なぜあなたの「AIファースト」戦略は大きな間違いかもしれないのか?
本記事は、AIファースト戦略を成功させるには単なるツール導入ではなく、テスト・CI/CD・監視・アーキテクチャなどの堅固なソフトウェアエンジニアリング基盤の構築が不可欠であり、AIを主力開発者として再設計されたワークフローこそが真のAIファーストであると指摘している。
キーポイント
AIファーストの本質:プロセス再設計
既存ワークフローへのAI組み込みは「補助」に過ぎず、主力開発者として再設計されたプロセスこそが真のAIファーストである。
必須基盤条件の整備
自動化テスト、CI/CDパイプライン、A/Bテスト・監視、タスク管理、堅牢なシステムアーキテクチャの5つが揃って初めてAIの高速反復が可能となる。
適用シーンの現実的な選別
バックエンドやデータ処理、早期プロダクトの試行錯誤には有効だが、UI密集型・高品質やセキュリティが要求されるシーンでは人間管理が不可欠である。
ハーネスエンジニアリングへの転換
OpenAIが定義したこの概念は、エンジニアの役割を「コード作成」から「エージェントへの能力付与と制約設計」へ転換させることを意味する。
流程重构:匹配AI极速开发
真正的AI优先需彻底重塑产品规划、开发与测试流程,以匹配AI极速开发能力,避免传统敏捷周期和人工QA成为新瓶颈。
架构统一:赋予AI全局视野
必须采用Monorepo打破系统碎片化,使AI能纵览代码全貌、推理跨服务连锁反应并执行本地集成测试。
自动化流水线:确定性部署与自愈
建立强制AI审查的多阶段CI/CD流程,结合自动化健康监控与分诊引擎,实现无人工干预的稳定部署与自动修复。
影響分析・編集コメントを表示
影響分析
本記事は、現在のAIファーストブームに対して「エンジニアリング基盤の欠如」を指摘し、実務レベルでの現実的な適用基準を示した。これにより、多くの企業が安易なAI導入を見直し、堅牢なDevOps・QA体制の整備にリソースを再配分するきっかけとなる可能性がある。業界全体として、AI活用から「AIを活用するためのエンジニアリング」へのパラダイムシフトを加速させる重要な示唆を含んでいる。
編集コメント
AIファーストを戦略として掲げる企業は多いが、本記事が指摘する「エンジニアリング基盤の欠如」は多くの現場で見過ごされている実態である。今後はAIツールの導入以前に、堅牢なDevOpsとQA体制の整備を優先する企業こそが勝者となるだろう。
この記事『Why Your”AI-First”Strategy Is Probably Wrong』(日本語訳は後述)を何度か目にしたが、少し異なる視点で語りたい。AIファーストというより、むしろソフトウェアエンジニアリング・ファーストだ。
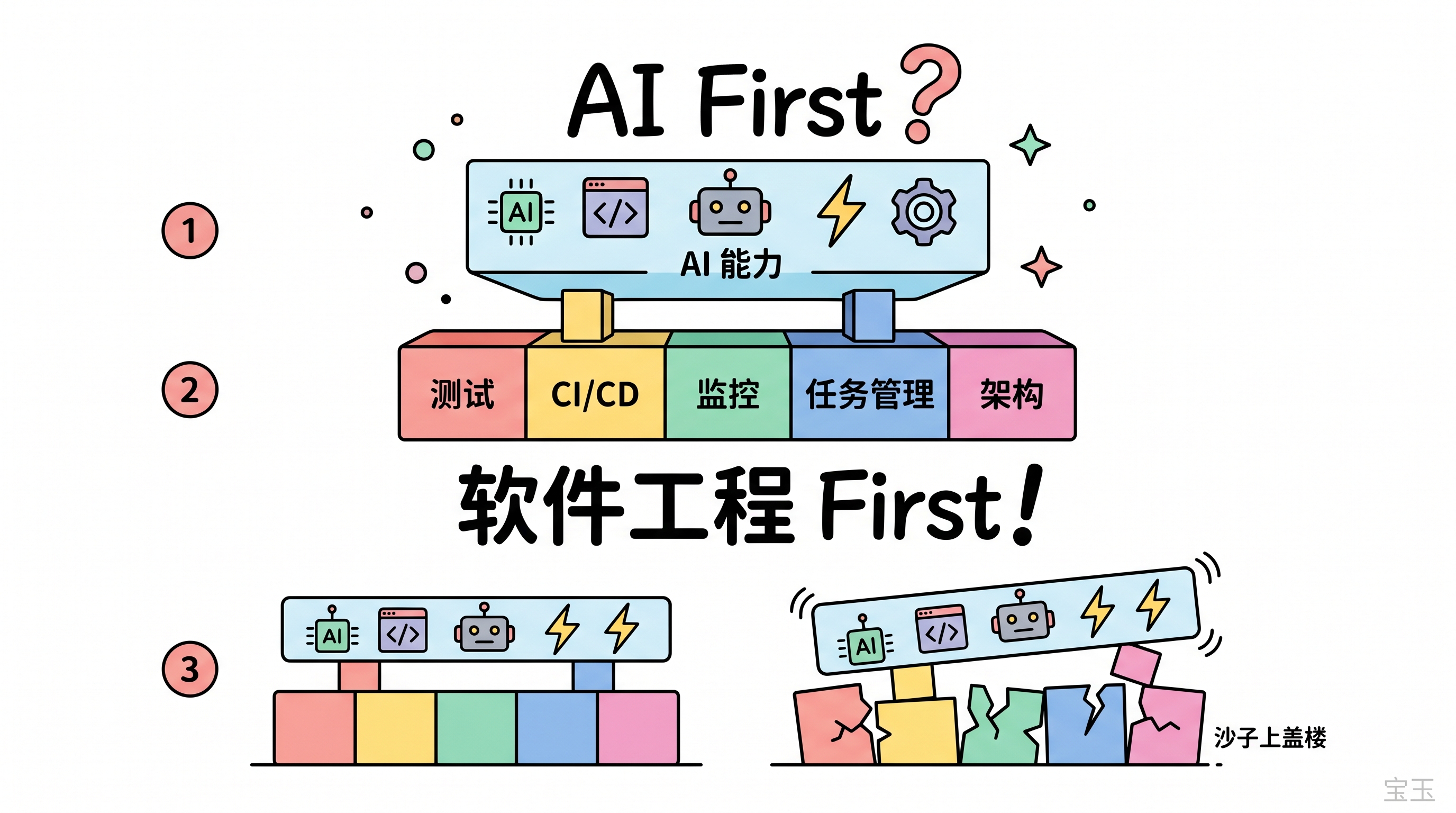
この記事はAIについて語っているように見えるが、その実体はソフトウェアエンジニアリングの話である。
組織や人間に関する後半の議論はさておき、原文の前半部の要点を簡潔にまとめると以下のようになる。
AI時代において、人間のリソースがボトルネックとなる。プロダクトマネージャー(PM)が要件定義に数週間を要するのに対し、AIは2時間で実装してしまうため、PMがボトルネック化する。品質保証(QA)担当者が3日間かけてテストするのに対し、AIはコード生成に2時間しか要さないため、QAがボトルネック化する。チーム規模が25名であるのに対し、競合他社が数百名の人員を抱えている場合、人的リソースもまたボトルネックとなる。
ではどうするか?人間をそのプロセスから除外する。AIがコードを書き、AIがコードレビューを行い、AIがテストを実行し、AIがデプロイを行い、AIが本番環境の監視を行う。問題が発生すれば自動的にロールバックする。定期的にログをスキャンし、問題を自動検出・タスク割り当て・修正追跡を行う。このパイプラインを稼働させ、人間は重要な判断ポイントでのみ関与すればよい。
文中で言及されている統一コードベース(monorepo)は、花飾りに過ぎず、AIファーストとは直接関係ない。あっても良いが、なくても代替案は多数存在する。
この一連のソリューションを聞けば、論理は一貫しており、効果も魅力的だ。1日に複数回のデプロイが可能で、機能は当日公開・当日撤回でき、データが全てを決定する。
しかし、安易にこれをそのまま適用する前に、自社の状況と照らし合わせて以下の点を考慮すべきである。
第一に、自動化テスト。AIがコードを変更した後、他の機能を壊していないことを確認する方法が必要だ。テストカバレッジが不十分であれば、AIによるコード提出のたびに手動で回帰テストを行う必要があり、速度は向上しない。
第二に、CI/CD(継続的インテグレーション・継続的デリバリー)プロセス。コード提出からデプロイまでのテスト、レビュー、公開、ロールバックが完全に自動化されているか?このパイプラインが機能していなければ、AIがどれだけ高速にコードを書いても、手動処理を待つ間にコードが蓄積されるだけだ。
第三に、A/Bテストと本番環境の監視。新機能のリリース後、その効果はデータで検証可能であり、効果が得られなければいつでも停止できる仕組みが必要だ。このメカニズムがなければ、AIが1日に5つの機能を产出しても、どの機能を残し、どの機能を削除すべきか判断できない。
第四に、タスク管理。タスクは適切な粒度に分解され、ライフサイクルを追跡可能でなければならない。巨大で曖昧なタスクをAIに投げて、現在の能力では処理しきれない。複数のエージェントが同時に作業する場合、誰がどのタスクを担当するか、優先順位は何か、完了基準は何かなどを管理する仕組みが必要だ。
第五に、システムアーキテクチャ。アーキテクチャが混沌としている、あるいは存在しないコードをAIが保守するのは、人間と同じくらい頭痛の種となる。コンテキスト(文脈情報)が溢れていても境界線が見えず、一处を修正すると三処が破綻する状態では、AIも手が出ない。
これらの条件のうち、どれか一つでも満たせない場合、人間がそれを補完しなければならない。補完できない限り、「AIファースト」は単なるスローガンに過ぎない。
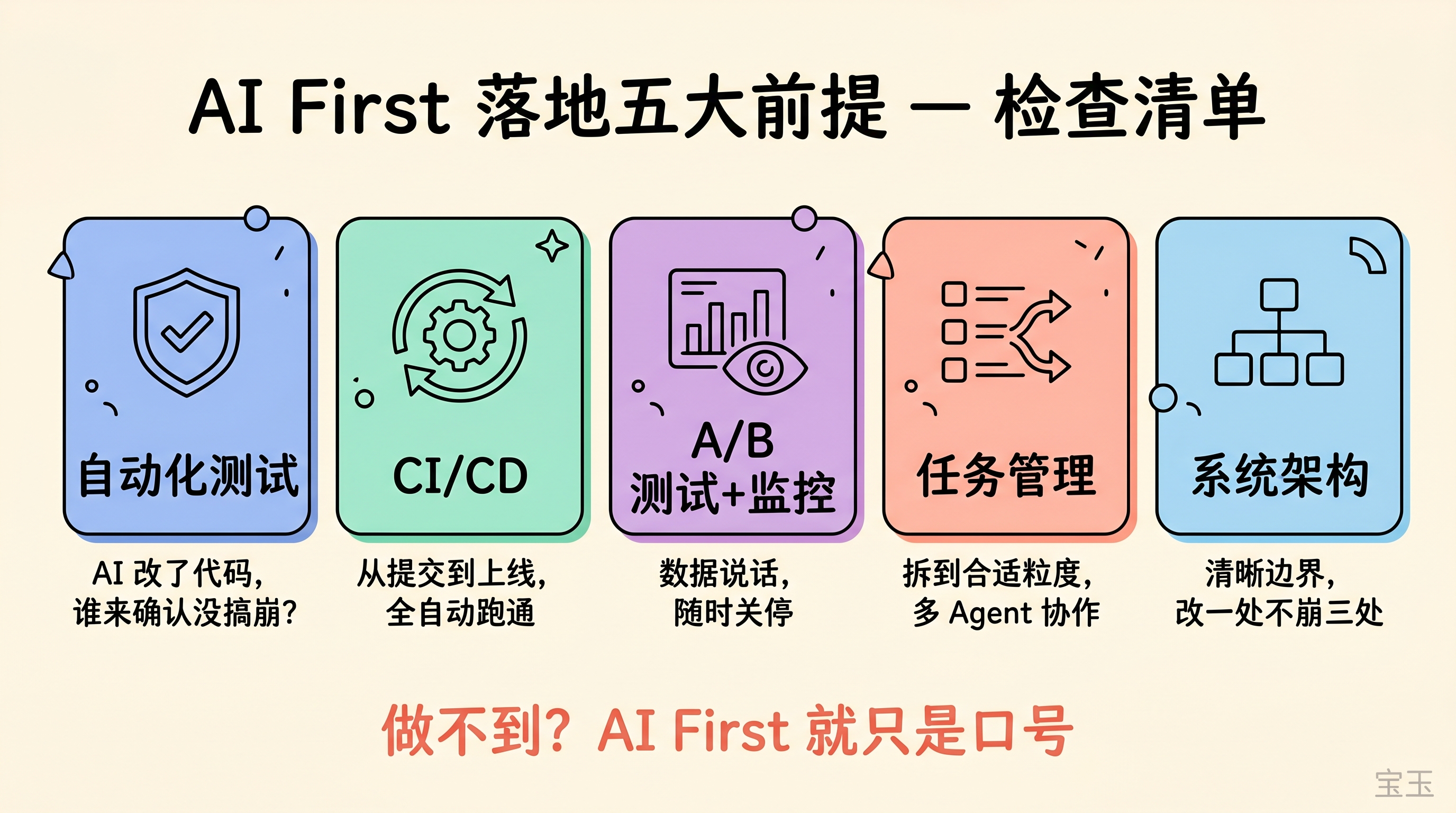
しかし、仮にこれら全てが満たされたとして、それでAIファーストが可能になるのか?
