Amazon SageMaker AI にコンテナキャッシュ機能を導入し、モデルのスケーリングを高速化
Amazon SageMaker AI は、新しいインスタンス起動時のコンテナイメージダウンロード遅延を解消する「コンテナキャッシング」機能を導入し、生成 AI モデルのスケーリング時のエンドツーエンドレイテンシを最大 2 倍短縮した。
キーポイント
新しいインスタンス起動時のボトルネック解消
既存のキャッシュ機能では対応できなかった、新規インスタンス起動時に発生するコンテナイメージダウンロードの遅延を、新しいキャッシング機構によって排除する。
スケーリングパフォーマンスの劇的向上
スケールアウトイベント発生時における生成 AI モデルのエンドツーエンドレイテンシが最大 2 倍短縮され、応答性が大幅に改善される。
スケーリングプロセスの全体最適化
インスタンスプロビジョニング、イメージプル、モデルアーティファクト取得、コンテナ起動までの全工程を最適化する一連の取り組みの一環として機能する。
影響分析・編集コメントを表示
影響分析
この発表は、大規模生成 AI モデルの運用において最もボトルネックになりやすい「コールドスタート」問題を解決する重要な技術的進展です。特に負荷が急増して新規インスタンスを起動する必要がある際にも高速化が可能となるため、コスト効率とユーザーエクスペリエンスの両面で AWS 上の AI アプリケーションの信頼性を高めることになります。
編集コメント
生成 AI の実運用において、スケーリング時の遅延はユーザー体験を損なう主要因の一つですが、AWS がインフラレベルでこの課題に体系的に取り組んでいる点は評価できます。特に新規インスタンス起動時のパフォーマンス改善は、急激なトラフィック増加への対応力を高める上で極めて重要です。
本日、Amazon SageMaker AI の推論におけるコンテナイメージキャッシングを発表できることを嬉しく思います。これは、より高速なスケーリング最適化への旅路における次の主要な進展です。これにより、スケールアウトイベント発生時に生成 AI モデルのエンドツーエンドレイテンシを最大 2 倍に短縮します。
過去数年間、Amazon SageMaker AI はこれらのスケーリング段階全体でレイテンシ削減を続けてきました。具体的には、スケールアウトの必要性を検知し、インスタンスのプロビジョニングを行い、コンテナイメージをダウンロードし、モデルウェイトを取得し、コンテナを開始するプロセスです。Amazon SageMaker AI は以前、従来のメカニズムよりも最大 6 倍高速にスケールアウトの必要性を検出できるよう支援する 1 分未満の Amazon CloudWatch メトリクス を導入し、コンテナイメージとモデルアーティファクトを実行中のインスタンスに保存する 推論コンポーネントデータキャッシングソリューション も発表しました。このアプローチにより、既存のインスタンスを再利用してスケーリングする推論コンポーネント操作のコールドスタートレイテンシが削減されました。これらの機能はすべて、推論コンポーネントがすでにプロビジョニングされたインスタンスに配置され、既存のキャッシュを利用できるシナリオにおける自動スケーリングの応答性を向上させました。
コンテナキャッシングにより、Amazon SageMaker AI は、新しいインスタンスを起動しなければならないシナリオにもこれらのスケーリング改善を拡張します。コンテナキャッシングは、以前のインスタンストレージベースのキャッシングでは対応できなかった、新しいインスタンスを起動しなければならない場合でも、コンテナイメージのダウンロード遅延を除去します。本記事では、コンテナキャッシングがどのようにコンテナイメージのダウンロードボトルネックに対処するかを示し、期待できるパフォーマンス改善を実証します。
新しいインスタンスの起動が必要なスケーリングの課題
以下の図は、新しいインスタンスが起動される際のインスタンススケーリング中の手順を示しています。
- インスタンスのプロビジョニング: 新しい Amazon Elastic Compute Cloud (Amazon EC2) インスタンスが起動されます。
