エージェント改善ループはトレースから始まる
LangChain Blogは、エージェントの改善におけるトレーシングの基礎的役割と、それが自動化された評価者や人間によるレビューを通じてAIデータフライホイールを駆動する仕組みについて解説している。
キーポイント
トレーシングの基礎的役割
エージェントの理解と改善において、トレースは不可欠な基礎プリミティブ(基本要素)として位置づけられている。
AIデータフライホイールの構築
トレースは自動化された評価ツール、人間のレビュー、オフライン評価、回帰テストを統合し、継続的な改善サイクル(データフライホイール)を可能にする。
実用的な改善プロセス
単なるログ出力ではなく、トレーシングを活用することで、エージェントの動作を定量的・定性的に評価し、モデルやプロンプトの最適化につなげる具体的な手法が示唆されている。
影響分析・編集コメントを表示
影響分析
本記事は、エージェント開発のベストプラクティスにおいて「観測可能性(トレーシング)」が設計段階から不可欠であることを強調しており、開発現場における品質保証プロセスの見直しを促す。LangChainエコシステム内での標準的なワークフローとして定着すれば、エージェントの信頼性向上と開発効率化に大きく貢献する可能性がある。
編集コメント
エージェントの実用化において「いかに改善するか」が課題となる中、その起点としてトレーシングの重要性を明確に示した重要な提言である。開発者は単なるログ出力ではなく、評価可能なデータとしてのトレーシング設計を意識すべきだ。
主要なポイント
- エージェントとは、モデルを中心に複数のレイヤーで構成されるシステムです。更新可能な要素には、モデルの重み(weights)、オーケストレーションコード、そしてコンテキスト(プロンプト、指示、スキル)が含まれます。どの部分を変更すべきかを判断するには、トレース(trace:実行履歴やログ)からの証拠が必要です。
- トレースはあらゆる場所から取得できます。ステージング環境、テスト実行、ベンチマーク、ローカル開発、そして特に本番環境(production)からです。ソースがどこであれ、改善ループは同じです。
- このループには、トレースに評価(evals)や人間のフィードバックを追加し、失敗パターンを特定し、対象を絞った変更を行い、リリース前に検証するというプロセスが必要です。各サイクルはより良いデータと、より信頼性の高い反復処理を生み出します。
- LangSmith は、最初のトレースから回帰テスト(regression)を防ぐ CI/CD までのゲートに至るまで、このループのすべてのステップを結びつけます。
エージェントの改善ループは原理的には単純です:トレースを取得し、それを充実させ、そこから改善し、繰り返す。このガイドでは、その実践的な方法について解説します。
