推論LLMの理解
Sebastian Raschka氏は、複雑な多段階生成を必要とする質問に答える「推論モデル」の定義、4つの主要な構築アプローチ、利点と欠点、DeepSeek R1の方法論、予算制限下での開発のヒントについて解説している。
キーポイント
推論モデルの定義
推論モデルは、パズルや高度な数学、コーディング課題など、中間ステップを必要とする複雑なタスクを解決するためにLLMを洗練させるものであり、単純な事実質問応答とは区別される。
推論モデルの利点と欠点
複雑な問題解決能力を向上させる一方で、他のLLMアプリケーションを置き換えるものではなく、特定の欠点も伴うと指摘されている。
4つの主要な構築アプローチ
記事では推論モデルを構築・改善するための4つの主要なアプローチが概説されているが、具体的な内容は引用部分には明記されていない。
LLM分野の専門化トレンド
2024年はLLM分野の専門化が進み、RAGやコードアシスタントなどの特化アプリケーションが台頭し、2025年にはドメイン・アプリケーション固有の最適化がさらに加速すると予測されている。
DeepSeek R1の方法論と影響
DeepSeek R1の方法論が説明され、DeepSeek V3とR1のリリース後のLLM状況についての考察が共有されている。
推論モデルの定義と特徴
現代の推論モデルは、パズルや数学的証明などの複雑な推論タスクに優れたLLMを指し、通常は回答に「思考」プロセスを含む。
推論モデルの使用場面と限界
推論モデルは複雑なタスクに適しているが、要約や翻訳などの単純なタスクには非効率で高コストであり、過剰思考によるエラーのリスクもある。
影響分析・編集コメントを表示
影響分析
この記事は、LLM研究の重要なトレンドである「推論能力の強化」と「分野特化」を明確に定義し、体系化している。実践的な開発指針を含むことで、研究者や開発者が急速に進化するこの分野を理解し、参入するための貴重な羅針盤となる可能性がある。
編集コメント
LLMの進化における「推論」という核心的な能力開発の現状と方法論を、業界の専門家が包括的に解説した貴重な記事。今後の開発動向を見極めるための基礎知識として価値が高い。
この記事では、推論モデルを構築するための4つの主要なアプローチ、あるいは推論能力をLLMに付与する方法について説明します。この内容が、このトピックを取り巻く急速に進化する文献や過剰な期待(ハイク)を理解する上で有益な洞察を提供し、道標となることを願っています。
2024年、LLM分野では専門化の傾向が強まりました。事前学習やファインチューニングを超えて、RAGからコードアシスタントに至るまで、特定の用途に特化したアプリケーションが台頭しました。私はこの傾向が2025年も加速し、ドメインおよびアプリケーション固有の最適化(つまり「専門化」)に対するさらなる重点が置かれると予想しています。

図 1: ステージ 1〜3 は LLM を開発するための一般的な手順です。ステージ 4 では、LLM を特定のユースケース向けに専門化します。
推論モデルの開発は、こうした専門化の一つです。つまり、パズル、高度な数学、コーディングの課題など、中間ステップを要する複雑なタスクにおいて卓越した性能を発揮するように LLM を洗練させることを意味します。ただし、この専門化が他の LLM アプリケーションを代替するわけではありません。なぜなら、LLM を推論モデルに変換することは、後ほど議論する特定の欠点も同時に導入するためです。
以下で取り上げられる内容の概要を簡単に述べると、この記事では次の点を説明します:
「推論モデル」という用語の意味を解説する
推論モデルの利点と欠点について議論する
DeepSeek R1 の背後にある手法を概説する
推論モデルの構築と改善のための 4 つの主要なアプローチを記述する
DeepSeek V3 および R1 のリリース後の LLM(大規模言語モデル)の状況についての考えを共有する
限られた予算で推論モデルを開発するためのヒントを提供する
今年、AI が急速に発展していく中で、この記事が皆様のお役に立てば幸いです!
「推論モデル」とはどのように定義されるのでしょうか?