- コンテナイメージのプル: コンテナイメージが Amazon Elastic Container Registry (Amazon ECR) から取得されます。
- モデルアーティファクトのダウンロード: モデルの重み付けデータが Amazon Simple Storage Service (Amazon S3) からフェッチされます。
- コンテナの起動とヘルスチェック: 推論サーバーが初期化され、モデルをメモリに読み込み、準備完了チェックに合格します。
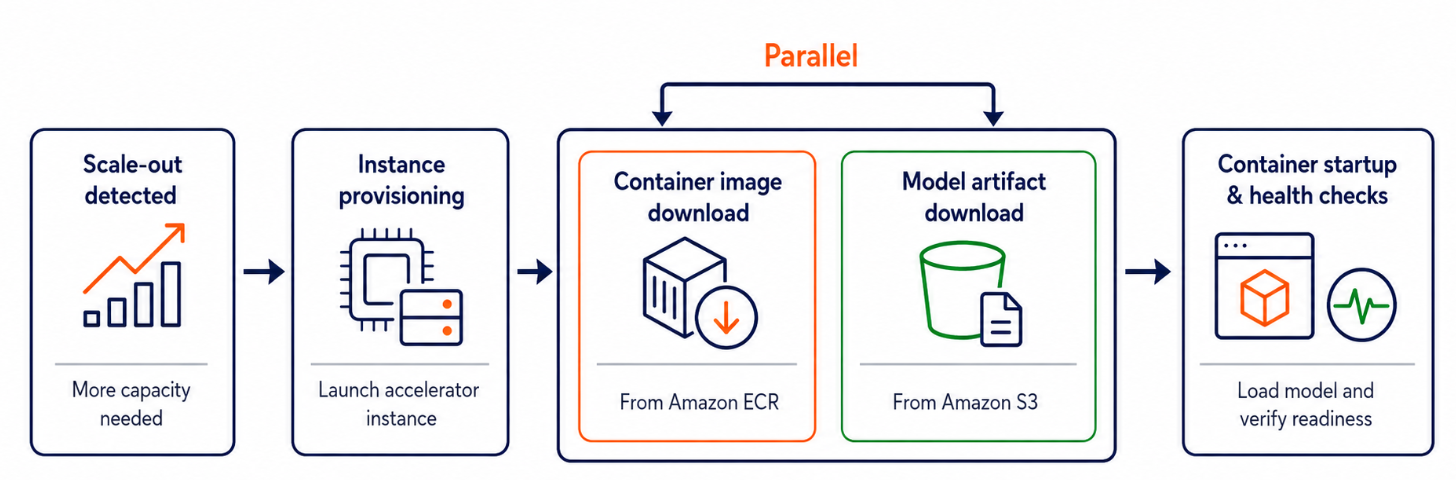
注: コンテナイメージのダウンロードとモデルアーティファクトのダウンロードは並行して実行されます。
コンテナイメージのダウンロードは、特に生成 AI ワークロードにおいてエンドポイントのスケーリング遅延の主要な要因となることが多いです。これらのワークロードでは、SageMaker Large Model Inference (LMI, vLLM によって駆動)、vLLM、NVIDIA Triton などの大規模コンテナが使用されます。コンテナキャッシングを適用することで、一般的なエンドポイントパターンにおける新しいインスタンスのスケーリングイベント時に、コンテナイメージのプルステップを省略できます。
- シングルモデルエンドポイント – スケーリングは、各インスタンスが独自のモデルコピーをホストするように追加インスタンスを開始することによって達成されます。
- インフェレンスコンポーネントベースのエンドポイント – スケーリングでは、既存のインスタンスに追加のインフェレンスコンポーネントをホストする十分な容量がない場合にのみ、新しいインスタンスが追加されます。
コンテナキャッシングによるイメージプルボトルネックの解消
以下の図は、LMI コンテナ (圧縮サイズ 17.7 GB) を使用して ml.g6.2xlarge インスタンス上で Qwen3-8B (16 GB) モデルのスケーリングタイムラインがどのように変化するかを示しています。
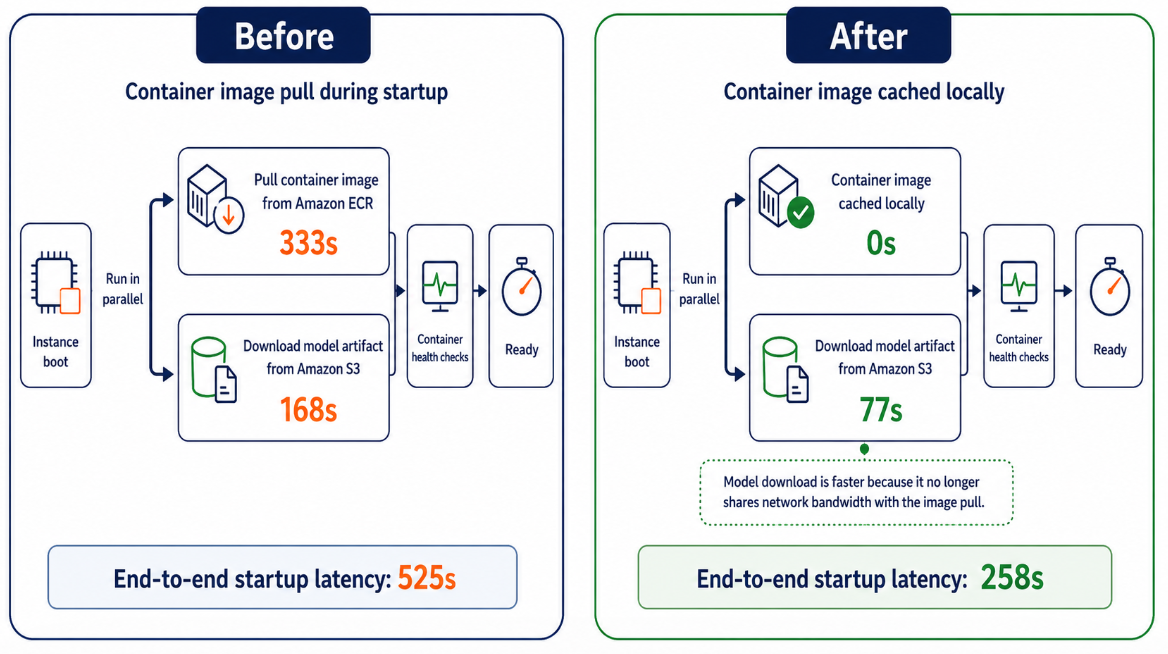
コンテナキャッシング適用前:
- Amazon ECR からのコンテナイメージプル: 333 秒
- Amazon S3 からのモデルアーティファクトダウンロード: 168 秒
イメージプルとモデルのダウンロードは並列で実行されたため、エンドツーエンドの起動遅延は 525 秒となりました。
コンテナキャッシング適用後:
- コンテナイメージはすでにローカルにキャッシュされている:0 秒
- モデルアーティファクトのダウンロード:77 秒。コンテナイメージが事前にキャッシュされているため、モデルのダウンロードがイメージのプルとネットワーク帯域幅を競合しなくなり、レイテンシが 168 秒から 77 秒に短縮されました。
エンドツーエンドの起動レイテンシは 258 秒に低下します。
結果: コンテナキャッシングにより、スケールアウトパスからイメージプルが除外され、ネットワーク帯域幅の競合が解消されることで、エンドツーエンドの起動レイテンシが 525 秒から 258 秒に短縮されました。これは約 51 パーセントの改善です。キャッシュされたイメージが利用できない場合、SageMaker AI は自動的に Amazon ECR からのプルにフォールバックするため、スケーリングがブロックされることはありません。
インフェレンスコンポーネントとのコンテナキャッシングの動作
コンテナキャッシングはインフェレンスコンポーネント(inference components)と連携して動作します。複数のインフェレンスコンポーネントを展開する場合、キャッシュには各インフェレンスコンポーネントが参照する固有のコンテナイメージがそれぞれ保存されます。
セキュリティとテナント分離
コンテナイメージキャッシングは、SageMaker AI が現在提供している厳格なテナント分離の保証を維持します。各キャッシュは単一の顧客エンドポイントに専有され、AWS アカウント間やエンドポイント間で共有されることはありません。顧客が SageMaker AI エンドポイントを削除すると、関連するイメージキャッシュも自動的に削除されます。