エージェントを体系的に改善するには、フィードバックループが必要です。まずエージェントの動作のトレース(実行履歴)を収集し、評価や人間のフィードバックでそれを充実させ、何が失敗しておりその理由は何かを特定し、対象を絞った変更を行い、それらが機能したことを確認してからリリースします。その後、より高いベースラインから再び繰り返します。
このループを動かすのはトレースです。これらのトレースは、ステージング環境やベンチマークの実行、ローカル開発、そして何より本番環境など、さまざまな場所から取得できます。重要なのは、これらのトレースを収集し、それを強化(エンリッチ)して、そのデータをシステム改善に活用することです。
このガイドでは、フィードバックループの各ステップを順を追って解説します。
トレースは原材料である
ハリソンはこう明確に述べています:「ソフトウェアではコードがアプリケーションを文書化するのに対し、AIではトレースが行う。」
従来のアプリケーションでは、コードがシステムが行うことの権威ある記録です。これを読み、推論し、テストを行い、原理的にすべての挙動を理解することができます。
一方、エージェントシステムでは、コードはエージェントが*許可されている*行動を示します。トレースは、特定の入力と条件下で、この実行においてエージェントが実際に*何を行ったか*を示します。

トレースは、エージェントの実行全体を記録します。すべてのLLM呼び出し、ツール呼び出し、検索ステップ、中間出力、そしてそれらを結びつける一連の意思決定が含まれます。これは、特定の条件下で、この入力に対して、この実行においてエージェントが実際に何を行ったかという記録です。
生ログは、何が起こったかを示します。評価者によってスコアリングされ、レビュアーによって注釈が付けられた強化されたログは、それに対してどう対処すべきかを教えてくれます。このループの残りの部分は、その強化レイヤーを構築し、それを使用して対象的で検証された改善を行うことです。
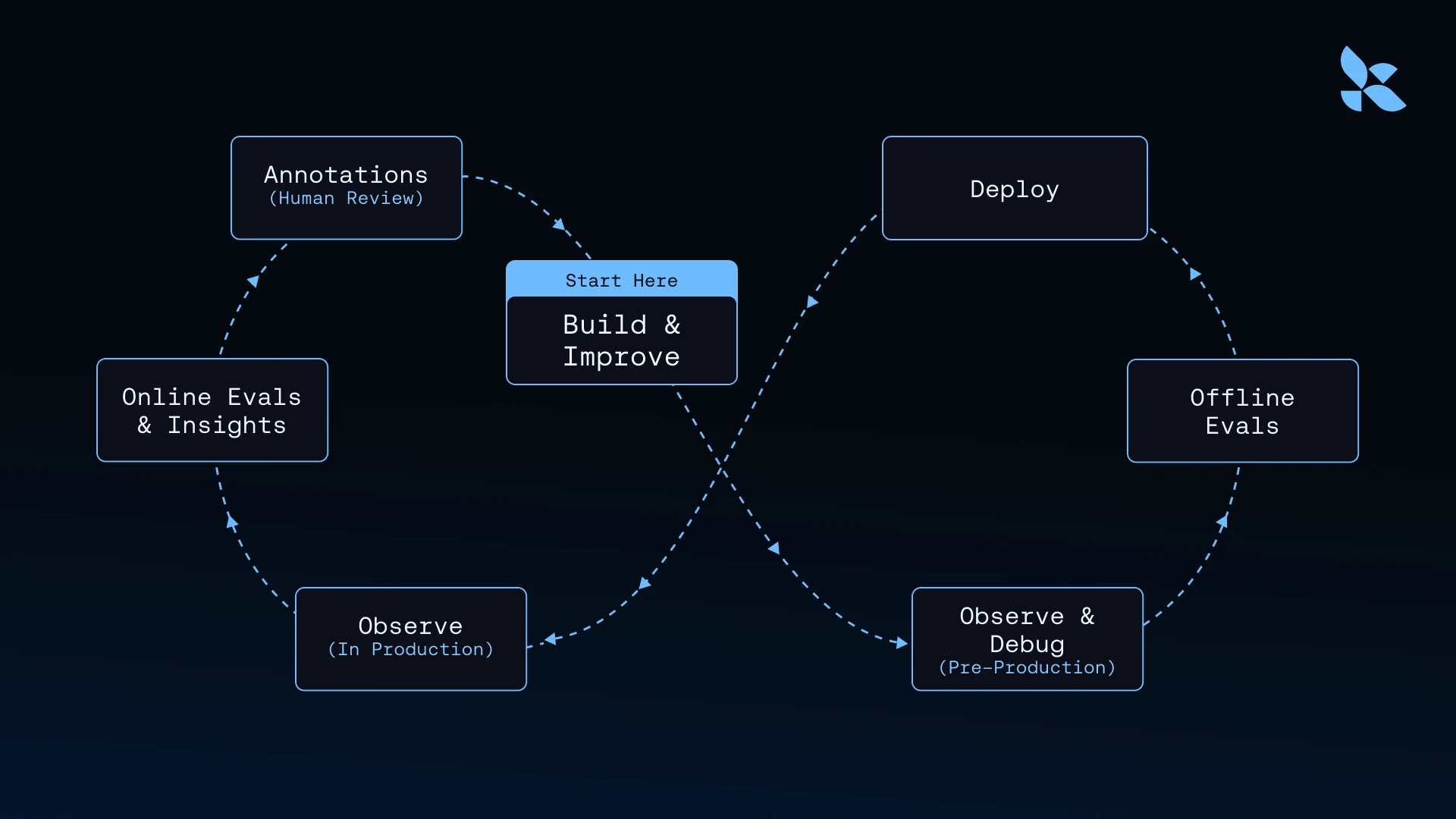
エージェント改善ループ

ログが取得できれば、エージェントの改善は具体的かつ反復可能になります。ループは以下のようになります。
1. 構築と改善: 既知のもの、つまりエージェント、タスク、そして何がより良くなる可能性があるかという仮説から始めます。開発者はネガティブなスコアを持つログをレビューし、失敗パターンをフィルタリングして、悪い結果を生み出した軌跡を検査します。何を修正すべきかを推測するのではなく、観察された動作から逆算して作業を行います。生ログから浮き彫りになる失敗モードが、コードやプロンプトの変更への入力となります。
2. 観察とデバッグ(本番環境前): 開発者は更新されたエージェントをステージング環境で実行します。ログは、正式な評価の前であっても、修正が意図通りに動作するかどうかを明らかにします。
