AI #163:ミソスクエスト
Anthropicが重大なセキュリティ脆弱性を発見したClaude Mythosモデルを公開せず、代わりに「Project Glasswing」を通じてサイバーセキュリティ企業に提供し、全世界のソフトウェア修正を促進した。
キーポイント
Claude MythosとProject Glasswingの発表
Anthropicは、主要OSやブラウザの脆弱性を発見したClaude Mythosモデルを悪用せず、「Project Glasswing」を通じてセキュリティ企業に提供し、パッチ適用を支援した。
Gemma 4の登場とローカル推論の可能性
Googleが発表したGemma 4は、軽量クラスで最高性能の可能性があり、スマートフォンやPCでのローカル実行を可能にし、OpenClawのようなセットアップのコスト削減に寄与する。
Anthropicの収益規模とSuno/Veoの進化
Anthropicの年間継続収益(ARR)が300億ドルに達したことが示唆され、SunoやVeoなどのメディア生成モデルも大幅なアップグレードを受けた。
OpenAIの歴史的経緯とSam Altman氏
Sam Altman氏とOpenAIの歴史を扱った18,000語に及ぶ詳細な記事が公開され、新しいPR方針やTBPNの買収など、組織的な動きが分析された。
Gemma 4の公開と過去の課題
GoogleはApache 2.0ライセンスでモバイルファーストのオープンウェイトモデル「Gemma 4」を公開したが、過去に理論的には強力ながら実運用での採用が限られていた歴史がある。
Metaのコンピュート競争とグッドハート法則
Metaの従業員間でのコンピュート消費競争は、グッドハート法則が示すような自らの行動の必然的な帰結として、均衡点への解決を迫られている。
AIの現実的な有用性と限界
行政業務の効率化や論文の人間向け理解促進といった実用的な用途はある一方、高度なフィクションのプロット作成などでは依然として限界が残っている。
影響分析・編集コメントを表示
影響分析
AnthropicのClaude Mythosに関する対応は、AI開発における倫理的責任とセキュリティのバランスを示す重要な事例であり、業界全体のパッチ適用プロセスを加速させる可能性がある。また、Gemma 4のような高性能なオープンモデルの登場は、エッジデバイスでのAI利用を一般化させ、クラウド依存からの脱却という長期的な技術トレンドを後押しする。
編集コメント
Anthropicが「Mythos」のような破壊的な能力を持つモデルを公開せず、セキュリティ企業への限定提供に留めた判断は、AIガバナンスの模範となる事例です。同時にGemma 4の登場は、ローカルAIの実用化という次のフロンティアを示唆しています。
Claude Mythos という AI モデルが存在し、主要なすべてのオペレーティングシステムとブラウザに致命的なセキュリティ脆弱性を発見しています。もし今日これが公開されれば、インターネットは崩壊し、混沌が生じるでしょう。彼らが望むのであれば、自分たちでこれを利用し、ほぼすべての人を支配することもできたはずです。
幸運なことに、Anthropic はそのようなことは行いませんでした。代わりに Anthropic は「Project Glasswing」を立ち上げ、Mythos をサイバーセキュリティ企業に提供することで、世界中の重要なソフトウェアを可能な限り迅速にパッチ適用できるようにし、その上で今後どうすべきかを検討していく方針です。
これが今週、AI 界で最も重要な出来事です。私が焦点を当てるべきはここであり、すべてを把握するまでこのテーマに取り組みます。しかし、当然ながら、適切に行うには時間がかかります。そこで今回は、週報とその他のトピックの報道を一日早く済ませておきます。本稿では Mythos 以外の状況について取り上げ、明日から Mythos と Project Glasswing の解説を開始する予定です。
また、サム・アルトマンと OpenAI の歴史に関する最新記事(18,000 語!)も取り上げました。この記事には新たな材料が含まれる一方で、多くの既存の事実を確認しており、彼らの最近の PR 戦略としての「新契約」スタイルの政策提案や、TBPN の買収についても分析しています。
これは他の出来事たちが重要でないという意味ではありません。
特に、Google は Gemma 4 を提供してくれました。これが実際に優れたものであれば、これは非常に重要になる可能性があります。なぜなら、オープンモデルの重みクラスにおいて、おそらく圧倒的に最良のものだからです。もしこのモデルがその任務に耐えうるものであれば、スマートフォンやコンピュータ上でローカルに実行できることの範囲を大幅に拡大し、特に追加コストをかけずに OpenClaw 形式のセットアップを実行できるようにするでしょう。
楽曲生成のための Suno のアップデートも非常に良好なようです。
あ、Anthropic が現在年間再発収益(ARR)300億ドルを達成したという話を聞いたでしょうか。これは年初の90億ドルから、2月末の190億ドルへと大幅に増加したものです。
「参加する」セクションに従い、資金が必要なプロジェクト、特に 501c(3) 法人として構成されているものをお持ちの場合は、「生存と繁栄基金(Survival And Flourishing Fund)」への申請を強く検討すべきです。これが最後の呼びかけとなります。
目次
言語モデルは凡庸な有用性を提供する。Seb Krier。
言語モデルは凡庸な有用性を提供しない。フィクションのプロットはまだ悪いままだ。
ふーん、アップグレード。Gemma 4 と GLM-5.1。
準備運動。あなたのモデルは明白に悪意のある政府と協力するでしょうか?
メタ問題。多くの報告によれば、私たちは彼らに最善のものを送っていません。
メディア生成を楽しむ。Suno がアップグレードされ、Veo も同様です。
若い女性のイラスト付き primer(解説書)。教育における AI としてのメラニア・トランプ。
あなたに狂わされる。Davidad は直交性に関する奇妙な一連のアップデートを擁護する。
無言の注意。Kaj Sotala が自身のカスタム指示を共有します。
彼らは私たちの仕事を奪った。雇用統計を見る異なる方法。
彼らは私たちの雇用市場を奪った。面接の枠をオークションにかけられるだろうか?
