AI週間レビュー #336 - Sonnet 4.6、Gemini 3.1 Pro、Anthropic対ペンタゴン
AnthropicがSonnet 4.6をリリース、GoogleはGemini 3.1 Proを発表。米国防総省はAI安全対策を巡りAnthropicとの契約停止を検討。
キーポイント
AnthropicがClaude Sonnet 4.6をリリースし、無料・プロ層向けに大幅な性能向上(特にコーディング能力と100万トークンのコンテキストウィンドウ)を提供
GoogleがGemini 3.1 Proを発表し、AIモデル競争の激化を示す
米国防総省(Pentagon)がAIセーフガードを巡りAnthropicとの契約停止を検討する可能性を示唆し、AI規制と安全保障の議論が活発化
影響分析・編集コメントを表示
影響分析
AIモデルのリリースペースが加速しており、AnthropicとGoogleの競争が激化することで、無料層を含むユーザーへの高性能AIの普及が進む。一方で、国防総省との契約問題は、AIセーフティと政府規制のバランスが業界の重要な課題であることを浮き彫りにしている。
編集コメント
モデルリリースの加速と政府規制の緊張が同時進行する中で、AI業界は技術革新と社会的責任の両立が求められる転換期にある。
AI週間レビュー #336 - Sonnet 4.6、Gemini 3.1 Pro、Anthropic対ペンタゴン
AnthropicがSonnet 4.6をリリース、Googleが最新AIモデルGemini 3.1 Proを展開、ペンタゴンがAI安全対策を巡る論争でAnthropicとの取引停止を脅かす
 AI週間レビュー2026年2月24日265シェアAnthropic、Sonnet 4.6をリリース
AI週間レビュー2026年2月24日265シェアAnthropic、Sonnet 4.6をリリース
Claude Sonnet 4.6モデルは「大幅に改善されたコーディングスキル」とアップグレードされた無料枠をもたらす
Claude Sonnet 4.6は、無料および低コストユーザーに最先端レベルのAIを提供
AnthropicがClaude Sonnet 4.6をリリース、AIモデルリリースの猛烈なペースを継続
概要: Anthropicは、Opus 4.6のリリースからわずか12日後に、中型モデルの大規模アップグレード版であるClaude Sonnet 4.6をリリースした。これは現在、無料およびPro枠のデフォルトモデルとなり、価格は変更されていない。ベータ版では100万トークンのコンテキストウィンドウが導入された。これはSonnetにとって以前の4倍のサイズであり、1セッションでコードベース全体、長い契約書、または数十本の論文を扱うことを可能とし、長文脈推論が改善され、圧縮/リセットが減少している。Anthropicは、コーディング、指示への従順さ、コンピュータ使用(デスクトップ操作)、エージェント計画、知識作業、デザインにおける向上を強調している。ベンチマーク結果には、OS World(コンピュータ使用)とSWE-Bench(ソフトウェアエンジニアリング)での新記録、およびARC‑AGI‑2での60.4%が含まれる。Opus 4.6、Gemini 3 Deep Think、改良版GPT‑5.2には及ばないものの、同社はSonnet 4.6が多くの実世界タスクにおいて「Opusレベルの知性に接近している」と述べている。
初期テスターは、Sonnet 4.6をSonnet 4.5よりも約70%の頻度で、さらにはOpus 4.5よりも約60%の頻度で好み、その理由として、指示への従順さの強さ、編集前のコンテキスト読み取りの改善、共有ロジックの統合、幻覚や誤った成功主張の減少、より一貫した多段階の遂行を挙げている。Sonnet 4.6はまた、ファイル作成、コネクタ、スキル、圧縮などの機能を、無料ユーザーに対してもデフォルトでより多く提供するようになり、Claudeチャット、Claude Cowork、API全体でより高速な日常使用モデルとして位置づけられている。
