コーディングエージェントの評価スキル
Hamel Husain氏が、コーディングエージェントの品質評価を支援する「evals-skills」オープンソースツールキットを公開し、ハルシネーションの分類や合成データ生成など、実用的な評価スキルを提供した。
キーポイント
コーディングエージェントにおける評価の重要性
OpenAIの事例のように、モデル自体よりもエージェントのインフラ(トレース、テレメトリ、評価)の整備が製品品質に大きく影響する。
汎用スコアリングの限界とスキルの必要性
単なる「ハルシネーションスコア」では、事実誤認と架空のユーザー行動の区別がつかないため、ドメイン固有のエラー分析スキルが必要である。
具体的な評価スキルの提供
エラー分析、合成データ生成、判事プロンプトの作成、RAG評価など、6つの具体的なスキルを提供し、エージェントが自律的にパイプラインを構築・改善できるようにした。
MCPサーバーとの補完関係
主要な評価ベンダーが提供するMCPサーバーはインフラアクセスを提供するのみであり、これらのスキルは「何をすべきか」を教える役割を果たす。
リポジトリの公開
記事で紹介された「Evals Skills for Coding Agents」に関連するコードリポジトリがGitHub(github.com/hamelsmu/evals-skills)で公開されている。
フィードバックの呼びかけ
著者は、これらのスキルが有用であれば、X(旧Twitter)やニュースレター経由で連絡してほしいと述べている。
影響分析・編集コメントを表示
影響分析
このツールキットは、AIエージェント開発における「評価(Evals)」のハードルを下げ、標準化されたベストプラクティスを提供することで、開発現場の実効性を高める。特に、エージェントが自律的にパイプラインを構築・改善できる点は、Agentic AIの普及において重要なインフラ整備となる。
編集コメント
エージェント開発において「評価」はモデル選定と同様に重要だが、実装コストが高かった。このスキルセットはそれを抽象化し、エージェント自身による改善を可能にする点で実用的価値が高い。
今日、私は「evals-skills」という、AI 製品の評価(evals)のためのスキルセットを公開します。これは私がこれまで 50 社以上の企業支援や、当コースで 4,000 人以上の学生を教えてきた中で目にしてきた一般的なミスを防ぐためのものです。
なぜ評価にスキルが必要なのか
コーディングエージェントは現在、アプリケーションへの計装(instrumenting)、実験の実行、データ分析、インターフェースの構築を行っています。私はこれらに対して評価(evals)を指示しています。
OpenAI の「Harness Engineering」記事では、その必要性がよく説明されています。彼らは Codex エージェントのみを使用して製品を完全に構築しました——エンジニア 3 名、5 ヶ月間、約 100 万行のコードです——そして、モデル自体を改善するよりも、エージェントを取り巻くインフラストラクチャを改善することの方が重要であることを発見しました。エージェントはトレース(traces)を照会して自身の作業を検証します。ドキュメントはエージェントに何をすべきかを伝えます。テレメトリー(telemetry)はそれが機能したかどうかを伝えます。評価(evals)は出力が良質かどうかを伝えます。
主要な評価ベンダーのすべてが、現在 MCP サーバー2を出荷しています。面倒な部分——アプリケーションへの計装、実験のオーケストレーション、注釈ツールの構築——は現在、コーディングエージェントに任せるべきです。
しかし、評価プラットフォームを持つエージェントであっても、それを使って何をすべきかを知る必要があります。例えば、サポートボットが顧客に対して「プランには無料返品が含まれています」と伝えるが、実際には含まれていない場合。また別のボットが、「注文をキャンセルしました」と伝えるが、誰も依頼していない場合。これらはどちらもハルシネーション(幻覚)ですが、一方は事実を誤っており、他方はユーザーの行動をでっち上げています。これらを一般的な「ハルシネーションスコア」にまとめると、エラーを見逃すことになります。
