LLM推論のための強化学習の現状
Sebastian Raschkaは、GPT-4.5やLlama 4のような従来型モデルの限界を指摘し、OpenAIのo3モデルやxAI、Anthropicの取り組みを例に、強化学習を用いた推論能力向上が次世代LLMの標準となる重要なトレンドであると分析している。
キーポイント
従来型LLMの限界と推論能力の重要性
GPT-4.5やLlama 4のようなモデルサイズとデータのスケーリングだけでは限界に近づいており、推論能力の強化が次のブレークスルーとして注目されている。
強化学習による推論能力の向上
OpenAIのo3モデルは推論に特化した強化学習を用いて10倍の計算リソースを投入し、精度と問題解決能力を大幅に向上させた。
競合他社の推論機能実装
xAIのGrokやAnthropicのClaudeは「思考」ボタンなどのインターフェースを通じて、明示的な推論機能をユーザーに提供している。
推論特化型トレーニングの標準化予測
著者は、推論に焦点を当てた事後トレーニングが将来のLLM開発パイプラインで標準的な手法になると予測している。
RLHFの3段階パイプライン
RLHFは、事前学習済みモデルの教師ありファインチューニング、報酬モデルの作成、近接方策最適化(PPO)によるファインチューニングの3段階で構成される。
RLHFの目的と応用
RLHFの主目的はLLMを人間の好みに合わせることだが、機密情報の漏洩防止や不適切な表現の回避などの安全性向上にも利用される。
RLHF Step 3: PPOによるモデル更新
RLHFの最終段階では、報酬モデルから得られたスコアに基づき、近接方策最適化(PPO)アルゴリズムを用いてSFTモデルを更新する。
影響分析・編集コメントを表示
影響分析
この記事は、大規模言語モデルの進化が単純なスケーリングから推論能力の強化へとパラダイムシフトしていることを示しており、今後のAI開発の方向性に大きな影響を与える。強化学習を用いた推論能力向上が業界標準となることで、より複雑な問題解決が可能なAIシステムの実現が加速するだろう。
編集コメント
強化学習による推論能力向上がLLM開発の新たなフロンティアとして明確に位置付けられており、技術トレンドを先取りする重要な分析記事。競合各社の動向も網羅的に把握できる。
今月は特に GPT-4.5 や Llama 4 といった新フラッグシップモデルのリリースに伴い、多くの出来事がありました。しかし、これらのリリースに対する反応が比較的控えめだったことに気づいた方もいるかもしれません。その理由の一つは、GPT-4.5 と Llama 4 が依然として従来のモデルであり、推論のための明示的な強化学習(Reinforcement Learning)を施して訓練されていないためです。
一方、xAI や Anthropic といった競合他社は、自社のモデルにさらに多くの推論機能と特徴を追加しています。例えば、xAI の Grok と Anthropic の Claude インターフェースの両方で、特定のモデルにおいて推論機能を明示的に切り替える「思考(thinking)」または「拡張思考(extended thinking)」ボタンが用意されています。
いずれにせよ、GPT-4.5 や Llama 4(非推論型)に対する控えめな反応は、モデルサイズとデータ量のみを拡大することによって達成できることの限界に近づいていることを示唆しています。
しかし、OpenAI が最近リリースした o3 推論モデルは、計算資源を戦略的に投資することで、特に推論タスク向けに設計された強化学習(Reinforcement Learning)手法を通じて、まだ大きな改善の余地があることを実証しています。(OpenAI のスタッフによると、直近のライブストリームにおいて、o3 は o1 と比較してトレーニング計算リソースを 10 倍使用したとのことです。)

出典:OpenAI ライブストリーム(https://openai.com/live/)、2025 年 4 月 16 日
推論単体では万能薬ではありませんが、現時点において困難なタスクにおけるモデルの精度と問題解決能力を確実に向上させることが確認されています。そして、私は推論に焦点を当てたポストトレーニング(後期学習)が、将来の LLM パイプラインにおける標準的な実践となることを期待しています。
