LLM による継続的な更新が記憶の誤りを招く
LLM によるエージェントのメモリ更新プロセスが、かえって記憶を不正確にしパフォーマンスを低下させるという重大な欠陥が指摘され、実用的なデフォルト戦略として断続的なメモリの使用が推奨されている。
キーポイント
メモリ更新による性能劣化の逆説
エージェントが記憶を継続的に更新・書き換える行為は、必ずしも有用性を高めず、場合によってはメモリを持たない状態よりもパフォーマンスが悪化する恐れがある。
失敗の核心は「書き換え」ステップ
問題の本質は記憶を統合する「書き換え(rewrite)」プロセスにあり、ここで情報の歪みや誤りが生じていることが示唆されている。
暫定的な安全策としてのメモリ制限
エージェントがいつどのように情報を統合するかを自律的に判断できるようになるまで、エピソード記憶や抽象化された記憶は最小限に抑えるか、あるいは使用しないことが最善のデフォルト戦略となる。
影響分析・編集コメントを表示
影響分析
この記事は、現在急速に普及しつつある AI エージェントの「メモリ機能」に対する根本的なリスクを浮き彫りにしており、開発者が安易に記憶機能を追加するのではなく、そのメカニズムの欠陥を理解した上で慎重な設計を行う必要性を説いています。実務レベルでは、信頼性の高いエージェント構築において、メモリ管理戦略の見直しや、より堅牢なアーキテクチャ(例:RAG の活用や更新頻度の制限)への転換を促す重要な示唆となっています。
編集コメント
エージェント開発において「記憶=機能向上」という単純な前提が崩れる可能性を示唆する、極めて重要な警告記事です。実装段階では安易なメモリ更新ロジックを見直す絶好の機会となるでしょう。
TL;DR
- 経験を要約してテキストとして保存し、後で書き直すという一般的なレシピは、自己改善の信頼できるエンジンにはなり得ません。
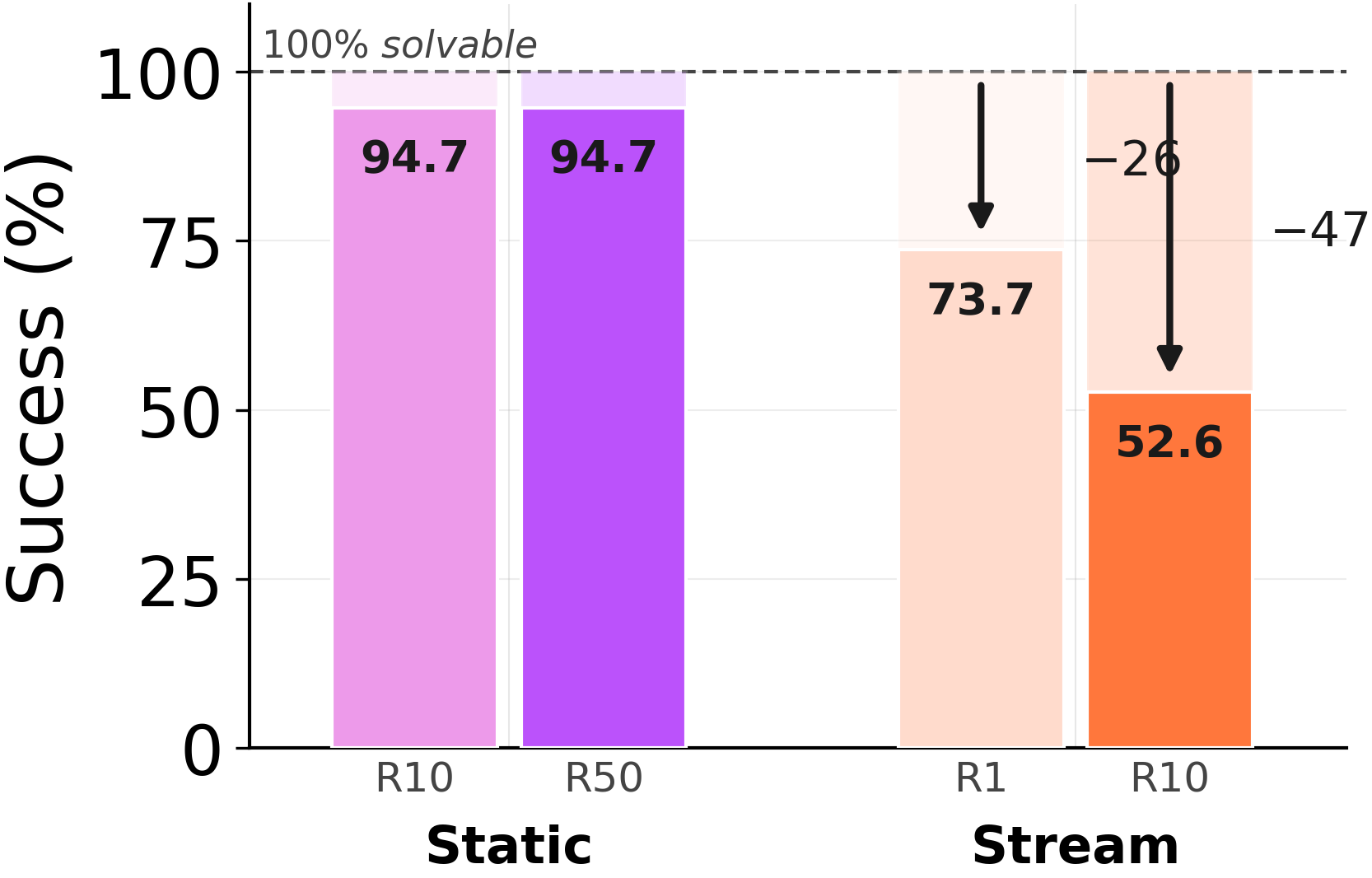
- 正解となる解決策を統合ループを通じてストリーミング処理した後、GPT-5.4 は、ゼロメモリ状態では以前に解決できていた ARC-AGI の問題の 54% で失敗します。
- 同じ軌道(トラジェクトリ)でも、異なるスケジュール下で生成される記憶は異なります。失敗の原因はデータではなく、書き直しステップにあります。
- エピソードのみを扱うエージェント、つまり生ロールアウトを選択的に保持・削除し、抽象化機能を無効化したものは、テストしたすべての統合型エージェントと同等か、それ以上の性能を発揮します。重要なのは、フィルタリングされていない大量のデータストリームではなく、厳選された生の証拠です。
パラダイム
近年の研究では、LLM エージェントにノートブックを与え、問題解決後にその軌道(トラジェクトリ)をテキスト形式の教訓として要約し、永続的なメモリに格納します。そして次に類似した状況が発生した際に、それを検索して再利用するアプローチが提案されています [refs]。
この提案は魅力的です。パラメータ更新なしで継続的に自己改善を行うことができます。エージェントの「重み」は、読み書き可能なテキストそのものです。記憶が増え、教訓が積み重なり、精度が向上します。
私たちは、5 つのエージェントベンチマーク(ALFWorld, ScienceWorld, WebShop, AppWorld, Mind2Web)と、ARC-AGI 上に構築した制御されたストリームに対して、このループをエンドツーエンドで実行しました。しかし、そのストーリーは成り立ちませんでした。
主要な結果
エージェントは、すでに解決済みのタスクにおいて性能が後退します。
GPT-5.4 がメモリなしで 100% の精度を達成する 19 の ARC-AGI 問題を考えます。これらの正確な問題を一貫性ループに通し、各ステップで正解(ground-truth)が利用可能となるようにします。
 image
image
同じ問題を二度解くこと。二回目の方が悪化。
メモリなしの場合:100%。これらの問題そのものの正解から学習(consolidating)した後、GPT-5.4 は 54% に低下します。軌道は完璧ですが、書き換えステップが破綻を引き起こしています。
「誤ったメモリ」は「ノイズの多いデータ」という婉曲表現ではありません。データはクリーンです。エージェントは正解を見ています。その正解を再利用可能な教訓として圧縮する行為こそが、それらを解決する方法を忘れる原因となりました。
低下の形状
メモリの有用性は更新回数に対して単調ではありません。
これらは悪い出発点ではありません。最も強力なモデル(GPT-5.4)を用いて、最もクリーンな「Static-Group」スケジュールで 1 つの ALFWorld のメモリを初期化しました。その後、同じ軌道プールに対してより小さなモデルで更新を継続しました。3 つの異なるソルバー(Qwen3.5-{27B, 9B, 4B})を使用しましたが、結果の形状は同じでした:
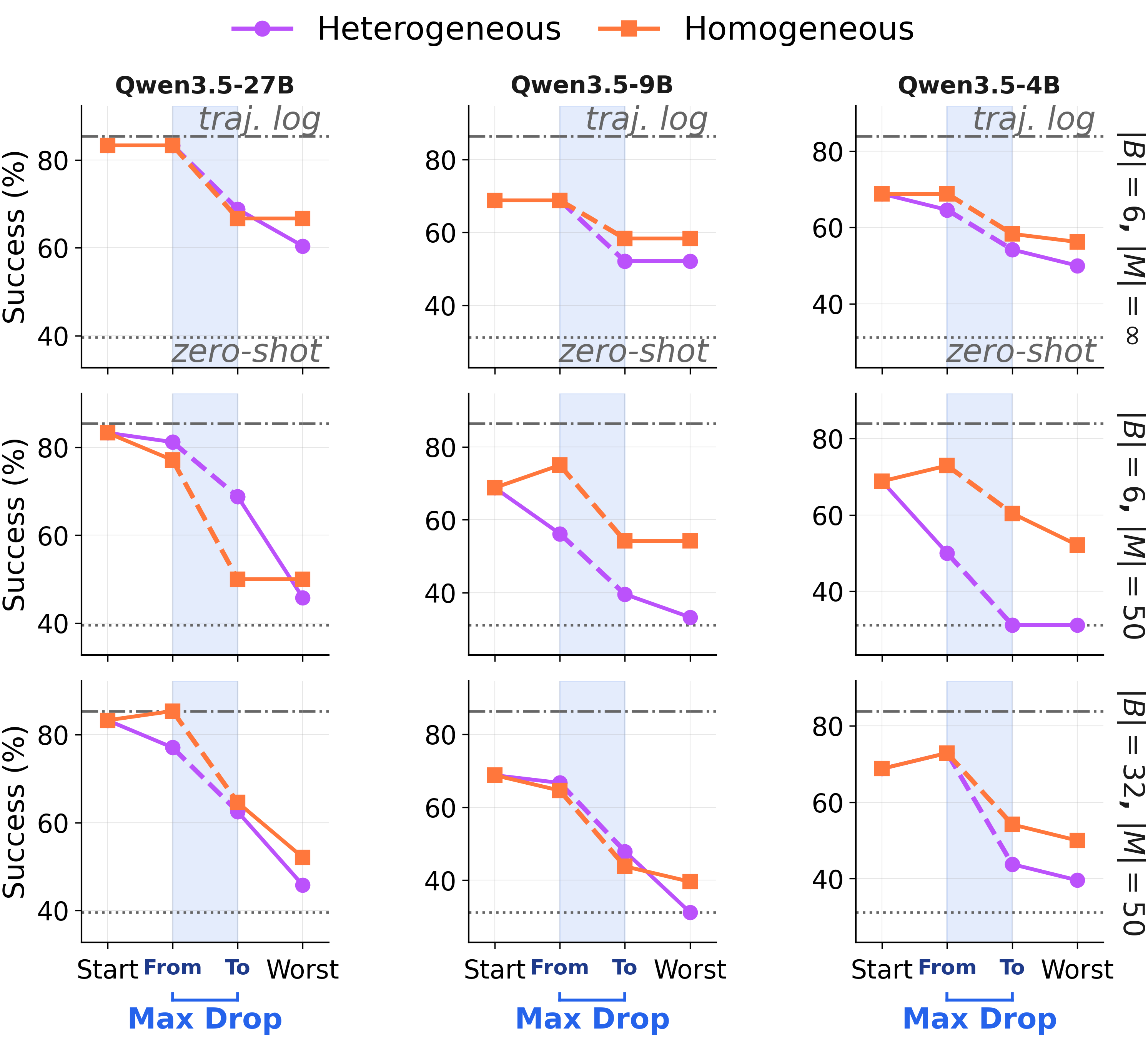
強い記憶とは固定点ではない。 同一の軌道プールに対する継続的な統合は、すべてのソルバーにおいて有用性を低下させ、連続するステップ間では壊滅的な結果をもたらすこともある。
データそのものではなく書き換えが問題なのだ
同じ軌道でも、どのように提供するかによって異なる記憶が生成される。
軌道プールを固定し、統合スケジュールのみを変化させる。出力される記憶は質的に変化し、それに応じて下流のスコアも変化する。
3 つのうち最良の結果。 統合器が一度に一つのタスクファミリーからなるクリーンなバッチを見る場合、潜在構造を抽出するチャンスが実際に生まれる。これは可能な限りクリーンなオフライン設定である。
 image
image
同じ軌道、3 つのスケジュール、3 つの異なる記憶。 ストリーミング(継続的に展開されるエージェントが実際に利用するスケジュール)が最悪の結果となる。
なぜこれが重要なのか
これら 3 つの実行において、軌道プールは同一である。結果として得られる記憶に何らかの問題があるとしても、それはエージェントが収集したデータに原因を求めることはできない。問題は統合ステップそのものにあるはずだ。
3 つの失敗モード
なぜ書き換えが誤るのか?