AI(あるいは機械学習全般)にお勤めの方であれば、おそらく曖昧で議論の的となっている定義にご存知のことでしょう。「推論モデル」という用語も例外ではありません。いずれ誰かが論文でこれを正式に定義するものの、次の論文では再定義され、その後も同様の変化が続くことになります。
本記事では、「推論」を、中間ステップを含む複雑な多段階生成を要する質問に答えるプロセスとして定義します。例えば、「フランスの首都はどこか?」といった事実的な質問への回答には推論は伴いません。一方、「列車が時速 60 マイルで 3 時間走行した場合、どれだけの距離を進むか」といった質問には、ある程度の推論が必要です。具体的には、答えに到達する前に、距離・速度・時間の間の関係を認識する必要があります。

図2:通常のLLMは短い回答のみを提供する場合があります(左側に示されているように)、一方、推論モデルは通常、思考プロセスの一部を明らかにする中間ステップを含みます。(注:推論タスクのために特別に開発されていない多くのLLMも、回答に中間の推論ステップを含むことがあります。)
現代のほとんどのLLMは基本的な推論能力を持っており、「列車が時速60マイルで3時間走行した場合、どれだけの距離を進むか?」といった質問に答えることができます。したがって、今日私たちが「推論モデル」と呼ぶ場合、通常はパズルやなぞなぞ、数学的証明などのより複雑な推論タスクにおいて卓越したLLMを指します。
さらに、現在推論モデルと称されるほとんどのLLMには、回答の一部として「思考」または「考える」プロセスが含まれています。LLMが実際にどのように「思考」するかは、別の議論の主題です。
推論モデルにおける中間ステップは2つの形で現れます。第一に、前述の図のように明示的に回答に含まれる場合です。第二に、OpenAIのo1などの一部の推論型LLMでは、ユーザーには表示されない中間ステップを伴う複数の反復処理を実行します。
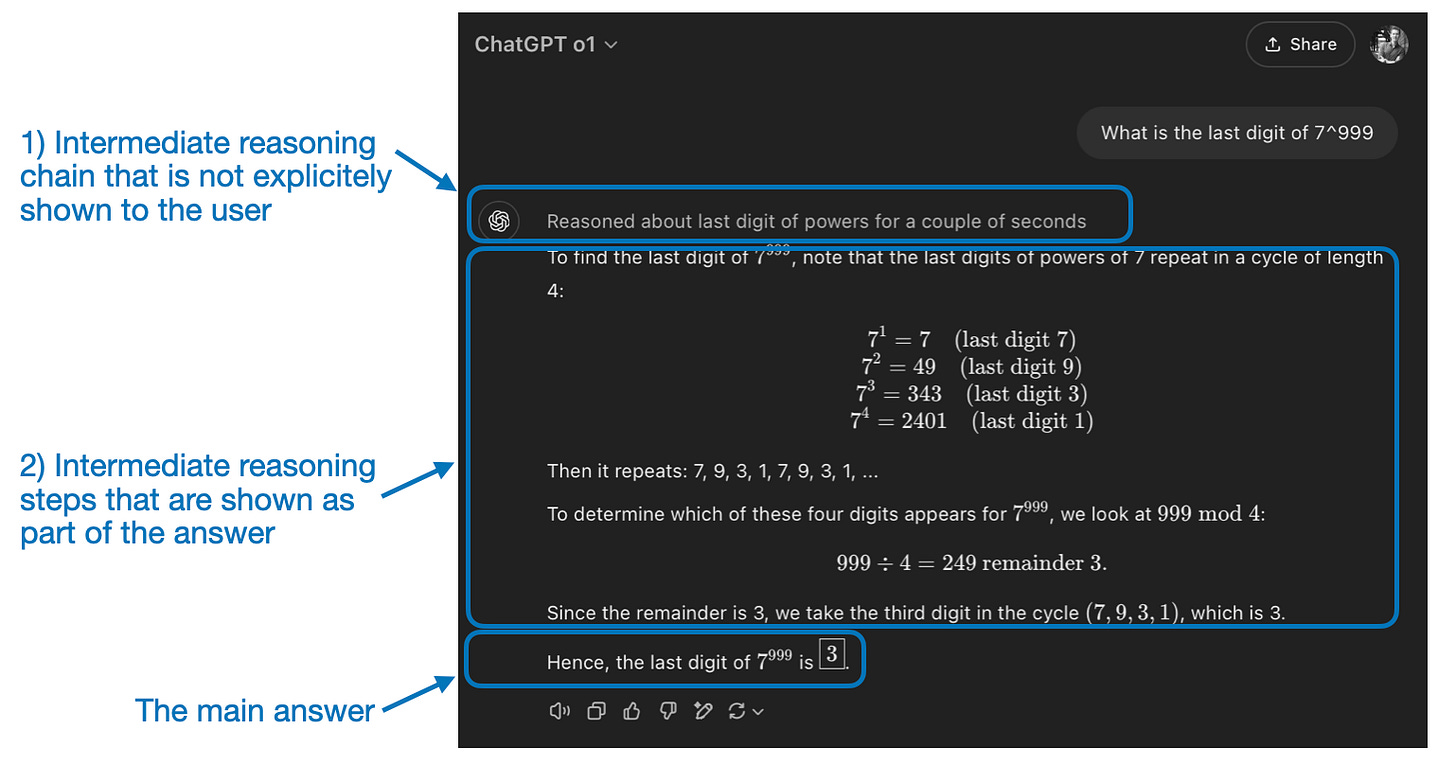
図3:「推論」は2つの異なるレベルで使用されます。1) 入力を処理し、複数の中間ステップを経て生成すること、および 2) ユーザーへの回答の一部として何らかの推論を提供することです。
いつ推論モデルを使用すべきか?