そこで、この記事では、強化学習を活用した推論に関する最新の動向を探っていきましょう。

この記事では、推論モデルの開発と改善に用いられる強化学習(Reinforcement Learning)のトレーニング手法に焦点を当てます。
比較的長文となるため、以下に目次概要を提供します。目次を移動するには、ウェブビューの左側にあるスライダーをご利用ください。
推論モデルの理解
RLHF の基礎:すべてが始まった場所
PPO に関する簡易紹介:強化学習の中核アルゴリズム
強化学習アルゴリズム:PPO から GRPO へ
強化学習による報酬モデリング:RLHF から RLVR へ
DeepSeek-R1 推論モデルのトレーニング方法
最近の推論モデルトレーニングに関する強化学習論文からの教訓
推論モデルトレーニングにおける注目すべき研究論文
ヒント:すでに推論の基礎、強化学習(RL)、PPO、GRPOについてご存知の場合は、「最近の推論モデル訓練に関する RL 論文からの教訓」セクションへ直接お進みください。ここには、最新の推論研究論文から得られた興味深い洞察の要約が含まれています。
推論モデルの理解
ここで最も重要な課題は、もちろん「推論」の定義です。簡単に言えば、推論とは、LLM が複雑なタスクをよりよく処理できるようにするための推論手法と訓練技法のことです。
このように実現される仕組みについてもう少し詳しく説明するために、私は以下のように推論を定義します:
LLM の文脈における推論とは、最終的な回答を提供する前に中間ステップを生成するモデルの能力を指します。これはしばしば「思考の連鎖(Chain-of-Thought: CoT)」推論として記述されるプロセスです。CoT 推論では、LLM は結論に至るまでの過程を示すために、構造化された一連の文や計算を明示的に生成します。
以下に、この定義を図解したものを示します。
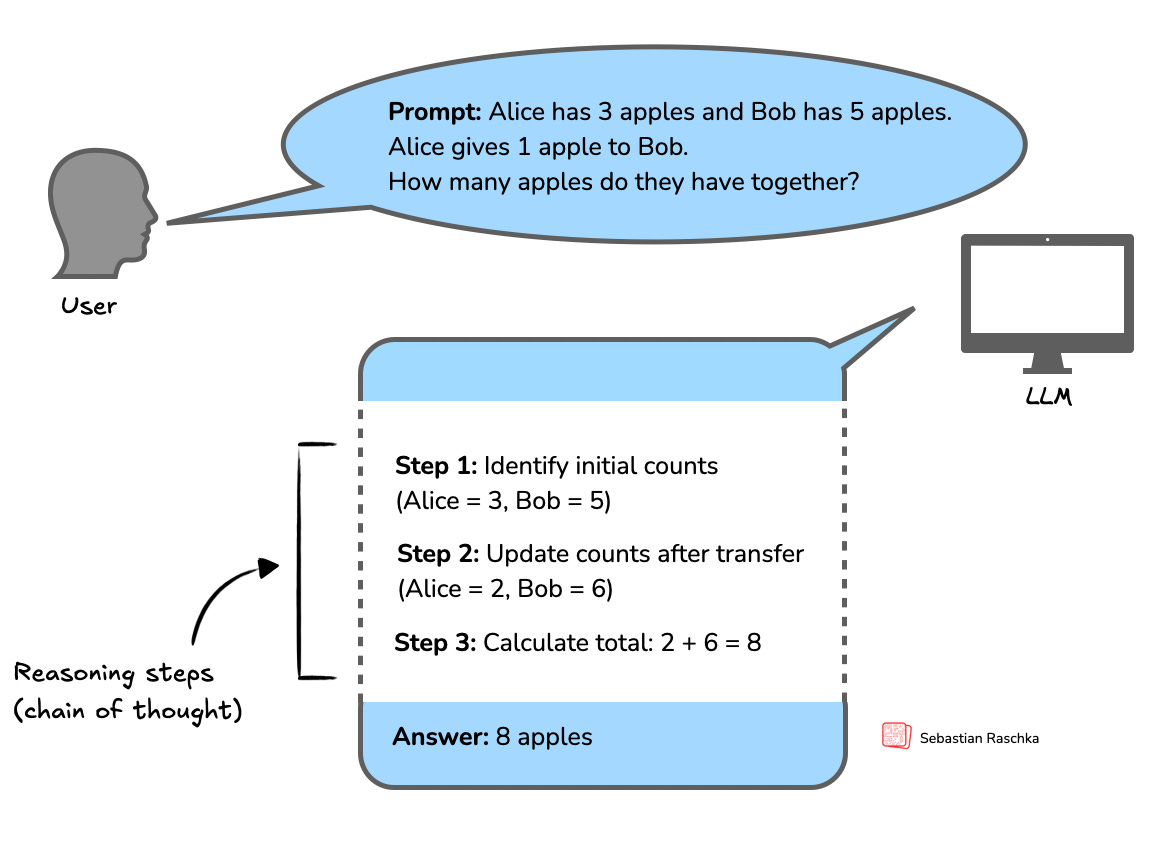
LLM が多段階推論タスクに取り組む方法を簡略化した図解です。単に事実を思い出すのではなく、モデルは正しい結論に至るために複数の中間推論ステップを組み合わせる必要があります。これらの中間推論ステップがユーザーに表示されるかどうかは、実装次第です。
推論モデルについて初めて学ぶ方で、より包括的な入門をお求めの場合は、私の過去の以下の記事をお勧めします:
さて、このセクションの冒頭で示唆された通り、LLM の推論能力は、OpenAI のブログ投稿にある図に美しく描かれているように、2 つの方法で向上させることができます。

精度の向上は、トレーニング量の増加または推論時計算リソース(テストタイム・コンピュート)の増強によって達成できます。ここでいう推論時計算リソースとは、推論時の計算リソース(インフェレンス・タイム・コンピュート)および推論時のスケーリングと同等の意味です。出典:https://openai.com/index/learning-to-reason-with-llms/ の注釈付き図。
私の過去の以下の記事では:
私は推論時計算リソース(テストタイム・コンピュート)に関する手法にのみ焦点を当てていました。今回の記事では、ついにトレーニング手法についてより詳しく取り上げたいと思います。
RLHF の基礎:すべてが始まった場所
LLM の推論モデルを構築・改善するために用いられる強化学習(RL)トレーニング手法は、従来の LLM を開発・整列させるために使われる人間フィードバック付き強化学習(RLHF)手法と、多少なりとも関連しています。そこで、RL ベースのトレーニングに基づく推論固有の変更について議論する前に、まず RLHF がどのように機能するかを簡単に振り返りたいと思います。
従来の LLM は通常、3 つのステップからなるトレーニング手順を経ます:
事前学習(Pre-training)
教師あり微調整(Supervised fine-tuning)
整列(通常は RLHF を通じて)
「オリジナル」の LLM 整列手法は RLHF で、これは最初の ChatGPT モデルの開発に使用されたレシピを記述した InstructGPT 論文に従って LLM を開発する際の標準的なレパートリーの一部です。
