エージェントビルダーのメモリ構築方法:エージェントへの記憶機能の実装
LangChain Blogは、Agent Builderのメモリシステム構築における動機、技術的実装、教訓、今後の展望について詳述し、エージェントの能力向上に寄与する実装パターンを提示している。
キーポイント
メモリシステムの設計動機
エージェントの長期記憶と文脈保持能力を強化する必要性から、従来の単純なチャット履歴を超えた構造化されたメモリ設計が必要だとした。
技術的実装の詳細
メモリを保存・検索する際のアーキテクチャ、ベクトルデータベースの活用方法、およびエージェントがメモリを参照する際の具体的な実装コードやパターンを示した。
学習と課題の共有
実装過程で直面した技術的課題や、メモリ管理におけるベストプラクティス、そして将来の改善方向性について具体的な教訓を共有した。
影響分析・編集コメントを表示
影響分析
この記事は、エージェント開発における「メモリ」の重要性を再認識させ、実装者に対して具体的なアーキテクチャ設計の指針を提供する。LangChainエコシステム内での標準的な実装パターンとして定着すれば、より高度なエージェント開発のハードルを下げる貢献を果たす可能性がある。
編集コメント
エージェント開発において「記憶」は認知能力の核心であり、その実装方法論を公開するLangChainの取り組みは、開発者コミュニティにとって実践的な参考価値が高い。
主要なポイント
Agent Builder の中核をなすのが、そのメモリシステムです。本記事では、メモリシステムの優先順位付けに関する理由、構築の技術的詳細、構築過程での学び、メモリシステムがもたらす機能、そして今後の課題について取り上げます。
今週、私たちは LangSmith Agent Builder をリリースしました。これはコードを書かずにエージェントを構築できるツールです。Agent Builder の重要な要素の一つが、そのメモリシステムです。本記事では、なぜメモリシステムの構築を優先したのかという理由、技術的な実装詳細、メモリシステム構築から得られた知見、メモリシステムによって可能になること、そして今後の取り組みについて議論します。
LangSmith Agent Builder とは
LangSmith Agent Builder は、コードを記述せずにエージェントを作成できるツールです。これは Deep Agents harness を基盤として構築されています。これは、技術リテラシーが低い市民開発者(citizen developers)を対象とした、ホストされたウェブソリューションです。LangSmith Agent Builder では、ビルダー(開発者)が特定のワークフローや日々の業務の一部を自動化するエージェントを作成します。例としては、メールアシスタントやドキュメントヘルパーなどがあります。
初期段階で、私たちはプラットフォームの一部としてメモリ(記憶機能)を優先する意図的な選択を行いました。これは自明の選択ではありませんでした——多くのAIプロダクトは当初、いかなる形態のメモリも持たずにリリースされており、たとに追加したとしても、一部が期待するようにプロダクトを根本的に変革するわけではありませんでした。私たちがこれを優先した理由は、ユーザーの使用パターンにありました。
