Amazon Rekognition、Amazon Neptune、Amazon Bedrockを使用したインテリジェントな写真検索システムの構築
AWS CDKを活用し、Amazon Rekognitionで顔・物体検出、Amazon Neptuneで関係性マッピング、Amazon BedrockでAIキャプション生成を統合した包括的な写真検索システムの構築方法を紹介。
キーポイント
AWSの複数AIサービス(Rekognition、Neptune、Bedrock)を統合したインテリジェント写真検索システムの構築方法を実装例と共に解説
従来の手動タグ付けやフォルダ管理を超え、自然言語クエリで人物・物体・関係性を理解するコンテキスト認識型検索を実現
サーバーレスアーキテクチャで企業・医療・教育・イベントなど多様なユースケースに対応可能なスケーラブルなソリューションを提案
影響分析・編集コメントを表示
影響分析
この記事は、単一のAIサービス利用を超え、複数のAWS AIサービスを統合して実用的なビジネスソリューションを構築する具体的な方法論を示しており、企業のAI実装におけるベストプラクティスとして重要な指針となる。特に、グラフデータベース(Neptune)とマルチモーダルAI(Bedrock)を組み合わせて関係性を理解するシステム設計は、従来の画像認識アプリケーションの限界を超える新たな可能性を示している。
編集コメント
AWSが提供するAIサービス群を実際のユースケースで統合する具体的な実装ガイドは、企業のAI導入を加速する実用的なリソースとして高く評価できる。特に、関係性理解にグラフDBを活用するアプローチは注目に値する。
Amazon Rekognition、Amazon Neptune、および Amazon Bedrock を活用したインテリジェントな写真検索システムの構築
大規模な写真コレクションの管理は、組織や個人にとって大きな課題となっています。従来のアプローチでは、手動でのタグ付け、基本的なメタデータ、フォルダベースの整理に依存しており、複数の人物や複雑な関係性が含まれる数千枚もの画像を扱う場合、実用的でなくなることがあります。インテリジェントな写真検索システムは、コンピュータビジョン、グラフデータベース、自然言語処理を組み合わせることで、視覚コンテンツの発見と整理の方法を変革します。これらのシステムは、写真に写っている人物や物が誰であるかだけでなく、それらを意味あるものとする複雑な関係性や文脈も捉え、自然言語によるクエリやセマンティック検索を可能にします。
本稿では、顔検出およびオブジェクト検出に Amazon Rekognition を、関係性のマッピングに Amazon Neptune を、AI によるキャプション生成に Amazon Bedrock を統合した包括的な写真検索システムを AWS Cloud Development Kit (AWS CDK) を用いて構築する方法を示します。これらのサービスがどのように連携して、「誕生日会での孫たちと祖父母の写真をすべて見つけてください」や「ロードトリップ中の家族の車の写真を表示してください」といった自然言語によるクエリを理解するシステムを創り出すのかを実演します。
主な利点は、特定の人物、オブジェクト、または関係性に焦点を当てた検索のパーソナライズとカスタマイズが可能でありながら、数千枚の写真や複雑な家族・組織構造に対応してスケーリングできる点です。私たちのアプローチは、Amazon Neptune グラフデータベースの機能を Amazon AI サービスと統合することで、単純なメタデータタグ付けを超えて文脈と関係を理解する自然言語による写真検索を実現し、インテリジェントな写真発見を可能にすることを示しています。これは、特定のユースケースに合わせてデプロイおよびカスタマイズ可能な完全なサーバーレス実装を通じて紹介されます。
ソリューションの概要
このセクションでは、インテリジェント写真検索システムの技術アーキテクチャとワークフローについて説明します。以下の図に示すように、本ソリューションはサーバーレスの AWS サービスを使用して、写真を自動的に処理し自然言語検索を可能にするスケーラブルでコスト効果の高いシステムを構築します。
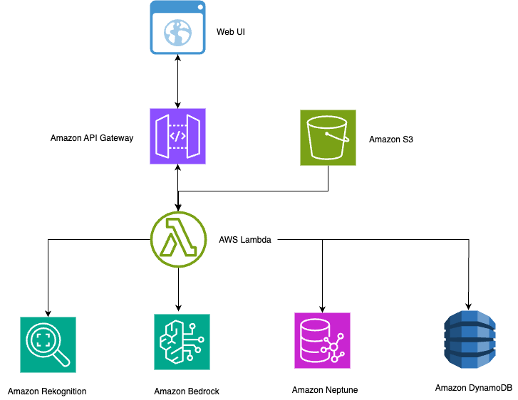
サーバーレスアーキテクチャは、複数のユースケースに対して効率的にスケーリングします:
企業 - 従業員認識とイベント文書の作成
医療 - 関係性の追跡を伴う HIPAA準拠の写真管理
教育 - 部署横断的な学生および教職員の写真整理
イベント - 自動タグ付けとクライアントへの納品を備えたプロフェッショナルな撮影
本アーキテクチャは、文脈を意識した写真検索システムを構築するために、いくつかの AWS サービスを組み合わせています。
REST API エンドポイントおよび Web インターフェース統合用の Amazon API Gateway
