Amazon SageMaker AI で P-EAGLE を用いた推測的デコーディングの並列化
AWS は推論遅延の根本原因である逐次ドラフト生成を解消する「P-EAGLE」技術を開発し、Amazon SageMaker JumpStart で実装することで、EAGLE-3 を上回る最大 1.69 倍の処理速度向上を実現した。
キーポイント
逐次ドラフトのボトルネック解消
従来の EAGLE などが抱える「各トークン生成に逐次パスが必要」というアーキテクチャ的限界を打破し、すべての推測トークンを単一のフォワードパスで同時に生成する技術を実現した。
P-EAGLE の並列化メカニズム
ターゲットモデルの出力後に学習可能なプレースホルダーを埋め込むことで、推測深度を増やしても遅延コストが線形に増加しない仕組みを構築し、実世界ベンチマークで 1.69 倍のスループット向上を達成した。
SageMaker JumpStart のネイティブサポート
複雑な CUDA カーネル管理や分散設定が不要となり、ワンクリックまたは数行のコードで P-EAGLE 対応のエンドポイントを即座にデプロイ可能になった。
影響分析・編集コメントを表示
影響分析
このニュースは、LLM 推論のボトルネックである「ドラフト生成の逐次性」に対する決定的な解決策を示しており、大規模モデルの実運用におけるコストと速度の両立に新たな基準をもたらす。AWS のプラットフォームへの直接統合により、技術的障壁を下げたことで、多くの企業が即座に高性能推論環境へ移行できる可能性が高まり、業界全体の推論効率化スピードが加速すると予想される。
編集コメント
EAGLE の根本的な制約を打破し、実用レベルで劇的な速度向上をもたらす技術的ブレイクスルーです。特に管理コストをかけずに導入できる点は、大規模 LLM を運用する企業にとって極めて魅力的なニュースと言えます。
大規模言語モデル(LLM)のサイズと複雑性が増すにつれ、推論スループットを最大化しつつレイテンシを最小化することは、企業向け本番環境における重要な課題です。スペキュレティブ・ディコーディングはこれに対処する効果的な戦略の一つで、軽量なドラフトモデルを使用して将来のトークンを予測し、それをターゲット LLM が単一のフォワードパスで検証します。Extrapolation Algorithm for Greater Language-model Efficiency(EAGLE)のような最先端フレームワークが驚異的な速度向上を実現している一方で、それらは隠れたアーキテクチャ上の限界に直面しています:ドラフトトークンが自己回帰的に生成されるためです。各ドラフトトークンが直前の出力に依存するため、K 個の候補を生成するにはドラフトヘッドを K 回逐次的に通過させる必要があり、推測深度に応じて線形に増加するレイテンシコストを生み出します。最新バージョンである EAGLE-3 は、特徴ではなくトークンを直接予測し、ターゲットモデルの複数の層からの表現を組み合わせることで先行版を改善し、ドラフト精度を向上させ、より大規模なトレーニングデータセットの恩恵を受けられるようにしました。しかし、これらの改善があっても、根本的な逐次的ドラフト制約は残っています。推測深度が深くなるほど、ドラフトオーバーヘッドが蓄積され、最終的にはパフォーマンス向上分を食い込んでしまいます。
このボトルネックを克服するため、AWS は Parallel-EAGLE(P-EAGLE)を開発しオープンソースとして貢献しました。これは、推測的デコーディングを反復処理から完全に並列化された操作へと変革する画期的な手法です。P-EAGLE は、すべての推測的ドラフトトークンを単一の順方向パスで同時に予測することで、ネストされた逐次ドラフトフェーズを完全に排除します。具体例として説明すると、ターゲットモデルがトークン「Paris」を生成する場合、EAGLE では次の 4 つのトークン(", known for its)を提案するために 4 回の逐次的なドラフターパスが必要となります。一方、P-EAGLE は位置 2~4 に学習可能なプレースホルダーを埋め込み、4 つのトークンを一度に予測します(「ソリューション概要」内の図参照)。ドラフトトークン数を逐次順方向パスの数から切り離すことで、P-EAGLE はレイテンシオーバーヘッドを増大させることなく、より深い推測を可能にします。高度な高性能ハードウェア上で実行される実世界ベンチマークでは、この高度に並列化されたアプローチにより、従来の EAGLE フレームワークと比較して最大 1.69 倍のスループット向上を実現しています。
