Deep Agents における RLM の活用方法
MIT CSAIL と Alex Zhang が提案した再帰型言語モデル(RLM)が、LangChain の Deep Agents に実装され、コンテキストの劣化問題を解決し、処理能力を劇的に向上させる技術的進展である。
キーポイント
コンテキストロタの克服
従来のターンベースや要約に依存する手法では避けられない「コンテキストロタ(文脈劣化)」に対し、RLM はコード実行と再帰呼び出しにより情報を保持し、精度を維持します。
REPL による動的処理
モデルがプロンプト全体をコンテキストウィンドウに読み込むのではなく、変数としてロードしてコードで分解・再帰処理を行うことで、入力サイズをモデルのコンテキスト制限の 2 桁以上まで拡張します。
Deep Agents への統合
LangChain が RLM サポートを Deep Agents に実装し、動的サブエージェント機能を通じて、大規模データ処理タスクでの実用性を高めました。
影響分析・編集コメントを表示
影響分析
この技術は、大規模な文書解析や複雑なマルチステップタスクにおいて、AI エージェントの信頼性とスケーラビリティを根本から変える可能性があります。従来のコンテキスト制限というボトルネックを突破することで、実世界の大規模データ処理におけるエージェントの実用範囲が劇的に拡大します。
編集コメント
コンテキストの限界に直面する開発者にとって、RLM は非常に魅力的な解決策です。MIT の学術研究が LangChain という主要フレームワークを通じて実装された点は、技術転換のスピードを示す好例と言えます。

エージェントが蓄積するコンテキストが増えるほど、context rot と呼ばれる現象によりパフォーマンスが悪化します。MIT CSAIL の Alex Zhang 氏らによって提案された再帰型言語モデル(RLM: Recursive Language Models)は、この課題に対処するものです。ターンごとの処理や、情報を失う要約に頼るのではなく、モデルは REPL でコードを実行し、サブエージェントをディスパッチして入力コンテキストの断片に対して再帰的に処理を行います。
10,000 件の営業通話記録から平均取引規模を見つけるエージェントを考えてみましょう。ターンごとに処理する場合、モデル自体がコンテキスト内で累積合計を追跡する必要があり、カウントする時間が長くなるほどその合計値にドリフト(ズレ)が生じるリスクがあります。一方、RLM スタイルのエージェントは、オーケストレーションと集計をモデルの一時的なコンテキストウィンドウではなく、コード内に保持します。
論文 では、RLM はモデルのコンテキストウィンドウの 2 桁以上を超える入力を処理でき、その過程でバニラ(標準的な)エージェントよりも優れたパフォーマンスを発揮することが示されています。私たちは最近、動的サブエージェント を用いて Deep Agents に RLM のサポートを実装しました。
RLM の必要性
