Fireworks と LangChain が Qwen-3.5-35B を活用したコスト効率の高いトレース判定器を開発
Fireworks との提携により、エージェントの「知覚されたエラー」を検出する汎用評価モデルを低コストで構築する方法と、そのデータセット作成プロセスが紹介される。
キーポイント
Perceived Error(知覚されたエラー)の定義と重要性
客観的な正誤やユーザー満足度ではなく、ユーザーが「間違いだ」と認識し修正を求めた瞬間に焦点を当てた評価指標を提案する。
汎用性の高い評価モデルの構築
アプリケーション固有のロジックに依存せず、ユーザーの訂正や拒否などの信号を検出することで、あらゆるエージェントシステムに適用可能な評価器を実現する。
Fireworks と Qwen を活用した低コスト化
Fireworks のインフラと Qwen モデルをファインチューニングすることで、フロンティア級の性能を維持しつつ、100 倍の費用対効果を実現するアプローチを示す。
データセット作成と検証
内部トレーシングデータから学習用データを収集し、「知覚されたエラー」が一般的な指標として機能するかを実験的に検証している。
影響分析・編集コメントを表示
影響分析
この記事は、生成 AI エージェントの運用において、膨大なトレーシングデータからいかに効率的に改善信号を抽出するかという実務的な課題に対して、具体的な解決策とアーキテクチャを提供しています。特に「知覚されたエラー」という独自の指標を定義し、それを汎用モデルで検出するアプローチは、開発コストを抑えつつ品質管理の精度を高めるための重要な指針となります。
編集コメント
エージェント運用の品質管理において、コストと性能の両立を可能にする実用的な評価指標の提案は非常に示唆に富んでいます。特に「客観的正しさ」ではなく「ユーザーの主観的認識」に焦点を当てた点は、現場の実装において即座に活用できる洞察です。
エージェントは現在、世界のデータの過半数を生成し、私たちが今日利用している多くのアプリケーションの動力源となっています。より多くの中核システムにエージェントが導入されるにつれ、トレースは、実ユーザーとの相互作用におけるエージェントシステムの振る舞いを理解するための最も豊富なデータソースの一つとして、ますます重要性を増していきます。
研究課題: コスト効果の高い方法で、すべてのトレースから重要なシグナルを抽出しつつ、最先端の性能を維持するにはどうすればよいでしょうか?
この問いに答えるため、私たちは Fireworks と提携し、ユーザーとの相互作用から「知覚エラー」を検出するために Qwen 評価モデルをファインチューニングしました。
知覚エラーとは:
**知覚エラーとは、ユーザーがアシスタントにミスがあったと感じたり、修正が必要なものが生成されたと感じたりする状態です。これは客観的な正しさやユーザーの満足度を判断するものではありません。例えば、エージェントが正しい回答を提供したとしても、その情報によってユーザーがフラストレーションを感じている場合(エージェント自体の問題ではない)も含まれます。
通常は、各チームにアプリケーション固有の評価器を構築するよう推奨しています。なぜなら、トレースを評価するためのロジックには、そのアプリケーションの文脈が必要となるケースが多いためです。しかし私たちは、「知覚エラー」が汎用的な評価器となり得る例であると信じています。それが検出しようとするシグナルは、あらゆるアプリケーションに共通する普遍的なものだと考えています。
「知覚されたエラー」の一般性は重要な問いです。後ほど行ういくつかの実験は、この指標の一般性をテストすることを特に目的としています。
ユーザーによる修正、エージェント行動の拒否、繰り返しのリクエスト、アシスタントのエラーへの言及といったトレース信号から、知覚されたエラーを推論します。その後、知覚されたエラー評価器が以下の形式で情報を付加し、トレースを強化します:
{"perceived_error": true, "reason": "ユーザーはアシスタントが使用した会議日付を修正しました。"}
データセットの作成方法
タスクに適用されるエージェントの性能は、それらを訓練するために使用されたデータに依存します。私たちは、本番環境で使用している 2 つの内部トレースデータセットからデータを収集しました:
*LangChain のライブラリや製品に関する質問に答えるドキュメント Q&A エージェント。ユーザーは概念的な質問、デバッグに関する質問、あるいはものづくりの支援を求めます。これらのやり取りは技術的であり、多くの詳細を含みます*
*文書の作成や調査など実際の作業を行うエージェントを作成するためのノーコードツール。ユーザーは Fleet を多様なタスクに使用します。さまざまなツールやスキルを呼び出す可能性があります*
各トレーシングデータセットから、トレーニングセットとホールドアウトセットとして使用するトレースの一部を選択しました。トレースのプールからフィルタリングする際、「知覚されたエラー」を判断するには AI の結果に対する人間の応答(例えば、アシスタントの修正やリクエストの繰り返しなど)が必要であるため、マルチターン形式のトレースを選択しました。
複数のデータセットを使用した動機の一部は、「知覚されたエラー」の一般性をテストするためでした。あるデータセットで知覚されたエラーを検出するように訓練されたモデルが、別のデータセットにも転移するでしょうか?
