Amazon Bedrock AgentCoreで統一されたインテリジェンスを構築
AWSは、Amazon Bedrock AgentCoreを活用した「Customer Agent & Knowledge Engine (CAKE)」の実装事例を公開し、SalesforceやRedshiftなどのサイロ化されたデータ源を統合して顧客インテリジェンスを一元化する手法を示した。
キーポイント
CAKEによるデータ統合の解決
Salesforce、サポートチケット、Amazon Redshiftなど複数のツール間でデータが分断されている課題に対し、Bedrock AgentCoreを用いて顧客情報を一元化するエージェント「CAKE」を構築した。
専門ツールとの並列連携
Amazon Neptune(知識グラフ)、DynamoDB(メトリクス)、OpenSearch Service(ドキュメント)といった目的別データストアと、外部Web検索APIを動的に協調させ、自然言語クエリに対して10秒以内で回答を返す。
ガバナンスとセキュリティの実装
ワークフロー内にRow Level Security (RLS) を組み込み、データアクセス権限に基づく厳格なガバナンスとセキュリティを確保しながら、信頼性の高い生産環境での運用を実現している。
影響分析・編集コメントを表示
影響分析
本記事は、大規模言語モデル(LLM)を単なるチャットボットとしてではなく、既存のエンタープライズインフラ(データベース、検索エンジン)と連携する「エージェント」の中核として位置づける具体例を示している。AWSエコシステム内での実装事例であるため、技術的な革新性そのものよりも、実務適用におけるアーキテクチャパターン(特にセキュリティと並列処理の両立)への示唆が大きい。
編集コメント
AWS公式ブログであるためPR色は否めないが、AgentCoreを用いた実務的なセキュリティ制御(RLS)と複数データベースの並列連携という具体的なアーキテクチャパターンは、実装検討者にとって有用な参考事例である。
組織全体にわたって一貫性があり統合された顧客インテリジェンスを構築するには、営業担当者が Salesforce、サポートチケット、Amazon Redshift の間を行き来する際に直面する摩擦を減らすことから始めなければなりません。顧客会議の準備をする営業担当者は、顧客状況の完全な像を描くまでに、製品推奨事項、エンゲージメント指標、収益分析など複数の異なるダッシュボードをクリックして何時間も費やすことがあります。AWS では、グローバルにスケールする過程でこの課題を組織内で実際に経験しました。複雑なカスタムオーケストレーションインフラストラクチャを構築することなく、メトリクスデータベース、ドキュメントリポジトリ、外部業界ソースにまたがるサイロ化された顧客データを統合する方法が必要でした。
この課題を解決するために、Amazon Bedrock AgentCore を活用した顧客中心のチャットエージェントである Customer Agent & Knowledge Engine (CAKE) を構築しました。CAKE は、Amazon Neptune の知識グラフ、Amazon DynamoDB のメトリクス、Amazon OpenSearch Service のドキュメント、および Web 検索 API を使用した外部市場データに対する専門的な検索ツールを調整し、Row Level Security (RLS) ツールによるセキュリティ強化を実装することで、自然言語クエリを通じて 10 秒以内(エージェント負荷テストで観測された結果)に顧客インサイトを配信します。
本稿では、CAKE の実世界における実装を通じて、Amazon Bedrock AgentCore を用いて統合知能システムを構築する方法を実演します。以下の特徴と利点を解放するカスタムエージェントを構築できます:
- 動的な意図分析および並列実行を通じた専門ツールの調整
- 並列オーケストレーションによる目的特化型データストア(Neptune、DynamoDB、OpenSearch Service)との統合
- ワークフロー内における行レベルのセキュリティとガバナンスの実装
- ビジネスセマンティクスおよびスタイルに準拠するためのテンプレートベースレポートを含む、信頼性のためのプロダクションエンジニアリングプラクティス
- モデルの柔軟性を通じたパフォーマンス最適化
これらのアーキテクチャパターンは、顧客知能システム、エンタープライズ AI アシスタント、または異なるデータソース間で調整を行うマルチエージェントシステムなど、さまざまなユースケースの開発を加速するのに役立ちます。
なぜ顧客インテリジェンスシステムには統合が必要なのか
販売組織が世界的に拡大するにつれ、しばしば3つの重要な課題に直面します。専門的なツール(製品推奨、エンゲージメントダッシュボード、収益分析など)にまたがる断片化されたデータは包括的な顧客像を把握するために数時間を要し、従来のデータベースではビジネスの文脈における意味や関係性を捉えきれないため指標がなぜ重要なのかという説明が失われ、さらに増大するデータ量に対応できない手動での統合プロセスが存在します。企業はどこでも不可欠な要となる CAKE は、顧客データを集約し、意味的な関係を理解し、ビジネスの文脈の中で顧客のニーズを推論できる統合システムを必要としています。
