ML ワークロード向け EC2 キャパシティブロックと SageMaker 学習プランによる短期 GPU 容量の確保
AWS は、GPU 供給不足の課題に対し、EC2 Capacity Blocks for ML や SageMaker training plans を導入することで、短期間かつ確実な GPU リソースの確保とコスト最適化を可能にする新ソリューションを発表した。
キーポイント
GPU サプライチェーンの逼迫と課題
ML トレーニングや推論需要の高まりにより、業界全体で GPU 供給が需給バランスを崩し、リソースが希少化している。既存のオンデマンド予約(ODCR)は長期契約が必要で短時間利用には不向きかつ割高という課題がある。
EC2 Capacity Blocks for ML の導入
AWS は、テスト、評価、イベント対応など「短期間」の GPU 需要に対応するため、予約型容量ブロック(Capacity Blocks)を ML ワークロード向けに提供開始した。これにより、事前コミットなしで特定期間の容量を確保できる。
SageMaker training plans との連携
EC2 の新機能に加え、Amazon SageMaker においてもトレーニングプラン(training plans)が強化され、短時間のモデル検証やリリース前の推論容量準備を効率的に行えるよう支援する。
オンデマンド利用のリスクと代替案
オンデマンドインスタンスは即座に開始できるが、供給状況により再利用できないリスクがあり、結果として過剰稼働によるコスト増を招く。新ソリューションはこの不確実性を解消する。
影響分析・編集コメントを表示
影響分析
この発表は、AI ハードウェアの深刻な不足状況下において、企業や研究機関が短期的かつ確実な計算リソースを確保するための重要な手段を提供するものである。特に、実験的な ML ワークロードや突発的な需要に対応できるため、開発サイクルの加速とコスト効率の向上に直結し、業界全体の GPU 活用効率を高める影響がある。
編集コメント
AI ハードウェアの供給不足が常態化する中、AWS が提供する「短期間・高信頼性」のリソース確保ソリューションは、開発現場のボトルネック解消に即効性がある。特に予算制約のあるスタートアップや、突発的な需要に対応する大企業にとって、コストと可用性の両立を可能にする重要なツールとなるだろう。
さまざまな規模の企業が、グラフィックプロセッシングユニット(GPU)ベースの機械学習(ML)トレーニング、ファインチューニング、推論ワークロードを採用するにつれ、GPU 容量への需要が業界全体の供給を上回っています。この不均衡により GPU は希少なリソースとなっています、ML ワークロードに信頼性の高い GPU 計算リソースへのアクセスを必要とする顧客にとって課題が生じています。
GPU 容量の制限に直面した場合、オンデマンド容量予約(ODCRs) の作成を検討するかもしれません。ODCR は、計画された定常状態のワークロードで使用パターンが明確な場合に適用されます。GPU インスタンス、特に P タイプインスタンスに対する短期間の ODCR 利用可能性はしばしば限られています。さらに、長期契約がない場合、ODCR はオンデマンドレートで課金されるため、コスト上の利点はありません。このため、テスト、評価、イベントなどの短期的または探索的なワークロードには ODCR は不適切です。短期間の GPU 容量を確保するためのガイド付きアプローチが必要となります。
本記事では、Amazon Elastic Compute Cloud (Amazon EC2) Capacity Blocks for ML および Amazon SageMaker training plans を活用して、短期間のワークロード向けに予約済み GPU 容量を確保する方法について解説します。これらのソリューションは、負荷テストやモデル検証、時間制限のあるワークショップの実施、あるいはリリース前に推論用容量の準備が必要な際に、GPU の可用性に関する課題に対処するために役立ちます。