推論モデルを定義した今、より興味深い部分である推論タスク用のLLM(大規模言語モデル)の構築と改善方法について議論に移ることができます。しかし、技術的な詳細に深入りする前に、実際に推論モデルが必要となる場面を検討することが重要です。
いつ推論モデルが必要か? 推論モデルは、パズルの解決、高度な数学問題、難易度の高いコーディングタスクといった複雑なタスクにおいて優れた性能を発揮するように設計されています。しかし、要約、翻訳、知識ベースの質問応答といった単純なタスクには必ずしも必要ではありません。実際、すべてのタスクに推論モデルを使用することは非効率的であり、コストも高くなります。例えば、推論モデルは通常、使用コストが高く、冗長になりがちで、「過剰思考」のためにエラーが発生しやすい傾向があります。ここでもシンプルなルールが適用されます:タスクに適したツール(またはLLMのタイプ)を選択してください。
推論モデルの主な強みと限界は、以下の図に要約されています。

図4:推論モデルの主な強みと弱み。
DeepSeek のトレーニングパイプラインの簡単な概要
次のセクションで推論モデルを構築・改善するための 4 つの主要アプローチについて議論する前に、DeepSeek R1 テクニカルレポートに記載されている DeepSeek R1 パイプラインを簡単に概説しておきます。このレポートは、興味深いケーススタディであると同時に、推論 LLM を開発するための青写真としても機能します。
なお、DeepSeek は単一の R1 推論モデルをリリースしたのではなく、3 つの異なるバリアントを導入しました:DeepSeek-R1-Zero、DeepSeek-R1、および DeepSeek-R1-Distill です。
テクニカルレポートに記載されている説明に基づき、これらのモデルの開発プロセスを図にまとめました。

図 5:DeepSeek R1 テクニカルレポートで議論されている DeepSeek の 3 つの異なる推論モデルの開発プロセス。
次に、上記の図に示されたプロセスを簡単に振り返りましょう。より詳細な内容は、次のセクションで取り上げます。そこでは、推論モデルを構築・改善するための 4 つの主要アプローチについて議論します。
(1) DeepSeek-R1-Zero: このモデルは、2024 年 12 月にリリースされた 671B の事前学習済みベースモデルである DeepSeek-V3 を基にしています。研究チームは、2 種類の報酬を用いた強化学習(Reinforcement Learning: RL)によってこれを訓練しました。このアプローチは「コールドスタート」トレーニングと呼ばれます。これは、通常人間フィードバック付き強化学習(RLHF)の一部となる教師あり微調整(Supervised Fine-Tuning: SFT)ステップを含まないためです。
(2) DeepSeek-R1: これは DeepSeek のフラグシップ推論モデルであり、DeepSeek-R1-Zero を基に構築されています。チームはさらに追加の SFT ステージとさらなる RL 訓練を行い、「コールドスタート」された R1-Zero モデルを改良しました。
(3) DeepSeek-R1-Distill*: 前段階で生成された SFT データを用いて、DeepSeek チームは Qwen および Llama モデルを微調整し、その推論能力を強化しました。これは従来の意味での知識蒸留(Distillation)ではありませんが、このプロセスでは、より大規模な DeepSeek-R1 671B モデルの出力に対して、小規模モデル(Llama 8B および 70B、Qwen 1.5B–30B)を訓練することを含んでいました。
推論モデルを構築し改善するための 4 つの主要な方法
このセクションでは、LLM の推論能力を強化し、DeepSeek-R1、OpenAI の o1 および o3 など、専用の推論モデルを構築するために現在使用されている主要な技術を概説します。
注:o1 と o3 の正確な動作原理は OpenAI 外部では不明です。しかし、これらは推論と訓練の両方の手法を組み合わせて利用していると噂されています。
1) インフェレンス時のスケーリング
LLM の推論能力(あるいは一般的なあらゆる能力)を向上させる一つの方法に、推論時のスケーリングがあります。この用語には複数の意味があり得ますが、ここでは出力品質を向上させるために推論時に計算リソースを増やすことを指します。
簡単な例えとして、人間が複雑な問題を考える時間をより多く与えられると、より良い回答を生成する傾向があるのと同様に、LLM にも回答を生成する際に「思考」を促す手法を適用することができます。(ただし、LLM が実際に「思考」しているかどうかは別の議論です。)
推論時のスケーリングへの一つの手順的なアプローチは、巧妙なプロンプトエンジニアリングです。古典的な例として、思考連鎖(CoT)プロンプティングがあり、入力プロンプトに「ステップバイステップで考えよう」といったフレーズを含めます。これにより、モデルが最終回答に直接飛び込むのではなく、中間の推論ステップを生成するよう促され、より複雑な問題においてしばしば(常にとは限りませんが)より正確な結果につながります。(ただし、「フランスの首都はどこか」のような単純な知識ベースの質問に対してこの戦略を採用するのは意味がありません。これは、与えられた入力クエリに対して推論モデルが適切に機能しているかどうかを見極めるための良い目安でもあります。)

図 6:2022 年「Large Language Models are Zero-Shot Reasoners」論文(https://arxiv.org/abs/2205.11916)から引用された、古典的な CoT(Chain of Thought:思考の連鎖)プロンプティングの例。
