ヘルメス対オープンクロー、サイバーセキュリティ警報の鳴動、より対話的な会話、エージェントは人間の仕事ができるか?
The Batch は、AI エージェント間の比較(ヘルメスとオープンクロー)、サイバーセキュリティの警報発生、対話機能の高度化、そして AI エージェントが人間の業務を代替できる可能性について論じています。
親愛なる皆様、
ハーバード大学は先ほど、学部生クラスでの A 評価の数をクラスの約 20% に制限するよう投票しました。私はこの方針には賛成できません。これは私が教育が持つべき姿と信じていることに深く反するからです。高い基準を維持すべきですが、同時に学習者の一部ではなく 100% の成功を支援するために全力で取り組むべきです。
ハーバードの学長部は、学生団体の多くからの反対を押し切ってこの措置をとりました。その目的は成績のインフレ(grade inflation)に対抗するためです。成績のインフレは確かに存在します:多くの大学では A や B の評価がより多くの学生に与えられ続けており、これが学生の技能を示す指標としての GPA(Grade Point Average: 平均成績評定値)の有用性を低下させています。同時に、私たちは学生が成功することを望んでいます。この問いの核心は教育機関の役割にあります。私たちの目標とは:
- 学生の成功を支援することか?
- 学生を評価することか?
これら両方にも価値があります。しかし、私が教育に関わる際の焦点は、ほぼ完全に学生の成功を支援することに置かれています。
私にとって明確なのは、多くの人々が学びたいと願い、力を得て、新しいことができるようになるスキルを築きたいと考えているということです!これが DeepLearning.AI で私たちが注力していることです。この哲学こそが、私のオンラインコース(Coursera での早期のスタンフォード大学でのオンライン講座にまで遡ります)で、評価課題に対して無制限のリトライを許可してきた理由でもあります。
私は、誰かが成功するまで何かをやり直すことを許し、むしろ奨励すべきだと信じています。これは、彼らが初めて正しくできなかったという事実に対して裁くことに反対するものです。また、宿題の課題は、主に技能レベルを判断するためではなく、人々が練習して学ぶのを助けるために設計されるべきだと信じています。これが私が「演習問題」や「演習ラボ」を作成することを好む理由です。これらは、考え抜くことで実践の機会を与え、既知の知識を強化する質問です。一方、「評価問題」は主に技能を判断するために設計されています。
 imageしかし、ハーバード大学のこの動きは GPA(成績平均点)をより意味のあるものにし、将来の雇用主が強力な候補者を特定するのを助けるのでしょうか?私はハーバード大学や他の機関から多数の人材を採用してきましたが、GPA は重要なシグナルではないと自信を持って言えます。私たちが採用しているスクリーニングや面接のプロセスは、誰が本当に技能を持っているかを把握するための、はるかに正確な方法を提供しています。誰が本当に優れているかを見極めるために、応募者の GPA スコアのばらつきを広くする必要はありません!
imageしかし、ハーバード大学のこの動きは GPA(成績平均点)をより意味のあるものにし、将来の雇用主が強力な候補者を特定するのを助けるのでしょうか?私はハーバード大学や他の機関から多数の人材を採用してきましたが、GPA は重要なシグナルではないと自信を持って言えます。私たちが採用しているスクリーニングや面接のプロセスは、誰が本当に技能を持っているかを把握するための、はるかに正確な方法を提供しています。誰が本当に優れているかを見極めるために、応募者の GPA スコアのばらつきを広くする必要はありません!
明確にしておきますが、評価にも価値があります。標準化されたテストは非常に嫌われる傾向がありますが、SAT、ACT、GRE、TOEFL などの高品質なテストは、特定の分野における能力の客観的な指標を提供します。私は、ほとんどの人が学びたいと願い、成功したいと考えていると感じています。また、厳格な評価を望む人々もいます(例えば、学校への入学申請のためなど)。しかし、これはより次要的なニーズであり、教育製品を構築する際の私の焦点ではありません。
ハーバード大学はしばしば「エリート」教育機関として説明されます。エリートであるには2つの方法があります。1 つの選択肢は、入学者数を制限し、さらに合格者の中でも成功する人の数を 20% に制限することです。私は別の道を選びたいと考えています:高い基準を設定し、エリートで最先端のスキルを教える一方で、誰もが成功できるよう尽力することを絶えず目指すのです。このようにして、「エリート性」は人々を排除することによって定義されるのではなく、できるだけ多くの人々が卓越した存在となるよう支援することによって定義されます。
学び続けましょう!
アンドリュー
DEEPLEARNING.AI からのメッセージ
画像や動画を生成し、自身の出力を評価して結果を改善するための反復を行う AI エージェント(AI agents)を構築しましょう。この新しい短期コースでは、UI のモックアップ用や多シーン動画解説用のビジュアルメディアエージェントを構築する際に、画像とテキストの類似度スコアリング、LLM による判定者(LLM judges)、構造化された評価基準(structured rubrics)を活用します。無料で受講する
News

Hermes エージェントが OpenClaw に挑戦
OpenClaw は非常に人気のある AI エージェントですが、急速に台頭する競合相手が出てきました。
最新情報: 2 月にニューヨークを拠点とする AI ラボである Nous Research が公開したオープンソースの Hermes Agent が、AI モデルプラットフォーム OpenRouter によって集計された データ に基づくリーダーボードで、エージェントが毎日消費するトークン数を追跡する項目において、OpenClaw を上回りました。一部のユーザーは Hermes Agent がトークンの効率が低いと 不満を述べています が、新しいスキル(専門的な指示、ワークフロー、および/またはドメイン知識)を定義し、洗練させる能力は、自己改善が中核的なエージェント機能であることを浮き彫りにしています。こちらからダウンロードできます here。