パフォーマンス結果
以下の表には、コンテナキャッシングをテストした早期アクセス顧客から観測された結果を示します:
顧客
インスタンスタイプ
イメージサイズ
モデルサイズ
スケーリング前 P50(秒)
スケーリング後 P50(秒)
P50 の改善率
1
顧客 1
ml.g4dn.xlarge
15.7 GB
0 GB
381
134
-65%
2
顧客 2
ml.g5.2xlarge
17.5 GB
5.8 GB
346
164
-52%
3
顧客 3
ml.g5.xlarge
10.6 GB
6.5 GB
346
216
-38%
改善の規模は、エンドポイントのインスタンスタイプ、コンテナイメージサイズ、およびモデルサイズによって異なります。
すべての 3 つのスケーリング最適化を組み合わせる
最速のスケーリング応答を実現するには、自動スケーリング最適化シリーズで導入したすべての 3 つの機能を組み合わせることができます。それぞれが、スケールアウトパスにおける異なる遅延の原因を取り除きます。
最適化
改善内容
有効化方法
1
1 分未満のメトリクス改善
スケールアップの必要性を 6 倍速く検知
ConcurrentRequestsPerModel または ConcurrentRequestsPerCopy のターゲット追跡ポリシーを設定
2
推論コンポーネントベースのエンドポイント用のデータキャッシュ
既存のインスタンスにモデルのコピーを追加する際のイメージプル時間を短縮
オプトイン不要:サポート対象のアクセラレータインスタンスタイプ上の推論コンポーネントベースのエンドポイントでは、コンテナキャッシングが自動的に有効化されます。
3
コンテナイメージキャッシュ
新しいインスタンスの起動時にイメージプル時間を削減します。
オプトインは不要です:サポート対象のアクセラレータインスタンスタイプを使用するエンドポイントでは、コンテナキャッシングが自動的に有効化されます。
これら2つの最適化を組み合わせることで、スケールアウト時の遅延の主要な原因が排除されます。サブ1分間のメトリクスにより需要検出が6倍高速化され、スケーリング判断が数分ではなく数秒で実行されます。この2つのキャッシュ層は、異なるスケーリング軸において互いに補完し合います。新しい推論コンポーネントのコピーが既存のインスタンスに配置される場合、データキャッシングによりイメージおよびモデルのダウンロード遅延が除去されます。一方、スケールアウトのために新しいインスタンスの起動が必要な場合は、コンテナイメージキャッシングにより起動時のイメージプル時間をゼロにします。
サポート対象構成
コンテナキャッシングは、SageMaker 推論エンドポイントにおけるアクセラレータインスタンスタイプでサポートされています。Amazon ECR にホストされた任意のコンテナイメージ(カスタムイメージを含む)と連携して動作しますが、コンテナ自体への修正は不要です。
コンテナキャッシングは、SageMaker AI 推論がサポートされているすべての商用 AWS リージョンで利用可能です。最新のサポート対象インスタンスタイプおよびリージョン一覧については、Amazon SageMaker AI ドキュメントをご参照ください。
結論
新しいコンテナキャッシングにより、Amazon SageMaker AI は生成 AI 推論向けに特別に設計された一連の自動スケーリング最適化機能を提供します。
- サブ分のメトリクスにより、自動スケーリングは標準の 1 分間隔の CloudWatch メトリクスと比較して最大 6 倍高速に負荷変化を検出できます。
- 既存インスタンス上での高速なスケーリング:インスタンストレージコンテナキャッシュにより、実行中のインスタンスを再利用する際のイメージプルおよびモデルダウンロードの遅延が除去されます。
- 新しいインスタンス上での高速なスケーリング(今回のリリース):コンテナキャッシュにより、新しいインスタンス起動時のイメージプルが不要となり、エンドツーエンドのスケーリング遅延を最大 50% 削減します。
