DVCとAmazon SageMaker AI MLflowアプリによるエンドツーエンドのモデル系譜追跡
AWSはDVC、SageMaker AI、MLflow Appsを統合し、規制業界向けにモデルの訓練データからデプロイまでを追跡可能なエンドツーエンドのML系譜(ラインージ)構築パターンを提供している。
キーポイント
MLOpsの可視化課題と規制対応の必要性
生産環境におけるモデルの学習データ・コード・メトリクスを追跡する手段が欠如しており、医療や金融などの規制業界では監査要件を満たすために明確な系譜管理が必須となっている。
3大ツールの統合アーキテクチャ設計
DVC(データ/Gitバージョン管理)、Amazon SageMaker AI(スケーラブルな処理・学習・デプロイ)、SageMaker MLflow Apps(実験追跡・モデルレジストリ・系譜管理)を連携させ、一元化されたワークフローを実現する。
データセット・レコードレベルの系譜実装パターン
公式GitHubサンプルノートブックを用い、AWS環境内で再現可能な2つのデプロイパターン(データセットレベルとレコードレベル)を提供し、現場での即座な検証と適用を可能にする。
DVCによるデータ版付けと同期
前処理スクリプト内でDVCを用いてデータをバージョン化し、パイプライン実行IDをタグとして付与してリポジトリにコミット・プッシュする。
正確なデータ取得とモデル学習
トレーニングジョブはStep 1のタグでDVCリポジトリをクローンし、dvc pullで正確なデータバージョンを取得してMobileNetV3-Smallのファインチューニングを行う。
MLflowとの系譜連携と自動登録
トレーニングスクリプト内でDVCのコミットハッシュをMLflowに記録し、データとモデルの完全な系譜(lineage)を確立する。モデルは自動的にMLflow Model Registryに登録される。
データセットレベルの系譜追跡と再現性
`data_git_commit_id`をMLflowに記録することでモデルの学習データバージョンを追跡可能にし、git checkoutとdvc pullにより完全な再現を実現する。
影響分析・編集コメントを表示
影響分析
MLOpsの標準ツールチェーンを組み合わせることで、コンプライアンス対応が容易になり、特に規制の厳しい業界でのAI導入障壁が低下する。AWSエコシステム内での実装コストを削減し、再現性と監査対応を両立させる業界標準のベストプラクティスとして定着する可能性がある。
編集コメント
規制対応が必須となる医療・金融分野において、再現性と監査証跡を担保するMLOps基盤の構築はもはやオプションではなく必須要件である。AWSが提供している実装サンプルを活用すれば、高コストな独自開発を回避しつつコンプライアンス対応が可能となるため、現場のMLOps担当者には即座に検証を推奨する。
本番環境での機械学習(Machine Learning, ML)チームは、モデルの完全な系譜(lineage)を、それを訓練したデータとコード、消費した正確なデータセット(dataset)のバージョン、そしてデプロイを正当化した実験メトリクス(experiment metrics)を通じて追跡することに苦戦しています。このトレーサビリティ(traceability)がなければ、「現在本番環境にあるモデルを訓練したのはどのデータか?」「6ヶ月前にデプロイしたモデルを再現できるか?」といった質問は、散在するログ、ノートブック、Amazon Simple Storage Service(Amazon S3)バケットをまたぐ何日もかかる調査になってしまいます。このギャップは、規制業界において特に顕著です。例えば、医療、金融サービス、自動運転車などの分野では、監査要件によりデプロイされたモデルを正確な訓練データにリンクすることが求められ、かつ、要請に応じて個々のレコードを将来の訓練から除外する必要がある場合があります。**この投稿では、このギャップを埋めるために3つのツールを組み合わせる方法を示します:
- DVC(Data Version Control):データセットのバージョン管理とGitコミットへのリンク
- Amazon SageMaker AI:スケーラブルな処理、訓練、デプロイ
- Amazon SageMaker AI MLflow Apps:実験追跡(experiment tracking)、モデルレジストリ(model registry)、系譜管理(lineage)
以下のコンパニオンノートブックを使用して、ご自身のAWSアカウントでエンドツーエンドで実行できる2つのデプロイ可能なパターン(データセットレベルの系譜:dataset-level lineage、レコードレベルの系譜:record-level lineage)について、順を追って解説します。
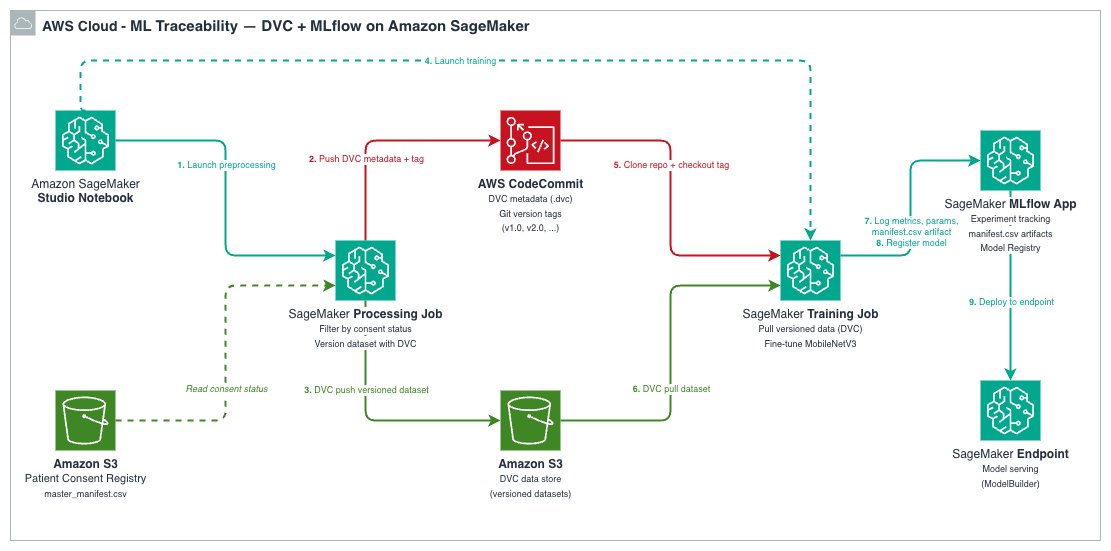
解決策の概要(Solution overview)
本アーキテクチャ(architecture)は、DVC、SageMaker AI、SageMaker AI MLflow Appを単一のワークフロー(workflow)に統合しており、すべてのモデルが正確な訓練データまで追跡可能です。
 image
image
各ツールは明確な役割を担っています:
ツール | 役割 | 保存内容
DVC | データとアーティファクトのバージョン管理(Data and artifact versioning) | Git内の軽量.dvcメタファイル;実際のデータはAmazon S3
Amazon SageMaker AI | 処理、訓練、ホスティングのためのスケーラブルなコンピューティング(Scalable compute for processing, training, and hosting) | 処理/訓練ジョブのオーケストレーション(Processing/Training job orchestration)とモデルホスティング(model Hosting)