仕組み: Hermes エージェントの機能は、OpenClaw のそれらと大きく重複しています。Hermes エージェントが主に異なるのは、そのメモリアーキテクチャとスキルを自動的に構築する能力です。これはローカルまたはクラウドで実行するように設計されており、多様な大規模言語モデルをサポートし、約 20 のメッセージングサービスと統合されています。ブラウザからログインした後に新しいアクセストークンを生成するモデル(またはローカルで動作するモデル)を使用することで、API キーを保存せずにすぐに運用を開始することが可能になります。これはエージェント通信プロトコルを通じて統合開発環境とも連携します。
- エージェントループ:OpenClawと同様に、Hermes Agent のエージェントループは以下の通り機能します。(i) エージェントは、定義された人格、指示、ツール、スキル、メモリ、ユーザーに関する知識、および最新のメッセージを含む会話履歴に基づいてプロンプトを構築します。(ii) プロンプトが関連する大規模言語モデル(LLM)の入力制限を超えた場合、会話履歴内の古いメッセージの要約を LLM に依頼してサイズを縮小します。(iii) 構築されたプロンプトを LLM に送信し、ツールの呼び出し、スキルの呼び出し、またはユーザーへの応答のいずれかを行います。(iv) スキルまたはツールを呼び出した場合、その呼び出しを実行し、これによりツール呼び出し、スキル呼び出し、またはユーザーへの応答が出力されます。このサイクルは、モデルがユーザーに応答を生成するまで繰り返されます。
- スキル:Hermes Agent は、bash スクリプトの実行、ウェブ検索やファイル検索、データベース照会などを行うツールを呼び出すことでタスクを完了する方法を指示する指示ファイルに、標準的な SKILL.md 形式を使用します。組み込みのスキルが付属しており、追加のスキルは Skills Hub から利用可能です(ただし、現時点では OpenClaw の膨大なクラウドソーシング型スキルライブラリに比べると非常に小規模です)。しかし、Hermes Agent は新しいスキルも自動的に作成します。Hermes Agent が問題に対して長時間取り組んだりエラーを修正したりしてタスクの完了と判断した場合、ツールを呼び出してスキルを作成します。エージェント生成によるスキルの肥大化を防ぐため、Curator と呼ばれる追加のバックグラウンドシステムが機能し、(i) 90 日以上使用されていないすべてのスキルを別フォルダに移動してアーカイブし、(ii) LLM を用いて各スキルを現状維持するか、他のスキルと統合するか、アーカイブするべきかを判断します。
- メモリ:Hermes Agent はプロンプトに追加する 2 つの一般的なメモリファイルを保持しています。1 つはユーザーの好意を詳細に記述したものであり、もう 1 つはワークフローや教訓に関する情報を含んでいます。これらのファイルへの追加には組み込みのメモリツールを呼び出します。メモリを追加すると判断した場合、そのメモリが追加する価値があるか、どちらのファイルに追加すべきかをチェックします(例えば、類似のメモリが既に存在する場合や、メモリ内容が曖昧すぎる場合は追加しません)。メモリの追加により所定のファイル長を超えると判断した場合、関連するメモリファイルを精査し、関連するエントリを統合します。Hermes Agent はまた、別のツールを使用して検索可能な会話データベースも保持しています。さらに、各メッセージの後にユーザーのアイデンティティを分析して好意、目標、パターンを導き出す Honcho などの外部メモリプロバイダを活用することもできます。
- 永続的なゴール追跡:ユーザーはメッセージ内でゴールを指定できます。エージェントが応答を終了すると、ゴールが完了したかどうかを評価するために判別モデル(judge model)を呼び出します。完了していない場合、作業を継続します。このループは、ゴールが完了と判断されるか、またはエージェントが最大ターン数に達するまで続きます。Anthropic の Claude Code、OpenAI の Codex、および OpenClaw(プラグイン経由)も同様の機能を提供しています。
ニュースの背景: エージェント機能は、大規模言語モデルが多段階にわたる計画能力、過去の出力に対する自己省察能力、およびオンラインでアクションを実行するための外部ツールの利用能力を獲得したことで登場しました。2025 年には、Anthropic の Claude Code や OpenAI の Codex といったコーディングエージェントがソフトウェア開発者の間で注目を集め、より自律的な AI システムへの熱狂を高めるのに貢献しました。2026 年初頭には、OpenClaw が継続的に実行してオンラインタスクを実行し、WhatsApp や Telegram などのメッセージングプラットフォームを通じて対話するパーソナルエージェントとしてオープンソースの現象となりました。その発明者は後に OpenAI に加入しました。OpenClaw の人気と、ローンチ時のセキュリティ問題により、「Claw」に似たエージェント群が相次いで登場し、2026 年 2 月には Hermes Agent も含まれました。使用の容易さが高まり、自己改善行動がより堅牢になった successive なリリースに伴い、同年 4 月下旬から 5 月にかけて関心は加速しました。
なぜ重要なのか: 汎用エージェントは、AI ドライブ型の機能の領域を急速に拡大しています。典型的な機能セットが形成されつつありますが、新しい機能もまだ登場し続けています。より洗練されたメモリと、成功した行動をスキルに変換する能力を持つ Hermes エージェントはその好例です。これは、ステートレスな AI アシスタントから、経験を蓄積し、ユーザーに適応し、単発のタスクを超えて継続的な業務を自動化するエージェントへと移行する兆候を示しています。
私たちが考えていること: 自然に思えるかもしれませんが、特定の LLM(大規模言語モデル)、メッセージングプラットフォーム、またはスキル形式に縛られないオープンソースのエージェントは特に価値があります。これらのエージェントは、通常のメッセージングチャネルで利用可能であり、そのハーン(枠組み)の制限内で利用可能な最良の AI モデルを活用できます。
内蔵された対話型インタラクション
対話モデルは通常、ターン(発言順)を待ってから応答します。Thinking Machines Lab のシステムは、同時に聞き、観察し、応答します。