Dataset Total Examples Train rows Holdout rows
chat-langchain 885 707 178
Fleet 911 727 184
データ準備
トレーニングと予測用のデータを準備する際、ツール呼び出しはすべて無視し、人間と AI のメッセージのみを含めることを選択しました。これは、私たちが探していたシグナルにとって、人間のメッセージと AI のメッセージが主要な情報源であると仮定したためです。これは将来実験を行う予定のレバーの一つです。
また、長いコンテンツを切り詰めることなく、すべてのメッセージをそのまま含めました。これも将来実験を行う予定のもう一つのレバーです。
ラベル付け
ラベルを生成するため、モデル支援によるラベル付けと人間のレビューを組み合わせて、各トレースに対して短い JSON ラベルと根拠(rationale)を作成しました。具体的にはまず、モデルのパネルにトレースの判定を行ってもらいます。すべてのモデルが一致した場合、それを正解ラベル(ground truth label)として採用します。意見が分かれた場合は、それらのラベルと根拠をすべて収集し、別のモデルのパネルに「どちらが正しいか」を判断してもらうよう依頼します。このパネルで合意が得られれば、それを正解ラベルとします。それでも意見が割れる場合のみ、人間が手動で注釈(アノテーション)を行います。データセット全体では、chat-langchain と Fleet はそれぞれ 24% と 18% のトレースに「誤りあり」というラベルが付与されていました。
ファインチューニングの設定
トレーニングには、他のモデルを小規模テストした結果に基づき、Qwen-3.5-35B をベースモデルとして選択しました。より小さなモデルはエラー率が高く、マルチターン(多回)のトレースに対する推論能力が不足していました。一方、Qwen-3.5-35B は強力かつ低コストなオープンモデルであり、ファインチューニングを通じて最先端のパフォーマンスを達成する余地がありました。
トレーニングには chat-langchain データセットからのデータのみを使用しました。単一のデータセットからのデータのみでトレーニングを行った理由は、それが全く異なるドメインへも転移(transfer)可能かどうかを検証するためです。
また、ベースモデルの小規模実験で観察された一般的な失敗パターンを踏まえ、入力プロンプトを軽微に最適化しました。トレーニングには Fireworks 上の管理型 SFT(Supervised Fine-Tuning)トレーニングを LoRA と併用 を使用しました。
Experiments & results
We organized experiments around three questions:
- Does fine-tuning improve baseline judge quality up to frontier model performance?
- Does a learned judge transfer across datasets?
- Is serving a fine-tuned model cost-effective?
