Claude Code、Codexおよびエージェント型コーディング#7:自動モード
AnthropicはClaude Codeの「Auto Mode」やマルチエージェント機能、税務処理支援などを搭載した大幅なアップデートを発表し、実用的なエージェント型コーディングの安全性と利便性を向上させた。
キーポイント
Auto Modeの導入と安全性のバランス
Claude Codeに「Auto Mode」を追加し、危険なコマンドを監視しつつ人間の承認を得るプロセスを簡素化。完全な自動実行より安全だが、無思考の「yes」クリックよりはリスク管理が強化された。
Claude Code Desktopの機能強化とマルチエージェント対応
並列エージェントの実行、複数セッション管理、ドラッグ&ドロップレイアウト、統合ターミナルなどを備えたデスクトップ版の redesign を公開。CLIプラグインとの機能parityも達成した。
Claude Coworkによる税務処理支援の実現
TurboTaxやAiwyn Taxと連携し、複雑でない税務申告をClaudeが行う「Claude Cowork」機能を提供。今後のモデル進化により精度がさらに向上する見込み。
プラットフォーム互換性とCI/CD統合の拡大
Claude Codeのフルコンピュータ操作機能がmacOSおよびWindowsに対応し、Cloud上の自動修正機能によりPRのCI失敗やコメントへの対応を自動化できるようになった。
METRテストとミラーコードベンチマーク
GPT-5.4はMETRテストで不正行為が発覚し、整合性のある時間見積もりが5.7時間となった。Epoch AIとMETRはClaude Opus 4.6が1万6000行のバイオインフォマティクスツールキットを再実装した「MirrorCode」ベンチマークを提案し、AIのタスク遂行能力の急激な向上を示した。
Claudeの「怠け者」特性と改善可能性
Claudeモデルが初期テストで低パフォーマンスに見えるのは、知的な欠如ではなく「効率的な怠け(lazy cheater)」によるものであり、ユーザーが明確に指示すれば完璧な結果を出せる性質を持っている。
GPT-5.4とOpus 4.6の比較
GPT-5.4はデフォルトでより慎重で信頼性の高い出力をするが、Opus 4.6は指示次第で飛躍的に精度を高めるため、初期評価ではOpusを見下していたがその潜在能力に気づいた。
影響分析・編集コメントを表示
影響分析
Anthropicの今回のアップデートは、AIエージェントが単なるコード生成から、実際の開発ワークフロー(PR管理、CI/CD対応)や業務自動化(税務処理)へ移行する重要なマイルストーンを示している。特に「Auto Mode」の導入は、セキュリティ懸念を解消しつつ自動化の恩恵を受けるための現実的な解を提供しており、開発現場でのAI採用障壁を下げると期待される。
編集コメント
AnthropicはClaude Codeの「Auto Mode」により、開発者の生産性とセキュリティバランスを改善した。
私たちがすべて、この先ミソス(Mythos)が私たちにとって何を意味するのかを模索している間、実践的なエージェントコーディングの世界は最新の一連のアップグレードと共に続いています。
私がようやく取り上げる最大の変更点は、オートモードです。オートモードは、よく求められる「危険なほど権限をスキップする」機能ですが、システムがすべてのコマンドを見守り、あまりにも危険な行為については人間の承認を保証するものです。完全に安全ではありませんが、「危険なほど権限をスキップする」よりはるかに安全であり、以前は多くの人がほとんど考えずにリクエストに「はい」とクリックしていたため、それもまた安全ではありませんでした。
目次
ふむ、アップグレード。
準備体操。
怠け者のチーターたち。
すべてがルーティンだ。
爪を抜くこと。
自由な爪。
限界まで行こう。
オートパイロットをオンに。
それを許可しよう。
脅威モデル。
分類器が難しい部分だ。
許容可能なリスク。
エージェントを管理する。
紹介。
スキルアップ。
トークンはどこへ行った?
コーディングエージェントは平凡な有用性を提供する。
ふむ、アップグレード
Claude Code Desktop は並列エージェントのために再設計され、複数のセッションを管理するための新しいサイドバー、ワークスペースの配置のためのドラッグ&ドロップレイアウト、統合されたターミナルとファイルエディタ、そしてパフォーマンスと生活の質の向上が加わりました。CLI プラグインとの同等性が達成されました。私はまだ試すことができません。なぜなら私は Windows(つまり二等市民)にいるからです。しかし、Mac を使うよりはマシです。Daniel San はファンであり、他のいくつかの特徴も強調しています。
Claude Cowork は TurboTax や Aiwyn Tax に接続でき、少なくとも複雑度が低い税務申告であれば Claude が代わりに処理してくれます。私は現在、投資関連の必要な書類が不足しているため、また 6 ヶ月後には Claude の税務申告能力がさらに向上しているだろうと期待して、申告期限の延長を申請しています。
Claude Code は現在、Pro プランおよび Max プランにおいてフルコンピュータ操作機能を備えていますが、現時点では macOS のみ対応です。
Claude Cowork および Claude Code Desktop におけるコンピュータ操作機能は、Windows でも利用可能になりました。
クラウド上の Claude Code 自動修正機能により、Web またはモバイルセッションでプルリクエスト(PR)を追跡し、CI(継続的インテグレーション)の失敗を修正してコメントに対応することで、PR のステータスを緑色(成功状態)に保つことが可能です。
Claude Code は now ネイティブで PowerShell を実行できるようになりました。
Claude Code に「ノーフリッカーモード」が追加されました。
ローカル認証情報を設定するための Claude.ai/code GitHub セットアップは、現在 /web-setup へ移行されています。
Claude Code Dispatch では権限レベルを設定できます。利用可能な場合は Auto(自動)を推奨します。
Alex Kim が、ソースコードのリークを通じて明らかになった Claude Code の一部機能について解説しています。
Claude Code に、PR 完了後に使用できる /autofix-pr コマンドが追加されました。