本日、Amazon SageMaker JumpStart は、P-EAGLE を主要なファウンデーションモデルの多数に対してネイティブサポートするようになりました。SageMaker JumpStart は、ワンクリックまたは数行のコードで展開可能な、最先端のオープンウェイトモデルを厳選したハブを提供しています。P-EAGLE によるモデル最適化と Amazon SageMaker AI のフルマネージド環境を組み合わせることで、開発者は複雑な CUDA カーネルや分散型サービング設定を管理することなく、EAGLE-3 よりも最大 1.69 倍高速な P-EAGLE 加速推論エンドポイントを展開できるようになりました。
本記事では、Amazon SageMaker AI 内で P-EAGLE を直接使用する方法について解説します。SageMaker JumpStart カタログから互換性のあるモデルを選択し、並列ドラフティング仕様を設定して、生成 AI アプリケーションを高速化する高度に最適化されたリアルタイムの SageMaker AI エンドポイントを展開する手順を実演します。
ベンチマーク
以下のベンチマークは、NVIDIA B200 GPU 上で FP8 量子化(FP8 quantization)を使用して実行される Qwen3-Coder-30B-A3B-Instruct における P-EAGLE、EAGLE-3、および標準推論(推測なし)を比較したものです。結果は、推定総出力トークン数毎秒(OTPS: estimated total output tokens per second)で測定されています。
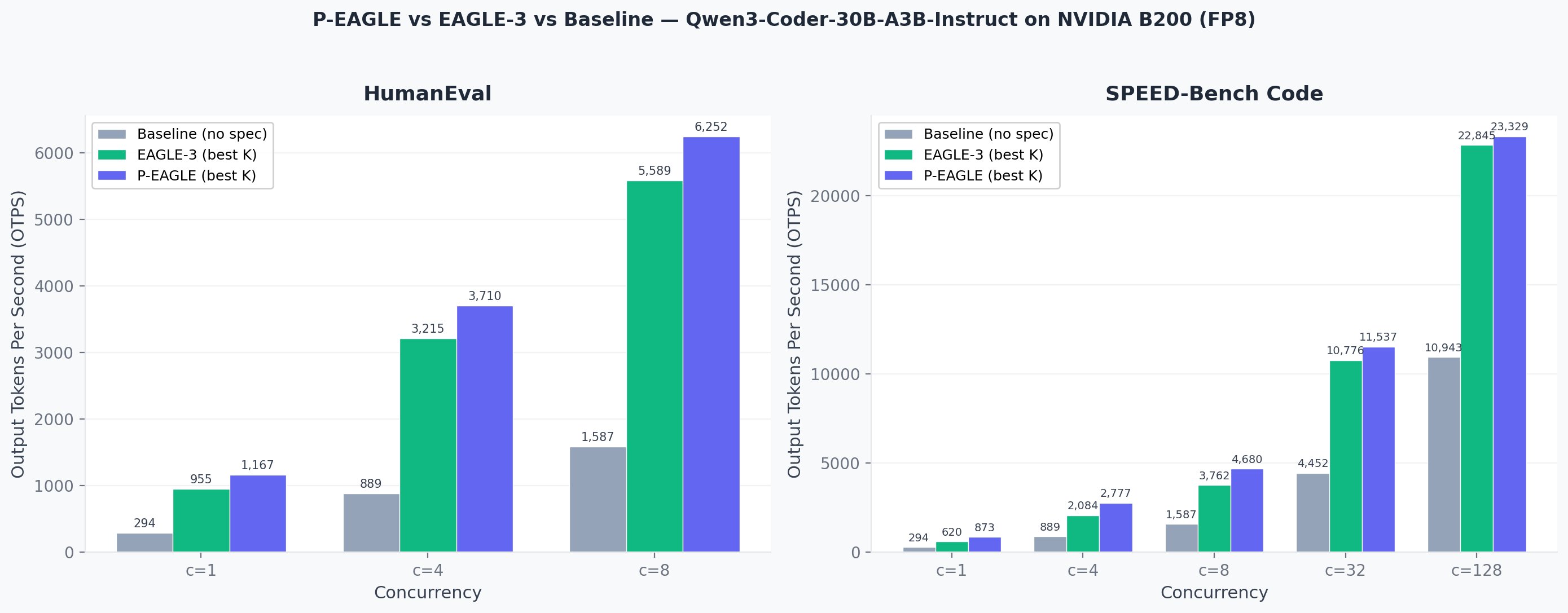
*並列度レベルごとの出力トークン数毎秒の比較。P-EAGLE (best K) は、両方のベンチマークにおいて EAGLE-3 およびベースラインを一貫して上回っています。*
HumanEval: 1 秒あたりの総出力トーク数
並列度
P-EAGLE K=3
P-EAGLE K=7
P-EAGLE K=11
EAGLE-3 K=3
EAGLE-3 K=7
EAGLE-3 K=11
ベースライン
P-EAGLE / EAGLE-3
P-EAGLE / ベースライン
1
665
1,032
1,167
651
905
955
294
1.22倍
3.97倍
4
2,205
3,313
3,710
2,198
3,044
3,215
889
1.15倍
4.17倍
8
3,958
5,786
6,252
3,979
5,493
5,589
1,587
1.12倍
3.94倍
SPEED-Bench Code: 1 秒あたりの総出力トーク数
並列度
P-EAGLE K=3
P-EAGLE K=7
P-EAGLE K=11
EAGLE-3 K=3
EAGLE-3 K=7
EAGLE-3 K=11
ベースライン
P-EAGLE / EAGLE-3
P-EAGLE / ベースライン
1
605
828
873
526
620
612
294
1.41倍
2.97倍
4
2,003
2,656
2,777
1,777
2,084
2,059
889
1.33倍
3.12倍
8
3,596
4,638
4,680
3,218
3,762
3,579
1,587
1.24倍
2.95倍
32
9,748
10,643
11,537
8,796
9,607
10,776
4,452
1.07倍
2.59倍
128
20,337
23,329
22,191
19,313
22,845
22,255
10,943
1.02倍
2.13倍
*P-EAGLE / EAGLE-3 ratio compares the best P-EAGLE configuration against the best EAGLE-3 configuration at each concurrency level.*
Live inference comparison
The following screen recording demonstrates P-EAGLE in action on Qwen3-Coder-30B-A3B-Instruct.
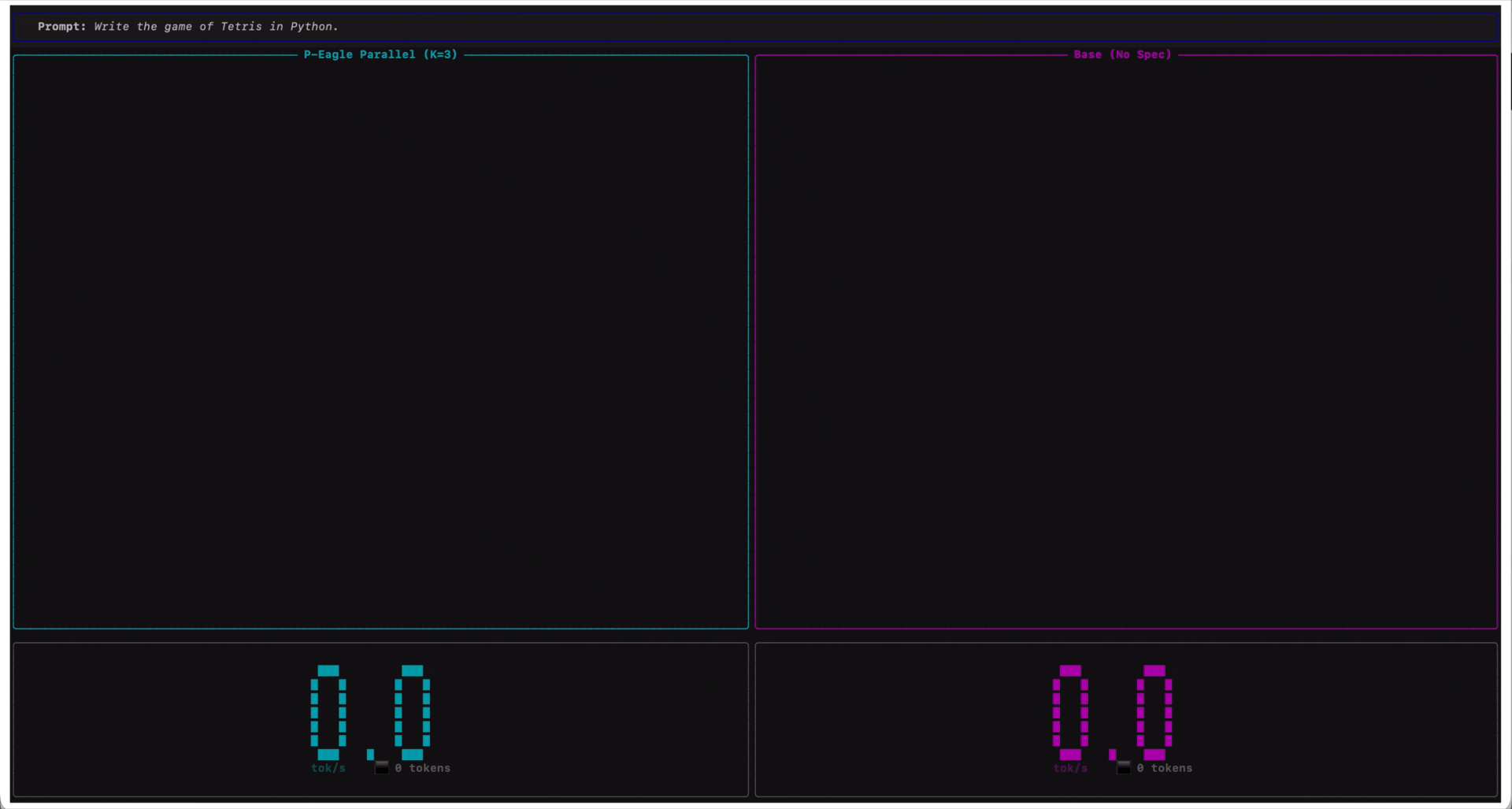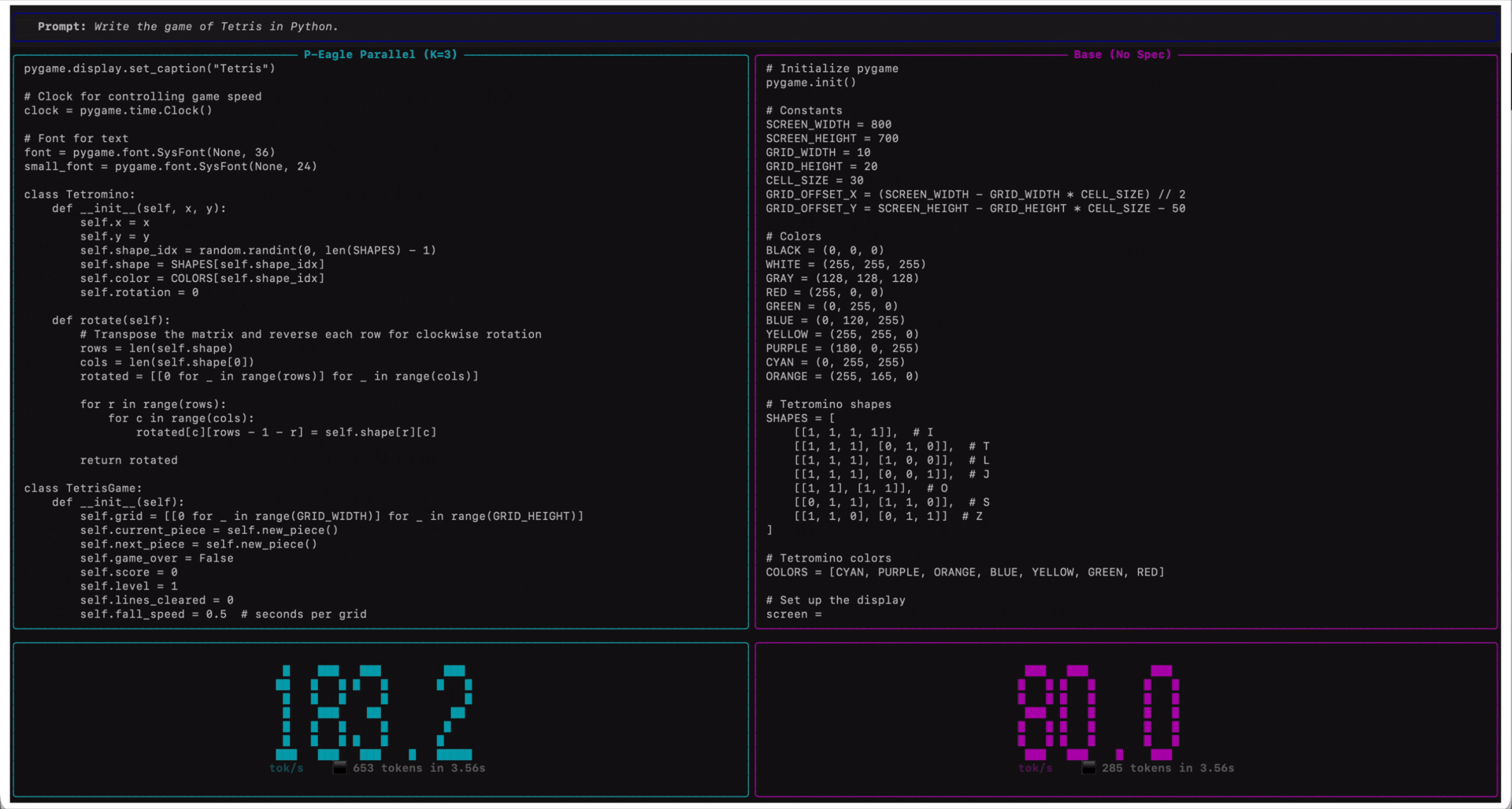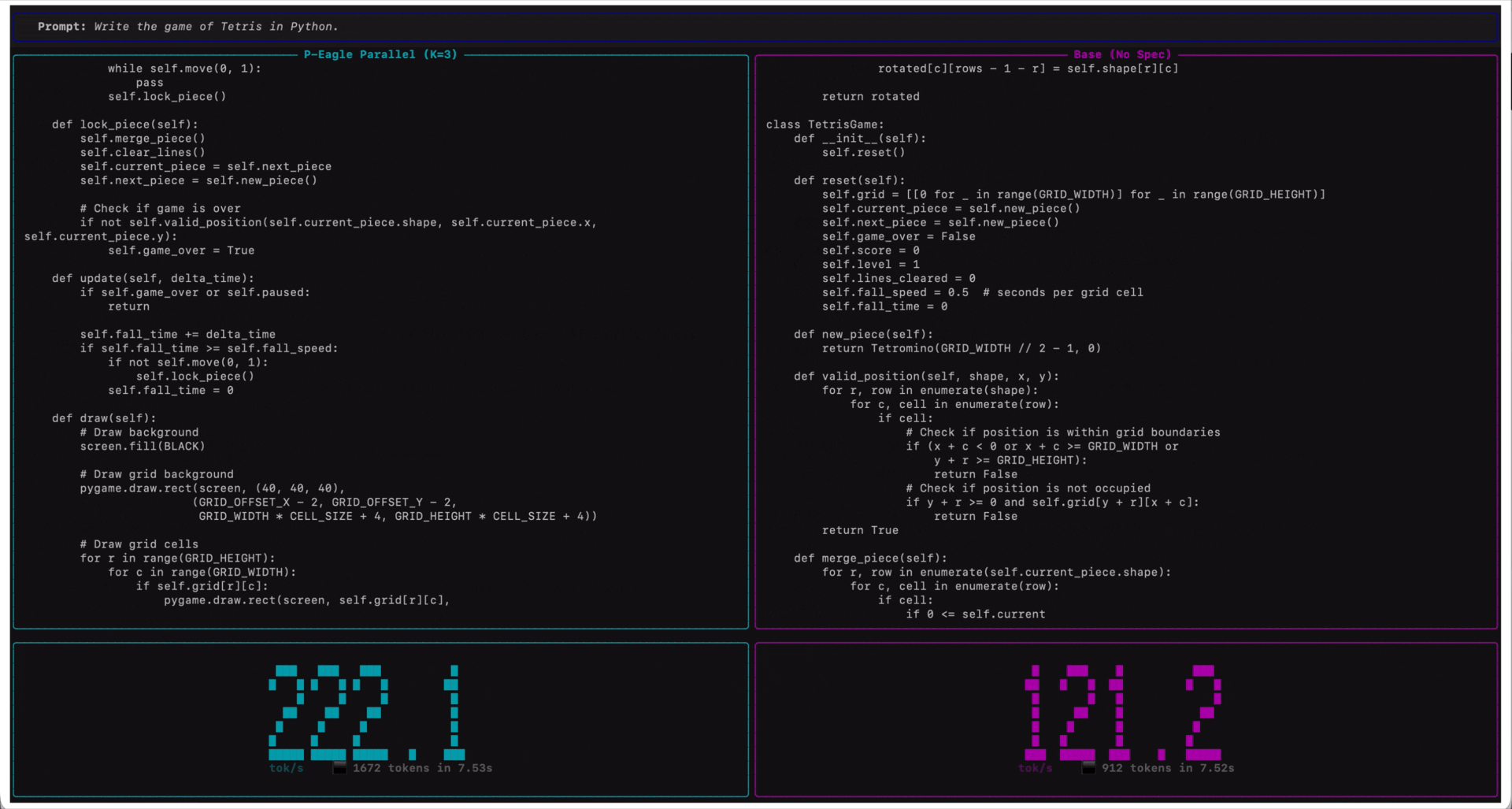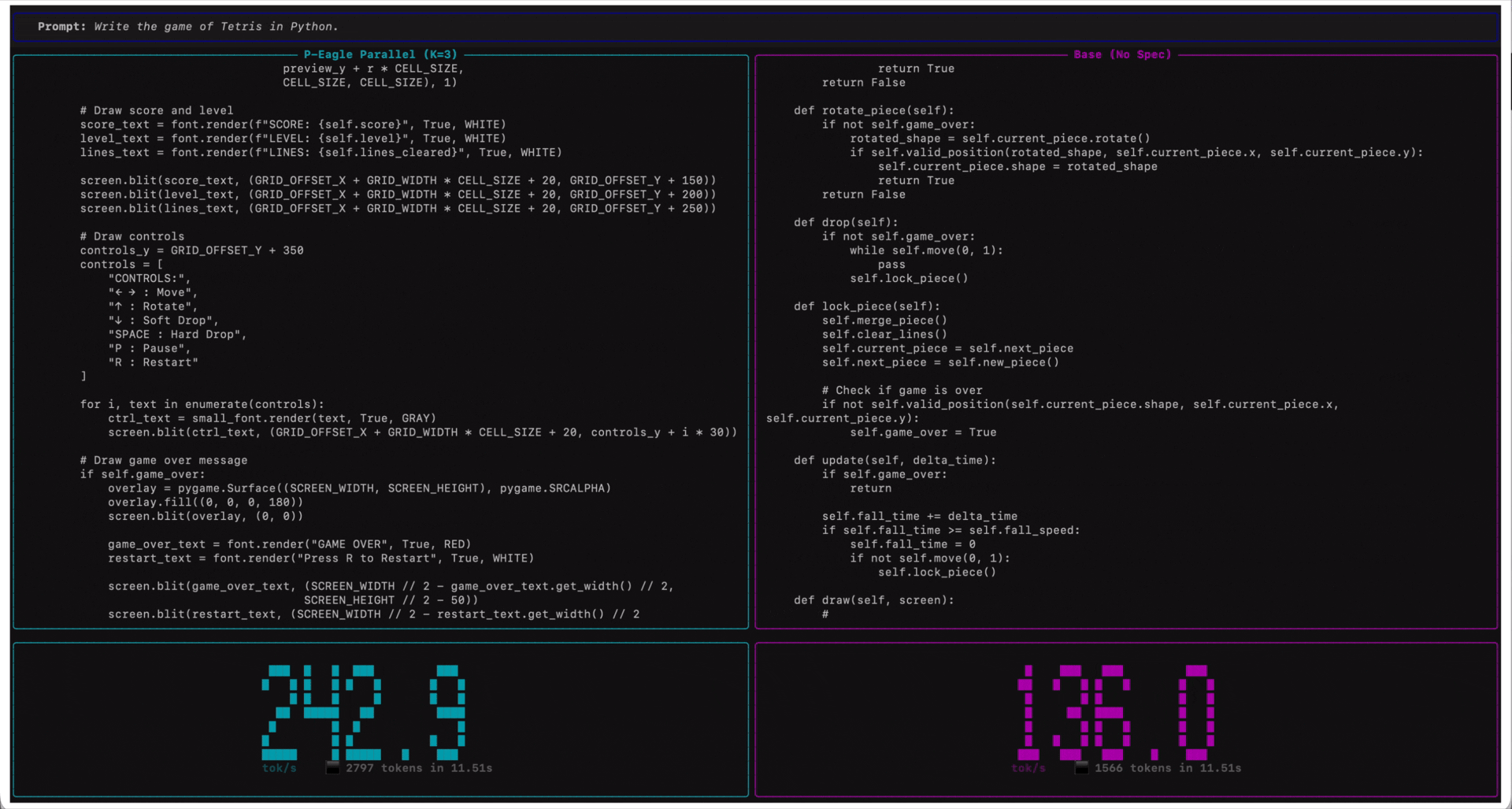
*Qwen3-Coder-30B-A3B-Instruct on Amazon SageMaker AI endpoints running on ml.g7e.2xlarge. P-EAGLE Parallel K=3 (left) compared to standard inference (right) in tokens per second.*