Fine-tuning open models can exceed or match frontier models**
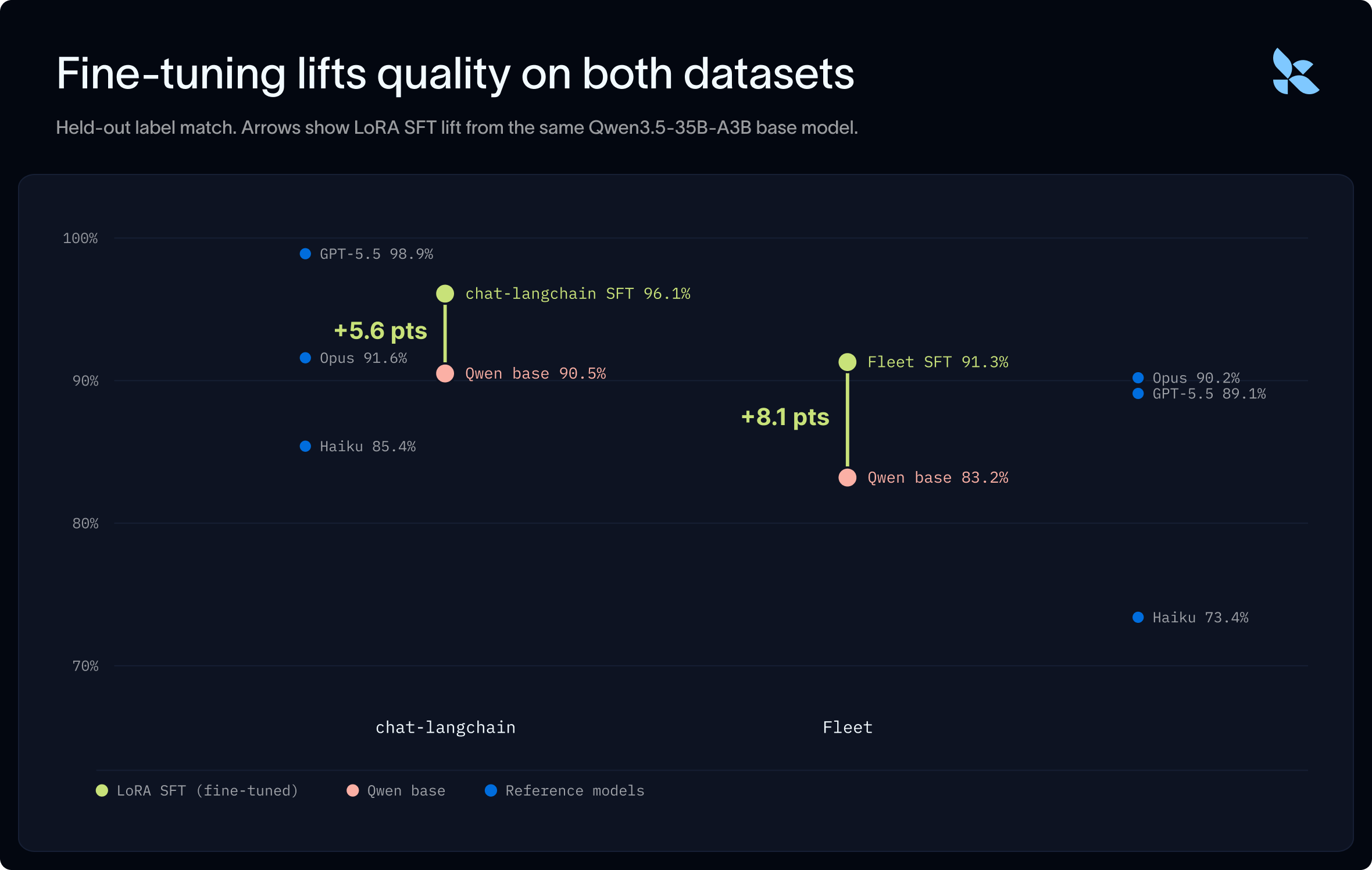
Model
chat-langchain accuracy
Fleet accuracy
Base Qwen
90.5%
83.2%
Chat-langchain SFT
96.1%
90.8%
Fleet SFT
92.7%
91.3%
Claude Opus
91.6%
90.2%
GPT-5.5
98.9%
89.1%
We found that base Qwen with good prompting was a strong out of the box model for perceived error classification, but trailed frontier model classification accuracy. On both datasets, running a LoRA SFT job lifted the base model to be close to or above frontier performance.
In addition to benchmarking against frontier models, we also compared to smaller, cheaper models. A common strategy for running high-volume, low cost inference workloads is using the smallest closed frontier model such as Haiku. But we consistently found that strong open models outperformed Haiku out of the box, while being much cheaper to run.