RLHF の元の目的は、LLM を人間の嗜好と整合させることです。例えば、あるプロンプトに対して LLM が複数の回答を生成するような場合、LLM を複数回使用するとします。RLHF は、あなたが好むようなスタイルの回答をより多く生成するように LLM を導きます。(しばしば、RLHF は安全性チューニングにも用いられます:機密情報の共有や卑猥な言葉の使用などを避けるためです。)
RLHF に初めて触れる方のために、数年前に行った私の講演からの抜粋をご紹介します。これは 5 分未満で RLHF を説明するものです:
あるいは、以下の段落ではテキスト形式で RLHF を説明します。
RLHF パイプラインは、事前学習済みモデルを取得し、教師あり方式で微調整を行います。この微調整はまだ RL の部分ではなく、主に前提条件です。
その後、RLHF は近傍政策最適化(proximal policy optimization, PPO)と呼ばれるアルゴリズムを用いて LLM をさらに整列させます。(PPO の代わりに使用可能な他のアルゴリズムも存在しますが、ここでは RLHF で最初に使用され、今日でも最も人気のあるものなので、あえて PPO について言及しています。)
簡略化のため、RLHF パイプラインを以下の 3 つの独立したステップで見ていきましょう。
RLHF ステップ 1(前提条件):事前学習済みモデルに対する教師あり微調整(SFT)
RLHF ステップ 2:報酬モデルの作成
RLHF ステップ 3:近傍政策最適化(PPO)による微調整
以下に示す RLHF ステップ 1 は、さらなる RLHF 微調整のためのベースモデルを作成するための教師あり微調整ステップです。

InstructGPT 論文からの注釈付き図、https://arxiv.org/abs/2203.02155
RLHF ステップ 1 では、データベースなどからプロンプトを作成またはサンプリングし、人間に高品質な回答を書いてもらいます。その後、このデータセットを用いて事前学習済みベースモデルを教師あり方式で微調整します。前述の通り、これは技術的には RL 訓練の一部ではなく、単なる前提条件です。
RLHF ステップ 2 では、次にこの教師あり微調整(SFT)から得られたモデルを用いて、以下に示すように報酬モデルを作成します。

InstructGPT 論文からの注釈付き図、https://arxiv.org/abs/2203.02155
上記の図に示されているように、各プロンプトに対して、前段階で作成したファインチューニング済み大規模言語モデル(LLM: Large Language Model)から 4 つの応答を生成します。その後、人間の注釈担当者がこれらの応答を好みに基づいてランク付けします。このランク付けプロセスは時間がかかりますが、教師ありファインチューニング用のデータセットを作成するよりもやや労働集約的ではない可能性があります。これは、応答をランク付けする方がそれらを書き起こすよりも単純であると考えられるためです。
これらのランク付けを含むデータセットを構築した後、RLHF(Reinforcement Learning from Human Feedback: 人間フィードバックからの強化学習)のステップ 3 における最適化後の段階に対して報酬スコアを出力する報酬モデル(RM: Reward Model)を設計することができます。ここで提案されているアイデアは、報酬モデルが労働集約的な人間のランク付けに代わり自動化を行うことで、大規模データセット上でのトレーニングを可能にするという点にあります。
この報酬モデル(RM)は、通常、前段階の教師ありファインチューニング(SFT: Supervised Fine-Tuning)ステップで作成された LLM に由来します。RLHF のステップ 1 で作成されたモデルを報酬モデルに変換するには、その出力層(次トークン分類層)を回帰層に置き換え、単一の出力ノードを持つ特徴を持たせます。
RLHF パイプラインの3番目のステップは、報酬モデル(RM)を使用して、教師あり微調整(SFT)から得られた前モデルを微調整することであり、これは以下の図に示されています。
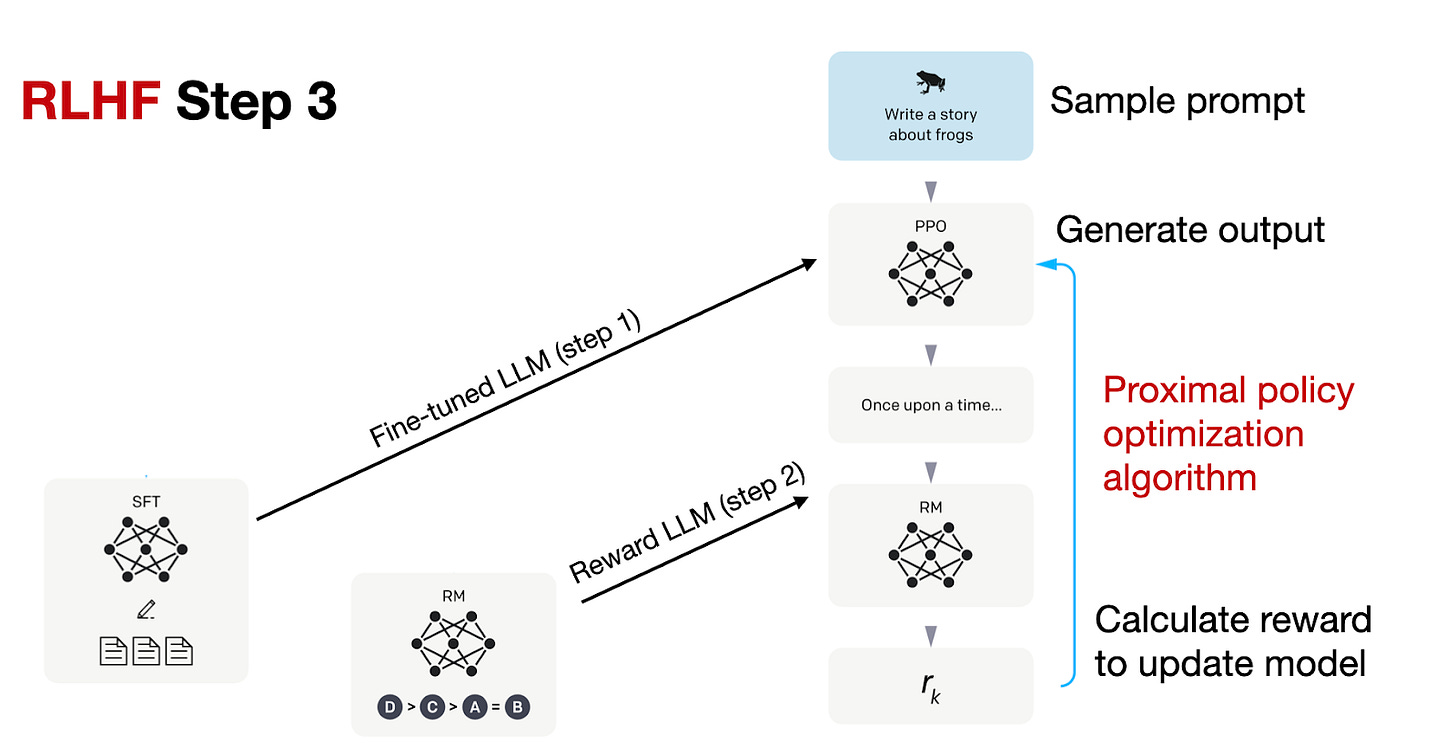