ソリューション概要と短期間 GPU オプション
AWS では、短期間のワークロード向けに GPU 容量を利用する方法がいくつかあります。
オンデマンド GPU インスタンス
オンデマンドインスタンスは、通常、短期間の GPU 利用における最初の選択肢となります。起動時に容量が利用可能であれば、事前のコミットメントなしで即座に GPU インスタンスの使用を開始できます。これは、アドホックな実験や短時間のテスト、開発タスクに適しています。
オンデマンドの GPU キャパシティは、リージョンごとの供給状況と現在の需要に依存しており、可用性は急速に変化する可能性があります。インスタンスを停止またはスケールダウンした場合、必要な時に同じキャパシティを再取得できない場合があります。この不確実性により、必要以上に GPU インスタンスを実行し続ける傾向が生じ、コストが増加することがあります。ワークロードが潜在的な起動遅延に耐えられる場合や、タイミングに柔軟性がある場合にオンデマンドインスタンスを選択してください。
スポット GPU インスタンス
スポットインスタンス を利用すると、GPU 計算コストを 最大 90% 削減できますが、その代わり可用性の確実性は犠牲になります。スポットキャパシティは AWS リージョン内の未使用キャパシティに依存します。Amazon EC2 がキャパシティを必要とする場合、インスタンスが中断される可能性があります。したがって、スポットインスタンスは中断に対応できるワークロードにのみ適しています。
ML ワークロードにおいては、進捗のチェックポイント保存と再起動が可能であれば、スポットインスタンスは効果的に機能します。推奨されるユースケースには、定期的なチェックポイントを持つ分散トレーニングジョブ、再試行可能なバッチ推論ワークロード、部分的なキャパシティ欠損に耐えるように設計されたワークショップ環境が含まれます。
Amazon EC2 Capacity Blocks for ML
Amazon EC2 Capacity Blocks for ML は、特定の時間枠に対して GPU 容量を予約するものであり、予約期間中にインスタンスを起動した際に、要求されたインスタンスが確実に利用可能になります。ODCR とは異なり、Capacity Blocks は完全にセルフサービスで提供され、GPU インスタンスに対する短期間の可用性を向上させるとともに、40〜50% の割引率を実現します。各 Capacity Block は、特定の期間に対して選択したインスタンスタイプの特定数を予約するものです。以下のようなことが可能です:
- 開始時刻を最大 8 週間先まで予約できます。
- 期間は 1〜14 日(1 日単位)または 15〜182 日(7 日単位)から選択できます。
- 1 つの Capacity Block あたり最大 64 インスタンスを構成できます。
- AWS Organizations 内の複数のアカウントにまたがる複数の Capacity Block で、特定の日付に最大 256 インスタンスを構成できます(この制限に達するには最小 4 つのブロックが必要で、ブロックは並行して実行可能です)。
- オートメーション組織は Capacity Blocks を購入し、複数のアカウントにプロビジョニングすることで、異なるワークロードが追加コストなしで予約された容量プールを利用できるようにします。
Capacity Blocks は、オペレーティングシステム、ネットワーク、オーケストレーション層をユーザー自身が管理する、Amazon EC2 上で直接実行されるワークロードに対して適用されます。
サービスレベルアグリーメント (SLA) およびハードウェア障害: 予約中にハードウェアに障害が発生した場合、影響を受けるインスタンスを停止し、手動で同じ Capacity Blocks 予約内に代替インスタンスを起動することができます。システムは約 10 分間のクリーンアップ処理後に、予約された容量スロットをあなたの予約に戻します。Amazon EC2 は、ハードウェアの劣化時にインスタンスを再起動できるよう、追加費用なしで各 Capacity Block 内にバッファを維持しています。