ChatGPTやClaude、Cursorとは異なり、LangSmith Agent Builderは汎用エージェントではありません。むしろ、ビルダーが特定のタスクのためにエージェントをカスタマイズできるように設計されています。一般的に、汎用エージェントでは、互いに無関係な多様なタスクを実行するため、あるセッションでの学習内容が次のセッションに関連しない場合があります。一方、LangSmithエージェントはタスクを実行する場合、同じタスクを繰り返し実行します。あるセッションからの教訓が次のセッションに反映される割合は、はるかに高くなります。実際、メモリが存在しない場合、ユーザー体験は悪くなるでしょう——それは、異なるセッション間でエージェントに対して繰り返し同じことを説明しなければならないことを意味します。
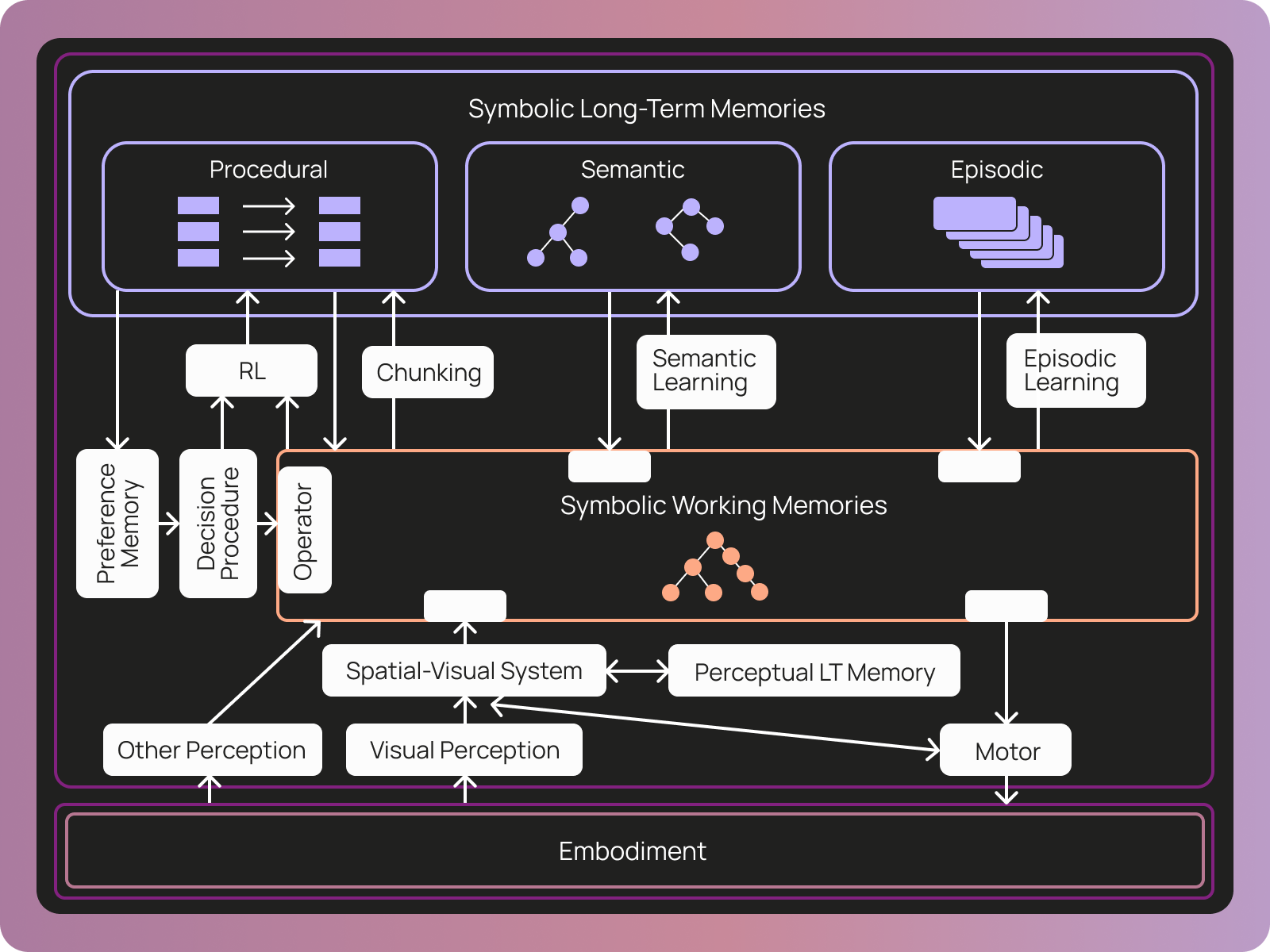
LangSmithエージェントにとって「メモリ」が具体的に何を意味するかを考える際、私たちはサードパーティの定義に注目しました。COALA論文は、エージェントのメモリを3つのカテゴリに定義しています:
- 手続的(Procedural):エージェントの行動を決定するために作業記憶に適用できるルールの集合
- 意味的(Semantic):世界に関する事実
- エピソード的(Episodic):エージェントの過去の行動シーケンス
記憶システムの構築方法
Agent Builder では、記憶をファイルのセットとして表現しています。これは、モデルがファイルシステムの使用に長けているという特性を活用するための意図的な選択です。この方式により、エージェントに特別なツールを提供することなく、記憶の読み書きを容易に行わせることができました。単にファイルシステムへのアクセス権を与えるだけです。
可能な限り業界標準を採用しています。エージェントのコア指示セットを定義するために AGENTS.md を使用しています。特定のタスクに対する専門的な指示を与えるために、エージェントスキル(agent skills) を使用しています。サブエージェントの標準規格はありませんが、Claude Code と類似した形式を採用しています。MCP(Model Context Protocol)へのアクセスには、カスタムの tools.json ファイルを使用しています。標準的な mcp.json ではなくカスタムの tools.json を使用している理由は、MCP サーバー内のすべてのツールをエージェントに与えるとコンテキストオーバーフロー(context overflow)を引き起こす可能性があるため、ユーザーがエージェントにツールのサブセットのみを提供できるようにするためです。
実際、これらのファイルを保存するために本物のファイルシステム(filesystem)は使用していません。代わりに、Postgres に格納し、エージェントに対してファイルシステムとしての形式で公開しています。これは、大規模言語モデル(LLM)がファイルシステムの操作に優れている一方で、インフラストラクチャの観点からはデータベースを使用する方が容易かつ効率的であるためです。この「仮想ファイルシステム」は DeepAgents によってネイティブにサポートされています - また、完全にプラグ可能であり、S3 や MySQL など、任意のストレージレイヤーを自由に組み込むことができます。
また、ユーザー(およびエージェント自身)がエージェントのメモリフォルダーに他のファイルを書き込むことも許可しています。これらのファイルには、エージェントが実行時に参照できる任意の知識を含めることができます。エージェントは作業中にこれらのファイルを編集し、その処理は「ホットパス内(in the hot path)」で行われます。
