JavaScriptにはより良いストリームAPIが必要だ
Cloudflareは、Web Streams標準APIの設計上の制約を指摘し、現代のJavaScript言語機能を活用した代替アプローチが2倍から120倍の高速化を実現すると主張し、次世代ストリーミングAPIへの議論を提起している。
キーポイント
Web Streams標準APIの限界
WHATWG Streams Standardはブラウザとサーバー間で共通APIを提供したが、設計当時の制約(非同期イテレーションの欠如など)により、現代の開発パターンやパフォーマンス要件に適合しなくなっている。
代替アプローチの提案とパフォーマンス
Cloudflareは、現代のJavaScript言語プリミティブを活用した代替ストリーミングAPIを提案し、Cloudflare WorkersやNode.jsなど主要ランタイムで2倍から120倍の高速化を実証している。
設計思想の転換
既存のリーダー/ライター獲得モデルに依存するのではなく、非同期シーケンスを消費するためのidiomaticな方法(for await...ofなど)を基盤とした設計へ移行する必要性を強調している。
Web Streamsの過度な手続き
リーダーの取得、ロック管理、および{value, done}プロトコルは設計上の選択に過ぎず、本質的な必要性ではなくAPIオーバーヘッドである。
非同期反復の限界
for await...ofはボイラープレートコードを削減するが、BYOB読み取りなどの機能へのアクセス不可や、内部の複雑さが隠蔽されたままになるという問題が残る。
ロック管理の脆弱性
複数のコンシューマーによる読み取りの競合を防ぐロックモデルは、releaseLock()の呼び出し忘れなどにより簡単に失敗し、ストリームを利用不能にするリスクがある。
ロック管理の複雑さと自動管理への移行
従来の getReader/releaseLock による手動ロック管理は実装側の負担が大きく、async iterables を用いた自動ロック管理によりユーザー視点での扱いが容易になった。
影響分析・編集コメントを表示
影響分析
この記事は、JavaScriptエコシステムにおけるデータストリーミング処理の基盤技術に対する根本的な見直しを促すものであり、Cloudflare WorkersやNode.jsなどの主要プラットフォームの将来のAPI設計に大きな影響を与える可能性がある。開発者にとっては、パフォーマンス最適化の新たな選択肢が提示されたことを意味し、業界全体として「Web標準」への依存から脱却し、言語の進歩に追従した実装へ移行する契機となる。
編集コメント
Cloudflareによるこの批判的アプローチは、長年標準であったWeb Streams APIの脆弱性を指摘するものであり、JavaScriptランタイム間の互換性とパフォーマンスの両立という課題解決への重要な一歩となる。開発者は、既存コードベースとの互換性リスクを評価しつつ、新APIの採用検討を進める必要がある。
ストリームでのデータ処理は、アプリケーションを構築する上で基本的な要素です。あらゆる場所でストリーミングを機能させるために、WHATWG ストリーム標準(非公式には「Web ストリーム」と呼ばれる)が策定され、ブラウザとサーバー間で共通の API を確立することを目的としています。これはブラウザに実装され、Cloudflare Workers、Node.js、Deno、Bun によって採用され、fetch() などの API の基盤となりました。これは大きな取り組みであり、設計者たちは当時の制約やツールを用いて困難な問題に取り組んでいました。
しかし、Web ストリーム上で数年間構築を続け、Node.js と Cloudflare Workers の両方で実装し、顧客とランタイムの生産環境での問題をデバッグし、開発者があまりにも多くの一般的な落とし穴を乗り越えるのを支援してきた結果、標準 API には漸進的な改善だけでは容易に修正できない根本的な使いやすさとパフォーマンスの問題があると考えに至りました。これらの問題バグではなく、10 年前であれば妥当だったかもしれない設計決定の結果であり、今日の JavaScript 開発者のコード記述方法と一致していないのです。
本稿では、私が Web ストリームに見るいくつかの根本的な課題を探索し、より良い可能性を示す JavaScript の言語プリミティブを中心に構築された代替アプローチを紹介します。
ベンチマークでは、この代替案は私がテストしたすべてのランタイム(Cloudflare Workers、Node.js、Deno、Bun、および主要なブラウザを含む)において、Web Streams よりも 2 倍から 120 倍高速に動作します。これらの改善は巧妙な最適化によるものではなく、現代的な JavaScript の言語機能をより効果的に活用するための根本的に異なる設計選択によるものです。私は過去の成果を貶めるためにここにいるのではありません。私がここにいるのは、今後何が実現可能かについて対話を始めるためです。
私たちの出発点
Streams Standard は 2014 年から 2016 年の間に策定され、「低レベルな I/O プリミティブに効率的にマッピングされるデータのストリームを作成、合成、消費するための API を提供する」という野心的な目標を持っていました。Web Streams 以前、ウェブプラットフォームにはストリーミングデータを扱う標準的な方法がありませんでした。
当時、Node.js は独自のストリーミング API を持っており、それがブラウザでも動作するように移植されていましたが、WHATWG はその charter(憲章)が Web ブラウザのニーズのみを考慮するものとしているため、それを出発点として採用しないことを選びました。サーバーサイドランタイムはその後、Cloudflare Workers と Deno がそれぞれネイティブな Web Streams サポートとランタイム間互換性を優先事項として確立した後に、Web Streams を採用しました。
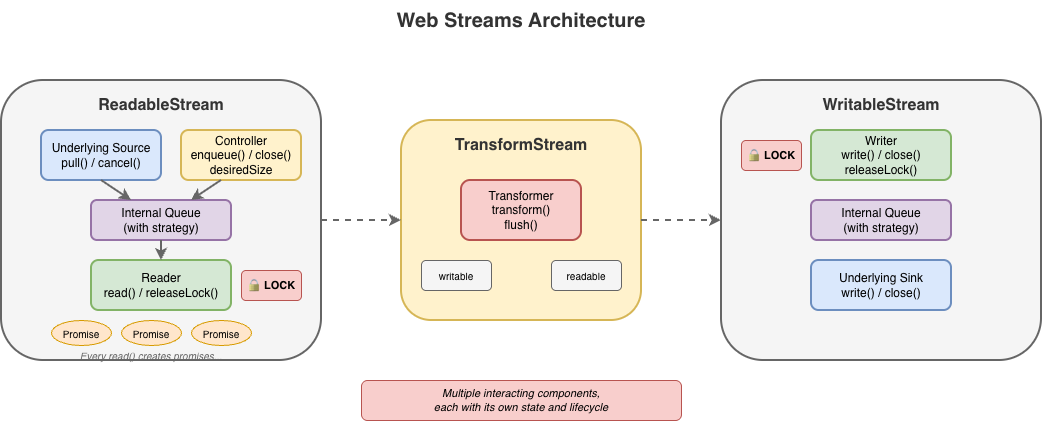
