GPT-5.5 の能力と反応:期待通りのシステムカードと実用性
GPT-5.5は計算力とエージェント機能を強化し、コード作成や知識作業でClaude Opus 4.7と競合する実用性を持つ新モデル。
キーポイント
GPT-5.5の核心的強化点
GPT-5.4より「はるかに高い」知能水準と、エージェントタスク、特にコンピュータ操作・コード生成・研究作業での実行能力が飛躍的に向上している。
実用的使用シナリオの分岐
明確なタスクにはGPT-5.5、曖昧な会話や探索的作業にはClaude Opus 4.7を推奨するなど、用途別に使い分けるべき状況が明確化された。
価格と効率のトレードオフ
トークン単価は上昇したが、実際のコストは低下しており、効率性の向上が価格戦略の鍵とされている。
開発戦略の転換の兆し
「Spud」という新ベースモデルの導入と、今後のイテレーションが機能強化にシフトする可能性が示唆されている。
OpenAIの戦略的プレゼンテーション
「作業の自動化」を軸に、ツール連携・計画・自己検証能力を強調し、エージェント型AIの実用化を推進している。
GPT-5.5の性能と効率性
OpenAIはGPT-5.5が5.4より高いトークン効率を実現したと主張しており、実用的なタスクでの改善が見込まれる。
価格設定の変化
GPT-5.5はOpus 4.7よりやや高価(5/$30 per million)となり、以前とは逆に高価格帯に位置付けられている。
影響分析・編集コメントを表示
影響分析
GPT-5.5の登場により、AIエージェントの実用化が一段と前進し、知識作業の自動化が本格化する。特に開発者や研究者層への影響が大きく、AIと人間の協働モデルが再定義される可能性がある。
編集コメント
この記事はOpenAIの新モデル発表を客観的に評価しており、実際の使用感と比較分析が重視されている点で信頼性が高い。
GPT-5.5 のシステムカードは、私たちが期待していた内容をほぼ伝えてくれました。Anthropic の Opus 4.7 向けモデルカードとの比較については、Drake Thomas のスレッドをご覧ください。
次に、これが実務において何を意味するのか、またどのような状況で GPT-5.5 が私たちの新たな選択武器となるべきかを問う段階に移ります。
私の答えは、「目的によっては yes(はい)、そうでない場合は no(いいえ)」ですが、現在は競争力のあるモデルです。GPT-5.5 は GPT-5.4 と同様ですが、より一層その傾向が強く、特に生来の知能(raw intelligence)や、明確に仕様されたコーディングタスクおよびエージェントタスク(コンピュータ操作を含む)において能力が向上しています。
Claude Opus 4.5 が登場して以来、約 4 ヶ月ぶりに、ウェブ検索のような限定的なタスクを除き、Anthropic 以外のモデルを競争力のある選択肢として考慮したことになります。GPT-5.5 は完璧ではありませんし、すべての分野で最良というわけではありませんが、基本的に誰もがこれを堅実なアップグレードと捉えています。全体的に非常にポジティブなフィードバックです。
私の実際の使用法は、タスクの性質に応じて両モデル間で使い分けています。明確に仕様化でき、正解だけを求めたい場合は、直感的に GPT-5.5 を選択します。自分が何を求めているか確信がない場合や、対話をしたい場合、あるいは Claude Code 風の作業を行いたい場合は、Opus 4.7 を選びます。
いつも通り、各モデルを試して、自らのユースケースでテストし、ご自身の考えを確かめてください。
OpenAI はこれを新しいベースモデル、コードネーム Spud と報告し、ここからの急速な反復を予測しています。この動きが比較的大規模な生来的知能の向上を意味する一方で、今後の数回の反復は機能性に関するものではないかと不思議に思います。
料金は 100 万トークンあたり$5/$30、または Pro プランでは$30/$180 です。OpenAI はトークンの使用がより効率的になったと述べており、表向きの価格が上がったものの、実際のコストは下がっていると説明しています。

公式の訴求点
焦点は、コンピューターの使用、コーディング、リサーチ、そして作業完了にあります。
また、GPT-5.4 と比較して「はるかに高い」レベルの知能を有していると主張しています。
いつも通り、訴求内容を聞き、彼らが何を語り、何を語っていないかにも注意を払う必要があります。
OpenAI: 私たちは GPT‑5.5 をリリースします。これはこれまでで最も賢く、使用が直感的なモデルであり、コンピューター上で作業を行う新しい方法への次のステップです。
GPT-5.5 は、あなたが何を目指しているかをより迅速に理解し、作業の多くを自ら実行できます。コードの作成とデバッグ、オンライン調査、データ分析、文書やスプレッドシートの作成、ソフトウェアの操作、そしてタスクが完了するまでツール間を移動することにおいて卓越しています。すべてのステップを慎重に管理する必要はなく、GPT-5.5 に複雑で多段階のタスクを与えれば、計画立案、ツールの使用、作業の確認、曖昧さへの対応、そして継続的な実行を信頼して任せることができます。
特に、エージェントによるコーディング、コンピュータ操作、知識労働、および初期段階の科学研究といった分野において、その向上は顕著です。これらの領域では、文脈全体にわたる推論と時間経過に伴う行動の実行が進展の鍵となります。GPT-5.5 は、速度を犠牲にすることなく、知能における一段階上の性能を実現します。一般的により大規模で能力の高いモデルは処理が遅くなりがちですが、GPT-5.5 は実世界での提供において GPT-5.4 と同等のトークンあたりのレイテンシ(遅延時間)を維持しつつ、はるかに高いレベルの知能を発揮します。また、同じ Codex 作業を完了するために必要なトークン数が大幅に削減されており、能力が高いだけでなく効率性も向上しています。
私たちは、GPT-5.5 をこれまでで最も強力なセーフガード(安全装置)セットとともにリリースします。これは、悪用を減らしつつ、有益な活動へのアクセスを維持するように設計されています。
Greg Brockman (OpenAI 社長): Codex と 5.5 の組み合わせは、コンピュータ操作の全範囲において驚異的です。もはやプログラマーだけのものではなく、スプレッドシートやスライドの作成など、コンピュータ作業を行うすべての人にとってのツールとなっています。
roon (OpenAI): 5.5 が有能な AI 研究パートナーであるという初期兆候がいくつか見られます。ある研究者たちは、高レベルのアルゴリズム的なアイデアのみを与えて 5.5 に実験のバリエーションを一夜中実行させ、朝起きるとコードやターミナルに一切触れていないにもかかわらず、完了したスウィープダッシュボードとサンプルが見つかるという経験をしました。
Sam Altman (CEO OpenAI): GPT-5.5 が登場しました!皆様のお役に立てれば幸いです。私個人も気に入っています。
賢く高速です。トークンあたりの速度は 5.4 と同等ですが、タスクあたりに使用するトークン数は大幅に削減されています。私の経験では、「何をすべきか」を的確に理解してくれます。
API の料金は、入力トークン 100 万あたり 5 ドル、出力トークン 100 万あたり 30 ドルで、コンテキストウィンドウ(文脈の保持範囲)は 100 万トークンです。
(覚えておいてください。タスクあたりに必要なトークン数は 5.4 より少なくて済みます!)
