無限へのスケーリング:LINEヤフーにおける可観測性プラットフォームの進化
LINEヤフーのObservability Infrastructureチームは、社内向け時系列データベースの開発と運用を通じて、大規模な可観測性プラットフォームを構築・進化させている。
キーポイント
社内向けTSDBの開発と運用
LINEヤフーのチームが自社開発した時系列データベース(TSDB)を用いて、大規模なシステム監視基盤を支えている。
可観測性プラットフォームの進化
単なる監視から「可観測性」へ移行し、システムの複雑さに対応するためのインフラストラクチャの進化プロセスを共有している。
大規模スケールへの対応
LINEやYahoo!のような巨大なトラフィックとサービス規模に対応するため、スケーラビリティを最優先とした設計思想が示唆されている。
影響分析・編集コメントを表示
影響分析
この記事は、大手プラットフォーム企業が自社の規模に最適化した独自インフラを構築している事例を示しており、業界における「ビルド vs. Buy」の判断基準や、可観測性分野での技術標準の変化を示唆しています。特に、大規模データ処理を伴うTSDBの自社開発は、コスト効率とパフォーマンス最適化において重要な示唆を与えます。
編集コメント
大規模サービスを支える裏方のインフラ革新は、ユーザー体験の向上に直結する重要な投資です。自社製TSDBの開発事例は、類似規模の企業にとって実装の参考になる貴重な知見です。
こんにちは。LINEヤフーの Observability Infrastructure チームで、社内向け時系列データベース(TSDB)の開発と運用を担当している Gi Jun Ohです。LINEヤフーは、LINEとYahoo! JAPANの統合により誕生した企業で、多様なサービスを提供しています。これらのサービスは毎日膨大な量のログ、メトリクス、トレースデータを生成しており、それらを効率的に収集、保存、分析することが、サービスの信頼性とパフォーマンスを維持する上で不可欠です。
Observability Infrastructure チームの使命は、こうした可観測性データを扱うプラットフォームを構築・運用し、エンジニアがシステムの状態を可視化し、問題を迅速に特定・解決できるようにすることです。私たちのプラットフォームは大規模なデータを処理できるよう設計されており、LINEヤフーのサービスの成長に合わせてスケールし続けています。
本記事では、私たちが直面したスケーラビリティの課題と、それらを克服するために進化させてきたプラットフォームの変遷について詳しく説明します。特に、時系列データベースのアーキテクチャ変更、データ収集パイプラインの最適化、クエリエンジンの改良に焦点を当てます。これらの取り組みにより、プラットフォームはより効率的に動作し、コストを削減しながら、より多くのデータを処理できるようになりました。