Web ストリームの設計は、JavaScript の非同期反復処理よりも前に存在します。for await...of 構文が導入されたのは ES2018 であり、ストリーム標準が最初に確定されてから 2 年後のことでした。このタイミングにより、当初の API は、最終的に JavaScript で非同期シーケンスを消費するための慣用的な方法となる機能を活用できませんでした。代わりに、仕様は独自のリーダー/ライター取得モデルを導入しましたが、その決定は API のあらゆる側面に波及効果をもたらしました。
一般的な操作における過度な手続き
ストリームの最も一般的なタスクは、完了まで読み込むことです。Web ストリームでそれがどのように見えるかを示します:
// まず、ストリームに対して排他ロックを与えるリーダーを取得します
const reader = stream.getReader();
const chunks = [];
try {
// 次に、返されたプロミスに対して繰り返し read を呼び出し await して、データのチャンクを生成するか、完了したかを示します。
while (true) {
const { value, done } = await reader.read();
if (done) break;
chunks.push(value);
}
} finally {
// 最後に、ストリームのロックを解放します
reader.releaseLock();
}
このパターンがストリーミングに本質的に組み込まれていると考えるかもしれません。しかし、そうではありません。リーダーの取得、ロック管理、そして { value, done } プロトコルはすべて設計上の選択事項であり、必須要件ではありません。これらは、Web Streams 仕様書がいつどのようにして作成されたかという結果生じたものです。非同期反復処理(async iteration)は、時間を経て到着するシーケンスを扱うためにまさに存在する機能ですが、Streams 仕様が策定された当時はまだ存在していません。ここでの複雑さは、根本的な必要性によるものではなく、純粋な API のオーバーヘッドです。
Web Streams が now await...of をサポートするようになった今、代替アプローチを検討してみましょう:
const chunks = [];
for await (const chunk of stream) {
chunks.push(chunk);
}
これはボイラープレート(定型コード)が大幅に減る点で優れていますが、すべてを解決するわけではありません。非同期反復処理は、本来そのために設計された API に後付けされたものであり、その影響が見て取れます。BYOB(Bring Your Own Buffer:独自のバッファを使用する読み込み)のような機能は、反復処理を通じてアクセスできません。リーダー、ロック、コントローラーの背後にある複雑さは依然として存在し、単に隠されているだけです。何か問題が起きたり、API の追加機能が必要になったりすると、開発者は再び元の API の泥沼の中に迷い込み、ストリームがなぜ「ロック」されているのか、releaseLock() が期待通りに動作しなかった理由を理解しようとしたり、自分が制御できないコード内のボトルネックを探し回ったりすることになります。
ロックの問題
Web Streams は、複数のコンシューマーによる読み込みの混在を防ぐためにロックモデルを使用しています。getReader() を呼び出すと、ストリームはロックされます。ロックされている間、他の誰かが直接ストリームから読み込んだり、パイプしたり、キャンセルしたりすることはできません。実際にリーダーを保持しているコードのみがそれらを実行できます。
これは一見合理的に思えますが、どのように簡単に失敗するかを見てみましょう:
async function peekFirstChunk(stream) {
const reader = stream.getReader();
const { value } = await reader.read();
// Oops — forgot to call reader.releaseLock()
// And the reader is no longer available when we return
return value;
}
const first = await peekFirstChunk(stream);
// TypeError: Cannot obtain lock — stream is permanently locked
for await (const chunk of stream) { /* never runs */ }
releaseLock() を呼び忘れるとストリームが永久的に破損します。locked プロパティはストリームがロックされていることを示しますが、なぜロックされたのか、誰がロックしたのか、あるいはそのロックがまだ使用可能かどうかについては教えてくれません。パイプ処理(piping)は内部でロックを取得するため、目に見えない形でパイプ操作中にストリームが使えなくなることがあります。
保留中の読み込み(pending reads)を伴う場合のロック解放に関するセマンティクスも長年不明確でした。read() を呼び出して await せずに releaseLock() を呼んだ場合、どうなるのでしょうか?仕様は最近、ロック解放時に保留中の読み込みをキャンセルすると明確化されましたが、実装によって挙動が異なり、以前の未定義の動作に依存していたコードが壊れる可能性があります。
ただし、ロック自体が悪いわけではありません。実際、アプリケーションがデータを適切かつ整然と消費または生成することを保証するために重要な役割を果たしています。課題は、getReader() や releaseLock() といった API を使用した元のマニュアル実装にあります。非同期反復可能オブジェクト(async iterables)による自動的なロックおよびリーダー管理の登場により、ユーザー視点から見たロックの扱いが大幅に容易になりました。
実装者にとって、ロックモデルは非常に複雑な内部の管理処理を大幅に追加することになります。すべての操作においてロック状態を確認する必要があり、リーダーを追跡する必要があります。また、ロック、キャンセル、エラー状態間の相互作用は、すべて正しく処理しなければならないエッジケースのマトリックスを生み出します。