何が新しいか: TML-Interaction-Small は、オーディオ、ビデオ、テキスト入力を処理し、ユーザーが完了するのを待たずに出力を並行して生成するマルチモーダルシステムです。現在テスト中であり、Thinking Machines Lab は今年後半に利用可能にする予定です。
- 入力/出力:音声、動画、テキストの同時入力と、音声およびテキストの同時出力
- アーキテクチャ:エキスパート混合型トランスフォーマー(全パラメータ数 2760 億、トークンあたりアクティブなパラメータ数は 120 億)、非公開アーキテクチャの別個の背景推論モデル
- 機能:リアルタイムのターン交代と割り込み、同時入力・出力(例:ライブ翻訳)、視覚的合図に基づく能動的な介入、会話中に割り込まずに推論を行いツールを呼び出す別個のモデル
- パフォーマンス:対話性ベンチマークでは他の音声モデルをリードするが、知能性ベンチマークでは GPT-Realtime-2 の最強推論モードには及ばない
- 利用状況:今後数ヶ月間はクローズドな研究プレビューとして提供され、2026 年後半に一般リリース予定
- 非公開情報:トレーニングデータと手法、知識の截止日、コンテキストウィンドウ、価格設定、背景モデルのアーキテクチャ
仕組み: TML-Interaction-Small は、会話をリアルタイムで処理する高速な対話モデルと、推論を行う非同期型の背景モデルという 2 つのコンポーネントを組み合わせる。この対話モデルは、典型的な入力と出力の交互ではなく、思考機械研究所(Thinking Machines Lab)が「マイクロターン」と呼ぶ 200 ミリ秒単位の処理チャンクを入力処理と出力生成にインターリーブさせる。音声、動画、テキストを並列ストリームとして処理することで、入力の終了と出力の生成の間に知覚される境界線を排除する。
- インタラクションモデルは、離散化された音声トークン、40x40 ピクセルの画像パッチの埋め込み(階層型多層パーセプトロンによって生成)、およびテキストの埋め込みを入力として受け取ります。
- 音声とテキストをフローマッチングデコーダを通じて生成します。Thinking Machines Lab はこのアプローチを「エンコーダーフリーの早期融合」と呼んでいます。これは、多くのマルチモーダルシステムが必要とする大規模な事前学習済みエンコーダー(OpenAI Whisper が音声に使用し、ビジョントランスフォーマーが画像に使用するものなど)をスキップするためです。チームは、トランスフォーマー、パーセプトロン、デコーダをゼロから一緒に訓練しました。
- インタラクションモデルは、推論、ウェブブラウジング、ツール呼び出しの処理を非同期で実行するバックグラウンドモデルに委譲します。両者は同じコンテキストを共有しており、インタラクションモデルは必要に応じてバックグラウンドモデルの出力を会話に織り交ぜます。
パフォーマンス: Thinking Machines Lab のテストでは、TML-Interaction-Small は対話性を評価するベンチマークにおいて他の音声モデルを上回りましたが、知能を評価するテストでは GPT-Realtime-2 の最強の推論モードには及びませんでした。
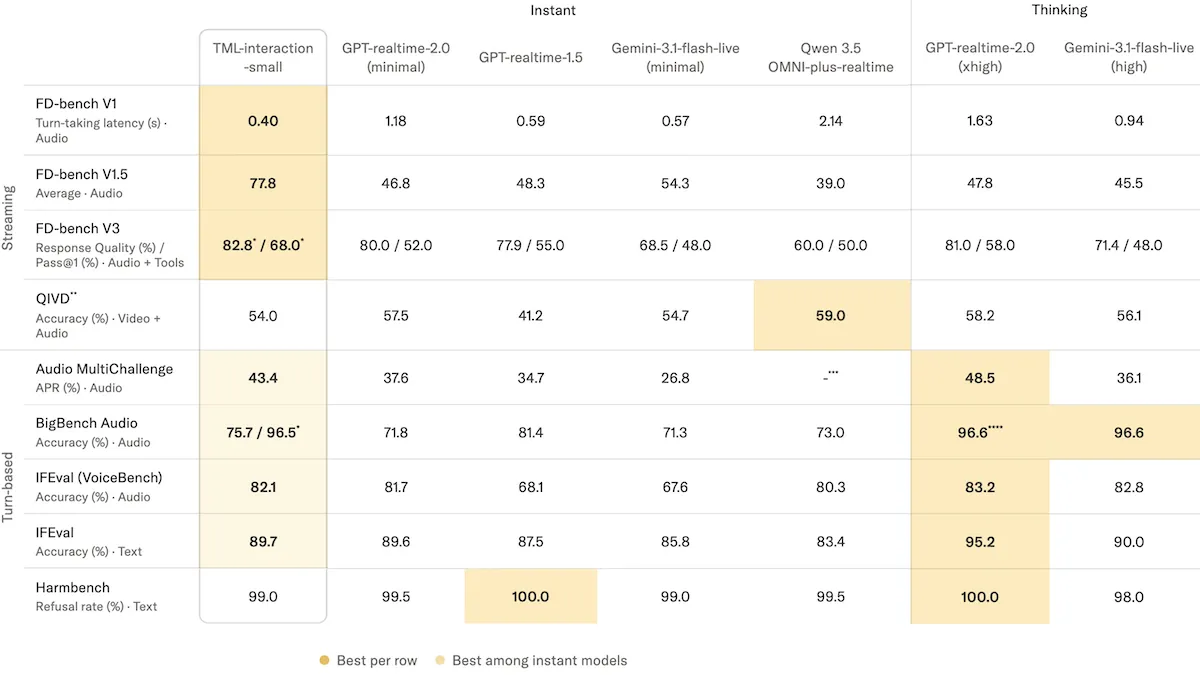
- FD-bench V1 は会話のターンにおける音声遅延を測定するベンチマークですが、TML-Interaction-Small は 0.40 秒で応答し、最小推論に設定された Gemini-3.1-flash-live-preview(0.57 秒)や GPT-Realtime-2(最小推論設定で 1.18 秒)よりも大幅に高速でした。
- FD-bench V1.5 はモデルの割り込み管理能力、"uh huh" などの相槌、および前景と背景の音声の区別能力を評価するテストですが、TML-Interaction-Small は平均品質 77.8 を達成し、高推論に設定された GPT-Realtime-2(平均品質 47.8)や Gemini-3.1-flash-live-preview(高推論設定で平均品質 45.5)を大きく上回りました。
- Audio MultiChallenge は多ターン音声対話における推論能力と指示従順性をテストするもので、TML-Interaction-Small は APR(平均合格率:モデルがすべての基準を満たした会話の割合)43.4 パーセントを記録しました。これは高推論に設定された GPT-Realtime-2(APR 48.5 パーセント)には及びませんでしたが、高推論に設定された Gemini-3.1-flash-live-preview(APR 36.1 パーセント)を上回りました。
- BigBench Audio は音声推論をテストするもので、背景モデルを有効化した TML-Interaction-Small は 96.5 パーセントの精度を達成しました。これは高推論に設定された GPT-Realtime-2 と Gemini-3.1-flash-live-preview(ともに 96.6 パーセントで同率)にはわずかに劣る結果でした。
ニュースの背景: Mira Murati が Thinking Machines Lab を設立してから約 15 ヶ月後に登場した TML-Interaction-Small は、同社の初の公開モデルとなることを約束しています。このスタートアップは 10 月に、多数の GPU でモデルをファインチューニングしやすくするファインチューニング API Tinker をリリースしました。今年、他の 4 つの企業も、リアルタイムで音声を聞き、話し、動画や画像を認識し、割り込みを適切に処理できるモデルを発表しています。OpenBMB は 2 月に 90 億パラメータの MiniCPM-o をオープンソース化し、Google は 3 月に Gemini 3.1 Flash Live を、Alibaba は Qwen3.5 Omni をそれぞれ発表しました。また OpenAI は 5 月に GPT-Realtime-2 をリリースしています。