3. オフライン評価: 強化されたトレースは再現可能なテストケースに変換されます。繰り返される失敗モードが評価者となり、問題を引き起こした実際の入力のセットがデータセットとなります。リリース前に開発者は更新されたエージェントに対してオフライン評価スイートを実行し、具体的な「改善前」と「改善後」の比較を行います。修正が機能すればスコアは向上し、回帰(regression)が発生した場合はユーザーに届く前にそれが浮上します。合格した評価は恒久的なテストスイートに追加されます。
4. デプロイ: 修正がリリースされ、新しいトレースの蓄積が始まります。次のサイクルはより高いスタート地点から始まります。
5. 監視(本番環境において): 本番環境でのエージェントの実行ごとにトレースが生成されます。これには入力、出力、軌跡(trajectory)、ツール呼び出し、トークン使用量、レイテンシが含まれます。これらは次のサイクルの生素材であり、エージェントが実際に何を行ったかという真の根拠となります。
6. オンライン評価とインサイト: 追加のシグナルを伴う場合、生のトレースはより有用になります。自動化された評価器が出力を継続的にスコアリングします。インサイトレポートは、大量のトレースにわたる使用パターン、失敗モード、エッジケースを浮上させます。
7. アノテーション: 人間のレビュアーは選択されたトレースに、評価、修正、コメントを付して注釈を付けます。各強化レイヤーは生の行動記録にコンテキストを追加し、次のビルドサイクルに戻ってフィードされるラベル付きデータを構築します。
このループは複利のように機能し、各サイクルがより良いデータを生成します。トレースが増えるほど、失敗モードの例が多くなります。例が増えるほど評価が精密になり、評価が精密になるほど反復が信頼できます。
LangSmith によるトレースからの自動データ生成
エージェントの改善を駆動するデータには、自動的に生成されるものと人間が生成するものの2つのカテゴリがあります。LangSmith はこの両方の作成をサポートします。データを自動的に生成するには、オンライン評価ツール(Online Evaluators)と Insights Agent を使用できます。
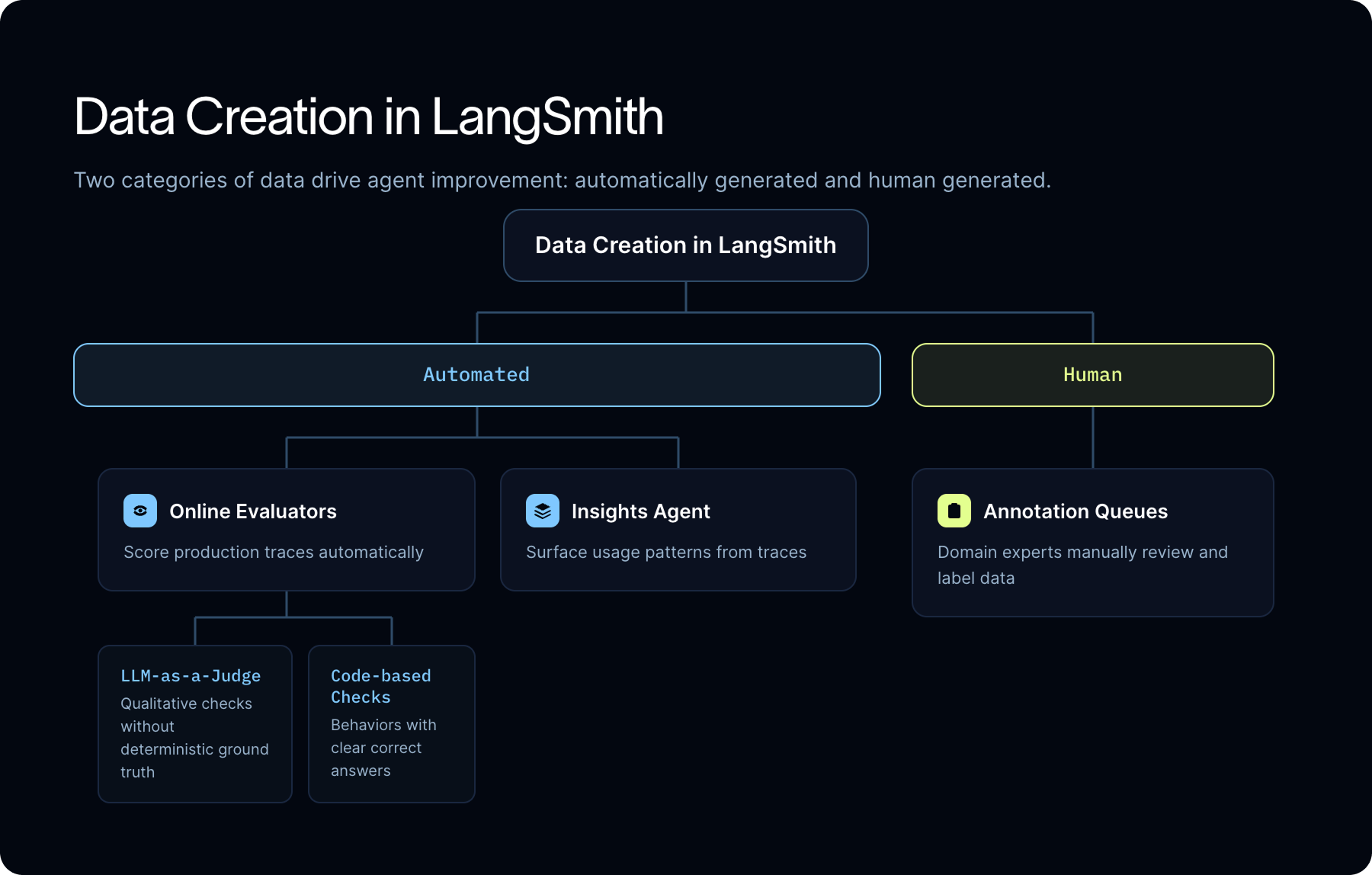
オンライン評価ツール(Online Evaluators)
オンライン評価ツールは、本番環境のトレースに対して自動的に実行され、設定可能な品質基準に基づいて出力にスコアを付けます。すべてのトレース、サンプリングされたサブセット、または特定の基準に基づいてフィルタリングされたサブセットに対して実行するように構成できます。
評価方法は、評価対象によって異なります。
確定的な正解(Ground Truth)が存在しない定性的な次元については、有用性、トーン、関連性、ポリシー準拠、事実上の妥当性を評価します。LLM-as-a-judge(LLM 判定者)を使用します。この評価ツールは、最終的な応答だけでなく、完全なトランジェクトリ(軌跡)を評価するために LLM を呼び出します。エージェントは正しいツールを、正しい順序で、正しいパラメータで使用したでしょうか?
