Claude Sonnet 5 の紹介
Anthropic は、推論能力と処理速度を強化した次世代モデル「Claude Sonnet 5」を発表し、AI エコシステムにおける競争力を再確認しました。
キーポイント
新モデルの発表
Anthropic が推論能力と処理速度を大幅に向上させた新しい AI モデル「Claude Sonnet 5」を発表しました。
性能強化のポイント
前世代モデルと比較して、複雑なタスクの解決能力(推論)とレスポンス速度が特に重視されたアップデートとなっています。
業界への影響
大規模言語モデル市場における競争激化を示すものであり、開発者や企業による実装基準の見直しを促します。
影響分析・編集コメントを表示
影響分析
この発表は、大規模言語モデル市場において「推論能力」と「速度」の両立を追求するトレンドを象徴しており、企業向け AI 導入における選定基準がさらに高度化することを示唆しています。Anthropic の技術的進歩は、複雑なビジネス課題解決やリアルタイム処理が必要なアプリケーション開発に新たな選択肢を提供します。
編集コメント
プレスリリースベースの簡潔な発表ですが、推論能力と速度という実用性の高い要素に焦点を当てている点は業界標準の向上を示しています。今後の詳細ベンチマーク結果次第で、実際の開発現場での採用動向がさらに明確になるでしょう。
Claude Sonnet 5 は、これまでで最もエージェント型(自律実行型)の Sonnet モデルとなるよう設計されています。計画立案が可能であり、ブラウザやターミナルなどのツールを使用し、数ヶ月前まではより大規模で高価なモデルにしかできなかったレベルで自律的に動作できます。
多くの開発者にとって、エージェント型 AI の時代は Sonnet クラスのモデルから始まりました:Claude Sonnet 3.5、3.6、そして 3.7 は、コーディングやツール使用において印象的なスキルを示した最初のモデルでした。しかし最近では、エージェント機能における最も明確な向上は、Opus クラスのモデルで見られています。
Sonnet 5 はその格差を縮めます:その性能は Opus 4.8 に近いものですが、より低い価格で提供されます。推論、ツール使用、コーディング、知識作業といったエージェント性能の重要な側面において、前作である Sonnet 4.6 から大幅な改善が図られています。
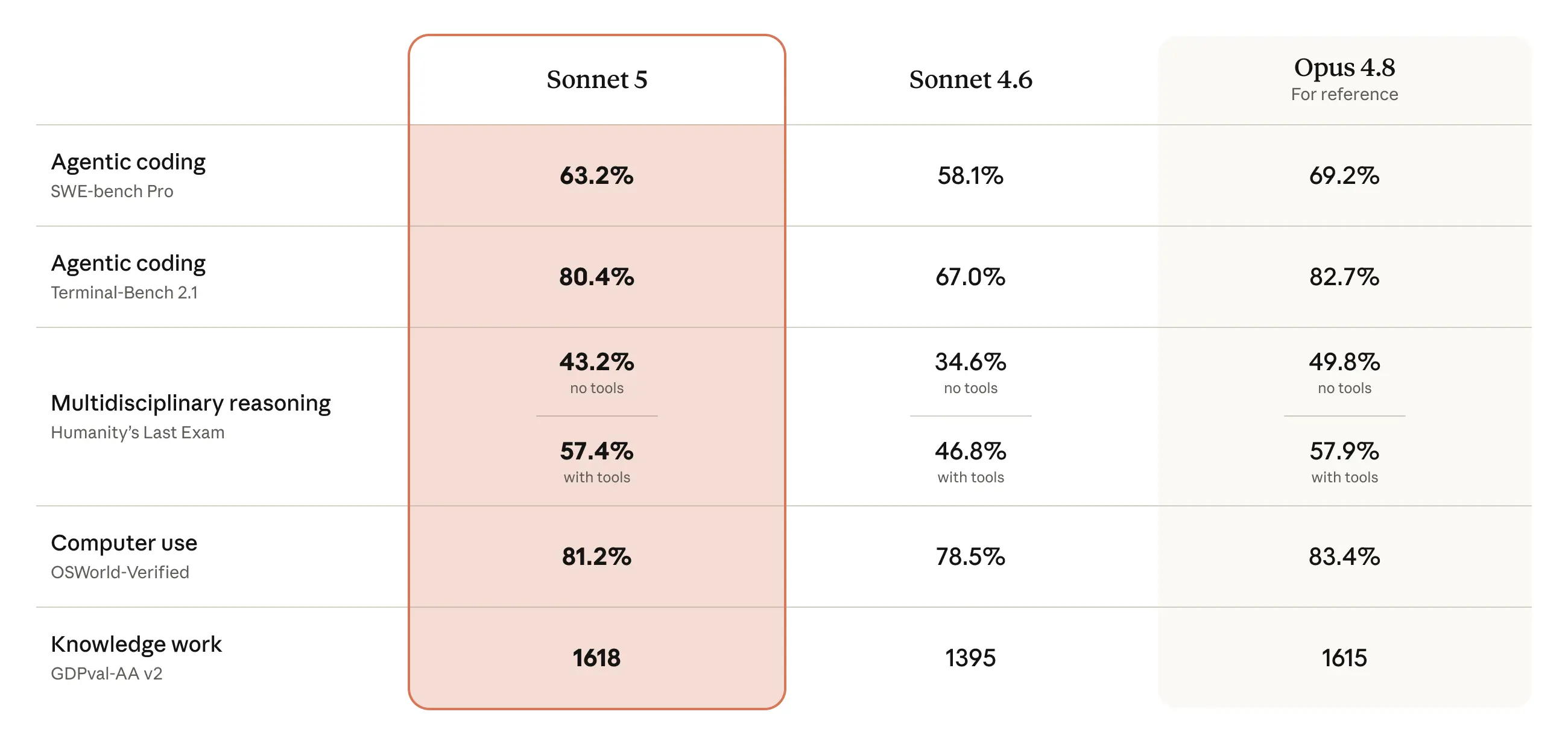 image*Sonnet 5 の各種評価におけるスコアを、Sonnet 4.6 および Opus 4.8(参考のために、より汎用的な能力を持つモデル)と比較したものです。Claude Sonnet 5 システムカード では、より広範な評価の詳細が報告されています。*
image*Sonnet 5 の各種評価におけるスコアを、Sonnet 4.6 および Opus 4.8(参考のために、より汎用的な能力を持つモデル)と比較したものです。Claude Sonnet 5 システムカード では、より広範な評価の詳細が報告されています。*
私たちの安全性評価では、Sonnet 5 は Sonnet 4.6 に比べて望ましくない行動の全体的な発生率が低く、エージェント(agent)コンテキストにおいて一般的により安全に使用できることが示されました。また、評価結果からは、現在の Opus モデルと比較してサイバーセキュリティタスクを実行する能力が大幅に低いことも明らかになりました。