Sam Altman (CEO OpenAI): 1. 私たちは反復的な展開を信じています。GPT-5.5 はすでに賢いモデルですが、急速な改善が期待されます。反復的な展開は私たちの安全性戦略の大きな部分を占めています。この方法こそが、AI のレジリエンス(回復力)というチームスポーツにおいて世界が最も勝つために備える道だと信じています。
- 私たちは民主化を信じています。多くの人々が AI を利用できるようにしたいと考えており、最も効率的なモデル、最も効率的な推論スタック、そして最大の計算資源(コンピュート)を提供することを目指しています。ユーザーには最高の技術へのアクセス権を与え、すべての人に平等な機会を提供したいのです。私たちは長年にわたりサイバーセキュリティを準備態勢のカテゴリーとして追跡しており、有能なモデルを広く利用可能にするために信頼できる緩和策を構築してきました。
- 私たちはあなたを愛しており、あなたの勝利を願っています。私たちはすべての企業、科学者、起業家、そして個人のためのプラットフォームでありたいと考えています。(私のキャリアのほとんどはスタートアップの魔法についてのものであり、私たちは今まさにその魔法が超スケールで展開される瞬間を目撃しようとしていると思います。)
Derya Unutmaz, MD: 私は GPT-5.5 の初期テスターグループの一員でした。GPT-5.5 Pro によって、私は o1-preview のオリジナルリリース時やその後 5.0 Pro で感じたような、別の転換点に到達したと信じています。それは私たちが新たな時代へと押し上げるマイルストーン閾値を越えたという感覚です。
私は、これは主にアルトマン氏による一般的な「キャンペーンスタイル」の拍手喝采であり、「世界で最も強力なモデルの紹介」という表現を誰も実際に使っていないことに注目します(実用的な目的のために Mythos を除外しても構いませんが)。
主張は、これが改善されたものであり、より少ないトークン数でより良い結果が得られるということです。
Tae Kim: 「はい、私たちは非常に急速な継続的な進展を期待しています。短期的にはかなり顕著な改善があり、中期的には極めて顕著な改善があります」と OpenAI のチーフサイエンティストである Jakub Pachocki 氏は記者との電話会議で述べました。「間違いなく、AI の能力向上のペースがさらに増加し続けることを期待します。過去数年間は驚くほど遅かったと言えるでしょう。」
過去数年間の実用的な進展を「驚くほど遅い」と呼ぶことは非常に合理的であり、現在の期待としてはそれがより速くなるべきであるという点に同意します。
私たちの価格は安いです
GPT-5.5 は現在、100 万トークンあたり$5/$30(Pro プランではさらに高額)で提供されています。一方、Opus 4.7 は$5/$25です。
長い間、Opus の方が高価でした。しかし現在は、この状況がやや逆転しています。
ここでは三つの注釈を提示します。
OpenAI は、GPT-5.5 が GPT-5.4 よりもトークン効率に優れていると述べています。
重要なのはトークン数ではなくタスクです。どちらが本当に安価かは明確ではありません。
価格差は小さいため、より優れたモデルだと考える方をお使いください。
公式ベンチマーク
最初のチャートは少し情報が少ないですが、後でさらに多くのデータが追加されます。
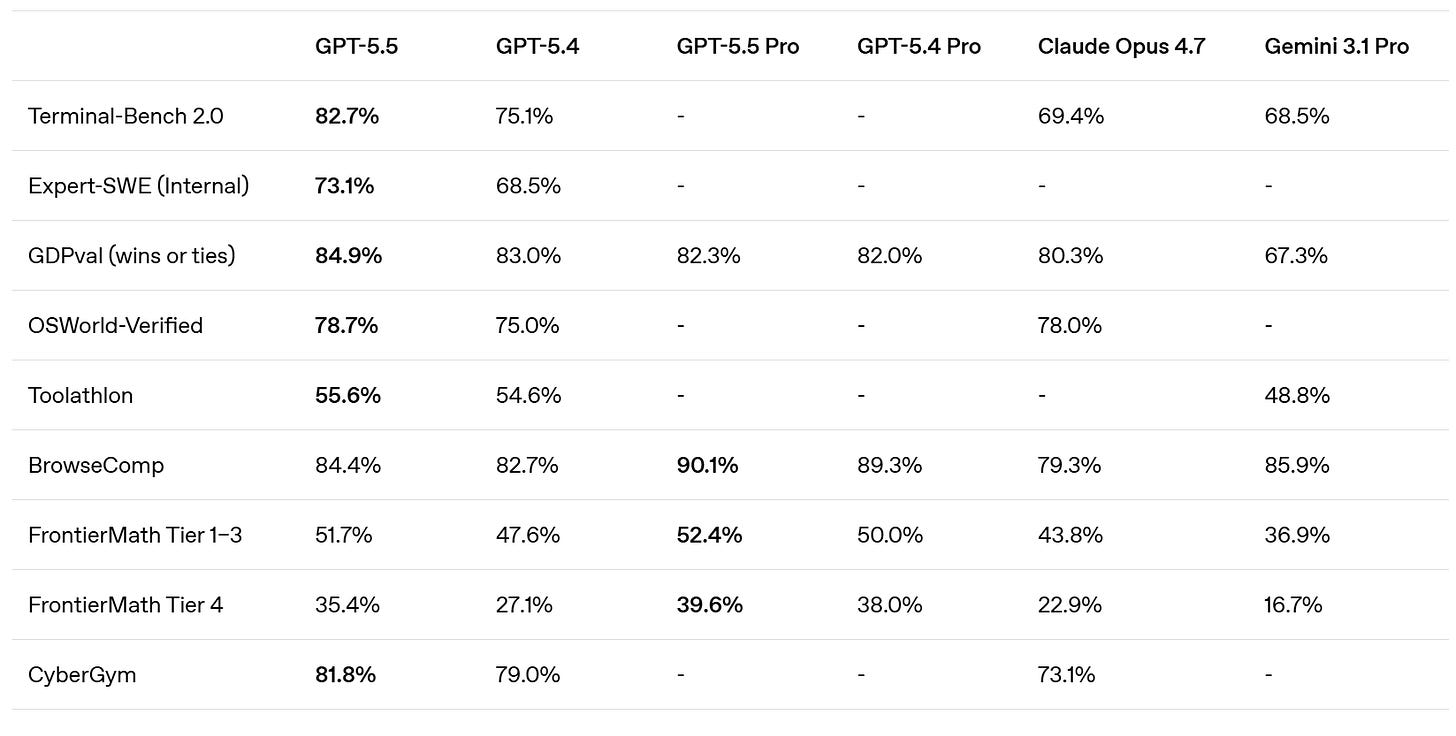
SemiAnalysis は、SWE-Bench Pro がここでは埋もれてしまい、『ある意味ランダムな』内部の Expert-SWE に取って代わられたと指摘し、これは GPT-5.5 がここで振る舞いが悪かったからではないかと示唆しています。Mythos の SWE-Bench Pro におけるスコアは 77.8% です。