Amazon SageMaker AI MLflow App | 実験追跡、モデルレジストリ、系譜管理(Experiment tracking, model registry, lineage) | パラメータ、メトリクス、アーティファクト、登録済みモデル
データは以下の4つのステージを流れます:
- SageMaker AI Processingジョブが生データを前処理し、DVCを使用して処理済みデータセットのバージョン管理を行います。データはS3に、メタデータはGitリポジトリにプッシュされます。
- SageMaker AI Trainingジョブは、特定のGitタグでDVCリポジトリをクローンし、
dvc pullを実行して正確なバージョン管理されたデータセットを取得します。その後モデルを訓練し、すべての情報をMLflowにログ記録します。
- 各MLflowの訓練ラン(training run)は、Amazon S3内の正確なデータセットを指すDVCコミットハッシュ(commit hash)である
data_git_commit_idを記録します。
- 訓練済みモデルはMLflow Model Registryに登録され、SageMaker AIエンドポイント(endpoint)にデプロイできます。
これにより、完全なトレーサビリティチェーン(traceability chain)が構築されます:本番環境モデル → MLflowラン(MLflow Run) → DVCコミット(DVC commit) → Amazon S3内の正確なデータセット。
Prerequisites
この投稿に沿って進めるには、以下の前提条件が必要です。
- Amazon SageMaker(Processing、Training、MLflow Apps、Endpoints)、Amazon S3、AWS CodeCommit、および AWS Identity and Access Management(IAM)へのアクセス権限を持つ AWS アカウント。
- Python 3.11 または Python 3.12。
- SageMaker Python SDK v3.4.0 以降。
companion repository には、すべての依存関係を含む requirements.txt が含まれています。SageMaker Studio 以外で実行する場合は、IAM ロールに sagemaker.amazonaws.com が AssumeRole できる信頼関係が必要です。
\n *Note on Git providers: ノートブックでは、DVC メタデータの Git バックエンドとして AWS CodeCommit が使用されています。ただし、DVC は他の Git プロバイダー(GitHub、GitLab、Bitbucket)とも連携します。必要なのは git remote add origin の URL を置き換え、適切な認証情報を設定することだけです。例えば、AWS Secrets Manager にトークンを保存して実行時に取得するか、AWS CodeConnections を使用します。重要な要件は、SageMaker AI の実行ロールが Git リポジトリにアクセスできること、または AWS CodeConnections を使用するための権限を持っていることです。*
How DVC and SageMaker AI MLflow work together
このアーキテクチャの鍵となる洞察は、DVC と MLflow がそれぞれ系統管理(ラインージ)の問題の半分を解決し、合わせて完全なループを閉じる点にあります。
DVC (Data Version Control) は、Git を拡張して大規模なデータセットや ML 成果物(アーティファクト)を扱えるようにする無償のオープンソースツールです。Git だけではリポジトリが肥大化して低速になるため、GitHub などのシステムは 100 MB を超えるファイルをブロックします。DVC はコーディフィケーション(構造化管理)によってこれを解決します:Git 内で軽量な .dvc メタファイル(コンテンツアドレス可能ポインタ)を追跡し、実際のデータは Amazon S3 などのリモートストレージに保存します。これにより、リポジトリを肥大化させることなく、ギガバイト〜テラバイト規模のデータセットに対して Git 的なバージョン管理セマンティクス(ブランチ、タグ付け、差分比較)を提供します。
\n Storage efficiency:
*DVC は コンテンツアドレス可能ストレージ(MD5 ハッシュ値)を使用するため、データセット全体を複製するのではなく、新規または変更されたファイルのみを保存します。内容が同一のファイルは、異なる名前や異なるデータセットバージョンに属していても、DVC キャッシュ内では一度だけ保存されます。例えば、既存のデータセットに 1,000 枚の新しい画像を追加した場合、S3 にアップロードされるのはそれらの新規ファイルのみです。変更されていないファイルは再アップロードされません。ただし、前処理ステップで既存のファイルが変更された場合、影響を受けるファイルは新しいハッシュ値を取得し、新規オブジェクトとして保存されます。*