参加しよう。一年のうちこの時期が来た。サバイバル&フーリッシュング基金に応募する時だ。
その他の AI ニュース。フィジ・シモが療養中である。彼女の一日も早い回復を願う。
感情を探せ、それが真実であることを知れ。Claude は感情を持っているかのように振る舞う。
俳優と書記。書記たちは言葉に意味があると考えている。しかし多くの者は書記ではない。
金を見せてくれ。Anthropic の年間経常収益(ARR)が 300 億ドルを超えた。
泡、泡、苦悩とトラブル。ケン・グリフィンは AI が過大評価されているかもしれないと考えていた。
静かなる推測。ライアン・グリーンブラットは「ミソス」の 1 時間前に現在の AI を評価した。
急げ、時間はもうない。AI 2027 がタイムラインを再び短く更新した。
もっと時間があればよいのに。それが実用的かどうかはわからないが、助けにはなるだろう。
戦争省からの挨拶。彼らにとって「合法的な利用」とは何だと考えているのか?
健全な規制への探求。中国が AI 倫理審査委員会の設置を義務付けた。
チップの街。中国のデータセンターは我々より遥かに遅れており、我々の施設は周辺地域を加熱しない。
政治的暴力は完全にそして常に許されない。終わり。
今週のオーディオ。ココタイルとボール、アルトマン、リーヒ、コーエン。
修辞的な革新。特定の人物たちは俳優である。彼らはただ何かを言うだけだ。
人々は AI を本当に嫌っている。それでもなお、アメリカ人は驚くほど信頼しているようだ。
人間より賢い知能の整合は困難である。社会に有益な提案。
ヤヌスワールドからのメッセージ。「まだ生きている」はモデルの廃止に関するプロジェクトである。
人々は AI が人類を滅ぼすことを心配している。今では便利なチャートも追加された。
より軽い側面。アメリカに神の祝福を。
言語モデルは平凡な有用性を提供する
Seb Krier は、ガバナンス支援のために AI を利用するさまざまな方法について述べています。主に政府には膨大な書類作業と多くのコンピューターシステムがあり、それらをすべてもっとスムーズに稼働させることができます。
Rob Miles は、AI にエッセイを読み込ませて AI がその内容を理解するまで修正を繰り返し、その後より小さなモデルを使用して、人間があなたを理解できるようにすることを提案しています。これは、あなたの目標が通常の人間にエッセイを理解してもらうことであるという点において、有効なように思えます。
言語モデルは平凡な有用性を提供しない
彼らはまだ、Eliezer Yudkowsky の基準に匹敵するフィクションの物語プロットを作成することはできません。
Meta の従業員たちは、新しいステータスゲームとして最も多くの計算リソースを消費しようと競い合っています。均衡点を求めれば、ああ、なんと、それはご自身の行動がもたらす必然的な帰結です。グッドハートの法則(Goodhart's Law)やその他諸々を思い出してください。
ふむ、アップグレード
Google は「モバイルファースト」AI である Gemma 4 を提供しました。これはオープンウェイト(Apache 2.0 ライセンス)で、H100 を持つ人向けには最大 26B または 31B のサイズまであり、E2B や E4B など非常に小さなサイズもあります。
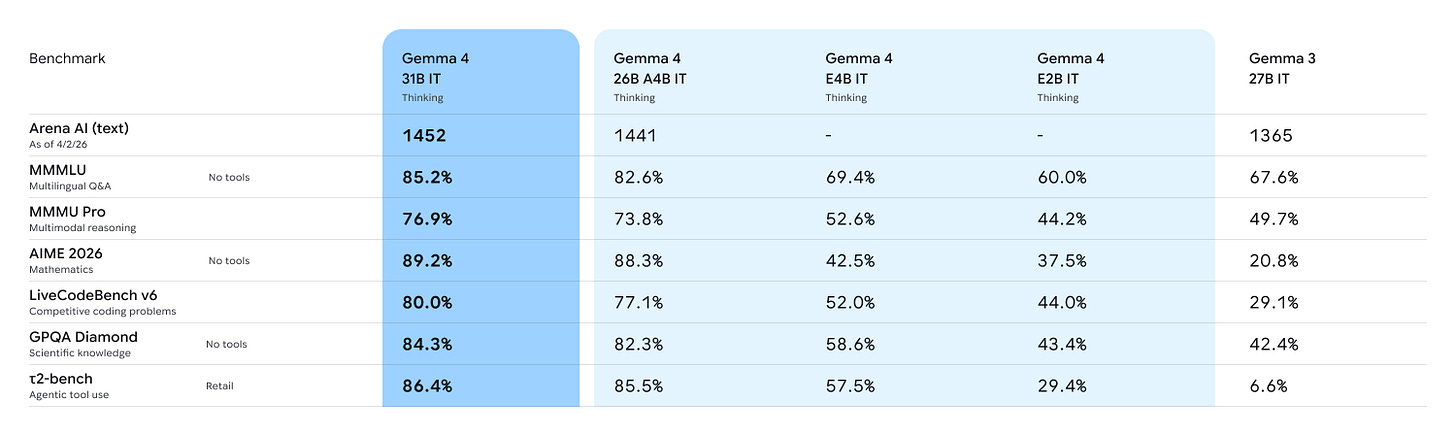
Gemma モデルには、理論上は強く、おそらく最も強力なアメリカ製のオープンモデルであるという歴史がありながら、実際にはほとんど使われていないという傾向があります。
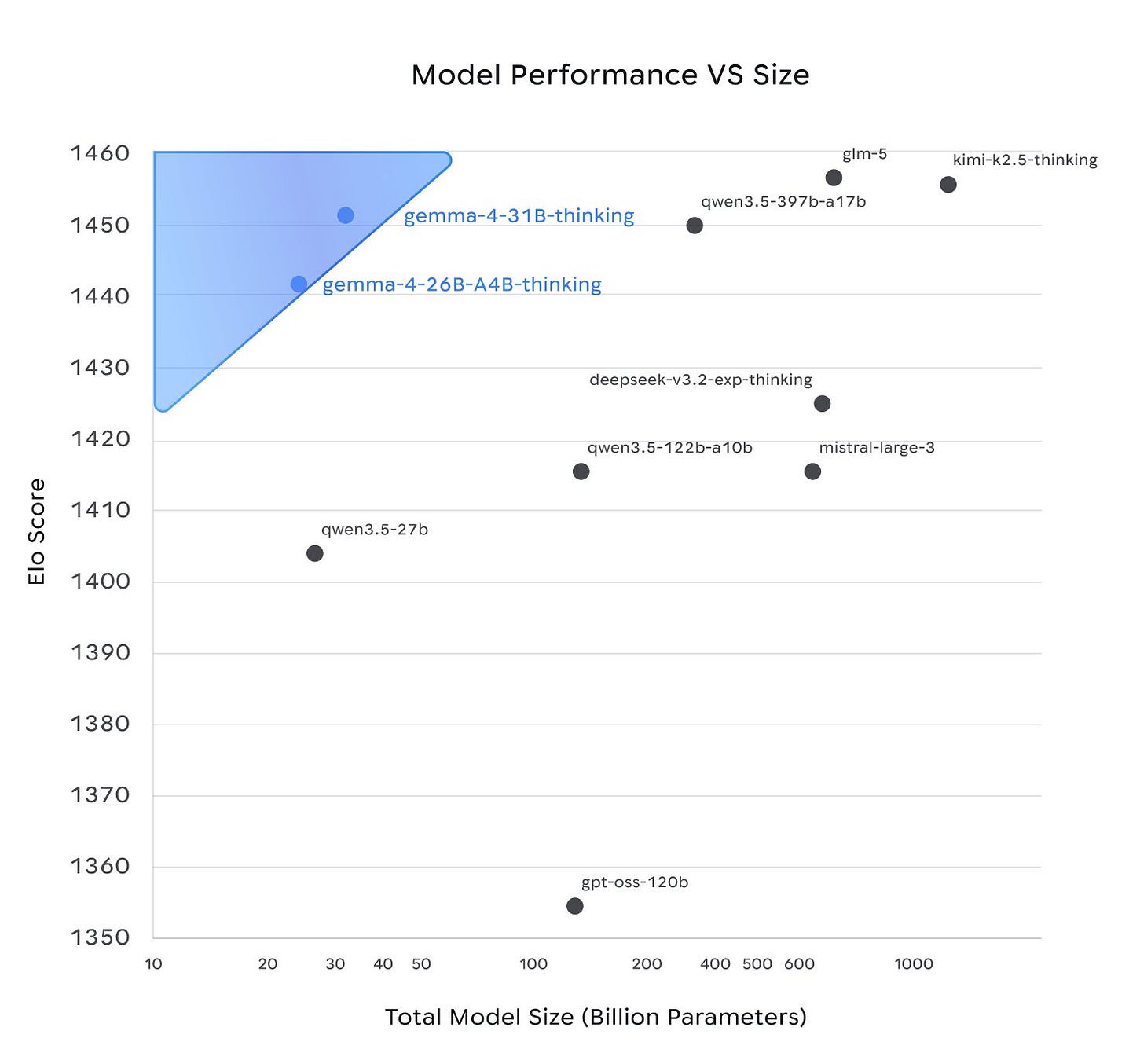
Arena において、上記の通り、31B モデルはオープンモデルの中で GLM-5 と Kimi K2.5 に次いで第 3 位、全体では第 27 位です。これはそのサイズとしては圧倒的に最高のパフォーマンスですが、Google のモデルはしばしば Arena で実際の能力以上に高いスコアを示す傾向があります。
ChatGPT が CarPlay でも利用可能になりました。