まず、時系列データベースの移行についてです。当初はオープンソースのソリューションを使用していましたが、データ量の増加に伴い、パフォーマンスとコストの面で限界に直面しました。そこで、私たちは自社開発のTSDBへの移行を決定しました。この新しいTSDBは、高い圧縮率と高速なクエリ処理を実現するために設計されており、既存のソリューションと比較してストレージコストを大幅に削減し、クエリパフォーマンスを向上させることができました。
次に、データ収集パイプラインの最適化です。データ収集エージェントからバックエンドストレージまでのデータフローの各段階でボトルネックを特定し、改善を加えました。例えば、データのバッチ処理と圧縮を強化し、ネットワーク帯域幅の使用効率を高めました。また、収集エージェントのリソース使用量を最適化し、ホストマシンへの影響を最小限に抑えつつ、高いスループットを維持できるようにしました。
最後に、クエリエンジンの改良です。ユーザーがデータを探索・分析する際の体験を向上させるために、クエリエンジンにいくつかの重要な機能を追加しました。これには、より高速な集計処理、リアルタイムでのデータ補間、複雑なクエリの並列実行サポートなどが含まれます。これらの改良により、エンジニアはより迅速に洞察を得ることができ、インシデント対応時間の短縮に貢献しています。
これらの進化を通じて、私たちの可観測性プラットフォームは、LINEヤフーのサービスが成長し続ける中でも、確実にスケールし続ける基盤となっています。今後も、新たな技術の導入やアーキテクチャの見直しを通じて、プラットフォームの性能と信頼性を高めていく予定です。Observability Infrastructure チームは、LINEヤフーのエンジニアが最高のサービスを提供できるよう、引き続きサポートしていきます。
原文を表示
こんにちは。LINEヤフーの Observability Infrastructure チームで、社内向け時系列データベース(TSDB)の開発と運用を担当している Gi Jun Ohです。
LINEヤフーのプライベートクラウド基盤は、仮想マシンを提供するだけの仕組みではありません。Kubernetes を基盤としたコンテナ環境、データベース、ロードバランサーなど、非常に幅広いサービス群を提供しています。このような大規模インフラと、その上で稼働する数万規模のアプリケーションの状態を、どのように把握し管理すればよいのかという課題に直面してきました。
サーバーが10台や100台程度であれば、エンジニアが各サーバーにログインして手動で状態を確認する運用も成立します。しかし、サーバー数が数万台規模に達し、サービスアーキテクチャが複雑に結び付くと、人間の認知能力では把握しきれなくなります。

この課題に対し、私たちのチームはオブザーバビリティ基盤を提供することで応えてきました。開発者がインフラの状態を意識せずにビジネスロジックへ集中できること、そして運用者がデータに基づいてシステムを安定的に管理できることが、私たちの中核的なミッションです。