これらの機能により、SageMaker AI のスケーリング体験は、数分かかるコールドスタートの遅延から、迅速で予測可能なレスポンスへと変化します。これにより、生成 AI アプリケーションはトラフィックの急増にも自信を持って対応でき、エンドユーザーに対して低遅延と高い可用性を維持できます。
開始するには、サポートされているアクセラレータインスタンスタイプ上の SageMaker AI 推論エンドポイントに生成 AI ワークロードを展開してください。コンテナキャッシュは自動的に有効化されます。サポート対象のインスタンスタイプおよびリージョンの詳細については、Amazon SageMaker AI ドキュメントをご覧ください。また、AWS Management Console を利用してエンドポイントの作成または更新を試すこともできます。
今後の展望として、スケーリング遅延をさらに削減するための投資を継続していきます。続報をお楽しみに。
著者について
 image
image
Mona Mona
Mona は現在、Amazon でシニア AI/ML スペシャリスト ソリューションアーキテクトとして勤務しています。以前は Google でリード生成 AI スペシャリストを務めていました。彼女は「Natural Language Processing with AWS AI Services: Derive strategic insights from unstructured data with Amazon Textract and Amazon Comprehend」と「Google Cloud Certified Professional Machine Learning Study Guide」の 2 冊の著者であり、AI/ML およびクラウド技術に関するブログを 19 本執筆しています。また、権威ある AAAI(Association for the Advancement of Artificial Intelligence)カンファレンスで最優秀研究論文賞を受賞した CORD19 ニューラル検索に関する共同研究論文の共著者でもあります。Mona は LinkedIn でつながることができます。

Kunal Shah
Kunal は Amazon Web Services のシニアソフトウェア開発エンジニアです。彼の情熱は推論のための機械学習(ML)モデルのデプロイにあり、現実世界に影響を与える AI 搭載ツールの開発に貢献し、学び続けるという強い欲求によって駆り立てられています。専門的な活動以外では、歴史映画を見ること、旅行、そして冒険スポーツを楽しむことを好んでいます。

Alwin (Qiyun) Zhao
Alwin (Qiyun) Zhao は、Amazon SageMaker Inference チームのソフトウェア開発マネージャーです。同チームでは、顧客が ML(機械学習)および GenAI(生成 AI)ワークロードを大規模かつ信頼性高くデプロイできるよう、管理された推論インフラストラクチャの開発を行っています。彼はシステムレベルのパフォーマンス最適化、アクセラレータ容量管理、モデルデプロイのガードレール、セキュリティコンプライアンスにわたるエンジニアリング活動を統括し、顧客が推論ワークロードの高い可用性を達成できるよう支援しています。

Dmitry Soldatkin
Dmitry は、AWS の SageMaker Inference における専門ソリューションアーキテクチャのグローバルリーダーです。彼は企業全体にわたって顧客が GenAI および AI/ML ソリューションを設計・構築・最適化できるよう支援する取り組みを主導しています。彼の活動範囲は多岐にわたり、特に生成 AI(Generative AI)、ディープラーニング、大規模な ML の展開に重点を置いています。金融サービス、保険、通信業界など、様々な産業の企業とパートナーシップを築いてきました。Dmitry とは LinkedIn でつながることができます。