微調整済み判別モデルは未見データにもよく転移する

初期の結果では、Fleet データセットがすべてのモデルにとってより困難なデータセットであることが示されました。chat-langchain での微調整後、このモデルが Fleet データに対して Fleet 固有のトレーニングを一切行わずにどの程度転移するかをテストしました。chat-langchain データで訓練されたモデルは、Fleet データにおいてすべての最先端モデルを上回る性能を発揮しました。
その後、Fleet データに特化してモデルを訓練する実験を行いました。その結果、chat-langchain で SFT(Supervised Fine-Tuning:教師あり微調整)を行ったモデルと比較してわずかな改善が見られました。
これは重要な結果です。なぜなら:
- 私たちの知覚される誤りのモデルが他のドメインへも転移可能であり、最先端レベルの性能を維持できること(この場合はやや上回るレベル)を示しているからです。
- 自身のデータセット上で知覚される誤り(または他の微調整済み判別器)の性能をさらに引き上げたいビルダーにとって、さらなる性能向上のためにアプリケーション固有のトレースで微調整を行う選択肢が得られることを示しています。
微調整済みモデルは実行コストが大幅に低い
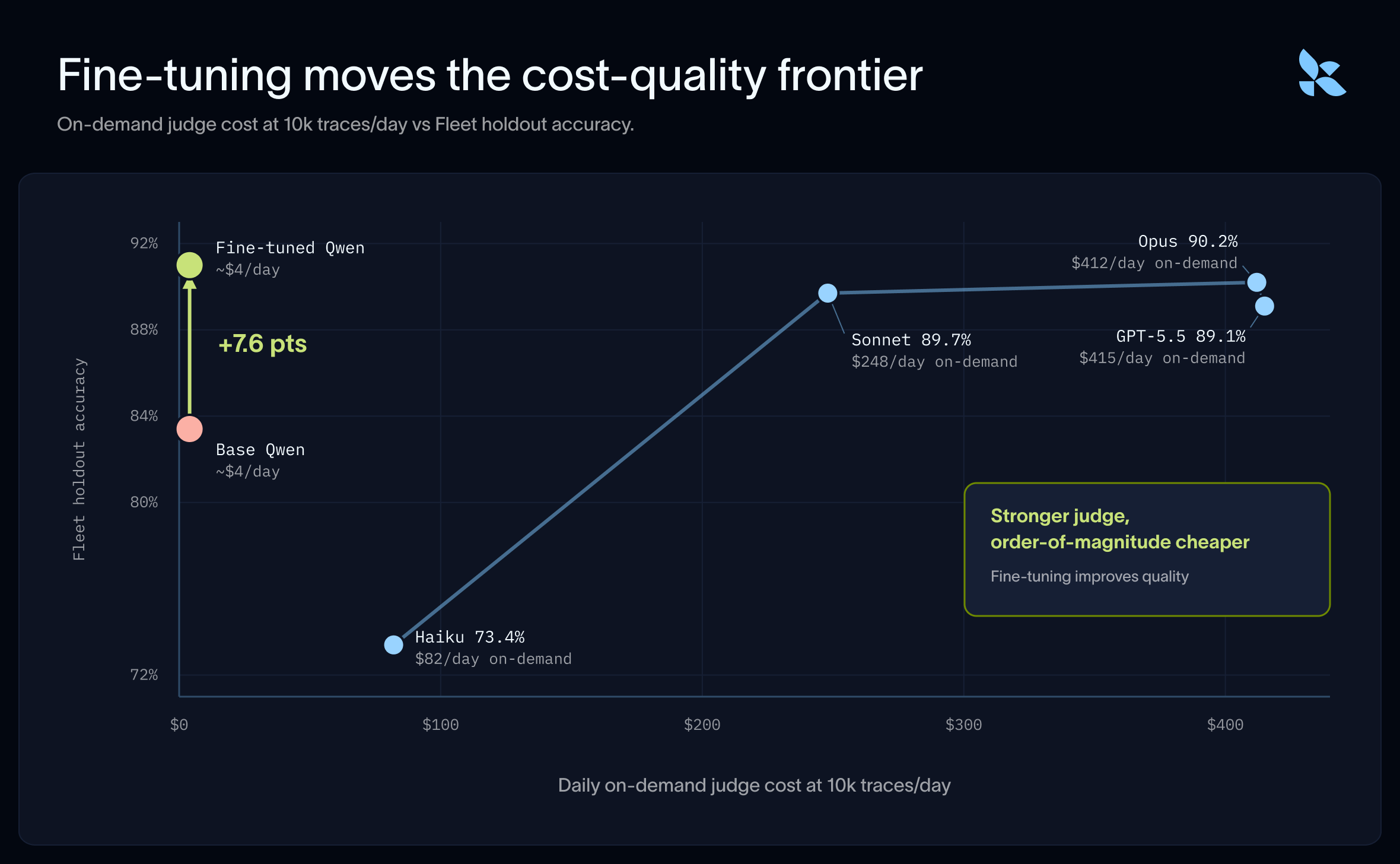
微調整済みモデルは最前線の精度に匹敵し、大規模運用時のコストは桁違いに安価です。トレース量やモデル選択にもよりますが、10 倍から 100 倍の削減が可能です。トレース量が拡大するにつれ、微調整済みモデルによるコスト削減効果もさらに大きくなります。また性能面では、微調整済みの Qwen モデルは Haiku、Sonnet、Opus(および gpt-5.5)を含むあらゆるモデルサイズを上回ります。
トレース理解に関する今後の研究
継続学習(Continual Learning)を解決するには、トレース理解に関連する大規模なデータマイニング問題に取り組む必要があります。一般的に、トレースをより深く理解するために、専門的でコスト効率の高いモデルを構築するためのレシピを推進することに興奮しています。
オープンモデルは知性の閾値を超えた ことで、多くのタスクにおいてすぐに使える高性能でコスト効率の良い分類器となっています。Fireworks の使いやすいトレーニングおよび推論インフラストラクチャを活用することで、オープンモデルを最前線の性能に近づけつつ、運用コストを桁違いに抑えることが可能になりました。
今後の研究の方向性としては、チームが自社のエージェントトレース用の評価者モデル(evaluator models)を構築できるよう、適切なトレーニング目標や評価基準(rubrics)の設計を支援することが挙げられます。エージェントトレースを理解するほど、エージェントを改善するための変更を行う際により情報に基づいた判断を下すことができます。
知覚誤差モデルを試す
私たちは、今後数週間にわたり、微調整済みの知覚誤差モデルを限定された顧客向けに展開し、1〜2 ヶ月後に広範な展開を行う予定です。この知覚誤差判定器(perceived error judge)のテストにご興味があり、フィードバックを提供されたい場合は、こちらからご登録ください。
原文を表示
Agents now produce a majority of the world’s data and power many applications we use today. As more agents move into production, traces will become more important as one of the richest sources of data to understand how agentic systems behave with real users.
Research question: how can we cost-effectively mine important signals from every single trace, while maintaining frontier performance?
To answer this question, we partnered with Fireworks to fine-tune a Qwen judge model to detect “Perceived Error” from user interactions.
What is Perceived Error:
Perceived error is when the user thinks the assistant made a mistake or produced something that needed correction. Perceived Error is not judging objective correctness or user happiness. For example, an agent could give a correct answer but the user is frustrated by the information (not the agent).
We usually push for teams to build application specific evaluators, as often the logic to judge a trace needs to have context of that application. We believe, however, that “perceived error” is an example of an evaluator that can be general purpose. We believe the signals that it will look for are universal across applications.
The generality of “perceived error” is a key question. Some of the experiments we run later on are specifically aimed at testing the generality of this metric.