明確な正解がある行動に対しては、コードベースのチェックを使用してください。スキーマ検証、完全一致条件、フォーマット準拠、ビジネスルールの遵守、およびツールの正確性はすべて決定論的に評価可能であり、それらをLLM(大規模言語モデル)の判定者にルーティングするよりも高速かつ低コストで実行できます。
反復される洞察とレポート

LangSmithのInsights Agentは、本番環境のトレースに対して自動クラスタリングを実行し、使用パターン、失敗モード、およびエッジケースを浮き彫りにします。これはモニタリングとは異なります:すでに定義した指標を追跡しているのではなく、探すことすら知らなかったパターンを発見しています。
顧客対応エージェントを管理するチームは、「ユーザーはこのエージェントを使って実際に何をしているのか?」と問いかけるかもしれません。Insights Agentは数千のトレースを分析し、意図によってグループ分けして、誰も予想していなかったものを含む主要なカテゴリを表面化できます。同じ分析を負のフィードバックや低いスコアを持つトレースに適用することで、エージェントがどこで一貫して不足しており、その理由は何かを明らかにできます。
自動化の限界:人間の判断が依然として重要である
自動評価器と洞察はスケーラビリティに優れていますが、人間の判断を置き換えるものではありません。
ドメインの専門知識を持つ人間でなければ評価できないエージェントの振る舞いがあります。根拠はありそうだが不正確な判例を引用する法務調査エージェントは、LLM(大規模言語モデル)による自動審査を欺く可能性があります。技術的には正しくても臨床的に不適切な助言を与える医療情報エージェントは、自動チェックでは問題ないように見えます。専門分野における微妙な失敗には、「正解」が何を意味するかを理解するレビューアーが必要です。
そこで登場するのが注釈キュー(アノテーションキュー)です。

チームはフィルタを使用して、選択された本番環境のトレース(実行履歴)を注釈キューにルーティングできます。これには、自動スコアが低いトレース、特定の特徴領域からのトレース、エンドユーザーから「低評価」のフィードバックを受けたトレースなどが含まれます。レビューアーは完全なコンテキストを確認し、評価、修正、コメント、および編集された出力を残すことができます。
実際には、チームは注釈キューを以下の4つの主要な方法で活用しています:
- オンライン評価者の整合性調整:レビュアーはトレースにラベルを付け、LLM-as-a-judge(LLMによる評価者)を較正します。レビュアーと自動化された評価者の間で意見が分かれた場合、そのようにラベル付けされた例は、スコアが人間の判断を反映するまでグラダー(採点者)を調整するために活用されます。
- オフラインデータセットの正解(Ground Truth)作成:レビュアーは、トレースに対する正しい最終出力にラベルを付けます。これらはオフライン評価スイートにおける期待される回答となり、本番環境の入力に対して将来のバージョンの正確性をテストすることを可能にします。
- オープンエンドな出力の評価:単一の正解が存在しない場合、レビュアーは良好な回答を定義する基準にラベルを付けます。この構造化されたフィードバックは、正確な一致チェックでは扱いきれないような微妙な次元における評価者の基盤となります。
- 自然言語による注釈:レビュアーは、トレースに対して自由形式のコメントや修正を付加します。これらはインサイトエージェント(Insights Agent)の分析に流れ、スコアだけでは見えないパターンを浮き彫りにします。
最初のユースケースと残りの3つを区別する価値があります。オンライン評価者の整合性のために注釈を付けることは、ライブモニタリングの改善につながります。つまり、継続的で自動化されたスコアリングをより正確にしているのです。他の3つは主にオフラインデータセットの構築、そして出荷前に修正をテストできる正解や品質ラベルの作成に関するものです。
実際には、2つのレビュアーのプロファイルが一般的です。
- 一般レビュアー:契約社員、注釈担当者、カスタマーサクセスチームは、表面的な品質シグナルを評価できます。彼らは、回答が有用だったか、可視情報に対して正確だったか、トーンが適切だったかを判断します。
- ドメインエキスパート:エージェントが対応する分野の製品マネージャー、SME(専門知識を持つ者)、およびスペシャリストは、自動化が完全に見逃すような失敗を含む、文脈におけるエージェントの行動が適切だったかどうかを判断できます。
多くの場合、この時点ではまだヒューマン・イン・ザ・ループ(人間による監視)が必要です。
強化されたトレースの活用:構築と改善
強化されたトレースは、エージェントが一貫してどこで失敗するかを理解するための生データとなります。
複数のトレースにわたって現れるパターンは、個々の例よりも具体的で実行可能です。あなたは、エージェントが特定のタイプのクエリを常に誤解している、あるいは特定の文脈で常に間違ったツールを選択しているといった傾向に気づき始めます。
個々の実行をスポットチェックするだけでは、パターンレベルの理解を得ることは困難です。それには、本番環境での実際の行動から得られた、一貫したラベル付けされた大規模なデータが必要です。
修正策は、トレースが明らかにする内容に依存します。エージェントがあるクラスのクエリに対して誤ったツールを選択している場合、それはツールの説明を更新するかルーティングロジックを追加する必要があることを意味します。マルチステップタスクの途中で推論が逸脱している場合、より制約の厳しいシステムプロンプトを使用するか、タスクを小さく焦点を絞ったステップに分割します。エージェントが事実上は正しい出力を生成するものの、ユーザーの実際の意図を見落としている場合、通常はプロンプトレベルの問題であり、「良い」状態が指示書の中でどのように定義されるかを明確にする必要があります。そして時折、トレースは構造的な問題を明らかにします:エージェントが全く異なるツールを必要としている場合や、特定の意思決定ポイントで人間が関与するチェックポイントをワークフローに追加する必要がある場合です。
これらの変更のすべては、仮説的な失敗モードではなく、特定の観測された行動によって裏付けられます。開発者は、どのトレースが失敗し、どのように失敗し、注釈付きフィードバックがその理由を何と言っているかを正確に見ることができるため、プロンプトを書き直しています。
オフライン評価により、これらのプロンプトおよびコード変更を測定可能にします。
本番環境の失敗をオフライン評価に変える
修正すべき対象を特定したら、その修正が実際に機能することを確認する方法が必要です。ここでオフライン評価が登場します。
これらの評価用のデータセットは、本番環境から取得すべきです:実際のトレース、実際のクエリ、実際の失敗。
それらの評価が実際に測定する内容は、注釈作業によって生成された結果に依存します。2つの異なるアプローチがあります:
- 正解(Ground truth)の正確性:レビュアーがトレースに対して正しい最終出力をラベル付けしている場合、その正確性について直接テストできます。洗練されたエージェントをデータセットに対して実行し、エージェントの出力とラベル付けされた正解を比較します。修正が機能すればスコアは向上し、回帰(regression)を引き起こす場合、評価(eval)がユーザーに届く前にそれを検出します。
- 基準に基づくスコアリング:すべての出力に単一の正解があるわけではありません。オープンエンドなタスクの場合、レビュアーは応答そのものではなく、良好な応答を定義する基準にラベルを付けます。オフライン評価(Offline evals)は、これらの基準を使用して更新版からの出力にスコアを付け、正確な一致を必要とせずに、関連性、完全性、トーンなどの次元での改善を測定できます。