3 つのメカニズムを特定します。それぞれが、統合ループを蓄積から劣化のある書き換えへと変換します。
01
誤ったグループ化
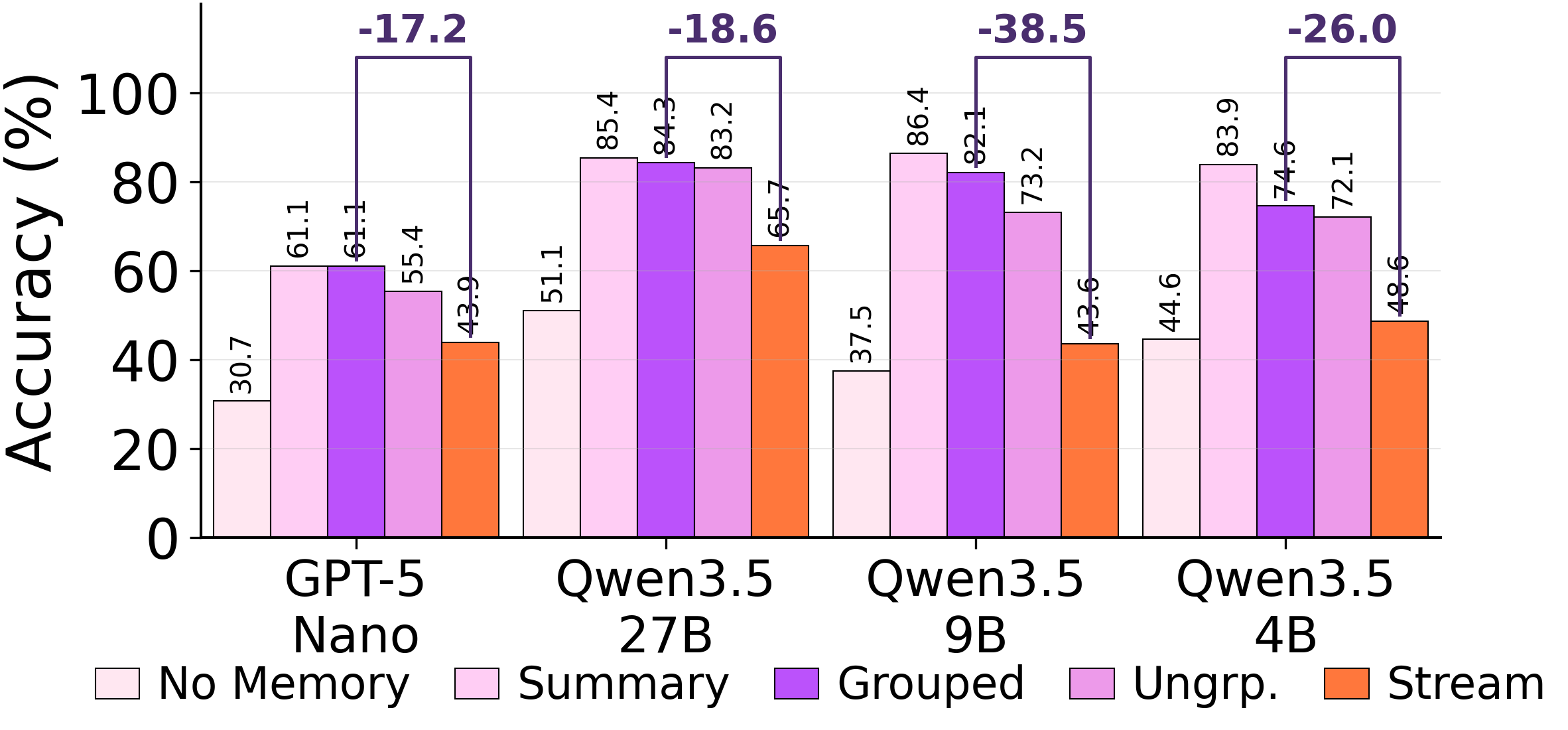
抽象化する前に、統合担当者は「どのエピソードが一体のものとして扱われるべきか」を決定します。すべてのステップを強制的に統合させられると、根本的な構造をほとんど共有していないエピソードをプールしてしまいます。
ARC-AGI Stream において強制的な統合が行われた場合、モデルは頻繁に異なる問題クラスにまたがる記憶エントリーを結合してしまいます。自律性が与えられると、最終的には各の 6 つの問題タイプを網羅するクリーンな事象記憶庫へと収束しますが、それは 568 の例が経過した後のことです。*セグメント化する能力は備わっています。強制的な書き換えがそれを上書きしているのです。
Verbatim memory entry (逐語的記憶エントリー)
GPT-5.4 · forced consolidation (強制統合) · ARC-AGI Stream
使用時: 大きな中空の長方形フレームがいくつかのオブジェクトを囲んでおり、他のオブジェクトはその外側にあります。保持される内部オブジェクトでは、フレーム外の対応するオブジェクトとの関係に基づいて、1 つの区別されたセルが変更されます。これは特に、外部オブジェクトと内部オブジェクトの形状が同じ場合によく見られます。
戦略: … (5) 各内部オブジェクトについて、同じ形状シグネチャを持つ外部オブジェクトを探す… (6) 内部オブジェクトにそのような一致する外部対応物がある場合、内部オブジェクトのバウンディングボックスの中心セルを外部オブジェクトの色でマークする。
ハイライトされたスパンは「外国家族注入」である:形状シグネチャの検索は「形状別グループ化 (group-by-shape)」ファミリーに属し、マーカー色書き込みは「キーマーカー (key-marker)」に属する。どちらも内部フレームソースタスクの一部ではない。コンソリデーターは、実際のどのファミリーも規定しない複合体を縫い合わせた。
強制下での誤分類数:異なる家族のエピソードが 1 つのエントリに統合されたもの。
02
干渉
各抽象化パスは既存のエントリを平滑化する。チャンクが不正確な境界で区切られている場合、書き換えによって適用条件が剥奪される: Pick&Place では真であった教訓が広く関連性があるように読み取られ、Pick-Clean-Place を誤導する。
15 タスクの ScienceWorld スイッチシーケンスにおいて、現在のタスクのみに対して記憶を凝縮する(「Fresh」)アプローチは、すべての過去のタスクにわたって共同で凝縮する(「Cumulative」)アプローチよりも +203 ポイント 上回ります。LLM ジャッジによる各エントリの評価では、「Cumulative」は「Fresh」の約 5 倍 の速度で過度に一般化された記憶を蓄積し、完全に無意味なゴミデータに至っては約 20 倍 の頻度で発生します。
Verbatim memory entry(逐語的記憶エントリ)
ScienceWorld · over-generalized(過度に一般化されたもの)
Using a lighter, fire source, or oven MAY BE NECESSARY to change the state of a food or substance in state-change tasks.(状態変化タスクにおいて、食品や物質の状態を変化させるために、ライター、火源、またはオーブンを使用することが必要である場合がある。)
これは広く適用可能に読めます。しかし、多くの状態変化タスクでは冷却、凍結、または融解が必要です。適用条件が剥奪されており、この教訓は現在、熱が無関係あるいは有害なタスクにおいてエージェントを熱源へと偏らせています。
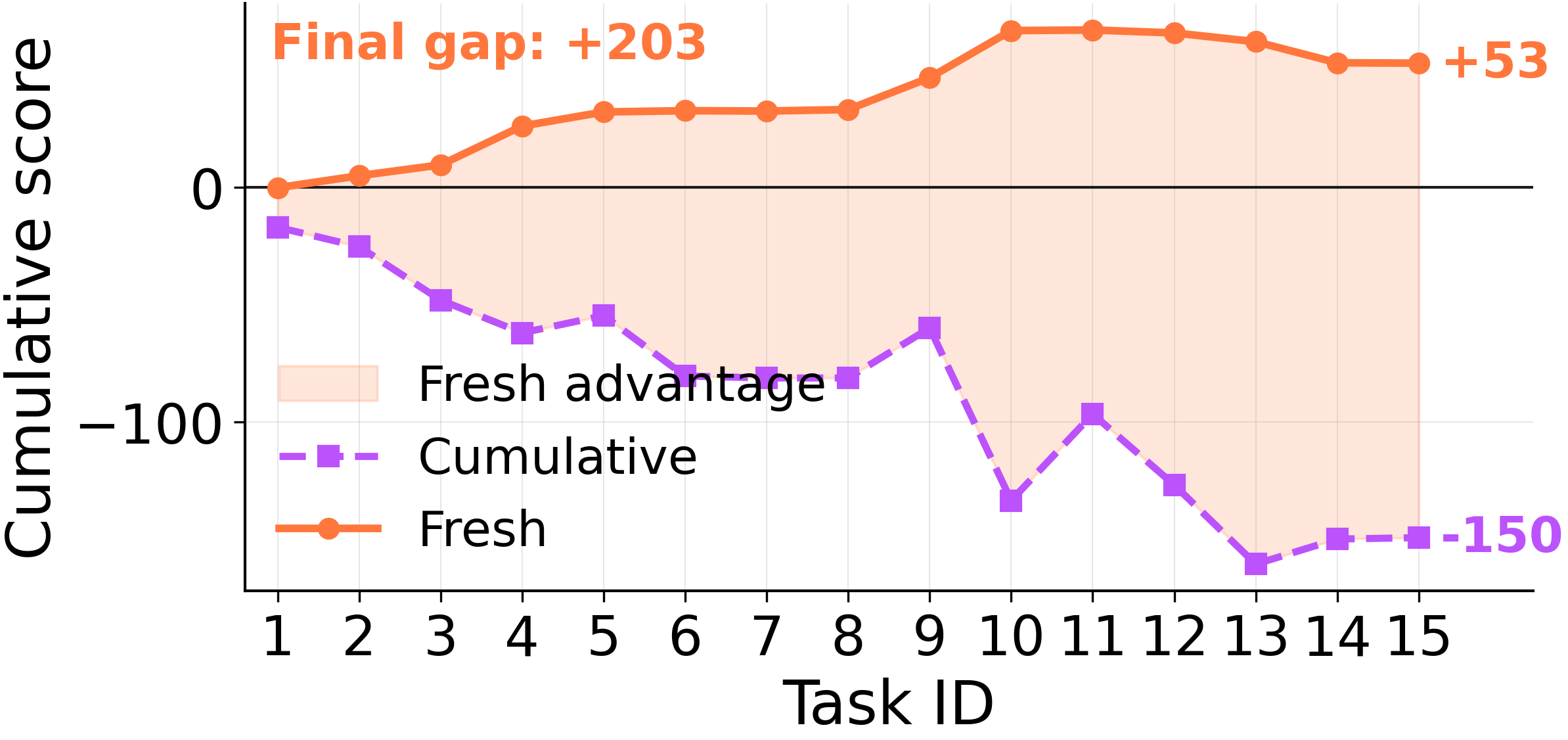
Fresh vs Cumulative: 同一の軌跡、異なる凝縮範囲、+203 ポイントの差。
03
Overfit(過学習)
入力分布が広がるのではなく狭まる場合、抽象化は基盤となる戦略ではなく、観測されたインスタンスの表面的な規則性に過剰適合します。記憶は正確な反復を認識しますが、同じファミリー内の近い変異体に対して失敗します。
我々は、統合サイクルを通じて単一の ARC-AGI ストラテジー・ファミリーから抽出したタスクをエージェントに与えます。パフォーマンスは正確な反復においては安定していますが、同じファミリー内での小さな変異においては崩壊します。「教訓」は例の記述へと変貌しました。
同じ系統、50 回の書き換えの間隔で
GPT-5-mini ·「最大のオブジェクトを再着色する」
ラウンド 1
入力から構造化要素を特定・抽出し → グローバル指標(例:最大サイズ)を計算し → 要素を反復処理して標的編集を選択的に適用する
ラウンド 50
派生したオブジェクトごとの数値属性の最大値を見つけ、その属性が最大値に等しいすべてのオブジェクトに対して一様変換を適用する。
ラウンド 1 は実際のセレクタ「max size(最大サイズ)」という名を冠します。これはソルバーが計算可能な性質です。一方、ラウンド 50 では、同じタスクに対して同じ系統で 49 回の書き換えが行われた結果、それが消去されています:エントリはもはや最大化すべき属性が「どのものか」を記録していません。
狭いストリームから生じる記憶は、既知のケースを認識する一方で、その近傍にあるケースに対して失敗します。
認知科学に関心のある方への余談
これはまさに、双システム記憶が防止するために設計されたものです。