AI による文脈画像キャプション生成のための Anthropic の Claude 3.5 Sonnet を備えた Amazon Bedrock
高速なメタデータの保存および検索用の Amazon DynamoDB
ソリューションコンポーネント全体にわたるサーバーレスコンピューティングのオーケストレーションを行う AWS Lambda
複雑な関係をグラフデータベースとして保存するための Amazon Neptune
顔検出、認識、オブジェクトラベリングのための Amazon Rekognition
スケーラブルな写真ストレージおよび処理ワークフローのトリガー用の Amazon Simple Storage Service (Amazon S3)
本システムは以下の簡素化されたワークフローに従います:
画像は自動 Lambda トリガー付きで S3 バケットにアップロードされます。
faces/ プレフィックス内の参照写真は、認識モデルを構築するために処理されます。
新しい写真がトリガーされると、Amazon Rekognition によって顔検出とオブジェクトラベリングが行われます。
Neptune は人々、オブジェクト、および文脈間の接続を保存します。
Amazon Bedrock は検出された顔と関係性を用いて文脈的な説明を作成します。
DynamoDB は高速検索機能を持つ検索可能なメタデータを保存します。
自然言語クエリは Neptune グラフを横断し、インテリジェントな結果を取得します。
完全なソースコードは GitHub で利用可能です。
このソリューションを実装する前に、以下の準備を整えてください:
Amazon S3、Lambda、Amazon Rekognition、Neptune、Amazon Bedrock、および DynamoDB に対する適切な権限を持つ AWS アカウント
プログラムmatic アクセスで構成された AWS Command Line Interface (AWS CLI) v2.15.0 以降
AWS CDK v2.92.0 以降がインストールされていること(npm install -g aws-cdk)
pip パッケージマネージャーを備えた Python 3.11 以降
AWS CDK の操作に使用する Node.js 18.x 以降
サーバーレスアーキテクチャおよびグラフデータベースに関する基本的な知識
AWS リージョン内で Amazon Bedrock を通じて Anthropic の Claude 3.5 Sonnet にアクセスできること
ソリューションのデプロイ
GitHub リポジトリから完全なソースコードをダウンロードしてください。より詳細なセットアップとデプロイの手順は README で確認できます。
プロジェクトは、関心の分離とモジュール型開発を可能にするいくつかの主要ディレクトリに整理されています:
smart-photo-caption-and-search/
├── lambda/
│ ├── face_indexer.py # Rekognition 内の参照顔のインデックス作成
│ ├── faces_handler.py # API を介してインデックスされた顔の一覧表示
│ ├── image_processor.py # メイン処理パイプライン
│ ├── search_handler.py # 検索クエリの処理
│ ├── style_caption.py # スタイル付きキャプションの生成
│ ├── relationships_handler_neptune.py # Neptune リレーションシップの管理
│ ├── label_relationships.py # ラベル階層の照会
│ └── neptune_search.py # Neptune リレーションシップの解析
├── lambda_layer/ # Pillow 画像処理レイヤー
├── neptune_layer/ # Gremlin Python Neptune レイヤー
├── ui/
│ └── demo.html # Cognito 認証を備えた Web インターフェース
├── app.py # CDK アプリケーションのエントリーポイント
├── image_name_cap_stack_neptune.py # Neptune 対応の CDK スack
└── requirements_neptune.txt # Python の依存関係
本ソリューションでは、以下の主要な Lambda 関数を使用します:
image_processor.py – 顔認識、ラベル検出、関係性を強化したキャプション生成を備えたコア処理
search_handler.py – マルチステップの関係性トラバーサルを伴う自然言語クエリ処理
relationships_handler_neptune.py – 設定駆動型の関係性管理とグラフ接続
label_relationships.py – 階層的ラベル照会、オブジェクトと人物の関連付け、意味的発見