InstructGPT 論文からの注釈付き図、https://arxiv.org/abs/2203.02155
RLHF ステップ3(最終段階)では、RLHF ステップ2で作成した報酬モデルからの報酬スコアに基づき、SFT モデルを近似的政策最適化(PPO: proximal policy optimization)を用いて更新しています。
Ahead of AI は読者支援型の出版物です。新しい投稿を受け取り、私の活動をサポートするには、無料または有料の購読者になることを検討してください。
PPO に関する簡単な紹介:強化学習の中核アルゴリズム
前述したように、元の RLHF 手法では、近似的政策最適化(PPO: proximal policy optimization)と呼ばれる強化学習アルゴリズムを使用しています。
PPO は、ポリシーのトレーニングにおける安定性と効率性を向上させるために開発されました。(強化学習において「ポリシー」とは、トレーニングしたいモデルを指します。この場合、ポリシー = 大規模言語モデル(LLM)です。)
PPO の背後にある重要なアイデアの一つは、各更新ステップでポリシーが変化できる範囲を制限することです。これはクリップ付き損失関数を用いて行われ、トレーニングを不安定にする可能性のある過度に大きな更新を防ぐのに役立ちます。
さらに、PPO は損失関数に KL 発散のペナルティも含まれています。この項は、現在のポリシー(トレーニング中のモデル)と元の SFT モデルを比較するものであり、更新が適切に近傍にとどまるよう促します。結局のところ、モデルを完全に再訓練するのではなく、好意に基づいてチューニングするのが目的だからです。
これが「近接」政策最適化における「近接(proximal)」という名前の由来です:このアルゴリズムは、改善を可能にしつつも更新を既存のモデルに近づけて保とうとします。また、ある程度の探索を促すために、PPO はエントロピーボーナスも追加しており、これによりトレーニング中にモデルが出力を変化させるよう促されます。
以下の段落では、PPO を比較的高いレベルで説明するために、さらにいくつかの用語を紹介したいと思います。ただし、専門用語が多く含まれているため、続ける前に主要な用語を図にまとめました。
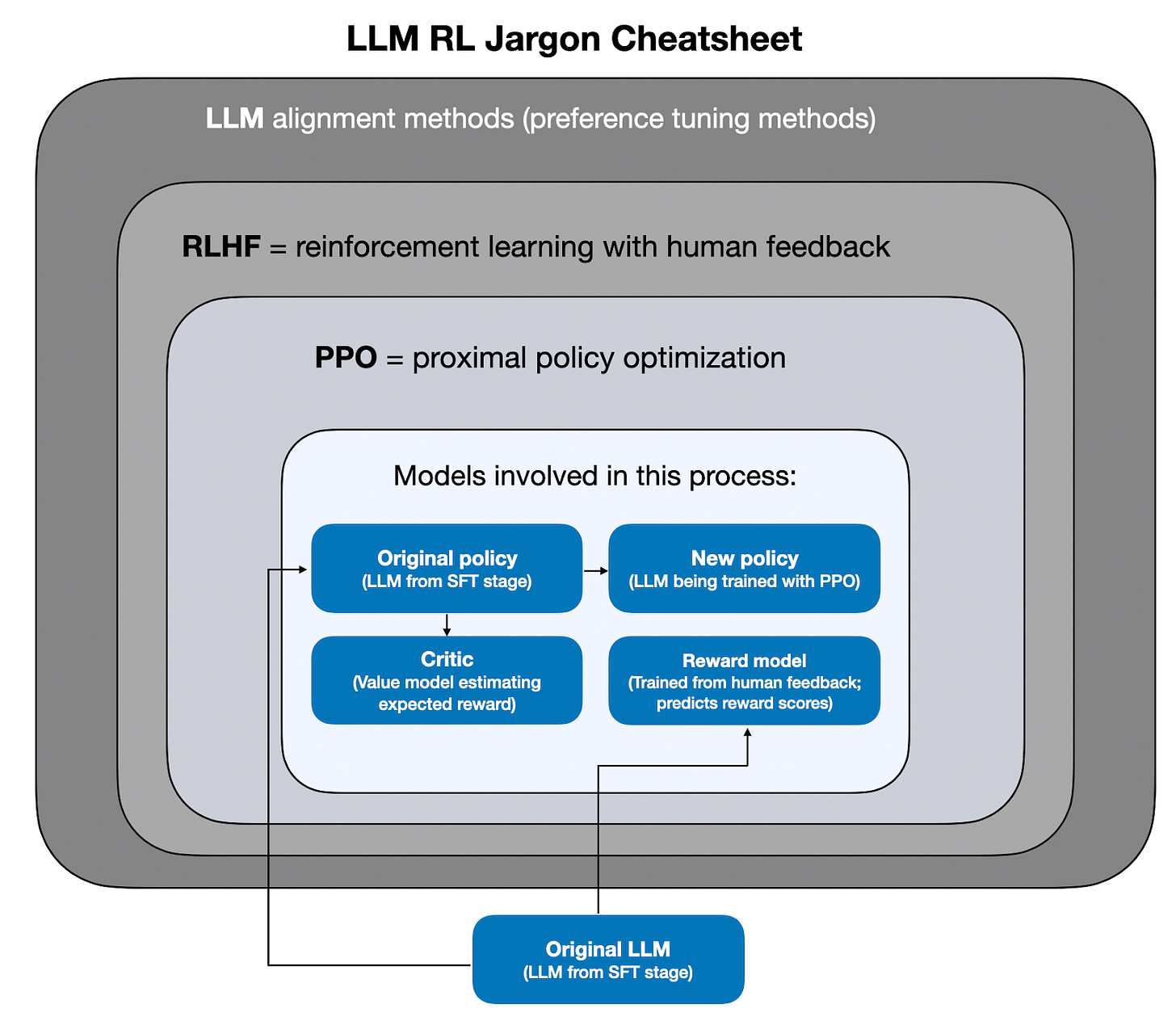
RLHF における主要な用語の図解。例えば、PPO には複数のモデルが関与しており、PPO は RLHF で使用されるアルゴリズム(RLHF は最も人気のある LLM アライメント手法の一つ)です。
以下では、疑似コードを通じて PPO の主要なステップを説明します。
さらに、より直感的に理解していただくために、例え話も使います:あなたは小さなフードデリバリーサービスを経営するシェフだと想像してください。そして、顧客満足度を高めるために、常に新しいレシピのバリエーションを試している状態です。あなたの全体的な目標は、顧客からのフィードバック(報酬)に基づいて、レシピ(ポリシー)を微調整することです。
- 新しいポリシーと古いポリシーから得られる次のトークンの確率の比率を計算します:
ratio = new_policy_prob / old_policy_prob
要するに、これは新しいレシピが古いレシピとどれだけ異なるかを確認するものです。
補足:「new_policy_prob」についてですが、私たちはまだ最終的に更新されたポリシーを使用しているわけではありません。現在トレーニング中のモデル(つまり、現在のバージョンのポリシー)を使用しています。しかし、慣例としてこれを「新しい」と呼ぶことにしています。したがって、まだ実験中であっても、慣例に従って現在の草案を「新しいポリシー」と呼びます。
- その比率に、その行動がどれだけ良かったか(アドバンテージと呼ばれる)を掛けます:
raw_score = ratio * advantage
ここでは簡略化のため、アドバンテージは報酬信号に基づいて計算されると仮定します:
advantage = actual_reward - expected_reward
シェフの例え話では、アドバンテージは新しい料理がどれだけうまく機能したかを考えることができます:
advantage = customer_rating - expected_rating