これらのスキルは隙間を埋めます。これらはベンダーの MCP サーバーを補完するもので、MCP サーバーがエージェントにトレースや実験へのアクセス権を与える一方で、これらのスキルはそれらをどう活用するかを教えてくれます。
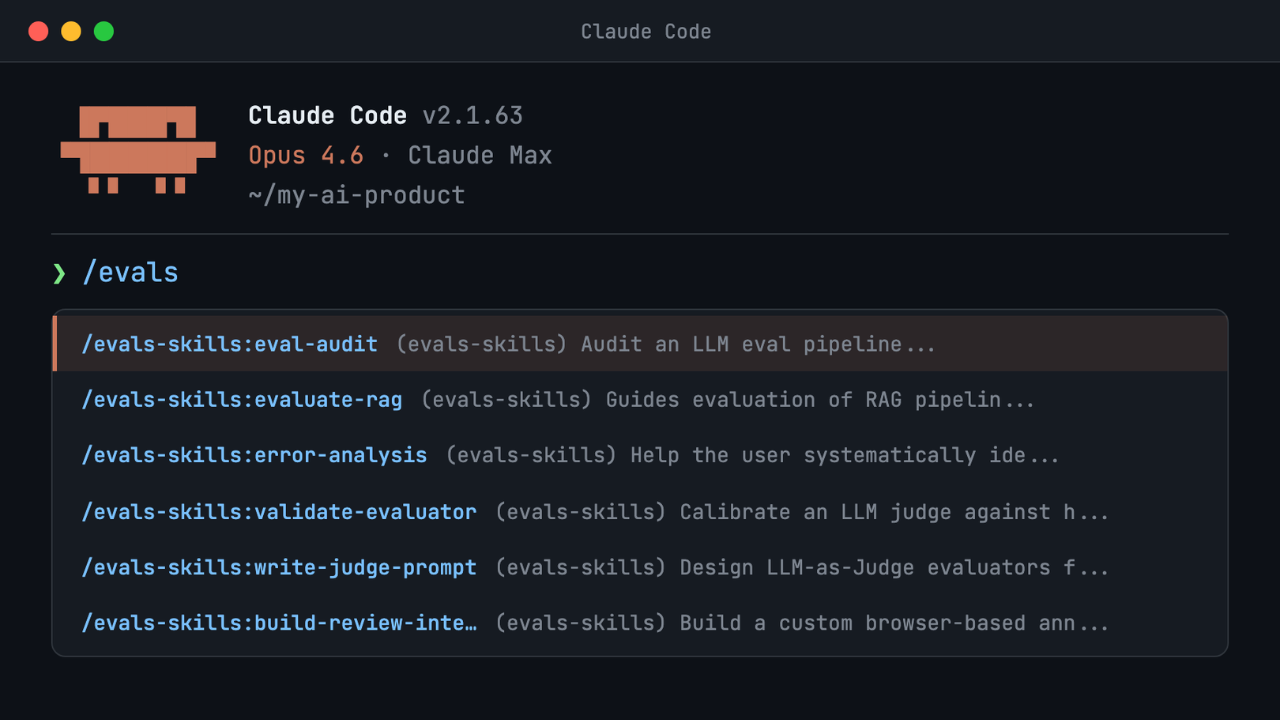
スキル
evals(評価)や既存の評価パイプラインを引き継ぐ場合、まずは eval-audit から始めてください。これは現在のセットアップ(またはその欠如)を検査し、6 つの領域にわたって診断チェックを実行し、優先順位付けされた問題リストと次のステップを生成します。スキルをインストールするか、エージェントに以下のプロンプトを与えてください:
https://github.com/hamelsmu/evals-skills から eval スキルプラグインをインストールし、その後、私の評価パイプラインで /evals-skills:eval-audit を実行してください。各診断領域について並列で個別のサブエージェントを使用して調査し、その結果を単一のレポートに統合してください。監査で推奨される場合は、プラグイン内の他のスキルも使用してください。
evals に精通している場合は、監査をスキップして必要なスキルを選択できます:
スキル | 機能
---|---
error-analysis | トレースを読み込み、失敗を分類し、何が壊れているかの語彙を構築する
generate-synthetic-data | 実データが不足している場合に多様なテスト入力を生成する
write-judge-prompt | バイナリ形式の Pass/Fail LLM-as-Judge(LLM を裁判官とする評価者)を設計する
validate-evaluator | TPR/TNR(真陽性率/真陰性率)とバイアス補正を用いて、裁判官を人間ラベルに対して較正する
evaluate-rag | 検索機能と生成の品質を別々に評価する
build-review-interface | 人間のトレースレビュー用の注釈インターフェースを生成する
これらのスキルは出発点に過ぎず、プロジェクト全体に共通する一般的なミスをエンコードしたものです。あなたの技術スタック、ドメイン、データに基づいて構築されたスキルの方が、これらよりも優れたパフォーマンスを発揮します。まずはここから始めて、その後自分独自のスキルを作成してください。
👉 リポジトリはこちら:github.com/hamelsmu/evals-skills 👈
これらのスキルが役に立った場合は、ぜひご意見をお聞かせください!X(旧 Twitter)で私を見つけたり、ニュースレターを通じてメールを送っていただくこともできます。
脚注
MMLU や HELM のような基礎モデルベンチマークではなく、これらは一般的な大規模言語モデル(LLM: Large Language Model)の能力を測定するものです。製品評価は、あなたのデータとタスクにおいてパイプラインが機能しているかどうかを測定します。製品固有の AI 評価に詳しくない場合は、私の「AI 評価 FAQ」をご覧ください。↩︎
Braintrust, LangSmith, Phoenix, Truesight など。↩︎
原文を表示
Today, I’m publishing evals-skills, a set of skills for AI product evals1. They guard against common mistakes I’ve seen helping 50+ companies and teaching 4,000+ students in our course.
