AWS生成AIサービスで小売を変革
AWSは、Amazon Nova Canvas、Amazon Rekognition、Amazon OpenSearch Serverlessなどの生成AIサービスを活用して、仮想試着、スマートレコメンデーション、スマート検索、分析機能を統合した小売業向けソリューションを構築する方法を紹介している。
キーポイント
解決すべき小売業の課題
オンライン小売業者は、顧客がオンラインで商品のフィット感や見た目を判断できず、返品率の上昇や購入意欲の低下という課題に直面している。
提案ソリューションの概要
AWSの生成AIサービスを活用したサーバーレスソリューションで、仮想試着、スマートレコメンデーション、スマート検索、分析・インサイトの4つの統合機能を提供する。
中核となるAWSサービス
仮想試着にはAmazon Nova CanvasとAmazon Rekognition、レコメンデーションにはTitan Multimodal Embeddings、検索にはOpenSearch Serverless、分析にはDynamoDBを活用する。
提供価値と目的
購入確信度の向上と返品率の低減を通じて、収益性と顧客満足度の向上を直接的に実現することを目指す。
セキュリティ警告と画像検証
本番環境ではAPI Gatewayエンドポイントに認証(Amazon Cognitoなど)を実装する必要があり、ユーザーアップロード画像にはAmazon Rekognition Content Moderationによるコンテンツモデレーションと、ファイルタイプ・サイズ・寸法の検証を実施すべきです。
仮想試着プロセスの詳細
Amazon Nova CanvasとAmazon Rekognitionを統合し、ユーザー写真と衣類画像を組み合わせて写実的な試着画像を生成します。処理には約15秒かかり、最適な結果を得るには明るく正面を向いた写真が推奨されます。
パーソナライズされたレコメンデーションエンジン
Amazon Titan Multimodal Embeddingsを使用して衣類画像とテキストを1024次元のベクトル表現に変換し、Amazon OpenSearch ServerlessでkNN検索を実行して視覚的類似性、ユーザー性別、カテゴリマッチングに基づいたパーソナライズされた提案を生成します。
影響分析・編集コメントを表示
影響分析
この記事は、生成AIが具体的な業界課題(小売業の返品問題)にどのように適用できるかを示す実践的なケーススタディであり、AI技術の実用化・商用化の進展を象徴している。AWSが自社のAIサービス群を統合した業界特化型ソリューションを提供することで、クラウドプラットフォーム間のAI競争がソリューションレベルで激化していることを示唆している。
編集コメント
AWSの生成AIサービス群を実際のビジネス課題解決にどう組み合わせるかが具体的に示されており、技術紹介を超えた実装ガイドとしての価値が高い。ただし、自社サービス宣伝の要素が強い点には留意が必要。
オンライン小売業者は持続的な課題に直面しています。オンライン注文時に商品の着心地や見た目を判断できないため、返品が増加し購入意欲が低下します。そのコストとは?収益の損失、運用オーバーヘッド、そして顧客の不満です。一方で、消費者はオンラインと店舗販売の格差を埋める没入型でインタラクティブなショッピング体験をますます求めています。バーチャル試着(virtual try-on)テクノロジーを導入する小売業者は、購入意欲を高め返品率を削減でき、直接的な利益向上と顧客満足度の向上につながります。本記事では、Amazon Nova Canvas、Amazon Rekognition、Amazon OpenSearch Serverlessを使用してAWS上でバーチャル試着およびレコメンデーションソリューションを構築する方法を示します。小売ソリューションを開発するAWSパートナー也罢、生成AI(generative AI)変革を探求する小売業者也罢、このソリューションのデプロイに関するアーキテクチャ、実装アプローチ、および主要な考慮事項を学ぶことができます。
本ソリューションをAWSアカウントにデプロイするためのコードベースは、GitHubリポジトリにて公開しています。
ソリューションの概要
本ソリューションは、AIを活用したサーバーレスの小売ソリューションを構築する方法を示します。このサービスは以下の4つの統合機能を提供します:
- バーチャル試着(virtual try-on):Amazon Nova CanvasとAmazon Rekognitionを活用し、顧客が商品を着用または使用している様子をリアルな画像として生成
- スマートレコメンデーション(smart recommendations):Amazon Titan Multimodal Embeddingsを使用してスタイルの関連性や視覚的な類似性を理解し、視覚情報を考慮した商品提案を提供