Getting started with P-EAGLE on SageMaker JumpStart
Amazon SageMaker JumpStart provides a one-click deployment experience for foundation models with P-EAGLE parallel speculative decoding. At launch, the following four models are available with pre-trained P-EAGLE heads:
- GPT-OSS-120B.
- GPT-OSS-20B.
- Qwen3-Coder-30B-A3B-Instruct.
- Gemma-4-31B-IT.
You can deploy each of these models directly from the JumpStart model hub with P-EAGLE pre-configured. No manual drafter training, custom containers, or vLLM configuration is required. This walkthrough demonstrates the deployment process using Qwen3-Coder-30B-A3B-Instruct.
Prerequisites
To follow this walkthrough, you need:
- Amazon SageMaker AI にアクセスできる AWS アカウント。
- 少なくとも 1 つのユーザープロファイルが設定された Amazon SageMaker AI ドメイン。
- SageMaker リアルタイム推論エンドポイント用の ml.g7e.2xlarge(または同等の GPU インスタンス)に対するサービスクォータ。
ステップ 1: Amazon SageMaker Studio を開き、JumpStart に移動する
- Amazon SageMaker AI コンソールを開く。
- ユーザープロファイルを選択する。
- [Open Studio](Studio を開く)を選択する。
- Amazon SageMaker Studio 内で、左側のサイドバーにある [JumpStart / Models] に移動する。
*左側のナビゲーションに JumpStart / Models が表示された Amazon SageMaker Studio のホームページ。
ステップ 2: P-EAGLE と互換性のあるモデルを検索する
JumpStart モデルハブで、Qwen3-Coder-30B-A3B-Instruct を検索してください。これは、アクティブな混合専門家(mixture-of-experts)構成において 30 億パラメータのうち 30 億パラメータが活性化される高性能推論モデルであり、推測デコーディングの加速のための候補となります。
*JumpStart モデルハブで「qwen3-coder-30b」を検索中。
ステップ 3: モデルカードを確認する
モデルを選択して、そのカードページを開きます。ここでは、モデルのハイライト、ライセンス情報、およびサポートされているデプロイオプションを確認できます。右上隅にある [Deploy](デプロイ)ボタンを選択してください。これにより、P-EAGLE が事前に設定されたワンクリックデプロイフローが開かれます。
*Qwen3-Coder-30B-A3B-Instruct のモデルカードで、Evaluate(評価)、Deploy(デプロイ)、Train(トレーニング)のアクションを表示している様子。
ステップ 4: デプロイメントの設定
Deploy を選択すると、エンドポイント設定ページが表示されます。下部にある Models セクションでは、モデルが Inference Optimized(推論最適化)としてタグ付けされており、P-EAGLE のスペキュレーティブ・ディコーディング(speculative decoding)が事前に構成されていることを示しています。モデル名の隣にある右矢印を選択して展開し、環境変数を表示します。
*インスタンスタイプ、カウント、推論タイプの設定を含むデプロイメント設定ページ。
ステップ 5: P-EAGLE のスペキュレーティブ構成の確認
Environment variables セクションまでスクロールします。P-EAGLE の主要な設定は、SM_VLLM_SPECULATIVE_CONFIG という環境変数であり、以下のように事前に設定されています:
{"model": "/opt/ml/additional-model-data-sources/eagle", "method": "eagle3", "num_speculative_tokens": 3, "parallel_drafting": true}
これは、vLLM 推論サーバーに事前学習済み P-EAGLE ドラフターヘッドを読み込むよう指示するものです。P-EAGLE は、EAGLE-3 アーキテクチャの並列ドラフト拡張機能としてネイティブに統合されています。「parallel_drafting」を true に指定すると、P-EAGLE パイプラインが有効化され、内部で自動的に並列マルチトークンドラフティングが行われます。num_speculative_tokens パラメータは、各フォワードパスでドラフトされるトークンの数を制御します。
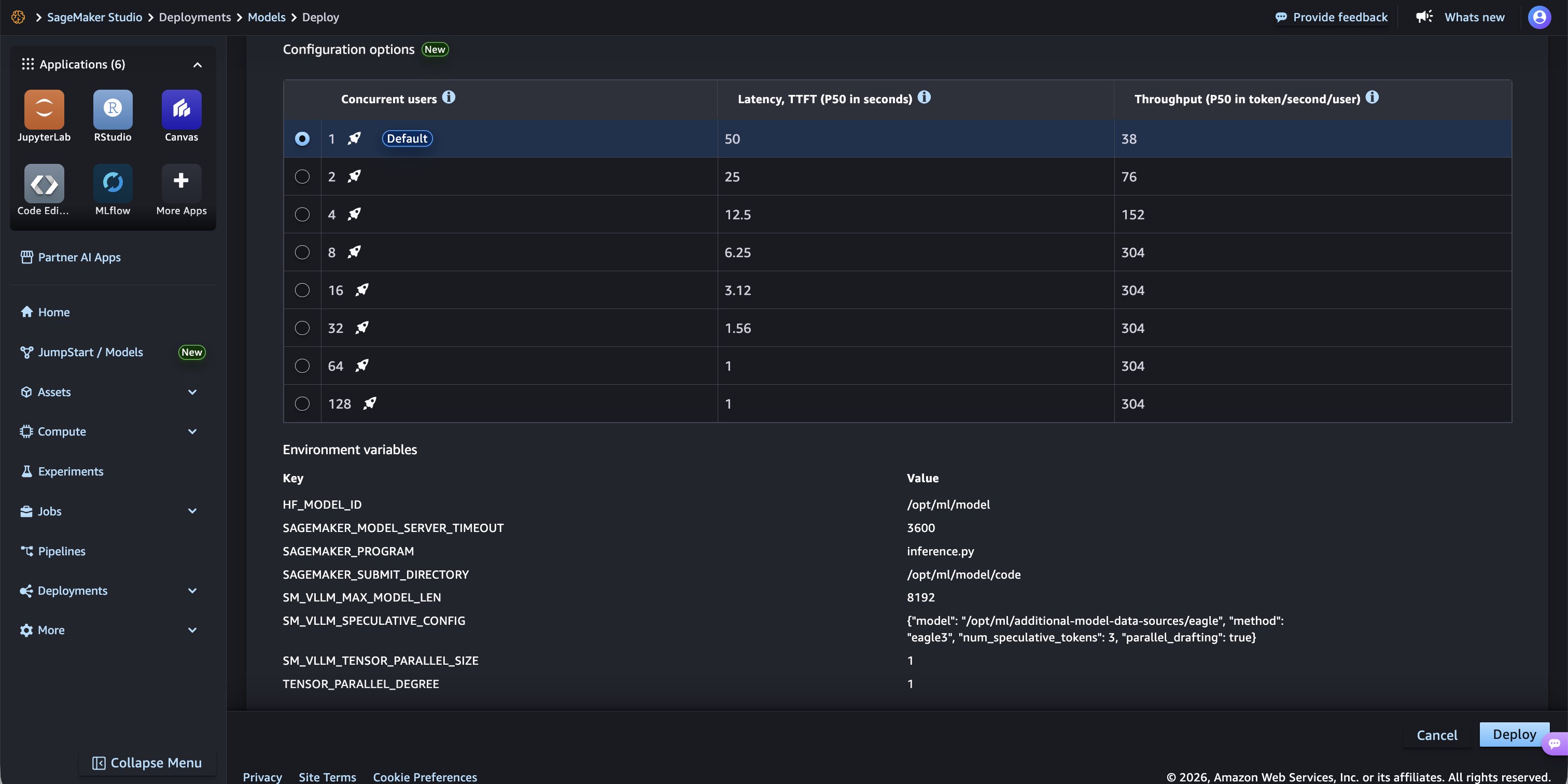
*P-EAGLE ドラフター設定を含む SM_VLLM_SPECULATIVE_CONFIG を示す環境変数。
ステップ 6: エンドポイントがサービス開始するのを待つ
Deploy(デプロイ)を選択してエンドポイントを作成します。SageMaker AI はインスタンスをプロビジョニングし、モデルアーティファクトと P-EAGLE ドラフターヘッドをダウンロードした後、vLLM 推論サーバーを開始します。数分後、エンドポイントの状態がIn service(サービス中)(緑色)に遷移し、モデルが推論リクエストを受け付ける準備ができていることが確認されます。
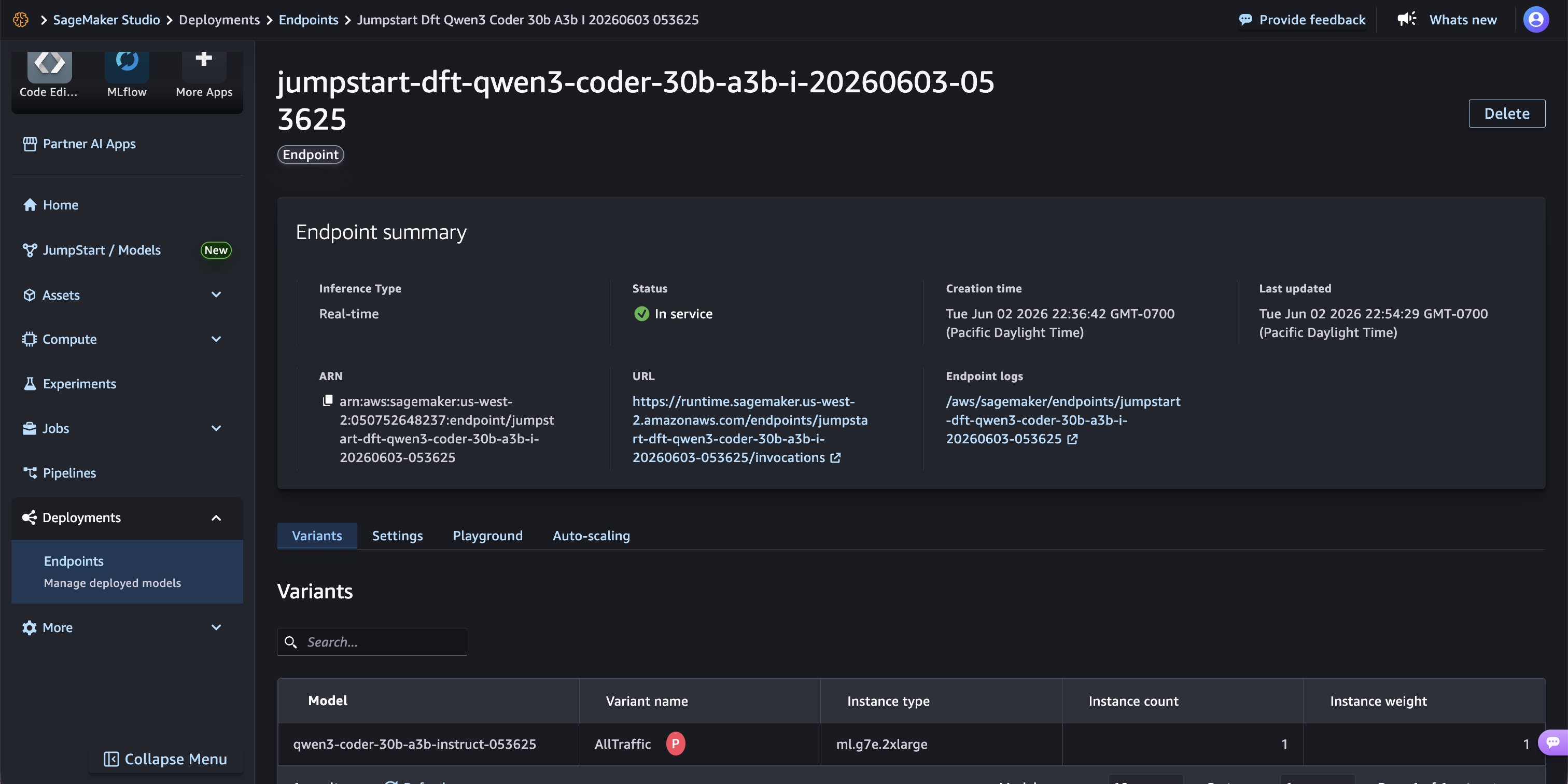
*ml.g7e.2xlarge 上でリアルタイム推論タイプとして「In service」状態を示すエンドポイントサマリー。
ステップ 7: プレイグラウンドでエンドポイントをテストする
エンドポイントページのPlayground(プレイグラウンド)タブに移動し、AWS Management Console から直接推論をテストします。vLLM 互換のチャット完了形式であるペイロードを使用してください。以下のようなものです:
「Send Request」を選択してエンドポイントを呼び出します。レスポンスは右側のInference Resultパネルに表示され、モデルが生成した完成テキストとレイテンシ指標が表示されます。
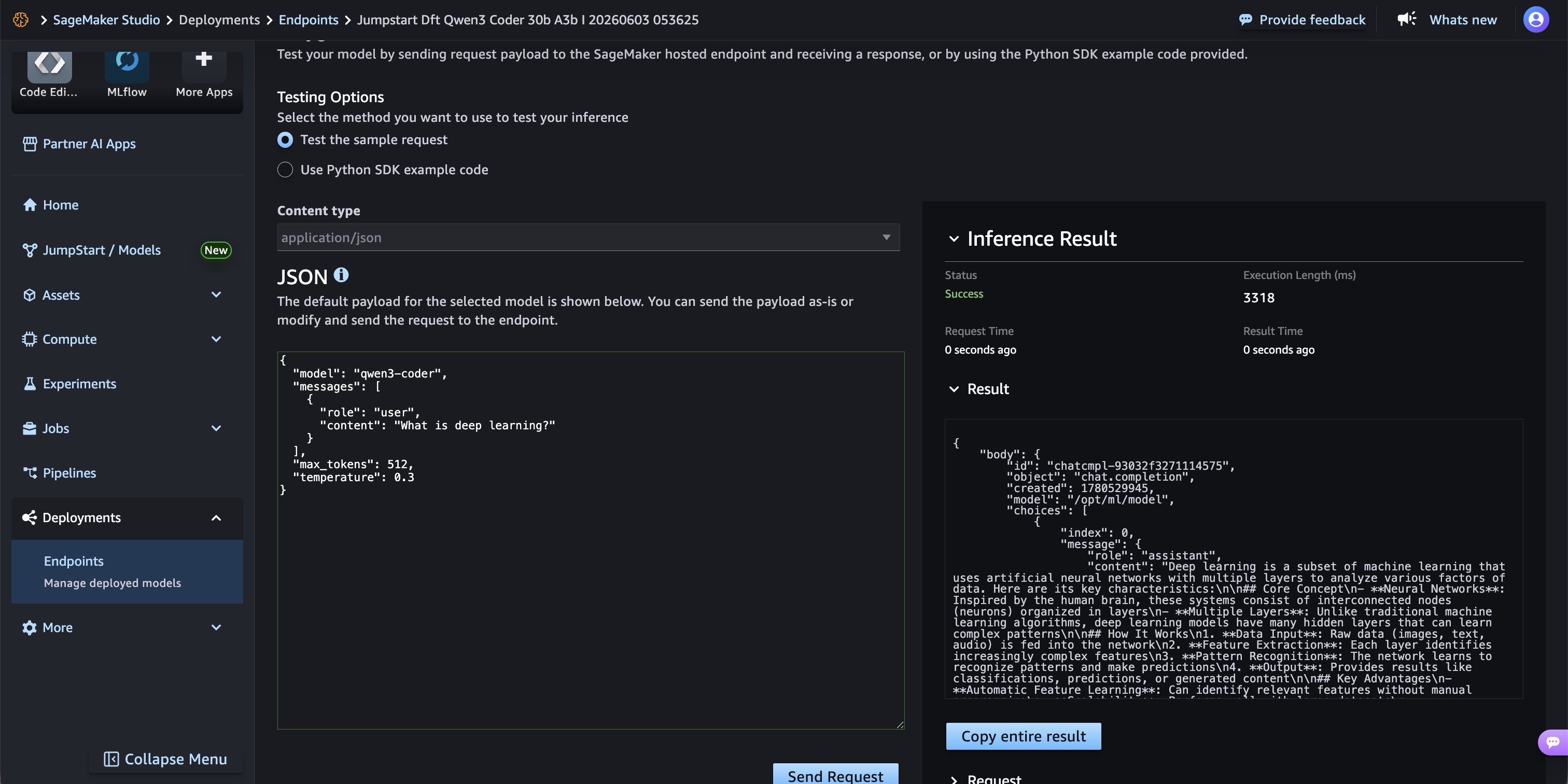
*P-EAGLE 推論デコーディング(speculative decoding)が有効な状態で、3,318 ミリ秒で正常なレスポンスが返された様子を示す推論結果。
このエンドポイントは、標準的な自己回帰型デコーディングと比較してスループットが向上し、本番トラフィックの処理に準備が整っています。
ステップ 8: クリーンアップ
重要: SageMaker AI のリアルタイム推論エンドポイントは、実際にリクエストを処理しているかどうかに関わらず、稼働中は課金されます。不要なコストを防ぐために、必要なくなった時点でエンドポイントを削除してください。
エンドポイントを削除するには、以下の手順に従ってください。
- Amazon SageMaker Studio コンソールに移動し、左側のサイドバーから「Deployments」>「Endpoints」を選択します。
- リストから該当のエンドポイントを選択します。
- 右上のアクションバーから「Delete」を選択します。
- 確認ダイアログで、「I confirm that I want to delete the endpoint」にチェックを入れ、「Delete endpoint」を選択します。
*Amazon SageMaker Studio のエンドポイント削除確認ダイアログ。*
ソリューション概要
P-EAGLE は、自己回帰型 EAGLE 内の逐次的依存連鎖を学習可能なプレースホルダー表現に置き換えることで、並列ドラフト生成を実現します。これらのプレースホルダーにより、すべてのドラフト位置が同時に計算可能となり、推測深度とドラフター(drafter)のレイテンシとの間の線形関係が解消されます。
自己回帰型 EAGLE における逐次的依存
自己回帰型 EAGLE では、単一のトークンをドラフトするには2つの入力が必要です:(1) 直前に予測されたトークンの*トークン埋め込み(token embedding)*、および (2) 直前の位置でドラフターによって生成された*隠れ状態(hidden state)*。トークン t1 を予測する場合、ドラフターはターゲットモデルが最後に生成したトークンの埋め込みと、その生成時にターゲットモデルが出力した隠れ状態を入力として受け取ります。t2 を予測するには、t1 の埋め込みと t1 の予測に使用された隠れ状態が必要ですが、これらは最初の順方向パス(forward pass)が完了する*後で*初めて利用可能になります。この連鎖は各 subsequent 位置に対して繰り返されます。K 個のドラフトトークンを生成するには、K 回の逐次的な順方向パスが必要です。
