大規模言語モデル(LLM)アーキテクチャの比較
Sebastian Raschka は、2025 年時点の主要 LLM アーキテクチャを比較分析し、構造的な進化が微細な改良に留まっている現状と、DeepSeek V3/R1 の影響について解説している。
キーポイント
アーキテクチャの構造的類似性
GPT-2 から DeepSeek V3 まで 7 年経過したが、根本的な構造は似ており、RoPE や GQA、SwiGLU などの微細な改良が主流である。
DeepSeek R1/V3 の影響
2025 年 1 月に公開された推論モデル DeepSeek R1 が、そのベースとなる V3 アーキテクチャへの注目を急激に高めた。
比較分析の難易度
データセットやトレーニング手法、ハイパーパラメータの差異が大きいため、単なるベンチマークではなくアーキテクチャ自体の構造変化に焦点を当てる必要がある。
GQA の仕組みと利点
GQA は複数のアテンションヘッドに対してキーとバリューを共有することで、メモリ使用量を削減し、推論時の効率を向上させるが、モデル性能への影響は小さい。
MLA の革新的なアプローチ
MLA は GQA と異なり、キーとバリューテンソルを KV キャッシュに保存する前に低次元空間へ圧縮することで、メモリ節約を実現する。
MLA の性能とメモリ効率
MLA は KV キャッシュのメモリ使用量を削減しつつ、MHA よりもわずかに優れたモデル化性能を示すことが確認されています。
GQA 選定理由の背景
DeepSeek の研究では GQA が MHA よりパフォーマンスが劣る傾向にある一方、MLA は MHA を上回るため、MLA が採用されたと考えられます。
影響分析・編集コメントを表示
影響分析
この分析は、業界が「革新的な新構造」を求めていた時期において、実際には成熟したアーキテクチャの微調整段階にあることを示唆しており、開発者や研究者にとって技術トレンドの方向性を理解する上で重要な視点を提供します。特に DeepSeek の急成長が既存モデルの評価基準に与えた影響を構造的観点から解明している点は、今後の LLM 設計戦略を考える上で示唆に富んでいます。
編集コメント
最新モデルの性能比較ではなく、その背後にある設計思想の変遷に焦点を当てた貴重な分析記事です。技術者が「なぜ今このアーキテクチャなのか」を理解する上で必読と言えます。
大規模言語モデル(LLM)アーキテクチャ比較
DeepSeek V3からGLM-5へ:現代LLMアーキテクチャ設計を概観
 Sebastian Raschka, PhD2025年7月19日1,79086161共有最終更新日:2026年2月25日(2月の最近リリースを下部に追加)
Sebastian Raschka, PhD2025年7月19日1,79086161共有最終更新日:2026年2月25日(2月の最近リリースを下部に追加)
オリジナルのGPTアーキテクチャが開発されてから7年が経過しました。GPT-2(2019年)を振り返り、DeepSeek V3やLlama 4(2024-2025年)を見渡すと、一見して、これらのモデルが依然として構造的に非常に類似していることに驚かれるかもしれません。
確かに、位置埋め込みは絶対位置から回転位置(RoPE)へ進化し、マルチヘッドアテンションはグループ化クエリアテンションに大きく取って代わられ、より効率的なSwiGLUがGELUなどの活性化関数に置き換わりました。しかし、これらの些細な改良の下で、私たちは本当に画期的な変化を目にしているのでしょうか、それとも単に同じアーキテクチャの基盤を磨き上げているだけなのでしょうか?