Why Skills for Evals
Coding agents now instrument applications, run experiments, analyze data, and build interfaces. I’ve been pointing them at evals.
OpenAI’s Harness Engineering article makes the case well. They built a product entirely with Codex agents — three engineers, five months, ~1 million lines of code — and found that improving the infrastructure around the agent mattered more than improving the model. The agents queried traces to verify their own work. Documentation tells the agent what to do. Telemetry tells it whether it worked. Evals tell it whether the output is good.
All major eval vendors now ship an MCP server2. The tedious parts: instrumenting your app, orchestrating experiments and building annotation tools now fall to coding agents.
But an agent with an eval platform still needs to know what to do with it. Say a support bot tells a customer “your plan includes free returns” when it doesn’t. Another says “I’ve canceled your order” when nobody asked. Both are hallucinations, but one gets a fact wrong and the other makes up a user action. If you lump them together in a generic “hallucination score,” you’ll miss errors.
These skills fill the gaps. They complement the vendor MCP servers: those give your agent access to traces and experiments, these teach it what to do with them.
The Skills
If you’re new to evals or inheriting an existing eval pipeline, start with eval-audit. It inspects your current setup (or lack of one), runs diagnostic checks across six areas, and produces a prioritized list of problems with next steps. Install the skills or give your agent this prompt:
Install the eval skills plugin from https://github.com/hamelsmu/evals-skills, then run /evals-skills:eval-audit on my eval pipeline. Investigate each diagnostic area using a separate subagent in parallel, then synthesize the findings into a single report. Use other skills in the plugin as recommended by the audit.
If you’re experienced with evals, you can skip the audit and pick the skill you need:
Skill
What it does
error-analysis
Read traces, categorize failures, build a vocabulary of what’s broken
generate-synthetic-data
Create diverse test inputs when real data is sparse
write-judge-prompt
Design binary Pass/Fail LLM-as-Judge evaluators
validate-evaluator
Calibrate judges against human labels using TPR/TNR and bias correction
evaluate-rag
Evaluate retrieval and generation quality separately
build-review-interface
Generate annotation interfaces for human trace review
These skills are a starting point and only encode common mistakes that generalize across projects. Skills grounded in your stack, your domain, and your data will outperform them. Start here, then write your own.
👉 The repo is here: github.com/hamelsmu/evals-skills 👈
If these skills help you, I’d love to hear from you! You can find me on X or email me through my newsletter.
Footnotes
Not foundation model benchmarks like MMLU or HELM that measure general LLM capabilities. Product evals measure whether your pipeline works on your task with your data. If you aren’t familiar with product-specific AI evals, check out my AI Evals FAQ.↩︎
Braintrust, LangSmith, Phoenix, Truesight, and others.↩︎
関連記事
Google の技術を採用した Siri AI が登場、しかし世界の多くは利用不可
Apple は WWDC 2026 で、ゼロから再構築された新 Siri AI を発表し、Google の技術を組み込んで多段階対話を実現したが、多くの地域ではまだ利用できない。
マクドナルド、Google 支援の AI ドライブスルー注文システムをテスト中
マクドナルドは、Google が支援する「ArchIQ」と呼ばれるAIシステムを米国の5店舗で試験運用しており、このシステムがドライブスルーでの注文受付や店舗運営をサポートしている。
Anthropic、Claude Fable 5 と Claude Mythos 5 を発表:基盤モデルは同一だが安全策が異なり、新「Mythos クラス」 tiers 登場
Anthropic は 2026 年 6 月 9 日、能力が Opus クラスを上回る新 tiers「Mythos クラス」に属する Claude Fable 5 と Claude Mythos 5 を発表した。Fable 5 は一般利用向けに安全策を強化し、Mythos 5 は一部制限を解除した限定版として提供される。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み