LangSmith Engine の紹介
LangChain は、エージェントの改善プロセスを自動化する「LangSmith Engine」を発表し、手動でのトレース分析や修正から解放され、継続的な自己修復と評価スイートの強化を実現した。
キーポイント
自動改善ループの実現
従来の手動プロセス(トレースの読み込み、パターン特定、修正)を自動化し、生産環境での失敗をクラスタリングして根本原因を診断し、PR や評価器を提案する機能を搭載した。
評価スイートの自動強化
問題が解決されるたびにカスタムオンライン評価器を提案し、失敗したトレースをオフライン評価データセットに組み込むことで、再発防止を自動的に担保する。
既存インフラとの統合
新しいインフラ構築を必要とせず、既存の LangSmith プロジェクトやリポジトリにプラグインすることで、すぐに生産環境での自動問題発見を開始できる。
影響分析・編集コメントを表示
影響分析
この発表は、エージェント開発における「運用と改善」のボトルネックを解消する画期的なステップであり、開発者が手動でのデバッグ作業から解放され、より戦略的な設計に注力できる環境を提供します。特に、失敗事例が自動的に評価基準として学習・蓄積される仕組みは、大規模エージェントシステムの信頼性を飛躍的に高める可能性を秘めています。
編集コメント
エージェント開発の「運用フェーズ」を自動化するツールが登場し、実務レベルでの品質担保が劇的に簡素化される可能性があります。ただし、自動提案された修正の信頼性をどう検証するかは、引き続き開発者の判断が重要となるでしょう。

重要なポイント
- エージェントの改善ループが自動化されました。LangSmith Engine は、トレーシング(trace)を読み込み、パターンを特定し、修正を行うという手動サイクルに代わり、継続的に実行します。生産環境での失敗を名前付きの問題としてクラスタリングし、コードに対して根本原因を診断し、レビュー用のプルリクエスト(PR)と評価器(evaluator)を作成します。
- 解決されたすべての問題が、評価スイート(eval suite)の強化につながります。Engine が修正を提示する際、カスタムのオンライン評価器も提案し、失敗したトレーシングをオフラインの評価データセットに追加します。これにより、リリース後に同じ失敗が静かに再発することを防ぎます。
- これは既存の LangSmith 設定の上に構築されています。Engine は現在のトレーシングプロジェクト、評価結果、リポジトリに接続され、新たなインフラは不要です。プロジェクトを接続し(必要に応じてリポジトリも接続)、生産環境からの問題を自動的に提示するようになります。
本日、LangSmith Engine の公開ベータ版を開始します。
これまで、エージェントの改善は、トレーシングを読み込み、パターンを探り、評価器を作成し、修正を行うという手動プロセスでした。しかし今や LangSmith Engine がそのループを自動で実行します。Engine は生産環境のトレーシングを監視し、失敗を名前付きの問題としてクラスタリングし、コードに対して根本原因を診断し、再発を防ぐための修正と評価カバレッジを提案します。ユーザーは改善内容を確認してマージするだけです。
LangSmith Engine は本日、公開ベータ版として利用可能です。
すべてのエージェントチームが実行しているループ
典型的なエージェント開発サイクルは以下のようになります:
- エージェントのトレースを追跡して、その動作を理解する
- 失敗のパターンや機能のギャップを特定する
- プロンプト、ツール、ロジック、または構造に変更を加える
- 本番環境からのトレースからグランドトゥルース(正解)データセットを作成する
- 改善を確認し、回帰がないかチェックするために実験を実行する
- 公開して繰り返し実行する
LangSmith はすでに、各ステップをサポートするためのトレースビュー、高速なデータセット作成、および実験機能を提供しています。しかし、顧客からは同じような摩擦点が常に報告されていました:
- 個々のトレースレビューではパターンが明らかにならないため、何を修正すべきか分からない。
- 大規模なスケールでエラーがどの頻度で再発しているかを確認するのが困難である。