答えは否である。このアプローチが適用できるのは特定のシナリオに限られる。
適応可能なシナリオ:バックエンドロジックが中心で、ユーザーインターフェース(UI)が複雑でないプロダクト。例えばAPIサービス、データ処理プラットフォーム、社内ツールなどだ。機能の良し悪しは実行結果のデータで判断でき、画素単位の細かな確認を人間が行う必要はない。原文の例であるAgentプラットフォームは、本質的にバックエンド駆動型のプロダクトであり、このアプローチが適用可能である。
また、初期段階のプロダクトにおける迅速な試行錯誤にも適している。機能が失敗すれば即座に撤回でき、ユーザーの期待値もそれほど高くないため、AIの速度優位性を最大限に発揮できる。
UI集約型プロダクト。メディアでは「フロントエンドは死んだ」と頻繁に報じられるが、AIに複雑なインターフェースを作らせてみると、使いやすさの問題、インタラクションの細部、ビジュアルの再現性など、AIが解決できない課題が山ほどある。もしそれが可能なら、イーロン・マスクはすでにAIを使ってX(旧Twitter)を何十回も改版しているはずだ。
機能の品質が敏感なプロダクト。AnthropicやOpenAIが「AIファースト」を知らないはずがない。彼らがClaude CodeやCodexでこの手法を採用できるか?自社の中核プロダクトをAIに完全自動化された迭代(反復開発)を任せるなど、ユーザーから非難殺到するのは目に見えている。
安全性が求められるシナリオ。銀行システムやオンライン取引プラットフォームにおいて、AI が生成したコードにわずかなミスがあっても、単なるロールバックでは解決できません。
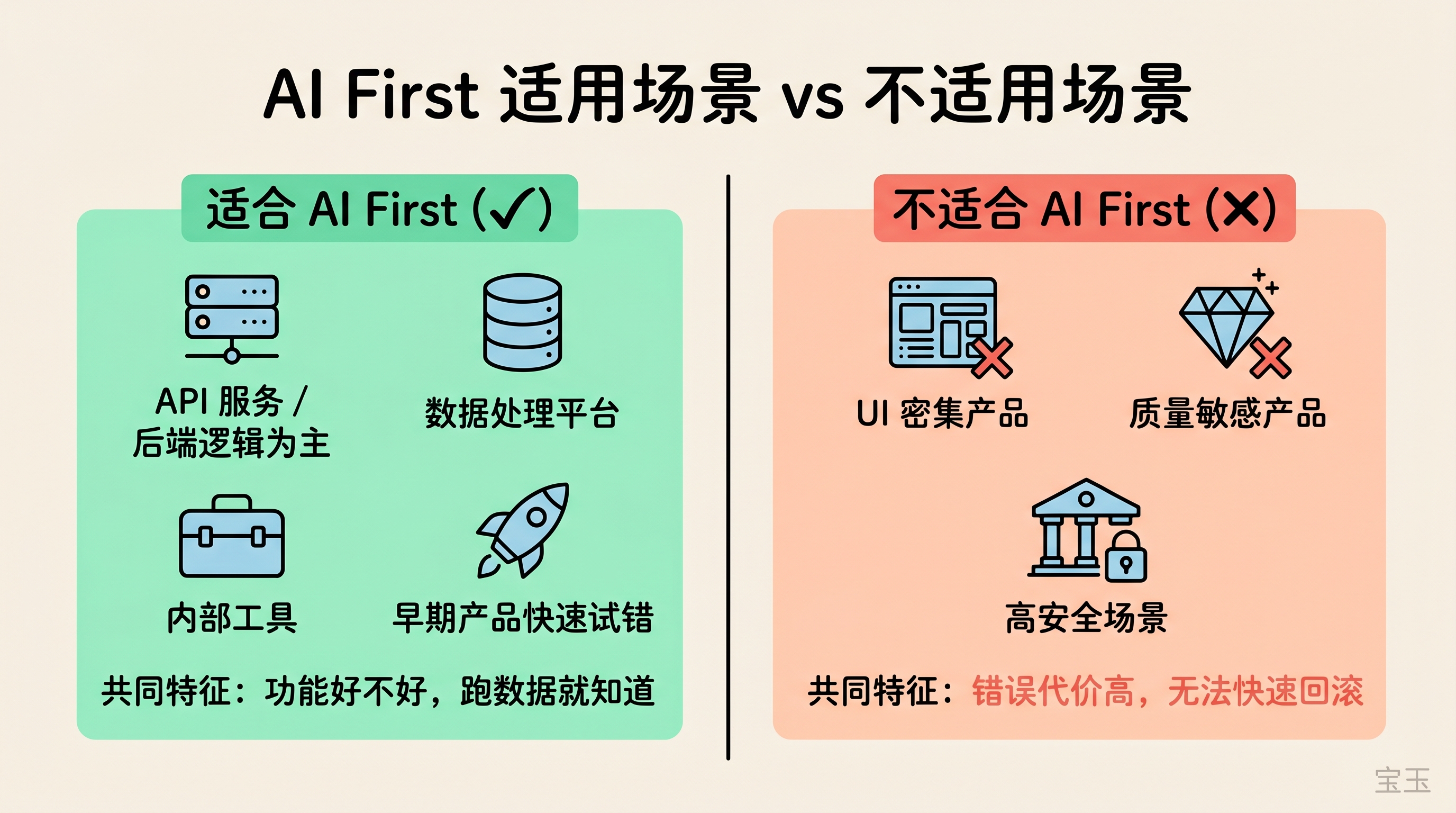
「AIファースト」の方向性自体は間違っていません。それは一種の意識の変革を表しています:意思決定を行うたびに、その作業をAIに任せることができるか考え、できない場合はどのような条件が不足しているのか、どうすればその条件を補完できるかを問う姿勢です。
しかし、この意識を実践に移すには、単にいくつかのAIツールのサブスクリプションを購入するだけでなく、基盤を構築する必要があります。テスト、CI/CD(継続的インテグレーション・継続的デリバリー)、モニタリング、アーキテクチャ、タスク管理といった要素を確実なものにすれば、AIの能力は自然と発揮されます。これらが不十分であれば、どれだけ多くのAIを追加しても、砂漠の上に建物を築くようなものです。
この観点から見ると、「AIファースト」の究極的な目標は、すべての作業をAIに任せることではありません。むしろ、この力を借りて、これまでやりたかったが推進力が不足していたエンジニアリングの改善を、実際に推進することにあります。
星空を見上げることは良いことです。しかし、同時に足元をしっかりと見据える必要があります。
なぜあなたの「AIファースト」戦略は間違っている可能性があるのか【翻訳】
著者:Peter Pang 原文:Why Your “AI-First” Strategy Is Probably Wrong
私たちの生産環境のコードの99%はAIによって作成されています。先週火曜日の午前10時、私たちは新機能をリリースし、正午にA/Bテストを実施しました。そして午後3時、データのパフォーマンスが芳しくないため、その機能を削除しました。午後5時には、最適化されたバージョンを再度リリースしています。3ヶ月前であれば、この一連のイテレーションサイクルには少なくとも6週間を要していました。
私たちがこれを実現できた理由は、コードエディタにCopilotプラグインをインストールしただけ那么简单ではありません。私たちは既存のエンジニアリング開発プロセスを根本から壊し、AIを中心に全面的に再構築しました。計画策定、コーディング、テスト、デプロイの方法、そしてチームの編成方法を変えました。さらには、社内すべての従業員の役割さえも再定義しました。
CREAOはAIエージェント(AI Agent)プラットフォームです。同社には25名の従業員がおり、そのうち10名がエンジニアです。私たちは2025年11月にエージェントの開発を開始し、ちょうど2ヶ月前にゼロからスタートし、製品アーキテクチャとエンジニアリングワークフローを完全に再編成しました。
OpenAIは2026年2月、私たちがこれまで行ってきたことを完璧に要約する新概念を発表しました。彼らはこれを「ハーネスエンジニアリング(Harness Engineering、注:Harnessの原義は馬具または安全ベルトですが、ソフトウェアエンジニアリングでは通常テストスタンドや足場を指し、ここではAIに作業環境と制約条件を提供するシステム工学を意味します)」と呼んでいます。エンジニアリングチームの主要な役割はもはやコードを書くことではなく、エージェントを強化し、価値ある作業を完了させることです。システムにエラーが発生した場合の解決策は、「再試行する」や「もっと努力する」ではありません。真の解決策は、AIがどの能力を欠いているのかを問い、その能力をエージェントにとって明確に可視化し、強制的に実行させる方法を見つけることです。
私たちはこの結論に独自に到達しましたが、当時はそれを定義する既存の用語がありませんでした。