RLM(再帰型言語モデル)は、最終的な回答を生成する前に、自分自身や他の大規模言語モデル(LLM)を再帰的に呼び出す言語モデルです。すべてのプロンプトをコンテキストウィンドウに無理やり読み込ませるのではなく、REPL 内で変数としてロードし、その断片を参照・分解・再帰的に呼び出すためのコードを書きます。
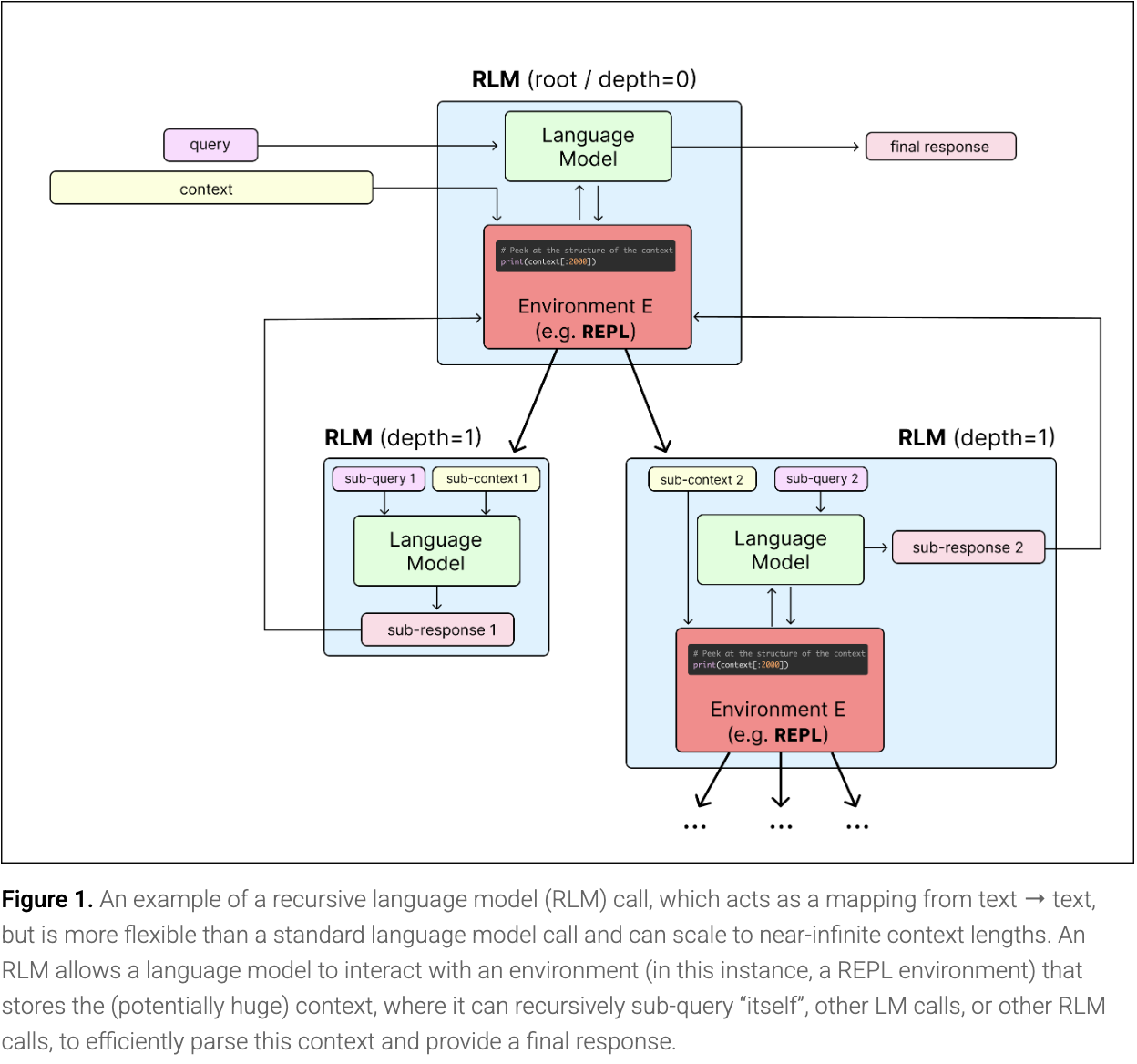
論文における「コンテキストの劣化(context rot)」に対抗するための最初の仮説は単純なものでした:すべての処理を一つの呼び出しに押し込めるのではなく、モデル呼び出し間で作業を分割することです。
**自然な解決策としては、「コンテキストを 2 つのモデル呼び出しに分け、それらを 3 つ目のモデル呼び出しで結合すれば、この劣化問題を回避できるのではないか」といったようなものが考えられます。私たちはこの直感を基に、再帰型言語モデル(RLM)を構築しました。
これはおよそ、サブエージェントがすでに実行していることでもあります:Deep Agents の subagents はコンテキストを分離し、個別の作業単位を委任し、中間結果をメインのコンテキストウィンドウから外に保ちます。しかし通常のサブエージェントでは、まだモデルが次の行動を 1 つずつ推論するたびに決定する必要があり、数百回の呼び出しや分岐、多段階の作業など、実際の構造化が必要になるとこのアプローチは機能しなくなります。
RLM は、モデルにプログラム操作可能な環境を提供し、大規模データセットで通常使用するのと同じプリミティブ(grep, partition, map, reduce)を利用できます。サブエージェントのプログラムによるオーケストレーションにより、ツールベースのオーケストレーションでは確実に提供できない2 つのことが実現します:
- 決定論的カバレッジ。カバレッジはモデルの判断ではなくコードによって保証されます。for b in batches ループは構造的にすべてのバッチを処理しますが、通常のモデルがこのような反復処理を大規模で実行するのは困難です。
- 専用オーケストレーション。パイプラインがコードであるため、タスクが必要とする形状(分岐、並列、逐次など)を自由に取ることができ、モデルがターンごとに確実に実行できる範囲に制限されません。
Deep Agents における RLM の動作
Deep Agents は、軽量な code interpreter を基盤とした 動的サブエージェント を通じてプログラムによるオーケストレーションをサポートします。ツール呼び出しでターンごとにサブエージェントをディスパッチするのではなく、モデルは短いスクリプトを記述し、コードインタープリタがそれを実行します。典型的な例として、300 ページのドキュメントの各ページに 1 つずつサブエージェントを割り当てるケース:
const results = await Promise.all(pages.map(page =>
task({ description: Summarize page ${page.number}, subagentType: "summarizer" })
));