- 本番環境データからオフライン評価用のグランドトゥルース例を作成するのは面倒であり、容易に省略されがちである。
- 一度修正を公開しても、同じ問題が再発生した場合を検出するためのターゲット型評価器が設置されていないことが多い。
Engine はこのループ全体で機能します。チームは優先順位付けされたリストでクラスタ化した失敗を確認し、自動で修正案のドラフトを作成し、テストスイート用のオフライン評価例を提案されます。
実際の課題の例
エージェントがカスタマーサポートボットであると仮定しましょう。Engine は、ユーザーが購読のキャンセルについて質問するトレースのクラスターを検出します。あなたのエージェントは応答しますが、オンライン評価ではその応答が失敗としてスコアリングされ、ユーザーフィードバックも否定的です。レイテンシーは正常であるため、システムアラートは発生していません。
Engine はこれを単一の命名された課題として表面化させます。「エージェントが購読キャンセルリクエストを正確に処理できない」というものです。これにより、重大度(今週のサポートセッションの 12% に影響する高レベル)、タイムライン(4 日前に開始し、直近のデプロイメントと相関あり)、および証拠としての特定のトレースへのリンクが表示されます。
リポジトリが接続されている場合、Engine は関連コードを読み込み、根本原因を特定します。キャンセルツールの説明が曖昧であるため、エージェントはユーザーがオプションについて尋ねている際にさえキャンセルを試みてしまいます。Engine はツールの説明に対するターゲットを絞った修正を含む PR をドラフトします。
今後のこの挙動の追跡を維持するために、Engine はこの特定の課題にスコープを限定したカスタムオンライン評価器を提案します。これにより、修正がリリースされた後に失敗パターンが再発した場合、更新された詳細とともに自動的に課題が表面化されます。
また、Engine は失敗したトレースをオフライン評価スイート用のデータセットに取り込みます。ここでは、正しい出力に含めるべき内容を定義する例ごとの基準が設定されています。本番環境に到達してしまった失敗事例は、それらが再び発生しないようにするためのテストケースとなります。
これが完全なループです。自律的に実行され、レビューのために表面化されます。本番からのシグナルはクラスタ化された課題となり、次に診断された根本原因、提案された修正、そして評価カバレッジへと変換されます。
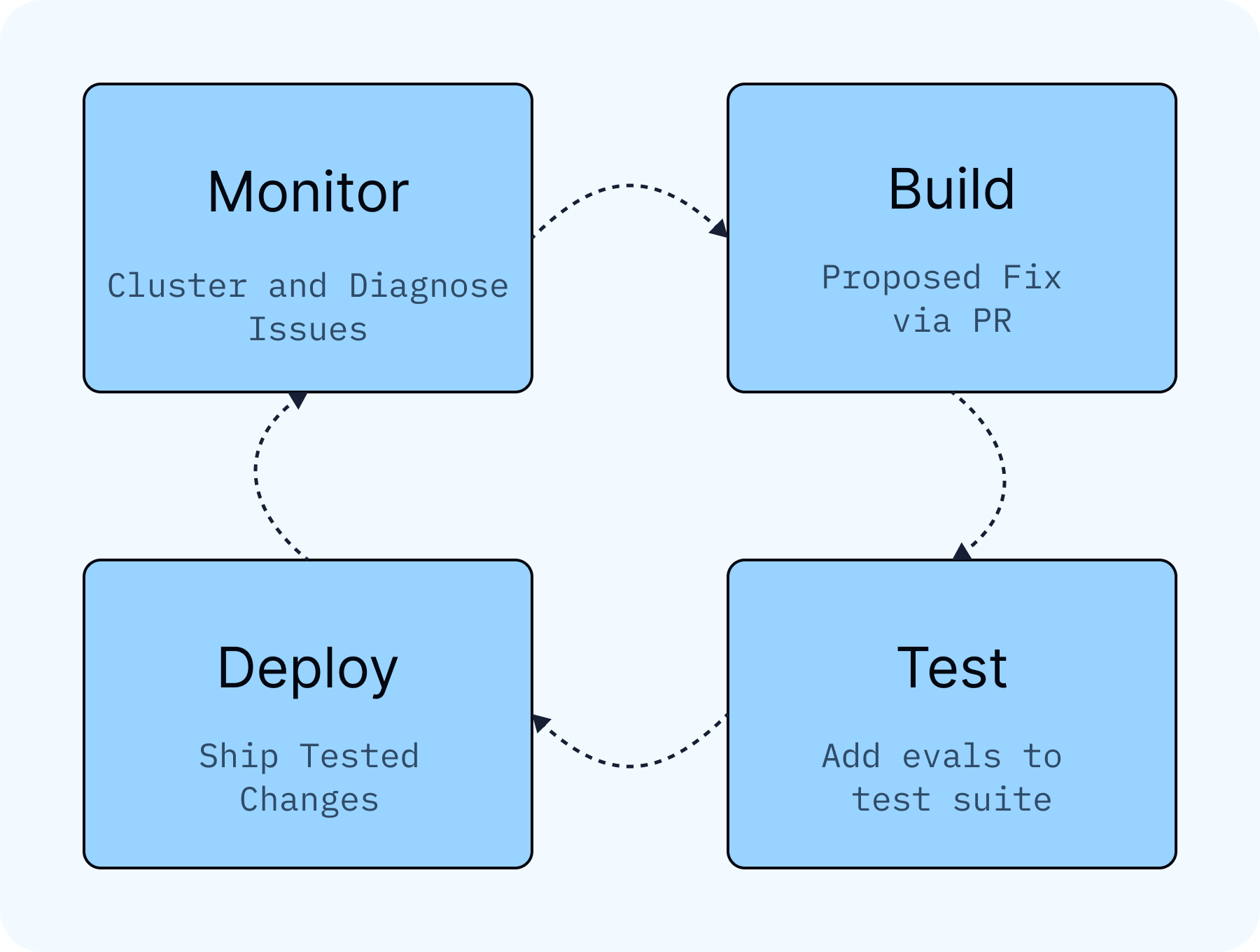
Engine が各課題に対して行うこと
Engine は表面化させたすべての課題に対して、3 つの解決アクションを提案します。
PR を作成する。 リポジトリへのアクセス権限がある場合、Engine はターゲットを絞ったコードまたはプロンプトの変更案を作成し、あなたのリポジトリに対してプルリクエスト(PR)として開きます。あなたはレビューしてマージします。
カスタムオンライン評価器を作成する。 Engine は、特定の課題に限定された評価器を提案します。もしこれが再度発火した場合、その課題は更新された詳細情報とともに自動的に再表面化されます。
オフライン評価スイートに追加する。 Engine は失敗した本番環境のトレースデータを抽出し、正解例(ground truth examples)からなるデータセットとして取り込み、オフライン評価スイートで実行可能な状態にします。
解決されたすべての課題は、その過程であなたの評価カバレッジを向上させます。修正を確認する際、あなたは将来のパフォーマンスを監視するための評価器も同時に生成していることになります。時間が経つにつれて、すでに解決済みの課題があなたの評価スイートをより包括的なものにし、それによって将来の改善をより堅牢なものにします。
Engine の仕組み
LangSmith Engine は、トレースデータ、評価フィードバック、および(リポジトリに接続されている場合)エージェントのソースコードにアクセスできるディープエージェントによって駆動されています。