BYOB: 対価のない複雑さ
BYOB(Bring Your Own Buffer:バッファを自分で用意する)読み込みは、ストリームからの読み取り時に開発者がメモリバッファを再利用できるように設計されました。これは高スループットシナリオを対象とした重要な最適化です。この考え方は妥当です:各チャンクごとに新しいバッファを割り当てるのではなく、自分でバッファを提供し、ストリームがそれを埋めるというものです。
実際には(はい、例外を見つけることは常に可能ですが)、BYOB は測定可能な利益をもたらすためにほとんど使用されていません。デフォルトの読み込みに比べて API は大幅に複雑化しており、別のリーダータイプ(ReadableStreamBYOBReader)や他の専門クラス(例:ReadableStreamBYOBRequest)が必要となり、慎重なバッファライフサイクル管理と ArrayBuffer の分離セマンティクスに関する理解が求められます。BYOB 読み込みでバッファを渡すと、そのバッファは分離され(ストリームへ転送され)、潜在的に異なるメモリに対する別のビューが返されます。この転送ベースのモデルはエラーが発生しやすく混乱を招きます:
const reader = stream.getReader({ mode: 'byob' });
const buffer = new ArrayBuffer(1024);
let view = new Uint8Array(buffer);
const result = await reader.read(view);
// 'view' は現在、切り離されて使用できなくなっているはずです
// (実装によっては常にそうなるわけではありません)
// result.value は新しいビューであり、異なるメモリ領域を指している可能性があります
view = result.value; // 再代入が必要です
BYOB は非同期反復処理や TransformStreams と併用できないため、ゼロコピー読み込みを実現したい開発者は、手動のリーダーループに戻らざるを得ません。
実装者にとって、BYOB は大きな複雑さを加えます。ストリームは保留中の BYOB リクエストを追跡し、部分的な埋め込みを処理し、バッファの切り離しを正しく管理し、BYOB リーダーと背後にあるソース間の調整を行う必要があります。Readable Byte Streams の Web Platform Tests には、BYOB のエッジケースに特化した専用テストファイルが含まれています:切り離されたバッファ、不正なビュー、エンキュー後のレスポンス順序などです。
BYOB はユーザー側にも実装者側にも複雑さを強いる一方で、実際にはほとんど採用されていません。ほとんどの開発者はデフォルトの読み込みを使用し、割り当てオーバーヘッドを受け入れています。
カスタム ReadableStream インスタンスのユーザランド実装の多くは、単一のストリームでデフォルトと BYOB の両方の読み込みサポートを正しく実装するために必要な一連の手続きに手間をかけません。それには正当な理由があります。正しく実装するのは難しく、多くの場合、コードの大部分がデフォルトの読み込みパスにフォールバックすることになります。以下の例は、「正しい」実装が行う必要があることを示しています。これは大きく、複雑で、エラーを起こしやすく、一般的な開発者が実際に直面したくないレベルの複雑さです:
new ReadableStream({
type: 'bytes',
async pull(controller: ReadableByteStreamController) {
if (offset >= totalBytes) {
controller.close();
return;
}
// Check for BYOB request FIRST
const byobRequest = controller.byobRequest;
if (byobRequest) {
// === BYOB PATH ===
// Consumer provided a buffer - we MUST fill it (or part of it)
const view = byobRequest.view!;
const bytesAvailable = totalBytes - offset;
const bytesToWrite = Math.min(view.byteLength, bytesAvailable);
// Create a view into the consumer's buffer and fill it
// not critical but safer when bytesToWrite != view.byteLength
const dest = new Uint8Array(
view.buffer,
view.byteOffset,
bytesToWrite
);
// Fill with sequential bytes (our "data source")
// Can be any thing here that writes into the view
for (let i = 0; i < bytesToWrite; i++) {
dest[i] = (offset + i) & 0xFF;
}
offset += bytesToWrite;
// Signal how many bytes we wrote
byobRequest.respond(bytesToWrite);
} else {
// === DEFAULT READER PATH ===
// No BYOB request - allocate and enqueue a chunk
const bytesAvailable = totalBytes - offset;
const chunkSize = Math.min(1024, bytesAvailable);
const chunk = new Uint8Array(chunkSize);
for (let i = 0; i < chunkSize; i++) {
chunk[i] = (offset + i) & 0xFF;