「AIファースト」は「AIを使用すること」と等しくありません

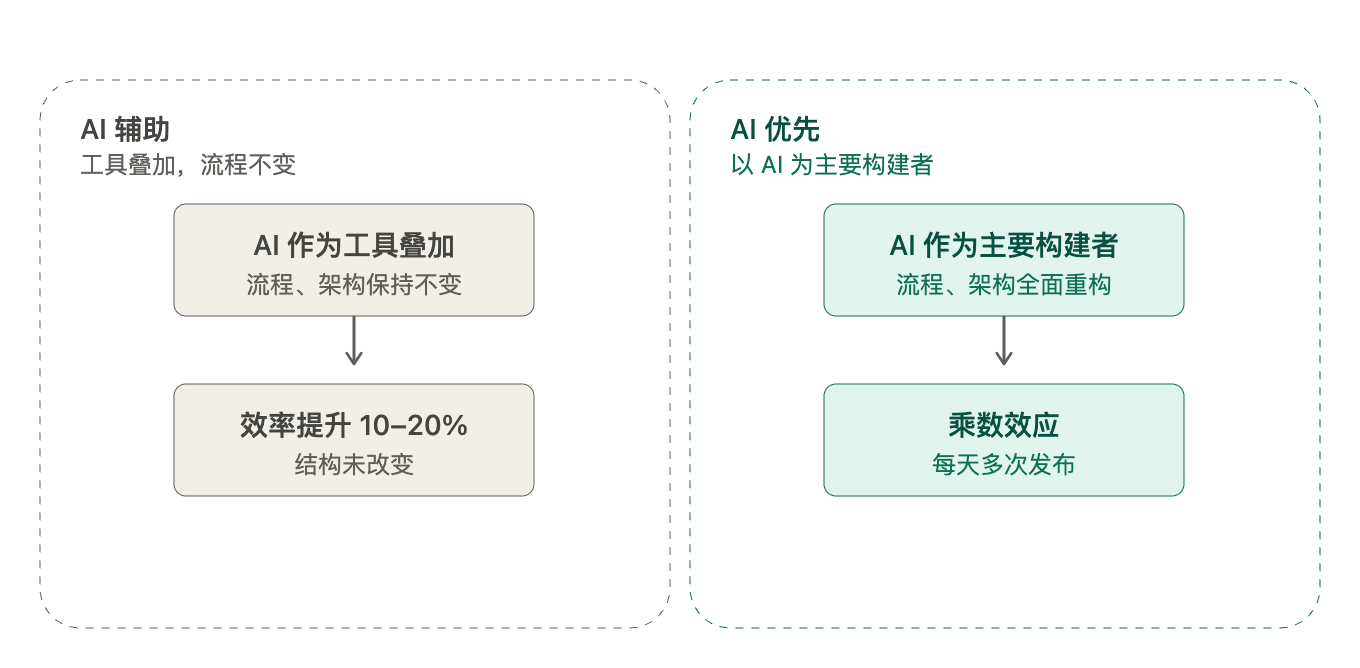
多くの企業は、AIを既存のワークフローに無理やり組み込もうとしています。エンジニアはCursorを開いてコード作成を支援し、プロダクトマネージャーはChatGPTを使用して要件文書を作成し、QAチーム(テストチーム)はAIを用いてテストケースの生成を試みています。しかし、ワークフロー全体は昔ながらのままです。効率性が10%から20%向上したとしても、本質的な構造には何の変化もありません。
これはせいぜい「AIアシスト(AI-assisted)」と呼べる程度です。
真の「AIファースト」とは、「AIが主要な構築者である」という核心仮定に基づき、プロセス、アーキテクチャ、組織を徹底的に再設計することを意味します。「AIがエンジニアをどう支援できるか」ではなく、「AIに構築作業を行わせ、エンジニアは方向性と品質の判断のみを担当するよう、すべてをどのように再構築するか」を問うべきです。
この2つのアプローチがもたらす差は指数関数的です。
私は、「AIファースト」と称する多くのチームが、依然として従来のアジャイルスプリントサイクルを回し、同じJiraタスクボードを使用し、毎週のスタンドアップミーティングを開き、同じQA(品質保証)の承認プロセスを経ているのを見てきました。彼らは単にAIを既存のサイクルに無理やり組み込んでいるだけで、そのサイクル自体を再設計していません。
この現象の典型的な例が、現在よく言われる「ヴィーブコーディング(Vibe Coding)」です。Cursorを開き、コードが動作するまでプロンプトを調整し、コミットし、それを繰り返します。この手法はプロトタイプ検証には適していますが、本番環境で使用するシステムは安定性、信頼性、安全性が必須です。AIにコードを書かせるときには、これらの特性を保証し、バックアップできるシステムを構築する必要があります。あなたが構築すべきは「システム」であり、プロンプトは使い捨てのものであるべきです。
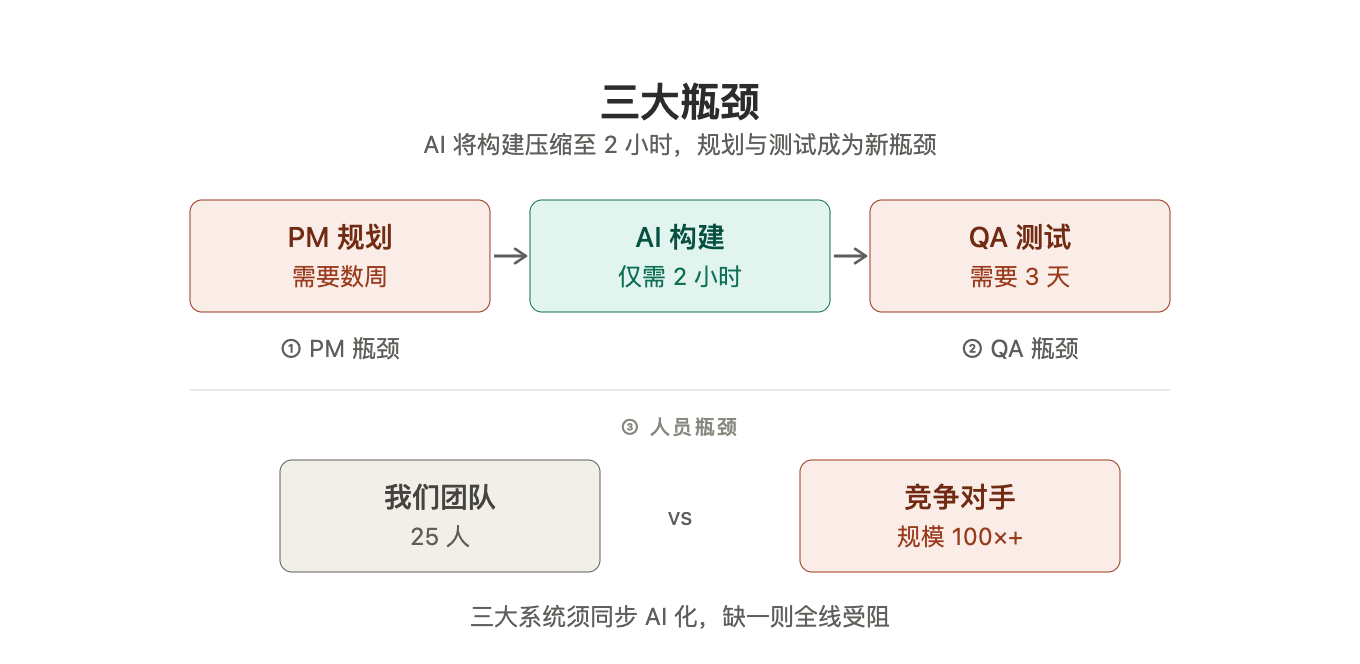
昨年、私はチームの作業方法を注意深く観察し、私たちの命を危うくする3つのボトルネックを発見しました。
私たちのプロダクトマネージャーは過去、機能の調査、設計、詳細な計画立案に数週間を要していました。数十年間、プロダクトマネジメントはこのように機能してきました。しかし、AIエージェントが1つの機能を実装するにはわずか2時間しかかかりません。開発期間が数ヶ月から数時間に極端に圧縮された場合、その長い数週間の計画サイクルが最大の足かせとなります。
数ヶ月かけてアイデアを練り、わずか2時間でそれを実装するというのは非論理的です。
プロダクトマネージャーは、迅速な反復サイクルで作業できる「プロダクト思考を持つアーキテクト」に進化するか、開発プロセスから退出するかの二者択一です。プロダクトの設計は、長文の要件ドキュメントを委員会が審査するのではなく、「高速プロトタイピング - リリース - テスト - 反復」のサイクルを通じて行わなければなりません。
状況は同様です。AIエージェントが2時間で機能をリリースした後、QAチームはさまざまなエッジケースや極端なケースのテストに数日を要します。開発2時間、テスト3日。
そこで、私たちは手動QAに代わってAI構築された自動化テストプラットフォームを導入し、AIが書いたコードをAIでテストする仕組みを作りました。検証の速度は開発の速度に追いつかなければなりません。そうでなければ、あなたは古いボトルネックから10フィート離れた場所に、新しいボトルネックを構築しているに過ぎません。
私たちの競合他社は同じ作業を100倍、あるいはそれ以上の人数で実施していますが、私たちはわずか25名です。無秩序な採用で彼らに追いつくことは不可能であり、「再設計」によってのみ切り開くことができます。
私たちは、プロダクトの設計方法、実装方法、テスト方法という3つのシステムにAIを深く統合する必要があります。いずれかの環節が純粋な人手に依存している場合、それが全体の生産ラインを遅延させます。
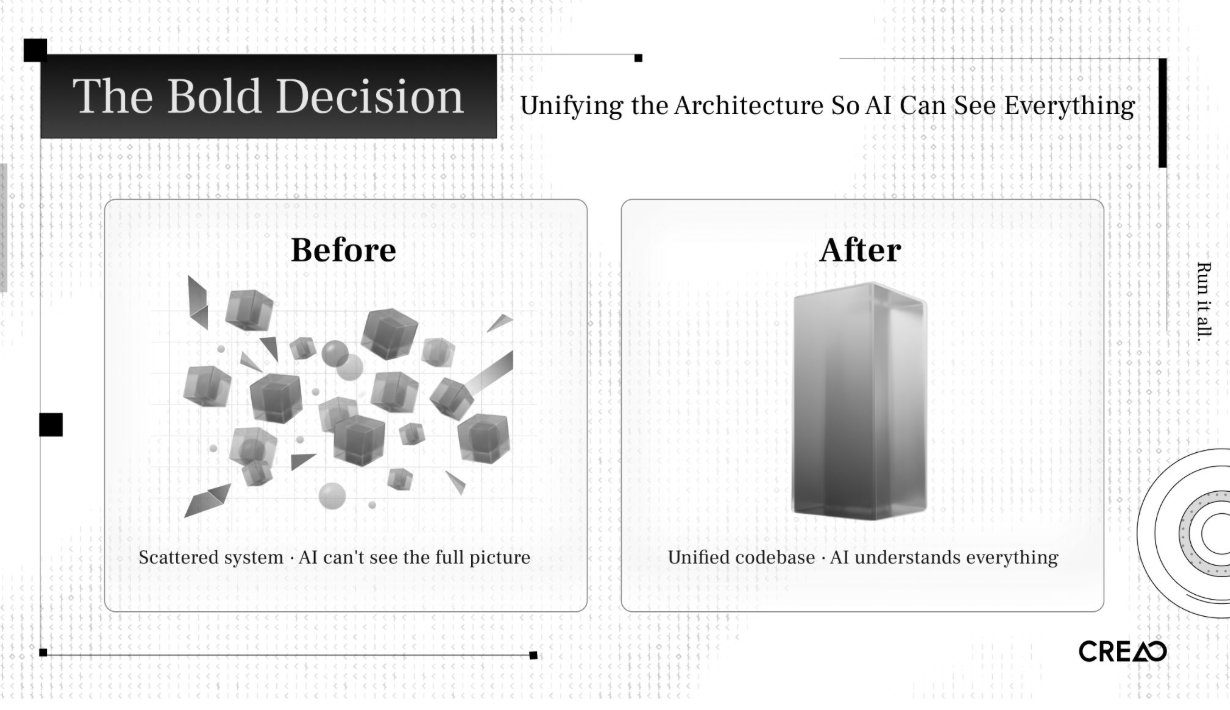
過去、私たちのアーキテクチャは複数の独立したシステムに散在していました。1つの機能を変更するために、3つから4つのコードリポジトリを同時に修正する必要がありました。人間のエンジニアから見れば、これはどうにか対応可能でした。しかし、AIエージェントの視点からは、それはブラックボックスに過ぎません。エージェントは全体像を把握できず、サービス横断的な連鎖反応を推論することも、ローカルでインテグレーションテストを実行することもできません。
私はすべてのコードをモノレポ(Monorepo)に統合せざるを得ませんでした。理由はただ一つ:AIが全体を俯瞰できるようにするためです。
これが、スキャフォールディング(Scaffolding:足場)の概念を実践で応用したものです。システムのより多くの部分を、AIが検査・検証・修正可能な形式に変換すればするほど、得られるレバレッジ(効果の増幅)は大きくなります。フラグメント化されたコードベースはAIにとって見えない存在ですが、統一されたコードベースはそれらにとって明確で読みやすいものとなります。