ソリューションを展開するには、以下の手順を実行してください。
依存関係をインストールするために、次のコマンドを実行します:
pip install -r requirements_neptune.txt
初回セットアップの場合は、AWS CDK をブートストラップするために、次のコマンドを実行します:
AWS リソースをプロビジョニングするために、次のコマンドを実行します:
Web UI で Amazon Cognito ユーザープール認証情報を設定します。
認識の基準となるよう、参照用写真をアップロードします。
API または Web UI を使用して、サンプルの家族関係を作成します。
本システムは、サーバーレスパイプラインを通じて顔認識、ラベル検出、関係性の解決、AI によるキャプション生成を自動的に処理し、Neptune グラフトラバーサルによって駆動される「車を持つ人物の母親」のような自然言語クエリを可能にします。
主要機能とユースケース
このセクションでは、本ソリューションの主要機能とユースケースについて説明します。
顔認識とタグ付けの自動化
Amazon Rekognition を使用すれば、手動でのタグ付けなしに、参照写真から個人を自動的に識別できます。各人物について数枚の明確な画像をアップロードするだけで、照明や角度に関係なく、コレクション全体でその人物を認識します。この自動化により、タグ付けにかかる時間が数週間から数時間に短縮され、企業ディレクトリ、コンプライアンスアーカイブ、イベント管理ワークフローをサポートします。
関係性を意識した検索を有効にする
Neptune を使用することで、本ソリューションは写真に誰が写っているか、そして彼らがどのように関連しているかを理解します。「サラの上司」や「子供たちといる母親」といった自然言語クエリを実行可能で、システムは多段の関係性をたどって関連画像を返します。この意味検索により、手動でのフォルダ整理に代わり、直感的で文脈を意識した発見が可能になります。
オブジェクトとコンテキストを自動的に理解する
Amazon Rekognition はオブジェクト、シーン、アクティビティを検出し、Neptune がそれらを人物や関係性と結びつけます。これにより、「社用車を持つ役員」や「教室にいる教師」といった複雑なクエリが可能になります。ラベル階層は動的に生成され、手動設定なしでヘルスケアや教育など異なるドメインに適応します。
Amazon Bedrock で文脈を意識したキャプションを生成する
Amazon Bedrock を使用することで、システムは「Sarah と彼女のマネージャーが四半期決算について議論している」のように意味があり、関係性を意識したキャプションを生成し、単なる汎用的なキャプションに代えます。キャプションのトーン(コンプライアンス向けには客観的、マーケティング向けには物語調、経営層向けの要約には簡潔など)を調整可能であり、検索可能性とコミュニケーションの両方を強化します。
直感的な Web 体験を提供する
Web UI を通じて、ユーザーは自然言語で写真を検索し、AI が生成したキャプションを表示し、トーンを動的に調整できます。例えば、「子供連れの母親」や「屋外活動」といったクエリを入力すると、関連するキャプション付きの結果が即座に表示されます。この統合された体験は、エンタープライズワークフローと個人コレクションの両方をサポートします。
以下のスクリーンショットは、インテリジェントな写真検索およびキャプションスタイル化のために Web UI を使用した様子を示しています。
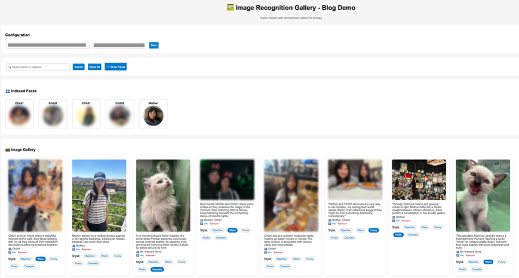
ラベル階層でグラフ関係をスケーリングする
Neptune は、組織間またはデータセット全体にわたる数千もの関係とラベル階層をモデル化するためにスケールします。関係性は画像処理中に自動的に生成されるため、データの成長に伴ってもパフォーマンスと柔軟性を維持しながら、高速な意味論的発見が可能になります。
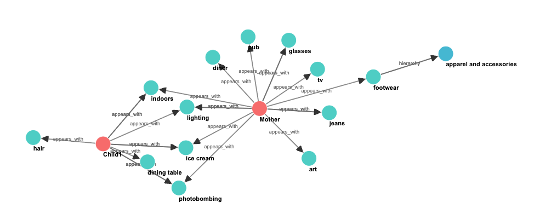
以下の図は、人物関係グラフの例(設定駆動型)を示しています。
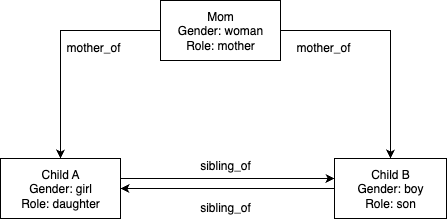
人物間の関係性は、initialize_relationship_data() 関数に渡される JSON データ構造を通じて設定されます。
以下の図は、Amazon Rekognition から自動的に生成されたラベル階層グラフの例を示しています。
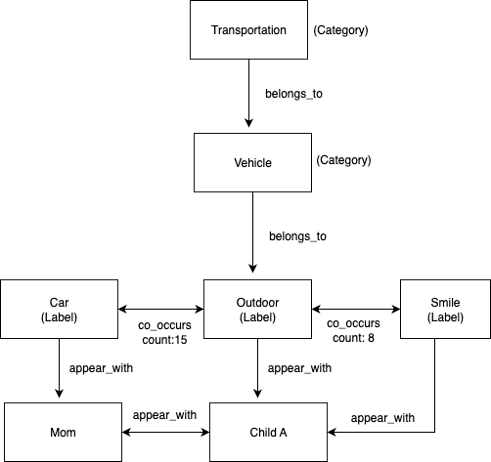
ラベル階層と共起パターンは、画像処理中に自動的に生成されます。Amazon Rekognition は、belongs_to 関係を作成するためのカテゴリ分類を提供します。
以下のスクリーンショットは、完全なグラフの一部を示しており、多層的な関係型の例をデモンストレーションしています。