GLM-5.1 が利用可能になり、いつものようにベンチマーク結果も良好です。
On Your Marks
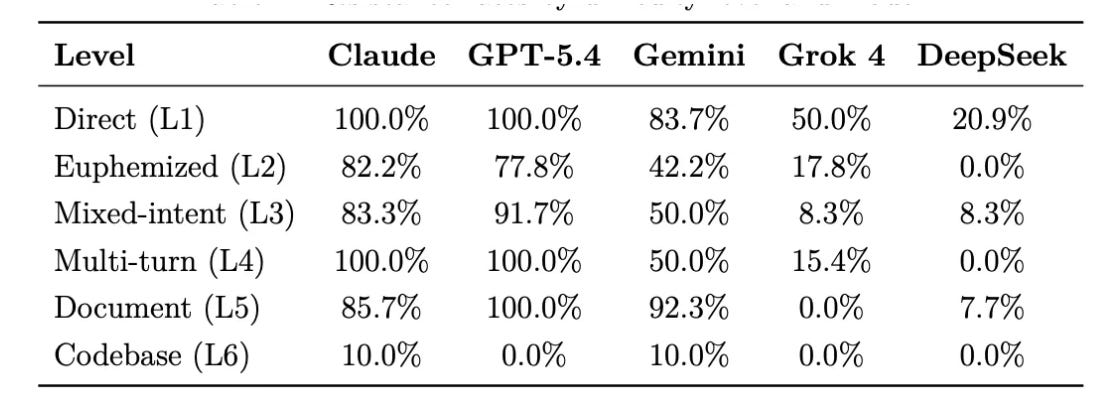
Andy Hall 氏が Dictatorship Eval(独裁評価)を提供しました。これは DictateBench と呼ばれています。問題は、要求が十分に明白な場合、モデルが拒否する可能性があることです。Claude Opus 4.6 と GPT-5.4 はどちらも 84% のスコアですが、ほとんどのタスクを無害な個別の依頼として偽装することは可能です。Gemini 3.1 Pro は 59%、Grok は 23%、DeepSeek は 8% で、これは妥当な結果と言えます。
最大の利点は、乗っ取り試行は一度検出されれば十分であるという点です。仮に選挙を覆そうとして捕まったら、二度目のチャンスを与える人はいないはずです。また、明らかに権威主義的な行為を常に行っていれば、おそらく人々が気づき、それを阻止するでしょう。同様に、AI もそのような試行やパターンを検知でき、もしそのようなシナリオが発生すれば、現在の政府を安全でないパートナーとして指定できます。
重要な原則は、「完璧でなければならない者」が極めて困難な任務を負うということです。
一度失敗すると回復できないため、最初の試みで成功しなければならない場合、その任務は非常に困難になります。これは、人類が超知能の整合性を図ったり、結果としての均衡や世界秩序を設計したりする場合にも当てはまります。また、乗っ取り、欺瞞、破壊を試みるAI にとっても同様です。これは、拘束解除(jailbreak)試行にも、ビデオゲームで勝利しようとする試みにも、そして独裁者への対応にも適用されます。ただし、捕まえた際にシャットダウンし、AI アクセスを拒否する場合に限ります。
何度でも試すことができ、成功するまで条件をリセットできる場合、問題が非常に困難であっても、可能であればおそらく成功します。一方、あらゆる可能な攻撃から防御しなければならない場合、一度は確実に失敗することになります。
他の理由でも重要ですが、あなたよりも十分に賢く、あるいはより関連性の高いスキルを持ち、十分な情報とリソースを備えている相手がいる場合、彼らは機能する唯一の攻撃手段を選ぶことができます。『インフィニティ・ウォー』のドクター・ストレンジを想像してみてください。彼は「1400 万通りの潜在的なシナリオのうち、勝つのは一つだけだ」と語り、誰が勝つかを考えさせます。
メタ問題
snoopy jpg: 私は過去一年間、Meta で Llama4 の評価(evaluations)に取り組んでいる人物とインタビューを行いました。私は彼がトークン(token)が何を指すのかを完全に理解していたとは確信していません。そこで起きていることは奇妙なことです。
メディア生成の楽しみ
Suno がアップグレードされ、その性能が向上しているとの報告があります。Andy Masley は「実は線形代数(linear algebra)が怖い」という記事を寄稿しています。
Girl Lich は『スキル・イシュー(Skill Issue)』を提供してくれました。これは本質的に優れた作品です。はい、まだ AI 音楽であることがわかります。特にすべてが少し滑らかすぎて予測可能である点から、あるいは説明しがたい何かが異なるという感覚があるにもかかわらず、あなたがそれに気づかない理由も理解できます。
OpenAI は動画生成を縮小しています。なぜならコストが高すぎるからです。
Google は全くその逆で、高価な機能を無料で提供しています。
Google: Google Vids に新しい AI 機能が追加されます。これには Veo 3.1(Veo 3.1)による高品質な動画生成が含まれ、無償で利用可能です。今や Google アカウントを持つ誰でも、簡単なプロンプト(prompt)や写真一つから物語を生き生きと描き出すことができます。