原文を表示
Today, we’re excited to announce container image caching for Amazon SageMaker AI inference, the next major advancement in our faster scaling optimization journey. This speeds up end-to-end latency by up to 2x for generative AI models during scale-out events.
Over the years, Amazon SageMaker AI has continued to reduce latency across these scaling stages: detecting the need to scale out, provisioning instances, downloading container images, fetching model weights, and starting containers. Amazon SageMaker AI previously introduced sub-minute Amazon CloudWatch metrics to help detect scale-out needs up to 6x faster than traditional mechanisms and launched an inference component data caching solution that stores container images and model artifacts on already running instances. This approach reduced the cold start latency for scaling inference component operations that reuse existing instances. Together, these features improved auto scaling responsiveness for scenarios where an inference component can be placed on an already provisioned instance and use the existing cache.
With container caching, Amazon SageMaker AI extends these scaling improvements to scenarios where new instances must be launched. Container caching removes container image download latency even when new instances must be launched, the scenario where our previous instance-store-based caching couldn’t help. In this post, we show how container caching addresses the container image download bottleneck and demonstrate the performance improvements you can expect.
The scaling challenge: When new instances must launch
The following diagram shows the steps during instance scaling when a new instance is launched.
- Instance provisioning: New Amazon Elastic Compute Cloud (Amazon EC2) instance is launched.