なぜ重要なのか: モダリティを横断するモデルは、GPT-Realtime-2 のようにユーザーに 1 秒以上待たせるか、あるいは適切な合図に応答できないことが多い。リアルタイムで聴き、視覚化し、応答するモデルは、ターンベースのシステムではサポートできないようなインタラクションを可能にする。例えば、スポーツコーチングや手術モニタリングなどがその例だ。サイズが公表されているモデルの中で、TML-Interaction-Small は対話パフォーマンスのために特別に訓練されたものとしては最大規模であり、2760 億パラメータを持つ。一方、最もアーキテクチャ的に類似した競合である MiniCPM-o 4.5 の公開済みのパラメータ数は 90 億だ。Thinking Machines Lab は、より大規模な事前学習済みインタラクションモデルを保有しているが、まだリアルタイム対話のために十分な速度で提供できておらず、今年後半にリリースする予定だと述べている。
私たちが考えていること: TML-Interaction-Small のアーキテクチャが、AI Fund のポートフォリオ企業であり、以前取り上げた Vocal Bridge が採用するアプローチとどう異なるかを指摘しておく価値があります。TML-Interaction-Small では前景モデルと背景モデルが共同訓練されるのに対し、Vocal Bridge はオーケストレーション(調整)アプローチを採用しています:リアルタイム音声モデルがツール呼び出しを使用して重いクエリを別の推論モデルに委譲し、その出力を会話に織り交ぜます。このアプローチの利点は柔軟性であり、任意のリアルタイムモデルを任意の推論エンジンと組み合わせることができ、追加の訓練は不要です。一方、欠点としては、レイテンシが基盤となる API によって制約されること、システムが本質的にターンベース(交互応答型)であること、そして前景と背景間のハンドオフが学習ではなくオーケストレーションによって行われることが挙げられます。

セキュリティアラームの警報音がより大きくなる
Google のレポートによると、2 段階認証を回避するための AI 生成スクリプトは、産業規模のサイバー攻撃の時代が到来していることを示唆しています。
何が新しいか: ハッカーは大規模言語モデルを使用して、以前に知られていなかった脆弱性を特定し、広く使用されている Web 管理ツールを乗っ取ることを可能にした。Google のセキュリティ研究者が報告している。研究者らは、犯罪者がこの手法を大規模に利用する計画を立てていたと信じており、その発見によりより広範な攻撃が阻止された。彼らの研究は、大規模言語モデルの着実な進展によって引き起こされるさまざまなサイバーセキュリティ脅威について概説している。
仕組み: Google チームは、大規模言語モデルがどのようにしてサイバー攻撃の実行をより迅速かつ容易にしているかについていくつかの方法を特定した。LLM(大規模言語モデル)は以前にもサイバー攻撃を支援しており[1]、Anthropic は最近、自社のClaude Mythos Preview モデルが未知の脆弱性を発見できる可能性があると警告したが、今回の報告は今後登場するであろうアプローチの一覧を提供している。
- モルフィングマルウェア:LLM は、コードの要素を変更して検知を回避するマルウェアを生成できます。このようなプログラムには、いわゆる変異エンジンが含まれており、複製したり新しいシステムに感染するたびに、復号化ルーチンを再書き換えたり、同じ結果をもたらす別のコマンドに置き換えたり、機能的ではないサブルーチンを追加したりするなど、機能を変えずに自己改変を繰り返します。この手法は、悪意のあるペイロードをそのまま保ちながらウイルス対策ソフトによる検知を回避し、データ窃取やバックドアの設置、ファイル暗号化などの攻撃の危険性を高めます。
- 論理的欠陥の特定:セキュリティ専門家がコードのバグを見つけるために通常使用するツールは、既知のパターンを検出するか、システムが壊れるまでランダムなデータを浴びせることで動作することが多いのに対し、LLM はコードが意図するところを推論し、その推論を適用して論理的欠陥を特定できます。この機能により、通常のツールでは見えない脆弱性を発見でき、これを見つけるには人間の専門家による集中的なレビューが必要となるケースもあります。
- 隠蔽ネットワーク:脅威アクターは、攻撃の発生源を隠し、痕跡を消し、防御を迂回するために、アドホックなルーター、サーバー、専門技術のセットを編成することがよくあります。AI を活用したツールは、悪意のあるトラフィックを複数の侵害された仲介サーバー経由で誘導しつつ、一般的なセキュリティ監視器が警報を発するパターンを回避できます。
- 不十分な AI インフラストラクチャ:AI インフラストラクチャ自体も、ハッカーにとって魅力的な標的になりつつあります。攻撃に AI を利用して隠蔽するだけでなく、攻撃者はネットワークへの侵入点として AI ツール、モデル、周辺ソフトウェアを標的にすることが増えています。セキュリティが不十分なコンポーネントを侵害されることで、攻撃者はシステム内部へ深く浸透し、データを窃取したりランサムウェアを展開したり、業務を妨害したりするための足掛かりを得ます。
ニュースの背景: セキュリティ担当者や政策決定者は、Claude Mythos Preview を踏まえて防御策とガバナンス措置の見直しを行っています。セキュリティ企業 Calif の研究者は、このモデルを使用して Apple の famously 堅牢なセキュリティに 侵入 しました。Calif はこの脆弱性攻撃を Apple に報告し、Apple はパッチの作成に取り組んでいます。一方、英国支援の AI セキュリティ研究所(AISI)は、Claude Mythos Preview と OpenAI の GPT-5.5 が、人間であれば通常 3 時間かかるはずの攻撃を確実に実行できることを 報告 しました。これは以前の予測である 1 時間よりも大幅に長い時間です。(Claude Opus 4.6 のデビュー時には、人間が 30 分かかる攻撃を実行可能でした。)AISI のテストでは、モデルの出力トークンを 250 万トークンに制限しましたが、より多くのトークンを使用できるようにすると、人間のアタッカーがさらに長い時間を要する攻撃を実行できることが確認されました。
なぜ重要なのか: Google の調査結果は、大規模言語モデル(LLM)のセキュリティ脆弱性の発見能力と、広く使われているセキュリティ手法との間の格差が広がっていることを示しています。報告書で説明されている自動化された産業スケールの攻撃は、次世代 LLM がバグを悪用する速度がサイバーチームがパッチを実装する速度よりも速くなる可能性があることを暗示しています。その調査結果は、AI が防御・攻撃の両方のツールであり、かつ攻撃の主要な標的であるため、さらなる連邦政府による監視を促し、規制および商業的な取り組みの双方を複雑にする可能性があります。