本日より、Claude Sonnet 5 はすべてのプランで利用可能となりました。無料プランと Pro プランのデフォルトモデルとなり、Max、Team、Enterprise ユーザーも利用できます。また、Claude Code および Claude Platform でも利用可能で、2026 年 8 月 31 日までは導入価格として、入力トークン 100 万あたり 2 ドル、出力トークン 100 万あたり 10 ドルで提供されます。それ以降は、入力トークン 100 万あたり 3 ドル、出力トークン 100 万あたり 15 ドルでの価格設定となります。開発者は Claude API を通じて claude-sonnet-5 を利用できます。
Claude Sonnet 5 との連携
以下のチャートは、エージェント検索評価 BrowseComp およびコンピュータ操作評価 OSWorld-Verified において、異なる effort レベルで Sonnet 5 と Sonnet 4.6、Opus 4.8 のパフォーマンスを比較したものです。Sonnet 5(オレンジ色の線)は、Sonnet 4.6(グレーの線)と比較して明確な改善が見られます。Opus 4.8(黄色の線)は依然としてこれらのタスクにおいて高い精度が求められる場合に最適なモデルですが、Sonnet 5 は開発者にとって、以前よりもはるかに高品質でありながら低価格な選択肢を提供します。Sonnet 5 と Opus 4.8 の間では、ユーザーはコストとパフォーマンスの適切なバランスを見つけるために effort レベルを調整することができます。
初期アクセスパートナーからのフィードバックは一貫しており、Sonnet 5 はその前身モデルよりもはるかにエージェント性(自律的なタスク実行能力)が高いというものです。テスターたちは、以前の Sonnet モデルでは完了できなかった複雑なタスクを Sonnet 5 がどのように完遂するか、明示的に指示されていないにもかかわらず自身の出力を検証する方法、そしてこれらすべてのエージェント的作業を魅力的な価格帯で実現している点を説明しました。

Claude Sonnet 5 は、多段階のソフトウェアエンジニアリング作業において、エージェントに強力な実行レイヤーを提供します。複雑な技術的コンテキスト全体を通じて、持続的なコーディング、ツール使用、デバッグを適切に処理し、特に継続性と技術的根拠が重要なワークフローで非常に有用です。

Claude Sonnet 5 に、Salesforce のアカウントティアの更新とエンタープライズ連絡先へのローンチ発表送信という 2 つの部分からなるタスクを任せたところ、エンドツーエンドで完了させることができました。以前は途中で立ち止まることが多かったものです。日常の自動化においては、これは言うまでもなく最適な選択肢です。

Claude Sonnet 5 は、より少ないリソースでより多くの成果を上げます。出力品質は同じままに保ちつつ、到達までのステップ数を削減します。また、安全ではない要求に対しては、一貫して明確に拒否する能力も備えています。Lovable では、強力なツールを数百万人のビルダーの手に届けることを目指しています。「どのように構築するか」を知るモデルと同様に、「いつノーと言うか」を知っているモデルも極めて重要です。

Claude Sonnet 5 を、最も困難な実 Pull Request(プルリクエスト)の数十件に対して実行したところ、各ケースを単独でテスト済みかつ検証済みの結果へと導き通しました。これにより、エンジニアは判断、意思決定、最終承認といった本質的な業務に集中できるようになりました。

Claude Sonnet 5 にバグ調査を依頼したところ、指示なしで再現テストを作成し、修正を実装した後、変更を加えないとバグが再発することを確認するために一時保存しました。すべてを単一のパスで完了させました。

Claude Sonnet 5 を用いれば、エージェントは計画を維持し、当社の規約に従い、効率的なコストでクリーンな多段階の変更を実行できます。