注記: Capacity Blocks には以下の制限があります:
- P5, Trn1, Trn2 などの特定の Amazon EC2 インスタンスファミリーのみをサポートしており、すべての GPU インスタンスタイプを網羅しているわけではありません。
- ml.p4dn や ml.p5 など、Amazon SageMaker が管理するインスタンスタイプの容量を予約することはできません。
- 共有して Amazon SageMaker と併用することはできません。
- 移動や分割はできません。
- UltraServer Capacity Blocks は購入された AWS アカウントにスコープが限定されており、アカウント間や AWS Organization 内での共有はできません。
Amazon SageMaker トレーニングプラン
Amazon SageMaker トレーニングプラン は、トレーニングジョブ、Amazon SageMaker HyperPod クラスター、推論など、Amazon SageMaker AI 管理環境における ML ワークロード用の GPU 容量を予約するためのアクセスを提供します。SageMaker トレーニングプランは EC2 Capacity Blocks と互換性はありません。SageMaker トレーニングプランを使用すると、以下のことができます:
- 特定の GPU ベースのインスタンスと期間に対して予約をスケジュールします。
- 基盤となるインフラストラクチャを管理することなく、キャパシティにアクセスできます。
- 最新の NVIDIA GPU や AWS Trainium アクセラレータを含む、さまざまなアクセラレーテッドコンピューティングオプションを利用できます。
G タイプのインスタンス(G6 インスタンスを除く)は現在、SageMaker トレーニングプランではサポートされていない点にご注意ください。G6 インスタンスが必要な場合は、AWS アカウントチームにお問い合わせください。特定の AWS リージョン、期間、数量オプションにおけるサポート対象のインスタンスタイプに関する詳細情報は、サポート対象のインスタンスタイプ、AWS リージョン、および価格をご覧ください。
Amazon SageMaker トレーニングプランは以下のものに適用されます:
- SageMaker トレーニングジョブ
- SageMaker HyperPod クラスター
- SageMaker Inference ワークロード
Amazon SageMaker AI にインスタンスのプロビジョニング、スケーリング、ライフサイクルの管理を任せつつ、定義された期間中に予約キャパシティを確保したい場合にこのオプションを選択してください。
意思決定フレームワーク:適切なオプションの選択
短期間の GPU ストラテジーを計画する際は、以下の 3 つの主要な要素に基づいてオプションを評価する必要があります:
- 利用形態:オンデマンドから予約済み容量へ。
- コストモデル:オンデマンド価格、またはオンデマンドより低い価格での事前コミットメント。
- ワークロード環境:Amazon SageMaker が管理するワークロードと比較した、Amazon EC2 の直接アクセス。
- 短期から長期の容量計画へ:本記事では短期間の GPU 容量を確保することに焦点を当てていますが、長期的または反復的なワークロードに対する計画が必要になる場合もあるでしょう。過去のデータに基づいた評価を行うか、あるいは短期間の GPU リソースを使用してワークロードの負荷テストを実行し、本番環境で必要なインスタンスの数と種類についてより深く理解することができます。本番デプロイメントや大量の GPU 容量を必要とする大規模イベントに対しては、少なくとも 3 週間前には計画を開始してください。AWS アカウントチームと連携して要件を評価し、スケジュールに合致する容量戦略を開発してください。
