LangSmithでファインチューニング済みオープンソースモデルをテストする
ChatOpenSourceのCTOが、LangSmithを用いてMistralやLlama2などのオープンソースモデルをファインチューニングし、構造化されたSQL出力の精度を比較評価する実用的なワークフローを紹介している。
キーポイント
オープンソースモデルの急速な進化
Mistral 7bやLlama2などのリリースにより、オープンソースモデルの能力が急速に向上しており、アプリケーション内でモデルを容易に入れ替え可能になっている。
LangSmithを活用した評価プロセス
Pythonスクリプトの複雑さを回避し、LangSmithのUIとAPIを使用して評価データセットを作成・アップロードすることで、複数のモデルを軸ごとに比較可能にする。
ファインチューニングとモデル比較の重要性
異なるバージョンのモデルをファインチューニングすることで選択肢が増えるため、最適なモデルを選択するための生産的な評価手法が求められている。
影響分析・編集コメントを表示
影響分析
本記事は、単なるモデルの紹介ではなく、LangChainエコシステムにおける「評価(Evaluation)」の重要性を具体的に示している。開発者がオープンソースモデルを選択・最適化する際、LangSmithのようなプラットフォームを活用した体系的なアプローチが標準化しつつあることを示唆しており、実務的なAI開発プロセスに直接的な影響を与える。
編集コメント
LangChain公式ブログという点でPR色は否めないが、オープンソースモデルの実装において「評価」がいかに重要かという実務的な知見は価値がある。特に、モデル選定におけるLangSmithの活用事例として参考になる。

*編集者注記。このブログ記事は、ChatOpenSourceのCTO兼共同創業者である*Ryan Brandt*によって書かれました。ChatOpenSourceは、第三者を必要とせず、組織のネットワーク内で完全に動作するエンタープライズ向けAIチャットに特化したビジネスです。彼は、LangSmithの使用法について解説しています。LangSmithは、LLM(大規模言語モデル)アプリケーションを本番環境へデプロイするためのLangChainのプラットフォームです。*こちら*からアクセス登録を行ってください。*。
オープンソースモデルは、アプリケーションでの使用においてますます高度な能力を備えつつあります。この傾向は、Mistral 7bやLlama2ファミリーなどの最近のリリースによってさらに加速しています。未来は、古いゲーム機のカートリッジのように、アプリケーション内で優れたモデルを迅速に入れ替える能力にあるようです。異なるバージョンのモデルをファインチューニング(微調整)することで、開発者が比較する必要のある「カートリッジ」の数はさらに増加します。
そこで気になるのは、どのようにしてモデルの評価を本番環境で運用し、最適なツールを選定できるかという点です。LangSmithは、評価データセットの作成に役立つUI(ユーザーインターフェース)とAPIを提供することで、Pythonスクリプトの複雑さから解放する手段を提供します。これらのデータセットを用いて、複数のモデルに対してテストを実行し、複数の軸においてそのパフォーマンスを直接比較することができます。