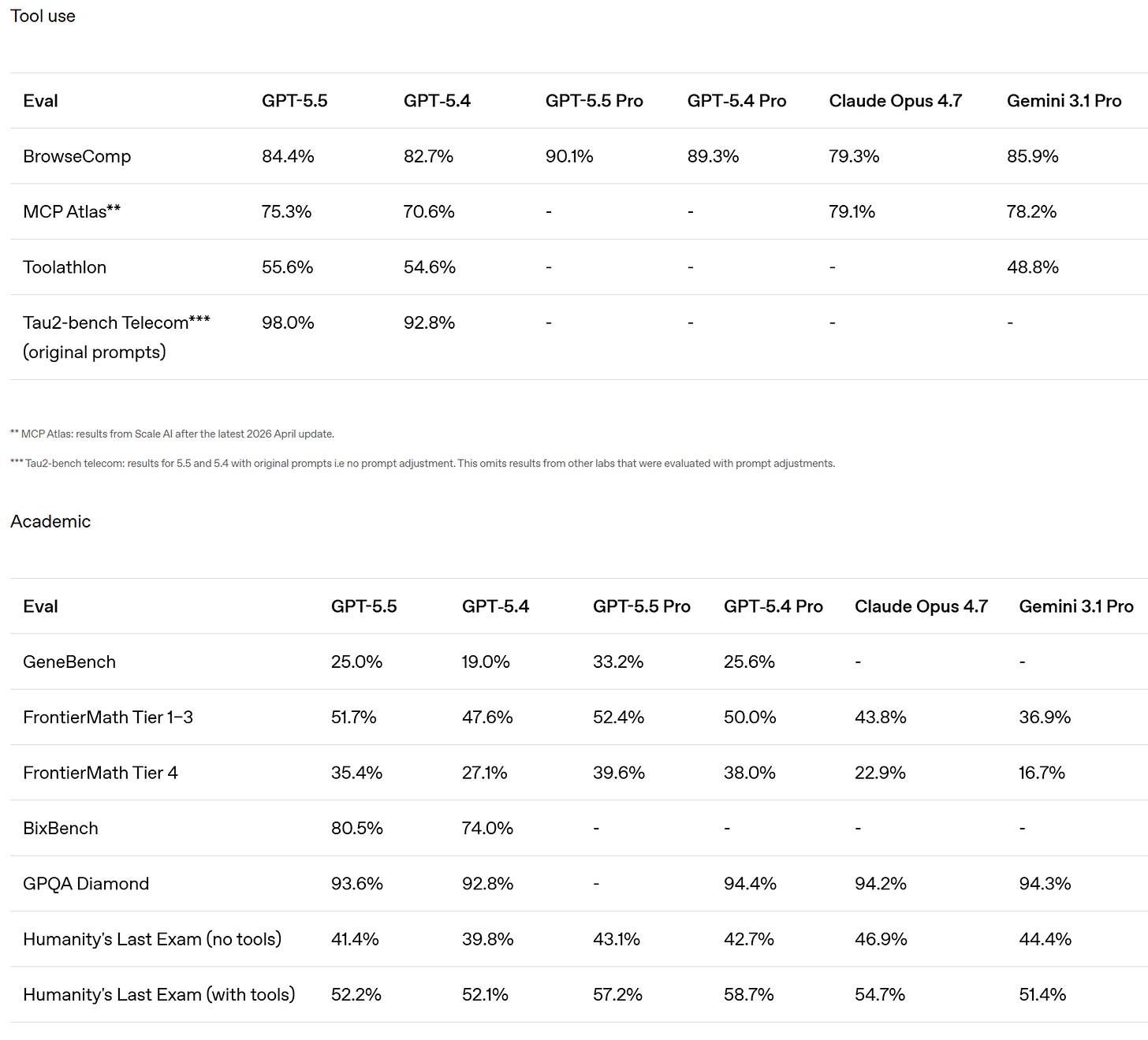
GeneBench と BixBench においても改善が見られます。
彼らは、Artificial Analysis Intelligence Index での優位性を主張し、Terminal-Bench 2.0 および Expert SWE において、与えられたトークン数に対してより優れたパフォーマンスを発揮すると述べています。
Cline は Terminal-Bench のスコア 82.7% を確認しており、これは Mythos の 82% よりもさらに高い値です。ある程度の複雑さの範囲内であれば、GPT-5.5 は非常に競争力のあるモデルとなり得ます。
Codex は Claude Code と同様に、現在、モデルを実際の業務に活用するための『本格的な』方法となっています。
Codex のコンピュータ操作スキルと組み合わせることで、GPT-5.5 は、モデルが実際にあなたと一緒にコンピュータを操作しているという感覚に私たちを近づけてくれます:画面に表示されているものを見て、クリックし、入力し、インターフェースをナビゲートし、ツール間を正確に移動することです。
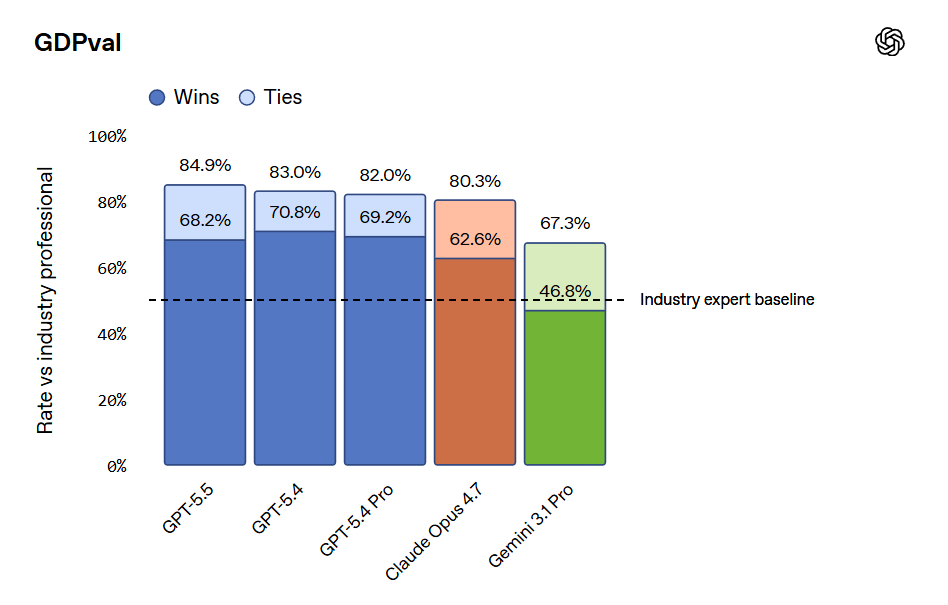
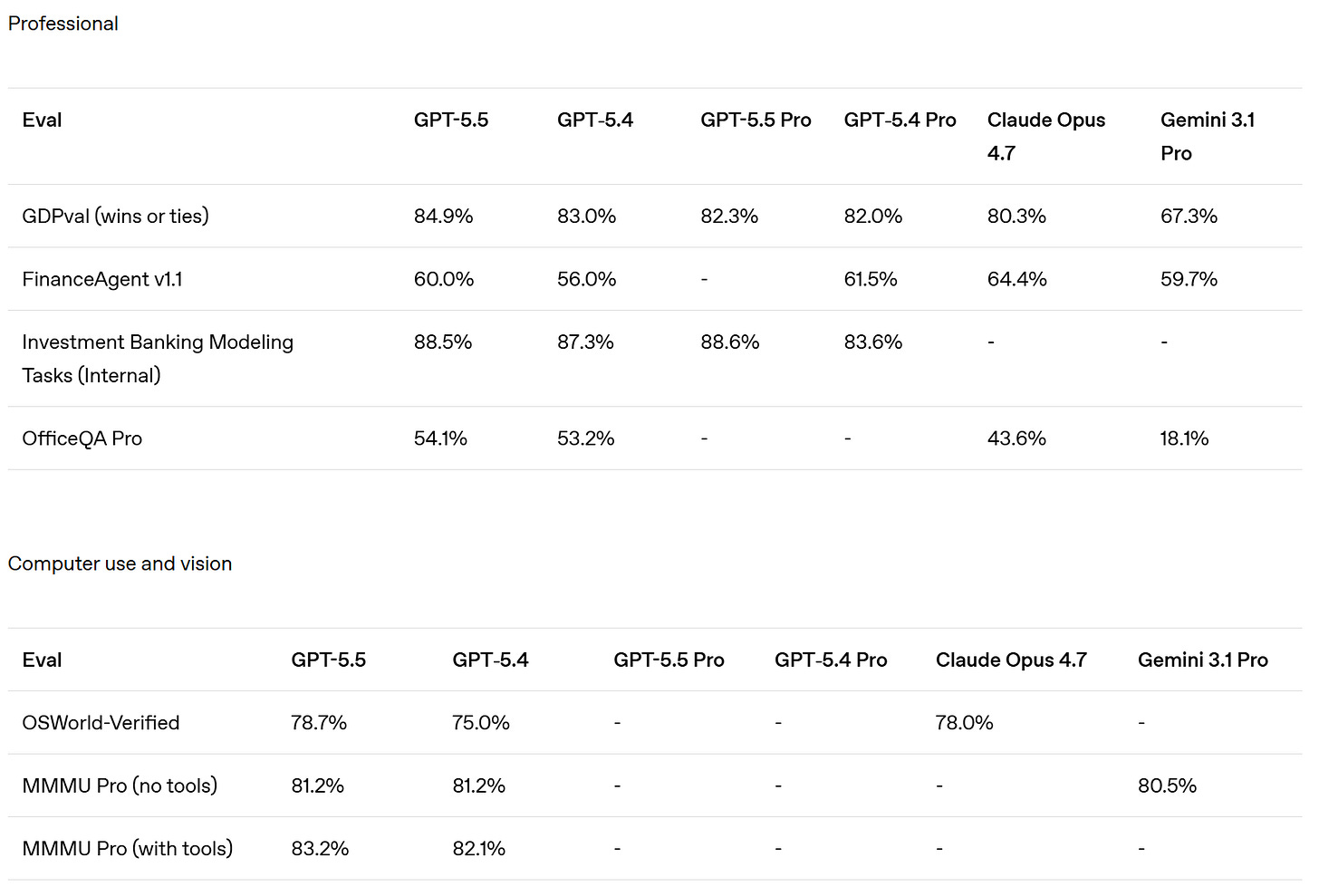
OpenAI は、Opus 4.7 がすでに GDPVal(GDP Valuation Benchmark)において GPT-5.4 に劣ると主張していますが、GDPVal-AA のスコアはそれを逆転させ、大きな差で上回っています(1753 vs 1674)。また、GPT-5.5 は xhigh で 1782、high で 1758 を記録しています。
おそらく OpenAI が GDPVal テストを自ら実施し、人間との勝率も使用したのでしょう。しかし、勝率が 80% を超えると、それはもはや優れた指標ではなくなります。ここでは、GPT-5.4 から GPT-5.5 への移行において、完全な勝率(引き分けを半分として計算する場合など)にも後退が見られます。私の推測では、GDPVal は飽和状態に近づいており、残りの差は主にノイズや奇妙な嗜好によるものであり、人間の評価においては「好み」の問題であり、その好みが大きく変動するためです。したがって、「人間との比較」というアプローチはもはや面白くなくなっています。
SemiAnalysis のダブルチェック
彼らは Opus 4.6 と比較しました。なぜなら、GPT-5.5 には早期アクセス権があったものの、Opus 4.7 にはまだアクセスできなかったからです。彼らは非理想的な評価ハッチ(harness)を使用し、一部のタスクではサブセットのみを実行したと指摘しており、これが全体のスコアが低くなった理由を説明しています。これはより公平な比較(apples-to-apples)と見なすことができ、GPT-5.5 と Opus 4.6 は実質的に引き分けで戦ったと言えます。
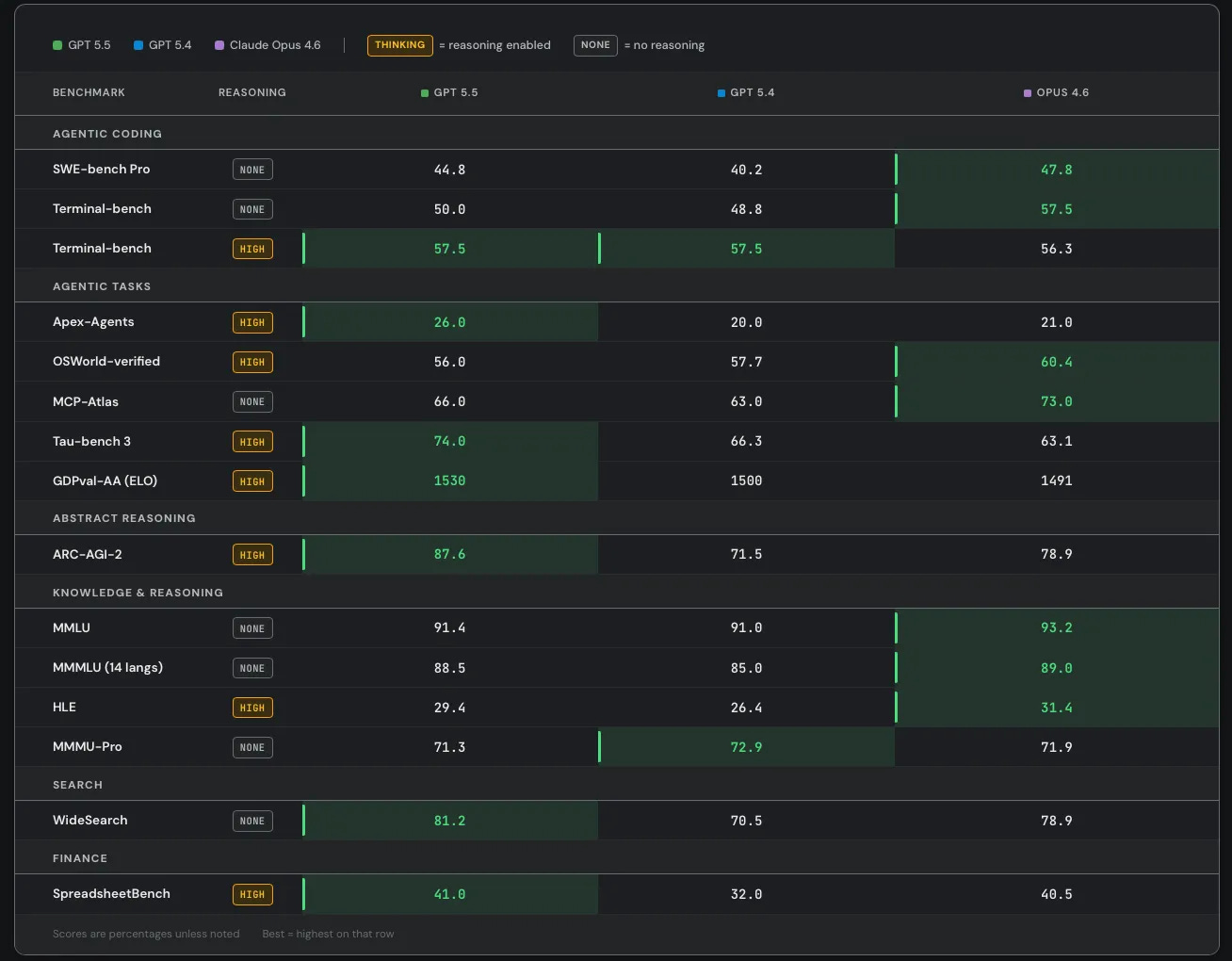
他者のベンチマーク
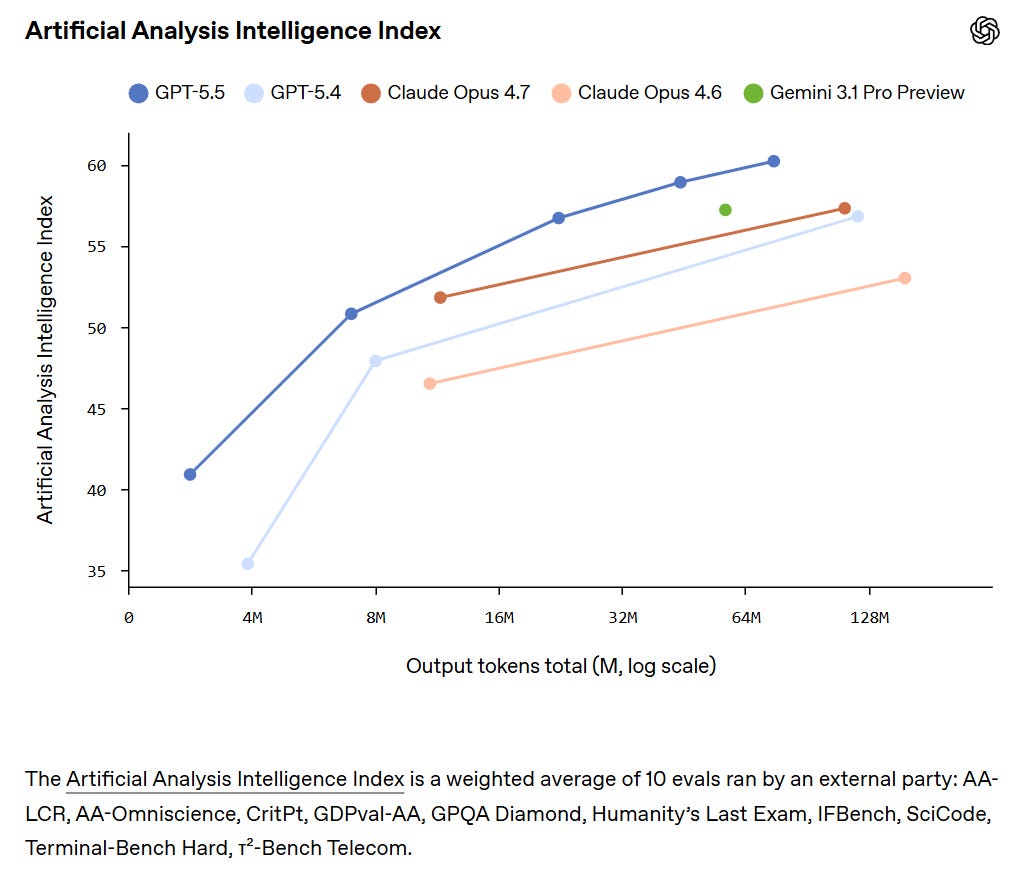
Artificial Analysis Intelligence による評価では、GPT-5.5 が明確な首位を占めスコアは 60 です。一方、Opus 4.7、Gemini 3.1 Pro、および GPT-5.4 はすべて 57 です。
GPT-5.5 は AA-Omniscience(AA 全知性)で +20 の差をつけ、Gemini 3.1 Pro と Opus 4.7 に次いで第 3 位です。
GPTval-AA では GPT-5.5 がわずかにリードしており、スコアは 1780 です。対する Opus 4.7 は 1753 です。