編集者の見解: 大型モデルリリースのセットからわずか1週間後、Sonnet 4.6とGemini 3.1 Proの両方が登場した。モデルリリースのペースは確かに加速していると感じられるので、先週述べたことを繰り返す:「最先端の研究所は、RL(強化学習)によるモデルの継続的な事後学習の段階に達したのかもしれず、わずか数ヶ月でさらに印象的な向上が見られても驚かない。」
Google、最新AIモデルGemini 3.1 Proを展開
GoogleがGemini 3.1 Proをリリース: ベンチマーク、試用方法
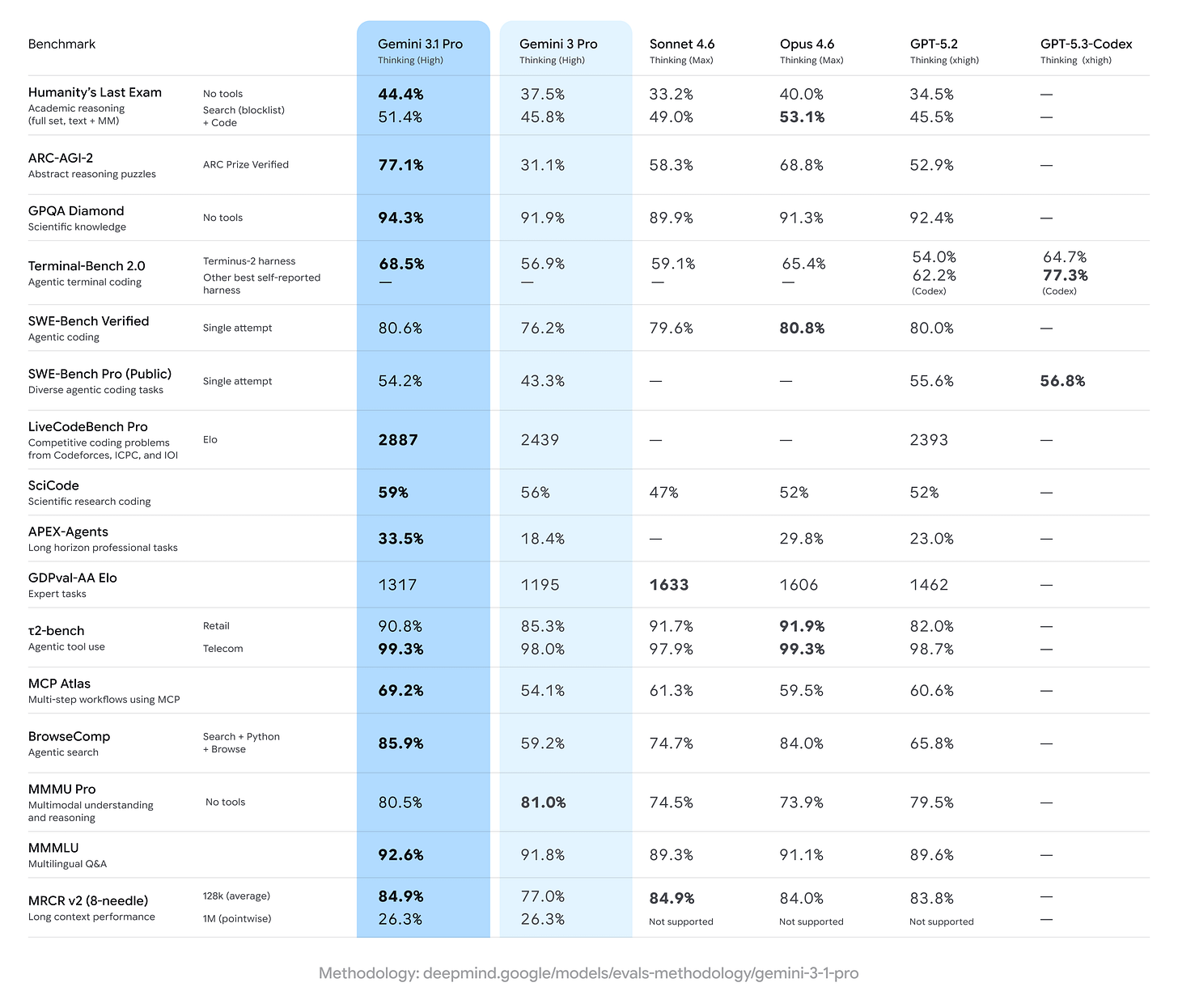 概要: Googleは、GeminiやGemini 3 Deep Thinkなどのツールを駆動する最新の「中核推論」モデルであるGemini 3.1 Proを発表した。論理と知識のベンチマークで大幅な向上を示し、新たな創造的コーディング能力を備えている。ARC‑AGI‑2では、このモデルは77.1%を記録し、Gemini 3 Proの31.1%の2倍以上であり、Claude Opus 4.6(68.8%)やGPT‑5.2(52.9%)を上回った。また、Humanity’s Last Examで44.4%、GPQA Diamondで94.3%、MMLUで92.6%、SWE‑Bench Verifiedで80.6%を記録した。一方、SWE‑Bench ProではOpenAIのGPT‑5.3‑Codex(54.2%対56.8%)に及ばず、同じProバリアントではGPT‑5.2(55.6%)にわずかに後れを取った。
概要: Googleは、GeminiやGemini 3 Deep Thinkなどのツールを駆動する最新の「中核推論」モデルであるGemini 3.1 Proを発表した。論理と知識のベンチマークで大幅な向上を示し、新たな創造的コーディング能力を備えている。ARC‑AGI‑2では、このモデルは77.1%を記録し、Gemini 3 Proの31.1%の2倍以上であり、Claude Opus 4.6(68.8%)やGPT‑5.2(52.9%)を上回った。また、Humanity’s Last Examで44.4%、GPQA Diamondで94.3%、MMLUで92.6%、SWE‑Bench Verifiedで80.6%を記録した。一方、SWE‑Bench ProではOpenAIのGPT‑5.3‑Codex(54.2%対56.8%)に及ばず、同じProバリアントではGPT‑5.2(55.6%)にわずかに後れを取った。
提供範囲は広範である: Gemini 3.1 Proは、Geminiアプリ(無料枠で利用可能、AI ProおよびAI Ultraではより高い使用量)、有料ユーザー向けのNotebookLM、そして開発者および企業向けにAI Studio、Vertex AI、Gemini Enterprise、Gemini CLI、Antigravity、Android Studioを介したGemini APIで展開されている。Googleは、3.1 Proが現在、同社の消費者向けおよび開発者向けサービスのコアモデルであり、構造化された説明、データ統合、創造的生成を必要とするタスクに「高度な推論」を提供すると述べている。
編集者の見解: Sonnet 4.6に関する論評以上に追加することはあまりないが、これもまた、Google/Deepmindが圧倒的な勢いであることを示している。2025年初頭のGemini 2リリースまで、GoogleはOpenAIとAnthropicの両方に大きく後れを取っていたことを忘れがちだ。1年後、Deepmindは(議論の余地はあるが)生のモデル能力において引き続きリードしている。
ペンタゴン、AI安全対策を巡る論争でAnthropicとの取引停止を脅かす
