Arcee AI、米国産オープンモデルに全集中
Arcee AI は、米国製オープンモデルの先駆けとして、NVIDIA Blackwell B300 を活用し約 2000 万ドルで 17 トリオントークン規模の「Trinity Large」モデルを開発・公開した。
キーポイント
米国製大規模オープンモデルの登場
Arcee AI は、米国国内で構築された最先端のオープンモデル「Trinity Large」をリリースし、既存のクローズドモデルや他社製オープンモデルに対抗する新たな選択肢を提供した。
NVIDIA Blackwell B300 による大規模トレーニング
400B パラメータ(13B アクティブ)の MoE アーキテクチャを持つモデルを、17 トリオントークンで学習させるという前例のない規模のトレーニングを、NVIDIA Blackwell B300 環境で行った。
コスト効率とリスク管理の実証
計算資源、人件費、データ、インフラを含め、この大規模プロジェクト全体を約 2000 万ドルで完遂し、スタートアップが最先端モデル開発に挑む際の現実的なコスト構造を示した。
真のベースモデルへのコミットメント
SFT データや学習率の調整が含まれていない「真のベースモデル」を公開することで、研究者や開発者が独自に微調整を行うための透明性と柔軟性を確保している。
米国製オープンモデルへの集中と Trinity シリーズ
Arcee AI は米国で構築されたオープンウェイトモデルに注力しており、400B パラメータ(13B アクティブ)の「Trinity Large」を含む複数のサイズでモデルを公開している。
技術的戦略:Muon 最適化と MoE アーキテクチャ
学習プロセスには Muon オプティマイザを採用し、計算効率を高めるため Mixture of Experts (MoE) アーキテクチャを活用してスケーラビリティを実現している。
オープンソースをビジネスの城壁へ
モデルやツール(MergeKit, DistillKit など)をオープンソース化することで、企業向けエンタープライズグレードの製品とエコシステムにおける競争優位性(モート)を築いている。
重要な引用
All in—compute, salaries, data, storage, ops—we pulled off this entire effort for $20 million.
The Trinity Large model, an MoE with 400B total and 13B active tokens trained to 17 trillion tokens is the first publicly shared training run at this scale on B300 Nvidia Blackwell machines.
We don't have infinite retries.
The Trinity Manifesto: US Open Weights
Open Source as a Business Moat
nobody really has a good business plan for open models, and you just gotta try to figure it out
影響分析・編集コメントを表示
影響分析
この記事は、スタートアップ企業が米国国内で最先端のオープンモデルを開発・公開する現実的な可能性を示す重要なマイルストーンです。特に、NVIDIA Blackwell B300 を活用した大規模トレーニングと、そのコスト構造の透明性は、業界全体がクローズドモデル依存から脱却し、オープンなエコシステムを構築する上で決定的な役割を果たすでしょう。
編集コメント
スタートアップが最先端の LLM 開発に挑む際の現実的なコストとリスクを赤裸々に語った内容であり、業界の「オープンモデル」競争における新たな基準を示す重要なニュースです。
Arcee AI は、オープンモデルの収益化において最も現実的なアプローチを取っていると私が評価しているスタートアップです。過去に特定の顧客ドメイン向けポストトレーニングオープンモデルで多くの経験(および収益)を積んできた彼らは、自らを証明すると同時に、米国で構築されたより大規模で高性能なオープンモデルを事前トレーニングすることでニッチ市場を埋める必要があると気づきました。彼らは私が「ATOM プロジェクト」に対して呼びかけた行動に最も熱心に答えてくれるグループであり、私はすぐに彼らと友人になりました。