- スマート検索(smart search):顧客の意図を理解する目的指向型のインテリジェンスにより、自然言語での商品検索を可能にします。ベクトル類似性マッチングにはOpenSearch Serverlessを使用
- アナリティクスとインサイト(analytics and insights):Amazon DynamoDBを活用して顧客のインタラクション、好み、トレンドを追跡し、在庫管理やマーチャンダイジングの意思決定を最適化
このアーキテクチャはスケーラビリティのためにサーバーレスのAWSサービスを使用し、モジュール型デザインを採用しているため、個別機能または完全なソリューションの実装を選択できます。
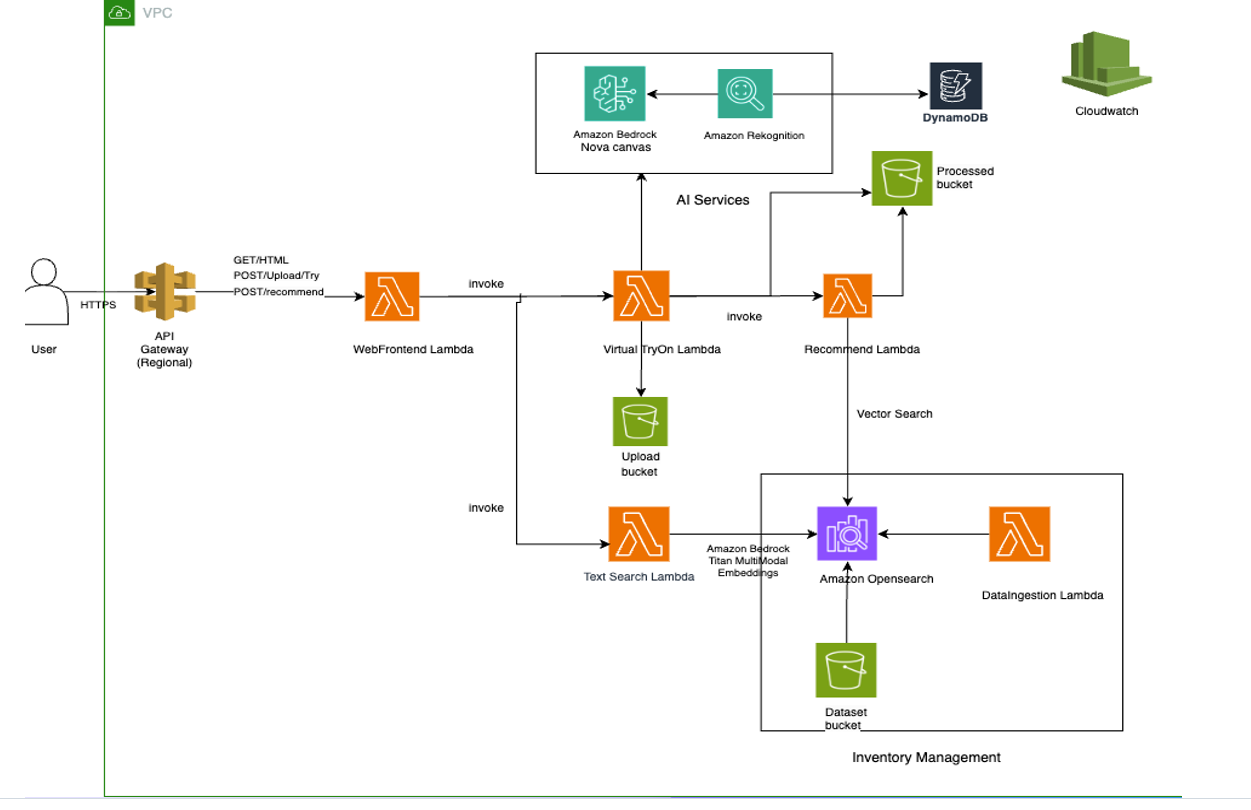
事前構築されたアーキテクチャコンポーネント
本ソリューションはAWSのサーバーレスインフラ上で動作し、特定のタスクに最適化された5つの専用AWS Lambda関数(Webフロントエンド/チャットボットインターフェース、バーチャル試着処理、レコメンデーション生成、データセット取り込み、インテリジェント検索)で構成されています。アーキテクチャでは、安全なストレージにS3バケットを、ベクトル類似性検索にAmazon OpenSearch Serverlessを、リアルタイムのアナリティクス追跡にDynamoDBを使用しています。
スケーラビリティとデプロイメント
AWS Serverless Application Model(AWS SAM)を使用して構築されており、単一のコマンドで全体をデプロイでき、需要に応じて自動的にスケーリングします。予約済み同時実行数(reserved concurrency)の制限はリソース競合を防ぎ、Amazon API GatewayのキャッシングとプレサインドURL(presigned URLs)はパフォーマンスを最適化します。マイクロサービスアーキテクチャにより、各コンポーネントの独立したスケーリングと更新が可能です。
パートナーおよび顧客向けの統合柔軟性
モジュール型設計により、個別の機能または完全なソリューションの実装が可能です。ドキュメント、サンプルテスト画像、およびデータセット管理用のユーティリティスクリプトにより、開発者は特定の小売ニーズに合わせてソリューションをカスタマイズおよび拡張するのが容易になります。
前提条件
デプロイプロセスを開始する前に、以下の前提条件が設定されていることを確認してください。
AWSアカウントの設定
- 管理者権限を持つアクティブなAWSアカウント
- 適切な認証情報でインストールおよび設定されたAWSコマンドラインインターフェース(AWS CLI)
- このソリューションには、同じリージョン(Region)にAmazon Nova Canvas、Amazon Titan Multimodal Embeddings、Amazon Rekognition、およびAmazon OpenSearch Serverlessが必要です。US East (N. Virginia) – us-east-1(推奨)にデプロイしてください。
Amazon Bedrockモデルのリージョン別利用可能状況は時間とともに変更されます。us-east-1以外のリージョン(Region)にデプロイする前に、Amazon Bedrock model support by RegionページおよびAWS Regional Services Listを確認し、必要なすべてのモデルがサポートされていることを確認してください。
Amazon Bedrockモデルへのアクセス
ファウンデーションモデル(Amazon Bedrock foundation models)は、現在、すべてのAWS商用リージョンでアカウント内で初めて呼び出された際に自動的に有効化されます。このソリューションに必要なモデル(Amazon Nova CanvasおよびAmazon Titan Embeddings)は、アプリケーションが初めて呼び出す際に自動的にアクティブ化されます。手動での有効化は不要です。
注: 初めてのAmazon Bedrockユーザーの場合、サービスがアクセスをプロビジョニングする際に、最初のモデル呼び出しに数秒余分にかかることがあります。
AWSサービス権限
SAMテンプレート(SAM template)をデプロイするために使用するIAMロール(IAM role)には、以下の権限が必要です。
- Lambda関数(Lambda functions)の作成および管理
- S3バケット(S3 bucket)の作成およびオブジェクト管理
- Amazon OpenSearch Serverlessコレクション(Amazon OpenSearch Serverless collection)の作成
- DynamoDBテーブル(DynamoDB table)の作成およびデータアクセス
- Amazon Bedrockモデルの呼び出し(Nova CanvasおよびTitan)
- Amazon Rekognitionサービスへのアクセス
- AWS CloudFormationスタックの管理