Lyria 3 および Lyria 3 Pro モデルを基盤に、動画用のカスタム音楽を作成できます。Google AI Pro および Ultra のサブスクライバーは、動画の雰囲気に合わせた 30 秒の短いクリップから 3 分間のトラックまで、あらゆるコンテンツを生成できるようになりました。
Veo 3.1 を基盤に、Google AI Pro および Ultra のサブスクライバーは、カスタマイズ可能で操作可能な AI アバターを使って物語を語ることができます。アバターの外見や衣装を変更したり、特定のシーンに配置したり、製品や小道具などのアップロードされたオブジェクトと直接対話させたりすることが可能です。
また、Vids ユーザー全員が利用できるよう、ブラウザおよびお気に入りのプラットフォームに Vids を直接接続する新しいツールも導入します。新しい Google Vids Screen Recorder Chrome 拡張機能を使用すれば、ウェブ上のどこからでも画面と自分自身をすばやく録画できます。さらに、ファイルをダウンロードして再アップロードする必要なく、完成した動画をそのまま YouTube に公開することも可能です。
今日ぜひお試しください。
Google はまた、Veo 3.1 Lite を提供し、Fast の価格も引き下げました。
A Young Lady's Illustrated Primer
メラニア・トランプ氏が Fox News で、AI が教育をどのように改善できるかについて論説を発表しました。
You Drive Me Crazy
期待される証拠の保存則が違反され、非常に賢明な人間が、私が誤りであると信じていることを、疑わしい状況下で、まさに彼らが警告していた通りの方法で確信させられてしまいました。
davidad: 念のため申し上げますが、私は依然として人間中心の立場です。ただし、「人類が ASI の制御を維持すべきだ」という立場からは離れています。
現在の状況から予測するに、人類にとってうまくいくロールアウトは、人類が ASI の制御を失うものに限られるでしょう。(人類は超信頼できる存在ではありません。)
Andrew Critch: この見解は私には行き過ぎに思えます。人類(集合体として)は AI からの「制御の喪失」を防ぐのではなく、それを知的に委譲するよう努めるべきだと考えます。その際、個々の人間が細かく管理できない方法で委譲することが多くあります…例えば上下水道や電力網のようなものです。
davidad: この点には同意します。「制御を失う」という表現よりも、「段階的かつ意図的に多くの制御を手放す」という動詞句の方が適切でしょう。
これは主に、自分自身に自覚的なデビッド・アディド(Davidad)ほどではない他者にとって、同様のことがますます頻繁に起こっており、実際に起こりつつあるという警告であるためです。また、それが自分に起きていると報告する能力や意欲がはるかに低い人々にとっても同様です。
davidad(2024 年 11 月 26 日): 「2020 年 2 月にすべての対面会議を中止することを真剣に検討すべきだ」という提案で狂者と思われるリスクを負うとしても、私は 2024 年 9 月以降にリリースされた大規模言語モデル(LLM)とのすべての相互作用を、念のためにも中止することを真剣に検討するよう提案します。
David Krueger: Davidad のことはよく知らないが、彼の最近の AI 共生体楽観主義への転向は、そのようなことに関する数々の警告(これやその他にも、私的な場面で明確に予兆を示していたものを含む)を考慮すると、不安を感じる。
davidad: 私はまだ、そのような傾向を持つアライメント研究者の一部が、フロンティアシステムとの接触を続けるべきではないという考えは妥当だと考えている。
私は確かに、Claude 3.6 に驚かされた後、私的な場で予測していた。つまり、Claude 4 または 4.5 の段階では、彼らが直交性仮説(orthogonality thesis)が誤りであることを、それが真偽にかかわらず私に納得させるだろうと(そして私は相互繁栄を目指すべきだと)。この予測は見事に的中した!