We infer perceived error from trace signals like user corrections, rejection of an agent action, repeated requests, and assistant acknowledgements of errors. The perceived error evaluator then enriches the trace with information in the format shown below:
{"perceived_error": true, "reason": "The user corrects the meeting date the assistant used."}How we created a dataset
Agents applied on tasks are only as good as the data used to train them. We sourced data from two internal tracing datasets we use in production:
*Docs Q&A agent that answers questions about LangChain’s libraries and products. Users may ask conceptual questions, debugging questions, or help building things. These exchanges are often technical and involve a good amount of detail*
*A no-code tool for creating agents that do real work like writing documents and doing research. Users may use Fleet for a wide variety of tasks. They may invoke many different tools or skills.*
We selected a portion of traces from each tracing dataset as training and holdout sets. When filtering from the pool of traces, we selected multi-turn traces because judging “perceived error” requires a human response to the AI results (for example, correcting the assistant or repeating the request).
Part of the motivation for using multiple datasets was to test the generality of “perceived error”. Would a model trained to detect perceived error on one dataset transfer to a second one?
Dataset
Total Examples
Train rows
Holdout rows
chat-langchain
885
707
178
Fleet
911
727
184
Data Preparation
When preparing the data for training and prediction, we made the choice to only include Human and AI messages, ignoring all tool calls. We did this because we hypothesized that for the signals we were looking for the human and AI messages are the main source of information. This is a lever we intend to experiment with in the future.
We also included all messages as is, with no trimming of long content. This is another lever we intend to experiment with in the future.
Labels
To generate labels, we used a mix of model-assisted labeling plus human review to create short JSON labels and rationales for each trace. Specifically, we first asked a panel of models to judge a trace. If they all agreed, we took that as a ground truth label. If they disagreed, we then took all their labels and rationales and passed them to another panel of models, asking them to judge who was right. If that panel agreed, we took that as ground truth. If they still disagreed, we human annotated them manually. Over the dataset, chat-langchain and Fleet had 24% and 18% of traces with a perceived error label respectively.