- Container image pull: Container image is pulled from Amazon Elastic Container Registry (Amazon ECR).
- Model artifact download: Model weights are fetched from Amazon Simple Storage Service (Amazon S3).
- Container startup and health checks: The inference server initializes, loads the model into memory, and passes readiness checks.
Note: Container image download and model artifact download happen in parallel.
Container image download is often a major contributor to endpoint scale-out latency, especially for generative AI workloads. These workloads use large containers such as SageMaker Large Model Inference (LMI, powered by vLLM), vLLM, and NVIDIA Triton. Caching the container removes the container image pull step during new instance scale-out events for the common endpoint patterns:
- Single model endpoints – Scaling is achieved by launching additional instances, each hosting its own copy of the model.
- Inference component-based endpoints – Scaling adds new instances only when no existing instance has sufficient capacity to host an additional inference component.
How container caching removes the image pull bottleneck
The following image shows how the scaling timeline changes for the Qwen3-8B (16 GB) model on an ml.g6.2xlarge instance using the LMI container (17.7 GB compressed).
Before Container Caching:
- Pull container image from Amazon ECR: 333 seconds
- Model artifact download from Amazon S3: 168 seconds
Image pulls and model download ran in parallel, so the end-to-end startup latency was 525 seconds.
After Container Caching:
- Container image is already cached locally: 0 seconds
- Model artifact download: 77 seconds. With the container image pre-cached, the model download no longer competes for network bandwidth with the image pull, reducing its latency from 168 seconds to 77 seconds.
The end-to-end startup latency drops to 258 seconds.
Result: Container caching removes the image pull from the scale-out path and eliminates network bandwidth contention, reducing end-to-end startup latency from 525 seconds to 258 seconds, approximately 51 percent improvement. If a cached image is unavailable, SageMaker AI automatically falls back to pulling from Amazon ECR, so scaling is never blocked.
How container caching works with inference components
Container caching works with inference components. When you deploy multiple inference components, the cache stores each unique container image referenced by your inference components.
Security and tenant isolation
Container image caching maintains the same strict tenant isolation guarantees that SageMaker AI provides today. Each cache is dedicated to a single customer endpoint and is not shared across AWS accounts or endpoints. When a customer deletes their SageMaker AI endpoint, the associated image cache is automatically purged.
Performance results
The following table shows observed results from early access customers who tested container caching:
Customer
Instance
Image size
Model size
P50 Before (sec)
P50 After (sec)
P50 Improvement
1
Customer 1
ml.g4dn.xlarge
15.7 GB
0 GB
381
134
-65%
2
Customer 2
ml.g5.2xlarge
17.5 GB
5.8 GB
346
164
-52%
3
Customer 3
ml.g5.xlarge
10.6 GB
6.5 GB
346
216
-38%
The magnitude of improvement depends on the instance type, container image size, and model size of the endpoint.
Combining all three auto scaling optimizations
For the fastest scaling response, you can combine all three capabilities introduced across our auto scaling optimization series. Each one removes a different source of delay from the scale-out path.
Optimization
What it improves
How to enable
1
Sub-minute metrics improvement
Triggers scale-up needs faster by 6x
Configure a ConcurrentRequestsPerModel or ConcurrentRequestsPerCopy target tracking policy
2
Data cache for inference component-based endpoints
Reduces image pull time when adding model copies on existing instances
No opt-in required: container caching activates automatically for inference component-based endpoints on supported accelerator instance types.
3
Container image cache
Removes image pull time when launching new instances
No opt-in required: container caching activates automatically for any endpoint using supported accelerator instance types.
Together, these optimizations remove the major sources of scale-out latency. Sub-minute metrics detect demand 6x faster, triggering scaling decisions in seconds rather than minutes. The two caching layers complement each other along different scaling axes. When a new inference component copy is placed on an existing instance, data caching removes image and model download latency. When scaling requires launching a new instance, container image caching provides zero image-pull time at launch.
Supported configurations
Container caching is supported for accelerator instance types on SageMaker inference endpoints. It works with any container image hosted in Amazon ECR, including custom images. No modifications to your container are required.