コストの検討
- ML 用 Capacity Blocks では事前支払いが必要であり、オンデマンド価格と比較して時間あたりの料率が 40〜50% 低下します。例えば米国東部(北バージニア)では、p5.48xlarge インスタンスは Capacity Blocks で時間あたり 34.608 ドル、オンデマンドでは 55.04 ドルです。
- SageMaker トレーニングプランの料金は、オンデマンド価格の 70〜75% オフで設定されています。予約をスケジュールする際に料金を事前にお支払いいただきます。AWS は供給と需要の動向に基づき定期的に価格を更新します。トレーニングプランの実行開始が価格変更後であっても、予約を作成した時点でのレートが適用されます。
- インスタンスが予約期間中ずっと稼働しない場合、予約による総コストがオンデマンド利用のコストを上回る可能性があります。ワークロードの実際の稼働時間要件に基づいて評価を行ってください。
- 免責事項:本セクションで言及されているすべての価格数値は、公開されている AWS の価格を出版日時点のものとして参照したものであり、変更される場合があります。最新の価格については、Amazon EC2 の価格ページおよび SageMaker AI の価格ページをご確認ください。
意思決定プロセス
制限の少ないオプションから始め、可用性やタイミングが重要となる段階で予約済みキャパシティへと移行してください。
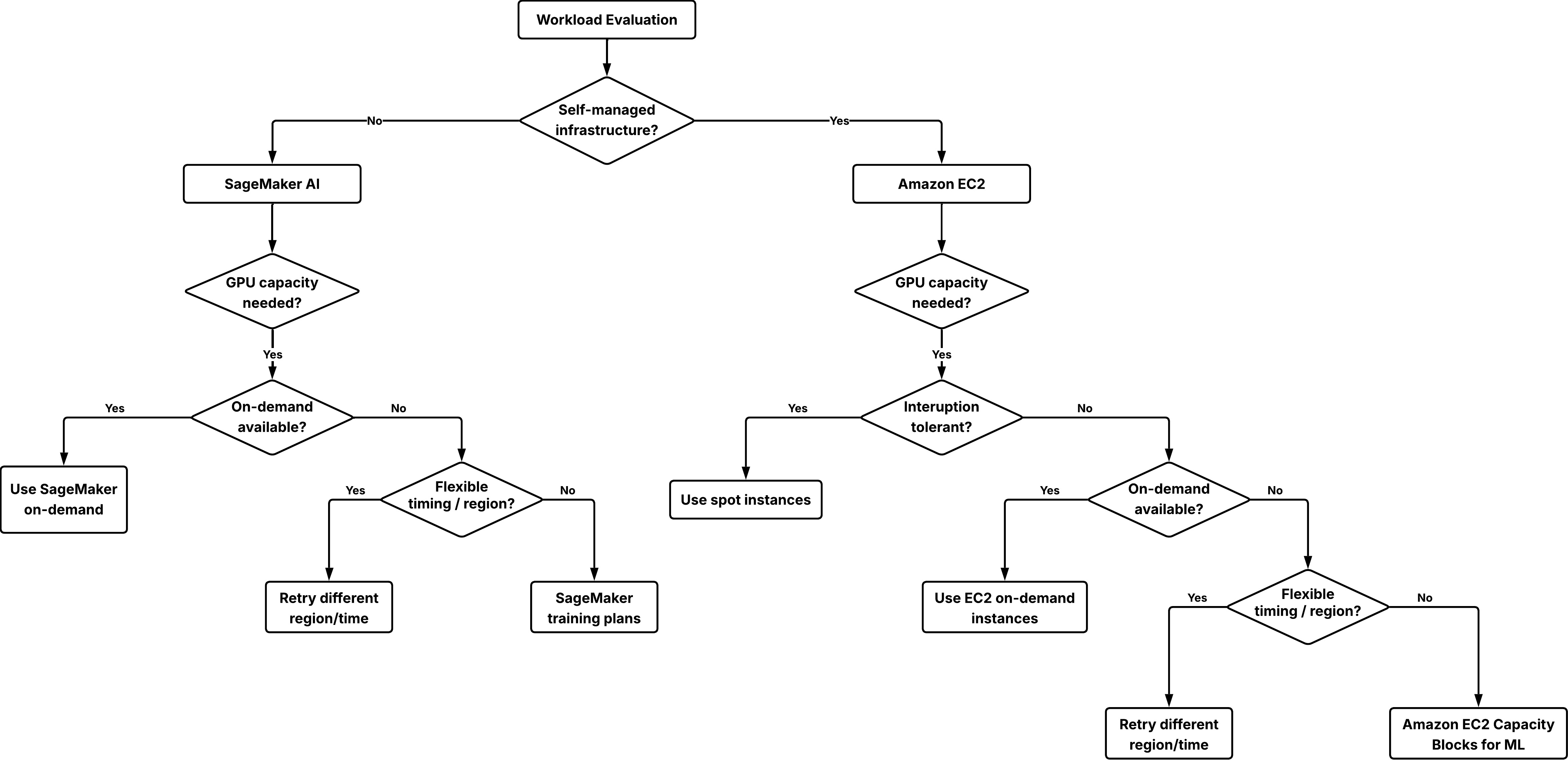
GPU キャパシティを確保するための適切なオプションを選択するための意思決定ツリー。
ステップ 1: インフラストラクチャ管理モデルの特定
- オペレーティングシステム、ネットワーク、オーケストレーションに対して完全な制御権限を必要とする場合は、Amazon EC2 を使用し、オンデマンドインスタンス、スポットインスタンス、または Capacity Blocks を利用してください。
- インフラストラクチャのプロビジョニングと運用を管理サービスが代行するものを希望される場合は、Amazon SageMaker AI を使用し、ml.* インスタンスタイプに対して SageMaker オンデマンドまたは SageMaker トレーニングプランを利用してください。
ステップ 2: まずオンデマンド容量を試す
Amazon EC2 および Amazon SageMaker AI のワークロードの両方において、まずはオンデマンド容量から開始してください。このアプローチは以下の利点があります:
- 事前のコミットメントを必要としない。
- 利用可能な場合、即時に開始できる。
初期起動が失敗した場合は、以下の柔軟性オプションを試してください:
- 容量が利用可能である可能性のある別の AWS リージョンを試す。
- 通常需要が低いオフピーク時間帯に開始時間を調整する。
- 中断を許容できるワークロードに対してスポットインスタンスを補完的に使用する。
ステップ 3: 確実性が必要な場合は予約済み容量を使用する
ワークロードが特定の時刻に開始しなければならない場合、または納期スケジュールが予約済みの GPU アクセスに依存している場合は、容量の予約が適切な選択肢となります:
- Amazon EC2 ワークロードの場合、ML 向けの Capacity Blocks を使用してください。
- Amazon SageMaker AI ワークロードの場合、トレーニングジョブ、HyperPod クラスター、または推論ワークロードのいずれかに対して Amazon SageMaker トレーニングプランを使用してください。
技術的実装:SageMaker トレーニングプランを用いた推論のための GPU キャパシティ予約
このセクションでは、Amazon SageMaker トレーニングプランによって管理される推論ワークロードに対して GPU キャパシティを予約し、使用する方法を示します。SageMaker トレーニングプランの予約は、選択されたターゲットリソースに固有のものであることに注意してください。推論用に購入したプランは、トレーニングジョブや HyperPod クラスターには使用できず、その逆も同様です。