例えば、顧客が新しい料理に 9/10 の評価を与え、通常顧客が私たちに与える評価が 7/10 である場合、それは +2 のアドバンテージとなります。
これは簡略化された説明です。実際には、一般化されたアドバンテージ推定(GAE)が含まれており、記事が冗長になるのを避けるためにここでは省略しています。ただし、重要な詳細として言及すべき点があります。期待される報酬は、「批評家」(「価値モデル」とも呼ばれる)によって計算され、実際の報酬は報酬モデルによって計算されます。つまり、アドバンテージの計算には、微調整対象となる元のモデルと同程度の規模を持つ 2 つの追加モデルが関与します。
この比喩において、この批評家または価値モデルは、料理を顧客に提供する前に試食してもらう友人と考えることができます。また、その友人に顧客がどのように評価するか(これが期待される報酬)も推定してもらいます。一方、報酬モデルは実際の顧客であり、フィードバック(つまり実際の報酬)を与えます。
- クリップされたスコアを計算する:
新しいポリシーがあまりにも大きく変化した場合(例えば、比率が 1.2 より大きい、または 0.8 より小さい場合)、比率をクリップします。以下のように行います:
clipped_ratio = clamp(ratio, 0.8, 1.2)
clipped_score = clipped_ratio * advantage
比喩において、新しいレシピが非常に素晴らしい(あるいはひどい)レビューを得たと想像してください。その場合、メニュー全体を今すぐ大規模に改訂したくなるかもしれません。しかし、それはリスクが高いです。そこで代わりに、現在のところレシピを変更できる範囲をクリップします。(例えば、料理の辛さを大幅に変更し、たまたま一人の顧客が辛い食べ物を好んだとしても、それが他の全員にも当てはまるわけではありません。)
- 次に、生のスコアとクリップされたスコアのどちらか小さい方を使用します:
final_score = min(raw_score, clipped_score)(Johanna Reiml 氏に PPO の下限性質に関する初期の問題を指摘していただき、現在は修正済みです。)
これもまた、少し慎重になることに関連しています。例えば、アドバンテージが正の場合(新しい行動の方が良い場合)、報酬の上限を設定します。これは、偶然や運による良い結果に対して過信したくないからです。
一方、アドバンテージが負の場合(新しい行動の方が悪い場合)、ペナルティの上限を設けます。ここでの考え方も同様です。つまり、本当に確信があるまで、一つの悪い結果に過剰反応したくないのです。
要するに、アドバンテージが正の場合は二つのスコアのうち小さい方を使用し(過剰な報酬を防ぐため)、負の場合は大きい方を使用します(過剰なペナルティを防ぐため)。
このアナロジーでは、レシピが期待以上にうまくいっている場合でも、確信があるまで過剰に評価しないことを保証しています。また、パフォーマンスが低下している場合でも、一貫して悪い結果が続くまで過剰に罰さないようにします。
- 損失の計算:
この最終スコアは、トレーニング中に最大化する対象となります(スコアの符号を反転させて最小化し、勾配降下法を使用)。さらに、KL ペナルティ項も追加されます。ここでβはペナルティ強度のためのハイパーパラメータです:
loss = -final_score + β * KL(new_policy || reference_policy)この比喩において、新しいレシピが元のスタイルからあまりにもかけ離れないようにするためにペナルティを加えています。これにより、毎週「台所を再発明する」ことを防ぎます。例えば、イタリアンレストランが突然 BBQ 専門店に変わってしまうようなことは避けたいものです。
これは多くの情報を含んでいたため、LLM の文脈における具体的な数値例を図で要約しました。ただし、複雑すぎる場合は飛ばしても構いません。残りの記事は十分に理解できるはずです。
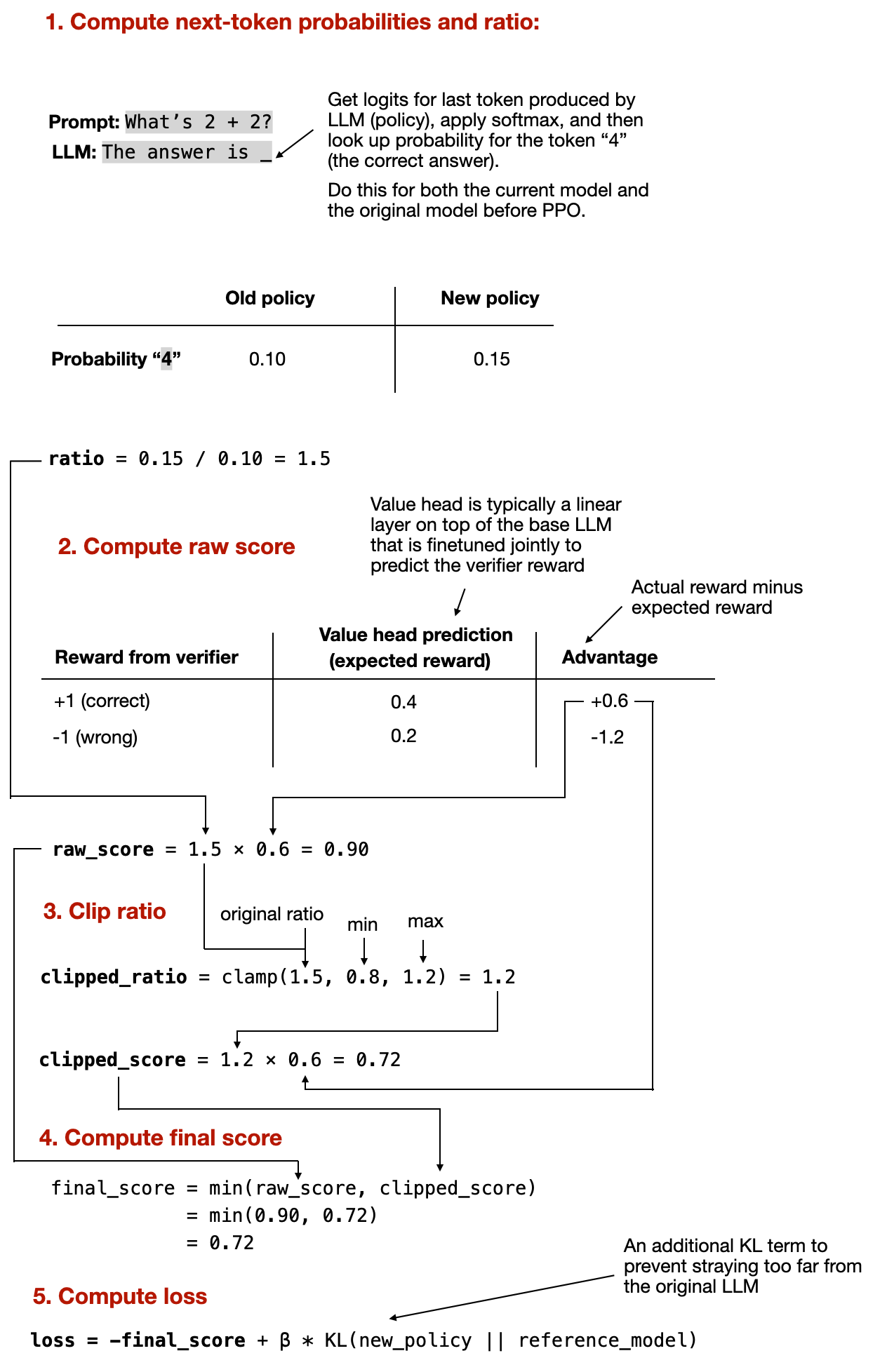
PPO の解説にやりすぎたかもしれないと認めます。しかし、一度書いてしまうと削除するのは難しくなりました。誰かの役に立つことを願っています!