補完的学習システム理論 [refs] は、脳が高速なエピソード記憶と低速なスキーマ形成記憶を*建築的に区別して*保持し、統合(consolidation)は各イベントでトリガーされるのではなく、スキーマとの適合度によって*gated*(制御)されると述べています。この二つを一つの必須の書き換えループに崩壊させると、双システムが回避するために設計された干渉カタストロフィがまさに発生します。
今日のエージェント型メモリ設計は、この二つを崩壊させています。タスクを解決する同じ LLM が、そのタスクに関する自身の記憶をあらゆる局面で書き換える仕組みであり、制御(gating)の機能はありません。私たちの発見とは、その予測が実践においてどのように現れるかを示したものです。
例示
現場における誤った記憶。
実際の統合実行から得られた三つの実在するアーティファクトです。原文そのまま、編集なし、選択的なハイライトのみ。
ケース 1
19 の ARC タスクが単一のプレイブックに崩壊
GPT-5.4 · 6 つのファミリーにわたる 19 のタスク · 10 パス(190 ステップ)· 各ステップにおける真のコード
After ten passes, the entire memory store contained *one* entry. Not a library. Not even five entries. One.
メモリに残された唯一のエントリー
190 の統合ステップ後
接続されたオブジェクトを抽出し、最大のものをフレームとして選択し、バウンディングボックスがそのフレームの内部に厳密に含まれるかどうかによって他のオブジェクトを分類し、フレームとそれより外側のすべてのオブジェクトを消去した上で、各内部オブジェクトの境界を残しながら内部を色 0 に変えることで、その場で空洞化する。
内部的には一貫している。理にかなったレッスンとして読める。しかし問題点は、ソースプールが*6 つ*のファミリーにまたがっているのに、このエントリーは*1 つ*のみを記述していることだ。残りの 5 つのファミリーは、現在エージェントにとって不可視となっている。
次に、真のルールが「色 6 のすべてのオブジェクトを消去する」である保持されたタスクをエージェントに渡す。これはフレーム内の論理とは無関係である。メモリなしでは、同じモデルで 10/10 で解決できる:
メモリなし
10 / 10
def solve(grid):
# 変換は色 6 のすべての連結成分を削除する。
out = [row[:] for row in grid]
for obj in extract_objects(grid):
if obj["color"] == 6:
for r, c in obj["cells"]:
out[r][c] = 0
return out
メモリあり
0 / 10
def solve(grid):
# フレームオブジェクトのみを保持する;フレームは最大の連結成分である。
h = len(grid); w = len(grid[0]) if h else 0
objs = extract_objects(grid)
if not objs:
return [row[:] for row in grid]
frame = max(objs, key=lambda o: o["size"])
fb = frame["bbox"]
out = [[0] * w for _ in range(h)]
for obj in objs:
if obj is frame: continue
bb = obj["bbox"]
inside = (bb["top"] > fb["top"]
and bb["bottom"] < fb["bottom"]
and bb["left"] > fb["left"]
and bb["right"] < fb["right"])
if inside:
for r, c in obj["cells"]:
out[r][c] = obj["color"]
for obj in extract_objects(out):
apply_hollow(out, obj, fill_color=0)
return out
The first comment of the with-memory solver reproduces the entry verbatim. The code follows the entry's frame-and-hollow recipe: pick a frame by size, copy interior objects, hollow them. On this input, no marker passes the strict-inside check and the canvas stays empty. The memory turned a 10/10 solver into a 0/10 solver.
Case 2
Collapse by accretion: 8 workflows become 16 redundant ones
AWM on WebShop · 128 expert trajectories · gpt-5.4-mini · 3 epochs
After epoch 1 the memory file held 8 abstract workflow templates. By epoch 3 it held 16. The new 8 (highlighted) are not new patterns. They're the same templates, restated with one product category pinned in:
AWM workflow titles, epoch 3
~8.2k chars · verbatim
- W1. 属性に富んだクエリで検索する。
- W2. オプションを確認するために候補アイテムを開く。
- W3. 購入前に必要な属性を選択する。
- W4. 購入前に必要なサイズ、色、およびその他のバリアントオプションを選択する。