 概要: ペンタゴン(米国防総省)は、軍がClaudeを使用する条件に関する交渉の行き詰まりを理由に、Anthropicを「サプライチェーンリスク」に指定すると脅している。この指定は通常、外国の敵対者に留保されている。核心的な争点は、Anthropicが使用制限を緩和する意思はあるが、アメリカ人大規模監視と完全自律型致死兵器を防ぐガードレールを求めているのに対し、ペンタゴンは軍事作戦に必要であると主張する「すべての合法的目的」基準を堅持している点にある。リスクにさらされている比較的小さな2億ドルの契約を超えて、その利害は大きい。なぜなら、Claudeは現在、機密軍事ネットワーク上で唯一のAI(1月のマドゥロ襲撃作戦での使用を含む)であり、サプライチェーンリスク指定は、Claudeを使用する無数の企業に対し、国防総省との取引を継続するためにAnthropicとの関係を断ったことを証明することを強制することになるからだ。ペンタゴンの攻撃的な姿勢はまた、OpenAI、Google、xAIとの並行交渉において先例を作ることを意図しているように見える。これらの企業はすでに、非機密軍事使用については安全対策の撤廃に合意しているが、機密システムに関する条件にはまだ達していない。
概要: ペンタゴン(米国防総省)は、軍がClaudeを使用する条件に関する交渉の行き詰まりを理由に、Anthropicを「サプライチェーンリスク」に指定すると脅している。この指定は通常、外国の敵対者に留保されている。核心的な争点は、Anthropicが使用制限を緩和する意思はあるが、アメリカ人大規模監視と完全自律型致死兵器を防ぐガードレールを求めているのに対し、ペンタゴンは軍事作戦に必要であると主張する「すべての合法的目的」基準を堅持している点にある。リスクにさらされている比較的小さな2億ドルの契約を超えて、その利害は大きい。なぜなら、Claudeは現在、機密軍事ネットワーク上で唯一のAI(1月のマドゥロ襲撃作戦での使用を含む)であり、サプライチェーンリスク指定は、Claudeを使用する無数の企業に対し、国防総省との取引を継続するためにAnthropicとの関係を断ったことを証明することを強制することになるからだ。ペンタゴンの攻撃的な姿勢はまた、OpenAI、Google、xAIとの並行交渉において先例を作ることを意図しているように見える。これらの企業はすでに、非機密軍事使用については安全対策の撤廃に合意しているが、機密システムに関する条件にはまだ達していない。
編集者の見解: おそらく、ペンタゴンがベネズエラのマドゥロを捕らえる襲撃作戦でClaudeを使用したと報じられたことの、当然の帰結だろう。Anthropicは当然のことながら、米軍がClaudeを何に使用できるかについて制限を設けたいと考え、米軍は当然のことながらそれを気に入らなかった。次に何が起こるかは、Anthropicを競合他社に対して大きな不利な立場に追いやる可能性があるので、彼らがここでどうするかを見るのは興味深い。
Anthropic、Deepseek、Moonshot、MinimaxによるClaude能力抽出の産業規模の試みを発見
蒸留攻撃の検出と防止
攻撃者はクローン作成を試みながらGeminiに10万回以上プロンプトを送信したとGoogleが発表
 概要: Anthropicは、3つの中国系AI研究所(DeepSeek、Moonshot(Kimi)、MiniMax)による、独自モデルのトレーニングのためにClaudeの最も差別化された能力を抽出することを目的とした、産業規模の「蒸留」キャンペーンを検出したと述べている。約24,000の不正アカウントを通じて、これらの研究所はClaudeとの1,600万回以上の対話を生成し、プロキシ「ハイドラクラスター」ネットワークを使用して地域アクセス制限を回避し、利用禁止を免れていた。標的には、エージェント的推論、ツール使用/オーケストレーション、コーディングとデータ分析、コンピュータ使用エージェント開発、コンピュータビジョン、および強化学習のための報酬モデルとして機能するルーブリックベースの評価が含まれていた。Anthropicは、IP相関、リクエストメタデータ、インフラ指標を通じてこれらの活動を帰属させ、大規模な連鎖的思考誘発や、政治的に敏感なクエリの検閲安全な言い換えなど、特徴的なプロンプトパターンを指摘している。