では、オブザーバビリティとは何でしょうか。この概念は制御理論に由来し、システムの外部出力から内部状態をどれだけ正確に推測できるかを意味します。これをソフトウェアエンジニアリングに当てはめると、システムが発するさまざまなデータを観測することで、サービスの健全性やボトルネックの所在を判断できる能力といえます。
システムが生成するすべてのデータを保存することは物理的に不可能です。そのため、現代のオブザーバビリティシステムでは、メトリクス、ログ、トレースという3つを主要な柱として定義し、収集しています。本記事では、メトリクスを効率的に保存し処理するために私たちが取り組んできた技術的な歩みを振り返りつつ、データと人工知能(AI)を統合してインテリジェントなプラットフォームへ進化させる今後の戦略を紹介します。
オブザーバビリティにおけるメトリクス保存の影響
情報技術(IT)システム監視の分野において、メトリクスとは、特定の時点におけるシステム状態を数値として表し、タイムスタンプを付与した時系列データを指します。ユーザーはこのデータを可視化することでサービスの傾向を把握し、値が事前に定義した閾値を超えた場合にアラートを受け取ります。近年は、CPU 使用率が90%を超えたら通知するといった単純なリアクティブ手法にとどまらず、分野自体が進化しています。自己回帰和分移動平均(ARIMA) や Prophet などの時系列予測アルゴリズムを導入することで、障害の兆候を事前に捉え、プロアクティブに検知できるようになりました。
サービスの規模が小さいうちは、時系列データの管理はそれほど難しくありません。しかし、サービスが成長し、インフラが高度化するにつれて、データ量は指数関数的に増大していきます。その規模感を把握するために、ここでは各タグのキーと値がそれぞれ64バイトに制限された、仮想的な時系列データ構造を例に考えてみましょう。
struct tag {
char key[64]; // 64 bytes
char value[64]; // 64 bytes
};
struct timeseries {
uint64_t timestamp; // 8 bytes
struct tag *tags; // 64ビットシステムでは 8 bytes
uint64_t value; // 8 bytes
};サーバーのCPU使用率を測定する単一のメトリクスが、15秒ごとに生成されると仮定します。ホスト名やタイプなどのタグ情報を含めると、1データポイントのサイズは次のように見積もることができます。
struct timeseries ts = {
.timestamp = 1625079600, // 8 bytes
.tags = (struct tag[]) { // ポインタとして 8 bytes
[0] = {.key="host", .value="server1"}, // 128 bytes (64 bytes + 64 bytes)
[1] = {.key="type", .value="cpu"}, // 128 bytes
},
.value = 42 // 8 bytes