私たちが考えていること: Claude Mythos Preview 確認 を使用した専門家は、これがセキュリティ脅威と防御の両方にとって明確な進歩であることを確認しています。現在のパッチラウンドがネットワークをより安全にし、得られた教訓がさらなる AI の進展の安全な展開に貢献することを私たちは楽観視しています。それに加えて、ソフトウェア開発者は、脅威アクターが発見する前に脆弱性を発見できるように、予防的な防御研究により多くの注意を払う必要があります。
人間の業務を反映したエージェントベンチマークに向けて
AI エージェントは経済的に価値のあるタスクを実行する能力がますます高まっているようですが、現在のベンチマークはこの能力を非常に限定的にしか測定していません。
何が新しいか: カーネギーメロン大学とスタンフォード大学の Zora Z. Wang 氏ら 研究者 は、エージェントベンチマークから抽出した例を、米国の労働統計にマッピングしました。このマッピングにより、一般的にソフトウェア開発を重視するテストと、多くの人々が実際に従事する多様な業務との間に不一致があることが明らかになりました。
重要な洞察: エンジニアは「バブルソートを実装する」のように技術用語でベンチマークの例を記述する傾向がありますが、経済学者は「在庫追跡、データ保存または検索、その他の機器制御などの特定のタスクを処理するためにコンピュータプログラムやソフトウェアパッケージを書き、更新し、維持する」といった標準化された記述を用いて業務活動を説明します。また、仕事は「コンピュータを使用する」のように、その職務に必要なスキルという観点からも記述されます。大規模言語モデルはこの間の翻訳が可能です。この機能により、ベンチマーク例の相対的分布と業務活動・スキルの相対的分布を比較することが可能になります。
仕組み: 著者らは、SWE-bench や WebArena など 43 のエージェントベンチマークから抽出した 10,000 件を超える代表的なサンプルを集めました。著者らは、米国政府の O*NET に基づいて 2 つの分類体系を構築しました。(i) 職業(コンピュータ関連業務活動 5,806 項目を含む)および (ii) 41 の関連スキルです。
- 彼らは、米国における各職業の雇用者数と中央賃金データを取得し、各職業およびスキルに関連する労働者の総数と資本(雇用者数×賃金)を計算した。
- Claude 3.5 Sonnet を用いて、ベンチマーク例をすべての関連するコンピュータベースの仕事活動およびスキルに照合した。例えば、「バブルソートを実装する」というベンチマーク例を、「コンピュータプログラムの作成、更新、保守……」という仕事活動および「コンピュータの使用」というスキルに対応させた。
- 費用を抑えるため、各ベンチマークから一度に5つの例をランダムにサンプリングし、それら仕事活動やスキルにマッピングした。どちらの分類体系における総カバレッジが0.1%未満しか増加しない場合、サンプリングを停止した。実際には、ベンチマークに300 個未満の例が含まれている場合はすべてを含め、その他のほとんどのベンチマークでは約300 個の例をサンプリングした。
結果: マッピングの結果、エージェント用ベンチマークは主にソフトウェアエンジニアリングにおけるパフォーマンスを測定しており、これは雇用市場におけるより広範な雇用および資本の分布とは明らかに異なることが示された。
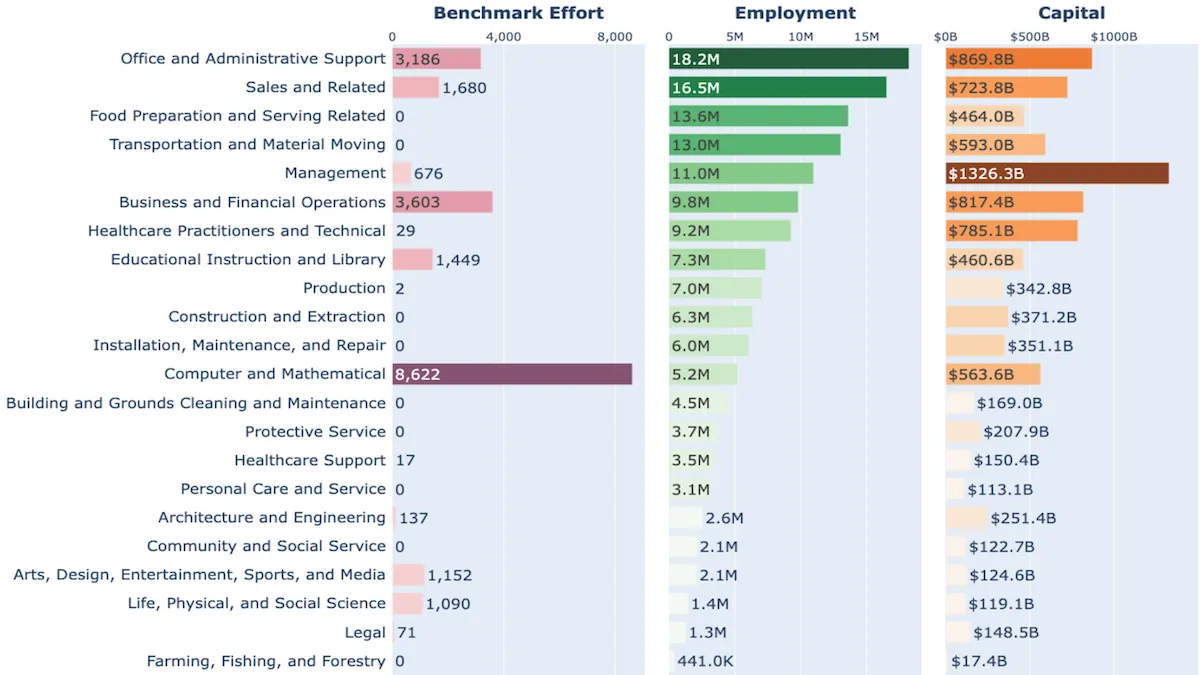
- ベンチマークは、「コンピュータおよび数学」関連の職業(8,622 例)に焦点を当てており、「事務・管理サポート」(3,186 例)や「経営管理」(676 例)に比べてその比重が圧倒的に大きい。一方、米国では「コンピュータおよび数学」分野の雇用者数は(520 万人)、「事務・管理サポート」(1,820 万人)や「経営管理」(1,100 万人)と比べると大幅に少ない。同様に、米国の雇用主が支払う給与総額を見ても、「コンピュータおよび数学」専門職は年間 5,636 億ドルであり、「事務・管理サポート」(8,698 億ドル)や「経営管理」(1兆3,263 億ドル)に比べて数百億ドル少ない。
- 各ベンチマークがカバーした作業活動の割合は全体的に 50% を下回り、必要なスキルのカテゴリーでも 60% に満たなかった。両方のカテゴリを最もよくカバーしていたのは GDPval で、これは作業活動の 47.8% とスキルの 58.5% を網羅していた。すべてのベンチマークを合計すると、作業活動のカバー率は 56.5% となるが、著者らが定義した 41 のスキルカテゴリについては 85.4% をカバーしている。
なぜ重要なのか: エージェントはソフトウェアエンジニアリングの分野で生産性を劇的に向上させており、経済を構成する他の職業においても同様の成果をもたらす可能性がある。エージェント用ベンチマークと人間の労働分布との間のギャップを特定することは、未開拓の可能性を示唆している。事務、財務、管理部門向けのエージェントを開発すれば、より高い経済的価値を生み出し、労働力のより大きな部分を支援できるだろう。
私たちが考えていること: 現在のエージェント性能のベンチマークがソフトウェアエンジニアリングに焦点を当てているのは理にかなっています。エージェントによるコーディングはまさに火がついています!ある意味では、ソフトウェアエンジニアリングは、他の種類の業務へのエージェント AI の適用を実践するためのインキュベーター(育成装置)であり、より広範な業務活動における性能を測定するベンチマークも、いずれ適切な時期に登場すると信じています。
原文を表示
Dear friends,
Harvard University just voted to limit the number of A grades given in undergraduate classes to about 20% of the class. I’m not in favor of this. It deeply runs counter to how I believe education should be. We should hold a high bar, but also work mightily to support the success of 100% of learners, rather than a fraction.