他のシナリオについては以下の通りです:
- SageMaker トレーニングジョブまたは SageMaker HyperPod クラスターのキャパシティを予約する場合は、「トレーニングジョブ用または HyperPod クラスター用のトレーニングプランの作成」を参照してください。
- ワークロードが Amazon EC2 上で直接実行され、固定期間における予約キャパシティを必要とする場合は、「ML 向け Capacity Blocks」を参照してください。
前提条件
開始する前に、以下の事項を確認してください:
- 適切な AWS Identity and Access Management (IAM) 権限を持つ AWS アカウント。
トレーニングプランを作成するには、AmazonSageMakerTrainingPlanCreateAccess マネージドポリシーを使用してください。
- エンドポイントの作成、説明、削除を行うには、以下のポリシーを使用します:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "sagemaker:CreateEndpointConfig", "sagemaker:CreateEndpoint", "sagemaker:DescribeEndpoint", "sagemaker:DeleteEndpoint", "sagemaker:DeleteEndpointConfig" ], "Resource": [ "arn:aws:sagemaker:*:*:endpoint/*", "arn:aws:sagemaker:*:*:endpoint-config/*" ] } ] }
- 作成済みでデプロイの準備が整った SageMaker AI モデルリソース。手順については、モデルの作成を参照してください。
- AWS Command Line Interface (AWS CLI) バージョン 2.0 以降。
トレーニングプランの作成
開始するには、Amazon SageMaker AI コンソール にアクセスし、左側のナビゲーションペインでトレーニングプランを選択して、トレーニングプランの作成をクリックします。
 image
image
Amazon SageMaker AI コンソール内のトレーニングプランページ。
例えば、推論エンドポイント用に希望のトレーニング日と期間(1 日間)、インスタンスタイプと数量(1 ml.trn1.32xlarge)を選択し、トレーニングプランの検索をクリックしてください。
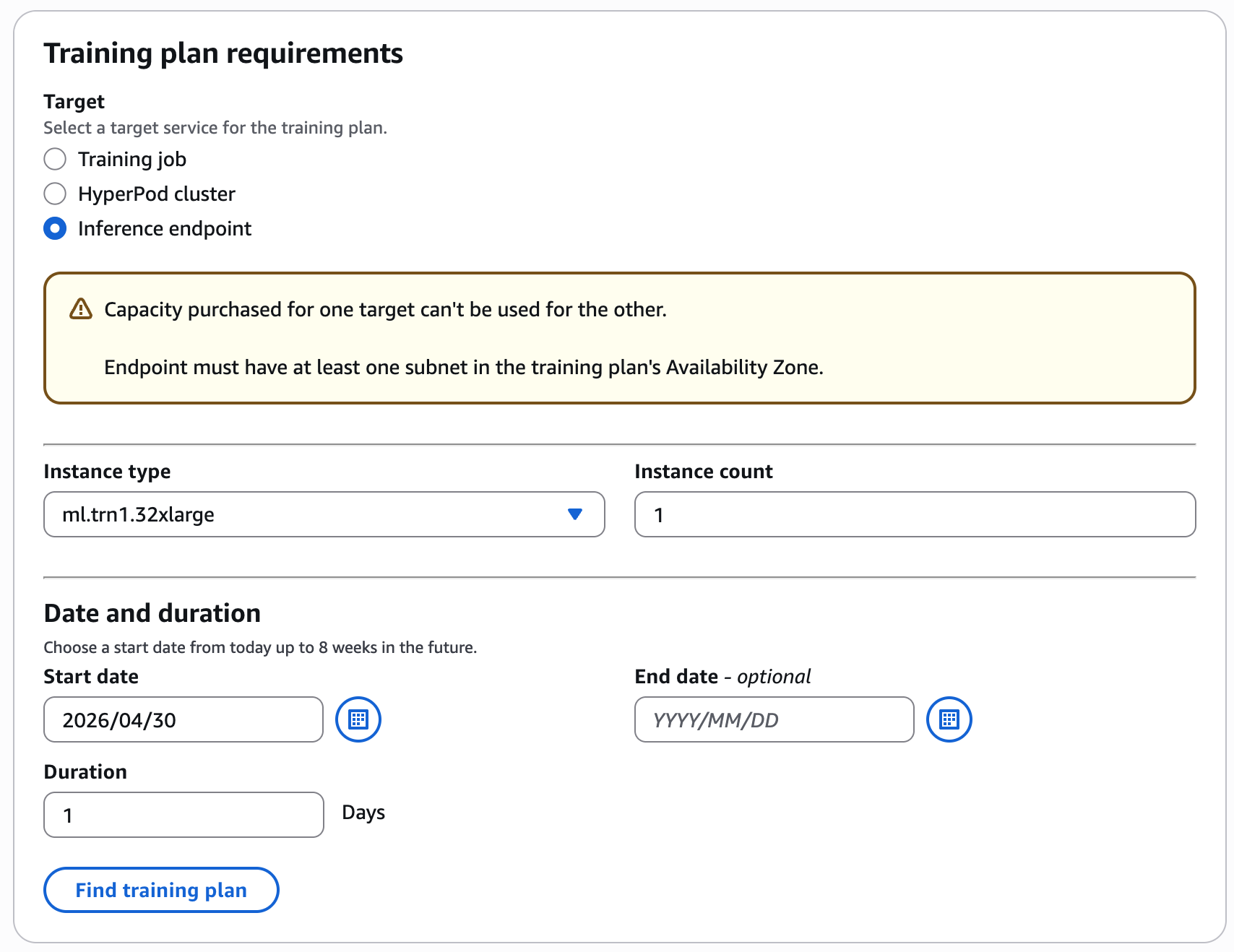
推論ワークロード用のインスタンスタイプ、インスタンス数、日付、期間を選択してトレーニングプランを構成します。
コンソールには、合計価格が表示された利用可能なプランがリストされます。
原文を表示
As companies of various sizes adopt graphic processing units (GPU)-based machine learning (ML) training, fine-tuning and inference workloads, the demand for GPU capacity has outpaced industry-wide supply. This imbalance has made GPUs a scarce resource, creating a challenge for customers who need reliable access to GPU compute resources for their ML workloads.