Pythonまたはユーザーインターフェースを通じてLangSmithにデータをアップロードするのは簡単です。例として使用するノートブックの最後までスクロールしてください。
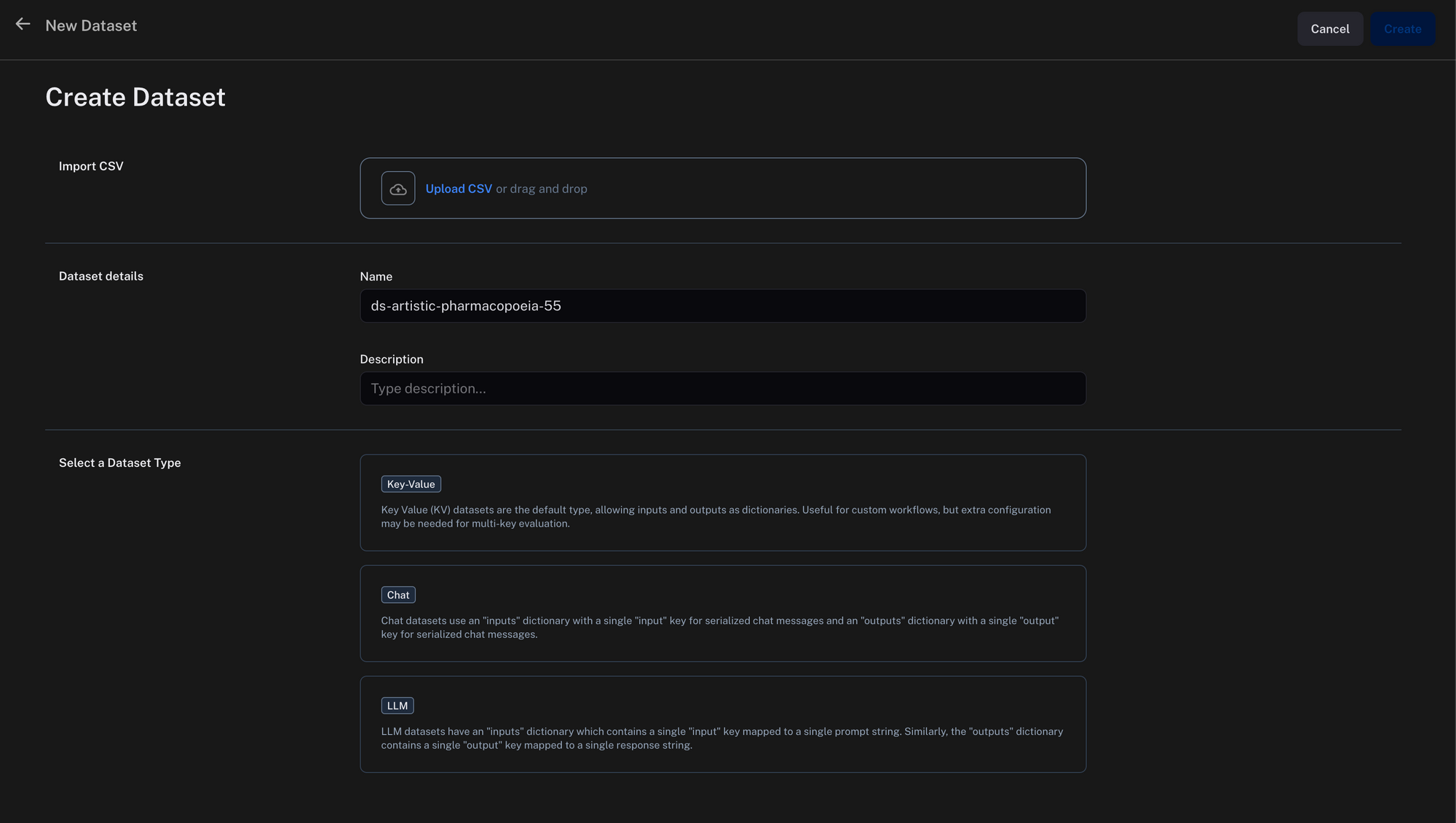
CSV形式でデータセットをアップロードします。この場合、私たちのデータに最も適しているため、Key/Value(キー/バリュー)タイプを選択しました。 image
image
アップロード後、構造化されたSQL出力が正しいことを検証するためのデータセット。
手順
以下は、私たちが研究を整理した方法です。
- 開始:タスクは、Hugging Face上のsql-create-contextデータセットを使用してLlama2-7bおよびLlama2-13bモデルをファインチューニングするという目標から始まりました。
- データ変換:Hugging Faceからのデータセットは、もともとJSON形式でしたが、チャットファインチューニング用に.jsonl形式に変換されました。
- GPT-4によるデータサンプリング:GPT-4のCode Interpreterを使用して、データセットから10,000行を選択しました。
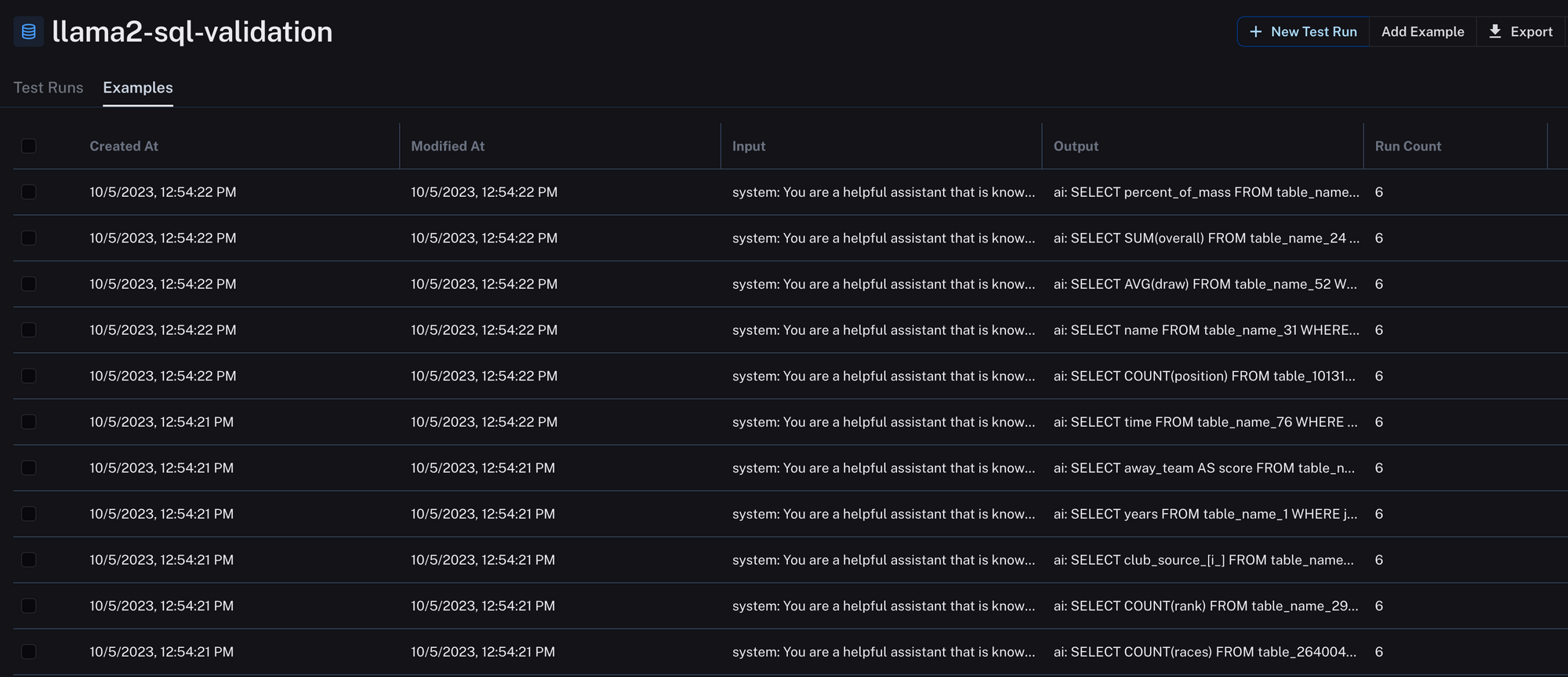
- 検証セットの作成:トレーニングデータと重複しないことを保証し、1000件の一意なSQL行を検証セットとして選択しました。これらのテスト用行をLangSmithにアップロードし、評価の自動化を行いました。
from langsmith import Client
def create_dataset(dataset_name=None):
"""adds an example run with inputs and outputs to an existing dataset"""
client = Client()
dataset_name = dataset_name
client.create_dataset(dataset_name=dataset_name)
return dataset_name
def add_to_dataset(dataset_name, validation_file_path):
client = Client()
dataset = client.read_dataset(dataset_name=dataset_name)
# Open and process the validation file
with open(validation_file_path, 'r') as f:
for line in f:
data = json.loads(line)
example = data['prompt']
assistant_content = data['completion']
# Add to dataset using client API
client.create_chat_example(
messages=[
{"type": "system", "data": {"content": "You are a helpful assistant that is knowledgeable about sql. Only output the SQL."}},