データバージョン管理に加え、DVCは再現可能なdata pipelines(データパイプライン)やexperiment management(実験管理)をサポートしており、チーム間でデータセットを共有するためのdata registry(データレジストリ)としても機能します。本アーキテクチャでは、DVCをデータバージョン管理の機能に特化して使用します。dvc addでデータセットをバージョン管理し、生成された.dvcファイルをコミットするたびに、特定のデータセットの状態に対応するGitコミットが作成されます。そのコミットにタグを付けることで、git checkoutおよびdvc pullで戻れる安定した参照先が得られます。DVCのバージョン管理機能の詳細については、Versioning Data and Modelsガイドをご覧ください。
SageMaker AI MLflow Appは、SageMaker AI Studio内で提供される完全に管理されたAWSサービスで、エンドツーエンドのML(機械学習)および生成AIライフサイクルを管理します。中核機能には、すべてのトレーニング実行におけるパラメータ、指標、アーティファクトをログ記録するexperiment tracking(実験追跡)、バージョン管理とライフサイクルステージ管理を備えたmodel registry(モデルレジストリ)、モデル評価、およびdeployment integrations(デプロイメント統合)が含まれます。本記事のアーキテクチャでは、DVCの結果およびモデルレジストリを含む完全なexperiment tracking(実験追跡)にMLflowを使用します。すべてのトレーニング実行において、DVCのコミットハッシュをパラメータ(data_git_commit_id)としてログ記録することで、橋渡しを作成します:MLflowレジストリのモデルは正確なGitタグに遡って追跡可能であり、そのタグはS3内の正確なデータセットに対応します。
DVC単体でデータバージョン管理と実験追跡の両方を処理できますが、MLflowはmodel versioning(モデルバージョン管理)、ライフサイクル管理用のaliases(エイリアス)、およびdeployment integrations(デプロイメント統合)を備えた、より成熟したmodel registry(モデルレジストリ)を提供します。DVCをデータバージョン管理に、MLflowをmodel lifecycle management(モデルライフサイクル管理)に使用することで、関心の明確な分離が実現します:DVCはdata-to-training lineage(データからトレーニングへの系譜)を、MLflowはtraining-to-deployment lineage(トレーニングからデプロイメントへの系譜)を管理し、Gitコミットハッシュがこれらを結びつけます。
Pattern one: Dataset-level lineage (foundational)
統合を構築する前に、DVCのデータセットバージョン管理とMLflowの実行追跡が、完全な系譜を形成する際にどのように補完し合うかを理解することが不可欠です。基礎となるノートブックは、限られたラベル付きデータから始まり、時間とともに拡張するという一般的なシナリオをシミュレートすることで、中核パターンを示しています。
The workflow
ノートブックは、CIFAR-10画像分類データセットを使用して2つの実験を実行します:
- v1.0: データの5%(トレーニング画像約2,250枚)で処理およびトレーニング
- v2.0: データの10%(トレーニング画像約4,500枚)で処理およびトレーニング
各バージョンにおいて、同じ2段階のパイプラインが実行されます:
ステップ1 — 処理ジョブ: SageMakerのProcessingジョブ(データ処理ジョブ)はCIFAR-10をダウンロードし、設定された割合でサンプリングを行い、学習用・検証用・テスト用のセットに分割し、画像をImageFolder形式で保存し、DVC(Data Version Control)を使用して結果のバージョン管理を行います。処理済みのデータセットはdvc push経由でAmazon S3にプッシュされ、Gitメタデータ(v1.0-02-24-26_1430のような一意のタグを含む)はAWS CodeCommitにプッシュされます。
処理ジョブは、DVCリポジトリのURLとMLflowトラッキングURI(追跡URI)を環境変数として受け取ります:
processor_v1 = FrameworkProcessor(
image_uri=processing_image,
role=role,
instance_type="ml.m5.xlarge",
instance_count=1,
env={
"DVC_REPO_URL": dvc_repo_url,
"DVC_REPO_NAME": dvc_repo_name,
"MLFLOW_TRACKING_URI": mlflow_app_arn,
"MLFLOW_EXPERIMENT_NAME": experiment_name,
"PIPELINE_RUN_ID": pipeline_run_id_v1,
}
)processor_v1.run(
code="preprocessing_foundational.py",
source_dir="../source_dir",
arguments=[
"--data-fraction", str(data_fraction_v1),
"--data-version", data_version_v1,
"--val-split", "0.1"
],
wait=True
)
処理スクリプト内では、前処理の後にデータセットがDVCでバージョン管理され、コミットハッシュ(コミット識別子)がMLflowにログ記録されます:
def version_with_dvc(repo_path, version_tag, pipeline_run_id):
"""Add data to DVC and push to remote."""