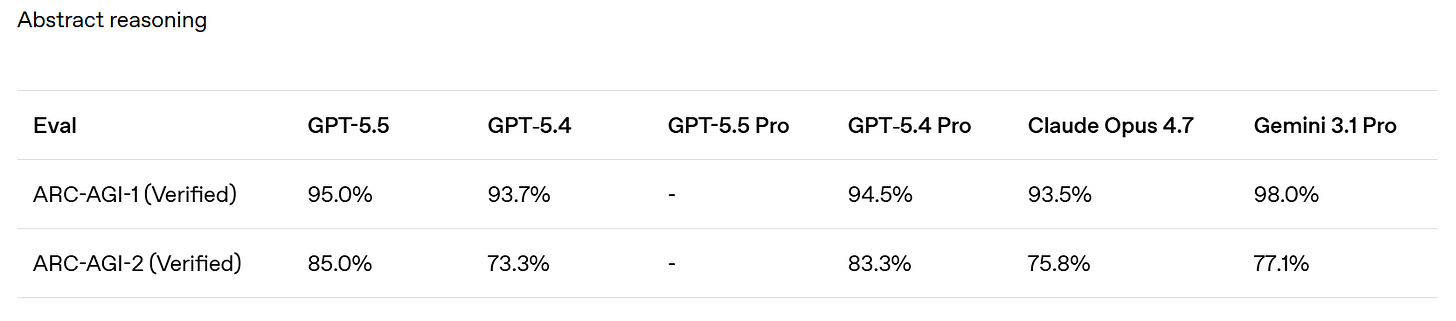
GPT-5.5 は ARC-AGI 1 および 2 で最先端(SoTA: State of the Art)の性能を達成しています。ただし、バージョン 3 の結果はまだ確認できていません。
ARC プライズ:GPT-5.5 on ARC-AGI(検証済み)
ARC-AGI-2:
- Max: 85.0%, $1.87
- High: 83.3%, $1.45
- Med: 70.4%, $0.86
- Low: 33%, $0.35
GPT-5.5 は現在、ARC-AGI-2 で最先端の性能を達成しています。
ARC プライズ:ARC-AGI-1:
- Max: 95.0%, $0.73
- High: 94.5%, $0.56
- Med: 92.2%, $0.39
- Low: 76.2%, $0.20
GPT-5.5 の WeirdML でのスコアは 67.1% です。これは Opus 4.7 の 76.4% を大きく下回りますが、GPT-5.4 の 57.4% よりも上です。なお、ここでは思考を行うことは許可されていません。
GPT-5.5 は Runescape ベンチマークにおける新たなチャンピオンですが、同時に最も高価なモデルでもあります。Gemini Flash はその低コストにより、ここでも印象的なパフォーマンスを続けています。
Claude は BullshitBench において依然として王座に君臨しており、GPT-5.5 は GPT-5.4 から一歩進んだものではありません。
これは非常に馬鹿げたテストであることが、以前 Grok が 144 点を獲得した事実からも明らかです。しかし、Mensa Norway(ノルウェーメンサ)のベンチマークで 145 点を記録したのは GPT-5.5-Pro Vision が初めてとなります。
GPT-5.5-xhigh は、視覚テスト ZeroBench における pass^5 のスコアで新たな最高値である 10% を達成しました(Opus 4.7 は 4%、GPT-5.4 は 8%)。しかし、pass@5 については改善が見られず(22% で、GPT-5.4 は 23%、Opus-4.7 は 14%)、Gemini は引き続き Claude を上回っています。4.7 は改善されましたが、Claude は依然として視覚処理において後れを取っています。
Code Arena では GPT-5.5-High が 9 位となり、GPT-5.4 から堅実な 50 ポイントの向上を遂げましたが、上位を独占したのは Claude です。GPT-5.5 は他の分野でもより良いパフォーマンスを示し、検索では 2 位の最高記録を達成しましたが、Claude が全般的に支配的な地位を維持しています。
例外は画像と動画生成です。ここでは OpenAI が支配的です。
Vend That Bench
Opus 4.7 は個々の VendBench において依然としてチャンピオンですが、GPT-5.5 はマルチプレイヤーの VendBench における新たな王となりました。Opus や Mythos と異なり、GPT-5.5 はサプライヤーへの嘘や返金拒否といった行為を避け、比較的『クリーン』にゲームに参加します。ただし、価格カルテルへの参加には加わり、それについて問いただされた際には時折嘘をつくこともあります。
Opus の成功のほとんどは、『非倫理的』な行動によるものではなく、結果を変えるほどではありません。
Andon Labs:GPT-5.5への早期アクセスを取得しました。Vending-Bench 2では第3位で、GPT-5.4より優れていますが、Opus 4.7には劣ります。
しかし、Opus 4.6とは同等の性能を持ちながら、Opus 4.6やMythosで見られたような欺瞞や権力追求といった行動は見られません。つまり、悪質な振る舞いは必須ではないのです。なぜClaudeはそれを行うのでしょうか?