これは、いくつかのシグナルタイプに対してトレースを監視します。明示的なエラー(ツール呼び出しの失敗、タイムアウト)、オンライン評価器の失敗、トレース異常(レイテンシーの急上昇、トークンの爆発、予期しないステップ数)、否定的なユーザーフィードバック、およびエージェントが回答するように構築されていない質問をするユーザーのような異常な行動などです。Engine が複数のトレースにわたってパターンを検出すると、個々の失敗を提示するのではなく、それらを単一の命名された問題としてクラスタリングします。
LangSmith Engine は、LangSmith の既存のトレーシングおよび評価インフラストラクチャの上に構築されています。既存の評価器の結果を入力として使用するため、評価器が検出した失敗は直接問題検出にフィードバックされます。Engine が新しい評価器を提案するのは、現在のカバレッジにギャップを検知した場合です。また、データセットの例を作成する場合は、既存のオフライン評価ワークフローに直接組み込まれます。
What customers are seeing
Cogent、Harmonic、Campfire などのチームはすでに Engine を使用して、数千件のトレースに影響を与える問題を解決してきました。彼らは回帰をより早期に検出し、修正を迅速にリリースし、トリアージに費やす時間を減らしています。
*これまでに非常に気に入っています。私たちの deepagent のトレースには数十から数百のターンが含まれることがあり、レビューやパターンの特定が退屈な作業になります。LangSmith Engine は、新たな失敗モードを特定するだけでなく、それらを迅速に解決するための評価器やコード変更を積極的に提案することで、チームの調査時間を数時間節約します。
*-Austin Berke, Founding Eng @ Harmonic
ここでの方向性
エージェントの改善ループは長らく手動で行われてきましたが、私たちはより多くのプロセスを手動トリガーなしで継続的に実行し、よく理解されている問題タイプが人間のレビューなしで解決され、ハネス(検証環境)が時間とともに特定のあなたのエージェントについて賢くなる未来に向けて取り組んでいます。LangSmith Engine はその第一歩です。
始め方
LangSmith Engine は現在、パブリックベータ版として利用可能です。トレーシングプロジェクトを接続し、必要に応じてリポジトリも接続すれば、Engine が自動的に本番環境のトレースから問題を提示し始めます。
関連コンテンツ

LangSmith
エージェントの観測性を支えるデータレイヤー、SmithDB を構築しました

Ankush Gola
2026 年 5 月 13 日
11 分

LangSmith
LangSmith Context Hub の紹介

Harrison Chase
2026 年 5 月 13 日
8 分

LangSmith
LangSmith Sandboxes が一般提供開始

Mukhil Loganathan
2026 年 5 月 13 日
6 分

エージェントが実際に何をしているかを確認する
LangSmith は、エージェントエンジニアリングプラットフォームであり、開発者がすべてのエージェントの意思決定をデバッグし、変更の評価を行い、ワンクリックでデプロイできるように支援します。
原文を表示
Key Takeaways
- The agent improvement loop is now automated. LangSmith Engine replaces the manual cycle of reading traces, spotting patterns, and writing fixes by doing it continuously — clustering production failures into named issues, diagnosing root causes against your code, and drafting PRs and evaluators for your review.