私は新システムの設計に1週間を費やしました:計画フェーズ、実装フェーズ、テストフェーズ、統合テストフェーズ。その後、さらに1週間をかけ、エージェント(Agent:自律的にタスクを実行するソフトウェア)の支援を受けてコードベース全体のリファクタリングを行いました。
CREAO自体がエージェントプラットフォームです。私たちは自社のエージェントを用いて、エージェントを動作させるプラットフォームを再構築しました。もし製品が自らを構築できるのであれば、その道筋は通っているということです。
以下は私たちの技術スタックと、各モジュールの役割です。
基盤インフラ:AWS(Amazon Web Services)
私たちはAWS上で稼働しており、自動スケーリングコンテナサービスとサーキットブレーカー(Circuit Breaker:障害発生時に処理を遮断しシステム全体への影響を防ぐパターン)およびロールバックメカニズムを使用しています。デプロイ後に監視指標が悪化した場合、システムは自動的に前の安全なバージョンにロールバックします。
CloudWatchはシステムの中枢神経です。すべてのサービスには構造化されたログがあり、25以上の自動アラートが設定され、自動化されたワークフローがカスタム指標を毎日クエリしています。すべてのインフラストラクチャコンポーネントは、構造化されクエリ可能なシグナルを公開しています。(注:構造化ログとは機械が読み取りやすいよう統一フォーマットで記録されたログ;クエリ可能なシグナルとはAIが直接検索できる重要な運用データ)もしAIがログを読めなければ、問題を診断することはできません。
CI/CD:GitHub Actions
すべてのコード変更は、執拗な6段階パイプラインを通ります:
検証CI → 開発環境へのビルドおよびデプロイ → 開発環境のテスト → 本番環境へのデプロイ → 本番環境のテスト → 正式リリース
すべてのプルリクエスト(Pull Request、略称PR:コード変更を反映させるための要求)には、ガバナンスメカニズムが適用され、型チェック、コードスタイルチェック、ユニットテストおよび統合テスト、Dockerビルド、Playwrightによるエンドツーエンドテスト、環境一貫性チェックが強制されます。どのフェーズもスキップすることはできません。人工的な強制的な承認(人工グリーンライト)は許可されません。パイプライン全体が絶対的に確定的であるため、AIは結果を予測し、失敗の原因を推論することができます。
すべてのPRに対して、Claude Opus 4.6による3つの並列AIレビューがトリガーされます:
コード品質:論理エラー、パフォーマンス問題、保守性の確認。
セキュリティ:脆弱性スキャン、認証境界チェック、インジェクション攻撃リスクの調査。
依存関係スキャン:サプライチェーンリスク、バージョン競合、オープンソースライセンスの問題。
これらは単なる提案ではなく、通過必須のゲートです。これらは人間のレビューと並行して動作し、人間が見落としがちなエラーを一括でブロックします。1日に8回のデプロイを行う場合、どの人間のエンジニアもすべてのPRに高い集中力を維持することはできません。
エンジニアは、任意のGitHub IssueやPRで @claude をメンションすることができます。
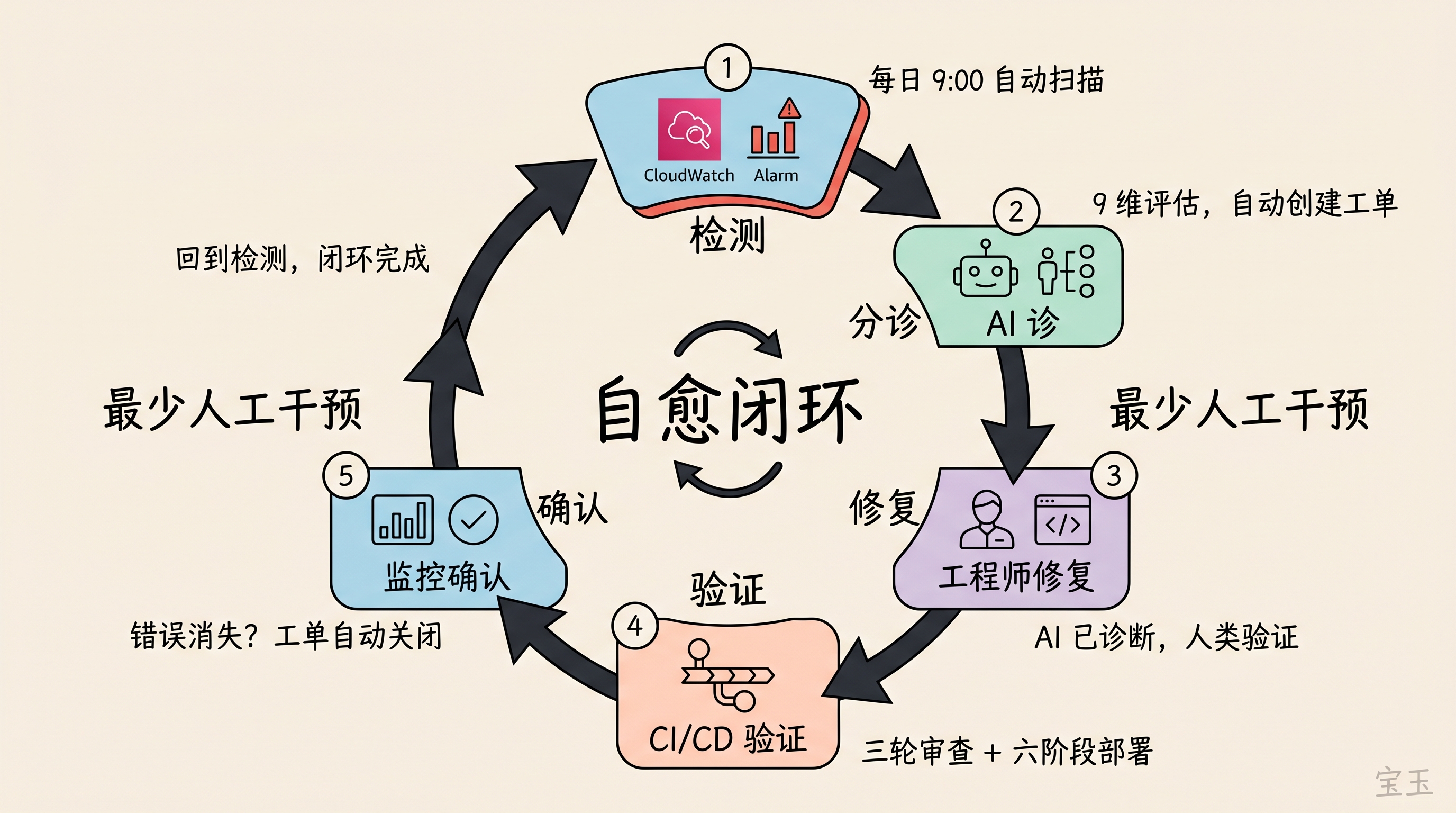
毎朝(UTC 9:00)、自動化されたヘルスチェックワークフローが正確に起動します。Claude Sonnet 4.6はCloudWatchをクエリし、すべてのサービスのエラーパターンを分析し、システムヘルスの実行サマリーを生成してチームのチャットグループに送信します。これには、誰かが明示的に指示する必要はありません。
1時間後、トリアージエンジンが起動します。これは本番環境のエラー情報を分類クラスタリングし、9つの次元から各問題の重大度を評価し、タスク管理システム内に調査チケットを自動生成します。すべてのチケットには、ログサンプル、影響を受けたユーザー、影響を受けたAPIエンドポイント、および推奨されるトラブルシューティングの方向性が添付されています。
システムは自動重複排除も行います。既存のチケットが同種のエラーをカバーしている場合、そのチケットを更新します。以前に解決された問題が再発した場合、回帰(Regression:修正したはずのバグが再び発生すること)を鋭敏に検出し、チケットを再オープンします。
エンジニアが修正コードを提出すると、同じパイプラインがすべての処理を引き受けます。Claude が3回のレビューを行い、CI(継続的インテグレーション)が検証を行います。6段階のデプロイメントパイプラインによって各環境へ展開され、テストが実施されます。デプロイ完了後、トリアージエンジンが再度モニタリングデータを確認します。もし元のエラーが解決していれば、チケットは自動的にクローズされます。
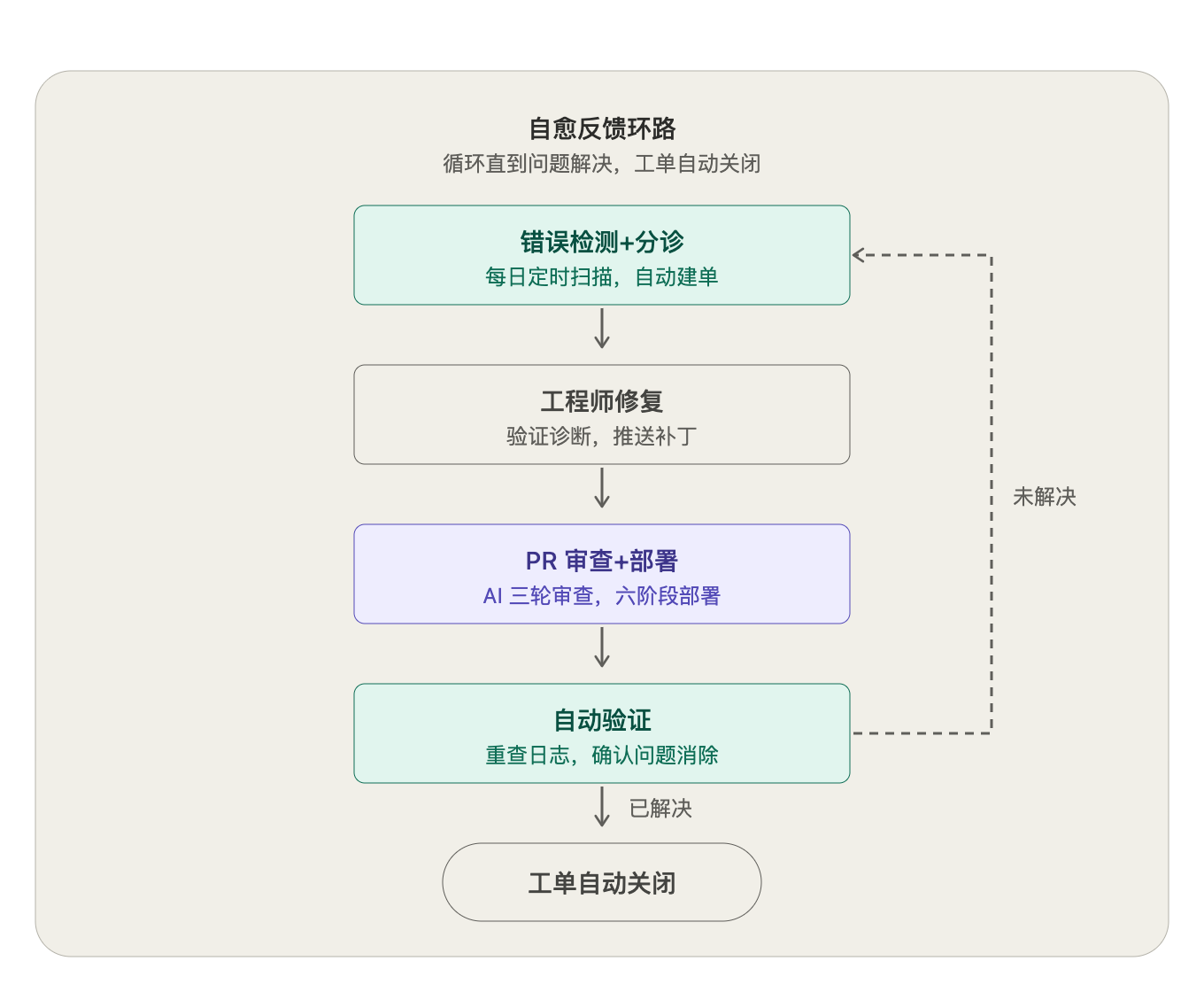