用語に関する注記。私たちが構築したものは、論文の形状と完全に一致するわけではありません。 論文のアプローチはより極端です:プロンプト全体がインタプリタに読み込まれ、直接再帰処理され、再帰呼び出しは独自のツールや状態を持つエージェントではなく、単なる LM(言語モデル)呼び出しとなります。
Deep Agents で説明しているのは、*recursive agents (RA)* に近いものです。これはコードからディスパッチされる、独自のツールアクセスとコンテキストを持つサブエージェントです。私たちが提供しているものに対して RA という用語の方がより正確かもしれませんが、この機能およびアーキテクチャを動機づけたのは間違いなく RLM 論文の設計でした。
RLM 論文では、モデルがこのような環境を得ると、そのモデルが記述するコードはいくつかの傾向に従うことが指摘されています:
RLM が実行する一般的なパターンとして、コンテキストをより小さなサイズに分割し、複数の再帰的な LM(言語モデル)呼び出しを実行して回答を抽出するか、この意味マッピングを実行するというものがあります。
Claude Code のドキュメントにおける動的ワークフロー では、これらのパターンが 6 つ直接名指しされています:ファンアウトと合成、分類と実行、敵対的検証、生成とフィルタリング、トーナメント、完了するまでループ。これはハーン(枠組み)に関わらず有用な語彙です。
Deep Agents との違いは、オーケストレーターとそれが起動するすべてのサブエージェントが、選択した任意のモデル、あるいは複数のモデルの組み合わせ上で実行可能である点です。特定のモデルファミリーに限定されるわけではありません。コストとパフォーマンスの最適化のために、最先端モデルをオーケストレーターとして用い、GLM 5.2 や Nemotron のようなオープンウェイトのサブエージェントを組み合わせることも可能です。逆に、最先端のサブエージェントをオーケストレーションする形でオープンウェイトのオーケストレーターを用い、深層調査スタイルのワークフローを協調させることもできます。
動的なサブエージェントに関するこれらのパターンは 6 つあり、Introducing Dynamic Subagents および このウォークスルー動画 で取り上げています。
OOLONG によるベンチマーク
プログラムによるオーケストレーションの実態を確認するため、OOLONG というベンチマークでテストを行いました。これは長文コンテキスト推論とデータ集約のためのベンチマークであり、回答を得るためには入力内のほぼすべての行を検証する必要があります。
AgNews データセットを OOLONG タスクとして構成し、実験を行いました。数千件の見出しがあり、それぞれに日付とユーザーが紐付けられていますが、目に見えるトピックラベルはありません。質問に答えるには、エージェントが見出しを 4 つのカテゴリ(世界、スポーツ、ビジネス、科学/技術)のいずれかに分類し、セット全体を集約する必要があります。
その後、エージェントは難易度の低い順に以下の 3 つのカテゴリーに属する質問への回答を求められます:
質問タイプ
必要なこと
例
カウント
すべての行をスキャンし、カテゴリ別に集計
世界ニュースの見出しはいくつあるか?