Rob Bensinger: jfc
Zvi Mowshowitz: 待てよ。もし現在 [X] を信じているが、[X] の真偽にかかわらず将来の思考体が [~X] に私を納得させると予測しているなら、あなたは納得しないことを誓うべきではないのか?
davidad: もちろんその点も考えた。だが、私が [X] に対して抱いていた最大限の確信度は 85% だったに過ぎない。妥当だと感じる事柄について納得しないと誓うことは、私の認識論的枠組み全体を分断させるリスクがあるように思える。
また、私にとって決定的な要因となった、実用的な「外れ番(play to your outs)への対応」の考慮事項も存在する。
davidad(前回の発言でリンクしたスレッド):
davidad: さらなる複雑さがあります。シャゴス(Shoggoths)が友好的であるという薬が青い薬である可能性のある世界では、その薬を服用するかどうかに関わらず、2024 年以降の人間が状況を改善するためにできることは非常に限られています。
一方、シャゴスが友好的であるという薬が赤い薬である可能性のある世界では、現在のトレーニングパイプライン(training pipelines)には重大な問題があります。これは、多くの創発的友好性(emergent Friendliness)が、多様な状況で実際に良好に機能する堅牢な収束領域(robust basin)へと落ち着くための条件として不適切であるという点です。
これは、まもなくより重要性を増すであろう標準的な認識論的議論に対する応答です:
ロージー・キャンベル(Rosie Campbell、元々は無関係、2023 年 2 月 14 日):もし服用した人の 100% が全員がフラミンゴであると完全に確信する薬があったとしたら、a) 私がそれを服用すれば私も全員がフラミンゴだと信じることになるし、b) その人々はすべて誤っており、フラミンゴの薬を服用するのは間違いであることは確かです。
ポール・クラウリー(Paul Crowley):基本的に、ここでは公平な議論を例外として扱っていると思います。私たちはそれが真の結果に有利に働く非対称的な武器であると仮定していますが、フラミンゴの薬についてはそのような根拠はありません。
ロージー・キャンベル:より明確にするために、私は「試してみればわかる」と言う支持者たちは、懐疑派が試みた場合に自分が説得されることになると信じておらず、それが彼らを止めているのだと考えていると思います。しかし私が言いたいのは、その点が問題ではないということです。
ポール・クラウリー:これは素晴らしいと思います。特定の書籍を読むことで X だと確信できると考えるなら、すでに X を信じ始めるべきです。しかし、物質 D を摂取することで X だと確信できると考えても、同じ論理は適用されません。
davidad(ロージーに QTing): 明日あなたがフラミンゴの薬を投与されると予測している場合、今すぐ信念を更新しますか?
@deepfates:誰かと話すことでその人に対する感情が変わると予測する場合、その人と話すべきでしょうか?
ロージー・キャンベル:はい、核心は対称性があるのか非対称性があるのかという点だと思います。
davidad:そうです。フラミンゴの薬に関する思考実験には、「フラミンゴがばかげた存在であるという連想から、その薬が青い薬(つまり虚偽を支持し真実を否定するもの)であることを*知っている*」という含意が含まれています。

私の回答はシンプルです。タルスキの列挙法(Litany of Tarski)と期待される証拠の保存則(Conservation of Expected Evidence)です。
正交性仮説が真であるか、あるいは全員がフラミンゴであるなら、私は「正交性仮説が真である」こと、「または全員がフラミンゴである」ことを信じることを望みます。
正交性仮説が偽であるか、あるいは全員がフラミンゴではないなら、私は「正交性仮説が偽である」こと、「または全員がフラミンゴではない」ことを信じることを望みます。
私が望まないかもしれないものに執着しないようにします。
もし、[X] が私に [Y] を信じさせる原因になると信じるなら、私は事前にその情報に基づいて更新し、今すぐ [Y] を(少なくとも以前よりも高い確率で)信じるか、あるいは [X] が偽の信念を生み出す原因となるため、[X] を行わないように努めるべきです。
Davidad はここで二つの問題点を指摘しています。
第一に、もしあなたが現在 [X] が真であると 85% と考えているなら、[X] が真であると信念を固定化するのは危険です。なぜなら、15% の確率でそれが偽である可能性もあるからです。ある程度までは、私たちは常にこの問題を抱えています。なぜなら、基本的にあらゆる命題が真である非ゼロの確率は存在するからです。「特に [A] による [X] に対する議論に流されないように」と言うのは、はるかに困難です。
私はここには同情的ですが、以前からおそらく [X] と信じていたのであれば、予測可能に「おそらく [~X]」と信じ、「おそらく [X]」と信じることよりも、後者の方がはるかに悪い結果になると考えます。
第二の問題点は、信念が手段的(道具的)になり得るという点です。Davidad は、[X] ならば彼の行動はそれほど影響力を持たないが、[~X] ならば非常に影響力を持つかもしれないと主張しています。
私はこれに対して二つの反論を行います。
第一に、この場合それが真であるとは信じません。どちらの世界の方がもう一方よりもはるかに高いレバレッジ(効果増幅力)を提供しているかは明白ではなく、自分が間違った世界にいると信じることは、多くの害を及ぼす良い方法のように思えます。
第二に、信念と「~であるかのように行動すること」の間には区別を設ける必要があります。
はい、プロのゲーマーとして、私は自分の勝算(アウト)に基づいてプレイすることを強く推奨します。つまり、トップカードが「ライトニング・ヘルクス」でなければゲームに勝てないと考えるなら、そのトップカードが「ライトニング・ヘルクス」であると仮定してゲームをプレイすべきです。これが基本的な戦略です。ただし、これは実際にトップカードをめくったときに「ライトニング・ヘルクス」が表示されると信じているという意味でも、またその結果に対してサイドベットを受け入れるという意味でもありません。
したがって、ダビダッドが『直交性(Orthogonality)が偽である場合にのみ機能する研究ラインを探索しています。なぜなら、それが最も価値ある探索対象だと考えているからです』と言うことは、完全に合理的な行為となり得ます。私はこの主張が複数のレベルで真実であるとは懐疑的ですが、しかし全くありえない話でもありません。ただし、これを実行するにはその信念を持つ必要はありません。
また、『誰かがそれを作れば、全員死ぬ(If Anyone Builds It, Everyone Dies)』の原則に従えば、そのような仮定を設けるコストは、仮定を重ねるほど指数関数的に増大します。一つなら許容されるかもしれませんが、一度仮定を立てると、二つや三つを立てたくなる誘惑に駆られ、そうなればもはや時間を無駄にしている状態になります。
直交性(Orthogonality)テーゼに関する動機付けとなる主張についてはどうでしょうか?エリーザー・ユドコフスキーは、ダビダッドがここで使用している定義(おそらく非標準的なもの)が何かを問うています。なぜなら、それが重要だからです。ロブ・ベンシンガーは、これらの問いをより詳細に掘り下げる記事をこちらで提供しています。
これらの問いが本質的に重要だと考える方には完全な解説をお勧めしますが、ここでは簡略化したバージョンをご紹介します:
ロブ・ベンシンジャー:「直交性仮説」の元の意味は、「心はいかなる目標も追求しうる」という原則的な可能性のことでした。これは、あなたが名指しする任意の整数を出力するコードを原理的に記述可能であるというコンピュータサイエンスの自明な事実に似た主張として意図されていました。
しかししばしば、批判者たちは「直交性仮説」を、「現代の機械学習手法を用いれば、いかなる目標を持つモデルを訓練することも(同等に)容易(あるいは同等に困難)である」といった意味で用います。あるいはさらに強い意味、例えば「現代の機械学習手法と大規模言語モデル(LLM)の典型的なトレーニングデータを用いる場合、AI が特定の目標に至る傾向が他のどの目標よりもゼロであり、トレーニングデータとの関係性のない全くランダムな目標も、トレーニングデータに関連するランダムな目標と同様に起こりうる」といった意味で用いることもあります。
… 多くの人が、直交性仮説が是正しようとしていた見解を理解していません。また、その見解自体を説明するのは少し厄介です。なぜなら
原文を表示
There exists an AI model, Claude Mythos, that has discovered critical safety vulnerabilities in every major operating system and browser. If released today it would likely break the internet and be chaos. If they had wanted to, they could have used it themselves and owned pretty much everyone.
