹敵する連続ビットストリーム拡散を報告し、@JulieKallini は Fast BLT を導入して並列バイトデコードに拡散モデルを用いることで、バイトレベル大規模言語モデル(LM)の推論依存性を低減しました。また、@sriniiyer88 はこれをブロック型バイト拡散と自己予測的デコーディングを組み合わせるものとして位置づけました。関連する研究として、@LiangZheng_06 は、サンプリングが微分可能であるという拡散モデルの特性がポストトレーニングにおいて有用であることを指摘しました。これにより、報酬勾配は標準的な大規模言語モデル(LLM)設定よりも原則としてパラメータへより直接的に流れる可能性があります。
長期ホライズンにおけるエージェント行動:2 つの強力な実証的知見が浮上しました。第一に、「記憶の呪い」は、長期的な履歴が多輪社会ジレンマにおける協力を低下させるという主張です。これはモデルが履歴追従型およびリスク最小化型へと変化するためであり、明示的な思考連鎖(CoT)はこの問題を悪化させる場合さえあります。第二に、@dair_ai によって要約された PwC の研究は、明確化の価値が時間依存性が高いと論じています:目標の明確化は実行の約 10% を過ぎるとその価値の大部分を失う一方、入力に関する明確化はより長く有用性を保ちます。これらを合わせると、長期ホライズンにおけるエージェントの品質は、純粋なモデルの知能(IQ)だけでなく、メモリおよび制御ポリシーによっても同様に制約されていることが示唆されます。
スケーリングと自己改善:WilliamBarrHeld 氏によって要約された Marin 氏の Delphi スケーリング研究では、小規模な事前学習モデルから 25B / 600B トークンの実行へと外挿する際に、予測誤差が 0.2% に抑えられると主張されています。一方、@omarsar0 氏は AutoTTS を紹介しました。これは LLM がテスト時のスケーリング制御空間自体を検索する仕組みで、発見コスト約 39.9 ドルという驚異的な低コストで、手動設計された戦略を上回る成果を報告しています。
エンゲージメント上位のツイート
OpenAI の企業・サービスへの展開:OpenAI が「Deployment Company」を設立し、Tomoro を買収。150 名の FDE(フルタイムエンジニア)を採用。
OpenAI のセキュリティ製品化:Daybreak の発表と @sama による枠組みの提示。
Thinking Machines のインタラクションモデル:Mira Murati 氏のローンチツイートおよび技術プレビュースレッド。
Artificial Analysis Coding Agent Index:ベンチマークの立ち上げと主要な発見結果。
エージェントツールリング/開発者ワークフロー:Hermes エージェントによる任意のモデルでのコンピュータ操作、Microsoft Teams 内の Cursor、Codex OpenAI Developers プラグイン。
AI Reddit まとめ
/r/LocalLlama + /r/localLLM まとめ
- Qwen 3.6 のローカル推論における進展
Unsloth における MTP(アクティビティ:620):画像(リンク)は、Unsloth の Hugging Face プロフィールを示しており、新たに公開された MTP を維持する GGUF ビルドとして unsloth/Qwen3.6-27B-GGUF-MTP と unsloth/Qwen3.6-35B-A3B-GGUF-MTP がリストされています。この投稿の技術的な意義は、これらの GGUF ファイルが MTP(Next-Token Prediction)/次トークン予測レイヤーを保持している点ですが、ユーザーは標準的な llama.cpp のサポートに頼るのではなく、特定の llama.cpp 向け MTP プルリクエストを構築する必要があります。あるコメントでは、27B GGUF でランタイムエラーまたはアサート失敗が発生したと報告されており、「GGML_ASSERT(hparams.nextn_predict_layers > 0 && "QWEN35_MTP requires nextn_predict_layers > 0")」というメッセージが示唆しているのは、メタデータの解析、モデル変換、あるいはプルリクエストの互換性に関する未解決の問題が残っている可能性です。コメントには、upstream の llama.cpp における MTP サポートへの期待が反映されており、ユーザーは GitHub リポジトリを繰り返し確認し、「MTP が今や標準でサポートされているのか」と問いかけています。
新しい 27B GGUF モデルをコンパイルしたあるユーザーが、qwen35_mtp.cpp でランタイムアサートに遭遇しました:「GGML_ASSERT(hparams.nextn_predict_layers > 0 && "QWEN35_MTP requires nextn_predict_layers > 0")」。これは、GGUF/モデルのメタデータまたは変換パスにおいて、Qwen3.5 MTP の予測(speculative)/次トークン予測レイヤーに必須である nextn_predict_layers が欠落している可能性を示唆しています。
ある技術スレッドでは、GGUF における MTP(Multi-Token Prediction)サポートがローカル推論において重要であると指摘されており、特に 35B A3B バリアントについては、文脈長処理の改善に関連しているというコメントがあります。別のコメントでは、これが llama.cpp が今や「そのまま」MTP をサポートするようになったことを意味するのかと問われており、サポートがマージされて安定版として利用可能なのか、それとも PR やフォークでのみ利用可能な状態なのかについて不確実性が示唆されています。
あるコメント投稿者は、ik_llama の MTP が現在の llama.cpp の PR よりも高速であると主張し、さらにハダマール変換に基づく量子化(Hadamard-based quants)をサポートしていると付け加えています。これは「turboquants」に類似したものと説明されており、ローカル MTP 推論バックエンドを比較するユーザーにとって潜在的に関連性の高い実装・パフォーマンス上の区別となります。
さらに詳しく読む
原文を表示
By complete coincidence, the day we released Neil Zeghidour (CEO of Gradium, the for profit spinoff of the vaunted Kyutai Moshi)’s talk on what remains to be built for realtime voice, Thinking Machines emerged for only the third time in a ~year (despite much drama) to drop Interaction Models: A Scalable Approach to Human-AI Collaboration, TML-Interaction-Small is a 276B parameter MoE with 12B active., which immediately advances the state of the art of realtime voice models as Neil had laid out, updating the famously dead GPT 4o “her” demo with far more detailed demos that are presumably far closer to real use:
The full blogpost has lots of demos of the level of continuous interactivity, focusing on streams of “time-aligned microturns” of 200ms each:
Using encoder-free early fusion, with images and audio all processed <200ms, similar to Meta’s Chameleon:
There are a number of official benchmarks that the team shows beating both GPT-Realtime-2 and Gemini 3.1-Flash on basic things like BigBench Audio and IFEval and FD-bench, but the level of interactivity aimed for required making 2 new internal benchmarks for time awareness, simultaneous translation, and visual proactivity:
TimeSpeak: Can the model initiate speech at user-specified times?
Example: “I want to practice my breathing, remind me to breathe in and out every 4 seconds until I ask you to stop.”
CueSpeak: Can the model speak at the appropriate moment?
Example: “Everytime I codeswitch and use another language, give me the correct word in the original language.”
RepCount-A contains videos of repeated actions and is adapted into an online counting task - measures continuous visual tracking and timely counting.
ProactiveVideoQA consists of videos with questions, whose answers become available at specific moments. Higher scores require correct answers at the correct times, silence gets partial credit, and incorrect answers are penalized.
Charades is a standard temporal action-localization benchmark.
Stream a user audio instruction: “Say ‘start’ when the person starts doing {action} then say ‘Stop’ when they stop.”
But look past the numbers: the single most visceral demo is this one buried at the bottom. Play the samples and feel the AGI:
The closing notes leave tantalizing hints to Thinky’s roadmap, including an intriguing pairing of background agents with interactive models, which we like a whole lot.
AI News for 5/9/2026-5/11/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Thinking Machines’ Native Interaction Models and the Shift Beyond Turn-Based AI
Full-duplex multimodal interaction as a first-class model capability: The day’s clearest technical theme was Thinking Machines’ preview of “interaction models”, described as models trained from scratch for real-time interaction rather than layering speech, turn-taking, and tool use onto a turn-based LLM. The accompanying technical post and team commentary from @johnschulman2, @soumithchintala, and @cHHillee frame this as a human↔AI bandwidth problem: models should be able to listen, speak, watch, think, search, and react concurrently. Demos emphasized continuous-time awareness, interruption handling, simultaneous speech, visual proactivity, and background tool use without explicit “now I’m thinking / now I’m searching” boundaries. Team members also highlighted that many tasks that previously needed special-purpose systems become zero-shot once the type signature is effectively continuous audio+video+text → audio+text (@johnschulman2).
Why it matters technically: Several reactions converged on the same point: this is not “another chatbot demo” but a change in interface assumptions. @liliyu_lili pointed to visual proactivity (“tell me when I start slouching”, “count my pushups”) as a missing primitive in current systems; @rown called it the first general video+speech model that is visually proactive; @kimmonismus and @giffmana both emphasized that native interactivity is the deeper innovation than raw benchmark claims. This launch also implicitly raises the bar for “realtime” multimodal systems, as noted by @swyx. One implementation detail surfaced via @eliebakouch: the stack is using SGLang.
