AIトレーニングのリダイレクトが正規コンテンツを強制
Cloudflareは既存のcanonicalタグをAI学習用クローラー向けに自動でHTTP 301リダイレクトに変換する新機能を公開し、古いコンテンツによるモデル学習のリスクを軽減する。
キーポイント
AIクローラーの信号無視と古知識継承リスク
noindexや非表示バナーを無視するAI学習クローラーが古いドキュメントを学習データとして取り込むため、エージェントが古くなった基礎情報を継承するリスクがある。
既存の制御手法の限界
検索エンジン向けのnoindexやブロック、robots.txtではAIクローラーへの適切な誘導が困難であり、維持コストも膨大になるため、具体的な学習先指示が必要とされる。
canonicalタグを活用した自動リダイレクト機能
既存のHTML canonicalタグを、検証済みAI学習クローラー向けに自動でHTTP 301リダイレクトに変換する「Redirects for AI Training」を全有料プランでワンクリック有効化できる。
AIクローラー応答の可視化
RadarのAI Insightsページで、AIクローラーが受信するHTTPステータスコード(2xx〜5xx)の分析機能を追加し、ウェブ全体のクローラー対応状況を把握可能にした。
AIクローラー限定の自動canonicalリダイレクト
検証済みAI Crawlerカテゴリ(GPTBot、ClaudeBot等)からのリクエストに対し、ページ内の<link rel="canonical">タグを自動で解析し、301リダイレクトを発行する。
適用外と設計上の制限
人間やAIエージェントのアクセスは影響を受けない。既存学習データの修正、未検証クローラー、ドメイン跨ぎのcanonicalタグ、および自己参照タグは意図的に除外されている。
手動リダイレクトルールとの比較優位性
コンテンツ変更時に同期がずれるリスクを回避でき、スケーラビリティとプラン制限の観点から、手動でのルール管理やユーザーエージェント追跡に依存しない。
影響分析・編集コメントを表示
影響分析
本機能は、大規模言語モデルの学習データソースとしてウェブコンテンツを無差別にスキャンするAIクローラーへの対策として実用的な解決策を提供する。開発者は追加コードなしで既存のSEO慣習(canonicalタグ)を活用できるため、導入ハードルが低い。今後はAI学習データの品質管理と正確性に関する業界標準の議論を加速させる可能性がある。
編集コメント
検索エンジン向けのSEO施策をAI学習クローラー向けに転用する発想が秀逸だ。ただし、すべてのAIクローラーベンダーが「verified」ステータスを承認するかどうかは今後のエコシステム次第であり、プラットフォーム依存のリスクにも注意が必要である。

前述のように、Radarのデータエクスプローラーでは、追加のフィルターを適用することでデータをさらに詳細に掘り下げることができます。例えば、どのクローラーが最も多くの存在しないコンテンツをリクエストしているか(結果として404応答ステータスコードを返す)、そのリクエストトラフィックが時間とともにどのように推移しているか、あるいはどの業界がAIトレーニングクローラーに対して最も多くのリダイレクト(3xx)応答ステータスコードを送信しているか、その活動が時間とともにどのように変化しているかなどを確認できます。


応答ステータスコードのデータは、集計値としても、ボットごとのデータとしても、Cloudflare Radar APIを通じて利用可能です。
AIトレーニング用リダイレクトでは、クローラーがオリジンから受け取る内容を制御することができます。Radarのステータスコード分析では、ウェブの他の部分がAIクローラーにどのように応答しているかを確認できます。AIクロール制御の「概要」ページにある「クイックアクション」からAIトレーニング用リダイレクトを有効にし、サイト上のアドバイザリーシグナルを強制的に反映させることを今日から始めましょう。
質問がある場合や、ご自身の観察結果を共有したい場合は、Cloudflareコミュニティでの議論に参加するか、Discordで私たちを見つけてください。
原文を表示
Cloudflare's Wrangler CLI has published several major versions over the past six years, each containing at least some critical changes to commands, configuration, or how developers interact with the platform. Like any actively maintained open-source project, we keep documentation for older versions available. The v1 documentation carries a deprecation banner, a noindex meta tag, and canonical tags pointing to current docs. Every advisory signal says the same thing: this content is outdated, look elsewhere. AI training crawlers don’t reliably honor those signals.