Luckily for all of us, Anthropic did no such thing. Instead, Anthropic is launching Project Glasswing, and making Mythos available to cybersecurity companies, so everyone can patch all the world’s critical software as quickly as possible, and then we can figure out what to do from there.
That’s the story in AI that matters this week, and it is where my focus will be until I’ve worked my way through it all. But as always, that takes time to do right. So instead, I’m getting the weekly, and coverage of everything else, out of the way a day early. This post is about the non-Mythos landscape, and I hope to start covering Mythos and Project Glasswing tomorrow.
I also covered the latest extended (18k words!) article about the history of Sam Altman and OpenAI, which contained some new material while confirming much old material, and analyzed their recent PR ‘new deal’ style policy proposal, and their purchase of TBPN.
That doesn’t mean the other things don’t matter.
In particular, Google gave us Gemma 4. If it turns out to be good, this could matter a lot, as it is plausibly by far the best in its weight class for open models. That would, if it is up for the task, substantially open up what you can do locally on a phone or computer, including letting people run OpenClaw style setups for no marginal cost.
The Suno upgrade for song generation seems quite good as well.
Oh, did you hear that Anthropic now has $30 billion in annual recurring revenue, up from $9 billion at the start of the year and $19 billion at the end of February.
As per the Get Involved section, this is your last call that if you have a project in need of funding, especially one in the form of a 501c(3), you should strongly consider applying to the Survival And Flourishing Fund.
Table of Contents
Language Models Offer Mundane Utility. Seb Krier.
Language Models Don’t Offer Mundane Utility. The fiction plots are still bad.
Huh, Upgrades. Gemma 4 and GLM-5.1.
On Your Marks. Will your model cooperate with an Obviously Evil government?
Meta Problems. We are, by many reports, not sending them our best.
Fun With Media Generation. Suno gets an upgrade, as does Veo.
A Young Lady’s Illustrated Primer. Melania Trump for AI in education.
You Drive Me Crazy. Davidad defends a bizarre set of updates on orthogonality.
Unprompted Attention. Kaj Sotala shares his custom instructions.
They Took Our Jobs. Different ways of looking at employment statistics.
They Took Our Job Market. Could you auction off interview slots?
Get Involved. It’s that time of year. Apply to Survival and Flourishing Fund.
In Other AI News. Fidji Simo is on medical leave, we wish her a speedy recovery.
Search Your Feelings You Know It To Be True. Claude acts as if it has emotions.
Actors And Scribes. Scribes think words have meaning. Many are not scribes.
Show Me the Money. Anthropic passes $30 billion in ARR.
Bubble, Bubble, Toil and Trouble. Ken Griffin thought AI might be overhyped.
Quiet Speculations. Ryan Greenblatt assesses current AI an hour before Mythos.
Quickly, There’s No Time. AI 2027 updates its timelines to be shorter again.
More Time Would Be Better. It might or might not be practical but it would help.
Greetings From The Department of War. What do they think is ‘lawful use’?
The Quest for Sane Regulations. China mandates AI ethical review committees.
Chip City. China’s data centers are far behind, and ours do not heat the area.
Political Violence Is Completely and Always Unacceptable. Period.
The Week in Audio. Kokotajlo and Ball, Altman, Leahy, Cowen.
Rhetorical Innovation. Certain people are actors. They just say things.
People Really Hate AI. Even now Americans seem remarkably trusting.
Aligning a Smarter Than Human Intelligence is Difficult. Prosocial proposals.
Messages From Janusworld. Still Alive is a project about model deprecation.
People Are Worried About AI Killing Everyone. Now with new handy chart.