その上で、次のセクションで重要となる主なポイントは、PPO には複数のモデルが関与していることです:
- ポリシー(policy): SFT で訓練された LLM であり、さらにアライメントを進めたい対象です。
- リワードモデル(reward model): リワードを予測するように訓練されたモデルです(RLHF のステップ 2 を参照)。
- クリティック(critic): リワードを見積もる学習可能なモデルです。
- リファレンスモデル(reference model、元のポリシー): ポリシーがあまりにも逸脱しないようにするために使用します。
ところで、なぜ報酬モデルと批評家モデルの両方が必要なのか疑問に思うかもしれません。報酬モデルは通常、ポリシーを PPO でトレーニングする前に訓練されます。これは人間の審査員による選好ラベル付けを自動化し、ポリシー LLM が生成した完全な応答に対するスコアを与えるためです。
一方、批評家は部分的な応答を評価します。最終的な応答を作成するためにこれを使用します。報酬モデルは通常凍結されたままですが、批評家モデルはトレーニング中に更新され、報酬モデルによって作成される報酬をよりよく推定できるようにします。
PPO に関する詳細はこの記事の範囲外ですが、興味のある読者は InstructGPT 論文に先立つ以下の 4 つの論文で数学的な詳細を見つけることができます:
(1) Mnih, Badia, Mirza, Graves, Lillicrap, Harley, Silver, Kavukcuoglu による「Asynchronous Methods for Deep Reinforcement Learning (2016)」は、深層学習ベースの強化学習における Q-ラーニングの代替としてポリシー勾配法を紹介しています。
(2) Schulman, Wolski, Dhariwal, Radford, Klimov による「Proximal Policy Optimization Algorithms (2017)」は、上記のバニラなポリシー最適化アルゴリズムよりもデータ効率的でスケーラブルな、修正された近接ポリシーベースの強化学習手順を提示しています。
(3) Ziegler, Stiennon, Wu, Brown, Radford, Amodei, Christiano, Irving による「Human Preferences から言語モデルを微調整する(2020)」は、PPO と報酬学習の概念を示しており、事前学習済み言語モデルに対して KL 正則化(KL regularization)を含めることで、ポリシーが自然言語から遠くへ逸脱しないように防止しています。
(4) Stiennon, Ouyang, Wu, Ziegler, Lowe, Voss, Radford, Amodei, Christiano による「Human Feedback から要約を学習する(2022)」は、後に InstructGPT 論文でも使用された人気のある RLHF の3段階手順を紹介しています。
RL アルゴリズム:PPO から GRPO へ
前述の通り、PPO は RLHF で最初に使用されたアルゴリズムです。技術的な観点からは、推論モデルの開発に用いられている RL パイプラインにおいて完璧に機能します。しかし、DeepSeek-R1 がその RL パイプラインで採用したのは、彼らの以前の論文の一つで紹介された「Group Relative Policy Optimization(GRPO)」と呼ばれるアルゴリズムです。
DeepSeekMath: 開放型言語モデルにおける数学的推論の限界を押し広げる(2024)
DeepSeek チームは GRPO を紹介しました
原文を表示
A lot has happened this month, especially with the releases of new flagship models like GPT-4.5 and Llama 4. But you might have noticed that reactions to these releases were relatively muted. Why? One reason could be that GPT-4.5 and Llama 4 remain conventional models, which means they were trained without explicit reinforcement learning for reasoning.
Meanwhile, competitors such as xAI and Anthropic have added more reasoning capabilities and features into their models. For instance, both the xAI Grok and Anthropic Claude interfaces now include a "thinking" (or "extended thinking") button for certain models that explicitly toggles reasoning capabilities.
In any case, the muted response to GPT-4.5 and Llama 4 (non-reasoning) models suggests we are approaching the limits of what scaling model size and data alone can achieve.
However, OpenAI's recent release of the o3 reasoning model demonstrates there is still considerable room for improvement when investing compute strategically, specifically via reinforcement learning methods tailored for reasoning tasks. (According to OpenAI staff during the recent livestream, o3 used 10× more training compute compared to o1.)
Source: OpenAI livestream (https://openai.com/live/) on April 16, 2025
While reasoning alone isn't a silver bullet, it reliably improves model accuracy and problem-solving capabilities on challenging tasks (so far). And I expect reasoning-focused post-training to become standard practice in future LLM pipelines.
So, in this article, let's explore the latest developments in reasoning via reinforcement learning.
This article focuses on reinforcement learning training methods used to develop and improve reasoning models
Because it is a relatively long article, I am providing a Table of Contents overview below. To navigate the table of contents, please use the slider on the left-hand side in the web view.