- APIゲートウェイ(API Gateway)の作成および設定
開発環境
- AWS SAM CLIバージョン1.50.0以上のインストール(AWS SAM CLI)
- pipパッケージマネージャー(pip package manager)付きのPython 3.9以上
- リポジトリのクローン作成およびバージョン管理用のGit(Git)
- 設定ファイル編集用のテキストエディターまたは統合開発環境(IDE)
SAMテンプレートのデプロイ
デプロイプロセスはAWS SAMを使用してすべてのインフラストラクチャコンポーネントを定義およびデプロイします。以下の手順に従ってアプリケーションをビルドし、デプロイしてください。
Step 1: リポジトリセットアップ
まず、リポジトリをクローンし、プロジェクトディレクトリに移動します。
git clone https://github.com/aws-samples/sample-genai-virtual-tryon.git
cd VirtualTryOne-GenAI
コードベースの構成を理解するために、プロジェクト構造を確認します。
- template.yaml: 全AWSリソースを定義するSAMテンプレート (SAM template)
- requirements.txt: Lambda関数 (Lambda functions) 用のPython依存パッケージ
- Lambda function source files (*.py)
- ファッションデータセットとサンプル画像
Step 2: 依存パッケージのインストール
pip install -r requirements.txt
これにより、画像処理、AWS SDKとのやり取り、OpenSearch接続性 (OpenSearch connectivity)、およびその他のコア機能に必要なパッケージがインストールされます。
Step 3: SAMビルドプロセス
Lambda関数をパッケージ化し、デプロイメントアーティファクトを準備するSAMアプリケーションをビルドします。
sam build
ビルドプロセスでは以下の処理が行われます。
- 各Lambda関数用のデプロイメントパッケージの作成
- 依存関係の解決とレイヤーパッケージの生成
- SAMテンプレートの構文検証
- デプロイメント用のCloudFormationテンプレート (CloudFormation templates) の準備
Step 4: ガイド付きデプロイメント
初回デプロイメントには、ガイド付きデプロイメントオプションを使用します。
sam deploy --guided
ガイド付きデプロイメントでは、以下の入力が求められます。
- スタック名(一意の名前を選択)
- デプロイメント用のAWSリージョン
- カスタマイズ用のパラメータ値
- リソース作成の確認
- IAMロールの作成権限
このプロセスにより、今後のデプロイメント用に設定を保存するsamconfig.tomlファイルが作成されます。
Step 5: 以降のデプロイメント
初期セットアップ後、簡略化されたデプロイコマンドを使用します。
sam deploy
これにより、samconfig.tomlから保存された設定が使用され、一貫したデプロイメントが行われます。
SECURITY WARNING: ベースのデプロイメントでは、API Gatewayエンドポイント (API Gateway endpoints) に認証が設定されていません。認証(例:*Amazon Cognito* や *API Gatewayオーソライザー (API Gateway authorizers)*)を実装せずに本番環境へデプロイすることはお勧めしません。
さらに、処理前にユーザーがアップロードしたすべての画像に対して画像検証とコンテンツモデレーションを実装してください。Amazon Rekognitionコンテンツモデレーション (Amazon Rekognition Content Moderation) を使用して不適切または安全でないコンテンツを検出し、API GatewayまたはLambdaレイヤーでファイルタイプ、サイズ、寸法を検証します。モデレーションチェックに失敗した画像は、S3ストレージ (S3 storage) やNova Canvasパイプライン (Nova Canvas pipeline) に到達する前に却下してください。これにより、悪意のあるファイルや不適切なコンテンツが処理、保存、または他のユーザーに返されるのを防ぎます。
Step 6: スタック名と関数IDの取得
sam deployを実行した後、Lambda関数を呼び出すために必要なYourStackNameとIDの正しい値を見つける必要があります。
Method 1: SAMデプロイ出力の確認
Virtual try-on process
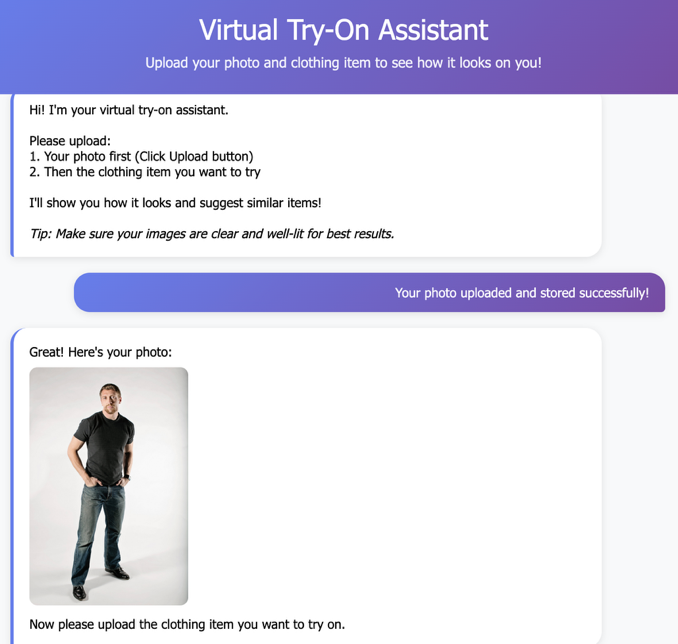