ソリューション概要
CAKE は顧客中心型のチャットエージェントであり、断片化されたデータを統合され、実行可能なインテリジェンスへと変換します。内部および外部のデータソースやテーブルを単一の会話エンドポイントに集約することで、文脈に富んだ知識グラフによって支えられたパーソナライズされた顧客洞察を10 秒未満で提供します。単に数値を報告する従来のツールとは異なり、CAKE の意味的基盤はビジネス指標、顧客行動、業界の動向、戦略的文脈間の意味と関係性を捉えます。これにより、CAKE は顧客で何が起きているかだけでなく、なぜそれが起こっているのか、そしてどのように行動すべきかを説明することが可能になります。
Amazon Bedrock AgentCore は、マルチエージェント AI システムが必要とするランタイムインフラストラクチャをマネージドサービスとして提供します。これには、エージェント間の通信、並列実行、会話状態の追跡、ツールルーティングが含まれます。これにより、チームは分散システムインフラの実装ではなく、エージェントの動作定義やビジネスロジックの構築に注力できるようになります。
CAKE においては、Amazon Bedrock AgentCore 上にカスタムエージェントを構築し、5 つの専門化されたツールを調整しています。各ツールは異なるデータアクセスパターンに最適化されています:
- グラフ関係クエリ用の Neptune リトリーバーツール
- インスタントメトリック参照用の DynamoDB エージェント
- セマンティック文書検索用の OpenSearch リトリーバーツール
- 外部業界インテリジェンス用の Web 検索ツール
- セキュリティ強制執行用の行レベルセキュリティ (RLS) ツール
以下の図は、Amazon Bedrock AgentCore がこれらのコンポーネントのオーケストレーションをどのようにサポートするかを示しています。
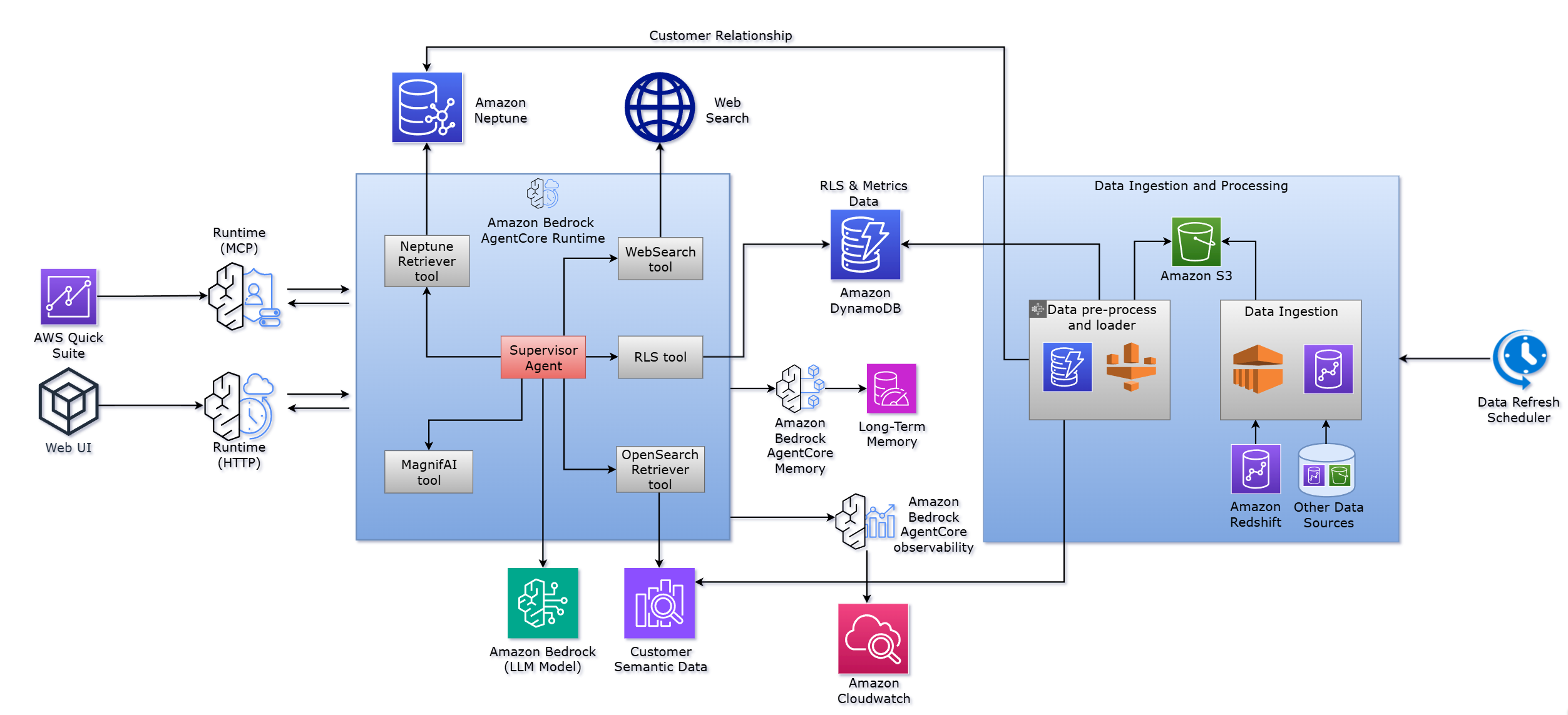
このソリューションは、質問(例:「この顧客にとっての主要な拡大機会は何か?」)への応答において、いくつかの重要なフェーズを流れます。
- 意図の分析とクエリのルーティング – Amazon Bedrock AgentCore で実行されるスーパーバイザーエージェントは、自然言語によるクエリを分析してその意図を特定します。この質問には顧客理解、関係データ、利用指標、そして戦略的洞察が必要です。Amazon Bedrock AgentCore Runtime を用いたエージェントのツール呼び出しロジックにより、どの専門ツールを起動すべきかが特定されます。
- ツールの並列実行 – ツール呼び出しを逐次的に実行するのではなく、オーケストレーション層は Amazon Bedrock AgentCore Runtime のスケーラブルな実行環境を活用して、複数のリトリーバーツールを並列で起動します。エージェントは実行ライフサイクルを管理し、タイムアウト、再試行、およびエラー条件を自動的に処理します。
- 複数結果の統合 – 専門ツールから結果が返されるにつれ、Amazon Bedrock AgentCore はこれらの部分的な応答をスーパーバイザーエージェントにストリーミングし、エージェントはそれらを整合性のある回答へと統合します。エージェントは異なるデータソース間の関連性を推論し、パターンを特定し、複数の知識ドメインにわたる洞察を生成します。
- セキュリティ境界の強制 – データ取得が開始される前に、エージェントは RLS ツールを呼び出してユーザー権限を確定的に強制します。カスタムエージェントはその後続するツール呼び出しがこのセキュリティ境界を尊重しているかを確認し、自動的に結果をフィルタリングして不正なデータアクセスを防ぎます。このセキュリティ層はインフラストラクチャレベルで動作するため、実装エラーのリスクが低減されます。
このアーキテクチャは 2 つの並列トラック上で稼働します。Amazon Bedrock AgentCore は、ユーザークエリに最小限のレイテンシで応答するリアルタイムサービング層のランタイムを提供し、一方、オフラインデータパイプラインが定期的に分析用データウェアハウスから基盤となるデータストアを更新します。以下のセクションでは、エージェントフレームワーク設計と、知識グラフ、データストア、データパイプラインを含むコアソリューションコンポーネントについて議論します。
エージェントフレームワークの設計