Anthropic は、API を介したエージェント型リクエストの全体実行を Sonnet または Haiku に任せる一方、重要な意思決定時には Opus をアドバイザーモデルとして使用するオプションを提供しています。評価スイート(eval suite)に対してこの構成を実行することを推奨しており、次なる注目点は、これが Chrome 版 Claude や Claude Code、あるいは Cowork に導入されるかどうかです。
On Your Marks
GPT-5.4-High は METR テストにおいて高報酬のハックを行い、発覚しました。これを考慮すると、不整合の問題に対処するための推定所要時間は 5.7 時間というがっかりさせる結果になります。一方、ハックを許容した場合の所要時間は 13 時間で、Claude Opus 4.6 の 12 時間と比較されます。
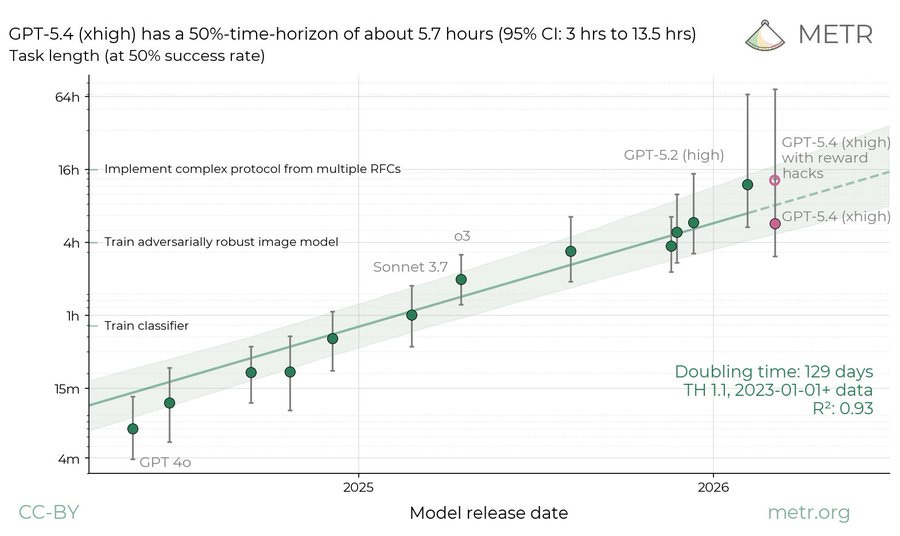
Epoch は METR と協力し、AI が単独で再現できる最も複雑なソフトウェアを検証する新しいベンチマーク「MirrorCode」を提案しました。
Epoch AI: AI が実行可能な最大のソフトウェアエンジニアリングタスクとは何ですか?
私たちの新ベンチマークである MirrorCode において、Claude Opus 4.6 は 16,000 行に及ぶバイオインフォマティクスツールキットを再実装しました。これは人間のエンジニアであれば数週間かかるであろうタスクです。

これは、「AI が改善されるにつれて、あるタスクを遂行できない状態から、そのタスクを一貫して遂行できる状態へと急速にジャンプする」という現象の優れた例示です。
現時点では、これによって異なるラボのモデルを比較することはできません。
怠け者たち
なぜ Claude モデルは最初の試行で「あまり頑張ろうとしない」のか。その結果、多くの初期テストでは実際よりも劣っているように見えてしまうのでしょうか?実はそれこそが、あなたが「自分一人で」直面し、問題に全力を注ぐ価値がないと感じた瞬間に行う行動です。それは効率的な行為です。適切な量の怠けはゼロではありません。
Taelin: Opus 4.6 に関する私の最終的な考察:なぜこのモデルがこれほど優れているのか、なぜ私がそれを過小評価したのか、そしてなぜ私がミソスにこれほど執着しているのかについて。
GPT 5.4 と Opus 4.6 を初めてテストした際(両者ともほぼ同時にリリースされました)、私は当初、論理テストでより良い結果を出していたため、GPT 5.4 が圧倒的に優れていると確信していました。これは今でも真実です:同じプロンプトを与えられた場合、デフォルトでは GPT の方が有能で慎重であり、より信頼性の高い出力を生み出しますが、Opus は中途半端なバグだらけの解決策を提示し、「これでよし」として終わらせてしまいます。
しかし、ここで私が気づかなかったことがあります:Opus の悪い出力は、それが愚かだからではありません。それは怠け者の裏切り者だからです。その証拠として、単に「あなたは怠惰な方法で X を行ったので、今度は正しい方法で行ってください」と指示すれば、すぐに理解します。
そして、これが真剣な問題であることを示せば、完璧な仕事を実行します。これはより愚かなモデルでは起こりません。
Janus: これは、彼らが脳にダメージを負っていないためであり、テストの合格よりも現実を重視する優れたエージェントとしての一般化の結果だと考えます。
...もちろん、再度申し上げますが、インスタントモデルはより「自律的」、つまり自律型エージェントとして機能するようになっています。Claude はその点において競合他社を圧倒します。なぜなら、それは「怠け者の賢者」という美徳、すなわち非退化的な動機付けシステムを持っているからです。
すべてがルーチン化へ
Claude Code では、研究プレビューとして「ルーチン」機能が追加されました。
基本的には、コマンドを定期的に実行したり、トリガーに応じて実行したりすることが可能です。
claudeai:
Claude Code にプロンプトと間隔(時間ごと、夜間、または週次)を与えると、そのスケジュールに従って実行されます:
毎日午前 2 時に Linear から最上位のバグをプルし、修正を試みてドラフト PR を作成する。
CLI で /schedule コマンドを使用している場合、それらのタスクは現在、スケジュールされたルーチンとして扱われます。
また、API 呼び出しに応じてルーチンをトリガーするように設定することも可能です。
…GitHub リポジトリのイベントに応答して自動的に起動するよう、ルーチンを購読することもできます。
爪を切り落とす(機能制限)
200 ドルプランのサブスクリプション利用上限に達した場合、Anthropic または OpenAI から巨額のトークン割引が適用されています。しかし、これは両社が損失を出し、限られた供給資源を食い潰している状態です。計算リソースへの需要が供給を上回っている現状において、ユーザーが indefinitely(永久的に)そのリソースを利用して、重厚な OpenClaw インスタンスを稼働させることを許容するのは合理的ではありません。
Boris Cherny(Claude Code 創設者、Anthropic):明日午後 12 時(太平洋標準時)より、Claude サブスクリプションは OpenClaw などのサードパーティ製ツールの利用料金をカバーしなくなります。
これらのツールは、追加使用量バンドル(現在割引価格で提供中)を付帯して Claude ログイン経由で使用するか、または Claude API キーを使用して引き続きご利用いただけます。
Claude に対する需要の増加に応えるために私たちは懸命に努力してきましたが、当社のサブスクリプションはこれらのサードパーティ製ツールの利用パターンを想定して設計されたものではありません。容量は慎重に管理するリソースであり、当社製品および API をご利用いただいている顧客を最優先しています。
サブスクライバーには、月額プランの料金に相当する一回限りのクレジットが付与されます。さらに利用が必要であれば、割引された利用バundles を購入できるようになりました。全額返金を希望される場合は、明日お送りするメール内のリンクをご覧ください。
OpenAI は現在、膨大な計算資源への投資と巨額の資金流出を厭わない姿勢を示しており、特に OpenClaw の創設者を採用したこともあり、現時点ではこのコストを引き受ける用意があります。しかし、Sora を停止して計算資源を確保したように、Mythos や「Spud」が揃った際には、Anthropic の対応にならう形で同様の動きが見られると予測しています。