}
offset += chunkSize;
controller.enqueue(chunk);
}
},
cancel(reason) {
console.log('Stream canceled:', reason);
}
});
ホストランタイムが、fetch Response のボディなどとして、ランタイム自体からバイト指向の ReadableStream(バイト指向可読ストリーム)を提供する場合、ランタイム側が BYOB リード(BYOB: Bring Your Own Buffer。バイナリデータを読み込む際に、呼び出し元が用意したバッファを直接利用する方式)の最適化された実装を提供するのはしばしばはるかに容易です。しかし、それらの実装も依然としてデフォルト読み取りパターンと BYOB 読み取りパターンの両方を処理できる能力を持たねばならず、その要件には相当な複雑さが伴います。
バックプレッシャー:理論上は良いが、実装では破綻している
バックプレッシャー — 遅いコンシューマーが速いプロデューサーに速度を落とすよう信号を送る機能 — は、Web Streams において第一級概念とされています。理論的にはそうですが、実際にはこのモデルには深刻な欠陥があります。
主要なシグナルはコントローラー上の desiredSize です。これは正の値(データを欲している)、ゼロ(容量いっぱいで受け入れ不可)、負の値(過剰状態)、または null(クローズ済み)となり得ます。プロデューサーはこの値を確認し、正でない場合はエンキューイングを停止すべきです。しかし、これを強制する仕組みは何もありません:controller.enqueue() は desiredSize が深く負の値であっても常に成功します。
new ReadableStream({
start(controller) {
// これを行うことを止めるものは何もない
while (true) {
controller.enqueue(generateData()); // desiredSize: -999999
}
}
});
ストーム実装はバックプレッシャーを無視することが可能であり、実際に行われています。また、仕様で定義された一部の機能は明示的にバックプレッシャーを破綻させます。例えば tee() は単一のストリームから 2 つのブランチを作成します。一方のブランチが他方よりも速く読み取ると、データが無制限の内部バッファに蓄積されます。速いコンシューマーが、遅いコンシューマーが追いつく間に無制限のメモリ増大を引き起こす可能性があります — これを設定したり、 slower ブランチをキャンセルする以外にこれを回避する方法はありません。
Web Streams は、highWaterMark オプションやカスタマイズ可能なサイズ計算という形で、バックプレッシャーの動作を調整するための明確なメカニズムを提供していますが、これらは desiredSize を無視するほど容易に無視されがちであり、多くのアプリケーションは単にこれらの機能に注意を払っていません。
WritableStream 側にも同様の問題が存在します。WritableStream には highWaterMark と desiredSize が備わっており、データプロデューサーが注視すべき writer.ready プロミスも存在しますが、実際にはしばしば無視されています。
const writable = getWritableStreamSomehow();
const writer = writable.getWriter();
// Producers are supposed to wait for the writer.ready
// It is a promise that, when resolves, indicates that
// the writables internal backpressure is cleared and
// it is ok to write more data
await writer.ready;
await writer.write(...);
実装者にとって、バックプレッシャーは複雑さを増すだけで保証を提供するものではありません。キューサイズの追跡や desiredSize の計算、適切なタイミングで pull() を呼び出すための機構をすべて正しく実装する必要があります。しかし、これらのシグナルが勧告的なものであるため、これらすべての作業が行われても、バックプレッシャーが解決すべき問題自体を防ぐことは実際にはできません。
プロミスの隠れたコスト
Web Streams の仕様では、多くの箇所でプロミスの作成が必要とされています。これらは頻繁にホットパス(重要な実行経路)に含まれ、かつユーザーには見えない形で実装されています。各 read() 呼び出しは単にプロミス返すだけでなく、内部ではキュー管理、pull() コーディネーション、バックプレッシャーのシグナリングのために追加のプロミスが作成されます。
このオーバーヘッドは、バッファ管理、完了通知、およびバックプレッシャー信号に対して仕様でプロミスへの依存を定めているために義務付けられています。その一部は実装固有のものですが、記された仕様に従う限り、多くの部分は避けられないものです。高頻度のストリーミング(動画フレーム、ネットワークパケット、リアルタイムデータなど)においては、このオーバーヘッドは無視できないほど大きくなります。
問題が複雑化するのはパイプラインの場合です。各 TransformStream はソースとシンクの間にもう一つの層のプロミス機構を追加します。仕様には同期の高速パスが定義されていないため、データが即座に利用可能な場合でも、プロメスメカニズムは依然として実行されます。
実装者にとって、このプロミス中心の設計は最適化の機会を制限しています。仕様では特定のプロミス解決順序が義務付けられており、微妙な準拠違反のリスクを冒さずに操作をバッチ処理したり、不要な非同期境界をスキップしたりすることが困難になります。実装者が行っている多くの内部最適化は存在しますが、これらは複雑で正しく実装するのが難しいものです。