subprocess.check_call(["dvc", "add", "dataset"], cwd=repo_path)
subprocess.check_call(["git", "add", "dataset.dvc", ".gitignore"], cwd=repo_path)
subprocess.check_call(
["git", "commit", "-m", f"Add dataset version {version_tag}"],
cwd=repo_path
)
subprocess.check_call(["git", "tag", pipeline_run_id], cwd=repo_path)
subprocess.check_call(["dvc", "push"], cwd=repo_path)
subprocess.check_call(["git", "push", "origin", "main"], cwd=repo_path)
subprocess.check_call(["git", "push", "origin", pipeline_run_id], cwd=repo_path)
commit_id = subprocess.check_output(
["git", "rev-parse", "HEAD"], cwd=repo_path
).decode().strip()
return commit_id ステップ2 — 学習ジョブ: SageMaker AIのTrainingジョブ(モデル学習ジョブ)は、ステップ1の正確なタグでDVCリポジトリをクローンし、dvc pullを実行してバージョン管理されたデータセットをダウンロードし、事前学習済みのMobileNetV3-Smallモデルのファインチューニングを行います。トレーニングスクリプトは、パラメータ(DVCコミットハッシュを含む)、エポックごとの指標、および学習済みモデルをMLflowにログ記録します。モデルは自動的にMLflow Model Registry(モデルレジストリ)に登録されます。
重要なラインージの橋渡し(DVCコミットハッシュをMLflowにログ記録すること)は、トレーニングスクリプト内で発生します:
# Fetch data: clone DVC repo at the exact tag, then dvc pull
data_git_commit_id = fetch_data_from_dvc()
with mlflow.start_run(run_name=run_name) as run:
mlflow.log_params({
"data_version": data_version,
"data_git_commit_id": data_git_commit_id, #MLflow で確認できる内容
両方の実験が完了すると、MLflow UI は以下のスクリーンショットに示すように、2つのランを並べて表示します。MLflow の実験では、以下を比較できます:
- データバージョンごとの学習および検証精度の曲線
- 各ランの正確なハイパーパラメータおよびデータバージョン
- 各モデルを DVC データセット(Data Version Control)にリンクする
data_git_commit_id
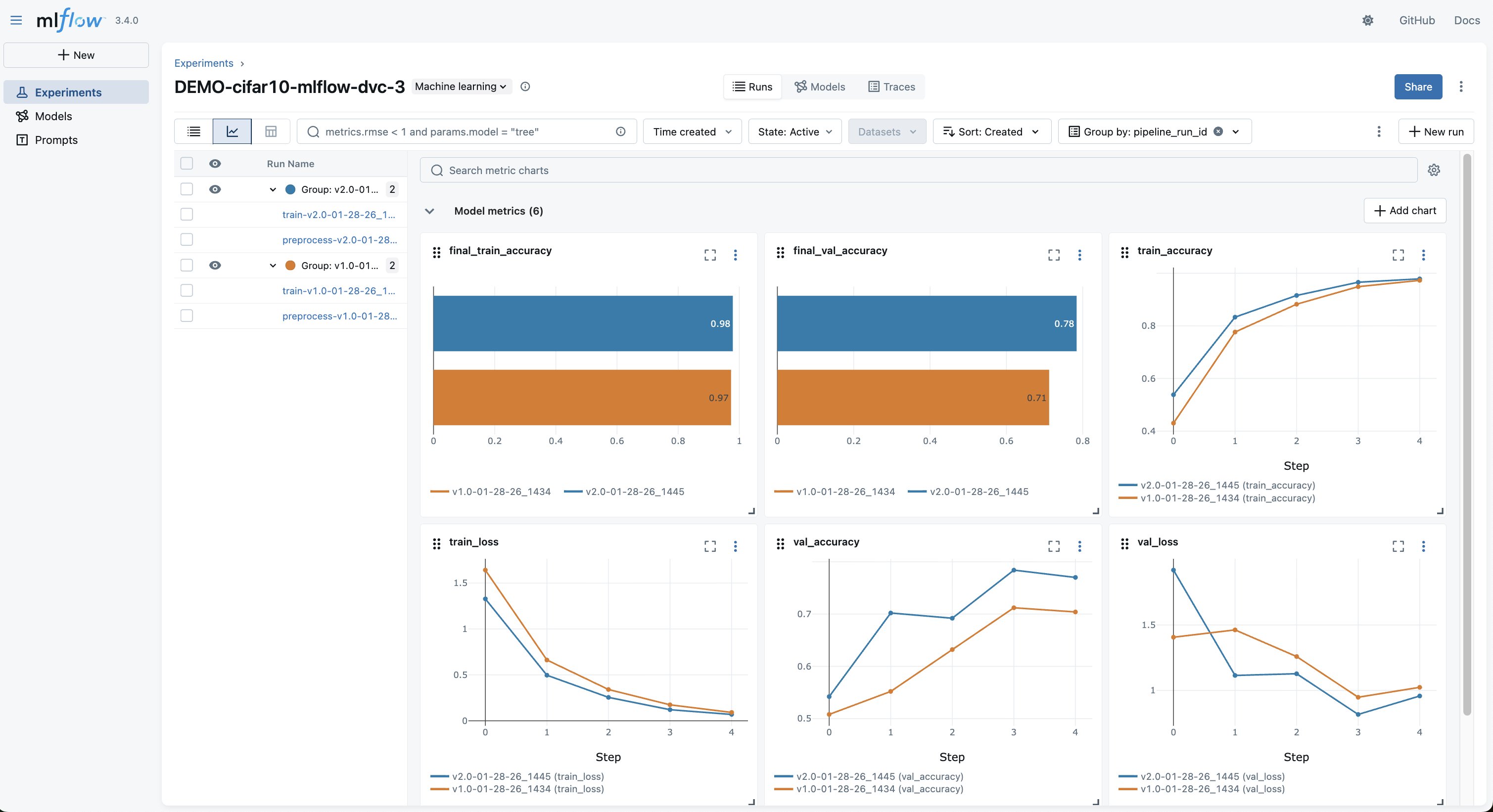
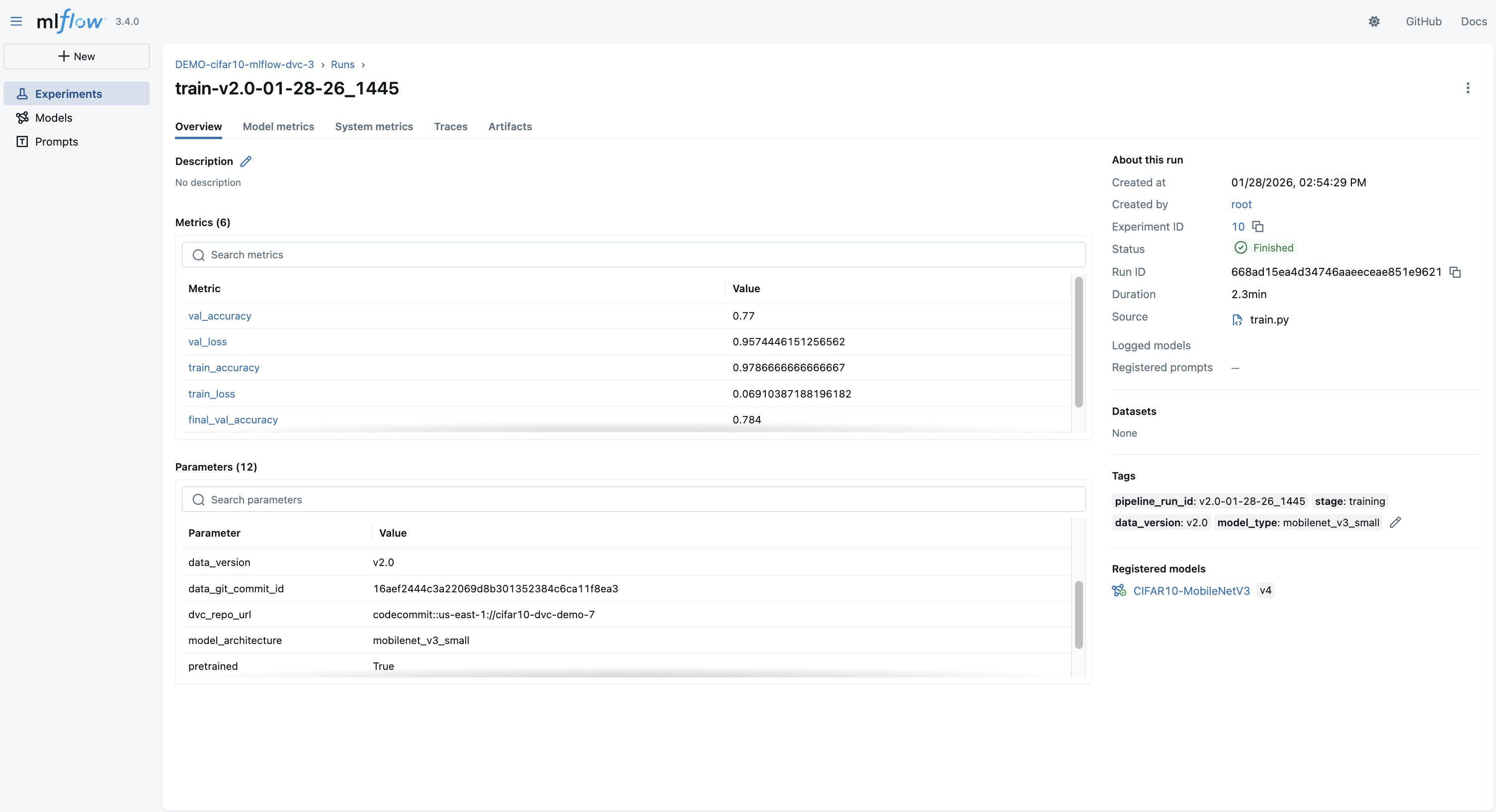
特定のランを選択すると、以下のスクリーンショットに示すように、詳細情報全体、損失曲線、パラメータ、および S3 内の正確なデータセットにリンクする DVC コミットが表示されます。