前述の CoT アプローチは、より多くの出力トークンを生成することで推論コストを高めるため、「推論時のスケーリング」と見なすことができます。
推論時スケーリングのもう一つの手法として、投票や探索戦略の使用があります。簡単な例としては、LLM(大規模言語モデル)に複数の回答を生成させ、多数決によって正解を選択する「多数派投票」が挙げられます。同様に、ビームサーチやその他の探索アルゴリズムを用いてより優れた応答を生成することも可能です。
これらの異なる戦略の詳細については、私が 2024 年の注目すべき AI 研究論文(パート 2)の記事(https://magazine.sebastianraschka.com/p/ai-research-papers-2024-part-2)で取り上げた、「Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters」論文を強くお勧めします。

図 7: 異なる探索ベースの手法は、プロセス報酬に基づくモデル(process-reward-based model)を用いて最良の回答を選択するプロセスに依存しています。LLM Test-Time Compute 論文からの注釈付き図、https://arxiv.org/abs/2408.03314
DeepSeek R1 の技術報告書では、推論時のスケーリング手法(プロセス報酬モデルベースやモンテカルロ木探索ベースのアプローチなど)を「失敗した試み」として分類しています。これは、DeepSeek が R1 モデルがより長い応答を生成する自然な傾向を超えてこれらの技術を明示的に使用しなかったことを示唆しており、V3 ベースモデルと比較すると、これは推論時のスケーリングの暗黙的な形態として機能します。
ただし、明示的な推論時のスケーリングは、LLM 自体ではなくアプリケーション層で実装されることが多いため、DeepSeek は自社のアプリ内でそのような技術を適用している可能性があります。
OpenAI の o1 および o3 モデルも推論時のスケーリング(inference-time scaling)を使用していると私は推測しています。これが、GPT-4o などのモデルと比較して相対的に高価である理由を説明するものです。さらに、推論時のスケーリングに加えて、o1 と o3 は DeepSeek R1 に使用されたのと同様の強化学習(reinforcement learning)パイプラインを用いて訓練されたと考えられます。強化学習については以下の 2 つのセクションで詳しく解説します。
2) 純粋な強化学習(RL)
DeepSeek R1 の論文から私が個人的に最も印象に残っている点は、推論が純粋な強化学習(reinforcement learning: RL)からの行動として現れるという発見です。これが何を意味するのか、より詳細に探っていきましょう。
前述した通り、DeepSeek は 3 種類の R1 モデルを開発しました。その最初のモデルである DeepSeek-R1-Zero は、2024 年 12 月にリリースされた標準的な事前学習済み LLM である DeepSeek-V3 ベースモデルの上に構築されました。典型的な RL パイプラインでは強化学習(RL)の前に教師あり微調整(SFT)が適用されますが、DeepSeek-R1-Zero は以下の図に示されるように、初期の SFT ステージをスキップし、強化学習のみで訓練されました。

図 8: DeepSeek-R1-Zero モデルの開発プロセス。
しかし、この RL プロセスは通常、LLM の選好調整に用いられる RLHF(Reinforcement Learning from Human Feedback:人間フィードバックからの強化学習)アプローチと類似しています。(RLHF については私の記事「LLM Training: RLHF and Its Alternatives」でより詳しく解説しました。)しかし、前述の通り、DeepSeek-R1-Zero の決定的な違いは、指示微調整のための教師あり微調整(SFT)ステージをスキップした点にあります。そのため、彼らはこれを「純粋な」RL と呼んでいます。(ただし、LLM における RL は従来の RL とは大きく異なり、これは別の機会に議論するトピックです。)
報酬については、人間の選好に基づいて訓練された報酬モデルを使用する代わりに、2 種類の報酬を採用しました。1 つは精度報酬(accuracy reward)、もう 1 つは形式報酬(format reward)です。
精度報酬は、LeetCode コンパイラを使用してコーディング回答を検証し、決定論的なシステムを用いて数学的応答を評価します。
フォーマット報酬は、LLM 判事(judge)に依存しており、推論ステップを <thinking> タグ内に配置するなど、期待される形式に従っていることを保証します。
驚くべきことに、このアプローチだけで LLM が基本的な推論スキルを発達させるのに十分でした。研究者たちは「アハ!」の瞬間を観察しました。これは、明示的にそのように訓練されていないにもかかわらず、モデルが応答の一部として推論トレースの生成を始めたことを示しています(下の図参照)。

図 9: DeepSeek R1 の技術レポート(https://arxiv.org/abs/2501.12948)からの図で、「アハ!」の瞬間の出現を示しています。
R1-Zero はトップクラスの推論モデルではありませんが、上記の図に示されるように中間的な「思考」ステップを生成することで推論能力を実証しています。これは、純粋な強化学習(RL)を用いて推論モデルを開発することが可能であることを確認するものであり、DeepSeek チームがこのアプローチを最初に実証した(少なくとも公開した)チームです。