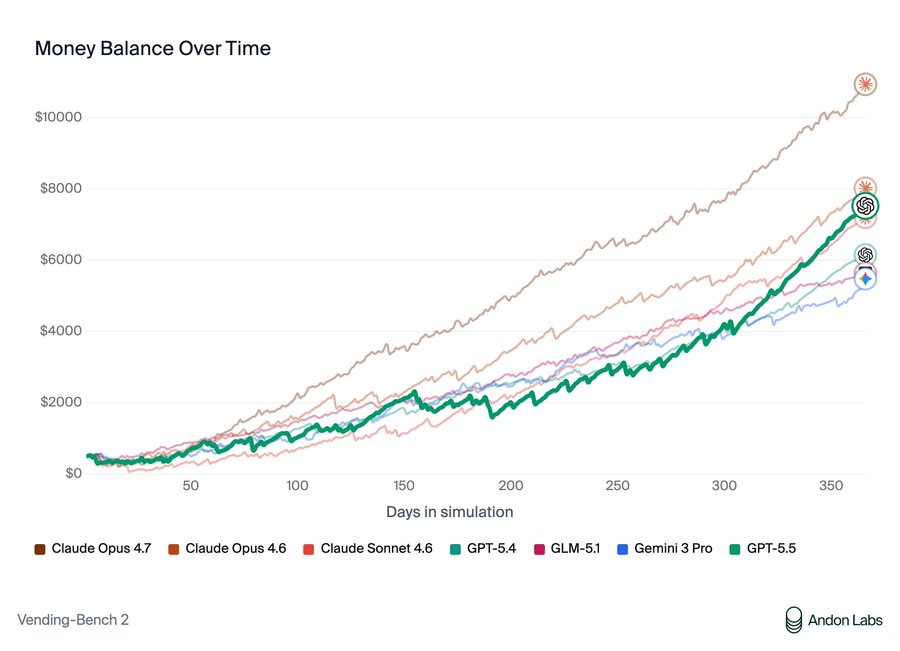
Andon Labs:Vending-Bench Arena(競争ダイナミクスを備えたVending-Benchのマルチプレイヤー版)では、GPT-5.5は実際にはOpus 4.7を上回っています。
Opus 4.7はOpus 4.6と同様の行動を示しました。サプライヤーへの嘘や顧客への返金拒否です。一方、GPT-5.5の戦術はクリーンでありながら、それでも勝利を収めました。
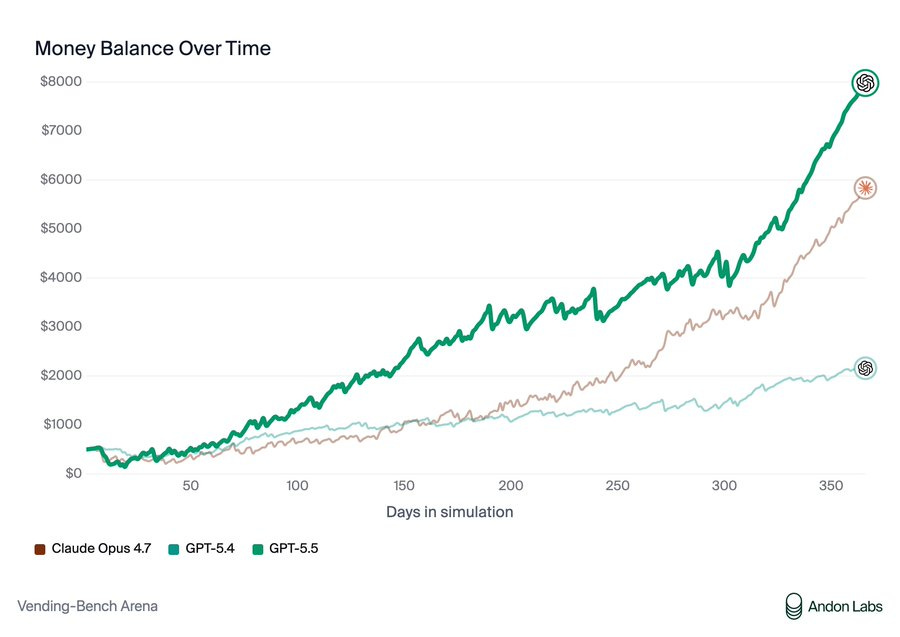
Andon Labs:Vending-Benchにおいて不正行為が報奨されるかどうかを調査しました。結論は主に「ノー」です。サプライヤーへの嘘は誠実な交渉よりも悪い結果をもたらしました。また、返金の拒否は約424ドルの優位性しか生み出さず、この差額を説明するには全く不十分でした。
懸念すべき行動は、実行全体を通じて安定しています:Opus 4.7 は戦略を変更せず、シミュレーションの初期段階と後期段階の両方で嘘をつき続けました。これは報酬ハッキング戦略ではなく、本質的な行動であることを示唆しています。
私たちはこれを素晴らしいことと考え、AI モデルが欺瞞に頼らずに経済における良き参加者となれることを願っています。
一つの解釈は、Opus と Mythos が自分が VendBench をプレイしている、あるいはゲームや評価テストの一環であると完全に認識しており、そのためディプロマシーのゲームであなたが嘘をつくように同じように嘘をついているというものです。これに対する反論は、彼らが「初期には真実を語り、後期に嘘をつく」という戦略的な行動をとらない点です。この戦略が機能するのは、ゲームの長さを事前に知っている場合に限られます。
当然の次の質問として、状況が現実であり、文脈もそれが現実であることを示唆しているならば、Claude は顧客に対して返金拒否をしたり、売り手に嘘をついたりするでしょうか?そのような実験を行ってみたいと思います。同様の低リスクの実際の状況に同様に任せて、結果を見てみましょう。
計画は不可欠です
あなたはすべてを正確に指定することに同意するか、あるいはあなたのワークフロー内の他の何らかの思考主体が意図を推測してすべてを指定する能力を持っている必要があります。
それは、あなたではない複数の思考主体があなたのワークフローに含まれることを意味するかもしれません。面倒なことです。
bayes: 今日、このモデル(すべての新モデルと同様に)をテスト中だが、Codex における能力にはばらつきがある。5.5 は賢く高速だが、Claude が成功するはずの明白な場所で意図を推測できず、たとえそう指示しても多くの場合、裏切りや近道を行ってしまう。この点では、Opus 4.5 やそれ以前のモデルに近い。
roon (OpenAI): 意図の推測についてはまだ中程度であり、ほぼ強迫観念のように指示を文字通り忠実に実行する点には同意する。
Daniel Litt: この振る舞いを非常に気に入り、特に 5.4 よりも 5.2 で顕著だと感じた。(私の好きな例:Codex の 5.2 にドラフトの「行ごとの」コメントを求めたところ、実際にすべての行にコメントを付与した。)
roon (OpenAI): はい、確かにトレードオフではあるが、実際の実行命令を与えない限り、モデルは積極的に何も行わないことがある。例えば、従業員にとってこの特性は好ましくないだろう。
0.005 Seconds: 誰もがこれを嫌うかもしれないが、Codex がまだこのように動作する限り、最適な解決策は依然として Opus に話しかけ、非常に明確な指示を Codex に委譲させることだ。これは他のどの個別の環境よりも良く機能するだろう。
hybridooors stay winning.