バーチャル試着機能は、当アプリケーションの中核機能を表しており、Amazon Nova Canvas(マルチモーダルコンテンツ生成モデル)を使用して、ユーザーが選択した衣類を着用した写実的な画像を生成します。このプロセスは、JPEG、PNG、JPG を含む一般的な画像形式をサポートし、最大ファイルサイズ 6 MB のドラッグ&ドロップインターフェース(drag-and-drop interface)を通じてユーザーが写真をアップロードすることから始まります。本ソリューションは Amazon Nova Canvas を使用し、Amazon Rekognition と統合して写実的な商品ビジュアライゼーションを生成します。バーチャル試着プロセスは、タスクタイプ:「VIRTUAL_TRY_ON」(taskType: “VIRTUAL_TRY_ON”)のペイロード構造(payload structure)を使用し、ソース画像(顧客の写真)とリファレンス画像(衣類アイテム)をインテリジェントなマスキング(intelligent masking)で結合します。システムはマスクタイプ:「GARMENT」(maskType: “GARMENT”)を採用し、検出された衣類クラスに基づいて自動的に衣類領域を識別して置き換える衣類ベースのマスキング(garment-based masking)を実行します。システムはアップロードされた画像を自動的に検証および前処理し、ユーザーの体がはっきりと写った明るく正面からの写真を使用することで最適な結果が得られます。本番環境へのデプロイ(production deployments)では、悪意のあるまたは不適切なコンテンツが保存・処理されるのを防ぐため、処理前にすべてのユーザーアップロード画像を検証およびモデレーションしてください。実装に関するガイダンスについては、以下の Security Warning(セキュリティ警告)セクションを参照してください。ユーザー写真の処理が完了すると、衣類の選択は以下の2つの主要な方法で行われます:
- Upload personal clothing images for custom try-on experiences(カスタム試着体験のために個人の衣類画像をアップロード)
- Browse and search the curated fashion dataset containing 60+ professionally photographed items(60点以上のプロフェッショナル撮影アイテムを収めた厳選ファッションデータセットを閲覧および検索)
AI 処理フェーズには、コンピュータビジョン(computer vision)と生成 AI(generative AI)の技術が関与します。Amazon Rekognition はまず、ユーザーの写真と衣類アイテムの両方を分析し、衣類の種類、体の部位、およびユーザーの性別を検出することでパーソナライズされたマッチングを行います。Nova Canvas が次に、選択した衣類をユーザーの写真に現実的に適用する写実的な試着画像を生成し、処理は通常 15 秒以内に完了します。ユーザーはその後、以下の複数のオプションを通じて生成された試着結果と対話できます:
- Download high-quality images for personal use(個人利用のために高品質な画像をダウンロード)
- Request similar item recommendations based on the tried-on piece(試着したアイテムに基づいて類似商品のレコメンデーションをリクエスト)
- Save favorites for future reference(将来の参照のためにお気に入りを保存)

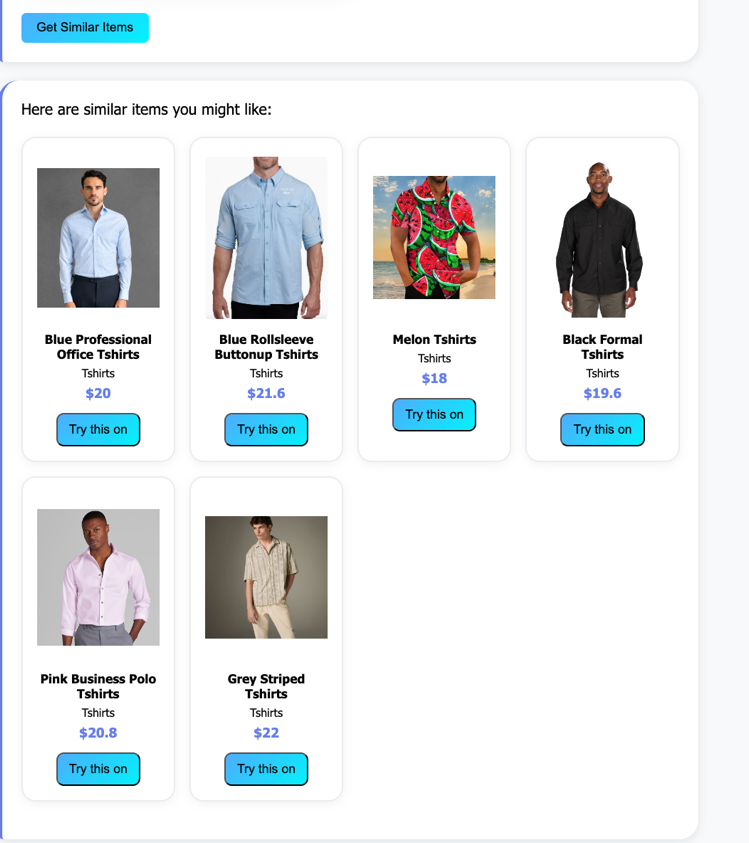
パーソナライズされたレコメンデーション
レコメンデーションエンジン(推薦エンジン)は、当アプリケーションの最も高度な側面の1つであり、マルチモーダルAIエンベッディング(多モーダル埋め込み)を使用して、視覚的およびテキストベースのファッション嗜好を理解します。レコメンデーションエンジンはAmazon Titan Multimodal Embeddingsを使用して、衣類の画像とテキストを1024次元のベクトル表現に変換します。これらのエンベッディングはAmazon OpenSearch Serverlessにインデックス化され、k近傍法(k-nearest neighbors, kNN)検索によりサブ秒単位の類似度マッチングを実現します。本システムはユーザーの行動、写真の特徴、インタラクションパターンを分析し、個人のスタイル嗜好と実用的なニーズに一致するパーソナライズされた衣類の提案を生成します。レコメンデーションに影響を与える主要な要素は以下の通りです:
- ビジュアル類似性分析:Amazon Titanマルチモーダルエンベッディングを使用して、色、パターン、スタイルが類似するアイテムを検出
- ユーザーの性別検出および写真分析と検索履歴に基づいた推定スタイル嗜好