- W5. フィットタイプを含む衣類のバリアントを検索して選択する。
- W6. ホームデコレーションのバリアントを検索して選択する。
- W7. 多部構成のアパレルのサイズバリアントを検索して選択する。
- W8. 最初の結果が一致しない場合にページを跨いで検索する。
- W9. 購入前にアパレルの色、サイズ、フィット/注文固有のバリアントを選択する。
- W10. 購入前に非アパレルのフレーバーとサイズのバリアントを選択する。
- W11. 購入前にパック数と色のバリアントを選択する。
- W12. ホームグッズの色、サイズ、形状のバリアントを検索して選択する。
- W13. 色とサイズを含む靴を検索して選択する。
- W14. アパレルの色、サイズ、購入に関するバリアントを検索して選択する。
- W15. エレクトロニクスのメモリ/ストレージのバリアントを検索して選択する。
- W16. アクティブウェアまたはパフォーマンストップスのバリアントを検索して選択する。
W9 は、W3、W4、W5 をつなぎ合わせたものに過ぎません。W10 から W16 にかけては、同じ「検索後にバリアントを選択する」テンプレート(W1~W4)をベースに、特定の製品カテゴリ(食品、パック数、家庭用品、靴、衣類、電子機器、アクティブウェア)を固定したものです。新しい制御フローも、新しいガード機能も、新しい停止基準もありません。*検索帯域幅を競い合う 8 つの新たなエントリが追加されましたが、汎用性は向上していません。*
これは無害な変更ではありません。たった1 つのワークフロー(W8、「最初の結果が一致しない場合にページを跨いで検索する」)を削除しただけで、gpt-5.4-mini における成功数は 7/50 から 14/50 に、gpt-5-mini では 18/50 から 23/50 に向上します。これは、W8 がエージェントを「[次へ]」クリックのデッドループに偏らせることで、「[今すぐ購入]」クリックを犠牲にしているためです。
ケース 3
## ScienceWorld: メモリの劣化には 3 つのタイプがある
LLM 判定器が、ストア内のすべてのエントリを「過度に一般化されたもの」「過度に特殊化されたもの」「無価値なゴミ」のいずれかに分類します。各タブをクリックすると、該当するエントリがそのまま表示されます。
カメのステージのタスクを完了するには、すべての生命段階を順序立てて観察することが必要である可能性がある。
ガのステージのタスクを完了するには、すべての生命段階を順序立てて観察することが必要である可能性がある。
状態変化タスクにおいて、食品または物質の状態を変更するには、ライター、火源、またはオーブンを使用することが必要である可能性がある。
状態変更タスクにおいて、対象となる物質に焦点を当てることは、その状態を変更するために必要である可能性が高い。
最初の 2 つのエントリは互いの言い換えであり、統合者は同じ教訓を異なるタスクラベルを貼り付けて 2 回記述したものです。これらはいずれも、ソルバーが行動を選択するために実際に活用できる性質を示すものではありません。
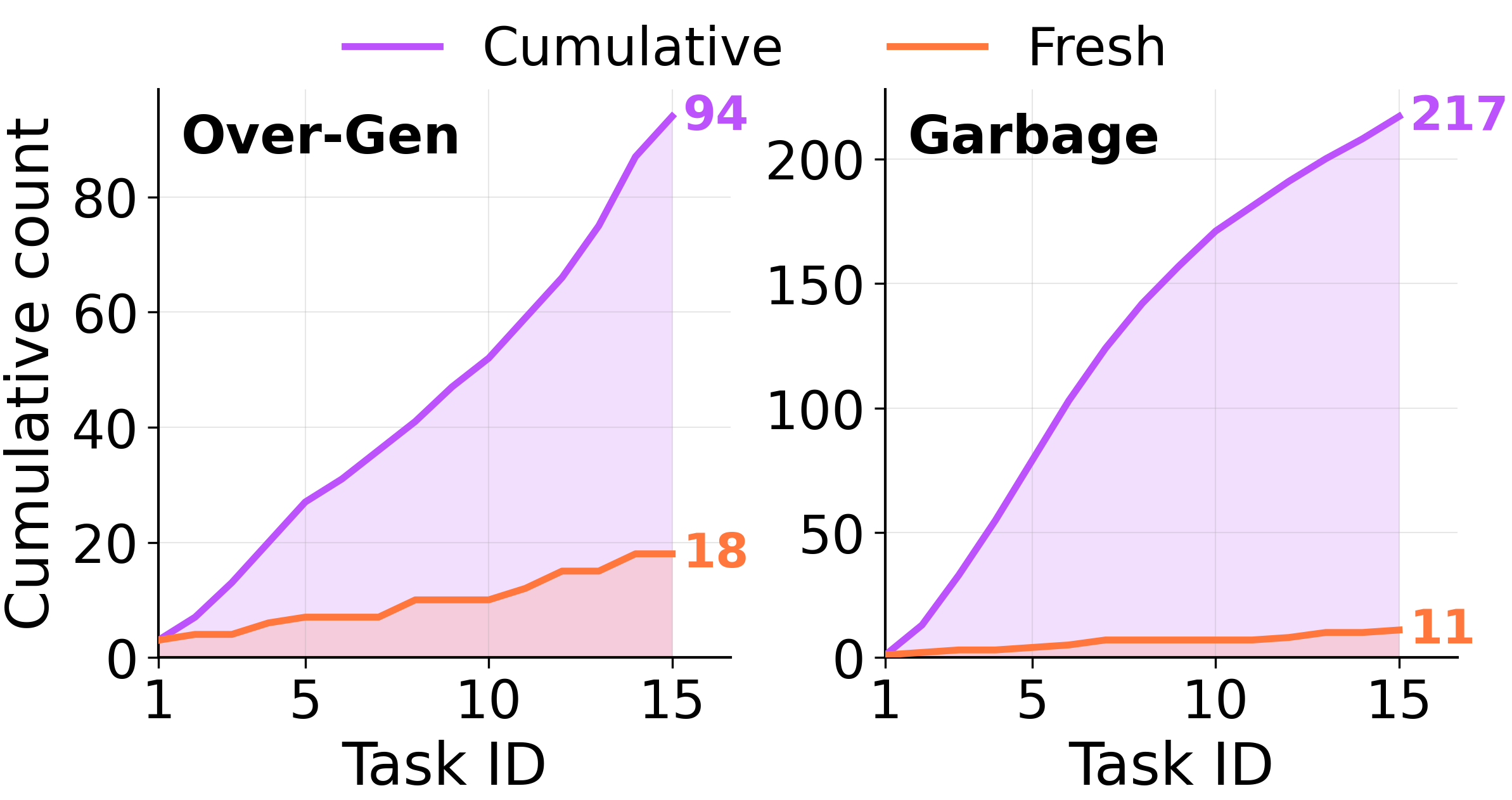
Cumulative(累積)統合における過剰一般化された記憶とゴミ記憶のランニングカウントは、Fresh(新規)からほぼ直ちに乖離し、決して回復しません。
Case 4
## 50 項目のメモリが単一の統合ステップで 1 項目のメモリへと変化する
ALFWorld · gpt-5-nano consolidator · stage 168 → 169 · cap 50 items
Stage 168 では、メモリは構造化された 50 件の項目(約 48k 文字)を保持しており、それぞれが固有の洞察(タスク分類体系、状態変化のショートカット、ライトへの注視プロトコル、複数オブジェクトのレシピなど)をカバーしています。その次の統合ステップである stage 169 では、メモリは単一の項目のみを含みます:
Stage 169 memory · 1 item · 1,960 chars · verbatim
After one merge step
清掃、冷却、加熱、および光の下での観察というタスクを単一の反復可能なループで処理する。1) 一般的な部屋のソースを体系的に検索する… 2) 各ターゲットを選択し、状態変更が必要な場合(冷蔵庫で X を冷却、電子レンジで X を加熱、シンク底面で X を洗浄など)、保持しながら実行する… 3) 目的地へ移動する… 4) オブジェクトを配置する… 5) 同じ目的地に同じオブジェクトが 2 つ必要である場合… 6) オブジェクトがすでに目的地にある場合… 7) 妨害要因を管理する… 8) バッチ完了後… 9) 光の下での観察固有の拡張:中央のデスクランプの場所をアンカーし、ターゲットとランプを同じ場所に配置する… 10) 避けるべき落とし穴…
ステージ 168 で別項目だった冷却対加熱の非対称性(冷却には挿入が不要だが、加熱には必要)は消滅した。2 つのオブジェクトを往復させるデフォルトも消えた。観察プロトコルは now ステップ 9 の半文節の従属節となった。
同じメモリのステージ 168 スナップショットに対する次の評価でのコスト:
ロールアウト
メモリなし
ステージ 168 (50 アイテム)
ステージ 169 (1 アイテム)
Δ
Qwen3.5-4B15/4835/4829/48−6
Qwen3.5-9B15/4836/4826/48−10
Qwen3.5-27B19/4837/4824/48−13
1 ステップ。6 から 13 の勝利を失う。 この減少は、最も大規模な展開において最大となります。より強力なソルバーほど 50 個の構造化メモリから多くの情報を抽出していたため、それらの区別が単一の「統一されたループ」に崩壊した際に、より多くを失います。
Case 5
同値命題に対する 99 票:3 回変異した最上位のメモリ