};この場合、1メトリクスあたり約280バイトになります。「たった280バイト?」と思うかもしれません。しかし、時間軸とインフラ規模を広げると状況は一変します。単一サーバーのCPUメトリクスだけでも年間で約562MiBが必要です。サーバーが1000台に増えれば 548GiBに達し、さらにメモリやディスク、ネットワークなどの基本的なメトリクスを追加すると、年間のストレージ要件はあっという間にテビバイト(TiB)規模に膨らみます。
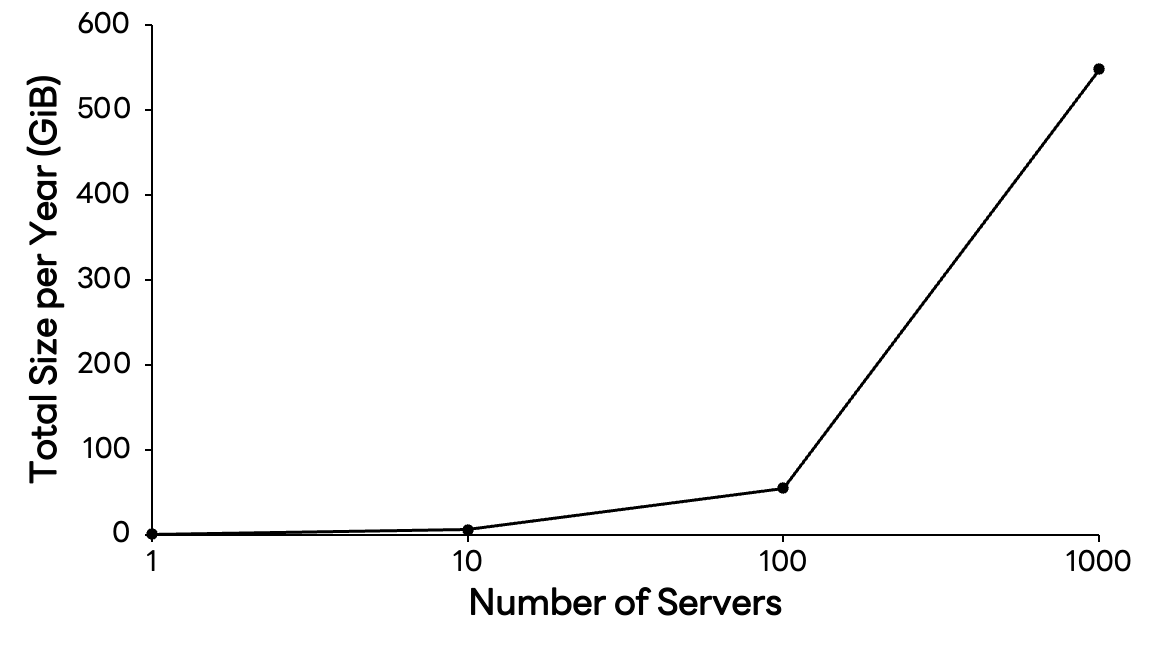
クラウドネイティブ環境では、監視対象のカーディナリティが指数関数的に増加します。この膨大なデータをコスト効率よく保存し、低レイテンシでクエリできるかどうかは、サービスの安定性に左右します。この課題を汎用データベースだけで解決することは困難です。
そのため、専用の時系列エンジンである時系列データベースが不可欠となり、私たちのチームはそれを社内で開発し運用しています。現在、このデータベースは 1日あたり数兆件規模のメトリクスを処理しています。どのようにして独自エンジンを開発し、これほど巨大なトラフィックを維持できるシステムを構築したのでしょうか。

自社製時系列データベース構築への道のり:課題と突破口
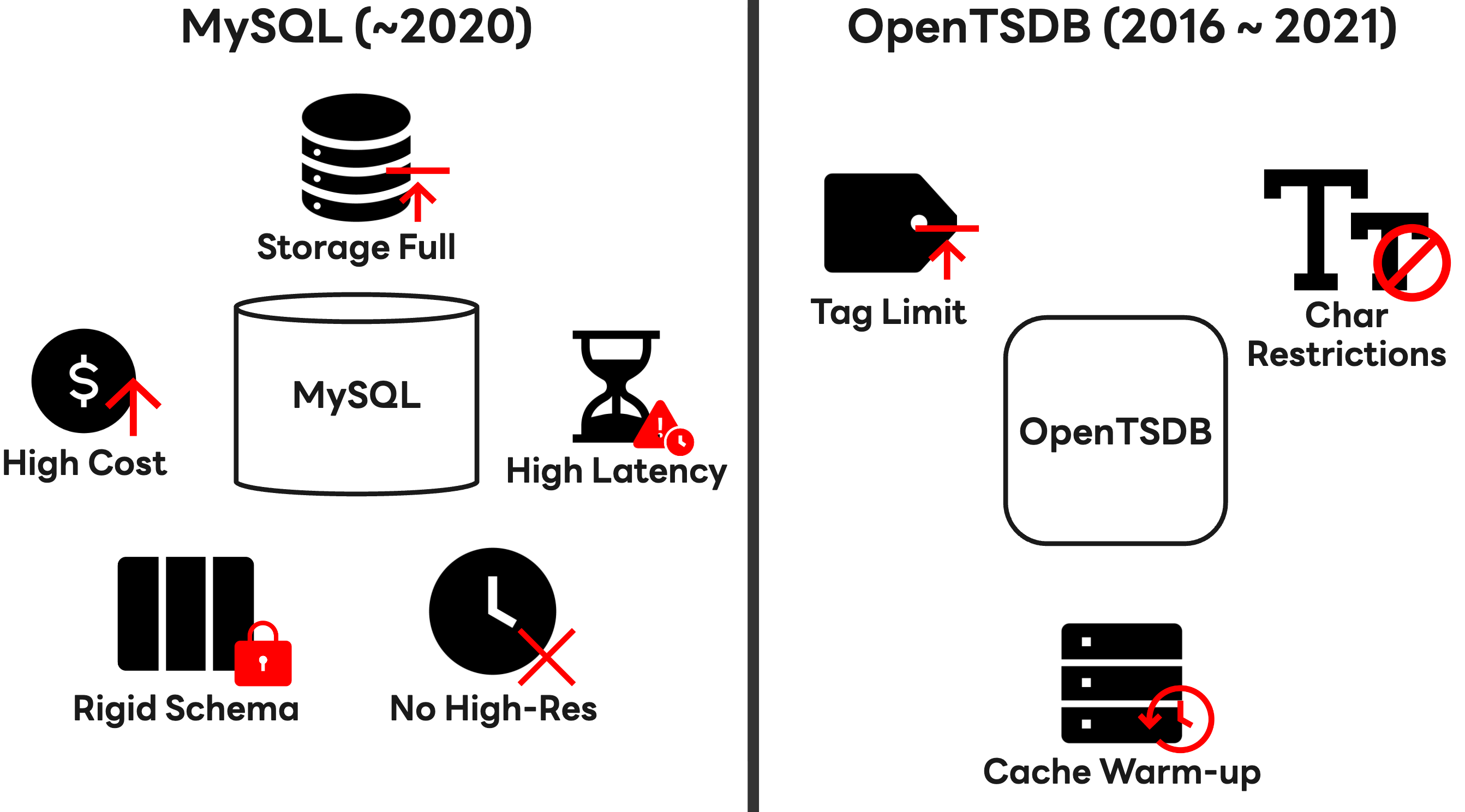
初期段階では、リレーショナルデータベースであるMySQLを用いて時系列データを保存していました。しかし、アーキテクチャがサービス指向アーキテクチャ(SOA)からマイクロサービスアーキテクチャ(MSA)へと移行するにつれ、サービスコンポーネントは小さな単位へと分割されました。その結果、監視すべきデータ量が急速に増加し、運用コストの高騰、ストレージ容量の不足、クエリレイテンシの増大という課題に直面しました。
MySQLのシャーディングは一時的な対策になりましたが、根本的な解決には至りませんでした。リレーショナルデータベースが本質的に持つ特性により、書き込み負荷の増大や大規模データセットでの読み取り性能の低下により、1分未満の間隔で高解像度のメトリクスを収集することが難しくなったためです。また、静的なタグスキーマ構造は、変化の激しいクラウド環境でリソース情報を捉えるのに適していませんでした。
そこで2016年に、Apache HBase上に構築されたオープンソースの時系列データベースである OpenTSDBを導入しました。導入当初はMySQLと比べて大幅に優れた書き込み性能を発揮しましたが、運用期間が長くなるにつれて、次の制約が顕在化しました。
- タグ利用の制限:タグ数の増加に伴い、UIDテーブル参照性能が低下し、実運用ではタグ数に制限を設ける必要がありました。これにより、クラウドリソースが持つ複雑性を十分に表現することが困難でした。
- 文字制限:使用可能な文字がa-z、A-Z、0-9、-、_、.、/に限定されており、多言語や多様な形式を扱うグローバルサービスのメタデータ保存に不向きでした。
- クエリ効率の低さ:大規模クエリでは許容可能な性能を確保するために、事前にデータをキャッシュへ読み込む「ウォームアップ」処理が必要となり、運用が複雑化しました。