評価(eval)としてエンコードされた失敗モードは、テストスイートに恒久的に残すべきです。これにより、エージェントが処理できるようになった内容の耐久性のある記録と、既存の問題を再導入しないことを保証するゲートが作成されます。
オンライン評価とオフライン評価の併用

オンライン評価者(Online evaluators)は、ライブの動作を継続的に監視します。品質のドリフトを検出し、新たな失敗パターンを表面化させ、人間によるレビューが必要なトレースにフラグを立てます。ただし、リリース前に変更を検証することはできません。
オフライン評価は、そのために役立ちます。これらは本番環境への変更が行われる前に、開発段階で整備されたデータセットに対して実行される制御実験です。
これらを組み合わせることで、本番環境での観察と安全な反復の間に橋渡しを行います。オンライン評価は「何が間違っているか」を明らかにし、オフライン評価は「修正が実際にその問題を解決しているか」を確認します。
評価としてエンコードされた失敗モードは、テストスイートに恒久的に残すべきです。これにより、エージェントが処理できるようになった内容の耐久性のある記録と、将来の変更によってすでに解決した問題が再導入されないことを保証するゲートが作成されます。
プロンプトの変更、モデルの更新、ワークフローの変更、アーキテクチャの変更のいずれにおいても、リリース前に蓄積された評価スイートに対して実行する必要があります。同じ評価セットを継続的に実行し、バージョンやモデル構成間でスコアを比較することで、改善ループを測定可能なものに変えることができます。各反復が単に異なるエージェントではなく、より良いエージェントを生み出したことを証明できます。
ループ内でのコーディングエージェント
改善ループはより自動化されつつあり、トレーシングもその中心に位置し続けています。
LangSmith CLI and Skills は、コーディングエージェントにターミナルから直接 LangSmith データへのエキスパートレベルのアクセスを提供します。LangSmith Skills を装備した Claude Code は、評価セットにおいてパフォーマンスが 17% から 92% に跳ね上がりました。
実際には、開発者はコーディングエージェントに対して過去30日間の本番環境でのトレース(実行履歴)を取得し、低評価のフィードバックが付いたトレースを抽出し、それらが表す失敗パターンを特定し、その例から評価基準を作成し、それに対処するためのプロンプトやコードの変更案を提案するよう指示できます。これら一連の作業は、実際の行動データに基づき、単一のターミナルセッション内で完結します。
しかし、トレースデータを持たないコーディングエージェントは、不完全な情報に基づいて変更を行います。コードレビューの観点からは妥当に見える修正を提案しますが、その失敗を引き起こした実行軌跡(トレース)を見ることができないため、実際の失敗モードを見逃してしまいます。一方、豊富なトレース情報を用いて作業するコーディングエージェントは、シニアエンジニアが使用するのと同じ情報に基づいて判断しています。
トレースはエージェント改善ループの中核です
信頼性の高いエージェントは、個々のトレースのデバッグから構築されるものではありません。それらは、トレース中心の改善ループによって構築されます。
このループはトレースから始まり、再びトレースに戻ります。すべての評価器(evaluator)はトレース上で動作します。すべての注釈はトレースに付随します。すべてのオフラインデータセットはトレースから構築されます。すべての回帰テストは、実際のトレースで観測された事象に対して検証されます。次の修正を提案するコーディングエージェントも、それを行うためにトレースから読み取ります。
そのため、トレースは単なるデバッグツールではありません。それは全体の改善ループを可能にする基本要素であり、すべての評価、すべての人間のフィードバック、そしてすべての体系的な改善の源泉となる基盤です。
ループはトレースから始まります。そして、次のループは戻ってきたトレースから始まります。
追加の読み物
- 「エージェントの観測可能性は、エージェント評価を可能にします」
- 「本番環境にデプロイするまで、エージェントが何をするかは分かりません」
- LangSmith ドキュメント - 「オフライン評価の種類」
- LangSmith ドキュメント - 「オンライン評価の種類」
- LangSmith ドキュメント - 「注釈キュー」
- LangSmith ドキュメント - 「インサイト」
関連コンテンツ

ケーススタディ
LangSmith
Credit Genie が Insights Agent を活用して AI 財務アシスタントを改善した方法




D. Li,
J. Ngai,
G. Lozano Palacio,
C. Yuan
2026 年 4 月 20 日
5 分

概念ガイド
Deep Agents
本番環境のディープエージェントを支えるランタイム


S. Runkle,
V. Trivedy
2026年4月20日
24分

観測可能性(Observability)と評価(Evals)
LangSmith
LangSmithにおける再利用可能な評価器と評価テンプレート


C. Qiao,
J. Talbot
2026年4月16日
4分

エージェントが実際に何を行っているかを確認する
LangSmithは、エージェントエンジニアリングプラットフォームであり、開発者がすべてのエージェントの意思決定をデバッグし、評価(eval)の変更を確認し、ワンクリックでデプロイすることを支援します。
原文を表示
Key Takeaways
- An agent is a system around a model with several layers you can update: the model weights, the orchestration code, and the context (prompts, instructions, skills). Knowing what to change requires evidence from traces.
- Traces can come from anywhere: staging, test runs, benchmarks, local development, and especially from production. The improvement loop is the same regardless of source.
- The loop requires enriching traces with evals and human feedback, identifying failure patterns, making targeted changes, and validating before shipping. Each cycle generates better data and more reliable iteration.
- LangSmith connects every step of this loop, from the first trace to the CI/CD gate that prevents regressions from shipping.