本日、彼らはこの転換の集大成としてフラッグシップモデル「Trinity Large」を発表します。この発表を前に、CEO の Mark McQuade 氏、CTO の Lucas Atkins 氏、事前トレーニング責任者の Varun Singh 氏と座談会を行い、以下について幅広く議論しました。
オープンモデルとクローズドモデルの現状(および将来)
オンプレミス展開用のオープンモデル販売というビジネス
Arcee AI の物語とこのトレーニングランへの「全振り」
ATOM プロジェクト
6 ヶ月でフロンティアモデル訓練チームを構築する過程
その他多くの素晴らしいトピック。私はこれをとても気に入り、あなたもきっと気に入ると思います。
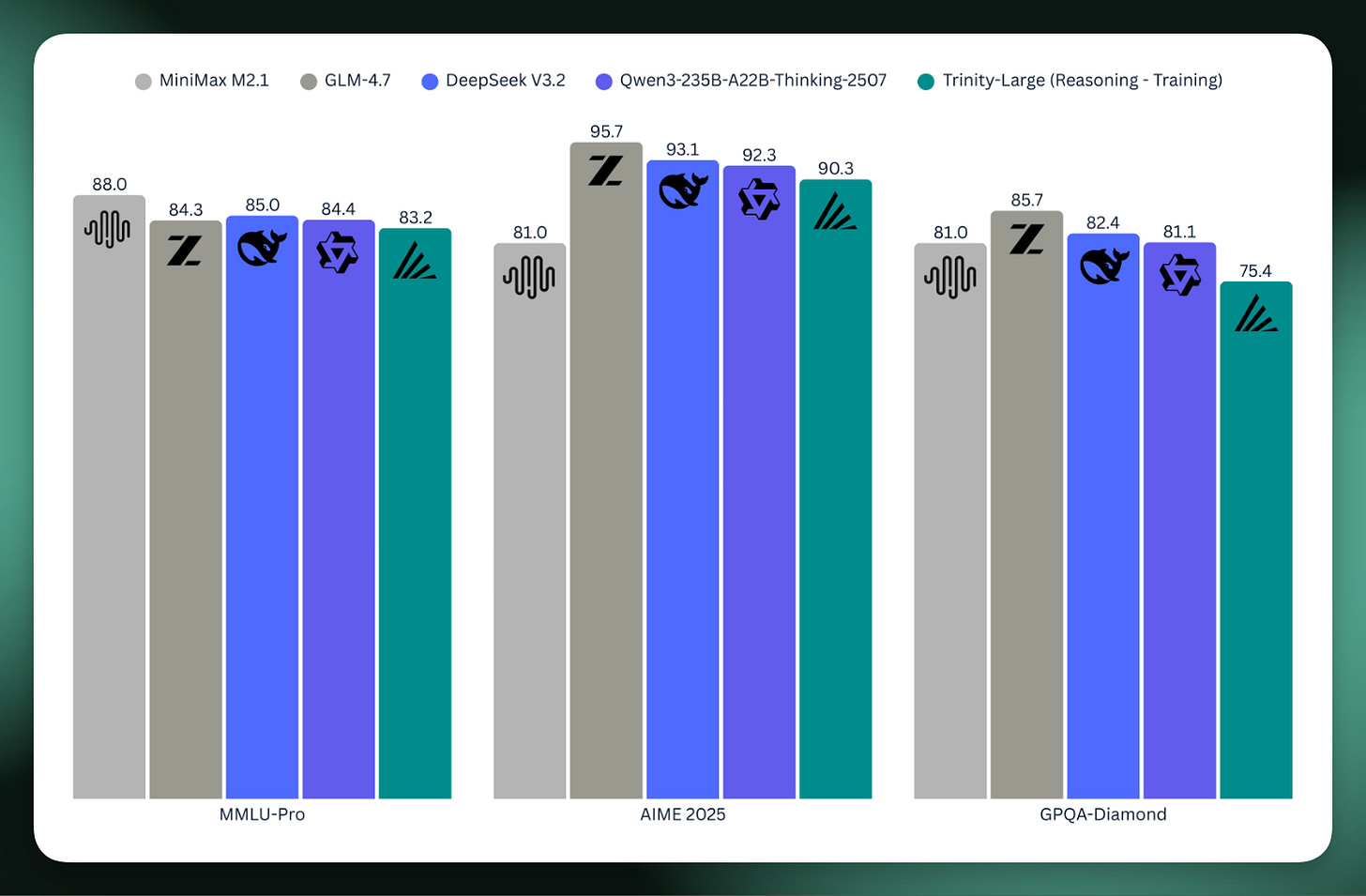
上記のブログ記事および技術レポートには、モデルのトレーニングに関する多くの素晴らしい詳細が含まれており、私はまだその内容を掘り下げています。Arcee がこれまで行ってきた素晴らしい取り組みの一つは、「真のベースモデル」を公開することです。これらは、SFT(Supervised Fine-Tuning:教師あり微調整)データや学習率の減衰(learning rate annealing)を含んでいません。Trinity Large モデルは、MoE(Mixture of Experts:専門家混合)アーキテクチャを採用し、総パラメータ数は 400B、アクティブなトークン数は 13B で、17 トリリオンのトークンを学習済みです。これは、Nvidia Blackwell の B300 マシン上でこの規模で公開されたトレーニング実行の最初の例となります。
プレビューとして、現在進行中の推論モデルのスコアが、今日のオープンモデル界隈における主要な競合他社と比較して共有されました。米国で構築されたオープンモデルがこのようにスケールアップすることは、大きな一歩です。
すべての詳細をここで明かすわけにはいきませんので、ぜひポッドキャストをお聞きください。ただし、ブログ記事の「コスト」に関するセクションは、ポッドキャストのトーンをよく設定しています。これは、オープンモデルをどのように、そしてなぜ構築すべきかについて非常に率直な議論が行われるものです。
このトレーニングを開始した際、私たちはこれに匹敵する事前学習(pretraining)をこれまで一度も行ったことがありませんでした。
これが成功する保証はありませんでした。モデル設計も、データも、トレーニング自体も、運用面もです。例えば、朝起きて、多額の費用がかかるジョブが破綻している状態から目覚めることになり、再起動するか救済を試みるかを決断しなければならないような状況です。
すべてに注力しました——計算資源、給与、データ、ストレージ、運用。この全体的な取り組みを 2,000 万ドルで成し遂げました。4 つのモデルが、6 ヶ月という短期間でこれを実現しました。
この数字は私たちにとっては大きなものです。しかし、最先端研究所が単に事業を継続するために費やす金額と比較すれば、まだ小さいです。私たちは無限回の再試行ができるわけではありません。
この投稿を投稿した後、すぐにそのモデルを試してみようと思います。みなさんがどのような発見をするかも楽しみです。
共有する
Apple Podcasts、Spotify、YouTube、およびポッドキャストが聴けるあらゆる場所で視聴できます。他の Interconnects のインタビューについては、こちらをご覧ください。
ゲスト
Lucas Atkins — X, LinkedIn — CTO; 事前トレーニングとアーキテクチャを主導し、Trinity Manifesto を執筆しました。
Mark McQuade — X, LinkedIn — 創設者/CEO; 以前は Hugging Face(収益化)、Roboflow に在籍。エンタープライズグレードのオープンウェイトモデルとツールリングの実装に注力しています。
Varun Singh — LinkedIn — 事前トレーニングリーダー。
インタビューの大部分は Lucas と行われますが、Mark と Varun も適切なタイミングで素晴らしい補足を加えてくれます。
リンク
コア:
Trinity Large(総計 400B、アクティブ 13B)コレクション、ブログ記事。現在インストラクションモデル、間もなく推論モデルを提供します。
Trinity Mini、総計 26B、アクティブ 3B(ベース、事前アニーリングチェックポイントの公開を含む)
Trinity Nano Preview、総計 6B、アクティブ 1B(ベース)
オープンソースカタログ:https://www.arcee.ai/open-source-catalog
API ドキュメントとプレイグラウンド(デモ)