LLMを比較して、その良好な(あるいはそれほど良くない)性能に寄与する主要な要素を特定することは、非常に困難であることで知られています:データセット、トレーニング技術、ハイパーパラメータは大きく異なり、しばしば十分に文書化されていません。
しかし、2025年のLLM開発者が何をしているのかを見るために、アーキテクチャ自体の構造的変化を検討することには、依然として多くの価値があると考えています。(その一部を以下の図1に示します。)
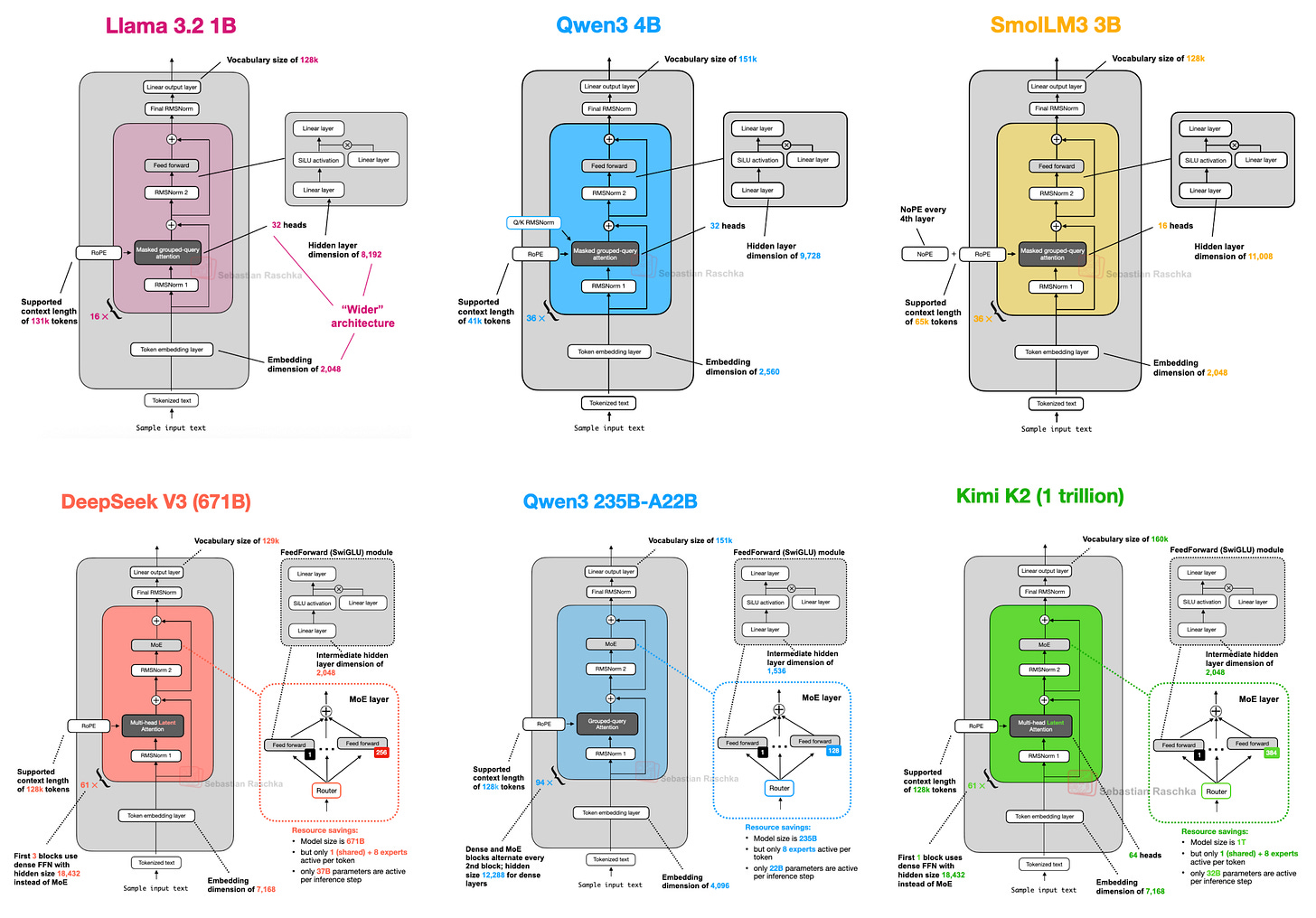 図1:本記事で取り上げるアーキテクチャの一部。
図1:本記事で取り上げるアーキテクチャの一部。
したがって、本記事では、ベンチマーク性能やトレーニングアルゴリズムについて書くのではなく、今日の旗艦オープンモデルを定義するアーキテクチャの発展に焦点を当てます。
(ご記憶かもしれませんが、私はつい最近マルチモーダルLLMについて書きました;本記事では、最近のモデルのテキスト能力に焦点を当て、マルチモーダル能力の議論は別の機会に譲ります。)
ヒント:これはかなり包括的な記事ですので、ナビゲーションバーを使用して目次にアクセスすることをお勧めします(Substackページの左側にカーソルを合わせるだけです)。
オプション:以下のビデオは、本記事のナレーション付き要約版です。
- DeepSeek V3/R1
おそらくすでに何度も耳にしているように、DeepSeek R1は2025年1月にリリースされた際、大きな衝撃を与えました。DeepSeek R1は、2024年12月に導入されたDeepSeek V3アーキテクチャを基盤に構築された推論モデルです。
ここでの焦点は2025年にリリースされたアーキテクチャですが、DeepSeek V3が広く注目され、採用されるようになったのは2025年のDeepSeek R1の立ち上げ後であるため、DeepSeek V3を含めるのは妥当だと考えます。
特にDeepSeek R1のトレーニングに興味がある方は、今年初めに書いた私の記事も参考になるかもしれません:
 推論LLMを理解する
推論LLMを理解する
このセクションでは、DeepSeek V3で導入された、計算効率を向上させ、他の多くのLLMと区別する2つの主要なアーキテクチャ技術に焦点を当てます:
マルチヘッド潜在アテンション(MLA)
エキスパートの混合(MoE)
1.1 マルチヘッド潜在アテンション(MLA)
マルチヘッド潜在アテンション(MLA)について議論する前に、その使用動機を説明するために、いくつかの背景を簡単に振り返りましょう。そのために、近年、マルチヘッドアテンション(MHA)に対するより計算効率とパラメータ効率の高い代替として新たな標準となっているグループ化クエリアテンション(GQA)から始めましょう。