The agent improvement loop is simple in principle: get traces, enrich them, improve from them, repeat. This guide walks through how to do that in practice.
Improving an agent systematically requires a feedback loop. You collect traces of agent behavior, enrich them with evaluations and human feedback, identify what's failing and why, make targeted changes, and validate that those changes worked before shipping. Then you repeat from a higher baseline.
This loop is powered by traces. These traces can come from many places – from staging environments, benchmark runs, local development, and especially from production. What matters is collecting these traces, enriching them, and using that data to improve the system.
This guide walks through each step of that feedback loop.
Traces are the raw material
Harrison put it directly: "In software, the code documents the app; in AI, the traces do."
In a traditional application, the code is the authoritative record of what the system does. You can read it, reason about it, test against it, and understand every behavior in principle.
In an agentic system, the code tells you what the agent is *allowed* to do. The traces tell you what it actually *did* in this run, with this input, under these conditions.
A trace captures the full execution of an agent run: every LLM call, every tool invocation, every retrieval step, every intermediate output, and the sequence of decisions connecting them. It's the record of what the agent actually did with this input, under these conditions, in this run.
A raw trace tells you what happened. An enriched trace, scored by evaluators and annotated by reviewers, tells you what to do about it. The rest of this loop is about building that enrichment layer and using it to make targeted, validated improvements.
The agent improvement loop
Once you have traces, improving an agent becomes concrete and repeatable. The loop looks like this:
1. Build and improve: Start with what you know – an agent, a task, and a hypothesis about what could be better. Developers review traces with negative scores, filter for failure patterns, and inspect the trajectory that produced a bad outcome. Instead of guessing at what to fix, they work backward from observed behavior. The failure modes that emerge from real traces become the input to code and prompt changes.
2. Observe and debug (pre-production): Developers run the updated agent in a staging environment. Traces reveal whether the fix behaves as intended before any formal evaluation.
3. Offline evals: Enriched traces get converted into reproducible test cases. A recurring failure mode becomes an evaluator. A set of real inputs that exposed a problem becomes a dataset. Before shipping, developers run the offline eval suite against the updated agent, producing a concrete before-and-after comparison. If the fix works, scores improve. If it introduces a regression, that surfaces before it reaches users. Passing evaluations get added to the permanent test suite.
4. Deploy: The fix ships, and new traces start accumulating. The next cycle begins from a higher starting point.
5. Observe (in production): Every agent run in production generates a trace: inputs, outputs, trajectory, tool calls, token usage, latency. This is the raw material for the next cycle, and the source of truth for what the agent actually did.