このブログ記事を書いている最中、Vercel の Malte Ubl が、Node.js の Web ストリーム実装の性能向上に取り組む Vercel による研究について記した独自のブログ記事を公開しました。その記事では、Web ストリームのあらゆる実装が直面する根本的なパフォーマンス最適化の問題について議論されています:
「あるいは pipeTo() を考えてみてください。各チャンクは完全な Promise チェーン(読み込み、書き込み、バックプレッシャーの確認、繰り返し)を通過します。各読み取りごとに {value, done} 形式の結果オブジェクトが割り当てられます。エラー伝播により追加の Promise ブランチが発生します。
これらに誤りはありません。ストリームがセキュリティ境界を越えるブラウザでは、キャンセルセマンティクスが完全に厳密である必要があり、パイプの両端を制御できない場合もあるため、これらの保証は重要です。しかしサーバー側では、React Server Components を 1KB チャンクで 3 つの変換処理を経由してパiping する場合、コストが積み重なります。
私たちはネイティブ WebStream の pipeThrough をベンチマークし、1KB チャンクで 630 MB/s の結果を得ました。一方、Node.js の pipeline() は同じパススルー変換で約 7,900 MB/s です。これは 12 倍の差であり、その違いはほぼ完全に Promise とオブジェクト割り当てのオーバーヘッドによるものです。」
- Malte Ubl, https://vercel.com/blog/we-ralph-wiggumed-webstreams-to-make-them-10x-faster
彼らの研究の一環として、Node.js の Web ストリーム実装に対する一連の改善案をまとめました。これにより、特定のコードパスにおけるプロミスが排除され、最大 10 倍という劇的なパフォーマンス向上が可能になります。これはまさに、プロミスは有用ではあるものの、大きなオーバーヘッドをもたらすという点を証明するものです。Node.js のコアメンテナーの一人として、Malte 氏と Vercel のチームによるこれらの改善案を正式に採用されるよう尽力できることを楽しみにしています。
最近の Cloudflare Workers へのアップデートにおいて、私は同様の修正を内部データパイプラインに加え、特定のアプリケーションシナリオで生成される JavaScript プロミスの数を最大 200 倍削減しました。その結果、これらのアプリケーションにおけるパフォーマンスは数桁もの改善が見られました。
実世界の失敗事例
未消費のボディによるリソース枯渇
fetch() がレスポンスを返したとき、そのボディは ReadableStream(読み込み可能なストリーム)です。ステータスだけを確認して、ボディを消費したりキャンセルしたりしなかった場合どうなるでしょうか?答えは実装によって異なりますが、一般的な結果としてリソースリークが発生します。
async function checkEndpoint(url) {
const response = await fetch(url);
return response.ok; // ボディは一切消費またはキャンセルされない
}
// ループ内では、接続プールが枯渇する可能性があります
for (const url of urls) {
await checkEndpoint(url);
}
このパターンは、undici(Node.js に組み込まれた fetch() 実装)を使用する Node.js アプリケーションで接続プールの枯渇を引き起こし、他のランタイムでも同様の問題が発生しています。ストリームは基盤となる接続への参照を保持しており、明示的な消費やキャンセルが行われない場合、その接続はガベージコレクションが行われるまで残存し続ける可能性があります。しかし、負荷が高い状況下では、ガベージコレクションがすぐに発生するとは限りません。
この問題は、ストリームの分岐を暗黙的に作成する API によってさらに複雑化されます。Request.clone() と Response.clone() は、ボディストリームに対して暗黙的な tee() 操作を実行します — これは見落としやすい詳細です。ログ記録やリトライロジックのためにリクエストを複製するコードは、独立した消費が必要な分岐されたストリームを無意識に作成し、結果としてリソース管理の負担が倍増します。
さて、確かなのは、これらの種類の問題は実装上のバグであるということです。接続リークは確かに undici が自らの実装内で修正すべきものでしたが、仕様の複雑さがこうした問題への対処を容易にするものではありません。
"Node.js の fetch() 実装におけるストリームの複製は、見た目よりも困難です。リクエストまたはレスポンスのボディを複製すると、tee() を呼び出すことになります — これは単一のストリームを 2 つの消費が必要な分岐に分割する操作です。もし一方のコンシューマーが他方よりも速く読み込む場合、データはメモリ内で無制限にバッファリングされ、遅い方のコンシューマーを待機することになります
原文を表示
Handling data in streams is fundamental to how we build applications. To make streaming work everywhere, the WHATWG Streams Standard (informally known as "Web streams") was designed to establish a common API to work across browsers and servers. It shipped in browsers, was adopted by Cloudflare Workers, Node.js, Deno, and Bun, and became the foundation for APIs like fetch(). It's a significant undertaking, and the people who designed it were solving hard problems with the constraints and tools they had at the time.