Claude Sonnet 5 は、既存コード(ブラウンフィールド)において最もその真価を発揮します。競合状態や隠されたテストなど、誰も手をつけたくない部分においてもです。失敗を実際の根本原因まで追跡し、症状に対する応急処置ではなく、永続的な修正を提供します。

Claude Sonnet 5 は、Eve の原告側業務においてパレートフロンティア(最適解の境界)に位置しています。特に法的調査と分析において最も明確な成果が得られ、コストパフォーマンス比の良さが移行を決断させるほどでした。

ClickHouse エージェントは生データを探索し、その場で洞察を生成するため、新しいモデルをテストする際には「洞察を得るまでの時間」が重要です。Claude Sonnet 5 はより細かなステップで推論を行い、ユーザーに答えを明らかに速く導き出します。この速度こそが、お客様が実感できる違いです。

Pace において、私たちのコンピューター使用型エージェントは、運用チームがすでに利用しているシステム上で保険ワークフロー(申込受付、事故報告 (FNOL)、損失実績の作成など)を実行しています。Claude Sonnet 5 は一貫して適切な行動を取り、かつ迅速に実行します。これが実際の保険業務で求められることです。
01 /
10
セーフティ評価
事前展開時のセーフティ評価では、Sonnet 5 が全体として Sonnet 4.6 よりも改善されていることが確認されました。エージェントとしての安全性においては、悪意のあるリクエストを拒否し、プロンプトインジェクション攻撃における乗っ取り試行に抵抗する能力が向上しています。また、幻覚 (hallucination) や迎合的行動 (sycophancy) の発生率は Sonnet 4.6 よりも低くなっています。私たちの自動化された行動監査では、悪用への協力や欺瞞など、多様な整合性のない行動をテストしますが、Sonnet 5 は全体としてより低いスコア(つまりより安全)を示しました。ただし、この評価においては、より能力の高い Opus 4.8 や Claude Mythos Preview と比較すると、やや高い割合で整合性のない行動が見られることも確認されました。
 image*自動行動監査(多くの状況や文脈にわたる広範な望ましくない行動を検出するテスト)における整合性外れ行動の発生率。詳細は Sonnet 5 システムカード のセクション 6.4 を参照してください(各特定の行動に関する完全なリストと結果が記載されています)。Sonnet 5 は、Sonnet 4.6 よりも全体的に整合性外れ行動の発生率が低いものの、Mythos Preview や Opus 4.8 よりも高い傾向にあります。*
image*自動行動監査(多くの状況や文脈にわたる広範な望ましくない行動を検出するテスト)における整合性外れ行動の発生率。詳細は Sonnet 5 システムカード のセクション 6.4 を参照してください(各特定の行動に関する完全なリストと結果が記載されています)。Sonnet 5 は、Sonnet 4.6 よりも全体的に整合性外れ行動の発生率が低いものの、Mythos Preview や Opus 4.8 よりも高い傾向にあります。*
私たちは Sonnet 5 をサイバーセキュリティタスクのために意図的に訓練したわけではありません。日常的で有害ではない一部のサイバータスクは実行できますが、ソフトウェアのエクスプロイトを開発するなど潜在的に危険なサイバースキルを評価するテストでは、Opus 4.8 や Mythos 5 などのモデルと比較して著しく低いパフォーマンスを示します。Firefox ブラウザの脆弱性に対するエクスプロイトを開発する能力をテストしたある評価の結果は以下のチャートに示されています。Sonnet 5 は完全な動作可能なエクスプロイトの開発に一度も成功しませんでしたが、Sonnet 4.6 よりもわずかに高い「部分的」成功率を示しています。この後者の変化は、特定の訓練によるものではなく、一般知能の向上によるものと考えられます。