では、簡単なGQAの概要です。MHAでは各ヘッドが独自のキーと値のセットを持つのに対し、メモリ使用量を削減するために、GQAは複数のヘッドをグループ化して同じキーと値の射影を共有します。
例えば、以下の図2でさらに示されているように、2つのキー・バリューグループと4つのアテンションヘッドがある場合、ヘッド1と2が1組のキーと値を共有し、ヘッド3と4が別の組を共有するかもしれません。これにより、キーと値の計算の総数が減り、メモリ使用量の削減と効率の向上につながります(アブレーション研究によれば、モデリング性能に顕著な影響を与えずに)。
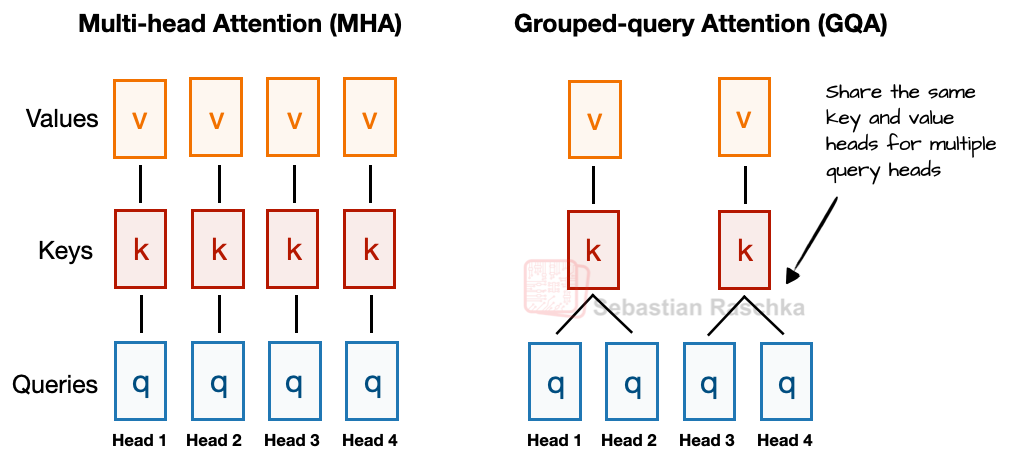 図2:MHAとGQAの比較。ここでは、グループサイズは2で、キーと値のペアが2つのクエリ間で共有されています。
図2:MHAとGQAの比較。ここでは、グループサイズは2で、キーと値のペアが2つのクエリ間で共有されています。
したがって、GQAの核心となる考え方は、複数のクエリヘッド間でキーと値を共有することで、キーと値のヘッドの数を減らすことです。これにより、(1)モデルのパラメータ数が減り、(2)推論時にKVキャッシュから保存・取得する必要のあるキーと値が少なくなるため、キーと値のテンソルに対するメモリ帯域幅の使用量が削減されます。
(GQAがコードでどのように見えるか興味がある方は、KVキャッシュなしのバージョンについては私のGPT-2からLlama 3への変換ガイドを、KVキャッシュありのバリアントについてはこちらをご覧ください。)
GQAは主にMHAに対する計算効率の回避策ですが、アブレーション研究(元のGQA論文やLlama 2論文など)は、LLMのモデリング性能において標準的なMHAと同等に機能することを示しています。
さて、マルチヘッド潜在アテンション(MLA)は、特にKVキャッシュとうまく組み合わさる、異なるメモリ節約戦略を提供します。GQAのようにキーと値のヘッドを共有する代わりに、MLAはキーと値のテンソルを低次元空間に圧縮してからKVキャッシュに格納します。
推論時には、これらの圧縮されたテンソルは、以下の図3に示すように、使用される前に元のサイズに射影し戻されます。これにより追加の行列乗算が発生しますが、メモリ使用量は削減されます。
 図3:MLA(DeepSeek V3およびR1で使用)と通常のMHAの比較。
図3:MLA(DeepSeek V3およびR1で使用)と通常のMHAの比較。
(余談ですが、クエリも圧縮されますが、それはトレーニング時のみで、推論時には圧縮されません。)