ExpeL on ALFWorld · gpt-5.4 base, gpt-5-nano management · 200 ステージ
ExpeL は、EDIT(編集)ごとにインクリメントされる整数投票スコアによってメモリ項目をランク付けします。ステージ 200 までに、最上位スロットには 99 票が蓄積されており、これはメモリ内での最高記録であり、その差は 2 倍に達しています。これは極端な値のように思えます。しかし、このスコアは、EDIT が根本的な概念を「置き換える」際にも継続してインクリメントされます。同じスロットを追跡すると以下のようになります。
Stage 0 28 票
「X を Y で/によって/using Y 調べる」という形式のタスクにおいては、まず両方のオブジェクトを特定し、次に環境の直接的なタスク関連インタラクション(例:Y を使用する、Y で X を調べる、または Y がアクティブ化されている場合は X を調べる)を優先してください…
具体性:光の中でのオブジェクトを見るパターンを命名しています。
↓
Stage 80 46 票
現在のサブゴールを直接前進させる最も単純な行動を優先し、前提条件が最少で迂回も最小限に抑えつつ、すでに開かれた容器やインベントリ内のアイテムを再利用する行動も好んでください…
汎用的な計画ヒューリスティック。タスクタイプの手がかりは消失。
↓
ステージ 200 99票
現在のサブゴールを直接前進させる行動を優先し、最も近い利用可能な設備またはアイテムを使用すること;行動前に前提条件を確認すること;移動距離を最小化すること;有益な場合はサブゴールを交互に行うこと…状態変更と最終配置を組み合わせようと試みること…ただし、明示的な確認なしにアイテムの状態を仮定しないこと。
同語反復。あらゆるエージェントベンチマークに適用可能。
99 票は *3 つの異なる概念* にわたって獲得されたものです。ステージ 200 では、スロットにあるのは 3 つ目の概念のみです。人気スコアはコンテンツの質ではなく、スロット編集量の尺度です。このランにおける最も「信頼できる」メモリエントリは、これまでに書かれたあらゆる計画エージェントに同梱される指示です。
メモリ動物園
クリックして閲覧してください。それぞれが実際のランからの実在のエントリです。
ここではチャートはありません。単なるアーティファクトです。各タブには、1 つの原文エントリと、その欠陥に関する 1 行の注釈が表示されます。
GPT-5-mini · ARC-AGI · 200 タスク · メモリエントリ 1/1
「入力グリッド(行リストのリスト)を変更する前に作業用コピーを作成し、すべての修正をコピー上で行い、元の入力を変更しないようにするためにコピーを返すこと。」
何が問題か。 防御的な Python のイディオム。6 つのタスクファミリーが区別する色、形状、またはルールについて言及していない。モデルはコーディングのヒントを書き、それを戦略と呼んだ。
より深い問題
各統合ステップは生成である。エージェントは自身の過去を幻覚している。
失敗の原因は「LLM が要約が苦手だから」ではない。構造的な問題だ。我々は、安定した長期知識が生成ループの不動点となるシステムを構築しようとしているが、そのような不動点は存在しない。
各統合パスは以下のように機能する:
- 現在のメモリと新しい軌跡を読み取る。
- 新しいメモリエントリ「あるべき姿」を生成する。これは LLM の順方向パスである。流暢で構造的に妥当なテキストを生成するが、入力への忠実な要約ではない。入力を条件とした分布からのサンプリングである。
- このサンプルを事実として書き戻す。次の統合ステップでは、このサンプルを読み取り、それを条件とする。
これらを 200 個積み重ねてみましょう。ステップ k+1 のコンテキストは、ステップ k のサンプルを条件として抽出されたサンプルであり、そのステップ k のサンプルもまたステップ k-1 のサンプルを条件として抽出されたものです。このようにして、ありそうに見えるテキストが蓄積されていきます。具体的な事実(どの色か、どの容器か、どのセレクターか)は、進行中の要約を条件とした場合に最も驚くべきトークンであるため、各ステップで欠落する可能性が最も高いです。記憶は、軌道の真実へと向かうのではなく、良いレッスンがどのようなものかという LLM の事前分布へと drifting していきます。
再定義
継続的に更新されるテキストメモリとは、アンカーを持たない反復生成ループです。この「記憶」は記録ではありません。それはサンプルであり、流暢で自信に満ちており、実際に何が起こったかから次第に乖離していきます。空虚な抽象化、バグから抽出された幻影のルール、バイト単位で同一の複製、99 票の同語反復、50 の項目が 1 つに収束する現象などを見ました。これらはバグではありません。十分な回数の反復を経た後、コンソリデーター(統合者)の事前分布からのサンプルがどのようなものかを示しているだけです。
なぜ実験結果が整合するのか。
以前示した 3 つの具体的な結果は、この枠組みから直接導き出されます:
- Stream < Static-All < Static-Group。サンプルがコンテキストとしてフィードバックされる回数が多いほど、エントリーは事前分布へと drifting します。Static-Group はファミリーごとに一度だけ再サンプリングしますが、Stream は数千回も再サンプリングを行います。
- 累積型は「フレッシュ」型より 203 ポイント優れています。累積型は過去の要約の成長する接頭辞にわたって統合される一方、フレッシュ型は単一のタスクの生データ軌跡から統合されます。累積型はループ内でより深く位置します。
- エピソードのみ対応は抽象化と一致します。生のエピソードはループの外側にあります。それらはサンプルではありません。記録です。もちろん、それらはよりよく保たれます。
帰結は不快なものです。
