概念ドリフト下でのトレーニングデータの重要性を学習する
Google Researchの研究者は、世界の絶え間ない変化がAIモデル開発に大きな課題をもたらし、特に「遅い概念ドリフト」と呼ばれる現象により、すべてのトレーニングデータが等しく関連性があるというデフォルトの前提が崩れるため、トレーニングデータの重要性を再評価する必要があると論じている。
キーポイント
概念ドリフトによるAIモデルの課題
世界の絶え間ない変化は、過去のデータで訓練されたAIモデルが将来の入力を正確に表現できないという課題を生み出す。特に「遅い概念ドリフト」は、視覚的特徴などが長期間にわたって徐々に変化する現象であり、物体認識モデルなどに影響を与える。
トレーニングデータの等価性前提の崩壊
すべてのトレーニングデータが等しく関連性があるというデフォルトの前提は、実際には成立しないことが多い。CLEARベンチマークの例では、10年間で物体の視覚的特徴が大きく変化しており、データの時間的関連性を考慮する必要がある。
実践的アプローチの必要性
概念ドリフトに対処するためには、単に大量のデータを集めるだけでなく、データの時間的関連性や変化パターンを考慮したトレーニング戦略が必要となる。これは実世界でのAIモデルの持続的な性能維持に不可欠である。
オンライン学習と継続学習の限界
オンライン学習や継続学習は最新データのみに焦点を当て、古いデータからの信号を失い、データインスタンスの寄与が内容に関係なく時間とともに均一に減衰するという問題がある。
インスタンス条件付き減衰時間スケールの提案
各インスタンスに重要度スコアを割り当て、補助モデルを使用してトレーニングインスタンスとその経過時間からスコアを生成し、主要モデルと共同で学習することで、非定常学習の課題に対処する。
提案手法の有効性
非定常学習のベンチマークデータセットで他の堅牢な学習方法よりも大幅な改善を達成し、大規模ベンチマークでは学習データの再重み付けにより最大15%の相対精度向上を示した。
オフライン学習と継続学習の比較
オフライン学習は全期間のデータをランダム順で繰り返し学習し、継続学習は月次データを時系列順で学習する。学習終了時点では両者は同量のデータを見ているが、継続学習モデルはカタストロフィックフォゲッティングにより性能が低い。
影響分析・編集コメントを表示
影響分析
この記事は、AIモデルの開発と運用における根本的な前提を問い直すものであり、特に実世界での持続的な性能維持という実務的な課題に光を当てている。概念ドリフトへの対処は、AIシステムの信頼性と実用性を高める上で重要な研究分野となる可能性が高い。
編集コメント
AI研究の実務的な課題に焦点を当てた良質な記事。概念ドリフトという専門的なテーマを、具体的な例(CLEARベンチマーク)を通じて分かりやすく説明している点が評価できる。
Nishant Jain(博士課程在籍研究者)および Pradeep Shenoy(研究科学者)によって Google Research から投稿されました
私達の周囲の世界は絶えず変化しており、これは AI モデルの開発において大きな課題となっています。多くの場合、モデルは将来受け取る可能性のある入力を正確に反映するであろうと期待して、縦断データ(longitudinal data)を用いて訓練されます。より一般的には、「すべての訓練データが同程度に関連性がある」というデフォルトの仮定は、実際にはしばしば崩れます。例えば、以下の図は CLEAR 非定常学習ベンチマークからの画像を示しており、物体の視覚的特徴が 10 年という期間にわたってどのように大きく進化するか(私達が「緩慢な概念ドリフト」と呼ぶ現象)を説明しています。これは物体分類モデルにとって課題となっています。
CLEAR ベンチマークからのサンプル画像。(Lin ら . に基づき改変)
オンライン学習や継続的学習といった代替アプローチでは、最新の少量データを繰り返しモデルに適用して常に最新の状態を維持します。これにより、過去のデータからの学習は後の更新によって徐々に消去されるため、結果として最新のデータが優先されます。しかし現実世界では、異なる種類の情報が失われる速度は様々であり、そのため2つの重要な課題があります:1) 設計上、これらの手法は*最新*のデータにのみ焦点を当てており、消去された古いデータからのシグナルを見失います。2) データの内容に関わらず、データインスタンスからの寄与は時間経過とともに*均一に*減衰します。