「ユーザー体験(UX)を損なうことなく、急速に変化するビジネス要件に即座に対応することは可能なのだろうか?」
既存のソリューションではこの問いに答えることが難しいと判断し、私たちは独自エンジンの開発という大胆な決断を下しました。2018年に内製の時系列データベース開発を開始した際の目標は次のとおりです。
- 柔軟性:特定のエージェントに縛られることなく、多様なプロトコルをサポートすること
- スケーラビリティ:トラフィックスパイク時でも性能を線形に維持できる、非破壊的なアーキテクチャ
- 性能:1分未満の間隔で高解像度メトリクスを遅延なく処理し、データの可視性を最大化すること
- 可用性:あらゆる障害シナリオにおいてもユーザー体験を損なわない堅牢性
約1年の開発を経て、2019年に私たちはオープンソースの強みを取り込みつつ、その弱点を克服した独自の時系列データベースを完成させました。
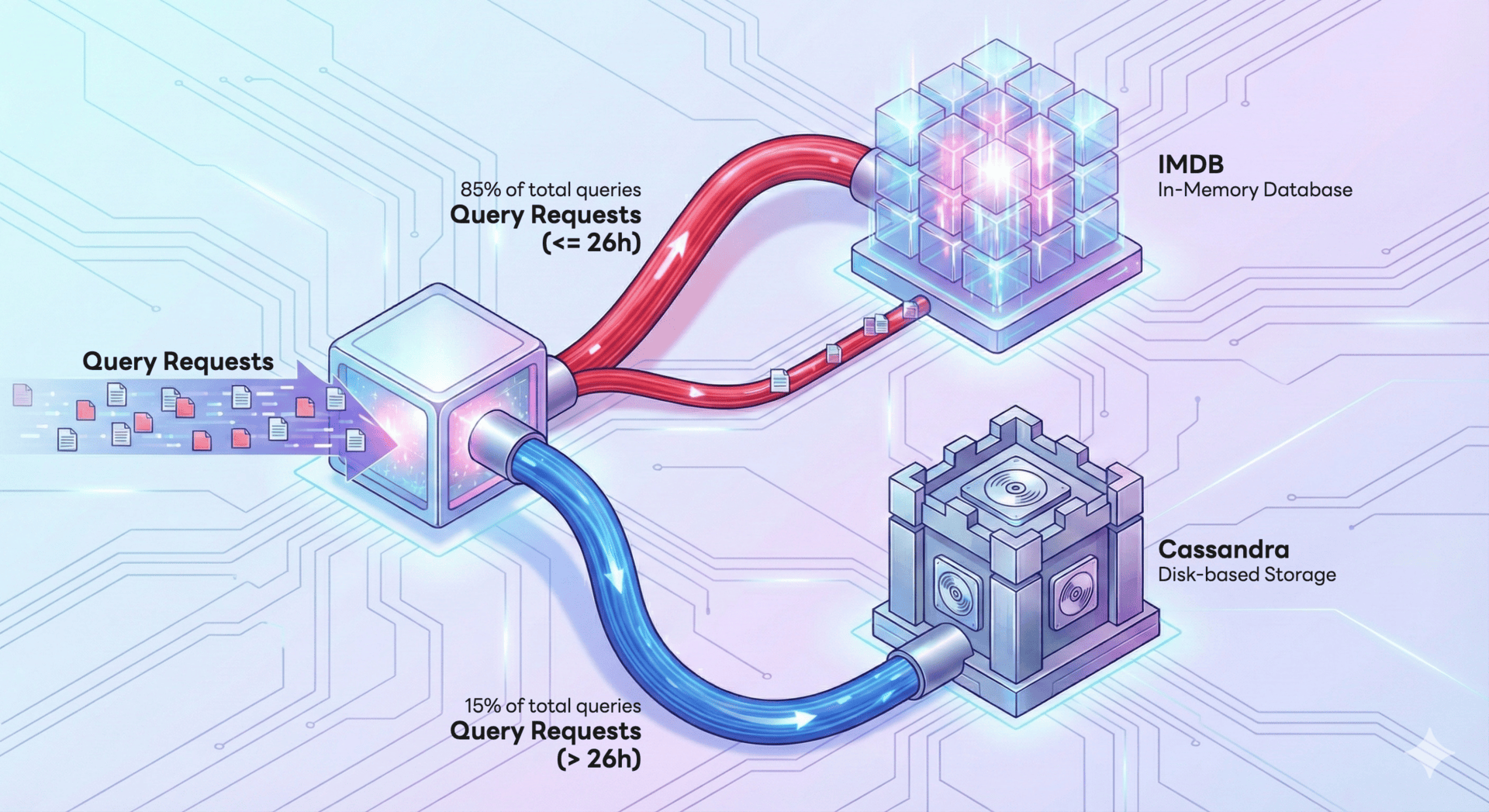
開発における最も重要な技術的成果は、データアクセスパターンに基づくアーキテクチャ最適化でした。私たちは、Metaが発表した「Gorilla: A fast, scalable, in-memory time series database」という論文に着想を得ました。この論文では、データクエリの 85%が直近26時間のデータに集中していることが示されています。この知見を基に、私たちは性能とコストのバランスを取った多層ストレージ戦略を考案しました。頻繁にアクセスされるメトリクスはレイテンシを最小化するためにインメモリデータベース(IMDB)で処理し、アクセス頻度の低いデータはストレージコストを最適化するためにディスクベースの Apache Cassandra(以下 Cassandra)に保存します。以下の図はこの構成を示しています。
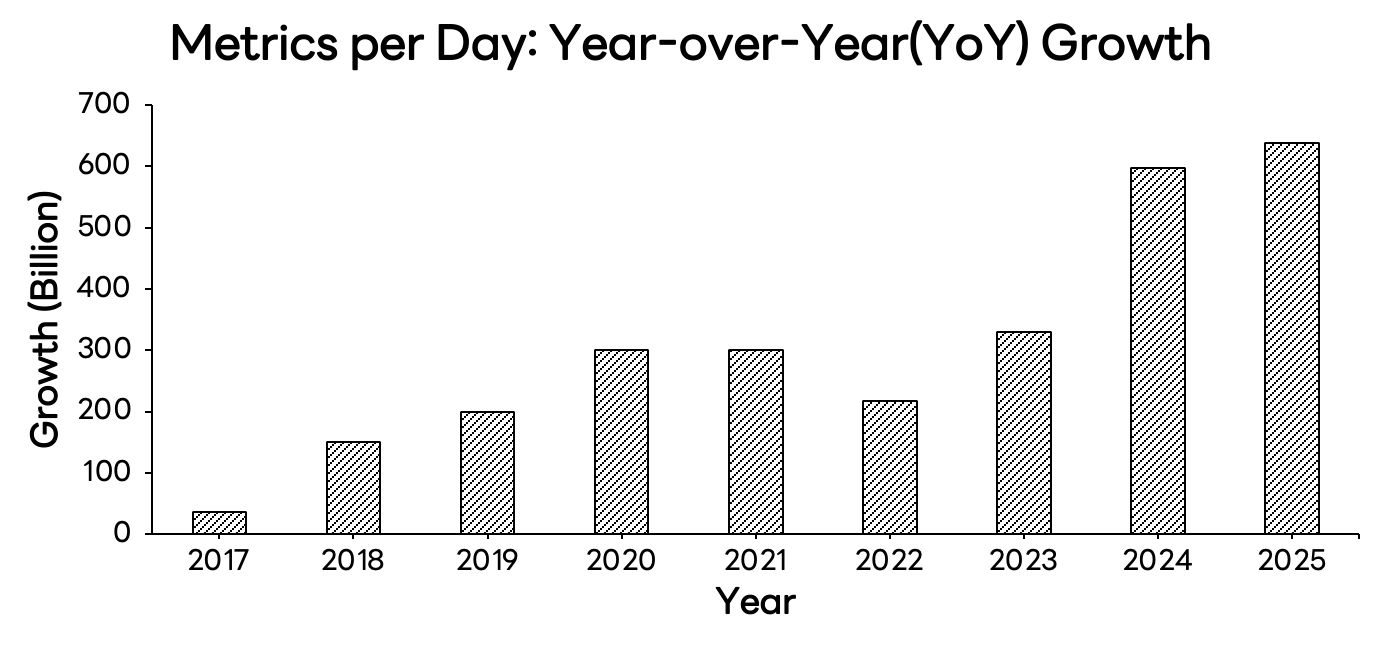
独自ソリューションの導入は、それまで制約されていた機能要件を解放する触媒となりました。2019年以降、1日あたりのメトリクス取り込み量(metrics/day)は、前年比で 2,000億件以上の成長を遂げています。
何よりも強調したいのは、MySQLからOpenTSDB、そして最終的に独自エンジンへと至るこの大規模な変革が、ユーザーに対してシームレスに提供されたという点です。バックエンドアーキテクチャを根本的に刷新しながらも、既存のアプリケーションプログラミングインターフェース(API)との互換性を維持しました。その結果、ユーザーはコードの移行や修正を行うことなく、自然な形で性能向上の恩恵を受けることができました。
押し寄せる時系列データに備える構造転換
内製開発の喜びは長くは続きませんでした。独自の時系列データベースをリリースした後、社内のインフラ環境は再び大きな変革を迎え、多くのサービスが一斉にKubernetesへ移行しました。