We use AI Crawl Control on developers.cloudflare.com, so we know that bots in the AI Crawler Category visited 4.8 million times over the last 30 days, and they consumed deprecated content at the same rate as current content. The advisory signals made no measurable difference. The effect is cumulative because AI agents don't always fetch content live; they draw on trained models. When crawlers ingest deprecated docs, agents inherit outdated foundations.
Today, we’re launching Redirects for AI Training to let you enforce that verified AI training crawlers are redirected to up-to-date content. Your existing canonical tags become HTTP 301 redirects for verified AI training crawlers, automatically, with one toggle, on all paid Cloudflare plans.
And because status codes are ultimately how the web communicates policy to crawlers, Radar's AI Insights page now includes Response status code analysis showing the various types (successful (2xx), redirection (3xx), client error (4xx), and server error (5xx) of status codes AI crawlers receive across all Cloudflare traffic as a view of how the web responds to AI crawlers today.
AI training crawlers face dead ends today
For search engines, noindex functions as a rich signal system, but there’s no equivalent inline directive a page can carry that says “don’t train on this”. Keeping a deprecated page live with a warning banner may work for humans, who read the notice and navigate on, but AI training crawlers ingest the full text and risk treating the banner as just one more paragraph, returning thousands of times even after the warning is visible.
Blocking creates its own problem: it produces a void with no signal about what the crawler should learn instead. robots.txt offers limited protection, but as automated traffic grows, maintaining per-crawler, per-path, per-content-update directives requires hefty manual upkeep. What crawlers need is specific direction: “Here is where the current content lives.”
The <link rel="canonical"> tag is an HTML element defined in RFC 6596 that tells search engines and automated systems which URL represents the authoritative version of a page. It’s already present on 65-69% of web pages and is generated automatically by platforms like EmDash, WordPress, and Contentful. That infrastructure declares what the current version of your content is, and Redirects for AI Training enforces it.
How it works
Redirects for AI Training operates on two inputs: Cloudflare's cf.verified_bot_category field and the <link rel="canonical"> tags already in your HTML. The AI Crawler category covers bots that crawl for AI model training, including GPTBot, ClaudeBot, and Bytespider, and is distinct from the AI Assistant and AI Search categories that cover AI Agents.
When a request arrives from a verified AI Crawler, Cloudflare reads the response HTML. If a non-self-referencing canonical tag is present, Cloudflare issues a 301 Moved Permanently to the canonical URL before returning the response. Human traffic, search indexing, and other automated traffic is unaffected.
Here’s what the exchange looks like for a GPTBot request to a deprecated path:
GET /durable-objects/api/legacy-kv-storage-api/
Host: developers.cloudflare.com
User-Agent: Mozilla/5.0 (compatible; GPTBot/1.1; +https://openai.com/gptbot)
HTTP/1.1 301 Moved Permanently
Location: https://developers.cloudflare.com/durable-objects/api/sqlite-storage-api/
What this does not do
It doesn't retroactively correct training data already ingested or cover unverified crawlers outside the AI Crawler bot category. Humans and AI Agents visiting deprecated pages will not be redirected. We also exclude cross-origin canonicals by design (tags directing to preferred URLs on different domains), since they’re often used for domain consolidation rather than content freshness. To avoid loops, self-referencing canonicals (a tag on a page pointing to its own URL) don't trigger a redirect either.
Why not just use redirect rules?
Single Redirect Rules can target AI crawlers by user-agent string, and if a site has just a handful of known deprecated paths, that works. But it doesn't scale: every new deprecated path requires a change to the rule, user-agents must be manually tracked, and it would contribute to plan limitations that may otherwise be used for campaign URLs or domain migrations. Redirect rules also manually re-encode what canonical tags already declare and fall out of sync as content changes.
What we found on our own documentation site
Our own experience shows that this problem is real. We run AI Crawl Control on developers.cloudflare.com using the same dashboard available to all Cloudflare customers. In March 2026, legacy Workers documentation was crawled around 46,000 times by OpenAI, 3,600 times by Anthropic, and 1,700 times by Meta.
That crawling of deprecated pages may be why when we asked a leading AI assistant in April 2026, "How do I write KV values using the Wrangler CLI?", it gave an out-of-date answer: "You write to Cloudflare KV via the Wrangler CLI using the kv:key put command."