When you encounter GPU capacity limitations, you might consider creating on-demand capacity reservations (ODCRs). ODCRs apply to planned, steady-state workloads with well-understood usage patterns. Short-term ODCR availability for GPU instances, particularly P-type instances, is often limited. Additionally, without a long-term contract, ODCRs are billed at on-demand rates, offering no cost advantage. This makes ODCRs unsuitable for short or exploratory workloads such as testing, evaluations, or events. A guided approach to secure short-term GPU capacity becomes necessary.
In this post, you will learn how to secure reserved GPU capacity for short-term workloads using Amazon Elastic Compute Cloud (Amazon EC2) Capacity Blocks for ML and Amazon SageMaker training plans. These solutions can address GPU availability challenges when you need short-term capacity for load testing, model validation, time-bound workshops, or preparing inference capacity ahead of a release.
Solution overview and short-term GPU options
There are several ways to access GPU capacity on AWS for short-term workloads:
On-demand GPU instances
On-demand instances are usually the first option for short-term GPU usage. If capacity is available at launch time, you can start using GPU instances immediately without prior commitment. This works well for ad hoc experiments, short tests and development tasks.
On-demand GPU capacity depends on regional supply and current demand, and availability can change quickly. If you stop or scale down an instance, you might not be able to reacquire the same capacity when needed again. This uncertainty often leads to keeping GPU instances running longer than needed, which can increase cost. Choose on-demand instances when your workload can tolerate potential launch delays or when timing is flexible.