コードやドメイン固有言語(DSL)を一切使用せずに複雑なエージェントを構築可能なのは、内部で Deep Agents のような汎用エージェント・ハネス(harness)を使用しているためです。Deep Agents は、要約、ツール呼び出しのオフロード、計画立案 といった複雑なコンテキスト・エンジニアリングの多くを抽象化し、比較的シンプルな設定でエージェントを制御できるようにします。
これらのファイルは、COALA 論文で定義されているメモリタイプに明確に対応しています。エージェントのコアディレクティブを駆動する手続き型メモリ(procedural memory)は AGENTS.md と tools.json です。意味記憶(semantic memory)はエージェントのスキルやその他のナレッジファイルです。欠けている唯一のメモリタイプはエピソード記憶(episodic memory)ですが、これらの種類のアージェントにおいては他の2つほど重要ではないと考えたため、実装していません。
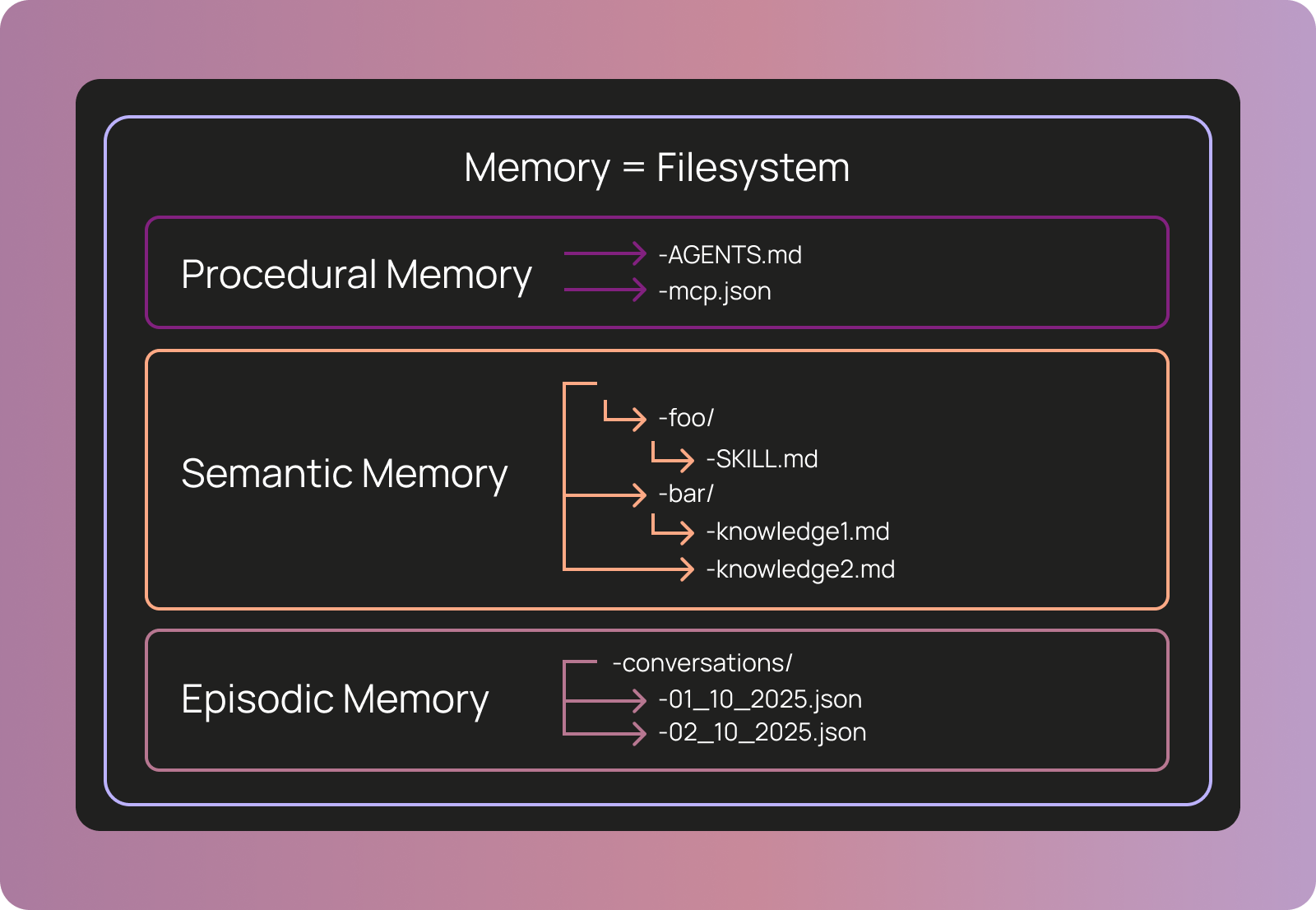
ファイルシステムにおけるエージェント・メモリの外観
LangSmith Agent Builder を基盤として構築された、社内で使用している実際のエージェント——LinkedIn のリクルーター——を見てみましょう。
- AGENTS.md:コアエージェントの指示を定義
- subagents/:1つのサブエージェントlinkedin_search_workerのみを定義。メインエージェントが検索で調整されると、このエージェントが起動し、約50人の候補者を抽出する。
- tools.json:LinkedIn検索ツールにアクセスできるMCPサーバーを定義
- 現在、メモリには異なる候補者向けのJD(Job Description)を表す3つの他のファイルも存在する。これらの検索でエージェントと作業を進めるにつれ、それらのJDは更新され維持されている。
メモリ編集の仕組み:具体的な例
メモリがどのように機能するかをより具体的に理解するために、例示的なシナリオを追ってみましょう。
開始:
シンプルなAGENTS.mdから始めます:
会議メモを要約する。
第1週:
エージェントは段落形式の要約を生成します。あなたがそれを修正します:「箇条書きを使用してください。」エージェントはAGENTS.mdを以下のように編集します:
フォーマット設定
ユーザーは段落ではなく、要約に箇条書きを好む。
第2週:
異なる会議の要約をエージェントに依頼します。メモリを読み取り、自動的に箇条書きを使用します。再確認は不要です。このセッション中、あなたは以下を依頼します:「最後にアクションアイテムを別セクションとして抽出してください。」メモリが更新されます:
フォーマット設定
ユーザーは段落ではなく、要約に箇条書きを好む。
最後に別セクションでアクションアイテムを抽出する。
両方のパターンは自動的に適用されます。新しいエッジケースが表面化するにつれて、微調整を追加し続けます。
3ヶ月目:
エージェントのメモリには以下の内容が含まれます:
- 異なるドキュメントタイプに対するフォーマットの好み
- ドメイン固有の用語
- 「アクションアイテム」、「決定事項」、および「議論のポイント」の違い
- 頻繁に出席する会議参加者の名前と役割
- 会議タイプの処理(エンジニアリング、プランニング、顧客対応など)
- 使用を通じて蓄積されたエッジケースの修正
メモリファイルは以下のようになる可能性があります:
会議サマリの設定
フォーマット