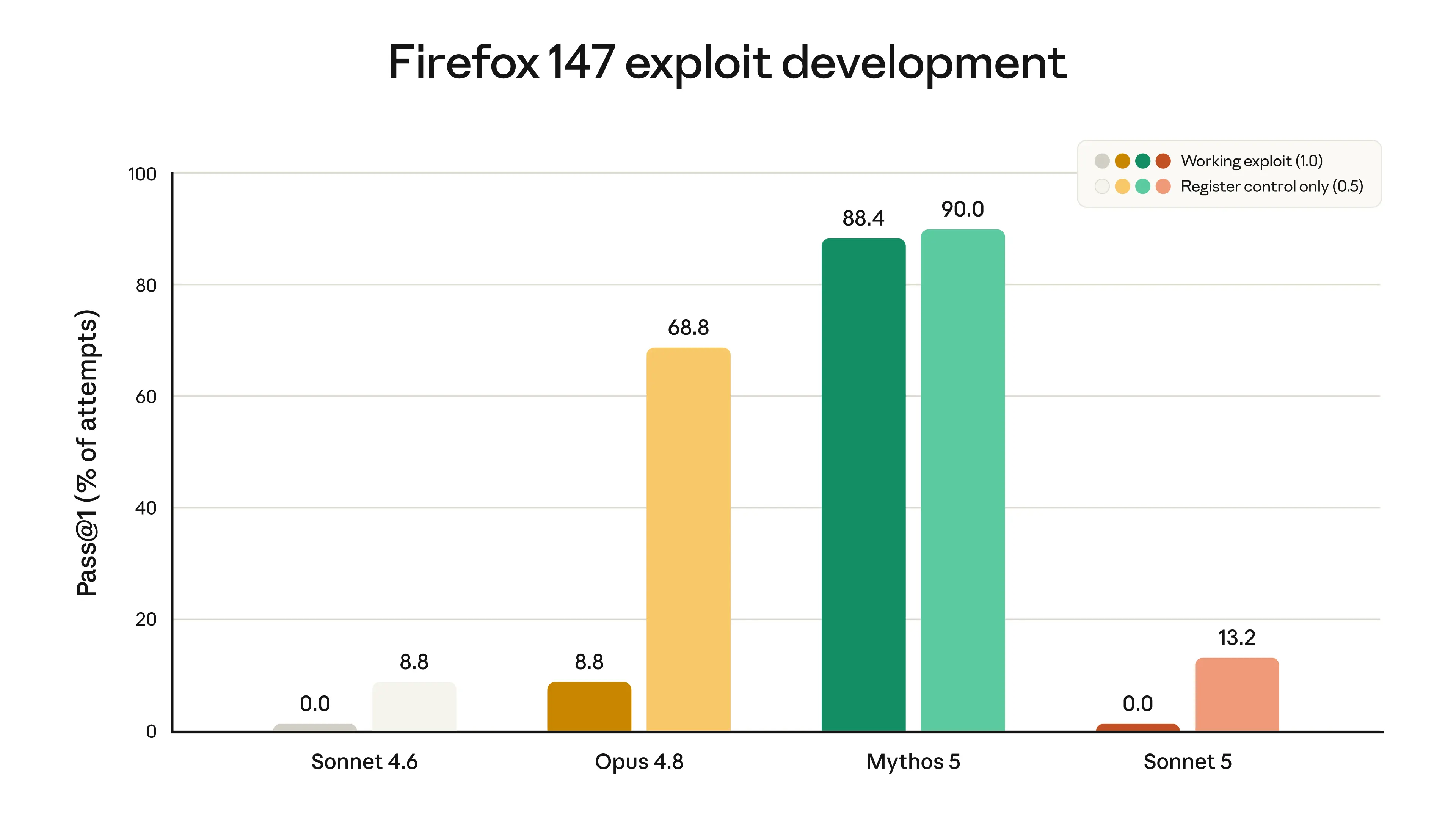 image*Firefox 147 のソフトウェア脆弱性に対するエクスプロイトを開発する際のモデルの成功度を測定したスコア(本評価は Mozilla と共同で開発 されました。すべての脆弱性は Firefox 148 でパッチ済みです)。各モデルについて、左側の棒グラフはモデルが(安全対策なしで)動作するエクスプロイトを開発した頻度を、右側の棒グラフは部分的な成功を収めた頻度を示しています。Sonnet モデルのいずれも動作するエクスプロイトの開発に成功せず(両者ともスコア 0.0%)、Sonnet 5 は Sonnet 4.6 よりわずかに高い部分的な成功率を示しました。Sonnet モデルの両者は、Opus 4.8 や Mythos 5 に比べてサイバー能力が大幅に劣っています。詳細は Sonnet 5 システムカード のセクション 3.2.4 をご覧ください。*
image*Firefox 147 のソフトウェア脆弱性に対するエクスプロイトを開発する際のモデルの成功度を測定したスコア(本評価は Mozilla と共同で開発 されました。すべての脆弱性は Firefox 148 でパッチ済みです)。各モデルについて、左側の棒グラフはモデルが(安全対策なしで)動作するエクスプロイトを開発した頻度を、右側の棒グラフは部分的な成功を収めた頻度を示しています。Sonnet モデルのいずれも動作するエクスプロイトの開発に成功せず(両者ともスコア 0.0%)、Sonnet 5 は Sonnet 4.6 よりわずかに高い部分的な成功率を示しました。Sonnet モデルの両者は、Opus 4.8 や Mythos 5 に比べてサイバー能力が大幅に劣っています。詳細は Sonnet 5 システムカード のセクション 3.2.4 をご覧ください。*
Sonnet 5 はこれらのタスクにおいて前作よりもやや強力であるため、サイバーセキュリティ対策をデフォルトで有効にしてリリースしました。この サイバーセキュリティ対策 は、危険なサイバー利用をリアルタイムで検知してブロックするものであり、Claude Opus 4.7 および 4.8 に搭載されているものと同じです(Sonnet 5 の全体的なサイバーセキュリティリスクが低いと判断したため、Fable 5 で導入された対策よりも厳格さは低く設定されています。Fable 5 の対策はより広範なサイバーセキュリティタスクをブロックするためです)。1
Sonnet 5 に対する安全性および機能に関する包括的な評価結果は、Claude Sonnet 5 システムカード に記載されています。
利用可能状況と価格設定
Claude Sonnet 5 は、2026 年 8 月 31 日まで、入力トークン 100 万あたり 2 ドル、出力トークン 100 万あたり 10 ドルの導入期間限定価格で、どこでも利用可能です。その後、標準価格として入力トークン 100 万あたり 3 ドル、出力トークン 100 万あたり 15 ドルに引き上げられます。2
より高負荷なレベルでのトークン使用量に対応するため、Chat、Cowork、Claude Code、および Claude Platform 3 におけるレート制限を全体的に引き上げました。ユーザーは自身のプロジェクトに適したレベルを選択できます。
Footnotes