6. Online evals and Insights: Raw traces become more useful when they carry additional signals. Automated evaluators score outputs continuously. Insights reports surface usage patterns, failure modes, and edge cases across large volumes of traces.
7. Annotations Human reviewers annotate selected traces with ratings, corrections, and comments. Each enrichment layer adds context to the raw behavioral record, building the labeled data that feeds back into the next build cycle.
The loop compounds because each cycle generates better data. More traces mean more examples of failure modes. More examples mean more precise evaluations. More precise evaluations mean more reliable iteration.
How LangSmith generates data from traces automatically
There are two categories of data that drive agent improvement: automatically generated and human generated. LangSmith helps you create both. To generate data automatically, you can use online evaluators and Insights Agent.
Online evaluators
Online evaluators run automatically on production traces, scoring outputs against configurable quality criteria. You can configure them to run on all traces, a sampled subset, or filtered subsets based on specific criteria.
The grading method depends on what you're evaluating.
For qualitative dimensions without deterministic ground truth, helpfulness, tone, relevance, policy adherence, factual plausibility, use an LLM-as-a-judge. The evaluator calls an LLM to assess not just the final response but the full trajectory: did the agent use the right tools, in the right order, with the right parameters?
For behaviors with clear right answers, use code-based checks. Schema validation, exact-match conditions, format conformity, business rule compliance, and tool correctness can all be evaluated deterministically, and doing so is faster and cheaper than routing them through an LLM judge.
Recurring insights and reports
LangSmith's Insights Agent runs automated clustering over production traces to surface usage patterns, failure modes, and edge cases. This is different from monitoring: you're not tracking metrics you already defined, you're discovering patterns you didn't know to look for.
A team managing a customer-facing agent might ask: "What are users actually trying to do with this agent?" Insights Agent can analyze thousands of traces, group them by intent, and surface the top categories, including ones no one anticipated. The same analysis applied to traces with negative feedback or low scores reveals where the agent is consistently falling short and why.
Where automation stops: human judgment still matters
Automated evaluators and insights scale well, but they don't replace human judgment.
Some agent behaviors can only be assessed by someone with domain expertise. A legal research agent that cites plausible-sounding but inaccurate precedents might fool an LLM judge. A medical information agent that gives technically correct but clinically inappropriate guidance looks fine to an automated check. Nuanced failures in specialized domains require reviewers who understand what "correct" actually means.
That's where annotation queues come in.
Teams can route selected production traces into annotation queues using filters: traces with low automated scores, traces from a specific feature area, traces that received thumbs-down feedback from end users. Reviewers see the full context and can leave ratings, corrections, comments, and edited outputs.
There are four main ways teams use annotation queues in practice:
- Aligning online evaluators: Reviewers label traces to calibrate LLM-as-a-judges. When reviewers and the automated evaluator disagree, those labeled examples help tune the grader until its scores reflect human judgement.
- Creating ground truth for offline datasets: Reviewers label the correct final output for a trace. These become the expected answers in your offline eval suite, letting you test future versions for correctness against production inputs.
- Scoring open-ended outputs: When there's no single correct answer, reviewers label the criteria that define a good response. This structured feedback becomes the basis for evaluators on dimensions that are too nuanced for exact-match checks.
- Natural language annotations: Reviewers attach freeform comments and corrections to traces. These flow into Insights Agent analysis, surfacing patterns that scores alone won't show.
It's worth distinguishing between the first use case and the rest. Annotating to align online evaluators improves your live monitoring: you're making continuous, automated scoring more accurate. The other three are primarily about building offline datasets, creating the ground truth and quality labels that let you test a fix before it ships.
Two reviewer profiles are common in practice.
- General reviewers: Contractors, annotators, customer success teams can assess surface-level quality signals. They judge if the response was helpful, if it was accurate relative to visible information, and if the tone was appropriate.
- Domain experts: Product managers, SMEs, and specialists in the field the agent serves can judge whether the agent behaved correctly in context, including failures that automation will miss entirely.
Often, at this point in time, you still need a human-in-the-loop.
What to do with enriched traces: build and improve
Enriched traces become the raw material for understanding where an agent consistently fails.
The pattern that emerges across multiple traces is more actionable than any individual example. You’ll start to see that your agent consistently misunderstands queries of a certain type or always selects the wrong tool in a particular context.
Pattern-level understanding is hard to gain by spot-checking individual runs. It requires data at scale, with consistent labels, from real production behavior.
The fix depends on what the traces reveal. If the agent is selecting the wrong tool for a class of queries, that might mean updating tool descriptions or adding routing logic. If the reasoning drifts partway through a multi-step task, a more constrained system prompt or breaking the task into smaller, more focused steps. If the agent produces outputs that are factually correct but miss the user's actual intent, that's usually a prompt-level issue and requires clarifying what "good" looks like in the instructions. And sometimes the trace reveals a structural problem: the agent needs a different tool entirely, or the workflow needs a human-in-the-loop checkpoint at a specific decision point.