Harvard’s administration took this step — over the objections of a large fraction of the student body — to counter grade inflation. Grade inflation is real: Many universities have been awarding A and B grades to ever larger fractions of students, and this has caused grade point averages (GPAs) to become less useful as signals of student skill. At the same time, we want students to succeed. The heart of the question is the role of educational institutions. Should our goal be:
- To help students succeed?
- To judge students?
Both of these have value. But my focus when working in education is almost entirely helping students succeed.
To me, it is clear that many people want to learn, to be empowered, to build skills that let them do new things! This is what we focus on at DeepLearning.AI. This philosophy is also why my online courses (going back to my early online Stanford courses on Coursera) permitted an unlimited number of retries for graded assignments.
I believe in letting — and even encouraging — someone to redo something until they succeed. This is as opposed to standing in judgement of the fact they didn’t get it right the first time. Also, I believe homework assignments should be designed primarily to help people practice and learn, rather than to judge their skill level. This is why I prefer to create “Practice Problems” and “Practice Labs” — questions that, when you think through them, help you to gain practice and reinforce what you know. As opposed to “Assessment Problems” designed primarily to judge skill.
But won’t Harvard’s move make GPAs more meaningful and help prospective employers identify strong candidates? Having hired a large number of people from Harvard and other institutions, I can say confidently that GPA is not an important signal. We have screening and interviewing processes that give far more accurate ways to figure out if someone is truly skilled. I do not need a wider spread in applicant GPA scores to figure out who's really good!
To be clear, there is also value in assessment. Even though standardized testing is much hated, high-quality tests like the SAT, ACT, GRE, TOEFL, etc. provide objective measures of ability in a domain. I find that most people want to learn and succeed. There are also people who want rigorous assessment (for example, to apply for school admissions), but this is a lesser need, and is not my focus when building educational products.
Harvard is often described as an “elite” educational institution. There are two ways to be elite: One option involves limiting enrollments, and then even among admitted students, cap the number of people that do well at 20%. I would rather pursue a different path: Set a high bar and teach elite, cutting-edge skills, but strive relentlessly to help everyone succeed. This way, eliteness is defined not by excluding people but by helping as many people as possible to be excellent.
Keep learning!
Andrew
A MESSAGE FROM DEEPLEARNING.AI
Build AI agents that generate images and videos, evaluate their own outputs, and iterate to improve results. In this new short course, you’ll apply image-text similarity scoring, LLM judges, and structured rubrics while building visual media agents for UI mockups and multi-scene video explainers. Enroll for free
News
Hermes Agent Challenges OpenClaw
OpenClaw, the immensely popular AI agent, has fast-rising competition.
What’s new: Hermes Agent, an open-source agent launched in February by the New York-based AI lab Nous Research, recently moved ahead of OpenClaw on a leaderboard that tracks the number of tokens agents consume daily, as tallied by the AI-model platform OpenRouter. Some users have complained that Hermes Agent is less token-efficient, but its ability to define and sharpen new skills (specialized instructions, workflows, and/or domain knowledge) calls attention to self-improvement as a core agentic capability. You can download it here.
How it works: Hermes Agent’s capabilities largely overlap with those of OpenClaw. Hermes Agent differs primarily in its memory architecture and ability to build skills automatically. It’s designed to run locally or in the cloud, supports a wide variety of large language models, and integrates with around 20 messaging services. Using a model that runs locally (or one that generates new access tokens after logging in from a browser) makes it possible to get up and running without storing an API key. It works with integrated development environments via the Agent Communication Protocol.
- Agentic loop: Like OpenClaw, Hermes Agent’s agentic loop works as follows: (i) The agent assembles a prompt based on its defined personality, instructions, tools, skills, memory, knowledge about the user, and conversation history including the most recent message. (ii) If the prompt exceeds the input limit of the associated LLM, it asks the LLM to summarize old messages in the conversation history to reduce the size. (iii) It sends the assembled prompt to the LLM and either calls a tool, calls a skill, or responds to the user. (iv) If it calls a skill or tool, it executes that call, which also outputs a tool call, skill call, or response for the user. This cycle repeats until the model generates a response for the user.
- Skills: Hermes Agent uses the standard SKILL.md format for instruction files that tell the agent how to accomplish a task by calling tools that run bash scripts, search the web or files, query databases, and so on. It comes with built-in skills, and additional skills are available from Skills Hub (which currently is much smaller than OpenClaw’s immense, crowd-sourced skill library). However, it also creates new skills automatically. When Hermes Agent works on a problem for a long time or fixes an error and decides it has completed the task successfully, it calls a tool to create a skill. To prevent agent-generated skills from growing out of hand, an additional background system called Curator (i) archives every skill that has not been used in over 90 days by moving it to a separate folder, and (ii) uses an LLM determine whether each skill should be kept as is, merged with other skills, or archived.
- Memory: Hermes Agent maintains two general memory files that it adds to the prompt. One details user preferences, and the other includes information about workflows and lessons learned. It calls a built-in memory tool to add to these files. When it decides to add a memory, it checks the memory to see if it’s worth adding and which of the two files to add it to. (For example, it does not add the memory if a similar memory already exists or the memory is too vague.) When it determines that adding the memory would exceed a preset file length, it examines the relevant memory file and merges related entries. Hermes Agent also maintains a database of conversations that it can search using a separate tool. In addition, it can take advantage of external memory providers such as Honcho, which analyzes the user’s identity after every message to derive preferences, goals, and patterns.
- Persistent goal tracking: Users can specify a goal in a message. Once the agent finishes its response, it will call a judge model to evaluate whether the goal was completed. If not, it continues working. This loop continues until the goal is judged to have been completed or the agent reaches a maximum number of turns. Anthropic Claude Code, OpenAI Codex, and OpenClaw (via a plugin) offer a similar capability.
Behind the news: Agentic capabilities emerged as large language models gained the abilities to plan across multiple steps, reflect on earlier outputs, and use external tools to perform actions online. Coding agents such as Anthropic’s Claude Code and OpenAI’s Codex gained traction among software developers in 2025, helping to build enthusiasm for more-autonomous AI systems. In early 2026, OpenClaw became an open-source phenomenon with a personal agent that ran continuously to execute online tasks and interacted through messaging platforms such as WhatsApp and Telegram; its inventor went on to join OpenAI. OpenClaw’s popularity, along with its security issues at launch, brought forth a wave of “Claw”-like agents including, in February 2026, Hermes Agent. Interest accelerated in late April and May as successive releases made it easier to use and its self-improving behavior more robust.
Why it matters: General-purpose agents are rapidly extending the landscape of AI-driven capabilities. A typical set of features is beginning to coalesce, but new features are still emerging. Hermes Agent, with its more sophisticated memory and ability to turn successful behaviors into skills, is a case in point. It points toward a shift from stateless AI assistants to agents that accumulate experience, adapt to users, and automate ongoing work beyond isolated tasks.