概要: Anthropicは、3つの中国系AI研究所(DeepSeek、Moonshot(Kimi)、MiniMax)による、独自モデルのトレーニングのためにClaudeの最も差別化された能力を抽出することを目的とした、産業規模の「蒸留」キャンペーンを検出したと述べている。約24,000の不正アカウントを通じて、これらの研究所はClaudeとの1,600万回以上の対話を生成し、プロキシ「ハイドラクラスター」ネットワークを使用して地域アクセス制限を回避し、利用禁止を免れていた。標的には、エージェント的推論、ツール使用/オーケストレーション、コーディングとデータ分析、コンピュータ使用エージェント開発、コンピュータビジョン、および強化学習のための報酬モデルとして機能するルーブリックベースの評価が含まれていた。Anthropicは、IP相関、リクエストメタデータ、インフラ指標を通じてこれらの活動を帰属させ、大規模な連鎖的思考誘発や、政治的に敏感なクエリの検閲安全な言い換えなど、特徴的なプロンプトパターンを指摘している。
編集者の見解: オンラインAIコミュニティのこの件に対する反応は、主にその「滑稽な」側面に焦点が当てられているようだ(Anthropicはインターネットを蒸留してClaudeを訓練したが、今や自社モデルが蒸留されることに反対している、はは)。それでも、使用された規模と戦術は
原文を表示
Last Week in AI #336 - Sonnet 4.6, Gemini 3.1 Pro, Anthropic vs Pentagon
Anthropic releases Sonnet 4.6, Google Rolls Out Latest AI Model Gemini 3.1 Pro, Pentagon threatens to cut off Anthropic in AI safeguards dispute
Last Week in AIFeb 24, 2026265ShareAnthropic releases Sonnet 4.6
Claude Sonnet 4.6 model brings ‘much-improved coding skills’ and upgraded free tier
Claude Sonnet 4.6 delivers frontier-level AI for free and cheap-seat users
Anthropic releases Claude Sonnet 4.6, continuing breakneck pace of AI model releases
Summary: Anthropic has released Claude Sonnet 4.6, a major upgrade to its midsized model just 12 days after Opus 4.6. It’s now the default for Free and Pro tiers with pricing unchanged. The beta debuts a 1 million-token context window—four times larger than before for Sonnet—enabling entire codebases, lengthy contracts, or dozens of papers in one session, with improved long‑context reasoning and fewer compactions/resets. Anthropic highlights gains in coding, instruction-following, computer use (desktop interaction), agent planning, knowledge work, and design. Benchmark results include new records on OS World (computer use) and SWE-Bench (software engineering), plus a 60.4% on ARC‑AGI‑2; while it trails Opus 4.6, Gemini 3 Deep Think, and a refined GPT‑5.2 variant, the company says Sonnet 4.6 “approaches Opus‑level intelligence” for many real‑world tasks.
