エージェントフレームワークとエージェントの可観測性について
LangChain Blogは、モデル性能の向上に伴いエージェントフレームワークが「イージーボタン」から「運用可能な基盤」へ進化し、LangGraphやDeepAgentsのような柔軟なオーケストレーションと、モデルに依存しない観測可能性(LangSmith)の重要性を強調している。
キーポイント
エージェントフレームワークの進化と必要性
LLMの性能向上により単純なチェーンからワークフローやツール呼び出しループへパターンが変化したが、ベストプラクティスのエンコードや生産性向上のためフレームワークは依然として有用であり、モデルの進化に追従して進化する必要がある。
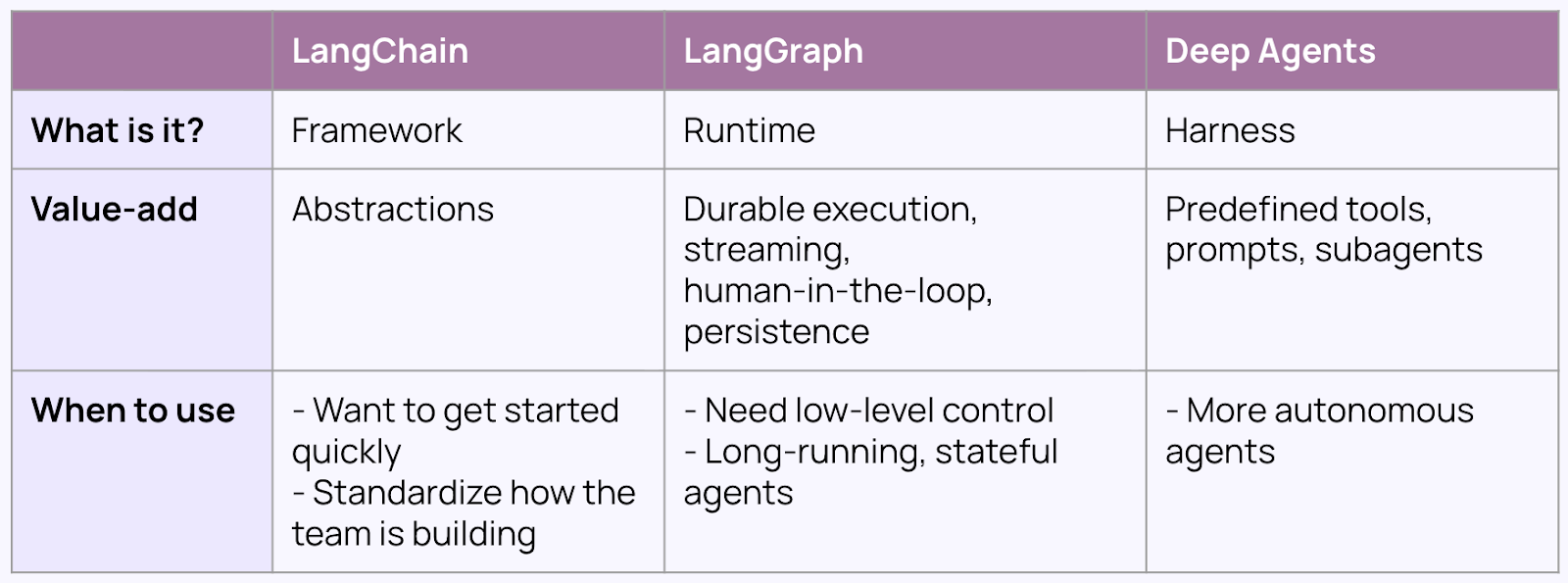
LangGraphとDeepAgentsの役割分担
低レベルで柔軟な状態管理を提供するLangGraphと、長期的なタスク計画やサブエージェント調整に対応した高性能な「バッテリーIncluded」ハarnessであるDeepAgentsを区別し、ユースケースに応じた適切なツール選択の重要性を示している。
モデル非依存の観測可能性(Observability)
エージェント構築手法がどうであれ、LangSmithによる観測は不可欠であり、オープンソースのLangChainやLangGraphを使用していない場合でも利用可能であるという、プラットフォーム中立性の立場を明確にしている。
DeepAgentsの特性とLangGraphとの関係
モデル非依存でLLMに委譲できる柔軟なエージェントハネス「deepagents」は、LangGraphのランタイム上で動作し、長期タスクやサブエージェント調整をサポートする。
フレームワーク選択と採用のバランス
AI分野は標準化が追いつかないほど急速に変化するが、単純なLLM呼び出しには不要であり、フレームワークは開発速度と成功確率を高めるために活用すべきである。
LangSmithの独立した設計思想
LangSmithは特定のフレームワークに依存せず、OpenTelemetry対応や他社SDKとの互換性を持たせることで、フレームワークを選ばない観測と評価プラットフォームとして構築された。
トレーシングの重要性
エージェントの振る舞いを理解し、デバッグやモニタリングを行うためにはトレーシングが不可欠であり、エージェントのロジックはコードではなくトレーシングに記録される。
影響分析・編集コメントを表示
影響分析
この記事は、LLM開発の現場における「フレームワーク依存」から「実装と観測の分離」というパラダイムシフトを示唆しています。LangChainが自社のエコシステム(LangSmith)への導線を保ちつつ、競合他社や独自実装を排除しない姿勢は、業界標準ツールとしての地位確立に向けた重要な戦略表明であり、開発者の技術選定に大きな影響を与える可能性があります。
編集コメント
LangChainが「フレームワークの有用性」を再定義し、自社の観測ツール(LangSmith)をプラットフォーム中立の標準として位置づける戦略は、開発者コミュニティからの信頼獲得に寄与する可能性があります。
LLMが向上するたびに、同じ疑問が戻ってきます:「エージェントフレームワークはまだ必要ですか?」これは当然の質問です。モデルの性能が向上し進化するにつれて、エージェントを構築する最良の方法は変化しますが、根本的に、エージェントはモデルを囲むシステムです。ですから、エージェントは消え去ることはありません――ただ、同様に進化する必要があるだけです。私たちは現在、3世代のエージェントフレームワークを構築してきましたが、それぞれが前の世代とは異なる様相を呈していました。そこで、私たちが確信していることをお伝えします:
エージェントフレームワークは、モデルと同じ速さで進化する場合にのみ、依然として有用です。
エージェントの可観測性は、どのように構築したかに関わらず機能すべきです。それが、私たちのオープンソース(LangChainやLangGraph)を使用していなくてもLangSmithが機能する理由です。
この記事は、その両方の確信について述べています。
なぜ2026年においてエージェントフレームワークが依然として関連性を持つのか