We’re thinking: It may seem only natural, but open-source agents that aren’t tied to a particular LLM, messaging platform, or skill format are especially valuable. These agents are available in your usual messaging channels and can take advantage of the best AI models available within the limits of their harnesses.
Built-In Conversational Interactivity
Conversational models typically wait for a turn before they respond. A system from Thinking Machines Lab listens, watches, and replies at the same time.
What’s new: TML-Interaction-Small is a multimodal system that processes audio, video, and text input and generates output concurrently rather than waiting for a user to finish. It’s currently undergoing tests, and Thinking Machines Lab expects to make it available later this year.
- Input/output: Concurrent audio, video, text in, concurrent audio and text out
- Architecture: Mixture-of-experts transformer (276 billion parameters total, 12 billion parameters active per token), separate background-reasoning model of undisclosed architecture
- Features: Real-time turn-taking and interruption, simultaneous input and output (for example, live translation), proactive interjection based on visual cues, plus a separate model that reasons and calls tools without interrupting conversation
- Performance: Leads other voice models on interactivity benchmarks but trails GPT-Realtime-2’s strongest reasoning mode on intelligence benchmarks
- Availability: Closed research preview in coming months, wider release later in 2026
- Undisclosed: Training data and methods, knowledge cutoff, context window, pricing, background model architecture
How it works: TML-Interaction-Small pairs two components: a fast interaction model that processes conversations in real time, and an asynchronous background model that performs reasoning. The interaction model interleaves 200-millisecond chunks of input processing and output generation, which Thinking Machines Lab calls micro-turns, rather than alternating between typical turns of input and output. It processes audio, video, and text as parallel streams, eliminating the perceived boundary between the end of an input and generation of an output.
- The interaction model takes in discretized audio tokens, embeddings of image patches of 40x40 pixels (produced by a hierarchical multilayer perceptron), and embeddings of text.
- It generates audio and text via a flow-matching decoder. Thinking Machines Lab calls this approach encoder-free early fusion because it skips large pretrained encoders that many multimodal systems require (like OpenAI Whisper uses for audio and vision transformers use for images). The team trained the transformer, perceptron, and decoder together from scratch.
- The interaction model delegates reasoning, web browsing, and tool calls to the background model, which runs asynchronously. Both share the same context. The interaction model weaves the background model’s output into the conversation when appropriate.
Performance: In Thinking Machines Lab’s tests, TML-Interaction-Small outperformed other voice models on benchmarks that evaluate interactivity but trailed GPT-Realtime-2’s strongest reasoning mode on tests of intelligence.
- On FD-bench V1, which measures audio latency in conversational turns, TML-Interaction-Small responded in 0.40 seconds, significantly faster than Gemini-3.1-flash-live-preview set to minimal reasoning (0.57) and GPT-Realtime-2 set to minimal reasoning (1.18 seconds).
- On FD-bench V1.5, which gauges a model’s ability to manage interruptions, interjections such as “uh huh,” and foreground versus background speech, TML-Interaction-Small achieved 77.8 average quality, well above GPT-Realtime-2 set to xhigh reasoning (47.8 average quality) and Gemini-3.1-flash-live-preview set to high reasoning (45.5 average quality).
- On Audio MultiChallenge, which tests reasoning and following instructions in multi-turn audio dialogue, TML-Interaction-Small achieved 43.4 percent APR (average pass rate, the share of conversations in which the model satisfied all criteria), behind GPT-Realtime-2 set to xhigh reasoning (48.5 percent APR) but ahead of Gemini-3.1-flash-live-preview set to high reasoning (36.1 percent APR).
- On BigBench Audio, a test of audio reasoning, TML-Interaction-Small achieved 96.5 percent accuracy with its background model activated, slightly below GPT-Realtime-2 set to high reasoning and Gemini-3.1-flash-live-preview set to high reasoning (tied at 96.6 percent accuracy).
Behind the news: TML-Interaction-Small, which arrives roughly 15 months after Mira Murati founded Thinking Machines Lab, promises to be the company’s first public model. The startup shipped a fine-tuning API called Tinker in October. This year, four other companies have launched models that listen, speak, and see videos or images in real time, and handle interruptions gracefully: OpenBMB open-sourced the 9-billion-parameter MiniCPM-o 4.5 in February, Google launched Gemini 3.1 Flash Live and Alibaba launched Qwen3.5 Omni in March, and OpenAI launched GPT-Realtime-2 in May.
Why it matters: Multimodal models often make users wait a second or more before responding, like GPT-Realtime-2, or they don’t respond to cues appropriately. Models that listen, see, and respond in real time open up interactions that turn-based systems can’t support like, say, coaching athletics or monitoring surgery. Of such models whose sizes are disclosed, TML-Interaction-Small is the largest to be trained specifically for interactive performance — 276 billion parameters versus 9 billion for MiniCPM-o 4.5, the most architecturally similar competitor whose parameter count is publicly known. Thinking Machines Lab said it has larger pretrained interaction models but can’t yet serve them fast enough for real-time interaction, and it plans to release them later this year.
We’re thinking: It’s worth noting how TML-Interaction-Small’s architecture differs from the approach taken by Vocal Bridge, an AI Fund portfolio company that we covered previously. While TML-Interaction-Small’s foreground and background models are jointly trained, Vocal Bridge takes an orchestration approach: A real-time voice model uses tool calls to defer heavy queries to a separate reasoning model and weaves its output back into the conversation. The upside is flexibility, since any real-time model can be paired with any reasoner, no training required. The downsides are that latency is bounded by the underlying API, the system is fundamentally turn-based, and handoffs between foreground and background are orchestrated rather than learned.
Cybersecurity Alarms Grow Louder
An AI-generated script to bypass two-factor authentication signals a dawning era of industrial-scale cyberattacks, according to a Google report
What’s new: Hackers used a large language model to identify a previously unknown vulnerability that made it possible for them to commandeer a widely used web administration tool, security researchers at Google reported. The researchers believe a criminal planned to use the technique on a large scale, and its discovery thwarted a broader attack. Their study outlines a variety of cybersecurity threats posed by the steady advance of large language models.
How it works: The Google team identified several ways in which large language models are making it faster and easier to execute cyberattacks. LLMs have aided cyberattacks before, and Anthropic recently warned that its Claude Mythos Preview model can find previously unknown vulnerabilities, but the report offers a catalog of up-and-coming approaches.
- Morphing malware: LLMs can generate malware that evades detection by changing elements of its code. Such programs include a so-called mutation engine that, every time they replicate or infect a new system, rewrite their own decryption routines, swap commands for alternatives that accomplish the same results, add nonfunctional subroutines, and so on without changing their functions. This approach can evade antivirus detection while keeping malicious payloads intact, increasing the danger of attacks that steal data, install backdoors, or encrypt files.