ソーシャルメディア: GitHub, Hugging Face, X, LinkedIn, YouTube
Trinity モデル:
Trinity モデルページ:https://www.arcee.ai/trinity
The Trinity Manifesto(読むことを強くお勧めします): https://www.arcee.ai/blog/the-trinity-manifesto
Trinity HF コレクション — (Trinity Mini & Trinity Nano プレビュー)
旧モデル:
AFM-4.5B(およびベースモデル)— 彼らの最初のオープンで、社内事前学習されたモデル(ブログ投稿)。
5 つのオープンウェイトモデル(ブログ):3 つの生産用モデルは以前、同社の SaaS プラットフォームに限定されていたが、AFM への焦点シフトに伴いリリースされた研究用モデル 2 つを含む。Arcee-SuperNova-v1, Virtuoso-Large, Caller, GLM-4-32B-Base-32K, Homunculus
オープンソースツール:
MergeKit — モデル統合ツールキット(LGPL ライセンスの復帰)
DistillKit — 知識蒸留ライブラリ
EvolKit — 進化的手法による合成データ生成
関連記事:
Datology における Arcee のケーススタディ
チャプター
00:00:00 イントロ:Arcee AI、Trinity モデル & Trinity Large
00:08:26 企業の事前学習への移行
00:13:00 技術的決定事項:Muon と MoE(Mixture of Experts)
00:18:41 スケーリングと MoE 訓練の課題
00:23:14 事後学習および RL(強化学習)戦略
00:28:09 チーム構成とデータスケーリング
00:31:31 トリニティ宣言:米国製オープンウェイト
00:42:31 専門特化型モデルと蒸留
00:47:12 インフラストラクチャおよび 400B モデルのホスティング
00:50:53 オープンソースをビジネスの堀として
00:56:31 予測:2026 年の最良モデル
01:02:29 ライトニングラウンド & 結論
今すぐ購読する
文字起こし
ElevenLabs Scribe v2 で生成され、Claude Code with Opus 4.5 でクリーニングされた文字起こし。
00:00:06 ネイサン・ランバート:私はアーシー AI チームの皆さんと一緒にいます。個人的に、私はアーシーを少しファンになりました。なぜなら、彼らがオープンモデルの構築を中心に会社を立ち上げようとしている取り組みは、勇ましく非常に理にかなった方法だと考えるからです。実際、オープンモデルに対する良いビジネスプランを持っている人は誰もいませんし、それを理解しようと試み、時間をかけてより優れたモデルを構築していくしかないのです。オープンソースソフトウェアと同様に、公開で開発を行うことが、これを実現する最善の方法だと思います。つまり、これはあなたが何に取り組むにしても、すぐに走り出すための車輪のようなものです。今週、彼らはこれまでで最大のモデルを発表します。私は大規模な MoE(Mixture of Experts)のオープンモデルをもっと見てみたいと非常に楽しみにしています。昨年、中国から少なくとも 10 のプロバイダーがこうしたモデルを出しているのを確認しました。明らかにこれは国際的な潮流であり、多くの人がモデルを構築していますが、何らかの理由でアメリカではオープンモデルを構築する人の数が少ないようです。モデルを構築している場所であれば、その仕事の質に立脚できると思います。とにかく、これ以上長々とは話しません。電話に出ているのはルカス、マーク、そしてヴァルーンです。彼らの一部は知っていますが、私たちは友人関係にあります。このモデルについて話し合い、アメリカでオープンモデルを構築することについて議論しましょう。ポッドキャストにお越しいただきありがとうございます。
00:01:16 マーク・マククエイド:お招きいただきありがとうございます。
00:01:18 ルカス・アトキンス:はい、はい。お招きいただきありがとうございます。とても楽しみです。
00:01:20 ヴァルーン・シンガー:ここにおいでできて光栄です。
00:01:20 ネイサン・ランバート:この「Trinity Large」について、人々が知っておくべきことは何でしょうか?実際のモデル名は何ですか?あなたはこのことに対してどれほど興奮しているのですか?
00:01:29 ルーカス・アトキンス:ええと、はい。
00:01:29 ネイサン・ランバート:つまり、ついに達成されたのでしょうか?