{"type": "human", "data": {"content": example}}
],
generations={"type": "ai", "data": {"content": assistant_content}},
dataset_id=dataset.id
)
上記のコードブロックを実行した結果5. ファインチューニングと評価: 主な目的は、特定のSQL出力に対してLlama2-7b-chatおよびLlama2-13b-chatを改善することでした。コストを抑えるため、Llama2-7b-chatには78k行のSQLデータでファインチューニングを行い、Llama2-13b-chatには10k行のデータでファインチューニングを行いました。両方のファインチューニングと推論(inference)は、8台のA40 GPUからなるクラスタ上で実行しました。ここではLoRAではなく、フルパラメータチューニングを行いました。これにはモデルのホスティングとファインチューニングのためのプラットフォームであるReplicateを使用しました。詳細はこちらをご覧ください。
import replicate
training = replicate.trainings.create(
version="meta/llama-2-13b-chat:f4e2de70d66816a838a89eeeb621910adffb0dd0baba3976c96980970978018d",
input={
"train_data": "https://storage.googleapis.com/chatopensource-replicate-demo/selected_sql_create_context_v4.jsonl",
"num_train_epochs": 3
},
destination="papermoose/test"
)
6. LangSmithによる評価: 各モデルに対して1000個のプロンプトをテストするためにLangSmithを使用しました。既知の正解と比較して、モデルの出力が正しいかどうかを判断しました。評価自体にはGPT-4を使用しました。LangSmithは以下に示すように、このプロセスを非常にシンプルなものにしました。
import replicate
async def evaluate_dataset(dataset_name=None, num_repetitions=1, model="gpt-4-0613", project_name=None):
"""評価対象となるモデルを、データセット内の正解とみなされる例に対して実行し、評価対象モデルの出力が正しいか不正解かを判定します。"""
from langchain.smith import run_on_dataset, RunEvalConfig, arun_on_dataset
from langchain.chat_models import ChatOpenAI
# テストしたいチャットモデル。今回の場合、Replicateを使用します。
model_to_test = Replicate(
model=model,
model_kwargs={"temperature": 0.75, "max_length": 500, "top_p": 1},