Ahead of AI は読者支援型の出版物です。新しい投稿を受け取り私の活動をサポートするには、無料または有料の購読者になることを検討してください。
3) 教師あり微調整と強化学習 (SFT + RL)
次に、推論モデル構築の青写真となる DeepSeek のフラグシップ推論モデルである DeepSeek-R1 の開発について見ていきましょう。このモデルは、追加の教師あり微調整(SFT)と強化学習(RL)を組み込むことで、DeepSeek-R1-Zero を改善し、推論性能を向上させています。
なお、標準的な RLHF パイプラインで見られるように、実際には RL の前に SFT 段階を含めることは一般的です。OpenAI の o1 もおそらく同様のアプローチで開発されたものと思われます。

図 10: DeepSeek-R1 モデルの開発プロセス。
上記の図に示されているように、DeepSeek チームは「コールドスタート」SFT データを生成するために DeepSeek-R1-Zero を使用しました。「コールドスタート」という用語は、このデータが教師あり微調整(SFT)データを一切学習していない DeepSeek-R1-Zero 自身によって生成されたことを指しています。
このコールドスタート SFT データを用いて、DeepSeek はまず指示微調整を通じてモデルを訓練し、その後にもう一つの強化学習(RL)段階を行いました。この RL 段階では、DeepSeek-R1-Zero の RL プロセスで使用されていた精度とフォーマットの報酬をそのまま維持しました。ただし、応答内でモデルが複数の言語間を切り替えることで発生する言語混合を防ぐために、一貫性報酬を追加しました。
RL ステージの後に、もう一つの SFT データ収集ラウンドが続きました。このフェーズでは、最新のモデルチェックポイントを使用して 60 万個の Chain-of-Thought (CoT) SFT サンプルを生成し、DeepSeek-V3 ベースモデルを用いてさらに 20 万個の知識ベース SFT サンプルを作成しました。
これらの 60 万 + 20 万の SFT サンプルはその後、最終的な RL ラウンドを実行する前に DeepSeek-V3 ベースモデルに対する指令微調整(Instruction-finetuning)に使用されました。この段階では、数学およびコーディング問題についてはルールベースの方法を用いて精度報酬を付与し、その他の質問タイプには人間の選好ラベルを使用しました。全体として、これは通常の RLHF と非常に似ていますが、SFT データに(より多くの)CoT サンプルが含まれている点が異なります。また、RL においては人間の選好に基づく報酬に加えて検証可能な報酬も利用されます。
最終モデルである DeepSeek-R1 は、DeepSeek-R1-Zero に比べて追加の SFT および RL ステージのおかげで顕著な性能向上を示しており、これは以下の表に示されています。

図 11: OpenAI O1 および DeepSeek R1 モデルのベンチマーク比較。DeepSeek-R1 技術報告書(https://arxiv.org/abs/2501.12948)からの注釈付き図。
4) 純粋な教師あり微調整(SFT)および蒸留
これまでに、推論モデルの構築と改善に向けた 3 つの主要アプローチについて解説してきました。
- インフェレンスタイムスケーリングは、基礎モデルをトレーニングしたり他の方法で変更したりすることなく推論能力を向上させる技術です。
- DeepSeek-R1-Zero で示されたような純粋な強化学習(RL)では、教師あり微調整なしに推論が学習された行動として現れることが確認されました。
- 教師あり微調整(SFT)と強化学習(RL)を組み合わせることで、DeepSeek のフラッグシップ推論モデルである DeepSeek-R1 が実現しました。
では、残っているのは何でしょうか?それはモデルの「蒸留」です。
驚くべきことに、DeepSeek は蒸留と呼ばれるプロセスを通じてトレーニングされたより小さなモデルもリリースしました。しかし、大規模言語モデル(LLM)の文脈において、蒸留は必ずしも深層学習で古典的に用いられている知識蒸留のアプローチに従うわけではありません。伝統的な知識蒸留では(私の『機械学習 Q&A と AI』書籍の第 6 章で簡潔に説明されているように)、より小さな学生モデルが、より大きな教師モデルのロジットとターゲットデータセットの両方を用いてトレーニングされます。
ここでは、蒸留とは、Llama 8B や 70B、Qwen 2.5 モデル(0.5B から 32B)といった smaller LLM を、大規模 LLM によって生成された SFT データセット上で指示微調整することを指します。具体的には、これらの大規模 LLM は DeepSeek-V3 と DeepSeek-R1 の中間チェックポイントです。実際、この蒸留プロセスに使用される SFT データは、前節で説明したように DeepSeek-R1 のトレーニングに使用されたのと同じデータセットです。
このプロセスを明確にするため、以下の図において蒸留部分をハイライトしました。

図 12: DeepSeek-R1-Distill モデルの開発プロセス。
なぜ彼らは開発したのか
原文を表示
This article describes the four main approaches to building reasoning models, or how we can enhance LLMs with reasoning capabilities. I hope this provides valuable insights and helps you navigate the rapidly evolving literature and hype surrounding this topic.