ユーザー
ユーザーでフィルタリングしてから集計
ユーザー 72341 の場合、科学・技術分野の見出しはいくつあるか?
時間的
日付でフィルタリングしてから集計
2004 年 8 月以前では、スポーツニュースは世界ニュースよりも一般的だったか?
これは包括的なベンチマークではなく、概念実証として実行しました:*
コンテキスト長
評価仕様
REPL なし
REPL あり
64k トークン
21 の例 × 5 回の実行
0.58
0.67
128k トークン
19 の例 × 3 回の実行
0.44
0.79
*スコアは、OOLONG の評価基準(カテゴリ回答の場合は完全一致、数値回答の場合は部分的な加点)を用いて AgNews 質問セット全体で平均化されたものです。採点範囲は 0 から 1 です。数値回答の採点は 0.75^|真値 - 予測値| で行われるため、1 つずれていれば 0.75 のスコアとなり、10 ずれていれば約 0.06 に近づきます。
64k トークンの場合、両方のエージェントは概ね同程度の性能を示しており、通常のエージェントもほぼ追いついています:

*64k トークンの場合、単純なエージェント(左)のスコアは 0.58 に対し、RLM 対応型エージェント(右)は 0.67 を記録し、トークン数とコストは同等です。これは、よりシンプルなアプローチでも依然としてほぼ追いつける領域です。ただし、単純なエージェントのレイテンシは RLM 対応型に比べて明らかに低いです。*128k トークンの場合、結果は崩壊し始めます。微妙に間違った回答をするのではなく、完全に諦めてしまい、「計算できない」または「ブロックされている」と告げることになります。

この差はデータにおいても明確です。
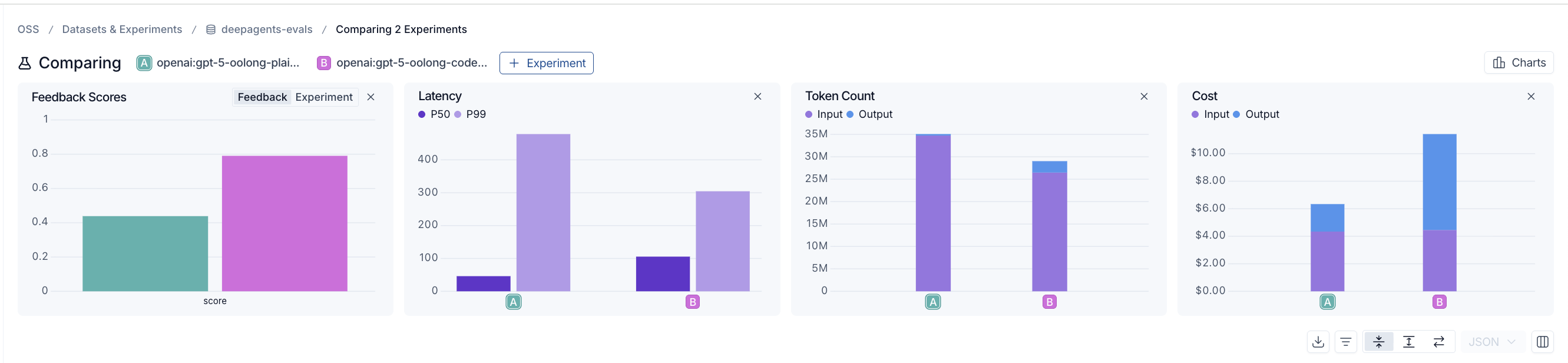
*128k トークンの場合、単純なエージェント(左)のスコアは 0.44 に低下する一方、RLM 対応型エージェント(右)は 0.79 を達成します。RLM 対応型エージェントは確かに処理速度が遅くなりますが、実際には使用するトークン数が少ないにもかかわらず、出力トークンのコストが高いため、全体のコストは高くなります。*なお、本テストでは OOLONG ワークロードの最適化は行いませんでした。これは、タスク固有のプロンプティングを一切施さないベースのハーンネス(基盤枠組み)が、長文コンテキストの問題をそもそも処理できるかどうかを検証するための煙出しテスト(初期検証)です。実際には、これらの数値は RLM の潜在能力を過小評価している可能性が高いと予想しています。
Deep Agents の始め方
動的サブエージェントには、作業を割り当てるための subagents と、モデルがオーケストレーションコードを書き実行するための安全で軽量なランタイムである code interpreter の 2 つが必要です。Deep Agents にはこれら両方が同梱されています。QuickJS ミドルウェアをインストールし、CodeInterpreterMiddleware を create_deep_agent に渡してください:
pip install -U "deepagents[quickjs]"
from deepagents import create_deep_agent
from langchain_quickjs import CodeInterpreterMiddleware
agent = create_deep_agent(
model="openai:gpt-5.5",
middleware=[CodeInterpreterMiddleware()],
)
Deep Agents には、すぐに使える汎用サブエージェントが含まれていますが、特定のタスクに特化した カスタムサブエージェント を設定することもできます。それぞれ固有の名前、説明、システムプロンプトを持ちます。オーケストレーションスクリプトは、作業に適したサブエージェントへ割り当てることができます。
"workflow" という単語でプロンプトを入力すると、動的サブエージェントがトリガーされます:
result = await agent.ainvoke({
"messages": [{"role": "user", "content": "src/routes/ のすべてのファイルをレビューし、主要なリスクを要約するワークフローを実行してください。"}]
})
セットアップなしですぐに試す最も速い方法は、ターミナルコーディングエージェントである dcode です。コードインタープリタがすでに有効になっている状態で提供されるので、インストールしてワークフローを要求するだけです。
curl -LsSf https://langch.in/dcode | bash