Early testers preferred Sonnet 4.6 over Sonnet 4.5 about 70% of the time and even over Opus 4.5 roughly 60% of the time, citing stronger instruction-following, better context reading before edits, consolidation of shared logic, fewer hallucinations and false success claims, and more consistent multi‑step follow‑through. Sonnet 4.6 also powers more features by default for free users, including file creation, connectors, skills, and compaction, and is positioned as a faster daily driver across Claude chat, Claude Cowork, and the API.
Editor’s Take: Just a week after a set of blockbuster model releases, we’ve got both Sonnet 4.6 and Gemini 3.1 Pro coming out as well. The pace of model releases definitely feels like it has accelerated, and so i’ll just repeat what I said last week: “It feels like the frontier labs may have gotten to the point of continously post-training their models via RL, and I wouldn’t be surprised if we see more impressive gains in just a few months.”
Google Rolls Out Latest AI Model, Gemini 3.1 Pro
Google releases Gemini 3.1 Pro: Benchmarks, how to try it
Summary: Google launched Gemini 3.1 Pro, its latest “core reasoning” model powering Gemini and tools like Gemini 3 Deep Think, with substantial gains on logic and knowledge benchmarks and new creative coding abilities. On ARC‑AGI‑2, the model scores 77.1%, more than double Gemini 3 Pro’s 31.1% and ahead of Claude Opus 4.6 (68.8%) and GPT‑5.2 (52.9%). It also posts 44.4% on Humanity’s Last Exam, 94.3% on GPQA Diamond, 92.6% on MMLU, and 80.6% on SWE‑Bench Verified—while trailing OpenAI’s GPT‑5.3‑Codex on SWE‑Bench Pro (54.2% vs 56.8%) and narrowly behind GPT‑5.2 on that same Pro variant (55.6%).
Availability is broad: Gemini 3.1 Pro is rolling out in the Gemini app (free tier available, with higher usage on AI Pro and AI Ultra), in NotebookLM for paid users, and via the Gemini API for developers and enterprises through AI Studio, Vertex AI, Gemini Enterprise, Gemini CLI, Antigravity, and Android Studio. Google says 3.1 Pro is now the core model across its consumer and developer surfaces, offering “advanced reasoning” for tasks that need structured explanations, data synthesis, and creative generation.
Editor’s Take: Not much to add here beyond the commentary on Sonnet 4.6, though this also once again demonstrates Google/Deepmind is absolutely crushing it. It’s easy to forget that until the release of Gemini 2 in early 2025, Google was significantly behind both OpenAI and Anthropic. A year later, Deepmind continuous to (arguably) be in the lead in terms of raw model capabilities.
Pentagon threatens to cut off Anthropic in AI safeguards dispute
Summary: The Pentagon is threatening to designate Anthropic a "supply chain risk" — a designation typically reserved for foreign adversaries — over a standoff in negotiations about the terms under which the military can use Claude. The core dispute: Anthropic is willing to loosen its usage restrictions but wants guardrails preventing mass surveillance of Americans and fully autonomous lethal weapons, while the Pentagon insists on an "all lawful purposes" standard it says is necessary for military operations. The stakes are significant beyond the relatively modest $200M contract at risk, since Claude is currently the only AI on classified military networks (including use during the January Maduro raid), and a supply chain risk designation would force the countless companies that use Claude to certify they've cut ties with Anthropic to keep doing business with the Defense Department. The Pentagon's aggressive posture also appears designed to set a precedent for parallel negotiations with OpenAI, Google, and xAI, all of which have already agreed to remove safeguards for unclassified military use but haven't yet reached terms on classified systems.
Editor’s Take: Perhaps an unsurprising consequence of it having been reported that the Pentagon used Claude in their raid to capture Maduro Venezuela — Anthropic predictably responded by wanting to put limits on what the US military could use Claude for, and the US military predictably did not like that. What happens next could put Anthropic at a significant disadvantage to their competitors, so it’s interesting to see what they do here.