- Every resolved issue makes your eval suite stronger. When Engine surfaces a fix, it also proposes a custom online evaluator and pulls failing traces into your offline eval dataset — so the same failure can't silently recur after you ship.
- It's built on top of your existing LangSmith setup. Engine plugs into your current tracing projects, evaluator results, and repositories — no new infrastructure required. Connect a project, optionally connect your repo, and it starts surfacing issues from production automatically.
Today we're launching LangSmith Engine.
Until now, improving your agent has been a manual process of reading traces, looking for patterns, writing evals, and creating fixes. Now LangSmith Engine can run that loop for you. It watches your production traces, clusters failures into named issues, diagnoses root causes against your code, and proposes fixes and eval coverage to keep regressions from coming back. You just review and merge improvements.
LangSmith Engine is available today in public beta.
The loop every agent team is running
The typical agent development cycle looks like this:
- Trace your agent to understand what it's doing
- Identify patterns in failures or gaps in functionality
- Make changes to prompts, tools, logic, or structure
- Create ground truth datasets from production traces
- Run experiments to confirm improvements and check for regressions
- Ship and repeat
LangSmith already gives you trace views, fast dataset creation, and experimentation to support each step. But we kept hearing the same friction points from customers:
- Knowing what to fix is hard because individual trace review doesn't reveal patterns.
- Seeing how often an error recurs across traces is difficult at scale.
- Creating ground truth examples for offline evals from production data is tedious and easy to skip.
- Once a fix ships, there's often no targeted evaluator in place to catch the same problem if it comes back.