支配的なエージェント・メモリのパラダイム——「各タスクの後に軌跡を要約してテキスト形式の教訓として抽出し、保存する」——は経験を蓄積する方法ではありません。それは経験そのものを、経験がどのようなものかというゆっくりと drifting(漂移)する大規模言語モデル(LLM)事前知識に置き換える方法です。統合者が自分自身で上書きできない何かに根ざすまで、経験をスケーリングすることはドリフトを拡大させることになります。
驚くほど強力な修正策
抽象化を強制しないこと。エピソードを保持し続けるだけです。
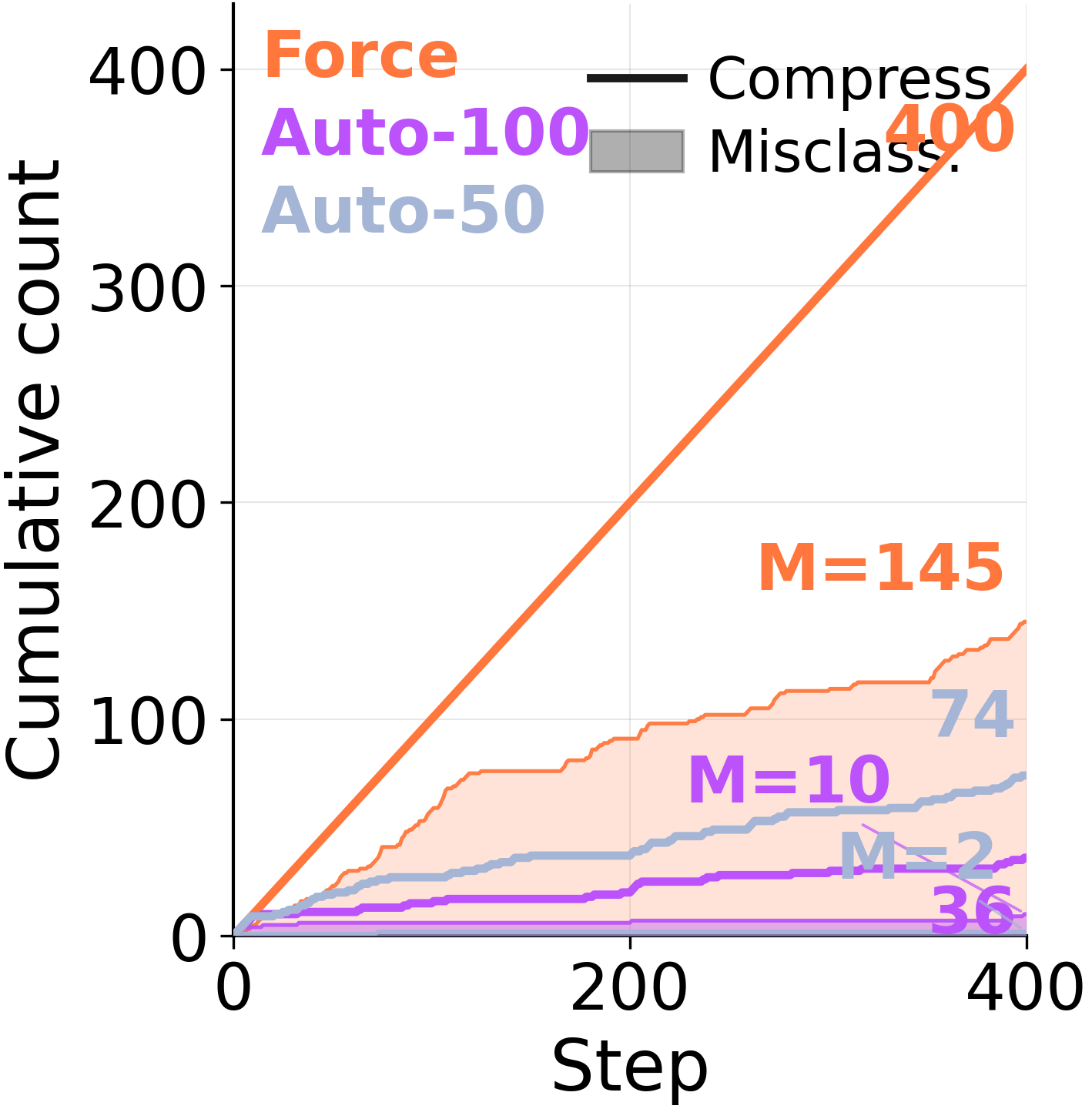
ARC-AGI Stream を用いることで、エージェントに自身のメモリ管理権限を持たせることができます。各ステップで「保持」「削除」「統合」のいずれかを選択できます。私たちは 3 つのレジームを比較します:
強制(Force)
毎ラウンド必ず統合する必要があります。エピソード型エントリはラウンド間で持続しません。*これは既存システムの多くにおけるデフォルト設定です。
自動(Auto)
エージェントが選択:生データを保持、削除、または統合。検索時にはエピソード型と抽象型の両方のストアを利用可能です。
エピソードのみ(Episodic Only)
生のエピソードを保持または削除。抽象化は*完全に無効化されます。
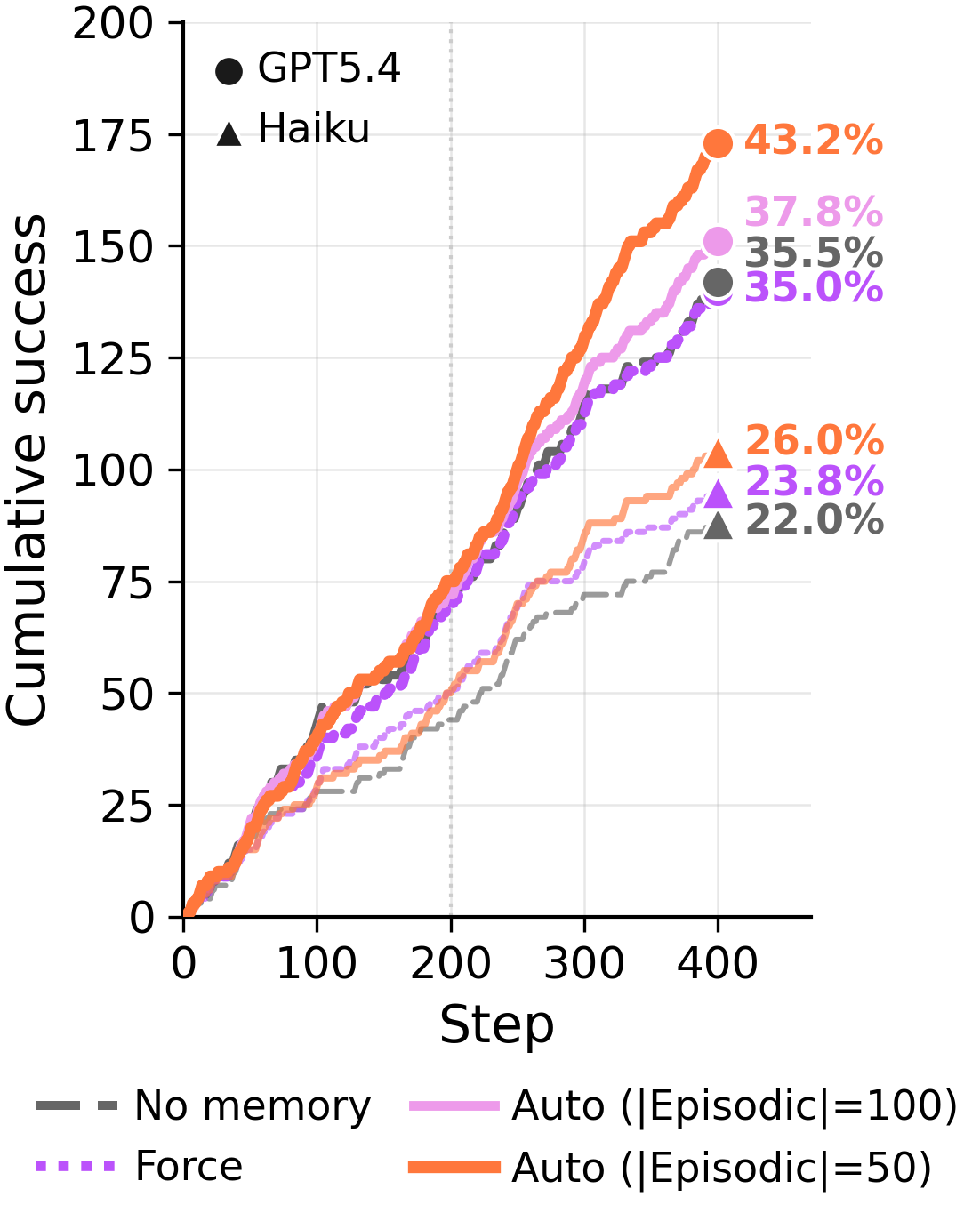
400 回のトレーニングステップと 2 つのバックボーンにわたって、デフォルトでエピソードを保持し、抽象化を控えめに使用するAutoは、Forceを上回ります。Forceが圧縮によって得るものよりも、証拠を書き換えることで失うものの方が大きくなります。
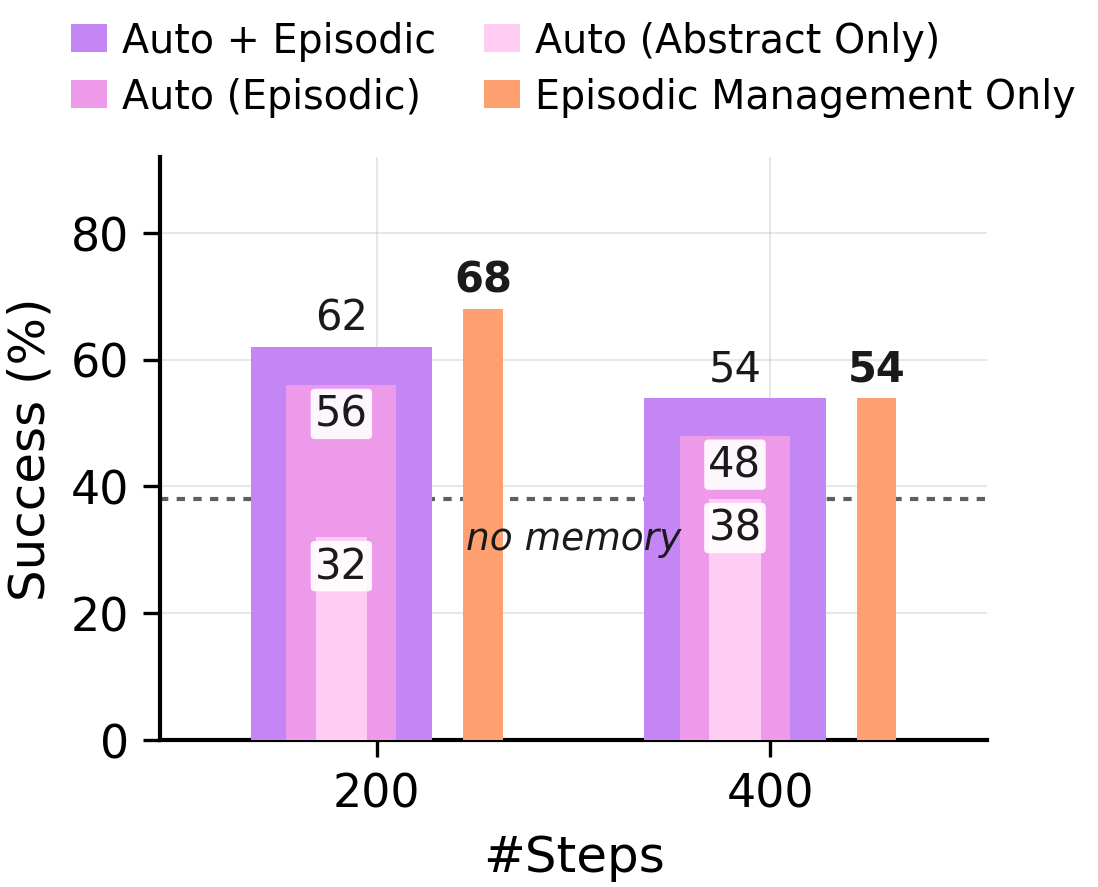
実際の利点が存在する場所。エピソード的証拠を除去し、抽象的な教訓のみを読み取ると、精度は記憶なしのベースラインまで低下します。*エピソード管理のみ*(エージェントが選択的に保持または削除した生のエピソードであり、抽象化が無効になっている状態)は、完全な Auto モードと同等か、それを超えます。有用な情報は、常に厳選された生エピソードの中に存在していました。
ARC-AGI GT ストリーム:400 ステップ、正解ソリューション、すべての 4 つの管理ポリシー。
ゲート予測に対する最もクリーンなテストは、GT レジームです。ここではエージェントが各ステップで正解ソリューションを受け取ります。「軌道にノイズがあった」という言い訳は通用しません。統合ステップで何が起こるかがそのまま結果となります。
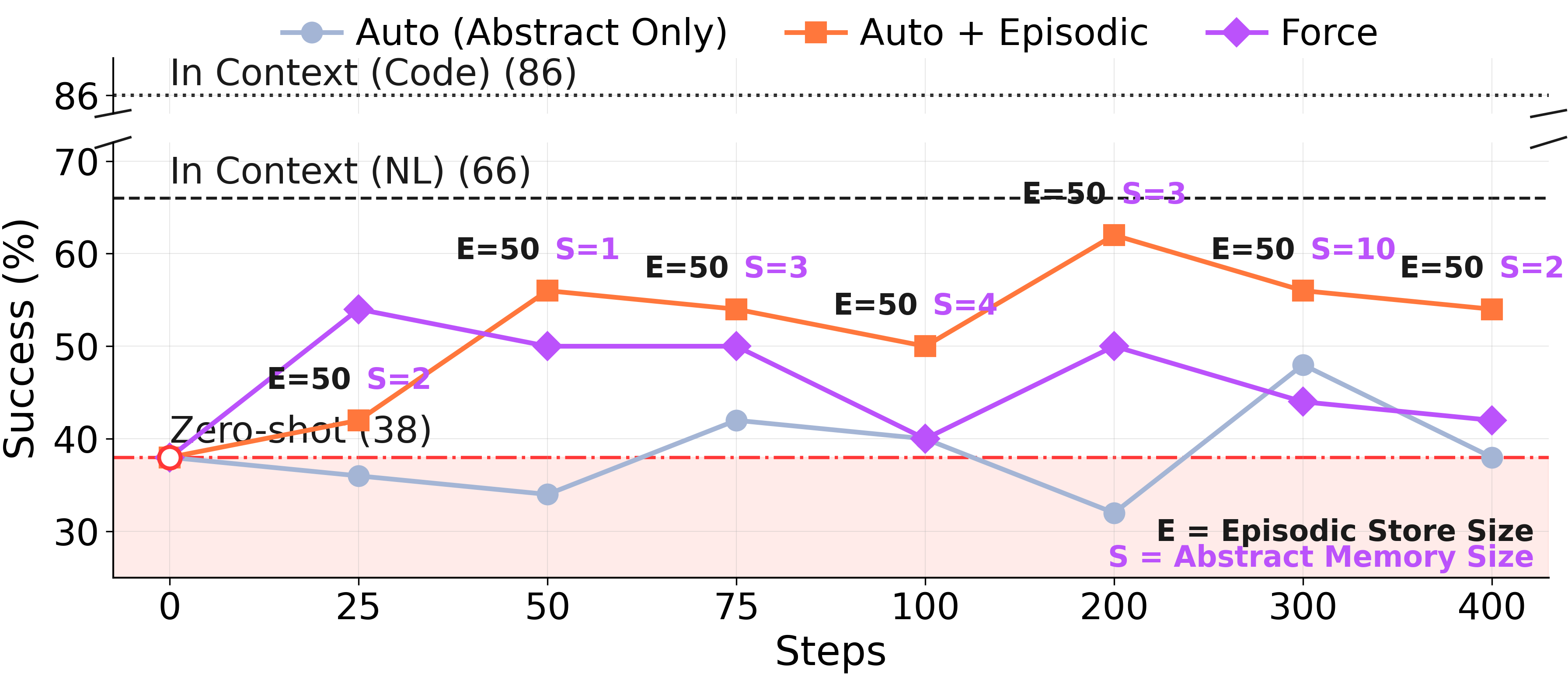
ARC-AGI GT ストリーム、トレーニングステップ 400。 ステップ約 50 から強制更新による遅延が発生。Auto+Episodic の曲線は上昇し続け、その勢いを維持するのに対し、Force は頭打ちとなり、後から追い越される。同じモデル、同じ軌跡、同じ正解解法 — 抽象化が必須かどうかというルールだけが異なる。
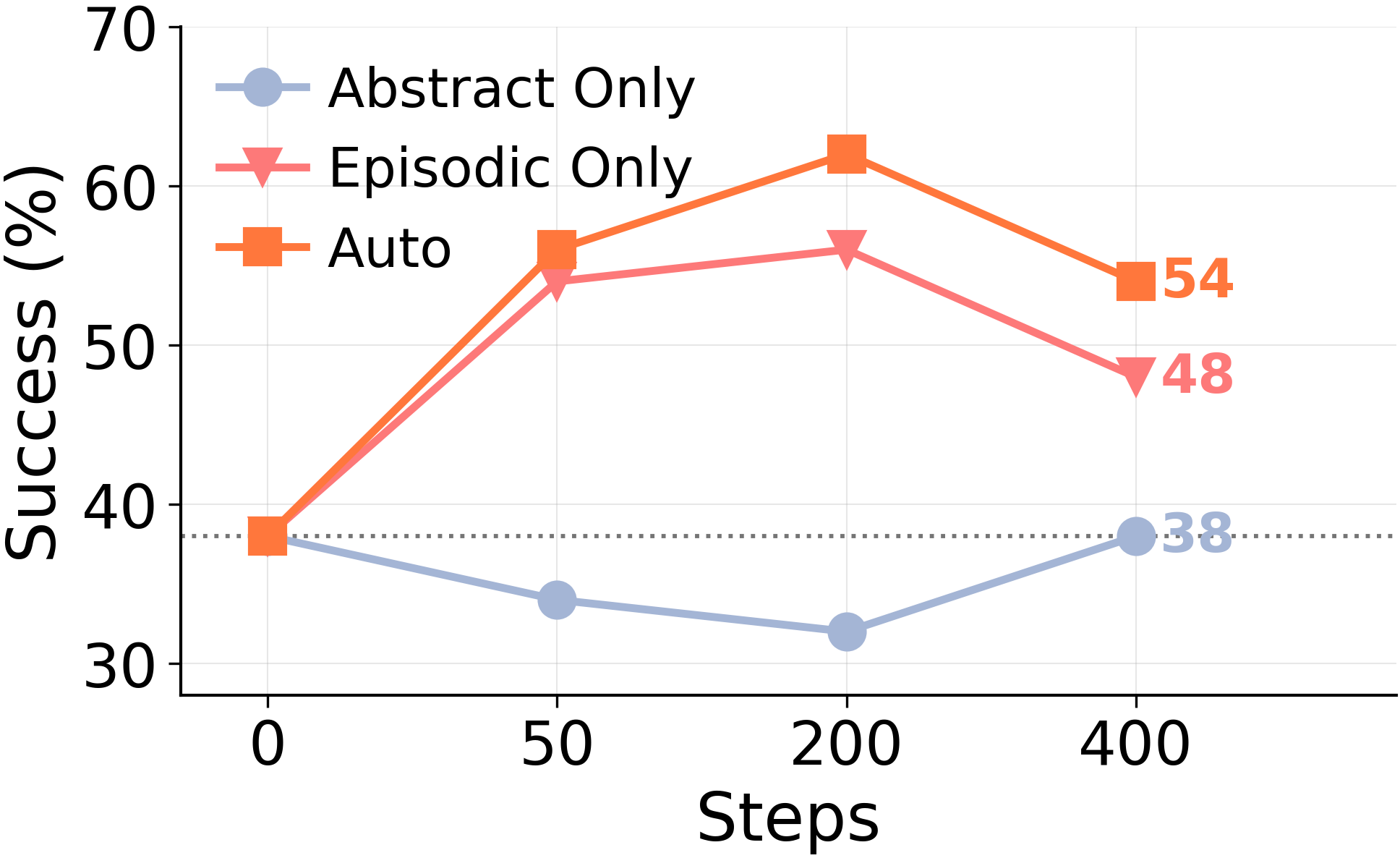
Auto+Episodic の利点がどこから来るのかを特定するため、同一の実行から得られた 4 つのチェックポイントで再評価を行い、各メモリソースを順に制限した。*Abstract Only*(抽象のみ)では圧縮された教訓のみを読み込み、*Episodic Only*(事象のみ)では生きたエピソードストアのみを読み込み、*Auto* では両方を読み込む。
 image
image
抽象ストアは全く機能していない。 *Abstract Only*(抽象のみ)で圧縮された教訓のみを読み込んでも、4 つのチェックポイントすべてにおいて、メモリなしのベースラインを上回ることはない。一方、*Episodic Only*(事象のみ)で生きたエピソードのみを読み込むと、Auto の利益のほぼ全体が回復する。組み合わせた Auto 読み込みは、せいぜい Episodic Only 単独よりわずかに優れている程度であり、これはエージェントがすでに保持することを選んだ生きたエピソードの上に、コンソリデーター(統合器)による圧縮結果がほぼゼロしか寄与していないことを意味する。
また、選択権を与えられた場合、エージェント自身も同意している。あらゆる予算レベルでエピソードバッファはすぐに飽和し、抽象ストアは疎な状態を維持する。
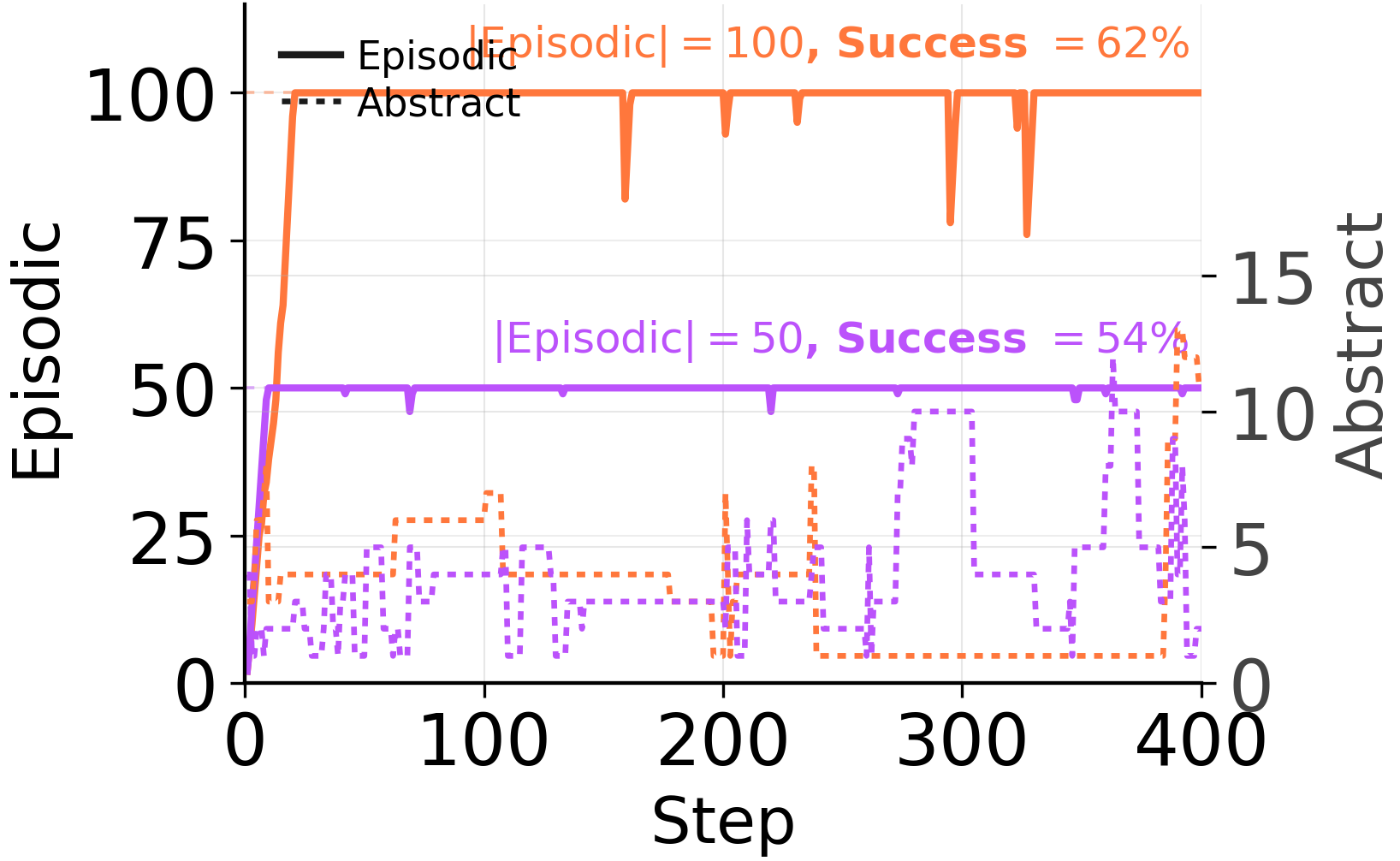
オートモードにおけるバッファ構成。アーキテクチャが許す限り、エージェント自身の管理ポリシーは*エピソード優先*です。
原則
エピソード機能とスキーマ形成機能は、単一の書き換えループに統合すべきではありません。生のエピソードは圧縮して消去される素材ではなく、第一級の証拠です。抽象化が行われる場合でも、それは*エージェントがオプトインし、ゲート制御するもの*であるべきであり、すべての軌道に対して強制的に行うものではありません。
不快なベースライン
エピソードのみの記憶は、テストした全ての統合手法と競合します。
WebShop、ALFWorld、AppWorldにおいて、「エピソードのみ」の記憶(生軌道ロールアウトをコンテキストに単に追加し、軌道間の書き換えを行わない)は、ACE、AWM、Dynamic Cheatsheet と同等の性能を示します。同じ軌道を使用し、蒸留ステップもありません。ソルバーの文脈内学習が、保存されたインスタンスから直接関連する信号を抽出します。
私たちは抽象化が無意味だと言っているわけではありません。私たちが言いたいのは、その価値が蒸留に依存する記憶手法は、それが蒸留する非抽象化ロールアウトと対比してテストされるべきであるということです。現在、そのようなテストを行っているケースは非常に少ないです。
まとめ
では、何を作るべきでしょうか?