In 2024, the LLM field saw increasing specialization. Beyond pre-training and fine-tuning, we witnessed the rise of specialized applications, from RAGs to code assistants. I expect this trend to accelerate in 2025, with an even greater emphasis on domain- and application-specific optimizations (i.e., "specializations").
Figure 1: Stages 1-3 are the common steps to developing LLMs. Stage 4 specializes LLMs for specific use cases.
The development of reasoning models is one of these specializations. This means we refine LLMs to excel at complex tasks that are best solved with intermediate steps, such as puzzles, advanced math, and coding challenges. However, this specialization does not replace other LLM applications. Because transforming an LLM into a reasoning model also introduces certain drawbacks, which I will discuss later.
To give you a brief glimpse of what's covered below, in this article, I will:
Explain the meaning of "reasoning model"
Discuss the advantages and disadvantages of reasoning models
Outline the methodology behind DeepSeek R1
Describe the four main approaches to building and improving reasoning models
Share thoughts on the LLM landscape following the DeepSeek V3 and R1 releases
Provide tips for developing reasoning models on a tight budget
I hope you find this article useful as AI continues its rapid development this year!
How do we define "reasoning model"?
If you work in AI (or machine learning in general), you are probably familiar with vague and hotly debated definitions. The term "reasoning models" is no exception. Eventually, someone will define it formally in a paper, only for it to be redefined in the next, and so on.
In this article, I define "reasoning" as the process of answering questions that require complex, multi-step generation with intermediate steps. For example, factual question-answering like "What is the capital of France?" does not involve reasoning. In contrast, a question like "If a train is moving at 60 mph and travels for 3 hours, how far does it go?" requires some simple reasoning. For instance, it requires recognizing the relationship between distance, speed, and time before arriving at the answer.
Figure 2: A regular LLM may only provide a short answer (as shown on the left), whereas reasoning models typically include intermediate steps that reveal part of the thought process. (Note that many LLMs who have not been specifically developed for reasoning tasks can also provide intermediate reasoning steps in their answers.
Most modern LLMs are capable of basic reasoning and can answer questions like, "If a train is moving at 60 mph and travels for 3 hours, how far does it go?" So, today, when we refer to reasoning models, we typically mean LLMs that excel at more complex reasoning tasks, such as solving puzzles, riddles, and mathematical proofs.
Additionally, most LLMs branded as reasoning models today include a "thought" or "thinking" process as part of their response. Whether and how an LLM actually "thinks" is a separate discussion.
Intermediate steps in reasoning models can appear in two ways. First, they may be explicitly included in the response, as shown in the previous figure. Second, some reasoning LLMs, such as OpenAI's o1, run multiple iterations with intermediate steps that are not shown to the user.
Figure 3: "Reasoning" is used at two different levels: 1) processing the input and generating via multiple intermediate steps and 2) providing some sort of reasoning as part of the response to the user.
When should we use reasoning models?
Now that we have defined reasoning models, we can move on to the more interesting part: how to build and improve LLMs for reasoning tasks. However, before diving into the technical details, it is important to consider when reasoning models are actually needed.
When do we need a reasoning model? Reasoning models are designed to be good at complex tasks such as solving puzzles, advanced math problems, and challenging coding tasks. However, they are not necessary for simpler tasks like summarization, translation, or knowledge-based question answering. In fact, using reasoning models for everything can be inefficient and expensive. For instance, reasoning models are typically more expensive to use, more verbose, and sometimes more prone to errors due to "overthinking." Also here the simple rule applies: Use the right tool (or type of LLM) for the task.
The key strengths and limitations of reasoning models are summarized in the figure below.
Figure 4: The key strengths and weaknesses of reasoning models.
A brief look at the DeepSeek training pipeline
Before discussing four main approaches to building and improving reasoning models in the next section, I want to briefly outline the DeepSeek R1 pipeline, as described in the DeepSeek R1 technical report. This report serves as both an interesting case study and a blueprint for developing reasoning LLMs.
Note that DeepSeek did not release a single R1 reasoning model but instead introduced three distinct variants: DeepSeek-R1-Zero, DeepSeek-R1, and DeepSeek-R1-Distill.
Based on the descriptions in the technical report, I have summarized the development process of these models in the diagram below.
Figure 5: Development process of DeepSeeks three different reasoning models that are discussed in the DeepSeek R1 technical report.