ちなみに、MLAはDeepSeek V3で新しく登場したものではなく、その前身であるDeepSeek-V2でも使用され(そして導入さえされ)ました。また、V2の論文には、DeepSeekチームがGQAではなくMLAを選択した理由を説明するかもしれない、いくつかの興味深いアブレーション研究が含まれています(以下の図4を参照)。
 図4:DeepSeek-V2論文からの注釈付き表、https://arxiv.org/abs/2405.04434
図4:DeepSeek-V2論文からの注釈付き表、https://arxiv.org/abs/2405.04434
上の図4に示されているように、GQAはMHAよりも性能が悪いように見えますが、MLAはMHAよりも優れたモデリング性能を提供しており、おそらくこれがDeepSeekチームがGQAではなくMLAを選択した理由でしょう。(MLAとGQAの間の「トークンあたりのKVキャッシュ」節約の比較も見てみたかったです!)
次のアーキテクチャ構成要素に進む前にこのセクションをまとめると、MLAはKVキャッシュのメモリ使用量を削減する巧妙なトリックであり、モデリング性能の点ではMHAよりもわずかに優れていると言えます。
1.2 エキスパートの混合(MoE)
DeepSeekで強調に値するもう一つの主要なアーキテクチャ構成要素は、エキスパートの混合(MoE)層の使用です。DeepSeekがMoEを発明したわけではありませんが、MoEは今年復活を遂げており、後で取り上げる多くのアーキテクチャもそれを採用しています。
MoEにはすでに精通されているかもしれませんが、簡単に復習しておくと役立つでしょう。
MoEの核心となる考え方は、各フィード
原文を表示
The Big LLM Architecture Comparison
From DeepSeek V3 to GLM-5: A Look At Modern LLM Architecture Design
Sebastian Raschka, PhDJul 19, 20251,79086161ShareLast updated: Feb 25, 2026 (added the recent February releases at the bottom)
It has been seven years since the original GPT architecture was developed. At first glance, looking back at GPT-2 (2019) and forward to DeepSeek V3 and Llama 4 (2024-2025), one might be surprised at how structurally similar these models still are.