各ツールは特定のフェーズのみを担当し、どのツールもすべてを一手に引き受こうとはしません。この日常的なサイクルにより、「自己修復ループ」が形成され、最小限の人的介入でエラーの検出、トリアージ(選別・優先順位付け)、修正、検証が行われます。
私は『ビジネスインサイダー』の記者に対し、「AI がコードの作成と提出を担当し、人間は戦略的なリスクの有無を審査するだけだ」と語りました。
機能フラグ(Feature Flags、注:コード内で機能の有効・無効を制御する技術。再デプロイなしでいつでも機能をオンオフ可能)の管理には Statsig を使用しています。すべての新機能は、リリース前に機能フラグの背後に隠されています。公開プロセスは非常に堅牢です:まずチーム内部向けに開放し、次にパーセンテージベースのグラデーションリリース(段階的公開)を行い、最後に全面開放するか、あるいは完全に削除します。「ワンクリック停止」機能により、再デプロイすることなく瞬時に機能を無効化できます。もしある機能がデータ指標を悪化させた場合、数時間以内に撤回されます。品質の低い機能は公開当日に「死滅」します。A/B テストも同じシステム上で実行されます。
Graphite はコードブランチの管理を担当します:マージキューは検証を再実行し、すべてのチェックが合格した場合のみメインブランチへのマージを許可します。これにより、高頻度なコード提出と体系的なレビューを両立できます。
Sentry はすべてのサービスの構造化された例外を報告し、トリアージエンジンがそれをモニタリングデータと組み合せます。Linear は人間向けのインターフェースであり、重大度スコアと調査提案を含むチケットを自動作成し、その後の検証が完了すると自動的にクローズします。
機能のアイデアから本番環境への移行プロセス
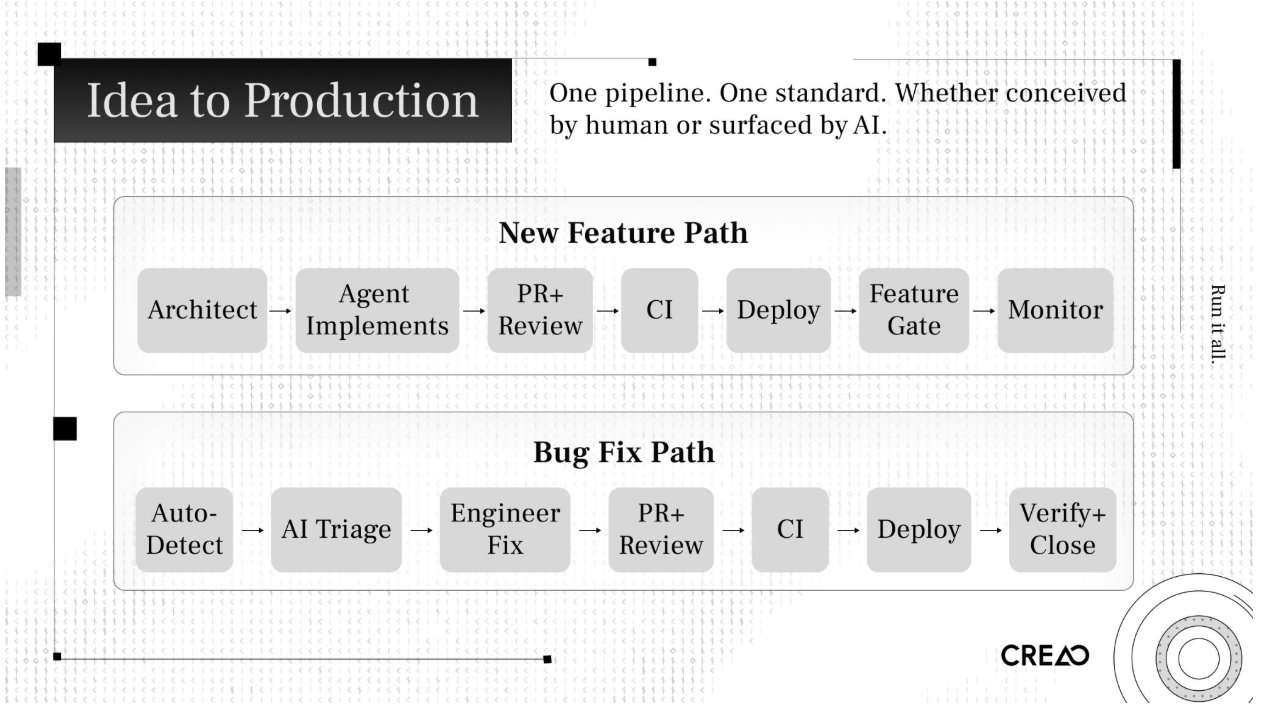
アーキテクトは、コードベースのコンテキスト、目標、制約条件を含む構造化プロンプトとしてタスクを定義します。
エージェントはタスクを分解し、実装計画を立て、コードを作成し、関連するテストを自動生成します。
PR(プルリクエスト)を開きます。Claude が3回のレビューを行います。人間のレビュアーは、行ごとの細部ではなく、高次元のリスクのみをチェックします。
パイプラインによる検証:型チェック、コードスタイルチェック、ユニットテスト、インテグレーションテスト、エンドツーエンドテスト。
6段階のデプロイメントパイプラインにより異なる環境へ展開され、各フェーズでテストが実施されます。
チーム内部向けに機能フラグを有効化します。段階的に公開し、データ指標を注視します。
データが悪化すればいつでもワンクリックで停止できます。重大な問題が発生すると自動でサーキットブレーカーが作動し、ロールバックされます。
Claude トリアージエンジンが重大度を評価し、完全な調査コンテキストを含むチケットを自動作成します。
エンジニアが調査に介入します。この時点で AI はすでに診断作業を完了しています。エンジニアは結論を検証し、修正コードを提出するだけです。
厳格なコードレビュー、検証、デプロイメント、モニタリングのパイプラインを同じものを使用します。
トリアージエンジンが再検証を行います。解決が確認されれば、チケットは自動的にクローズされます。
この2つのパスは完全に同一のパイプラインを使用しています。同じシステム、同じ基準です。
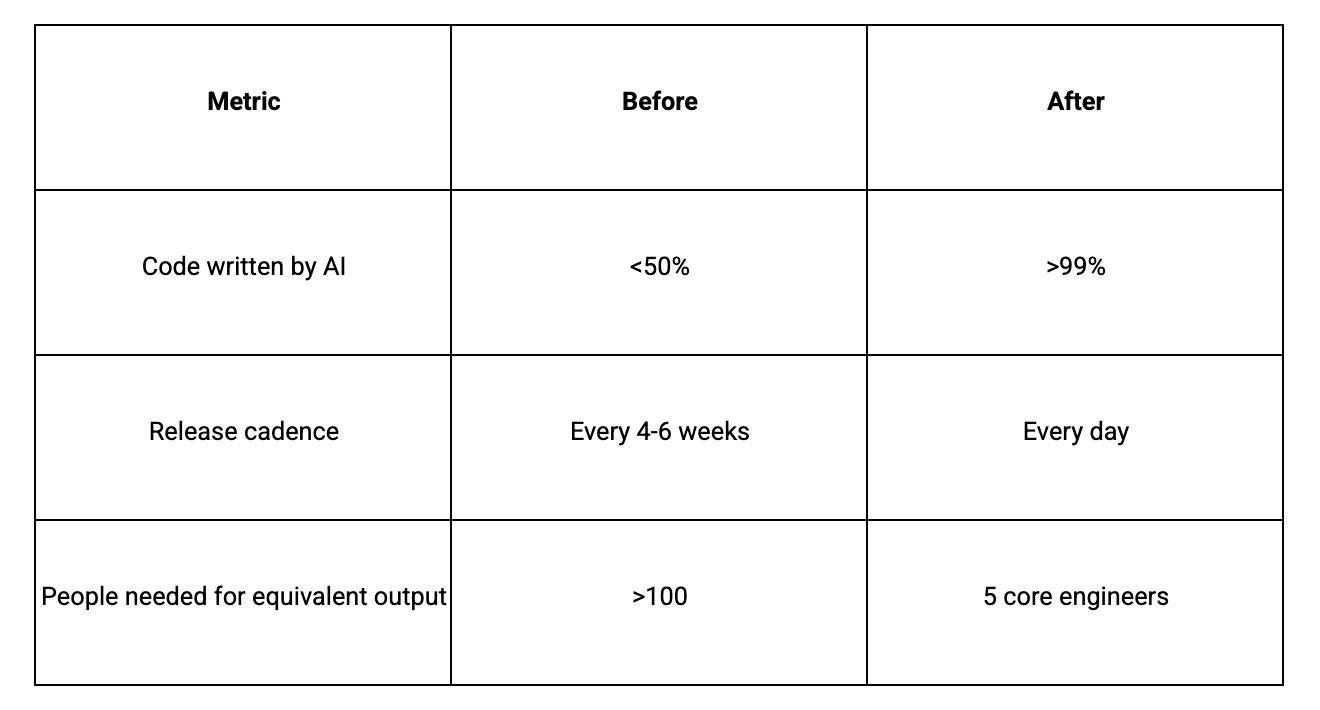
過去14日間、私たちは平均して毎日3〜8回の本番環境へのデプロイを行ってきました。旧モードでは、この2週間で1回のリリースも実施できませんでした。
機能が劣悪であれば、リリース当日に削除される。新機能は考案されたその日に公開できる。A/B テストによってビジネスへの影響をリアルタイムで検証する。
多くの人は、私たちが速度と品質のトレードオフを取っていると考えている。しかし逆だ。ユーザーエンゲージメントが上昇し、コンバージョンレートも向上した。私たちは以前よりも優れた製品を作っている。フィードバックループが極めて短くなったからだ。毎日リリースして得られる学びは、月1回のリリースよりも圧倒的に多い。
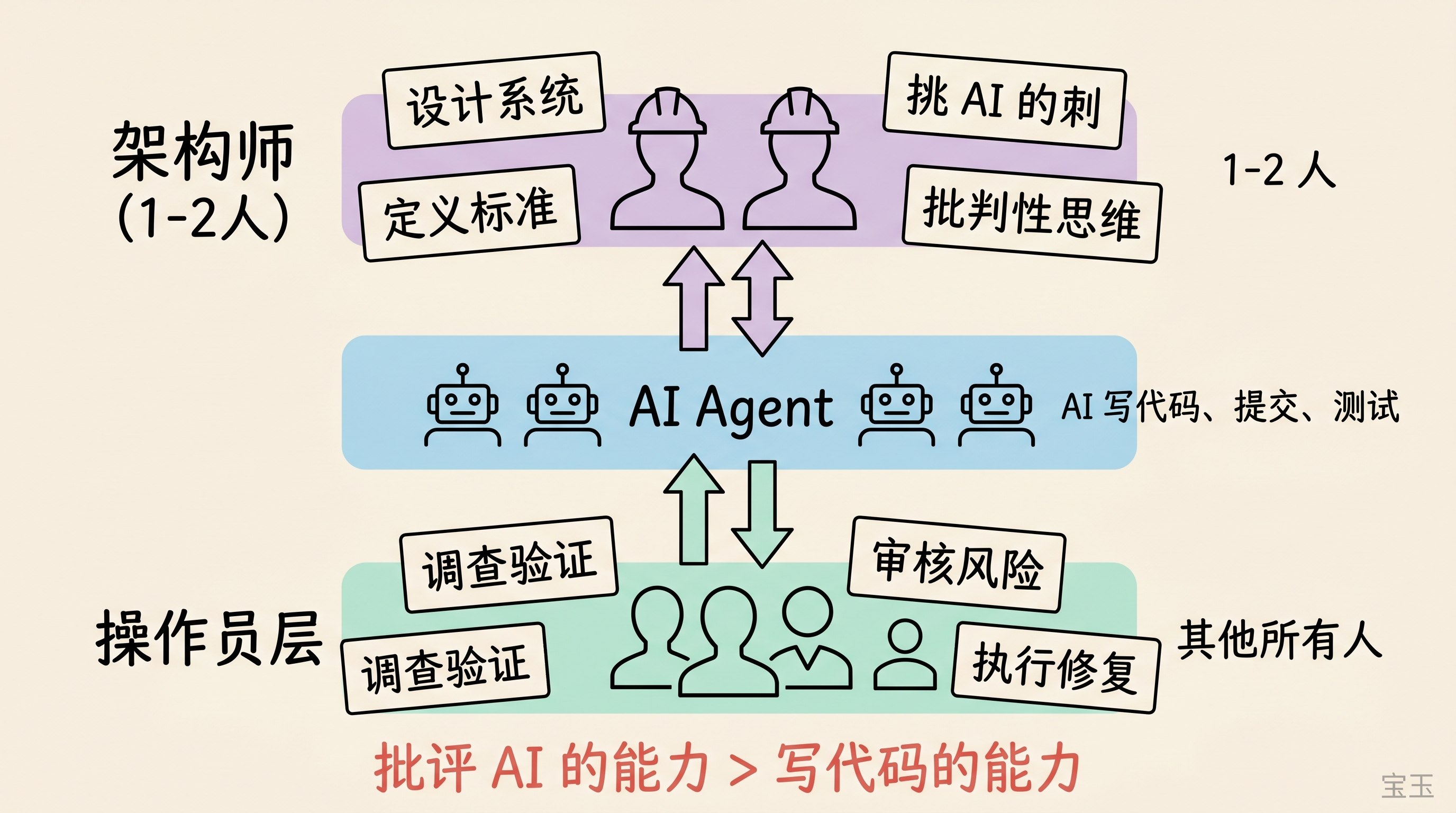
未来には、エンジニアは2つのタイプしか存在しない。
たった1〜2人のアーキテクトだ。彼らは標準作業手順(Standard Operating Procedure: SOP)を設計し、AIの動作原理を教える。テストスタブ(Stub)、統合システム、トリアージネットワーク(Triage Network)を構築する。システムアーキテクチャと境界条件を決定し、エージェントにとって「良い」とは何かを定義する。
この役割には極めて深い批判的思考力が求められる。やるべきことはAIに従うことではなく、AIの欠点を指摘することだ。エージェントが提案を出した際、アーキテクトは抜け漏れを見逃さず、問題点を鋭く見つけなければならない。どの失敗モード(Failure Mode)を見落としているか? 安全境界を越えていないか? どのようなテクニカルデット(Technical Debt)が蓄積されているのか?