00:01:32 ルーカス・アトキンス:ええと、ご存知の通り、これはリリース前に少し早めに録画しているため、まだすべての準備を整えている最中です。また、この規模での推論(inference)は常に課題となりますが、私たちは-- 私たちの最初の密なモデルである 45 億パラメータ(4.5B)を昨年 2025 年 7 月にリリースして以来、ちょうど 6 ヶ月間のスプリントを行ってきました。つまり、これは常に大規模なモデルのリリースに奉仕してきたものです。このモデルは 4,000 億パラメータ(400B)を有するスパース型混合専門家モデル(MoE)で、アクティブなパラメータ数は 130 億です。ええと、はい、私たちは非常に興奮しています。これは過去 6 ヶ月間、当社が集中して取り組んできたすべてのものであり、あなたが構築している人々がその成果を使い始めることができるようになったことを本当に嬉しく思います。
00:02:16 ネイサン・ランバート:はい、現実的な質問をすれば、「これは過去 6 ヶ月間のモデルの ballpark(概算範囲)に収まっていると思いますか?」となります。実際、あなたが目指すべき基準はそこにあるはずです。オープンモデルには高いハードルがあり、あなたがターゲットとしているものに対してどう評価するかです。これらのモデルがその基準を満たしていると感じますか?あるいは、MiniMax のように全体で 230B(2,300 億パラメータ)程度、それより少ない規模のものとの比較になります。それが何なのかは私にはわかりませんが、アクティブパラメータが 100 億から 200 億程度ではないでしょうか。DeepSeek は 600 の範囲にあり、Kimi は 1 トリリオンの範囲にあります。つまり、これは人々が知る大規模な MoE(Mixture of Experts:専門家混合モデル)の比較的小さな側に位置しています。特にアクティブパラメータが 13B(1,300 億)と言われたときは、非常にスパース性(疎性)が高いと言えます。そのため、これらのモデル間でどう比較すべきかについては、私には確信が持てません。MiniMax はより小さいというデータ分析を行った結果、この比較は少し無理があるのかもしれません。重要なのは、良いものを作り、人々がそれを使うかどうかを確認することです。
00:03:06 ルーカス・アトキンス:はい、つまり、生計算リソースの観点から言えば、サイズとしてはミニマックスと GLM 4.5 の中間あたりですね。GLM は確か 380B で、アクティブパラメータは 34B だったと思います。つまり、総数は少し高めですが、アクティブ部分は半分になっています。この方針を決めたときは確かに難しかったです。7 月に密なモデルをリリースしたときのことですが、すぐに非常に大きなモデルを作る必要があると直感しました。その際の難しい点は、開発に 6 ヶ月かかることを事前に把握しておく必要があります。設計を開始した時点で競合他社に対抗できるモデルを作ろうとしても、この業界では 6 ヶ月の間に多くのことが起こるため、それは現実的ではありません。そこで、事前学習をやり直し、ターゲットは GLM 4.5 ベースモデルに設定しました。4.6 や 4.7 はその上でポストトレーニング(後期微調整)が行われているからです。性能面では、私たちが目指す範囲内に収まっています。技術的には「Trinity Large Preview」と呼んでいますが、これは追加で 1 ヶ月分の RL(強化学習)を実施する必要があるためです。
00:04:29 ネイサン・ランバート:私もそこにいました。
00:04:31 ルーカス・アトキンス:はい、はい。でも、ご存知の通り、私たちが現在取り組んでいるチェックポイントでは、AIME 2025 で少なくとも 85 点台後半、GPQA Diamonds では 75 点、MMLU Pro では 82 点を達成しています。まだ強化学習(RL)による改善を続けていますが、とにかく満足しています。特に、これが私たちの最初の大きなトレーニングランだったことを考えると、単にモデルを訓練し終えたこと自体が極めて大きな成果でしたが、それが実際に本格的に有用なモデルとして機能しているというのは、まさに花の飾りのようなものです。
00:05:03 ネイサン・ランバート:はい、大きな視点からいきましょう。えーと、振り返ってみましょう。私たちはこの完全なトリニティ(三位一体)のモデルを持っています。面白い点がありますね。えーと、そのドキュメントに入れましたか?いいえ、Nano Preview についてです。これは最も小さい...あなたは魅力的で不安定だと言います。モデルカードが本当に面白いです。ChatGPT でこれについて深く調査したところ、ChatGPT Pro が隣に「魅力的で不安定」とタグ付けされていました。そして私は考えました:これはハルシネーション(幻覚)でしょうか?そしてモデルカードには、「これはチャット調整されたモデルで、ユーザーが愛するであろう楽しい性格と魅力を持っています。えーと、私たちは...境界を押し広げています。8 億のアクティブパラメータを持ち、そのため特定のユースケースでは不安定になる可能性があります」とあります。これは最も小さなスケールでのことです...私は正直に言うことを評価しますし、この話は会話の中で何度も出てくるでしょう。そして次に Mini があります。えーと、1B アクティブで 6B トータルといった感じだったと思います。私の手元には正確な数字がありません。どこかにあります。えーと-
00:05:52 ルーカス・アトキンス:はい、Nano は 6B で、アクティブは 1 でした。
00:05:55 ネイサン・ランバート:ああ、そうですか、そうですか。
00:05:55 ルーカス・アトキンス:そして Mini は 26 で、アクティブは 3B です。
00:05:58 ネイサン・ランバート:はい。つまり-
00:06:00 ネイサン・ランバート:これらは、トレーニングのスキルを構築する必要があるという観点に基づいているのでしょうか、それともコミュニティから聞こえてきたニーズを満たそうとしているのでしょうか。文脈として、以前に最初のオープンモデルはベースモデルとポストトレーニング済みモデルである Arcee 4.5B で、これは人気があったデンスモデルでした。その前には、リリースした多くのポストトレーニングファインチューンがありました。つまり、それまではポストトレーニング専門のショップのようなものでしたが、この歴史的背景を埋めることが重要だと考えます。なぜなら、多くの人々が今回初めてこの話を聴くことになるからです。
00:06:34 ルーカス・アトキンス:はい、ええと、私たちがミニとナノのサイズを選んだのは、特にミニの 26B(Active 3B)に焦点を当てたものでした。その理由は、大規模モデルの開発リスクを低減するためです。つまり、これはすべて、400B クラスのモデルを実現するという目標に向けた一連の取り組みの一環なのです。私たちは、元々 4.5B のモデルを開発した経験から、訓練に必要な要素は全て紙面上に揃っていても、実際には予想外の極めて大きな困難が伴うことを学びました。特に MoE(Mixture of Experts)モデルのパフォーマンスを追求する際、効率的で高速な MoE の訓練を実現することについては、私たちが確実に解決すべき課題であると認識していました。そこで、私たちはミニサイズを、過度に高価ではなく、かつ大規模モデル開発に向けた豊富なデータを得られる適切な基盤として位置づけました。一方、ナノサイズの登場は、余剰の計算リソースがあったことと、非常に深い構造を持つ小規模モデルに関する研究をさらに進めたいという強い意欲によるものです。MoE においてこのようなアプローチが試された例はこれまであまり見られなかったため、私たちは訓練を開始し、初期ベンチマークの結果が良好だったことから、「では、全データセットで実施しよう」と判断しました。ただし、これらのリリースに対する最も大きな関心と評価はミニモデルに向けられました。長期的な ROI(投資対効果)の観点から考えれば、小規模モデルこそが私たちの強みとなる領域だと確信しています。なぜなら、小規模モデルを最適化することで企業は莫大なコスト削減を実現できるからです。しかし同時に、私たちは大規模モデルのフロンティアを開拓し続けることも間違いなく目指していきます。