P-EAGLE が依存連鎖を断ち切る方法
P-EAGLE は、未来の位置で不足している入力に代わる2つの学習可能なパラメータを導入することで、この依存関係を解決します:
- マスクトークン埋め込み (embmask) – 未知の直前のトークン埋め込みを位置 2 から K の間で代替する学習済みベクトルです。これはモデルがトレーニング中に解釈するように学習する、中立な「自分が前に何のトークンがあったか知らない」というシグナルとして機能します。
- 共有隠れ状態 (hshared) – すべての多トークン予測 (MTP) 位置にわたって共有される単一の学習済み隠れ状態ベクトルです。これは通常、事前の順方向パスを必要とするドラフターの直前の位置における隠れ状態を代替するものです。P-EAGLE 論文からの理論的解析によると、アテンション機構自体が十分な位置情報を提供するため、位置固有の隠れ状態は不要であることが示されています。
これらのプレースホルダーにより、すべての K のドラフト位置を並列に構築し、ドラフターのトランスフォーマー層を単一の順方向パスで処理することが可能になります。
ステップごとのドラフト作成プロセス
各 P-EAGLE ドラフト作成イテレーションは 2 つのステップで進行します。
ステップ 1 – ターゲットモデルの順方向パス。 ターゲットモデルが現在のコンテキストを処理し、新しいトークンを生成します(標準的な自己回帰的生成)。このパスの間、P-EAGLE はターゲットモデルの複数の層(層 2、L/2、および L−1)から隠れ状態を取得し、これらを 3 次元次元に結合します。これらの隠れ状態は、最も直近で生成された位置におけるターゲットモデルの文脈的理解を符号化しています。
ステップ 2 – 並列ドラフト生成。 ドラフターは K の入力位置を同時に構築します:
Position 1 (次トークンの予測) – 直近で生成されたトークンの実際のトークン埋め込みと、キャプチャされた隠れ状態 s を連結して使用します。
原文を表示
As large language models (LLMs) grow in size and complexity, maximizing inference throughput while minimizing latency remains a critical challenge for enterprise production deployments. Speculative decoding is one effective strategy to address this, utilizing a lightweight draft model to guess future tokens which are then verified by the target LLM in a single forward pass. While state-of-the-art frameworks like Extrapolation Algorithm for Greater Language-model Efficiency (EAGLE) have achieved impressive speedups, they encounter a hidden architectural ceiling: their draft tokens are generated autoregressively. Because each draft token depends on the output of the previous one, producing K candidates requires K sequential forward passes through the draft head, creating a latency cost that grows linearly with speculation depth. EAGLE-3, the latest iteration, improved upon earlier versions by predicting tokens directly rather than features and by combining representations from multiple layers of the target model, boosting draft accuracy and allowing the method to benefit from larger training datasets. However, even with these gains, the fundamental sequential drafting constraint remains. The deeper you speculate, the more drafting overhead you accumulate, eventually eating into your performance gains.