Each of these changes is informed by specific, observed behavior rather than hypothetical failure modes. A developer is rewriting a prompt because they can see exactly which traces failed, how they failed, and what the annotated feedback says about why.
Offline evaluations then make these prompt and code changes measurable.
Turning production failures into offline evaluations
Once you've identified what to fix, you need a way to test that the fix actually works. That's where offline evaluations come in.
The dataset for those evals should come from production: real traces, real queries, real failures.
What those evaluations actually measure depends on what the annotation work produced. There are two distinct approaches:
- Ground truth correctness: When reviewers have labeled the correct final output for a trace, you can test directly for correctness. Run your refined agent against the dataset and compare the agent's output to the labeled ground truth. If the fix works, scores improve. If it introduces a regression, the eval catches it before it reaches users.
- Criteria-based scoring: Not every output has a single correct answer. For open-ended tasks, reviewers label the criteria that define a good response rather than the response itself. Offline evals use those criteria to score outputs from updated versions, letting you measure improvement on dimensions like relevance, completeness, or tone without requiring an exact match.
Every failure mode you encode as an eval should stay in your test suite permanently. That creates a durable record of what your agent has learned to handle, and a gate that ensures future changes don't reintroduce problems you already solved.
Online + offline evals together
Online evaluators monitor live behavior continuously. They catch quality drift, surface emerging failure patterns, and flag traces for human review. But they don't let you validate a change before it ships.
Offline evaluations help with that. They're controlled experiments you run on curated datasets in development, before any change reaches production.
Together, they create a bridge between production observation and safe iteration. Online evals tell you what's going wrong. Offline evals confirm whether your fix actually addresses it.
Every failure mode you encode as an eval should stay in your test suite permanently. That creates a durable record of what your agent has learned to handle, and a gate that ensures future changes don't reintroduce problems you already solved.
Every prompt change, model update, workflow modification, or architecture change should run against the accumulated eval suite before shipping. Running the same eval sets continuously and comparing scores across versions and model configurations turns the improvement loop into something measurable. You can demonstrate that each iteration produced a better agent, not just a different one.
Coding agents in the loop
The improvement loop is becoming more automated, and tracing stays at the center of that too..
The LangSmith CLI and Skills give coding agents expert-level access to LangSmith data directly from the terminal. When equipped with LangSmith Skills, on our eval set, Claude Code's performance jumped from 17% to 92%.
In practice, a developer can instruct a coding agent to pull the last 30 days of production traces, isolate traces with thumbs-down feedback, identify the failure patterns they represent, draft evaluations from those examples, and propose prompt or code changes to address them. All of that happens within a single terminal session, grounded in real behavioral data.
But a coding agent without trace data makes changes based on incomplete information. It will propose fixes that look reasonable from a code-review perspective but miss the actual failure mode because they can't see the execution trajectory that produced it. A coding agent working from enriched traces is working from the same information a senior engineer would use.
Tracing is the cornerstone of your agent improvement loop
Reliable agents aren't built from debugging individual traces. They're built from a trace-centered improvement loop.
The loop begins with tracing and returns to tracing. Every evaluator runs on traces. Every annotation is attached to a trace. Every offline dataset is built from traces. Every regression test validates against what was observed in real traces. The coding agent that proposes the next fix reads from traces to do it.
That is why tracing is not just a debugging tool. It's the primitive that makes the entire improvement loop possible, the foundation from which all evaluation, all human feedback, and all systematic improvement is derived.
The loop starts with a trace. And the next loop starts with the trace that comes back.
Additional reading
- "Agent observability powers agent evaluation"
- "You don't know what your agent will do until it's in production"
- LangSmith Docs - "Offline evaluation types"
- LangSmith Docs - "Online evaluation types"
- LangSmith Docs - "Annotation queues"
- LangSmith Docs - "Insights"
Related content
Case Studies
LangSmith
How Credit Genie used Insights Agent to improve their AI financial assistant
D. Li,
J. Ngai,
G. Lozano Palacio,
C. Yuan
April 20, 2026
5
min
Conceptual Guide
Deep Agents
The runtime behind production deep agents
S. Runkle,
V. Trivedy
April 20, 2026
24
min
Observability & Evals
LangSmith
Reusable Evaluators and Evaluator Templates in LangSmith
C. Qiao,
J. Talbot
April 16, 2026
4
min
See what your agent is really doing
LangSmith, our agent engineering platform, helps developers debug every agent decision, eval changes, and deploy in one click.
関連記事
トークンストリームからエージェントストリームへ
LangChain と LangGraph が、Deep Agents の最新ストリーミング機能を活用し、型安全なイベントやマルチモーダル出力を実現するプロダクション対応のエージェントアプリケーション構築を可能にした。
エージェントの観測可能性:本番環境でのLLMエージェントの監視と評価方法
LLMエージェントの本番環境におけるモニタリングには、新しい観測ツールが必要である。大規模なAIエージェントのトレース、評価、改善を行う手法について解説する。
LangChainガイド:観測可能性を用いたAIエージェントのデバッグと評価方法
LangChainは、観測可能性を活用してAIエージェントを効果的に評価する方法を解説する。トレーシングや推論のデバッグ、パフォーマンス分析を通じて、エージェントの動作を反復改善する手法を示している。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み