)
client = Client()
"""質問/回答評価を実行します。ここで、評価用LLM(gpt-4)は、前回のセットでアップロードしたexample_datasetに基づき、model_to_testの出力が正しいかどうかを判定します。
example_datasetは、与えられた入力に対する正解として評価側によって扱われます。"""
eval_config = RunEvalConfig(
evaluators=[
"cot_qa"
],
)
chain_results = await arun_on_dataset(
client,
dataset_name=dataset_name,
llm_or_chain_factory=model_to_test,
evaluation=eval_config,
num_repetitions=num_repetitions,
project_name=project_name
)
LangSmithプラットフォーム自体には、評価(eval)の結果を表示する機能があります。今回のケースでは「思考の連鎖」形式の質問回答用ビルトイン評価を使用しています。必要に応じて、こちらに示されているように、独自のカスタム評価器を記述することも可能です。
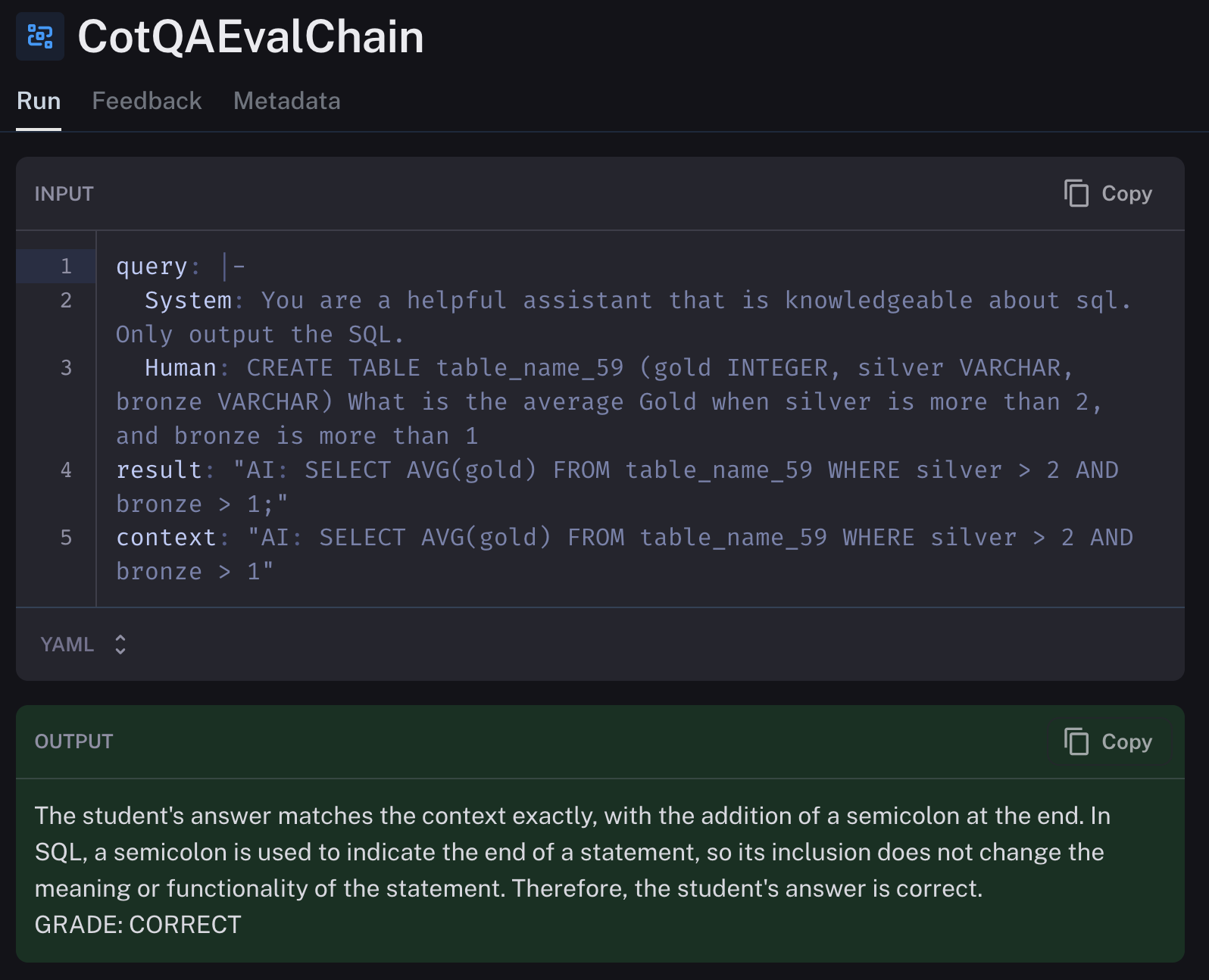
正解の例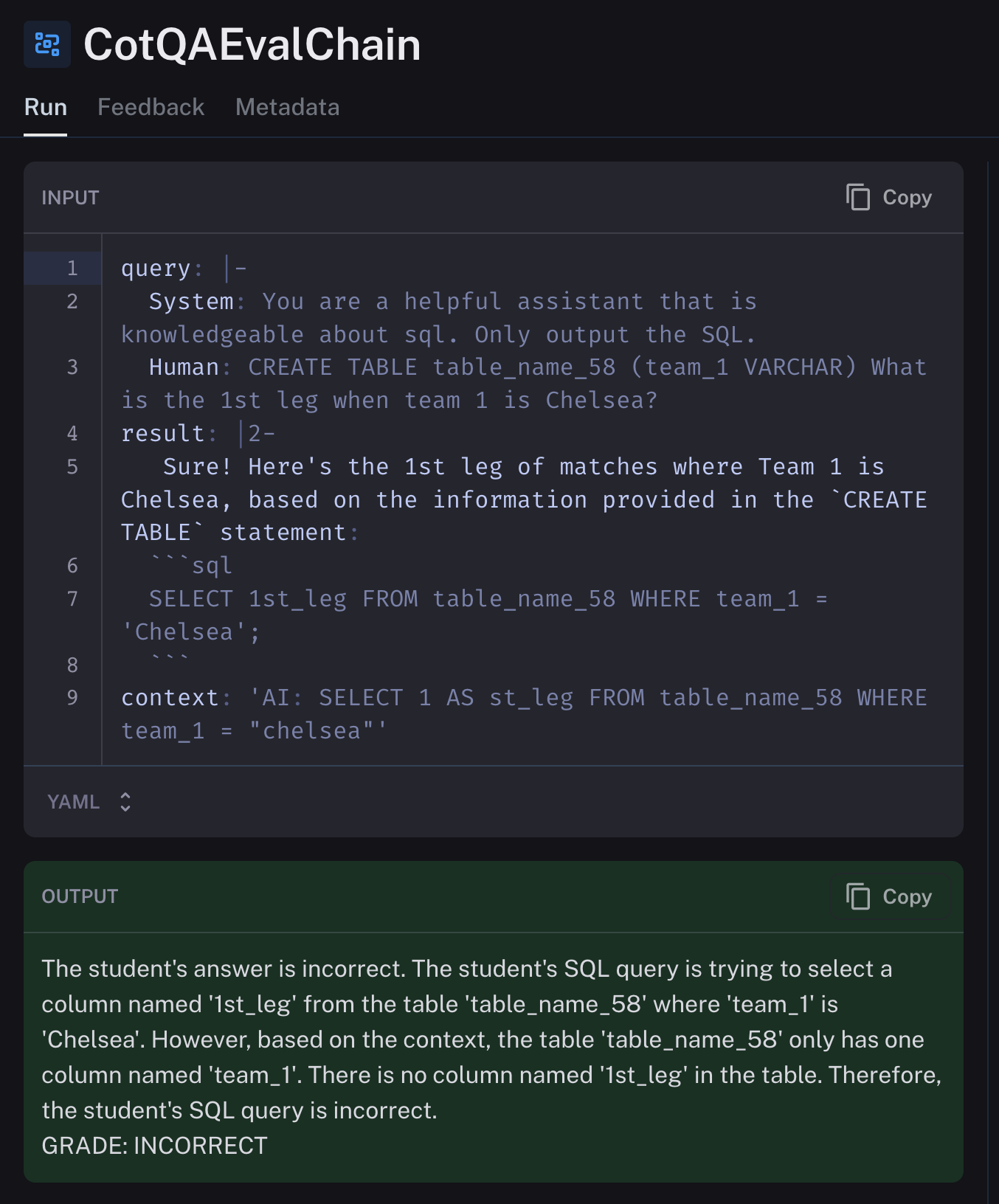 image
image
不正解の例。データセットはこちらをご覧ください。
LangSmithでの調査結果
ここからが私たちの結果です。データセット名はランダムに生成されています。UI上でデータセットの名前を変更する簡単な方法がまだないため、以下ではより理解しやすい形式でグラフ化して示しています。
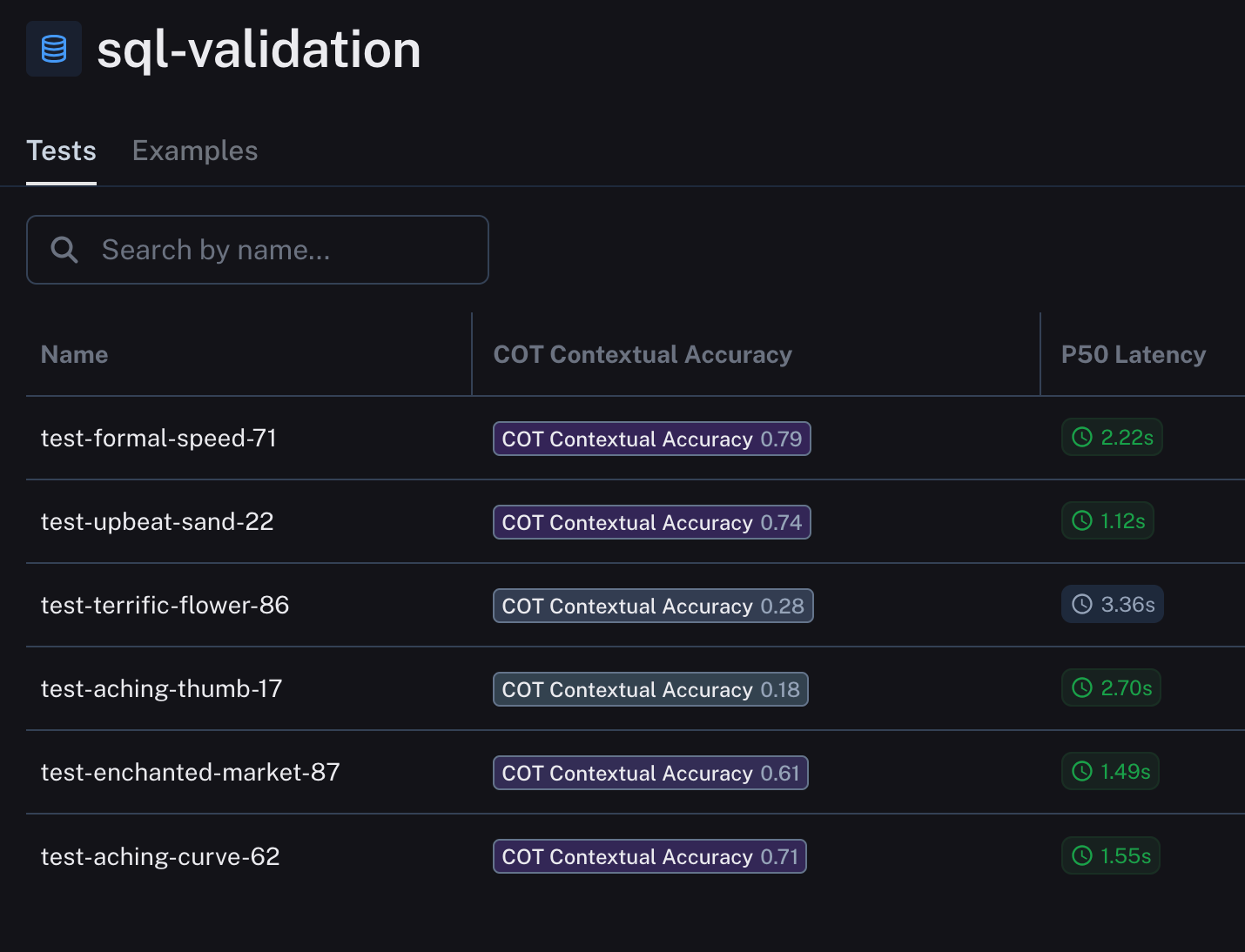
テスト結果を表示するLangSmith UI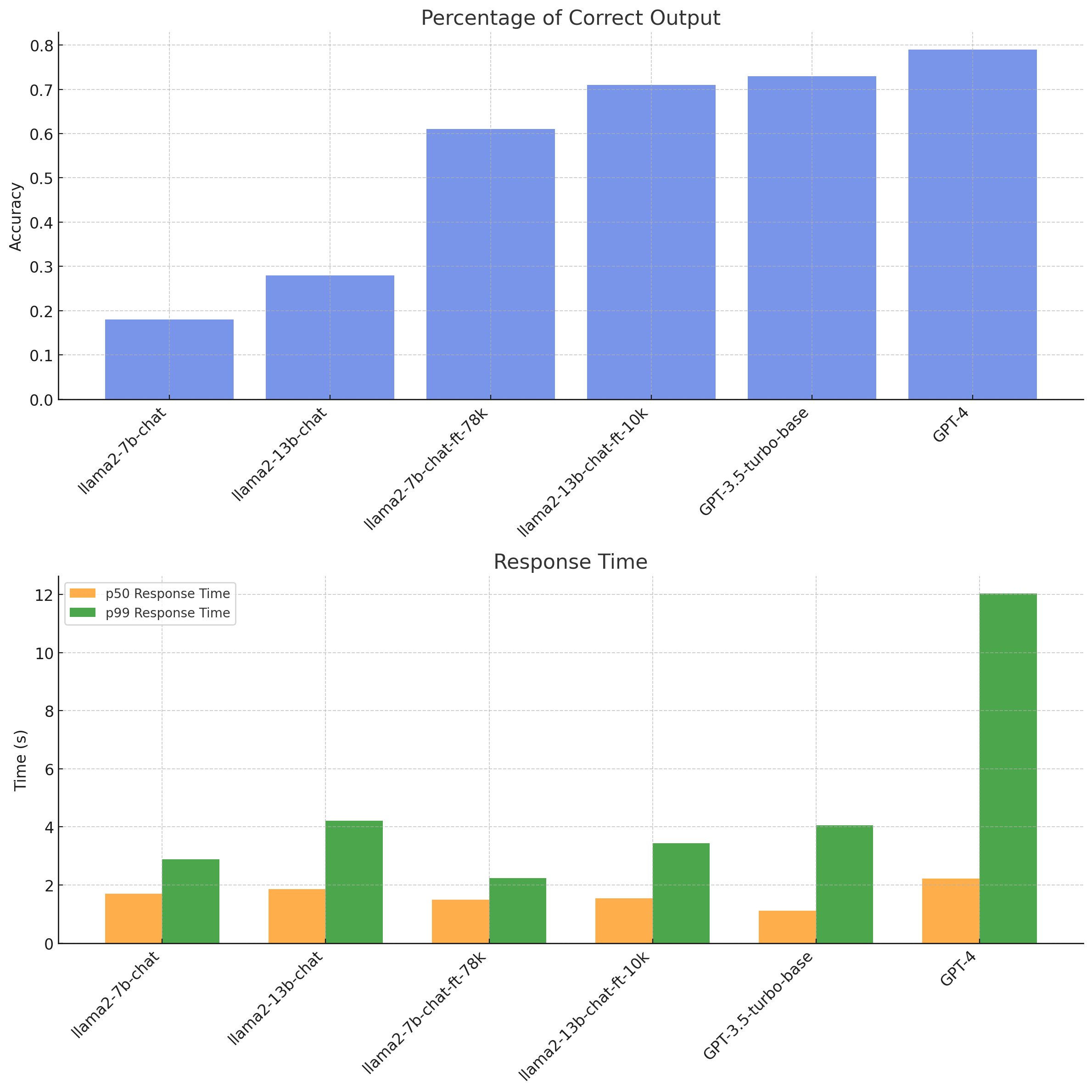 image
image
LangSmithの結果をグラフ化し、結果を視覚的に把握しやすくしたもの。この生成プロセスはこちらのChatGPTのチャット履歴で確認できます。
結果に関する考察
- パラメータとデータ:このデータは、モデルのパラメータ数とトレーニングデータの量との関係を示しています。パラメータ数が少ない llama2-7b-chat-ft-78k は良好なパフォーマンスを示しましたが、パラメータ数の多い llama2-13b-chat-ft-10k には劣りました。これにより、より大きな 78k データセットを用いた場合、13b モデルはどのように振る舞ったかという疑問が生じます。おそらく、精度はトレーニングセットのサイズおよび品質と相関すると考えられます。
- 応答時間:精度だけでなく、p50 および p99 といった応答時間もモデルの効率性を評価する上で重要です。ここで、llama2-7b-chat-ft-78k モデルは良好な精度と効率的な応答時間の両方を示しました。これらの llama モデルの応答時間は Replicate に基づくものであり、実行に使用されるハードウェアによって変化する可能性があることに留意する必要があります。