私たちの最近の研究「Instance-Conditional Timescales of Decay for Non-Stationary Learning」では、将来のデータに対するモデルのパフォーマンスを最大化するために、トレーニング中に各インスタンスに重要度スコアを割り当てる手法を提案します。これを実現するため、トレーニングインスタンスとその年齢(経時情報)を用いてこれらのスコアを生成する補助モデルを採用しています。このモデルは、主モデルと同時に学習されます。私たちは上記の両課題に対処し、非定常学習のための一連のベンチマークデータセットにおいて、他の堅牢な学習手法よりも顕著な性能向上を実現しました。例えば、非定常学習に関する最近の大規模ベンチマーク(10 年間にわたる約 3,900 万枚の写真)では、学習されたトレーニングデータの重み付け再調整を通じて、相対精度で最大 15% の向上を示しました。
教師あり学習における概念ドリフトの課題
遅い概念ドリフトの定量的な洞察を得るために、10 年間にわたるソーシャルメディアウェブサイトから収集された約 3900 万枚の写真を含む「最近の写真分類タスク」[https://arxiv.org/abs/2108.09020] に基づいて分類器を構築しました。私たちは、ランダムな順序でトレーニングデータを複数回反復処理するオフライン学習と、データの各月を時系列(時間的)順に複数回反復処理する継続学習を比較しました。モデルの精度は、トレーニング期間中およびその後の両モデルが凍結され、新しいデータに対してさらに更新されない期間(以下参照)の両方で測定されました。トレーニング期間の終了時点(左パネル、x 軸=0)では、両方のアプローチが同じ量のデータを処理していますが、大きな性能差が見られます。これは壊滅的忘却によるものです。これは継続学習における問題で、モデルのトレーニングシーケンスの初期段階からのデータに関する知識が制御不能な形で低下する現象です。一方、忘却には利点もあります。テスト期間中(右側に示す)では、継続学習されたモデルは古いデータへの依存度が低いため、オフラインモデルよりもはるかに緩やかに劣化します。テスト期間における両モデルの精度の低下は、データが確かに時間とともに進化していることを裏付けるものであり、両方のモデルは次第に重要性を失っていきます。
写真分類タスクにおけるオフライン学習モデルと継続的学習モデルの比較。
時間感度のあるトレーニングデータの重み付け
私たちは、オフライン学習(利用可能なすべてのデータを効果的に再利用する柔軟性)と継続的学習(古いデータの影響を低減する能力)の両方の利点を組み合わせた手法を設計し、緩やかな概念ドリフトに対処します。このアプローチはオフライン学習を基盤としつつ、過去のデータの影響力に対する慎重な制御と、将来のモデル劣化を軽減するように設計された最適化目的関数を追加しています。
ある期間に収集されたトレーニングデータを用いてモデル *M* を訓練したい場合を考えます。私たちは、各データポイントの内容と経過年数に基づいて重みを割り当てるヘルパーモデルも同時に訓練することを提案します。この重みは、モデル *M* のトレーニング目的関数におけるそのデータポイントの寄与度をスケーリングする役割を果たします。重みの目的は、将来のデータに対する *M* の性能を向上させることです。
私たちの研究 our work では、ヘルパーモデルが *メタ学習* される方法、つまりモデル *M* そのものの学習を支援する形で *M* と同時に学習される仕組みについて説明しています。ヘルパーモデルにおける重要な設計上の選択は、インスタンス関連の寄与と年齢関連の寄与を因数分解された形で分離した点にあります。具体的には、複数の異なる固定時間スケールの減衰からの寄与を組み合わせて重みを設定し、特定のインスタンスが最も適した時間スケールにどのように割り当てられるかという近似された「割当」を学習します。私たちの実験では、この形式のヘルパーモデルが、制約のない結合関数から単一の時間スケール(指数関数的または線形)の減衰に至るまで、多くの他の代替案を上回る性能を示すことが分かりました。これは、そのシンプルさと表現力の組み合わせによるものです。詳細は 論文 をご覧ください。
インスタンス重みスコアリング
下の上部の図は、学習されたヘルパーモデルが CLEAR オブジェクト認識チャレンジ において、より現代的な外観を持つオブジェクトに対して確かに重みを高くしていることを示しています。一方、古びた外観のオブジェクトは対応して重みが低く設定されています。さらに詳しく検討すると(下の下部の図、勾配ベースの 特徴重要度 評価)、ヘルパーモデルが画像内の主要なオブジェクトに焦点を当てていることがわかります。これは、例えばインスタンス年齢と偽相関する可能性がある背景の特徴などとは対照的です。