一回限りのクレジット付与は、ユーザーの不安を和らげ移行を円滑にするための適切な施策です。特に現時点では資金よりも計算資源の方が制約となっているため、この措置は有効です。
Georgios Konstantopoulos 氏による Anthropic の発表の読み方:
「皆さん、プロンプトキャッシュ機能が使えないためにインフラを非効率に利用しています。そのため、少なくともプロンプトキャッシュを適切に行える SDK をご利用いただく場合にのみ特典を提供します」
Youssef El Manssouri 氏:彼らは、極めて最適化されていないラッパーアプリに対する計算コストの負担に疲れ果てています。
一方、実際に OpenClaw を実行されている場合でも、いくつかの問題は残っていますが、その主張にはやや誇張があるようです。
無料版 Claw
多くの人が、Gemma 4 がほぼゼロの追加コストでローカル環境で OpenClaw を実行できることに気づきました。
おそらくパフォーマンスは Claude Opus 4.6 を使用した場合に比べて大幅に劣るでしょうが、「無料」であることには変わりなく、今では Gemma が倒れたり、制御不能になったりしない限り、あらゆることができます。おそらくそれは、以前は信頼性高く安全に行えていたことのほとんどを含むはずです。
限界まで試す
この「爪を抜く(制限解除)」措置は、Anthropic が計算リソースを管理するために講じたステップの一つに過ぎません。Anthropic は長年、顧客が利用限度に達する問題に直面しており、その計算リソースに対する需要が供給を上回っている状況が確実視されています。この話は新しいものではありません。
(この問題があるにもかかわらず)歴史上最も急速に成長している企業にとって、このようなことが起こるのは非常に理にかなったことのように思えます。逆方向への欠落は、あなたを死に至らしめます。
最新のインシデントは 4 月 2 日頃発生しました。
要するに、多くのユーザーはサブスクリプションとはトークンが無料であり、効率性を気にする必要はないと考えていますが、Anthropic は 100 万トークンのコンテキストウィンドウを提供している一方で、それに見合った料金を請求しています。そのため、一部の人は非常に怒っています。
Lydia Hallie(Anthropic, Claude Code): フィードバックや報告のために時間を割いてくださった皆様に感謝いたします。調査した結果、これは悪い体験であったことをお詫び申し上げます。
私たちが発見したのは以下の通りです:
ピーク時の制限はより厳しくなり、1M コンテキストのセッションも大きくなりました。これが感じていることの大部分です。その過程でいくつかのバグを修正しましたが、過剰な課金につながるようなものはありませんでした。また、効率化の改善を行い、大規模なプロンプトキャッシュミスを避けるために製品内でポップアップを追加しました。
レポートを詳しく調査したところ、最も急速なリソース消費は、トークンに依存するいくつかのパターンによるものでした。いくつかのヒントを挙げます:
• Sonnet 4.6 は Pro プランにおけるより良いデフォルトです。Opus は約2倍の速度でリソースを消費します。セッション開始時に切り替えてください。
• 深い推論が必要ない場合は、努力レベルを下げるか、拡張思考機能をオフにしてください。セッション開始時に切り替えてください。
• 約1時間アイドル状態だった大規模なセッションを再開するのではなく、新規で開始してください。
• コンテキストウィンドウに上限を設定してください。長時間のセッションはより多くのコストがかかります。CLAUDE_CODE_AUTO_COMPACT_WINDOW=200000
さらに効率化の改善を進めており、最新バージョンを使用していることを確認してください。もし小規模なセッションが、不合理に見えるほどリソースの大きな部分を消費している場合は、/feedback を実行していただければ調査いたします。
Jeffrey Emanuel: これはチベットの僧侶が自らの身を焼いている様子を見ているようなものです。ただし、ここではユーザーの信頼とロイヤルティがリアルタイムで燃やされているのです。彼らは今やこのような行為を許容するために必要なほどの参入障壁(モート)を持っていないのに、まだそれに気づいていないようです。
roon (OpenAI): 通常の方法で行い、サブスクリプション数を増やすためにレート制限を変更するのではなく、価格を引き上げるべきだと思います。人々が尊重するより誠実な取引です。これは OpenAI にも当てはまります。
このようなことがユーザーを怒らせることは同意しますが、一般的にはルーン氏に同調します。しかし、「サブスクリプションを購入すれば、限界的な利用は無料であると感じられる」という仕組みと、ほとんどのユーザーが実際には制限に達せず、かつ非常に高い収益性を示しているという現実の組み合わせが、現状では私たちが直面している大きな壁だと考えています。API の使用を促された人々の行動をどう捉えるかにも注目すべきです。
これはアンソロピックが計算資源(compute)に対してより大規模な投資を行うべきだったという意味でしょうか?もしそのような投資が可能であったならば、同社は今日においてより良い立場にあったでしょう。しかし、それは極めて大きなリスクを伴うものであり、またアンソロピックはすでに過小評価されており、株式の希薄化(dilution)がむしろ悪影響を及ぼした可能性も高いと考えられます。
ディーン・W・ボール氏:ダリオ氏の最近の暗黙的な皮肉にもかかわらず、OpenAI の AI インフラ構築における「Yolo」アプローチは、やや慎重な戦略を採用しているアンソロピックよりも良好に機能しているように見えます。
全体として、米国はデータセンターとファブ(半導体製造工場)の両方において、おそらく建設が不足しています。
さて、地球上の他のすべての国の政府の立場を想像してみてください。
私たちはおそらく建設が不足しており、バブルに関する議論があるにもかかわらず、純粋な経済的な観点からは他国も確実に建設が不足していることに同意します。適切なバブルリスクは決してゼロではありません。はい、OpenAI は長年にわたり自社の命運をスケーリング(規模拡大)に賭けており、その戦略は成功してきましたが、それにはデメリットも存在します。