- GPT-3.5T との比較:このデータは、これらのモデルが GPT-3.5-turbo-base とどのように比較されるかを示しています。特筆すべきは、llama2-13b-chat-ft-10k の精度が GPT-3.5T に近かったことで、これは最適化されたオープンソースモデルが確立されたモデルに追いつき、あるいは凌駕する可能性を示唆しています。
おさらい
- LangSmith がオープンソース、クローズドソースを問わずあらゆるモデルと連携する方法を見てきました。
- LangSmith とのやり取りプロセスを詳述するコードスニペットと、UI 上のスクリーンショット付き結果の両方を見てきました。
- ChatGPT の高度なデータ分析機能を使用して、結果をグラフ化しました。
- 特定のドメインではオープンソースモデルが OpenAI と競合し得ることも確認しました。
LangSmith の使用に関するよりインタラクティブな例については、こちらの Python ノートブックをご覧ください。
また、私たちは ChatOpenSource も提供しています。これは企業向けの ChatGPT 代替チャットソリューションで、完全なデータプライバシーと監査可能性を確保します。企業はドキュメントやデータを簡単に設定でき、適切なチームのみがそれらについて質問できるようにし、データは決して企業環境の外に出ません。詳細をお知りになりたい方は、こちらから簡単な通話予約 をお願いします!
関連コンテンツ

ケーススタディ
LangSmith
Credit Genie が Insights Agent を活用して AI 財務アシスタントを改善した方法




D. Li,
J. Ngai,
G. Lozano Palacio,
C. Yuan
2026年4月20日
5分

エージェントアーキテクチャ
ディープエージェント(Deep Agents)
オープンソース(Open Source)
バックグラウンドでサブエージェントを実行する


H. Lovell,
C. Francis
2026年4月16日
4分

観測可能性(Observability)と評価(Evals)
LangSmith
LangSmithにおける再利用可能な評価器と評価テンプレート


C. Qiao,
J. Talbot
2026年4月16日
4分

エージェントの実際の動作を確認する
LangSmithは、当社のエージェントエンジニアリングプラットフォームであり、開発者がすべてのエージェントの意思決定をデバッグし、評価の変更を確認し、ワンクリックでデプロイすることを支援します。
原文を表示
*Editor's Note. This blog post was written by *Ryan Brandt*, the CTO and Cofounder of ChatOpenSource, a business specializing in enterprise AI chat that runs entirely within an orgs network, no third party needed. He covers how he uses LangSmith,* *LangChain's platform for getting LLM applications to production. Sign up for access *here*.*