CLEAR ベンチマーク(カメラおよびコンピュータカテゴリ)から抽出したサンプル画像のうち、ヘルパーモデルによってそれぞれ最高重みと最低重みが割り当てられたものを示します。
CLEAR ベンチマークからのサンプル画像に対する、当社のヘルパーモデルによる特徴重要度分析。
結果
大規模データにおける性能向上
まず、前述の YFCC100M データセット 上で実施される大規模な 写真分類タスク(PCAT)を調査します。学習には最初の 5 年分のデータを使用し、テストにはその後の 5 年分を使用します。当社の手法(以下、赤色で示す)は、重み付けを行わないベースライン(黒色)や他の多くの堅牢な学習技術と比較して大幅に改善されています。興味深いことに、当社の手法は意図的に、遠い過去における精度(将来再発する可能性が低い訓練データに対するもの)を犠牲にして、テスト期間における顕著な向上を実現しています。また、期待通り、当社の手法はテスト期間において他のベースラインよりも劣化が少ないことが確認されています。
PCAT データセット上での当社の手法と関連するベースラインの比較。
広範な適用性
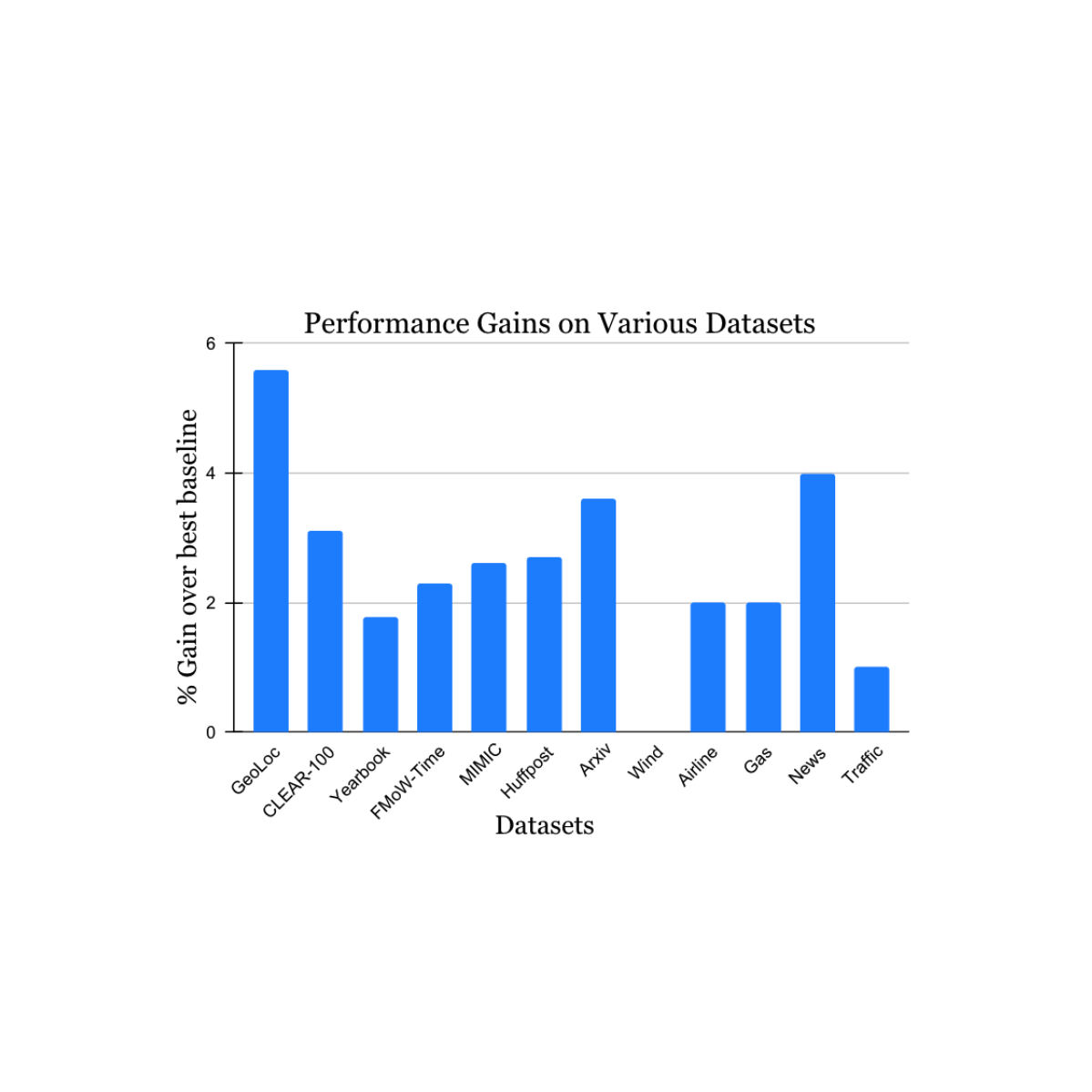
学術文献から入手した非定常学習課題用データセットの幅広い範囲において、我々の知見を検証しました(詳細は 1、2、3、4 を参照)。これらはデータソースとモダリティ(写真、衛星画像、ソーシャルメディアテキスト、医療記録、センサー読み取り値、表形式データ)およびサイズ(1 万件から 3900 万件のインスタンスまで)にわたります。各データセットについて、既知の最良手法と比較したテスト期間における有意な性能向上を報告します(以下参照)。なお、各データセットにおける以前の最良手法は異なる場合があります。これらの結果は、我々のアプローチの広範な適用可能性を示しています。
自然な概念ドリフトを研究する多様なタスクにおける本手法の性能向上。報告された向上値は、各データセットにおける以前の既知の最良手法に対するものです。
継続学習への拡張
最後に、私たちの研究の興味深い拡張について考察します。前述の研究では、継続学習(continual learning)に着想を得たアイデアを用いることで、オフライン学習が概念ドリフト(concept drift)に対処できるようになる方法を説明しました。しかし、場合によってはオフライン学習自体が実行不可能なこともあります。例えば、利用可能なトレーニングデータの量が大きすぎて維持や処理ができないようなケースです。
私たちは、各データバケット(bucket)の文脈内で時間的な重み付け(temporal reweighting)を適用することで、継続学習へのアプローチを単純かつ直接的に適応させました。この提案は依然として継続学習が持ついくつかの限界を残しています。例えば、モデルの更新は最も新しいデータのみに対して行われ、すべての最適化決定(私たちの重み付けを含む)もそのデータ上でのみ行われます。それでもなお、私たちのアプローチは、通常の継続学習や写真分類ベンチマークにおける広範な他の継続学習アルゴリズムを常に上回っています(以下参照)。私たちのアプローチはここで比較された多くのベースラインのアイデアと補完的であるため、それらと組み合わせることでさらに大きな効果が見込めると期待しています。
継続学習に適応させた私たちの手法の結果を、最新のベースラインと比較したものです。
結論
私たちは、データドリフトの課題に対処するために、過去の手法の強みを組み合わせました。すなわち、データの効率的な再利用に優れるオフライン学習と、より最近のデータを重視する継続的学習です。私たちの研究が、実践における概念ドリフトに対するモデルの頑健性を向上させ、慢性的な概念ドリフトという至る所に存在する問題への対応において、関心の高まりと新たなアイデアを生み出すことを願っています。
謝辞
*本研究の初期段階で多くの興味深い議論をいただいたマイク・モザー氏に感謝するとともに、開発過程における非常に有益な助言とフィードバックにも深く感謝いたします。*
原文を表示
Posted by Nishant Jain, Pre-doctoral Researcher, and Pradeep Shenoy, Research Scientist, Google Research