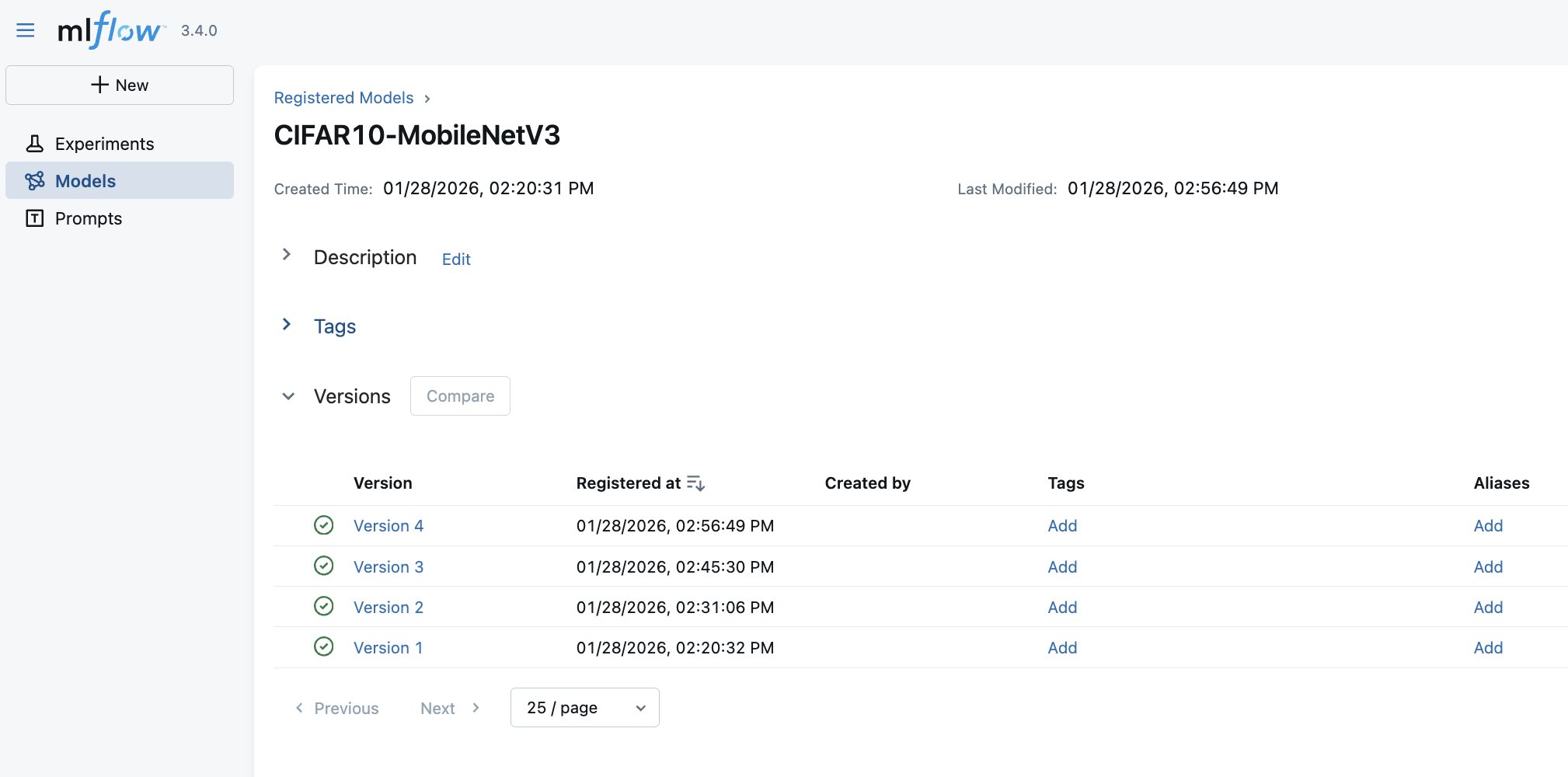
最後に、学習済み人工知能および機械学習(AI/ML)モデルは、以下のスクリーンショットに示すように、バージョン履歴およびそれらを生成したトレーニングランへのリンクとともに MLflow Model Registry に自動的に登録されます。さらに、SageMaker AI Model Registry と統合された SageMaker AI MLflow App を使用すると、MLflow は登録済みモデルを SageMaker AI Model Registry に自動的にログ記録します。
モデルのデプロイ
ノートブックは、ModelBuilder を使用して、MLflow Model Registry から推奨モデル(v2.0、より多くのデータで学習済み)を SageMaker AI リアルタイムエンドポイントにデプロイします。デプロイ後、生画像バイトでエンドポイントを呼び出し、クラス予測を取得できます。完全なデプロイおよび推論コードはノートブック内に記載されています。
このパターンが回答する内容
データセットレベルの系譜(ラインージ)を使用すると、以下の質問に回答できます:
- 「このモデルを学習したのはどのデータバージョンか?」 — MLflow のランで
data_git_commit_idを参照する - 「このモデルの学習データを再現できるか?」 —
git checkoutおよびdvc pullを実行して正確なデータセットを復元する - 「モデルのパフォーマンスが変化した理由か?」 — MLflow でランを比較し、それぞれをデータバージョンに追跡する
追加作業なしでは回答できないのはこれです:「レコード X はこのモデルの学習データに含まれていたか?」。完全なデータセットを取得して検索する必要があります。ここでパターン 2 が登場します。
パターン 2:レコードレベルの系譜(医療コンプライアンス)
パターン 2 はデータセットレベルのアプローチを直接基盤として構築し、マニフェストと同意登録簿を通じてレコード/患者レベルの追跡可能性を追加します。この医療コンプライアンスの例ノートブックは、ML ライフサイクル全体でデータセットだけでなく個別レコードも追跡する必要がある規制環境向けに、基礎パターンを拡張したものです。
重要な追加要素:マニフェスト
異なる点はマニフェストです。マニフェストは、各データバージョン内のすべての個別レコードをリストアップした構造化 CSV です:
patient_id,scan_id,file_path,split,label
PAT-00001,PAT-00001-SCAN-0001,train/normal/00042.png,train,normal
PAT-00023,PAT-00023-SCAN-0015,train/tubercolosis/00015.png,train,tubercolosis
...
このマニフェスト(manifest)は、DVCでバージョン管理されたデータセットディレクトリ内に保存され、*かつ*、すべてのトレーニング実行(training run)時にMLflowアーティファクト(MLflow artifact)としてログ記録されます。これにより、DVCから完全なデータセットを取得することなく、MLflowから個々のレコードを直接クエリすることが可能になります。
The consent registry