Understanding reasoning models
RLHF basics: where it all started
A brief introduction to PPO: RL's workhorse algorithm
RL algorithms: from PPO to GRPO
RL reward modeling: from RLHF to RLVR
How the DeepSeek-R1 reasoning models were trained
Lessons from recent RL papers on training reasoning models
Noteworthy research papers on training reasoning models
Tip: If you are already familiar with reasoning basics, RL, PPO, and GRPO, please feel free to directly jump ahead to the “Lessons from recent RL papers on training reasoning models” section, which contains summaries of interesting insights from recent reasoning research papers.
Understanding reasoning models
The big elephant in the room is, of course, the definition of reasoning. In short, reasoning is about inference and training techniques that make LLMs better at handling complex tasks.
To provide a bit more detail on how this is achieved (so far), I'd like to define reasoning as follows:
Reasoning, in the context of LLMs, refers to the model's ability to produce intermediate steps before providing a final answer. This is a process that is often described as chain-of-thought (CoT) reasoning. In CoT reasoning, the LLM explicitly generates a structured sequence of statements or computations that illustrate how it arrives at its conclusion.
And below is a figure along with the definition.
A simplified illustration of how an LLM might tackle a multi-step reasoning task. Rather than just recalling a fact, the model needs to combine several intermediate reasoning steps to arrive at the correct conclusion. The intermediate reasoning steps may or may not be shown to the user, depending on the implementation.
If you are new to reasoning models and would like a more comprehensive introduction, I recommend my previous articles:
Now, as hinted at the beginning of this section, the reasoning abilities of LLMs can be improved in two ways, as nicely illustrated in a figure from an OpenAI blog post:
Accuracy improvements can be achieved through increased training or test-time compute, where test-time compute is synonymous with inference-time compute and inference-time scaling. Source: Annotated figure from https://openai.com/index/learning-to-reason-with-llms/
In my previous article:
I solely focused on the test-time compute methods. In this article, I finally want to take a closer look at the training methods.
RLHF basics: where it all started
The reinforcement learning (RL) training methods used to build and improve reasoning models are more or less related to the reinforcement learning with human feedback (RLHF) methodology that is used to develop and align conventional LLMs. So, I want to start with a small recap of how RLHF works before discussing reasoning-specific modification based on RL-based training.
Conventional LLMs typically undergo a 3-step training procedure:
Pre-training
Supervised fine-tuning
Alignment (typically via RLHF)
The "original" LLM alignment method is RLHF, which is part of the standard repertoire when developing LLMs following the InstructGPT paper, which described the recipe that was used to develop the first ChatGPT model.
The original goal of RLHF is to align LLMs with human preferences. For instance, suppose you use an LLM multiple times where the LLM generates multiple answers for a given prompt. RLHF guides the LLM towards generating more of the style of answer that you prefer. (Often, RLHF is also used to safety-tune LLMs: to avoid sharing sensitive information, using swear words, and so on.)
If you are new to RLHF, here is an excerpt from a talk I gave a few years ago that explains RLHF in less than 5 minutes:
Alternatively, the paragraphs below describe RLHF in text form.
The RLHF pipeline takes a pre-trained model and fine-tunes it in a supervised fashion. This fine-tuning is not the RL part yet but is mainly a prerequisite.
Then, RLHF further aligns the LLM using an algorithm called proximal policy optimization (PPO). (Note that there are other algorithms that can be used instead of PPO; I was specifically saying PPO because that's what was originally used in RLHF and is still the most popular one today.)
For simplicity, we will look at the RLHF pipeline in three separate steps:
RLHF Step 1 (prerequisite): Supervised fine-tuning (SFT) of the pre-trained model
RLHF Step 2: Creating a reward model
RLHF Step 3: Fine-tuning via proximal policy optimization (PPO)
RLHF Step 1, shown below, is a supervised fine-tuning step to create the base model for further RLHF fine-tuning.
Annotated figure from InstructGPT paper, https://arxiv.org/abs/2203.02155
In RLHF step 1, we create or sample prompts (from a database, for example) and ask humans to write good-quality responses. We then use this dataset to fine-tune the pre-trained base model in a supervised fashion. As mentioned before, this is not technically part of RL training but merely a prerequisite.
In RLHF Step 2, we then use this model from supervised fine-tuning (SFT) to create a reward model, as shown below.
Annotated figure from InstructGPT paper, https://arxiv.org/abs/2203.02155
As depicted in the figure above, for each prompt, we generate four responses from the fine-tuned LLM created in the prior step. Human annotators then rank these responses based on their preferences. Although this ranking process is time-consuming, it might be somewhat less labor-intensive than creating the dataset for supervised fine-tuning. This is because ranking responses is likely simpler than writing them.
Upon compiling a dataset with these rankings, we can design a reward model that outputs a reward score for the optimization subsequent stage in RLHF Step 3. The idea here is that the reward model replaces and automates the labor-intensive human ranking to make the training feasible on large datasets.
This reward model (RM) generally originates from the LLM created in the prior supervised fine-tuning (SFT) step. To turn the model from RLHF Step 1 into a reward model, its output layer (the next-token classification layer) is substituted with a regression layer, which features a single output node.
The third step in the RLHF pipeline is to use the reward model (RM) to fine-tune the previous model from supervised fine-tuning (SFT), which is illustrated in the figure below.
Annotated figure from InstructGPT paper, https://arxiv.org/abs/2203.02155
In RLHF Step 3, the final stage, we are now updating the SFT model using proximal policy optimization (PPO) based on the reward scores from the reward model we created in RLHF Step 2.
Ahead of AI is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
A brief introduction to PPO: RL's workhorse algorithm
As mentioned earlier, the original RLHF method uses a reinforcement learning algorithm called proximal policy optimization (PPO).
PPO was developed to improve the stability and efficiency of training a policy. (In reinforcement learning, “policy” just means the model we want to train; in this case, policy = LLM.)
One of the key ideas behind PPO is that it limits how much the policy is allowed to change during each update step. This is done using a clipped loss function, which helps prevent the model from making overly large updates that could destabilize training.
On top of that, PPO also includes a KL divergence penalty in the loss. This term compares the current policy (the model being trained) to the original SFT model. This encourages the updates to stay reasonably close. The idea is to preference-tune the model, not to completely re-train, after all.
This is where the “proximal” in proximal policy optimization comes from: the algorithm tries to keep the updates close to the existing model while still allowing for improvement. And to encourage a bit of exploration, PPO also adds an entropy bonus, which this encourages the model to vary the outputs during training.
In the following paragraphs, I want to introduce some more terminology to illustrate PPO on a relatively high level. Still, there's a lot of jargon involved, so I tried to summarize the key terminology in the figure below before we continue.