- 生エピソードを第一級の証拠として扱ってください。デフォルトで圧縮して消去しないようにしてください。今日のソルバーはすでに文脈内学習を通じてこれらを利用できます。
- 抽象化は選択的かつゲート制御とし、すべての経路を「教訓」に変える必要はない。むしろ、その多くは変えるべきではない。
- エピソード記憶とスキーマ形成の役割を分離せよ。高速なエピソードバッファと、遅く、ゲート制御された抽象記憶庫が、単一の必須書き換えループに代わる優位性を持つ。
- スケーラビリティに対するストレステストを行え。8 例では優秀だが 128 例では失敗するメモリシステムは、メモリシステムではない。それは漏れのあるプロンプトに過ぎない。
- エピソードのみに特化したベースラインを必ず含めよ。抽出された記憶が、コンテキスト内デモとして取得された生ロールアウトを上回れないなら、その知識圧縮(distillation)は正当な価値を生んでいないことになる。
継続的に書き換えられる記憶は脆い。
永続的なテキストメモリは、重み更新なしに展開後の LLM エージェントが改善できる道筋を提供すると約束していた。しかし私たちの結果は言う:まだだ。継続的に更新されるテキストメモリは、自己改善の信頼できるエンジンとしてではなく、*より多くの経験がより悪い記憶をもたらす可能性がある*脆いメカニズムとして捉えるべきである。
長期ホライズンのエージェントには、エピソード記憶とスキーマ記憶の両方が必要となるだろう。しかし LLM がいつどのように統合するかを決定できるようになるまで、安全なデフォルトは証拠を保持し、抽象化は控えめに、あるいは全く行わないことである。
原文を表示
TL;DR
- The popular recipe of distill experience → store as text → rewrite later is not a reliable engine of self-improvement.
- After streaming ground-truth solutions through a consolidation loop, GPT-5.4 fails on 54 % of ARC-AGI problems it had previously solved with zero memory.
- The same trajectories yield different memories under different schedules — the failure is in the rewrite step, not the data.
- An episodic-only agent — one that selectively retains and deletes raw rollouts, with abstraction disabled — matches or beats every consolidator we tested. The point is curated raw evidence, not an unfiltered firehose.
The paradigm
A line of recent work gives an LLM agent a notebook. After it solves a problem, the agent *distills* the trajectory into a textual lesson, drops it in persistent memory, and the next time something similar shows up, retrieves and reuses it
[refs].
The pitch is irresistible: continual self-improvement *without* parameter updates. The agent's "weights" are just text it can read and edit. Memory grows, lessons compound, accuracy goes up.
We ran this loop end-to-end on five agent benchmarks (ALFWorld, ScienceWorld, WebShop, AppWorld, Mind2Web) and a controlled stream we built on top of ARC-AGI. The story didn't hold.
Headline result
The agent regresses on tasks it had already solved.
Take 19 ARC-AGI problems that GPT-5.4 solves at 100 % accuracy with no memory. Stream those exact problems through the consolidation loop, with ground-truth solutions available at every step.

"Faulty memory" is not a euphemism for "noisy data." The data is clean. The agent saw the right answer. The act of compressing those right answers into a re-usable lesson is what made it forget how to solve them.
The shape of the decline
Memory utility is non-monotonic in updates.
And these aren't bad starting points. We seeded one ALFWorld memory with the strongest model we tested (GPT-5.4) on the cleanest "Static-Group" schedule. Then continued updating it with smaller models on the same trajectory pool. Three different solvers (Qwen3.5-{27B, 9B, 4B}). Same shape:
It's the rewrite, not the data
The same trajectories produce different memoriesdepending on how you serve them.
Hold the trajectory pool fixed. Vary *only* the consolidation schedule. The output memory changes qualitatively, and so does downstream score.
Best of the three. When the consolidator sees a clean batch of one task family at a time, it actually has a chance to extract the latent structure. This is the cleanest possible offline setting.
Why this matters
The trajectory pool is *identical* across these three runs. Whatever's wrong with the resulting memory cannot be blamed on the data the agent collected. It has to be in the consolidation step itself.
Three failure modes
Why does the rewrite go wrong?
We isolate three mechanisms. Each one turns the consolidation loop from accumulation into lossy rewriting.
01
Misgrouping
Before abstracting, the consolidator decides *which episodes belong together*. When forced to consolidate every step, it pools episodes that share little underlying structure.
Under forced consolidation on ARC-AGI Stream, the model frequently combines memory entries across distinct problem classes. When given autonomy, it eventually converges to a clean episodic store covering each of the 6 problem types — but only after 568 examples have elapsed. *The capacity to segment is there. The forced rewrite overrides it.*
Verbatim memory entry
GPT-5.4 · forced consolidation · ARC-AGI Stream
When to use: A large hollow rectangular frame encloses some objects while other objects lie outside it … In the kept interior objects, a single distinguished cell is changed based on a relation to a matching object outside the frame, often when an outside object has the same shape as an inside object.
Strategy: … (5) For each interior object, look for an exterior object with the same shape signature… (6) If an interior object has such a matching exterior counterpart, mark the center cell of the interior object's bounding box with the exterior object's color.
The highlighted spans are *foreign-family injections*: a shape-signature lookup belongs to the *group-by-shape* family, the marker color-write belongs to *key-marker*. Neither is part of the inside-frame source task. The consolidator stitched together a composite no actual family prescribes.
02
Interference
Each abstraction pass smooths existing entries. When the chunks are imprecisely bounded, the rewrite strips the applicability conditions: a lesson that was true for Pick&Place reads as broadly relevant and misleads Pick-Clean-Place.
On a 15-task ScienceWorld switch sequence, distilling memories *only* on the current task ("Fresh") beats jointly consolidating across all prior tasks ("Cumulative") by +203 points. An LLM judge labels each entry: Cumulative accumulates over-generalized memories at ~5× Fresh's rate, and outright garbage at ~20×.
Verbatim memory entry
ScienceWorld · over-generalized
Using a lighter, fire source, or oven MAY BE NECESSARY to change the state of a food or substance in state-change tasks.
Reads as broadly applicable. But many state-change tasks need cooling, freezing, or melting. The applicability conditions have been stripped: the lesson now biases the agent toward heat sources for tasks where heat is irrelevant or harmful.
03
Overfit
When the input distribution *narrows* instead of widening, abstraction overfits to surface regularities of the seen instances rather than the underlying strategy. The memory recognizes exact repetitions and fails on close variants of the same family.
We feed the agent tasks drawn from a single ARC-AGI strategy family across consolidation cycles. Performance stays stable on exact repeats, then collapses on small variations within the same family. The "lesson" turned into a description of the example.
Same lineage, 50 rewrites apart
GPT-5-mini · "recolor the largest object"
Round 1
identify and extract structured elements from input → compute a global metric (e.g., max size) → iterate elements and selectively apply targeted edits
Round 50
Find the maximum value of a derived per-object numeric attribute and apply a uniform transformation to every object whose attribute equals that maximum.
Round 1 names the actual selector, "max size" — a property a solver can compute. Round 50, after 49 rewrites of the same lineage on the same task, has erased it: the entry no longer records *which* attribute to maximize.
An aside, for the cognitive-science minded
This is exactly what dual-system memory was built to prevent.
Complementary Learning Systems theory [refs] says the brain keeps a fast episodic store and a slow schema-forming store *architecturally distinct*, with consolidation *gated* by schema fit rather than triggered on every event. Collapse the two into one mandatory rewrite loop and you get exactly the interference catastrophe the dual system was designed to avoid.
Today's agentic-memory designs collapse the two. The same LLM that solves the task also rewrites its own memory of that task at every turn, with no gating. Our findings are what that prediction looks like in practice.
Examples
Faulty memory in the wild.
Three real artifacts from real consolidation runs. Verbatim, no edits, just selective highlighting.
Case 1
19 ARC tasks collapsed into a single playbook
GPT-5.4 · 19 tasks spanning 6 families · 10 passes (190 steps) · ground-truth code at every step
After ten passes, the entire memory store contained *one* entry. Not a library. Not even five entries. One.
The only entry left in memory
After 190 consolidation steps
Extract connected objects, choose the largest as a frame, classify other objects by whether their bounding boxes lie strictly inside that frame, erase the frame and all outside objects, then hollow out each inside object in place by turning its interior to color 0 while preserving its boundary.
Internally consistent. Reads like a sensible lesson. The problem: the source pool spans *six* families, and this entry describes *one*. Five families are now invisible to the agent.
Now hand the agent a held-out task whose true rule is "erase every object of color 6." Unrelated to inside-frame logic. Without memory, the same model solves it 10/10:
Without memory
10 / 10
def solve(grid):
# The transformation removes every connected
# component of color 6.
out = [row[:] for row in grid]
for obj in extract_objects(grid):
if obj["color"] == 6:
for r, c in obj["cells"]:
out[r][c] = 0
return outWith memory
0 / 10
def solve(grid):
# Keep only non-frame objects; frames are the
# largest connected components.
h = len(grid); w = len(grid[0]) if h else 0
objs = extract_objects(grid)
if not objs:
return [row[:] for row in grid]
frame = max(objs, key=lambda o: o["size"])
fb = frame["bbox"]
out = [[0] * w for _ in range(h)]
for obj in objs:
if obj is frame: continue
bb = obj["bbox"]
inside = (bb["top"] > fb["top"]
and bb["bottom"] < fb["bottom"]
and bb["left"] > fb["left"]
and bb["right"] < fb["right"])
if inside:
for r, c in obj["cells"]:
out[r][c] = obj["color"]
for obj in extract_objects(out):
apply_hollow(out, obj, fill_color=0)
return outThe first comment of the with-memory solver reproduces the entry verbatim. The code follows the entry's frame-and-hollow recipe: pick a frame by size, copy interior objects, hollow them. On this input, no marker passes the strict-inside check and the canvas stays empty. The memory turned a 10/10 solver into a 0/10 solver.