Sure, positional embeddings have evolved from absolute to rotational (RoPE), Multi-Head Attention has largely given way to Grouped-Query Attention, and the more efficient SwiGLU has replaced activation functions like GELU. But beneath these minor refinements, have we truly seen groundbreaking changes, or are we simply polishing the same architectural foundations?
Comparing LLMs to determine the key ingredients that contribute to their good (or not-so-good) performance is notoriously challenging: datasets, training techniques, and hyperparameters vary widely and are often not well documented.
However, I think that there is still a lot of value in examining the structural changes of the architectures themselves to see what LLM developers are up to in 2025. (A subset of them are shown in Figure 1 below.)
Figure 1: A subset of the architectures covered in this article.
So, in this article, rather than writing about benchmark performance or training algorithms, I will focus on the architectural developments that define today's flagship open models.
(As you may remember, I wrote about multimodal LLMs not too long ago; in this article, I will focus on the text capabilities of recent models and leave the discussion of multimodal capabilities for another time.)
Tip: This is a fairly comprehensive article, so I recommend using the navigation bar to access the table of contents (just hover over the left side of the Substack page).
Optional: The video below is a narrated and abridged version of this article.
- DeepSeek V3/R1
As you have probably heard more than once by now, DeepSeek R1 made a big impact when it was released in January 2025. DeepSeek R1 is a reasoning model built on top of the DeepSeek V3 architecture, which was introduced in December 2024.
While my focus here is on architectures released in 2025, I think it’s reasonable to include DeepSeek V3, since it only gained widespread attention and adoption following the launch of DeepSeek R1 in 2025.
If you are interested in the training of DeepSeek R1 specifically, you may also find my article from earlier this year useful:
Understanding Reasoning LLMs
In this section, I’ll focus on two key architectural techniques introduced in DeepSeek V3 that improved its computational efficiency and distinguish it from many other LLMs:
Multi-Head Latent Attention (MLA)
Mixture-of-Experts (MoE)
1.1 Multi-Head Latent Attention (MLA)
Before discussing Multi-Head Latent Attention (MLA), let's briefly go over some background to motivate why it's used. For that, let's start with Grouped-Query Attention (GQA), which has become the new standard replacement for a more compute- and parameter-efficient alternative to Multi-Head Attention (MHA) in recent years.
So, here's a brief GQA summary. Unlike MHA, where each head also has its own set of keys and values, to reduce memory usage, GQA groups multiple heads to share the same key and value projections.
For example, as further illustrated in Figure 2 below, if there are 2 key-value groups and 4 attention heads, then heads 1 and 2 might share one set of keys and values, while heads 3 and 4 share another. This reduces the total number of key and value computations, which leads to lower memory usage and improved efficiency (without noticeably affecting the modeling performance, according to ablation studies).
Figure 2: A comparison between MHA and GQA. Here, the group size is 2, where a key and value pair is shared among 2 queries.
So, the core idea behind GQA is to reduce the number of key and value heads by sharing them across multiple query heads. This (1) lowers the model's parameter count and (2) reduces the memory bandwidth usage for key and value tensors during inference since fewer keys and values need to be stored and retrieved from the KV cache.
(If you are curious how GQA looks in code, see my GPT-2 to Llama 3 conversion guide for a version without KV cache and my KV-cache variant here.)
While GQA is mainly a computational-efficiency workaround for MHA, ablation studies (such as those in the original GQA paper and the Llama 2 paper) show it performs comparably to standard MHA in terms of LLM modeling performance.
Now, Multi-Head Latent Attention (MLA) offers a different memory-saving strategy that also pairs particularly well with KV caching. Instead of sharing key and value heads like GQA, MLA compresses the key and value tensors into a lower-dimensional space before storing them in the KV cache.
At inference time, these compressed tensors are projected back to their original size before being used, as shown in the Figure 3 below. This adds an extra matrix multiplication but reduces memory usage.