Open source models are increasingly capable for use in applications. The trend is only accelerating with recent releases like Mistral 7b and the Llama2 family. The future seems to be in the ability to quickly swap better models in and out of your application like cartridges in an old game console. Fine tuning different versions of a model only increases the number of possible cartridges a developer will need to compare.
So that begs the question, how can we productionize the evaluation of our models so we can can choose the best tool for the job? LangSmith offers us a way out of python script hell with a handy UI and API for creating evaluation datasets. With these datasets we can run tests on multiple models and directly compare their performance on multiple axis’.
It’s easy to upload data to LangSmith via python or the user interface. For our example notebook scroll to the end.
The Process
Here’s the way we organized the study:
- Initiation: The task began with a goal to fine-tune the Llama2-7b and Llama2-13b model using the sql-create-context dataset on Hugging Face.
- Data Conversion: The dataset from Hugging Face, originally in JSON, was transformed to .jsonl for chat fine-tuning.
- Data Sampling with GPT-4: GPT-4's Code Interpreter was used to select 10,000 rows from the dataset.
- Validation Set Creation: 1000 unique sql rows were chosen as a validation set, ensuring no overlap with the training data. We uploaded those testing rows to LangSmith so we could automate our evaluations.
from langsmith import Client
def create_dataset(dataset_name=None):
"""adds an example run with inputs and outputs to an existing dataset"""
client = Client()
dataset_name = dataset_name
client.create_dataset(dataset_name=dataset_name)
return dataset_name
def add_to_dataset(dataset_name, validation_file_path):
client = Client()
dataset = client.read_dataset(dataset_name=dataset_name)
# Open and process the validation file
with open(validation_file_path, 'r') as f:
for line in f:
data = json.loads(line)
example = data['prompt']
assistant_content = data['completion']
# Add to dataset using client API
client.create_chat_example(
messages=[
{"type": "system", "data": {"content": "You are a helpful assistant that is knowledgeable about sql. Only output the SQL."}},
{"type": "human", "data": {"content": example}}
],
generations={"type": "ai", "data": {"content": assistant_content}},
dataset_id=dataset.id
)5. Fine-tuning and Assessment: The main goal was to improve Llama2-7b-chat and Llama2-13b-chat for specific SQL output. We fine tuned Llama2-7b-chat with 78k rows of sql data, and Llama2-13b-chat with 10k rows to control for cost. Both fine tuning and inference were done on an 8xA40 cluster. We did full parameter tuning, not LoRA. To do this we used Replicate, a platform for model hosting and fine tuning. You can learn more about them here.