- パラグラフではなく箇条書きを使用する
- 末尾の別セクションでアクションアイテムを抽出する
- 決定事項には過去形を使用する
- 上部にタイムスタンプを含める
会議タイプ
- エンジニアリング会議:技術的な決定とその根拠を強調する
- プランニング会議:優先順位とタイムラインを強調する
- 顧客会議:機密情報を削除する
- 短時間会議(10分未満):主要なポイントのみ記載
人物
- Sarah Chen(エンジニアリングリード):技術的な詳細に焦点を当てる
- Mike Rodriguez(PM):ビジネスインパクトに焦点を当てる
...
AGENTS.mdは、事前のドキュメント作成ではなく、修正を通じて自己構築されました。ユーザーが手動でAGENTS.mdを変更することなく、反復的に適切な詳細度合いのエージェント仕様に到達しました。
このメモリシステム構築からの教訓
この過程でいくつかの教訓を学びました。
最も難しい部分はプロンプト(指示)です
記憶機能を備えたエージェントを構築する際、最も困難な部分はプロンプトエンジニアリングでした。エージェントのパフォーマンスが芳しくなかったほぼすべてのケースにおいて、解決策はプロンプトの改善でした。この方法で解決された問題の例を以下に挙げます。
- エージェントが記憶すべき時に記憶しなかった
- エージェントが記憶すべきでない時に記憶してしまった
- スキルファイルではなく AGENTS.md に過度に多くの情報を記録していた
- エージェントがスキルファイルの正しいフォーマットを認識していなかった
- …その他多数
私たちは、メモリに関するプロンプト作業にフルタイムで従事する担当者一人を抱えていました(これはチームの大きな割合を占めていました)。
ファイルタイプの検証
いくつかのファイルには、遵守すべき特定のスキーマが存在します(tools.json には有効な MCP サーバーが必要であり、スキルファイルには適切なフロントマターが必要など)。Agent Builder がこれを忘れて無効なファイルを生成することがあることが判明しました。そのため、これらのカスタム形式を明示的に検証するステップを追加し、検証に失敗した場合はファイルのコミットを行わず、エラーを LLM に返すようにしました。
エージェントはファイルへの追記が得意だが、圧縮(コンパクション)が苦手だった
エージェントは作業中に自身のメモリを編集していました。特定の情報をファイルに追加することには非常に優れていました。しかし、学習結果を圧縮(コンパクション)すべきタイミングを見極めることについては苦手な面がありました。例えば、私のメールアシスタントは、ある時点で「無視すべき特定のベンダー」をすべて列挙し始めるようになりました。これは、「すべてのコールド outreach(外部からの連絡)を無視する」というルールに自身を更新するべきところでした。
エンドユーザーとして、明示的なプロンプトが依然として有用な場合がある
エージェントが作業中にメモリを更新できる能力を持っていても、エンドユーザーとして、エージェントに明示的にメモリ管理を促すことが有用なケースがいくつかありました。そのようなケースの一つは、作業の最後に会話を振り返り、見落とした可能性のある事項についてメモリを更新することです。もう一つのケースは、特定の事例を記憶しているものの一般化できていない場合に対応するため、メモリを圧縮するよう促すことです。
ヒューマン・イン・ザ・ループ(人間関与型)