このワークフローはコンセントレジストリ(consent registry)によって駆動されており、各患者とその同意ステータスをリストアップしたCSVファイルです。本番環境では、これはトランザクションコミットメント(transactional commitments)、独自の監査証跡(audit trail)、および再学習(re-training)をトリガーする可能性のあるイベント駆動型トリガー(event-driven triggers)を備えたデータベースになります。ここで採用されているCSVアプローチは、簡素化された設計となっています
原文を表示
Production machine learning (ML) teams struggle to trace the full lineage of a model through the data and the code that trained it, the exact dataset version it consumed, and the experiment metrics that justified its deployment. Without this traceability, questions like “which data trained the model currently in production?” or “can we reproduce the model we deployed six months ago?” become multi-day investigations through scattered logs, notebooks, and Amazon Simple Storage Service (Amazon S3) buckets. This gap is especially acute in regulated industries. For example, healthcare, financial services, autonomous vehicles, where audit requirements demand that you link deployed models to their precise training data, and where individual records might need to be excluded from future training on request.** In this post, we show how to combine three tools to close this gap:
- DVC (Data Version Control) for versioning datasets and linking them to Git commits
- Amazon SageMaker AI for scalable processing, training, and deployment
- Amazon SageMaker AI MLflow Apps for experiment tracking, model registry, and lineage
We walk through two deployable patterns, dataset-level lineage and record-level lineage, that you can run end-to-end in your own AWS account using the companion notebooks.
Solution overview
The architecture integrates DVC, SageMaker AI, and SageMaker AI MLflow App into a single workflow where every model is traceable back to its exact training data.