エージェントのパターンは、チェーニングからワークフローオーケストレーションへ、そしてファイルシステムとメモリを伴うループ内ツール呼び出しへと移行してきました。私たちはそれらすべてのためのフレームワークを構築し、ユースケースに基づいてそれぞれに存在意義があると信じています。以下にその進化の過程を示します:
オリジナルのLangChainは2023年に人気を博しました。それは、LLMを実用的に活用する方法を知っている人がほとんどいなかったためです。このフレームワークは、一連の統合と中核的な抽象化を通じて、基盤モデルをデータやAPIに接続する最も簡単な方法の一つを提供しました。当初は確かに独断的すぎたかもしれません――本番環境対応のツールというよりは、プロンプティングやRAGについて学ぶための「簡単ボタン」に近いものでした。その夏までに生成AIの第一波が落ち着き始めると、エージェントフレームワークは無意味だという批判が高まりました。
私たちはその批判を耳にしましたが、実際の使用状況で目にしていたこととは相容れないものでした。LLMアプリを構築するチームの大多数は、完全に独力で進めるよりも迅速に動くための方法を必要としていました。優れたフレームワークは:
ベストプラクティスをフレームワーク自体にエンコードする
ボイラープレートコードを削減する
より高い品質レベルに到達することを容易にする
大規模なチーム全体で標準と可読性を生み出す
本番環境へのよりクリーンな道筋を整備する
そこで、私たちは強化に乗り出しました。ただし、別のフレームワークでです。
オーケストレーションとランタイム
LangGraphはより低レベルで柔軟性が高いものでした。耐久性と状態保持をサポートするランタイムを含んでおり、これは人間とエージェント、およびエージェント間のコラボレーションにとって重要であることが判明しました。これは、人々がLangChainについて提起していた多くの制御上の懸念に対処しました。私たちは最終的に2025年にオリジナルのLangChainをより合理化されたものに書き換えましたが、異なる問題には異なるツールが必要であることも認識しました。
より最近では、DeepAgentsを構築しました:これは、より高性能で柔軟性の高い、バッテリー内蔵型のエージェントハーネスです。長期的なタスクの計画、ループ内ツール呼び出し、ファイルシステムへのコンテキストのオフロード、サブエージェントのオーケストレーションをサポートします。エージェントハーネスが今機能するのは、LLMの推論能力が向上しており、多くのオーケストレーションパターンをハードコーディングするのではなく、より多くの決定をLLMに委任できるためです。概念的にはClaude Agent SDKに最も似ていますが、モデルに依存しません。私たちの知る限り、これは特定のLLMやアプリケーションスタックに縛られていない唯一のエージェントハーネスです。
今日、私たちは異なるユースケースに対してこれらの異なるフレームワークを推奨しています。LangChainとDeepAgentsは、長時間実行のためのLangGraphのランタイム上に構築されています。
劇的に聞こえるかもしれませんが、私たちは3年間で3世代のエージェントを目にしてきました:RAGとして始まったものがエージェント的ワークフローになり、それがより自律的なループ内ツール呼び出しエージェントへと進化したのです。
フレームワークに対する最大の批判は、AI分野の進化が速すぎて標準が形成されないという点です。そこには真実があります。しかし、私たちはまた、AIの競争から身を引き、物事が落ち着くのを待つことは敗北の戦略であるとも信じています。フレームワークは、飛び込み、より速く構築し、成功の確率を高めるのに役立ちます。そのことを理解していても、ツールは変化し続けるでしょう。また、すべてのものにフレームワークが必要なわけでもありません。単純なLLMリクエストであれば、フレームワークを追加することは過剰かもしれません。
なぜLangSmithはLangChainオープンソースから独立しているのか
初期の段階で、私たちは品質がエージェントを本番環境に投入する上での最大の障壁であると認識しました。私たちは、目的に特化したエージェントの可観測性と評価がツールキットの必須部分であると信じていました(今も信じています)。