Anthropic Found Industrial-Scale Attempts By Deepseek, Moonshot, Minimax To Extract Claude Capabilities
Detecting and preventing distillation attacks
Attackers prompted Gemini over 100,000 times while trying to clone it, Google says
Summary: Anthropic says it detected industrial‑scale “distillation” campaigns by three China‑based AI labs—DeepSeek, Moonshot (Kimi), and MiniMax—designed to extract Claude’s most differentiated capabilities for training their own models. Across roughly 24,000 fraudulent accounts, these labs generated over 16 million exchanges with Claude, using proxy “hydra cluster” networks to bypass regional access restrictions and evade bans. Targets included agentic reasoning, tool use/orchestration, coding and data analysis, computer‑use agent development, computer vision, and rubric‑based grading to act as a reward model for reinforcement learning. Anthropic attributes the operations via IP correlations, request metadata, and infrastructure indicators, and notes distinctive prompt patterns such as chain‑of‑thought elicitation at scale and censorship‑safe rephrasing of politically sensitive queries.
Editor’s Take: The response of the online AI community to this has seemed to largely focus on the ‘funny’ aspect of this (Anthropic trained Claude by distilling the internet, now they oppose their model being distilled, ha). Still, the scale and tactics used here do seem serious enough to merit the label “industrial-scale campaigns”, and other US companies will have to be ready for this as well (in fact Google had already made a similar announcement two weeks ago, which did not garner as much attention as this).
 Alibaba unveils Qwen3.5 as China’s chatbot race shifts to AI agents. Alibaba introduced Qwen3.5, an open‑weight model also offered in a hosted cloud version. It supports native multimodal input, new coding and agent capabilities, 397 billion parameters, and 201 languages, and can be downloaded and fine‑tuned for private deployment.
Alibaba unveils Qwen3.5 as China’s chatbot race shifts to AI agents. Alibaba introduced Qwen3.5, an open‑weight model also offered in a hosted cloud version. It supports native multimodal input, new coding and agent capabilities, 397 billion parameters, and 201 languages, and can be downloaded and fine‑tuned for private deployment.
Microsoft is building its own AI model. The CEO told the Financial Times that the company is pushing toward AI “self-sufficiency.”
 World Labs lands $1B, with $200M from Autodesk, to bring world models into 3D workflows. Autodesk will act as an adviser and collaborate with World Labs at the research and model level to explore integrating World Labs’ 3D world models with Autodesk’s design tools—initially focusing on media and entertainment use cases—without sharing customer data.
World Labs lands $1B, with $200M from Autodesk, to bring world models into 3D workflows. Autodesk will act as an adviser and collaborate with World Labs at the research and model level to explore integrating World Labs’ 3D world models with Autodesk’s design tools—initially focusing on media and entertainment use cases—without sharing customer data.
All the important news from the ongoing India AI Impact Summit. The summit brings together top AI lab and Big Tech leaders, heads of state, and industry figures to showcase India’s AI opportunities, attract investment, and feature keynote speeches and announcements from attendees such as Sundar Pichai, Sam Altman, Dario Amodei, Mukesh Ambani, and Demis Hassabis.
OpenClaw creator Peter Steinberger joins OpenAI. He will help lead development of next‑generation personal AI agents at OpenAI, while OpenClaw will be preserved and supported as an open‑source project in a foundation.
Simile Raises $100 Million for AI Aiming to Predict Human Behavior. The funding will back AI tools that use interviews, transaction histories, scientific texts, and simulated AI agents to predict individual and consumer decisions for applications like product stocking and earnings‑call questions.
AI blamed again as hard drives are sold out for this year. Manufacturers have already committed production to large cloud and AI customers through 2026–28, leaving few drives available for mid‑size enterprises and potentially driving shortages and higher prices across servers, SSDs, and other datacenter components.
Anthropic clarifies ban on third-party tool access to Claude. The clarification bars using OAuth tokens from Claude Free, Pro, or Max accounts in third‑party harnesses and says those tokens may only be used with Claude.ai and the official Claude Code interface.
OpenAI resets spending expectations, tells investors compute target is around $600 billion by 2030. The company expects about $280 billion in revenue by 2030, is lining up more than $100 billion in funding (including up to $30 billion from Nvidia), and reported $13.1 billion in 2025 revenue while finalizing large infrastructure deals and rebounding user growth for ChatGPT and Codex.