In fact, the correct syntax (as at April 2026) is wrangler kv key put; the colon syntax (kv:key put) was deprecated in Wrangler 3.60.0. Our documentation carries an inline deprecation notice, but it's unclear how training pipelines interpret them.
So we enabled Redirects for AI Training on developers.cloudflare.com and measured the response. In the first seven days, 100% of AI training crawler requests to pages with non-self-referencing canonical tags were redirected and were not served with deprecated content.
We expect that redirecting crawlers to current content eventually improves AI-generated answers about legacy tools. Given the closed nature of training pipelines and variability in recrawl timing, this is a hypothesis we will continue to verify. But what the crawler receives at the point of access has seen immediate improvement.
How to enable
If your site has canonical tags, your existing content hierarchy can now be enforced for verified AI training crawlers. Cloudflare's verified bot classification handles crawler identification automatically.
In the dashboard: on any domain, go to AI Crawl Control > Quick Actions > Redirects for AI training > toggle on.
For path-specific control via Configuration Rules and Cloudflare for SaaS, see the full documentation.
How the web responds to AI crawlers
Redirects for AI Training turns one status code, 301 Moved Permanently, into an enforcement mechanism for your content policy. But 301 is one signal in a broader conversation between origins and crawlers. A 200 OK means content was served. A 403 Forbidden means access was blocked. A 402 Payment Required tells the client it needs to pay for access. Taken together, the distribution of status codes across AI crawler traffic reveals how the web is actually responding to crawlers at scale.
Radar’s AI Insights page now includes a Response status code analysis graph illustrating the distribution of the top response status codes or response status code groupings (selectable via a dropdown) for AI crawler traffic. The data can be filtered by industry set; the crawl purpose filter can also be applied in Data Explorer. Filtered analyses provide a perspective into whether certain types of crawlers behave differently, or if request patterns and distributions vary by industry.