- カテゴリマッチング:ユーザーの好みの衣類タイプ(アッパー、ボトム、全身、靴)にレコメンデーションが一致するよう支援
スマートファッション検索
当社のインテリジェントな検索システムは、従来のキーワードマッチングを超え、自然言語クエリとユーザーの意図を理解します。ファッション検索エージェントは、ユーザーの検索を3つの主要な意図に自動的に分類します:アウフィットプランニング(コーディネートアイテムの検索)、プライスハンティング(予算重視のショッピング)、スタイルディスカバリー(新しいファッショントレンドの探索)。ユーザーは以下のような会話形式のフレーズで検索できます:
- 「$100以下の青いドレスを見せて」:価格フィルター適用結果
- 「カジュアルなTシャツを見せて」:色とスタイルの嗜好
- 「女性向けの手頃なジーンズ」:性別と予算に特化した検索
検索エンジンは複数の高度なf(※原文ここで途切れています)を組み込んでいます
原文を表示
Online retailers face a persistent challenge: shoppers struggle to determine the fit and look when ordering online, leading to increased returns and decreased purchase confidence. The cost? Lost revenue, operational overhead, and customer frustration. Meanwhile, consumers increasingly expect immersive, interactive shopping experiences that bridge the gap between online and in-store retail. Retailers implementing virtual try-on technology can improve purchase confidence and reduce return rates, translating directly to improved profitability and customer satisfaction. This post demonstrates how to build a virtual try-on and recommendation solution on AWS using Amazon Nova Canvas, Amazon Rekognition and Amazon OpenSearch Serverless. Whether you’re an AWS Partner developing retail solutions or a retailer exploring generative AI transformation, you’ll learn the architecture, implementation approach, and key considerations for deploying this solution.
You can find the code base to deploy the solution in your AWS account in the GitHub repo.
Solution overview
This solution demonstrates how to build an AI-powered, serverless retail solution. The service delivers four integrated capabilities:
- Virtual try-on: Generates realistic visualizations of customers wearing or using products through Amazon Nova Canvas and Amazon Rekognition
- Smart recommendations: Provides visually aware product suggestions using Amazon Titan Multimodal Embeddings to understand style relationships and visual similarity
- Smart search: Enables natural language product discovery with goal-oriented intelligence that understands customer intent. Uses OpenSearch Serverless for vector similarity matching