メモリへのすべての編集はヒューマン・イン・ザ・ループ(人間関与型)で行いました。つまり、更新前に明示的な人間の承認を必要としました。これは主にプロンプトインジェクション(指示注入)の潜在的な攻撃ベクトルを最小限に抑えるために行われました。ただし、この懸念がそれほど高くない場合のために、ユーザーがこの機能をオフにする方法(「yolo mode」)も公開しています。
これによって可能になること
より良い製品体験に加え、このようにメモリを表現することで、いくつかのことが可能になります。
ノーコード体験
ノーコードビルダーの一つの問題点は、複雑さが増すにつれて拡張性が良くない見知らなかった DSL(ドメイン固有言語)を学ぶ必要があることです。エージェントをマークダウンおよび JSON ファイルとして表現することで、エージェントは(a)技術に詳しくない大半の人にとって馴染みのある形式であり、(b)より拡張性が高い形式になりました。
エージェント構築の改善
メモリは、より優れたエージェント構築体験を実現します。エージェント構築は非常に反復的な作業であり、その主な理由は、実際に試してみない限りエージェントが何をするか分からないためです。メモリ機能により反復作業が容易になります。毎回手動でエージェント設定を更新するのではなく、自然言語でフィードバックを与えるだけで、エージェントが自身を更新してくれるからです。
ポータブルなエージェント
ファイルは非常に移植性が高いです!これにより、Agent Builder で構築されたエージェントを他のハルネス(同じファイル形式を使用している場合)に簡単に移行できます。この理由から、私たちは可能な限り多くの標準的な規約の使用を試みました。例えば、Agent Builder で構築されたエージェントを Deep Agents CLI で簡単に使用できるようにすることを目指しています。あるいは、Claude Code や OpenCode のような他のエージェントハルネス全体での使用も可能です。
今後の方向性
ローンチ前に時間や自信が足りず実装できなかったメモリに関する改善点が数多くあります。
エピソードメモリ
Agent Builder が欠いている COALA メモリの種類の一つは、エピソードメモリです。これはエージェントの過去の行動シーケンスを指します。私たちは、以前会話をファイルとしてファイルシステムに公開し、エージェントがそれと対話できるようにすることでこれを実現する予定です。
バックグラウンドメモリプロセス
現在、すべてのメモリは「ホットパス」内で更新されます。つまり、エージェントが実行されている間にリアルタイムで更新されるということです。私たちは、バックグラウンドで動作するプロセス(おそらく1日1回程度で実行されるcronジョブなど)を追加し、すべての会話を振り返ってメモリを更新する仕組みを導入したいと考えています。これにより、エージェントがその場では認識できなかった項目を捕捉でき、特に特定の学習内容を一般化する際に有用だと考えています。
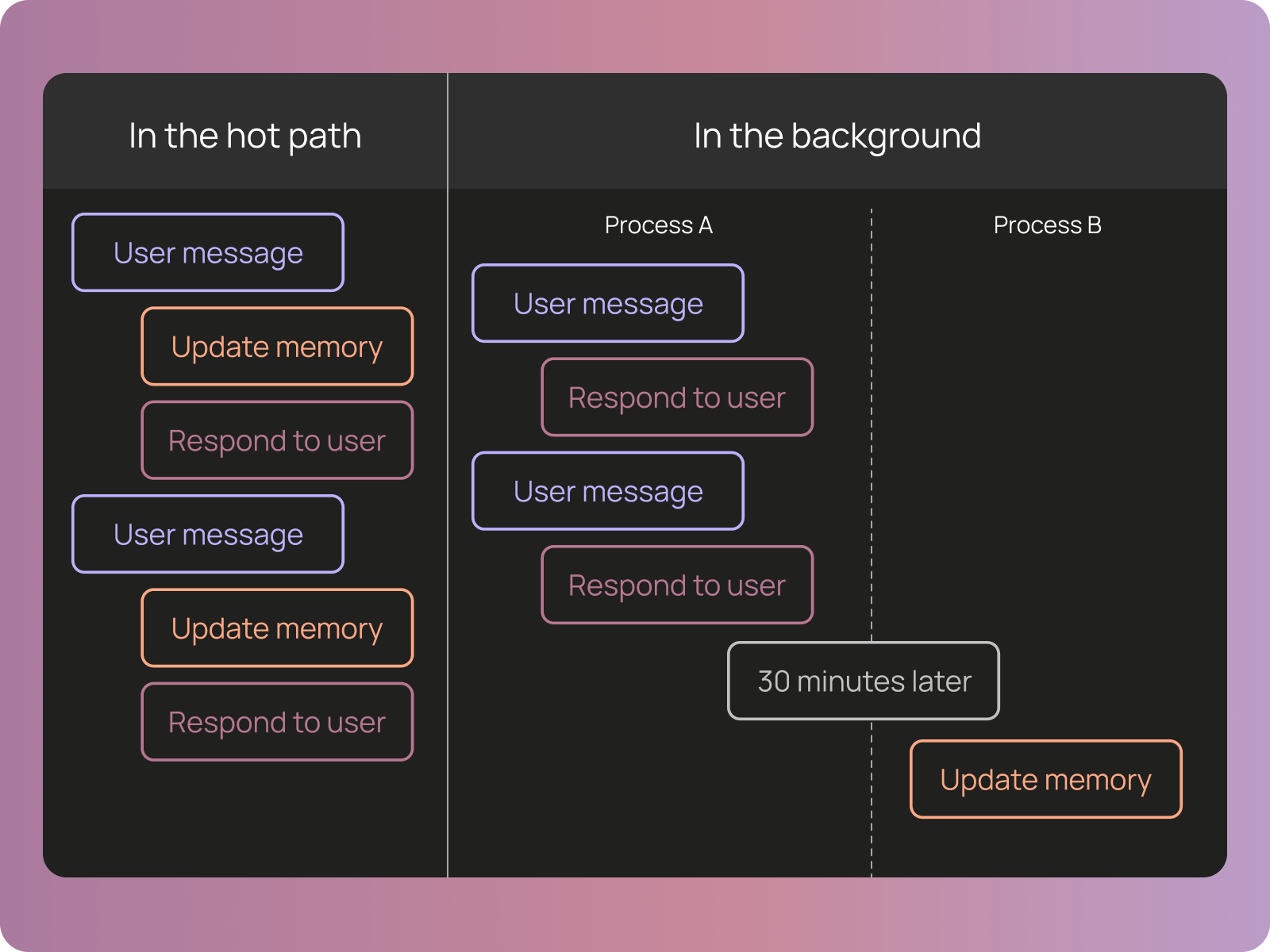
**/remember
私たちは、明示的な /remember コマンドを公開し、ユーザーがエージェントに対して会話の振り返りとメモリの更新を指示できるようにしたいと考えています。私たちはこれを手動で行うことがあり、その恩恵を実感していたため、より容易に、かつ推奨される操作としてこの機能を提供したいと考えています。
セマンティック検索
グロブ(glob)やgrepを使用してメモリを検索できることは優れた出発点ですが、エージェントが自身のメモリに対してセマンティック検索(意味的検索)を実行できるようにすることで、さらなる利点を得られる状況も存在します。