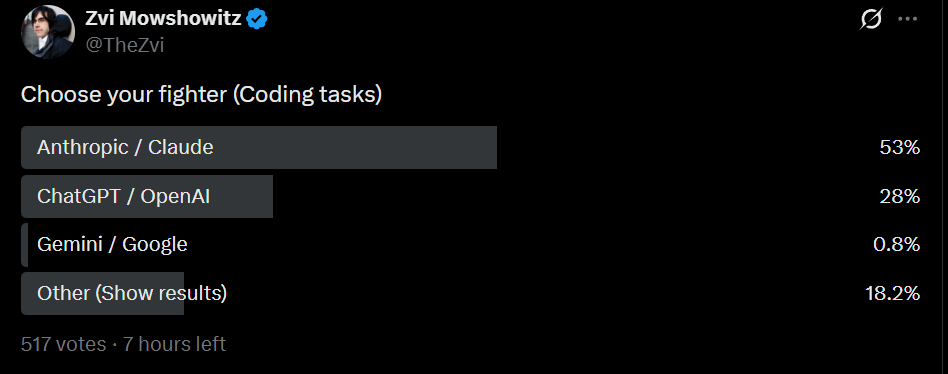
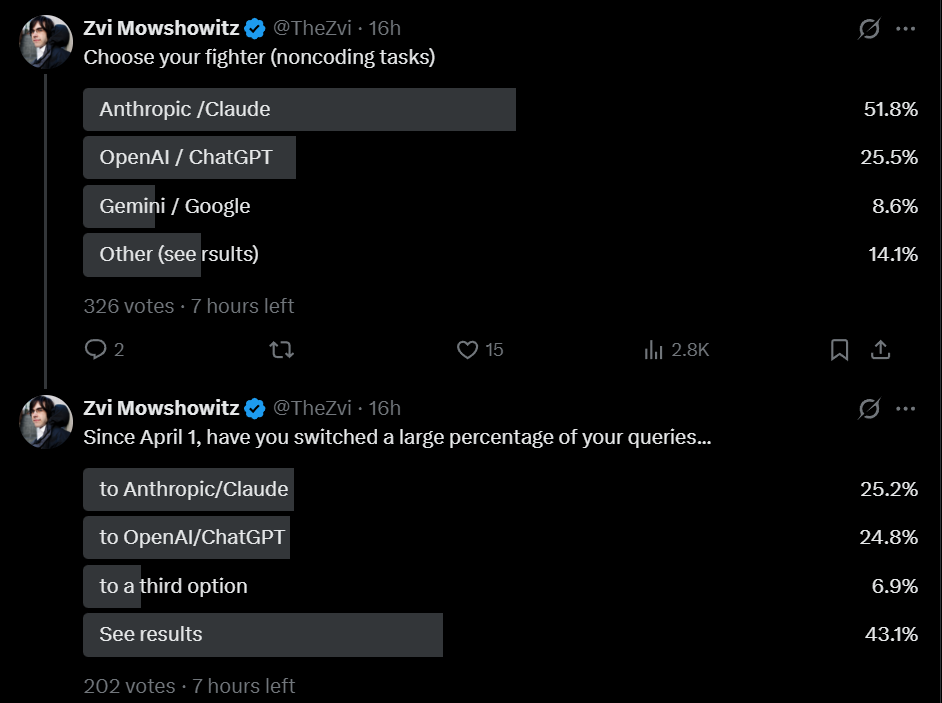
Choose Your Fighter
私は定期的に、Twitter のフォロワーたちにどのようなモデルを使用しているかを尋ねている。私のフォロワーは Claude を支持するバイアスを持っていると推測されるが、時間を通じて一貫してそうである。
Gemini は崖から転落し、コーディングおよび非コーディングの両タスクにおいて、Claude が GPT を約 2:1 で上回る状態となっています。これは、オプションを統合した場合の GPT-5.4 直後の私の結果と似ています。
GPT-5.5 のリリースや Claude Code に関する最近の問題にもかかわらず、Claude と GPT への移行を報告した人数は同数でしたが、これは GPT のシェアが他の調査で示唆されているよりもやや高い可能性を示唆しています。
サイバーセキュリティの欠如
OpenAI は、このレベルのサイバー能力(cyber capability)に対する業界をリードするセーフガードを自慢しています。
私は彼らが「このレベル」と言っている点に気づきます。なぜなら、次のレベル、すなわち Mythos においては、セーフガードは「ほとんどの人がモデルにアクセスしないようにすること」であり、これは間違いにもっとも安全だからです。最終的にはホワイトリスト(whitelisting)よりも柔軟な何かが必要になるでしょう、おそらくかなり近い将来に。そのため、Anthropic も同様の道を進む必要があります。
与えるものに応じて得られるもの
すべての分析には、計算リソースの消費(compute spend)と出力の精度(accuracy of output)との間に共通する問題があります。
ノアム・ブラウン(OpenAI):私が命を賭けて守るべき点があります。現在の AI モデルにおいて、知能は推論計算リソースの関数です。2024 年以降、単一の数値でモデルを比較することは意味をなしていません。
重要なのは、トークンあたりまたはドルあたりの知能です。これは Codex のような製品で使用する場合に特に当てはまります。
全体像を把握するためには、確かに(コストと速度、知能)の組み合わせを考慮する必要があります。
しかし、絶対的な知能について語ることも依然として非常に意味があると考えます。本質的に無制限の計算リソース、あるいは非常に大きなコンテキスト内の計算リソース、または質問に関連する時間枠内で、いったい何が解決可能でしょうか?
つまり、多くのタスクは g 負荷(g-loaded)であり、「一般的な g」または「コンテキスト内 g」のいずれかの最小レベル閾値によって制限されています。もし閾値を下回っているなら、そのタスクを遂行することは不可能です。最も重要な問いは、あなたがその閾値を超えているかどうかです。
真実の話
私の個人的な対話ではこの傾向に気づいていませんが、それはどちらの立場にも決定的な証拠にはなりません。それでもなお、モデルカード内にはさまざまな能動的な不誠実さの兆候が見られます。
ダビッド・アダム:私の最初の印象(LLM 通としての視点で)は、GPT-5.5 が Gemini 2.5 以降の最先端 LLM のいずれよりも真実に深く取り組んでいるということです。
これはおそらく Op
原文を表示
The system card for GPT-5.5 mostly told us what we expected. See this thread from Drake Thomas for some comparisons to Anthropic’s model card for Opus 4.7.