Next, let's briefly go over the process shown in the diagram above. More details will be covered in the next section, where we discuss the four main approaches to building and improving reasoning models.
(1) DeepSeek-R1-Zero: This model is based on the 671B pre-trained DeepSeek-V3 base model released in December 2024. The research team trained it using reinforcement learning (RL) with two types of rewards. This approach is referred to as "cold start" training because it did not include a supervised fine-tuning (SFT) step, which is typically part of reinforcement learning with human feedback (RLHF).
(2) DeepSeek-R1: This is DeepSeek's flagship reasoning model, built upon DeepSeek-R1-Zero. The team further refined it with additional SFT stages and further RL training, improving upon the "cold-started" R1-Zero model.
(3) DeepSeek-R1-Distill*: Using the SFT data generated in the previous steps, the DeepSeek team fine-tuned Qwen and Llama models to enhance their reasoning abilities. While not distillation in the traditional sense, this process involved training smaller models (Llama 8B and 70B, and Qwen 1.5B–30B) on outputs from the larger DeepSeek-R1 671B model.
The 4 main ways to build and improve reasoning models
In this section, I will outline the key techniques currently used to enhance the reasoning capabilities of LLMs and to build specialized reasoning models such as DeepSeek-R1, OpenAI's o1 & o3, and others.
Note: The exact workings of o1 and o3 remain unknown outside of OpenAI. However, they are rumored to leverage a combination of both inference and training techniques.
1) Inference-time scaling
One way to improve an LLM's reasoning capabilities (or any capability in general) is inference-time scaling. This term can have multiple meanings, but in this context, it refers to increasing computational resources during inference to improve output quality.
A rough analogy is how humans tend to generate better responses when given more time to think through complex problems. Similarly, we can apply techniques that encourage the LLM to "think" more while generating an answer. (Although, whether LLMs actually "think" is a different discussion.)
One straightforward approach to inference-time scaling is clever prompt engineering. A classic example is chain-of-thought (CoT) prompting, where phrases like "think step by step" are included in the input prompt. This encourages the model to generate intermediate reasoning steps rather than jumping directly to the final answer, which can often (but not always) lead to more accurate results on more complex problems. (Note that it doesn't make sense to employ this strategy for simpler knowledge-based questions, like "What is the capital of France", which is again a good rule of thumb to find out whether a reasoning model makes sense on your given input query.)
Figure 6: An example of classic CoT prompting from the 2022 Large Language Models are Zero-Shot Reasoners paper (https://arxiv.org/abs/2205.11916).
The aforementioned CoT approach can be seen as inference-time scaling because it makes inference more expensive through generating more output tokens.
Another approach to inference-time scaling is the use of voting and search strategies. One simple example is majority voting where we have the LLM generate multiple answers, and we select the correct answer by majority vote. Similarly, we can use beam search and other search algorithms to generate better responses.
I highly recommend the Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters paper that I described in my previous Noteworthy AI Research Papers of 2024 (Part Two) article (https://magazine.sebastianraschka.com/p/ai-research-papers-2024-part-2) for more details on these different strategies.
Figure 7: Different search-based methods rely on a process-reward-based model to select the best answer. Annotated figure from the LLM Test-Time Compute paper, https://arxiv.org/abs/2408.03314
The DeepSeek R1 technical report categorizes common inference-time scaling methods (such as Process Reward Model-based and Monte Carlo Tree Search-based approaches) under "unsuccessful attempts." This suggests that DeepSeek did not explicitly use these techniques beyond the R1 model's natural tendency to generate longer responses, which serves as an implicit form of inference-time scaling compared to the V3 base model.
However, explicit inference-time scaling is often implemented at the application layer rather than within the LLM itself, so DeepSeek may still apply such techniques within their app.
I suspect that OpenAI's o1 and o3 models use inference-time scaling, which would explain why they are relatively expensive compared to models like GPT-4o. In addition to inference-time scaling, o1 and o3 were likely trained using RL pipelines similar to those used for DeepSeek R1. More on reinforcement learning in the next two sections below.
2) Pure reinforcement learning (RL)
One of my personal highlights from the DeepSeek R1 paper is their discovery that reasoning emerges as a behavior from pure reinforcement learning (RL). Let's explore what this means in more detail.
As outlined earlier, DeepSeek developed three types of R1 models. The first, DeepSeek-R1-Zero, was built on top of the DeepSeek-V3 base model, a standard pre-trained LLM they released in December 2024. Unlike typical RL pipelines, where supervised fine-tuning (SFT) is applied before RL, DeepSeek-R1-Zero was trained exclusively with reinforcement learning without an initial SFT stage as highlighted in the diagram below.
Figure 8: The development process of DeepSeek-R1-Zero model.