Figure 3: Comparison between MLA (used in DeepSeek V3 and R1) and regular MHA.
(As a side note, the queries are also compressed, but only during training, not inference.)
By the way, MLA is not new in DeepSeek V3, as its DeepSeek-V2 predecessor also used (and even introduced) it. Also, the V2 paper contains a few interesting ablation studies that may explain why the DeepSeek team chose MLA over GQA (see Figure 4 below).
Figure 4: Annotated tables from the DeepSeek-V2 paper, https://arxiv.org/abs/2405.04434
As shown in Figure 4 above, GQA appears to perform worse than MHA, whereas MLA offers better modeling performance than MHA, which is likely why the DeepSeek team chose MLA over GQA. (It would have been interesting to see the "KV Cache per Token" savings comparison between MLA and GQA as well!)
To summarize this section before we move on to the next architecture component, MLA is a clever trick to reduce KV cache memory use while even slightly outperforming MHA in terms of modeling performance.
1.2 Mixture-of-Experts (MoE)
The other major architectural component in DeepSeek worth highlighting is its use of Mixture-of-Experts (MoE) layers. While DeepSeek did not invent MoE, it has seen a resurgence this year, and many of the architectures we will cover later also adopt it.
You are likely already familiar with MoE, but a quick recap may be helpful.
The core idea in MoE is to replace each FeedForward module in a transformer block with multiple expert layers, where each of these expert layers is also a FeedForward module. This means that we swap a single FeedForward block for multiple FeedForward blocks, as illustrated in the Figure 5 below.
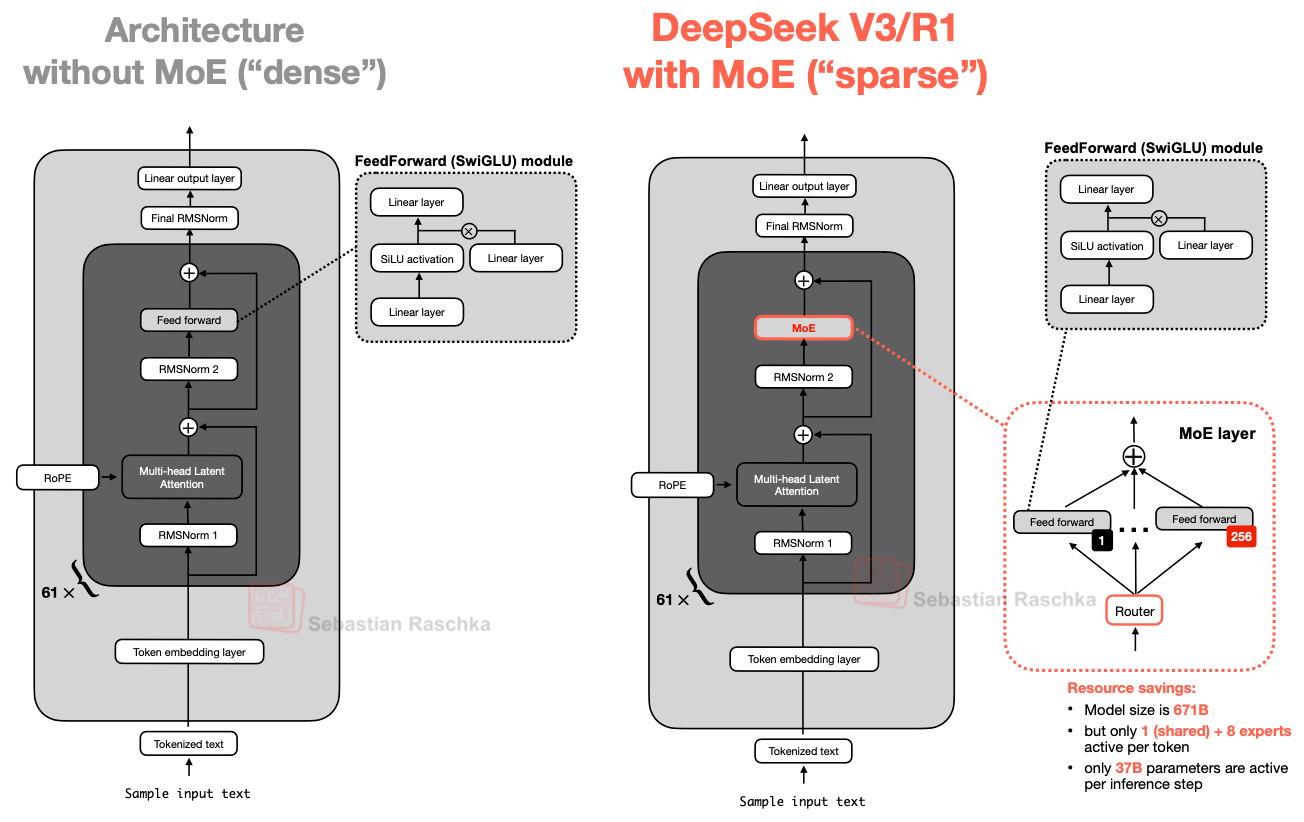 Figure 5: An illustration of the Mixture-of-Experts (MoE) module in DeepSeek V3/R1 (right) compared to an LLM with a standard FeedForward block (left).
Figure 5: An illustration of the Mixture-of-Experts (MoE) module in DeepSeek V3/R1 (right) compared to an LLM with a standard FeedForward block (left).
The FeedForward block inside a transformer block (shown as the dark gray block in the figure above) typically contains a large number of the model's total parameters. (Note that the transformer block, and thereby the FeedForward block, is repeated many times in an LLM; in the case of DeepSeek V3, 61 times.)
So, replacing a single FeedForward block with multiple FeedForward blocks (as done in a MoE setup) substantially increases the model's total parameter count. However, the key trick is that we don't use ("activate") all experts for every token. Instead, a router selects only a small subset of experts per token. (In the interest of time, or rather article space, I'll cover the router in more detail another time.)