But after years of building on Web streams — implementing them in both Node.js and Cloudflare Workers, debugging production issues for customers and runtimes, and helping developers work through far too many common pitfalls — I've come to believe that the standard API has fundamental usability and performance issues that cannot be fixed easily with incremental improvements alone. The problems aren't bugs; they're consequences of design decisions that may have made sense a decade ago, but don't align with how JavaScript developers write code today.
This post explores some of the fundamental issues I see with Web streams and presents an alternative approach built around JavaScript language primitives that demonstrate something better is possible.
In benchmarks, this alternative can run anywhere between 2x to 120x faster than Web streams in every runtime I've tested it on (including Cloudflare Workers, Node.js, Deno, Bun, and every major browser). The improvements are not due to clever optimizations, but fundamentally different design choices that more effectively leverage modern JavaScript language features. I'm not here to disparage the work that came before — I'm here to start a conversation about what can potentially come next.
Where we're coming from
The Streams Standard was developed between 2014 and 2016 with an ambitious goal to provide "APIs for creating, composing, and consuming streams of data that map efficiently to low-level I/O primitives." Before Web streams, the web platform had no standard way to work with streaming data.
Node.js already had its own streaming API at the time that was ported to also work in browsers, but WHATWG chose not to use it as a starting point given that it is chartered to only consider the needs of Web browsers. Server-side runtimes only adopted Web streams later, after Cloudflare Workers and Deno each emerged with first-class Web streams support and cross-runtime compatibility became a priority.
The design of Web streams predates async iteration in JavaScript. The for await...of syntax didn't land until ES2018, two years after the Streams Standard was initially finalized. This timing meant the API couldn't initially leverage what would eventually become the idiomatic way to consume asynchronous sequences in JavaScript. Instead, the spec introduced its own reader/writer acquisition model — and that decision rippled through every aspect of the API.
image
Excessive ceremony for common operations
The most common task with streams is reading them to completion. Here's what that looks like with Web streams:
// First, we acquire a reader that gives an exclusive lock
// on the stream...
const reader = stream.getReader();
const chunks = [];
try {
// Second, we repeatedly call read and await on the returned
// promise to either yield a chunk of data or indicate we're
// done.
while (true) {
const { value, done } = await reader.read();
if (done) break;
chunks.push(value);
}
} finally {
// Finally, we release the lock on the stream
reader.releaseLock();
}
You might assume this pattern is inherent to streaming. It isn't. The reader acquisition, the lock management, and the { value, done } protocol are all just design choices, not requirements. They are artifacts of how and when the Web streams spec was written. Async iteration exists precisely to handle sequences that arrive over time, but async iteration did not yet exist when the streams specification was written. The complexity here is pure API overhead, not fundamental necessity.
Consider the alternative approach now that Web streams now do support for await...of:
const chunks = [];
for await (const chunk of stream) {
chunks.push(chunk);
}
This is better in that there is far less boilerplate, but it doesn't solve everything. Async iteration was retrofitted onto an API that wasn't designed for it, and it shows. Features like BYOB (bring your own buffer) reads aren't accessible through iteration. The underlying complexity of readers, locks, and controllers are still there, just hidden. When something does go wrong, or when additional features of the API are needed, developers find themselves back in the weeds of the original API, trying to understand why their stream is "locked" or why releaseLock() didn't do what they expected or hunting down bottlenecks in code they don't control.
The locking problem
Web streams use a locking model to prevent multiple consumers from interleaving reads. When you call getReader(), the stream becomes locked. While locked, nothing else can read from the stream directly, pipe it, or even cancel it — only the code that is actually holding the reader can.
This sounds reasonable until you see how easily it goes wrong:
async function peekFirstChunk(stream) {
const reader = stream.getReader();
const { value } = await reader.read();
// Oops — forgot to call reader.releaseLock()
// And the reader is no longer available when we return
return value;
}
const first = await peekFirstChunk(stream);
// TypeError: Cannot obtain lock — stream is permanently locked
for await (const chunk of stream) { /* never runs */ }
Forgetting releaseLock() permanently breaks the stream. The locked property tells you that a stream is locked, but not why, by whom, or whether the lock is even still usable. Piping internally acquires locks, making streams unusable during pipe operations in ways that aren't obvious.
The semantics around releasing locks with pending reads were also unclear for years. If you called read() but didn't await it, then called releaseLock(), what happened? The spec was recently clarified to cancel pending reads on lock release — but implementations varied, and code that relied on the previous unspecified behavior can break.
That said, it's important to recognize that locking in itself is not bad. It does, in fact, serve an important purpose to ensure that applications properly and orderly consume or produce data. The key challenge is with the original manual implementation of it using APIs like getReader() and releaseLock(). With the arrival of automatic lock and reader management with async iterables, dealing with locks from the users point of view became a lot easier.