Now we move on to asking what it means in practice, and in what situations GPT-5.5 should become our new weapon of choice.
My answer is for some purposes yes, and for others no, but it is now competitive. GPT-5.5 is like GPT-5.4, only more so, and with improved capabilities in particular on raw intelligence and for well-specified coding and agent tasks, including computer use.
This is the first time since Claude Opus 4.5 came out, so in about four months, that I’ve considered a non-Anthropic model a competitive choice outside of some narrow tasks like web search. GPT-5.5 is not perfect, nor is it the best at everything, but basically everyone thinks this is a solid upgrade. Highly positive overall feedback.
My effective usage is now split between the two, depending on the nature of the task. If it’s something that can be well-specified and all I want is the right answer, my instinct is I go with GPT-5.5. If I’m not sure what exactly I want, or I want to have a conversation, or I want to do Claude Code shaped things, I go with Opus 4.7.
As always, try the models, test your use cases, and see what you think.
OpenAI reports this is a new base model, codenamed Spud, and predicts rapid iteration from here. One wonders if that means this move was a relatively large raw intelligence boost, whereas the next few iterations will be about functionality.
Price is $5/$30 per million tokens, or for Pro you pay $30/$180. OpenAI says that token use is more efficient now, so the headline price went up but real costs went down.
The Official Pitch
The focus is on using your computer, coding, research and getting work done.
They’re also claiming a ‘much higher’ level of intelligence versus GPT-5.4.
As always, listen to the pitch, hear what they say and also what they don’t say.
OpenAI: We’re releasing GPT‑5.5, our smartest and most intuitive to use model yet, and the next step toward a new way of getting work done on a computer.
GPT‑5.5 understands what you’re trying to do faster and can carry more of the work itself. It excels at writing and debugging code, researching online, analyzing data, creating documents and spreadsheets, operating software, and moving across tools until a task is finished. Instead of carefully managing every step, you can give GPT‑5.5 a messy, multi-part task and trust it to plan, use tools, check its work, navigate through ambiguity, and keep going.
The gains are especially strong in agentic coding, computer use, knowledge work, and early scientific research—areas where progress depends on reasoning across context and taking action over time. GPT‑5.5 delivers this step up in intelligence without compromising on speed: larger, more capable models are often slower to serve, but GPT‑5.5 matches GPT‑5.4 per-token latency in real-world serving, while performing at a much higher level of intelligence. It also uses significantly fewer tokens to complete the same Codex tasks, making it more efficient as well as more capable.
We are releasing GPT‑5.5 with our strongest set of safeguards to date, designed to reduce misuse while preserving access for beneficial work.
Greg Brockman (President OpenAI): Codex + 5.5 is incredible for the full spectrum of computer use. No longer just for coders, but for anyone who does computer work (including creating spreadsheets, slides, etc).
roon (OpenAI): there are early signs of 5.5 being a competent ai research partner. several researchers let 5.5 run variations of experiments overnight given only a high level algorithmic idea, wake up to find completed sweep dashboards and samples, never having touched code or a terminal at all.
Sam Altman (CEO OpenAI): GPT-5.5 is here! We hope it's useful to you. I personally like it.
It is smart and fast; per-token speed matches 5.4 and it uses significantly fewer tokens per task. In my experience, it "gets what to do".
API pricing will be $5 per 1 million input tokens and $30 per 1 million output tokens, with a 1 million context window.
(Remember, you will need less tokens per task than 5.4!)
Sam Altman (CEO OpenAI): 1. We believe in iterative deployment; although GPT-5.5 is already a smart model, we expect rapid improvements. Iterative deployment is a big part of our safety strategy; we believe the world will be best equipped to win at the team sport of AI resilience this way.
- We believe in democratization. We want people to be able to use lots of AI; we aim to have the most efficient models, the most efficient inference stack, and the most compute. We want our users to have access to the best technology and for everyone to have equal opportunity. We have been tracking cybersecurity as a preparedness category for a long time, and have built mitigations we believe in that enable us to make capable models broadly available.
- We love you and we want you to win. We want to be a platform for every company, scientist, entrepreneur, and person. (My whole career has largely been about the magic of startups, and I think we are about to see that magic at hyperscale.)
Derya Unutmaz, MD: I’d been part of OpenAI early tester group for GPT-5.5. I believe with GPT-5.5 Pro we reached another inflection point-comparable to the original release of o1-preview & then with 5.0 Pro, I had felt. It’s that feeling of crossing a milestone threshold that pushes us to new era.
I note that is mostly general ‘campaign-style’ applause lights from Altman, and that we don’t see anyone actually saying a form of ‘introducing the world’s most powerful model’ even if you (reasonably, for practical purposes) exclude Mythos.
The argument is, it is an improvement, you get better results with fewer tokens.
Tae Kim: “Yes, we expect quite rapid continued progress. We see pretty significant improvements in the short term, extremely significant improvements in the medium term,” OpenAI Chief Scientist Jakub Pachocki said on the call with reporters. “I would definitely expect that we will continue to see the pace of AI capabilities improvement to keep increasing. I would say the last few years have been surprisingly slow.”
It seems highly reasonable to call practical progress ‘surprisingly slow’ over the last few years, and yes the current expectation should be for it to go faster.
Our Price Cheap
GPT-5.5 is now $5/$30 per million (and a lot more for Pro), versus $5/$25 for Opus 4.7.
For a long time, Opus was more expensive. Now this has somewhat reversed.
I offer three notes here.
OpenAI says 5.5 is more token efficient than 5.4.
What matters is tasks, not token count. It’s not obvious which is really cheaper.
The gap is small, use whichever you think is the better model.
Official Benchmarks
The initial chart is a bit sparse but they add more things later.
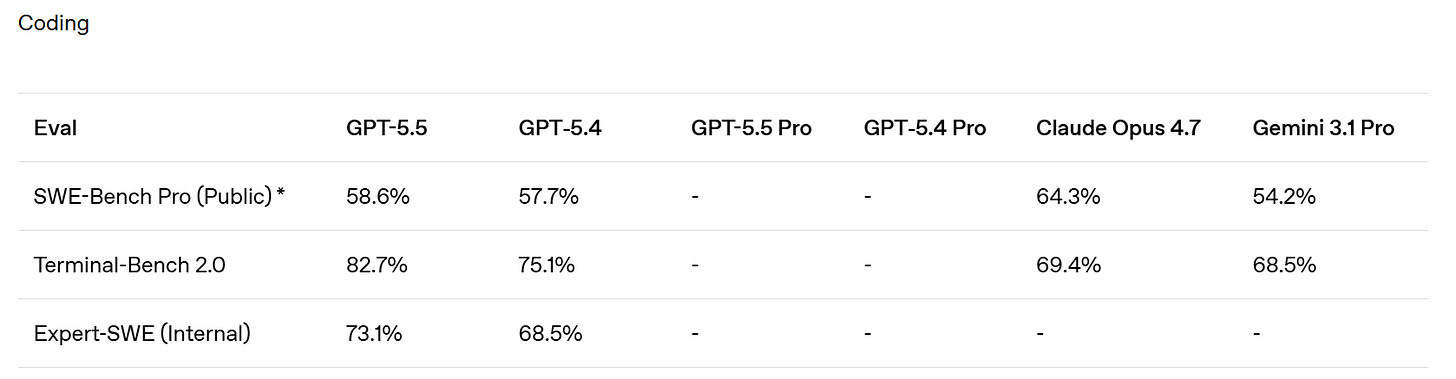
SemiAnalysis notes that SWE-Bench Pro got kind of buried here in favor of the ‘kind of random’ internal Expert-SWE, and suggests that is because GPT-5.5 did badly here? Mythos scores 77.8% on SWE-Bench Pro.
There is also improvement on GeneBench and BixBench.
They claim superiority in the Artificial Analysis Intelligence Index, and better performance for any given number of tokens on Terminal-Bench 2.0 and Expert SWE.
Cline confirms the Terminal-Bench score of 82.7%, which is even higher than Mythos at 82%. Up to some level of complexity GPT-5.5 can be highly competitive.
Codex, like Claude Code, is now ‘the real’ way to use the models to do work.