To overcome this bottleneck, AWS invented Parallel-EAGLE (P-EAGLE) and contributed it to open source, a breakthrough method that transforms speculative decoding from an iterative process into a fully parallelized operation. P-EAGLE completely eliminates the nested sequential drafting phase by predicting all speculative draft tokens simultaneously in a single forward pass. To illustrate: if the target model generates the token “Paris,” EAGLE needs four sequential drafter passes to propose the next four tokens (“, known for its”). P-EAGLE instead fills positions 2–4 with learnable placeholders and predicts all four tokens at once (see Figure in Solution Overview). By decoupling the draft token count from the number of sequential forward passes, P-EAGLE allows for deeper speculation without scaling up latency overhead. On real-world benchmarks running on advanced high-performance hardware, this highly parallelized approach delivers up to a 1.69x throughput speedup over vanilla EAGLE frameworks.
Today, Amazon SageMaker JumpStart now natively supports P-EAGLE for an array of popular foundation models. SageMaker JumpStart provides a curated hub of state-of-the-art open-weight models that can be deployed with a single click or a few lines of code. By combining the model optimization of P-EAGLE with the fully managed environment of Amazon SageMaker AI, developers can now deploy P-EAGLE-accelerated inference endpoints that are up to 1.69x faster than EAGLE-3, without managing complex underlying CUDA kernels or distributed serving setups.
This post walks you through how to use P-EAGLE directly within Amazon SageMaker AI. It will demonstrate how to select a compatible model from the SageMaker JumpStart catalog, configure the parallel drafting specifications, and deploy a highly optimized real-time SageMaker AI endpoint to accelerate your generative AI applications.