00:08:26 ネイサン・ランバート:はい。えーと、会社にとって有用な小規模モデルの話に戻る前に、トレーニングについてもう一度掘り下げておきたいんです。というのも、オープンエコシステムについては今後 20 分以上話し合うことになるからです。そこで哲学的な観点から、貴社が科学的詳細を共有することに対してどう考えているのか気になります。例えば、モデルの中で技術的に最も興奮する点は何か、あるいは課題は何かといった質問に答えていただけるでしょうか?それらについてお話しされるおつもりですか?それは会社の方針とは無関係(オルソゴナル)な問題だと感じますか?私には、これらはすべて起こりうる出来事のように思えます。貴社のこの取り組みの枠組みは、大規模モデルを軌道に乗せることに奉仕するものだと捉えています。特に、6 ヶ月以内にモデルが実装されることを想定している必要があります。モデルをトレーニングしていない人にとっては、これは考えにくいことかもしれません。私自身も、OLMo 3 のポストトレーニングスタックを更新しようと考えているのですが、現在は思考(thinking)に非常に依存した SFT(Supervised Fine-Tuning:教師あり微調整)を行っており、思考時間の点であまり動的ではありません。しかし、このモデルをデプロイする人々がいるとは考えにくく、おそらくファインチューニングするのも難しいでしょう。6 ヶ月後にツール使用型モデルがどこに向かうかを考えるのは非常に困難です。これは非常に難しいタスクであり、実際に着手するには多大な勇気が必要です。そこで、私が経験したことを自己省察する枠組みについて、お聞かせいただければ幸いです。特に、Muon オプティマイザを使用していることなどにより、6 ヶ月先の展望を現実のものとするのがいかに困難だったかについて、何か共有いただけることがあれば大変助かります。データについては、Datology がその多くを生産していることは周知の事実であり、貴社はおそらくこれらのパートナーと連携して推進されているのでしょう。何が機能し、何が機能しないかについて多くのフィードバックを提供されていることも間違いありません。ですので、共有可能な情報があれば、それは有用だと考えます。
00:10:08 ルーカス・アトキンス:ええと、私は、データ側のことを考えているのですが、例えば Datology については、少なくともこれらのモデルにおいては、そのパートナーシップは私たちの研究チームの延長のようなものだったと思います。私たちは彼らと非常に密接に協力してきましたし、もちろん、私たちのモデルがうまくいっていることは、彼らにとっても良いことですからね。しかし、そこには確かに、ご存知のように、小規模なアブレーション実験(ablation study)を大規模に適用した際に、必ずしも望んだ通りにならないという課題がありました。そのため、Large 版で使用するデータセットを得るまでに、かなりの反復作業が必要でした。6 ヶ月先を見据えて、どのように進めるかを考えるにあたって、もちろん最大の課題は計算資源(compute)です。私たちはファウンデーションモデル企業として資金を調達したことがなく、数千台の GPU を前もって確保するような大規模なコミットメントを行ったこともありません。そのため、ポストトレーニング(post-training)の多くに常時稼働する大規模クラスターを持っていなかったのです。もし以前であれば、64 台の H100 で十分だったかもしれませんが、当然ながら今回はさらに多くの資源が必要となりました。まず最初に取り組んだことは-
00:11:29 ネイサン・ランバート:それはまだ人々が予想するよりも少ないです。つまり、モデルをリリースしていますが...そのモデルは国全体のニュースになるようなものではなくても、コミュニティの人々はそれを知っていました。例えば、Moondream を思い浮かべます。ヴィク(Vik)は...非常に限られた計算リソースしか持っていないのに、それを非常に効果的に活用しています。彼の成功ぶりがよくわかりますよね?彼自身も、30 台...いや、64 台の GPU を持っていると言っています。つまり、限られた計算資源で実際に優れた機械学習(ML)の成果を生み出すことについては、全く別の議論が必要なのです。私はこれについてヴィクと話すべきですが、それ以外の点では
00:12:03 ルーカス・アトキンス:いいえ、それは…そうなんです。多分…はい、事前学習(pre-training)の側面に入る際、非常に大きな贈り物でした。なぜなら、私たちはすでに、「計算資源を最小限に抑えていかに最大限の効果を得るか」ということを考えていたからです。しかし、私たちが大規模モデルのトレーニングに使用している 22,048 台の NVIDIA B300(B300)からなるクラスターを準備するまでには、かなりの時間がかかりました。そのクラスターへのアクセスが可能になる時期がわかった時点で、Mini や Nano のタイムラインなど、他のすべてのことが明確になりました。もちろん、Mini や Nano については 512 台の NVIDIA H100(H100)の方が入手しやすいことは明白でした。この点を整理したことで、本格的に「事前学習というテーマにおいて、どのような研究が最良か」を探るゲームが始まりました。具体的には、十分なポテンシャルと先行事例を持つ論文や出版物は何か、つまり、他の研究室で採用されたものか、信頼できるチームからの成果か、あるいは論文内のアブレーション(ablation)や評価設定が十分であり、私たちに確信を与えられるようなものかを検討しました。そして結局、MoE(Mixture of Experts:専門家の混合モデル)のアーキテクチャをどうするかを決めるのに約 2 か月ほど費やし、その後は「では、これを実際のトレーニングパイプラインにどう実装するか」という段階に移りました。当時、Muon という最適化手法はポストトレーニング(post-training)の分野で多くの人が取り組んでいましたが、
原文を表示
Arcee AI is a the startup I’ve found to be taking the most real approach to monetizing their open models. With a bunch of experience (and revenue) in the past in post-training open models for specific customer domains, they realized they needed to both prove themselves and fill a niche by pretraining larger, higher performance open models built in the U.S.A. They’re a group of people that are most eagerly answering my call to action for The ATOM Project, and I’ve quickly become friends with them.