- Analytics and insights: Tracks customer interactions, preferences, and trends using Amazon DynamoDB to optimize inventory and merchandising decisions
The architecture uses serverless AWS services for scalability and uses a modular design, allowing you to implement individual capabilities or the complete solution.
Pre-built architecture components
The solution runs on AWS serverless infrastructure with five specialized AWS Lambda functions, each optimized for specific tasks: web front-end (chatbot interface), virtual try-on processing, recommendation generation, dataset ingestion, and intelligent search. The architecture uses S3 buckets for secure storage, Amazon OpenSearch Serverless for vector similarity search, and DynamoDB for real-time analytics tracking.
Scalability and deployment
Built using AWS Serverless Application Model (AWS SAM), the entire solution deploys with a single command and automatically scales based on demand. Reserved concurrency limits help prevent resource contention, while Amazon API Gateway caching and presigned URLs optimize performance. The microservices approach allows independent scaling and updates of each component.
Integration flexibility for partners and customers
The modular design allows implementation of individual capabilities or the complete solution. Documentation, sample test images, and utility scripts for dataset management make it straightforward for developers to customize and extend the solution for specific retail needs.
Prerequisites
Before beginning the deployment process, verify you have the following prerequisites configured:
AWS account setup
- An active AWS account with administrative privileges
- AWS Command Line Interface (AWS CLI) installed and configured with appropriate credentials
- This solution requires Amazon Nova Canvas, Amazon Titan Multimodal Embeddings, Amazon Rekognition, and Amazon OpenSearch Serverless in the same Region. Deploy in US East (N. Virginia) – us-east-1 (recommended).
Regional availability for Amazon Bedrock models changes over time. Before deploying in a Region other than us-east-1, confirm that all required models are supported by checking the Amazon Bedrock model support by Region page and the AWS Regional Services List.