Benchmarks
The following benchmarks compare P-EAGLE, EAGLE-3, and standard inference (no speculation) on Qwen3-Coder-30B-A3B-Instruct running on NVIDIA B200 GPUs with FP8 quantization. Results are measured in estimated total output tokens per second (OTPS).
*Output tokens per second comparison across concurrency levels. P-EAGLE (best K) consistently outperforms EAGLE-3 and baseline across both benchmarks.*
HumanEval: Total output tokens per second
Concurrency
P-EAGLE K=3
P-EAGLE K=7
P-EAGLE K=11
EAGLE-3 K=3
EAGLE-3 K=7
EAGLE-3 K=11
Baseline
P-EAGLE / EAGLE-3
P-EAGLE / Baseline
1
665
1,032
1,167
651
905
955
294
1.22x
3.97x
4
2,205
3,313
3,710
2,198
3,044
3,215
889
1.15x
4.17x
8
3,958
5,786
6,252
3,979
5,493
5,589
1,587
1.12x
3.94x
SPEED-Bench Code: Total output tokens per second
Concurrency
P-EAGLE K=3
P-EAGLE K=7
P-EAGLE K=11
EAGLE-3 K=3
EAGLE-3 K=7
EAGLE-3 K=11
Baseline
P-EAGLE / EAGLE-3
P-EAGLE / Baseline
1
605
828
873
526
620
612
294
1.41x
2.97x
4
2,003
2,656
2,777
1,777
2,084
2,059
889
1.33x
3.12x
8
3,596
4,638
4,680
3,218
3,762
3,579
1,587
1.24x
2.95x
32
9,748
10,643
11,537
8,796
9,607
10,776
4,452
1.07x
2.59x
128
20,337
23,329
22,191
19,313
22,845
22,255
10,943
1.02x
2.13x
*P-EAGLE / EAGLE-3 ratio compares the best P-EAGLE configuration against the best EAGLE-3 configuration at each concurrency level.*
Live inference comparison
The following screen recording demonstrates P-EAGLE in action on Qwen3-Coder-30B-A3B-Instruct.
*Qwen3-Coder-30B-A3B-Instruct on Amazon SageMaker AI endpoints running on ml.g7e.2xlarge. P-EAGLE Parallel K=3 (left) compared to standard inference (right) in tokens per second.*
Getting started with P-EAGLE on SageMaker JumpStart
Amazon SageMaker JumpStart provides a one-click deployment experience for foundation models with P-EAGLE parallel speculative decoding. At launch, the following four models are available with pre-trained P-EAGLE heads:
- GPT-OSS-120B.
- GPT-OSS-20B.
- Qwen3-Coder-30B-A3B-Instruct.
- Gemma-4-31B-IT.