Today, they’re releasing their flagship model — Trinity Large — as the culmination of this pivot. In anticipation of this release, I sat down with their CEO Mark McQuade, CTO Lucas Atkins, and pretraining lead, Varun Singh, to have a wide ranging conversation on:
The state (and future) of open vs. closed models,
The business of selling open models for on-prem deployments,
The story of Arcee AI & going “all-in” on this training run,
The ATOM project,
Building frontier model training teams in 6 months,
and other great topics. I really loved this one, and think you well too.
The blog post linked above and technical report have many great details on training the model that I’m still digging into. One of the great things Arcee has been doing is releasing “true base models,” which don’t contain any SFT data or learning rate annealing. The Trinity Large model, an MoE with 400B total and 13B active tokens trained to 17 trillion tokens is the first publicly shared training run at this scale on B300 Nvidia Blackwell machines.
As a preview, they shared the scores for the underway reasoning model relative to the who’s-who of today’s open models. It’s a big step for open models built in the U.S. to scale up like this.
I won’t spoil all the details, so you still listen to the podcast, but their section of the blogpost on cost sets the tone well for the podcast, which is a very frank discussion on how and why to build open models:
When we started this run, we had never pretrained anything remotely like this before.
There was no guarantee this would work. Not the modeling, not the data, not the training itself, not the operational part where you wake up, and a job that costs real money is in a bad state, and you have to decide whether to restart or try to rescue it.
All in—compute, salaries, data, storage, ops—we pulled off this entire effort for $20 million. 4 Models got us here in 6 months.
That number is big for us. It’s also small compared to what frontier labs spend just to keep the lights on. We don’t have infinite retries.
Once I post this, I’m going to dive right into trying the model, and I’m curious what you find too.
Share
Listen on Apple Podcasts, Spotify, YouTube, and where ever you get your podcasts. For other Interconnects interviews, go here.
Guests
Lucas Atkins —X,LinkedIn — CTO; leads pretraining/architecture, wrote the Trinity Manifesto.
Mark McQuade — X, LinkedIn — Founder/CEO; previously at Hugging Face (monetization), Roboflow. Focused on shipping enterprise-grade open-weight models + tooling.
Varun Singh — LinkedIn — pretraining lead.
Most of this interview is conducted with Lucas, but Mark and Varun make great additions at the right times.
Links
Core:
Trinity Large (400B total, 13B active) collection, blog post. Instruct model today, reasoning models soon.
Trinity Mini, 26B total 3B active (base, including releasing pre-anneal checkpoint)
Trinity Nano Preview, 6B total 1B active (base)
Open Source Catalog: https://www.arcee.ai/open-source-catalog
API Docs and Playground (demo)
Socials: GitHub, Hugging Face, X, LinkedIn, YouTube
Trinity Models:
Trinity models page: https://www.arcee.ai/trinity
The Trinity Manifesto (I recommend you read it): https://www.arcee.ai/blog/the-trinity-manifesto
Trinity HF collection — (Trinity Mini & Trinity Nano Preview)
Older models:
AFM-4.5B (and base model) — their first open, pretrained in-house model (blog post).
Five open-weights models (blog): three production models previously exclusive to their SaaS platform plus two research models, released as they shifted focus to AFM — Arcee-SuperNova-v1, Virtuoso-Large, Caller, GLM-4-32B-Base-32K, Homunculus
Open source tools:
MergeKit — model merging toolkit (LGPL license return)
DistillKit — knowledge distillation library
EvolKit — synthetic data generation via evolutionary methods
Related:
Datology case study w/ Arcee
Chapters
00:00:00 Intro: Arcee AI, Trinity Models & Trinity Large
00:08:26 Transitioning a Company to Pre-training
00:13:00 Technical Decisions: Muon and MoE
00:18:41 Scaling and MoE Training Pain
00:23:14 Post-training and RL Strategies
00:28:09 Team Structure and Data Scaling
00:31:31 The Trinity Manifesto: US Open Weights
00:42:31 Specialized Models and Distillation
00:47:12 Infrastructure and Hosting 400B
00:50:53 Open Source as a Business Moat
00:56:31 Predictions: Best Model in 2026
01:02:29 Lightning Round & Conclusions
Subscribe now
Transcript
Transcript generated with ElevenLabs Scribe v2 and cleaned with Claude Code with Opus 4.5.
00:00:06 Nathan Lambert: I’m here with the Arcee AI team. I personally have become a bit of a fan of Arcee, ‘cause I think what they’re doing in trying to build a company around building open models is a valiant and very reasonable way to do this, ‘cause nobody really has a good business plan for open models, and you just gotta try to figure it out, and you gotta build better models over time. And like open-source software, building in public, I think, is the best way to do this. So this kind of gives you the wheels to get the, um... You get to hit the ground running on whatever you’re doing. And this week, they’re launching their biggest model to date, which I’m very excited to see more kind of large-scale MoE open models. I think we’ve seen, I don’t know, at least ten of these from different providers from China last year, and it’s obviously a thing that’s gonna be international, and a lot of people building models, and the US kind of, for whatever reason, has fewer people building, um, open models here. And I think that wherever people are building models, they can stand on the quality of the work. But whatever. I’ll stop rambling. I’ve got Lucas, Mark, um, Varun on the, on the phone here. I’ve known some of them, and I consider us friends. We’re gonna kind of talk through this model, talk through building open models in the US, so thanks for hopping on the pod.
00:01:16 Mark McQuade: Thanks for having us.