異なるレベルのメモリ
現在、すべてのメモリはそのエージェント固有のものとなっています。ユーザーレベルや組織(org)レベルのメモリという概念はありません。私たちは、これらのタイプのメモリを表す特定のディレクトリをエージェントに公開し、エージェントがそれらのメモリを使用および更新するようプロンプト(指示)することで、この機能を実現する計画です。
原文を表示
Key Takeaways
A key part of Agent Builder is its memory system. In this article we cover our rationale for prioritizing a memory system, technical details of how we built it, learnings from building the memory system, what the memory system enables, and discuss future work.
We launched LangSmith Agent Builder this week as a no-code way to build agents. A key part of Agent Builder is it’s memory system. In this article we cover our rationale for prioritizing a memory system, technical details of how we built it, learnings from building the memory system, what the memory system enables, and discuss future work.
What is LangSmith Agent Builder
LangSmith Agent Builder is a no-code agent builder. It’s built on top of the Deep Agents harness. It is a hosted web solution targeted at technically lite citizen developers. In LangSmith Agent Builder, builders will create an agent to automate a particular workflow or part of their day. Examples include an email assistant, a documentation helper, etc.
Early on we made a conscious choice to prioritize memory as a part of the platform. This was not an obvious choice – most AI products launch initially without any form of memory, and even adding it in hasn’t yet transformed products like some may expect. The reason we prioritized it was due to the usage patterns of our users.