For implementers, the locking model adds a fair amount of non-trivial internal bookkeeping. Every operation must check lock state, readers must be tracked, and the interplay between locks, cancellation, and error states creates a matrix of edge cases that must all be handled correctly.
BYOB: complexity without payoff
BYOB (bring your own buffer) reads were designed to let developers reuse memory buffers when reading from streams — an important optimization intended for high-throughput scenarios. The idea is sound: instead of allocating new buffers for each chunk, you provide your own buffer and the stream fills it.
In practice, (and yes, there are always exceptions to be found) BYOB is rarely used to any measurable benefit. The API is substantially more complex than default reads, requiring a separate reader type (ReadableStreamBYOBReader) and other specialized classes (e.g. ReadableStreamBYOBRequest), careful buffer lifecycle management, and understanding of ArrayBuffer detachment semantics. When you pass a buffer to a BYOB read, the buffer becomes detached — transferred to the stream — and you get back a different view over potentially different memory. This transfer-based model is error-prone and confusing:
const reader = stream.getReader({ mode: 'byob' });
const buffer = new ArrayBuffer(1024);
let view = new Uint8Array(buffer);
const result = await reader.read(view);
// 'view' should now be detached and unusable
// (it isn't always in every impl)
// result.value is a NEW view, possibly over different memory
view = result.value; // Must reassign
BYOB also can't be used with async iteration or TransformStreams, so developers who want zero-copy reads are forced back into the manual reader loop.
For implementers, BYOB adds significant complexity. The stream must track pending BYOB requests, handle partial fills, manage buffer detachment correctly, and coordinate between the BYOB reader and the underlying source. The Web Platform Tests for readable byte streams include dedicated test files just for BYOB edge cases: detached buffers, bad views, response-after-enqueue ordering, and more.
BYOB ends up being complex for both users and implementers, yet sees little adoption in practice. Most developers stick with default reads and accept the allocation overhead.
Most userland implementations of custom ReadableStream instances do not typically bother with all the ceremony required to correctly implement both default and BYOB read support in a single stream – and for good reason. It's difficult to get right and most of the time consuming code is typically going to fallback on the default read path. The example below shows what a "correct" implementation would need to do. It's big, complex, and error prone, and not a level of complexity that the typical developer really wants to have to deal with:
new ReadableStream({
type: 'bytes',
async pull(controller: ReadableByteStreamController) {
if (offset >= totalBytes) {
controller.close();
return;
}
// Check for BYOB request FIRST
const byobRequest = controller.byobRequest;
if (byobRequest) {
// === BYOB PATH ===
// Consumer provided a buffer - we MUST fill it (or part of it)
const view = byobRequest.view!;
const bytesAvailable = totalBytes - offset;
const bytesToWrite = Math.min(view.byteLength, bytesAvailable);
// Create a view into the consumer's buffer and fill it
// not critical but safer when bytesToWrite != view.byteLength
const dest = new Uint8Array(
view.buffer,
view.byteOffset,
bytesToWrite
);
// Fill with sequential bytes (our "data source")
// Can be any thing here that writes into the view
for (let i = 0; i < bytesToWrite; i++) {
dest[i] = (offset + i) & 0xFF;
}
offset += bytesToWrite;
// Signal how many bytes we wrote
byobRequest.respond(bytesToWrite);
} else {
// === DEFAULT READER PATH ===
// No BYOB request - allocate and enqueue a chunk
const bytesAvailable = totalBytes - offset;
const chunkSize = Math.min(1024, bytesAvailable);
const chunk = new Uint8Array(chunkSize);
for (let i = 0; i < chunkSize; i++) {
chunk[i] = (offset + i) & 0xFF;
}
offset += chunkSize;
controller.enqueue(chunk);
}
},
cancel(reason) {
console.log('Stream canceled:', reason);
}
});
When a host runtime provides a byte-oriented ReadableStream from the runtime itself, for instance, as the body of a fetch Response, it is often far easier for the runtime itself to provide an optimized implementation of BYOB reads, but those still need to be capable of handling both default and BYOB reading patterns and that requirement brings with it a fair amount of complexity.
Backpressure: good in theory, broken in practice
Backpressure — the ability for a slow consumer to signal a fast producer to slow down — is a first-class concept in Web streams. In theory. In practice, the model has some serious flaws.
The primary signal is desiredSize on the controller. It can be positive (wants data), zero (at capacity), negative (over capacity), or null (closed). Producers are supposed to check this value and stop enqueueing when it's not positive. But there's nothing enforcing this: controller.enqueue() always succeeds, even when desiredSize is deeply negative.
new ReadableStream({
start(controller) {
// Nothing stops you from doing this
while (true) {
controller.enqueue(generateData()); // desiredSize: -999999
}
}
});
Stream implementations can and do ignore backpressure; and some spec-defined features explicitly break backpressure. tee(), for instance, creates two branches from a single stream. If one branch reads faster than the other, data accumulates in an internal buffer with no limit. A fast consumer can cause unbounded memory growth while the slow consumer catches up — and there's no way to configure this or opt out beyond canceling the slower branch.