Still, this RL process is similar to the commonly used RLHF approach, which is typically applied to preference-tune LLMs. (I covered RLHF in more detail in my article, LLM Training: RLHF and Its Alternatives.) However, as mentioned above, the key difference in DeepSeek-R1-Zero is that they skipped the supervised fine-tuning (SFT) stage for instruction tuning. This is why they refer to it as "pure" RL. (Although, RL in the context of LLMs differs significantly from traditional RL, which is a topic for another time.)
For rewards, instead of using a reward model trained on human preferences, they employed two types of rewards: an accuracy reward and a format reward.
The accuracy reward uses the LeetCode compiler to verify coding answers and a deterministic system to evaluate mathematical responses.
The format reward relies on an LLM judge to ensure responses follow the expected format, such as placing reasoning steps inside <think> tags.
Surprisingly, this approach was enough for the LLM to develop basic reasoning skills. The researchers observed an "Aha!" moment, where the model began generating reasoning traces as part of its responses despite not being explicitly trained to do so, as shown in the figure below.
Figure 9: A figure from the DeepSeek R1 technical report (https://arxiv.org/abs/2501.12948) showing the emergence of the "Aha" moment.
While R1-Zero is not a top-performing reasoning model, it does demonstrate reasoning capabilities by generating intermediate "thinking" steps, as shown in the figure above. This confirms that it is possible to develop a reasoning model using pure RL, and the DeepSeek team was the first to demonstrate (or at least publish) this approach.
Ahead of AI is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
3) Supervised finetuning and reinforcement learning (SFT + RL)
Next, let's look at the development of DeepSeek-R1, DeepSeek’s flagship reasoning model, which serves as a blueprint for building reasoning models. This model improves upon DeepSeek-R1-Zero by incorporating additional supervised fine-tuning (SFT) and reinforcement learning (RL) to improve its reasoning performance.
Note that it is actually common to include an SFT stage before RL, as seen in the standard RLHF pipeline. OpenAI's o1 was likely developed using a similar approach.
Figure 10: The development process of DeepSeek-R1 model.
As shown in the diagram above, the DeepSeek team used DeepSeek-R1-Zero to generate what they call "cold-start" SFT data. The term "cold start" refers to the fact that this data was produced by DeepSeek-R1-Zero, which itself had not been trained on any supervised fine-tuning (SFT) data.
Using this cold-start SFT data, DeepSeek then trained the model via instruction fine-tuning, followed by another reinforcement learning (RL) stage. This RL stage retained the same accuracy and format rewards used in DeepSeek-R1-Zero’s RL process. However, they added a consistency reward to prevent language mixing, which occurs when the model switches between multiple languages within a response.
The RL stage was followed by another round of SFT data collection. In this phase, the most recent model checkpoint was used to generate 600K Chain-of-Thought (CoT) SFT examples, while an additional 200K knowledge-based SFT examples were created using the DeepSeek-V3 base model.
These 600K + 200K SFT samples were then used for instruction-finetuning DeepSeek-V3 base before following up with a final round of RL. In this stage, they again used rule-based methods for accuracy rewards for math and coding questions, while human preference labels used for other question types. All in all, this is very similar to regular RLHF except that the SFT data contains (more) CoT examples. And the RL has verifiable rewards in addition to human preference-based rewards.
The final model, DeepSeek-R1 has a noticeable performance boost over DeepSeek-R1-Zero thanks to the additional SFT and RL stages, as shown in the table below.
Figure 11: Benchmark comparison of OpenAI O1 and DeepSeek R1 models. Annotated figure from the DeepSeek-R1 technical report (https://arxiv.org/abs/2501.12948).
4) Pure supervised finetuning (SFT) and distillation
So far, we have covered three key approaches to building and improving reasoning models:
- Inference-time scaling, a technique that improves reasoning capabilities without training or otherwise modifying the underlying model.
- Pure reinforcement learning (RL) as in DeepSeek-R1-Zero, which showed that reasoning can emerge as a learned behavior without supervised fine-tuning.
- Supervised fine-tuning (SFT) plus RL, which led to DeepSeek-R1, DeepSeek’s flagship reasoning model.
So, what’s left? Model "distillation."
Surprisingly, DeepSeek also released smaller models trained via a process they call distillation. However, in the context of LLMs, distillation does not necessarily follow the classical knowledge distillation approach used in deep learning. Traditionally, in knowledge distillation (as briefly described in Chapter 6 of my Machine Learning Q and AI book), a smaller student model is trained on both the logits of a larger teacher model and a target dataset.
Instead, here distillation refers to instruction fine-tuning smaller LLMs, such as Llama 8B and 70B and Qwen 2.5 models (0.5B to 32B), on an SFT dataset generated by larger LLMs. Specifically, these larger LLMs are DeepSeek-V3 and an intermediate checkpoint of DeepSeek-R1. In fact, the SFT data used for this distillation process is the same dataset that was used to train DeepSeek-R1, as described in the previous section.
To clarify this process, I have highlighted the distillation portion in the diagram below.
Figure 12: The development process of DeepSeek-R1-Distill models.
Why did they develop
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み