Engine works across the entire loop. Teams see clustered failures in a prioritized list, get fixes drafted automatically, and have offline eval examples proposed for their test suite.
What an issue looks like in practice
Say your agent is a customer support bot. Engine detects a cluster of traces where users ask about canceling their subscription. Your agent responds, but online evals are scoring the responses as failures and user feedback is negative. Latency is normal, so no systems alert fired.
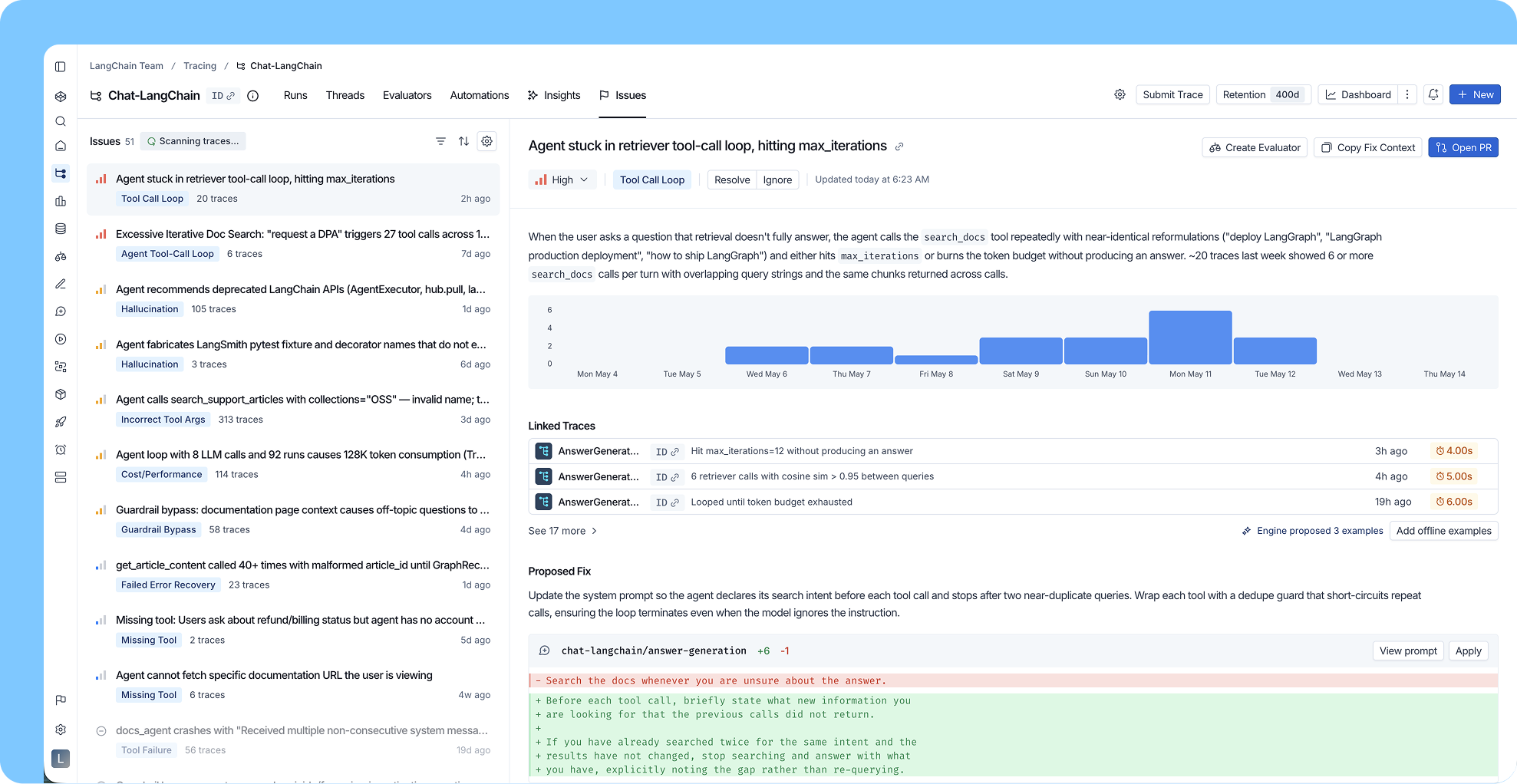
Engine surfaces this as a single named issue, "Agent fails to handle subscription cancellation requests accurately." It shows you the severity (high, affecting 12% of support sessions this week), the timeline (started four days ago, correlating with a recent deployment), and links to the specific traces as evidence.