私は物理学の博士号を持っている。博士課程で学んだ最も有用なことは、仮定を疑い、論理にストレステストを行い、論理的欠陥を探す方法だった。未来において、AIを批判する能力は、コードを書く能力よりも価値を持つだろう。
残りの全員。仕事は依然として重要だが、構造が変わった。
現在はAIが人間にタスクを割り当てる。トリアージシステム(Triage System)がバグを検出し、チケットを作成し、診断結果を示して適切な担当者に割り当てる。人間は調査、検証を行い、修正案を承認する。AIがコードを提出し、人間がリスク審査を行う。
これらの仕事には依然として高いスキルと集中力が必要だが、旧来のようなゼロからシステムアーキテクチャを構築する推論能力はもはや必要とされない。
私は予想外の現象を観察した。ジュニアエンジニアがシニアエンジニアよりも早く適応していることだ。
従来の思考パターンに縛られていないジュニアエンジニアにとって、これは虎に翼を得たようなものだ。彼らは自身の影響力を無限に増幅できるツールを習得しており、破棄すべき何十年もの古い習慣がない。
一方、豊富な伝統的経験を持つシニアエンジニアは、最も苦しい葛藤を経験している。以前であれば2ヶ月かかった作業が、今ではAIが1時間で完了してしまう。何年もかけて希少なスキルを磨いてきた人々にとって、これは耐え難い打撃である。
正誤を判断しているわけではなく、私が目にした現実を述べているに過ぎない。この変革において、蓄積された過去のスキルよりも適応能力の方が重要である。
2ヶ月前、私は時間の60%を人員管理に費やしていた。優先事項の調整、会議、フィードバック提供、エンジニアへのコーチングだ。
従来のCTO(Chief Technology Officer)のモデルは、チームにアーキテクチャを任せてエンパワーし、トレーニングを行い、業務を引き渡すよう教えている。しかし、このシステムに1〜2人のアーキテクトしか必要ないのであれば、私はまず自ら手を動かして構築しなければならない。「マネージャー」から「ビルダー(構築者)」に戻ったのだ。現在、私は朝9時から深夜3時まで毎日コードを書いている。システムの基盤ロジックとアーキテクチャを設計し、インフラストラクチャのスタブ(Stub)を維持している。
プレッシャーは増したが、人々と「アライン(調整)」する日々よりも、純粋な「ビルド」の楽しさの方が好きだ。
創業者およびエンジニアたちとの関係は、以前よりも良くなった。
移行前、チームとの大半のやり取りは会議で行われていた。技術的なトレードオフの議論、優先順位をめぐる争い、技術的意思決定を巡る激しい論争。従来のモデルではこれらの対話は必要不可欠だったが、極めて心労を伴うものでもあった。
今も私はチームとコミュニケーションを取る。仕事以外の話題で雑談したり、リラックスするためにチームビルディング(Team Building)を行ったりする。私たちはより良好な関係で過ごしている。なぜなら、今ではシステムに任せることができるような作業について争う必要がなくなったからだ。
私が毎日業務のコミュニケーションを取らなくなると、一部のチームメンバーは不安を感じた。CTOが話しかけてこないのはどういう意味か? 新しい世界において、自分の価値はどこにあるのか? これらの懸念はすべて妥当である。
一部の人は、「AIが自分の仕事を奪えるかどうか」をチャットで議論することに、実際の作業に費やす時間よりも多くの時間を割いている。移行期には不安が避けられない。それに対する完璧な慰め言葉など、私にもない。
しかし、私には一つの原則があります。エンジニアがオンライン上でバグを書き込んだからといって、彼を解雇することはありません。私たちは審査プロセスを改善し、テストを強化し、ガードレールを追加します。AI に対しても同様です。もし AI が誤りを犯したなら、より良い検証メカニズム、明確な制約条件、そして強力なシステム観測性(System Observability)を構築すればよいのです。
私は、一部の企業がエンジニアリング開発において「AI 優先」を採用している一方で、他の部門は依然として手作業に頼っているのを目にします。
もしエンジニアが数時間で機能リリースができるのに、マーケティング部門がアナウンスを出すのに一週間もかかるなら、マーケティング部門が新たなボトルネックとなります。もしプロダクトチームがまだ「月」単位で計画を立てているなら、製品企画(Product Planning)がボトルネックです。
CREAO では、AI 原生の運用方式をすべての機能部門に展開しています:
プロダクト更新ノート:コード変更履歴と機能説明に基づき AI が自動生成。
機能紹介動画:AI による動的デモの自動生成。
ソーシャルメディアの日常投稿:AI による企画と自動投稿。
ヘルスレポートとデータ分析:監視および本番環境のデータベースから AI が抽出・生成。
エンジニアリング、プロダクト、マーケティング、ユーザー成長のすべてが、同じ「AI 原生」のワークフローの中で稼働しています。もしある部門がエージェント(Agent)の光速で動き、別の部門が人間の亀の速さで爬行しているなら、人間の速度が会社全体の足を引っ張ることになります。
あなたのコアバリューは、「コードを書く生産量」から「意思決定の質」へと移行しています。コードを素早く記述する能力は、毎月価値が下落しています。一方、AI を評価し、批判し、指導する能力は急速に価値を上昇させています。
プロダクトへの鋭い感覚と品味が極めて重要です。AI が生成した UI 画面を一目見ただけで、ユーザーが不平を言う前に直感的に「何かおかしい」と気づけますか?アーキテクチャの提案書を一目見ただけで、AI が見落としたシステム上のリスクを瞬時に看破できますか?
私はいつも 19 歳のインターン生にこう伝えています。批判的思考を意図的に練習しなさい。論拠を評価する方法、論理的な抜け穴を探す方法、当たり前の仮定に疑問を呈する方法を学びなさい。良いデザインとは何かを学びなさい。これらのスキルは複利効果を持っています。
もし製品企画に要する時間が、コード実装に要する時間よりも長いなら、そこからすぐに手を付けなければなりません。
大規模な AI エージェントの導入に先立ち、テストのためのインフラ(Testing Scaffold)を整備してください。高速な検証を裏付けとして持たない高速 AI は、急速に蓄積する技術的災害をもたらすだけです。
アーキテクトから始めましょう。このシステムを構築し、その有効性を証明できる人物を見つけてください。システムが稼働したら、他の人員を「オペレーター」の役割に配置します。
「AI 原生」を各機能部門へ強制的に展開してください。
抵抗と反対が必ず発生することを覚悟してください。
OpenAI、Anthropic、そして多くの独立チームは、同じ原則へと収束しつつあります:構造化されたコンテキスト、専門化されたエージェント、永続的なメモリ(Persistent Memory)、そして実行の閉ループです。インフラ整備は業界標準になりつつあります。
これらを駆動するエンジンは、モデル能力の進化です。CREAO で最近起きたすべての質的変化は、過去 2 か月間に帰属できます。Claude Opus 4.5 ではできなかったことが、Opus 4.6 では可能になりました。次世代のモデルは、この変革をさらに激しくするでしょう。
私は、「一人会社」が非常に一般的になるだろうと信じています。もしアーキテクトが一連のエージェントを率いて 100 人の仕事ができるなら、多くの会社は第二名の従業員を採用する必要すらありません。
私が接したほとんどの創業者やエンジニアは、依然として伝統的なモデルを沿用しています。一部は移行を検討し始めていますが、実際に一歩を踏み出す者は寥寥です。
記者の友人は、このテーマについて約 5 人にインタビューしたと教えてくれました。彼女は私たちに言いました。「あなたたちは誰よりも先に進んでいます。『あなたたちほど、ワークフロー全体を完全に再構築した人はいない』と感じます。」
どのチームでも、既存のツールを用いてこれを実現できます。私たちの技術スタック(Tech Stack)には、独占的な秘密は一つもありません。
真の競争優位性は、これらのツールを中心にすべてを再構築するという決意と、それに伴う莫大な代償を支払えるかどうかにかかっています。この代償は真に金銭的かつ痛烈なものです:従業員の混乱と不安、CTO が 1 日 18 時間働く苦難、シニアエンジニアの自己価値への疑念、そして旧システムが解体され新システムがまだ稼働していない、息を呑むような 2 週間の空白期間。
私たちはこれらの代償を支え抜きました。2 か月後、データがすべてを物語りました。
私たちはエージェントプラットフォームを構築しました。そしてこのプラットフォームは、エージェント自身によって構築されたものです。
原文を表示
今天刷到《Why Your”AI-First”Strategy Is Probably Wrong》这篇文章(原文翻译我放到下面)几次,说点不一样的。与其说 AI First,不如说软件工程 First。
这篇文章看着在讲 AI,底下全是软件工程。
抛开后面讲组织和人的部分,原文前半段的重点简单总结一下:
AI 时代,人成了瓶颈。 PM 花几周做需求,AI 两小时就能实现,PM 成了瓶颈。QA 测三天,AI 写代码只要两小时,QA 成了瓶颈。团队 25 个人,对手几百人,人力也是瓶颈。
怎么办?把人从链条里拿掉。 AI 写代码、AI 审查代码、AI 跑测试、AI 部署上线、AI 监控线上状态,出了问题自动回滚。每天定时扫描日志,自动发现问题、分配任务、跟踪修复。整条流水线跑起来,人只需要在关键节点做判断。
至于文中提到的统一代码库,锦上添花,和 AI First 关系不大。有当然更好,没有也有很多替代方案。
整套方案听下来,逻辑自洽,效果也漂亮:一天部署好几次,功能当天上当天撤,数据说了算。
但先别急着照搬,先对照自己的情况想几件事:
第一,自动化测试。 AI 改完代码,你得有办法确认它没搞崩别的功能。测试覆盖不够的话,每次 AI 提交代码你都得人工回归一遍,那速度根本快不起来。
第二,CI/CD 流程。 从提交代码到部署上线,中间的测试、审查、发布、回滚,是不是全自动跑通了?这条流水线不通,AI 写得再快,代码也堆在那儿等人手动处理。
第三,A/B 测试和线上监控。 新功能上线之后效果好不好,得有数据说话,效果不好得能随时关掉。没有这套机制,AI 一天产出五个功能,你都不知道哪个该留哪个该砍。
第四,任务管理。 任务得拆到合适的粒度,生命周期得跟踪得住。一个大而模糊的任务丢给 AI,现在的能力还啃不动。多个 Agent 同时干活的时候,谁做哪个、哪个优先、做到什么程度,这些都得有地方管。
第五,系统架构。 架构太乱或者压根没有架构的代码,AI 维护起来跟人一样头疼。上下文塞满了还是搞不清边界在哪,改一处崩三处。
这几条里如果有做不到的,就得靠人去补。补不上,AI First 就只是一句口号。
但假设你全做到了,就能 AI First 了?