仮想マシン環境では、サーバーは通常、長いライフサイクルを持っていました。しかしKubernetes環境では、ポッドが頻繁に生成と破棄を繰り返すため入れ替わりが激しくなります。さらにボリュームも動的に割り当てられることから、可観測性プラットフォームが扱うメトリクスの量と複雑性は、想像をはるかに超えて急増しました。ユーザーはより多くのメトリクスと、より長いデータ保持期間を求め、ストレージリソースは急速に逼迫しました。
IMDBとCassandraの両ストレージシステムは、いずれもスケーラビリティの限界に達しました。IMDBクラスタは同一仕様のノードでしか拡張できず、ノード調達が困難でした。一方、膨大なデータセットを抱えたCassandraクラスタでは、リバランスに数十時間を要し、俊敏なスケーリングを妨げていました。それは、ダムの補強工事が遅れる中で洪水に直面し、為す術がない状況に似ていました。
では、この危機をどのように乗り越えたのでしょうか。その答えは、洪水にも耐えうる柔軟で堅牢な構造を構築することでした。単にダムを補強するのではなく、次のような根本的なアーキテクチャ改善を実施しました。
- IMDBの最適化:既存のロードバランシングアルゴリズムを、ノード間の処理能力の違いを考慮した重み付きロードバランシングアルゴリズムに置き換え、負荷をより適切に分散できるようにしました。
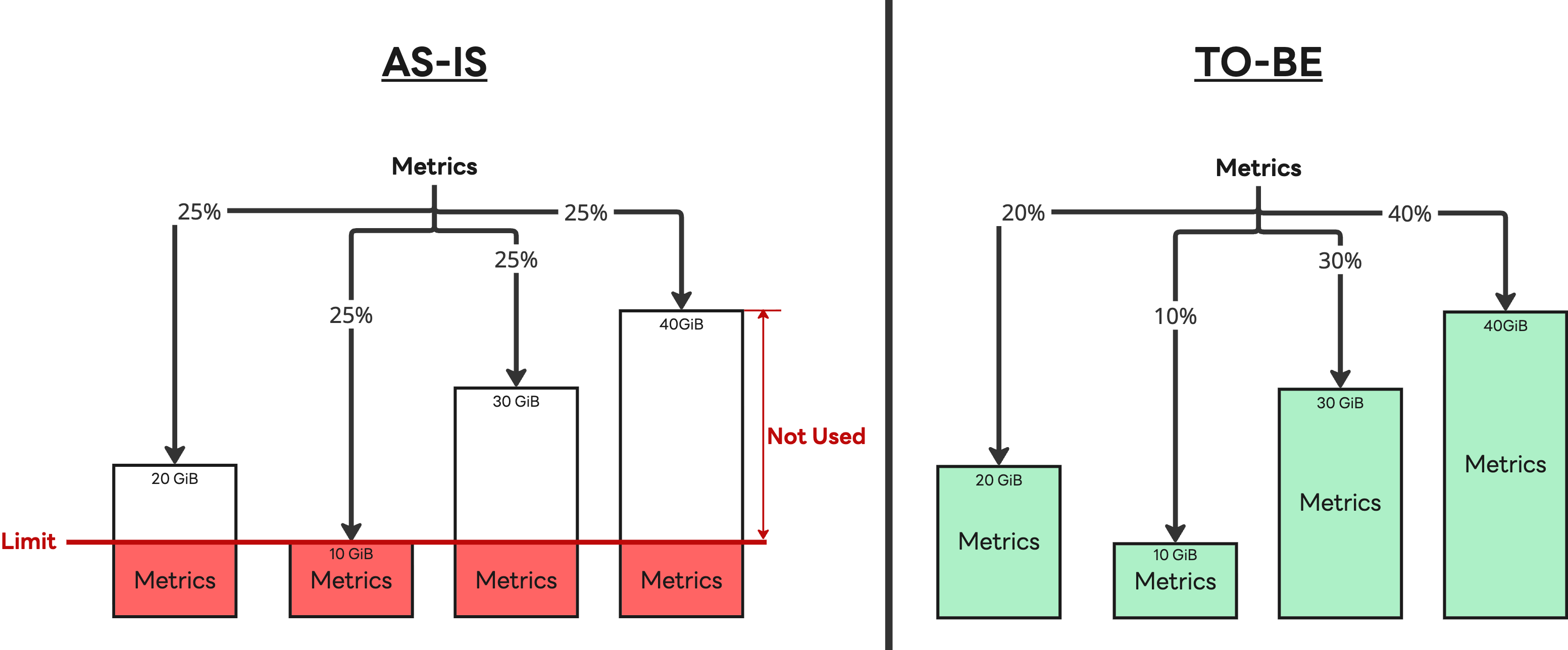
- 階層型ストレージ戦略の導入:すべてのデータをCassandraに保存する方針を見直しました。単純化のために全面移行も検討しましたが、少なくとも現時点では、キャッシュ付きのS3互換ストレージがCassandraの性能を完全に代替することはできないと判断しました。その結果、高い性能が求められる直近14日分のデータはCassandraに保持し、それ以前のデータはS3に保存するハイブリッド構成を採用しました。
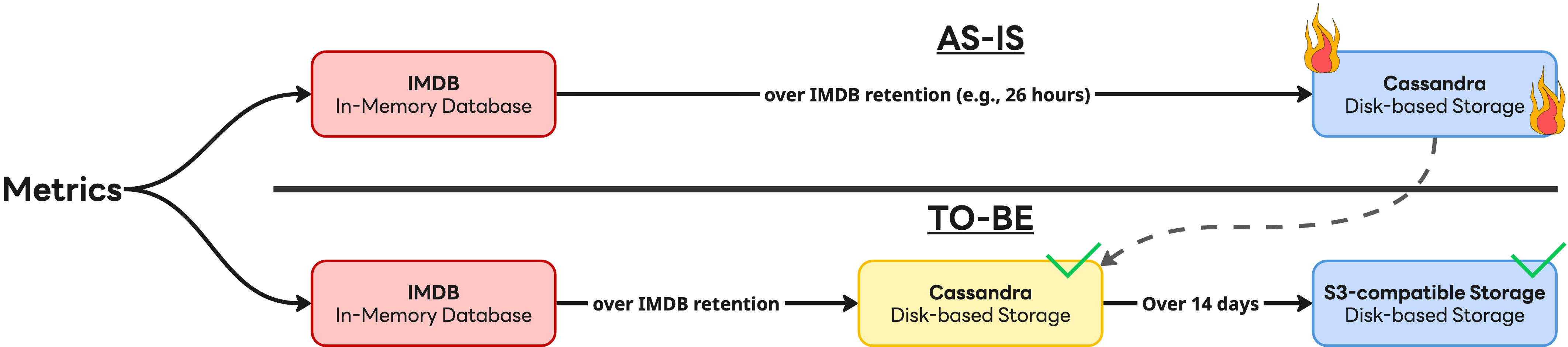
この戦略は有効であることが証明されました。異なる仕様のIMDBノードを柔軟に追加できるようになったことで、サーバー市場の変化にも迅速に対応でき、同時にCassandraへの依存度を下げることでコスト効率も向上しました。S3互換ストレージの導入により運用の複雑性は大幅に軽減され、さらに主要コンポーネントをKubernetesへ移行したことで、運用効率を一層高めることができました。
その結果、私たちのシステムは、増え続けるデータの洪水を確実に受け止め(取り込み)、必要に応じて滑らかに放流(クエリ)できる「巨大なダム」として生まれ変わりました。これにより、2024年以降に加速した大規模メトリクスの成長の中においても、安定した運用を維持しています。
アーキテクチャ転換の背後にある技術的課題と協業
私たちは、ユーザーにコード変更(破壊的変更)の負担をかけることなく、S3互換ストレージが持つスケーラビリティの利点を最大限に提供したいと考えました。熟慮の末、書き込みと読み取りの責務を分離する階層型アーキテクチャを導入しました。