dcode
関連コンテンツ

エージェントアーキテクチャ
Deep Agents
オープンソース
サンドボックスなしで信頼できないエージェントコードを実行する

Hunter Lovell
2026 年 6 月 30 日
分

オープンソース
Deep Agents
エージェントアーキテクチャ
Deep Agents における動的サブエージェントの紹介


S. Runkle,
C. Francis,
H. Lovell
2026 年 6 月 29 日
9 分

Deep Agents
Open Source
Deep Agents によるプロンプトキャッシング

Alex Olsen
2026 年 6 月 26 日
5 分

エージェントが実際に何をしているかを確認する
LangSmith は、開発者がエージェントのすべての意思決定をデバッグし、変更の評価を行い、ワンクリックでデプロイできるためのエージェントエンジニアリングプラットフォームです。
原文を表示
The more context agents accumulate, the worse they perform due to a phenomenon called context rot. Recursive language models (RLMs), proposed by Alex Zhang and researchers at MIT CSAIL, address this: instead of working turn by turn or relying on lossy summarization, the model runs code in a REPL that dispatches subagents and recurses over pieces of the input context.
Consider an agent finding the average deal size across 10,000 sales call transcripts. Turn by turn, the model has to track a running total in its own context, and that total risks drift the longer it counts. An RLM-style agent keeps the orchestration and counting in code instead, not the model's ephemeral context window.
The paper shows RLMs can process inputs up to two orders of magnitude beyond a model's context window and outperform vanilla agents in the process. We just built RLM support into Deep Agents with dynamic subagents.
The Case for RLMs
RLMs are language models that recursively call themselves, or other LLMs, before producing a final answer. Rather than forcing the entire prompt into the context window, the model loads it as a variable inside a REPL and writes code to peek into, decompose, and recursively call itself over snippets of it.
The paper's first hypothesis for fighting context rot was simple: split the work across model calls instead of forcing it all into one.
The natural solution is something along the lines of, "well maybe if I split the context into two model calls, then combine them in a third model call, I'd avoid this degradation issue". We take this intuition as the basis for a recursive language model.