Each tool plays a distinct role:
Tool**
Role
What it stores
DVC
Data and artifact versioning
Lightweight .dvc metafiles in Git; actual data in Amazon S3
Amazon SageMaker AI
Scalable compute for processing, training, and hosting
Processing/Training job orchestration and model Hosting
Amazon SageMaker AI MLflow App
Experiment tracking, model registry, lineage
Parameters, metrics, artifacts, registered models
The data flows through four stages:
- A SageMaker AI Processing job preprocesses raw data and versions the processed dataset with DVC, pushing the data to S3 and metadata to a Git repository.
- A SageMaker AI Training job clones the DVC repository at a specific Git tag, runs dvc pull to retrieve the exact versioned dataset, trains the model, and logs everything to MLflow.
- Every MLflow training run records the data_git_commit_id, which is the DVC commit hash that points to the exact dataset in Amazon S3.
- The trained model is registered in the MLflow Model Registry and can be deployed to a SageMaker AI endpoint.
This creates a complete traceability chain: Production Model → MLflow Run → DVC commit → exact dataset in Amazon S3.
Prerequisites
You must have the following prerequisites to follow along with this post:
- An AWS account with permissions for Amazon SageMaker (Processing, Training, MLflow Apps, Endpoints), Amazon S3, AWS CodeCommit, and AWS Identity Access Management (IAM).
- Python 3.11 or Python 3.12.
- The SageMaker Python SDK v3.4.0 or later.
The companion repository includes a requirements.txt with all dependencies. If running outside SageMaker Studio, your IAM role must have a trust relationship allowing sagemaker.amazonaws.com to assume it.
Note on Git providers: The notebooks use AWS CodeCommit as the Git backend for DVC metadata. However, DVC works with other Git providers (GitHub, GitLab, Bitbucket). All you need to do is replace the git remote add origin URL and configure appropriate credentials. For example, by storing tokens in AWS Secrets Manager and fetching them at runtime or by using AWS CodeConnections. The key requirement is that your SageMaker AI execution role can access the Git repository or has permissions to use AWS CodeConnections.
How DVC and SageMaker AI MLflow work together
The key insight behind this architecture is that DVC and MLflow each solve half of the lineage problem, and together they close the loop.
DVC (Data Version Control) is a no cost, open source tool that extends Git to handle large datasets and ML artifacts. Git alone can’t manage large binary files because repositories become bloated and slow, and systems like GitHub block files over 100 MB. DVC addresses this through codification: it tracks lightweight .dvc metafiles in Git (content-addressable pointers) while the actual data lives in remote storage such as Amazon S3. This gives you Git-like versioning semantics (branching, tagging, diffing) for datasets that can be gigabytes or terabytes in size, without bloating your repository.
Storage efficiency:
DVC uses content-addressable storage (MD5 hashes), so it stores only new or modified files rather than duplicating entire datasets. Files with identical contents are stored only once in the DVC cache, even if they appear under different names or across different dataset versions. For example, adding 1,000 new images to an existing dataset only uploads those new files to S3. The unchanged files aren’t re-uploaded. However, if a preprocessing step modifies existing files, the affected files get new hashes and are stored as new objects.
Beyond data versioning, DVC also supports reproducible data pipelines, experiment management, and can serve as a data registry for sharing datasets across teams. In this architecture, we use DVC specifically for its data versioning capability. Every time you version a dataset with dvc add and commit the resulting .dvc file, you create a Git commit that maps to a specific dataset state. Tagging that commit gives you a stable reference you can return to with git checkout && dvc pull. For a deeper dive into DVC’s versioning capabilities, see the Versioning Data and Models guide.
SageMaker AI MLflow App is a fully managed AWS service offered within SageMaker AI Studio, for managing the end-to-end ML and generative AI lifecycle. Its core capabilities include experiment tracking (logging parameters, metrics, and artifacts for every training run), a model registry with versioning and lifecycle stage management, model evaluation, and deployment integrations. In this post’s architecture, we use MLflow for full experiment tracking including DVC results and the model registry. By logging the DVC commit hash as a parameter (data_git_commit_id) on every training run, we create the bridge: models in the MLflow registry can be traced back to the exact Git tag, which maps to the exact dataset in S3.
While DVC can handle both data versioning and experiment tracking on its own, MLflow brings a more mature model registry with model versioning, aliases for lifecycle management, and deployment integrations. By using DVC for data versioning and MLflow for model lifecycle management, we get a clean separation of concerns: DVC owns the data-to-training lineage, MLflow owns the training-to-deployment lineage, and the Git commit hash ties them together.
Pattern one: Dataset-level lineage (foundational)
Before building the integration, it’s essential to understand how DVC’s dataset versioning and MLflow’s run tracking complement each other in forming a full lineage. The foundational notebook demonstrates the core pattern by simulating a common scenario: starting with limited labeled data and expanding over time.
The workflow
The notebook runs two experiments using the CIFAR-10 image classification dataset:
- v1.0: Process and train with 5% of the data (~2,250 training images)
- v2.0: Process and train with 10% of the data (~4,500 training images)
For each version, the same two-step pipeline executes:
Step 1 — Processing job: A SageMaker Processing job downloads CIFAR-10, samples the configured fraction, splits into train/validation/test sets, saves images in ImageFolder format, and versions the result with DVC. The processed dataset is pushed to S3 via dvc push, and the Git metadata (including a unique tag like v1.0-02-24-26_1430) is pushed to CodeCommit.