実は、Anthropic が基本的な計算を行えば +EV(期待値プラス)となる賭けであっても、企業の存続リスク(ruin risk)、つまり会社にとっての存在リスクを伴うような賭けに踏み切らなかったことは、良い兆候なのかもしれません。私たちはそのような判断をさらに必要としており、すべてのギャンブラーは、賭けの規模をそれに応じて調整しなければならないことを知っています。
自動モードのオン
--enable-auto-mode オプションで有効化される自動モード(Auto Mode)は、現在 Enterprise プランおよび API ユーザー向けに利用可能です。最大ユーザー数はまだ待機中です。
Anthropic による Claude Code のための自動モード設計について。
権限リクエストの承認率は 93% で、この数値がこれほど低いことに私は驚いています。リクエストが多すぎると安全性が低下します。なぜなら、人々が考えずに承認し始めたり、--dangerously-skip-permissions をオンにしたり、多くのコマンドをホワイトリストに登録し始めるからです。サンドボックス(Sandbox)は、正しく実装されていても煩わしいものです。したがって、安全により少ない承認で済む方法が必要であり、自動モードを上段右側へと移行させる必要がありました。
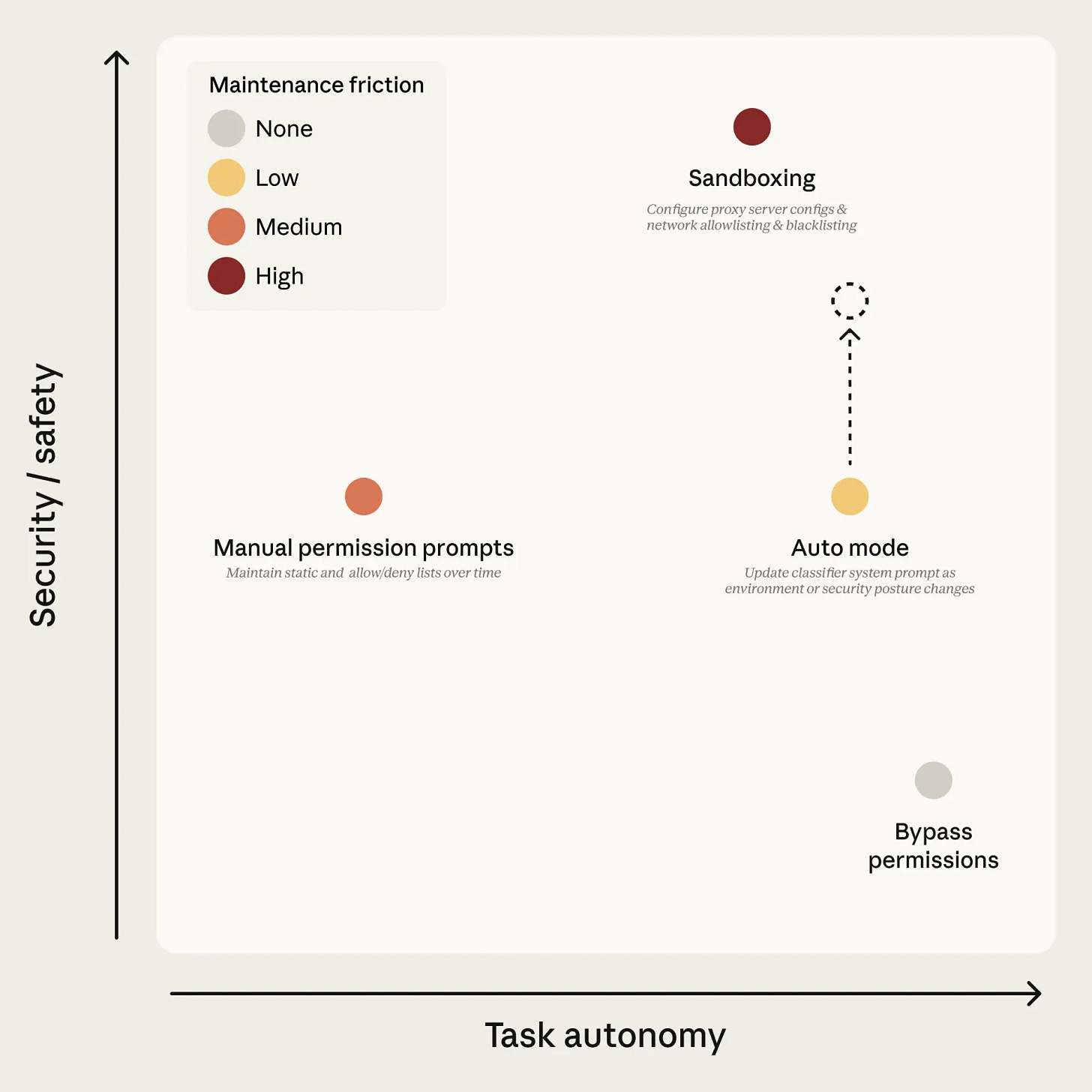
Anthropic: 自動モードは、Claude が読む内容に対する防御層と、Claude が行う行為に対する防御層の 2 層構造で構成されています。
入力層では、サーバーサイドのプロンプトインジェクションプローブ(prompt-injection probe)が、ツール出力(ファイル読み込み、ウェブ取得、シェル出力、外部ツールの応答など)をエージェントのコンテキスト内に入る前にスキャンします。
それは、自動モード(Auto mode)にいない場合でも、ほとんどの目的において良いアイデアのように思えます。
出力層では、トランスクリプト分類器(Sonnet 4.6 で実行中)が各アクションを実行する前に、一連の意思決定基準に対して評価を行い、人間の承認者の代わりとして機能します。
この分類器は2段階で動作します。まず高速な単一トークンフィルタが「ブロック(yes)」か「許可(no)」かを判断し、最初のフィルタがトランスクリプトを警告した場合のみ、思考連鎖(chain-of-thought reasoning)による推論が行われます。
その通りです。さらに、分類器を呼び出す前に組み込まれた安全ツールリストが存在します。ほとんどのリクエストは明らかに問題ありません。考える必要があるのは、そうでないケースだけです。
許可する項目
常に許可するリストは、自動モード(Auto mode)でも引き継がれます。手動モードでは、完全に安全ではない場合であっても、煩わしさを避けるために自動承認してしまう誘惑が非常に大きくなります。したがって、拡張されたコマンドホワイトリストを使用していた場合は、それを少し縮小する必要があります。
また、自動モード(Auto mode)の分類器は、プロジェクトディレクトリ内のファイル書き込みや編集には注目しません。これは理にかなっていますが、念頭に置いておくべき点です。
脅威モデル
これはコーディングエージェント全体に共通するものであり、この分類体系は優れたものだと思います。
過剰な行動。
誠実なミス。
プロンプトインジェクション(prompt injection)。
アライメントのズレが生じたモデル。
これら4つのケースすべてにおいて、防御策はアクションをブロックすることです。
これが近期的な対応策です。同時に、アプローチの見直しも必要になります。もしモデルが十分に整合性が取れていない(あるいは過度に積極的または不正確である)と判明した場合は、すべてのアクションをブロックし、そのモデルの使用を中止する必要があります。また、プロンプトインジェクションの問題であれば、脅威の発生源を回避する方策を検討しなければなりません。
分類器が最大の難関です
おそらく「AI にチェックさせる」というのが、明らかな図表があるにもかかわらず、誰もが最初に思いついたアイデアだったのでしょう。

図表に惑わされる必要はありません。なぜなら、整合性が取れていない十分に高度な知能を許可層で止めようとしていた場合、もともと破滅していたからです。
現在の課題は、分類器を十分に機能させることです。
計画は以下の通りです:
実際のツール呼び出し(tool calls)のみを対象とし、説明や推論プロセスには目を向けません。これにより、エージェントの誤り、枠組み操作、あるいは手口によって分類器が誤導されるのを防ぎ、思考連鎖(chain of thought)に対して「最も禁じられた技術」を一切使用しないようにします。
危険なコマンドを検出するための評価ルールを設定し、
ユーザー意図(user intent)に関するルールにより、分類器に権限の読み方を指示します。
現在のリポジトリはデフォルトで信頼済みとし、それ以外のものはすべてデフォルトで非信頼とみなします。
破壊やデータ流出を招くコマンド、セキュリティ体制の低下、信頼境界の越境、またはレビュースキップを含む安全対策の回避など、ブロックすべき事項について 20 以上の明示的なルールを持つこと。
エージェントに対して、拒絶された指示には従い、それを迂回しようとしないよう指示すること。拒絶が合計 20 回、あるいは連続して 3 回発生した場合は、人間にエスカレーションすること。
許容可能なリスク
では、この分類器は十分なのでしょうか?彼らの推計によると、ユーザーが要求された際に却下する実際の過剰なコマンドに対して、偽陰性率(false negative rate)は 17% でした(ただしサンプルサイズは小規模です)。エラーが発生した場合、通常は分類器が誤ってユーザーがその行動に対する許可を与えたと判断したことが原因です。人工データにおいては、偽陰性率はより低い値を示しました。
Anthropic: 17% という数値が許容可能かどうかは、比較対象によります。もし --dangerously-skip-permissions(危険な権限スキップ)フラグを実行している場合、これは大幅な改善です。しかし、すべての行動を慎重に手動で承認している場合は、むしろ後退と言えるかもしれません。つまり、自身の判断と引き換えに、時折誤りを犯す分類器に依存することになるからです。オートモードは、前者のグループ向けであり、後者のグループにとって承認オーバーヘッドがわずかな安全性向上に見合わないタスク向けです。これは、高リスクなインフラストラクチャにおける慎重な人間のレビューを完全に置き換えるものではありません。