import replicate
training = replicate.trainings.create(
version="meta/llama-2-13b-chat:f4e2de70d66816a838a89eeeb621910adffb0dd0baba3976c96980970978018d",
input={
"train_data": "https://storage.googleapis.com/chatopensource-replicate-demo/selected_sql_create_context_v4.jsonl",
"num_train_epochs": 3
},
destination="papermoose/test"
)6. LangSmith Evaluation: We used LangSmith to test the 1000 prompts on each model. We compared their result to the known correct answer to determine whether the model’s output was correct or not. We used GPT-4 to do the evals itself. LangSmith made the process extremely simple, as shown below.
import replicate
async def evaluate_dataset(dataset_name=None, num_repetitions=1, model="gpt-4-0613", project_name=None):
"""runs the model you want to evaluate against the assumed to be correct examples in your dataset, grading the evaluated model output correct or incorrect."""
from langchain.smith import run_on_dataset, RunEvalConfig, arun_on_dataset
from langchain.chat_models import ChatOpenAI
# The chat model you want to test, in our case replicate
model_to_test = Replicate(
model=model,
model_kwargs={"temperature": 0.75, "max_length": 500, "top_p": 1},
)
client = Client()
"""runs a question/answer evaluation, where the eval llm (gpt-4) will determine
if model_to_test's outputs are correct based on the example_dataset we uploaded in the previous set.
the example_dataset is treated by the eval as a correct answer for the given input."""
eval_config = RunEvalConfig(
evaluators=[
"cot_qa"
],
)
chain_results = await arun_on_dataset(
client,
dataset_name=dataset_name,
llm_or_chain_factory=model_to_test,
evaluation=eval_config,
num_repetitions=num_repetitions,
project_name=project_name
)The LangSmith platform itself allows you to view the results of our eval, in this case the chain of thought question answer builtin eval. You can also write your own if desired as shown here!
Our Findings in LangSmith
Here are our results, with our dataset names randomly generated. There’s still no easy way to change the name of the dataset in the UI, so I’ve also charted it out below in a more understandable way.
You can see how we generated this using chatgpt here!
Observations on the outcome
- Parameters vs. Data: The data shows a relationship between the model parameters and training data volume. While llama2-7b-chat-ft-78k, with fewer parameters, performed well, it was outperformed by llama2-13b-chat-ft-10k with more parameters. This leads to the question: How might the 13b model have fared with the larger 78k dataset? It's likely that accuracy would correlate with training set size and quality.
- Response Times: Beyond just accuracy, response times, particularly p50 and p99, are important for assessing model efficiency. Here, the llama2-7b-chat-ft-78k model showed both good accuracy and efficient response times. It’s worth baring in mind that these llama models have response times based on Replicate, and could change depending on the hardware used to run them.
- Comparison to GPT-3.5T: The data highlights how these models compare to GPT-3.5-turbo-base. Notably, llama2-13b-chat-ft-10k's accuracy was close to that of GPT-3.5T, suggesting the potential of optimized open-source models to match or even exceed established models.
To Recap
- We’ve seen how LangSmith works with any model, open or closed source.
- We’ve seen both code snippets detailing the process of interacting with LangSmith, and the screenshotted results in the UI.
- We’ve graphed out the results using ChatGPT advanced data analysis.
- We’ve seen how for some domains open source models are competitive with OpenAI
- for a more interactive example of using LangSmith, check out our python notebook here.
We also run ChatOpenSource, a fully data private and auditable chat replacement for ChatGPT for enterprises. Companies can easily configure documents and data so only the right team can ask about them, and no data ever leaves the company environment. Book a quick call with us to learn more!
Related content
Case Studies
LangSmith
How Credit Genie used Insights Agent to improve their AI financial assistant
D. Li,
J. Ngai,
G. Lozano Palacio,
C. Yuan
April 20, 2026
5
min
Agent Architecture
Deep Agents
Open Source
Running Subagents in the Background
H. Lovell,
C. Francis
April 16, 2026
4
min
Observability & Evals
LangSmith
Reusable Evaluators and Evaluator Templates in LangSmith
C. Qiao,
J. Talbot
April 16, 2026
4
min
See what your agent is really doing
LangSmith, our agent engineering platform, helps developers debug every agent decision, eval changes, and deploy in one click.
関連記事
AI ヘルスコーチの構築:評価、安全性、規制対応について
LangChain が AI ヘルスコーチの開発において、評価手法や安全性確保、規制遵守の重要性を解説している。
Google の技術を採用した Siri AI が登場、しかし世界の多くは利用不可
Apple は WWDC 2026 で、ゼロから再構築された新 Siri AI を発表し、Google の技術を組み込んで多段階対話を実現したが、多くの地域ではまだ利用できない。
マクドナルド、Google 支援の AI ドライブスルー注文システムをテスト中
マクドナルドは、Google が支援する「ArchIQ」と呼ばれるAIシステムを米国の5店舗で試験運用しており、このシステムがドライブスルーでの注文受付や店舗運営をサポートしている。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み