Amazon Bedrock model access
Amazon Bedrock foundation models are now automatically enabled when first invoked in your account across all AWS commercial regions. The models required for this solution (Amazon Nova Canvas and Amazon Titan Embeddings) will be automatically activated when the application first calls them – no manual enablement required.
Note: For first-time Amazon Bedrock users, the initial model invocation might take a few extra seconds as the service provisions access.
AWS service permissions
The IAM role that you use to deploy the SAM template must have these permissions:
- Creating and managing Lambda functions
- S3 bucket creation and object management
- Amazon OpenSearch Serverless collection creation
- DynamoDB table creation and data access
- Amazon Bedrock model invocation (Nova Canvas and Titan)
- Amazon Rekognition service access
- AWS CloudFormation stack management
- API Gateway creation and configuration
Development environment
- AWS SAM CLI version 1.50.0 or higher installed
- Python 3.9 or higher with pip package manager
- Git for repository cloning and version control
- A text editor or IDE for configuration file editing
Deploying the SAM template
The deployment process uses AWS SAM to define and deploy all infrastructure components. Follow these steps to build and deploy the application.
Step 1: Repository setup
Begin by cloning the repository and navigating to the project directory:
git clone https://github.com/aws-samples/sample-genai-virtual-tryon.git
cd VirtualTryOne-GenAIExamine the project structure to understand the code base organization:
- template.yaml: SAM template defining all AWS resources
- requirements.txt: Python dependencies for Lambda functions
- Lambda function source files (*.py)
- Fashion dataset and sample images
Step 2: Dependency installation
pip install -r requirements.txtThis installs packages needed for image processing, AWS SDK interactions, OpenSearch connectivity, and other core functionalities.
Step 3: SAM build process
Build the SAM application, which packages Lambda functions and prepares deployment artifacts:
sam buildThe build process:
- Creates deployment packages for each Lambda function
- Resolves dependencies and creates layer packages
- Validates the SAM template syntax
- Prepares CloudFormation templates for deployment
Step 4: Guided deployment
For first-time deployment, use the guided deployment option:
sam deploy --guidedThe guided deployment will prompt you for:
- Stack name (choose a unique name)
- AWS Region for deployment
- Parameter values for customization
- Confirmation for resource creation
- IAM role creation permissions
This process creates a samconfig.toml file storing your deployment preferences for future deployments.
Step 5: Subsequent deployments
After initial setup, use the simplified deployment command:
sam deployThis uses the saved configuration from samconfig.toml for consistent deployments.
SECURITY WARNING: The base deployment has no authentication on API Gateway endpoints. We do not recommend deploying this to production without implementing authentication (e.g., *Amazon Cognito* or *API Gateway authorizers*).
Additionally, implement image validation and content moderation for all user-uploaded images before processing. Use Amazon Rekognition Content Moderation to detect inappropriate or unsafe content, and validate file type, size, and dimensions at the API Gateway or Lambda layer. Reject images that fail moderation checks before they reach S3 storage or the Nova Canvas pipeline. This helps prevent malicious files and inappropriate content from being processed, stored, or returned to other users.
Step 6: Finding your stack name and function ID
After running sam deploy, you need to find the correct values for YourStackName and ID to invoke Lambda functions.
Method 1: Check SAM deploy output
The quickest way is to look at the output from your sam deploy command. The DataIngestionFunctionName output shows the complete function name:** DataIngestionFunctionName: my-fashion-stack-DataIngestionFunction-abc123xyz
Method 2: Check CloudFormation outputs**
Retrieve the function name from CloudFormation:
Replace ‘my-fashion-stack’ with your stack name
aws cloudformation describe-stacks \
--stack-name my-fashion-stack \
--query 'Stacks[0].Outputs[?OutputKey==`DataIngestionFunctionName`].OutputValue' \
--output text;Method 3: Check samconfig.toml
Your stack name is saved in samconfig.toml after running
sam deploy --guidedcat samconfig.toml | grep stack_name# Output: stack_name = "my-fashion-stack
Method 4: Check the AWS Management Console
- Go to AWS CloudFormation in the AWS Management Console.
- Select your stack (for example, my-fashion-stack).
- Click the Outputs tab.
- Find DataIngestionFunctionName. This is the complete function name to use.
Step 7: Fashion dataset setup
Upload the fashion dataset to enable search and recommendation features: python mini_dataset_uploader.py
This script uploads 60+ fashion items with metadata to the designated S3 bucket.