00:01:18 Lucas Atkins: Yeah, yeah. Thanks for having us. Excited.
00:01:20 Varun Singh: Nice to be here.
00:01:20 Nathan Lambert: What- what should people know about this Trinity Large? What’s the actual name of this model? Like, how stoked are you?
00:01:29 Lucas Atkins: So to- yeah.
00:01:29 Nathan Lambert: Like, are you, like, finally made it?
00:01:32 Lucas Atkins: Uh, you know, we’re recording this a little bit before release, so it’s still like, you know, getting everything buttoned up, and inference going at that size is always a challenge, but we’re-- This has been, like, a six-month sprint since we released our first dense model, which is 4.5B, uh, in, in July of last year, 2025. So, um, it’s always been in service of releasing large. I- it’s a 400B, um, thirteen billion active sparse MoE, and, uh, yeah, we’re, we’re super excited. This has just been the entire thing the company’s focused on the last six months, so really nice to have kind of the fruits of that, uh, start to, start to be used by the people that you’re building it for.
00:02:16 Nathan Lambert: Yeah, I would say, like, the realistic question: do you think this is landing in the ballpark of the models in the last six months? Like, that has to be what you shop for, is there’s a high bar- ... of open models out there and, like, on what you’re targeting. Do you feel like these hit these, and somebody that’s familiar, or like MiniMax is, like, two thirty total, something less. I, I don’t know what it is. It’s like ten to twenty B active, probably. Um, you have DeepSeeks in the six hundred range, and then you have Kimi at the one trillion range. So this is still, like, actually on the smaller side of some of the big MoEs- ... that people know, which is, like, freaking crazy, especially you said 13B active. It’s, like- ... very high on the sparsity side. So I don’t actually know how you think about comparing it among those. I was realizing that MiniMax is smaller, doing some data analysis. So I think that it’s like, actually, the comparison might be a little bit too forced, where you just have to make something that is good and figure out if people use it.
00:03:06 Lucas Atkins: Yeah, I mean, if, if from raw compute, we’re, we’re roughly in the middle of MiniMax and then GLM 4.5, as far as, like, size. Right, GLM’s, like, three eighty, I believe, and, and thirty-four active. Um, so it-- you know, we go a little bit higher on the total, but we, we cut the, uh, the active in half. Um, it was definitely tricky when we decided we wanted to do this. Again, it was July when... It, it was July when we released, uh, the dense model, and then we immediately knew we wanted to kind of go, go for a really big one, and the, the tricky thing with that is knowing that it’s gonna take six months. You, you can’t really be tr-- you can’t be building the model to be competitive when you started designing it, because, you know, that, obviously, a lot happens in this industry in six months. So, um, when we threw out pre-training and, and a lot of our targets were the GLM 4.5 base model, um, because 4.6 and 4.7 have been, you know, post-training on top of that. Um, and, like, in performance-wise, it’s well within where we want it to be. Um, it’s gonna be... Technically, we’re calling it Trinity Large Preview because we just have a whole month of extra RL that we want to do. Um- But-
00:04:29 Nathan Lambert: I’ve been, I’ve been there.
00:04:31 Lucas Atkins: Yeah, yeah. But i- you know, we’re, we’re in the, um, you know, mid-eighties on AIME 2025, uh, GPQA Diamonds, uh, seventy-five, um, at least with the checkpoint we’re working with right now. We’re still doing more RL on it, but, um, you know, MMLU Pro, uh, eighty-two. So we’re, we’re, we’re happy. We’re really-- Like, for it being our first big run, like, just getting it trained was, was an extreme accomplishment, but then for it to actually be, like, a, a genuinely useful model is a, a cherry on top.
00:05:03 Nathan Lambert: Yeah, let’s go big picture. Uh, like, let’s recap. We have all of the... We have this full trinity of models. I think that there’s a fun note. Uh, did I put it in this doc? Yeah, on Nano Preview, which was the smallest- ... you’re, like, charming and unstable. The model card’s really funny. Um, ChatGPT, doing deep research on this, I was like, ChatGPT Pro just tagged next to it, “charming and unstable.” And I was like: Is this a hallucination? And then in the model card, you have, like: “This is a chat-tuned model with a delightful personality and charm we think users will love. Uh, we think- ... it’s pushing the boundaries, eight hundred million, um, active parameter, and as such, may be unstable in certain use cases.” This is at the smallest scale- ... which is like, I appreciate saying it as it is, and that’ll come up multiple times in the conversation. And then you have Mini, which is like, um, I think it was, like, 1B active, 6B total type thing. In my-- I, I don’t have it, the numbers right in front of me. I have it somewhere else. Um-
00:05:52 Lucas Atkins: Yeah, Nano was, Nano was the 6B, uh, 1 active.
00:05:55 Nathan Lambert: Oh, yeah, yeah.
00:05:55 Lucas Atkins: And then, and the Mini was twenty-six, 3B active.
00:05:58 Nathan Lambert: Yeah. So, like-
00:06:00 Lucas Atkins: Um, yeah.
00:06:00 Nathan Lambert: -are these based on more of, like, you need to build out your training chops, or are you trying to fill needs that you’ve-... heard from community, and like, I think for context, previously, your first open model was a base and post-trained model, which was Arcee 4.5B, which was a dense model- -which people like. And prior to that, you had, like, a long list of, like, post-training fine tunes that you had released. So before that, it was like a post-training shop, and I think that kind of history is i- important to fill in, ‘cause I think most people-- a lot of people are gonna meet you for the first time listening to this.