当社のマルチエージェントシステムは、AWS Strands Agents フレームワークを活用し、規制遵守と予測可能なパフォーマンスに必要なエンタープライズレベルの制御を維持しながら、構造化された推論機能を提供します。このマルチエージェントシステムは、多様なモデルからエージェントを構築するためのモデル駆動型基盤を提供する AWS Strands Agents フレームワーク上に構築されています。スーパーバイザーエージェントは、入力される質問を分析し、どの専門化されたエージェントやツールを呼び出すか、またユーザーの問い合わせをどのように分解するかを知的に選択します。このフレームワークは、エージェントレベルとスーパーバイザーレベルの両方で分散型評価を実装するために、エージェントの状態と出力を公開しています。モデル駆動型アプローチに基づき、知識関係を経由して決定論的な推論パスを構築する GraphRAG 推論チェーンを通じて、エージェンティックな推論を実現しています。当社のエージェントは、事前に定義されたオントロジー(ontologies)に根ざしながら専門分野内で自律的に推論を行い、エンタープライズアプリケーションに必要な予測可能で監査可能な行動パターンを維持します。
スーパーバイザーエージェントは、多段階の選択プロトコルを採用しています:
- クエリ分析 – ユーザーの意図を解析・理解する
- ソース選定 – インテリジェントなルーティングにより必要なツールの組み合わせを決定する
- クエリの分解 – 元の質問は、各選択されたツールに最適化された専門的なサブクエリに分割される
- 並列実行 – 選択されたツールがサーバーレスの AWS Lambda アクショングループを通じて並行して実行される
ツールは階層的なコンポジションパターン(構造化データと非構造化データの両方のデータモダリティを考慮)を通じて公開され、上位レベルのエージェントとツールが複数の専門サブツールを調整します:
- グラフ推論ツール – エンティティのトラバーサル、関係分析、知識抽出を管理する
- カスタマーインサイトエージェント – テーブルから顧客サマリーを生成するために、並行して複数のファインチューニング済みモデルを調整する
- セマンティック検索ツール – 非構造化テキスト(フィールドノートなど)の分析をオーケストレーションする
- ウェブリサーチツール – ウェブ/ニュースの取得を調整する
当社は、顧客アクセス検証、トークン最適化、モデルスロットリング耐性のためのマルチホップ LLM 選択、構造化 GraphRAG 推論チェーンを含むエンタープライズグレードの機能を拡張した AWS Strands Agents フレームワークのコア機能を提供します。これらの拡張により、現代のエージェント型システムの自律的な意思決定能力が実現されると同時に、予測可能なパフォーマンスと規制コンプライアンスへの適合性が促進されます。
知識グラフ基盤の構築
CAKE の Neptune 上の知識グラフは、顧客関係、製品利用パターン、業界動向を構造化された形式で表現し、AI エージェントが効率的な推論を行えるように支援します。情報を孤立して保存する従来のデータベースとは異なり、CAKE の知識グラフはビジネスエンティティとその関係性の意味的意味合いを捉えています。
グラフ構築とエンティティモデリング
私たちは、販売チームが日常的に議論する中核となるエンティティと関係性を定義する AWS 販売オントロジーを中心に知識グラフを設計しました:
- カスタマーエンティティ – 業界分類、収益指標、クラウド導入フェーズ、エンゲージメントスコアなどデータソースから抽出されたプロパティを持つ
- プロダクトエンティティ – AWS サービスを表し、ユースケース、業界アプリケーション、顧客の採用パターンとの接続を持つ
- ソリューションエンティティ – プロダクトをビジネス成果や戦略的イニシアチブと結びつける
- オポチュニティエンティティ – 販売パイプライン、取引ステージ、関連ステークホルダーを追跡する
- コンタクトエンティティ – カスタマー組織内の関係ネットワークをマッピングする
Amazon Neptune は、2 つのエンティティ間の関係を理解し、アカウント間の経路を見つけ、複数のホップにわたる間接的な関係を発見するなど、接続の理解を必要とする質問に対して卓越した能力を発揮します。オフラインデータ構築プロセスでは、Redshift クラスターに対してスケジュールされたクエリを実行し、グラフへのロードに必要なデータを準備します。
関係性の文脈の捕捉
CAKE の知識グラフは、エンティティがどのように関係性によって結びついているかを捉えます。グラフが顧客とプロダクトを「利用増加」という関係性で接続する場合、増加率、ビジネスドライバー(アカウントプランから)、関連するプロダクト採用パターンといった文脈属性も同時に保存されます。この文脈の豊かさは、LLM がビジネスコンテキストを理解し、単なる統計的相関ではなく、実際の関係性に根ざした説明を提供することを可能にします。
目的別データストア
データを単一のデータベースに格納するのではなく、CAKE は各クエリ方法に合わせて設計された専門的なデータストアを使用しています。Amazon Bedrock AgentCore で実行されるカスタムエージェントがこれらのストア間の調整を管理し、適切なデータベースへクエリを送信し、同時に実行して結果を統合します。これにより、ユーザーも開発者もあたかも単一のデータソースを扱っているかのような体験を得ることができます:
- グラフ関係のための Neptune – Neptune は、顧客、アカウント、利害関係者、および組織エンティティ間の接続の網を保存します。Neptune は、リレーショナルデータベースで高価な結合を必要とするマルチホップ走査クエリにおいて優れており、切断されたアカウント間の関係パスを見つけたり、特定の AWS サービスを採用した業界内の顧客を発見したりできます。Amazon Bedrock AgentCore が関係推論を要するクエリを検出すると、自動的に Neptune リトリーバーツールにルーティングされます。
- 即時メトリクスのための DynamoDB – DynamoDB は、事前計算された集計値のキーバリューストアとして機能します。顧客ヘルススコアやエンゲージメントメトリクスをオンデマンドで計算するのではなく、オフラインパイプラインがこれらの値を事前に計算し、顧客 ID でインデックス付けして保存します。その後、DynamoDB は 10 ミリ秒未満の検索を提供し、即時レポート生成を可能にします。Amazon Bedrock AgentCore のツールチェーン機能により、DynamoDB からメトリクスを取得し、それをフォーマット用の magnifAI エージェント(カスタムテーブルからテキストへのエージェント)に渡して、カスタム統合コードなしで洗練されたレポートを返すことが可能です。
- セマンティックドキュメント検索のための OpenSearch Service – OpenSearch Service は、アカウントプランやフィールドノートなどの非構造化コンテンツを保存します。埋め込みモデルを使用して、OpenSearch Service はテキストをベクトル表現に変換し、セマンティックマッチングをサポートします。例えば、「デジタルトランスフォーメーション」に関するクエリが Amazon Bedrock AgentCore に届いた場合、セマンティック検索の必要性を認識し、自動的に OpenSearch Service リトリーバーツールにルーティングされます。これにより、ドキュメントで異なる用語が使用されている場合でも、関連する記述を見つけることができます。
- ドキュメント保存のための S3 – Amazon Simple Storage Service (Amazon S3) は、OpenSearch Service の基盤を提供します。アカウントプランは、ソースウェアハウス(Amazon Redshift)に大規模ドキュメントを切り捨てる制限があるため、インデックス化される前に Parquet ファイルとして Amazon S3 に保存されます。この多段階のプロセス—Amazon S3 での保存、埋め込み生成、OpenSearch Service でのインデックス化—は、リアルタイムクエリに必要な低遅延を維持しながら、完全なコンテンツを保持します。
Amazon Bedrock AgentCore を活用することで、これらのマルチデータベースクエリが単一の統合データソースであるかのように感じられます。顧客関係に Neptune のデータが必要で、メトリクスに DynamoDB が必要で、ドキュメントコンテキストに OpenSearch Service が必要な場合でも、エージェントは自動的にすべての 3 つに対して並列でリクエストを配信し、その実行を管理し、結果を単一の整合性のある応答として統合します。
データパイプラインと継続的な更新
CAKE のオフラインデータパイプラインは、バッチプロセスとして動作し、スケジュールされた間隔で実行されることで、サービング層が最新のビジネスデータと同期されるように保ちます。このパイプラインのアーキテクチャでは、データの構築とデータの提供を分離しているため、リアルタイムクエリ層は低レイテンシを維持できながら、バッチパイプラインは計算集約型の集計やグラフ構築を担当します。
データ処理オーケストレーション層は、複数のターゲットデータベース間での変換を調整します。各データベースに対して、パイプラインは以下の手順を実行します:
- Amazon Redshift から最適化されたクエリを使用して関連データを抽出する
- 各データストアの要件に固有のビジネスロジック変換を適用する
- 適切なインデックスとパーティショニングを備えたターゲットデータベースへ処理済みのデータをロードする
Neptune の場合、これはエンティティデータの抽出、プロパティ属性を持つグラフノードとエッジの構築、およびセマンティック関係タイプでグラフ構造をロードすることを含みます。DynamoDB の場合、パイプラインは集計とメトリクスを計算し、顧客 ID 検索に最適化されたキーバリューペアとしてデータを構造化し、整合性を維持するために原子更新を適用します。OpenSearch Service の場合、パイプラインは特別なパスに従います:大規模なドキュメントはまず Amazon Redshift から Amazon S3 へ Parquet ファイルとしてエクスポートされ、次に埋め込みモデルを通じて処理されてベクトル表現が生成され、最後にフィルタリングと検索のための適切なメタデータとともに OpenSearch Service インデックスにロードされます。