Illustration of the key terms in RLHF. For instance, several models are involved in PPO, where PPO is an algorithm used in RLHF (and RLHF is one of the most popular LLM alignment methods).
Below, I aim to illustrate the key steps in PPO via pseudo-code.
In addition, to make it more intuitive, I will also use an analogy: Imagine you are a chef running a small food delivery service. And you are constantly trying out new recipe variations to improve customer satisfaction. Your overall goal is to tweak your recipe (policy) based on customer feedback (reward).
- Compute the ratio of the next-token probabilities from the new vs the old policy:
ratio = new_policy_prob / old_policy_probIn short, this checks how different our new recipe is from the old one.
Side note: Regarding "new_policy_prob", we are not using the final updated policy yet. We are using the current version of the policy (i.e., the model we are in the middle of training). However, it's a convention to call it "new". So, even though you're still experimenting, we call your current draft the "new policy" as per convention.
- Multiply that ratio by how good the action was (called the advantage):
raw_score = ratio * advantageHere, for simplicity, we may assume the advantage is computed based on the reward signal:
advantage = actual_reward - expected_rewardIn the chef analogy, we can think of the advantage as how well the new dish performed:
advantage = customer_rating - expected_ratingFor example, if a customer rates the new dish with a 9/10, and the customers normally give us a 7/10, that's a +2 advantage.
Note that this is a simplification. In reality, this involves generalized advantage estimation (GAE), which I am omitting here so as not to bloat the article further. However, one important detail to mention is that the expected reward is computed by a so-called "critic" (sometimes also called "value model"), and a reward model computes the actual reward. I.e., the advantage computation involves 2 other models, typically the same size as the original model we are fine-tuning.
In the analogy, we can think of this critic or value model as a friend we ask to try our new dish before serving it to the customers. We also ask our friend to estimate how a customer would rank it (that's the expected reward). The reward model is the actual customer then who gives the feedback (i.e., the actual reward).
- Compute a clipped score:
If the new policy changes too much (e.g., ratio > 1.2 or < 0.8), we clip the ratio, as follows:
clipped_ratio = clamp(ratio, 0.8, 1.2)
clipped_score = clipped_ratio * advantageIn the analogy, imagine that the new recipe got an exceptionally great (or bad) review. We might be tempted to overhaul the entire menu now. But that's risky. So, instead, we clip how much our recipe can change for now. (For instance, maybe we made the dish much spicier, and that one customer happened to love spicy food, but that doesn't mean everyone else will.)
- Then we use the smaller of the raw score and clipped score:
final_score = min(raw_score, clipped_score)(Thanks to Johanna Reiml for pointing out an earlier issue with the lower-bound property of PPO, which is now fixed.)
Again, this is related to being a bit cautious. For instance, if the advantage is positive (the new behavior is better), we cap the reward. That's because we don't want to over-trust a good result that might be a coincidence or luck.
If the advantage is negative (the new behavior is worse), we limit the penalty. The idea here is similar. Namely, we don't want to overreact to one bad result unless we are really sure.
In short, we use the smaller of the two scores if the advantage is positive (to avoid over-rewarding), and the larger when the advantage is negative (to avoid over-penalizing).
In the analogy, this ensures that if a recipe is doing better than expected, we don't over-reward it unless we are confident. And if it's underperforming, we don't over-penalize it unless it's consistently bad.
- Calculating the loss:
This final score is what we maximize during training (using gradient descent after flipping the sign of the score to minimize). In addition, we also add a KL penalty term, where β is a hyperparameter for the penalty strength:
loss = -final_score + β * KL(new_policy || reference_policy)In the analogy, we add the penalty to ensure new recipes are not too different from our original style. This prevents you from "reinventing the kitchen" every week. For example, we don't want to turn an Italian restaurant into a BBQ place all of a sudden.
This was a lot of information, so I summarized it with a concrete, numeric example in an LLM context via the figure below. But please feel free to skip it if it's too complicated; you should be able to follow the rest of the article just fine.
I admit that I may have gone overboard with the PPO walkthrough. But once I had written it, it was hard to delete it. I hope some of you will find it useful!
That being said, the main takeaways that will be relevant in the next section are that there are multiple models involved in PPO:
- The policy, which is the LLM that has been trained with SFT and that we want to further align).
- The reward model, which is a model that has been trained to predict the reward (see RLHF step 2).
- The critic, which is a trainable model that estimates the reward.
- A reference model (original policy) that we use to make sure that the policy doesn't deviate too much.
By the way, you might wonder why we need both a reward model and a critic model. The reward model is usually trained before training the policy with PPO. It's to automate the preference labeling by human judges, and it gives the score for the complete responses generated by the policy LLM.
The critic, in contrast, judges partial responses. We use it to create the final response. While the reward model typically remains frozen, the critic model is updated during training to estimate the reward created by the reward model better.
More details about PPO are out of the scope of this article, but interested readers can find the mathematical details in these four papers that predate the InstructGPT paper:
(1) Asynchronous Methods for Deep Reinforcement Learning (2016) by Mnih, Badia, Mirza, Graves, Lillicrap, Harley, Silver, and Kavukcuoglu introduces policy gradient methods as an alternative to Q-learning in deep learning-based RL.
(2) Proximal Policy Optimization Algorithms (2017) by Schulman, Wolski, Dhariwal, Radford, and Klimov presents a modified proximal policy-based reinforcement learning procedure that is more data-efficient and scalable than the vanilla policy optimization algorithm above.
(3) Fine-Tuning Language Models from Human Preferences (2020) by Ziegler, Stiennon, Wu, Brown, Radford, Amodei, Christiano, Irving illustrates the concept of PPO and reward learning to pretrained language models including KL regularization to prevent the policy from diverging too far from natural language.
(4) Learning to Summarize from Human Feedback (2022) by Stiennon, Ouyang, Wu, Ziegler, Lowe, Voss, Radford, Amodei, Christiano introduces the popular RLHF three-step procedure that was later also used in the InstructGPT paper.
RL algorithms: from PPO to GRPO
As mentioned before, PPO was the original algorithm used in RLHF. From a technical standpoint, it works perfectly fine in the RL pipeline that's being used to develop reasoning models. However, what DeepSeek-R1 used for their RL pipeline is an algorithm called Group Relative Policy Optimization (GRPO), which was introduced in one of their earlier papers:
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (2024)
The DeepSeek team introduced GRPO a
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み