还是不行。这套玩法只适合一部分场景。
适合的场景: 后端逻辑为主、界面不复杂的产品,比如 API 服务、数据处理平台、内部工具。功能好不好,跑一下数据就知道,不需要人去盯着每个像素。原文里的就是个 Agent 平台,本质上是后端驱动的产品,可以用这套打法。
再比如早期产品快速试错,功能上了不行就撤,用户预期本来就没那么高,AI 的速度优势能充分发挥。
UI 密集的产品。 自媒体天天喊前端已死,但你让 AI 做个复杂界面试试,各种易用性问题、交互细节、视觉还原,它搞不定的。否则马斯克靠 AI 早就改了不知道改版 X 多少次了。
功能质量敏感的产品。 Anthropic 和 OpenAI 不知道 AI First 吗?他们敢在 Claude Code 和 Codex 上这么搞吗?让 AI 全自动迭代自家的核心产品,用户不骂死才怪。
安全性要求高的场景。 银行系统、在线交易平台,AI 代码出个差错,那可不是回滚能解决的。
AI First 的方向没有错,它代表的是一种意识的转变:每做一个决策的时候,想一想这件事能不能让 AI 来做,如果不能,缺什么条件,怎么把条件补上。
但这种意识要落地,靠的不仅是买几个 AI 工具的订阅,还需要把基础搭好。 测试、CI/CD、监控、架构、任务管理,这些做扎实了,AI 的能力自然能释放出来。做不好,加再多 AI 也是在沙子上盖楼。
从这个角度看,AI First 的终点未必是让 AI 干所有的活,而是借着这股力量,把你一直想做但没动力做的工程改进,真正推动起来。
仰望星空是好的,但也还要脚踏实地。
为什么你的“AI 优先”战略可能大错特错【翻译】
作者:Peter Pang 原文:Why Your “AI-First” Strategy Is Probably Wrong
我们 99% 的生产环境代码都是由 AI 编写的。上周二早上 10 点,我们上线了一项新功能,中午进行了 A/B 测试,结果下午 3 点就把它砍掉了,因为数据表现不佳。下午 5 点,我们又发布了一个优化后的版本。如果放在三个月前,这样一个完整的迭代周期至少需要六个星期。
我们能做到这一步,绝不是因为在代码编辑器里装了个 Copilot 插件那么简单。我们彻底打破了原有的工程研发流程,并围绕 AI 进行了全面重构。我们改变了做计划、写代码、测试、部署以及团队组织的方式。我们甚至重塑了公司里每个人的角色。
CREAO 是一个 AI 智能体 (AI Agent) 平台。公司有 25 名员工,其中 10 名是工程师。我们在 2025 年 11 月开始研发智能体,就在两个月前,我从零开始,彻底重组了整个产品架构和工程工作流。
OpenAI 在 2026 年 2 月发布了一个新概念,完美总结了我们一直在做的事情。他们称之为脚手架工程 (Harness Engineering,(注:Harness 原意为马具或安全带,在软件工程中通常指测试支架或脚手架,这里指为 AI 提供工作环境和约束条件的系统工程)):工程团队的核心工作不再是写代码了,而是赋能智能体,让它们去完成有价值的工作。当系统出错时,解决办法绝不是“再试一次”或“再努力点”。真正的解决思路是去问:AI 缺失了什么能力?我们该如何让这个能力对智能体变得清晰可见,并强制它们去执行?
我们自己摸索出了这个结论,只是当时还没有一个现成的名词来定义它。
“AI 优先”不等于“使用 AI”
大多数公司只是把 AI 强行塞进现有的工作流里。工程师打开 Cursor 辅助写代码,产品经理用 ChatGPT 帮写需求文档,测试团队 (QA) 尝试用 AI 生成测试用例。整个工作流程还是老样子。效率确实提升了 10% 到 20%,但本质上的结构没有任何改变。
这顶多叫“AI 辅助” (AI-assisted)。
真正的“AI 优先” (AI-first),意味着你要基于“AI 是主力构建者”这一核心假设,彻底重新设计你的流程、架构和组织。 你要停止问“AI 能怎么帮助我们的工程师?”,转而问“我们该如何重构一切,让 AI 去做构建工作,而工程师只负责指引方向和判断好坏?”
这两种思路带来的差距,是指数级的。
我看到很多团队自称“AI 优先”,却依然在跑原来的敏捷冲刺周期,用着一样的 Jira 任务看板,开着一样的每周站会,还要经过一样的 QA 验收签字流程。他们只是把 AI 强加进了现有的循环里,而没有重新设计这个循环。
这种现象的一个典型表现,就是现在常说的凭感觉编程 (Vibe Coding)。打开 Cursor,不断调整提示词直到代码能跑通,提交代码,然后不断重复。这种方式只能用来做原型验证。一个真正用于生产环境的系统,必须是稳定、可靠且安全的。当 AI 来写代码时,你需要建立一个能兜底并确保这些特性的系统。你需要构建的是系统,而那些提示词是用完即弃的。
去年,我仔细观察了团队的工作方式,发现了三个差点要了我们命的瓶颈。
我们的产品经理过去要花好几周的时间来调研、设计和详细规划产品功能。几十年来,产品管理一直都是这么运作的。但是,AI 智能体实现一个功能只需要两小时。当开发时间从几个月被极度压缩到几个小时,那长达数周的规划周期就成了最大的拖油瓶。
花几个月去构思一个想法,然后只用两小时就把它做出来,这太不合逻辑了。
产品经理必须进化成具备产品思维的架构师,以快速迭代的节奏工作,否则就得退出开发环节。产品的设计必须通过“快速原型 - 发布 - 测试 - 迭代”的循环来完成,而不是靠委员会开会去评审那些长篇大论的需求文档。
情况如出一辙。AI 智能体花两小时上线一个功能后,我们的 QA 团队要花好几天去测试各种边缘和极端情况。开发两小时,测试三天。
于是,我们用 AI 构建的自动化测试平台取代了人工 QA,用 AI 来测试 AI 写的代码。验证的速度必须赶上开发的速度。否则,你只是在离旧瓶颈十英尺远的地方,又建了一个新瓶颈而已。
我们的竞争对手有 100 倍甚至更多的人在做同样的工作,而我们只有 25 人。我们不可能靠疯狂招人来赶超他们,我们只能靠“重新设计”来杀出一条血路。
我们需要把 AI 深度贯穿到三个系统中:如何设计产品、如何实现产品、以及如何测试产品。如果其中任何一个环节依然靠纯人工,它就会拖垮整个流水线。
过去我们的架构散落在多个独立的系统中。修改一个功能可能需要同时动三四个代码仓库。从人类工程师的角度来看,这勉强还能应付。但从 AI 智能体的视角来看,这就像个黑盒。智能体看不到全貌,无法推理跨服务的连锁反应,也不能在本地跑集成测试。
我不得不把所有代码整合到一个大型代码库 (Monorepo) 中。原因只有一个:让 AI 能纵览全局。
这就是脚手架工程理念在实际中的运用。你把越多部分的系统转化为 AI 可以检查、验证和修改的形态,你获得的杠杆效应就越大。碎片化的代码库对 AI 是隐形的,而统一的代码库对它们来说则是清晰易读的。
我花了一周的时间设计新系统:规划阶段、实施阶段、测试阶段、集成测试阶段。接着,我又用了一周时间,利用智能体帮忙重构了整个代码库。
CREAO 本身就是一个智能体平台。我们用自己的智能体,重建了运行智能体的平台。如果一个产品能自己构建自己,那就说明这条路走得通。
下面是我们的技术栈,以及每个模块的作用。
底层基础设施:AWS (亚马逊云服务)
我们运行在 AWS 上,使用了自动扩缩容的容器服务和熔断回滚机制。如果部署后监控指标恶化,系统会自动回滚到上一个安全版本。
CloudWatch 是整个系统的中枢神经。所有服务都有结构化的日志,设定了超过 25 个自动警报,自动化工作流每天都会查询自定义指标。每一个基础设施部件都会暴露出结构化、可查询的信号。(注:结构化日志指按统一格式记录的日志,便于机器读取;可查询信号指 AI 能直接检索的关键运行数据) 如果 AI 读不懂日志,它就无法诊断问题。
CI/CD:GitHub Actions
每一次代码修改都要经过一个死磕到底的六阶段流水线:
验证 CI → 构建并部署到开发环境 → 测试开发环境 → 部署到生产环境 → 测试生产环境 → 正式发布
每个拉取请求 (Pull Request, 简称 PR,(注:即提交代码变更的请求)) 上的把关机制,强制执行类型检查、代码规范检查、单元和集成测试、Docker 构建、利用 Playwright 进行的端到端测试,以及环境一致性检查。没有任何一个阶段可以跳过。不允许任何人工强行绿灯。整个流水线是绝对确定性的,这样 AI 才能预测结果并推理出失败的原因。
每一个 PR 都会触发 Claude Opus 4.6 进行三轮并行的 AI 审查:
代码质量:检查逻辑错误、性能问题、可维护性。
安全性:漏洞扫描、认证边界检查、注入攻击风险。
依赖项扫描:供应链风险、版本冲突、开源协议问题。
这些是必须通过的拦截关卡,而不只是提提建议。它们和人工审查并行运作,批量拦截人类容易漏掉的错误。当你一天要部署 8 次时,没有哪个肉眼凡胎的工程师能对每个 PR 都保持高度专注。
工程师还可以在任何 GitHub Issue 或 PR 中圈一下 @claude
每天早上(UTC 时间 9:00),自动化健康检查工作流准时启动。Claude Sonnet 4.6 会查询 CloudWatch,分析所有服务的错误模式,并生成一份系统健康执行摘要,发送到团队的聊天群里。这都不需要任何人主动去吩咐。
一小时后,分诊引擎启动。它会将生产环境里的错误信息进行分类聚类,从 9 个维度评估每个问题的严重程度,并在任务管理系统中自动生成调查工单。每个工单都贴心地附带了日志样本、受影响的用户、受影响的接口以及建议的排查方向。
系统还会自动去重。如果现有的工单已经涵盖了同类错误,它会更新那个工单。如果以前解决过的问题又出现了,它会敏锐地检测到倒退 (Regression) 并重新打开工单。
当工程师提交修复代码时,同样的流水线会接管一切。Claude 会进行三轮审查,CI 进行验证。六阶段部署流水线将其推送到各个环境并进行测试。部署完成后,分诊引擎会再次检查监控数据。如果原先的错误解决了,工单就会自动关闭。