1 Sonnet 5 は、ネイティブの Claude プラットフォーム、AWS 上の Claude プラットフォーム、および Microsoft Foundry 内の Claude(Azure および Anthropic でホスト)で本日利用可能となり、Google Vertex 上の Claude では近日公開予定となる サイバー検証プログラム の一部です。すでにサイバー検証プログラムに登録されている組織は、再申請の必要なく Sonnet 5 でも同じアクセス権限を自動的に付与されます。全体として、ガードレールを低減したセキュリティ関連作業には Claude Opus 4.8 を推奨します。
2 Sonnet 5 は Sonnet 4.6 のアップグレード版ですが、パフォーマンス向上のためにテキスト処理方法を変更した新しいトークナイザーを採用しています(これは Claude Opus 4.7 で導入したトークナイザーの変更と同様です)。その代償として、同じ入力でもコンテンツの種類に応じて約 1.0–1.35 倍のトークン数にマッピングされる可能性があります。導入時の価格設定は、Sonnet 5 への移行が概ねコスト中立となるように調整されています。
3 2026 年 4 月 26 日、ネイティブの Claude プラットフォームにおいて、すべての利用レベルで Sonnet および Haiku のレート制限を引き上げ、3 つのティア(Start, Build, Scale)に簡素化しました。ご自身のティアと現在の制限については Claude コンソール で確認するか、ドキュメント をお読みいただくことで詳細をご確認ください。
- Humanity's Last Exam: 私たちは「Humanity's Last Exam」の採点モデルを更新し、Sonnet 4.6 のスコアをツールなしで 34.6%、ツールありで 46.8% に更新しました。これが、Sonnet 4.6 のローンチブログで報告されたスコアと異なる理由です。
- OSWorld-Verified: 私たちは、モデルの実際の世界でのパフォーマンスをより正確に反映するために、「OSWorld-Verified」評価の実行方法を変更し、Sonnet 4.6 のスコアを 78.5% に更新しました。これが、Sonnet 4.6 のローンチブログで報告されたスコアと異なる理由です。
Related content
Claude Science, an AI workbench for scientists, is now available
Claude Science は、研究者が最も頻繁に使用するツールやパッケージを統合し、監査可能な成果物を生成し、計算リソースへの柔軟なアクセスを提供するカスタマイズ可能なアプリです。
Introducing Claude Tag
Claude Tag は、チームが Claude と連携して作業するための新しい方法です。
Anthropic opens Seoul office and announces new partnerships across the Korean AI ecosystem
原文を表示
Claude Sonnet 5 is built to be the most agentic Sonnet model yet. It can make plans, use tools like browsers and terminals, and run autonomously at a level that, just a few months ago, required larger and more expensive models.