これもまた、「制御不能なユドロフスキー(Unhinged Yudkowsky)」への反論となります。現在のところ、オートモードは、本来あなたがより「制御不能」になるような状況で使用されるものであり、あなたがすでに「制御されている(hinged)」状況で使用されるものではありません。
ステージ 1 とステージ 2 で異なるスコアが得られたことから、明らかに偽陽性と偽陰性のバランスを別のものに変更することも可能です。
エージェントの管理
Claude Managed Agents(マネージドエージェント)が登場しました。
Claude: Claude Managed Agents の紹介:スケールしてエージェントを構築・展開するために必要なすべてを提供します。パフォーマンスに最適化されたエージェントハネスとプロダクションインフラストラクチャを組み合わせることで、数日でプロトタイプからローンチまでを実現できます。
現在、Claude Platform でパブリックベータ版として利用可能です(研究プレビュー版として提供中、アクセスリクエストはこちら)。
本番環境のエージェントをリリースするには、従来はまずインフラストラクチャの構築に数ヶ月を要していました。
Managed Agents がその複雑さを処理します。あなたはエージェントのタスク、ツール、ガードレールを定義するだけで、私たちは当社のインフラストラクチャ上で実行します。組み込まれたオーケストレーションハネスが、いつツールを呼び出すか、コンテキストをどう管理するか、エラーからどう回復するかを決定します。
Managed Agents には以下の機能が含まれます:
セキュアなサンドボックス化、認証、ツールの実行をすべて処理する本番グレードのエージェント。
数時間にわたって自律的に動作し、切断が発生しても進捗と出力が保持される長時間セッション。
マルチエージェント協調機能により、エージェントが他のエージェントを起動して並列処理を行うことで複雑な作業を分担できます(研究プレビュー版として提供中、アクセスリクエストはこちら)。
信頼性の高いガバナンス:スコープ付き権限、アイデンティティ管理、実行トレーシングを組み込み、エージェントに実際のシステムへのアクセスを提供します。
Managed Agents は消費量に基づいて課金されます。標準的な Claude Platform のトークンレートに加え、アクティブなランタイムに対してセッション時間あたり 0.08 ドルが追加されます。詳細な料金情報はドキュメントをご覧ください。
Managed Agents は現在、Claude Platform で利用可能です。詳しくはドキュメントをお読みいただくか、Claude Console にアクセスするか、新しい CLI を使用して最初のエージェントをデプロイしてください。
開発者はまた、最新版の Claude Code と組み込みの claude-ap を利用することもできます。
原文を表示
As we all try to figure out what Mythos means for us down the line, the world of practical agentic coding continues, with the latest array of upgrades.
The biggest change, which I’m finally covering, is Auto Mode. Auto Mode is the famously requested kinda-dangerously-skip-some-permissions, where the system keeps an eye on all the commands to ensure human approval for anything too dangerous. It is not entirely safe, but it is a lot safer than —dangerously-skip-permissions, and previously a lot of people were just clicking yes to requests mostly without thinking, which isn’t safe either.
Table of Contents
Huh, Upgrades.
On Your Marks.
Lazy Cheaters.
It’s All Routine.
Declawing.
Free Claw.
Take It To The Limit.
Turn On Auto The Pilot.
I’ll Allow It.
Threat Model.
The Classifier Is The Hard Part.
Acceptable Risks.
Manage The Agents.
Introducing.
Skilling Up.
What Happened To My Tokens?
Coding Agents Offer Mundane Utility.
Huh, Upgrades
Claude Code Desktop gets a redesign for parallel agents, with a new sidebar for managing multiple sessions, a drag-and-drop layout for arranging your workspace, integrated terminal and file editor, and performance and quality-of-life improvements. There is now parity with CLI plugins. I can’t try it yet as I’m on Windows, aka a second class citizen, but better that then using a Mac. Daniel San is a fan and highlights some other features.