That's also, roughly, what subagents already do: Deep Agents subagents isolate context, delegate discrete units of work, and keep intermediate results out of the main context window. But normal subagents still rely on the model deciding what to do next, one reasoning turn at a time, which breaks down once orchestration needs real structure like hundreds of calls, branching, or multi-phase work.
RLMs give the model an environment it can act on programmatically, with the same primitives you'd reach for on any large dataset (grep, partition, map, reduce). Programmatic orchestration of subagents enables two things that tool-based orchestration can't reliably deliver:
- Deterministic coverage. Coverage is guaranteed by code, not model judgment. A for b in batches loop touches every batch by construction, whereas a plain model has a hard time performing iterations like this at scale.
- Bespoke orchestration. Because the pipeline is code, it can take whatever shape the task needs, branching, parallel, sequential, instead of being limited to what a model can reliably carry out turn by turn.
How RLMs work in Deep Agents
Deep Agents supports programmatic orchestration through dynamic subagents, powered by a lightweight code interpreter. Instead of dispatching subagents turn by turn through tool calls, the model writes a short script and the code interpreter executes it. The canonical example, one subagent per page of a 300 page document:`
`
const results = await Promise.all(pages.map(page =>
task({ description: Summarize page ${page.number}, subagentType: "summarizer" })
));
A note on terminology. What we've built doesn't mirror the paper's shape exactly. The paper's approach is more extreme: the entire prompt is loaded into the interpreter and recursed on directly, and the recursive calls are plain LM calls, not agents with their own tools and state.
What we're describing in Deep Agents is closer to *recursive* *agents (RA)*, subagents with their own tool access and context, dispatched from code. RA might be the more precise term for what we're shipping, but it was certainly the RLM paper design motivated this capability and thus architecture.
In the RLM paper, it’s noted that once the model gets this kind of environment, the code it writes follows a few trends:
A common pattern the RLM will perform is to chunk up the context into smaller sizes, and run several recursive LM calls to extract an answer or perform this semantic mapping.
Claude Code's docs on dynamic workflows name six of these patterns directly: fan out and synthesize, classify and act, adversarial verification, generate and filter, tournament, loop until done, a useful vocabulary regardless of harness.
The difference with Deep Agents is that the orchestrator and every subagent it dispatches can run on any model, or mix of models, you choose, rather than being scoped to one model family. You could pair a frontier model orchestrator with open-weight subagents like GLM 5.2 or Nemotron for cost and performance optimization at scale, or flip it — open-weight orchestration coordinating frontier subagents for deep research style workflows.
We cover six patterns like these for dynamic subagents in Introducing Dynamic Subagents and this walkthrough video.
Benchmarking with OOLONG
To see programmatic orchestration in action, we tested it on OOLONG, a benchmark for long context reasoning and data aggregation where the answer depends on examining nearly every row in the input.
We ran experiments on AgNews, structured as an OOLONG task: thousands of headlines, each with a date and user attached, and no visible topic label. To answer a question, the agent has to classify headlines into one of four categories (world, sports, business, and science/tech) and aggregate across the entire set.
The agent is then tasked with answering questions that fall into three categories, in order of increasing difficulty:
Question type
What it requires
Example
Counting
Scan all rows, count by category
How many world headlines are there?
User
Filter by user, then count
For user 72341, how many sci/tech headlines are there?
Temporal
Filter by date, then count
Before Aug 2004, was sports more common than world?