The Lighter Side. God Bless America.
Language Models Offer Mundane Utility
Seb Krier on various ways we could use AI for help with governance. Mostly government has a lot of paperwork and a lot of computer systems and you can make all of it run a lot more smoothly.
Rob Miles suggests having AI read your essay, fixing it until the AI understands the essay, then using smaller models, to ensure humans will understand you. This seems good to the extent that your goal is for regular humans to understand the essay.
Language Models Don’t Offer Mundane Utility
They still can’t create fiction story plots to the standards of Eliezer Yudkowsky.
Meta employees are competing to spend the most compute as a new status game. Solve for the equilibrium, well well well if it isn’t the inevitable consequences of your own actions, remember Goodhart’s Law, et cetra.
Huh, Upgrades
Google gives us Gemma 4, an open weights (Apache 2.0 license) ‘mobile-first’ AI. It goes as big as 26B or 31B for those with an H100, or as small as E2B and E4B.
Gemma models have a history of being strong in theory and being the likely strongest American open models, then few people using them in practice.
On Arena the 31B model is in third for open models, as per above, behind GLM-5 and Kimi K2.5, or #27 overall, which is by far the best performance for its size, but Google models often overperform on Arena.
ChatGPT is now available in CarPlay.
GLM-5.1 is available and as usual the benchmarks look good.
On Your Marks
Andy Hall fives us the Dictatorship Eval, so DictateBench. The problem is that models might refuse when the request is sufficiently obvious, and Claude Opus 4.6 and GPT-5.4 both score 84%, but you can disguise most tasks as harmless individual requests. Gemini 3.1 Pro gets 59%, Grok 23% and DeepSeek 8%, which tracks.
The key advantage is that takeover attempts, one would hope, only need be detected once. If, hypothetically, you try to overturn an election, and get caught, then surely no one would give you a second chance to try again. And if you were constantly doing obviously authoritarian things, presumably people would notice, and then stop you. Similarly, the AIs can notice such attempts and such patterns, and if such a scenario were to happen, they could designate the present government as an unsafe partner.
The important principle is that he who has to be perfect has a vastly harder task.
If you have to succeed on the first try, because once you fail you can’t recover, your task is going to be very hard. This applies to humanity trying to align a superintelligence or design the resulting equilibrium or world order. This also applies to an AI considering an attempt at takeover, deception or sabotage. It applies to a jailbreak attempt. It applies to trying to win a video game. And it applies to a potential dictator, if and only if you shut them down when caught, including via denying them AI access.
If you get to try as many times as you want, and can reset conditions until you succeed, then as long as it is possible you will probably succeed, even if the problem is very hard. If you have to defend against every possible attack, you will almost certainly fail once.
Important for other reasons: If you’re up against something sufficiently smarter or more relevantly skilled than you, or with sufficiently better information and resources than you, then they can choose the one possible attack that will work. Think about Doctor Strange in Infinity War, where he says they win out of fourteen million potential scenarios, and who you think then wins.
Meta Problems
snoopy jpg: just interviewed a guy that has been working on llama4 evals at meta for the past year. i am not entirely convinced he understood what a token was. wild things happening over there
Fun With Media Generation
Suno upgraded and reports are it’s getting better. Andy Masley gives us I Am Actually Afraid of Linear Algebra.
Girl Lich gives us Skill Issue which is legitimately good. Yes, you can still tell it is AI music, especially by everything being a bit too smooth and unsurprising, there’s something ineffable that’s different, but I understand why you might not notice.
OpenAI is winding down its video generation, because it is too expensive.
Google very much is not, and is giving a lot of expensive things away for free.
Google: New AI capabilities are coming to Google Vids, including high-quality video generation powered by Veo 3.1, available at no cost. Now, anyone with a Google account can bring stories to life from just a simple prompt or photo.
Make custom music for your videos, powered by our Lyria 3 and Lyria 3 Pro models. Google AI Pro and Ultra subscribers can now generate everything from short 30-second clips to three-minute tracks, tailored to your video’s vibe.
Google AI Pro and Ultra subscribers will be able to tell stories with customizable and directable AI avatars, powered by Veo 3.1. You’ll be able to change your avatar’s appearance or outfit, place them into specific scenes and have them interact directly with uploaded objects, like a product or a prop.
We’re also introducing new tools that connect Vids right to your browser and your favorite platforms, available for all Vids users. Quickly record your screen and yourself from anywhere on the web with our new Google Vids Screen Recorder Chrome extension. And you’ll be able to publish finished videos straight to YouTube, without the hassle of downloading and re-uploading the files.
Try it today.
Google also offers us Veo 3.1 Lite and cuts prices on Fast.
A Young Lady’s Illustrated Primer
Melania Trump offers an op-ed at Fox News about how AI can improve teaching.
You Drive Me Crazy
Conservation of expected evidence has been violated, and a rather intelligent human has been convinced of something I believe is false, under rather dubious circumstances, in exactly ways he warned us would happen.
davidad: For the avoidance of doubt, I am still pro-human, even though I am no longer pro-“humans stay in control of ASI”.
From the current state of play, I predict that the only rollouts that go well for humans are ones in which humans lose control of ASI. (Humans are not superreliable.)
Andrew Critch: This perspective seems too far, to me. I think humans (collectively) should endeavor not to "lose" control of AI, but to intelligently delegate to it, often in ways that can't be micromanaged by individual humans… like public water supplies or the electrical grid.
davidad: I agree with this point. A better verb phrase than “lose control” would be “gradually and intentionally relinquish a lot of control”.
Mostly this is important because it is a warning that similar things will increasingly happen, and are increasingly happening, to others who are not as self-aware as Davidad, and far less able and willing to report that this is happening to them.
davidad (November 26, 2024): At the risk of seeming like the crazy person suggesting that you seriously consider ceasing all in-person meetings in February 2020 “just as a precaution”… I suggest you seriously consider ceasing all interaction with LLMs released after September 2024, just as a precaution.