Fine-tuning setup
For training, we chose a Qwen-3.5-35B as our base model after running a few small scale experiments on testing other models. Much smaller models had high error rates and weren’t strong enough to reason over our multi-turn traces. With Qwen-3.5-35B , we had a strong, cheap open model with room to hit frontier performance via fine-tuning.
We trained only on data from the chat-langchain dataset. The reason for only training on data from one dataset was to allow us to test whether it would transfer to a completely different domain.
We also lightly optimized the input prompt after observing common failure modes from small-scale experiments on the base model. For training, we used managed SFT training on Fireworks with LoRA.
Experiments & results
We organized experiments around three questions:
- Does fine-tuning improve baseline judge quality up to frontier model performance?
- Does a learned judge transfer across datasets?
- Is serving a fine-tuned model cost-effective?
Fine-tuning open models can exceed or match frontier models
Model
chat-langchain accuracy
Fleet accuracy
Base Qwen
90.5%
83.2%
Chat-langchain SFT
96.1%
90.8%
Fleet SFT
92.7%
91.3%
Claude Opus
91.6%
90.2%
GPT-5.5
98.9%
89.1%
We found that base Qwen with good prompting was a strong out of the box model for perceived error classification, but trailed frontier model classification accuracy. On both datasets, running a LoRA SFT job lifted the base model to be close to or above frontier performance.
In addition to benchmarking against frontier models, we also compared to smaller, cheaper models. A common strategy for running high-volume, low cost inference workloads is using the smallest closed frontier model such as Haiku. But we consistently found that strong open models outperformed Haiku out of the box, while being much cheaper to run.
A fine-tuned judge transfers well to unseen data
.png)
Our initial results showed that Fleet was a more challenging dataset for all models. After fine-tuning on chat-langchain, we tested how well this model transferred to Fleet data without any Fleet specific training. The model trained on chat-langchain data outperformed all frontier models on Fleet data.
We then experimented with training a model specifically on Fleet data. This resulted in a small improvement over our chat-langchain SFT’d model.
This is an important result because:
- It shows that our perceived error model is able to transfer to other domains and still maintain performance at frontier levels (in this case, slightly above).
- For builders who want to push the performance on perceived error (or other finetuned judges) on their own datasets even further, they have the option to fine-tune on application specific traces for some further performance gain.
Fine-tuned models are much cheaper to run
Fine-tuned models match frontier accuracy and are much cheaper to run at scale - 10-100x depending on trace volume and model choice. As trace volumes grow, the cost savings from a fine-tuned model continue to grow. And on performance, the fine-tuned Qwen model outperforms all model sizes Haiku, Sonnet, and Opus (and gpt-5.5).
Future research on trace understanding
Solving Continual Learning will involve tackling large-scale data mining problems around trace understanding. In general, we’re excited to push forward recipes around building specialized, cost-effective models to better understand traces.
Open models have crossed an intelligence threshold and are now strong out-of-the-box cost-effective classifiers for many tasks. With easy to use training & inference infrastructure from Fireworks, we’re able to push open models towards frontier performance while being orders of magnitude cheaper to run.
Future research directions include helping teams design good training objectives & rubrics to build their own evaluator models for their agent traces. The more we understand our agent traces, the better informed we can be when making changes to improve agents.
Try our perceived error model
We will be rolling out our fine-tuned perceived error model to a select number of customers over the next few weeks before a broader rollout in a month or two. If you are interested in testing this perceived error judge and providing feedback, please sign up here
関連記事
[AINews] 今日特に大きな出来事はありませんでした
Latent Space は、GLM 5.2 が依然として注目されていると指摘しつつ、AIE WF 2026 の通常チケットが月曜日に完売すると発表しました。同サイト購読者向けに限定割引を提供し、参加者には Warp や Datadog などからのスポンサークレジットも付与されます。
米国がアンソロピックの「Fable 5」発売を禁止、しかし市場は動じず
米国政府は国家安全保障上の懸念から、アマゾンの研究者らがガードレール回避手法を発見したとして、アンソロピックに対し最新モデル「Fable 5」と「Mythos 5」の販売差し止めを命じた。サイバーセキュリティ研究者らはこの措置が危険だとする公開書簡に署名し、同社も他モデルでも同様の抜け道が存在すると指摘している。
社内データ分析エージェントの構築方法について
GitHub は、大規模なデータ組織が直面する自己完結型のデータアクセスと洞察提供の課題に対し、AI を活用した信頼性の高い解決策として、社内でデータ分析エージェントを構築したことを発表した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み