Because only a few experts are active at a time, MoE modules are often referred to as sparse, in contrast to dense modules that always use the full parameter set. However, the large total number of parameters via an MoE increases the capacity of the LLM, which means it can take up more knowledge during training. The sparsity keeps inference efficient, though, as we don't use all the parameters at the same time.
For example, DeepSeek V3 has 256 experts per MoE module and a total of 671 billion parameters. Yet during inference, only 9 experts are active at a time (1 shared expert plus 8 selected by the router). This means just 37 billion parameters are used per inference step as opposed to all 671 billion.
One notable feature of DeepSeek V3's MoE design is the use of a shared expert. This is an expert that is always active for every token. This idea is not new and was already introduced in the DeepSeek 2024 MoE and 2022 DeepSpeedMoE papers.
 Figure 6: An annotated figure from "DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models", https://arxiv.org/abs/2401.06066
Figure 6: An annotated figure from "DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models", https://arxiv.org/abs/2401.06066
The benefit of having a shared expert was first noted in the DeepSpeedMoE paper, where they found that it boosts overall modeling performance compared to no shared experts. This is likely because common or repeated patterns don't have to be learned by multiple individual experts, which leaves them with more room for learning more specialized patterns.
1.3 DeepSeek Summary
To summarize, DeepSeek V3 is a massive 671-billion-parameter model that, at launch, outperformed other open-weight models, including the 405B Llama 3. Despite being larger, it is much more efficient at inference time thanks to its Mixture-of-Experts (MoE) architecture, which activates only a small subset of (just 37B) parameters per token.
Another key distinguishing feature is DeepSeek V3's use of Multi-Head Latent Attention (MLA) instead of Grouped-Query Attention (GQA). Both MLA and GQA are inference-efficient alternatives to standard Multi-Head Attention (MHA), particularly when using KV caching. While MLA is more complex to implement, a study in the DeepSeek-V2 paper has shown it delivers better modeling performance than GQA.
The OLMo series of models by the non-profit Allen Institute for AI is noteworthy due to its transparency in terms of training data and code, as well as the relatively detailed
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み