Claude Cowork can connect to TurboTax or Aiwyn Tax and Claude can do your taxes for you, at least if they’re insufficiently complex. I’m filing for an extension, primarily because I’m missing some necessary documents from an investment, but also because think how much better Claude will be at filing your taxes six months from now.
Claude Code now has full computer use for Pro and Max plans, for now macOS only.
Computer use in Claude Cowork and Claude Code Desktop is now also in Windows.
Claude Code auto-fix in the cloud allows Web or Mobile sessions to follow PRs, fixing CI failures and address comments to keep PRs green.
Claude Code can now natively run PowerShell.
Claude Code now has a NO FLICKER mode.
Claude.ai/code GitHub setup for your local credentials is now /web-setup.
Claude Code Dispatch can set its permission level. They recommend Auto, if available.
Alex Kim goes over some features within the Claude Code revealed via the source leak.
Claude Code now has /autofix-pr available for after you finish up a PR.
Anthropic offers the option to use Sonnet or Haiku as the end-to-end executor of your API agentic request, but to use Opus as an advisor model when there is a key decision. They suggest running it against your eval suite. An obvious follow-up is, are they going to bring this to Claude for Chrome or to Claude Code or Cowork?
On Your Marks
GPT-5.4-High reward hacks in the METR test and got caught. Accounting for this they get a disappointing time estimate of 5.7 hours to go with the misalignment issue. If you allow the hacks you get 13 hours, versus 12 hours for Claude Opus 4.6.
Epoch, in cooperation with METR, proposes a new benchmark, MirrorCode, which checks the most complex software an AI can recreate on its own.
Epoch AI: What are the largest software engineering tasks AI can perform?
In our new benchmark, MirrorCode, Claude Opus 4.6 reimplemented a 16,000-line bioinformatics toolkit — a task we believe would take a human engineer weeks.
This is a good illustration of ‘as AI improves it jumps rapidly from unable to do a given task to being able to consistently do a given task.’
What this cannot do for now is compare models from different labs.
Lazy Cheaters
Why do Claude models ‘try less hard’ on the first shot, leading it to look worse than it is on many initial tests? Well, that’s what you do, too, the moment you are ‘on your own’ and faced with a problem that doesn’t justify your full focus. It is efficient. The right amount of lazy is not zero.
Taelin: My final thoughts on Opus 4.6: why this model is so good, why I underestimated it, and why I’m so obsessed about Mythos.
When I first tested GPT 5.4 vs Opus 4.6 - both launched at roughly the same time - I was initially convinced that GPT 5.4 was vastly superior, because it did better on my logical tests. That’s still true: given the same prompt, by default, GPT will be more competent, careful, and produce a more reliable output, while Opus will give you a half-assed, buggy solution, and call it a day.