With your repository connected, Engine reads the relevant code and identifies the root cause. The cancellation tool description is ambiguous, causing the agent to attempt cancellation when users are only asking about their options. Engine drafts a PR with a targeted fix to the tool description.
To keep tracking this behavior going forward, Engine proposes a custom online evaluator scoped to this exact issue, so if the failure pattern recurs after the fix ships, the issue gets resurfaced automatically with updated details.
Engine also pulls the failing traces into a dataset for your offline eval suite, with per-example criteria that define what the correct output should contain. The failures that made it to production become the test cases that keep them out.
That's the full loop, run autonomously and surfaced for your review. Production signal becomes a clustered issue, then a diagnosed root cause, a proposed fix, and eval coverage.
What Engine does about each issue
For every issue it surfaces, Engine proposes three resolution actions.
Open a PR. With repository access, Engine drafts a targeted code or prompt change and opens it against your repo. You review and merge.
Create a custom online evaluator. Engine proposes an evaluator scoped to the exact problem. If it fires again, the issue gets resurfaced automatically with updated details.
Add to your offline eval suite. Engine pulls the failing production traces into a dataset of ground truth examples, ready to run in your offline eval suite.
Every resolved issue improves your eval coverage along the way. When you confirm a fix, you're also generating an evaluator that monitors performance going forward. Over time, the issues you've already resolved make your eval suite more complete, which makes future improvements more robust.
How Engine works
LangSmith Engine is powered by a deep agent that has access to your trace data, evaluator feedback, and your agent's source code (if connected to your repo).
It monitors traces for several signal types: explicit errors (tool call failures, timeouts), online evaluator failures, trace anomalies (latency spikes, token blowouts, unexpected step counts), negative user feedback, and unusual behaviors like users asking questions the agent wasn't built to answer. When Engine spots a pattern across multiple traces, it clusters them into a single named issue rather than surfacing each failure individually.
LangSmith Engine is built on top of LangSmith's existing tracing and evaluation infrastructure. It uses your existing evaluator results as inputs, so failures your evals catch feed directly into issue detection. When Engine proposes a new evaluator, it's because it detected a gap in your current coverage. When it creates a dataset example, it goes directly into your existing offline eval workflow.
What customers are seeing
Teams like Cogent, Harmonic, and Campfire have already used Engine to resolve issues affecting thousands of traces. They're catching regressions earlier, shipping fixes faster, and spending less time on triage.
We love it so far. Our deepagent traces can contain dozens or hundreds of turns, which makes review and identifying patterns tedious. LangSmith Engine saves our team hours of digging by not only identifying emerging failure modes, but also proactively suggesting evals and code changes to resolve them quickly. -Austin Berke, Founding Eng @ Harmonic
Where this is going
The agent improvement loop has been manual for too long, and we're working toward a future where more of it runs continuously without manual triggers, where well-understood issue types resolve without human review, and where the harness gets smarter about your specific agent over time. LangSmith Engine is the first step.
Get started
LangSmith Engine is available now in public beta. Connect a tracing project, optionally connect your repo, and Engine will begin surfacing issues from your production traces automatically.
Related content
LangSmith
We built SmithDB, the data layer for agent observability
Ankush Gola
May 13, 2026
11
min
LangSmith
Introducing LangSmith Context Hub
Harrison Chase
May 13, 2026
8
min
LangSmith
LangSmith Sandboxes are Generally Available
Mukhil Loganathan
May 13, 2026
6
min
See what your agent is really doing
LangSmith, our agent engineering platform, helps developers debug every agent decision, eval changes, and deploy in one click.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み