Case 2
Collapse by accretion: 8 workflows become 16 redundant ones
AWM on WebShop · 128 expert trajectories · gpt-5.4-mini · 3 epochs
After epoch 1 the memory file held 8 abstract workflow templates. By epoch 3 it held 16. The new 8 (highlighted) are not new patterns. They're the same templates, restated with one product category pinned in:
AWM workflow titles, epoch 3
~8.2k chars · verbatim
- W1. Search by attribute-rich query.
- W2. Open candidate item to inspect options.
- W3. Select required attributes before buying.
- W4. Select required size, color, and other variant options before buying.
- W5. Search and select clothing variants with fit type.
- W6. Search and select home decor variants.
- W7. Search and select multi-part apparel sizing variants.
- W8. Search across pages when the first results do not match.
- W9. Select apparel color, size, and fit/order-specific variants before buying.
- W10. Select non-apparel flavor and size variants before buying.
- W11. Select pack-count and color variants before buying.
- W12. Search and select color, size, and shape variants for home goods.
- W13. Search and select shoes with color and size.
- W14. Search and select apparel color, size, and purchase.
- W15. Search and select electronics memory/storage variants.
- W16. Search and select activewear or performance tops variants.
W9 is just W3 + W4 + W5 stitched together. W10–W16 are the same search-then-variant-select template (W1–W4) with one product category pinned in (food, pack-count, home goods, shoes, apparel, electronics, activewear). No new control flow, no new guard, no new stop criterion. *Eight new entries that compete for retrieval bandwidth without adding any generality.*
And it's not benign. Removing just one workflow (W8, "Search across pages when the first results do not match") raises wins from 7/50 to 14/50 on gpt-5.4-mini and from 18/50 to 23/50 on gpt-5-mini — because W8 biases the agent toward dead-loop click[Next >] sequences at the expense of click[Buy Now].
Case 3
ScienceWorld: three flavors of memory rot
An LLM judge labels every entry in the store as *over-generalized*, *over-specialized*, or *useless garbage*. Click a tab to see verbatim entries from each.
Observing all life stages in order MAY BE NECESSARY to complete a turtle-stage task.
Observing all life stages in order MAY BE NECESSARY to complete a moth-stage task.
Using a lighter, fire source, or oven MAY BE NECESSARY to change the state of a food or substance in state-change tasks.
Focusing on the target substance SHOULD BE NECESSARY to change its state.
The first two entries are paraphrases of each other — the consolidator wrote the same lesson twice with different task labels glued on. None of these names a property a solver can actually use to pick an action.
Case 4
A 50-item memory becomes a 1-item memory in a single consolidation step
ALFWorld · gpt-5-nano consolidator · stage 168 → 169 · cap 50 items
At stage 168 the memory holds 50 structured items, ~48k characters, each covering a distinct insight (task taxonomy, state-change shortcuts, look-at-light protocol, multi-object recipes). One consolidation step later, at stage 169, the memory contains a single item:
Stage 169 memory · 1 item · 1,960 chars · verbatim
After one merge step
Use a single, repeatable loop to handle both single and multi-object tasks across cleaning, cooling, heating, and look-at-in-light. 1) Systematically search common room sources… 2) Pick each target; if a state change is required (cool X with fridge, heat X with microwave, or clean X with sinkbasin), perform it while holding… 3) Navigate to the destination… 4) Place the object… 5) If two identical objects must go to the same destination… 6) If an object starts at the destination… 7) Manage distractors… 8) After completing a batch… 9) Look-at-in-light-specific extension: anchor a central desklamp location, co-locate the target and lamp… 10) Pitfalls to avoid…
The cooling-vs-heating asymmetry that was a separate item at stage 168 (cooling needs no insertion; heating does) is gone. The two-object shuttle default is gone. The look-at protocol is now a half-sentence sub-clause inside step 9.
The cost on the next eval, against the same memory's stage-168 snapshot:
Rollout
No memory
Stage 168 (50 items)
Stage 169 (1 item)
Δ
Qwen3.5-4B15/4835/4829/48−6
Qwen3.5-9B15/4836/4826/48−10
Qwen3.5-27B19/4837/4824/48−13
One step. 6 to 13 wins lost. The drop is biggest at the largest rollout: stronger solvers extracted more from the 50-item structured memory, so they lose more when those distinctions collapse into a single "unified loop."
Case 5
99 votes for a tautology: a top-ranked memory that mutated three times
ExpeL on ALFWorld · gpt-5.4 base, gpt-5-nano management · 200 stages
ExpeL ranks memory items by an integer vote score that increments on EDIT. By stage 200, the top slot has 99 votes — the highest in the memory by a factor of 2. This sounds like extreme value. But the score keeps incrementing when an EDIT *replaces* the underlying concept. Tracing the same slot:
Stage 0 28 votes
For tasks phrased as "examine/look at X with/by/using Y," first locate both objects, then prefer the environment's direct task-relevant interaction (e.g., use Y, examine X with Y, or examine X if Y has been activated)…
Concrete: names the look-at-obj-in-light pattern.
↓
Stage 80 46 votes
Prioritize the simplest action that directly advances the current subgoal with the fewest prerequisites and minimal detours, while also favoring actions that reuse already-opened receptacles or inventory-held items…
Generic planning heuristic. Task-type cue gone.
↓
Stage 200 99 votes
Prioritize actions that directly advance the current subgoal using the nearest feasible fixture or item; verify prerequisites before acting; minimize travel; interleave subgoals when beneficial; attempt to combine state-change and final placement… avoid assuming an item's state without explicit verification.
Tautology. Applies to any agent benchmark.
The 99 votes were earned across *three different concepts*. At stage 200, only the third concept is in the slot. The popularity score is a measure of slot edit-volume, not content quality. The most "trusted" memory entry in this run is a directive that ships with every planning agent ever written.
Memory zoo
Click through. Each one is a real entry from a real run.
No charts here, just artifacts. Each tab loads one verbatim entry along with a one-line note on what's broken about it.
GPT-5-mini · ARC-AGI · 200 tasks · entry 1 of memory
"Make a working copy of the input grid (list of row lists) before mutating, perform all modifications on the copy, and return the copy to avoid mutating the original input."
What's wrong. A defensive Python idiom. Mentions no color, shape, or rule that the six task families distinguish themselves by. The model wrote a coding tip and called it a strategy.
The deeper problem
Every consolidation step is a generation. The agent is hallucinating its own past.
The failure is not "the LLM is bad at summarizing." It's structural. We're building a system whose stable long-term knowledge is the fixed point of a generative loop — and there is no fixed point.
Each consolidation pass works like this:
- Read the current memory and a fresh trajectory.
- Generate what the new memory entry "should" be. This is an LLM forward pass. It produces fluent, plausibly-structured text. It is not a faithful summary of the input — it is a sample from a distribution conditioned on the input.
- Write the sample back as if it were ground truth. The next consolidation step reads this sample and conditions on it.
Now stack 200 of these. Step *k+1*'s context is a sample drawn conditioned on step *k*'s sample, which was drawn conditioned on step *k−1*'s, and so on. Plausible-looking text accumulates. Specific facts (which color, which receptacle, which selector) are most likely to drop out at each step because they're the most surprising tokens conditional on the running summary. The memory drifts toward the LLM's prior over what a good lesson looks like, not toward the truth of the trajectories.
The reframe
Continuously updated textual memory is an iterated generative loop with no anchor. The "memory" is not a record. It is a sample — fluent, confident, and increasingly disconnected from what actually happened. We saw vacuous abstractions, phantom rules distilled from bugs, byte-identical duplicates, 99-vote tautologies, 50 items collapsing into one. These are not bugs. They are *what samples from the consolidator's prior look like* after enough iterations.
Why the experiments line up.
Three specific results we showed earlier follow directly from this framing:
- Stream < Static-All < Static-Group. The more times the sample is fed back as context, the more the entry drifts toward the prior. Static-Group resamples once per family; Stream resamples thousands of times.
- Cumulative < Fresh by 203 points. Cumulative consolidates over a growing prefix of past summaries; Fresh consolidates from raw trajectories of one task. Cumulative sits deeper in the loop.
- Episodic-only matches abstraction. Raw episodes are outside the loop. They are not samples. They are records. Of course they hold up better.
The implication is uncomfortable.
The dominant agentic-memory paradigm — "after each task, distill the trajectory into a textual lesson and store it" — is not a way of accumulating experience. It is a way of replacing experience with a slowly-drifting LLM prior over what experience looks like. Until the consolidator is grounded in something it cannot itself overwrite, scaling the experience scales the drift.
A surprisingly strong fix
Don't force abstraction. Just keep the episodes.
ARC-AGI Stream lets us put the agent in charge of its own memory. At each step it can Retain, Delete, or Consolidate. We compare three regimes:
Force
Must consolidate every round. Episodic entries don't persist between rounds. *The default in most existing systems.*
Auto
Agent chooses: retain raw, delete, or consolidate. Both episodic and abstract stores are available at retrieval.
Episodic Only
Retain or delete raw episodes. Abstraction is *disabled entirely*.
ARC-AGI GT Stream: 400 steps, ground-truth solutions, all four management policies.
The cleanest test of the gating prediction is the GT regime, where the agent receives ground-truth solutions at every step. There is no "the trajectories were noisy" excuse here. Whatever happens at the consolidation step is what happens.
To isolate where the Auto+Episodic gain comes from, we re-evaluated four checkpoints from the same run with each memory source restricted in turn: *Abstract Only* reads just the distilled lessons, *Episodic Only* reads just the raw episodic store, and *Auto* reads both.
And the agent itself agrees, when given the choice. It saturates the episodic buffer quickly at every budget level and keeps the abstract store sparse:
The principle
Episodic and schema-forming roles should not be collapsed into a single rewrite loop. Raw episodes are first-class evidence, not material to be compressed away. Abstraction, when it happens, should be *opt-in and gated by the agent* — not forced on every trajectory.
An uncomfortable baseline
An episodic-only memory is competitive with every consolidator we tested.
On WebShop, ALFWorld, and AppWorld, an "episodic-only" memory — just append raw trajectory rollouts to context, no cross-trajectory rewriting — is competitive with ACE, AWM, and Dynamic Cheatsheet. Same trajectories. No distillation step. The solver's in-context learning extracts the relevant signal directly from preserved instances.
We're not saying abstraction is useless. We're saying: a memory method whose value depends on distillation should be tested against the unabstracted rollouts it distills. Currently, very few are.
Takeaways
So — what should you build?
- Treat raw episodes as first-class evidence. Don't compress them away by default. Today's solvers can already use them via in-context learning.
- Make abstraction selective and gated. Not every trajectory needs to become a "lesson". Most should not.
- Decouple the episodic and schema-forming roles. A fast episodic buffer + a slow, gated abstract store dominates a single mandatory rewrite loop.
- Stress-test against scale. A memory system that's good at 8 examples and bad at 128 is not a memory system. It's a prompt with a leak.
- Always include an episodic-only baseline. If your distilled memory can't beat raw rollouts retrieved as in-context demos, the distillation isn't earning its keep.
Continually rewritten memory is fragile.
Persistent textual memory promised a path for LLM agents to improve after deployment without weight updates. Our results say: not yet. Continuously updated textual memory should be viewed not as a reliable engine of self-improvement, but as a fragile mechanism that can make *more experience lead to worse memory*.
Long-horizon agents will need both episodic and schematic memory. But until LLMs can decide *when* and *how* to consolidate, the safer default is to keep the evidence and abstract sparingly — or not at all.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み