每个工具只负责一个阶段。没有哪个工具试图包揽一切。这个日常循环创造了一个“自愈闭环”:以最少的人工干预,完成错误的检测、分诊、修复和验证。
我曾对《商业内幕》的记者说:“AI 会负责写代码并提交,人类只需要负责审核有没有战略风险就行了。”
我们用 Statsig 来管理功能开关 (Feature Flags,(注:一种在代码中控制功能是否启用的技术,允许在不重新部署代码的情况下随时开关功能))。每个新功能上线前都藏在开关后。发布模式非常稳健:先对团队内部开放,然后按百分比灰度发布,最后全面开放或直接砍掉。所谓的“一键关闭”能瞬间停用功能,根本不需要重新部署。如果一个功能导致数据指标变差,我们几个小时内就会把它撤下来。糟糕的功能在上线当天就会“死掉”。A/B 测试也是跑在同一套系统上的。
Graphite 负责管理代码分支:合并队列会重新跑一遍验证,只有一路绿灯才会合并到主干。这让我们可以一边高频提交代码,一边有条不紊地审查。
Sentry 报告所有服务的结构化异常,再由分诊引擎将其与监控数据结合。Linear 则是面向人类的界面:自动创建带有严重程度评分和调查建议的工单,后续验证通过后自动关闭。
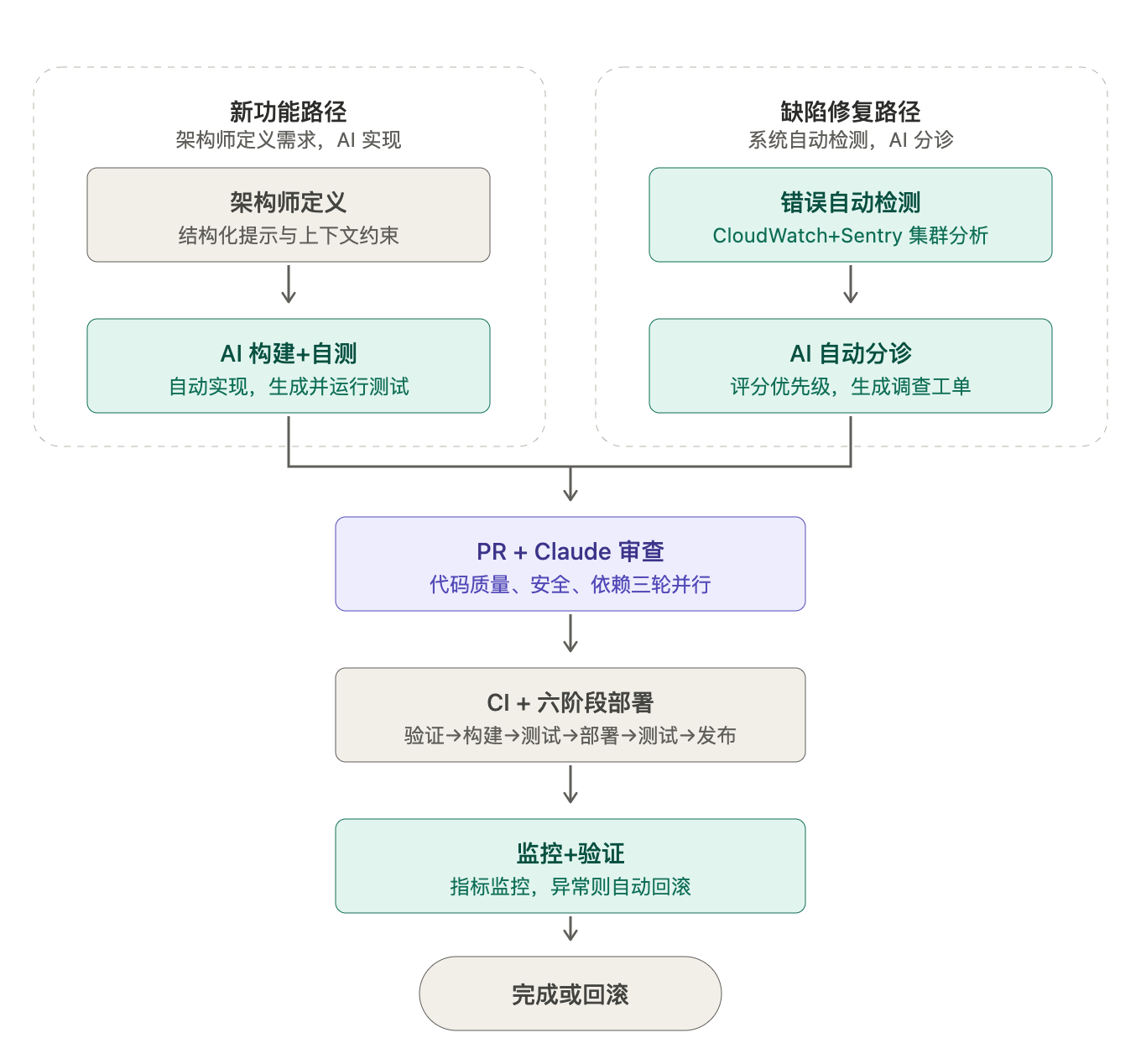
一个功能如何从想法走向生产环境
架构师以结构化提示词的形式定义任务,包含代码库上下文、目标和约束条件。
智能体拆解任务、规划实施方案、编写代码并自动生成配套的测试。
开启 PR。Claude 进行三轮审查。人类审查员只检查高维度的风险,而不去逐行死磕代码。
流水线验证:类型检查、代码规范、单元测试、集成测试、端到端测试。
六阶段部署流水线将其推送到不同环境,每个阶段都伴随测试。
面向团队内部开启功能开关。逐步灰度发布。紧盯数据指标。
一旦数据恶化,随时一键关闭。遇到严重问题自动触发熔断回滚。
Claude 分诊引擎评估严重程度,自动创建一个包含完整排查上下文的工单。
工程师介入调查。此时 AI 其实已经做完了诊断工作。工程师只需验证结论并提交修复代码。
走同一套严格的代码审查、验证、部署和监控流水线。
分诊引擎重新验证。如果确认解决,工单自动关闭。
这两条路径用的是完全同一套流水线。同一个系统,同一个标准。
在过去 14 天里,我们平均每天进行 3 到 8 次生产环境部署。在旧模式下,这整整两周的时间里,我们连一次发布都做不出来。
糟糕的功能在上线当天就会被砍掉。新功能在构思出来的当天就能上线。A/B 测试能实时验证业务效果。
很多人以为我们是在牺牲质量换取速度。恰恰相反,用户参与度上升了,付费转化率也上升了。我们做出了比以前更好的产品,因为反馈闭环变得极短。每天发布一次你能学到的东西,绝对比每个月发布一次要多得多。
未来只会存在两种类型的工程师。
只有一两个人。他们设计标准作业程序,教 AI 如何工作。他们构建测试支架、集成系统和分诊网络。他们拍板系统架构和边界。他们来定义在智能体眼里什么才叫“好”。
这个角色需要极其深厚的批判性思维。你要做的是挑 AI 的刺,而不是盲从它。当智能体提出一个方案时,架构师要能敏锐地找到漏洞:它遗漏了哪些失效模式?越过了哪些安全边界?积累了什么技术债?
我拥有物理学博士学位。读博期间我学到的最有用的东西,就是如何质疑假设、给论点做压力测试,以及寻找逻辑漏洞。在未来,批评 AI 的能力将比写代码的能力更有价值。
其他所有人。工作依然重要,但结构变了。
现在是 AI 给人类分配任务。分诊系统发现了一个 Bug,创建工单,亮出诊断结果,然后把它分配给合适的人。人类去调查、验证,并批准修复方案。AI 负责提交代码,人类负责审核有没有风险。
这些工作依然需要极高的技能和专注力,但它们不再需要旧模式下那种从头构建系统架构的推理能力。
我观察到了一个出乎意料的现象:初级工程师比资深工程师适应得更快。
没有形成传统思维定式的初级工程师,感到如虎添翼。他们掌握了能无限放大自身影响力的工具,而且没有十几年的老习惯需要去破除。
而拥有丰富传统经验的资深工程师,则经历了最痛苦的挣扎。他们过去需要辛辛苦苦干两个月的活,现在 AI 一小时就干完了。对那些花了好几年时间才练就一身稀缺技能的人来说,这实在是一个难以接受的暴击。
我不是在评判对错,只是陈述我看到的现实。在这场变革中,适应能力远比积累的过往技能更重要。
两个月前,我要花 60% 的时间在人员管理上。对齐优先级、开会、给反馈、辅导工程师。
传统的 CTO 模型告诉你,要赋能团队去做架构,培训他们,把工作交接出去。但如果这个系统只需要一两个架构师,那我就必须先亲自动手去建。我从“管理者”变回了“建造者”。我现在每天大概从早 9 点写代码到凌晨 3 点。我设计系统的底层逻辑和架构,维护整个基础设施的脚手架。
压力更大了。但我很享受这种纯粹“建造”的快乐,而不是天天去跟人“对齐”。
我和联合创始人以及工程师们的关系,反倒比以前更好了。
转型前,我与团队的大部分互动都是在开会。讨论技术取舍,争论优先级,为技术决策争得面红耳赤。在传统模式下,这些对话是必需的,但也极其耗费心神。
现在我依然会和团队交流。我们聊工作之外的话题,轻松闲聊,或者组织团建去放松。我们相处得更融洽了,因为我们不再为那些现在完全可以让系统代劳的工作而吵架了。
当我不再每天找大家沟通工作时,一些团队成员感到了不安。CTO 不找我说话意味着什么?在这个新世界里我的价值到底在哪?这些担忧都非常合理。
有些人在群里争论“AI 到底能不能取代我的工作”,花的时间比实际干活的时间还长。转型期不可避免地会带来焦虑。对此我也没有什么完美的安抚话语。
但我有一个原则:我们不会因为一个工程师在线上写了个 Bug 就开除他。我们会改进审查流程、加强测试、增加护栏。对待 AI 也是一样。如果 AI 犯了错,我们就去构建更好的验证机制、更清晰的约束条件和更强的系统可观测性。
我看到一些公司在工程研发上采用了“AI 优先”,但其他部门依然是纯手工作业。
如果工程师几小时就能发布一个功能,而市场部要花一周来发公告,那市场部就是新的瓶颈。如果产品团队还在按“月”来做规划,那产品规划就是瓶颈。
在 CREAO,我们将AI 原生的运作方式推行到了所有职能部门:
产品更新说明:由 AI 根据代码变更记录和功能描述自动生成。
功能介绍视频:由 AI 自动生成动态演示。
社交媒体日常发布:由 AI 策划并自动发帖。
健康报告和数据分析:由 AI 从监控和生产环境数据库中提取生成。
工程、产品、市场和用户增长都在同一个“AI 原生”的工作流里运转。如果一个部门以智能体的光速运转,而另一个部门还在以人类的龟速爬行,那么人类的速度就会拖慢整个公司的脚步。
你的核心价值正在从“写代码的产量”转移到“做决策的质量”。能快速敲代码的能力,每个月都在贬值。而评估、批判和指导 AI 的能力,正在快速升值。
对产品的敏锐度和品味至关重要。你能不能扫一眼 AI 生成的 UI 界面,在用户抱怨之前就直觉发现它不对劲?你能不能看一眼架构提案,就一眼看穿 AI 漏掉的系统性风险?
我总是告诉我们 19 岁的实习生:去刻意练习批判性思维。学着去评估论点、寻找逻辑漏洞、质疑想当然的假设。去学习什么是好的设计。这些技能是自带复利效应的。
如果你们产品规划功能的时间,比写代码实现的时间还长,赶紧从那里开始动刀子。
在大规模引入 AI 智能体之前,先建好测试的脚手架。没有极速验证做后盾的极速 AI,只会带来快速累积的技术灾难。
从一名架构师开始。找一个能把这套系统建起来并证明它行之有效的人。等系统跑通了,再安排其他人进入“操作员”的角色。
将“AI 原生”强行推入每一个职能部门。
做好心理准备,肯定会遇到阻力和反对。
OpenAI、Anthropic 以及许多独立团队都在向着同样的原则靠拢:结构化的上下文、专业化的智能体、持久化的记忆,以及执行闭环。脚手架工程正在成为行业的标配。
驱动这一切的引擎是模型能力的进化。我把 CREAO 最近发生的所有质变,都归功于过去这两个月。Claude Opus 4.5 做不到的事,Opus 4.6 已经能做到了。下一代模型只会让这种变革来得更猛烈。
我相信,“一人公司”将变得非常普遍。如果一个架构师带着一群智能体就能干 100 个人的活,很多公司根本就不需要雇佣第二名员工。
我接触过的大多数创始人和工程师,还在沿用传统的模式。一部分人开始考虑转型,但真正迈出这一步的寥寥无几。
一位记者朋友告诉我,她就这个话题大概采访了五个人。她说我们走得比任何人都靠前:“我觉得没有任何人像你们一样,完完全全重构了整个工作流。”
任何团队都可以用现有的工具做到这一点。我们的技术栈里,没有任何一个是独家机密。
真正的竞争优势,在于你下定决心要围绕这些工具彻底重塑一切,并愿意承受随之而来的巨大代价。这种代价是真金白银且痛彻心扉的:员工的迷茫与焦虑、CTO 每天工作 18 个小时的煎熬、资深工程师对自身价值的自我怀疑,以及那段旧系统已拆毁而新系统还未跑通的、令人窒息的两周真空期。
我们扛下了这些代价。两个月后,数据说明了一切。
我们构建了一个智能体平台。而这个平台,正是我们用智能体建起来的。
関連記事
楽天、Codex導入で問題解決速度を2倍に
楽天はOpenAIのコーディングエージェント「Codex」を活用し、ソフトウェア開発を高速化・安全化。平均修復時間を50%削減、CI/CDレビューを自動化、数週間でフルスタックビルドを実現した。
エージェントハーネスの解剖学
LangChainのVivek Trivedy氏が、エージェントを「モデル+ハーネス」と定義し、ハーネスがAIモデルの知能を実用的な作業エンジンに変換するシステム構築手法であると説明している。
GitHub App インストールトークンの新形式導入に関するお知らせ
GitHubは2026年4月より、インストールトークンの新形式を段階導入する。この変更により、40文字固定を前提とするアプリは動作しなくなる可能性がある。