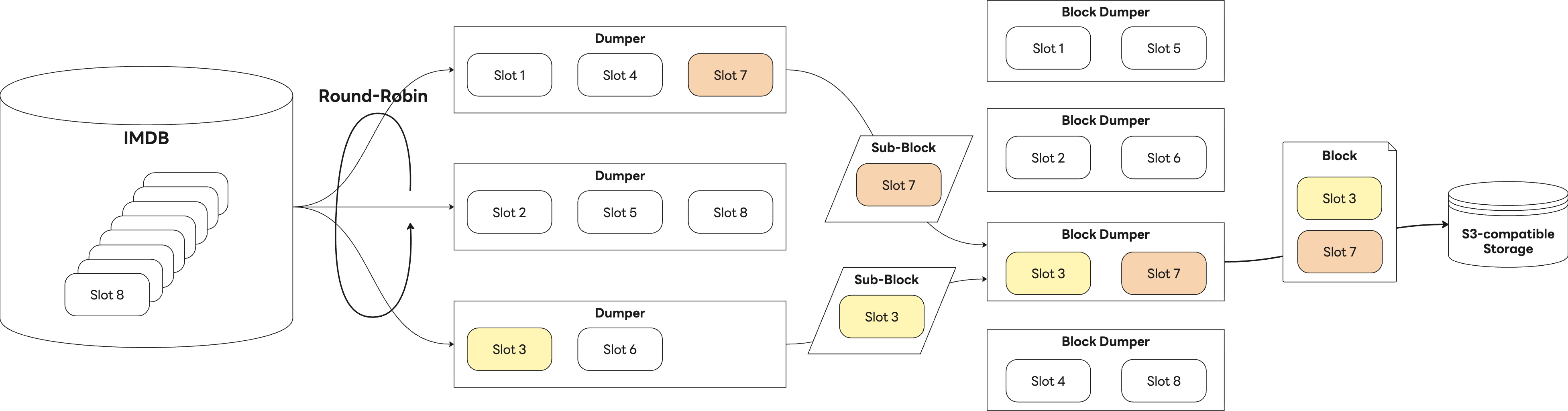
書き込み処理は2段階に分かれています。まず、Dumperと呼ばれるバッチジョブコンポーネントが、IMDBからスロットと呼ばれるメトリクスの束を読み取り、独自に定義したフォーマットに基づいてサブブロックへ変換します。次にBlock Dumperがこれらのサブブロックを集約し、単一のブロックとしてまとめた上でS3に保存します。以下の図は、書き込み処理全体の流れを示しています。
一方、データの読み取りはStorage Gatewayが担当し、これらのブロックを読み込んで処理します。次の図は、読み取り処理全体の流れを示しています。
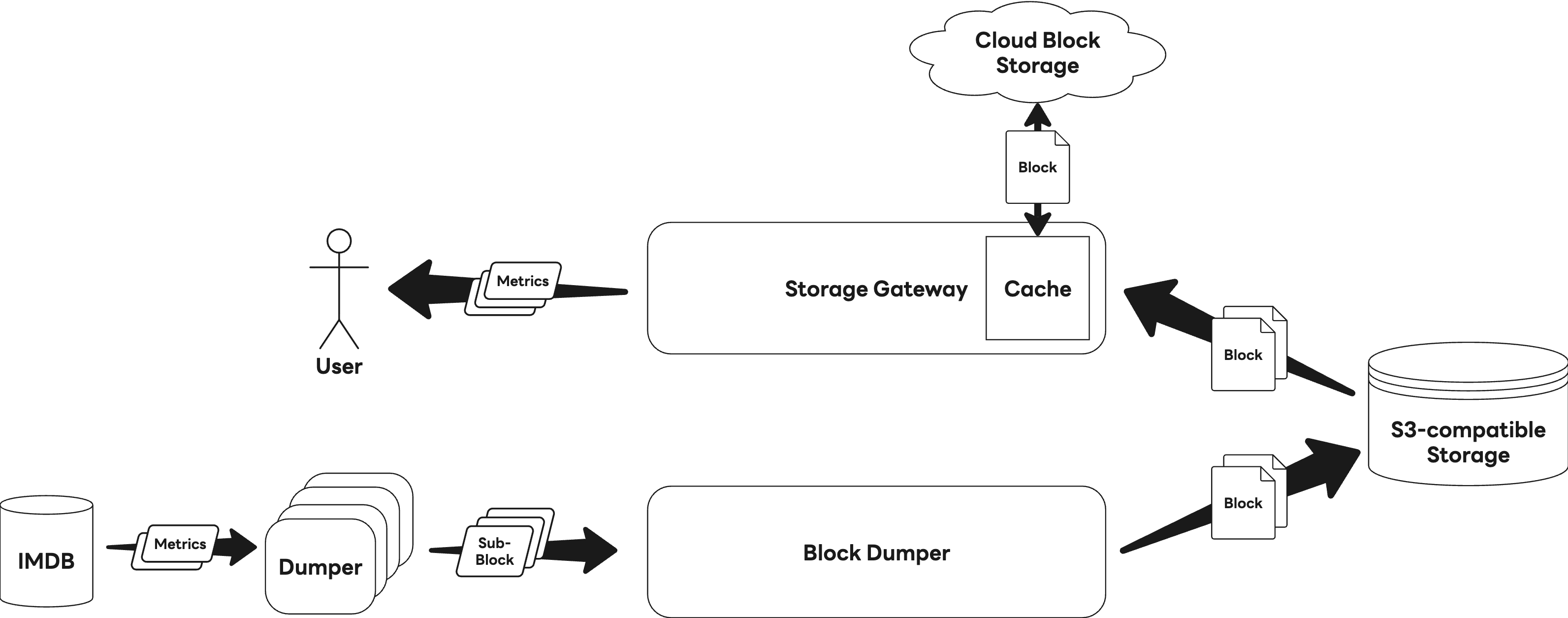
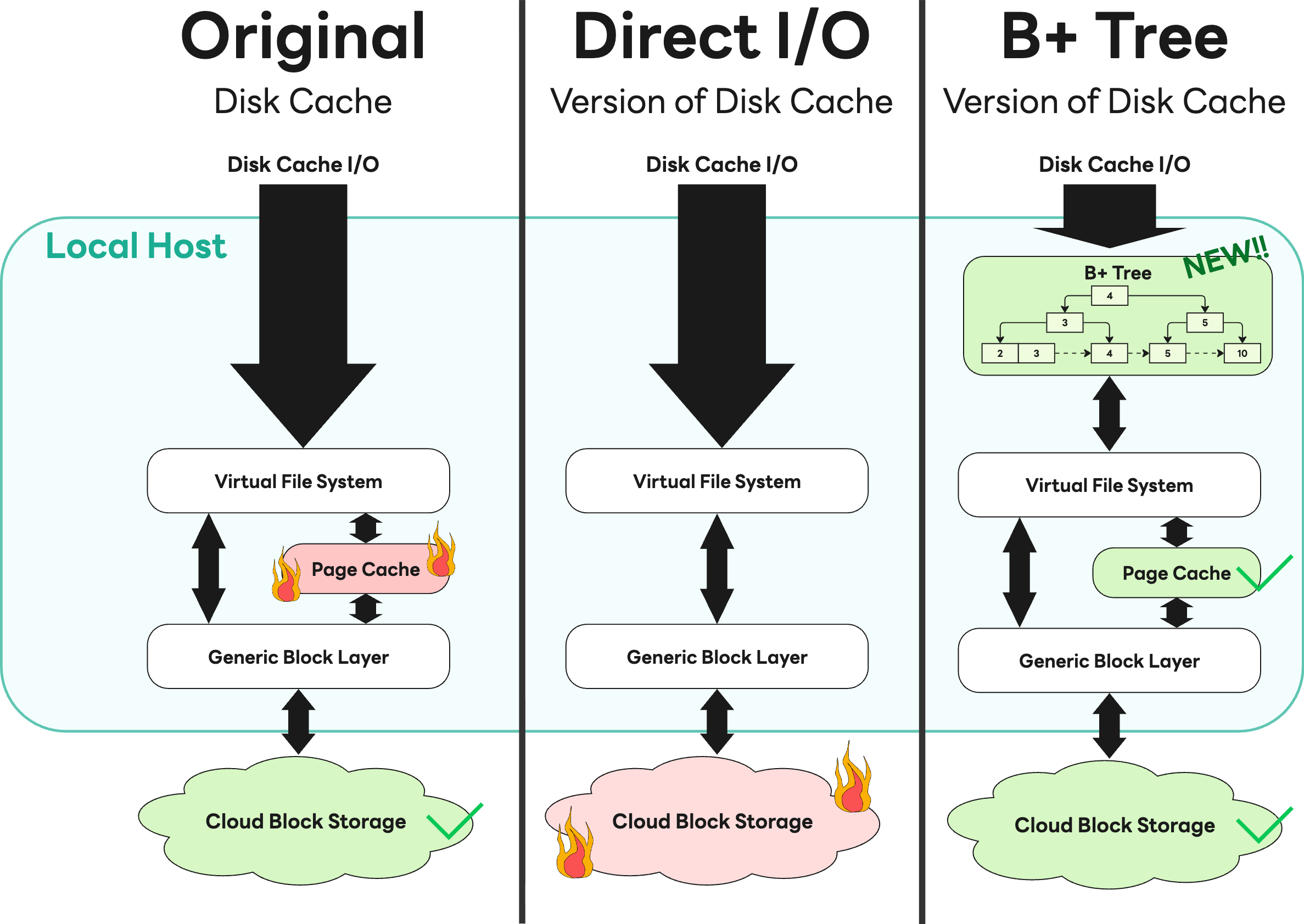
読み取り性能を最大化するため、Storage GatewayはS3から取得したブロックデータをディスクにキャッシュしています。しかし、このキャッシュは大量のI/Oが発生した際にページキャッシュ使用量の急増を引き起こし、最終的には急速なメモリ枯渇につながりました。
当初はダイレクトI/Oを適用することで解決を試みましたが、社内のクラウドストレージチームから、帯域を過剰に消費して他のサービスに影響を及ぼしているとの緊急報告がありました。私たちは直ちに問題を共有し、関係チームと密に連携しました。その結果、ダイレクトI/Oの採用を取りやめ、代わりにカーネルのページキャッシュを効率的に活用するB+木ベースのキャッシュを導入しました。この解決策により、インフラに過度な負荷をかけることなく性能を確保することができ、失敗をオープンに共有することが最適な結果につながることを示す、貴重な経験となりました。
未来の計画:これからの時系列データベース
AI時代の到来により、データの価値は記録から「予測」や「知能」へと進化しています。それに伴い、私たちのチームの方向性も、単なるデータの保存にとどまらず、より高度な活用へと広がっています。そのためには、まず組織内に分散して保存されている時系列データを統合することが欠かせません。

しかし、この統合プロセスがユーザーに移行の負担を強いるものであれば、技術的には進歩であっても、ビジネスの観点では利益よりも害の方が大きくなる可能性があることを、私たちは十分に認識しています。だからこそ、数兆件規模のレコードを移行しながらもユーザー体験を維持してきた、これまでに培った経験を再び活かすことを目指しています。この実証済みのノウハウを基に、組織内に散在するさまざまな時系列データベースを、単一の内製ソリューションへと統合する計画です。
この統合された内製プラットフォームは、AI駆動型イノベーションの利点を取り込みつつ、安定したサービスを実現し、最終的には次のような価値をユーザーに提供すると考えています。
- 集中型プラットフォーム:分散している時系列データを一か所に集約し、データアナリストやエンジニアがいつでもアクセスできる環境を構築します。