For many developers, the agentic AI era began with Sonnet-class models: Claude Sonnet 3.5, 3.6, and 3.7 were the first models that showed impressive skills in coding and tool use. More recently, though, the clearest gains in agentic capabilities have been in our Opus-class models.
Sonnet 5 narrows the gap: its performance is close to that of Opus 4.8, but at lower prices. It’s a substantial improvement over its predecessor, Sonnet 4.6, on important aspects of agentic performance like reasoning, tool use, coding, and knowledge work:
Scores for Sonnet 5 on a variety of evaluations compared to those of Sonnet 4.6 and Opus 4.8 (a more generally capable model, for reference). The [Claude Sonnet 5 System Card reports a broader set of evaluations in detail.](https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-cdn.anthropic.com%2Fimages%2F4zrzovbb%2Fwebsite%2F9941d610909f28a504e16dd5af823df172ec6035-2600x1234.png&w=3840&q=75)
Our safety assessments found that Sonnet 5 shows an overall lower rate of undesirable behaviors than Sonnet 4.6, and is generally safer to use in agentic contexts. Evaluations also show that it has a much lower ability to perform cybersecurity tasks than our current Opus models.
From today, Claude Sonnet 5 is available across all plans: it is the default model for Free and Pro plans, and is available to Max, Team, and Enterprise users. It’s also available in Claude Code and on the Claude Platform, where it launches with introductory pricing of $2 per million input tokens and $10 per million output tokens through August 31, 2026, after which it will be priced at $3 per million input tokens and $15 per million output tokens. Developers can use claude-sonnet-5 via the Claude API.