The constantly changing nature of the world around us poses a significant challenge for the development of AI models. Often, models are trained on longitudinal data with the hope that the training data used will accurately represent inputs the model may receive in the future. More generally, the default assumption that all training data are equally relevant often breaks in practice. For example, the figure below shows images from the CLEAR nonstationary learning benchmark, and it illustrates how visual features of objects evolve significantly over a 10 year span (a phenomenon we refer to as *slow concept drift*), posing a challenge for object categorization models.
Sample images from the CLEAR benchmark. (Adapted from Lin et al.)
Alternative approaches, such as online and continual learning, repeatedly update a model with small amounts of recent data in order to keep it current. This implicitly prioritizes recent data, as the learnings from past data are gradually erased by subsequent updates. However in the real world, different kinds of information lose relevance at different rates, so there are two key issues: 1) By design they focus *exclusively* on the most recent data and lose any signal from older data that is erased. 2) Contributions from data instances decay *uniformly over time* irrespective of the contents of the data.
In our recent work, “Instance-Conditional Timescales of Decay for Non-Stationary Learning”, we propose to assign each instance an importance score during training in order to maximize model performance on future data. To accomplish this, we employ an auxiliary model that produces these scores using the training instance as well as its age. This model is jointly learned with the primary model. We address both the above challenges and achieve significant gains over other robust learning methods on a range of benchmark datasets for nonstationary learning. For instance, on a recent large-scale benchmark for nonstationary learning (~39M photos over a 10 year period), we show up to 15% relative accuracy gains through learned reweighting of training data.