Web streams do provide clear mechanisms for tuning backpressure behavior in the form of the highWaterMark option and customizable size calculations, but these are just as easy to ignore as desiredSize, and many applications simply fail to pay attention to them.
The same issues exist on the WritableStream side. A WritableStream has a highWaterMark and desiredSize. There is a writer.ready promise that producers of data are supposed to pay attention but often don't.
const writable = getWritableStreamSomehow();
const writer = writable.getWriter();
// Producers are supposed to wait for the writer.ready
// It is a promise that, when resolves, indicates that
// the writables internal backpressure is cleared and
// it is ok to write more data
await writer.ready;
await writer.write(...);
For implementers, backpressure adds complexity without providing guarantees. The machinery to track queue sizes, compute desiredSize, and invoke pull() at the right times must all be implemented correctly. However, since these signals are advisory, all that work doesn't actually prevent the problems backpressure is supposed to solve.
The hidden cost of promises
The Web streams spec requires promise creation at numerous points — often in hot paths and often invisible to users. Each read() call doesn't just return a promise; internally, the implementation creates additional promises for queue management, pull() coordination, and backpressure signaling.
This overhead is mandated by the spec's reliance on promises for buffer management, completion, and backpressure signals. While some of it is implementation-specific, much of it is unavoidable if you're following the spec as written. For high-frequency streaming — video frames, network packets, real-time data — this overhead is significant.
The problem compounds in pipelines. Each TransformStream adds another layer of promise machinery between source and sink. The spec doesn't define synchronous fast paths, so even when data is available immediately, the promise machinery still runs.
For implementers, this promise-heavy design constrains optimization opportunities. The spec mandates specific promise resolution ordering, making it difficult to batch operations or skip unnecessary async boundaries without risking subtle compliance failures. There are many hidden internal optimizations that implementers do make but these can be complicated and difficult to get right.
While I was writing this blog post, Vercel's Malte Ubl published their own blog post describing some research work Vercel has been doing around improving the performance of Node.js' Web streams implementation. In that post they discuss the same fundamental performance optimization problem that every implementation of Web streams face:
"Or consider pipeTo(). Each chunk passes through a full Promise chain: read, write, check backpressure, repeat. An {value, done} result object is allocated per read. Error propagation creates additional Promise branches.
None of this is wrong. These guarantees matter in the browser where streams cross security boundaries, where cancellation semantics need to be airtight, where you do not control both ends of a pipe. But on the server, when you are piping React Server Components through three transforms at 1KB chunks, the cost adds up.
We benchmarked native WebStream pipeThrough at 630 MB/s for 1KB chunks. Node.js pipeline() with the same passthrough transform: ~7,900 MB/s. That is a 12x gap, and the difference is almost entirely Promise and object allocation overhead."
- Malte Ubl, https://vercel.com/blog/we-ralph-wiggumed-webstreams-to-make-them-10x-faster
As part of their research, they have put together a set of proposed improvements for Node.js' Web streams implementation that will eliminate promises in certain code paths which can yield a significant performance boost up to 10x faster, which only goes to prove the point: promises, while useful, add significant overhead. As one of the core maintainers of Node.js, I am looking forward to helping Malte and the folks at Vercel get their proposed improvements landed!
In a recent update made to Cloudflare Workers, I made similar kinds of modifications to an internal data pipeline that reduced the number of JavaScript promises created in certain application scenarios by up to 200x. The result is several orders of magnitude improvement in performance in those applications.
Real-world failures
Exhausting resources with unconsumed bodies
When fetch() returns a response, the body is a ReadableStream. If you only check the status and don't consume or cancel the body, what happens? The answer varies by implementation, but a common outcome is resource leakage.
async function checkEndpoint(url) {
const response = await fetch(url);
return response.ok; // Body is never consumed or cancelled
}
// In a loop, this can exhaust connection pools
for (const url of urls) {
await checkEndpoint(url);
}
This pattern has caused connection pool exhaustion in Node.js applications using undici (the fetch() implementation built into Node.js), and similar issues have appeared in other runtimes. The stream holds a reference to the underlying connection, and without explicit consumption or cancellation, the connection may linger until garbage collection — which may not happen soon enough under load.
The problem is compounded by APIs that implicitly create stream branches. Request.clone() and Response.clone() perform implicit tee() operations on the body stream — a detail that's easy to miss. Code that clones a request for logging or retry logic may unknowingly create branched streams that need independent consumption, multiplying the resource management burden.
Now, to be certain, these types of issues are implementation bugs. The connection leak was definitely something that undici needed to fix in its own implementation, but the complexity of the specification does not make dealing with these types of issues easy.
"Cloning streams in Node.js's fetch() implementation is harder than it looks. When you clone a request or response body, you're calling tee() - which splits a single stream into two branches that both need to be consumed. If one consumer reads faster than the other, data buffers unbounded in memory waiting for the slow b
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み