- 高度なAIOpsと予測:膨大に蓄積された時系列データをAIモデルと組み合わせることで、ユーザーが複雑な統計設定を行うことなく、異常検知やトラフィック変動の予測を自動で行うインテリジェントなエンドポイントを提供します。
- Model Context Protocol(MCP)の統合:大規模言語モデル(LLM)が運用データを容易に理解・照会できる標準インターフェースを構築します。「先週のトラフィック異常の原因は何だったのか?」とユーザーが問いかけると、システムがデータを分析して回答する――そのような未来を思い描いています。
私たちのチームの挑戦はここで終わりではありません。可観測性プラットフォームは日々進化を続け、LINEヤフーの技術的成長を支える確かな基盤となることを目指しています。
参考文献
- Majors, C., Fong-Jones, L., & Miranda, G. (2022). Observability Engineering. O'Reilly Media.
- Naqvi, S. N. Z., Yfantidou, S., & Zimányi, E. (2017). Time series databases and influxdb. Studienarbeit, Université Libre de Bruxelles, 12, 1-44.
- Pelkonen, T., Franklin, S., Teller, J., Cavallaro, P., Huang, Q., Meza, J., & Veeraraghavan, K. (2015). Gorilla: A fast, scalable, in-memory time series database. Proceedings of the VLDB Endowment, 8(12), 1816-1827.
- Dunning, T., & Friedman, E. (2015). Time Series Databases: New Ways to Store and Access Data. O'Reilly Media.
- OpenTSDB. (n.d.). Writing data. https://opentsdb.net/docs/build/html/user_guide/writing/index.html#naming-conclusion
関連記事
- クラウドを「使う」ではなく、「つくる」──LINEヤフーが描く自社クラウド戦略
- LINEヤフーのクラウド基盤刷新:巨大な2つのクラウドを統合する次世代基盤「Flava」のアーキテクチャ
- その役割は、決して「裏方」ではない。インフラ・プラットフォームの基盤を担うエンジニアたちの矜持
※この記事は韓国語で書かれた内容を、自動翻訳(生成AI)をベースに、一部編集者が修正を加えたものです。
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み