The challenge of concept drift for supervised learning
To gain quantitative insight into slow concept drift, we built classifiers on a recent photo categorization task, comprising roughly 39M photographs sourced from social media websites over a 10 year period. We compared offline training, which iterated over all the training data multiple times in random order, and continual training, which iterated multiple times over each month of data in sequential (temporal) order. We measured model accuracy both during the training period and during a subsequent period where both models were frozen, i.e., not updated further on new data (shown below). At the end of the training period (left panel, x-axis = 0), both approaches have seen the same amount of data, but show a large performance gap. This is due to catastrophic forgetting, a problem in continual learning where a model’s knowledge of data from early on in the training sequence is diminished in an uncontrolled manner. On the other hand, forgetting has its advantages — over the test period (shown on the right), the continual trained model degrades much less rapidly than the offline model because it is less dependent on older data. The decay of both models’ accuracy in the test period is confirmation that the data is indeed evolving over time, and both models become increasingly less relevant.
Comparing offline and continually trained models on the photo classification task.
Time-sensitive reweighting of training data
We design a method combining the benefits of offline learning (the flexibility of effectively reusing all available data) and continual learning (the ability to downplay older data) to address slow concept drift. We build upon offline learning, then add careful control over the influence of past data and an optimization objective, both designed to reduce model decay in the future.