Spot GPU instances
Spot instances can reduce your GPU compute costs by up to 90%, but they trade cost saving for availability certainty. Spot capacity depends on unused capacity in the AWS Region. Instances can be interrupted when Amazon EC2 needs the capacity back, thus spot instances are suitable only for workloads that can handle interruption.
For ML workloads, spot instances work well when you can checkpoint progress and restart. Recommended use cases include distributed training jobs with periodic checkpoints, batch inference workloads that can be retried, and workshop environments that are designed to tolerate partial capacity.
Amazon EC2 Capacity Blocks for ML
Amazon EC2 Capacity Blocks for ML reserves GPU capacity for a specific time window so that the requested instances will be available when you launch them during the reserved period. Unlike ODCRs, Capacity Blocks are fully self-service and offer better short-term availability for GPU instances with a 40-50% discounted rate. Each Capacity Block represents a reservation of a specific number of a selected instance type for a defined duration. You can:
- Reserve a start time up to eight weeks in advance.
- Choose a duration from 1–14 days (in 1-day increments) or 15–182 days (in 7-day increments).
- Configure up to 64 instances per Capacity Block.
- Configure up to 256 instances across multiple Capacity Blocks across accounts in your AWS Organizations on a particular date (minimum of four blocks needed to reach this limit; blocks can run concurrently).
- Organizations can purchase Capacity Blocks and provision them across multiple accounts, allowing different workloads to access a pool of reserved capacity at no additional cost.
Capacity Blocks apply to workloads that run directly on Amazon EC2, where you manage the operating system, networking, and orchestration layers yourself.
Service level agreement (SLA) and hardware failures: If hardware fails during your reservation, you can terminate the affected instance and manually launch a replacement into the same Capacity Blocks reservation. The system returns the reserved capacity slot to your reservation after approximately 10 minutes of cleanup. Amazon EC2 maintains a buffer within each Capacity Block to support relaunching instances in case of hardware degradation, at no additional cost.
Note: Capacity Blocks have the following limitations:
- Support only selected Amazon EC2 instance families, such as P5, Trn1 and Trn2, and do not cover every GPU instance type.
- Can’t reserve capacity for Amazon SageMaker-managed instance types such as ml.p4dn or ml.p5.
- Can’t be shared and used with Amazon SageMaker.
- Can’t be moved or split.
- UltraServer Capacity Blocks are scoped to the AWS account where purchased and can’t be shared across accounts or within AWS Organization.
Amazon SageMaker training plans
Amazon SageMaker training plans provide access to reserve GPU capacity for ML workloads in the Amazon SageMaker AI managed environment, such as training jobs, Amazon SageMaker HyperPod clusters and inference. SageMaker training plans aren’t interchangeable with EC2 Capacity Blocks. With SageMaker training plans, you can:
- Schedule reservations for specific GPU-based instances and durations.
- Access your capacity without managing underlying infrastructure.
- Use a range of accelerated computing options, including the latest NVIDIA GPUs and AWS Trainium accelerators.
Note that G-type instances (except G6 instances) aren’t currently supported by SageMaker training plans. If you need G6 instances, contact your AWS account team. For detailed information about the supported instance types in a given AWS Region, duration, and quantity options, see Supported instance types, AWS Regions, and pricing.
Amazon SageMaker training plans apply to:
- SageMaker training jobs
- SageMaker HyperPod clusters
- SageMaker Inference workloads
Choose this option when you want Amazon SageMaker AI to manage instance provisioning, scaling, and lifecycle while still securing reserved capacity during a defined window.
Decision framework: choosing the right option
When planning your short-term GPU strategy, you should evaluate options based on three key factors:
- Availability: From on-demand to reserved capacity.
- Cost model: On-demand pricing or upfront commitments with lower than on-demand pricing.
- Workload environment: Amazon EC2 direct access compared to Amazon SageMaker-managed workloads.
- From short-term to long-term capacity planning: While this post focuses on securing short-term GPU capacity, you might need to plan for longer-term or recurring workloads. You can run assessments based on historical data; or use short-term GPU resources to load test your workload and gain better understanding of the instance number and type needed for production. For production deployments or large-scale events requiring significant GPU capacity, start planning at least three weeks in advance. Work with your AWS account team to assess your requirements and develop a capacity strategy that meets your timeline.