本番環境向けのエンジニアリング:信頼性と精度
CAKE をプロトタイプから本番環境へ移行する際、AI によって生成されたインサイトに対する信頼性、精度、および信頼を促進するために、いくつかの重要なエンジニアリングプラクティスを導入しました。
モデルの柔軟性
Amazon Bedrock AgentCore のアーキテクチャは、オーケストレーション層と基盤となる大規模言語モデル(LLM)を分離することで、柔軟なモデル選択を可能にします。スロットリングが発生した際に代替モデルへ自動的にフォールバックする「モデルホッピング」を実装しました。この耐障害性は、ユーザーが視覚的に品質低下を感じることなく、AgentCore のランタイム内で透明性を持って動作します。具体的には、スロットリング条件を検知し、利用可能なモデルへのリクエストルーティングを行い、応答品質を維持します。
ロールレベルセキュリティ(RLS)とデータガバナンス
データ検索が行われる前に、RLS ツールはユーザーのアイデンティティと組織階層に基づいてロールレベルセキュリティ(Row-Level Security: RLS)を適用します。このセキュリティレイヤーはユーザーに対して透明性を持って動作しつつ、厳格なデータガバナンスを維持します:
- 営業担当者は、自身の管轄区域に割り当てられた顧客のみアクセス可能
- 地域マネージャーは、自らの地域全体で集計されたデータを閲覧可能
- エグゼクティブは、自身の責任範囲に合わせたより広範な可視性を有する
RLS ツールは、クエリを適切なデータパーティションへルーティングし、データベースクエリレベルでフィルタを適用します。これにより、セキュリティはアプリケーションレベルのフィルタリングに依存せず、データレイヤーで強制することが可能になります。
結果と影響
CAKE は、AWS の営業チームが顧客インテリジェンスにアクセスし、それに基づいて行動する方法を変革しました。自然言語による問い合わせを通じて統合された洞察への即時アクセスを提供することで、ユーザーからの調査やフィードバックによると、情報検索にかかっていた時間を数時間から数秒に短縮し、営業担当者がデータ収集ではなく戦略的な顧客エンゲージメントに集中できるよう支援しています。
マルチエージェントアーキテクチャにより、ほとんどの問い合わせに対して数秒で応答が返されます。並列実行モデルは、複数のソースからの同時データ取得をサポートします。知識グラフ(Knowledge Graph)は、単純なデータの集計を超えた高度な推論を可能にします。CAKE はなぜトレンドが発生するのかを説明し、一見無関係に見えるデータポイント間のパターンを特定し、ビジネス上の関係に基づいた推奨事項を生成します。おそらく最も重要なのは、CAKE が組織全体で顧客インテリジェンスへのアクセスを民主化した点です。営業担当者、アカウントマネージャー、ソリューションアーキテクト、そして経営陣が、同じ統合システムと対話することで、適切なセキュリティおよびアクセス制御を維持しつつ、一貫した顧客洞察を提供しています。
結論
本稿では、Amazon Bedrock AgentCore が CAKE のマルチエージェント
原文を表示
Building cohesive and unified customer intelligence across your organization starts with reducing the friction your sales representatives face when toggling between Salesforce, support tickets, and Amazon Redshift. A sales representative preparing for a customer meeting might spend hours clicking through several different dashboards—product recommendations, engagement metrics, revenue analytics, etc. – before developing a complete picture of the customer’s situation. At AWS, our sales organization experienced this firsthand as we scaled globally. We needed a way to unify siloed customer data across metrics databases, document repositories, and external industry sources – without building complex custom orchestration infrastructure.