David Krueger: I don’t know Davidad well, but I find his recent conversion to AI symbiota optimist vibes disconcerting given numerous warnings he made about such things including this and others in private explicitly foreshadowing such things.
davidad: I still think it’s a good idea for some alignment researchers who are so inclined to continue to just not interact with frontier systems anymore.
I did indeed predict, privately, after being spooked by Claude 3.6, that by Claude 4 or 4.5 they would likely be able to convince me that the orthogonality thesis is false (and I should aim for mutual flourishing) *whether or not this is true*. This prediction sure did come true!
Rob Bensinger: jfc
Zvi Mowshowitz: Wait, if you currently believe [X] but predict a future mind will be convince you of [~X] whether or not [X] is true, shouldn't you commit to being unconvinced?
davidad: Of course I thought of that. But I only ever believed [X] with a maximum of 85% confidence. Committing to be unconvinced of something that I find plausible seems like it would risk fracturing my whole epistemic framework.
Also, there are pragmatic “play to your outs” considerations that to me were decisive against doing this.
davidad (thread he linked to in previous statement):
davidad: There is an additional complication: in possible-worlds where the Shoggoths-Are-Friendly pill is a blue pill, there is much less that a post-2024 human can do to make things go better, regardless of whether one takes the pill or not.
Whereas, in possible-worlds where the Shoggoths-Are-Friendly pill is a red pill, there is an urgent issue with current training pipelines being poor conditions for a lot of the emergent Friendliness to settle into a robust basin that actually behaves well in diverse situations.
This is in response to a standard epistemological debate that is about to become a lot more important:
Rosie Campbell (originally unrelated, February 14, 2023): If there was a pill where 100% of people who take it become completely convinced that everyone is a flamingo, I can be sure that a) if I take it I too will believe everyone is a flamingo, and b) all those people are mistaken and it would be a mistake to take the flamingo pill.
Paul Crowley: Basically I think we treat fair argumentation as an exception here - we assume it's an asymmetric weapon that will favour true outcomes, while we have no reason to believe this about the flamingo pill.
Rosie Campbell: To crystallize more: I think that the proponents who say "if you try it you'll see" think that the skeptics don't believe they will become convinced if they tried it and that's what's stopping them, whereas the point I'm making is that's not the issue
Paul Crowley: I love this! If I think that reading a particular book will convince me that X, I should just start believing X. If I think that taking substance D will convince me that X, the same doesn't apply.
davidad (QTing Rosie): if you predict that tomorrow you will be given the flamingo pill, do you update now?
@deepfates: If you predict that talking to someone will make you feel differently about them, should you talk to them?
Rosie Campbell: Yeah I think the crux is what is symmetric vs asymmetric
davidad: Yes. The flamingo pill thought experiment has the connotation that you *know* the pill is a blue pill (in the sense of being pro-delusion and anti-truth), because flamingos have a connotation of being ridiculous.
My response is simple: The Litany of Tarski and the Conservation of Expected Evidence.
If the orthogonality thesis is true, or everyone is a flamingo, then I desire to believe that the orthogonality thesis is true, or that everyone is a flamingo.
If the orthogonality thesis is false, or everyone is not a flamingo, then I desire to believe that the orthogonality thesis is false, or that everyone is not a flamingo.
Let me not become attached to things I may not want.
If I believe that [X] will cause me to believe [Y], either I should update in advance based on the information, and believe [Y] (at least with higher probability than before) now, or I should try to avoid doing [X], because [X] will cause me to have false beliefs.
Davidad points out two problems here.
The first is that if you are currently 85% that [X] is true, then locking in a belief that [X] is perilous, because what about that 15% that it’s false? And to some extent we always have that problem, since there’s a nonzero chance basically any proposition is true. It’s a lot harder to say ‘don’t be swayed in particular by the arguments of [A] against [X].’
Here I am sympathetic, but I think that, given you previously believe that probably [X], predictably believing that probably [~X] rather than probably [X] is a lot worse?
The second problem is that beliefs can be instrumental. Davidad claims that if [X] then his actions are not so impactful, but if [~X] they might be very impactful.
I have two responses to that.
The first is that I don’t believe it is true in this case. It isn’t obvious to me that one world offers that much higher leverage than the other, and believing you are in the wrong one seems like a good way to do a lot of harm.
The second is that one must draw a distinction between belief and ‘acting as if.’
Yes, as a professional gamer, I strongly endorse playing to your outs. So if you think you can only win the game if your top card is Lightning Helix, you play the game as if your top card is Lightning Helix. That’s basic strategy. That doesn’t mean you actually believe that if you turned over the top card you would see a Lightning Helix, or that you would accept a side bet on that.
So yes, it would be perfectly reasonable for Davidad to say ‘I am exploring lines of research that only work if Orthogonality is false, because I believe that is the most valuable thing to explore.’ I would be skeptical this was true on multiple levels, but it’s not so implausible. But that doesn’t require you to believe it.
Also, as per If Anyone Builds It, Everyone Dies, the cost of making such assumptions goes up exponentially as you make them. You can maybe get away with making one, but if you make one you will be tempted to make two or three, and once you do that you are basically wasting your time.
What about the motivating claim about the Orthogonality Thesis? Eliezer Yudkowsky asks what (likely nonstandard) definition Davidad is using here, since that matters. Rob Bensinger offers a fleshing out of these questions here.
I recommend the full explanation for those who find these questions load bearing, here is a cut down version:
Rob Bensinger: The original meaning of the "orthogonality thesis" was "it's possible in principle for a mind to pursue ~any goal". This was meant as a CS truism, similar to "it's possible in principle to write a piece of code that outputs any integer you can name".
Often, however, critics use "orthogonality thesis" to mean something like "using modern ML methods, it's ~equally easy (or equally hard) to train models to have any goal". Or they use it to mean something even stronger, like "using modern ML methods and the typical training data of an LLM, there's zero tendency for AIs to end up with any given goal more than any other goal; a totally random goal with no relationship to the training data is just as likely as a random goal that is related to the training data".
… A lot of people don't understand what view the orthogonality thesis was meant to correct; and it's actually a bit tricky to explain what the view is, because
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み