私たちはそれをLangSmithと名付けました。なぜなら、エージェントフレームワークは一つだけではないだろうという直感があったからです。また、たとえ支配的なフレームワークがあったとしても、初期バージョンが認識できないほどの速さで進化しなければならないだろうと考えました。私たちは、誰もが私たちのフレームワークを使うわけではないことを認めましたが、それでもこのプラットフォームを使えるようにしたいと考えました。
そこで、私たちはLangSmithを、LangChainを使っているか、私たちの他のフレームワークを使っているか、あるいは全く使っていないかに関わらず動作するように構築しました。これは当時、自明な決定ではありませんでした。私たちは、自社のNext.jsを超えて多くのフロントエンドフレームワークをサポートするVercelのような企業からインスピレーションを得ました。
今日、LangSmithは多数のフレームワークとすぐに統合できます――AutoGen、Claude Agent SDK、CrewAI、Mastra、OpenAI Agents、PydanticAI、Vercel AI SDKなどです。OpenTelemetryベースのトレーシングをサポートしているため、OTEL仕様を出力するものは何でもLangSmithに取り込むことができます。また、フレームワークを全く使用せずに構築されたエージェントとも連携します。Clay、Harvey、Vantaを含む多くのLangSmith顧客は、私たちのオープンソースフレームワークを使用していませんが、可観測性と評価のためにLangSmithに依存しています。
エージェントエンジニアリングにおける構築とテストの収束
エージェントフレームワークに関わらず、トレースはエージェントの動作を理解する上で重要です。私たちは、エージェントトレースがいかに重要であるかについて書いてきました。なぜなら、それはエージェントのデバッグ、監視、評価などの基礎となるからです。エージェントでは、アプリケーションのロジックはコードではなくトレースに記録されます。エージェントを構築することはほんの第一歩に過ぎません。エージェントは非決定性のシステムであるため、実際にリリースするまで、どのような入力や出力が予想されるかわかりません。そのため、デバッグ、テスト、監視は、エージェントエンジニアリングと構築プロセス自体の重要な部分なのです。
ですから、もし私たちのOSSフレームワークを使用していないのであれば、その理由を聞かせてください!しかし、それによってLangSmithを使ってエージェントがどのように、なぜ失敗しているのかを解明するのを止めないでください。
ニュースレターにご登録ください
LangChainチームとコミュニティからの最新情報
お申し込みを処理しています...
成功しました!受信トレイを確認し、リンクをクリックして購読を確認してください。
申し訳ありません。エラーが発生しました。もう一度お試しください。
原文を表示
Every time LLMs get better, the same question comes back: "Do you still need an agent framework?" It's a fair question. The best way to build agents changes as the models get more performant and evolve, but fundamentally, the agent is a system around the model, so they will not disappear – they just need to evolve too.We've now built three generations of agent frameworks, and each one looked different from the last. So here's what we believe:
Agent frameworks are still useful, but only if they evolve as fast as the models do.