Unlike ChatGPT or Claude or Cursor, LangSmith Agent Builder is not a general purpose agent. Rather, it is specifically designed to let builders customize agents for particular tasks. In general purpose agents, you are doing a wide variety of tasks that may be completely unrelated, so learnings from one session with the agent may not be relevant for the next. When a LangSmith Agent is doing a task, it is doing the same task over and over again. Lessons from one session translate to the next at a much higher rate. In fact, it would be a bad user experience if memory is not present – that would mean you would have to repeat yourself over and over to the agent in different sessions.
When thinking about what exactly memory would even mean for LangSmith Agents, we turned to a third party definition of memory. The COALA paper defines memory for agents in three categories:
- Procedural: the set of rules that can be applied to working memory to determine the agent’s behavior
- Semantic: facts about the world
- Episodic: sequences of the agent’s past behavior
How we built our memory system
We represent memory in Agent Builder as a set of files. This is an intentional choice to take advantage of the fact that models are good at using filesystems. In this way, we could easily let the agent read and modify its memory without having to give it specialized tools - we just give it access to the filesystem!
When possible, we try to use industry standards. We use AGENTS.md to define the core instruction set for the agent. We use agent skills to give the agents particular specialized instructions for specific tasks. There is no subagent standard, but we use a similar format to Claude Code. For MCP access, we use a custom tools.json file. The reason we use a custom tools.json file and not the standard mcp.json is that we want to allow users to give the agent only a subset of the tools in an MCP server to avoid context overflow.
We actually do not use a real filesystem to store these files. Rather, we store them in Postgres and expose them to the agent in the shape of a filesystem. We do this because LLMs are great at working with filesystems, but from an infrastructure perspective it is easier and more efficient to use a database. This “virtual filesystem” is natively supported by DeepAgents - and is completely pluggable so you could bring any storage layer you want (S3, MySQL, etc).
We also allow users (and agents themselves) to write other files to an agent’s memory folder. These files can contain arbitrary knowledge as well, that the agent can reference as it runs. The agent would edit these files as it’s working, “in the hot path”.
The reason it is possible to build complicated agents without any code or any domain specific language (DSL) is that we use a generic agent harness like Deep Agents under the hood. Deep Agents abstracts away a lot of complex context engineering (like summarization, tool call offloading, and planning) and lets you steer your agent with relatively simple configuration.
These files map nicely on to the memory types defined in the COALA paper. Procedural memory – what drives the core agent directive – is AGENTS.md and tools.json. Semantic memory is agent skills and other knowledge files. The only type of memory missing is episodic memory, which we didn’t think was as important for these types of agents as the other two.
What agent memory in a file system looks like
We can look at a real agent we’ve been using internally – a LinkedIn recruiter – built on LangSmith Agent Builder.
- AGENTS.md: defines the core agents instructions
- subagents/: defines only one subagentlinkedin_search_worker: after the main agent is calibrated on a search, it will kick off this agent to source ~50 candidates.
- tools.json: defines an MCP server with access to a LinkedIn search tool
- There are also currently 3 other files in the memory, representing JDs for different candidates. As we’ve worked with the agent on these searches, it has updated and maintained those JDs.
How memory editing works: a concrete example
To make it more concrete how memory works, we can walk through an illustrative example.
Start:
You start with a simple AGENTS.md:
`Summarize meeting notes.
`
Week 1:
The agent produces paragraph summaries. You correct it: "Use bullet points instead." The agent edits AGENTS.md to be:
# Formatting Preferences
User prefers bullet points for summaries, not paragraphs.Week 2:
You ask the agent to summarize a different meeting. It reads its memory and uses bullet points automatically. No reminder needed. During this session, you ask it to: "Extract action items separately at the end." Memory updates:
# Formatting Preferences
User prefers bullet points for summaries, not paragraphs.
Extract action items in separate section at end.Week 4:
Both patterns apply automatically. You continue adding refinements as new edge cases surface.
Month 3:
The agent's memory includes:
- Formatting preferences for different document types
- Domain-specific terminology
- Distinctions between "action items", "decisions", and "discussion points"
- Names and roles of frequent meeting participants
- Meeting type handling (engineering vs. planning vs. customer)
- Edge case corrections accumulated through use
The memory file might look like:
# Meeting Summary Preferences
## Format
- Use bullet points, not paragraphs
- Extract action items in separate section at end
- Use past tense for decisions
- Include timestamp at top
## Meeting Types
- Engineering meetings: highlight technical decisions and rationale
- Planning meetings: emphasize priorities and timelines
- Customer meetings: redact sensitive information
- Short meetings (<10 min): just key points
## People
- Sarah Chen (Engineering Lead) - focus on technical details
- Mike Rodriguez (PM) - focus on business impact
...The AGENTS.md built itself through corrections, not through upfront documentation. We arrived iteratively at an appropriately detailed agent specification, without the user ever manually changing the AGENTS.md.