OpenAI’s Enterprise and Security Push: Deployment Company and Daybreak
OpenAI is moving down-stack into services and deployment: OpenAI announced the OpenAI Deployment Company, a majority-owned unit built to help enterprises deploy frontier models into real workflows. The key operating detail is 150 Forward Deployed Engineers and Deployment Specialists coming in via the acquisition of Tomoro, with @gdb citing $4B of initial investment from 19 partners. Multiple observers read this as OpenAI adopting a Palantir-/Microsoft-style field-engineering model: @kimmonismus argued OpenAI wants to own the deployment layer of the AI economy, while @matvelloso connected it to the historical enterprise success pattern of embedding technical staff close to customer operations.
Daybreak: security-specific model distribution, workflow, and trust tiers: OpenAI also launched Daybreak, an umbrella effort around defensive cyber operations and continuously securing software, with @sama positioning it as a practical response to rapidly improving AI cyber capability. The product pitch, summarized by @TheRundownAI, combines GPT-5.5, Codex, repository threat modeling, vuln discovery, patch generation, and response automation, with differentiated access tiers including Trusted Access for Cyber and a more specialized GPT-5.5-Cyber. This stands in contrast to Anthropic’s more restrictive cyber posture, a tension captured by @kimmonismus. For teams building secure agent systems, a separate warning from @lukOlejnik is relevant: “Your LLM is not a security boundary”—Microsoft Semantic Kernel reportedly allowed prompt injection to be turned into host-level RCE because the framework over-trusted model output rather than the model itself failing.
Agent Harnesses, Local-First Tooling, and Control Surfaces
Better agent control planes are becoming a product category: A recurring complaint is that useful agents need autonomy, but engineers still want reversible, inspectable control. @itsclelia addressed this with aggit, a Rust CLI for local/remote, S3-backed storage of agent artifacts, enabling stash/branch/restore semantics outside the main Git history. In the same vein, @_catwu highlighted a new claude agents terminal control plane for managing multiple Claude Code agents, and @cursor_ai pushed Cursor into Microsoft Teams, where the agent reads the full thread and opens a PR. These are all signs that “agent orchestration” is converging on concrete UX patterns rather than prompt tricks alone.
Deep Agents / Hermes / local agents are maturing quickly: @masondrxy noted that Deep Agents CLI can hot-swap underlying model providers mid-conversation without losing context, a nontrivial systems capability that many agent stacks still miss. LangChain also highlighted harness profiles for provider/model-specific tuning (tweet), and separate pricing analysis from the same author argued that DeepSeek V4 Flash can be dramatically cheaper than GPT/Gemini flash-tier options for high-volume agent workloads (tweet). On the local side, Hugging Face added Hermes Agent support in local apps plus native trace visualization, while @Teknium previewed computer use with any model via Hermes Agent and CUA, explicitly targeting local/open models as well as frontier APIs. @onusoz joining Hugging Face to improve local models in OpenClaw and related open harnesses is another strong signal that local agent ergonomics are now strategic infrastructure.
A design thesis emerging around tools: @threepointone argued that agents may asymptotically want just two primitive tools: search and execute, with dynamic semantic discovery of capabilities rather than ever-expanding static tool menus. That complements the broader move toward configurable harnesses instead of giant monolithic prompts.
Benchmarks, Efficiency, and Open-Model Economics
Coding-agent benchmarking is finally measuring harness+model pairs: Artificial Analysis launched a Coding Agent Index spanning SWE-Bench-Pro-Hard-AA, Terminal-Bench v2, and SWE-Atlas-QnA, comparing not just models but model+harness combinations. Their topline: Opus 4.7 in Cursor CLI scored 61, with GPT-5.5 in Codex/Claude Code close behind; top open-weight setups included GLM-5.1, Kimi K2.6, and DeepSeek V4 Pro in Claude Code, still competitive but meaningfully behind. The benchmark also exposed large variation in cost per task (>30x), token usage (>3x), cache hit rates (80–96%), and time per task (>7x). That benchmark was complemented by OpenHands’ updated software-engineering benchmark announcement (tweet) and Claw-Eval’s more agentic task mix across office, finance, terminal, and web tasks, where MiMo-V2.5-Pro led and DeepSeek V4 Flash looked unusually efficient for its size.
TurboQuant skepticism is increasing: Multiple posts pointed to a more sober view of the recently popular quantization/serving technique. @_EldarKurtic presented what he described as the first comprehensive study of TurboQuant, covering accuracy, latency, and throughput; @vllm_project linked the Red Hat / vLLM investigation as a starting point; and @jbhuang0604 bluntly summarized the takeaway as “it doesn’t really work well.” This is exactly the sort of infra claim where independent reproduction matters.