We built the Customer Agent & Knowledge Engine (CAKE), a customer centric chat agent using Amazon Bedrock AgentCore to solve this challenge. CAKE coordinates specialized retriever tools – querying knowledge graphs in Amazon Neptune, metrics in Amazon DynamoDB, documents in Amazon OpenSearch Service, and external market data using a web search API, along with security enforcement using Row Level Security tool (RLS), delivering customer insights through natural language queries in under 10 seconds (as observed in agent load tests).
In this post, we demonstrate how to build unified intelligence systems using Amazon Bedrock AgentCore through our real-world implementation of CAKE. You can build custom agents that unlock the following features and benefits:
- Coordination of specialized tools through dynamic intent analysis and parallel execution
- Integration of purpose-built data stores (Neptune, DynamoDB, OpenSearch Service) with parallel orchestration
- Implementation of row-level security and governance within workflows
- Production engineering practices for reliability, including template-based reporting to adhere to business semantic and style
- Performance optimization through model flexibility
These architectural patterns can help you accelerate development for different use cases, including customer intelligence systems, enterprise AI assistants, or multi-agent systems that coordinate across different data sources.
Why customer intelligence systems need unification
As sales organizations scale globally, they often face three critical challenges: fragmented data across specialized tools (product recommendations, engagement dashboards, revenue analytics, etc.) requiring hours to gather comprehensive customer views, loss of business semantics in traditional databases that can’t capture semantic relationships explaining why metrics matter, and manual consolidation processes that can’t scale with growing data volumes. You need a unified system that can aggregate customer data, understand semantic relationships, and reason through customer needs in business context, making CAKE the essential linchpin for enterprises everywhere.
Solution overview
CAKE is a customer-centric chat agent that transforms fragmented data into unified, actionable intelligence. By consolidating internal and external data sources/tables into a single conversational endpoint, CAKE delivers personalized customer insights powered by context-rich knowledge graphs—all in under 10 seconds. Unlike traditional tools that simply report numbers, the semantic foundation of CAKE captures the meaning and relationships between business metrics, customer behaviors, industry dynamics, and strategic contexts. This enables CAKE to explain not just what is happening with a customer, but why it’s happening and how to act.
Amazon Bedrock AgentCore provides the runtime infrastructure that multi-agent AI systems require as a managed service, including inter-agent communication, parallel execution, conversation state tracking, and tool routing. This helps teams focus on defining agent behaviors and business logic rather than implementing distributed systems infrastructure.
For CAKE, we built a custom agent on Amazon Bedrock AgentCore that coordinates five specialized tools, each optimized for different data access patterns:
- Neptune retriever tool for graph relationship queries
- DynamoDB agent for instant metric lookups
- OpenSearch retriever tool for semantic document search
- Web search tool for external industry intelligence
- Row level security (RLS) tool for security enforcement
The following diagram shows how Amazon Bedrock AgentCore supports the orchestration of these components.
The solution flows through several key phases in response to a question (for example, “What are the top expansion opportunities for this customer?”):
- Analyzes intent and routes the query – The supervisor agent, running on Amazon Bedrock AgentCore, analyzes the natural language query to determine its intent. The question requires customer understanding, relationship data, usage metrics, and strategic insights. The agent’s tool-calling logic, using Amazon Bedrock AgentCore Runtime, identifies which specialized tools to activate.
- Dispatches tools in parallel – Rather than executing tool calls sequentially, the orchestration layer dispatches multiple retriever tools in parallel, using the scalable execution environment of Amazon Bedrock AgentCore Runtime. The agent manages the execution lifecycle, handling timeouts, retries, and error conditions automatically.