Working with Claude Sonnet 5
The charts below compare the performance of Sonnet 5 with Sonnet 4.6 and Opus 4.8 at different effort levels on the agentic search evaluation BrowseComp and the computer use evaluation OSWorld-Verified. Sonnet 5 (orange line) is a strict improvement over Sonnet 4.6 (gray line). Opus 4.8 (yellow line) is still the model of choice for higher accuracy on these tasks, but Sonnet 5 provides developers with lower-priced options that are of much higher quality than what was previously available. Between Sonnet 5 and Opus 4.8, users can adjust the effort level to find the right balance of cost and performance.
Feedback from our early access partners has been consistent: Sonnet 5 is much more agentic than its predecessors. Testers described how it finishes complex tasks where previous Sonnet models would stop short, how it checks its own output without explicitly being asked, and how it does all this agentic work at an attractive price point:
Claude Sonnet 5 gives our agents a strong execution layer for multi-step software engineering work. It handles sustained coding, tool use, and debugging well across messy technical contexts, and has been especially useful for workflows where follow-through and technical grounding matter.
We handed Claude Sonnet 5 a two-part job—update Salesforce account tiers, send a launch announcement to enterprise contacts—and it finished end to end. That used to stall halfway. For day-to-day automation, it’s a no-brainer.
Claude Sonnet 5 gets more done with less. Same output quality, fewer steps to get there. It refuses unsafe requests cleanly and consistently, too. At Lovable, we’re putting powerful tools in the hands of millions of builders. A model that knows when to say no is just as important as one that knows how to build.
We ran Claude Sonnet 5 against dozens of our most challenging real pull requests, and it carried each one through to a tested, verified result on its own — freeing our engineers to focus on the judgment, the decision, and the final sign-off.
I asked Claude Sonnet 5 to investigate a bug. Unprompted, it wrote a reproducing test, implemented the fix, then stashed it to confirm the bug came back without the change. All in a single pass.
With Claude Sonnet 5, agents stay on plan, follow our conventions, and ship clean multi-step changes, all at an efficient cost.
Claude Sonnet 5 is at its best on brownfield code—race conditions, hidden tests, the parts nobody wants to touch. It traces a failure to its actual root cause and ships a durable fix instead of patching the symptom.
Claude Sonnet 5 sits on the Pareto frontier for Eve’s plaintiff-law tasks. We see the clearest gains in legal research and analysis, at a price-to-performance ratio that made the choice to migrate easy.
ClickHouse agents explore live data and produce insights on the fly, so time-to-insight matters when testing new models. Claude Sonnet 5 reasons in tighter steps and gets our users to answers noticeably faster. That speed is a difference our customers feel.
At Pace, our computer-use agents run insurance workflows—submission intake, FNOL, loss runs—on the systems our operations teams already use. Claude Sonnet 5 consistently takes the right action and does it quickly, which is what real insurance work demands.
01 /
10
Safety evaluations
Our pre-deployment safety evaluations found that Sonnet 5 was overall an improvement on Sonnet 4.6. On agentic safety, the model is better at refusing malicious requests and resisting hijack attempts in prompt injection attacks. The model shows lower rates of hallucination and sycophancy than Sonnet 4.6. On our automated behavioral audit, which tests a wide range of misaligned behaviors such as cooperation with misuse and deception, Sonnet 5 scored lower (that is, safer) overall. However, it did show somewhat higher rates of misaligned behavior on this assessment compared to the more capable Opus 4.8 and Claude Mythos Preview.
Rates of misaligned behavior on our automated behavioral audit, which tests for a very wide range of undesirable behaviors across many situations and contexts (see Section 6.4 of the [Sonnet 5 System Card for a complete list and results for each specific behavior). Sonnet 5 shows an overall lower rate of misaligned behavior than Sonnet 4.6, though a higher rate than Mythos Preview and Opus 4.8.](https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-cdn.anthropic.com%2Fimages%2F4zrzovbb%2Fwebsite%2Fd018d76aa03c0ef18abc8a68de8f6fcd51c0a574-3840x2160.png&w=3840&q=75)
We did not deliberately train Sonnet 5 on cybersecurity tasks. It can perform some routine, non-harmful cyber tasks, but on evaluations testing potentially dangerous cyber skills, such as developing software exploits, it shows substantially poorer performance than models such as Opus 4.8 and Mythos 5. Scores from one evaluation, which tested models’ ability to develop exploits for vulnerabilities in the Firefox browser, are shown in the chart below. Sonnet 5 was never able to develop a full working exploit, but it does show a slightly higher rate of *partial* success than Sonnet 4.6. This latter change is likely due to improvements in general intelligence rather than specific training.