In the general example shown below, we can see that for the time period covered by the graph, just over 70% of requests were serviced successfully (200), while 10.1% of the requests were redirected (301, 302) to another URL, and 3.7% were for files that weren’t found (404). Access to content was blocked for 8.3% of requests, receiving a 403 response status code. Grouped, we find that nearly 74% of requests received successful responses (2xx), 13.7% received client error responses (4xx), 11.3% received redirection messages (3xx), and 1.2% were sent server error responses (5xx).
 image
image
 image
image
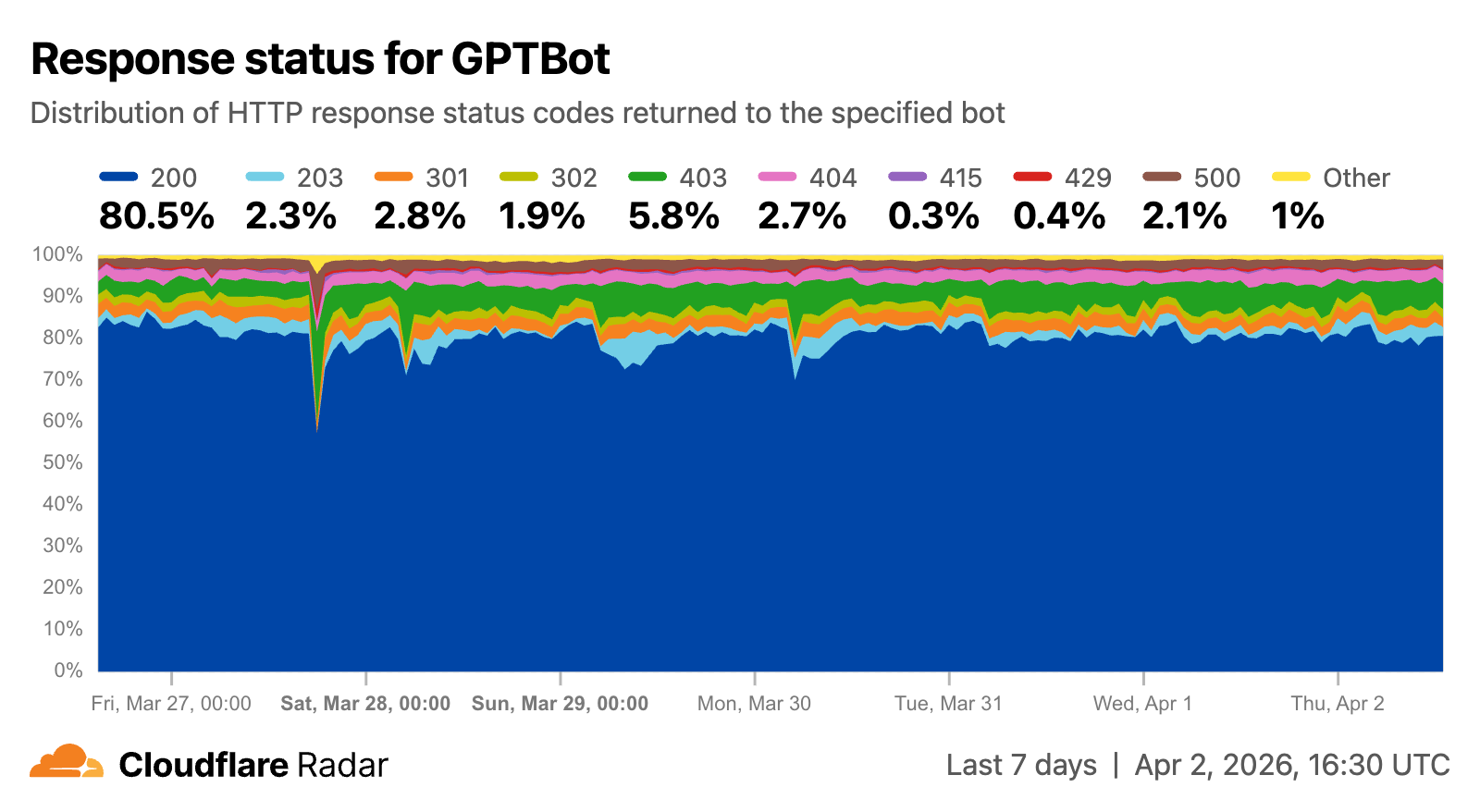
This analysis has also been added to individual bot pages to provide insight into this aspect of a crawler’s behavior as well. In the GPTBot example shown below, we can see that for the time period covered by the graph, just over 80% of requests were serviced successfully (200), while 4.7% of the requests were redirected (301, 302) to another URL, and just 2.7% were for files that weren’t found (404). Nearly 6% were blocked, with Cloudflare returning a 403 response status code. Grouped, we find that 83% of requests received successful responses (2xx), nearly 10% received client error responses (4xx), 5.1% received redirection messages (3xx), and the remaining 2.2% got server error responses (5xx).
image
image
As noted above, Radar’s Data Explorer enables users to drill down further into the data by applying additional filters. For example, we can look at things like which crawlers are requesting the most non-existent content (resulting in a 404 response status code), and how that request traffic trends over time, or which industries are sending the most Redirection (3xx) response status codes to Training crawlers, and how that activity trends over time.
image
image
Response status code data, both in aggregate and on a per-bot basis, is also available through the Cloudflare Radar API.
Redirects for AI Training lets you shape what crawlers receive from your origin; Radar's status code analysis lets you see how the rest of the web is doing the same. Enable Redirects for AI Training in AI Crawl Control > Overview > Quick Actions to start replacing advisory signals with enforced outcomes on your site today.
Have questions or want to share what you're seeing? Join the discussion on the Cloudflare Community or find us on Discord.
関連記事
AI の請求額が制御不能に。Cloudflare が今すぐ解決します
Cloudflare は、多くの企業が AI 導入でコスト超過に悩む現状に対し、AI 利用の費用管理を改善するソリューションを提供すると発表しました。
Vite 開発元 VoidZero が Cloudflare に参画
Vite や Vitest を開発する企業「VoidZero」がクラウドプロバイダー「Cloudflare」に合流し、同社全従業員も Cloudflare の一員となる。ただし、主要プロジェクトは引き続きオープンソースとして運営される方針を示した。
BGP AS_PATH の最初の AS を強制する仕組みの導入
Cloudflare は、Spamhaus が報告したルート乗っ取り事案を踏まえ、不正なアクターが未使用の自律システム番号(ASN)を利用して偽の AS_PATH を作成しトラフィックを誤誘導する手口に対処するため、BGP の経路情報において最初の AS 番号の検証を強化する措置を発表した。