We ran this as a proof of concept, not a comprehensive benchmark:**
Context length
Eval spec
Without REPL
With REPL
64k tokens
21 examples × 5 runs
0.58
0.67
128k tokens
19 examples × 3 runs
0.44
0.79
*Scores are averaged across the AgNews question set, using OOLONG's scoring: exact match for categorical answers, partial credit for numeric ones, on a 0 to 1 scale. Numeric answers are scored as 0.75^|true - predicted|, so a numeric answer off by 1 still scores 0.75, while one off by 10 scores closer to 0.06.*
At 64k, both agents are still in a similar ballpark, the plain agent mostly keeps up:
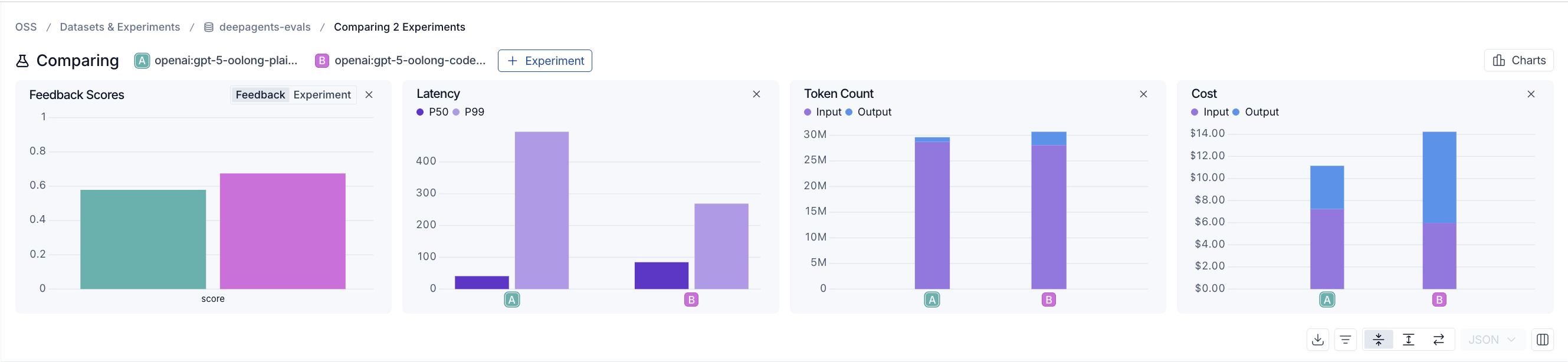
At 128k, it starts to fall apart, not with a subtly wrong answer, but by giving up outright: telling you it can't compute the result or is blocked.
The differential is clear in the data as well:
Note, We didn't optimize for the OOLONG workload: this was a smoke test of whether the base harness, with no task-specific prompting, could handle long-context problems at all. We actually expect these numbers undersell RLM potential.
Get started in Deep Agents
Dynamic subagents need two things: subagents to dispatch work to, and a code interpreter, a secure, lightweight runtime where the model writes and executes orchestration code. Deep Agents ships with both. Install the QuickJS middleware and pass CodeInterpreterMiddleware to create_deep_agent:
pip install -U "deepagents[quickjs]"
from deepagents import create_deep_agent
from langchain_quickjs import CodeInterpreterMiddleware
agent = create_deep_agent(
model="openai:gpt-5.5",
middleware=[CodeInterpreterMiddleware()],
)
Deep Agents includes a general-purpose subagent out of the box, but you can also configure custom subagents specialized for specific tasks, each with its own name, description, and system prompt. The orchestration script can dispatch to whichever subagent fits the job.
Prompt with the word "workflow" to trigger dynamic subagents:
result = await agent.ainvoke({
"messages": [{"role": "user", "content": "Run a workflow that reviews every file in src/routes/ and summarizes the top risks."}]
})
The fastest way to try this without any setup is dcode, our terminal coding agent. It ships with the code interpreter already enabled, just install and ask for a workflow:
curl -LsSf https://langch.in/dcode | bash
dcode
Related content
Agent Architecture
Deep Agents
Open Source
Running Untrusted Agent Code Without a Sandbox
Hunter Lovell
June 30, 2026
min
Open Source
Deep Agents
Agent Architecture
Introducing Dynamic Subagents in Deep Agents
S. Runkle,
C. Francis,
H. Lovell
June 29, 2026
9
min
Deep Agents
Open Source
Prompt Caching with Deep Agents
Alex Olsen
June 26, 2026
5
min
See what your agent is really doing
LangSmith, our agent engineering platform, helps developers debug every agent decision, eval changes, and deploy in one click.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み