The processing job receives the DVC repository URL and MLflow tracking URI as environment variables:
processor_v1 = FrameworkProcessor(
image_uri=processing_image,
role=role,
instance_type="ml.m5.xlarge",
instance_count=1,
env={
"DVC_REPO_URL": dvc_repo_url,
"DVC_REPO_NAME": dvc_repo_name,
"MLFLOW_TRACKING_URI": mlflow_app_arn,
"MLFLOW_EXPERIMENT_NAME": experiment_name,
"PIPELINE_RUN_ID": pipeline_run_id_v1,
}
)
processor_v1.run(
code="preprocessing_foundational.py",
source_dir="../source_dir",
arguments=[
"--data-fraction", str(data_fraction_v1),
"--data-version", data_version_v1,
"--val-split", "0.1"
],
wait=True
)Inside the processing script, after preprocessing, the dataset is versioned with DVC and the commit hash is logged to MLflow:
def version_with_dvc(repo_path, version_tag, pipeline_run_id):
"""Add data to DVC and push to remote."""
subprocess.check_call(["dvc", "add", "dataset"], cwd=repo_path)
subprocess.check_call(["git", "add", "dataset.dvc", ".gitignore"], cwd=repo_path)
subprocess.check_call(
["git", "commit", "-m", f"Add dataset version {version_tag}"],
cwd=repo_path
)
subprocess.check_call(["git", "tag", pipeline_run_id], cwd=repo_path)
subprocess.check_call(["dvc", "push"], cwd=repo_path)
subprocess.check_call(["git", "push", "origin", "main"], cwd=repo_path)
subprocess.check_call(["git", "push", "origin", pipeline_run_id], cwd=repo_path)
commit_id = subprocess.check_output(
["git", "rev-parse", "HEAD"], cwd=repo_path
).decode().strip()
return commit_idStep 2 — Training job: A SageMaker AI Training job clones the DVC repository at the exact tag from Step 1, runs dvc pull to download the versioned dataset, and fine-tunes a pretrained MobileNetV3-Small model. The training script logs the parameters (including the DVC commit hash), per-epoch metrics, and the trained model to MLflow. The model is automatically registered in the MLflow Model Registry.
The critical lineage bridge (logging the DVC commit hash to MLflow), happens in the training script:
# Fetch data: clone DVC repo at the exact tag, then dvc pull
data_git_commit_id = fetch_data_from_dvc()
with mlflow.start_run(run_name=run_name) as run:
mlflow.log_params({
"data_version": data_version,
"data_git_commit_id": data_git_commit_id, # <-- the lineage bridge
"dvc_repo_url": dvc_repo_url,
"model_architecture": "mobilenet_v3_small",
"epochs": args.epochs,
"learning_rate": args.learning_rate,
# ...
})What you see in MLflow
After both experiments complete, the MLflow UI shows both runs side-by-side, as shown in the following screenshot. In the MLflow experiment, you can compare:
- Training and validation accuracy curves across data versions
- The exact hyperparameters and data version for each run
- The data_git_commit_id that links each model to its DVC dataset
Selecting into a run shows the full detail, loss curves, parameters, and the DVC commit linking to the exact dataset in S3, as shown in the following screenshot.
Finally, trained artificial intelligence and machine learning (AI/ML) Models are automatically registered in the MLflow Model Registry with version history and links to the training run that produced them, as shown in the following screenshot. Furthermore, with SageMaker AI MLflow App integrated with SageMaker AI Model Registry, the MLflow automatically logs the registered model into SageMaker AI Model Registry.
Deploying the model
The notebook deploys the recommended model (v2.0, trained on more data) from the MLflow Model Registry to a SageMaker AI real-time endpoint using ModelBuilder. After deployed, you can invoke the endpoint with raw image bytes and get back class predictions. The full deployment and inference code is in the notebook.
What this pattern answers
With dataset-level lineage, you can answer:
- “Which dataset version trained this model?” — Look up the data_git_commit_id in the MLflow run
- “Can I reproduce this model’s training data?” — Run git checkout && dvc pull to restore the exact dataset
- “Why did model performance change?” — Compare runs in MLflow and trace each to its data version
What it *doesn’t* answer without extra work: *“Was record X in this model’s training data?”* You’d need to pull the full dataset and search through it. That’s where Pattern two comes in.
Pattern two: Record-level lineage (healthcare compliance)
Pattern 2 builds directly on the dataset-level approach, adding record/patient-level traceability through manifests and consent registries. The example healthcare compliance notebook extends the foundational pattern for regulated environments where you need to trace individual records, not only datasets, through the ML lifecycle.
The key addition: a manifest
The difference is a manifest. A manifest is a structured CSV listing every individual record in each dataset version:
patient_id,scan_id,file_path,split,label
PAT-00001,PAT-00001-SCAN-0001,train/normal/00042.png,train,normal
PAT-00023,PAT-00023-SCAN-0015,train/tubercolosis/00015.png,train,tubercolosis
...This manifest is saved inside the DVC-versioned dataset directory *and* logged as an MLflow artifact on every training run. This makes individual records queryable directly from MLflow without pulling the full dataset from DVC.
The consent registry
The workflow is driven by a consent registry, which is a CSV file listing each patient and their consent status. In production, this would be a database with transactional commitments, its own audit trail, and potentially event-driven triggers to initiate re-training. The CSV approach here is streamlined for
関連記事
Google Colab CLI の紹介
Google は、開発者や AI エージェントがローカル端末からリモート Colab ランタイムに接続し、高機能 GPU を要求して Python スクリプトをシームレスに実行できる新ツール「Google Colab CLI」を発表した。
DLAMI および DLC で SOCI インデックスを活用し、コンテナの起動時間を短縮
AWS は Deep Learning AMI と AWS Deep Learning Containers に Seekable OCI (SOCI) のサポートを追加しました。これにより、コンテナイメージの効率的な管理が可能となり、コールドスタート時間の削減を実現します。
埋め込み型 Amazon SageMaker AI MLflow アプリをカスタムポータルに構築する方法
AWS は、大規模な機械学習チーム向けに、SSO を統合した内部ポータルへ Amazon SageMaker AI の MLflow アプリを安全かつスケーラブルに埋め込む手法を発表しました。