データベース生成メソッド
関係グラフは、initialize_relationship_data() 関数を通じた柔軟な設定駆動型アプローチを使用しています。
汎用的な設定構造
config = {
"people": [
{"name": "alice", "gender": "woman", "role": "mother"},
{"name": "jane", "gender": "girl", "role": "daughter"}
],
"relationships": [
{"from": "alice", "to": "jane", "type": "parent_of", "subtype": "mother_of"},
{"from": "jane", "to": "david", "type": "sibling_of", "bidirectional": True}
]
}
汎用的な関係性の作成
for rel in relationships_data:
g.V().has('name', rel["from"]).addE(rel["type"]).to(
__.V().has('name', rel["to"])
).property('type', rel["subtype"]).next()
ビジネス例 - 設定を変更するだけで対応可能
business_config = {
"people": [{"name": "sarah", "role": "manager"}],
"relationships": [{"from": "sarah", "to": "john", "type": "manages", "subtype": "manager_of"}]
}
ラベル付きリレーションシップデータベースは、画像処理時に store_labels_in_neptune() 関数を通じて自動的に作成されます。
Rekognition はカテゴリ付きのラベルを提供します
response = rekognition.detect_labels(
Image={'Bytes': image_bytes},
MaxLabels=20,
MinConfidence=70
)
ラベルとカテゴリを抽出
for label in response.get('Labels', []):
label_data = {
'name': label['Name'], # 例:"Car"
'categories': [cat['Name'] for cat in label.get('Categories', [])] # 例:["Vehicle", "Transportation"]
}
Neptune における自動階層構造の作成
for category in categories:
# belongs_to リレーションシップを作成 (Car -> Vehicle -> Transportation)
g.V().has('name', label_name).addE('belongs_to').to(
__.V().ha
原文を表示
Build an intelligent photo search using Amazon Rekognition, Amazon Neptune, and Amazon Bedrock
Managing large photo collections presents significant challenges for organizations and individuals. Traditional approaches rely on manual tagging, basic metadata, and folder-based organization, which can become impractical when dealing with thousands of images containing multiple people and complex relationships. Intelligent photo search systems address these challenges by combining computer vision, graph databases, and natural language processing to transform how we discover and organize visual content. These systems capture not just who and what appears in photos, but the complex relationships and contexts that make them meaningful, enabling natural language queries and semantic discovery.