Agent observability should work no matter how you build. That’s why LangSmith works even if you don’t use our open source (LangChain or LangGraph).
This post is about both of those bets.
Why agent frameworks are still relevant in 2026
Agent patterns have moved from chaining to workflow orchestration to tool-calling-in-a-loop with file-systems and memory. We’ve built frameworks for them all and believe each has its place based on your use case. Here’s how they’ve evolved:
The original langchain got popular in 2023 because few people knew how to make practical use of LLMs. The framework offered one of the easiest ways to connect foundation models to your data or APIs through a set of integrations and core abstractions. It was arguably too opinionated at the start — more of an "easy button" for learning about prompting and RAG than a production-ready tool. As the first wave of generative AI started to settle by that summer, criticism that agent frameworks were pointless grew louder.
We heard the criticism, but it was hard to square with what we were seeing in actual usage. The vast majority of teams building LLM apps needed ways to move faster than going it completely alone. Good frameworks:
Encode best practices into the framework itself
Reduce boilerplate code
Make it easier to reach a higher level of quality
Create standards and readability across large teams
Pave a cleaner path to production
So we doubled down. On a different framework.
Orchestration and run-time
langgraph was lower level and more flexible. It included a runtime that supported durability and statefulness, which turned out to be important for human-agent and agent-agent collaboration. It addressed many of the control concerns people had raised about langchain. We did eventually rewrite the original langchain in 2025 to be more streamlined, but we also recognized that different problems need different tools.
More recently, we built deepagents: a batteries-included agent harness that's more performant and more flexible. It supports planning for long-horizon tasks, tool-calling-in-a-loop, context offloading to a filesystem, and subagent orchestration. An agent harness works now because LLMs are getting better at reasoning and you can delegate more decisions to the LLM vs. hard coding as many orchestration patterns. It's most similar in concept to Claude Agent SDK, but model-agnostic. To our knowledge, it's the only agent harness that is not tied to any specific LLM or application stack.
Today, we recommend these different frameworks for different use cases. langchain and deepagents are built on top of langgraph’s runtime for long running execution.
It sounds dramatic, but we’ve seen three generations of agents in three years: what started as RAG became agentic workflows, which evolved into more autonomous tool-calling-in-a-loop agents.
The biggest knock against frameworks is that the AI space evolves too quickly for standards to form. There's truth to that. But we also believe that sitting out of the AI game waiting for things to settle is a losing strategy. Frameworks help you dive in, build faster, and increase your odds of success. Even knowing that, the tools will keep changing. And you also don’t need a framework for everything. If it’s a simple LLM request, adding a framework may be too heavy handed.
Why LangSmith is independent from LangChain open source
Early on, we recognized that quality was the biggest barrier to getting agents into production. We believed, and still do, that purpose-built agent observability and evals were a required part of the toolkit.
We called it LangSmith, because we had the intuition that there wouldn't be only one agent framework. And even if there were a dominant one, it would have to evolve at a pace that would make early versions unrecognizable. We acknowledged not everyone would use our frameworks, but wanted them still to be able to use this platform.
So we built LangSmith to work regardless of whether you used langchain, any of our other frameworks, or nothing at all. This wasn't an obvious decision at the time. We drew inspiration from companies like Vercel, which supports many frontend frameworks beyond their own Next.js.
Today, LangSmith integrates with a number of frameworks out of the box — AutoGen, Claude Agent SDK, CrewAI, Mastra, OpenAI Agents, PydanticAI, Vercel AI SDK, and more. It supports OpenTelemetry-based tracing, so anything that emits the OTEL spec can be ingested by LangSmith. And it works with agents built using no framework at all. Many LangSmith customers, including Clay, Harvey, and Vanta, don't use our open source frameworks but rely on LangSmith for observability and evals.
Building and testing converge in agent engineering
Regardless of your agent framework, traces are critical to understanding agent behavior. We've been writing about how important the agent trace is because it's the foundation for agent debugging, monitoring, evals, and more. With agents, your app logic is documented in traces, not code. Building the agent is only the first step. Agents are non-deterministic systems, so you have no idea what inputs or outputs to expect until you ship it. That’s why debugging, testing, and monitoring are critical parts of agent engineering and the building process itself.
So if you’re not using our OSS frameworks, we’d like to hear why! But, don’t let it stop you from figuring out how and why your agent is failing with LangSmith.
Join our newsletter
Updates from the LangChain team and community
Processing your application...
Success! Please check your inbox and click the link to confirm your subscription.
Sorry, something went wrong. Please try again.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み