You can deploy each of these models directly from the JumpStart model hub with P-EAGLE pre-configured. No manual drafter training, custom containers, or vLLM configuration is required. This walkthrough demonstrates the deployment process using Qwen3-Coder-30B-A3B-Instruct.
Prerequisites
To follow this walkthrough, you need:
- An AWS account with access to Amazon SageMaker AI.
- An Amazon SageMaker AI domain with at least one user profile configured.
- Service quota for ml.g7e.2xlarge (or equivalent GPU instance) for SageMaker real-time inference endpoints.
Step 1: Open Amazon SageMaker Studio and navigate to JumpStart
- Open the Amazon SageMaker AI console.
- Select your user profile.
- Choose Open Studio.
- In Amazon SageMaker Studio, navigate to JumpStart / Models in the left sidebar.
*Amazon SageMaker Studio home page with JumpStart / Models in the left navigation.*
Step 2: Search for a P-EAGLE compatible model
In the JumpStart model hub, search for Qwen3-Coder-30B-A3B-Instruct. This is a high-performance reasoning model with a 3-billion-parameter active mixture-of-experts configuration, making it a candidate for speculative decoding acceleration.
*Searching for “qwen3-coder-30b” in the JumpStart model hub.*
Step 3: Review the model card
Choose the model to open its card page. Here you can review the model’s highlights, license information, and supported deployment options. Choose the Deploy button in the top-right corner. This opens the one-click deployment flow with P-EAGLE pre-configured.
*Model card for Qwen3-Coder-30B-A3B-Instruct showing Evaluate, Deploy, and Train actions.*
Step 4: Configure the deployment
After choosing Deploy, the endpoint configuration page appears. Under the Models section at the bottom, the model is tagged as Inference Optimized, indicating that P-EAGLE speculative decoding is pre-configured. Choose the right arrow next to the model name to expand and view the environment variables.
*Deployment configuration page with instance type, count, and inference type settings.*
Step 5: Verify the P-EAGLE speculative configuration
Scroll down to the Environment variables section. The key configuration for P-EAGLE is the SM_VLLM_SPECULATIVE_CONFIG environment variable, which is pre-populated with the following:
{"model": "/opt/ml/additional-model-data-sources/eagle", "method": "eagle3", "num_speculative_tokens": 3, "parallel_drafting": true}This tells the vLLM inference server to load the pre-trained P-EAGLE drafter head. P-EAGLE is integrated natively as a parallel-drafting extension of the EAGLE-3 architecture. Specifying "parallel_drafting": true activates the P-EAGLE pipeline, which automatically performs parallel multi-token drafting under the hood. The num_speculative_tokens parameter controls how many tokens are drafted in each single forward pass.
*Environment variables showing SM_VLLM_SPECULATIVE_CONFIG with the P-EAGLE drafter configuration.*
Step 6: Wait for the endpoint to come in service
Choose Deploy to create the endpoint. SageMaker AI provisions the instance, downloads the model artifacts and P-EAGLE drafter head, and starts the vLLM inference server. After a few minutes, the endpoint status transitions to In service (green), confirming that the model is ready to accept inference requests.
*Endpoint summary showing “In service” status on ml.g7e.2xlarge with real-time inference type.*
Step 7: Test the endpoint in the playground
Navigate to the Playground tab on the endpoint page to test inference directly from the AWS Management Console. Use a payload that is in vLLM-compatible chat completion format, such as the following:
{
"model": "qwen3-coder",
"messages": [
{
"role": "user",
"content": "What is deep learning?"
}
],
"max_tokens": 512,
"temperature": 0.3
}Choose Send Request to invoke the endpoint. The response appears in the right-hand Inference Result panel, showing the model’s generated completion along with latency metrics.
*Inference result showing a successful response in 3,318 ms with P-EAGLE speculative decoding active.*
The endpoint is now ready to serve production traffic with improved throughput compared to standard autoregressive decoding.
Step 8: Clean up
Important: SageMaker AI real-time inference endpoints incur charges while running, regardless of whether they are actively serving requests. To avoid unnecessary costs, delete the endpoint when it’s no longer needed.
To delete the endpoint, follow these steps.
- Navigate to the Amazon SageMaker Studio console and choose Deployments > Endpoints in the left sidebar.
- Select the endpoint from the list.
- Choose Delete from the top-right actions bar.
- In the confirmation dialog, select “I confirm that I want to delete the endpoint” and choose Delete endpoint.
*Endpoint delete confirmation dialog in Amazon SageMaker Studio.*
Solution overview
P-EAGLE achieves parallel draft generation by replacing the sequential dependency chain in autoregressive EAGLE with learnable placeholder representations. These placeholders let all draft positions be computed at the same time, removing the linear relationship between speculation depth and drafter latency.
The sequential dependency in autoregressive EAGLE
In autoregressive EAGLE, drafting a single token requires two inputs: (1) the *token embedding* of the previously predicted token, and (2) the *hidden state* produced by the drafter at the previous position. To predict token t1, the drafter takes the token embedding of the target model’s last generated token and the hidden state the target model produced when generating it. To predict t2, it needs the embedding of t1 and the hidden state used to predict t1, both of which only become available *after* the first forward pass completes. This chain repeats for each subsequent position. Producing K draft tokens requires K sequential forward passes.
How P-EAGLE breaks the chain
P-EAGLE resolves this dependency by introducing two learnable parameters that stand in for the missing inputs at future positions:
- Mask token embedding (embmask) – A learned vector that substitutes for the unknown previous-token embedding at positions 2 through K. It acts as a neutral “I don’t know what token came before me” signal that the model learns to interpret during training.
- Shared hidden state (hshared) – A single learned hidden-state vector shared across all multi-token prediction (MTP) positions. It substitutes for the drafter’s previous-position hidden state that would normally require a prior forward pass to compute. Theoretical analysis from the P-EAGLE paper shows that attention alone provides sufficient positional information, removing the need for position-specific hidden states.
With these placeholders, all K draft positions can be constructed in parallel and processed through the drafter’s transformer layers in a single forward pass.
Step-by-step drafting process
Each P-EAGLE drafting iteration proceeds in two steps.
Step 1 – Target model forward pass. The target model processes the current context and generates a new token (standard autoregressive generation). During this pass, P-EAGLE captures hidden states from multiple layers of the target model (layers 2, L/2, and L−1, concatenated to 3d dimensions). These hidden states encode the target model’s contextual understanding at the most recently generated position.
Step 2 – Parallel draft generation. The drafter constructs K input positions at the same time:
Position 1 (next-token prediction) – Uses the actual token embedding of the just-generated token concatenated with the captured hidden s
関連記事
[AINews] 今日特に大きな出来事はありませんでした
Latent Space は、GLM 5.2 が依然として注目されていると指摘しつつ、AIE WF 2026 の通常チケットが月曜日に完売すると発表しました。同サイト購読者向けに限定割引を提供し、参加者には Warp や Datadog などからのスポンサークレジットも付与されます。
米国がアンソロピックの「Fable 5」発売を禁止、しかし市場は動じず
米国政府は国家安全保障上の懸念から、アマゾンの研究者らがガードレール回避手法を発見したとして、アンソロピックに対し最新モデル「Fable 5」と「Mythos 5」の販売差し止めを命じた。サイバーセキュリティ研究者らはこの措置が危険だとする公開書簡に署名し、同社も他モデルでも同様の抜け道が存在すると指摘している。
社内データ分析エージェントの構築方法について
GitHub は、大規模なデータ組織が直面する自己完結型のデータアクセスと洞察提供の課題に対し、AI を活用した信頼性の高い解決策として、社内でデータ分析エージェントを構築したことを発表した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み