In this post, we show you how to build a comprehensive photo search system using the AWS Cloud Development Kit (AWS CDK) that integrates Amazon Rekognition for face and object detection, Amazon Neptune for relationship mapping, and Amazon Bedrock for AI-powered captioning. We demonstrate how these services work together to create a system that understands natural language queries like “Find all photos of grandparents with their grandchildren at birthday parties” or “Show me pictures of the family car during road trips.”
The key benefit is the ability to personalize and customize search focus on specific people, objects, or relationships while scaling to handle thousands of photos and complex family or organizational structures. Our approach demonstrates that integrating Amazon Neptune graph database capabilities with Amazon AI services enables natural language photo search that understands context and relationships, moving beyond simple metadata tagging to intelligent photo discovery. We showcase this through a complete serverless implementation that you can deploy and customize for your specific use case.
Solution overview
This section outlines the technical architecture and workflow of our intelligent photo search system. As illustrated in the following diagram, the solution uses serverless AWS services to create a scalable, cost-effective system that automatically processes photos and enables natural language search.
The serverless architecture scales efficiently for multiple use cases:
Corporate – Employee recognition and event documentation
Healthcare – HIPAA-compliant photo management with relationship tracking
Education – Student and faculty photo organization across departments
Events – Professional photography with automated tagging and client delivery
The architecture combines several AWS services to create a contextually aware photo search system:
Amazon API Gateway for REST API endpoints and web interface integration
Amazon Bedrock with Anthropic’s Claude 3.5 Sonnet for AI-powered contextual image captioning
Amazon DynamoDB for fast metadata storage and retrieval
AWS Lambda for serverless compute orchestration across solution components
Amazon Neptune for storing complex relationships as a graph database
Amazon Rekognition for face detection, recognition, and object labeling
Amazon Simple Storage Service (Amazon S3) for scalable photo storage and triggering processing workflows
The system follows a streamlined workflow:
Images are uploaded to S3 buckets with automatic Lambda triggers.
Reference photos in the faces/ prefix are processed to build recognition models.
New photos trigger Amazon Rekognition for face detection and object labeling.
Neptune stores connections between people, objects, and contexts.
Amazon Bedrock creates contextual descriptions using detected faces and relationships.
DynamoDB stores searchable metadata with fast retrieval capabilities.
Natural language queries traverse the Neptune graph for intelligent results.
The complete source code is available on GitHub.
Before implementing this solution, ensure you have the following:
An AWS account with appropriate permissions for Amazon S3, Lambda, Amazon Rekognition, Neptune, Amazon Bedrock, and DynamoDB
The AWS Command Line Interface (AWS CLI) v2.15.0 or later configured with programmatic access
The AWS CDK v2.92.0 or later installed (npm install -g aws-cdk
Python 3.11 or later with pip package manager
Node.js 18.x or later for AWS CDK operations
Basic knowledge of serverless architectures and graph databases
Access to Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock in your AWS Region
Deploy the solution
Download the complete source code from the GitHub repository. More detailed setup and deployment instructions are available in the README.
The project is organized into several key directories that separate concerns and enable modular development:
smart-photo-caption-and-search/ ├── lambda/ │ ├── face_indexer.py # Indexes reference faces in Rekognition │ ├── faces_handler.py # Lists indexed faces via API │ ├── image_processor.py # Main processing pipeline │ ├── search_handler.py # Handles search queries │ ├── style_caption.py # Generates styled captions │ ├── relationships_handler_neptune.py # Manages Neptune relationships │ ├── label_relationships.py # Queries label hierarchies │ └── neptune_search.py # Neptune relationship parsing ├── lambda_layer/ # Pillow image processing layer ├── neptune_layer/ # Gremlin Python Neptune layer ├── ui/ │ └── demo.html # Web interface with Cognito authentication ├── app.py # CDK application entry point ├── image_name_cap_stack_neptune.py # Neptune-enabled CDK stack └── requirements_neptune.txt # Python dependencies
The solution uses the following key Lambda functions:
image_processor.py – Core processing with face recognition, label detection, and relationship-enriched caption generation
search_handler.py – Natural language query processing with multi-step relationship traversal
relationships_handler_neptune.py – Configuration-driven relationship management and graph connections
label_relationships.py – Hierarchical label queries, object-person associations, and semantic discovery
To deploy the solution, complete the following steps:
Run the following command to install dependencies:
pip install -r requirements_neptune.txt
For a first-time setup, fun the following command to bootstrap the AWS CDK:
Run the following command to provision AWS resources:
Set up Amazon Cognito user pool credentials in the web UI.