00:06:34 Lucas Atkins: Yeah, it, it, um, we chose those sizes for Mini and Nano, uh, specifically Mini, um, the 26B, 3B Active, because we wanted to de-risk, uh, large. Like, th- this has all been in service of getting to a model of, of, you know, the 400B class. So, um, we, you know, learned from doing the original 4.5B, that you might have everything on paper that you need to train a model, but i- inevitably, there’s tremendous, you know, difficulties that come up, and, um, it, it’s-- we, we definitely knew we wanted to make sure that we, you know, solved some of... E- especially when it came to just doing an MoE model performance, uh, you know, like a, like an efficient, fast train of an MoE. So, um, we thought that that was a good ground where we could, you know, it wasn’t crazy expensive, uh, but gave us a lot of data, uh, going into large. And then Nano just came about because we had some extra compute time, and we really want to do more research on, like, smaller models that are very deep. Um, and we hadn’t really seen that in an MoE before, so that one was very much we started training it, and then it, you know, early benchmarks were good, so we said, “Well, we’ll just do the whole dataset.” Um, and, uh, but most of the love for those releases went into, to Mini. So I, I definitely think that long term, uh, from an ROI perspective, the smaller models are going to be where we shine, just because there’s a tremendous amount of, of cost savings a company can get from, from optimizing on a, on a smaller model. Um, but, but we, uh, w- we’re definitely gonna be trying to push the, the large frontier, too.
00:08:26 Nathan Lambert: Yeah. Um, I’d like to kind of double-click on training before going back to the small model that’s useful for companies, ‘cause we’re gonna have-- we’re gonna end up talking for, like, twenty minutes plus about open ecosystem. So I kind of am curious, like, philosophically, how your company feels about, like, sharing scientific details. So if I ask you, like, what are the things you’re technically most excited about in the model, or, like, what are the pain points? Like, uh, like, are you willing to talk about these things? Like, I- Do you feel like it’s kind of orthogonal to the company? Like, I feel like a lot of it is just, like, things that happen. I think your framing of all of this is in service of getting the big model going. And particularly, of, like, you have to be thinking about your model as landing in six months, is probably... Like, for people not training models, it’s hard to think about, ‘cause even I- ... like, I’m thinking about trying to refresh our post-training stack for OLMo 3, and I’m like, the thinking model, the, um, we are pretty SFT heavy right now, and it makes it not very dynamic in terms of the thinking time. But it’s just like, I can’t see people deploying this model, or probably will have a hard time fine-tuning it. And it’s like to think about where tool use models are going in six months, like, seems pretty hard. Um, it’s a very hard task to do, so it takes a lot of gumption to actually set out and do it. So I, I would just appreciate the framing, kind of self-reflecting on what I go through. So if you have anything that you think was, like, particularly hard to actually land the six-month outlook, because you use Muon as an optimizer, or is it Muon? And some of these things. I think the data, it’s well known that Datology is cranking a lot of this, and you probably provide-- I think of it as like you’re kind of driving and working with these partners, and I’m sure you provide a lot of feedback on what’s working and what’s not. So- ... anything you’re willing to share, I think it’s useful.
00:10:08 Lucas Atkins: Uh, I, I think, um, I mean, on the data side, like Datology, I-- at least for these models, that, that partnership has very much been almost an extension of our own research team. Like, we’ve worked very closely with them, and, um, obviously, our model’s doing well, you know, i- is, is, is good for them. So, um, but it, it-- there was definitely, you know, and you know this better than most, like, small-scale ablations, when you throw them at scale, sometimes, you know, uh, the-- i- it doesn’t always turn out how you want. So there was quite a lot of iterating there to at least get the dataset we used for Large. Um, I, I would say that as far as looking out six months and then figuring out how we wanted to... Obviously, the big one was compute. We don’t, um, you know, we, we never raised as, like, a foundation model company, so we’ve ne- we haven’t signed massive commits for, you know, thousands of GPUs before. Um, we didn’t have a, a, a massive cluster that was always active, uh, for a lot of our post-training. So if they came before, um, you know, we had sixty-four, uh, H100s, that was pretty sufficient for that kind of work, but obviously, this necessitated quite a bit more. Um, but the first thing was-
00:11:29 Nathan Lambert: That’s still less than people would guess. Like, you’re releasing models- ... that weren’t like, your models weren’t catching national news, but people in the community knew about them. And, like, uh, i- I think of, like, Moondream when I think about that. Like, vik has- ... such little compute, and he puts it to so use. Like, you, like, see how successful he is? And he tells you that he has, I don’t know, thirty... Like, l- it might be, like, sixty-four GPUs. Like, uh- ... there’s, uh, uh, that’s a whole separate conversation on building- ... actual good ML output on little compute. I, I should ta- I should chat with vik about this, but aside
00:12:03 Lucas Atkins: No, it’s, it is-- I think it was... Yeah, it, it, it was very much a gift going into the pre-training side because-... we were kind of already thinking, All right, how do we do the mu- you know, the most with the, the least amount of compute? But, um, you know, we-- it took us quite a while to get the cluster that we have been training large on, which is twenty-two thousand forty-eight B300s. Um, and once we figured out when we were going to get that, get access to that cluster, everything else kind of became clear as far as, like, timelines for Mini and Nano and, and when we wanted to do that. Uh, obviously, you know, five hundred and twelve H100s was easier to come across, um, for Mini and Nano. So once we figured that out, um, it really became, uh, this game of, okay, how can we find, like, the best research on the topic of, of pre-training, and what is kind of... What are the, the, the papers and publications that are coming out, um, that have enough potential and enough precedence, either because, uh, another lab used them, it comes from a reputable team, uh, the ablations and the, the evaluation setup, like in the paper, was sufficient enough to give us confidence. Uh, and then we basically spent, I don’t know, it was probably about two months just figuring out what we wanted our architecture to be for the MoE, then figuring out, okay, now that that’s what we want to do, how do we implement all of that in the actual training pipeline? Uh, how can we-- you know, at that time, there had been many people who’d done Muon, but, um, for post-training, and,
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み