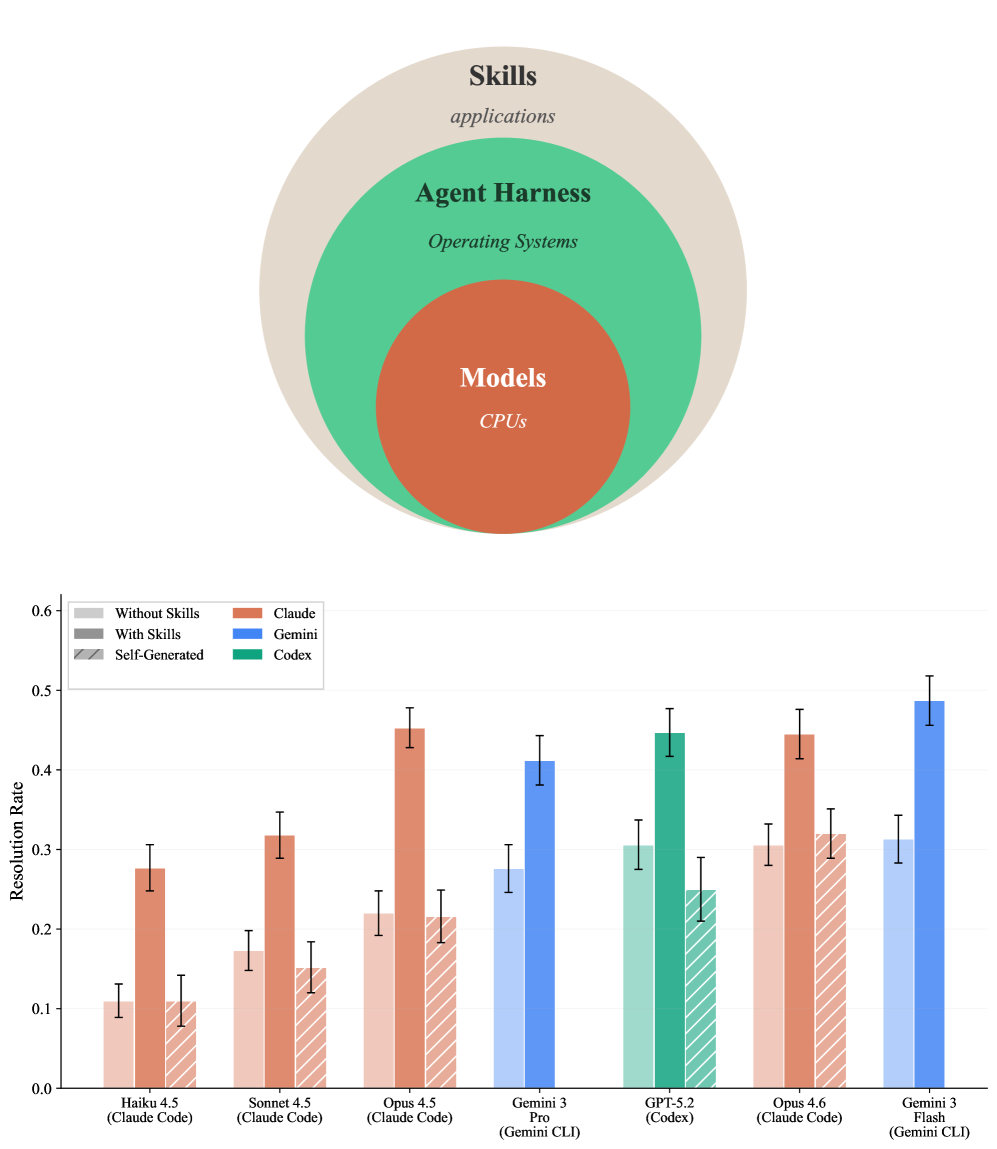 SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks. This benchmark measures how curated versus self‑generated Skills affect agent success across 84 terminal‑based tasks, evaluating seven model‑harness configurations over 7,308 trajectories to identify which Skill components, harness behaviors, and failure modes drive gains or harms.
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks. This benchmark measures how curated versus self‑generated Skills affect agent success across 84 terminal‑based tasks, evaluating seven model‑harness configurations over 7,308 trajectories to identify which Skill components, harness behaviors, and failure modes drive gains or harms.
Think Deep, Not Just Long: M
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み