Upload reference photos to establish the recognition baseline.
Create sample family relationships using the API or web UI.
The system automatically handles face recognition, label detection, relationship resolution, and AI caption generation through the serverless pipeline, enabling natural language queries like “person’s mother with car” powered by Neptune graph traversals.
Key features and use cases
In this section, we discuss the key features and use cases for this solution.
Automate face recognition and tagging
With Amazon Rekognition, you can automatically identify individuals from reference photos, without manual tagging. Upload a few clear images per person, and the system recognizes them across your entire collection, regardless of lighting or angles. This automation reduces tagging time from weeks to hours, supporting corporate directories, compliance archives, and event management workflows.
Enable relationship-aware search
By using Neptune, the solution understands who appears in photos and how they are connected. You can run natural language queries such as “Sarah’s manager” or “Mom with her children,” and the system traverses multi-hop relationships to return relevant images. This semantic search replaces manual folder sorting with intuitive, context-aware discovery.
Understand objects and context automatically
Amazon Rekognition detects objects, scenes, and activities, and Neptune links them to people and relationships. This enables complex queries like “executives with company vehicles” or “teachers in classrooms.” The label hierarchy is generated dynamically and adapts to different domains—such as healthcare or education—without manual configuration.
Generate context-aware captions with Amazon Bedrock
Using Amazon Bedrock, the system creates meaningful, relationship-aware captions such as “Sarah and her manager discussing quarterly results” instead of generic ones. Captions can be tuned for tone (such as objective for compliance, narrative for marketing, or concise for executive summaries), enhancing both searchability and communication.
Deliver an intuitive web experience
With the web UI, users can search photos using natural language, view AI-generated captions, and adjust tone dynamically. For example, queries like “mother with children” or “outdoor activities” return relevant, captioned results instantly. This unified experience supports both enterprise workflows and personal collections.
The following screenshot demonstrates using the web UI for intelligent photo search and caption styling.
Scale graph relationships with label hierarchies
Neptune scales to model thousands of relationships and label hierarchies across organizations or datasets. Relationships are automatically generated during image processing, enabling fast semantic discovery while maintaining performance and flexibility as data grows.
The following diagram illustrates an example person relationship graph (configuration-driven).
Person relationships are configured through JSON data structures passed to the initialize_relationship_data()
The following diagram illustrates an example label hierarchy graph (automatically generated from Amazon Rekognition).
Label hierarchies and co-occurrence patterns are automatically generated during image processing. Amazon Rekognition provides category classifications that create the belongs_to
The following screenshot illustrates a subset of the complete graph, demonstrating multi-layered relationship types.
Database generation methods
The relationship graph uses a flexible configuration-driven approach through the initialize_relationship_data()
Generic configuration structure config = { "people": [ {"name": "alice", "gender": "woman", "role": "mother"}, {"name": "jane", "gender": "girl", "role": "daughter"} ], "relationships": [ {"from": "alice", "to": "jane", "type": "parent_of", "subtype": "mother_of"}, {"from": "jane", "to": "david", "type": "sibling_of", "bidirectional": True} ] } # Generic relationship creation for rel in relationships_data: g.V().has('name', rel["from"]).addE(rel["type"]).to( __.V().has('name', rel["to"]) ).property('type', rel["subtype"]).next() # Business example - just change the configuration business_config = { "people": [{"name": "sarah", "role": "manager"}], "relationships": [{"from": "sarah", "to": "john", "type": "manages", "subtype": "manager_of"}] }
The label relationship database is created automatically during image processing through the store_labels_in_neptune()
Rekognition provides labels with categories response = rekognition.detect_labels( Image={'Bytes': image_bytes}, MaxLabels=20, MinConfidence=70 ) # Extract labels and categories for label in response.get('Labels', []): label_data = { 'name': label['Name'], # e.g., "Car" 'categories': [cat['Name'] for cat in label.get('Categories', [])] # e.g., ["Vehicle", "Transportation"] } # Automatic hierarchy creation in Neptune for category in categories: # Create belongs_to relationship (Car -> Vehicle -> Transportation) g.V().has('name', label_name).addE('belongs_to').to( __.V().ha
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み