Cost consideration
- Capacity Blocks for ML require upfront payment and offer 40-50% lower hourly rates compared to on-demand pricing. For example in US East (N. Virginia), p5.48xlarge costs $34.608/hour with Capacity Blocks versus $55.04/hour on-demand.
- SageMaker training plans are priced 70-75% below on-demand rates. You pay the price up front at the time you schedule the reservation. AWS regularly updates prices based on trends in supply and demand. You pay the rate that’s current at the time that you make the reservation, even if the training plan starts later after the price changes.
- If your instances don’t run continuously throughout the reservation period, the total cost of making reservations might exceed on-demand cost. Evaluate based on your workload’s actual runtime needs.
- Disclaimer: All pricing figures referenced in this section are based on publicly available AWS pricing as of the date of publication and are subject to change. For the most current pricing, refer to Amazon EC2 pricing and SageMaker AI pricing.
Decision process
Start with the least restrictive option and move toward reserved capacity when availability or timing becomes critical.
Decision tree to choose the right option for securing GPU capacity.
Step 1: Determine your infrastructure management model
- If you need full control over the operating system, networking, and orchestration, use Amazon EC2 and use on-demand instances, spot instances, or Capacity Blocks.
- If you want a managed service that handles infrastructure provisioning and operations for you, use Amazon SageMaker AI and use SageMaker on-demand or SageMaker training plans for ml.* instance types.
Step 2: Try on-demand capacity first
For both Amazon EC2 and Amazon SageMaker AI workloads, start with on-demand capacity. This approach:
- Requires no prior commitment.
- Allows immediate start if capacity is available.
If an initial launch fails, try these flexibility options:
- Try a different AWS Region where capacity might be available.
- Adjust the start time to off-hours when demand is typically lower.
- Use spot instances as a supplement on workloads that can tolerate interruption.
Step 3: Use reserved capacity when certainty is required
If your workload must start at a specific time or your delivery timeline depends on reserved GPU access, reserving capacity becomes the appropriate choice:
- For Amazon EC2 workloads, use Capacity Blocks for ML.
- For Amazon SageMaker AI workloads, use Amazon SageMaker training plans for either training jobs, HyperPod clusters, or inference workloads.
Technical implementation: Reserving GPU capacity for inference with SageMaker training plans
This section shows you how to reserve and use GPU capacity for inference workloads managed by Amazon SageMaker training plans. Note that SageMaker training plans reservations are specific to the selected target resource. A plan purchased for inference can’t be used for Training Jobs or HyperPod clusters, or the reverse.
For other scenarios:
- If you’re reserving capacity for SageMaker training jobs or SageMaker HyperPod clusters, refer to create training plans for training jobs or HyperPod clusters.
- If your workload runs directly on Amazon EC2 and requires reserved capacity for a fixed window, refer to Capacity Blocks for ML.
Prerequisites
Before you begin, confirm that you have:
- An AWS account with appropriate AWS Identity and Access Management (IAM) permissions.
For creating training plans, use AmazonSageMakerTrainingPlanCreateAccess managed policy.
- For creating, describing, and deleting inference endpoints, use the following policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"sagemaker:CreateEndpointConfig",
"sagemaker:CreateEndpoint",
"sagemaker:DescribeEndpoint",
"sagemaker:DeleteEndpoint",
"sagemaker:DeleteEndpointConfig"
],
"Resource": [
"arn:aws:sagemaker:*:*:endpoint/*",
"arn:aws:sagemaker:*:*:endpoint-config/*"
]
}
]
}- A SageMaker AI model resource created and ready for deployment. For instructions, see create a model.
- The AWS Command Line Interface (AWS CLI) version 2.0 or later.
Create a training plan
To get started, go to the Amazon SageMaker AI console, choose Training plans in the left navigation pane, and choose Create training plan.
The Training plans page in the Amazon SageMaker AI console.
For example, choose your preferred training date and duration (1 day), instance type and count (1 ml.trn1.32xlarge) for Inference Endpoint, and choose Find training plan.
Configure your training plan by selecting the instance type, instance count, date and duration for your inference workload.
The console displays available plans with the total price.
<img aria-describedby="caption-atta
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み