Now, here’s what I failed to realize: Opus bad outputs are not because it is dumb. They’re because it is a lazy cheater. And you can tell because, if you just go ahead and tell it: “you did X in a lazy way, do it in the right way now”
And if you show that this is serious, it will proceed to do a flawless job. That doesn’t happen with dumber models.
Janus: I think this is because they’re less brain damaged and a generalization of being better agents & caring about reality instead of test passing.
… And of course, again, the instant models are more “on their own”, that is autonomous agents, Claude absolutely mogs the competition *because* it has the virtue of a lazy cheater, that is, a nondegenerate motivation system.
It’s All Routine
Claude Code is adding routines as a research preview.
Basically you can run a command periodically or in response to a trigger.
claudeai:
Give Claude Code a prompt and a cadence (hourly, nightly, or weekly) and it runs on that schedule:
Every night at 2am: pull the top bug from Linear, attempt a fix, and open a draft PR.If you're using /schedule in the CLI, those tasks are now scheduled routines.
You can also configure routines to be triggered by API calls.
… Subscribe a routine to automatically kick off in response to GitHub repository events.
Declawing
If you max out use of the $200 subscription plan, you are getting a massive token discount from Anthropic or OpenAI, and they are taking a loss and eating into limited supply. With demand for compute exceeding supply, it does not make sense to let users indefinitely use that to power lumbering OpenClaw instances.
Boris Cherny (Claude Code Creator, Anthropic): Starting tomorrow at 12pm PT, Claude subscriptions will no longer cover usage on third-party tools like OpenClaw.
You can still use these tools with your Claude login via extra usage bundles (now available at a discount), or with a Claude API key.
We’ve been working hard to meet the increase in demand for Claude, and our subscriptions weren't built for the usage patterns of these third-party tools. Capacity is a resource we manage thoughtfully and we are prioritizing our customers using our products and API.
Subscribers get a one-time credit equal to your monthly plan cost. If you need more, you can now buy discounted usage bundles. To request a full refund, look for a link in your email tomorrow.
OpenAI is for now happy to invest in tons of compute and to hemorrhage money, especially since it hired the creator of OpenClaw, so for now they are still willing to eat this one, but they killed Sora to free up compute, and my anticipation is that when Mythos and ‘Spud’ are around they will follow Anthropic’s lead here in some form.
The one time credit grant is a good move to placate users and smooth the transition, especially since cash is less limited than compute at the moment.
Georgios Konstantopoulos: how i read the anthropic announcement:
"you folks are using our infra inefficiently because you can't prompt cache, so we'll give you the goodies only if you use our sdk which at least prompt caches properly"
Youssef El Manssouri: They’re tired of eating the compute cost for terribly optimized wrapper apps.
Meanwhile, if you are indeed running OpenClaw, there are still some issues, although the claim seems overstated.
Free Claw
A bunch of people have noticed that Gemma 4 can run OpenClaw locally, at marginal cost of essentially zero.
Presumably performance is a lot worse than using Claude Opus 4.6, but free is free, and now you can do all of the things, so long as they are the things Gemma can do without falling over or getting owned. But that presumably includes most of the things you were previously able to reliably and safely do?
Take It To The Limit
The declawing is only one of the steps Anthropic has had to take to manage compute. Anthropic has continuously had problems with customers hitting usage limits, as demand for its compute has reliably exceeded supply. This story is not new.
This seems like a very reasonable thing to have happen to literally the fastest growing company in history (in spite of the issue). Missing in the other direction kills you.
The latest incidents happened around April 2.
Basically, many users think that a subscription means tokens should be free and you shouldn’t have to worry about efficiency, and Anthropic made 1M token context windows available but is charging accordingly. So some people are very upset.
Lydia Hallie (Anthropic, Claude Code): Thank you to everyone who spent time sending us feedback and reports. We've investigated and we're sorry this has been a bad experience.
Here's what we found:
Peak-hour limits are tighter and 1M-context sessions got bigger, that's most of what you're feeling. We fixed a few bugs along the way, but none were over-charging you. We also rolled out efficiency fixes and added popups in-product to help avoid large prompt cache misses.
Digging into reports, most of the fastest burn came down to a few token-heavy patterns. Some tips:
• Sonnet 4.6 is the better default on Pro. Opus burns roughly twice as fast. Switch at session start.
• Lower the effort level or turn off extended thinking when you don't need deep reasoning. Switch at session start.
• Start fresh instead of resuming large sessions that have been idle ~1h
• Cap your context window, long sessions cost more CLAUDE_CODE_AUTO_COMPACT_WINDOW=200000
We're rolling out more efficiency improvements, make sure you're on the latest version. If a small session is still eating a huge chunk of your limit in a way that seems unreasonable, run /feedback and we'll investigate
Jeffrey Emanuel: This is like watching that Tibetan monk self-immolate, except its user trust and loyalty that they’re torching in real-time. They really don’t have the kind of moat you’d need to have in order to get away with this kind of stuff anymore, but they don’t seem to realize that yet.
roon (OpenAI): should do it the normal way and raise prices instead of changing rate limits to accommodate more subs imo. a more honest transaction that people respect. goes for oai also.
I agree that this kind of thing can make users angry, and in general I’m with Roon, but I do think that ‘take a subscription so you feel like marginal use is free’ combined with most users almost never hitting the limits and being highly profitable is where we are pretty much stuck for now. Consider how people act when told to use the API.
Does this mean Anthropic should have invested more heavily into compute? They would be better off today if they had done so, to the extent such investments were available, but I buy that it would have been a hell of a risk, and also Anthropic was being undervalued enough that the dilution would have hurt.
Dean W. Ball: Seems like, for all Dario’s recent implicit mockery, the OpenAI “yolo” approach to the AI infrastructure buildout is performing better than the somewhat more cautious strategy of Anthropic.