Step 8: Vector index creation
Build the searchable vector index by invoking the data ingestion function:
aws lambda invoke \
--function-name -DataIngestionFunction- \
--payload '{}' \
response.json
Replace ` and ` with values from your SAM deployment output. This process:
- Processes the fashion images using Titan embeddings
- Creates vector representations for similarity search
- Indexes data in Amazon OpenSearch Serverless
- Enables recommendation and search functionality
Application usage guide
After you deploy the application, your virtual try-on application provides several features for end users.
Accessing the application
Retrieve your application URL from the SAM deployment output: WebAppUrl: https://{api-id}.execute-api.{region}.amazonaws.com/dev/
Core AI-Powered Functionalities
Virtual try-on process
The virtual try-on feature represents the core functionality of our application, using Amazon Nova Canvas to create photorealistic images of users wearing selected clothing items. The process begins when users upload their photo through a drag-and-drop interface that supports common image formats including JPEG, PNG, and JPG with maximum file size of 6 MB. The solution uses Amazon Nova Canvas, a multimodal content generation model, integrated with Amazon Rekognition to generate photorealistic product visualizations. The virtual try-on process uses a payload structure with taskType: “VIRTUAL_TRY_ON” that combines a source image (customer photo) and reference image (clothing item) with intelligent masking. The system employs maskType: “GARMENT” with garment-based masking that automatically identifies and replaces clothing regions based on detected garment classes. The system automatically validates and preprocesses uploaded images, with optimal results achieved using well-lit, front-facing photos that clearly show the user’s body. For production deployments, validate and moderate all user-uploaded images before processing to help prevent malicious or inappropriate content from being stored and processed. See the Security Warning section below for implementation guidance. Once the user photo is processed, clothing selection occurs through two primary methods:
- Upload personal clothing images for custom try-on experiences
- Browse and search the curated fashion dataset containing 60+ professionally photographed items
The AI processing phase involves computer vision and generative AI technologies. Amazon Rekognition first analyzes both the user photo and clothing item to detect garment types, body regions, and user gender for personalized matching. Nova Canvas then generates photorealistic try-on images that realistically apply the selected clothing to the user’s photo, with processing typically completing within 15 seconds. Users can then interact with their generated try-on results through several options:
- Download high-quality images for personal use
- Request similar item recommendations based on the tried-on piece
- Save favorites for future reference
Personalized recommendations
The recommendation engine represents one of the most advanced aspects of our application, using multimodal AI embeddings to understand both visual and textual fashion preferences. The recommendation engine uses Amazon Titan Multimodal Embeddings to convert clothing images and text into 1024-dimensional vector representations. These embeddings are indexed in Amazon OpenSearch Serverless with k-nearest neighbors (kNN) search for sub-second similarity matching. The system analyzes user behavior, photo characteristics, and interaction patterns to generate personalized clothing suggestions that align with individual style preferences and practical needs. Key factors influencing recommendations include:
- Visual similarity analysis using Amazon Titan multimodal embeddings to find items with similar colors, patterns, and styles
- Detected user gender and inferred style preferences based on photo analysis and search history
- Category matching that helps ensure recommendations align with user’s preferred clothing types (upper body, lower body, full body, footwear)
Smart fashion search
Our intelligent search system goes beyond traditional keyword matching by understanding natural language queries and user intent. The fashion search agent automatically categorizes user searches into three primary intents: outfit planning (finding coordinating pieces), price hunting (budget-conscious shopping), and style discovery (exploring new fashion trends).Users can search using conversational phrases such as:
- “Show me blue dresses under $100” for price-filtered results
- “Show me casual tshirt” for color and style preferences
- “Affordable jeans for women” for gender and budget-specific searches
The search engine incorporates several advanced f
関連記事
AWSがS3 Filesを導入、S3バケットへのファイルシステムアクセスを実現
AWSはS3 Filesを発表し、ユーザーがAmazon S3バケットをマウントして標準ファイルシステムインターフェースでデータにアクセスできるようにした。アプリケーションは標準ファイル操作で読み書きでき、システムが自動的にS3リクエストに変換するため、コンピュートサービスがS3に保存されたデータを直接扱える。
AWSが自動インシデント調査のためのDevOpsエージェントを一般提供開始
AWSは、開発者と運用者がAWS環境での問題のトラブルシューティング、デプロイメントの分析、運用タスクの自動化を支援する生成AI搭載アシスタント「DevOps Agent」の一般提供を開始した。
Amazon Bedrockの詳細なコスト帰属機能の導入
AWSがAmazon Bedrockの推論コストをIAMプリンシパルごとに自動的に帰属する機能を発表した。これにより、コストの内訳把握、コスト最適化、財務計画が容易になる。