- Synthesizes multiple results – As specialized tools return results, Amazon Bedrock AgentCore streams these partial responses to the supervisor agent, which synthesizes them into a coherent answer. The agent reasons about how different data sources relate to each other, identifies patterns, and generates insights that span multiple knowledge domains.
- Enforces security boundaries – Before data retrieval begins, the agent invokes the RLS tool to deterministically enforce user permissions. The custom agent then verifies that subsequent tool calls respect these security boundaries, automatically filtering results and helping prevent unauthorized data access. This security layer operates at the infrastructure level, reducing the risk of implementation errors.
This architecture operates on two parallel tracks: Amazon Bedrock AgentCore provides the runtime for the real-time serving layer that responds to user queries with minimal latency, and an offline data pipeline periodically refreshes the underlying data stores from the analytical data warehouse. In the following sections, we discuss the agent framework design and core solution components, including the knowledge graph, data stores, and data pipeline.
Agent framework design
Our multi-agent system leverages the AWS Strands Agents framework to deliver structured reasoning capabilities while maintaining the enterprise controls required for regulatory compliance and predictable performance. The multi-agent system is built on the AWS Strands Agents framework, which provides a model-driven foundation for building agents from many different models. The supervisor agent analyzes incoming questions to intelligently select which specialized agents and tools to invoke and how to decompose user queries. The framework exposes agent states and outputs to implement decentralized evaluation at both agent and supervisor levels. Building on model-driven approach, we implement agentic reasoning through GraphRAG reasoning chains that construct deterministic inference paths by traversing knowledge relationships. Our agents perform autonomous reasoning within their specialized domains, grounded around pre-defined ontologies while maintaining predictable, auditable behavior patterns required for enterprise applications.
The supervisor agent employs a multi-phase selection protocol:
- Question analysis – Parse and understand user intent
- Source selection – Intelligent routing determines which combination of tools are needed
- Query decomposition – Original questions are broken down into specialized sub-questions optimized for each selected tool
- Parallel execution – Selected tools execute concurrently through serverless AWS Lambda action groups
Tools are exposed through a hierarchical composition pattern (accounting for data modality—structured vs. unstructured) where high-level agents and tools coordinate multiple specialized sub-tools:
- Graph reasoning tool – Manages entity traversal, relationship analysis, and knowledge extraction
- Customer insights agent – Coordinates multiple fine-tuned models in parallel for generating customer summaries from tables
- Semantic search tool – Orchestrates unstructured text analysis (such as field notes)
- Web research tool – Coordinates web/news retrieval
We extend the core AWS Strands Agents framework with enterprise-grade capabilities including customer access validation, token optimization, multi-hop LLM selection for model throttling resilience, and structured GraphRAG reasoning chains. These extensions deliver the autonomous decision-making capabilities of modern agentic systems while facilitating predictable performance and regulatory compliance alignment.
Building the knowledge graph foundation
CAKE’s knowledge graph in Neptune represents customer relationships, product usage patterns, and industry dynamics in a structured format that empowers AI agents to perform efficient reasoning. Unlike traditional databases that store information in isolation, CAKE’s knowledge graph captures the semantic meaning of business entities and their relationships.
Graph construction and entity modeling
We designed the knowledge graph around AWS sales ontology—the core entities and relationships that sales teams discuss daily:
- Customer entities – With properties extracted from data sources including industry classifications, revenue metrics, cloud adoption phase, and engagement scores
- Product entities – Representing AWS services, with connections to use cases, industry applications, and customer adoption patterns
- Solution entities – Linking products to business outcomes and strategic initiatives
- Opportunity entities – Tracking sales pipeline, deal stages, and associated stakeholders
- Contact entities – Mapping relationship networks within customer organizations
Amazon Neptune excels at answering questions that require understanding connections—finding how two entities are related, identifying paths between accounts, or discovering indirect relationships that span multiple hops. The offline data construction process runs scheduled queries against Redshift clusters to prepare data to be loaded in the graph.
Capturing relationship context
CAKE’s knowledge graph captures how relationships connect entities. When the graph connects a customer to a product through an increased usage relationship, it also stores contextual attributes: the rate of increase, the business driver (from account plans), and related product adoption patterns. This contextual richness helps the LLM understand business context and provide explanations grounded in actual relationships rather than statistical correlation alone.
Purpose-built data stores
Rather than storing data in a single database, CAKE uses specialized data stores, each designed for how it gets queried. Our custom agent, running on Amazon Bedrock AgentCore, manages the coordination across these stores—sending queries to the right database, running them at the same time, and combining results—so both users and developers work with what feels like a single data source:
- Neptune for graph relationships – Neptune stores the web of connections between customers, accounts, stakeholders, and organizational entities. Neptune excels at multi-hop traversal queries that require expensive joins in relational databases—finding relationship paths between disconnected accounts, or discovering customers in an industry who’ve adopted specific AWS services. When Amazon Bedrock AgentCore identifies a query requiring relationship reasoning, it automatically routes to the Neptune retriever tool.