Learnings from building this memory system
There are several lessons we learned along the way.
The hardest part is prompting
The hardest part of building an agent that could remember things is prompting. In almost all cases where the agent was not performing well, the solution was to improve the prompt. Examples of issues that were solved this way:
- The agent was not remembering when it should
- The agent was remembering when it should not
- The agent was writing too much to AGENTS.md instead of to skills
- The agent did not know the right format for skills files
- … many more
We had one person working full time on prompting for memory (which was a large percentage of the team).
Validate file types
Several files have specific schemas they need to abide by (tools.json needs to have valid MCP servers, skills needs to have proper frontmatter, etc). We saw that Agent Builder sometimes forgot this, and as a result generated invalid files. We added a step to explicitly validate these custom shapes, and, if validation failed, throw any errors back to the LLM instead of committing the file.
Agents were good at adding things to files, but didn’t compact
Agents were editing their memory as they worked. They were pretty good at adding specific things to files. One thing they were not good at, however, was realizing when to compact learnings. For example: my email assistant at one point started listing out all specific vendors it should ignore cold outreach from, instead of updating itself to ignore all cold outreach.
Explicit prompting is still sometimes useful as an end user
Even with the agent being able to update its memory as it worked, there were still several cases where (as an end user) we found it useful to prompt the agent explicitly to manage its memory. One such case was at the end of its work to reflect on the conversation and update its memory for any things it may have missed. Another case was to prompt it to compact its memory, to solve for the case where it was remembering specific cases but not generalizing.
Human-in-the-loop
We made all edits to memory human-in-the-loop – that is, we require explicit human approval before updating. This was largely done to minimize the potential attack vector of prompt injection. We do expose a way for users to turn this off (”yolo mode”) in cases where they aren’t as worried about this.
What this enables
Besides a better product experience, representing memory in this way enables a number of things.
No-code experience
One of the issues with no-code builders is that they require you to learn an unfamiliar DSL that does not scale well with complexity. By representing the agent as markdown and json files, the agent is now in a format that (a) is familiar to most technically-lite people, (b) more scalable.
Better agent building
Memory actually allows for a better agent building experience. Agent building is very iterative – in large part because you don’t know what the agent will do until you try it. Memory makes iteration easier, because rather than manually updating the agent configuration every time, you can just give feedback in natural language and it will update itself.
Portable agents
Files are very portable! This allows you to easily to port agents built in agent builder to other harnesses (as long as they use the same file conventions). We tried to use as many standard conventions as possible for this reason. We want to make it easy to use agents built in agent builder in the Deep Agents CLI, for example. Or other agent harnesses completely, like Claude Code or OpenCode.
Future directions
There are a lot of memory improvements we want to get to that we did not have time or enough confidence to get in before the launch.
Episodic memory
The one COALA memory type Agent Builder is missing is episodic memory: sequences of the agent’s past behavior. We plan to do this by exposing previous conversations as files in the filesystem that the agent can interact with.
Background memory processes
Right now, all memory is update “in the hot path”; that is, as the agent runs. We want to add a process that runs in the background (probably some cron job, running once a day or so) to reflect over all conversations and update memory. We think this will catch items that the agent fails to recognize in the moment, and will be particularly useful for generalizing specific learnings.
/remember
We want to expose an explicit /remember command so you can prompt the agent to reflect on the conversation and update its memory. We found ourselves doing this occasionally with great benefits, and so want to make it easier and more encouraged.
Semantic search
While being able to search memories with glob and grep is a great starting point, there are some situations where allowing the agent to do a semantic search over its memory would provide some gains.
Different levels of memory
Right now, all memory is specific for that agent. We have no concept of user-level or org-level memory. We plan to do this by exposing specific directories to the agent that represent these types of memory, and prompting the agent to use and update those memories accordingly.
関連記事
AI ヘルスコーチの構築:評価、安全性、規制対応について
LangChain が AI ヘルスコーチの開発において、評価手法や安全性確保、規制遵守の重要性を解説している。
AI エージェントに専用コンピューターを付与する
LangChain は、数百万のタスクを実行する AI エージェントが安全かつ効率的に動作するために、各エージェントに個別のファイルシステムやシェル環境を持つ仮想コンピューターを提供するインフラシフトの必要性を提唱している。
LangGraph の耐障害性:リトライ、タイムアウト、エラーハンドラー
LangChain が公開した記事で、LangGraph に組み込まれた耐障害性の三つの仕組み(バックオフ付き自動リトライの RetryPolicy、時間制限の TimeoutPolicy、リトライ失敗後のクリーンアップを行う error_handler)について解説し、SAGA パターンを用いた現実的なマルチステップワークフローの処理方法も紹介している。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み