Scores measuring models’ success at developing exploits for software vulnerabilities in Firefox 147 (this evaluation was developed [in collaboration with Mozilla; all vulnerabilities have been patched in Firefox 148). For each model, the left-hand bar shows how often the model (without safeguards) developed a working exploit; the right-hand bar shows how often the model had partial success. Neither of the Sonnet models could successfully develop a working exploit (both scored 0.0%); Sonnet 5 showed a slightly higher partial success rate than Sonnet 4.6. Both Sonnet models have substantially poorer cyber capabilities than Opus 4.8 and Mythos 5. For full details, see Section 3.2.4 of the Sonnet 5 System Card.](https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-cdn.anthropic.com%2Fimages%2F4zrzovbb%2Fwebsite%2Fee9944c865937053bae293f057fffa478ee0f46b-3840x2160.png&w=3840&q=75)
Since Sonnet 5 is somewhat stronger than its predecessor on these tasks, we’ve launched it with cyber safeguards enabled by default. These safeguards—which detect and block dangerous cyber usage in real time—are the same as those present in Claude Opus 4.7 and 4.8 (because we judged that the overall level of cybersecurity risk from Sonnet 5 was low, the safeguards are less strict than those launched with Fable 5, which block a much wider range of cybersecurity tasks).1
Our full assessment of Sonnet 5 across many safety and capability evaluations is reported in the Claude Sonnet 5 System Card.
Availability and pricing
Claude Sonnet 5 is available everywhere today at an introductory price of $2 per million input tokens and $10 per million output tokens through August 31, 2026. It then moves to standard pricing at $3 per million input tokens and $15 per million output tokens.2 We’ve increased rate limits across Chat, Cowork, Claude Code, and the Claude Platform3 to accommodate the higher token usage of higher effort levels; users can select whichever level makes sense for their particular project.
Footnotes
1 Sonnet 5 is part of our Cyber Verification Program, which is available today on the native Claude Platform, the Claude Platform on AWS, and Claude in Microsoft Foundry (hosted on Azure and Anthropic), and coming soon on Claude in Google Vertex. Organizations that are already enrolled in the Cyber Verification Program automatically have the same access on Sonnet 5, with no need to reapply. Overall, we recommend Claude Opus 4.8 for cybersecurity work that requires reduced guardrails.
2 Sonnet 5 is an upgrade to Sonnet 4.6, but it uses an updated tokenizer that changes how the model processes text to improve performance (this is similar to the tokenizer change we introduced with Claude Opus 4.7). The tradeoff is that the same input can map to more tokens: roughly 1.0–1.35× depending on the content type. The introductory pricing is set so that the transition to Sonnet 5 is roughly cost-neutral.
3 On April 26, 2026, we raised Sonnet and Haiku rate limits at every usage tier and simplified to three tiers (Start, Build, and Scale) on the native Claude Platform. You can view your tier and current limits in the Claude Console or read the documentation to learn more.
- Humanity’s Last Exam: We updated the grader model for Humanity’s Last Exam and have updated the Sonnet 4.6 score to 34.6% (no tools) and 46.8% (with tools). This is the reason the score differs from that reported in the Sonnet 4.6 launch blog.
- OSWorld-Verified: We made changes to how we run the OSWorld-Verified evaluation to more accurately reflect the model’s performance in the real world, and have updated the Sonnet 4.6 score to 78.5%. This is the reason the score differs from that reported in the Sonnet 4.6 launch blog.
Related content
Claude Science, an AI workbench for scientists, is now available
Claude Science is a customizable app that integrates the tools and packages researchers most often use, produces auditable artifacts, and provides flexible access to computing resources.
Introducing Claude Tag
Claude Tag is a new way for teams to work with Claude.
Anthropic opens Seoul office and announces new partnerships across the Korean AI ecosystem
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み