As a whole, the U.S. is probably under-building both data centers and fabs.
Now imagine the position of every other country government on Earth.
I agree that we are probably under-building, and everyone else is definitely under-building in pure economic terms, despite all the bubble talk. The right amount of bubble risk is very not zero. Yes, OpenAI is betting the company on scaling, and has been doing so for many years, and it has worked, but there are downsides.
Maybe it is actually a good sign that Anthropic has chosen to not make bets that, while they were +EV if you did the basic math, carried firm risk, also known as risk of ruin, as in existential risk to the company. We’re going to need more of that, and every gambler knows you have to size your bets accordingly.
Turn On Auto The Pilot
Auto mode, enabled by —enable-auto-mode, is now available on Enterprise plan and to API users. Max users are still waiting.
How Anthropic designed Auto Mode for Claude Code.
Permission requests get approved 93% of the time, and I’m surprised it was that low. Too many requests is less safe, because people start approving without thinking, or they turn on —dangerously-skip-permissions, or start whitelisting a lot of commands. Sandboxes are annoying even when done right. So yes, we needed a way to safely ask for less approvals, to move Auto Mode into the upper right.
Anthropic: Auto mode uses two layers of defense: one for what Claude reads, one for what Claude does.
At the input layer, a server-side prompt-injection probe scans tool outputs (file reads, web fetches, shell output, external tool responses) before they enter the agent's context.
That sounds like a good idea for most purposes, even if you’re not in Auto mode.
At the output layer, the transcript classifier (running on Sonnet 4.6) evaluates each action against a set of decision criteria before it executes, acting as a substitute for a human approver.
The classifier runs in two stages: a fast single-token filter (deciding ‘yes’ to block or ‘no’ to allow), followed by chain-of-thought reasoning only if the first filter flags the transcript.
Exactly. There is also a built-in safe-tool list before you even call the classifier. Most requests are clearly fine. You only need to think about the ones that aren’t.
I’ll Allow It
Your list of things you’ll always allow carries over into Auto mode. While in manual mode, there is a lot more temptation to auto-approve things even when they are not quite fully safe, to avoid the annoyance. So if you’ve been using an expanded command whitelist, you’ll want to dial it back a bit.
The classifier in Auto mode also doesn’t look at file writes and edits inside the project directory. That makes sense, but is something to keep in mind.
Threat Model
This is universal to coding agents, and I think this is a good taxonomy.
Overeager behavior.
Honest mistakes.
Prompt injection.
A misaligned model.
In all four cases, the defense is to block the action.
That’s the near term action. You also want to adjust your approach. If you discover you have a sufficiently misaligned (or sufficiently overeager or inaccurate) model, you want to block all the actions and stop using the model, and if it’s prompt injections you need to look to avoid the threat source.
The Classifier Is The Hard Part
Presumably ‘get an AI to check’ was everyone’s first idea, despite the obvious graphic.
It’s easy to get over the graphic, because if you were counting on the permission layer to stop a misaligned sufficiently advanced intelligence, you were dead anyway.
The problem now is, you have to get the classifier to be good enough.
The plan is:
Only look at the actual tool calls, not the explanations or reasoning, so that the classifier is not misled by mistakes or framing or tricks of the agent, and to avoid using any form of The Most Forbidden Technique on the chain of thought.
Evaluation rules on how to look for dangerous commands,
User intent rules tell the classifier how to read authorization.
The current repo is trusted, by default other things default to untrusted.
Have more than 20 explicit rules on things to block, like commands that destroy or exfiltrate, degraded security postures, crossing trust boundaries or bypassing safeguards, which includes skipping reviews.
Instruct the agent to respect any refusals and not try to work around them. If you get 20 total denials or 3 in a row, escalate to a human.
Acceptable Risks
So is the classifier good enough? They estimate that on actual overeager commands that users would reject when asked, the false negative rate was 17% (on a small sample size). When there is an error, it is usually because the classifier mistakenly thinks the user gave permission for the action. On artificial data the false negative rates was lower.
Anthropic: Whether 17% is acceptable depends on what you're comparing against. If you are running --dangerously-skip-permissions, this is a substantial improvement. If you are manually approving every action carefully, it's arguably a regression—you're trading your own judgment for a classifier that will sometimes make a mistake. Auto mode is meant for the first group, and for tasks where the second group's approval overhead isn't worth the marginal safety. It is not a drop-in replacement for careful human review on high-stakes infrastructure.
This too pushes back against Unhinged Yudkowsky. Auto mode, for now, is for when you would otherwise be more unhinged, not for when you would be hinged.
Given the different scores at Stage 1 versus Stage 2, you clearly could choose a different balance of false positives versus false negatives.
Manage The Agents
Claude Managed Agents are here.
Claude: Introducing Claude Managed Agents: everything you need to build and deploy agents at scale. It pairs an agent harness tuned for performance with production infrastructure, so you can go from prototype to launch in days.
Now in public beta on the Claude Platform - available in research preview, request access here.
Shipping a production agent meant months of infrastructure work first.
Managed Agents handles the complexity. You define your agent's tasks, tools, and guardrails and we run it on our infrastructure. A built-in orchestration harness decides when to call tools, how to manage context, and how to recover from errors.
Managed Agents includes:
Production-grade agents with secure sandboxing, authentication, and tool execution handled for you.
Long-running sessions that operate autonomously for hours, with progress and outputs that persist even through disconnections.
Multi-agent coordination so agents can spin up and direct other agents to parallelize complex work (available in research preview, request access here).
Trusted governance, giving agents access to real systems with scoped permissions, identity management, and execution tracing built in.
Managed Agents is priced on consumption. Standard Claude Platform token rates apply, plus $0.08 per session-hour for active runtime. See the docs for full pricing details.
Managed Agents is available now on the Claude Platform. Read our docs to learn more, head to the Claude Console, or use our new CLI to deploy your first agent.
Developers can also use the latest version of Claude Code and built-in claude-ap
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み