Suppose we wish to train a model, *M*,* *given some training data collected over time. We propose to also train a helper model that assigns a weight to each point based on its contents and age. This weight scales the contribution from that data point in the training objective for *M*. The objective of the weights is to improve the performance of *M* on future data.
In our work, we describe how the helper model can be *meta-learned, *i.e., learned alongside *M* in a manner that helps the learning of the model *M* itself. A key design choice of the helper model is that we separated out instance- and age-related contributions in a factored manner. Specifically, we set the weight by combining contributions from multiple different fixed timescales of decay, and learn an approximate “assignment” of a given instance to its most suited timescales. We find in our experiments that this form of the helper model outperforms many other alternatives we considered, ranging from unconstrained joint functions to a single timescale of decay (exponential or linear), due to its combination of simplicity and expressivity. Full details may be found in the paper.
Instance weight scoring
The top figure below shows that our learned helper model indeed up-weights more modern-looking objects in the CLEAR object recognition challenge; older-looking objects are correspondingly down-weighted. On closer examination (bottom figure below, gradient-based feature importance assessment), we see that the helper model focuses on the primary object within the image, as opposed to, e.g., background features that may spuriously be correlated with instance age.
Sample images from the CLEAR benchmark (camera & computer categories) assigned the highest and lowest weights respectively by our helper model.
Feature importance analysis of our helper model on sample images from the CLEAR benchmark.
Results
Gains on large-scale data
We first study the large-scale photo categorization task (PCAT) on the YFCC100M dataset discussed earlier, using the first five years of data for training and the next five years as test data. Our method (shown in red below) improves substantially over the no-reweighting baseline (black) as well as many other robust learning techniques. Interestingly, our method deliberately trades off accuracy on the distant past (training data unlikely to reoccur in the future) in exchange for marked improvements in the test period. Also, as desired, our method degrades less than other baselines in the test period.
Comparison of our method and relevant baselines on the PCAT dataset.
Broad applicability
We validated our findings on a wide range of nonstationary learning challenge datasets sourced from the academic literature (see 1, 2, 3, 4 for details) that spans data sources and modalities (photos, satellite images, social media text, medical records, sensor readings, tabular data) and sizes (ranging from 10k to 39M instances). We report significant gains in the test period when compared to the nearest published benchmark method for each dataset (shown below). Note that the previous best-known method may be different for each dataset. These results showcase the broad applicability of our approach.
Performance gain of our method on a variety of tasks studying natural concept drift. Our reported gains are over the previous best-known method for each dataset.
Extensions to continual learning
Finally, we consider an interesting extension of our work. The work above described how offline learning can be extended to handle concept drift using ideas inspired by continual learning. However, sometimes offline learning is infeasible — for example, if the amount of training data available is too large to maintain or process. We adapted our approach to continual learning in a straightforward manner by applying temporal reweighting *within the context of *each bucket of data being used to sequentially update the model. This proposal still retains some limitations of continual learning, e.g., model updates are performed only on most-recent data, and all optimization decisions (including our reweighting) are only made over that data. Nevertheless, our approach consistently beats regular continual learning as well as a wide range of other continual learning algorithms on the photo categorization benchmark (see below). Since our approach is complementary to the ideas in many baselines compared here, we anticipate even larger gains when combined with them.
Results of our method adapted to continual learning, compared to the latest baselines.
Conclusion
We addressed the challenge of data drift in learning by combining the strengths of previous approaches — offline learning with its effective reuse of data, and continual learning with its emphasis on more recent data. We hope that our work helps improve model robustness to concept drift in practice, and generates increased interest and new ideas in addressing the ubiquitous problem of slow concept drift.
Acknowledgements
*We thank Mike Mozer for many interesting discussions in the early phase of this work, as well as very helpful advice and feedback during its development.*
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み