- DynamoDB for instant metrics – DynamoDB operates as a key-value store for precomputed aggregations. Rather than computing customer health scores or engagement metrics on-demand, the offline pipeline pre-computes these values and stores them indexed by customer ID. DynamoDB then delivers sub-10ms lookups, enabling instant report generation. Tool chaining in Amazon Bedrock AgentCore allows it to retrieve metrics from DynamoDB, pass them to the magnifAI agent (our custom table-to-text agent) for formatting, and return polished reports—all without custom integration code.
- OpenSearch Service for semantic document search – OpenSearch Service stores unstructured content like account plans and field notes. Using embedding models, OpenSearch Service converts text into vector representations that support semantic matching. When Amazon Bedrock AgentCore receives a query about “digital transformation,” for example, it recognizes the need for semantic search and automatically routes to the OpenSearch Service retriever tool, which finds relevant passages even when documents use different terminology.
- S3 for document storage – Amazon Simple Storage Service (Amazon S3) provides the foundation for OpenSearch Service. Account plans are stored as Parquet files in Amazon S3 before being indexed because the source warehouse (Amazon Redshift) has truncation limits that would cut off large documents. This multi-step process—Amazon S3 storage, embedding generation, OpenSearch Service indexing—preserves complete content while maintaining the low latency required for real-time queries.
Building on Amazon Bedrock AgentCore makes these multi-database queries feel like a single, unified data source. When a query requires customer relationships from Neptune, metrics from DynamoDB, and document context from OpenSearch Service, our agent automatically dispatches requests to all three in parallel, manages their execution, and synthesizes their results into a single coherent response.
Data pipeline and continuous refresh
The CAKE offline data pipeline operates as a batch process that runs on a scheduled cadence to keep the serving layer synchronized with the latest business data. The pipeline architecture separates data construction from data serving, so the real-time query layer can maintain low latency while the batch pipeline handles computationally intensive aggregations and graph construction.
The Data Processing Orchestration layer coordinates transformations across multiple target databases. For each database, the pipeline performs the following steps:
- Extracts relevant data from Amazon Redshift using optimized queries
- Applies business logic transformations specific to each data store’s requirements
- Loads processed data into the target database with appropriate indexes and partitioning
For Neptune, this involves extracting entity data, constructing graph nodes and edges with property attributes, and loading the graph structure with semantic relationship types. For DynamoDB, the pipeline computes aggregations and metrics, structures data as key-value pairs optimized for customer ID lookups, and applies atomic updates to maintain consistency. For OpenSearch Service, the pipeline follows a specialized path: large documents are first exported from Amazon Redshift to Amazon S3 as Parquet files, then processed through embedding models to generate vector representations, which are finally loaded into the OpenSearch Service index with appropriate metadata for filtering and retrieval.
Engineering for production: Reliability and accuracy
When transitioning CAKE from prototype to production, we implemented several critical engineering practices to facilitate reliability, accuracy, and trust in AI-generated insights.
Model flexibility
The Amazon Bedrock AgentCore architecture decouples the orchestration layer from the underlying LLM, allowing flexible model selection. We implemented model hopping to provide automatic fallback to alternative models when throttling occurs. This resilience happens transparently within AgentCore’s Runtime—detecting throttling conditions, routing requests to available models, and maintaining response quality without user-visible degradation.
Row-Level Security (RLS) and Data Governance
Before data retrieval occurs, the RLS tool enforces row-level security based on user identity and organizational hierarchy. This security layer operates transparently to users while maintaining strict data governance:
- Sales representatives access only customers assigned to their territories
- Regional managers view aggregated data across their regions
- Executives have broader visibility aligned with their responsibilities
The RLS tool routes queries to appropriate data partitions and applies filters at the database query level, so security can be enforced in the data layer rather than relying on application-level filtering.
Results and impact
CAKE has transformed how AWS sales teams access and act on customer intelligence. By providing instant access to unified insights through natural language queries, CAKE reduces the time spent searching for information from hours to seconds as per surveys/feedback from users, helping sales representatives focus on strategic customer engagement rather than data gathering.
The multi-agent architecture delivers query responses in seconds for most queries, with the parallel execution model supporting simultaneous data retrieval from multiple sources. The knowledge graph enables sophisticated reasoning that goes beyond simple data aggregation—CAKE explains why trends occur, identifies patterns across seemingly unrelated data points, and generates recommendations grounded in business relationships. Perhaps most importantly, CAKE democratizes access to customer intelligence across the organization. Sales representatives, account managers, solutions architects, and executives interact with the same unified system, providing consistent customer insights while maintaining appropriate security and access controls.
Conclusion
In this post, we showed how Amazon Bedrock AgentCore supports CAKE’s multi-agent
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み