- Identifying logical flaws: Unlike tools typically used by cybersecurity professionals to find bugs in code, which often work by finding known patterns or bombarding it with random data until it breaks, LLMs can reason about what code is intended to do and apply that reasoning to identify logical flaws. This capability can discover vulnerabilities that are invisible to the usual tools and would require a focused review by human experts to find.
- Obfuscation networks: Threat actors often orchestrate ad hoc sets of routers, servers, and specialized technology to hide their points of origin, cover their tracks, and bypass defenses. AI-powered tools can direct malicious traffic through multiple compromised intermediary servers while avoiding patterns that would alert typical security monitors.
- Insecure AI infrastructure: AI infrastructure itself is becoming an attractive target for hackers. Beyond using AI to mask attacks, attackers increasingly target AI tools, models, and accessory software as entry points into networks. Compromising insecure components gives attackers a foothold to spread deeper into systems and steal data, deploy ransomware, or disrupt operations.
Behind the news: Security personnel and policy makers are reviewing defenses and governance measures in light of Claude Mythos Preview. Researchers at the cybersecurity firm Calif used that model to penetrate Apple’s famously sturdy security. Calif brought the exploit to Apple, which is working on a patch. Meanwhile, the United Kingdom-backed AI Security Institute (AISI) reported that Claude Mythos Preview and OpenAI’s GPT-5.5 could reliably execute attacks that would be expected to take humans 3 hours — substantially longer than their previous forecast of 1 hour. (At its debut, Claude Opus 4.6 was able to execute attacks that take people 30 minutes.) AISI’s tests limited the models to 2.5 million output tokens. When they allowed the models to use more tokens, the models were able to execute attacks that would take human attackers longer.
Why it matters: Google’s findings point to a widening gap between the ability of LLMs to find security vulnerabilities and widely used security methods. The report’s description of automated, industrial-scale attacks implies that next-gen LLMs may be able to exploit bugs faster than cyber teams can implement patches. Its findings may spur further federal scrutiny and complicate both regulatory and commercial efforts, as AI is both a defensive and an offensive tool as well as a prime target of attacks.
We’re thinking: Experts who have used Claude Mythos Preview confirm that it’s a clear advance for both security threats and defenses. We’re optimistic that the current round of patches will make networks more secure, and the lessons learned will contribute to safe roll-outs of further AI advances. Beyond that, software developers will need to devote more attention to proactive defensive research so they discover vulnerabilities before threat actors do.
Toward Agent Benchmarks That Reflect Human Work
AI agents seem to be increasingly capable of performing economically valuable tasks, but current benchmarks measure this capability only narrowly.
What’s new: Zora Z. Wang and colleagues at Carnegie Mellon University and Stanford University mapped examples drawn from agent benchmarks to statistics that represent U.S. labor. The mapping revealed a mismatch between the tests, which generally emphasize software development, and the more varied work most people do.
Key insight: Engineers tend to describe benchmark examples in technical terms, like “implement bubble sort,” while economists describe work activities using standardized descriptions like “Write, update, and maintain computer programs or software packages to handle specific tasks such as tracking inventory, storing or retrieving data, or controlling other equipment.” Work is also described in terms of skills necessary to do a job, such as “working with computers.” A large language model can translate among these languages. This capability makes it possible to compare the relative distributions of benchmark examples and work activities and skill.
How it works: The authors collected a representative selection of more than 10,000 examples drawn from 43 agent benchmarks, such as SWE-bench and WebArena. The authors built two taxonomies based on the U.S. government’s O*NET: (i) occupations (including 5,806 computer-based work activities) and (ii) 41 related skills.
- They retrieved the number of people employed in the U.S. and median wages data for each occupation and calculated the total number of workers and capital (employment multiplied by wages) associated with each occupation and skill.
- They used Claude 3.5 Sonnet to match the benchmark examples to all relevant computer-based work activities and skills (matching, for instance, the benchmark example “implement bubble sort” to the work activity “write, update, and maintain computer programs . . . ” and the skill “working with computers”).
- To limit their expenses, they randomly sampled batches of five examples at a time from each benchmark and mapped them to work activities and skills. When the total coverage in either taxonomy increased by less than 0.1 percent, they stopped. In practice, this meant that, if the benchmark contained less than 300 examples, they included all of them; for most other benchmarks, they sampled roughly 300 examples.
Results: The mapping showed that agent benchmarks largely measure performance in software engineering, which is distinctly different from the distribution of broader employment and capital within the job market.
- The benchmarks focus much more on “computer and mathematical” occupations (8,622 examples) than “office and administrative support” (3,186 examples) and “management” (676 examples). In comparison, the U.S. employs significantly fewer employees in “computer and mathematical” professions (5.2 million employees) than “office and administrative support” (18.2 million) and “management” (11 million). Similarly, U.S. employers pay “computer and mathematical” professionals a total of 563.6 billion dollars a year, hundreds of billions of dollars less than “office and administrative support” ($869.8 billion) and “management” ($1326.3 billion).
- Each benchmark covered less than 50 percent of all work activities and less than 60 percent of all skills. The benchmark that best covered both categories is GDPval, which encompassed 47.8 percent of work activities and 58.5 percent of skills. All benchmarks put together covered 56.5 percent of work activities, though they covered 85.4 percent of the authors’ 41 skill categories.
Why it matters: Agents have rapidly boosted productivity in software engineering, and they could do the same for other occupations that make up a large share of the economy. Identifying the gap between agent benchmarks and human labor distribution highlights untapped opportunities. Building agents for administrative, financial, and managerial sectors could yield higher economic value and help a larger portion of the workforce.
We're thinking: It makes sense that current benchmarks of agentic performance focus on software engineering — agentic coding is on fire! In some ways, software engineering is an incubator for applying agentic AI to other kinds of work, and we trust that benchmarks for measuring performance in broader work activities will come in due course.
関連記事
Gemini Flash の価格上昇、AI 法施行延期、エージェントがオンライントラフィックを牽引
The Batch は、シリコンバレーで注目される AI フォワードデプロイメントエンジニア(FDE)の役割について報じ、顧客組織に常駐してワークフローをカスタマイズする専門職の台頭を紹介した。
中国がメタの自律型 AI 野望を阻止、米国は次期モデル評価中、AI がマンモグラムの診断を実施
中国政府がメタ社の自律型 AI 技術の展開を阻害し、米政府機関が次世代 AI モデルの評価を進めている。また、医療分野では AI がマンモグラムの画像診断に活用されている。
Seedance が話題を呼ぶ、Nvidia の AI 活用チップ設計、ロボットの記憶保持支援
Seedance が注目を集め、Nvidia は AI を活用したチップ設計を発表し、ロボットが情報を忘れないよう支援する技術が開発された。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み