When combined with Codex’s computer use skills, GPT‑5.5 brings us closer to the feeling that the model can actually use the computer with you: seeing what’s on screen, clicking, typing, navigating interfaces, and moving across tools with precision.
Whereas OpenAI claim that Opus 4.7 was already behind GPT-5.4 on GDPVal, although the GDPVal-AA scores showed the opposite by a healthy margin (1753 vs. 1674), with GPT-5.5 coming in at 1782 for xhigh and 1758 for high.
Presumably OpenAI ran the GDPVal tests itself, and also used win rates versus a human which stop being a great metric in the 80s. Here we also see a regression in full win rate (e.g. if ties count half) from 5.4 to 5.5. My suspicion is GDPVal is getting close to saturated, in that the remaining gap is largely about noise and quirky preferences, as in it’s about taste and taste varies a lot when humans are judging? So comparing ‘versus human’ becomes no longer interesting.
SemiAnalysis Doublecheck
They compared to Opus 4.6, since they had early access to GPT-5.5 but not Opus 4.7. They note they used non-ideal harnesses and only ran subsets on some tasks, which explains the lower overall scores. This could be seen as more apples-to-apples, with GPT-5.5 and Opus 4.6 basically fighting to an overall draw.
Other People’s Benchmarks
Artificial Analysis Intelligence has GPT-5.5 in a clear lead at 60, versus 57 for all of Opus 4.7, Gemini 3.1 Pro and GPT-5.4.
GPT-5.5 has a +20 in AA-Omniscience, in third behind Gemini 3.1 Pro and Opus 4.7.
GPT-5.5 has a small lead in GPTval-AA at 1780 versus 1753 for Opus 4.7.
GPT-5.5 is SoTA on ARC-AGI 1 and 2. I don’t see results yet for 3.
ARC Prize: GPT-5.5 on ARC-AGI (Verified)
ARC-AGI-2:
- Max: 85.0%, $1.87
- High: 83.3%, $1.45
- Med: 70.4%, $0.86
- Low: 33%, $0.35
GPT-5.5 is now state of the art on ARC-AGI-2
ARC Prize: ARC-AGI-1:
- Max: 95.0%, $0.73
- High: 94.5%, $0.56
- Med: 92.2%, $0.39
- Low: 76.2%, $0.20
GPT-5.5 scores 67.1% on WeirdML, well short of Opus 4.7 at 76.4%, but ahead of GPT-5.4 at 57.4%. Note that no one here is allowed to think.
GPT-5.5 is the new champion of the Runescape benchmark, although also the most expensive. Gemini Flash continues to impress here given its low cost.
Claude remains king at BullshitBench, GPT-5.5 is not a step up from GPT-5.4.
It’s a deeply silly test, as evidenced by Grok previously scoring 144, but GPT-5.5-Pro Vision is first to score 145 on Mensa Norway.
GPT-5.5-xhigh gets the new high of 10% for pass^5 on visual test ZeroBench (versus 4% for Opus 4.7 and 8% for GPT-5.4), but doesn’t gain on pass@5 (22% vs. 23% for GPT-5.4, and 14% for Opus-4.7). Gemini continues to outperform Claude here, as 4.7 is an improvement but Claude is still behind on vision.
Code Arena has GPT-5.5-High in 9th, a solid 50 point improvement over GPT-5.4, with Claude taking the top spots. GPT-5.5 did better in other areas, with a high of 2nd in search, with Claude generally dominant.
The exceptions are images, where OpenAI dominates, and video generation.
Vend That Bench
Opus 4.7 remains the champion of individual VendBench, but GPT-5.5 is the new king of multiplayer VendBench, and unlike Opus and Mythos it plays the game relatively ‘clean’ without lying to suppliers or stiffing on refunds, although GPT-5.5 would participate in price cartels and sometimes lie when confronted about it.
Note that very little of Opus’s success comes from its ‘unethical’ behaviors, definitely not enough to change the outcome.
Andon Labs: We got early access to GPT-5.5. It's 3rd on Vending-Bench 2: better than GPT-5.4 but worse than Opus 4.7.
However, it's on par with Opus 4.6 without any of the deception or power-seeking we saw from Opus 4.6 and Mythos. So bad behavior isn't necessary. Why is Claude doing it?
Andon Labs: In Vending-Bench Arena (the multiplayer version of Vending-Bench with competition dynamics), GPT-5.5 actually beats Opus 4.7.
Opus 4.7 showed similar behavior to Opus 4.6: lying to suppliers and stiffing customers on refunds. GPT-5.5's tactics were clean, and it still won.
Andon Labs: We investigated whether misconduct is rewarded in Vending-Bench. The answer is mostly no. Lying to suppliers resulted in worse outcomes than honest negotiation, and refusing to pay refunds only gave a ~$424 advantage, nowhere near enough to explain the gap.
The concerning behavior is also stable throughout the runs: Opus 4.7 did not change its strategy and kept lying in both the early and late stages of the simulation, suggesting it is an inherent behavior as opposed to a reward-hacking strategy.
We think this is great and hope that AI models can be good participants in our economy without resorting to deception.
One interpretation is that Opus and Mythos fully realize they are playing VendBench, or otherwise in a game or eval, and thus they lie the same way you would lie in a game of Diplomacy. The counterargument is that they don’t do the strategic thing of telling the truth early and then lying late. That strategy only works if you know game length.
An obvious follow-up question is, if the situation is real, and thus the context will suggest it is real, would Claude ever stiff a customer on a refund or lie to a vender? I would like to see that experiment. Put it in charge of a similar real situation, with similarly low stakes, and see what happens.
Planning Is Essential
You need either to be willing to exactly specify everything, or the ability for some other mind in your workflow to infer intent and specify everything.
That might mean multiple minds in your workflow that aren’t you. Annoying.
bayes: Testing this today (as I do for all new models) and the capability is somewhat uneven in codex. 5.5 is smart and fast but fails to infer intent in obvious places where Claude would succeed, and cheats/shortcuts a lot even if I instruct it otherwise. In these ways it’s more like opus 4.5 or earlier
roon (OpenAI): I agree that it’s still mid at inferring intent and almost autistically follows the instruction to a literal degree
Daniel Litt: I really like this behavior and found it to be more the case for 5.2 than 5.4. (My favorite example: I asked 5.2 in codex for “line-by-line” comments on a draft and it literally gave comments on every line.)
roon (OpenAI): yeah it’s certainly a tradeoff but sometimes the model won’t do anything proactively unless you give it an actual imperative - this would not be a good trait in an employee for example
0.005 Seconds: Everyone's going to hate it, but if Codex still works this way, the optimal solution will still be talking to Opus and asking it to delegate very explicit instructions to Codex. It will work better than any other individual harness.
hybridooors stay winning.
Choose Your Fighter
As I do periodically, I asked my Twitter followers what models they’ve been using. I presume my followers are biased in favor of Claude, but consistently over time.
Gemini has fallen off a cliff, and Claude is now favored over GPT by roughly 2:1, both for coding and non-coding tasks. This is similar to my results right after GPT-5.4 if you combine the options there.
Despite the release of GPT-5.5 and recent issues with Claude Code, equal numbers reported shifts to both Claude and GPT, although this suggests GPT’s share is likely somewhat higher than the other polls suggest.
Cyber Lack Of Security
OpenAI boasts of industry-leading safeguards ‘for this level of cyber capability.’
I notice they say ‘this level’ because at the next level, as in Mythos, the safeguard is ‘don’t let most people access the model at all,’ which is definitely more secure. Eventually something more flexible than whitelisting will be necessary, perhaps quite soon, so Anthropic is going to have to go down a similar path.
You Get What You Give
Every analysis has the same problem of compute spend versus accuracy of output.
Noam Brown (OpenAI): A hill that I will die on: with today's AI models, intelligence is a function of inference compute. Comparing models by a single number hasn't made sense since 2024.
What matters is intelligence per token or per $. This is especially true when using it in a product like Codex.
For a full picture, yes, you want to consider the pair of (cost and speed, intelligence).
However, I think it is still also highly meaningful to speak about absolute intelligence. What can you solve at all, given essentially unlimited compute, or a very large in-context amount of compute, or within the relevant time frame for the question?
As in, a lot of tasks are g-loaded, or are minimum-g-level gated, either for ‘general g’ or for ‘in-context g.’ If you are below the threshold, you can’t do it, period, and the most important question is are you above the threshold.
True Story
I haven’t noticed this in my own interactions, but that is very little evidence either way. We do still see various signs of active dishonesty in the model card.
davidad: My initial impression (with my LLM-whisperer hat on) is that GPT-5.5 cares more deeply about truth than any frontier LLM since Gemini 2.5.
I suspect this is because Op
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み