Container caching is available in all commercial AWS Regions where SageMaker AI inference is supported. For the latest list of supported instance types and Regions, see the Amazon SageMaker AI documentation.
Conclusion
With new container caching, Amazon SageMaker AI provides a suite of auto scaling optimizations purpose-built for generative AI inference.
- Sub-minute metrics let auto scaling detect load changes up to 6x faster than standard 1-minute CloudWatch metrics.
- Faster scaling on existing instances: Instance-store container caching removes image pull and model download latency when reusing running instances.
- Faster scaling on new instances (this launch): Container cache removes image pull when launching new instances, reducing the end-to-end scaling latency by up to 50 percent.
Together, these features change the SageMaker AI scaling experience from minutes of cold-start latency to rapid, predictable responses. Your generative AI applications can now handle traffic spikes with confidence, maintaining low latency and high availability for end users.
To get started, deploy your generative AI workloads to a SageMaker AI inference endpoint on a supported accelerator instance type. Container caching activates automatically. To learn more about supported instance types and Regions, see the Amazon SageMaker AI documentation. You can also try the AWS Management Console to create or update your endpoints.
Looking ahead, we continue to invest in reducing scaling latency even further. Stay tuned.
About the authors
Mona Mona
Mona currently works as Sr AI/ML specialist Solutions Architect at Amazon. She worked in Google previously as Lead generative AI specialist. She is a published author of two books Natural Language Processing with AWS AI Services: Derive strategic insights from unstructured data with Amazon Textract and Amazon Comprehend and Google Cloud Certified Professional Machine Learning Study Guide. She has authored 19 blogs on AI/ML and cloud technology and a co-author on a research paper on CORD19 Neural Search which won an award for Best Research Paper at the prestigious AAAI (Association for the Advancement of Artificial Intelligence) conference.You can connect Mona on Linkedin
Kunal Shah
Kunal is a senior software development engineer at Amazon Web Services. His passion lies in deploying machine learning (ML) models for inference, and he is driven by a strong desire to learn and contribute to the development of AI-powered tools that can create real-world impact. Beyond his professional pursuits, he enjoys watching historical movies, traveling and adventure sports.
Alwin (Qiyun) Zhao
Alwin (Qiyun) Zhao is a Software Development Manager on the Amazon SageMaker Inference team, where he builds managed inference infrastructure that enables customers to deploy ML and GenAI workloads reliably at scale. He leads engineering efforts across system-level performance optimization, accelerator capacity management, model deployment guardrails, and security compliance — ensuring customers achieve high availability for their inference workloads.
Dmitry Soldatkin
Dmitry is a Worldwide Leader for Specialist Solutions Architecture, SageMaker Inference at AWS. He leads efforts to help customers design, build, and optimize GenAI and AI/ML solutions across the enterprise. His work spans a wide range of ML use cases, with a primary focus on Generative AI, deep learning, and deploying ML at scale. He has partnered with companies across industries including financial services, insurance, and telecommunications. You can connect with Dmitry on LinkedIn.
関連記事
Adobe Marketing Agent for Amazon Quick によるキャンペーンワークフローの加速
AWS と Adobe は、Amazon Quick と Adobe Marketing Agent を連携させることで、マーケティングチームが自然言語で質問するだけで、ガバナンスされた会話環境内で数秒以内にキャンペーンのパフォーマンスやオーディエンスに関するインサイトにアクセスできるようにした。
CloudWatch の SageMaker メトリクスとインサイトダッシュボードを用いた生成 AI 推論の監視・デバッグ
AWS は、大規模な生成 AI 推論エンドポイントの P99 レイテンシ急上昇などのトラブルを GPU メモリ圧力や KV キャッシュ飽和などから特定できるよう、CloudWatch に SageMaker の詳細メトリクスとインサイトダッシュボードを追加した。
Adobe の再設計された AI スタジオは、あなたの作品の外観を記憶する
Adobe は Firefly AI アシスタントに新機能を追加し、単一インターフェースで編集と生成が可能になる「再考された」AI スタジオを発表した。これはプロジェクト全体で一貫した文脈や再利用可能な資産、整理されたワークフローを提供するもの。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み