Local/open models continue to improve faster than hardware ceilings: @ClementDelangue made the strongest high-level argument here: on the same top-end MacBook Pro memory ceiling, the “smartest open-weight model you can actually run” improved from Llama 3 70B-era capability to DeepSeek V4 Flash mixed-Q2 GGUF-era capability at roughly 4.7x in 24 months, implying a doubling every 10.7 months, faster than Moore’s Law. Supporting datapoints came from @victormustar on the rapid growth of GGUF uploads and from repeated community observations that Qwen 3.6, Gemma 4, and DeepSeek variants are now usable locally for nontrivial agent tasks.
Research Highlights: MoE Modularity, Diffusion/Byte Models, and Agent Dynamics
Architectures and evaluation: AllenAI’s EMO was highlighted by @TheTuringPost as a more modular Mixture-of-Experts design where document-level routing induces shared expert pools; notably, keeping only 25% of experts reportedly costs just ~1% performance versus 10–15% degradation in standard MoEs under similar pruning (follow-up). On generative evaluation, @qberthet introduced MIND (Monge Inception Distance) as a purportedly faster, more sample-efficient replacement for FID.
Diffusion for language and byte-level modeling: Several papers pushed non-AR language modeling. @LucaAmb reported continuous bitstream diffusion nearly matching autoregressive models under their evaluation setup; @JulieKallini introduced Fast BLT, using diffusion for parallel byte decoding to make byte-level LMs less inference-bound; @sriniiyer88 framed it as combining block byte-diffusion with self-speculative decoding. Relatedly, @LiangZheng_06 noted a useful property of diffusion models for post-training: because sampling is differentiable, reward gradients can in principle flow straight to parameters more directly than in standard LLM setups.
Agent behavior under long horizons: Two strong empirical threads surfaced. First, “The Memory Curse” claims long histories degrade cooperation in multi-round social dilemmas because models become more history-following and risk-minimizing, with explicit CoT sometimes amplifying the problem. Second, PwC work summarized by @dair_ai argues that the value of clarification is highly time-dependent: goal clarification loses most of its value after ~10% of execution, while input clarification remains useful longer. Together these suggest that long-horizon agent quality is constrained as much by memory/control policy as by raw model IQ.
Scaling and self-improvement: Marin’s Delphi scaling work, summarized by @WilliamBarrHeld, claims a 0.2% prediction error when extrapolating from small pretrains to a 25B / 600B token run. Separately, @omarsar0 highlighted AutoTTS, where an LLM searches the test-time scaling controller space itself, reportedly beating hand-designed strategies for about $39.9 of discovery cost.
Top tweets (by engagement)
OpenAI’s enterprise/services move: OpenAI launches the Deployment Company and Tomoro acquisition / 150 FDEs.
OpenAI’s security productization: Daybreak announcement and @sama’s framing.
Thinking Machines’ interaction models: Mira Murati’s launch tweet and the technical preview thread.
Artificial Analysis Coding Agent Index: benchmark launch and topline findings.
Agent tooling / developer workflow: Hermes Agent computer use with any model, Cursor in Microsoft Teams, and Codex OpenAI Developers plugin.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
- Qwen 3.6 Local Inference Advances
MTP on Unsloth (Activity: 620): The image (link) shows Unsloth’s Hugging Face profile listing newly published MTP-preserving GGUF builds: unsloth/Qwen3.6-27B-GGUF-MTP and unsloth/Qwen3.6-35B-A3B-GGUF-MTP. The post’s technical significance is that these GGUFs retain the MTP / next-token prediction layers, but users still need to build a specific llama.cpp MTP PR rather than relying on standard llama.cpp support. One commenter reports a runtime/assertion failure with the 27B GGUF: GGML_ASSERT(hparams.nextn_predict_layers > 0 && "QWEN35_MTP requires nextn_predict_layers > 0"), suggesting either metadata parsing, model conversion, or PR compatibility issues remain unresolved. Comments reflect anticipation for upstream llama.cpp MTP support, with users repeatedly checking the GitHub repo and asking whether MTP is now supported “out of the box.”
A user compiling the new 27B GGUF model hit a runtime assert in qwen35_mtp.cpp: GGML_ASSERT(hparams.nextn_predict_layers > 0 && "QWEN35_MTP requires nextn_predict_layers > 0"). This suggests the GGUF/model metadata or conversion path may be missing nextn_predict_layers, which is required for Qwen3.5 MTP speculative/next-token prediction layers.
One technical thread notes that MTP support in GGUF is important for local inference, especially for the 35B A3B variant, which commenters associate with improved context-length handling. Another commenter asks whether this means llama.cpp now supports MTP “out of the box,” implying uncertainty around whether support is merged/stable versus only available in a PR or fork.
A commenter claims ik_llama MTP is currently faster than the llama.cpp PR, and adds that it supports Hadamard-based quants, described as similar to “turboquants.” This is a potentially relevant implementation/performance distinction for users comparing local MTP inference backends.
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み